
Abstract
Prior research suggests most students do not glean valid cues from provided visuals, resulting in reduced metacomprehension accuracy. Across 4 experiments, we explored how the presence of instructional visuals affects students’ metacomprehension accuracy and cue-use for different types of metacognitive judgments. Undergraduates read texts on biology (Study 1a and b) or chemistry (Study 2 and 3) topics, made various judgments (test, explain, and draw) for each text, and completed comprehension tests. Students were randomly assigned to receive only texts (text-only condition) or texts with instructional visualizations (text-and-image condition). In Studies 1b, 2 and 3, students also reported the cues they used to make each judgment. Across the set of studies, instructional visualizations harmed relative metacomprehension accuracy. In Studies 1a and 2, this was especially the case when students were asked to judge how well they felt they could draw the processes described in the text. But in Study 3, this was especially the case when students were asked to judge how well they would do on a set of comprehension tests. In Studies 2 and 3, students who reported basing their judgments on representation-based cues demonstrated more accurate relative accuracy than students who reported using heuristic based cues. Further, across these studies, students reported using visual cues to make their draw judgments, but not their test or explain judgments. Taken together, these results indicate that instructional visualizations can hinder metacognitive judgment accuracy, particularly by influencing the types of cues students use to make judgments of their ability to draw key concepts.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Metacognitive effects of instructional visuals: The role of cue use and judgment type
The ability to accurately monitor and judge one’s own learning is an important aspect of self-regulated learning. Monitoring accuracy is important because students need to effectively guide their time and attention to where it is most needed for optimal learning. In college, success is highly dependent on students’ ability to effectively comprehend informational text; thus, it is important for them to effectively monitor their comprehension. Effective comprehension monitoring involves making judgments about how well something has been learned and using that information to regulate subsequent learning and studying behaviors (e.g., deciding which topics to restudy or how much time to allocate to specific topics) (Wiley et al., 2016).
In the context of text comprehension, metacomprehension accuracy refers to the ability of an individual to predict how well they will do on comprehension tests after reading a set of texts. When students are given a set of topics to learn, several distinct measures of metacomprehension accuracy can be computed. Absolute accuracy is computed as the mean absolute deviation between judged and actual performance. This measure is sometimes referred to as calibration because it gives an idea of how far off a person's judgments are from actual performance. Although absolute accuracy has pragmatic utility for effective self-regulated learning, such as informing decisions about whether different types of study efforts are needed to achieve some specific learning goal (Dunlosky & Rawson, 2012), it can be influenced by non-metacognitive factors such as text or test difficulty. Thus, another measure of judgment accuracy, relative accuracy, is often preferred. Relative accuracy is independent of a learner’s absolute performance on a task and is generally considered a more accurate reflection of metacognitive monitoring (Griffin et al., 2019a, 2019b; Nelson & Narens, 1994). In metacomprehension paradigms, relative accuracy is typically computed as the intra-individual Pearson correlation or Goodman–Kruskal Gamma correlation between a learners predicted and actual performance across a set of tasks and captures how well learners can differentiate between performance outcomes for different tasks (Glenberg & Epstein, 1985; Maki & Berry, 1984). For both measures (Pearson or Gamma), perfect accuracy (a correlation of 1.0) would mean that texts assigned a high probability of being correctly understood were correctly understood as evidenced by performance on the corresponding test, and texts assigned a low probability of being correctly understood were incorrectly understood as evidenced by performance on the corresponding text. However, as noted by Griffin et al., (2019a, 2019b), Pearson's correlations are arguably more appropriate when judgments predict continuous comprehension scores from multi-item tests like those typically used in studies of text comprehension. While intra-individual Pearson correlations capture the degree of accuracy between continuous judgments and comprehension measures, Gamma only addresses the frequency of hits and misses (whether the prediction was right or wrong), without capturing how close those hits and misses are.
Other measures that apply signal detection theory (SDT), like d’ or meta d’, have also been used as measures of relative accuracy, however they are often not appropriate to use in metacomprehension paradigms because they too assume that both judgment and performance are discrete, rather than continuous (Fleming & Lau, 2014). Typically, these measures use item level data to compute probabilities that each have their own independently rated judgments, unlike in metacomprehension paradigms where a judgment applies only to a continuous aggregate score on multi-item tests. Because of the challenges associated with accurately measuring metacomprehension accuracy, we will report both Pearson’s r and Gamma as measures of relative accuracy throughout this manuscript.
Despite the importance of being able to accurately monitor one’s own comprehension, research has shown that monitoring accuracy is particularly poor when students are asked to judge their comprehension from expository text (Dunlosky & Lipko, 2007; Maki, 1998a, 1998b; Thiede et al., 2009). The primary explanation for poor metacomprehension accuracy is that students often use suboptimal cues when making their predictions. According to Koriat’s (1997) cue utilization framework, learners base their judgments of learning on two general types of cues: (a) those tied to their own subjective experiences during learning and (b) those tied to a priori assumptions about the task, the materials, or one’s own abilities. The latter, often referred to as heuristic cues, includes one’s interest in the topic, their familiarity or prior knowledge with the topic, or their own perceived ability (Wiley et al., 2016). These types of cues tend to be less accurate predictors of comprehension because they are not directly tied to the readers attempts at creating a mental model or situation model of the text they are reading. The former, often referred to as representation-based or situation model-based cues, develop from the process of trying to create a situation model of the text. These cues include whether a person feels like they could summarize or explain the topic to someone else and tend to be better predictors of actual comprehension. Although representation-based cues are better predictors of comprehension, research suggests students are more likely to rely on heuristic cues for making their judgments of learning (Thiede et al., 2010).
In the present study, we explored how the presence of instructional visualizations affects students’ metacomprehension accuracy and cue use for learning from complex texts in biology (Study 1a and 1b) and Chemistry (Study 2 and 3). We also explored how different types of judgments of learning—judgments of future test performance, judgments of one’s ability to explain the material, and judgments of one’s ability to draw the material—might be differentially impacted by the presence of visualizations. Overall, the goal was to clarify prior research on the metacognitive effects of instructional visualizations to determine whether these effects depend on the type of judgment students are asked to make.
Metacognitive Effects of Instructional Visualizations
Research has demonstrated that various factors can impact learners’ access to representation-based cues. One such factor is how the text is presented, such as whether the learning materials are presented as multimedia (a combination of text and images) or single media (text only). In science, technology, engineering, and mathematics (STEM), learning from expository text is especially difficult because it requires building relationships among complex concepts, generating inferences, and creating a coherent mental model of the processes or phenomena being described (McNamara et al., 2012). Further, understanding complex processes in STEM often requires mentally organizing and manipulating spatial information (Hegarty & Just, 1993; Sanchez & Wiley, 2014). For example, understanding concepts and processes like the circulatory system in biology or intermolecular force in chemistry requires generating mental representations that include multiple components, the structural and functional relations between those components, and dynamic processes occurring at scales that may not be directly perceptible.
Because learning from expository science text is challenging and requires students to generate spatial mental models, instructional visualizations like diagrams and illustrations are often used to supplement learning from science text. A vast literature has demonstrated that including visualizations can result in better learning compared to learning from text alone (see Mayer & Fiorella, 2022 for a review). However, research examining the effect of multimedia on metacomprehension accuracy is less robust and indicates that it may not always support more accurate metacomprehension (Jaeger & Wiley, 2014; Serra & Dunlosky, 2010; Wiley, 2019). For example, Serra and Dunlosky (2010) had students read a text about lightning formation that was paired with no images, conceptual diagrams, or decorative photographs. While students demonstrated better comprehension in the conceptual diagram condition, there was no difference in relative accuracy across the three conditions. In a similar study, Jaeger and Wiley (2014) found that the presence of conceptual images had no effect on relative accuracy compared to a text-only condition, but that decorative images led to worse relative accuracy. Finally, Wiley (2019) also found that the presence of conceptually relevant diagrams or animations had no effect on absolute accuracy compared to a text only condition, but decorative photographs resulted in worse judgment calibration.
One argument for why the presence of visuals, even those that are conceptually relevant, does not improve comprehension monitoring is that students may hold general beliefs about the utility of visuals which may affect their judgments of learning. For example, Serra and Dunlosky (2010) showed that students hold the belief that multimedia is more effective for learning than text alone even in cases where the images are not conceptually relevant and suggested that using this multimedia heuristic could lead to reduced comprehension monitoring accuracy. Similarly, Wiley (2019) found that the variance in learners’ judgments was best explained by their interest ratings for the learning materials. Based on this finding, Wiley argued that the interest evoked by the learning materials was contributing to their evaluations of their own understanding. Further, she suggested that students may experience an illusion of understanding when presented with visualizations because they may create a false sense of fluency.
On the other hand, the presence of visuals can also provide relevant experience-based cues from which students can make their judgments. For example, Ainsworth and Loizou (2003) showed that students who read a text paired with a conceptual diagram generated more self-explanations than students who read the text alone. Although instructional visuals have the potential to provide students with important representation-based cues (e.g., how well can I explain this diagram?), which should support metacomprehension accuracy, students may not spontaneously focus on these kinds of cues. For instance, Jaeger and Wiley (2014) found that it was only when students were prompted to self-explain while reading, that the presence of conceptual images led to improved metacomprehension accuracy. Further, they found that these students were more likely to report basing their judgments on comprehension-based cues. Other studies similarly suggest students do not spontaneously make sense of provided visualizations without explicit prompting (Renkl & Scheiter, 2017; Schnotz & Wagner, 2018; Schuler et al., 2019; Zhang & Fiorella, 2019).
Taken together, the impact of diagrams or visualizations on metacomprehension accuracy remains unclear. Some prior research has found no effect of diagrams on metacomprehension accuracy, and some have found positive effects, but only under conditions where students are encouraged to process the provided text and diagrams more deeply. Further, the current body of work is inconsistent in the measures they use to assess metacomprehension accuracy with some reporting only absolute accuracy and others reporting only one measure of relative accuracy.
Types of JOLs: Test Performance, Explaining, and Drawing
Research has indicated that the types of judgments learners are asked to make can impact metacomprehension accuracy. More specifically, the types of cues students focus on when making judgments of learning may depend on the specific type of judgment they are asked to make. Metacomprehension research typically asks students to make performance predictions regarding how well they expect to do on a future test (Prinz et al., 2020). However, this type of judgment might not sufficiently cue students to evaluate their understanding of the material, even when they expect a comprehension test that requires making inferences. Other research asks students to make generic ratings of their level of understanding of the material (i.e., a judgment of understanding; Pilegard & Mayer, 2015), yet this method also may not be concrete enough to activate valid experience-based cues. One problem with both kinds of judgment prompts is that they assume students view comprehension in terms of their understanding of text rather than in terms of their memory for the text, which is often not the case. Thus, when making these kinds of monitoring judgments, students may default to basing their judgments on memory-related cues rather than the more diagnostic representation-based cues (Thiede et al., 2010).
An alternative approach is asking students to make judgments about their ability to engage in effective sensemaking tasks, or generative learning activities (Fiorella & Mayer, 2016, 2022). For example, students may be prompted to rate how well they can explain the learning material to themselves or to a friend. Wiley, Jaeger, and colleagues (2018) found that framing judgments of learning in terms of explaining to a friend improved metacomprehension accuracy compared to standard test judgments. Judging one’s ability to explain may encourage students to try explaining the material to themselves internally, which should draw upon representation-based cues. Indeed, research has shown that self-explaining and explaining to others encourages students to better monitor and regulate their learning (Bisra et al., 2018; Chi, 2000; Roscoe, 2014).
Another generative activity that supports learning from science texts is drawing (Fiorella & Zhang, 2018; Van Meter & Garner, 2005). Drawing, like explaining, encourages students to relate the material to existing knowledge, generate inferences, and monitor their understanding (Fiorella & Mayer, 2016; Schleinschok et al., 2017; Thiede et al., 2022; Van Meter & Firetto, 2013; Wiley, 2019). However, students’ judgments of their ability to explain or draw might rely on different types of metacognitive cues. For example, students generally perceive drawing as more difficult and have less confidence in their ability to draw, likely because they have less experience using it as a learning strategy (Schukajlow et al., 2022). Furthermore, drawings can convey different aspects of the learning material that may be more or less informative of actual understanding. For example, Thiede and colleagues (2022) found that students who created organizational drawings exhibited better metacomprehension accuracy (based on judgments of test performance) than students who created representational drawings. Finally, judgments of drawing might be uniquely affected by specific features of the learning materials, such as the presence of instructional visuals. Prompting students to judge their ability to generate drawings may encourage students to make greater use of the provided visuals as cues to inform their judgments. Because students often glean superficial cues from provided visuals, judgments of drawing may negatively affect metacomprehension accuracy when compared to judgments of test performance or judgments of explaining. To date, no research has systematically tested how different types of judgments of learning influence metacomprehension accuracy when learning from illustrated and non-illustrated science texts.
