
Abstract
The COVID-19 has affected and threatened the world health system very critically throughout the globe. In order to take preventive actions by the agencies in dealing with such a pandemic situation, it becomes very necessary to develop a system to analyze the impact of environmental parameters on the spread of this virus. Machine learning algorithms and artificial Intelligence may play an important role in the detection and analysis of the spread of COVID-19. This paper proposed a twinned gradient boosting machine (GBM) to analyze the impact of environmental parameters on the spread, recovery, and mortality rate of this virus in India. The proposed paper exploited the four weather parameters (temperature, humidity, atmospheric pressure, and wind speed) and two air pollution parameters (PM2.5 and PM10) as input to predict the infection, recovery, and mortality rate of its spread. The algorithm of the GBM model has been optimized in its four distributions for best performance by tuning its parameters. The performance of the GBM is reported as excellent (where R2 = 0.99) in training for the combined dataset comprises all three outcomes i.e. infection, recovery and mortality rates. The proposed approach achieved the best prediction results for the state, which is worst affected and highest variation in the atmospheric factors and air pollution level.
Similar content being viewed by others

1 Introduction
After the first reported case of severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2) in Wuhan, China in December 2019, it spread exponentially covering approximately 215 countries worldwide by 28th June 2021 [1]. According to the WHO’s report, it has infected over 180,654,652 people, and 3,920,463 confirmed deaths globally by 28th June 2021. According to the report of the Ministry of Health and Family Welfare, Government of India, there is a total of 5,72,994 active cases, 29,30,9607 cured and discharged and 3,96,730 deaths by 28th June 2021 [2]. Governments made their all efforts to control the spread of COVID-19 at their level, including lockdown, social distancing measures, personal hygiene, testing, tracking, isolation, and trial of drugs already used for other diseases like malaria, HIV, tuberculosis, etc. Finally, vaccination became the main tool to control the spread of COVID-19. In India total of 32,36,63,297 vaccines are vaccinated of which 4.3% are fully vaccinated and 20% of the population are partially vaccinated upto 28th June 2021 [2].
Despite these all-available precautions, the 2nd surge in India was unexpected and affected a large percentage of the population. 2nd surge of COVID-19 spread started in 1st week of April 2021 and declined after the 1st week of June 2021. In nearly two months, the country started to struggle with inadequate of hospital beds, oxygen cylinders, essential medicines, and vaccines all around the country. On 30 April 2021, India became the first country that reported over 4,00,000 newly infected cases in a very single day (24 h). This unexpected speed of infection created a huge demand for basic essentials.
It has been observed that both spikes were reported during the particular climate conditions in India. Therefore, it becomes too necessary to study the impact of weather and atmospheric factor on the spread of COVID-19. Along with weather parameters the impact of air pollutants is equally, important to analyses its impact on COVID 19.
The initial research talks about the transmission of COVID-19 from bats to humans originating from the seafood market in Wuhan, China [1, 3,4,5]. However, the scientific exploration of its route of transmission is requisite. The close contact of humans increases its transmission rate rapidly, through the surface and air [6]. In some recent studies, the presence of coronavirus in the air, fecal swabs, and blood of active cases have been informed [7, 8]. The change of climate conditions provides a favorable environment to grow viruses resulting common flu. The particular climate conditions also affect the transmission rate of the pandemic by presenting emergent or hostile conditions for humans. It was confirmed in cases of past infectious diseases as well as in the case of transmission of the present situation of COVID-19 in some countries. Like the transmission rate of influenza was high at the low temperature and humidity. It is also confirmed in the case of severe acute respiratory syndrome (SARS) in July 2003 which affected by climate change [9].
As reported that COVID-19 has a similar genetic sequence to SARS, therefore, it is highly expected that its transmission rate will be affected by the change in weather parameters [10]. The effect of climate factors on the spread of COVID-19 in different countries has been established in some recent studies [11,12,13,14,15,16,17,18,19]. Besides, the atmospheric factor, air pollution level may also be an affecting factor of the transmission of COVID-19, as reported high-rise of COVID-19 cases in Italy [20]. The effect of concentration of nitrogen oxide on the fatality due to COVID-19 has also been reported in Italy [7]. The effect of lockdown and air pollution level at the spread rate of COVID-19 in Wuhan, China has been also reported [21], etc. Even the atmospheric factors and air pollution levels are highly correlated; the study based on their combined effect on the transmission rate of COVID-19 in India has not been reported yet. The present work tries to cover the combined effect of atmospheric factors and measures of air pollution on the spread of COVID-19 during 28th March 2020 to 20th May 2021 (Exclusively two major surges) period in India.
In the past few years, machine learning has become a very significant tool in the analysis and design of prediction models [22,23,24]. Many machine-learning models have been designed and applied efficiently in the analysis of COVID-19 cases [25,26,27,28,29]. Apart from the most famous deep learning methods, tree-based learning (extreme gradient boosting machine) was successfully applied to find the associations between microRNAs (miRNAs) and human diseases. This motivates us to design the twined gradient boosting machine (GBM) model to analyze the correlation among atmospheric factors (temperature, humidity, pressure, and wind speed), and air pollution (max and min of PM2.5 and PM10) with the infection, recovery, and death cases of COVID-19 daily in different states or places of India.
This paper proposes the following contributions:
-
i.
The data for the period of 25th March 2020 to 20th June 2021, has been collected, and analyzed to confirm the suitability of the dataset.
-
ii.
The analysis of the impact of atmospheric and air pollutant parameters on the spread of the disease
-
iii.
Analysis of the impact of atmospheric and air pollutant parameters on the recovery rate of the patient
-
iv.
Analysis of the impact of atmospheric and air pollutant parameters on the mortality rate of the disease
-
v.
The worst affected states were analyzed and tested for spread, recovery and mortality rate of COVID-19 separately.
Rest of the paper is organized in the following manner: Sect. 2 describes the process of data collection and its analysis. Section 3 presents the proposed gradient boosting machine (GBM) approach; Experimental setup and results are presented in Sect. 4. The next Sect. 5 discusses the results, and finally Sect. 6 summarizes the critical finding and future research directions in this domain.
2 Data Collection and Analysis
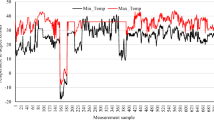
The data of eight atmospheric factors (maximum and minimum temperature, maximum and minimum air pressure, maximum and minimum air humidity, and maximum and minimum wind speed) and four measures of air pollution (maximum and minimum of PM2.5 and PM10) of the 21 significant states or places of India have been collected from the Indian meteorological department (IMD) and Indian central pollution control board (CPCB) during the period of 14th March 2020 to 20th May 2021 on daily basis (433 days) [30, 31]. The cases (number of infected, recovered, and death) of COVID-19 of similar states have been collected from an open-access source and information published by the ministry of health and family welfare, the government of India [32, 33]. The data of some states and union territories were not so significant for COVID-19, so it was not considered at all. The atmospheric factors, measures of air pollution, and cases of COVID-19 were used in combination for further analysis. The missing or doubtful values of the atmospheric factors, air pollution measures for some states at some days were replaced by the previous imputation technique. The variations of minimum and maximum temperature and humidity after imputation are shown in Fig. 1. The minimum and maximum of PM10 and PM2.5 are shown in Fig. 2. The statistics of the dataset are presented in Table 1.

