
Abstract
Introduction
Chronic kidney disease (CKD) is a serious condition associated with significant morbidity and healthcare costs. Despite this, early-stage CKD is often undiagnosed, and globally there is substantial variation in the effectiveness of screening and subsequent management. Microsimulations can estimate future epidemiological costs, providing useful insights for clinicians, policymakers and researchers. Inside CKD is a programme designed to analyse the projected prevalence and burden of CKD for countries across the world, and to simulate hypothetical intervention strategies that can then be assessed for potential impact on health and economic outcomes at a national and a global level.
Methods
Inside CKD uses a population-based approach that creates virtual individuals for a given country, with this simulated population progressing through a microsimulation in 1-year increments. A series of data inputs derived from national statistics and key literature defined the likelihood of a change in health state for each individual. Input modules allow for the input of nationally specific demographic and CKD status (including prevalence, diagnosis rates, disease stage and likelihood of renal replacement therapy), disease progression, critical comorbidities, and mortality. Health economics are reflected in cost data and a flexible intervention module allows for the testing of hypothetical policies—such as screening strategies—that may alter disease progression and outcomes.
Results
Using input data from the UK as a case study and a 6-year simulation period, Inside CKD estimated a prevalence of 9.2 million individuals (both diagnosed and estimated undiagnosed) with CKD by 2027 and a 5.0% increase in costs for diagnosed CKD and renal replacement therapy. External validation and sensitivity analyses confirmed the observed trends, substantiating the robustness of the microsimulation.
Conclusions
Using a microsimulation approach, Inside CKD extends the reach of current CKD policy analyses by factoring in multiple inputs that reflect national healthcare systems and enable analysis of the effect of multiple hypothetical screening scenarios on disease progression and costs.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Why carry out this study? |
The prevalence of chronic kidney disease (CKD) continues to grow globally, yet inertia in healthcare strategies undermines the timely diagnosis that could slow disease progression and improve patient outcomes |
Microsimulation methods are useful for depicting the complexity of CKD across a multitude of stages. Inside CKD extends the scope of existing programmes by including a broader range of flexible inputs capable of simulating a wide range of granular outputs, multiple tailored screening scenarios, and investigating their impact on virtual patient trajectories |
In this methodology paper, we describe the programme and how it can be implemented, summarize a UK case study, and explore the potential of the programme as a framework for complex disease modelling |
What was learned from this study? |
Validation tests and sensitivity analyses demonstrated that our model generated projections that were consistent with those in the published literature |
The microsimulation presented here provides robust, global data projections for CKD, using the UK as a case study. Inside CKD will be used to predict trends across many countries to provide a global overview of the burden of CKD, and these data may inform healthcare policy decisions, support clinical research, and improve patient outcomes |
Introduction
Chronic kidney disease (CKD), defined as a reduced glomerular filtration rate (GFR) and/or increased urinary albumin to creatine ratio, is a serious healthcare concern. The global all-age CKD prevalence has increased by nearly 30% since 1990, with current prevalence estimates giving an approximate range between 8% and 16% [1,2,3]. Disease severity correlates with the extent of GFR reduction and albuminuria, which are used to classify the disease from CKD stage 1 (mild disease) to CKD stage 5 (severe disease) [4]. CKD often develops as a result of underlying conditions—most commonly type 2 diabetes (T2D), hypertension and glomerulonephritis [5, 6]—and patients with CKD have an increased risk of adverse renal and cardiovascular morbidity, as well as increased all-cause mortality [6, 7]. As such, CKD is associated with significant healthcare expenditure [8, 9], with disease progression reflected in increasing costs [10, 11]. Overall, the end stage of CKD—kidney failure—accounts for 7.2% of all Medicare claims in the USA [8]. Data for the UK show that 1.3% of National Health Service (NHS) spending is dedicated to CKD, and more than half of this is spent on the 2% of patients with kidney failure [12].
Timely detection and proactive medical management can mitigate the severity of CKD, potentially improving clinical outcomes [13, 14]. Although there are established benefits to early diagnosis, CKD stage 1–2 is often asymptomatic or presents with non-specific symptoms; this makes the condition challenging to detect. A recent UK-based screening study identified as many as 44% of individuals living with undiagnosed CKD [15], and a multinational, observational study assessing prevalence of undiagnosed CKD found that up to 95% of people with CKD stage 3 disease were undiagnosed [16]. Given the low awareness of CKD among general community members and healthcare workers [17, 18], proactive diagnostic tests are unlikely to be routinely practised in clinics unless healthcare screening programmes are introduced. Screening therefore offers an opportunity for earlier diagnosis and treatment before the condition reaches an advanced stage in which more pronounced symptoms are experienced.
Screening and other national strategies are urgently needed if the clinical and economic burdens of CKD are to be addressed, yet the Global Burden of Disease study has revealed stark contrasts between countries for CKD prevalence, diagnostic trends and treatment. The researchers noted that they had not “seen the same degree of progress in prevention of CKD mortality” as for other important non-communicable diseases, citing an unmet need for improved management of CKD risk factors in primary care and expanded access to kidney healthcare as critical factors [1]. Notably, despite the high prevalence of CKD, many countries do not follow guidelines; data from the International Society of Nephrology Global Kidney Health Atlas suggest that of the 116 countries surveyed, 21% do not have CKD management or referral procedures, 83% do not have a national strategy to improve patient care prior to dialysis, and over half of low-income countries do not have management and/or referral guidelines for CKD [19].
