
Abstract
Fine particulate matter (PM2.5) has a considerable impact on the environment, climate change, and human health. Herein, we introduce a deep neural network model for deriving ground-level, hourly PM2.5 concentrations by Himawari-8 aerosol optical depth, meteorological variables, and land cover information. A total of 151,726 records were collected from 313 ground-level PM2.5 monitoring stations (spread across the North China Plain) to calibrate and test the proposed model. The sample- and site-based cross-validation yielded satisfactory performance, with correlation coefficients > 0.8 (R = 0.86 and 0.83, respectively). Furthermore, the variation in mean ground-level hourly PM2.5 concentrations, using 2017 data, showed that the proposed method could be applied for spatiotemporal continuous PM2.5 monitoring. This study will serve as a reference for the application of geostationary meteorological satellite to perform ground-level PM2.5 estimation and the utilization in atmospheric monitoring.
Similar content being viewed by others
Introduction
Fine particulate matter (PM2.5), which consists of particles with aerodynamic diameters < 2.5 µm, has attracted considerable scientific attention (Pope & Dockery, 2006). Previous studies have indicated that prolonged exposure to PM2.5 is affiliated with many human health issues including respiratory problems, cardiovascular disease, cancer, and infectious diseases (Bartell et al., 2013; Brauer et al., 2012; Chen et al., 2017; Crouse et al., 2012; Dominici et al., 2006; Gent et al., 2009; Guo et al., 2016; Lao et al., 2019; Pope, 2000; Zhang et al., 2020). Generally, ground monitoring sites can provide accurate PM2.5 measurements, but there are many regions for which measurements are unavailable as there are no monitoring networks. Thus, the sparse distribution of ground sites limits our capability to estimate the impacts of human exposure to PM2.5, with data on local meteorological effects and emission sources absent. Consequently, it is important that models that can accurately predict the broader spatiotemporal distribution of ground-level PM2.5 concentrations are developed.
Satellite has been applied to monitor ground-level PM2.5 emissions to fill in spatial gaps in ground measurement coverage (Chu et al., 2016; Hu et al., 2014; Kloog et al., 2012; Ma et al., 2014). Several studies were conducted for estimating PM2.5 concentrations from the aerosol optical depth (AOD), derived by satellite remote sensing, including multiple linear regression (Chu et al., 2016; Gupta & Christopher, 2008, 2009; Kacenelenbogen et al., 2006; Liu et al., 2005; Paciorek et al., 2008; Schaap et al., 2009; Wang, 2003; Yao et al. 2018), mixed-effect models (Just et al. 2015; Kloog et al. 2011, 2012, 2014; Lee et al. 2012; Zheng et al. 2016), geographically weighted regressions (Bai et al., 2016; Guo et al., 2017; He & Huang, 2018a, b; Hu, 2009; Ma et al., 2014; You et al., 2015; Zou et al., 2016), and chemical transport models (Crouse et al., 2012, 2016; Hystad et al., 2012; Liu et al., 2004; van Donkelaar et al., 2006; Wang & Chen, 2016). To improve the model performance, an increasing number of predictors, including meteorological information, land cover, and aerosol properties, were integrated. Thus, machine learning models, which are capable of complex nonlinear relationships fitting, have been applied to get PM2.5 concentrations from satellite observations. For example, random forests (Chen et al., 2018; Hu et al., 2017), deep belief networks (DBNs) (Li et al., 2018; Liu et al., 2018), deep neural networks (DNNs) (Wang & Sun, 2019), and machine learning models with high-dimensional expansion (Xue et al., 2019) have been used, and they have delivered superior prediction accuracy and applicability.
All these studies were limited to the use of polar orbit satellites, however, geostationary satellites are still rarely used in the estimation of PM2.5. These geostationary satellites are able to conduct more measurements and facilitate the capturing of atmospheric aerosol variation data hourly. In particular, with the launch and operation of next-generation geostationary meteorological satellites—such as the Advanced Geosynchronous Radiation Imager (AGRI) on board FengYun-4A, the Advanced Himawari Imager (AHI) on board Himawari-8/9, and the Advanced Baseline Imager (ABI) on board GOES-R—abundant AOD datasets have become available. The quality of these data has been validated: for example, it has been reported that the expected uncertainty for the Himawari-8 AOD is ± (0.1 + 0.3 × AOD) (Zhang et al., 2019), whereas the expected uncertainty for the MODIS (C6.1) 10 km AOD product is ± (0.05 + 0.15 × AOD) (Aldabash et al., 2020).
The North China Plain (NCP), which is renowned for experiencing severe atmospheric pollution events, has experienced high PM2.5 concentrations for decades owing to the rapid economic and population development that has taken place nearby. In this study, we applied the DNN methodology to estimate hourly ground-level PM2.5 concentrations over the NCP using Himawari-8 AHI AOD data.
The balance of this paper has been laid out as follows: data sets and a detailed description of the methodology may be found in “Materials and Methods” section, whereas the results and discussion have been given in “Results and Discussion” section. The study has been concluded in “Summary and Conclusions” section.