The Present Studies
In the present set of studies, undergraduates read a series of texts on biology (Study 1a and b) or chemistry (Study 2 and 3) topics, made multiple JOLs (test, explain, and draw) for each text, and completed comprehension tests. Students were randomly assigned to receive only texts or texts with instructional visualizations. In Studies 1b, 2, and 3, students were also asked to report the cues they used to make each judgment to examine the use of heuristic cues and representation-based cues, as well as the extent to which students used the provided visuals to inform their judgments.
The primary goal was to explore how the presence of instructional visuals affects metacomprehension accuracy. Prior research suggests that many students have misconceptions about the value of visual content and/or do not glean valid cues from provided visuals, resulting in reduced metacomprehension accuracy. We tested this possibility across two domains—biology and chemistry—which both make heavy use of visualizations but in unique ways. In biology, visualizations often depict the structure and function of animal organ systems, such as the respiratory system or the renal system. In chemistry, visualizations often involve more abstract symbolic representations of chemical properties and processes, such as when learning about gas laws or intermolecular forces. To date, it is not clear how visuals across disciplines might differentially impact metacomprehension accuracy. In the present set of studies, the diagrams were selected to depict important concepts described in the texts but were not specifically designed to enhance or support the overall text content. This design choice was made to more directly examine the impact of images on metacomprehension without creating overall differences in comprehension.
A second goal was to test how metacomprehension accuracy varies across different types of judgments—test performance, ability to explain, and ability to draw—and particularly, how these judgments might be affected by the presence of visuals. Prompting students to make different types of judgments may activate different types of cues to inform their judgments, thereby affecting how well their judgments reflect their actual performance on subsequent comprehension tests. In the present study, we were particularly interested in how judgments of drawing—which have not yet been explored in prior research—might be uniquely influenced by the presence of visuals.
Study 1a
Method
Participants and design
Participants were recruited from two large universities in the United States; 209 were recruited from a university in the Northeast and 44 students were recruited from a university in the Southeast.Footnote 1 This resulted in a total sample of 253 participants (201 female; Mage = 19.49, SD = 1.44) who received course credit for their participation in the study. The study was completed fully online due to the COVID-19 pandemic. Data from 90 participants had to be excluded from analysis (35%); 11 did not complete the study, 25 were repeat participants who completed the study twice, and 54 spent fewer than 20 min completing the entire study. This resulted in a final sample of 163 participants. Participants were randomly assigned to a text-with-image condition (n = 92) or a text-only condition (n = 71). All other aspects of the study were identical across conditions. The study was approved by the ethics committee of both universities where data was collected, and the study followed standards for ethical treatment of human subjects. The data for this study is available on OSF (osf.io/w3sqc/).
Materials
Texts
The texts were six passages that each described complex human biological systems (circulatory, respiratory, lymphatic, nervous, digestive, and renal). Each participant was assigned to read 4 of the 6 texts. Three sets were created such that one third of the participants read set 1 (circulatory, nervous, renal, lymphatic), one third read set 2 (respiratory, digestive, nervous, circulatory), and one third read set 3 (renal, lymphatic, digestive, respiratory). The texts were presented in 12-point Calibri font, varied in length from approximately 630 to 900 words and had Flesch-Kincaid grade levels of 9.65–12.33 (see Appendix A for an example). Participants completed the study fully online via Qualtrics and was designed to be compatible with computer and cellular phone screens.
Images
In the image condition, each text was paired with one image. The images were conceptual in nature and did not provide additional information beyond what was included in the text. More specifically, the diagrams were not designed to enhance or support the overall text content, but rather provided redundant information depicting parts of the biological processes described by the texts. No test items required reasoning from information presented only in the diagrams (see Appendix A for an example image). The images were always presented at the bottom of the page and were available throughout the reading of the entire text passage. This presentation format was the same across all texts.
Judgments
After reading each text, participants were instructed to make a set of predictive judgments. The first judgment asked them to predict how well they thought they would be able to explain the process described in the text to a friend (Explain Judgment). For example, after reading the text on the digestive system, they were asked, “On a scale from 1 to 10, how well would you be able to explain to a friend the path that food travels throughout the digestive system, including how nutrients are absorbed and how waste is expelled?” Next, they were asked to predict how well they would be able to do on a test of the material they read (Test Judgment). For all texts, they were asked, “If you were to take a test on the material that you just read, how many questions out of 5 would you answer correctly on the test?” Lastly, they were asked to make a judgment about how well they felt they could draw the process described in the text (Draw Judgment). For example, after reading the text on the digestive system they were asked, “On a scale from 1 to 10, how well would you be able to draw the path that food travels throughout the digestive system, including how nutrients are absorbed and how waste is expelled?”.
All judgments were converted to proportions. For the explain judgments, the proportion was out of 10, for the test judgments the proportion was out of 5, and for the draw judgments the proportion was out of 10. Because the tests and the judgments were on different scales, proportion scores were necessary for computing relative and absolute accuracy.
Tests
After reading the texts and making the set of judgments, participants completed a set of multiple-choice tests. Participants only completed tests on the 4 texts they were assigned to read. For each text, an 8-item multiple-choice inference test was created. These inference items required the reader to make connections between different parts of the text to generate the answers. The design of these items was in line with suggestions from Wiley et al. (2005) about what contributes to the validity of inference items. An example inference test item can be found in Appendix A. The range of difficulty for the inference-based items was 20–82 percent correct. The topics were presented in the same order for testing as they had been seen during reading, following standard procedure in this literature (e.g., Baker & Dunlosky, 2006; Griffin et al., 2009; Thiede et al., 2005, 2009).
All multiple-choice comprehension tests were scored by giving 1 point for each correctly selected response resulting in a maximum score of 8 for each test. These raw scores were then transformed into proportion scores by taking the total correct out of the total possible (8 for each test). As with most tests used in a classroom context, the multiple-choice test was explicitly designed for coverage of different parts of the to-be-learned information, rather than to test understanding of a single idea multiple times. In general, when Cronbach’s alpha has been reported for inference tests, tests based on three or fewer passages (with approximately 16 sentences per passage) often have reliability in the 0.5 to 0.6 range. In the present study, because each participant only completed 4 out of the 6 texts, we computed Cronbach’s alpha for the 32 items completed in each text/test order group. For participants who completed the tests on the circulatory system, nervous system, lymphatic system, and renal system (n = 62), Cronbach’s alpha was 0.67. For participants who completed the tests on the circulatory system, the nervous system, the respiratory system, and the digestive system (n = 48), Cronbach’s alpha was 0.64. For participants who completed the tests on the lymphatic system, the renal system, the respiratory system, and the digestive system (n = 53), Cronbach’s alpha was 0.75.
Procedure
The study was completed fully online via Qualtrics. Participants were randomly assigned to one of the two text conditions (text-with-image or text-only). After completing the informed consent, participants were given the following instruction:
The primary purpose of reading in science is to understand the causes of scientific phenomena. This means your goal for reading is to understand how and why things happen. To reach an understanding of a new topic in everyday life, we often need to connect information across multiple pieces of information. In today’s task your goal is to learn about various biological systems. It is important that you use information from the texts to support your conclusions and ideas.
Next, they were informed they would be reading a series of short texts on biological systems. They were told that after reading each text, they would be asked to make some judgments about the texts, and then would complete a set of comprehension tests for each text. They were further instructed that the comprehension tests would require them to make connections across different parts of the text to be able to correctly answer the questions. They were informed that once they completed a page, they would not be able to go back and revisit that page.
Next, participants began the reading portion of the study. They were encouraged to read carefully and take as much time as they needed. After reading each text, they were asked to make the three judgments of learning (explain, test, and draw). They repeated this process until they had read and judged 4 texts. Next, they completed the set of comprehension tests. The tests for each topic were presented in the same order that the participants had read the texts.
After completing all the tests, participants completed a short demographic survey which asked them to report their age, gender, year in school, college major, and how many college courses they had taken in science. Finally, they were also asked to report how much prior knowledge they had about each biology topic prior to participating in the study (0 – none at all, 10 – a lot).
Results
Metacognitive Judgments and Test Performance
Since relative metacomprehension accuracy is computed as a correlation between metacognitive judgments and comprehension test performance, descriptive data on these measures is reported first. As shown in Table 1, mean test performance did not significantly differ between the text-with-image and text-only conditions, t(161) = 0.07, p = 0.95, d = 0.01. Mean judgment magnitude did not significantly differ between the text-with-image and text-only conditions for the explain judgments, t(161) = 0.81, p = 0.42, d = 0.13, or the test judgments, t(161) = 1.89, p = 0.06, d = 0.30. However, there was a significant difference in judgment magnitude for the draw judgments, with participants in the text-with-image condition giving higher judgments, t(161) = 2.02, p = 0.045, d = 0.32.
Relative Metacomprehension Accuracy
Six relative accuracy scores were computed for each participant. First, we computed the intra-individual Pearson correlations for each judgment type. Explain relatively accuracy was computed as the intra-individual Pearson correlation between the explain judgments and test performance, test relative acracy was computed as the Pearson correlation between the test judgment and test performance, and draw relative accuracy was computed as the Pearson correlation between the draw judgment and test performance. We also computed Gamma correlations for each judgment type.
Pearson’s r correlations
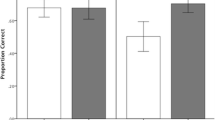
A series of independent samples t-tests were conducted to compare the text-with-image and text-only groups on each of the Pearson relative accuracy measures. There was no difference in test relative accuracy between the two groups, t(139) = 1.59, p = 0.12, d = 0.27. There was a marginal difference in explain relative accuracy, t(156) = 1.87, p = 0.06, d = 0.30. As shown in Fig. 1, participants in the text-only group tended to have higher explain relative accuracy than participants in the text-with-image group. Finally, there was a significant difference in draw relative accuracy between the two groups, with participants in the text-only condition showing greater relative accuracy than participants in the text-with-image condition, t(147) = 3.10, p = 0.002, d = 0.51.

Relative Metacomprehension Accuracy as a Function of Image Condition and Judgment Type in Study 1a. Note. Error bars represent standard error of the mean
Goodman–Kruskal Gamma Correlations
Gamma correlations were also computed for each judgment type and aligned with the pattern observed for Pearson correlations. As shown in Fig. 1, there was no difference in test relative accuracy between the text-only and text-with-image conditions, t(139) = 1.69, p = 0.09, d = 0.29, and there was a marginal difference in explain relative accuracy, t(155) = 1.71, p = 0.09, d = 0.28. For draw relative accuracy, gamma correlations were higher in the text-only condition than in the text-with-image condition, t(147) = 3.02, p = 0.003, d = 0.50.
Absolute Metacomprehension Accuracy
To provide a thorough consideration of metacognitive judgment accuracy, absolute accuracy was also computed. Absolute accuracy is the absolute difference between predicted and actual performance. With this measure, scores closer to zero indicate better calibration. As with relative accuracy, three separate scores were computed: explain absolute accuracy, test absolute accuracy, and draw absolute accuracy. There was no difference in absolute accuracy between the text-with-image and text-only conditions for the explain (text-only: M = 0.22, SD = 0.10, text-with-image: M = 0.21, SD = 0.09), test (text-only: M = 0.21, SD = 0.10, text-with-image: M = 0.21, SD = 0.09), or draw judgments (text-only: M = 0.23, SD = 0.10, text-with-image: M = 0.23, SD = 0.09), all ts < 1.
Discussion
The results of Study 1 indicated that the presence of conceptual images did not affect test performance. This finding is contrary to the multimedia effect in which text paired with conceptual diagrams supports greater comprehension (see e.g., Ainsworth, 2006; Butcher, 2014; Mayer, 2008 for reviews). However, research suggests that instructional visualizations only work to support comprehension if they are specifically designed to support comprehension and if people actively process them, which many students do not do spontaneously (Renkl & Scheiter, 2017; Schnotz & Wagner, 2018). Further, if participants are only superficially processing the visualizations, this could contribute to the generally lower levels of metacomprehension accuracy we observed in the image condition.
