
Abstract
Stochastic processes provide a mathematically elegant way to model complex data. In theory, they provide flexible priors over function classes that can encode a wide range of interesting assumptions. However, in practice efficient inference by optimisation or marginalisation is difficult, a problem further exacerbated with big data and high dimensional input spaces. We propose a novel variational autoencoder (VAE) called the prior encoding variational autoencoder (\(\pi \)VAE). \(\pi \)VAE is a new continuous stochastic process. We use \(\pi \)VAE to learn low dimensional embeddings of function classes by combining a trainable feature mapping with generative model using a VAE. We show that our framework can accurately learn expressive function classes such as Gaussian processes, but also properties of functions such as their integrals. For popular tasks, such as spatial interpolation, \(\pi \)VAE achieves state-of-the-art performance both in terms of accuracy and computational efficiency. Perhaps most usefully, we demonstrate an elegant and scalable means of performing fully Bayesian inference for stochastic processes within probabilistic programming languages such as Stan.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A central task in machine learning is to specify a function or set of functions that best generalises to new data. Stochastic processes (Ross 1966; Pavliotis 2014) provide a mathematically elegant way to define a class of functions, where each element from a stochastic process is a (usually infinite) collection of random variables. Popular examples of stochastic processes in computational statistics and machine learning are Gaussian processes (Rasmussen and Williams 2006), Dirichlet processes (Antoniak 1974), log-Gaussian Cox processes (Møller et al. 1998), Hawkes processes (Hawkes 1971), Mondrian processes (Roy and Teh 2009) and Gauss-Markov processes (Lindgren et al. 2011). Many of these processes are intimately connected with popular techniques in deep learning, for example, both the infinite width limit of a single layer neural network and the evolution of a deep neural network by gradient descent are Gaussian processes (Neal 1996; Jacot et al. 2018). However, while stochastic processes have many favourable properties, they are often cumbersome to work with in practice. For example, inference and prediction using a Gaussian process requires matrix inversions that scale cubicly with data size, log-Gaussian Cox processes require the evaluation of an intractable integral and Markov processes are often highly correlated. Bayesian inference can be even more challenging due to complex high dimensional posterior topologies. Gold standard evaluation of posterior expectations is done by Markov Chain Monte Carlo (MCMC) sampling, but high auto-correlation, narrow typical sets (Betancourt et al. 2017) and poor scalability have prevented use in big data and complex model settings. A plethora of approximation algorithms exist (Minka 2001; Ritter et al. 2018; Lakshminarayanan et al. 2017; Welling and Teh 2011; Blundell et al. 2015), but few actually yield accurate posterior estimates (Yao et al. 2018; Huggins et al. 2019; Hoffman et al. 2013; Yao et al. 2019). In this paper, rather than relying on approximate Bayesian inference to solve complex models, we extend variational autoencoders (VAE) (Kingma and Welling 2014; Rezende et al. 2014) to develop portable models that can work with state-of-the-art Bayesian MCMC software such as Stan (Carpenter et al. 2017). Inference on the resulting models is tractable and yields accurate posterior expectations and uncertainty.
An autoencoder (Hinton and Salakhutdinov 2006) is a model comprised of two component networks. The encoder \(e : {\mathcal {X}} \rightarrow {\mathcal {Z}}\) encodes inputs from space \({\mathcal {X}}\) into a latent space \({\mathcal {Z}}\) of lower dimension than \({\mathcal {X}}\). The decoder \(d : {\mathcal {Z}} \rightarrow {\mathcal {X}}\) decodes latent codes in \({\mathcal {Z}}\) to reconstruct the input. The parameters of e and d are learned through the minimisation of a reconstruction loss on a training dataset. A VAE extends the autoencoder into a generative model (Kingma and Welling 2014). In a VAE, the latent space \({\mathcal {Z}}\) is given a distribution, such as standard normal, and a variational approximation to the posterior is estimated. In a variety of applications, VAEs do a superb job reconstructing training datasets and enable the generation of new data: samples from the latent space are decoded to generate synthetic data (Kingma and Welling 2019). In this paper we propose a novel use of VAEs: we learn low-dimensional representations of samples from a given function class (e.g. sample paths from a Gaussian process prior). We then use the resulting low dimensional representation and the decoder to perform Bayesian inference.
One key benefit of this approach is that we decouple the prior from inference to encode arbitrarily complex prior function classes, without needing to calculate any data likelihoods. A second key benefit is that when inference is performed, our sampler operates in a low dimensional, uncorrelated latent space which greatly aids efficiency and computation, as demonstrated in the spatial statistics setting in PriorVAE (Semenova et al. 2022). One limitation of this approach (and of PriorVAE) is that we are restricted to encoding finite-dimensional priors, because VAEs are not stochastic processes. To overcome this limitation, we take as inspiration the Karhunen-Loève decomposition of a stochastic process as a random linear combination of basis functions and introduce a new VAE called the prior encoding VAE (\(\pi \)VAE). \(\pi \)VAE is a valid stochastic process by construction, it is capable of learning a set of basis functions, and it incorporates a VAE, enabling simulation and highly effective fully Bayesian inference.
We employ a two step approach: first, we encode the prior using our novel architecture; second we use the learnt basis and decoder network—a new stochastic process in its own right—as a prior, combining it with a likelihood in a fully Bayesian modeling framework, and use MCMC to fit our model and infer the posterior. We believe our framework’s novel decoupling into two stages is critically important for many complex scenarios, because we do not need to compromise in terms of either the expressiveness of deep learning or accurately characterizing the posterior using fully Bayesian inference.
We thus avoid some of the drawbacks of other Bayesian deep learning approaches which rely solely on variational inference, and the drawbacks of standard MCMC methods for stochastic processes which are inefficient and suffer from poor convergence.
Taken together, our work is an important advance in the field of Bayesian deep learning, providing a practical framework combining the expressive capability of deep neural networks to encode stochastic processes with the effectiveness of fully Bayesian and highly efficient gradient-based MCMC inference to fit to data while fully characterizing uncertainty.