The variation of the temperature (in.oC), humidity (in %)

The variation of PM25 and PM10 on a daily basis
The variation in cases of COVID-19 after imputation is shown in Fig. 3. Variations of pressure wind speed are presented in the Table 1.

The variation in COVID-19 cases in India on a daily basis
Eight atmospheric parameters and four measures of air pollution were considered as input in the proposed twined GBM to analyses the correlation and forecast the infected, recovered, and death cases of COVID-19, independently. The total 9,033 instances are taken for the preprocessing that was collected between 14th March 2020 to 20th May 2021 (21 states /places × 433 days). Out of this, 5974 with 17 attributes are taken for the training and remaining 3119 with 17 attributes are taken for the testing. The performance of the proposed GBM was also evaluated by predicting the COVID-19 cases state-wise. The atmospheric factors and air pollution measures were used as input of GBM simultaneously to check their mutual influence on the cases of COVID-19. Moreover, the minimum and the maximum values of the atmospheric factors (temperature, pressure, humidity, and wind speed) used as input of GBM and GBM are suitable in the understanding of their better impact on the distribution of COVID-19 cases. Moreover, to evaluate the impact of air pollution four measures maximum and minimum PM10 and PM2.5 have been included.
3 Gradient Boosting Machine (GBM) Approach
The gradient boosting machine (GBM) is an efficient method in regression analysis since it selects the adaptive characteristics of the dataset in the analysis. The optimal values of the predicted variables are obtained in several iterations by using the values of the dependent variable of the previous iteration and average weights. The GBM approach is implemented using the H2O package in R [33]. The basic steps of the GBM approach are described as follows [34]:
Step-1: For k = 1, 2… K {fk0 = 0}
Step-II: For m = 1, 2, 3 …M
Step-III: For k = 1, 2… K
Fitting regression tree to the targets \(r_{ikm}\), i = 1, 2… N to obtain the terminal regions \(R_{jim} , j = 1, 2, \ldots J_{m}\)
\(f_{k} \left( x \right) = f_{kM} \left( x \right)\), where k = 1, 2… K}
The additional classifier can support to further enhancing the performance metrics of the GBM without disturbing its overall speed. Such a combination reduces the process of parameter tuning by providing a parallelizable and distributable feature. Furthermore, it can result in optimal accuracy in big data analysis.
4 Analysis of Experimental Results
4.1 Statistical Analysis of the COVID-19 Dataset
Table 2 summarizes the statistical analysis using ANOVA method of the complete dataset (atmospheric factors, measures of air pollution, and cases of COVID-19). Results indicate that eight atmospheric factors, four pollution measures, and three significant parameters of COVID-19 are significant for further prediction modeling. Specifically, P-value is less than 0.05 indicates the confirmation in contrast to the null hypothesis for each of the dependent and independent variables. The F value represents the ratio of the variation between sample means and variation within the sample. Hence, a large value of F indicates a higher value of variation between sample means than within the sample. It also indicates that the null hypothesis is wrong (Table 2).
4.2 Experimental Setup
The GBM models was trained with learning rate = 0.01, sample rate = 0.8 the number of trees = 10,000, and folds = 10 on Intel(R) Core (TM) i7-8565U CPU @ 1.80 GHz 1.99 GHz with 8 GB RAM to get the optimal performance.
4.3 Gradient Boosting Machine Model Analysis Results
The optimal GBM model was obtained after tuning the parameters of distribution functions, including the learning rate, the number of trees, folds, etc. Four result-oriented distribution functions were used in GBM, including Poisson, Gaussian, Tweedie, and Gamma out of seven compared distributions (excluding Huber, Laplace, and Quantile). The performance of the twinned GBM model using four different distribution functions is summarized in Table 3 (the rest distribution is discarded). The performance measures, including the goodness-fit-measures (R2), root mean square error (RMSE), mean residual deviance (MRD), and mean average error (MAE) were used to evaluate the efficiency of the GBM. In the training, the optimal prediction performance of the GBM was achieved with the Poisson distribution (R2 = 0.99) in all the three metrics of COVID-19 as infected, recovered, and mortality cases as shown in Table 3. The performance metrics of the GBM model in the forecast of the COVID-19 cases of the test dataset are demonstrated in Figs. 4, 5, and 6, respectively. Figure 4 exhibits a detailed performance analysis of different distribution functions of GBM to forecast the infected, recovered, and mortality cases of COVID-19, respectively for the combined dataset of different states/places of India.