Results did indicate that the presence of images interfered with students’ relative accuracy (both Pearson and Gamma), but only when making judgments about their ability to draw key concepts—not when making judgments about their test performance or their ability to explain key concepts. These results suggest students may have relied on cues from the images when making judgments of drawing, but not for the other types of judgments. Because their relative accuracy for drawing judgments decreased, they appeared to rely on superficial cues that are not predictive of their actual test performance.
As previously described, poor monitoring accuracy likely results from the use of inappropriate cues as the basis for monitoring judgments (Koriat, 1997).
Representation-based cues typically lead to better accuracy because they are based on the learner’s experience of trying to understand the learning materials, whereas heuristic-based cues typically lead to worse accuracy because they are based on more generalized beliefs such as perceptions of ability, topic interest or familiarity, or perceptual features of the stimuli such as text length or font size (Griffin et al., 2008, 2013; Jaeger & Wiley, 2014; Thiede et al., 2010). To more directly assess how visualizations affected cue use, follow-up Study 1b was conducted.
Study 1b
The goal of Study 1b was to examine the types of cues students report using to make judgments of drawing with and without images present. As seen in Study 1a, students made less accurate judgments of drawing when images were present. Thus, in Study 1b, we wanted to examine the cues students report using to make their judgments.
Method
Participants and design
Fifty-five participants were recruited from a large university in the Northeast US, who received course credit for their participation. The study was conducted fully online due to the COVID-19 pandemic. Data from 8 participants were excluded from analysis (14.54%) for spending less than 15 min completing the study, resulting in a final sample of 47 participants (75.5% female; Mage = 20.15; SD = 1.76). There were 22 participants in the text-with-image condition and 25 participants in the text-only condition. The same materials were used as in Study 1a, but with two primary changes; comprehension was not assessed, and an additional set of cue-use questions were administered during the demographic questionnaire. The cue-use items asked participants to report what they based each of their three types of judgments on. For example, in the case of the drawing judgment the cue use question read as follows: “After reading each text, you were asked to rate how well you could draw the concepts you read about. When you were making these judgments, what were you basing them on?” The data for this study is available on OSF (osf.io/w3sqc/).
The purpose of Study 1b was to examine self-reported cue use. Responses to the open-ended cue-use questions were coded into two types. If the student referred to using their ability to explain, summarize or make connections while reading the text, or referenced how well they felt they could remember information from the texts, the student was coded as having used representation-based cues, following the coding from Thiede et al. (2010). If the student referred to their interest, prior knowledge, or familiarity with the topic, or referred to a generalized belief about themselves (e.g., “I am not very good at science”), the student was coded as having used heuristic-based cues. Additionally, all responses were coded for whether the participant reported using visual information when making their judgments. These visual judgments were further broken down by whether they referred to an external representation like a provided diagram (e.g., “I was basing them on the diagrams that were available in the readings”) or an internal representation like their ability to form a mental imagine of the material (e.g., “How well I was able to visualize the system in my head”). Two independent raters blind to condition scored all the responses with interrater reliability (Krippendorff’s Alpha) of 0.84 for explain judgment cues, 0.91 for test judgment cues, and 0.82 for draw judgment cues (Krippendorff, 2013); any cases of disagreement were resolved through discussion.
Results
To examine the frequency of cue type as a function of image condition, a series of Chi-square tests were performed. When looking at the explain judgments, there was no difference in self-reported representation-based versus heuristic cue use as a function of image condition, X2(1) = 0.90, p = 0.34 (see Table 2). There was also no difference in reported cue type by image condition for the test judgments, X2(1) = 0.24, p = 0.63. However, when looking at cue type for the draw judgments, participants in the text-only condition were more likely to report basing their judgments on their experiences with trying to understand or remember the text whereas people in the text-with-image condition were more likely to report basing their judgments on prior knowledge and other factors not directly related to processing the text, X2(1) = 7.57, p = 0.006.
We also examined how frequently participants reported using visual information to make their judgments. Out of all 47 participants, only one reported basing their explain judgment on visual information and none reported basing their test judgments on visual information. When we examined the frequency of reporting visual information as a basis for draw judgments, there were no differences overall, X2(1) = 0.12, p = 0.73, but 18 participants (approximately 38%) did report using visual cues (text-only: n = 9; text-with-image: n = 9). Thus, students were much more likely to mention visual cues when making drawing judgments compared to test or explain judgments.
We further examined these 18 responses to see whether the visual information students reported using was externally based (referring to provided images they have seen before) versus internally based (referring to their ability to generate a mental image). This resulted in a significant difference across image conditions, with participants in the text-only condition being more likely to report basing their judgments on their ability to generate an internal mental image (n = 8 out of 9) while those in the text-with-image condition were more likely to report basing their judgment on their ability to recall the image they saw or images they have seen in textbooks before (n = 7 out of 9), X2(1) = 68.10, p = 0.004.
Discussion
Results of Study 1b indicated that participants were more likely to rely on representation-based cues for their draw judgments when the texts did not include an image and were more likely to base their judgments on heuristic cues when the texts did include an image. These results align with the metacomprehension accuracy findings from Study 1a and with previous work showing that illustrated text can influence students to base their judgments on cues that are less relevant for comprehension (Jaeger & Wiley, 2014; Serra & Dunlosky, 2010; Wiley, 2019).
Across both conditions, only about one third of participants reported using visual information when making their drawing judgments. This result suggests that asking students to make a judgment regarding how well they would be able to generate a drawing does not necessarily stimulate them to think visually, which is significant considering visuospatial thinking is an important component of success in many STEM fields (Shea et al., 2001; Wai et al., 2009). Further, only when the texts were unillustrated did students tend to base their judgments on their own internal mental visualizations of the processes being described. When texts were illustrated, students tended to focus on their memory of the external visual, perhaps without using the external visual to reflect on the quality of their own mental model. Relying on memory for provided visualizations or other external visual information may be problematic for making accurate judgments of learning because research has shown that students only superficially examine conceptual diagrams alongside expository text (Renkl & Scheiter, 2017; Schnotz & Wagner, 2018) and images can lead to a false sense of fluency or illusions of understanding (e.g., Paik & Schraw, 2013; Serra & Dunlosky, 2010; Wiley, 2019).
The goal of Study 1b was to clarify findings from Study 1a by examining self-reported cue use. One limitation is that Studies 1a and 1b examined metacomprehension accuracy and cue use across separate studies with different samples of students. Thus, we cannot yet draw strong conclusions about the relationship between cue use and metacomprehension accuracy.
Study 2
The goal of Study 2 was to examine the relationship between metacomprehension accuracy and self-reported cue-use across different judgment of learning prompts more directly. Prior research indicates that students often rely on superficial cues when making judgments of learning, and that these cues are not predictive of their actual test performance (Bjork et al., 2013). Further, students who report basing their judgments on representation-based cues tend to demonstrate more accurate relative metacomprehension (Jaeger & Wiley, 2014; Thiede et al., 2009; Wiley et al., 2005). A major limitation of Studies 1a and 1b is that metacomprehension accuracy and cue-use were not measured in a single study, and thus, the relationship between these factors could not be assessed. In Study 2, we included comprehension measures, judgments of learning (test, explain and draw), and self-reported cue use in a single design to examine the relationship between these variables more effectively.
Another primary goal of Study 2 was to extend and replicate the results from Studies 1a and 1b to a new domain, chemistry. Like biology, chemistry makes heavy use of visualizations to support learning and comprehension. However, the types of visualizations and the ways they are used vary across the two domains. In biology, visualizations often depict the structure and function of animal organ systems, such as the respiratory system or the renal system (Wiley et al., 2017). In chemistry, visualizations often involve more abstract symbolic representations of chemical properties and processes, such as when learning about gas laws or intermolecular forces (Kozma & Russell, 1997). To date, it is not clear how visuals across disciplines might differentially impact metacomprehension accuracy.
Method
Participants and design
Sixty-two participants were recruited from a large university in the Northeast (41 female; Mage = 19.60, SD = 1.30) who received course credit for their participation in the study. Data from 14 participants had to be excluded from analysis (22%); 2 spent fewer than 15 min completing the entire study, and 12 had taken two or more college-level chemistry courses. This resulted in a final sample of 48 participants. Data for this study was collected during the COVID-19 pandemic, and although we were able to resume in person data collection, many participants from the subject pool were unwilling to come to in-person studies which impacted recruitment efforts. Participants were randomly assigned to a text-with-image condition (n = 22) or a text-only condition (n = 26). All other aspects of the study were identical across conditions. The study was approved by the ethics committee of the university where data was collected. The data for this study is available on OSF (osf.io/w3sqc/).
Materials
Texts
The texts were six passages each describing complex processes or theories in chemistry (molecular structure, collision theory, intermolecular force, thermodynamics, electrolytes, gas laws). As in Study 1a, participants were assigned to read 4 of the 6 texts. The texts were presented in 12-point Calibri font, varied in length from approximately 518 to 701 words and had Flesch-Kincaid grade levels of 9.5 – 13.9 (see Appendix B for an example). The study was conducted in the laboratory with 1 to 2 participants per session.
Images
Images were presented in the same manner as in Studies 1a and b. The images were conceptual in nature and did not provide additional information beyond what was included in the text. The diagrams were not specifically designed to enhance or support the overall text content. No test items required reasoning from information presented only in the diagrams (see Appendix B for an example image). The images were always presented at the bottom of the page and were available throughout the reading of the entire text passage.
Judgments
After reading each text, participants made test, explain, and draw judgments of learning. The explain and draw judgments were like those used in Studies 1a and 1b but were adapted to match the chemistry content in the texts. For example, for collision theory, participants were asked to rate how well they, “…would be able to draw the conditions required for a chemical reaction” on a 1–10 scale. The test judgment was the same as those used in Studies 1a and 1b but was measured on a 0–7 scale.
Tests
For each text, a 7-item multiple-choice inference test was created (see Appendix B for a sample test item). Participants completed tests on the 4 texts they were assigned to read. Item difficulty ranged from 21 to 79 percent correct. Tests were presented in the same order as they had been seen during reading. Cronbach’s alpha was computed for each set of 4 tests and ranged from 0.77 to 0.83.
Procedure
The study was completed in the same manner as Study 1a but was conducted in the lab. Participants were randomly assigned to the text-with-image or text-only conditions. Task instructions matched those used in Study 1a. After completing the consent form, participants completed the reading portion of the study. They read 4 texts and were prompted to make three judgments of learning (test, explain, and draw, in that order) immediately after completing reading of each text. They repeated this process until they had read and judged 4 texts. Next, they completed the set of comprehension tests. Finally, participants completed the same demographic survey that was used in study 1b, which included items asking them to report the cues they used when making their test, explain, and draw judgments.
Results
Metacognitive Judgments and Test Performance
As shown in Table 3, mean test performance did not differ between the text-with-image and text-only conditions, t(46) = 0.21, p = 0.84, d = 0.06. Mean judgment magnitude did not differ between the text-with-image and text-only conditions for the explain judgments, t(46) = 0.50, p = 0.62, d = 0.14, the test judgments, t(46) = 0.67, p = 0.51, d = 0.19, or the draw judgments, t(46) = 0.30, p = 0.76, d = 0.09.
Relative Metacomprehension Accuracy
Pearson’s r correlations
A series of independent samples t-tests were conducted to compare the text-with-image and text-only groups on each of the Pearson relative accuracy measures. As shown in Fig. 2, there was no difference between the text-with-image and text-only conditions in explain relative accuracy, t(44) = 0.29, p = 0.77, d = 0.08, or test relative accuracy, t(42) = 0.45, p = 0.66, d = 0.14. However, there was a marginal difference in draw relative accuracy between the two groups (with a medium effect size), with participants in the text-only condition showing greater relative accuracy than participants in the text-with-image condition, t(45) = 1.93, p = 0.06, d = 0.56.

Relative Metacomprehension Accuracy as a Function of Image Condition and Judgment Type in Study 2. Note. Error bars represent standard error of the mean
Goodman–Kruskal Gamma Correlations
Gamma correlations were also computed for each judgment type and aligned with the pattern observed for Pearson correlations (Fig. 2). There was no difference in test relative accuracy between the text-only and text-with-image, t(42) = 0.49, p = 0.63, d = 0.15, or explain relative accuracy, t(44) = 0.07, p = 0.95, d = 0.02. For draw relative accuracy, gamma correlations were marginally higher in the text-only condition than in the text-with-image condition, t(45) = 1.83, p = 0.075 d = 0.53.
