
Abstract
We show that (1) any constrained polynomial optimization problem (POP) has an equivalent formulation on a variety contained in an Euclidean sphere and (2) the resulting semidefinite relaxations in the moment-SOS hierarchy have the constant trace property (CTP) for the involved matrices. We then exploit the CTP to avoid solving the semidefinite relaxations via interior-point methods and rather use ad-hoc spectral methods for minimizing the largest eigenvalue of a matrix pencil. Convergence to the optimal value of the semidefinite relaxation is guaranteed. As a result we obtain a hierarchy of nonsmooth “spectral relaxations” of the initial POP. Efficiency and robustness of this spectral hierarchy is tested against several equality constrained POPs on a sphere as well as on a sample of randomly generated quadratically constrained quadratic problems.






Similar content being viewed by others


Data availability
All data analyzed during this study are publicly available.
References
Bagirov, A., Karmitsa, N., Mäkelä, M.M.: Introduction to Nonsmooth Optimization: Theory, Practice and Software. Springer, New York (2014)
Ben-Tal, A., Nemirovski, A.: Lectures on Modern Convex Optimization: Analysis, Algorithms, and Engineering Applications, vol. 2. Siam, Philadelphia (2001)
Bihain, A.: Optimization of upper semidifferentiable functions. J. Optim. Theory Appl. 44(4), 545–568 (1984)
Burer, S., Monteiro, R.D.: A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization. Math. Program. 95(2), 329–357 (2003)
Burke, J.V., Lewis, A.S., Overton, M.L.: A robust gradient sampling algorithm for nonsmooth, nonconvex optimization. SIAM J. Optim. 15(3), 751–779 (2005)
Chandrasekaran, V., Shah, P.: Relative entropy relaxations for signomial optimization. SIAM J. Optim. 26(2), 1147–1173 (2016)
Curtis, F.E., Que, X.: A quasi-Newton algorithm for nonconvex, nonsmooth optimization with global convergence guarantees. Math. Program. Comput. 7(4), 399–428 (2015)
Curto, R.E., Fialkow, L.A.: Truncated K-moment problems in several variables. J. Oper. Theory 189–226 (2005)
Dahl, J.: Semidefinite Optimization using MOSEK. ISMP, Berlin (2012)
d’Aspremont, A., El Karoui, N.: A stochastic smoothing algorithm for semidefinite programming. SIAM J. Optim. 24(3), 1138–1177 (2014)
Ding, L., Yurtsever, A., Cevher, V., Tropp, J.A., Udell, M.: An optimal-storage approach to semidefinite programming using approximate complementarity. SIAM J. Optim. 31(4), 2695–2725 (2021)
Doherty, A.C., Wehner, S.: Convergence of SDP hierarchies for polynomial optimization on the hypersphere. arXiv preprint arXiv:1210.5048, (2012)
Dressler, M., Iliman, S., de Wolff, T.: A positivstellensatz for sums of nonnegative circuit polynomials. SIAM J. Appl. Algebra Geom. 1(1), 536–555 (2017)
Haarala, M., Miettinen, K., Mäkelä, M.M.: New limited memory bundle method for large-scale nonsmooth optimization. Optim. Methods Softw. 19(6), 673–692 (2004)