Once a \(\pi \)VAE is trained and defined, the complexity of the decoder scales linearly in the size of the largest hidden layer. Additionally, because the latent variables are penalised via the KL term from deviating from a standard normal distribution, the latent space is approximately uncorrelated, leading to high effective sample sizes in MCMC sampling. The main contributions of this paper are:
-
We apply the generative framework of VAEs to perform full Bayesian inference. We first encode priors in training and then, given new data, perform inference on the latent representation while keeping the trained decoder fixed.
-
We propose a new generative model, \(\pi \)VAE, that generalizes VAEs to be able to learn priors over both functions and properties of functions. We show that \(\pi \)VAE is a valid (and novel) stochastic process by construction.
-
We show the performance of \(\pi \)VAE on a range of simulated and real data, and show that \(\pi \)VAE achieves state-of-the-art performance in a spatial interpolation task.
The rest of this paper is structured as follows. Sect. 2 details the proposed framework and the generative model along with toy fitting examples. The experiments on large real world datasets are outlined in Sect. 3. We discuss our findings and conclude in Sect. 4.
2 Methods
2.1 Variational autoencoders (VAEs)
A standard VAE has three components:
-
1.
An encoder network \(e(x,\gamma )\) which encodes inputs \(x \in {\mathcal {X}}\) using learnable parameters \(\gamma \),
-
2.
Random variables z for the latent subspace,
-
3.
A decoder network \(d(z,\psi )\) which decodes latent embeddings z using learnable parameters \(\psi \).
In the simplest case we are given inputs \(x\in {\mathbb {R}}^d = {\mathcal {X}}\) such as a flattened image or discrete time series. The encoder \(e(x,\gamma )\) and decoder \(d(z,\psi )\) are fully connected neural networks (though they could include convolution or recurrent layer). The output of the encoder network are vectors of mean and standard deviation parameters \(z_{\mu }\) and \(z_{sd}\). These vectors can thus be used to define the random variable \({\mathcal {Z}}\) for the latent space:
For random variable \({\mathcal {Z}}\), the decoder network reconstructs the input by producing \({\hat{x}}\):
To train a VAE, a variational approximation is used to estimate the posterior distribution
The variational approximation greatly simplifies inference by turning a marginalisation problem into an optimisation problem. Following (Kingma and Ba 2014), the optimal parameters for the encoder and decoder are found by maximising the evidence lower bound:
The first term in Eq. (4) is the likelihood quantifying how well \(\hat{x}\) matches x. In practice we can simply adopt the mean squared error loss directly, referred to as the reconstruction loss, without taking a probabilistic perspective. The second term is a Kullback-Leibler divergence to ensure that \({\mathcal {Z}}\) is as similar as possible to the prior distribution, a standard normal. Again, this second term can be specified directly without the evidence lower bound derivation: we view the KL-divergence as a regularization penalty to ensure that the latent parameters are approximately uncorrelated by penalizing how far they deviate from \({\mathcal {N}}(0,{\mathbb {I}})\).
Once training is complete, we fix \(\psi \), and use the decoder as a generative model. To simplify subsequent notation we refer to a fully trained decoder as d(z). Generating a new sample is simple: first draw a random variable \({\mathcal {Z}} \sim {\mathcal {N}}(0,{\mathbb {I}})\) and then apply the decoder, which is a deterministic transformation to obtain \(d({\mathcal {Z}})\). We see immediately that \(d({\mathcal {Z}})\) is itself a random variable. In the next section, we will use this generative model as a prior in a Bayesian framework by linking it to a likelihood to obtain a posterior.
2.2 VAEs for Bayesian inference
VAEs have been typically used in the literature to create or learn a generative model of observed data (Kingma and Welling 2014), such as images. (Semenova et al. 2022) introduced a novel application of VAEs in a Bayesian inference setting, using a two stage approach that is closely related to ours. In brief, in the first stage, a VAE is trained to encode and decode a large dataset of vectors consisting of samples drawn from a specified prior \(p(\theta )\) over random vectors. In the second stage, the original prior is replaced with the approximate prior: \(\theta := d({\mathcal {Z}})\) where \({\mathcal {Z}} \sim {\mathcal {N}}(0,{\mathbb {I}})\).
To see how this works in a Bayesian inference setting, consider a likelihood \(p(y\mid \theta )\) linking the parameter \(\theta \) to data y. Bayes’ rule gives the unnormalized posterior:
The trained decoder serves as a drop-in replacement for the original prior class in a Bayesian setting:
The implementation within a probabilistic programming language is very straightforward: a standard normal prior and deterministic function (the decoder) are all that is needed.
It is useful to contrast the inference task from Eq. (6) to a Bayesian neural network (BNN) (Neal 1996) or Gaussian process in primal form (Rahimi and Recht 2008). In a BNN with parameters \(\omega \) and hyperparameters \(\lambda \), the unnormalised posterior would be

Learning functions with VAE: a Prior samples from a VAE trained on Gaussian process samples b we fit our VAE model to data drawn from a GP (blue) plus noise (black points). The posterior mean of our model is in red with the \(95\%\) epistemic credible intervals shown in purple
The key difference between Eqs. (6) and (7) is the term \(p(\omega \mid \lambda )\). The dimension of \(\omega \) is typically huge, sometimes in the millions, and is conditional on \(\lambda \), whereas in Eq. (6) the latent dimension of \({\mathcal {Z}}\) is typically small (\(<50\)), uncorrelated and unconditioned. Full batch MCMC training is typically prohibitive for BNNs due to large datasets and the high-dimensionality of \(\omega \), but approximate Bayesian inference algorithms tend to poorly capture the complex posterior (Yao et al. 2019, 2018). Additionally, \(\omega \) tends to be highly correlated, making efficient MCMC nearly impossible. Finally, as the dimension and depth increases, the posterior distribution suffers from complex multimodality, and concentration to a narrow typical set (Betancourt et al. 2017). By contrast, off-the-shelf MCMC methods are very effective for Eq. (6) because the prior space they need to explore is as simple as it could be: a standard normal distribution, while the complexity of the model lives within the deterministic (and differentiable) decoder. In a challenging spatial statistics setting, (Semenova et al. 2022) used this approach and achieved MCMC effective sample sizes exceeding actual sample sizes, due to the incredible efficiency of the MCMC sampler.