Absolute Metacomprehension Accuracy
Differences in absolute accuracy were also examined. There were marginal differences in absolute accuracy between the text-only and text-with-image conditions for the explain judgments (text-only: M = 0.21, SD = 0.09, text-with-image: M = 0.26, SD = 0.12), t(45) = 1.86, p = 0.07, d = 0.53, and the test judgments (text-only: M = 0.21, SD = 0.10, text-with-image: M = 0.29, SD = 0.14), t(46) = 1.95, p = 0.06, d = 0.56. These differences indicated that students in the text-only condition tended to make more accurate explain and test judgments than students in the text-with-image condition. Further, students in the text-only condition made significantly more accurate draw judgments than students in the text-with-image condition (text-only: M = 0.23, SD = 0.09, text-with-image: M = 0.30, SD = 0.14), t(46) = 2.14, p < 0.04, d = 0.61.
Self-Reported Cue Use
Next, we explored whether students differed in their self-reported cue use after making judgments of learning. Cue use was coded in the same manner as in Study 1b. Three independent raters who were blind to the condition scored all the responses with interrater reliability (Krippendorff’s Alpha) of 0.94 for explain judgment cues, 0.88 for test judgment cues, and 0.91 for draw judgment cues (Krippendorff, 2013); any cases of disagreement were resolved through discussion.
To examine the frequency of cue type as a function of image condition, a series of Chi-square tests were performed. When looking at the explain judgments, there was no significant difference in self-reported representation-based versus heuristic cue use as a function of image condition, X2(1) = 0.14, p = 0.71 (see Table 2). There was also no significant difference in reported cue type by image condition for the test judgments, X2(1) = 0.49, p = 0.48. Unlike the results obtained in Study 1b, there was also no difference in self-reported cue type by image condition for the draw judgments, X2(1) = 0.02, p = 0.90.
We also examined how frequently participants reported using visual information to make their judgments. Out of all 48 participants, only one reported basing their explain judgment on visual information and none reported basing their test judgments on visual information. When we examined the frequency of reporting visual information as a basis for draw judgments there were no differences overall, X2(1) = 0.07, p = 0.79, but 23 participants (approximately 48%) did report using visual cues (text-only: n = 12; text-with-image: n = 11). Thus, as in Study 1b, students were much more likely to mention visual cues when making drawing judgments compared to test or explain judgments.
We further examined these 23 responses to see whether the visual information students reported using was externally or internally based. Consistent with Study 1b, this resulted in a significant difference across image conditions: participants in the text-only condition were more likely to report basing their judgments on their ability to generate an internal mental image (n = 11 out of 12), whereas those in the text-with-image condition were more likely to report basing their judgment on their ability to recall the provided image they saw or images they have seen in textbooks before (n = 11 out of 11), X2(1) = 19.33, p < 0.001.
Cue Use and Relative Metacomprehension Accuracy
Although there was no overall difference in how frequently participants reported using representation-based cues across conditions, we wanted to examine if using represented-based based cues supported more accurate relative metacomprehension. Because effects of condition were only seen for draw relative accuracy as measured by Pearson, we focused our analysis on this outcome measure. We conducted a 2 (cue type) × 2 (image condition) between-subjects ANOVA for draw relative accuracy measured with Pearson correlations. As previously reported, there was a marginal main effect of image condition indicating that participants in the text-only condition had higher relative accuracy than participants in the text-with-image condition, F(1, 43) = 3.13, p = 0.084, ƞp2 = 0.07. There was also a main effect of cue type indicating that participants who reported basing their judgments on representation-based cues had higher relative accuracy than participants who used heuristic cues, F(1, 43) = 5.42, p = 0.025, ƞp2 = 0.07 (see Fig. 3). The interaction between these variables was not significant, F < 1. Although the interaction was not significant, we did see that the use of representation-based cues was significantly associated with draw relative accuracy in the text-only condition, r(25) = 0.43, p = 0.033, but this association was not present when the texts were paired with images, r(22) = 0.24, p = 0.27.

Relative Accuracy Metacomprehension for Draw Judgments by Image Condition and Cue Type in Study 2. Note. Error bars represent standard error of the mean
The same analysis was conducted on draw relative accuracy measured with Gamma correlations as the dependent measure. Mirroring the Pearson results, there was no main effect of image condition, F(1, 43) = 2.65, p = 0.11, ƞp2 = 0.06. There was a main effect of cue type indicating that participants who reported basing their judgments on representation-based cues had higher relative accuracy than participants who used heuristic cues, F(1, 43) = 4.63, p = 0.037, ƞp2 = 0.10. The interaction between these variables was not significant, F < 1. Again, we did see that the use of representation-based cues was significantly associated with draw relative accuracy in the text-only condition, r(25) = 0.41, p = 0.04, but this association was not present when the texts were paired with images, r(22) = 0.22, p = 0.34.
Discussion
The results of Study 2 largely replicated those of Studies 1a and 1b but did so simultaneously in a single design and in the new domain of chemistry. Results indicated that the presence of conceptual images did not affect test performance or judgment magnitude overall. However, the presence of images did interfere with students’ relative accuracy, but only when making judgments about their ability to draw key concepts—not when making judgments about their test performance or their ability to explain key concepts. Contrary to the results of Study 1a, we found that the presence of images also impacted students’ absolute accuracy. There were marginal effects, with medium effect sizes, for absolute explain and test accuracy such that students in the image conditions showed greater absolute error between their judgments and test performance than students in the no image condition. Results also revealed a significant impact of images on student’s absolute draw accuracy. Taken together, the relative and absolute accuracy results from Study 2 add to the growing body of research demonstrating that instructional visualizations can harm the accuracy of students’ judgments of learning (Jaeger & Wiley, 2014; Serra & Dunlosky, 2010; Wiley, 2019) and further indicate that instructional visuals may especially harm judgment accuracy when students are asked to make judgments about how well they think they could draw the science concepts.
Unlike the results obtained in Study 1b, the results from Study 2 did not indicate an overall difference in cue use as a function of image condition. However, when we examined the use of visual cues for making drawing judgments, a similar pattern of results emerged. When the texts were unillustrated, students were more likely to base their judgments on their own internal mental visualizations of the processes being described whereas when the text included an illustration, their judgments were based on their memory of the externally presented visuals. Importantly, because Study 2 assessed comprehension, metacomprehension and cue use in a single design, we were able to examine the relationship between self-reported cue-use and metacomprehension accuracy. Participants who reported using representation-based cues as a basis for their draw judgments had more accurate draw relative metacomprehension than those who used heuristic-based cues. This result provides further evidence of the important link between using representation-based cues and accurate comprehension monitoring.
Study 3
A limitation of Studies 1a and 2 is that participants did not complete drawing-based assessments. Thus, relative and absolute accuracy for the drawing judgments were computed using performance on the multiple-choice inference tests. Although prior research has demonstrated that performance on inference tests and drawing tests are highly correlated (Fiorella & Kuhlmann, 2020; Schwamborn et al., 2010), there could be important differences between the kinds of knowledge assessed by these two types of assessments. For example, drawing assessments may provide information regarding learners’ ability to develop an accurate mental model depicting structure and spatial relationships between component parts while text-based inference tests may provide information about learners’ ability to develop an understanding of function and how changes to one part of a system or structure may impact the functioning of another part of the system. The presence of images could not only differentially impact students’ development of these different kinds of knowledge but could also have different effects on how they judge their knowledge. Therefore, a primary goal of Study 3 was to assess test and draw performance and test and draw metacomprehension accuracy using assessments that match the modality of the judgment type.
Method
Participants and design
An a priori power analysis was conducted using G*Power version 3.1.9.7 (Faul et al., 2007) to determine the minimum sample size required to conduct a one-way between subjects ANCOVA with one covariate. Results indicated the required sample size to achieve 80% power for detecting a medium effect, at a significance criterion of α = 0.05, was N = 125. Thus, 126 participants were recruited from a large university in the Southern U.S. (78 female; Mage = 20.00, SD = 3.45) who received course credit for their participation in the study. Data from 11 participants were excluded from analysis (8%); 2 spent fewer than 3 min reading the set of 4 texts and 9 had incomplete data due to experimenter error or non-compliance. This resulted in a final sample of 115 participants. Data was collected in the laboratory with 1–2 participants per session. Participants were randomly assigned to a text-with-image condition (n = 60) or a text-only condition (n = 55). The study was approved by the ethics committee of the university where data was collected. The data for this study is available on OSF (osf.io/w3sqc/).
Materials
Texts and images
The texts and images were the same as those used in Study 2. Participants were assigned to read 4 of the 6 texts, images were always presented at the bottom of the page and were available throughout the reading of the entire text passage.
Judgments
After reading each text, participants made two judgments of learning: test and draw judgments. These judgments were the same as those used in Study 2. Because we did not include an explanation assessment, we dropped the explain judgment from this study. Judgment order was counter-balanced across participants.
Tests
For each text, participants completed the same 7-item multiple-choice inference tests as used in Study 2. Scores on these tests were computed as the proportion of correct responses out of 7. Participants also completed a drawing test for each text they read. For each drawing test, they were given a sheet of 8.5 × 11 paper with instructions at the top asking them to draw a diagram. The specific prompt for each drawing test was tailored to the content of each text and designed to match the phrasing used in the drawing judgments. For example, for molecular collisions, students were asked to, “Draw a diagram that depicts the conditions required for an effective chemical reaction to occur. Your diagram should depict what the molecules look like before the collision, during the collision and after the collision.” At the end of each drawing prompt, students were also told to be sure to label all important parts in their drawing and they did not have were not given access to the text while completing their drawings. Drawing tests were administered in the same order as they had been seen during reading. A lab-developed rubric was used to score the quality of students’ final drawing tests. They received one point for each component accurately situated in their drawings, such as depicting two molecules in the correct orientation for the collision theory drawing test. The atomic structure and collision theory drawings were each worth 9 points, the electrolytes, gas laws and intermolecular force drawings were each worth 11 points, and the thermodynamics drawing was worth 10 points. Scores for each drawing were computed as the total number of points received out of the total points possible. For each drawing test, 20% were scored by two raters. Inter-rater reliability was high (Krippendorf’s α > 0.96), and so the remaining drawings were coded by a single rater. Examples of student-generated sketches can be found in Appendix C.
Procedure
The study was completed in the same manner as Study 2. Participants were randomly assigned to the text-with-image or text-only conditions. Task instructions matched those used in Study 2. After completing the consent form, participants completed the reading portion of the study. They read 4 texts and were prompted to make two judgments of learning (test and draw, counterbalanced) immediately after completing reading of each text. They repeated this process until they had read and judged 4 texts. Next, they completed the comprehension measures (multiple choice inference tests and drawing tests, counterbalanced). Finally, participants completed the same demographic survey that was used in Study 2, which included items asking them to report the cues they used when making their test and draw judgments.
Results
Metacognitive Judgments and Test Performance
As shown in Table 4, multiple-choice inference test performance did not differ between the text-with-image and text-only conditions, t(113) = 0.05, p = 0.96, d = 0.01. There was a marginal difference in drawing test performance with students in the text-with-image condition scoring slightly higher, t(113) = 1.83, p = 0.07, d = 0.34. Importantly, there was a strong significant correlation between inference and drawing test performance, r(115) = 0.66, p < 0.001. Mean judgment magnitude differed between the text-with-image and text-only conditions for the test judgments, t(113) = 2.10, p = 0.04, d = 0.39, and the draw judgments, t(113) = 3.06, p = 0.003, d = 0.57. For both judgment types, participants in the text-with-image condition made higher judgments.
Relative Metacomprehension Accuracy
Pearson’s r Correlations
A series of one-way ANCOVAs with judgment order included as a covariate were conducted to compare the text-with-image and text-only groups on each of the Pearson relative accuracy measures. As shown in Fig. 4, participants in the text-only group had more accurate test relative accuracy than participants in the text-with-image group, F(1, 102) = 5.73, p = 0.019, ƞp2 = 0.05, and there was no effect of judgment order, F(1, 102) = 1.23, p = 0.27, ƞp2 = 0.01.

Relative Metacomprehension Accuracy as a Function of Image Condition and Judgment Type in Study 3. Note. Error bars represent standard error of the mean
We computed draw relative accuracy in two ways. First, to be consistent with Studies 1a and 2, we computed draw relative accuracy as the intra-individual Pearson correlation between draw judgments and inference test performance. Using this measure of draw relative accuracy there was no effect of the covariate, F(1, 108) = 1.35, p = 0.25, ƞp2 = 0.01, and no effect of image condition, F(1, 108) = 0.98, p = 0.33, ƞp2 = 0.01 (Text-only: M = 0.21, SD = 0.48; Text-with-image: M = 0.11, SD = 0.57). Second, we computed draw relative accuracy as the intra-individual Pearson correlation between draw judgments and draw test performance (shown in Fig. 4).Footnote 2 Using this measure of draw relative accuracy, there was again no effect of the covariate, F(1, 111) = 1.58, p = 0.21, ƞp2 = 0.01, and no difference between image conditions, F(1, 111) = 1.65, p = 0.20, ƞp2 = 0.02.