Haarala, N., Miettinen, K., Mäkelä, M.M.: Globally convergent limited memory bundle method for large-scale nonsmooth optimization. Math. Program. 109(1), 181–205 (2007)
Helmberg, C., Overton, M.L., Rendl, F.: The spectral bundle method with second-order information. Opt. Methods Softw. 29(4), 855–876 (2014)
Helmberg, C., Rendl, F.: A spectral bundle method for semidefinite programming. SIAM J. Optim. 10(3), 673–696 (2000)
Henrion, D., Lasserre, J.-B.: Detecting global optimality and extracting solutions in gloptipoly. Posit. Polynomials Control 312, 293–310 (2005)
Henrion, D., Malick, J.: Projection methods in conic optimization. Handb. Semidefinite Conic Polynomial Optim. 565–600 (2012)
Josz, C., Henrion, D.: Strong duality in Lasserre’s hierarchy for polynomial optimization. Optim. Lett. 10(1), 3–10 (2016)
Journée, M., Bach, F., Absil, P.-A., Sepulchre, R.: Low-rank optimization for semidefinite convex problems. arXiv preprint arXiv:0807.4423, (2008)
Karmitsa, N.: LMBM-FORTRAN subroutines for Large-Scale nonsmooth minimization: user’s manual’. TUCS Techn. Rep. 77(856) (2007)
Kiwiel, K.C.: Proximity control in bundle methods for convex nondifferentiable minimization. Math. Program. 46(1–3), 105–122 (1990)
Kiwiel, K.C.: Convergence of the gradient sampling algorithm for nonsmooth nonconvex optimization. SIAM J. Optim. 18(2), 379–388 (2007)
Lasserre, J.B.: Global optimization with polynomials and the problem of moments. SIAM J. Optim. 11(3), 796–817 (2001)
Lasserre, J.-B.: Convergent SDP-relaxations in polynomial optimization with sparsity. SIAM J. Optim. 17(3), 822–843 (2006)
Lasserre, J.-B.: Moments, Positive Polynomials and Their Applications, vol. 1. World Scientific, Singapore (2010)
Lasserre, J.B.: An Introduction to Polynomial and Semi-algebraic Optimization, vol. 52. Cambridge University Press, Cambridge (2015)
Lasserre, J.B.: Homogeneous polynomials and spurious local minima on the unit sphere. Optim. Lett. 1–14 (2021)
Lasserre, J.B., Laurent, M., Rostalski, P.: Semidefinite characterization and computation of zero-dimensional real radical ideals. Found. Comput. Math. 8(5), 607–647 (2008)
Lasserre, J.B., Toh, K.-C., Yang, S.: A bounded degree SOS hierarchy for polynomial optimization. EURO J. Comput. Optim. 5(1–2), 87–117 (2017)
Laurent, M.: Revisiting two theorems of Curto and Fialkow on moment matrices. Proc. Am. Math. Soc. 133(10), 2965–2976 (2005)
Lehoucq, R.B., Sorensen, D.C., Yang, C.: ARPACK Users’ Guide: Solution of Large-Scale Eigenvalue Problems with Implicitly Restarted Arnoldi Methods. SIAM, Philadelphia (1998)
Lewis, A.S., Overton, M.L.: Nonsmooth optimization via quasi-Newton methods. Math. Program. 141(1–2), 135–163 (2013)
Mai, N.H.A., Bhardwaj, A., Magron, V.: The constant trace property in noncommutative optimization. In: Proceedings of the 2021 on International Symposium on Symbolic and Algebraic Computation, ISSAC ’21, pp. 297–304, New York, NY, USA. ). Association for Computing Machinery (2021)