Correlative capability of twinned GBM in the training for infected cases of COVID-19 in terms of the combined dataset

Correlative capability of twinned GBM in the training for recovery cases of COVID-19 in terms of the combined dataset

Correlative capability of twinned GBM in the training for mortality cases of COVID-19 in terms of the combined dataset
All seven worst-affected states (Maharashtra, Delhi, Karnataka, Kerala, Madhya Pradesh, Uttar Pradesh, and West Bengal) data were tested with the twinned GBM with the four most result-oriented distributions as Poisson, Gaussian, Tweedie, and Gamma distributions. Five performance parameters were used as R2, MSE, RMSE, MAE, and MRD to find the proper correlation and efficiency of the individual model. The test performance of seven states of India was summarized and presented in Tables 4, 5, 6, 7, 8, 9 and 10 and Figs. 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 and 21 respectively below:

Correlative capability of twined GBM to forecast the infection rate of COVID-19 in Maharashtra

Correlative capability of twined GBM to forecast the recovery rate of COVID-19 in Maharashtra

Correlative capability of twined GBM to forecast the mortality rate of COVID-19 in Maharashtra

Correlative capability of twined GBM to forecast the infection rate of COVID-19 in Delhi

Correlative capability of twined GBM to forecast the recovery rate of COVID-19 in Delhi

Correlative capability of twined GBM to forecast the mortality rate of COVID-19 in Delhi

Correlative capability of twined GBM to forecast the infection rate of COVID-19 in Karnataka

Correlative capability of twined GBM to forecast the recovery rate of COVID-19 in Karnataka

Correlative capability of twined GBM to forecast the mortality rate of COVID-19 in Karnataka

Correlative capability of twined GBM to forecast infection rate of COVID-19 in Kerala

Correlative capability of twined GBM to forecast recovery rate of COVID-19 in Kerala

Correlative capability of twined GBM to forecast mortality rate of COVID-19 in Kerala

Correlative capability of twined GBM to forecast infection rate of COVID-19 in Madhya Pradesh

Correlative capability of twined GBM to forecast recovery rate of COVID-19 in Madhya Pradesh

