
Abstract
To preserve rich detail information and high contrast, a novel image fusion algorithm is proposed based on rolling-guided filtering combined with deep feature extraction. Firstly, input images are filtered to acquire various scales decomposed images using rolling guided filtering. Subsequently, PCANet is introduced to extract weight maps to guide base layer fusion. For the others layer, saliency maps of input images are extracted by a saliency measure. Then, the saliency maps are optimized by guided filtering to guide the detail layer fusion. Finally, the final fusion result are reconstructed by all fusion layers. The experimental fusion results demonstrate that fusion algorithm in this study obtains following advantages of rich detail information, high contrast, and complete edge information preservation in the subjective evaluation and better results in the objective evaluation index. In particular, the proposed method is 16.9% ahead of the best comparison result in the SD objective evaluation index.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Image fusion is an indispensable technique for various computer vision tasks, which has significant applications in target recognition, video surveillance, and image enhancement [1,2,3,4]. Image fusion technology can also serve the internet of things [5, 6] domain and sensing technology [7, 8].The visible images have higher spatial resolution and provide the most visual detail but are more susceptible to factors such as surrounding environment and climate. The infrared images depict objects through thermal radiation and are resistant to interference from factors such as environment and climate but have lower resolution and poorer texture information. Infrared and visible images share complementary characteristics, which can produce robust and information rich fused images [9]. In the past five years, there are a lot of efficient algorithms have been designed to integrate features from multiple input images into a single fused image [10]. The most representative image fusion algorithms are in view of traditional algorithms named multi-scale transformation (MST) and deep learning (DL).
In MST domain, a number of universal image fusion algorithms are known, such as curvelet transform(CVT) [11], dual-tree complex wavelet transform(DTCWT) [12] and non-sampled contourlet transform (NSCT) [13] etc. By using these methods, input image is filtered into a diverse range of scale factors, such as multiple detail parts and single base part. Following that, based on the information contained in different layers, fusion rules suitable for each are designed. Ultimately, the final fusion result is produced by inverse transformation corresponding fusion layer. The fusion results obtained by the MST method are very much in line with the vision of the human visual system [14]. But these methods process the input images using a predefined basis function, making it challenging to recover useful texture feature of input image well and increasing computational complexity. But Fu et al. [15] used Rolling Guided Filtering (RGF) [16] for image fusion, which well preserved the salient and useful edge information of input image.
As for DL-based fusion methods, many novel networks structure are specially designed to learn feature information from the input images to produce single fusion image. Li et al. [17] used VGG- 19 networks to extract features from detail layer information, which makes the fusion result obtain more detailed feature information. Ma et al. [18] used Generative Adversarial Network (GAN) for infrared and visible image fusion, generating the fused image with a generative network. In contrast, the adversarial network makes the final fusion result with more detailed feature information. Although these DL-based methods are more capable of feature extraction, selecting network parameters is more complex. And Chan et al. [19] proposed a common and efficient deep learning network-PCANet, that has good performance in extracting feature information for image processing.
In all, this research presents a rolling filtering framework based on deep feature extraction for preserving preserve rich detail information and high contrast in fusion image. Firstly, we introduce a multi-level decomposition framework for the input images using rolling-guided filtering to retain more edge detail information. Then, a PCANet network is trained to extract useful object information and salient area feature in base layer to obtain fused weight map. And an obtained weight map is employed for guiding base part fusion. As for detail part fusion, we use Laplace filtering and Gaussian filtering to extract the saliency map. Next, initial weight map is generated by comparing the obtained saliency map, but there is noise and artifacts. So we apply guided filtering to refine initial weight map with the input image as the guided image to produce the according detail layers. In the end, the fused different layers obtained by above fusion rule are reconstructed to obtain a final fused image. The remainder of this study is as follows. Section 2 describes our proposed algorithm for fusing the input images in detail. In Sect. 3, the experiments are provided. For the conclusion of the methods of this paper is shown in Sect. 4.
2 The proposed method
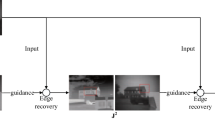
In this section, a novel multi-modal infrared and visible image fusion method is proposed. The framework diagram of the process is shown in Fig. 1. We will describe the details of the proposed method in the following.