Mai, N.H.A., Lasserre, J.-B., Magron, V., Wang, J.: Exploiting constant trace property in large-scale polynomial optimization. ACM Trans. Math. Softw. 48(4), 1–39 (2022)
Mifflin, R.: An algorithm for constrained optimization with semismooth functions. Math. Oper. Res. 2(2), 191–207 (1977)
Navascués, M., Pironio, S., Acín, A.: A convergent hierarchy of semidefinite programs characterizing the set of quantum correlations. New J. Phys. 10(7), 073013 (2008)
Nemirovsky, A., Yudin, D.: Problem complexity and method efficiency in optimization. Nauka (1983)
Nie, J.: Optimality conditions and finite convergence of Lasserre’s hierarchy. Math. Program. 146(1–2), 97–121 (2014)
Nie, J., Schweighofer, M.: On the complexity of Putinar’s Positivstellensatz. J. Complex. 23(1), 135–150 (2007)
Nocedal, J.: Updating quasi-Newton matrices with limited storage. Math. Comput. 35(151), 773–782 (1980)
Nocedal, J., Wright, S.: Numerical Optimization. Springer, New York (2006)
Overton, M.L.: Large-scale optimization of eigenvalues. SIAM J. Optim. 2(1), 88–120 (1992)
Overton, M.L., Womersley, R.S.: Second derivatives for optimizing eigenvalues of symmetric matrices. SIAM J. Matrix Anal. Appl. 16(3), 697–718 (1995)
Saad, Y.: Numerical Methods for Large Eigenvalue Problems, revised SIAM, Philadelphia (2011)
Schweighofer, M.: On the complexity of Schmüdgen’s positivstellensatz. J. Complex. 20(4), 529–543 (2004)
Shor, N.Z.: Quadratic optimization problems. Sov. J. Comput. Syst. Sci. 25, 1–11 (1987)
Trnovska, M.: Strong duality conditions in semidefinite programming. J. Electr. Eng. 56(12), 1–5 (2005)
Waki, H., Kim, S., Kojima, M., Muramatsu, M.: Sums of squares and semidefinite programming relaxations for polynomial optimization problems with structured sparsity. SIAM J. Optim. 17(1), 218–242 (2006)
Wang, J., Magron, V.: A second order cone characterization for sums of nonnegative circuits. In: Proceedings of the 45th International Symposium on Symbolic and Algebraic Computation, pp. 450–457 (2020)
Wang, J., Magron, V., Lasserre, J.-B.: Chordal-TSSOS: a moment-SOS hierarchy that exploits term sparsity with chordal extension. SIAM J. Optim. 31(1), 114–141 (2021)
Wang, J., Magron, V., Lasserre, J.-B.: TSSOS: A Moment-SOS hierarchy that exploits term sparsity. SIAM J. Optim. 31(1), 30–58 (2021)
Wang, J., Magron, V., Lasserre, J.B., Mai, N.H.A.: CS-TSSOS: correlative and term sparsity for large-scale polynomial optimization. ACM Trans. Math. Softw. 48(4), 1–26 (2022)
Weisser, T., Legat, B., Coey, C., Kapelevich, L., Vielma, J.P.: Polynomial and moment optimization in Julia and JuMP. In: JuliaCon (2019)
Yurtsever, A., Tropp, J.A., Fercoq, O., Udell, M., Cevher, V.: Scalable semidefinite programming. SIAM J. Math. Data Sci. 3(1), 171–200 (2021)
Acknowledgements
The authors would like to thank the associate editor and anonymous reviewers, whose insightful comments and careful proof-checks helped to improve the paper.