Correlative capability of twined GBM to forecast mortality rate of COVID-19 in Madhya Pradesh
5 Discussion of Results
Tree-based machine learning approaches have high accuracy in the analysis of small and big datasets in previous research studies [35, 36]. In the case of analysis of the disease data, the GBM was used to predict the association of miRNAs [35]. Besides, the improved performance of the GBM in the predictive modeling of the pandemic has been discussed [35]. This is the reason for selecting the GBM model in the prediction of the COVID-19 cases in India using the atmospheric factors and pollution levels. Due to a large geographical area, there is a huge variation in atmospheric factors (Fig. 1 and Table 1) in different states of India. Besides, the pollution levels also vary in different states, which is obvious from the variation of minimum and maximum PM10 and PM2.5 (Fig. 2 and Table 1). The basic statistics in Table 1 and Fig. 3 demonstrates the variation in the cases of COVID-19 in different states of India. The basic statistics on the atmospheric factors, pollution measures, and cases of COVID-19 suggest their unequal distribution.
The training performance results of twinned GBM for infected cases on the combined dataset of significant states of India provide R2 = 0.99, and RMSE = 834.90 with Poisson distribution, R2 = 0.97, and RMSE = 1527.28 with Gaussian distribution, R2 = 0.96, and RMSE = 1214.40 with Tweedie distribution and R2 = 0.85 and RMSE = 1239.84 with Gamma distributions. The training performance results of twinned GBM for recovered cases on the combined dataset of significant states of India provide R2 = 0.99, and RMSE = 712.99 with Poisson distribution, R2 = 0.98, and RMSE = 1244.66 with Gaussian distribution, R2 = 0.97, and RMSE = 1052.15 with Tweedie distribution and R2 = 0.81 and RMSE = 3272.82 with Gamma distributions. The training performance results of twinned GBM for mortality case on the combined dataset of significant states of India provides R2 = 0.99, and RMSE = 8.49 with Poisson distribution, R2 = 0.97, and RMSE = 14.64 with Gaussian distribution, R2 = 0.98 and RMSE = 11.55 with Tweedie distribution and R2 = 0.85 and RMSE = 38.20 with Gamma distributions. The complete performance result for infected, recovery, and mortality cases are presented in Table 3, Figs. 4, 5, and 6 respectively. The performance results of the twined GBM with all four selected four distributions (Poisson, Gaussian, Tweedie, and Gamma) are quite good and quite better it assures that there is a close correlation among the atmospheric factor, air pollutants, and COVID-19 parameters and the study may move for the further processing.
Now the trained model has applied the dataset to the seven largely affected states of India to explore the deeper analysis and correlation for testing. At first, one of the worst affected Maharashtra is taken for testing. Surprisingly the performance result of the infected case provides a very convincing correlation as R2 = 0.90, and RMSE = 5161.50 with Poisson distribution, R2 = 0.90, and RMSE = 5235.36 with Gaussian distribution, R2 = 0.88, and RMSE = 5692.20 with Tweedie distribution and R2 = 0.78 and RMSE = 7840.69 with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.87, and RMSE = 5935.77 with Poisson distribution, R2 = 0.89, and RMSE = 5432.84 with Gaussian distribution, R2 = 0.85 and RMSE = 6362.20 with Tweedie distribution and R2 = 0.71 and RMSE = 8767.26 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.84, and RMSE = 86.49 with Poisson distribution, R2 = 0.88, and RMSE = 75.96 with Gaussian distribution, R2 = 0.83 and RMSE = 90.38 with Tweedie distribution and R2 = 0.65 and RMSE = 130.92 with Gamma distributions. The complete performance result for Maharashtra is already shown in Table 4, Figs. 7, 8, and 9 respectively.
Secondly, the model is tested for the largely affected state of Delhi. The performance result of this testing is R2 = 0.75, and RMSE = 2664.40 with Poisson distribution, R2 = 0.78, and RMSE = 2724.86 with Gaussian distribution, R2 = 0.74, and RMSE = 2501.72 with Tweedie distribution and R2 = 0.69 and RMSE = 2957.83 with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.88, and RMSE = 5935.77 with Poisson distribution, R2 = 0.81, and RMSE = 5432.84 with Gaussian distribution, R2 = 0.85 and RMSE = 6362.20 with Tweedie distribution and R2 = 0.67 and RMSE = 8767.26 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.73, and RMSE = 36.07 with Poisson distribution, R2 = 0.72, and RMSE = 37.08 with Gaussian distribution, R2 = 0.69 and RMSE = 38.72 with Tweedie distribution and R2 = 0.51 and RMSE = 49.22 with Gamma distributions. The complete performance result for Maharashtra is already shown in Table 5, Figs. 10, 11, and 12 respectively.
Third, the trained model has applied the testing dataset of the significant state of Karnataka. The performance result of this testing is as R2 = 0.79, and RMSE = 4456.73 with Poisson distribution, R2 = 0.84 and RMSE = 3786.50 with Gaussian distribution, R2 = 0.74 and RMSE = 4945.09 with Tweedie distribution and R2 = 0.54 and RMSE = 6606.13 with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.55, and RMSE = 4969.39 with Poisson distribution, R2 = 0.63, and RMSE = 4463.39 with Gaussian distribution, R2 = 0.50, and RMSE = 5250 with Tweedie distribution and R2 = 0.31 and RMSE = 6143.52 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.64, and RMSE = 56.93 with Poisson distribution, R2 = 0.71, and RMSE = 51.71 with Gaussian distribution, R2 = 0.60, and RMSE = 60.03 with Tweedie distribution and R2 = 0.39 and RMSE = 74.71 with Gamma distributions. The complete performance result for Karnatka is already shown in Table 6, Figs. 13, 14, and 15 respectively.
Fourth, the trained model has applied the testing dataset of the significant state of Kerala. The performance result of this testing is as R2 = 0.76, and RMSE = 3982.07 with Poisson distribution, R2 = 0.76 and RMSE = 4027.15 with Gaussian distribution, R2 = 0.74, and RMSE = 4159.93 with Tweedie distribution and R2 = 0.59 and RMSE = 5251.54 with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.47, and RMSE = 5895.52 with Poisson distribution, R2 = 0.56, and RMSE = 5319.29 with Gaussian distribution, R2 = 0.43, and RMSE = 6212.97 with Tweedie distribution and R2 = 0.19 and RMSE = 6835.58 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.59, and RMSE = 11.37 with Poisson distribution, R2 = 0.37, and RMSE = 14.09 with Gaussian distribution, R2 = 0.58, and RMSE = 11.42with Tweedie distribution and R2 = 0.46 and RMSE = 13.08 with Gamma distributions. The complete performance result for Kerala is already shown in Table 7, Figs. 16, 17, and 18 respectively.
Fifth, the trained model has applied the testing dataset of the significant state of Madhya Pradesh. The performance result of this testing is R2 = 0.87, and RMSE = 1048.39 with Poisson distribution, R2 = 0.80, and RMSE = 1317.66 with Gaussian distribution, R2 = 0.86, and RMSE = 1109.07 with Tweedie distribution and R2 = 0.59 and RMSE = 1481.84 with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.88, and RMSE = 5895.52 with Poisson distribution, R2 = 0.81, and RMSE = 5319.29 with Gaussian distribution, R2 = 0.85, and RMSE = 6212.97 with Tweedie distribution and R2 = 0.67 and RMSE = 6835.58 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.84, and RMSE = 8.80 with Poisson distribution, R2 = 0.74, and RMSE = 11.29 with Gaussian distribution, R2 = 0.84, and RMSE = 8.70with Tweedie distribution and R2 = 0.65 and RMSE = 13.10 with Gamma distributions. The complete performance result for Madhya Pradesh is already shown in Table 8, Figs. 19, 20, and 21 respectively.
Sixth, the trained model has applied the testing dataset of the significant state of Uttar Pradesh. The performance result of this testing is as R2 = 0.79, and RMSE = 3552.24 with Poisson distribution, R2 = 0.80, and RMSE = 3225.86 with Gaussian distribution, R2 = 0.75, and RMSE = 3616.14 with Tweedie distribution and R2 = 0.67 and RMSE = 4131.75with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.88, and RMSE = 967.78 with Poisson distribution, R2 = 0.81, and RMSE = 1208.69 with Gaussian distribution, R2 = 0.85, and RMSE = 1068.95 with Tweedie distribution and R2 = 0.67 and RMSE = 1588.11 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.73, and RMSE = 36.07 with Poisson distribution, R2 = 0.72, and RMSE = 37.08 with Gaussian distribution, R2 = 0.69 and RMSE = 38.72 with Tweedie distribution and R2 = 0.51 and RMSE = 49.22 with Gamma distributions. The complete performance result for Uttar Pradesh is already shown in Table 9, Figs. 22, 23, and Figs. 24 respectively.