An example of using VAEs to perform inference is shown in Fig. 1 where we train a VAE with latent dimensionality 10 on samples drawn from a zero mean Gaussian process with RBF kernel (\(K(\delta )=e^{- \delta ^2/8^2}\)) observed on the grid \(0, 0.01, 0.02, \ldots , 1.0\). In Fig. 1 we closely recover the true function and correctly estimate the data noise parameter. Our MCMC samples showed virtually no autocorrelation, and all diagnostic checks were excellent (see Appendix). Solving the equivalent problem using a Gaussian process prior would not only be considerably more expensive (\({\mathcal {O}}(n^3)\)) but correlations in the parameter space would complicate MCMC sampling and necessitate very long chains to achieve even modest effective sample sizes.
This example demonstrates the promise that VAEs hold to improve Bayesian inference by encoding function classes in a two stage process. While this simple example proved useful in some settings (Semenova et al. 2022), inference and prediction is not possible at new input locations, because a VAE is not a stochastic process. As described above, a VAE provides a novel prior over random vectors. Below, we take the next step by introducing \(\pi \)VAE, a new stochastic process capable of approximating useful and widely used priors over function classes, such as Gaussian processes.
2.3 Encoding stochastic processes with \(\pi \)VAE
To create a model with the ability to perform inference on a wide range of problems we have to ensure that it is a valid stochastic process. Previous attempts in deep learning in this direction have been inspired by the Kolmogorov Extension Theorem and have focused on extending from a finite-dimensional distribution to a stochastic process. Specifically, (Garnelo et al. 2018) introduced an aggregation step (typically an average) to create an order invariate global distribution. However, as noted by (Kim et al. 2019), this can lead to underfitting.
We take a different approach with \(\pi \)VAE, inspired by the Karhunen-Loève Expansion (Karhunen 1947; Loeve 1948). Recall that a centered stochastic process f(s) can be written as an infinite sum:
for pairwise uncorrelated random variables \(\beta _j\) and continuous real-valued functions forming an orthonormal basis \(\phi _j(s)\). The random \(\beta _j\)’s provide a linear combination of a fixed set of basis functions, \(\phi _j\). This perspective has a long history in neural networks, cf. radial basis function networks.
What if we consider a trainable, deep learning parameterization of Eq. (8) as inspiration? We need to learn deterministic basis functions while allowing the \(\beta _j\)’s to be random. Let \(\Phi (s)\) be a feature mapping with weights w, i.e. a feed-forward neural network architecture over the input space, representing the basis functions. Let \(\beta \) be a vector of weights on the basis functions, so \(f(s) = \beta ^{\top } \Phi (s)\). We use a VAE architecture to encode and decode \(\beta \), meaning we maintain the random variable perspective and at the same time learn a flexible low-dimensional non-linear generative model.
How can we specify and train this model? As with the VAE in the previous section, \(\pi \)VAE is trained on draws from a prior. Our goal is to encode a stochastic process prior \(\Pi \), so we consider \(i = 1, \ldots , N\) function realizations denoted \(f_i(s)\). Each \(f_i(s)\) is an infinite dimensional object, a function defined for all s, so we further assume that we are given a finite set of \(K_i\) observation locations. We set \(K_i = K\) for simplicity of implementation i.e. the number of evaluations for each function is constant across all draws i. We denote the observed values as \(y_i^k := f_i(s_i^k)\). The training dataset thus consists of N sets of K observation locations and function values:
Note that the set of K observation locations varies across the N realizations.

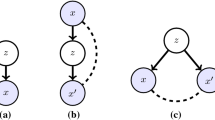
Schematic description of end-to-end trainig procedure for \(\pi \)VAE including the reconstruction loss. Dashed arrows contribute to the loss, blue circles are reconstructions, and grey boxes are functions
We now return to the architecture of \(\pi \)VAE (Fig. 2). The feature mapping \(\Phi (s)\) is shared across all \(i = 1, \ldots , N\) function draws, so it consists of a feedforward neural network and is parameterized by a set of global parameters w which must be learned. However, a particular random realization \(f_i(s)\) is represented by a random vector \(\beta _i\), for which we use a VAE architecture. We note the following non-standard setup: \(\beta _i\) is a learnable parameter of our model, but it is also the input to the encoder of the VAE. The decoder attempts to reconstruct \(\beta _i\) with an output \({{\hat{\beta }}}_i\). We denote the encoder and decoder as:
We are now ready to express the loss, which combines the two parts of the network, summing across all observations. Rather than deriving an evidence lower bound, we proceed directly to specify a loss function, in three parts. In the first, we use MSE to check the fit of the \(\beta _i\)’s and \(\Phi \) to the data:
In the second, we use MSE to check the fit of the reconstructed \({{\hat{\beta }}}_i\)’s and \(\Phi \) to the data:
We also require the standard variational loss:
Note that we do not consider reconstruction loss \(\Vert \beta _i - {{\hat{\beta }}}_i\Vert ^2\) because in practice this did not improve training.
To provide more intuition: the feature map \(\Phi (s)\) transforms each observed location to a fixed feature space that is shared for all locations across all functions. \(\Phi (s)\) could be an explicit feature representation for an RKHS (e.g. an RBF network or a random Fourier feature basis (Rahimi and Recht 2008)), a neural network of arbitrary construction or, as we use in the examples in this paper, a combination of both. Following this transformation, a linear basis \(\beta \) (which we obtain from a non-linear decoder network) is used to predict function evaluations at an arbitrary location. The intuition behind these two transformations is to learn the association between locations and observations while allowing for randomness—\(\Phi \) provides the correlation structure over space and \(\beta \) the randomness. Explicit choices can lead to existing stochastic processes: we can obtain a Gaussian process with kernel \(k(\cdot ,\cdot )\) using a single-layer linear VAE for \(\beta \) (meaning the \(\beta \)s are simply standard normals) and setting \(\Phi (s) = L^{\top } s\) for L the Cholesky decomposition of the Gram matrix K where \(K_{ij} = k(s_i,s_j)\).