Materials and Methods
Datasets
Ground-Level PM2.5 Measurements
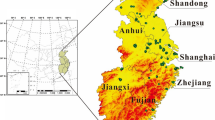
Ground-level PM2.5 concentration dataset was obtained from the China Environmental Monitoring Center (CEMC). Hourly PM2.5 measurements from 313 air quality sites in the NCP (as shown in Fig. 1) were collated for 2017. These concentrations represented the hourly averages established at the stations by the tapered element oscillating microbalance (TEOM). The accuracy of TEOM is ± 1.5 μg/m3 (You et al., 2016). The data are available at http://106.37.208.233:20035/.

North China Plain elevation. Ground-level data for the study were acquired from the air quality sites (white dots) (color figure online)
Himawari-8 AOD
Himawari-8 was launched by the Japan Meteorological Agency on October 7, 2014. It is a next-generation geostationary meteorological satellite. The AHI on board Himawari-8 has 16 channels. Its spatial temporal resolution is 0.5–2 km and 5–10 min, respectively (Yumimoto et al., 2016; Zhang et al., 2019).
The AOD products are provided with three levels: “Level2” (L2), “Level3” (L3), and “Level4” (L4) (Kikuchi et al., 2018). The spatial and temporal resolution of L3 is 0.05° and 1 h, respectively. In this study, the AOD data of L3 Version 3.0, which can be received from https://www.eorc.jaxa.jp/ptree/index.html, were collected to estimate hourly PM2.5 concentrations. It should be noted that a comprehensive AOD validation, as used in this study, can be found in our previous work (Zhang et al., 2019).
Meteorological and Land Cover Data
Meteorological data for 2017 were obtained from the second Modern-Era Retrospective analysis for Research and Applications (MERRA-2). It is the atmospheric product supported by National Aeronautics and Space Administration, with a spatial resolution of 0.5 × 0.625° (Gelaro et al., 2017; Rienecker et al., 2011). We extracted six hourly meteorological factors from this dataset: surface pressure (PS; as Pa), air temperature at 2 m (TMP; as K), E and N wind speed at 10 m above ground (EW and NW; as m/s), relative humidity (RH; as %), and planetary boundary layer height (PBLH; as m). The data can be downloaded from the website https://disc.gsfc.nasa.gov/datasets.
Landcover-related variables—surface albedo (ALBEDO; which is a unitless variable) and surface incoming shortwave flux (SWGDN; as W/m2)—were also extracted from the MERRA-2 data. Elevation (ELEV; as m) was terrain data at 1 km, whereas the normalized difference vegetation index (NDVI) was derived from MOD13A3, a monthly 1-km resolution dataset.
Based on the AOD, meteorological and land cover, there are 11 predictors were used to derive hourly PM2.5 concentrations over the NCP. That is AOD, surface pressure, air temperature, wind speed (E and N), PBLH, RH, ALBEDO, SWGDN, ELEV, and NDVI. Statistics for these datasets and predictors are listed in Table 1.
Methods
Data Integration
Firstly, because the original data involved various coordinate systems and spatial resolutions, all independent variables were recalibrated into the WGS84 coordinate system. Meteorological variables and land cover data were also recalibrated to, in this case, 0.05° resolution to ensure consistency. After these processes, the 11 predictors were matched with ground PM2.5 in a co-location procedure. The predictors were collected into a station-centered pixel. These selection process eventually gave rise to a dataset consisting of 151,726 records.
DNN Model
The concentrations of ground-level PM2.5 were affected by multiple factors, such as aerosol, meteorological, and surface cover. This complex relationship is difficult to describe accurately with a simple linear model, and so deep learning, which has been widely used in fitting complex, nonlinear relationships, was used to estimate ground-level PM2.5 concentrations. Thus, a DNN model (Hinton et al., 2012) was fitted using Eq. (1):
where f (\(\cdot\)) describes the prediction function. The meaning of each predictor has been described above.
Figure 2 shows the structure of the DNN model, where it can be seen that the model contained five hidden layers (which contained 60, 40, 30, 20, and 10 neurons), one input layer (which contained the 11 neurons shown in Eq. (1), and one output layer (which consisted of PM2.5 concentration estimates). This gave the proposed DNN model a structure of 11-60-40-30-20-10-1. It should be noted that the numbers of layers and neurons were chosen by increasing the numbers of neurons until the best estimation results were derived.

Structure of the DNN model used for PM2.5 estimation
Figure 3 illustrates the workflow used to estimate ground-level, hourly PM2.5. The process can be described as follows:
-
(1)
Conduct data integration, as described in “Data Integration” section. The derived AOD, meteorological variables, and land cover, which were consistent in time and space, were treated as model training and validation samples.
