
Abstract
Sound source separation (SSS) is a fundamental problem in audio signal processing, aiming to recover individual audio sources from a given mixture. A promising approach is multichannel non-negative matrix factorization (MNMF), which employs a Gaussian probabilistic model encoding both magnitude correlations and phase differences between channels through spatial covariance matrices (SCM). In this work, we present a dedicated hardware architecture implemented on field programmable gate arrays (FPGAs) for efficient SSS using MNMF-based techniques. A novel decorrelation constraint is presented to facilitate the factorization of the SCM signal model, tailored to the challenges of multichannel source separation. The performance of this FPGA-based approach is comprehensively evaluated, taking advantage of the flexibility and computational capabilities of FPGAs to create an efficient real-time source separation framework. Our experimental results demonstrate consistent, high-quality results in terms of sound separation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Sound source separation (SSS) is a fundamental problem in audio signal processing, aiming to recover individual audio sources from a given mixture. This task has numerous applications, including speech enhancement, instrument isolation in music recordings, and noise reduction, among others. More recently, augmented reality applications and object-based audio formats [1, 2] further increased interest in multichannel audio processing, including SSS.
Traditionally, non-negative matrix factorization (NMF) has been a popular choice for both blind and informed SSS. NMF factorizes an input matrix, typically the magnitude spectrogram, into rank-1 components. Originally designed for single-channel scenarios, the extension of NMF to multichannel setups required innovative techniques, such as aggregating channels into matrices or considering parallel factor models [3]. One promising approach is multichannel NMF (MNMF), which employs a Gaussian probabilistic model [4,5,6] encoding both magnitude correlations and phase differences between channels through spatial covariance matrices (SCM). In this context, [5] proposed an innovative method to estimate unconstrained SCM mixing filters along with a NMF magnitude model. The goal was to identify and separate repetitive frequency patterns associated with a single spatial location. To address spatial aliasing, [6] introduced an SCM model based on direction of arrival (DoA) kernels, which helps estimate inter-microphone time delays by considering the source looking direction. Carabias et al. [7] introduced a novel SCM kernel-based model in which the mixing filter is decomposed into two direction-dependent SCMs. This allows for the separate representation and estimation of time and level differences between array channels. While effective, these MNMF approaches come with high computational costs and sensitivity to parameter initialization.
To mitigate the computational cost associated with full-rank SCMs, some methods have been introduced, including rank-1 restrictions based on independent vector analysis (in the Independent Low-Rank Matrix Analysis, ILRMA [8]) or techniques based on diagonalization [9]. Furthermore, recent developments in unsupervised deep learning have brought full-rank spatial covariance analysis (FCA) to the forefront, utilizing generative models consisting of both full-rank spatial and deep spectral models [10]. Other studies have proposed efficient implementations to reduce the computational complexity of MNMF-based approaches. For instance, in [11], a mixed parallelism implementation was proposed, enabling real-time sound source separation on multi-core architectures by combining parallel and high-performance techniques. However, this approach was limited to servers with high computational capabilities. More recently, [12] introduced an efficient parallel kernel based on Cholesky decomposition to accelerate MNMF. Nevertheless, its applicability is confined to systems utilizing the Itakura-Saito divergence-based cost function.
However, despite ongoing endeavors to mitigate computational complexities, there has been relatively limited exploration into the efficient implementation of NMF algorithms on embedded systems such as field programmable gate arrays (FPGA). FPGAs are renowned for their versatility and flexibility, rendering them highly suitable for a wide array of applications, including SSS. The incorporation of MNMF algorithms into FPGA platforms represents an intriguing, yet largely uncharted domain with the prospective capacity to yield real-time and resource-efficient solutions.
In this work, we address this research gap by presenting a dedicated hardware architecture implemented on FPGA for efficient SSS using MNMF-based techniques. Our contributions encompass two key aspects: (i) the introduction of a MNMF approach based on a decorrelation constraint for SCM signal model estimation, tailored to the challenges of multichannel source separation, and (ii) the development of a real-time FPGA-based prototype for our proposed estimation algorithm. The target application for this approach is in noisy environments with multiple simultaneous speakers, where the separation of each source is of paramount interest. This capability can subsequently facilitate the application of speech enhancement techniques, for instance, in podcast broadcasting, leveraging embedded systems like FPGAs to achieve real-time streaming separation.
To the best of our knowledge, a comprehensive, versatile, and open-source system designed to tackle this challenge on an FPGA platform has not been previously introduced. As a proof of concept, we conducted multiple experiments using a multichannel dataset. Our approach has been rigorously tested and demonstrated consistent, high-quality results in terms of sound separation.
The remaining sections of this paper are structured as follows: Sect. 2 outlines the problem formulation and provides an overview of the typical MNMF approach. The proposed algorithm is detailed in Sect. 3. Section 4 delves into the optimization strategy pursued for implementing the algorithm on FPGA. In Sect. 5, we describe the evaluation setup and assess the performance of the proposed system. Lastly, Sect. 6 provides the concluding remarks for this paper.
2 Background
2.1 Problem formulation
The main goal of this research concerns to the demultiplexing of individual source signals from a set of audio mixtures acquired via a microphone array. For each microphone \(m \in [1,M]\), the observed signal \(x_m(n)\) is expressed as follows:
Here, \(x_m(n)\) represents the composite signal received by the microphone m, which incorporates signals from \(s \in [1,S]\) distinct sources. The temporal index is denoted as n. The spatial convolution operation is characterized by the mixing filters \(h_{ms}(\tau )\), which govern the relationship between the source signals \(y_s(n)\) and the mixed signals \(x_m(n)\).