2.1 Step 1: MST based on RGF
It is known to all that several challenges of image fusion based on MST are to decompose complementary feature between the source images effectively. So it is crucial to select a suitable decomposition method. The base layer is obtained by smoothing corresponding input images with the help of filtering techniques, which includes brightness and contour information. And detail layer have complementary feature of base layer ,that includes abundant detail and texture information. Edge-preserving filtering is used as decomposition methods for image fusion algorithms that has achieved excellent results, which can preserve valuable structural and edge information while blurring the source image. In this study, an effective decomposition algorithm is introduced based on RGF combined joint bilateral filter. We assume that the layer after being decomposed by the filter are the two most significant features for input images. Inspired by it, a flash decomposition method is raised, which contains two steps of smoothing input image structure and recovering the edge feature.
2.1.1 Smoothing the small structure
The motivation for our smoothed image is to fully transfer the detailed information from input image into detail part. This operation is able to be implemented by Gaussian filtering, which can be defined as:
where a and b denote the central and adjacent pixels, respectively, and N denotes their set. \(\delta _{s}\) is minimum standard deviation. G means input guide image.

The overview of the proposed infrared and visible image fusion method
2.1.2 Edge recovery
The process of iterative edge enhancement utilizes a joint bilateral filter known for its computational efficiency and superior edge-preserving capabilities. This filter is mathematically defined as:
In this formula, M serves as the normalizing factor. The terms \(\delta _{s}\) and \(\delta _{r}\) are argumentations that govern spatial and intensity area value, respectively. The symbol \(J^{t+1}\) is outcome after t-th iteration, with a typical setting of t = 4 for the iteration count.
This study applies repeated decompositions to the source images using the RGF technique. For the two distinct source images of infrared and visible light, denoted as \(I_{k}\) where k is in the set 1, 2, we define the base layer as \(I_{k}^{b,i}\). Subsequently, the detail layers are derived using the formula:
Here, \(I_{k}^{b,0}\) is corresponding input image represents \(I_{k}\), and \(I_{k}^{d,i}\) signifies the i-th detail layer of that source image.
2.2 Step 2: Integration of fundamental and detailed layers
Through the above decomposition operation, multiple detail layers containing rich details and a base layer with luminance information are generated.To retain more components in the source images, two fusion rules should be elaborately designed.
2.2.1 Fusing base layers
As depicted in Fig. 1, the foundational layer also contains residual useful low-frequency information. As the PCANet can efficiently extract the image information, it is wise to use PCANet to extract low-frequency information. The extraction results produced by PCANet are shown in Fig. 1. The PCANet uses principal component analysis(PCA) to learn multilevel filter clusters. The PCA filter is given by:
where \(map(\cdot )\) denotes that maps it to the matrix \(W\in R^{K_{1} K_{2} }\), \(pl(XX^{T} )\) denotes the \(l-th\) principal eigenvector of \(XX^{T}\). This size of sliding window is \(k_{1} \times k_{2}\).\(S_{1}\) indicates the number of PCA filters, which is established as 8 in this study. Subsequently, the map of weights \(W_{k}^{b}\) is obtained by using nuclear-norm to integrate feature maps, which is extracted by PCA filter. Finally, the fused base layer is obtained by:
where \(I_{n}^{b}\) represent corresponding base layer. \(W_{n}^{b}\) represents this weighting map for foundation a part, while \(F_b\) signifies the combined foundational layer.
2.2.2 Fusing detail layers
It is observable in Fig. 1 that the detailed layer is displayed by different feature information such as texture, edge and corner et al. Owing to the detailed information provided by the saliency map in input image, we employ a weight map that is derived from the saliency map for merging the detail layers.
At first, each source image undergoes Laplace filtering to yield a high-pass image denoted as \(H_{k}\).
where L represents a 3 \(\times\) 3 Laplacian filter. Following this, the saliency map \(S_{k}\) was con-structed by:
where g represents a Gaussian low-pass filter with dimensions \((2r_{g}+1 )+(2r_{g}+1)\), and the parameters \(r_{g}\) and \(\delta _{g}\) are both assigned the value of 5. Subsequently, to formulate the weight map, the saliency map undergoes a comparative analysis, which is described as follows:
where K denotes the total count of source images, and \(S_{K}^{i}\) represents the saliency value at pixel i in this \(K-th\) input image. A preliminary weight map corresponding to a saliency map is denoted as \(P_{k}^{1}\). Nevertheless, the initial weight map acquired according to the above method is usually not aligned with the target and contains noise, which may introduce artifacts in this detail layer fusion images. To improve the saliency detection performance and process the shortcomings, we employ the guided filtering to optimize the initial weight map.
