
Abstract
We consider the problem of computing a Gaussian approximation to the posterior distribution of a parameter given N observations and a Gaussian prior. Owing to the need of processing large sample sizes N, a variety of approximate tractable methods revolving around online learning have flourished over the past decades. In the present work, we propose to use variational inference to compute a Gaussian approximation to the posterior through a single pass over the data. Our algorithm is a recursive version of variational Gaussian approximation we have called recursive variational Gaussian approximation. We start from the prior, and for each observation, we compute the nearest Gaussian approximation in the sense of Kullback–Leibler divergence to the posterior given this observation. In turn, this approximation is considered as the new prior when incorporating the next observation. This recursive version based on a sequence of optimal Gaussian approximations leads to a novel implicit update scheme which resembles the online Newton algorithm and which is shown to boil down to the Kalman filter for Bayesian linear regression. In the context of Bayesian logistic regression, the implicit scheme may be solved, and the algorithm is shown to perform better than the extended Kalman filter, while being less computationally demanding than its sampling counterparts.










Similar content being viewed by others


Notes
Note that this is different from considering the variational distribution within an exponential family, as done at the end of Sect. 3.1.
References
Barber, D., Bishop, C.: Ensemble learning in Bayesian neural networks. In: Generalization in Neural Networks and Machine Learning, pp. 215–237. (1998)
Barfoot, T.D., Forbes, J.R., Yoon, D.J.: Exactly sparse gaussian variational inference with application to derivative-free batch nonlinear state estimation. Int. J. Robot. Res. 39(13), 1473–1502 (2020)
Barrau, A., Bonnabel, S.: Navigating with highly precise odometry and noisy GPS: a case study. IFAC-PapersOnLine 49(18), 618–623 (2016)
Barrau, A., Bonnabel, S.: Invariant Kalman filtering. Ann. Rev. Control Robot. Auton. Syst. 1, 237–257 (2018)
Bertsekas, D.P.: Incremental least squares methods and the extended Kalman filter. SIAM J. Optim. 6(3), 807–822 (1996)
Bierman, G.J.: Measurement updating using the U-D factorization. In: Conference on Decision and Control including the Symposium on Adaptive Processes, pp. 337–346. (1975)
Bishop, C.M.: Pattern Recognition and Machine Learning. Springer, New York (2006)
Broderick, T., Boyd, N., Wibisono, A., Wilson, A.C., Jordan, M.I.: Streaming variational Bayes. In: Advances in Neural Information Processing Systems, vol. 26. (2013)
Daudel, K., Douc, R., Portier, F.: Infinite-dimensional gradient-based descent for alpha-divergence minimisation. Ann. Stat. 49, 2250–2270 (2021)
Daunizeau, J.: Semi-analytical approximations to statistical moments of sigmoid and softmax mappings of normal variables. arXiv preprint arXiv:1703.00091 (2017)
Emtiyaz Khan, M., Liu, Z., Tangkaratt, V., Gal, Y.: Vprop: variational inference using RMSprop. arXiv arXiv–1712 (2017)
Gal, Y.: Uncertainty in Deep Learning. University of Cambridge, Cambridge (2016)
Hazan, E., Agarwal, A., Kale, S.: Logarithmic regret algorithms for online convex optimization. Mach. Learn. 69, 169–192 (2007)
Hu, Y., Wang, X., Lan, H., Wang, Z., Moran, B., Pan, Q.: An iterative nonlinear filter using variational Bayesian optimization. Sensors 18(12), 4222 (2018)
Jaakkola, T., Jordan, M.: A variational approach to Bayesian logistic regression models and their extensions. In: Sixth International Workshop on Artificial Intelligence and Statistics, vol. 82. (1997)
Jézéquel, R., Gaillard, P., Rudi, A.: Efficient improper learning for online logistic regression. arXiv preprint arXiv:2003.08109 (2020)
Khan, M.E., Lin, W.: Conjugate-computation variational inference: converting variational inference in non-conjugate models to inferences in conjugate models. In: AISTATS, pp. 878–887. (2017)