The convolutional mixing problem in (1) is further examined by considering the short-time Fourier transform (STFT) representation of \(x_m(n)\):
where \(\textbf{x}_{ft} = \left[ x_{ft1}, \dots ,x_{ftM}\right] ^\text {T}\) represents the time-frequency spectrograms of \(x_m(n)\), \(\textbf{h}_{fs} = \left[ h_{fs1}, \dots ,h_{fsM}\right] ^\text {T}\) denotes the frequency-domain mixing filter, and \(y_{fts}\) represents the time–frequency spectrograms of the source signals \(y_s(n)\). Note that \(f \in [1,F]\) and \(t \in [1,T]\).
The signal representation chosen in this study is based on the spatial covariance matrix (SCM) domain, which has been employed in prior works [5, 6, 11]. This domain is selected due to its capacity to capture both phase and amplitude differences among pairs of microphones within the multichannel mixture, while abstaining from relying on absolute phase information.
To compute the SCM, we initially construct the magnitude square-rooted matrix \(\hat{\textbf{x}}_{ft}\) for a specific time–frequency point (f, t) in the captured signal at each microphone, as follows:
where \(\text {sgn}(z) = z/|z|\) represents the signum function for complex numbers.
Subsequently, for each time–frequency point, the SCM is defined from the multichannel captured vector \(\hat{\textbf{x}}_{ft}\) through an outer product:
where \(^H\) stands for the Hermitian transpose. The matrices \(\textbf{X}_{ft} \in \mathbb {C}^{M\times M}\) for each time–frequency point \((f,t)\) encode the magnitude spectrum of each microphone signal along the main diagonal, and the magnitude correlation and phase difference between each microphone pair \((n,m)\) in the off-diagonal entries.
Thus, the convolutive mixing model in (2) can be equivalently expressed in the SCM domain as follows:
where \(\bar{y}_{fts}\) represents the magnitude spectrogram for each source \(s\), and \(\textbf{H}_{fs} \in \mathbb {C}^{M \times M}\) denotes the SCM representation of the spatial frequency response \(\textbf{h}_{fs}\).
2.2 Multichannel non-negative matrix factorization
Multichannel non-negative matrix factorization (MNMF) is an extension of the statistical NMF method and is used for separating individual audio sources from a multichannel signal. This technique assumes that the observed multichannel data can be factorized into non-negative matrices, which are then used to reconstruct the original source signals. The process is iterative. In each iteration, the algorithm aims to minimize the difference between the original matrix and the product of the decomposed matrices. This iterative refinement enables the algorithm to converge progressively to a solution that best represents the input data.
Many MNMF models have been proposed in the literature for multichannel source separation. Recently, models based on the local Gaussian model (LGM) have gained significant popularity due to their systematic approach in incorporating spatial and spectral cues [13]. The LGM framework, introduced by Duong et al. [14], represents each source as a complex-valued vector of length M, denoted by \(\textbf{y}_{fts} = [y_{fts1}, \dots , y_{ftsM}]^\text {T} \in \mathbb {C}^M\). In this approach, source signals are modeled as:
where \(\textbf{R}_{fts} \in \mathbb {C}^{M\times M}\) captures the spatial characteristics of the s-th source image at the point (f, t), and \(\lambda _{fts} \in \mathbb {R}\) is the spectral variance and models the spectral characteristics of the s-th source image at (f, t). In turn, this spectral variance, \(\lambda _{fts}\), is modeled through classical NMF as follows:
where \(w_{fks}\) and \(h_{kts}\) correspond to the basis functions and their corresponding time-varying gains, respectively.
In these models, \(\textbf{R}_{fs}\) may be modeled as a rank-1 SCM or a full-rank matrix. Rank-1 SCM-based methods, while computationally efficient [4], often yield suboptimal source modeling results. On the other hand, full-rank methods usually offer better quality in modeling the source, but they require significantly more computational resources [11, 15].
Recent developments have introduced several full-rank methods aimed at providing computationally efficient solutions [16,17,18,19]. These methods, however, may come with certain limitations, such as being tailored to specific array configurations [18], reducing only the SCM diagonal values [19], or relying on statistical independence among sources to derive spatial characteristics [9, 16].
This study proposes an implementation based on full-rank models to create a real-time system capable of addressing these high computational costs. The signal model considered, and the strategies followed for its implementation on an FPGA will be presented in the following sections.
3 Proposed MNMF algorithm for multichannel source separation

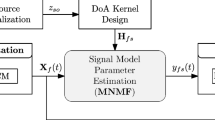
Block diagram of the proposed system
In this work, we propose a framework for source separation that can be efficiently executed on FPGA-based platforms. The proposed model is a multichannel signal processing approach based on SCM domain and MNMF algorithm. The ultimate goal is to present a system capable of achieving real-time source separation.
The complete system design adheres to the established framework employed in prior research conducted by the authors [11, 15, 20]. This framework integrates three critical stages: (1) signal representation, (2) signal model parameter estimation, and (3) signal reconstruction. The block diagram of the proposed method is depicted in Fig. 1. In the subsequent subsections, we provide detailed descriptions of the key functions within each stage.