-
(2)
Perform DNN model fitting. To this end, all the 151,726 records (belonging to 313 sites) were first used to train the model, after which sample- and site-based tenfold cross-validation (CV) was carried out to evaluate the performance. CV was conducted as follows:
-
(a)
For sample-based CV, the samples were randomly divided into ten sets, with each set accounting for approximately 10% of the records. For each CV process, nine sets were used for training samples, with the tenth used to make predictions. Then, we repeated ten times until the predictions from each set were established;
-
(b)
Site-based CV was conducted to examine model sensitivity with respect to the number of ground stations and performance with respect to spatial variations. The 313 sites were randomly split into ten sets, with each set accounting for approximately 10% of the sites. As for the sample-based CV, nine sets were used to fit the model, with the tenth used to make predictions. PM2.5 concentration predictions were finally obtained by completing ten CV cycles;
-
(c)
Finally, to evaluate the levels of agreement, linear fit statistics for model predictions vs observations were performed. The statistical indicators include the correlation coefficient (R), slope, y intercept, and prediction root mean squared error (RMSE).
-
(a)
-
(3)
Finally, the prediction data (locations with no ground PM2.5 observations) were input into the derived DNN model to obtain spatial distributions of hourly PM2.5 concentrations over the NCP.

Workflow applied to estimate ground-level, hourly PM2.5 concentrations
Results and Discussion
Descriptive Statistics
Variable histograms, covering all 151,726 samples, are presented in Fig. 4. The surface pressure (PS) was found to be almost exponentially distributed, whereas air temperature (TMP) was approximately bimodal in its distribution. The E wind speed, N wind speed, PBLH, surface albedo, surface incoming shortwave flux (SWGDN), RH, and NDVI were found to have approximately normal distributions. The other variables, including elevation, AOD, and PM2.5, exhibited similar logarithmic distributions. The minimum, maximum, and mean PM2.5 concentrations were 1, 534, and 55.13 µg/m3, respectively, whereas the minimum, maximum, and mean AOD were calculated to be 0, 2.99, and 0.4, respectively, with the high AOD and PM2.5 maximums indicating that severe pollution was experienced over the NCP. Their standard deviations were calculated as 0.34 and 42.15 mg/m3, respectively, indicating that there had been significant fluctuations in the atmospheric particulate matter concentrations.

Descriptive statistics for dependent and independent variables (minimums, maximums, means, and standard deviations). The meaning of each item is explained in text
Variable Importance Analysis
To evaluate the potential effect of each predictor to the proposed DNN, we conducted a variable importance analysis. In Fig. 5, the variables for predicting PM2.5 have been represented in the y axis, with the percentage RMSE increase without using the corresponding variable (%IncRMSE) shown on the x axis. The figure shows that AOD (55.07%) was the variable with the highest contribution, which would be attributable to its strong correlation with PM2.5 concentrations. The %IncRMSE calculated without using air temperature as a predictor was 45.92%, followed by PBLH (41.21%), SWGDN (35.07%), RH (34.86%), N wind speed (32.09%), surface pressure (30.63%), E wind speed (24.22%), and surface albedo (24.01%).

Variable importance analysis. The x axis indicates the percentage RMSE increase achieved without using the corresponding predictor (%IncRMSE)
Figure 5 also shows that elevation and NDVI were the weakest contributing variables for hourly PM2.5 concentrations. These relatively low contributions may have been due to the small elevation variations over the NCP (shown in Fig. 4j). Furthermore, hourly PM2.5 concentrations, usually with high frequency variations, were likely to be less affected by variables that varied only slowly over time, such as NDVI.
Model Performance and Validation
The scatter plot showing ground observed (x axis) and estimated (y axis) PM2.5 concentrations for sample- and site-based CVs is shown in Fig. 6a, b. The R, RMSE, slope, and y intercept of sample-based CVs were 0.86, 21.40 μg/m3, 0.81, and 10.22 μg/m3, respectively; with regard to the site-based CVs, the corresponding values were 0.83, 23.65 μg/m3, 0.76, and 13.17 μg/m3, respectively. This good level of consistency demonstrated that the proposed DNN model was capable of achieving satisfactory performance.

Scatter plots for tenfold cross-validations (CVs): a sample-based CV; b site-based CV
We noted that the site-based CV outcome was comparable with that of the sample-based CV, which indicated that the proposed model had good spatial prediction capability. In addition, both the regression linear fit slopes were < unity (0.81 and 0.76), which implied that the DNN model tended to develop results that were slightly underestimated in comparison with the observed PM2.5 concentration. This underestimation was confirmed by noting observed PM2.5 concentrations > 54 μg/m3.
We deduced two possible reasons for the ground-observed PM2.5 concentration underestimation by the model. Firstly, using spatially averaged AOD, meteorological, and land surface variables to estimate point ground-level PM2.5 meant that it was difficult for meteorological parameters with relatively coarse spatial resolution (0.5° × 0.625°) to characterize detailed spatial variations. The other reason was that a spatial average would lead to high values being averaged and low values being overwhelmed. Taken together, these points meant that when we compared spatially averaged estimations with ground measurements, low values appeared to be overestimated and high values underestimated.