In contrast to a standard VAE encoder that takes as input the data to be encoded, \(\pi \)VAE first transforms input data (locations) to a higher dimensional feature space via \(\Phi \), and then connects this feature space to outputs, y, through a linear mapping, \(\beta \). The \(\pi \)VAE decoder takes outputs from the encoder, and attempts to recreate \(\beta \) from a lower dimensional probabilistic embedding. This re-creation, \({\hat{\beta }}\), is then used as a linear mapping with the same \(\Phi \) to get a reconstruction of the outputs y. It is crucial to note that a single global \(\beta \) vector is not learnt. Instead, for each function \(i = 1, \ldots , N\) a \(\beta _i\) is learnt.
In terms of number of parameters, we need to learn w, \(\gamma \), \(\psi \), \(\beta _1, \ldots , \beta _N\). While this may seem like a huge computational task, K is typically quite small (\(<200\)) and so learning can be relatively quick (dominated by matrix multiplication of hidden layers). Algorithm 1 in the Appendix presents the step-by-step process of training \(\pi \)VAE.
2.3.1 Simulation and inference with \(\pi \)VAE
Given a trained embedding \(\Phi (\cdot )\) and trained decoder d(z), we can use \(\pi \)VAE as a generative model to simulate sample paths f as follows. A single function f is obtained by first drawing \({\mathcal {Z}} \sim {\mathcal {N}}(0,{\mathbb {I}})\) and defining \(f(s) := d({\mathcal {Z}})^{\top }\Phi (s)\). For a fixed \({\mathcal {Z}}\), f(s) is a deterministic function—a sample path from \(\pi \)VAE defined for all s. Varying \({\mathcal {Z}}\) produces different sample paths. Computationally, f can be efficiently evaluated at any arbitrary location s using matrix algebra: \(f(s) = d({\mathcal {Z}})^{\top }\Phi (s)\). We remark that the stochastic process perspective is readily apparent: for a random variable \({\mathcal {Z}}\), \(d({\mathcal {Z}})^{\top }\Phi (s)\) is a random variable defined on the same probability space for all s.
Algorithm 3 in the Appendix presents the step-by-step process for simulation with \(\pi \)VAE.
\(\pi \)VAE can be used for inference on new data pairs \((s_j,y_j)\), where the unnormalised posterior distribution is
with likelihood \(p(y_j\mid d,s_j,{\mathcal {Z}},\Phi )\) and prior \(p({\mathcal {Z}})\). MCMC can be used to efficiently obtain samples from the posterior distribution over \({\mathcal {Z}}\) using Eq. (12). An implementation in probabilistic programming languages such as Stan (Carpenter et al. 2017) is very straightforward.
The posterior predictive distribution of \(y_j\) at a location \(s_j\) is given by:
While Eqs. (12)-(13) are written for a single location \(s_j\), we can extend them to any arbitrary collection of locations without loss of generality, a necessary condition for \(\pi \)VAE to be a valid stochastic process. Further, the distinguishing difference between Eq. (6) and Eqs. (12)-(13) is conditioning on input locations and \(\Phi \). It is \(\Phi \) that ensures \(\pi \)VAE is a valid stochastic process. We formally prove this below.
Algorithm 2 in the Appendix presents the step-by-step process for inference with \(\pi \)VAE.
2.3.2 \(\pi \)VAE is a stochastic process
Claim. \(\pi \)VAE is a stochastic process.
Recall that, mathematically, a stochastic process is defined as a collection \(\{f(s) : s \in S\}\), where f(s) for each location \(s \in S\) is a random variable on a common probability space \((\Omega ,{\mathcal {F}},P)\), see, e.g., (Pavliotis 2014, Definition 1.1). This technical requirement is necessary to ensure that for any locations \(s_1,\ldots ,s_n \in S\), the random variables \(f(s_1),\ldots ,f(s_n)\) have a well-defined joint distribution. Subsequently, it also ensures consistency. Namely, writing \(f_i := f(s_i)\) and integrating \(f_n\) out, we get
Proof
For \(\pi \)VAE, we have \(f(\cdot ) := d({\mathcal {Z}}) \Phi (\cdot )\), where \({\mathcal {Z}}\) is a multivariate Gaussian random variable, hence defined on some probability space \((\Omega ,{\mathcal {F}},P)\). Since d and \(\Phi \) are deterministic (measurable) functions, it follows that \(f(s_i) := d({\mathcal {Z}}) \Phi (s_i)\) for any \(i=1,\ldots ,n\), is a random variable on \((\Omega ,{\mathcal {F}},P)\), whereby \(\{ f(s) : s \in S \}\) is a stochastic process. \(\blacksquare \)
We remark here that \(\pi \)VAE is a new stochastic process. If \(\pi \)VAE is trained on samples from a zero mean Gaussian process with a squared exponential covariance function, and similarly choose \(\Phi \) to have the same covariance function, and d is linear, then \(\pi \)VAE will be a Gaussian process. But for a non-positive definite \(\Phi \) and / or non-linear d, even if \(\pi \)VAE is trained on samples from a Gaussian process, it will not truly be a Gaussian process, but some other stochastic process which approximates a Gaussian process. We do not know the theoretical conditions under which \(\pi \)VAE will perform better or worse than existing classes of stochastic processes; its general construction means that theoretical results will be challenging to prove in full generality. We demonstrate below that in practice, \(\pi \)VAE performs very well.

Fitting to a cubic function with noise \(y \sim {\mathcal {N}}(x^3, 9)\). a \(\pi \)VAE trained on a class of cubic functions, b \(\pi \)VAE trained on samples from a Gaussian process with RBF kernel and c is a Gaussian process with RBF kernel. All methods use Hamiltonian Markov Chain Monte Carlo for posterior inference
2.4 Examples
We first demonstrate the utility of our proposed \(\pi \)VAE model by fitting the simulated 1-D regression problem introduced in (Hernández-Lobato and Adams 2015). The training points for the dataset are created by uniform sampling of 20 inputs, x, between \((-4,4)\). The corresponding output is set as \(y \sim {\mathcal {N}}(x^3, 9)\). We fit two different variants of \(\pi \)VAE, representing two different prior classes of functions. The first prior produces cubic monotonic functions and the second prior is a GP with an RBF kernel and a two layer neural network. We generated \(10^4\) different function draws from both priors to train the respective \(\pi \)VAE. One important consideration in \(\pi \)VAE is to chose a sufficiently expressive \(\Phi \), we used a RBF layer (see Appendix 1) with trainable centres coupled with two layer neural network with 20 hidden units each. We compare our results against 20,000 Hamiltonian Monte Carlo (HMC) samples (Neal 1993) implemented using Stan (Carpenter et al. 2017). Details of the implementation for all the models can be found in the Appendix.