3.1 Signal model
In this section, we describe the signal model used for the estimation of source spectrograms through the MNMF algorithm [5]. In this work, we follow the approach introduced by [6], where the mixing filter \(\textbf{H}_{fs}\) in (5) is decomposed into a linear combination of direction of arrival (DoA) kernels denoted as \(\textbf{W}_{fo} \in \mathbb {C}^{M\times M}\). Each DoA kernel is then multiplied by a spatial weights matrix \(\textbf{Z} \in \mathbb {R}_+^{S\times O}\), establishing meaningful relationships between the sources (S) and spatial directions (O). This modeling approach enriches the spatial context of the signal model, enhancing its capacity for source separation tasks. Note that similar approaches have been explored in the previous works [11, 15, 20,21,22]. Thus, the signal model is expressed as follows:
where \(z_{so}\) is initialized a priori to reduce the number of free parameters, and the DoA kernel matrix \(\textbf{W}_{fo}\) is computed as follows:
Here \(\theta _{nm}(f,o)= 2\pi f \tau _{nm}(\textbf{x}_o)\) denotes the phase difference derived from the time difference of arrival between sensors n and m for the frequency bin f and spatial position o. For the sake of brevity, the specific details of this kernel processing are omitted in this context; however, for a more comprehensive understanding, we direct the reader to refer to [5].
It is worth emphasizing that in this model, both \(\textbf{W}_{fo}\) and \(\textbf{Z}\) remain constant throughout the factorization process, with \(\textbf{Z}\) being initialized based on the spatial positions of sources within the acoustic scene.
3.2 MNMF parameter estimation
In this work, we estimate the source variances \(\bar{y}_{fts}\) using the majorization–minimization algorithm, a technique well-established in the previous studies [5, 6, 15]. However, our distinctive contribution lies in the novel incorporation of a decorrelation constraint for source modeling, a pioneering approach not previously explored in the field of SCM-MNMF-based research. This constraint is essential for enhancing source estimation accuracy, as the proposed signal model differs from the traditional NMF structure of bases and activations (shown in 7), so this constraint is necessary to achieve successful source separation. Furthermore, rather than using the Itakura-Saito divergence, we suggest taking advantage of the Euclidean distance as the cost function, as it is less computationally demanding, yet still produces satisfactory outcomes.
In this sense, the source decorrelation constraint implies that the source variances \(\bar{y}_{fts}\) are uncorrelated, and the correlation matrix \(\bar{y}_{fts}^\text {T} \bar{y}_{fts}\) is diagonal dominant. For this purpose, we propose to minimize the following regularized cost function:
where tr\((\cdot )\) is the matrix trace operator, and it can be computed as follows: \(\text {tr}(\textbf{A}) = \sum _{m=1}^M a_{mm}\). Thus, the global objective cost function can be formulated as follows:
where \(\lambda\) controls the importance of the decorrelation constraint.
To minimize this complex-valued function, we follow the optimization scheme of majorization in [5] using an auxiliary positive definite function which allows the factorization under non-negativity of the parameters restriction. Then, the derivation of the algorithm updates is achieved via partial derivation of this function. For the sake of brevity, we write directly the multiplicative update rule for source variances parameter. Further information about the derivation of these rules can be found in [5, 15]. Thus, the iterative update rule is formulated as follows:
where \(1_{ss}\) denotes an all-ones square matrix of size S.
3.3 Source reconstruction
The reconstruction of the source signals is performed using a generalized Wiener filtering strategy. Remember that \(\textbf{x}_{ft}\) is an M-dimensional complex vector representing STFT coefficients at frequency bin f and time frame t, and let \(\tilde{\textbf{y}}_{fts}\) be the STFT coefficient vector for the s-th separated signal. Then, the separated signals are obtained by the single-channel Wiener filter for the m-th channel as follows:
Finally, the multichannel time-domain signals are obtained by the inverse STFT of \(\tilde{\textbf{y}}_{fts}\), and frames are combined by weighted overlap-add.
The procedure of the whole system is summarized in Algorithm 1.

Pseudocode of the proposed MNMF system algorithm
4 Proposed architecture based on FPGA for the source separation implementation
In this section, we describe the strategy employed to achieve real-time implementation of the algorithm discussed in Sect. 3. The proposed architecture for this implementation is centered around FPGA technology. These platforms have emerged as a compelling choice for accelerating computationally intensive tasks. Their reconfigurable nature allows tailored hardware designs to be efficiently deployed for specific applications. In the context of audio source separation, FPGAs offer notable advantages, such as high parallelism, low-latency processing, and the capability to execute multiplications and logic operations with speed and efficiency. These characteristics position FPGAs as a top contender for handling the real-time demands of audio source separation. Consequently, this study focuses on the thorough examination and efficient implementation of the parameter estimation stage of the MNMF algorithm on FPGAs. This stage carries a substantial computational load, primarily due to its iterative nature and the involvement of multiple complex number matrix operations. Therefore, we have not addressed the implementation of the signal representation stage (i.e., fast Fourier transform (FFT) implementation) or the reconstruction stage (i.e., the implementation of 14), as these aspects represent a negligible computational load compared to the estimation stage and have already been extensively explored in the literature [11, 23].
The architecture proposed for the iterative estimation of the sources using the update rule (13) is depicted in Fig. 2. This architecture is composed of six main blocks, each represented by distinct colors in Fig. 2. Table 1 provides a description of the mathematical operations carried out in each of these subsystems. In the following, we outline the strategies employed for the implementation of each of these subsystems.
For the sake of simplicity in notation and because the proposed algorithm operates on a frame-by-frame basis, where each frame is treated independently, we will omit the time index t from the model parameters for the remainder of this section.