The spatial performance of the sample-based CV is illustrated in Fig. 7, where it can be seen that both R and RMSE (Figs. 7a, b, respectively) exhibit spatial variations. The R ranged between 0.48 and 0.93, whereas the RMSE ranged between 13.33 and 45.63, with 81% of R > 0.75 (254 sites out of 313), and 68% of the RMSE < 25 μg/m3 (213 out of the 313 sites). With respect to geographic distribution, sites in Henan Province performed better, with the RMSE being lower in Anhui and Zhejiang.

Cross-validation spatial performance: a R; b RMSE
Scatter plots for ground-observed (x axis) and estimated (y axis) daily and monthly PM2.5 concentrations are shown in Figs. 8a, b. The daily data R and RMSE were calculated to be 0.81 and 24.94 μg/m3, whereas the corresponding estimates for the monthly data were 0.90 and 9.91 μg/m3, respectively, showing that the model could accurately represent seasonal PM2.5 levels, with only small deviations.

Model validation scatter plots: a daily data; b monthly averages
Map of PM2.5 Estimation
The distributions of seasonal average PM2.5 over NCP in 2017 are shown in Fig. 9; in Fig. 9a–d; the seasonal variations in PM2.5 are clearly observable. The highest PM2.5 estimations were in winter, followed by spring, and then autumn, with the lowest values appearing in summer. Mean PM2.5 estimations for spring, summer, autumn, and winter were 48.93, 39.85, 48.06, and 74.78 μg/m3, respectively. The seasonal ground-level PM2.5 observations showed spatial distributions similar to those seen for the estimates, as shown in Figs. 9e–h. The R values of four seasons were 0.88, 0.86, 0.91, and 0.97, respectively (Figs. 9i–l), whereas the corresponding RMSEs were 4.53, 5.22, 4.83, and 5.80 μg/m3, respectively.

Spatial distributions for spring (March, April, and May), summer (June, July, and August), autumn (September, October, and November), and winter (December, January, and February) mean PM2.5 concentrations: a–d estimates; e–h ground-observations; i–l ground observation versus estimates distribution scatter plots
Annual estimated PM2.5 patterns for the NCP are plotted in Fig. 10. Generally, low AOD and PM2.5 levels occurred in NW Hebei Province, with its low population density and few industries. These spatial AOD (Fig. 10a) and PM2.5 (Fig. 10b) distribution results were not completely consistent, however, which indicated that their interrelationship was complex. Meanwhile, a heavily polluted region was revealed at the junction of the five provinces (Hebei, Henan, Anhui, Jiangsu, and Shandong). Scatter plots for annualized ground-level observations vs estimated PM2.5 levels are shown in Fig. 10c, with the R and RMSE calculated to be 0.94 and 3.64 μg/m3 (Fig. 10d), respectively.

Spatial distribution for annual average PM2.5 concentrations: a AOD; b estimates; c ground-level observations; d scatter plot for ground-level observations versus estimates
Annualized PM2.5 estimate averages for ten hours (00:00–09:00 (Coordinated Universal Time, UTC)), in 2017, are shown in Fig. 11, whereas Fig. 12 shows the corresponding ground-level observation frequencies. Figure 11 proves that the proposed model can provide at least ten hourly PM2.5 estimations in one day for any given area, i.e., it can provide PM2.5 concentration information at high frequencies. In Fig. 12, we can see that the spatial distribution of ground-level measurements exhibited temporal variations, peaking at noon, local time (03:00 UTC), whereas the data volume gradually decreased in the mornings and afternoons. This could be explained by the fact that the ability of the satellite to capture aerosol signals decreased as the solar zenith angle increased (Zhang et al., 2019).

Annualized PM2.5 estimate averages for different hours (as UTC) in 2017: a–j represent 00:00–09:00, respectively

Annualized frequencies for PM2.5 concentration estimates for different hours in 2017 (as UTC): a–j represent 00:00–09:00, respectively
Variations in annual average hourly PM2.5 estimations experienced by different cities are shown in Fig. 13. The cities were selected based on their distribution and representativeness for different regions. They displayed similar trends, i.e., over the period 00:00–09:00 (UTC), the PM2.5 levels peaked at certain times and then decreased. The peaks for Hefei (117.24, 31.84), Shijiazhuang (114.52, 38.03), Nanjing (118.80, 32.07), and Jinan (117.13, 36.64) appeared at either 02:00 or 03:00 (UTC), whereas Beijing (116.41, 39.90) and Zhengzhou (113.64, 34.75) peaked at 01:00. Minimum values were experienced by all cities at either 08:00 or 09:00 (UTC). Figure 13 shows that the proposed model could describe variety in PM2.5 concentrations at a temporal resolution of 1 h.