Inferring the intensity of a log-Gaussian Cox Process. a compares the posterior distribution of the intensity estimated by \(\pi \)VAE to the true intensity function on train and test data. b compares the posterior mean of the cumulative integral over time estimated by \(\pi \)VAE to the true cumulative integral on train and test data
Figure 3a presents results for \(\pi \)VAE with a cubic prior, Fig. 3b with an RBF prior, and Fig. 3c for standard Gaussian processes fitting using an RBF kernel. The mean absolute error (MAE) for all three methods are presented in Table 1. Both, the mean estimates and the uncertainty from \(\pi \)VAE variants, are closer, and more constrained than the ones using Gaussian processes with HMC. Importantly, \(\pi \)VAE with cubic prior not only produces better point estimates but is able to capture better uncertainty bounds. We note that \(\pi \)VAE does not exactly replicate an RBF Gaussian process, but does retain the main qualitative features inherent to GPs - such as the concentration of the posterior where there is data. Despite \(\pi \)VAE ostensibly learning an RBF function class, differences are to be expected from the VAE low dimensional embedding. This simple example demonstrates that \(\pi \)VAE can be used to incorporate domain knowledge about the functions being modelled.
In many scenarios, learning just the mapping of inputs to outputs is not sufficient as other functional properties are required to perform useful (interesting) analysis. For example, using point processes requires knowing the underlying intensity function, however, to perform inference we need to calculate the integral of that intensity function too. Calculating this integral, even in known analytical form, is very expensive. Hence, in order to circumvent the issue, we use \(\pi \)VAE to learn both function values and its integral for the observed events. Figure 4 shows \(\pi \)VAE prediction for both the intensity and integral of a simulated 1-D log-Gaussian Cox Process (LGCP).
In order to train \(\pi \)VAE to learn from the function space of 1-D LGCP functions, we first create a training set by drawing 10,000 different samples of the intensity function using an RBF kernel for 1-D LGCP. For each of the drawn intensity function, we choose an appropriate time horizon to sample 80 observed events (locations) from the intensity function. \(\pi \)VAE is trained on the sampled 80 locations with their corresponding intensity and the integral. \(\pi \)VAE therefore outputs both the instantaneous intensity and the integral of the intensity. The implementation details can be seen in the Appendix. For testing, we first draw a new intensity function (1-D LGCP) using the same mechanism used in training and sample 100 events (locations). As seen in Fig. 4 our estimated intensity is very close to true intensity and even the estimated integral is close to the true integral. This example shows that the \(\pi \)VAE approach can be used to learn not only function evaluations but properties of functions.

Deviation in land surface temperature for East Africa trained on 6000 random uniformly chosen locations (Ton et al. 2018). Plots: a the data, b our \(\pi \)VAE approach (testing MSE: 0.38), c a full rank GP with Matérn \(\frac{3}{2}\) kernel (testing MSE: 2.47), and d a low rank SPDE approximation with 1046 basis functions (Lindgren et al. 2011) and a Matérn \(\frac{3}{2}\) kernel (testing MSE: 4.36). \(\pi \)VAE not only has substantially lower test error, it captures fine scale features much better than Gaussian processes or neural processes
3 Results
Here we show applications of \(\pi \)VAE on three real world datasets. In our first example we use \(\pi \)VAE to predict the deviation in land surface temperature in East Africa (Ton et al. 2018). We have the deviation in land surface temperatures for \({\sim }89{,}000\) locations across East Africa. Our training data consisted of 6,000 uniformly sampled locations. Temperature was predicted using only the spatial locations as inputs. Figure 5 and Table 2 shows the results of the ground truth (a), our \(\pi \)VAE (b), a full rank Gaussian process with Matérn kernel (Gardner et al. 2018) (c), and low rank Gauss Markov random field (GMRF) (a widely used approach in the field of geostatistics) with 1, 046 (\(\frac{1}{6}\)th of the training size) basis functions (Lindgren et al. 2011; Rue et al. 2009) (d). We train our \(\pi \)VAE model on \(10^{7}\) functions draws from 2-D GP with small lengthscales between \(10^{-5}\) to 2. \(\Phi \) was set to be a Matérn layer ( see Appendix 1) with 1,000 centres followed by a two layer neural network of 100 hidden units in each layer. The latent dimension of \(\pi \)VAE was set to 20. As seen in Figure 5, \(\pi \)VAE is able to capture small scale features and produces a far better reconstruction than the both full and low rank GP and despite having a much smaller latent dimension of 20 vs 6000 (full) vs 1046 (low). The testing error for \(\pi \)VAE is substantially better than the full rank GP which leads to the question, why does \(\pi \)VAE perform so much better than a GP, despite being trained on samples from a GP? One possible reason is that the extra hidden layers in \(\Phi \) create a much richer structure that could capture elements of non-stationarity (Ton et al. 2018). Alternatively, the ability to use state-of-the-art MCMC and estimate a reliable posterior expectation might create resilience to overfitting. The training/testing error for \(\pi \)VAE is 0.07/0.38, while the full rank GP is 0.002/2.47. Therefore the training error is 37 times smaller in the GP, but the testing error is only 6 times smaller in \(\pi \)VAE suggesting that, despite marginalisation, the GP is still overfitting.