Top-level view of the architecture designed using a Simulink model, with key logic components organized as subsystems within larger rectangular boxes for improved clarity. The architecture shown is designed for two sources
Subsystem for the initialization of \(\bar{y}_{fs}\)
This block is responsible for the initial setup of \(\bar{y}_{fs}\) to prepare it for iterative estimation. Typically, this can be achieved by using a random number generator. In the context of hardware implementation, VHDL provides a built-in pseudo-random number generator capable of generating floating-point values within the range of 0–1. However, to conserve hardware resources, the use of a random number generator is omitted. Instead, it was decided to initialize all elements of \(\bar{y}_{fs}\) to one. In Fig. 2, it can be observed how this was implemented using constant value generators capable of generating a data point during each data cycle. In this manner, the elements of \(\bar{y}_{fs}\) are initialized with the outputs of these generators in the initial data cycles. Once \(\bar{y}_{fs}\) is initialized in this manner, an SR-latch adjusts the switching condition for all subsequent iterations. As a result, the values of \(\bar{y}_{fs}\) will correspond to those obtained by the update Eq. (13).
Subsystem for loading \(\textbf{H}_{fs}\) from read-only memory (ROM)
This subsystem plays a crucial role in the efficient implementation of the source separation algorithm. In the context of this algorithm, it is assumed that the positions of the sources are known in advance, enabling informed source separation. Consequently, \(\textbf{H}_{fs}\), the spatial frequency response associated with each source s, is predetermined and should be read from the FPGA’s memory. To achieve this, look-up tables (LUTs) are configured as read-only memory in order to store the matrices related to each source. These matrices are stored in separate blocks, which operate in parallel to enhance computational efficiency.
To facilitate reading \(\textbf{H}_{fs}\) from ROM, control logic is implemented. This control logic determines which addresses within the ROM need to be accessed, ensuring the correct \(\textbf{H}_{fs}\) is retrieved for the ongoing source separation process. Moreover, a straightforward counter is employed to indicate the current frequency bin that needs to be read. The counter’s output is connected to various parts of the system, where the current frequency bin must be accurately indicated.
Subsystem for computing \(\textbf{X}_{f}\) and \(\text {tr}(\textbf{X}_{f}\textbf{H}_{fs})\)
This subsystem is responsible for computing and storing the operation \(\text {tr}(\textbf{X}_{f}\textbf{H}_{fs})\). To achieve this, the subsystem firstly pre-processes the FFT of the temporal frames from each microphone to obtain the SCM representation \(\textbf{X}_f\). Figure 3 provides a graphical overview of the matrix multiplication required for calculating \(\textbf{X}_f\). In this example, the operation described in (4) is carried out, specifically for the case of four microphones. Note that in the final implementation, the square root operation and the signum function described in (3) have been omitted. This optimization conserves hardware resources for calculations without compromising separation quality.

Representation of the calculation of the SCM \(\textbf{X}_f\) from (4), for the case of four microphones. The middle illustration depicts the multiplication process for the first frequency bin
Subsequently, the subsystem computes the outer product of \(\textbf{X}_{f}\) and \(\textbf{H}_{fs}\) to calculate its trace. Figure 4 provides a graphical example of this operation for four microphones and two sources. Notably, non-diagonal elements are not computed in this system, as they are not required for the trace operator, resulting in significant resource savings. In the example illustrated, only four complex-valued multiplications are needed, compared to the 16 complex-valued multiplications in the standard matrix multiplication scheme.

Representation of the operation \(\text {tr}(\textbf{X}_{f}\textbf{H}_{fs})\) for the case of four microphones and two sources. The traces are calculated independently for each source
The results of the operation are preserved in specific adresses within the block random access memory (BRAM). The designated addresses play a crucial role in subsequent iterations of the algorithm. The subsystem receives the current frequency bin index from the ROM subsystem, determining which addresses in the BRAM need to be accessed.
It is important to emphasize that this operation needs to be calculated only once for each time frame, sparing the need for its recalculation during each MNMF iteration. Following its initial calculation, the result is retained in the FPGA BRAM and readily available for subsequent algorithm iterations.
Subsystem for computing \(\hat{\textbf{X}}_{f}\) and \(\text {tr}(\hat{\textbf{X}}_{f} \textbf{H}_{fs})\)
This subsystem constitutes part of the system core. First, the model estimate \(\hat{\textbf{X}}_{f}\) is computed. This computation is achieved by performing in parallel the multiplication of \(\textbf{H}_{fs}\) by \(\bar{y}_{fs}\) for all sources. Note that \(\textbf{H}_{fs}\) is a complex-valued matrix, while \(\bar{y}_{fs}\) is non-negative real-valued, so the result can be seen as a scaling operation of the complex values within \(\textbf{H}_{fs}\) by \(\bar{y}_{fs}\).
In addition to estimating \(\hat{\textbf{X}}_{f}\), this subsystem also calculates \(\hat{\textbf{X}}_{f} \textbf{H}_{fs}\) and its trace, following a similar approach as previously described.
Subsystem for calculating the constraint terms \((2\lambda \; \bar{y}_{fs})\) and \((2\lambda \; 1_{ss} \bar{y}_{fs})\)
The computation of \((2\lambda \; \bar{y}_{fs})\) and \((2\lambda \; 1_{ss} \bar{y}_{fs})\) takes place within the component highlighted in pink in Fig. 2. These values are essential for enforcing the cross-correlation constraint during the update of \(\bar{y}_{fs}\).
Subsystem for updating \(\bar{y}_{fs}\)
This subsystem is responsible for updating \(\bar{y}_{fs}\). As depicted in Fig. 2, \(\bar{y}_{fs}\) follows two paths: 1) to the system’s output, where it can be accessed by external logic, and 2) into the system’s feedback path, where it is required to continue being updated.