Policies to improve CKD management need to leverage approaches relevant to local resources and requirements; systematic screening has been identified as a key step in understanding prevalence and optimizing intervention [20]. Owing to constraints of time and budget, policymakers often rely on modelling to estimate future epidemiological trends, navigate uncertainty and project long-term implications for healthcare. Microsimulation analyses can complement clinical studies by conducting population-level analyses and projecting expected outcomes. A particular strength is that they allow for continuous, dynamic risk factors that can be modified over time, compared with the static risk factors employed in more traditional, macroscopic models. Patient-level approaches allow for recurring events across various health states, which can then be quantified by following a population of hypothetical individuals over time through a structured, robust model [21, 22]. This approach is valuable for policymakers who wish to consider how a specific demographic is affected by a condition, or how a disease is distributed differently on the basis of underlying characteristics. In this way, microsimulations can be used to evaluate scenarios that cannot be feasibly researched in the real-world setting, particularly for those seeking to anticipate how a given scenario may unfold decades into the future. Despite the clear benefits of models that explore ways to mitigate the burden of CKD, nuanced modelling for this type of simulation is currently lacking in the field. A systematic review explored 13 existing models for CKD, which could be stratified on the basis of progression driven by albuminuria or on linear GFR decline. The authors observed that current approaches do not adequately consider patient heterogeneity and that there is a need for models based on clinical rationale and extensive, high-quality data inputs [23].
For 20 years, the burden of CKD has been increasing globally, yet inertia and a lack of innovation have undermined the development of preventative policies; consequently, the pressure on dialysis units, treatment resources and transplant availability is growing annually. The impact on healthcare, society and patient quality of life is significant, particularly in a context in which COVID-19 has already stretched resources and is likely to continue to do so. Inside CKD is a programme designed to analyse the projected prevalence and burden of CKD and to simulate hypothetical intervention strategies that can then be assessed for potential impact on health and economic outcomes. Our research builds on previously developed software, research, methodological approaches and modelling [24,25,26,27,28], with initial simulations using continuous estimated GFR (eGFR) and albuminuria data from the Health Survey for England (HSE) to create a baseline cohort to reflect the UK population. This project aims to use microsimulation techniques to create a flexible framework for CKD using country-specific data inputs and to provide a nuanced, robust analysis of country-level burden of disease projections. This allows for the evaluation of key health policy decisions around screening and treatment of CKD based on local data.
Methods
Objectives
The overall objectives of Inside CKD are to project the clinical, epidemiological and economic burden of CKD between 2022 and 2027, and to assess the impact of potential policy interventions. Here, we report the development of a validated core microsimulation to model the burden of CKD, using findings for the UK as an initial case study.
Scientific Steering Committee
A scientific steering committee (SSC) was established to share insights into the design, implementation, interpretation and validation of the microsimulation. Specifically, the SSC offered advice regarding the modelling approach, clinical assumptions, addressing of gaps in available country-specific data, model calibrations, and interpretation of results from a global and a country-specific perspective. Members provided their expertise in a range of relevant fields (including health policy, economics, primary care, modelling and epidemiology), as well as clinical experience in CKD, and to ensure representation from across the countries included in the microsimulation.
Model Structure and Parameters
Inside CKD used a population-based approach, which included hypothetical 0–110-year-old individuals from participating countries and regions (Fig. 1). The perspective of the analysis was the public NHS in each country, but in cases in which there was no such system, the model was adapted to the commercial setting.

Global reach of the Inside CKD project. CKD chronic kidney disease
Microsimulations can be adjusted to different time frames, but for initial analyses on burden of disease, they were set to run from 2022 to 2027. This 6-year time frame was selected to reflect key changes to outcomes and to identify pivot points for health policy interventions. Six years is also the approximate length of a typical political term of office—a useful time frame for advocacy purposes. Extending beyond the 6-year period, although possible, would increase uncertainty and so this time horizon represents a balance of these two considerations.
Baseline Cohort
Each national-level microsimulation comprised 20 million virtual individuals who progressed through the microsimulation in 1-year increments. The individuals within the simulated populations were assigned baseline characteristics (age, sex and body mass index [BMI]) according to national statistics. They were also given an eGFR and albuminuria status at baseline, based on data from national health surveys, epidemiological surveys or other relevant literature. These clinical characteristics differentiated individuals without CKD from the CKD cohort, with the latter stratified by CKD stages 1–5 according to KDIGO (Kidney Disease Improving Global Outcomes) guidelines [4]. Some individuals with CKD stage 5 could, according to the guidelines of the country under consideration, receive renal replacement therapy (RRT) and thus represented a subgroup within the CKD stage 5 population. Those with CKD could also be assigned relevant comorbidities and/or complications on the basis of the known prevalence of each condition in the country-specific CKD population.