Goodman–Kruskal Gamma Correlations
Gamma correlations were also computed for each judgment type. For test relative accuracy, there was no effect of judgment order, F(1, 102) = 0.87, p = 0.35, ƞp2 = 0.008, but there was a significant effect of image condition, F(1, 102) = 6.16, p = 0.015, ƞp2 = 0.057. Participants in the text-only condition had more accurate test metacomprehension than participants in the text-with-image condition. For draw relative accuracy computed between draw judgment and draw performance, there was a significant effect of judgment order (test then draw: M = 0.23, SD = 0.62; draw then test: M = -0.02, SD = 0.62), F(1, 111) = 4.71, p = 0.032, ƞp2 = 0.04, but no effect of image condition, F(1, 102) = 0.87, p = 0.35, ƞp2 = 0.008.
Absolute Metacomprehension Accuracy
Differences in absolute accuracy were also examined (see Table 5) using a series of ANCOVAS with judgment order as the covariate. There was no effect of judgment order, F(1, 112) = 1.18, p = 0.28, ƞp2 = 0.01, or image condition on test absolute accuracy, F(1, 112) = 0.59, p = 0.44, ƞp2 = 0.01. There was also no effect of judgment order, F(1, 112) = 2.38, p = 0.13, ƞp2 = 0.02, or image condition, F(1, 112) = 0.01, p = 0.92, ƞp2 = 0.00, on draw absolute accuracy when it was computed using draw judgments and inference test performance. However, when draw absolute accuracy was computed using draw judgments and draw performance, there was no effect of judgment order, F(1, 112) = 0.05, p = 0.82, ƞp2 = 0.00, but there was an effect of image condition, F(1, 112) = 6.88, p = 0.01, ƞp2 = 0.06. This difference was driven by students in the text-only condition having better absolute accuracy for their draw judgments than students in the text-with-image condition.
Self-Reported Cue Use
Next, we explored whether students differed in their self-reported cue use after making judgments of learning. Cue use was coded in the same manner as in Studies 1b and 2. Two independent raters who were blind to the condition scored all the responses with interrater reliability (Krippendorff’s Alpha) of 0.83 for test judgment cues, and 0.88 for draw judgment cues (Krippendorff, 2013); any cases of disagreement were resolved through discussion.
To examine the frequency of cue type as a function of image condition, a series of Chi-square tests were performed. When looking at the test judgments, there was no difference in self-reported representation-based versus heuristic cue use as a function of image condition, X2(1) = 0.15, p = 0.70 (see Table 6). There was also no difference in reported cue type by image condition for the draw judgments, X2(1) = 0.09, p = 0.76.
We examined how frequently participants reported using visual information to make their judgments. Out of all 115 participants, only 2 reported basing their test judgment on visual information. When we examined the frequency of reporting visual information as a basis for draw judgments there were no differences overall, X2(1) = 2.48, p = 0.12, but 59 participants (approximately 51%) did report using visual cues (text-only: n = 24; text-with-image: n = 35).
We further examined these 59 responses to see whether the visual information students reported using was externally or internally based. Consistent with Studies 1b and 2, this resulted in a significant difference across image conditions: participants in the text-only condition were more likely to report basing their judgments on their ability to generate an internal mental image (n = 19) than their ability to recall a provided image (n = 5), whereas those in the text-with-image condition were more likely to report basing their judgment on their ability to recall the provided image they saw or images they have seen in textbooks before (n = 30) than their ability to generate an internal mental image (n = 5), X2(1) = 19.33, p < 0.001.
Cue Use and Relative Metacomprehension Accuracy
Although there was no difference in how frequently participants reported using representation-based cues across conditions, we wanted to examine if using represented-based based cues supported more accurate relative metacomprehension. Because effects of condition were only seen for test relative accuracy, we focused our analysis on this outcome measure. We conducted a 2 (cue type) × 2 (image condition) between-subjects ANCOVA for test relative accuracy as measured by Pearson, including judgment order as a covariate. There was no effect of the covariate, F(1, 100) = 1.76, p = 0.18, ƞp2 = 0.02. Mirroring the results previously reported, there was a marginal main effect of image condition indicating that participants in the text-only condition had higher test relative accuracy than participants in the text-with-image condition, F(1, 100) = 3.32, p = 0.071, ƞp2 = 0.03. There was a main effect of cue type indicating that participants who reported basing their judgments on representation-based cues had higher test relative accuracy than participants who used heuristic cues, F(1, 100) = 4.70, p = 0.033, ƞp2 = 0.05. These main effects were qualified by a significant interaction between image and condition and cue type, F(1, 100) = 4.73, p = 0.03, ƞp2 = 0.05 (see Fig. 5). In the text-only condition, students who reported basing their test judgments on representation-based cues had more accurate metacomprehension than students who based their judgments on heuristic-based cues, t(50) = 3.30, p = 0.002, d = 0.95. However, in the text-with-image condition, there was no difference in metacomprehension accuracy as a function of cue type, t(51) = 0.135, p = 0.89, d = 0.04.

Relative Metacomprehension Accuracy for Test Judgments by Image Condition and Cue Type in Study 3. Note. Error bars represent standard error of the mean
The same analysis was conducted for test relative accuracy measured with Gamma correlations as the dependent measure (Fig. 5). There was no effect of the covariate, F(1, 100) = 1.17, p = 0.28, ƞp2 = 0.01. There was a significant main effect of image condition indicating that participants in the text-only condition had higher test relative accuracy than participants in the text-with-image condition, F(1, 100) = 4.03, p = 0.047, ƞp2 = 0.039. There was a marginal effect of cue type indicating that participants who reported basing their judgments on representation-based cues had higher test relative accuracy than participants who used heuristic cues, F(1, 100) = 3.10, p = 0.08, ƞp2 = 0.03. Diverging from the Pearson correlation results, there was no interaction between image and condition and cue type, F(1, 100) = 2.71, p = 0.10, ƞp2 = 0.026.
Discussion
In Study 3, the presence of images increased judgment magnitude for both test and draw judgments. This result is consistent with prior research demonstrating that images can inflate JOLs, even in cases when they do not support improved understanding (Serra & Dunlosky, 2010). The presence of images also interfered with students’ relative metacomprehension accuracy, particularly when making judgments about test performance. Surprisingly, the images did not affect relative accuracy for drawing judgments. One possibility is that students may have focused on their perceived ability to reproduce the drawings rather than reflect on how drawing relates to their understanding. In this study, the inference test may have been a better measure of comprehension because the drawing tests essentially required recreating the presented diagrams, thus serving more as a measure of memory than comprehension. Example student-generated diagrams presented in Appendix C offer some anecdotal evidence of this; students in the text-with-image condition generated diagrams that more closely resembled the diagrams presented in the text. However, no effects of images on draw relative accuracy were found, even when computed as the correlation between drawing judgments and inference test performance or when computed as the correlation between drawing judgments and drawing test performance.
Results of Study 3 showed that when no images were present, test judgments based on representation-based cues resulted in more accurate metacomprehension, but this was not the case when images were present. This result aligns with those found in Study 2 for draw relative accuracy and cue use. Additionally, we found that about half of the students reported using visual information to make their draw judgments. Like Studies 1b and 2, when images were present, students focused on external visual information, whereas when images were not present, they focused on internal visual information like their ability to generate a mental image.
General Discussion
Prior research suggests that instructional visualizations can support learning from expository STEM text, however their effects on metacomprehension accuracy have been mixed. Across the present set of studies, we saw that instructional visualizations harmed relative metacomprehension accuracy. In Studies 1a and 2, this was especially the case when students were asked to judge how well they felt they could draw the processes described in the text. But in Study 3, this was especially the case when students were asked to judge how well they would do on a set of comprehension tests. Despite mixed effects across the present studies, the results suggest that the presence of instructional visuals interferes with students’ ability to accurately reflect on their own understanding.
One possible explanation for how instructional visualizations interfere with metacomprehension accuracy is that they cause students to focus on metacognitive cues not directly tied to their experiences with learning from the text. Prior research has demonstrated that basing judgments on heuristic or superficial cues like familiarity or interest can lead to lower judgment accuracy and learning outcomes compared to basing judgments on cues related to the quality of one’s mental representation of the text (Griffin et al., 2008, 2013; Jaeger & Wiley, 2014; Thiede et al., 2010). In the present set of studies, many students reported basing their judgments on representation-based cues, but the use of these cues was only related to better relative accuracy when no images were presented alongside the text. This finding adds nuance to the interpretation that visuals make heuristic or superficial cues more salient or available. If images simply increased the salience of heuristic cues, then we should have seen students reporting using those kinds of cues more often in the text-with-image conditions, however, we only saw this difference in Study 1b, and not in Studies 2 and 3. An alternative hypothesis is that visualizations give students a false sense of fluency which they interpret as an increased ability to understand or explain the concepts. In this case, students may report basing their judgments on comprehension, but they are misattributing their feeling of fluency to an estimate of comprehension or hold misconceptions about the value of visuals for supporting comprehension. However, because students could report using multiple cue types, even students in the image condition who reported using representation-based cues might have also relied on heuristic cues when making their judgments.
Further, we found that many students reported basing their drawing judgments on visual cues, however the type of visual cues differed depending on whether instructional visuals were present. When no visuals were presented alongside the text, students reported relying on internal visual representations like how well they could mentally imagine the concepts and processes described in the text to make their draw judgments. When visuals were included with the texts, students reported relying on how well they could recall the presented image, or a similar image seen in the past to make their draw judgments. This difference suggests that the images may have changed the way students interpreted the drawing judgment. That is, when images were present, they may have interpreted the drawing judgment as a judgment of their visual memory for the diagram rather than a judgment of their internal spatial representation of the concepts, which was the intention behind the drawing judgment. Further, the phrasing of the drawing judgments may have contributed to this interpretation. The drawing prompts were specific and closely tied to the information presented in the diagrams. Because of this alignment, students who saw the diagrams may have interpreted the drawing judgment to be about how well they could recreate the presented image. However, students in the text-only condition did not see diagrams, and thus, may have interpreted the drawing judgment to be about how well they could visually represent their own understanding. Future research should vary the specificity of drawing judgment prompts and how closely they align to information in provided visuals to examine if this creates systematic differences in the judgments students make and the cues they report basing their judgments on.
In contrast to the drawing judgments, participants generally did not report using visual information or cues to make their test or explain judgments in any of the present studies. This result is interesting because it suggests that, without explicit prompting, students do not consider their ability to visualize or generate a visualization as a valid cue for assessing comprehension. This is potentially problematic because learning in STEM is often highly related to one’s ability to think spatially (Shea et al., 2001; Wai et al., 2009) and one’s ability to mentally imagine a process is likely a valid cue for assessing one’s ability to perform well on a test or explain a concept to a friend. Still, even when explicitly asked about one’s ability to generate a visualization, like with drawing judgments, only about a third of participants reported basing their drawing judgments on visual information.
An important contribution of the current work was the inclusion of both absolute and relative measures of metacomprehension accuracy. In terms of relative accuracy, the overall pattern of results suggests that conceptual diagrams have at best no impact on relative accuracy and at worst, a negative impact on relative metacomprehension accuracy. These results align with Jaeger and Wiley (2014) such that conceptual images meant to support comprehension and metacomprehension accuracy did not serve to improve relative accuracy. In terms of absolute accuracy, the pattern of results generally indicated no differences between the text-with-image and text-only conditions, which aligns with results from Wiley (2019). However, Studies 2 and 3 did show significantly worse absolute accuracy for the draw judgments when images were present. These results suggest that while the diagrams did not necessarily harm students’ ability to differentiate between well understood and less understood material (relative accuracy), it did cause them to have poorly calibrated judgments overall (absolute accuracy). In the case of Study 3, we saw that students had more inflated drawing judgments when images were present. This result supports the idea that visualizations can give readers a false sense of fluency or make less valid cues more salient (Jaeger & Wiley, 2014; Wiley, 2019), particularly when they are prompted to reflect on their ability to recreate the visualizations themselves.