In this context, precise timing considerations are necessary to enable the correct propagation of data. The updated values of \(\bar{y}_{fs}\) must be delayed by \(F-1\) data cycles before entering the feedback path. This delay is crucial because the F frequency bins need to be processed by the logic before the values of the new iteration are fed back. It ensures that the correct sequencing and data synchronization are maintained within the system.
In essence, the architecture resembles a continuous flow of pipelined data. All F frequency bins circulate through the logic concurrently. As soon as the F-th frequency bin from one iteration traverses a specific section of the logic, the first bin of the new iteration enters the same part of the logic. Each subsystem is meticulously synchronized to ensure that data processing is performed in unison, allowing for the synchronized merging of data routes.
5 Evaluation and experimental results
5.1 Experimental setup
This section details the experimentation conducted to evaluate the proposed system. For our evaluation, we employed a subset of the SiSEC 2016 evaluation campaign dataset, a well-established benchmark for signal separation [24]. We selected six speech signal mixtures, encompassing both male and female recordings with two simultaneous speakers. The multichannel mixtures were generated by simulating source spatial positions, using mixing filters simulated with the Roomsim toolbox [25]. The simulation considered a rectangular room and a linear array of four omnidirectional microphones. The room’s reverberation time RT\(_{60}\),Footnote 1 which characterizes the acoustic environment, was set to either 100 ms for a semi-anechoic room and 400 ms for a reverberant room. The signals were processed at a 16-kHz sampling rate, and a 2048-point FFT with a 50% overlap was applied for signal analysis.
For a quantification of the separation results, the separated audio files are analyzed by using the BSS_Eval toolbox [26]. This toolbox compares the separated audio files to corresponding ground truth files and calculates energy ratios expressed in decibels for the signal-to-distortion ratio (SDR), the signal-to-interferences ratio (SIR), and the signal-to-artifacts ratio (SAR). The SDR calculates the ratio between the energy of the real source signal and the sum of the errors contributed by interference, noise, and artifacts [26]. Therefore, it can be argued that it represents a general form of measure for source separation quality. The BSS_Eval toolbox is widely accepted and applied in the scientific community, allowing a fair comparison with the work of other authors.
Regarding the testbed, we have utilized various FPGA simulation software tools to validate our development. In the forthcoming subsections, we will delve into the specifics of our experimental setup and methodology.
Finally, we conducted a comprehensive evaluation of three variants of the proposed algorithms to assess their performance. These variants include the reference algorithm, implemented in Matlab with double-precision floating-point format to ensure high numerical accuracy. Additionally, we tested two Simulink-based implementations of our pipeline structure: the unconstrained-bit model, which utilizes fixed-point variables without bitlength restrictions on multipliers, and the constrained-bit model, which incorporates fixed-point variables while limiting multipliers to a maximum bitlength of \(18 \times 18\) bits. This comparison allowed us to evaluate numerical precision and resource utilization across different implementations.
5.2 Separation results
The separation results obtained in the evaluation of the proposed database for two simultaneous speakers are presented in Fig. 5. This figure depicts the median outcomes for SDR, SIR, and SAR. To demonstrate the extreme separation performance, we present results for two unrealistic baseline methods: oracle mask separation and energy distribution (ED). The oracle separation computes the optimal Wiener mask value at each frequency and time component, assuming prior knowledge of the signals to be separated. Consequently, this approach represents the upper bound for the best achievable separation using the employed time–frequency representation. On the other hand, ED separation utilizes the mixture signal divided by the number of sources as input for the evaluation. This evaluation provides a starting point for comparing the performance of the proposed algorithm. As expected, the separation performance is notably superior in the semi-anechoic environment compared to the reverberant room. In the semi-anechoic setting, the proposed algorithm exhibits remarkable separation quality, yielding results nearly identical to oracle separation. It achieves nearly perfect source isolation, with SIR exceeding 18 dB and SAR reaching 15 dB, underscoring the absence of artifacts during the separation process. In the reverberant room, the obtained results are slightly inferior to oracle separation; nevertheless, they still exhibit over 4 dB in SDR and more than 9 dB in SIR. While the separation quality may not be as exceptional as in the semi-anechoic scenario, the listening quality of the separated signals remains entirely suitable for the intended application. These results underscore the system’s effectiveness in challenging acoustic environments, offering promising separation quality with potential applications in speech enhancement.

Objective results using the BSS_EVAL metrics [26] for the proposed dataset. Each bar indicates the median values of the obtained results
5.3 Computational results
Testbenches are created in Simulink [27] for simulating the design using ModelSim, a versatile software tool used for verifying behavioral, register-transfer level, and gate-level code simulations. It is employed to assess the VHDL code, platform-independently (without the need to specify a particular FPGA device), at the register-transfer level.
Figure 6 illustrates the simulation results. The MNMF algorithm iterations for a single time frame are executed. The input to the testbench consists of the frequency-domain signal \(\textbf{X}_f\), with 1024 complex values in each microphone channel. In each data cycle, one frequency bin is fed into the system. The expected output of the system for each source, denoted as Out1_ref and Out2_ref and determined using Matlab, is compared to the computed output values, referred to as Out1 and Out2, from the VHDL code. These output values represent the magnitude spectra of the two sources. Since each frequency bin is output individually, visualizing the output data as a curve provides insight into the separated magnitude spectra.
Additionally, the simulation provides two other outputs. The first is the current frequency bin index, which ranges from 0 to 1023 (Out4). The second output, a boolean variable (Out3), indicates whether the first bin is being transmitted at the moment, serving as a simple flag to signify the start of a new iteration.