Projected Populations
Virtual individuals were cycled annually through the microsimulation and aged each year from baseline to the final year. The data inputs (described in the modules below) defined the likelihood of a change in health state for any given individual. The probability that CKD emerged in individuals who were disease-free at baseline was informed by background eGFR decline and albuminuria in the general population. For individuals already diagnosed with CKD, the probability of progression was estimated using eGFR and urine albumin creatinine ratio (ACR) status, both of which were updated annually. As eGFR declined and/or ACR increased—both modelled in accordance with epidemiological data—the CKD stage was modified and the relative risk of complications (such as myocardial infarction [MI], stroke, heart failure [HF] and RRT) increased. All epidemiological data were country-specific if available. All-cause mortality risk increased in relation to CKD stage. Relative risk was dependent on two parameters—eGFR and ACR—with risk of adverse outcomes (such as disease progression and mortality) increasing for those with later stages of CKD. Individuals with comorbidities at baseline (and those who acquired comorbidities later in the model) had a rate of progression ascertained according to annual regression slopes (see Appendix S1 in the supplementary material).
Microsimulation
The microsimulation was composed of five input modules, corresponding to population, the CKD cohort, disease burden, health economics and interventions (Fig. 2). A module comprising a series of metrics enabled projected data to be visualized in various epidemiological outputs, such as prevalence and disease stage.

Overview of microsimulation modules. CKD chronic kidney disease, CV cardiovascular, eGFR estimated glomerular filtration rate, ESRD end-stage renal disease, HF heart failure, HTN hypertension, MI myocardial infarction, RRT renal replacement therapy, SGLT2i sodium-glucose cotransporter 2 inhibitor, T2D type 2 diabetes
Module 1: Population
This module created a cohort representative of the general population of a given country using disaggregated data for age and sex, when possible, for the following country-specific parameters: BMI, demographic statistics, population projections, total fertility rates, births by age of mother, migration and mortality. Data were derived from national population projections, country-specific databases (e.g. for the UK, data from the Office of National Statistics were used), or, when these were not available, the United Nations population prospects database [29]. At baseline, virtual individuals were created from demographic statistics representative for the simulation start year (2022). Women were stochastically allocated a number of children with a birth date within the 6-year period; number of children and years of birth were generated from national statistics of fertility and mothers’ age at birth (as valid in the start year). Population projections were included to account for dynamic changes in population growth over time, including birth rate and mortality according to overall population demographics as opposed to CKD characteristics. The prevalence of CKD and related comorbidities increased with age in accordance with country-specific epidemiological data.
Module 2: CKD Status
Every individual in the virtual population was allocated an eGFR and ACR based on known distributions of these variables extracted from the literature or country databases. An individual’s eGFR and albuminuria value were used to categorize individuals with a given CKD status at baseline; eGFR was categorized into six stages: ≤ 15 (G5), 15 ≤ 30 (G4), > 30 ≤ 45 (G3a), > 45 ≤ 60 (G3b), > 60 ≤ 90 (G2) and > 90 (G1) mL/min/1.73 m2, and ACR was then categorized into three stages: ≤ 30 (A1), > 30 ≤ 300 (A2) and > 300 (A3) mg/g of urinary creatinine consistent with KDIGO classifications [4]. Prevalence data were derived from representative, individual, population-level, cross-sectional studies (e.g. data were obtained, in part, from the HSE for the UK, and from the National Health and Nutrition Examination Survey for the USA) but, because many countries were lacking population health surveys, aggregate data from the published literature were reviewed and used as necessary. When individual-level data were not available, smoothing algorithms were applied to aggregated CKD prevalence data to calculate individual-level distributions of albuminuria and eGFR according to KDIGO guidelines [4].
This module enabled distributions of eGFR and ACR variables to be dynamically simulated across the whole population while accounting for changes in prevalence of CKD over time. The degree of change corresponded with age and CKD status—also modelled in the microsimulation. For each country, a multinomial logistic regression model based on annual health survey data and/or aggregated CKD data from the literature was used to develop projections of individual ACR and eGFR levels. However, this module also calculated projections of CKD status over time using eGFR slopes (described in the next section). This included both the risk of the baseline non-CKD cohort developing CKD and the risk of individuals with CKD progressing to a more advanced stage of the disease as they cycled through the microsimulation. Throughout the process, each individual’s ACR percentile remained fixed relative to others in the population even as the actual estimate was variable.
eGFR Slopes
eGFR slopes representing the rate of annual eGFR decline were used to determine the rate of CKD progression. Different slopes were assigned on the basis of an individual’s clinical characteristics. These slopes were based on a retrospective regression analysis of data from a comprehensive patient database, DISCOVER CKD. An existing methodology was used to quantify the progression of CKD using eGFR trajectories over time, and to identify covariates associated with overall, slow and rapid eGFR decline [30]. The estimates generated were then adapted for the Inside CKD microsimulation model to assign eGFR slopes on the basis of the characteristics of each individual from the previous year, taking into account comorbidities and complications. These slopes were assumed to be of a consistent gradient across all included countries, allowing for a comparison of global rates of disease progression. Patients in the microsimulation were grouped into slow or rapid progressors (Table 1) on the basis of their unadjusted eGFR trajectories, with thresholds for progression to RRT based on modified categories from the published literature [31, 32]. It should be noted that the model coefficients are from a predictive model in which the parameters are modelled jointly, and so the coefficients have no causal interpretation alone.