Correlative capability of twined GBM to forecast infection rate of COVID-19 in Uttar Pradesh

Correlative capability of twined GBM to forecast recovery rate of COVID-19 in Uttar Pradesh

Correlative capability of twined GBM to forecast mortality rate of COVID-19 in Uttar Pradesh
Seventh, the trained model has applied the testing dataset of the significant state of West Bengal. The performance result of this testing is as R2 = 0.79, and RMSE = 2012.91 with Poisson distribution, R2 = 0.78 and RMSE = 2066.74 with Gaussian distribution, R2 = 0.64 and RMSE = 2640.02 with Tweedie distribution and R2 = 0.68 and RMSE = 247,127 with Gamma distributions. In the case of recovery, it also approves the hypothesis with R2 = 0.80, and RMSE = 1723.12 with Poisson distribution, R2 = 0.72, and RMSE = 2053.87 with Gaussian distribution, R2 = 0.78, and RMSE = 1825.22 with Tweedie distribution and R2 = 0.60 and RMSE = 2475.82 with Gamma distributions. In the case of mortality, the performance results are also in the same hypothesis line as R2 = 0.78, and RMSE = 14.81 with Poisson distribution, R2 = 0.63, and RMSE = 19.17 with Gaussian distribution, R2 = 0.75 and RMSE = 15.64 with Tweedie distribution and R2 = 0.57 and RMSE = 20.60 with Gamma distributions. The complete performance result for West Bengal is already shown in Table 10, Figs. 25, 26, and 27 respectively.