Table 3 compares \(\pi \)VAE on the Kin40K (Schwaighofer and Tresp 2003) dataset to state-of-the-art full and approximate GPs, with results taken from (Wang et al. 2019). The objective was to predict the distance of a robotic arm from the target given the position of all 8 links present on the robotic arm. In total we have 40,000 samples which are divided randomly into \(\frac{2}{3}\) training samples and \(\frac{1}{3}\) test samples. We train \(\pi \)VAE on \(N = 10^{7}\) functions drawn from an 8-D GP, observed at \(K=200\) locations, where each of the 8 dimensions had values drawn uniformly from the range \((-2,2)\) and lengthscale varied between \(10^{-3}\) and 10. Once \(\pi \)VAE was trained on the prior function we use it to infer the posterior distribution for the training examples in Kin40K. Table 3 shows results for RMSE and negative log-likelihood (NLL) of \(\pi \)VAE against various GP methods on test samples. The full rank GP results reported in (Wang et al. 2019) are better than those from \(\pi \)VAE, but we are competitive, and far better than the approximate GP methods. We also note that the exact GP is estimated via maximising the log marginal likelihood in closed form, while \(\pi \)VAE performs full Bayesian inference; all posterior checks yielded excellent convergence measured via \(\hat{R}\) and effective samples sizes. Calibration was checked using posterior predictive intervals. For visual diagnostics see the Appendix.
Finally, we apply \(\pi \)VAE to the task of reconstructing MNIST digits using a subset of pixels from each image. Similar to the earlier temperature prediction task, image completion can also be seen as a regression task in 2-D. The regression task is to predict the intensity of pixels given the pixel locations. We first train neural processes on full MNIST digits from the training split of the dataset, whereas \(\pi \)VAE is trained on \(N = 10^{6}\) functions drawn from a 2-D GP. The latent dimension of \(\pi \)VAE is set to be 40. As with previous examples, the decoder and encoder networks are made up of two layer neural networks. The hidden units for the encoder are 256 and 128 for the first and second layer respectively, and the reverse for decoder.
Once we have trained \(\pi \)VAE we now use images from the test set for prediction. Images in the testing set are sampled in such a way that only 10, 20 or 30% of pixel values are observed. Inference is performed with \(\pi \)VAE to predict the intensity at all other pixel locations using Eq. (13). As seen from Fig. 6, the performance of \(\pi \)VAE increases with increase in pixel locations available during prediction but still even with 10% pixels our model is able to learn a decent approximation of the image. The uncertainty in prediction can be seen from the different samples produced by the model for the same data. As the number of given locations increases, the variance between samples decreases with quality of the image also increasing. Note that results from neural processes, as seen in Fig. 10, look better than from \(\pi \)VAE. Neural processes performed better in the MNIST case because they were specifically trained on full MNIST digits from the training dataset, whereas piVAE was trained on the more general prior class of 2D GPs.

MNIST reconstruction after observing only 10, 20 or 30% of pixels from original data

MCMC diagnostics for VAE inference presented in Figure 1: a and b shows the values for \(\hat{R}\) and \(\dfrac{N_{eff}}{N}\) for all parameters inferred with Stan. c shows the true distribution of observations along with the draws from the posterior predictive distribution
4 Discussion and conclusion
In this paper we have proposed a novel VAE formulation of a stochastic process, with the ability to learn function classes and properties of functions. Our \(\pi \)VAE s typically have a small (5-50) , uncorrelated latent dimension of parameters, so Bayesian inference with MCMC is straightforward and highly effective at successfully exploring the posterior distribution. This accurate estimation of uncertainty is essential in many areas such as medical decision-making.
\(\pi \)VAE combines the power of deep learning to create high capacity function classes, while ensuring tractable inference using fully Bayesian MCMC approaches. Our 1-D example in Fig. 3 demonstrates that an exciting use of \(\pi \)VAE is to incorporate domain knowledge about the problem. Monotonicity or complicated dynamics can be encoded directly into the prior (Caterini et al. 2018) on which \(\pi \)VAE is trained. Our log-Gaussian Cox Process example shows that not only functions can be modelled, but also properties of functions such as integrals. Perhaps the most surprising result is the performance of \(\pi \)VAE on spatial interpolation. Despite being trained on samples from a Gaussian process, \(\pi \)VAE substantially outperforms a full rank GP. We conjecture this is due to the more complex structure of the feature representation \(\Phi \) and due to a resilience to overfitting.
There are costs to using \(\pi \)VAE, especially the large upfront cost in training. For complex priors, training could take days or weeks and will invariably require the heuristics and parameter searches inherent in applied deep learning to achieve a good performance. However, once trained, a \(\pi \)VAE network is applicable on a wide range of problems, with the Bayesian inference MCMC step taking seconds or minutes.
Future work should investigate the performance of \(\pi \)VAE on higher dimensional settings (input spaces \(>10\)). Other stochastic processes, such as Dirichlet processes, should also be considered.
Availability of data and materials
All data used in the paper is available at https://github.com/MLGlobalHealth/pi-vae.
Code Availability
Code is available at https://github.com/MLGlobalHealth/pi-vae .