Module 3: Disease Burden
Some of the virtual patients with CKD were assigned a comorbidity at baseline, as per prevalence data from country-specific databases or publications. This was a dynamic variable, given that individuals without CKD could go on to develop it and/or other diseases. The comorbidities T2D and hypertension were included in the model because they are strongly associated with CKD and often constitute part of its aetiology. Annual disease progression was adjusted accordingly such that, in most cases, virtual individuals with CKD and a comorbidity had a greater decline in eGFR slopes than patients without CKD and were also at increased risk of complications. Complications, distinct from comorbidities, were defined as associated conditions arising as a consequence of CKD or as an increased risk associated with CKD; HF, MI and stroke were included. Relative risks for complications were used to estimate the number of virtual patients who experienced cardiovascular disease during the microsimulation. For each comorbidity and complication, data were collected for incidence and prevalence, specific to the country of interest.
RRT
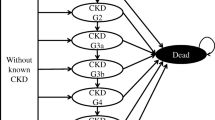
The proportion of individuals with RRT at baseline was derived from country-specific renal registries. On the basis of the country-specific threshold for RRT, individuals could progress to RRT during the microsimulation. From this point, the virtual individual was assigned to one of three main treatment pathways: to stay on their existing treatment pathway, to receive dialysis (haemodialysis or peritoneal dialysis), or to receive a renal transplant (Fig. 3). The health burden, costs and repercussions of this were reflected in the model.

Illustrative RRT pathway: people can cycle between different RRT modalities on the basis of eGFR, age and country-specific RRT pathway statistics. Country-specific statistics dictate the probability of transitioning between stages; this diagram is therefore illustrative as each country has its own RRT model. eGFR estimated glomerular filtration rate, RRT renal replacement therapy
Mortality
Every individual in the microsimulation had a probability of dying from any cause, based on their age and sex, and these probabilities were derived from national population statistics with relative risks for CKD ascertained from the revised KDIGO categories [4].
Module 4: Health Economics
Country-specific unit costs were corrected for inflation between the year the data were collected and the start year of the microsimulation. This adjustment was based on the gross domestic product deflator and International Monetary Fund data [33]. To address country-specific data gaps, unit costs were converted to the relevant local currencies using precise point positioning algorithms. Future costs and outcomes of healthcare interventions were discounted to present values, adjusting for differences in expenditure compared with outcomes. The model included direct costs associated with CKD stages (costs for CKD stages 1 and 2 were assumed to be zero) and RRT costs to calculate the economic burden for each country. Direct costs outside of RRT modalities excluded hospitalizations and were taken from the literature and/or national databases for two reasons: first, to be conservative regarding estimates; and second, to avoid a confounding effect by counting patients with CKD who were hospitalized for other conditions. No indirect costs were included in the model owing to a paucity of data. Health state utility weights were based on EuroQol-5 Dimension utility scores and used, with advice from the SSC, to calculate health-related quality of life (HRQoL). Health state utility weights, where zero represents death and one a state of perfect health, were estimated to a universal range: from 0.85 for CKD stage 1 and 2, to 0.73 for CKD stage 5 (pre-RRT), and 0.57 for individuals receiving peritoneal dialysis [34].
Module 5: Intervention Scenarios
The microsimulation can be modified to project the outcomes of diverse policy intervention types (e.g. different screening policies). The use and design of these interventions relies on a combination of data and assumptions, and input from the SSC on the needs of their respective countries. The microsimulation therefore has, for example, the potential to factor in screening programmes across different settings and populations, as well as national health interventions. Inside CKD allows policymakers and researchers to examine the impact of potential healthcare policies by comparing outcomes derived from theoretical interventions with a priori projections (i.e., if no intervention is attempted).
Outputs
The outputs of the microsimulation included—for baseline and the 6-year projection period—the annual prevalence of CKD by stage, comorbidities by CKD stage, and incidence of cardiovascular complications by type (MI, stroke and HF) and RRT (overall and by modality). Additionally, the associated costs for each outcome were quantified for different clinical characteristics, as was HRQoL. Table 2 summarizes the totality of potential outputs from the microsimulation. Differences in the data outputs between various policy intervention scenarios indicate which strategy may be of greater financial and patient benefit.
Management of Uncertainties and Reporting Uncertain Analyses
Missing Input Data
As described, a set of inputs was needed for each module. Of these, global inputs were derived for annual eGFR slopes that determined CKD progression rates, the relative risk of cardiovascular complications and all-cause mortality, as well as utility weights. The remaining parameters were generated from local data for each country (subject to availability). To identify sources of information, country-specific researchers collaborated with the SSC and completed a data capture template according to a standardized literature review. Data sources for each input are shown in Appendix S2 in the supplementary material. Each of these reviews assessed statistical databases and literature to locate country-specific demographic data, as well as incidence, prevalence and all-cause mortality data for CKD, HF, stroke and MI. Online databases (country-specific renal databases, PubMed and ScienceDirect) were searched for published data on age and sex-specific CKD prevalence data per country presented according to KDIGO classified measures of ACR and eGFR [4, 35]. In some cases, the raw data as identified were not appropriate for use (e.g. in some cases prevalence rather than incidence data were available), thus data transformations were used to calculate and/or adapt material for the module. These transformations are detailed in Appendix S3 in the supplementary material, which describes the microsimulation framework.