Funding
The first author was supported by the MESRI funding from EDMITT. The second author was supported by the FMJH Program PGMO (EPICS project) and EDF, Thales, Orange et Criteo, as well as from the Tremplin ERC Stg Grant ANR-18-ERC2-0004-01 (T-COPS project). This work has benefited from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie Actions, grant agreement 813211 (POEMA) as well as from the AI Interdisciplinary Institute ANITI funding, through the French “Investing for the Future PIA3” program under the Grant agreement n\(^{\circ }\)ANR-19-PI3A-0004. The third author was supported by the European Research Council (ERC) under the European’s Union Horizon 2020 research and innovation program (Grant Agreement 666981 TAMING).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Code availability
The full code was made available for review. We remark that a set of packages were used in this study, that were either open source or available for academic use. Specific references are included in this published article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Spectral minimizations of SDP
In this section, we provide the proofs of lemmas stated in Sects. 2.6.1 and 2.6.3. First we recall the following useful properties of \({\mathcal {S}}\) and \({\mathcal {S}}^+\):
-
If \({\textbf{X}}={{\,\textrm{diag}\,}}({\textbf{X}}_1,\dots ,{\textbf{X}}_l)\in {\mathcal {S}}\),
$$\begin{aligned} {\textbf{X}}\succeq 0\Longleftrightarrow {\textbf{X}}_j\succeq 0,\,j\in [l]\qquad \text { and }\qquad {{\,\textrm{trace}\,}}({\textbf{X}})=\sum _{j=1}^l {{\,\textrm{trace}\,}}({\textbf{X}}_j). \end{aligned}$$(49) -
If \({\textbf{A}}={{\,\textrm{diag}\,}}({\textbf{A}}_1,\dots ,{\textbf{A}}_l)\in {\mathcal {S}}\) and \({\textbf{B}}={{\,\textrm{diag}\,}}({\textbf{B}}_1,\dots ,{\textbf{B}}_l)\in {\mathcal {S}}\),
$$\begin{aligned} \langle {\textbf{A}}, {\textbf{B}}\rangle = \sum _{j=1}^l\langle {\textbf{A}}_j, {\textbf{B}}_j\rangle . \end{aligned}$$(50)
1.1.1 SDP with constant trace property
Proof of Lemma 3
The proof of (20) is similar in spirit to the one of Helmberg and Rendl in [17, Sect. 2]. Here, we extend this proof for SDP (13), which involves a block-diagonal positive semidefinite matrix. From (13),
The dual of this SDP reads:
where \({\textbf{I}}\) is the identity matrix of size s. From this,
Since \(\rho =\tau \), (20) follows. For the second statement, let \({\textbf{z}}^\star \) be an optimal solution of SDP (14). Then \({\textbf{b}}^\top {\textbf{z}}^\star =-\rho =-\tau \). In addition, \({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}}^\star \preceq 0\) implies that
so that \(\varphi ({\textbf{z}}^\star )\le -\tau \). Note that (20) indicates that \(\varphi ({\textbf{z}}^\star )\ge -\tau \). Thus, \(\varphi ({\textbf{z}}^\star )=-\tau \), yielding the second statement. \(\square \)
The following proposition recalls the differentiability properties of \(\varphi \).
Proposition 8
The function \(\varphi \) in (19) has the following properties:
-
1.
\(\varphi \) is convex and continuous but not differentiable.
-
2.
The subdifferential of \(\varphi \) at \({\textbf{z}}\) reads:
$$\begin{aligned} \partial \varphi ({\textbf{z}})=\{{\textbf{b}}-a{\mathcal {A}}{\textbf{W}} \,\ {\textbf{W}}\in {{\,\textrm{conv}\,}}({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}}))\}, \end{aligned}$$(51)where for each \({\textbf{A}}\in {\mathcal {S}}\),
$$\begin{aligned} {\varGamma }({\textbf{A}}):=\{{\textbf{u}}{\textbf{u}}^\top \,\ {\textbf{A}}{\textbf{u}}=\lambda _1({\textbf{A}}){\textbf{u}}\,\ \Vert {\textbf{u}}\Vert _2=1\}. \end{aligned}$$(52)
Proof
Properties 1–2 are from Helmberg–Rendl [17, Sect. 2] (see also [44, (4)]). \(\square \)
The following result is useful to recover an optimal solution of SDP (13) from an optimal solution of NSOP (20).
Lemma 8
Let \({\bar{\textbf{z}}}\) be an optimal solution of NSOP (20). Then:
-
1.
There exists \({\textbf{X}}^\star \in a{{\,\textrm{conv}\,}}({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}}))\) such that \({\mathcal {A}}{\textbf{X}}^\star ={\textbf{b}}\).
-
2.
Let \({\textbf{u}}\) be a normalized eigenvector corresponding to \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})\). If \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})\) has multiplicity 1 then \({\textbf{X}}^\star =a{\textbf{u}}{\textbf{u}}^\top \), thus \({\textbf{X}}^\star \) is an optimal solution of SDP (13).