HDL code simulation in ModelSim. Input spectrum of the time frame and expected ground truth outputs are provided to ModelSim as .dat-files
5.3.1 Resource utilization
The process of analyzing the HDL code generated from Simulink [27] for a specific target FPGA is possible by compiling it in the Quartus® Prime Software. In this case, we employed the Cyclone® IV series with part number EP4CGX150DF31C8. The software is well-informed about the available hardware resources associated with the chosen FPGA model. The design compilation encompasses several key steps, including:
-
Analysis and synthesis: This step involves the transformation of the HDL specification, which defines the desired circuit behavior, into a design implementation at the level of logic gates.
-
Fitting: It pertains to the placement and routing of logic within the provided hardware resources.
-
Assembly: This phase is responsible for generating programming files.
-
Timing analysis: It involves analyzing and validating the timing aspects of the design.
Upon completing these steps, a resource utilization report is automatically generated, providing valuable insights into how the FPGA resources are being employed.
Table 2 presents a description of resource utilization by both the unconstrained-bit model and the constrained-bit model. It is important to note that the number of logic elements within the FPGA is not a critical factor for either model. The resource utilization for total registers is also quite similar between these models, reflecting the structural similarities in their implementations. The primary distinguishing factor lies in the bitlength of certain variables within the system. This distinction was deliberately introduced to investigate whether the bitlength of the multipliers would impose any significant restrictions on the designs.
In FPGA architectures such as the Cyclone® IV, the multiplication operations are facilitated by dedicated DSP blocks, which are equipped with embedded 18-bit multipliers. The critical insight derived from the resource utilization data is that the unconstrained-bit model exhaustively utilizes all available multiplication resources, effectively making use of every embedded multiplier. This is in contrast with the constrained-bit model, which adheres to the 18-bit limitation on the multipliers, resulting in a more efficient allocation of resources.
The resource utilization data reveal the impact of bitlength constraints on the FPGA implementation. Understanding this distinction is crucial in determining the feasibility and efficiency of FPGA-based designs for signal separation applications.
5.3.2 Timing analysis

Divergence cost for an audio frame as a function of the number of iterations
In this work, the input audio is processed frame by frame. This means that capturing nodes record an audio frame, and the system must process it before the next one is captured. As described in Sect. 5.1, a frame is recorded every 0.064 s. Therefore, for a real-time implementation, the system must be capable of processing each frame in 64 ms or less.
Processing a frame on the FPGA involves a significant number of clock cycles. In this sense, the processing time of a frame is determined by the number of clock cycles and the maximum achievable clock frequency of the FPGA. Several parameters affect the number of clock cycles, but the most critical one is the number of MNMF iterations. Using a higher number of iterations per time frame ensures proper algorithm convergence and improves estimation results, but also increases the number of clock cycles.
As depicted in Fig. 7, we observe rapid convergence in the initial iterations, followed by a stabilization to a steady state where the estimations exhibit minimal fluctuations. As can be observed, in the range of 35–70 iterations, a suitable balance is reached between achieving quick processing times due to a lower iteration count and obtaining satisfactory convergence based on the cost function. For the FPGA implementation, it is imperative for the developed hardware architecture to perform computations quickly enough to complete 35–70 iterations within the provided time window of 0.064 s for processing a single audio frame.
The Timing Analyzer integrated into Quartus® Prime is utilized to explore achievable clock speeds. By supplying a constraint file during the synthesis process, a target clock frequency is specified. The maximum attainable clock frequency, referred to as FMAX, is determined based on propagation times for clock and data signals. While it is typically recommended to consider the I/O paths of the FPGA for timing analysis, in this case, such considerations have been omitted. This omission is due to the specific focus of this implementation, which solely addresses the MNMF estimation stage. The study of the remaining stages required for a complete system is beyond the scope of this work. In a comprehensive implementation, this system would serve as the core of a larger system, devoid of any I/O interfaces.
For both models, the critical path is the fixed-point division operation (13), required for updating \(\bar{y}_{fs}\). The real-valued division represents the slowest combinational logic path between consecutive registers, and consequently, it determines the maximum achievable clock frequency for the design. It is worth noting that the bit length of the division operation in the unconstrained-bit model is greater than that in the constrained-bit model. Since the precision of the division operation directly impacts the precision of the calculated values for \(\bar{y}_{fs}\), reducing the bit lengths in the division step is not a desirable solution.
However, it is crucial to acknowledge this aspect when selecting the oversampling factor. The timing analysis results have revealed that higher oversampling factors do not improve the model throughput significantly. This is due to the division operation remaining the critical path and not being accelerated by higher oversampling. As a result, the lowest feasible oversampling factor was chosen. A factor of 8 represents the minimum oversampling factor that still allows the timing-correct implementation of the feedback loop for \(\bar{y}_{fs}\) values.
With the highest attainable clock frequencies known, the maximum number of iterations can be determined. Within the 0.064-s time window, the achieved clock rate is used to calculate the number of available data periods per FFT frame. The first 1028 data periods are reserved for storing the trace \(\text {tr}(\textbf{X}_{f} \textbf{H}_{fs})\) in the FPGA’s BRAM. The remaining data periods can be allocated for the iterations, where 1024 data periods are required for a complete update of \(\bar{y}_{fs}\). In this context, the unconstrained-bit model achieved a maximum clock frequency of 5.3 Hz, while the constrained-bit model exhibited a clock frequency of 6.1 Hz.