A data hierarchy algorithm was developed to validate the quality of data available for the simulation. Data quality for each country was ranked to determine whether data were available at the patient level, and whether data were representative, accurate and complete. Given the scope of Inside CKD and the breadth of data assessed, inevitably not all countries had all the requisite data and/or data of the required quality. When individual patient-level data were not available, aggregated data reporting CKD prevalence were used as per the KDIGO guidelines [4]. In some cases, a data algorithm was used to suggest proxy data for a given, missing input. In brief, this involved a list of comparable regions for which a series of indicators (reflecting epidemiological, health systems and demographic factors) were available. This allowed researchers to choose from a list of proxy countries and to determine the extent to which these ‘clustered’ around demographic criteria. These proxy countries were created on the basis of similar values to the index country for the selected indicators. The SSC was also asked to provide qualitative insights into the appropriacy of potential proxy data sources and in some cases suggested more suitable alternatives. To ensure further accuracy, adjustments to the microsimulation were made to calibrate the model and to draw comparisons of model outputs (e.g. disease prevalence rates) with empirical data. Detailed information regarding calibration and specific transformations is given in Appendix S3.
Model Transparency and Validation
Five different types of validity were assessed in relation to this microsimulation: face validity, verification (or internal validity), external validity, predictive validity, and cross validity [36]. Model assumptions have been validated in previous research [26]. Face validity was assessed through evaluation of the microsimulation assumptions, structure, data sources, and results in relation to the stated aims and objectives. For the Inside CKD model, assumptions were based on peer-reviewed publications as identified by the data hierarchy assessment and as validated by expert opinions from the SSC. Internal (or technical) verification addressed whether the model’s calculations were working as intended and confirmed that our results were consistent with the model’s specification. The accuracy of coding was assessed using the code hosting platform GitHub (Version 2.9.0 [×64]) for version control and through unit testing undertaken by two coders working independently. For external validity, we compared the microsimulation with actual event data, simulating events that have occurred and comparing the results. To illustrate that the model accurately recreates an appropriate demographic distribution, the numbers of male and female participants were validated, as well as rates for fertility and disease incidence rates. Predictive validity was assessed when simulated results were compared with prospectively observed events. Cross validity was assessed by comparing the results of our microsimulations with those of other models that address similar issues (e.g. those using a Markov model to project CKD prevalence).
Sensitivity Analyses
Sensitivity analyses of key parameters were conducted to evaluate the robustness of potential findings to changes in assumptions, costs, outcome and discounting. Parametric uncertainty analyses were conducted on the following key microsimulation inputs: eGFR slopes, relative risks, RRT and diagnosis rates.
Statement of Ethics Compliance
This study was conducted in accordance with ethical principles of the Declaration of Helsinki and Good Clinical Practice guidelines. This study did not require informed consent or institutional/ethical review board approval because this was a non-interventional study based on secondary data use.
Results
The UK was the primary case study for our microsimulation. The estimated prevalence of CKD in the UK in 2022 is 13.4% (9.2 million individuals out of a total population of 68.5 million), which includes both diagnosed and undiagnosed individuals with all stages of the disease. Assuming no new policy interventions or change to the current standard of care, the microsimulation estimated that CKD prevalence will remain high at 13.3% (9.3 million individuals out of the total population), indicative of an absolute decrease of 0.1% and a relative increase of 1.1% by 2027. Within this group, the number of individuals with RRT (all modalities) is projected to rise to 78,479 by 2027. The total annual diagnosed CKD and RRT costs are predicted to rise from £3.03 billion in 2022 to £3.18 billion in 2027, representing a 5.0% increase. Notably, although RRT cases are projected to account for only 2.9% of the population diagnosed with CKD, RRT is projected to account for 37.4% of the total annual healthcare CKD costs.
Validation
External validation showed the microsimulation estimate was not possible within the same range of dates, and there was some variation noted across existing estimates. The microsimulation presented here appears to be slightly conservative relative to historical studies, but within the expected parameters: survey data from 2003 predicted a CKD prevalence of 12.6% in 2009/2010 rising to 13.9% in 2016 [37], and a modelling study from Public Health England predicted that between 2011 and 2036 the prevalence of CKD stage 3–5 among people aged 16 years and over is expected to increase to 4.2 million or 8.3% [38]. The Global Burden of Disease study predicted a percentage decrease of − 11.4% [− 13.7 to − 8.9] in age-standardized rates between 1990 and 2017, reflecting some variation in predicted direction of change, albeit for a different time frame [1]. In terms of costs, the NHS England report predicted costs of from £1.44 to £1.45 billion for 2009–2010; by comparison, the Inside CKD cost projections were greater, but it should be noted that the NHS England estimates covered costs associated with CKD stages 3–5 for England only (as opposed to all four UK nations) and were generated over a decade ago [39].
Sensitivity Analyses
Sensitivity analyses examined the impact of eGFR slopes generated by alternative sources on prevalence findings from three sources: current literature, the Clinical Practice Research Datalink and DISCOVER CKD (Table 3). These data suggest that the microsimulation is robust against alterations for this parameter.