Correlative capability of twined GBM to forecast infection rate of COVID-19 in West Bengal

Correlative capability of twined GBM to forecast recovery rate of COVID-19 in West Bengal

Correlative capability of twined GBM to forecast mortality rate of COVID-19 in West Bengal
The above-discussed performance parameter and the rest of the parameters are demonstrated in Tables 4, 5, 6, 7, 8, 9 and 10 and Figs. 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26 and 27 suggests that the Maharashtra had an ideal atmosphere for infection, recovery, and mortality with R2 = 0.99 in all three with the Poisson distribution. The testing model on Delhi is not so much performing on infection and recovery rate but it supports the mortality rate. The maximum performance was given by Gaussian distribution with R2 = 0.78 for the infection rate, R2 = 0.78 for recovery rate and R2 = 0.83 for the mortality rate. R2 = 0.84 for an infection rate for the Karnataka state, recovery provides R2 = 0.63 and mortality R2 = 0.71 by Gaussian distribution. Kerala infection rate R2 = 0.71 and recovery rate R2 = 0.56 provided by Gaussian distribution and mortality rate R2 = 0.59 by Poisson distribution does not support; it might lack non-arability/missing of the correct atmospheric or pollution dataset. Madhya Pradesh, maximum infection rate, recovery rate, and mortality rate R2 = 0.87, R2 = 0.88, and R2 = 0.84 respectively by Poisson distribution. Uttar Pradesh, maximum infection rate, recovery rate, and mortality rate R2 = 0.80, R2 = 0.88, and R2 = 0.73 respectively by Poisson distribution. West Bengal, maximum infection rate, recovery rate, and mortality rate R2 = 0.79, R2 = 0.80, and R2 = 0.78 respectively by Poisson distribution.
The COVID parameter according to the testing performance conclusion:
Infection Rate: Maharashtra > Madhya Pradesh > Uttar Pradesh > West Bengal > Karnataka > Delhi > Kerala.
Recovery Rate: Maharashtra > Madhya Pradesh > Uttar Pradesh > West Bengal > Karnataka > Kerala.
Mortality Rate: Maharashtra > Madhya Pradesh > Delhi > West Bengal > Uttar Pradesh > Delhi > Karnataka > Kerala.
The adverse effect of weather parameters like temperature and humidity on the cases of COVID-19 has been reported in some of the recently published research, like high spread rate at low temperature and humidity in Iran [11]; low spread rate at high humidity and temperature in China [16]; and low spread rate of high average humidity and temperature [15]. The impact of additional atmospheric factors like air pressure and wind speed are not been properly noticed in any recent studies. A positive correlation between air pollution and the cases of COVID-19 has been established in some studies, like air pollution and spread rate in Italy and China [7, 20, 21]. Moreover, the atmospheric factors and the air pollution levels are also related; therefore, the present study explored their combined effect (rate of spread) of COVID-19 in major states/places of India using the twinned GBM model. It was noticed that the states having lower mean temperature, humidity, and air pollution as Uttarakhand, Arunachal Pradesh, Himachal Pradesh, Sikkim, Mizoram, etc. have a smaller number of infected, and mortality cases and a higher number of recovered cases than other states/places with high mean temperature, humidity, and air pollution as Maharashtra, Delhi, Karnataka, Kerala, and Madhya Pradesh, etc. However, in some states, it is still difficult to understand the correlation between the spread rate of COVID-19, atmospheric factors, and air pollution measures. The collected data and the analysis outcomes of the different distribution of GBM suggest a significant correlation between the spread rate of COVID-19, atmospheric factors, and air pollution measures in most of the states of India. Besides, the high population density of some of the states and activities of people towards the government regulations, movement of migrant workers, social gatherings, etc. during the lockdown period are also some factors responsible for the spread of COVID-19.
Maharashtra, Delhi, Kerala, Karnataka, Madhya Pradesh, Uttar Pradesh, and West Bengal are worst affected states than other states of India. The predicted numbers of infected cases in Maharashtra, Madhya Pradesh, and Uttar Pradesh by different distribution of GBM are equal to their exact values for most of the day (Figs. 19, 20, 21, 22, 23 and 24). Therefore, Maharashtra was the ideal place for the spread and mortality. The missing information on the atmospheric factors, air pollution measures, and cases of COVID-19 in the duration of data collection may be one of the reasons for the average and poor forecast metrics of the different distribution of GBM for some states.
6 Conclusions and Future Research Scope