Khan, M.E., Nielsen, D.: Fast yet simple natural-gradient descent for variational inference in complex models. arXiv:1807.04489 (2018)
Khan, M. E., Nielsen, D., Tangkaratt, V., Lin, W., Gal, Y., Srivastava, A.: Fast and scalable bayesian deep learning by weight-perturbation in Adam. arXiv preprint arXiv:1806.04854 (2018)
Kunstner, F., Hennig, P., Balles, L.: Limitations of the empirical Fisher approximation for Natural gradient descent. Adv. Neural Inf. Process. Syst. 32, 4156–4167 (2019)
Lin, W., Khan, M. E., Schmidt, M.: Fast and simple natural-gradient variational inference with mixture of exponential-family approximations. arXiv preprint arXiv:1906.02914 (2019a)
Lin, W., Khan, M. E., Schmidt, M.: Stein’s lemma for the reparameterization trick with exponential family mixtures. arXiv preprint arXiv:1910.13398 (2019b)
Martens, J.: New insights and perspectives on the natural gradient method. J. Mach. Learn. Res. 21(146), 1–76 (2020)
McInerney, J., Ranganath, R., Blei, D.: The population posterior and bayesian modeling on streams. Adv. Neural Inf. Process. Syst. 28, 1153–1161 (2015)
Nesterov, Y., Spokoiny, V.: Random gradient-free minimization of convex functions. Found. Comput. Math. 17, 527–566 (2017)
Ollivier, Y.: Online natural gradient as a kalman filter. Electron. J. Stat. 12, 2930–2961 (2018)
Powell, M.J.D.: On nonlinear optimization since 1959. In: The Birth of Numerical Analysis, pp. 141–160. (2010)
Ranganath, R., Gerrish, S., Blei, D.: Black box variational inference. In: Artificial intelligence and statistics, PMLR, pp. 814–822. (2014)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. Stat. 400–407 (1951)
Sato, M.-A.: Online model selection based on the variational bayes. Neural Comput. 13(7), 1649–1681 (2001)
Schmidt, M., Le Roux, N., Bach, F.: Minimizing finite sums with the stochastic average gradient. Math. Program. 162(1–2), 83–112 (2017)
Smidl, V., Quinn, A.: Variational bayesian filtering. IEEE Trans. Signal Process. 56(10), 5020–5030 (2008)
Sykacek, P., Roberts, S.J.: Adaptive classification by variational kalman filtering. In: Advances in Neural Information Processing Systems, vol 15. MIT Press (2003)
Titsias, M., Lázaro-Gredilla, M.: Doubly stochastic variational Bayes for non-conjugate inference. In: International Conference on Machine Learning, pp. 1971–1979. (2014)
Wainwright, M.J., Jordan, M.I.: Graphical models, exponential families, and variational inference, foundations and trends®. Mach. Learn. 1(1–2), 1–305 (2008)
Waterhouse, S., Mackay, D., Robinson, T.: Bayesian Methods for Mixtures of Experts. MIT Press, Cambridge (1996)
Wenzel, F., Galy-Fajou, T., Donner, C., Kloft, M., Opper, M.: Efficient gaussian process classification using Pòlya-Gamma data augmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 5417–5424. (2019)
Acknowledgements
This work was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR-19-P3IA-0001(PRAIRIE 3IA Institute). We also acknowledge support from the French defence procurement agency (DGA) and from the European Research Council (grant SEQUOIA 724063). The authors would like to thank Eric Moulines and Jean-Pierre Nouaille as well as Hadi Daneshmand for fruitful discussions related to this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Generalization of Theorem 1
Theorem 1 can be generalized to any target distribution belonging to an exponential family of natural parameter \(\eta \) as follows:
Theorem 4
Considering an exponential family \(q_\eta \) of natural parameter \(\eta \), mean parameter m, and a strictly convex log partition function F such that \(q_\eta (\theta )=h(\theta )\exp (<\eta ,\theta >-F( {\eta }))\), the solution to the recursive variational approximation problem between a target distribution \(q_\eta \) and the one-sample posterior \(p(\theta |y_t) \propto p(y_t|\theta )q_{\eta _{t-1}}(\theta )\):
must satisfy the following implicit fixed point equation on the natural parameter:
If \(q_\eta \) is a Gaussian distribution, this fixed point equation is equivalent to the R-VGA updates given in Theorem 1.