Proof
By [1, Theorem 4.2], \({\textbf{0}}\in \partial \varphi ({\bar{\textbf{z}}})\). Combining this with Proposition 8.2, the first statement follows.
We next prove the second statement. Assume that \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})\) has multiplicity 1. Then \({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})=\{{\textbf{u}} {\textbf{u}}^\top \}\). The first statement implies that \({\textbf{X}}^\star =a{\textbf{u}}{\textbf{u}}^\top \). From this, \({\textbf{X}}^\star \succeq 0\) and \({\mathcal {A}}{\textbf{X}}^\star ={\textbf{b}}\), so that \({\textbf{X}}^\star \) is a feasible solution of SDP (13). Moreover,
Thus, \(\langle {\textbf{C}}, {\textbf{X}}^\star \rangle =-\tau \), yielding the second statement. \(\square \)
To obtain a convergence guarantee when solving NSOP (20) by LMBM [15, Algorithm 1], we need the following technical lemma:
Lemma 9
When applied to problem NSOP (20), the LMBM algorithm is globally convergent.
Proof
The convexity of \(\varphi \) yields that \(\varphi \) is weakly upper semismooth on \({{\mathbb {R}}}^m\) according to [37, Proposition 5]. From this, \(\varphi \) is upper semidifferentiable on \({{\mathbb {R}}}^m\) by using [3, Theorem 3.1]. Combining this with the fact that \(\varphi \) is bounded from below on \({{\mathbb {R}}}^m\), the result follows thanks to [3, Sect. 5] (see also the final statement of [1, Sect. 14.2]). \(\square \)
1.1.2 SDP with bounded trace property
Proof of Lemma 4
Let \({\textbf{X}}^\star \) be an optimal solution of SDP (13) and set  . By Condition 4 of Assumption 1, one has
. By Condition 4 of Assumption 1, one has

Similarly to the proof of Lemma 3, one obtains:

Let us prove that
Let \({\textbf{z}}\in {{\mathbb {R}}}^m\) be fixed and consider the following two cases:
-
Case 1 \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}})>0\). By (53) and (54),
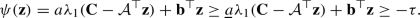
Thus, \(\psi ({\textbf{z}})\ge -\tau \).
-
Case 2 \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}})\le 0\). Then \({\mathcal {A}}^\top {\textbf{z}}-{\textbf{C}}\succeq 0\) and \(\psi ({\textbf{z}})={\textbf{b}}^\top {\textbf{z}}\ge -\rho =-\tau \) by (14).
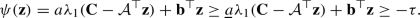
Let \(({\textbf{z}}^{(j)})_{j\in {{\mathbb {N}}}}\) be a minimizing sequence of SDP (14). Then \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}}^{(j)})\le 0\), \(j\in {{\mathbb {N}}}\), since \({\mathcal {A}}^\top {\textbf{z}}^{(j)}-{\textbf{C}}\succeq 0\) and \({\textbf{b}}^\top {\textbf{z}}^{(j)}\rightarrow -\tau \) as \(j\rightarrow \infty \) since \(\tau =\rho \). It implies that \(\psi ({\textbf{z}}^{(j)})={\textbf{b}}^\top {\textbf{z}}^{(j)}\rightarrow -\tau \) as \(j\rightarrow \infty \). From this and by (55), the first statement follows.
For the second statement, let \({\textbf{z}}^\star \) be an optimal solution of SDP (14). Since \({\mathcal {A}}^\top {\textbf{z}}-{\textbf{C}}\succeq 0\), \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}})\le 0\) and thus \(\psi ({\textbf{z}}^\star )={\textbf{b}}^\top {\textbf{z}}^\star = -\rho =-\tau \). Thus, \({\textbf{z}}^\star \) is an optimal solution of (26), yielding the second statement. \(\square \)
We consider the differentiability properties of \(\psi \) in the following proposition:
Proposition 9
The function \(\psi \) has the following properties:
-
1.