Annual mean variations in 2017 for hourly PM2.5 concentrations in selected study area cities
Summary and Conclusions
It is still a challenge to derive high temporal ground-level PM2.5 accurately using satellite-derived AOD data, especially for regions with higher particulate matter concentrations and complex compositions, such as the NCP, which has become heavily polluted with respect to PM2.5. Herein, we presented a DNN model that was calibrated using aerosol product (from a new-generation geostationary satellite Himawari-8), meteorological, and land cover information to estimate hourly ground-level PM2.5 concentrations of NCP. The estimated PM2.5 concentrations had a spatial and temporal resolution of 0.05° and 1 h, respectively, which can capture detailed variations in temporal PM2.5 distributions than would have been possible using polar orbit satellites such as MODIS. A total of 11 independent variables were used to fit the proposed model: AHI AOD, surface pressure, air temperature, E and N wind speeds, PBLH, RH, surface albedo, SWGDN, elevation, and NDVI. Through data integration, a total of 151,726 records related to 313 ground stations were collected. To validate the model performance, tenfold CV was conducted, and it was found that both sample-based (R = 0.86, RMSE = 21.40 μg/m3) and site-based (R = 0.83, RMSE = 23.65 μg/m3) CVs exhibited satisfactory performances. R values were calculated to be 0.81 and 0.90, respectively, for daily and monthly averaged PM2.5 levels.
When mapped, the estimated PM2.5 concentrations for the NCP showed clear seasonal variations, with the highest PM2.5 concentrations appearing in winter, followed by spring, autumn, and summer. The annual patterns showed that low PM2.5 concentration levels occurred in NW Hebei Province, whereas the area representing the junction of Hebei, Henan, Anhui, Jiangsu, and Shandong provinces was identified as being heavily polluted.
We also produced mapping, in which 2017 hourly data were used to generate annualized averages for ten hours (from 00:00 to 09:00 UTC). These results suggested that the proposed model could provide at least ten different hourly PM2.5 estimations daily, and thus, it had the capability to reveal high levels of atmosphere variation over time. Such successful testing allowed us to conclude that new-generation geostationary satellites have the potential to be used as useful data sources for ground-level PM2.5 estimation.
Availability of Data and Material
The ground PM2.5 measurements can be obtained from http://106.37.208.233:20035/. The Himawari-8 AOD can be obtained from https://www.eorc.jaxa.jp/ptree/index.html. The MERRA-2 data can be obtained from https://disc.gsfc.nasa.gov/datasets.
References
Aldabash, M., Balcik, F. B., & Glantz, P. (2020). Validation of MODIS C6.1 and MERRA-2 AOD using AERONET observations: A comparative study over Turkey. Atmosphere, 11(9), 905. https://doi.org/10.3390/ATMOS11090905
Bai, Y., Wu, L., Qin, K., Zhang, Y., Shen, Y., & Zhou, Y. (2016). A geographically and temporally weighted regression model for ground-level PM2.5 estimation from satellite-derived 500 m resolution AOD. Remote Sensing. https://doi.org/10.3390/rs8030262
Bartell, S. M., Longhurst, J., Tjoa, T., Sioutas, C., & Delfino, R. J. (2013). Particulate air pollution, ambulatory heart rate variability, and cardiac arrhythmia in retirement community residents with coronary artery disease. Environmental Health Perspectives, 121(10), 1135–1141. https://doi.org/10.1289/ehp.1205914
Brauer, M., Amann, M., Burnett, R. T., Cohen, A., Dentener, F., Ezzati, M., & Thurston, G. D. (2012). Exposure assessment for estimation of the global burden of disease attributable to outdoor air pollution. Environmental Science and Technology, 46(2), 652–660. https://doi.org/10.1021/es2025752
Chen, G., Li, S., Knibbs, L. D., Hamm, N. A., Cao, W., Li, T., & Guo, Y. (2018). A machine learning method to estimate PM2.5 concentrations across China with remote sensing, meteorological and land use information. Science of the Total Environment, 636, 52–60. https://doi.org/10.1016/j.scitotenv.2018.04.251
Chen, G., Zhang, W., Li, S., Zhang, Y., Williams, G., Huxley, R., & Guo, Y. (2017). The impact of ambient fine particles on influenza transmission and the modification effects of temperature in China: A multi-city study. Environment International, 98, 82–88. https://doi.org/10.1016/j.envint.2016.10.004
Chu, Y., Liu, Y., Li, X., Liu, Z., Lu, H., Lu, Y., & Xiang, H. (2016). A review on predicting ground PM2.5concentration using satellite aerosol optical depth. Atmosphere, 7(10), 129. https://doi.org/10.3390/atmos7100129