Practical Implications
On a practical level, the findings provide important implications for developing methods to support students’ metacognitive accuracy and self-regulated learning. First, the findings suggest that instructors cannot assume students will productively make use of visualizations for assessing their own level of comprehension. Students may not engage in the generative processing necessary for internalizing a visual representation and integrating it with their own mental model (Fiorella, 2022; Fiorella et al., 2021). Future research should consider interventions aimed at increasing attention to and engagement with instructional visualizations like combining drawing tasks and provided visualizations. For example, Zhang and Fiorella (2019) found that having students engage in a drawing task while reading, then seeing a provided visualization resulted in improved transfer performance compared to drawing after having already viewed the provided visualization. This result suggests drawing first prepared students to process the provided visualization more deeply because they compared it to their own drawing.
Second, students may not know how to effectively process visual representations. That is, students may require explicit instruction regarding how to integrate diagrams into their mental representations and specific instruction around the conventions of diagrams in different fields. For example, in biology, red and blue may indicate oxygenated versus deoxygenated blood, while in chemistry those same colors represent positive and negative charges. Being familiar with the conventions of diagrams in one field could create a false sense of fluency when attempting to understand diagrams in another field. Future research could examine the effect of self-explanation instructions that include a focus on explaining the diagram and how it aligns with the text. For example, Jaeger and Wiley (2011) instructed students to explain to themselves the meaning and relevance of the parts of each image, ask themselves questions about the arrows in each image, and think about how the information in the images connects to information in the texts. Compared to a decorative image condition where students were instructed to evaluate the usefulness of each image and consider whether they were helpful for understanding the text, students in the conceptual image explanation condition showed significantly more accurate relative metacomprehension (Pearson’s r = 0.58).
Additionally, the present set of findings suggest that students may not know what understanding or comprehension means, which is critical for accurately assessing one’s own levels of understanding. If instructors’ goals for student learning include generating inferences or applying knowledge in new contexts, then this is the kind of understanding students should be striving for and monitoring. However, under normal circumstances students are more likely to consider their memory for the text as a basis for their monitoring judgments (Griffin et al., 2019a, 2019b). Future research should examine how lessons regarding what it means to understand in science support students in making more accurate comprehension judgments. In a recent study by Griffin et al. (2024), middle school students were given an explicit lesson about what it means to comprehend in science and how to construct science explanations with multiple connected causes rather than a single cause. Students who received this lesson constructed essays with more critical concepts and more connections between those concepts compared to students who received an inquiry instruction that simply told them to explain how and why and use specific information to support your claims. Although this study did not assess how the causal explanation lesson impacted students’ metacognitive judgment accuracy, it could be predicted that these students would have more accurate metacomprehension. It is likely the case that to understand your understanding you first must understand what understanding means.
Beyond teaching students what it means to understand, we should also be thoughtful about how students are prompted to judge their understanding. In the present research, the goal of asking people to judge how well they could draw something was to get them to reflect on their own spatial mental models, but the prompts may not have done that. Rather than ask people how well they can draw something, it may be more appropriate to ask them about their ability to mentally visualize the information. Drawing judgments may cause students to think about how well they could recreate a diagram from memory, while visualization judgments may direct students to think about their own internal spatial representations. Similarly, if student learning assessments include inference and application questions, then test judgments should specifically indicate this. In fact, prior research has shown that giving students an expectation that they will complete inference tests improves metacomprehension accuracy, while giving the expectation that they will complete memory tests improves metamemory accuracy (Griffin et al., 2019a, 2019b).
Limitations and Future Directions
One drawback of the present work is that participants did not actually complete drawing-based assessments in all studies. Despite this, prior research provides justification for computing absolute and relative accuracy with the comprehension test scores. Many studies have found that learners’ actual drawing quality is strongly correlated with subsequent comprehension performance (e.g., Jaeger et al., 2018; Leutner et al., 2009; Mason et al., 2013; Scheiter et al., 2017; Schmeck et al., 2014; van Meter, 2001; van Meter et al., 2006), a finding referred to as the prognostic drawing effect (Schwamborn et al., 2010). Furthermore, performance on drawing-based post-tests tends to be strongly correlated with performance on comprehension- and transfer-based post-tests (Fiorella & Kuhlmann, 2020), which we also saw in Study 3. Because we expected each type of judgment to generally reflect one’s perceived understanding of the learning material, we linked each of these judgments to a common comprehension test in Studies 1a and 2.
Another limitation was that, despite adding a draw testing, increasing our sample size, and counter-balancing judgment order in Study 3, we did not replicate the effects of images on draw relative accuracy seen in Studies 1a and 2. In both studies 1a and 2, relative accuracy for the draw judgments was similar to the average levels seen in the literature when no images were present (r = 0.20 –0.30), but when images were present, relative accuracy dropped substantially (r = -0.15 – 0.02). In Study 3, we saw similar levels of relative accuracy for drawing judgments in the text-only condition (r = 0.22), but draw relative accuracy was less harmed by the presence of the images (r = 0.08) than what we saw in Studies 1a and 2. Several factors could potentially contribute to these differences. First, students in Study 3 demonstrated higher test performance (70% accuracy) and reported having taken more college science courses (approximately 2.33) than students in Studies 1a and 2 (approximately 50% accuracy and approximately 1 science course). It could be the case that students in Study 3 were less affected by the presence of the images because their prior knowledge and experience with college science courses allowed them to differentiate between well and less well understood material more effectively.
Prompting students to make multiple judgments for each text could have also impacted the sensitivity of the judgments. Regardless of judgment order, when participants are asked to make multiple types of judgments, their thoughts about one judgment could change what they consider in the other judgment(s). For example, research by Schaper et al. (2019) has demonstrated that asking students to make Judgments of Learning and Judgments of Source changes the sensitivity of the Judgments of Learning. Their study found that when a Judgment of Learning was asked alone, it was quite sensitive to source cues, but when a Judgment of Source was asked in addition, the Judgment of Learning was less sensitive to source cues. In the present set of studies, students made two or three judgments for each text. Thus, it is unclear how a judgment of drawing would fare if it were asked alone. Future research should examine judgments of drawing alone, without other judgments to assess more accurately what these kinds of judgments are based on and what influences them.
Another limitation was that results from the present set of studies did not support the multimedia learning effect—that is, we did not see higher comprehension scores in the text-with-image condition compared to the text-only condition. This is not particularly surprising given that many students do not spontaneously make sense of provided visualizations without explicit support (Renkl & Scheiter, 2017; Schnotz & Wagner, 2018; Schuler et al., 2019; Zhang & Fiorella, 2019). If students do not deeply process the visualizations, they will not construct a coherent mental model and they likely will only extract superficial metacognitive cues. Further, the visuals provided in the present set of learning materials did not adhere to all the recommended best practices for multimedia learning (Mayer & Fiorella, 2022). For example, the spatial contiguity principle suggests that visuals should closely situated to the most relevant part of the text rather than always being presented at the end of the passage (Schroeder & Cenkci, 2018). Also, the coherence principle suggests that visuals should depict specific parts of the text rather than operating more as a summary of multiple text points (Mayer, 2010). An interesting direction for future research would be to examine the differential effects of various conceptual diagrams on metacomprehension accuracy. Specifically, future work could compare metacomprehension accuracy in conditions where conceptual diagrams support improved comprehension to situations where the diagrams do not support improved comprehension. One could predict that in either case, the presence of images could harm metacomprehension accuracy if readers do not use the provided images to test or compare their own mental models.
Another important direction for future research on metacomprehension accuracy relates to developing better methods for assessing cue-use. Asking people at the end of the study to report what they based their judgments on—a method used in prior metacomprehension accuracy research (e.g., Jaeger & Wiley, 2014; Thiede et al., 2010)—may not be the most effective way to assess the role of cue-use. One issue is that people may not be aware of the cues they base their judgments on and if/how these cues change depending on the judgment prompt. In the case of spatial or visual cues, people may be unaware of their own mental images and because of this, there may be a verbal bias in cue reporting. To get around issues related to self-report, some researchers have examined features of student-generated summaries (Anderson & Thiede, 2008), key words (Engelen et al., 2018) or drawings (van de Pol et al., 2019; Van Loon et al., 2014) to examine the relationship more directly between specific types of verbal or visual cues and metacomprehension accuracy.
The present set of studies was also limited due to the COVID-19 pandemic. Studies 1a and 1b were conducted during the pandemic when all on-campus activities were suspended and thus, data collection needed to be transferred into an online format. Study 2 was also impacted by COVID-19 because although on-campus activities were allowed to resume, most participants were still hesitant to come to in-person laboratory studies thus making it difficult to obtain a large sample.
Finally, future research should consider the role of individual differences in spatial thinking in science text comprehension and metacomprehension. Several studies have demonstrated a link between spatial thinking and learning from science text (e.g., Fiorella & Mayer, 2017; Höffler & Leutner, 2011; Jaeger et al., 2016; Mayer, 1989; Sanchez & Wiley, 2010) and a link between spatial thinking and learning from drawing (Jaeger et al., 2018; Zhang & Fiorella, 2019). Based on these prior findings, it is possible that individuals with greater levels of spatial thinking skill are better able to generate mental images, and thus only those students can use cues based on their internal spatial mental models to make accurate understanding and performance judgments. On the other hand, students with lower levels of spatial thinking skill may be more reliant upon the heuristic-based cues that are salient when instructional visualizations are provided.
In conclusion, the present set of studies provides further evidence that instructional visualizations, although intended to be useful tools for supporting student comprehension and metacomprehension accuracy, may not always provide those benefits. Importantly, the present work indicates that instructional visualizations can harm metacomprehension accuracy if students do not actively engage with them or if they make heuristic-based metacognitive cues more salient. Finally, the present research indicates that asking students to make judgments about how well they could draw a scientific process or concept may be effective for getting students to attend to representation-based cues, but that this may only be the case when instructional visualizations are not present.
Data Availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Notes
Participant recruitment was greatly impacted by the COVID-19 pandemic. To increase recruitment, we used subject pools from both authors’ institutions. Data from these two samples did not differ in terms of age, gender, year in school, or self-reported number of science courses taken (all ps > .28).
A paired samples t-test comparing the two methods of computing draw relative accuracy (draw judgments with test performance versus draw judgments with draw test performance) was conducted and revealed no difference, t < 1.
References
Ainsworth, S. (2006). DeFT: A conceptual framework for considering learning with multiple representations. Learning and Instruction, 16(3), 183–198. https://doi.org/10.1016/j.learninstruc.2006.03.001
Ainsworth, S., & Loizou, A. T. (2003). The effects of self-explaining when learning with text or diagrams. Cognitive Science, 27, 669e681. https://doi.org/10.1207/s15516709cog2704_5
Anderson, M., & Thiede, K. W. (2008). Why do delayed summaries improve metacomprehension accuracy? Acta Psychologica, 128, 110–118. https://doi.org/10.1016/j.actpsy.2007.10.006
Baker, J. M., & Dunlosky, J. (2006). Does momentary accessibility influence metacomprehension judgments? The influence of study-judgment lags on accessibility effects. Psychonomic Bulletin & Review, 13, 60–65. https://doi.org/10.3758/BF03193813
Bisra, K., Liu, Q., Nesbit, J. C., Salimi, F., & Winne, P. H. (2018). Inducing self-explanation: A meta-analysis. Educational Psychology Review, 30(3), 703–725. https://doi.org/10.1007/s10648-018-9434-x
Bjork, R. A., Dunlosky, J., & Kornell, N. (2013). Self-regulated learning: Beliefs, techniques, and illusions. Annual Review of Psychology, 64, 417–444. https://doi.org/10.1146/annurev-psych113011-143823
Butcher, K. R. (2014). The multimedia principle. In R. E. Mayer (Ed.), The Cambridge handbook of multimedia learning (pp. 174–205). Cambridge University Press. https://doi.org/10.1017/CBO9781139547369.010
Chi, M. T. H. (2000). Self-explaining expository texts: The dual processes of generating inferences and repairing mental models. In R. Glaser (Ed.), Advances in instructional psychology (pp. 161–238). Erlbaum.