Through using guided filtering, we can make neighboring pixels which are similar in brightness have the same weight value. The source image \(I_{k}\) serves as a reference for guided image processing, and guided filtering is subsequently applied to \(P_{k}\), as demonstrated in?
In this context, \(W_{k}^{d_{i} }\) symbolizes the refined saliency weight map, enhanced through guided filtering. The function. \(GF(\cdot )\)signifies the guided filtering process. The parameters. \(r_{i}\)and \(\varepsilon _{i}\) are pivotal in guiding the filtering technique. Excessive smoothing might lead to a diminished visibility of edges and features in the image. Therefore, we should select a small filter size \(r_{i}\)and \(\varepsilon _{i}\).
Utilizing the refined saliency weight map from the input images, this composition of detailed fusion layer is achievable by the following method:
2.3 Step 3: Reconstruction
Ultimately, the final fusion result is generated by summing \(F_{b}\) and \(F_{d}\):
3 Experiments
3.1 Experimental settings
To thoroughly verify the proposed fusion strategy and decomposition method, we randomly selected three pairs of input images from TNO dataset [20]. Five typical and excellent image fusion algorithms published in the last five years are compared in the experiments. They are based on MST method DTCWT and LatLRR, the sparse representation method NSCT-SR and the DL method VGG-19 and Resnet50. EN quantifies the level of information retained in the input image in the fusion result through theoretical knowledge of information theory; MI mainly calculates the feature size of the information transferred from the input image to the fusion result; MS-SSIM focuses on evaluating the results by calculating the degree of structural similarity between the fused images obtained at different scales; SCD considers the results of evaluating the input image and the fused result in terms of overall correlation; and SD calculates the distribution and contrast of the fused result in relation to the input image to measure the fusion effect. All evaluation indicators used in this paper, a higher value indicates a better fusion result. Five mainstream infrared and visible image fusion quantitative metrics : en-tropy (EN) [21], mutual information (MI) [22], multiscale structure similarity measure (MS-SSIM) [23], sum of correlations of differences (SCD) [24] and stan-dard deviation (SD) [25], are used to evaluate the fused images produced by dif-ferent methods. EN quantifies the amount of information present in the fused image using information theory; MI measures the amount of information transferred from the source image to the fused image; MS-SSIM focuses on assessing the structural similarity of the fused image at different scales; SCD evaluates the fusion performance based on the overall correlation between the source image and the fused image; SD takes into account the distribution and contrast of the fused images to gauge the quality of the fusion result. In all these metrics, a higher value indicates a better fusion result. Here two groups of parameters on the proposed method are installed. We use RGF to perform a five-level (N = 5) decomposition of the source image. The val-ues of the smoothing control parameters for RGF are \(\delta _{s}^{i} =\left\{ 648,108,18,3 \right\}\), \(i=1,2,3,4\), all \(\delta _{r}\) values are set to 0.2. The parameter values of GF are \(r_{1} =45\), \(\varepsilon _{1} =0.3\), \(r_{2} =15\), \(\varepsilon _{2} =0.1\), \(r_{3} =5\), \(\varepsilon _{3} =0.03\), \(r_{4} =1\), \(\varepsilon _{4} =0.01\).
The fusion algorithm experiments were conducted using MATLAB R2020a on a system. The system is equipped with a GeForce RTX 2070 SUPER 8 G graphics card.