In the case of the unconstrained-bit model, it was possible to establish a fixed iteration count at 40, whereas the constrained-bit model allowed for an extended count of 47 iterations. Notably, both values remain within the previously examined range. Consequently, this raises the pivotal question of ascertaining which model proves superior: the unconstrained-bit model, offering heightened precision, or the constrained-bit model, which facilitates an increased number of iterations. Figure 8 clearly demonstrates that the model with reduced bit lengths outperforms the other by allowing more MNMF iterations. Under semi-anechoic conditions, SDR is notably better in the first source by 0.9 dB and 1.0 dB in the second source.

Comparison of developed models when both running at maximum iteration number in available time window for each frame
On the other hand, seeking to maximize the calculation speed of the developed system, efforts were directed toward enhancing the FMAX value. One approach involves mitigating factors that negatively affect the boundary conditions. If the operating temperature or voltage supply can be guaranteed to remain within the optimal range, it would result in a significant increase in FMAX. However, this option is not preferred as these boundary conditions are not always easy to monitor and control. An alternative solution is to explore the usage of different FPGA models. Advancements in technology have led to an increase in the number of transistors per unit area in newer devices, which, in turn, results in shorter conductor lengths and reduced signal propagation delays. Consequently, the HDL implementation was tested on newer models such as Cyclone® V and Cyclone® 10.
The Cyclone® V model, however, lacks the memory resources necessary to accommodate the unconstrained-bit model. Even for the constrained-bit model, the memory resources prove inadequate. Consequently, the precision of the DoA information was reduced from 18 bits to 16 bits, enabling synthesis on the Cyclone® V. Table 3 provides insights into the achievable clock frequencies and numbers of iterations for the tested FPGA models.
Remarkably, the number of iterations remains consistent across the different target devices. The Cyclone® V stands out with its remarkable attainable speeds for the constrained-bit model, translating to excellent separation performance. However, since the future goal encompasses a complete implementation of the whole algorithm, it is anticipated that the Cyclone® V memory resources may be insufficient. In contrast, the Cyclone® 10 does not yield additional iterations for the constrained-bit model but demonstrates superior performance with the unconstrained-bit model, rendering it a compelling alternative target platform.
6 Conclusion
In this study, we introduce an FPGA implementation designed for efficient SSS using MNMF-based techniques. A novel decorrelation constraint is presented to facilitate the factorization of the SCM signal model. This model is initialized with estimated source DoA information, enhancing the separation process and mitigating the sensitivity to parameter initialization. The performance of this FPGA-based approach is comprehensively evaluated, leveraging the flexibility and computational capabilities of FPGAs to create an efficient real-time source separation framework.
Our experimental results demonstrate that the proposed MNMF algorithm converges rapidly, achieving effective source separation with a limited number of iterations. This success is attributed to the application of the decorrelation constraint and the incorporation of DoA information. Similar to other FPGA implementations of NMF algorithms, we utilize constraints to expedite convergence and optimize resource utilization. Careful consideration of each computational step ensures that only essential calculations are performed, resulting in significant savings of hardware resources. The results affirm the feasibility of achieving real-time performance on FPGA platforms.
To the best of our knowledge, this study represents the first FPGA-based implementation of the MNMF model for sound source separation, employing the SCM.
Data availability
The data generated in this study are available from the corresponding author upon request.
Notes
RT\(_{60}\) is the time required for reflections of a direct sound to decay by 60 dB below the level of the direct sound.
References
Tylka JG, Choueiri EY (2020) Fundamentals of a parametric method for virtual navigation within an array of ambisonics microphones. J Audio Eng Soc 68(3):120–137
Pezzoli M, Borra F, Antonacci F, Tubaro S, Sarti A (2020) A parametric approach to virtual miking for sources of arbitrary directivity. IEEE/ACM Trans Audio Speech Lang Process 28:2333–2348
FitzGerald D, Cranitch M, Coyle E (2005) Non-negative tensor factorisation for sound source separation. In: IEEE Irish Signals and Systems Conference, vol 2005. IEEE, pp 8–12
Ozerov A, Fevotte C (2010) Multichannel nonnegative matrix factorization in convolutive mixtures for audio source separation. IEEE Trans Audio Speech Lang Process 18(3):550–563. https://doi.org/10.1109/TASL.2009.2031510
Sawada H, Kameoka H, Araki S, Ueda N (2013) Multichannel extensions of non-negative matrix factorization with complex-valued data. IEEE Trans Audio Speech Lang Process 21(5):971–982. https://doi.org/10.1109/TASL.2013.2239990
Nikunen J, Virtanen T (2014) Direction of arrival based spatial covariance model for blind sound source separation. IEEE/ACM Trans Audio Speech Lang Process 22(3):727–739. https://doi.org/10.1109/TASLP.2014.2303576