Discussion
Our microsimulation responds to a clear need from the scientific and health policy community that calls for robust policy analysis with reliable projections of the burden of disease for CKD. By using a microsimulation, Inside CKD enables recurring events across multiple health states for a virtual population to be quantified over time. Our model extends the reach of current microsimulations by providing flexibility in terms of what to investigate (e.g. the projected costs of future complications in a CKD cohort) and by allowing inputs that reflect local healthcare systems. The accumulation of microsimulations from across different countries can ultimately be used for multi-country analyses to create a global perspective. The interventions module may be of particular interest to policymakers because it allows different policy strategies to be tested and evaluated. Our hope is that Inside CKD will provide governments—and all those bearing responsibility for healthcare programmes—with an enhanced perspective on how they can improve CKD management.
It is important to note that our microsimulations resulted in estimates for the UK that are generally consistent with other projections in the literature [1, 37, 39, 40]. Findings from other countries will be cross-checked and validated by national health survey data or other gold standard resources as available, offering policymakers robust, reliable estimates for the CKD population, costs and other critical indicators. These can be used to inform national healthcare decisions, including those relating to budget and resource allocation. Crucially, the potential of Inside CKD rests with the ability to model policy actions into a projected future, thus observing the impact of different choices on health outcomes, disease progression and cost. These choices are likely to be reflected in outcomes at the population level, but in terms of direct, clinical practice, the greater hope must be that individual patients benefit from improved healthcare systems and optimized management of their CKD. Given repeated calls for such a tool, we believe Inside CKD offers a new standard for disease modelling, based on an approach that can be extrapolated and used to model other chronic diseases.
Another clear avenue for future research will be between-country comparisons, but a few caveats should be considered. It should, for example, be noted that thresholds for initiation of RRT are based on national data, therefore, future comparisons between RRT projections for different countries should be interpreted with care. Another consideration is that stark shifts in demographic trends unrelated to CKD (e.g. an increase in the proportion of elderly people in a population) may be a proxy for other shifts. For example, improved sanitation, healthcare and vaccination programmes may reduce the burden of infectious disease in a country such that the relative impact of chronic, long-term conditions (including CKD) rises. For this reason, between-country analyses should be approached with an awareness of the broader context and political landscape of the countries involved.
In terms of unpredictable change, it should be noted that Inside CKD was designed in, and for, a pre-COVID-19 world; the full implications of a global pandemic are still being realized, and the complex interplay between COVID-19 and pre-existing chronic conditions is still unclear, as is the extent to which COVID-19 may exacerbate the risks we have modelled within our CKD cohort. However, a recent meta-analysis suggests that the risk of COVID-19 infection is higher in patients with CKD receiving dialysis than in those with earlier stages of the disease or those who have received a transplant, and that COVID-19 increases the risk of mortality in people with CKD [41]. Future iterations of Inside CKD will be better placed to incorporate findings as they emerge. However, at this stage of modelling, when so much is uncertain, our microsimulation maintains the coherency of the knowledge base prior to the pandemic, and we as researchers acknowledge that this will almost certainly require modification in the years to come. The potential impact of the COVID-19 pandemic on the diagnosis and management of CKD over the projection period may prove an interesting avenue for future research.
The strength of our model rests primarily on its ability to factor in multiple, complex variables and their change over time. Most notably, we combine projected albuminuria data with linear GFR decline for a more accurate estimate of CKD progression. Our virtual population is highly heterogenous and, importantly, reflective of national or regional demographics for a country of interest. There are several limitations to our programme. Our approach assumes that there are no major changes in the management of CKD (e.g. changes in reimbursement, technology or intervention policy) over the projection period. In reality, this is unlikely to be the case, but for the purposes of modelling, when researchers may be considering hypothetical strategies as a precursor to their implementation, it is hoped that this limitation will not undermine the utility of the programme. Similarly, novel therapeutics and/or changes in the costs or availability of medicines within the time frame are not reflected but would, it can be hypothesized, have an impact in real terms. It is also the case that indirect cultural changes or advances may influence patient outcomes and costs in ways that are not easy to predict or model; inevitably, the changing and unpredictable circumstances of real-life situations may impact on the microsimulation in ways that are challenging to predict, so interpretation of any model must be made with this limitation in mind.
Conclusions
Inside CKD offers policymakers and researchers a robust, validated model that allows for flexible inputs and a multifactorial approach. This microsimulation addresses key gaps in modelling for CKD and is adaptable enough to reflect national epidemiology data. It reflects variation in comorbidity burden and differential progression rates that improve the accuracy of projected prevalence, cost and disease outcomes that can then be compared across countries. Inside CKD offers a comprehensive and innovative approach to modelling that can be used to trial healthcare policy interventions for improving outcomes in CKD.
References
GBD Chronic Kidney Disease Collaboration. Global, regional, and national burden of chronic kidney disease, 1990–2017: a systematic analysis for the Global Burden of Disease Study 2017. 2020. https://doi.org/10.1016/S0140-6736(20)30045-3.