This paper presents a correlation between the atmospheric factors, air pollution measures, and infection, recovery, and mortality rate of COVID-19 in the significant states/places of India. The paper proposed a twin GBM model to capture the deep and intrinsic nature of the different datasets. The experimental results confirms that the improved GBM model is proficient enough to determine the correlation among atmospheric parameters, air pollution measures, and COVID-19 impact (infection, recovery, and mortality rate) in the aggregate dataset of different states/places of India. The enhanced performance metrics (R2 and different errors mechanism) of the improved GBM establish a convinced connotation of transmission rates of COVID-19 with air pollution measures and atmospheric factors. Particularly in some states like Maharashtra, Delhi, Karnataka, Kerala, Madhya Pradesh, Uttar Pradesh, and West Bengal where maximum number of COVID-19 cases have been reported, the air pollution measures and atmospheric factors have a significant role in the spread of the pandemic. Future research will focus on improving the state-wise prediction efficiency of COVID-19 cases by considering more parameters of the weather and atmospheric pollutants.
Data Availability
Data may be provided on individual requests.
References
World Health Organization. (2019). Coronavirus disease (COVID-19) Pandemic. Retrieved from https://www.who.int/emergencies/diseases/novel-coronavirus-2019
Ministry of Health and Family Welfare, Government of India. Retrieved from https://www.mohfw.gov.in/
Adhikari, S. P., Meng, S., Wu, Y. J., Mao, Y. P., Ye, R. X., Wang, Q. Z., Sun, C., Sylvia, S., Rozelle, S., Raat, H., & Zhou, H. (2020). Epidemiology, causes, clinical manifestation and diagnosis, prevention and control of coronavirus disease (COVID-19) during the early outbreak period: A scoping review. Infectious Diseases of Poverty, 9(1), 1–12. https://doi.org/10.1186/s40249-020-00646-x
Singhal, T. (2020). A review of coronavirus disease-2019 (COVID-19). The Indian Journal of Pediatrics. https://doi.org/10.1007/s12098-020-03263-6
Xu, X., Chen, P., Wang, J., Feng, J., Zhou, H., Li, X., Zhong, W., & Hao, P. (2020). Evolution of the novel coronavirus from the ongoing Wuhan outbreak and modeling of its spike protein for risk of human transmission. Science China Life Sciences, 63(3), 457–460. https://doi.org/10.1007/s11427-020-1637-5
Guo, Y. R., Cao, Q. D., Hong, Z. S., Tan, Y. Y., Chen, S. D., Jin, H. J., Tan, K. S., Wang, D. Y., & Yan, Y. (2020). The origin, transmission and clinical therapies on coronavirus disease 2019 (COVID-19) outbreak–an update on the status. Military Medical Research, 7(1), 1–10. https://doi.org/10.1186/s40779-020-00240-0
Ogen, Y. (2020). Assessing nitrogen dioxide (NO2) levels as a contributing factor to the coronavirus (COVID-19) fatality rate. Science of the Total Environment, 726, 138605. https://doi.org/10.1016/j.scitotenv.2020.138605
Zhang, W., Du, R. H., Li, B., Zheng, X. S., Yang, X. L., Hu, B., Wang, Y. Y., Xiao, G. F., Yan, B., Shi, Z. L., & Zhou, P. (2020). Molecular and serological investigation of 2019-nCoV infected patients: Implication of multiple shedding routes. Emerging Microbes & Infections, 9(1), 386–389. https://doi.org/10.1080/22221751.2020.1729071
Lowen, A. C., Mubareka, S., Steel, J., & Palese, P. (2007). Influenza virus transmission is dependent on relative humidity and temperature. PLoS Pathog, 3(10), e151. https://doi.org/10.1371/journal.ppat.0030151
Lin, K., Fong, D. Y. T., Zhu, B., & Karlberg, J. (2006). Environmental factors on the SARS epidemic: Air temperature, passage of time and multiplicative effect of hospital infection. Epidemiology & Infection, 134(2), 223–230. https://doi.org/10.1017/S0950268805005054
Ahmadi, M., Sharifi, A., Dorosti, S., Ghoushchi, S. J., & Ghanbari, N. (2020). Investigation of effective climatology parameters on COVID-19 outbreak in Iran. Science of The Total Environment, 729, 138705. https://doi.org/10.1016/j.scitotenv.2020.138705
Ma, Y., Zhao, Y., Liu, J., He, X., Wang, B., Fu, S., Yan, J., Niu, J., Zhou, J., & Luo, B. (2020). Effects of temperature variation and humidity on the death of COVID-19 in Wuhan, China. Science of The Total Environment, 724, 138226. https://doi.org/10.1016/j.scitotenv.2020.138226
Mecenas, P., Bastos, R., Vallinoto, A., & Normando, D. (2020). Effects of temperature and humidity on the spread of COVID-19: A systematic review. MedRxiv. https://doi.org/10.1101/2020.04.14.20064923
Oliveiros, B., Caramelo, L., Ferreira, N. C., & Caramelo, F. (2020). Role of temperature and humidity in the modulation of the doubling time of COVID-19 cases. MedRxiv. https://doi.org/10.1101/2020.03.05.20031872
Qi, H., Xiao, S., Shi, R., Ward, M. P., Chen, Y., Tu, W., Su, Q., Wang, W., Wang, X., & Zhang, Z. (2020). ‘COVID-19 transmission in Mainland China is associated with temperature and humidity: A time-series analysis. Science of The Total Environment, 728, 138778. https://doi.org/10.1016/j.scitotenv.2020.138778