References
Antoniak, C.E.: Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems. Ann. Stat. 2(6), 1152–1174 (1974)
Betancourt, M., Byrne, S., Livingstone, S., Girolami, M.: The geometric foundations of Hamiltonian Monte Carlo. Bernoulli 5(4A), 3109–3138 (2017). https://doi.org/10.3150/16-BEJ810
Blundell, C., Cornebise, J., Kavukcuoglu, K., Wierstra, D.: Weight uncertainty in neural networks. In: 32nd international conference on machine learning, icml 2015. (2015)
Broomhead, D.S., Lowe, D.: Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks. DTIC. Retrieved from https://apps.dtic.mil/sti/citations/ADA196234 (1988)
Carpenter, B., Gelman, A., Hoffman, M.D., Lee, D., Goodrich, B., Betancourt, M., Riddell, A.: Stan : a probabilistic programming language. J. Stat. Softw. 76(1), 1–32 (2017). https://doi.org/10.18637/jss.v076.i01
Caterini, A.L., Doucet, A., Sejdinovic, D.: Hamiltonian variational auto-encoder. Adv. Neural Info. Process. Syst. (2018)
Gardner, J.R., Pleiss, G., Bindel, D., Weinberger, K.Q., Wilson, A.G.: Gpytorch: Blackbox matrix-matrix Gaussian process inference with GPU acceleration. Adv. Neural Info. Process. Syst. (2018)
Garnelo, M., Rosenbaum, D., Maddison, C.J., Ramalho, T., Saxton, D., Shanahan, M., Eslami, S.M.: Conditional neural processes. In: 35th international conference on machine learning, icml 2018. (2018)
Hawkes, A.G.: Spectra of some selfexciting and mutually exciting point processes. Biometrika 58(1), 83–90 (1971). https://doi.org/10.1093/biomet/58.1.83
Hernández-Lobato, J.M., Adams, R.: Probabilistic backpropagation for scalable learning of bayesian neural networks. In: International conference on machine learning (pp. 1861-1869) (2015)
Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Science 313(5786), 504–507 (2006)
Hoffman, M.D., Blei, D.M., Wang, C., Paisley, J.: Stochastic variational inference. J. Mach. Learn. Res. 14(1), 1303–1347 (2013)
Huggins, J.H., Kasprzak, M., Campbell, T., Broderick, T.: Practical posterior error bounds from variational objectives. arXiv preprint arXiv:1910.04102 (2019)
Jacot, A., Gabriel, F., Hongler, C.: Neural tangent kernel: convergence and generalization in neural networks. Adv. Neural Info. Process. Syst. (2018)
Karhunen, K.; On linear methods in probability theory. In: Annales academiae scientiarum fennicae, ser. al (Vol. 37, pp. 3-79) (1947)
Kim, H., Mnih, A., Schwarz, J., Garnelo, M., Eslami, S.M.A., Rosenbaum, D., Teh, Y.W. :Attentive Neural Processes. CoRR, abs/1901.0 (2019)
Kingma, D.P., Ba, J.: Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980 (2014)
Kingma, D.P., Welling, M.: Auto- Encoding Variational Bayes (VAE, reparameterization trick). ICLR 2014. (2014)
Kingma, D.P., Welling, M.: An introduction to variational autoencoders. Found. Trends ® Mach. Learn. 12(4), 307-392 (2019)
Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive uncertainty estimation using deep ensembles. Adv. Neural Info. Process. Syst. (2017)
Lindgren, F., Rue, H., Lindström, J.: An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. J. R. Stat. Soc.: Ser. B Stat. Methodol. 73(4), 423–498 (2011). https://doi.org/10.1111/j.1467-9868.2011.00777.x
Loeve, M.: Functions aleatoires du second ordre. Processus stochastique et mouvement Brownien, pp. 366-420 (1948)
Minka, T.P.: Expectation propagation for approximate bayesian inference. In: Proceedings of the seventeenth conference on uncertainty in artificial intelligence (pp. 362-369). San Francisco, CA, USA: Morgan Kaufmann Publishers Inc (2001)
Mishra, S., Rizoiu, M.-A., Xie, L.: Feature driven and point process approaches for popularity prediction. In: Proceedings of the 25th ACM international on conference on information and knowledge management (pp. 1069-1078). New York, NY, USA: Association for Computing Machinery. Retrieved from https://doi.org/10.1145/2983323.2983812 (2016)
Møller, J., Syversveen, A.R., Waagepetersen, R.P.: Log gaussian cox processes. Scand. J. Stat. 25(3), 451–482 (1998)
Neal, R.: Bayesian Learning for Neural Networks. Lecture notes in statistics -New York- Springer Verlag (1996)
Neal, R.M.: Probabilistic inference using Markov chain monte Carlo methods. University of Toronto Toronto, Ontario, Canada, Department of Computer Science (1993)
Park, J., Sandberg, I.W.: Universal approximation using radial-basis-function networks. Neural Comput. 3(2), 246–257 (1991). https://doi.org/10.1162/neco.1991.3.2.246
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Chintala, S.: Pytorch: an imperative style, highperformance deep learning library. Adv. Neural Info. Process. Syst. (pp. 8024-8035) (2019)
Pavliotis, G.A.: Stochastic processes and applications: diffusion processes, the fokkerplanck and langevin equations (Vol. 60). Springer (2014)
Rahimi, A., Recht, B.: Random features for large-scale kernel machines. Adv. Neural Info. Process. Syst. (pp. 1177-1184) (2008)
Rasmussen, C.E., Williams, C.K.I.: Gaussian processes for machine learning. MIT Press. Retrieved from http://www.worldcat.org/oclc/61285753 (2006)
Rezende, D.J., Mohamed, S., Wierstra, D.: Stochastic backpropagation and approximate inference in deep generative models. International conference on machine learning (pp. 1278-1286) (2014)
Ritter, H., Botev, A., Barber, D.: A scalable laplace approximation for neural networks. In: 6th international conference on learning representations, iclr 2018 - conference track proceedings (2018)
Ross, S.M.: Stochastic processes (Vol. 2). John Wiley & Sons (1996)
Roy, D.M., Teh, Y.W.: The Mondrian process. Advances in neural information processing systems 21 - proceedings of the 2008 conference (2009)
Rue, H., Martino, S., Chopin, N.: Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B Stat Methodol. 71(2), 319–392 (2009). https://doi.org/10.1111/j.1467-9868.2008.00700.x
Schwaighofer, A., Tresp, V.: Transductive and inductive methods for approximate gaussian process regression. Adv. Neural Info. Process. Syst. (pp. 977-984) (2003)
Semenova, E., Xu, Y., Howes, A., Rashid, T., Bhatt, S., Mishra, S., Flaxman, S.: Priorvae: encoding spatial priors with variational autoencoders for small-area estimation. J. R. Soc. Interface 19(191), 20220094 (2022)
Ton, J.-F., Flaxman, S., Sejdinovic, D., Bhatt, S.: Spatial mapping with Gaussian processes and nonstationary Fourier features. Spat. Stat. (2018). https://doi.org/10.1016/j.spasta.2018.02.002
Wang, K., Pleiss, G., Gardner, J., Tyree, S., Weinberger, K.Q., Wilson, A.G.: Exact gaussian processes on a million data points. Adv. Neural Info. Process. Syst. (pp. 14622-14632) (2019)
Welling, M., Teh, Y.W.: Bayesian learning via stochastic gradient langevin dynamics. In: Proceedings of the 28th international conference on machine learning, ICML 2011 (2011)
Yao, J., Pan, W., Ghosh, S., Doshi-Velez, F.: Quality of uncertainty quantification for bayesian neural network inference. arXiv preprint arXiv:1906.09686 (2019)
Yao, Y., Vehtari, A., Simpson, D., Gelman, A.: Yes, but did it work?: evaluating variational inference. In: 35th international conference on machine learning, ICML 2018 (2018)
Funding
SB acknowledge the The Novo Nordisk Young Investigator Award (NNF20OC0059309) which also supports SM. SB also acknowledges the Danish National Research Foundation Chair grant, The Schmidt Polymath Award and The NIHR Health Protection Research Unit (HPRU) in Modelling and Health Economics. SM and SB acknowledge funding from the MRC Centre for Global Infectious Disease Analysis (reference MR/R015600/1) and Community Jameel. SF acknowledges the EPSRC (EP/V002910/2) and the Imperial College COVID-19 Research Fund.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Ethics approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A MCMC diagnostics
Figure 7 presents the MCMC diagnostics for the 1-D GP function learning example shown in Figure 1. Both \(\hat{R}\) and effective sample size for all the inferred parameters (latent dimension of the VAE and noise in the observation) are well behaved with \(\hat{R} \le 1.01\) (Figure 7a) and effective sample size greater than 1 (Figure 7b). Furthermore, even the draws from the posterior predictive distribution very well capture the true distribution in observations as shown in Figure 7c.