Crouse, D. L., Peters, P. A., van Donkelaar, A., Goldberg, M. S., Villeneuve, P. J., Brion, O., & Burnett, R. T. (2012). Risk of nonaccidental and cardiovascular mortality in relation to long-term exposure to low concentrations of fine particulate matter: A Canadian national-level cohort study. Environmental Health perspectives, 120(5), 708–714. https://doi.org/10.1289/ehp.1104049
Crouse, D. L., Philip, S., Van Donkelaar, A., Martin, R. V., Jessiman, B., Peters, P. A., & Burnett, R. T. (2016). A new method to jointly estimate the mortality risk of long-term exposure to fine particulate matter and its components. Scientific Reports, 6(1), 1–10. https://doi.org/10.1038/srep18916
Dominici, F., Peng, R. D., Bell, M. L., Pham, L., McDermott, A., Zeger, S. L., & Samet, J. M. (2006). Fine particulate air pollution and hospital admission for cardiovascular and respiratory diseases. Journal of the American Medical Association, 295(10), 1127–1134. https://doi.org/10.1001/jama.295.10.1127
Gelaro, R., McCarty, W., Suárez, M. J., Todling, R., Molod, A., Takacs, L., & Zhao, B. (2017). The modern-era retrospective analysis for research and applications, version 2 (MERRA-2). Journal of Climate, 30(14), 5419–5454. https://doi.org/10.1175/JCLI-D-16-0758.1
Gent, J. F., Koutrakis, P., Belanger, K., Triche, E., Holford, T. R., Bracken, M. B., & Leaderer, B. P. (2009). Symptoms and medication use in children with asthma and traffic-related sources of fine particle pollution. Environmental Health Perspectives, 117(7), 1168–1174. https://doi.org/10.1289/ehp.0800335
Guo, Y., Tang, Q., Gong, D. Y., & Zhang, Z. (2017). Estimating ground-level PM2.5 concentrations in Beijing using a satellite-based geographically and temporally weighted regression model. Remote Sensing of Environment, 198, 140–149. https://doi.org/10.1016/j.rse.2017.06.001
Guo, Y., Zeng, H., Zheng, R., Li, S., Barnett, A. G., Zhang, S., & Williams, G. (2016). The association between lung cancer incidence and ambient air pollution in China: A spatiotemporal analysis. Environmental Research, 144, 60–65. https://doi.org/10.1016/j.envres.2015.11.004
Gupta, P., & Christopher, S. A. (2008). Seven year particulate matter air quality assessment from surface and satellite measurements. Atmospheric Chemistry and Physics, 8(12), 3311–3324. https://doi.org/10.5194/acp-8-3311-2008
Gupta, P., & Christopher, S. A. (2009). Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: Multiple regression approach. Journal of Geophysical Research Atmospheres, 114(14), D14205. https://doi.org/10.1029/2008JD011496
He, Q., & Huang, B. (2018a). Satellite-based high-resolution PM2.5 estimation over the Beijing–Tianjin–Hebei region of China using an improved geographically and temporally weighted regression model. Environmental Pollution, 236, 1027–1037. https://doi.org/10.1016/j.envpol.2018.01.053
He, Q., & Huang, B. (2018b). Satellite-based mapping of daily high-resolution ground PM2.5 in China via space-time regression modeling. Remote Sensing of Environment, 206, 72–83. https://doi.org/10.1016/j.rse.2017.12.018
Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A. R., Jaitly, N., & Kingsbury, B. (2012). Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine, 29(6), 82–97. https://doi.org/10.1109/MSP.2012.2205597
Hu, X., Belle, J. H., Meng, X., Wildani, A., Waller, L. A., Strickland, M. J., & Liu, Y. (2017). Estimating PM2.5 concentrations in the conterminous united states using the random forest approach. Environmental Science and Technology, 51(12), 6936–6944. https://doi.org/10.1021/acs.est.7b01210
Hu, X., Waller, L. A., Lyapustin, A., Wang, Y., Al-Hamdan, M. Z., Crosson, W. L., & Liu, Y. (2014). Estimating ground-level PM2.5 concentrations in the Southeastern United States using MAIAC AOD retrievals and a two-stage model. Remote Sensing of Environment, 140, 220–232. https://doi.org/10.1016/j.rse.2013.08.032
Hu, Z. (2009). Spatial analysis of MODIS aerosol optical depth, PM2.5, and chronic coronary heart disease. International Journal of Health Geographics, 8(1), 27. https://doi.org/10.1186/1476-072X-8-27
Hystad, P., Demers, P. A., Johnson, K. C., Brook, J., van Donkelaar, A., Lamsal, L., & Brauer, M. (2012). Spatiotemporal air pollution exposure assessment for a Canadian population-based lung cancer case-control study. Environmental Health, 11(1), 1–13. https://doi.org/10.1186/1476-069X-11-22
Just, A. C., Wright, R. O., Schwartz, J., Coull, B. A., Baccarelli, A. A., Tellez-Rojo, M. M., & Kloog, I. (2015). Using high-resolution satellite aerosol optical depth to estimate daily PM2.5 geographical distribution in Mexico City. Environmental Science and Technology, 49(14), 8576–8584. https://doi.org/10.1021/acs.est.5b00859