Carabias-Orti JJ, Cabanas-Molero P, Vera-Candeas P, Nikunen J (2018) Multi-source localization using a DOA kernel based spatial covariance model and complex nonnegative matrix factorization. In: 2018 IEEE 10th Sensor Array and Multichannel Signal Processing Workshop (SAM), IEEE, pp 440–444
Kitamura D, Ono N, Sawada H, Kameoka H, Saruwatari H (2016) Determined blind source separation unifying independent vector analysis and nonnegative matrix factorization. IEEE/ACM Trans Audio Speech Lang Process 24(9):1626–1641. https://doi.org/10.1109/TASLP.2016.2577880
Sekiguchi K, Bando Y, Nugraha AA, Yoshii K, Kawahara T (2020) Fast multichannel nonnegative matrix factorization with directivity-aware jointly-diagonalizable spatial covariance matrices for blind source separation. IEEE/ACM Trans Audio Speech Lang Process 28:2610–2625. https://doi.org/10.1109/TASLP.2020.3019181
Bando Y, Sekiguchi K, Masuyama Y, Nugraha AA, Fontaine M, Yoshii K (2021) Neural full-rank spatial covariance analysis for blind source separation. IEEE Signal Process Lett 28:1670–1674. https://doi.org/10.1109/LSP.2021.3101699
Muñoz-Montoro AJ, Carabias-Orti JJ, Cortina R, García-Galán S, Ranilla J (2021) Parallel multichannel blind source separation using a spatial covariance model and nonnegative matrix factorization. J Supercomput 77(10):12143–12156. https://doi.org/10.1007/s11227-021-03771-y
Muñoz-Montoro AJ, Carabias-Orti JJ, Salvati D, Cortina R (2023) Efficient parallel kernel based on Cholesky decomposition to accelerate multichannel nonnegative matrix factorization. J Supercomput 79:1–16
Ozerov A, Févotte C, Vincent E (2018) An introduction to multichannel NMF for audio source separation. In: Makino S (ed) Audio Source Sep. Springer, Cham, pp 73–94
Duong NQK, Vincent E, Gribonval R (2010) Under-determined reverberant audio source separation using a full-rank spatial covariance model. IEEE Trans Audio Speech Lang Process 18(7):1830–1840. https://doi.org/10.1109/TASL.2010.2050716
Carabias-Orti JJ, Nikunen J, Virtanen T, Vera-Candeas P (2018) Multichannel blind sound source separation using spatial covariance model with level and time differences and nonnegative matrix factorization. IEEE/ACM Trans Audio Speech Lang Process 26(9):1512–1527. https://doi.org/10.1109/TASLP.2018.2830105
Sekiguchi K, Nugraha AA, Bando Y, Yoshii K (2019) Fast multichannel source separation based on jointly diagonalizable spatial covariance matrices. In: 2019 27th European Signal Processing Conference (EUSIPCO), pp 1–5. https://doi.org/10.23919/EUSIPCO.2019.8902557
Ito N, Nakatani T (2019) Fastmnmf: joint diagonalization based accelerated algorithms for multichannel nonnegative matrix factorization. In: ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, pp 371–375
Mitsufuji Y, Uhlich S, Takamune N, Kitamura D, Koyama S, Saruwatari H (2020) Multichannel non-negative matrix factorization using banded spatial covariance matrices in wavenumber domain. IEEE/ACM Trans Audio Speech Lang Process 28:49–60. https://doi.org/10.1109/TASLP.2019.2948770
Mitsufuji Y, Takamune N, Koyama S, Saruwatari H (2021) Multichannel blind source separation based on evanescent-region-aware non-negative tensor factorization in spherical harmonic domain. IEEE/ACM Trans Audio Speech Lang Process 29:607–617. https://doi.org/10.1109/TASLP.2020.3045528
Munoz-Montoro AJ, Carabias-Orti JJ, Cabanas-Molero P, Canadas-Quesada FJ, Ruiz-Reyes N (2022) Multichannel blind music source separation using directivity-aware MNMF with harmonicity constraints. IEEE Access 10:17781–17795. https://doi.org/10.1109/ACCESS.2022.3150248
Nikunen J, Politis A (2018) Multichannel NMF for source separation with ambisonic signals. In: 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), pp 251–255. https://doi.org/10.1109/IWAENC.2018.8521344
Muñoz-Montoro AJ, Carabias-Orti JJ, Vera-Candeas P (2021) Ambisonics domain singing voice separation combining deep neural network and direction aware multichannel NMF. In: 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP), IEEE, pp 1–6
Muñoz-Montoro AJ, Suarez-Dou D, Carabias-Orti JJ, Canadas-Quesada FJ, Ranilla J (2020) Parallel multichannel music source separation system. J Supercomput 77:619–637. https://doi.org/10.1007/s11227-020-03282-2
Liutkus A, Stöter F-R, Rafii Z, Kitamura D, Rivet B, Ito N, Ono N, Fontecave J (2017) The 2016 signal separation evaluation campaign. In: International Conference on Latent Variable Analysis and Signal Separation, Springer, pp 323–332
Campbell DR, Palomaki KJ, Brown G (2005) A MATLAB simulation of “shoebox’’ room acoustics for use in research and teaching. Comput Inf Syst 9:48–51
Vincent E, Gribonval R, Fevotte C (2006) Performance measurement in blind audio source separation. IEEE Trans Audio Speech Lang Process 14(4):1462–1469. https://doi.org/10.1109/TSA.2005.858005
The MathWorks Inc. (2023) HDL Coder Toolbox (R2023a). https://www.mathworks.com
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was supported by the Spanish Ministry of Science, Innovation and Universities (MCIN/AEI/10.13039/501100011033) under research project PID2020-119082RB-C21,C22, by the Regional Government of Asturias through grant AYUD/2021/50994 and by the REPERTORIUM project: “Grant agreement number 101095065. Horizon Europe. Cluster II. Culture, Creativity and Inclusive society. Call HORIZON-CL2-2022-HERITAGE-01-02.”
Author information
Authors and Affiliations
Contributions
All the authors contributed equally to this study.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Diel, P., Muñoz-Montoro, A.J., Carabias-Orti, J.J. et al. Efficient FPGA implementation for sound source separation using direction-informed multichannel non-negative matrix factorization. J Supercomput (2024). https://doi.org/10.1007/s11227-024-05945-w
Accepted:
Published:
DOI: https://doi.org/10.1007/s11227-024-05945-w