Hill NR, Fatoba ST, Oke JL, et al. Global prevalence of chronic kidney disease—a systematic review and meta-analysis. PLoS ONE. 2016;11:e0158765.
Murton M, Goff-Leggett D, Bobrowska A, et al. Burden of chronic kidney disease by KDIGO categories of glomerular filtration rate and albuminuria: a systematic review. Adv Ther. 2021;38:180–200.
Levey AS, de Jong PE, Coresh J, et al. The definition, classification, and prognosis of chronic kidney disease: a KDIGO Controversies Conference report. Kidney Int. 2011;80:17–28.
Xie Y, Bowe B, Mokdad AH, et al. Analysis of the Global Burden of Disease study highlights the global, regional, and national trends of chronic kidney disease epidemiology from 1990 to 2016. Kidney Int. 2018;94:567–81.
Carpio EM, Ashworth M, Asgari E, et al. Hypertension and cardiovascular risk factor management in a multi-ethnic cohort of adults with CKD: a cross sectional study in general practice. J Nephrol. 2022;35:901–10.
Fletcher BR, Damery S, Aiyegbusi OL, et al. Symptom burden and health-related quality of life in chronic kidney disease: a global systematic review and meta-analysis. PLoS Med. 2022;19:e1003954.
Saran R, Robinson B, Abbott KC, et al. US renal data system 2019 annual data report: epidemiology of kidney disease in the United States. Am J Kidney Dis. 2020;75:A6–7.
Darlington O, Dickerson C, Evans M, et al. Costs and healthcare resource use associated with risk of cardiovascular morbidity in patients with chronic kidney disease: evidence from a systematic literature review. Adv Ther. 2021;38:994–1010.
Elshahat S, Cockwell P, Maxwell AP, Griffin M, O’Brien T, O’Neill C. The impact of chronic kidney disease on developed countries from a health economics perspective: a systematic scoping review. PLoS ONE. 2020;15:e0230512.
Wyld ML, Lee CM, Zhuo X, et al. Cost to government and society of chronic kidney disease stage 1–5: a national cohort study. Intern Med J. 2015;45:741–7.
National Institute for Health and Care Excellence (NICE). Chronic kidney disease in adults: assessment and management. 2015. PMID 32208570.
Levin A, Rigatto C, Brendan B, et al. Cohort profile: Canadian study of prediction of death, dialysis and interim cardiovascular events (CanPREDDICT). BMC Nephrol. 2013;14:121.
Shlipak MG, Tummalapalli SL, Boulware LE, et al. The case for early identification and intervention of chronic kidney disease: conclusions from a Kidney Disease: Improving global outcomes (KDIGO) controversies conference. Kidney Int. 2021;99:34–47.
Hirst JA, Hill N, O’Callaghan CA, et al. Prevalence of chronic kidney disease in the community using data from OxRen: a UK population-based cohort study. Br J Gen Pract. 2020;70:e285–93.
Virgitti JB, Moriyama T, Wittbrodt ET, et al. REVEAL-CKD: prevalence of undiagnosed early chronic kidney disease in France and Japan [Abstract]. J Am Soc Nephrol. 2021;32:715–6.
White SL, Polkinghorne KR, Cass A, Shaw J, Atkins RC, Chadban SJ. Limited knowledge of kidney disease in a survey of AusDiab study participants. Med J Aust. 2008;188:204–8.
Szczech LA, Stewart RC, Su HL, et al. Primary care detection of chronic kidney disease in adults with type-2 diabetes: the ADD-CKD Study (awareness, detection and drug therapy in type 2 diabetes and chronic kidney disease). PLoS ONE. 2014;9:e110535.
Bello AK, Levin A, Tonelli M, et al. Global Kidney Health Atlas: A report by the International Society of Nephrology on the current state of organization and structures for kidney care across the globe. Brussels, Belgium: International Society of Nephrology; 2017. pp. 107–137.
Nagib SN, Abdelwahab S, Amin GEE, Allam MF. Screening and early detection of chronic kidney disease at primary healthcare. Clin Exp Hypertens. 2021;43:416–8.
Rutter CM, Miglioretti DL, Savarino JE. Evaluating risk factor assumptions: a simulation-based approach. BMC Med Inform Decis Mak. 2011;11:55.
Rutter CM, Zaslavsky AM, Feuer EJ. Dynamic microsimulation models for health outcomes: a review. Med Decis Making. 2011;31:10–8.
Sugrue DM, Ward T, Rai S, McEwan P, van Haalen HGM. Economic modelling of chronic kidney disease: a systematic literature review to inform conceptual model design. Pharmacoeconomics. 2019;37:1451–68.
Kilpi F, Webber L, Musaigner A, et al. Alarming predictions for obesity and non-communicable diseases in the Middle East. Public Health Nutr. 2014;17:1078–86.
Knuchel-Takano A, Hunt D, Jaccard A, et al. Modelling the implications of reducing smoking prevalence: the benefits of increasing the UK tobacco duty escalator to public health and economic outcomes. Tob Control. 2018;27:e124–9.
Pimpin L, Cortez-Pinto H, Negro F, et al. Burden of liver disease in Europe: epidemiology and analysis of risk factors to identify prevention policies. J Hepatol. 2018;69:718–35.