Dunlosky, J., & Lipko, A. R. (2007). Metacomprehension: A brief history and how to improve its accuracy. Current Directions in Psychological Science, 16(4), 228–232. https://doi.org/10.1111/j.1467-8721,2007.00509.x
Dunlosky, J., & Rawson, K. A. (2012). Overconfidence produces underachievement: Inaccurate self evaluations undermine students’ learning and retention. Learning and Instruction, 22(4), 271–280. https://doi.org/10.1016/j.learninstruc.2011.08.003
Engelen, J. A., Camp, G., van de Pol, J., & de Bruin, A. B. (2018). Teachers’ monitoring of students’ text comprehension: can students’ keywords and summaries improve teachers’ judgment accuracy? Metacognition and Learning, 13(3), 287–307. https://doi.org/10.1007/s11409-018-9187-4
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
Fiorella, L. (2022). Learning by explaining after pauses in video lectures: are provided visuals a scaffold or a crutch? Applied Cognitive Psychology, 36, 1142–1149. https://doi.org/10.1002/acp.3994
Fiorella, L., & Kuhlmann, S. (2020). Creating drawings enhances learning by teaching. Journal of Educational Psychology, 112(4), 811–822. https://doi.org/10.1037/edu0000392
Fiorella, L., & Mayer, R. E. (2016). Eight ways to promote generative learning. Educational Psychology Review, 28(4), 717–741. https://doi.org/10.1007/s10648-015-9348-9
Fiorella, L., & Mayer, R. E. (2017). Spontaneous spatial strategy use in learning from scientific text. Contemporary Educational Psychology, 49, 66–79. https://doi.org/10.1016/j.cedpsych.2017.01.002
Fiorella, L., & Mayer, R. E. (2022). The generative activity principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 339–350). Cambridge University Press.
Fiorella, L., & Zhang, Q. (2018). Drawing boundary conditions for learning by drawing. Educational Psychology Review, 30(3), 1115–1137. https://doi.org/10.1007/s10648-018-9444-8
Fiorella, L., Pyres, M., & Hebert, R. (2021). Explaining and drawing activities for learning from multimedia: the role of sequencing and scaffolding. Applied Cognitive Psychology, 35(6), 1574–1584. https://doi.org/10.1002/acp.3871
Fleming, S. M., & Lau, H. C. (2014). How to measure metacognition. Frontiers in Human Neuroscience, 8, 443. https://doi.org/10.3389/fnhum.2014.00443
Glenberg, A. M., & Epstein, W. (1985). Calibration of comprehension. Journal of Experimental Psychology: Learning, Memory, and Cognition, 11(4), 702–718. https://doi.org/10.1037/0278-7393.11.1-4.702
Griffin, T. D., Wiley, J., & Thiede, K. W. (2008). Individual differences, rereading, and self-explanation: Concurrent processing and cue validity as constraints on metacomprehension accuracy. Memory & Cognition, 36, 93–103. https://doi.org/10.3758/MC.36.1.93
Griffin, T. D., Jee, B. D., & Wiley, J. (2009). The effects of domain knowledge on metacomprehension accuracy. Memory & Cognition, 37, 1001–1013. https://doi.org/10.3758/MC.37.7.1001
Griffin, T. D., Wiley, J., & Salas, C. (2013). Supporting effective self-regulated learning: The critical role of monitoring. In R. Azevedo & V. Aleven (Eds.), International handbook of metacognition and learning technologies (pp. 19–34). Springer Science.
Griffin, T. D., Mielicki, M. K., & Wiley, J. (2019a). Improving students’ metacomprehension accuracy. In J. Dunlosky & K. A. Rawson (Eds.), The Cambridge handbook of cognition and education (pp. 619–646). Cambridge University Press.
Griffin, T. D., Wiley, J., & Thiede, K. W. (2019b). The effects of comprehension-test expectancies on metacomprehension accuracy. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(6), 1066–1092. https://doi.org/10.1037/xlm0000634
Griffin, T. D., Jaeger, A. J., Britt, M. A., & Wiley. J. (2024). Improving multiple document comprehension with a lesson about multi-causal explanations in science. Instructional Science. Advanced online publication. https://doi.org/10.1007/s11251-023-09657-1
Hegarty, M., & Just, M. A. (1993). Constructing mental models of machines from text and diagrams. Journal of Memory and Language, 32, 717–742. https://doi.org/10.1006/jmla.1993.1036
Höffler, T. N., & Leutner, D. (2011). The role of spatial ability in learning from instructional animations—Evidence for an ability-as-compensator hypothesis. Computers in Human Behavior, 27, 209–216. https://doi.org/10.1016/j.chb.2010.07.042
Jaeger, A. J., & Wiley, J. (2011). Reducing illusions of comprehension from illustrated text [Abstract]. Annual Meeting of the Psychonomic Society, 4061, 83.
Jaeger, A. J., & Wiley, J. (2014). Do illustrations help or harm metacomprehension accuracy? Learning & Instruction, 34, 58–73. https://doi.org/10.1016/j.learninstruc.2014.08.002
Jaeger, A. J., Taylor, A. R., & Wiley, J. (2016). When, and for whom, analogies help: The role of spatial skills and interleaved presentation. Journal of Educational Psychology, 108, 1121–1139. https://doi.org/10.1037/edu0000121
Jaeger, A. J., Velazquez, M. N., Dawdanow, A., & Shipley, T. F. (2018). Sketching and summarizing to reduce memory for seductive details in science text. Journal of Educational Psychology, 110, 899–916. https://doi.org/10.1037/edu0000254
Koriat, A. (1997). Monitoring one’s own knowledge during study: A cue-utilization approach to judgments of learning. Journal of Experimental Psychology: General, 126(4), 349–370. https://doi.org/10.1037/0096-3445.126.4.349
Kozma, R. B., & Russell, J. (1997). Multimedia and understanding: Expert and novice responses to different representations of chemical phenomena. Journal of Research in Science Teaching: the Official Journal of the National Association for Research in Science Teaching, 34(9), 949–968. https://doi.org/10.1002/(SICI)1098-2736(199711)34:9%3c949::AID-TEA7%3e3.0.CO;2-U
Krippendorff, K. (2013). Content analysis: An introduction to its methodology (3rd ed.). Sage.
Leutner, D., Leopold, C., & Sumfleth, E. (2009). Cognitive load and science text comprehension: Effects of drawing and mentally imagining text content. Computers in Human Behavior, 25(2), 284–289. https://doi.org/10.1016/j.chb.2008.12.010
Maki, R. H. (1998a). Test predictions over text material. In D. J. Hacker, J. Dunlosky, & A. C. Graesser (Eds.), Metacognition in educational theory and practice (pp. 117–145). Erlbaum.
Maki, R. H. (1998b). Predicting performance on text: Delayed versus immediate predictions and tests. Memory & Cognition, 26, 959–964. https://doi.org/10.3758/BF03201176
Maki, R. H., & Berry, S. L. (1984). Metacomprehension of text material. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 663–679. https://doi.org/10.1037/0278-7393.10.4.663
Mason, L., Lowe, R., & Tornatora, M. C. (2013). Self-generated drawings for supporting comprehension of a complex animation. Contemporary Educational Psychology, 38, 211–224. https://doi.org/10.1016/j.cedpsych.2013.04.001
Mayer, R. E. (1989). Models for understanding. Review of Educational Research, 59, 43–64. https://doi.org/10.3102/00346543059001043
Mayer, R. E. (2008). Applying the science of learning: Evidence-based principles for the design of multimedia instruction. American Psychologist, 63(8), 760–769. https://doi.org/10.1037/0003-066X.63.8.760
Mayer, R. E., & Fiorella, L. (Eds.) (2022). The Cambridge handbook of multimedia learning (3rd ed.). New York, NY: Cambridge University Press.
Mayer, R. E. (2010). Techniques that reduce extraneous cognitive load and manage intrinsic cognitive load during multimedia learning (R. Moreno, Ed.). In J. L. Plass, R. Moreno, & R. Brünken (Eds.), Cognitive load theory (pp. 131–152). Cambridge University Press. https://doi.org/10.1017/CBO9780511844744.009
McNamara, D. S., Graesser, A. C., & Louwerse, M. M. (2012). Sources of text difficulty: Across genres and grades. In J. P. Sabatini, E. Albro, & T. O’Reilly (Eds.), Measuring up: Advances in how we assess reading ability (pp. 89 –116). Lanham, Maryland: R & L Education.
Nelson, T., & Narens, L. (1994). Why investigate metacognition? Knowing about knowing. The MIT Press.
Paik, E. S., & Schraw, G. (2013). Learning with animation and illusions of understanding. Journal of Educational Psychology, 105(2), 278–289. https://doi.org/10.1037/a0030281
Pilegard, C., & Mayer, R. E. (2015). Adding judgments of understanding to the metacognitive toolbox. Learning and Individual Differences, 41, 62–72. https://doi.org/10.1016/j.lindif.2015.07.002
Prinz, A., Golke, S., & Wittwer, J. (2020). To what extent do situation-model-approach interventions improve relative metacomprehension accuracy? Meta-Analytic Insights. Educational Psychology Review, 32(4), 917–949. https://doi.org/10.1007/s10648-020-09558-6
Renkl, A., & Scheiter, K. (2017). Studying visual displays: How to instructional support learning. Educational Psychology Review, 29(3), 599–621. https://doi.org/10.1007/s10648-015-9340-4
Roscoe, R. D. (2014). Self-monitoring and knowledge-building in learning by teaching. Instructional Science, 42, 327–351. https://doi.org/10.1007/s11251-013-9283-4
Sanchez, C. A., & Wiley, J. (2010). Sex differences in science learning: Closing the gap through animations. Learning and Individual Differences, 20, 271–275. https://doi.org/10.1016/j.lindif.2010.01.003
Sanchez, C. A., & Wiley, J. (2014). The role of dynamic spatial ability in geoscience text comprehension. Learning & Instruction, 31, 33–45. https://doi.org/10.1016/j.learninstruc.2013.12.007
Schaper, M. L., Kuhlmann, B. G., & Bayen, U. J. (2019). Metacognitive expectancy effects in source monitoring: Beliefs, in-the-moment experiences, or both? Journal of Memory and Language, 107, 95–110. https://doi.org/10.1016/j.jml.2019.03.009
Scheiter, K., Schleinschok, K., & Ainsworth, S. (2017). Why sketching may aid learning from science texts: Contrasting sketching with written explanations. Topics in Cognitive Science, 9, 866–882. https://doi.org/10.1111/tops.1226
Schleinschok, K., Eitel, A., & Scheiter, K. (2017). Do drawing tasks improve monitoring and control during learning from text? Learning and Instruction, 51, 10–25. https://doi.org/10.1016/j.learninstruc.2017.02.002
Schmeck, A., Mayer, R. E., Opfermann, M., Pfeiffer, V., & Leutner, D. (2014). Drawing pictures during learning from scientific text: Testing the generative drawing effect and the prognostic drawing effect. Contemporary Educational Psychology, 39, 275–286. https://doi.org/10.1016/j.cedpsych.2014.07.003
Schnotz, W., & Wagner, I. (2018). Construction and elaboration of mental models through strategic conjoint processing of text and pictures. Journal of Educational Psychology, 110(6), 850–863. https://doi.org/10.1037/edu0000246
Schroeder, N. L., & Cenkci, A. T. (2018). Spatial contiguity and spatial split-attention effects in multimedia learning environments: A meta-analysis. Educational Psychology Review, 30, 679–701. https://doi.org/10.1007/s10648-018-9435-9
Schukajlow, S., Blomberg, J., Rellensmann, J., & Leopold, C. (2022). The role of strategy-based motivation in mathematical problem solving: The case of learner-generated drawings. Learning and Instruction, 80, 101561. https://doi.org/10.1016/j.learninstruc.2021.101561
Schuler, A., Pazzaglia, F., & Scheiter, K. (2019). Specifying the boundary conditions of the multimedia effect: The influence of content and its disturbing between text and pictures. British Journal of Psychology, 110(1), 126–150. https://doi.org/10.1111/bjop.12341
Schwamborn, A., Mayer, R. E., Thillmann, H., Leopold, C., & Leutner, D. (2010). Drawing as a generative activity and drawing as a prognostic activity. Journal of Educational Psychology, 102, 872–879. https://doi.org/10.1037/a0019640
Serra, M. J., & Dunlosky, J. (2010). Metacomprehension judgments reflect the belief that diagrams improve learning from text. Memory, 18, 698–711. https://doi.org/10.1080/09658211.2010.506441
Shea, D. L., Lubinski, D., & Benbow, C. P. (2001). Importance of assessing spatial ability in intellectually talented young adolescents: A 20-year longitudinal study. Journal of Educational Psychology, 93(3), 604–614. https://doi.org/10.1037/0022-0663.93.3.604
Thiede, K. W., Dunlosky, J., Griffin, T. D., & Wiley, J. (2005). Understanding the delayed-keyword effect on metacomprehension accuracy. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(6), 1267–1280. https://doi.org/10.1037/0278-7393.31.6.1267
Thiede, K. W., Griffin, T. D., Wiley, J., & Redford, J. (2009). Metacognitive monitoring during and after reading. In D. J. Hacker, J. Dunlosky, & A. C. Graesser (Eds.), Handbook of metacognition in education (pp. 85–106). Routledge.