3.2 Visual assessment
It is commonly acknowledged that the most intuitive approach for assessing the effectiveness of infrared and visible image fusion methods is to directly evaluate the fusion results through the human visual system. Figure 2 illustrates the outcomes of the initial pre-registered NATO Camp infrared and visible image fusion. Figure 2a and b depict the source infrared and visible images, respectively. Figure 2c–h showcase results obtained through various infrared and visible fusion methods. It is evident that the fusion result using the Dual-Tree Complex Wavelet Transform (DTCWT) exhibits overall poor contrast, with blurred edges of the target object and weak fusion quality. The fusion outcome of Latent Low-Rank Representation (LatLRR) reveals deficiencies in plant details and exhibits artifacts around the target. Although the Non-Subsampled Contourlet Transform with Super-Resolution (NSCT SR) effectively emphasizes the target object, the pixels of the plant differ from those in the source infrared image, suggesting an excessive introduction of visible image information that degrades visual impact. Fusion results from VGG-19 and Resnet50 display reduced noise and a cohesive structure, but the texture details of the target are not sufficiently clear. The fusion method proposed in this study, however, maintains superior edge information for houses and people, offers higher contrast, and preserves transparent texture details.

Comparison of the results of different fusion methods for the first group of images
Figure 3c–h depict outcomes obtained through various infrared and visible fusion methods, respectively. Observing the results, it is evident that the aforementioned fusion method generally preserves the edge structure information of the target person and house in the fused image. However, the method proposed in this paper surpasses this, retaining comprehensive and highly clear detailed information of both the people and house windows within the red box, thereby ensuring excellent visibility. Figure 4 illustrates the outcomes of the third pre-registered UN Camp infrared and visible image fusion set. Figure 4a and b depict the source infrared and visible images, respectively, while Figure 4c–h present results obtained through different infrared and visible fusion methods. Notably, the overall appearance of the fusion results using the DTCWT method appears whitish. Additionally, useful texture feature from the input infrared image is absent in the sky within the red box, and feature regarding the roof edge structure is also missing. The fusion outcome from Latent Low-Rank Representation (LatLRR) lacks detailed target information within the red box, resulting in a less clear display and poor contrast. In the case of the Non-Subsampled Contourlet Transform with Super-Resolution (NSCT_SR) fusion method, the sky within the red box is distorted, introducing artifacts and lacking clarity. Fusion methods employing VGG-19 and ResNet50 maintain structural integrity with reduced noise but exhibit lower contrast. In contrast, our proposed algorithm is able to effectively integrate complementary information from the source images, preserving the major of structural and salient texture information from the input images.

Comparison of the results of different fusion methods for the second group of images

Comparison of the results of different fusion methods for the third group of images
3.3 Objective assessment
The data in Table 1 reveals that, in comparison to the other five methods, the method introduced in this paper demonstrates varying degrees of superiority across evaluation metrics such as EN, MI, MS-SSIM, SCD, and SD. Notably, it exhibits the highest leadership in SD and SCD metrics, signifying that the fusion outcomes of the proposed method exhibit pronounced contrast and a robust correlation between the final fusion result and the corresponding input image. In conclusion, this method presented in this paper proves to be effective.
4 Conclusion
In this research, we introduce a technique to conduct the image fusion of infrared and visible utilizing deep feature extraction and rolling-guided filtering. In contrast to alternative methods for merging infrared and visible images, the proposed approach adeptly preserves detailed information at image edges and highlights the target object. The experimental fusion outcomes reveal that the algorithm in this study exhibits clear advantages based on objective metrics including EN, MI, MS-SSIM, SD, and SCD. These advantages can be advantageous for subsequent tasks such as target recognition and small object detection. The upcoming phase of our study will concentrate on how to adaptively select decomposition layers and formulating more effective fusion rules to mitigate noise, artifacts, and retain more pertinent detailed information.
References
Nirmalraj, S., & Nagarajan, G. (2021). Fusion of visible and infrared image via compressive sensing using convolutional sparse representation. ICT Express, 7(3), 350–354.
Shrinidhi, V., Yadav, P., & Venkateswaran, N. (2018). IR and visible video fusion for surveillance. In: 2018 International conference on wireless communications, signal processing and networking (WiSPNET) (pp. 1–6), IEEE.
Jiang, M.-X., Deng, C., Shan, J.-S., Wang, Y.-Y., Jia, Y.-J., & Sun, X. (2019). Hierarchical multi-modal fusion FCN with attention model for RGB-D tracking. Information Fusion, 50, 1–8.
Li, C., Liang, X., Lu, Y., Zhao, N., & Tang, J. (2019). RGB-T object tracking: Benchmark and baseline. Pattern Recognition, 96, 106977.