\(\psi \) is convex and continuous but not differentiable.
-
2.
The subdifferential of \(\psi \) at \({\textbf{z}}\) reads:
$$\begin{aligned} \partial \psi ({\textbf{z}})={\left\{ \begin{array}{ll} \{{\textbf{b}}\}\text { if }\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}})< 0 ,\\ \{{\textbf{b}}-a{\mathcal {A}}{\textbf{W}} \,\ {\textbf{W}}\in {{\,\textrm{conv}\,}}({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}}))\}\text { if }\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}})> 0,\\ \{{\textbf{b}}-\zeta a{\mathcal {A}}{\textbf{W}} \,\ \zeta \in [0,1],\,{\textbf{W}}\in {{\,\textrm{conv}\,}}({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}}))\}\text { otherwise},\\ \end{array}\right. } \end{aligned}$$where \({\varGamma }(.)\) is defined as in (52).
Proof
Note that \(\psi \) is the maximum of two convex functions, i.e.,
with \(\varphi _1({\textbf{z}})=a\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\textbf{z}})+{\textbf{b}}^\top {\textbf{z}}\) and \(\varphi _2({\textbf{z}})={\textbf{b}}^\top {\textbf{z}}\). Thus, \(\psi \) is convex and
Note that \(\partial \varphi _2({\textbf{z}})=\{{\textbf{b}}\}\) and \(\partial \varphi _1({\textbf{z}})\) is computed as in formula (51). Thus, the result follows. \(\square \)
The following theorem is useful to recover an optimal solution of SDP (13) from an optimal solution of NSOP (26).
Lemma 10
Assume that \({\bar{\textbf{z}}}\) is an optimal solution of NSOP (26). The following statements are true:
-
1.
There exists
$$\begin{aligned} {\textbf{X}}^\star {\left\{ \begin{array}{ll} = {\textbf{0}}&{} \text { if } \lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})< 0,\\ \in \zeta a{{\,\textrm{conv}\,}}({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})) &{}\text { if } \lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})=0,\\ \in a{{\,\textrm{conv}\,}}({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}}))&{} \text { otherwise}, \end{array}\right. } \end{aligned}$$for some \(\zeta \in [0,1]\) such that \({\mathcal {A}}{\textbf{X}}^\star ={\textbf{b}}\).
-
2.
Let \({\textbf{u}}\) be a normalized eigenvector corresponding to \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})\). If \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})\) has multiplicity 1, then \({\textbf{X}}^\star = {{\bar{\xi }}}{\textbf{u}}{\textbf{u}}^\top \) with \({{\bar{\xi }}}\) defined as in (27) and \({\textbf{X}}^\star \) is an optimal solution of SDP (13).
Proof
Due to [1, Theorem 4.2], \({\textbf{0}}\in \partial \varphi ({\bar{\textbf{z}}})\). From this and by Proposition 9.2, the first statement follows. Let us prove the second statement. Assume that \(\lambda _1({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})\) has multiplicity 1. Then one has \({\varGamma }({\textbf{C}}-{\mathcal {A}}^\top {\bar{\textbf{z}}})=\{{\textbf{u}}{\textbf{u}}^\top \}\), yielding \({\textbf{X}}^\star ={{\bar{\xi }}}{\textbf{u}}{\textbf{u}}^\top \) with \({{\bar{\xi }}}\) defined as in (27), so that \({\textbf{X}}^\star \succeq 0\). From this and since \({\mathcal {A}}{\textbf{X}}^\star ={\textbf{b}}\), \({\textbf{X}}^\star \) is a feasible solution of SDP (13). Moreover,
Thus, \(\langle {\textbf{C}}, {\textbf{X}}^\star \rangle =-\tau \), yielding the second statement. \(\square \)
The next result proves that when applied to NSOP (26), the LMBM algorithm [15, Algorithm 1] converges.