MCMC diagnostics for \(\pi \)VAE inference presented in Table 3: a and b shows the values for \(\hat{R}\) and \(\dfrac{N_{eff}}{N}\) for all parameters inferred with Stan. c shows the true distribution of observations along with the draws from the posterior predictive distribution
Figure 8 presents the MCMC diagnostics for the kin40K dataset with \(\pi \)VAE as shown in Table 3. Both \(\hat{R}\) and effective sample size for all the inferred parameters (latent dimension of the VAE and noise in the observation) are well behaved with \(\hat{R} \le 1.01\) (Figure 8a) and effective sample size greater than 0.5 (Figure 8b). Furthermore, the draws from the posterior predictive distribution are shown against the true distribution in observations as shown in Figure 8c.

MCMC calibration for \(\pi \)VAE inference presented in Table 3: a shows the marginal predictive check using a leave one out probability integral transform and b shows the leave one out predictive intervals compared to observations
Figure 9 presents the MCMC calibration plots for the posterior. Both the marginal predictive check and leave one out predictive intervals plots demonstrate that our posterior is well calibrated.
Appendix B algorithm
\(\pi \)VAE proceeds in two stages. In the first stage (Algorithm 1) we train \(\pi \)VAE, using a very large set of draws from a pre-specified prior class. In the second stage (Algorithm 2) we use the trained \(\pi \)VAE from Algorithm 1 as a prior, combine this with data using a likelihood, and perform inference. MCMC for Bayesian inference or optimization with a loss function are alternative approaches to learn the best \({\mathcal {Z}}\) to explain the data. While these two algorithms are all that is needed to apply \(\pi \)VAE, for completeness Algorithm 3 shows how one can use a trained \(\pi \)VAE, which encodes a stochastic process, to sample realisations from this stochastic process.




MNIST reconstruction using neural processes after observing only 10, 20 or 30% of pixels from original data
Appendix C MNIST example
Figure 10 below is the MNIST example referenced in the main text for neural processes.
Appendix D implementation details
All models were implemented with PyTorch (Paszke et al. 2019) in Python. For Bayesian inference Stan (Carpenter et al. 2017) was used. For training while using a fixed grid, when not mentioned in main text, in each dimension was on the range -1 to 1. Our experiments ran on a workstation with two NVIDIA GeForce RTX 2080 Ti cards.
RBF and Matérn layers: RBF and Matérn layers are implemented as a variant of the original RBF networks as described in (Broomhead and Lowe 1988; Park and Sandberg 1991). In our setting we define a set of C trainable centers, which act as fixed points. Now for each input location we calculate a RBF or Matérn Kernel for all the fixed points. These calculated kernels are weighted for each fixed center and then summed over to create a scalar output for each location. We can describe the layer as follows:-
where s is an input location (point), \(\alpha _i\) is the weight for each center \(c_i\), and \(\rho \left( \Vert x-c_i \Vert \right) \) is RBF or Matérn kernel for RBF and Matérn layer respectively.
1.1 LGCP simulation example
We study the function space of 1-D LGCP realisations. We define a nonnegative intensity function at any time t as \(\lambda (t): T \rightarrow {\mathcal {R}}^+\). The number of events in an interval \([t_1,t_2]\) within some time period, \(y_{[t_1,t_2]}\), is distributed Poisson via the following Bayesian hierarchical model:
where \(\gamma \) is a constant event rate, set to 5 in our experiments.
To train \(\pi \)VAE on functions from an LGCP, we draw 10,000 samples from Eq (14), assuming k is an RBF kernel/covariance function with form \(e^{-\sigma x^2}\), with inverse lengthscale \(\sigma \) chosen randomly from the set \(\{8,16,32,64\}\). We then choose an observation window sufficiently large to ensure that 80 events are observed. This approach is meant to simulate the situation in which we observe a point process until a certain number of events have occurrence, at which point we conduct inference (Mishra et al. 2016).
Given the set of \(80 \times 10,000\) events, we train \(\pi \)VAE with their corresponding intensity and integral of the intensity over the corresponding observation window. The integral is calculated numerically. We concatenate the integral of the intensity at the end with the intensity itself (value of the function evaluated the specific location). Note, in this setup we have \(\beta \) setup as a \(2-D\) vector, first value corresponding to the intensity and second to the integral of the intensity. The task for \(\pi \)VAE is to simultaneously learn both the instantaneous intensity and the integral of the intensity. At testing, we expand the number of events (and hence the time horizon) to 100, and compare the intensity and integral of \(\pi \)VAE compared to the true LGCP. As seen in Fig 4, in this extrapolation, our estimated intensity is very close to the true intensity and even the estimated integral is close to the true (numerically calculated) integral. This example shows that the \(\pi \)VAE approach can be used to learn not only function evaluations but properties of functions.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mishra, S., Flaxman, S., Berah, T. et al. \(\pi \)VAE: a stochastic process prior for Bayesian deep learning with MCMC. Stat Comput 32, 96 (2022). https://doi.org/10.1007/s11222-022-10151-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-022-10151-w