Kacenelenbogen, M., Léon, J. F., Chiapello, I., & Tanré, D. (2006). Characterization of aerosol pollution events in France using ground-based and POLDER-2 satellite data. Atmospheric Chemistry and Physics, 6(12), 4843–4849. https://doi.org/10.5194/acp-6-4843-2006
Kikuchi, M., Murakami, H., Suzuki, K., Nagao, T. M., & Higurashi, A. (2018). Improved hourly estimates of aerosol optical thickness using spatiotemporal variability derived from Himawari-8 geostationary satellite. IEEE Transactions on Geoscience and Remote Sensing, 56(6), 3442–3455. https://doi.org/10.1109/TGRS.2018.2800060
Kloog, I., Chudnovsky, A. A., Just, A. C., Nordio, F., Koutrakis, P., Coull, B. A., & Schwartz, J. (2014). A new hybrid spatio-temporal model for estimating daily multi-year PM2.5 concentrations across northeastern USA using high resolution aerosol optical depth data. Atmospheric Environment, 95, 581–590. https://doi.org/10.1016/j.atmosenv.2014.07.014
Kloog, I., Koutrakis, P., Coull, B. A., Lee, H. J., & Schwartz, J. (2011). Assessing temporally and spatially resolved PM2.5 exposures for epidemiological studies using satellite aerosol optical depth measurements. Atmospheric Environment, 45(35), 6267–6275. https://doi.org/10.1016/j.atmosenv.2011.08.066
Kloog, I., Nordio, F., Coull, B. A., & Schwartz, J. (2012). Incorporating local land use regression and satellite aerosol optical depth in a hybrid model of spatiotemporal PM2.5 exposures in the mid-atlantic states. Environmental Science and Technology, 46(21), 11913–11921. https://doi.org/10.1021/es302673e
Lao, X. Q., Guo, C., Chang, L. Y., Bo, Y., Zhang, Z., Chuang, Y. C., & Chan, T. C. (2019). Long-term exposure to ambient fine particulate matter (PM2.5) and incident type 2 diabetes: A longitudinal cohort study. Diabetologia, 62(5), 759–769. https://doi.org/10.1007/s00125-019-4825-1
Lee, H. J., Coull, B. A., Bell, M. L., & Koutrakis, P. (2012). Use of satellite-based aerosol optical depth and spatial clustering to predict ambient PM2.5 concentrations. Environmental Research, 118, 8–15. https://doi.org/10.1016/j.envres.2012.06.011
Li, T., Shen, H., Yuan, Q., & Zhang, L. (2018). Deep learning for ground-level PM2.5 prediction from satellite remote sensing data. International Geoscience and Remote Sensing Symposium (IGARSS), 2018, 7581–7584. https://doi.org/10.1109/IGARSS.2018.8519036
Liu, Y., Cao, G., Zhao, N., Mulligan, K., & Ye, X. (2018). Improve ground-level PM2.5 concentration mapping using a random forests-based geostatistical approach. Environmental Pollution, 235, 272–282. https://doi.org/10.1016/j.envpol.2017.12.070
Liu, Y., Park, R. J., Jacob, D. J., Li, Q., Kilaru, V., & Sarnat, J. A. (2004). Mapping annual mean ground-level PM2.5 concentrations using Multiangle Imaging Spectroradiometer aerosol optical thickness over the contiguous United States. Journal of Geophysical Research D: Atmospheres, 109(22), 1–10. https://doi.org/10.1029/2004JD005025
Liu, Y., Sarnat, J. A., Kilaru, V., Jacob, D. J., & Koutrakis, P. (2005). Estimating ground-level PM2.5 in the eastern United States using satellite remote sensing. Environmental Science and Technology, 39(9), 3269–3278. https://doi.org/10.1021/es049352m
Ma, Z., Hu, X., Huang, L., Bi, J., & Liu, Y. (2014). Estimating ground-level PM2.5 in China using satellite remote sensing. Environmental Science and Technology, 48(13), 7436–7444. https://doi.org/10.1021/es5009399
Paciorek, C. J., Liu, Y., Moreno-Macias, H., & Kondragunta, S. (2008). Spatiotemporal associations between GOES aerosol optical depth retrievals and ground-level PM2.5. Environmental Science and Technology, 42(15), 5800–5806. https://doi.org/10.1021/es703181j
Pope, C. A. (2000). Epidemiology of fine particulate air pollution and human health: Biologic mechanisms and who’s at risk? Environmental Health Perspectives, 108(SUPPL. 4), 713–723. https://doi.org/10.2307/3454408
Pope, C. A., & Dockery, D. W. (2006). Health effects of fine particulate air pollution: Lines that connect. Journal of the Air and Waste Management Association, 56(6), 709–742. https://doi.org/10.1080/10473289.2006.10464485
Rienecker, M. M., Suarez, M. J., Gelaro, R., Todling, R., Bacmeister, J., Liu, E., & Woollen, J. (2011). MERRA: NASA’s modern-era retrospective analysis for research and applications. Journal of climate, 24(14), 3624–3648. https://doi.org/10.1175/JCLI-D-11-00015.1
Schaap, M., Apituley, A., Timmermans, R. M. A., Koelemeijer, R. B. A., & De Leeuw, G. (2009). Exploring the relation between aerosol optical depth and PM2.5 at Cabauw, the Netherlands. Atmospheric Chemistry and Physics, 9(3), 909–925. https://doi.org/10.5194/acp-9-909-2009