Lemma 11
LMBM applied to NSOP (26) is globally convergent.
The proof of Lemma 11 is similar to Lemma 9.
1.2 Converting moment relaxations to standard SDP
We will present a way to transform SDP (31) to the form (33) recalled as follows:
Let \(k\in {{\mathbb {N}}}\) be fixed. We will prove that there exists \({\textbf{A}}_j\in {\mathcal {S}}_k\), \(j\in [r]\), such that \({\textbf{X}}={\textbf{P}}_k{\textbf{M}}_k({\textbf{y}}){\textbf{P}}_k\) for some  if and only if \(\langle {\textbf{A}}_j, {\textbf{X}}\rangle =0\), \(j\in [r]\). Let
if and only if \(\langle {\textbf{A}}_j, {\textbf{X}}\rangle =0\), \(j\in [r]\). Let  . Then \({\mathcal {V}}\) is a linear subspace of \({\mathcal {S}}_k\) and
. Then \({\mathcal {V}}\) is a linear subspace of \({\mathcal {S}}_k\) and  . We take a basis \({\textbf{A}}_1,\dots ,{\textbf{A}}_r\) of the orthogonal complement \({\mathcal {V}}^\bot \) of \({\mathcal {V}}\). Notice that
. We take a basis \({\textbf{A}}_1,\dots ,{\textbf{A}}_r\) of the orthogonal complement \({\mathcal {V}}^\bot \) of \({\mathcal {V}}\). Notice that

with \({\textbf{X}}\in {\mathcal {S}}_k\), it implies that \({\textbf{X}}\in {\mathcal {V}}\) if and only if \(\langle {\textbf{A}}_j, {\textbf{X}}\rangle =0\), \(j\in [r]\).
Let us find such a basis \({\textbf{A}}_1,\dots ,{\textbf{A}}_r\). Let \({\textbf{A}}=(A_{\alpha ,\beta })_{\alpha ,\beta \in {{\mathbb {N}}}^n_k}\in {\mathcal {V}}^\bot \). Then for all \({\textbf{X}}=(X_{\alpha ,\beta })_{\alpha ,\beta \in {{\mathbb {N}}}^n_k}\in {\mathcal {V}}\), \(\langle {\textbf{A}}, {\textbf{X}}\rangle =0\). Note that if \({\textbf{X}}={\textbf{P}}_k{\textbf{M}}_k({\textbf{y}}){\textbf{P}}_k\), then one has
with \(w_{\alpha ,\beta }:=\theta _{k,\alpha }^{1/2}\theta _{k,\beta }^{1/2}\), for all \(\alpha ,\beta \in {{\mathbb {N}}}^n_k\). It implies that

Let \(\gamma \in {{\mathbb {N}}}^n_{2k}\) be fixed and let  be such that for \(\xi \in {{\mathbb {N}}}^n_{2k}\),
be such that for \(\xi \in {{\mathbb {N}}}^n_{2k}\),
Then

If \(\gamma \not \in 2{{\mathbb {N}}}^n\), we do not have the first term in the latter equality. Let us define
Note that \({\varLambda }_\gamma \) consists of values of A indexed by pairs of vectors \((\alpha , \beta )\) satisfying the lexicographic order relation \(\alpha \le \beta \). Moreover, it can be rewritten as \({\varLambda }_\gamma =\{A_{\alpha _j,\beta _j},\,j\in [t]\}\) where \((\alpha _1,\beta _1)<\dots <(\alpha _t,\beta _t)\) and \(t=|{\varLambda }_\gamma |\). Thus, if \(t\ge 2\), we can choose \({\textbf{A}}\) such that for all \(\alpha ,\beta \in {{\mathbb {N}}}^n_k\),
for some \(\mu \in [t]\backslash \{1\}\). We denote by \({\mathcal {B}}_\gamma \) the set of all such above \(A_{\alpha ,\beta }\) satisfying \(t=|{\varLambda }_\gamma |\ge 2\), otherwise let \({\mathcal {B}}_\gamma =\emptyset \). Then \(|{\mathcal {B}}_\gamma |=|{\varLambda }_\gamma |-1 \). From this and since \(( {\mathcal {B}}_\gamma )_{\gamma \in {{\mathbb {N}}}^{n}_{2k}}\) is a sequence of pairwise disjoint subsets of \({\mathcal {S}}_k\),

It must be equal to r as in (56). We just proved that \(\bigcup _{\gamma \in {{\mathbb {N}}}^{n}_{2k}} {\mathcal {B}}_\gamma \) is a basis of \({\mathcal {V}}^\bot \). Now we assume that \(\bigcup _{\gamma \in {{\mathbb {N}}}^{n}_{2k}} {\mathcal {B}}_\gamma =\{{\textbf{A}}_1,\dots ,{\textbf{A}}_r\}\).