Thiede, K. W., Griffin, T. D., Wiley, J., & Anderson, M. C. (2010). Poor metacomprehension accuracy as a result of inappropriate cue use. Discourse Processes, 47(4), 331–362. https://doi.org/10.1080/01638530902959927
Thiede, K. W., Wright, K. L., Hagenah, S., Wenner, J., Abbot, J., & Arechiga, A. (2022). Drawing to improve metacomprehension accuracy. Learning and Instruction, 77, 101541. https://doi.org/10.1016/j.learninstruc.2021.101541
van de Pol, J., de Bruin, A. B., van Loon, M. H., & van Gog, T. (2019). Students’ and teachers’ monitoring and regulation of students’ text comprehension: effects of comprehension cue availability. Contemporary Educational Psychology, 56, 236–249. https://doi.org/10.1016/j.cedpsych.2019.02.001
van Loon, M. H., de Bruin, A. B., van Gog, T., van Merriënboer, J. J., & Dunlosky, J. (2014). Can students evaluate their understanding of cause-and-effect relations? The effects of diagram completion on monitoring accuracy. Acta Psychologica, 151, 143–154. https://doi.org/10.1016/j.actpsy.2014.06.007
Van Meter, P. (2001). Drawing construction as a strategy for learning from text. Journal of Educational Psychology, 93, 129–140. https://doi.org/10.1037/0022-0663.93.1.129
Van Meter, P., & Firetto, C. M. (2013). Cognitive model of drawing construction. In G. Schraw, M. T. McCrudden, & D. Robinson (Eds.), Learning through visual displays (pp. 247–280). Information Age Publishing Inc.
Van Meter, P., & Garner, J. (2005). The promise and practice of learner generated drawing: Literature review and synthesis. Educational Psychology Review, 17, 285–325. https://doi.org/10.1007/s10648-005-8136-3
Van Meter, P., Aleksic, M., Schwartz, A., & Garner, J. (2006). Learner generated drawing as a strategy for learning from content area text. Contemporary Educational Psychology, 31, 142–166. https://doi.org/10.1016/j.cedpsych.2005.04.001
Wai, J., Lubinski, D., & Benbow, C. P. (2009). Spatial ability for STEM domains: Aligning over 50 years of cumulative psychological knowledge solidifies its importance. Journal of Educational Psychology, 101, 817–835. https://doi.org/10.1037/a0016127
Wiley, J. (2019). Picture this! Effects of photographs, diagrams, animations, and sketching on learning and beliefs about learning from a geoscience text. Applied Cognitive Psychology, 33, 9–19. https://doi.org/10.1002/acp.3495
Wiley, J., Griffin, T. D., & Thiede, K. W. (2005). Putting the comprehension in metacomprehension. Journal of General Psychology, 132, 408–428. https://doi.org/10.3200/GENP.132.4.408-428
Wiley, J., Thiede, K. W., & Griffin, T. D. (2016). Improving metacomprehension with the situation-model approach. In K. Mokhtari (Ed.), Improving reading comprehension through metacognitive reading instruction for first and second language readers (pp. 93–110). Rowman & Littlefield.
Wiley, J., Sarmento, D., Griffin, T. D., & Hinze, S. R. (2017). Biology textbook graphics and their impact on expectations of understanding. Discourse Processes, 54, 463–478. https://doi.org/10.1080/0163853X.2017.1319655
Wiley, J., Jaeger, A. J., Taylor, A. R., & Griffin, T. D. (2018). When analogies harm: The effects of analogies and valid cues on the metacomprehension of science text. Learning and Instruction, 55, 113–123. https://doi.org/10.1016/j.learninstruc.2017.10.001
Zhang, Q., & Fiorella, L. (2019). Role of generated and provided visuals in supporting learning from scientific text. Contemporary Educational Psychology, 59, 101808. https://doi.org/10.1016/j.cedpsych.2019.101808
Acknowledgements
The authors thank Daphne Harel, Alexa Ibrahim, Samuel Jackson, Cynthia Johnson, Shari Lieblich, Anne Vazquez, Samantha Visco, Erin Wing, and Berna Altunisik for their contributions to this research.
Funding
This research was supported in part by Grant #1956466 / 2307285 and #1955348 from the National Science Foundation. The opinions expressed are those of the authors and do not represent views of the National Science Foundation.
Author information
Authors and Affiliations
Contributions
AJJ and LF both made substantial contributions to the conception and design of the work; AJJ oversaw data collection; AJJ conducted data analysis and LF assisted with interpretation of data; AJJ initially drafted the work, with feedback by LF. AJJ completed all revisions with input by LF. All authors have approved the submitted version and have agreed to be accountable for the accuracy or integrity of any part of the work.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all individual participants involved in the study.
Competing interests
The authors declare that there are no known conflicts of interest to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Sample Biology Text, Image, and Inference Test Item from Studies 1a and 1b
The Nervous System
The nervous system is made up of interconnected cells called neurons that activate processes within the body. Neurons are the basic functional unit of the nervous system which generate electrochemical signals allowing them to transmit information over long distances. The nervous system can be separated into two sections: the central nervous system and the peripheral nervous system. The central nervous system includes the brain and spinal cord and is where information is processed. The peripheral nervous system is made up of neurons that carry information between the central nervous system and the rest of the body. There are three classes of neurons: sensory neurons, motor neurons, and interneurons.
Sensory neurons operate within the peripheral nervous system and bring signals into the central nervous system. Sensory neurons receive input about what is happening inside and outside of the body including touch, position, pain, and temperature. When sensory neurons receive inputs from outside and inside the body, they send signals to the central nervous system, which provides information about how to react to the initial input.
Motor neurons primarily operate within the central nervous system and also extend into the peripheral nervous system. Motor neurons carry signals out of the central nervous system to control skeletal muscles and other organs. When a motor neuron connected to a particular muscle receives input from the brain or spinal cord, it sends signals through long extensions to that muscle. The muscle then reacts according to the signal sent from the motor neuron.
Interneurons operate within the central nervous system and connect one neuron to another. They receive information from neurons (sensory or other interneurons) and send information to neurons (motor or other interneurons). For example, when a sensory neuron receives an input, it may send that signal to an interneuron, which in turn sends a signal to a motor neuron, causing a particular muscle to react. Other interneurons may send signals up to the neurons in the brain, causing a particular sensation or feeling. Interneurons are the most numerous class of neurons and are involved in processing all forms of communication, both in simple reflexes and more complex processing.
Neurons have a cell body, called the soma, and a nucleus, located at the center of the soma. Similar to all other types of cells, neurons carry out basic cellular processes, such as protein synthesis and energy production. What makes neurons unique is that they typically have two types of appendages that extend out from the soma. These include many short, branching appendages, called dendrites. Most neurons also have one longer appendage, called the axon.
The first two neuronal functions, receiving and processing information, takes place in the dendrites and soma. A single neuron has many sets of dendrites, and receives thousands of input signals, but not all signals will receive an action response. Incoming signals can be excitatory, meaning they make the neuron generate an electrical impulse or firing. Incoming signals can also be inhibitory, meaning they tend to keep the neuron from firing. Whether or not a neuron is excited into firing an impulse depends on the sum of all of the excitatory and inhibitory signals it receives.
If a neuron fires, the nerve impulse called the action potential, is conducted down the axon. Axons are covered in a casing called myelin that protects and keeps energy within the axon. Myelin allows the signal to travel down the axon more quickly. The end of the axon is split into multiple axon terminals. When the action potential arrives at the terminals, it normally triggers a chemical communication with a dendrite, axon, or soma of another neuron. The cell to which the axon terminal belongs (sending cell) is called the presynaptic cell, and the receiving cell is called the postsynaptic cell. The space between these two cells, called the synapse, is where the chemical signal is passed from the presynaptic cell to the postsynaptic cell.
At most synapses, information is transmitted from the presynaptic cell to the postsynaptic cell in the form of chemical messages, called neurotransmitters. When an action potential travels down an axon and reaches the axon terminal, it triggers the release of neurotransmitters from the presynaptic cell. Neurotransmitters cross the synapse and bind to membrane receptors on the postsynaptic cell, which then conveys an excitatory or inhibitory signal.
Nervous system function depends on groups of neurons that work and fire together. Individual neurons communicate with other neurons to stimulate or inhibit their activity, forming circuits that transmit incoming information and carry out a response. Neuronal circuits can be simple, composed of only a few neurons, or can involve more complex networks. An example of a simple circuit is the muscular response to a sensory input like a pin prick. The pin prick would stimulate sensory neurons within the muscle. Axons from these sensory neurons excite interneurons in the spinal cord, which then excite motor neurons connected to certain muscles. When the motor neurons fire, the muscles respond through physical movement. The ability to perceive sensory stimuli or perform higher order tasks depends on the organization of more complex neuronal networks in the nervous system.

Appendix B
Sample Chemistry Text, Image, and Inference Test Item from Study 2
Electrolytes vs. Nonelectrolytes
When some substances are dissolved in water, they undergo a physical change that yields ions—electrically charged atoms or molecules—in the solution. These substances are an important class of substances called electrolytes. If all or nearly all of the dissolved compound yields ions, it is a strong electrolyte. If only a small fraction of the dissolved substance produces ions, it is a weak electrolyte. A substance that does not yield any ions when it is dissolved is called a nonelectrolyte.
Polar molecules, like water (H2O), are attracted to these ions. This is because a polar molecule has an uneven distribution of electrons across the molecule. That is, one atom in the molecule is partially negatively charged due to a higher electron concentration and the other atom is partially positively charged due to a lower electron concentration. The hydrogen atoms in a water molecule are partially positively charged, while the oxygen atom is partially negatively charged. The partial charges attract charged ions. This attractive force is called the ion–dipole force.
When an ionic compound is dissolved in water, the ions in the solid separate and disperse uniformly throughout the solution because of the water molecules’ attraction to the ions. For example, consider sodium chloride (NaCl), or table salt, added to water. In water, NaCl dissociates completely into the sodium ion, Na + and the chloride ion, Cl-. The ion–dipole attraction causes the partially positive hydrogen end of the water molecule to be attracted to the negative chloride ions, while the partially negative oxygen end of the water molecule is attracted to the positive sodium ions. The water molecules surround and break apart the NaCl molecules, reducing the electrostatic forces between them. This process is called dissociation. Some ionic compounds, such as NaCl, will dissociate completely when dissolved, so they are classified as strong electrolytes.
On the other hand, when a nonelectrolyte is dissolved in water, it produces no ions. For example, sucrose (C12H22O11), or table sugar, is a covalent compound in which the atoms are held together by covalent bonds. In covalent bonds, atoms share electrons, and the molecule cannot dissociate into ions. Therefore, when sugar dissolves in water, it does not undergo a dissociation. Rather, it undergoes a physical change, where it is redistributed throughout the solution and the compounds in the solution are still just sugar and water. This is why sugar and other nonelectrolytes fail to conduct electricity.
A substance can be identified as a strong or weak electrolyte or nonelectrolyte by measuring the electrical conductivity of an aqueous, or water-based, solution containing the substance. The electrical conductance can be measured by immersing electrodes in a solution and then quantitatively measuring the electrical current flow or qualitatively measuring it by observing the relative brightness of a light bulb connected to the circuit. A strong electrolyte solution has high electrical conductance, while a weak electrolyte solution has weak electrical conductance. A non-electrolyte like pure water does not conduct electricity at all. Additionally, the higher the concentration of ions the more conductive the solution is. A strong electrolyte will dissolve completely, yielding a higher concentration of ions while a weak electrolyte will yield a lower concentration of ions because it does not dissociate completely; some of the non-dissociated compound remains dissolved in solution.

-
1.
What makes solid ionic compounds electrically non-conductive?
-
a.
The ions are not freely mobile when in the form of a solid compound.
-
b.
The electron concentration is not high enough.
-
c.
The electrostatic forces between the molecules are too weak.
-
d.
The solid ionic compounds are composed of covalent bonds.
-
a.
Appendix C
Sample Student-Generated Drawings from Students in the Text-Only Condition in Study 3
A) scored 7 points

B) scored 6 points

Sample Student-Generated Drawings from Students in the Text-With-Image Condition in Study 3
A) scored 7 points

B) scored 6 points

C) scored 11 points

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jaeger, A.J., Fiorella, L. Metacognitive effects of instructional visuals: the role of cue use and judgment type. Metacognition Learning 19, 249–291 (2024). https://doi.org/10.1007/s11409-023-09370-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11409-023-09370-x