Liu, X., & Zhang, X. (2019). Noma-based resource allocation for cluster-based cognitive industrial internet of things. IEEE Transactions on Industrial Informatics, 16(8), 5379–5388.
Liu, X., Zhai, X. B., Lu, W., & Wu, C. (2019). QoS-guarantee resource allocation for multibeam satellite industrial internet of things with NOMA. IEEE Transactions on Industrial Informatics, 17(3), 2052–2061.
Liu, X., Sun, Q., Lu, W., Wu, C., & Ding, H. (2020). Big-data-based intelligent spectrum sensing for heterogeneous spectrum communications in 5g. IEEE Wireless Communications, 27(5), 67–73.
Liu, X., Sun, C., Zhou, M., Wu, C., Peng, B., & Li, P. (2020). Reinforcement learning-based multislot double-threshold spectrum sensing with Bayesian fusion for industrial big spectrum data. IEEE Transactions on Industrial Informatics, 17(5), 3391–3400.
Liu, Y., Wang, L., Cheng, J., Li, C., & Chen, X. (2020). Multi-focus image fusion: A survey of the state of the art. Information Fusion, 64, 71–91.
Li, S., Kang, X., Fang, L., Hu, J., & Yin, H. (2017). Pixel-level image fusion: A survey of the state of the art. Information Fusion, 33, 100–112.
Nencini, F., Garzelli, A., Baronti, S., & Alparone, L. (2007). Remote sensing image fusion using the curvelet transform. Information Fusion, 8(2), 143–156.
Lewis, J. J., O’Callaghan, R. J., Nikolov, S. G., Bull, D. R., & Canagarajah, N. (2007). Pixel-and region-based image fusion with complex wavelets. Information Fusion, 8(2), 119–130.
Upla, K. P., Joshi, M. V., & Gajjar, P. P. (2014). An edge preserving multiresolution fusion: Use of contourlet transform and MRF prior. IEEE Transactions on Geoscience and Remote Sensing, 53(6), 3210–3220.
Liu, Y., Liu, S., & Wang, Z. (2015). A general framework for image fusion based on multi-scale transform and sparse representation. Information Fusion, 24, 147–164.
Fu, J., Li, W., Ouyang, A., & He, B. (2021). Multimodal biomedical image fusion method via rolling guidance filter and deep convolutional neural networks. Optik, 237, 166726.
Zhang, Q., Shen, X., Xu, L., & Jia, J. (2014). Rolling guidance filter. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part III 13 (pp. 815–830) , Springer.
Li, H., Wu, X. -J., & Kittler, J. (2018) Infrared and visible image fusion using a deep learning framework. In: 2018 24th international conference on pattern recognition (ICPR) (pp. 2705–2710), IEEE
Ma, J., Yu, W., Liang, P., Li, C., & Jiang, J. (2019). FusionGAN: a generative adversarial network for infrared and visible image fusion. Information Fusion, 48, 11–26.
Chan, T.-H., Jia, K., Gao, S., Lu, J., Zeng, Z., & Ma, Y. (2015). PCANet: a simple deep learning baseline for image classification? IEEE Transactions on Image Processing, 24(12), 5017–5032.
Toet, A. et al. (2014). TNO Image fusion dataset. Figshare. data
Roberts, J. W., Van Aardt, J. A., & Ahmed, F. B. (2008). Assessment of image fusion procedures using entropy, image quality, and multispectral classification. Journal of Applied Remote Sensing, 2(1), 023522.
Hossny, M., Nahavandi, S., & Creighton, D. (2008) Comments on’information measure for performance of image fusion’
Ma, K., Zeng, K., & Wang, Z. (2015). Perceptual quality assessment for multi-exposure image fusion. IEEE Transactions on Image Processing, 24(11), 3345–3356.
Aslantas, V., & Bendes, E. (2015). A new image quality metric for image fusion: The sum of the correlations of differences. AEU-International Journal of Electronics and Communications, 69(12), 1890–1896.
Rao, Y.-J. (1997). In-fibre Bragg grating sensors. Measurement science and technology, 8(4), 355.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cheng, W., Lin, B., Cheng, L. et al. Infrared and visible image fusion in a rolling guided filtering framework based on deep feature extraction. Wireless Netw (2024). https://doi.org/10.1007/s11276-024-03716-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s11276-024-03716-2