Pineda E, Sanchez-Romero LM, Brown M, et al. Forecasting future trends in obesity across Europe: the value of improving surveillance. Obes Facts. 2018;11:360–71.
Webber L, Xu M, Graff H. Modelling the long-term health impacts of changing exposure to NO2 and PM2.5 in London. 2020. https://www.london.gov.uk/sites/default/files/modelling_the_long-term_health_impacts_of_changing_exposure_to_no2_and_pm2.5_in_london_final_250220_-4.pdf. Accessed 22 Oct 2022.
United Nations. World Population Prospects 2022. https://population.un.org/wpp/. Accessed 14 July 2022.
Pecoits-Filho R, James G, Carrero JJ, et al. Methods and rationale of the DISCOVER CKD global observational study. Clin Kidney J. 2021;14:1570–8.
George LK, Koshy SKG, Molnar MZ, et al. Heart failure increases the risk of adverse renal outcomes in patients with normal kidney function. Circ Heart Fail. 2017;10:2.
Go AS, Yang J, Tan TC, et al. Contemporary rates and predictors of fast progression of chronic kidney disease in adults with and without diabetes mellitus. BMC Nephrol. 2018;19:146.
International Monetary Fund. International Monetary Fund Data. https://www.imf.org/en/Data. Accessed 14 July 2022.
Cooper JT, Lloyd A, Sanchez JJG, Sörstadius E, Briggs A, McFarlane P. Health related quality of life utility weights for economic evaluation through different stages of chronic kidney disease: a systematic literature review. Health Qual Life Outcomes. 2020;18:310.
Levey AS, Eckardt KU, Dorman NM, et al. Nomenclature for kidney function and disease: report of a kidney disease: improving Global Outcomes (KDIGO) Consensus Conference. Kidney Int. 2020;97:1117–29.
Eddy DM, Hollingworth W, Caro JJ, et al. Model transparency and validation: a report of the ISPOR-SMDM modeling good research practices task force-7. Med Decis Making. 2012;32:733–43.
Hounkpatin HO, Harris S, Fraser SDS, et al. Prevalence of chronic kidney disease in adults in England: comparison of nationally representative cross-sectional surveys from 2003 to 2016. BMJ Open. 2020;10: e038423.
Public Health England. Chronic Kidney Disease (CKD) prevalence model. October 2014 PHE publications gateway number: 2014386. https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/612303/ChronickidneydiseaseCKDprevalencemodelbriefing.pdf. Accessed 14 July 2022.
Kerr M, Bray B, Medcalf J, O’Donoghue DJ, Matthews B. Estimating the financial cost of chronic kidney disease to the NHS in England. Nephrol Dial Transplant. 2012;27(Suppl 3):73–80.
UK Kidney Association. UK Renal Registry. https://ukkidney.org/about-us/who-we-are/uk-renal-registry. Accessed 14 July 2022.
Chung EYM, Palmer SC, Natale P, et al. Incidence and outcomes of COVID-19 in people with CKD: a systematic review and meta-analysis. Am J Kidney Dis. 2021;78:804–15.
Acknowledgements
The authors would like to thank all investigators participating in the Inside CKD study programme and also the members of the Scientific Steering Committee (see Appendix S4 in the supplementary material).
Funding
Inside CKD is funded by AstraZeneca. Inside CKD is a project based on microsimulation data and so no drugs were supplied or funded. All statistical analyses were funded by AstraZeneca and conducted by HealthLumen. The corresponding author had full access to all data and had final responsibility for the decision to submit for publication. AstraZeneca also funded the Rapid Service Fee and Open Access Fee.
Medical Writing, Editorial, and Other Assistance
The authors thank Charlotte Mulcare writing on behalf of Oxford PharmaGenesis Ltd, Oxford, UK for providing medical writing and editorial support, which was sponsored by AstraZeneca in accordance with Good Publication Practice guidelines.
Author Contributions
The general content of the manuscript was agreed upon by all authors. The first draft of the manuscript was developed by Lise Retat and all authors contributed to its development. All authors approved the final version of the manuscript before its submission. An AstraZeneca team reviewed the manuscript during its development and was allowed to make suggestions. However, the final content was determined by the authors. Juan José García Sánchez is the guarantor of this work.
Disclosures
Navdeep Tangri and Steven Chadban are members of the SSC. Juan José García Sánchez and Claudia Cabrera are employees of AstraZeneca. Lise Retat is an employee of HealthLumen Limited and has received research support from AstraZeneca. Navdeep Tangri and Steven Chadban have received honoraria from AstraZeneca.
Compliance with Ethics Guidelines
This study was conducted in accordance with ethical principles of the Declaration of Helsinki and Good Clinical Practice guidelines. This study did not require informed consent or institutional/ethical review board approval because this is a non-interventional study based on secondary data use.
Data Availability
The data sets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Author information
Authors and Affiliations
Corresponding author
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Tangri, N., Chadban, S., Cabrera, C. et al. Projecting the Epidemiological and Economic Impact of Chronic Kidney Disease Using Patient-Level Microsimulation Modelling: Rationale and Methods of Inside CKD. Adv Ther 40, 265–281 (2023). https://doi.org/10.1007/s12325-022-02353-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12325-022-02353-5