van Donkelaar, A., Martin, R. V., & Park, R. J. (2006). Estimating ground-level PM2.5 using aerosol optical depth determined from satellite remote sensing. Journal of Geophysical Research Atmospheres, 111(21), D21201. https://doi.org/10.1029/2005JD006996
Wang, B., & Chen, Z. (2016). High-resolution satellite-based analysis of ground-level PM2.5 for the city of Montreal. Science of the Total Environment, 541, 1059–1069. https://doi.org/10.1016/j.scitotenv.2015.10.024
Wang, J. (2003). Intercomparison between satellite-derived aerosol optical thickness and PM2.5 mass: Implications for air quality studies. Geophysical Research Letters, 30(21), 2095. https://doi.org/10.1029/2003GL018174
Wang, X., & Sun, W. (2019). Meteorological parameters and gaseous pollutant concentrations as predictors of daily continuous PM2.5 concentrations using deep neural network in Beijing–Tianjin–Hebei. China. Atmospheric Environment, 211, 128–137. https://doi.org/10.1016/j.atmosenv.2019.05.004
Xue, T., Zheng, Y., Tong, D., Zheng, B., Li, X., Zhu, T., & Zhang, Q. (2019). Spatiotemporal continuous estimates of PM2.5 concentrations in China, 2000–2016: A machine learning method with inputs from satellites, chemical transport model, and ground observations. Environment International, 123, 345–357. https://doi.org/10.1016/j.envint.2018.11.075
Yao, F., Si, M., Li, W., & Wu, J. (2018). A multidimensional comparison between MODIS and VIIRS AOD in estimating ground-level PM2.5 concentrations over a heavily polluted region in China. Science of the Total Environment, 618, 819–828. https://doi.org/10.1016/j.scitotenv.2017.08.209
You, W., Zang, Z., Pan, X., Zhang, L., & Chen, D. (2015). Estimating PM2.5 in Xi’an, China, using aerosol optical depth: A comparison between the MODIS and MISR retrieval models. Science of the Total Environment, 505, 1156–1165. https://doi.org/10.1016/j.scitotenv.2014.11.024
You, W., Zang, Z., Zhang, L., Li, Y., & Wang, W. (2016). Estimating national-scale ground-level PM2.5concentration in China using geographically weighted regression based on MODIS and MISR AOD. Environmental Science and Pollution Research, 23(9), 8327–8338. https://doi.org/10.1007/s11356-015-6027-9
Yumimoto, K., Nagao, T. M., Kikuchi, M., Sekiyama, T. T., Murakami, H., Tanaka, T. Y., & Maki, T. (2016). Aerosol data assimilation using data from Himawari-8, a next-generation geostationary meteorological satellite. Geophysical Research Letters, 43(11), 5886–5894. https://doi.org/10.1002/2016GL069298
Zhang, L., Wilson, J. P., MacDonald, B., Zhang, W., & Yu, T. (2020). The changing PM2.5 dynamics of global megacities based on long-term remotely sensed observations. Environment International, 142, 105862. https://doi.org/10.1016/j.envint.2020.105862
Zhang, W., Xu, H., & Zhang, L. (2019). Assessment of Himawari-8 AHI aerosol optical depth over land. Remote Sensing, 11(9), 1108. https://doi.org/10.3390/rs11091108
Zheng, Y., Zhang, Q., Liu, Y., Geng, G., & He, K. (2016). Estimating ground-level PM2.5 concentrations over three megalopolises in China using satellite-derived aerosol optical depth measurements. Atmospheric Environment, 124, 232–242. https://doi.org/10.1016/j.atmosenv.2015.06.046
Zou, B., Pu, Q., Bilal, M., Weng, Q., Zhai, L., & Nichol, J. E. (2016). High-resolution satellite mapping of fine particulates based on geographically weighted regression. IEEE Geoscience and Remote Sensing Letters, 13(4), 495–499. https://doi.org/10.1109/LGRS.2016.2520480
Acknowledgements
The authors acknowledge Himawari-8/AHI AOD support by the P-Tree System, Japan Aerospace Exploration Agency (JAXA). MODIS data were supplied by NASA. The ground-based PM2.5 concentrations were obtained from the China Environmental Monitoring Center (CEMC). The MERRA-2 data were supported by Goddard Earth Sciences Data and Information Services Center (GES DISC).
Funding
This study was funded by National Natural Science Foundation of China, Grant number 41801255, Natural Science Foundation of Hebei Province, Grant number D2020409003, and Civil Aerospace Pre-research Project, Grant number D040102. Science for Earthquake Resilience, grant number XH19003Y.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Zhang, W., Zheng, F., Zhang, W. et al. Estimating Ground-Level Hourly PM2.5 Concentrations Over North China Plain with Deep Neural Networks. J Indian Soc Remote Sens 49, 1839–1852 (2021). https://doi.org/10.1007/s12524-021-01344-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12524-021-01344-3