Wang, M., Jiang, A., Gong, L., Luo, L., Guo, W., Li, C., Zheng, J., Li, C., Yang, B., Zeng, J., & Chen, Y. (2020). Temperature significant change COVID-19 Transmission in 429 cities. MedRxiv. https://doi.org/10.1101/2020.02.22.20025791
Zhu, Y., & Xie, J. (2020). Association between ambient temperature and COVID-19 infection in 122 cities from China. Science of The Total Environment, 724, 138201. https://doi.org/10.1016/j.scitotenv.2020.138201
Gupta, A., Banerjee, S., & Das, S. (2020). Significance of geographical factors to the COVID-19 outbreak in India. Modeling Earth Systems and Environment, 6, 2645–2653. https://doi.org/10.1007/s40808-020-00838-2
Baldasano, J. M. (2020). COVID-19 lockdown effects on air quality by NO2 in the cities of Barcelona and Madrid (Spain). Science of the Total Environment, 741, 140353. https://doi.org/10.1016/j.scitotenv.2020.140353
Conticini, E., Frediani, B., & Caro, D. (2020). Can atmospheric pollution be considered a co-factor in extremely high level of SARS-CoV-2 lethality in Northern Italy? Environmental Pollution, 261, 114465. https://doi.org/10.1016/j.envpol.2020.114465
Han, Y., Lam, J.C., Li, V.O., Guo, P., Zhang, Q., Wang, A., Crowcroft, J., Wang, S., Fu, J., Gilani, Z., & Downey, J. (2020). The Effects of Outdoor Air Pollution Concentrations and Lockdowns on COVID-19 Infections in Wuhan and Other Provincial Capitals in China. Preprints, 2020030364. https://doi.org/10.20944/preprints202003.0364.v1.
Jha, S. K., Pan, Z., Elahi, E., & Patel, N. (2019). A comprehensive search for expert classification methods in disease diagnosis and prediction. Expert Systems, 36(1), e12343. https://doi.org/10.1111/exsy.12343
Jiang, F., Jiang, Y., Zhi, H., Dong, Y., Li, H., Ma, S., Wang, Y., Dong, Q., Shen, H., & Wang, Y. (2017). Artificial intelligence in healthcare: Past, present and future. Stroke and Vascular Neurology, 2(4), 230–243. https://doi.org/10.1136/svn-2017-000101
Ramesh, A. N., Kambhampati, C., Monson, J. R., & Drew, P. J. (2004). Artificial intelligence in medicine. Annals of the Royal College of Surgeons of England, 86(5), 334–338. https://doi.org/10.1308/147870804290
Allam, Z. and Jones, D.S. (2020). On the coronavirus (COVID-19) outbreak and the smart city network: Universal data sharing standards coupled with artificial intelligence (AI) to benefit urban health monitoring and management’, In Healthcare (Vol. 8, No. 1, p. 46). Multidisciplinary Digital Publishing Institute. https://doi.org/10.3390/healthcare8010046.
Li, L., Qin, L., Xu, Z., Yin, Y., Wang, X., Kong, B., Bai, J., Lu, Y., Fang, Z., Song, Q., & Cao, K. (2020). Artificial intelligence distinguishes covid-19 from community acquired pneumonia on chest ct. Radiology. https://doi.org/10.1148/radiol.2020200905
McCall, B. (2020). COVID-19 and artificial intelligence: Protecting health-care workers and curbing the spread. The Lancet Digital Health, 2(4), e166–e167. https://doi.org/10.1016/S2589-7500(20)30054-6
Pham, Q. V., Nguyen, D. C., Hwang, W. J., & Pathirana, P. N. (2020). Artificial Intelligence (AI) and big data for coronavirus (COVID-19) pandemic: A survey on the state-of-the-arts. IEEE Access, 8, 130820–130839. https://doi.org/10.20944/preprints202004.0383.v1
Rao, A. S. S., & Vazquez, J. A. (2020). Identification of COVID-19 can be quicker through artificial intelligence framework using a mobile phone-based survey in the populations when cities/towns are under quarantine. Infection Control & Hospital Epidemiology. https://doi.org/10.1017/ice.2020.61
India Metrological Department, Ministry of Earth Sciences. Government of India. https://mausam.imd.gov.in/
Central Pollution Control Board, Ministry of Environment, Government of India. https://cpcb.nic.in/
A volunteer-driven crowdsourced effort to track the coronavirus in India. https://www.covid19india.org/
The H2O.ai Team (2015). h2o: R Interface for H2O, R package version 3.1.0.99999. http://www.h2o.ai
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction. Springer.
Chen, X., Huang, L., Xie, D., & Zhao, Q. (2018). EGBMMDA: Extreme gradient boosting machine for MiRNA-disease association prediction. Cell Death & Disease, 9(1), 1–16. https://doi.org/10.1038/s41419-017-0003-x
Geurts, P., Irrthum, A., & Wehenkel, L. (2009). Supervised learning with decision tree-based methods in computational and systems biology. Molecular Biosystems, 5(12), 1593–1605. https://doi.org/10.1039/B907946G
Funding
No funding is available for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares no conflict of interest directly or indirectly related to the work submitted for publication.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shrivastav, L.K., Kumar, R. Empirical Analysis of Impact of Weather and Air Pollution Parameters on COVID-19 Spread and Control in India Using Machine Learning Algorithm. Wireless Pers Commun 130, 1963–1991 (2023). https://doi.org/10.1007/s11277-023-10367-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-023-10367-7