Let us rewrite the constraints
as \(\langle {\textbf{A}}_j,{\textbf{X}}\rangle =0\), \(j=r+1,\dots ,m-1\) with \({\textbf{X}}={\textbf{P}}_k{\textbf{M}}_k({\textbf{y}}){\textbf{P}}_k\). From (57),
Let \(j\in [l_h]\) and \(\alpha \in {{\mathbb {N}}}^n_{2(k-\lceil h_j \rceil )}\) be fixed. We define \(\tilde{{\textbf{A}}}=({\tilde{A}}_{\mu ,\nu })_{\mu ,\nu \in {{\mathbb {N}}}^n_k}\) as follows:
Then (58) implies that \(\langle \tilde{{\textbf{A}}}, {\textbf{M}}_k({\textbf{y}})\rangle =0\). Since \({\textbf{M}}_k({\textbf{y}})={\textbf{P}}_k^{-1}{\textbf{X}}{\textbf{P}}_k^{-1}\),
where \({\textbf{A}}:={\textbf{P}}_k^{-1}\tilde{{\textbf{A}}}{\textbf{P}}_k^{-1}\), yielding the statement. Thus, we obtain the constraints \(\langle {\textbf{A}}_j,{\textbf{X}}\rangle =0\), \(j\in [m-1]\).
The final constraint \(y_0=1\) can be rewritten as \(\langle {\textbf{A}}_m, {\textbf{X}}\rangle =1\) with \({\textbf{A}}_m\in {\mathcal {S}}_k\) having zero entries except the top left one \([{\textbf{A}}_{m}]_{0,0}=1\). Thus, we select \({\textbf{b}}\) such that all entries of \({\textbf{b}}\) are zeros except \(b_m=1\).
The number m (or \(m_k\) when plugging the relaxation order k) of equality trace constraints \(\langle {\textbf{A}}_j,{\textbf{X}}\rangle =b_j\) is:

The function \(-L_{{\textbf{y}}}(f)=-\sum _\gamma f_\gamma y_{\gamma }\) is equal to \(\langle {\textbf{C}}, {\textbf{X}}\rangle \) with \({\textbf{C}}:={\textbf{P}}_k^{-1}\tilde{{\textbf{C}}}{\textbf{P}}_k^{-1}\), where \(\tilde{{\textbf{C}}}=({\tilde{C}}_{\mu ,\nu })_{\mu ,\nu \in {{\mathbb {N}}}^n_k}\) is defined by:
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mai, N.H.A., Lasserre, JB. & Magron, V. A hierarchy of spectral relaxations for polynomial optimization. Math. Prog. Comp. 15, 651–701 (2023). https://doi.org/10.1007/s12532-023-00243-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12532-023-00243-7
Keywords
- Polynomial optimization
- Moment-SOS hierarchy
- Maximal eigenvalue minimization
- Limited-memory bundle method
- Nonsmooth optimization
- Semidefinite programming