This theorem extends the results found in Khan and Lin (2017) and Khan and Nielsen (2018) to the recursive variational inference framework. Here, the implicit updates come directly from the critical point of our recursive form (95) and not from the application of an explicit natural gradient.
Proof
The recursive variational approximation for the target distribution \(q_\eta \) of log-partition function F may be rewritten as:
where c is a normalization constant and \(B_F\) is the Bregman divergence associated with the strictly convex log partition function F:
The derivative of the variational divergence (99) with respect to the natural parameter \(\eta _t\) gives:
which yields the desired result. The last equality comes from the properties of exponential families with a strictly convex log-partition function F: The mean parameter m is the Legendre dual of the natural parameter \(\eta \), i.e., \(<\eta ,m>=F(\eta )+F^*(m)\) and \(\nabla ^2 F(\eta )=\frac{\partial m}{\partial \eta }\).
Finally, if we apply this equation to the natural parameter for a Gaussian distribution \(\eta =\begin{pmatrix} P^{-1} \mu \\ -\frac{1}{2}P^{-1} \end{pmatrix}\), we retrieve the R-VGA updates. Indeed, to derive the R-VGA from the implicit version of the natural gradient we use the chain rule to relate the mean parameters to the natural parameters as proposed by Khan et al., in the context of batch variational approximation, in Khan et al. (2018) (Appendix C). In the Gaussian case, the mean is \(m=\begin{pmatrix} m_1=\mu \\ m_2=P+\mu \mu ^T \end{pmatrix}\) and the natural parameter is \(\eta =\begin{pmatrix} \eta _1=P^{-1}\mu \\ \eta _2=-\frac{1}{2}P^{-1} \end{pmatrix}\). The gradient with respect to the mean parameters \(m_1,m_2\) can be expressed as the gradient with respect to the sources parameters \(\mu ,P\) using the chain rule:
The updates
become:
which are the R-VGA equations indeed. \(\square \)
1.2 Proof of Theorem 2
Proof
In the case where p is a multivariate Gaussian distribution \(p(y_t|\theta ) \sim {{\mathcal {N}}}(y_t | H_t\theta , R_t)\), where \(H_t\) is the observation matrix, we have the relation:
and this last relation gives directly the second R-VGA update equation, rewriting (2) as:
which is the information update equation. We then rewrite the first R-VGA update Eq. (1) as:
If we note the Kalman gain \(K_t=P_tH_t^TR_t^{-1}\), we find the Kalman update equations for state (42), indeed:
where we have used the matrix formula: \((A^{-1}+B^TC^{-1}B)^{-1}B^TC^{-1}=AB^T(BAB^T+C)^{-1}\). The Kalman update equation for the covariance matrix (42) is then deduced from (107) using the Woodbury formula:
Equivalence to linear Kalman filter has thus been proved.
Equation (109) can be rewritten to find, combined with (107), the online Newton descent. Indeed, if we pose \(Q_t=P_t^{-1}\) as the estimation of the Hessian matrix up to the iteration t, we find directly:
This proves the equivalence to the online Newton descent. Now, it is well known the Kalman filter is optimal for the least mean squares problem; let us reformulate the proof to better show the connection to stochastic optimization.
Let us recall the form of the least mean squares cost function for t observations:
We express now the optimal \(\theta ^*_t=Q_t^{-1}v_t\) at time t in function of the optimal at time \(t-1\):
The two last equations show that the recursive least mean squares estimate is found by both online Newton and the linear Kalman filter. \(\square \)
1.3 Proof of Theorem 3
Proof
The proof is quite similar to the proof in the linear case. The update Eq. (3) can be rewritten using the same manipulations as in the linear case:
From (50) and (118), we deduce that R-VGA is equivalent to the explicit scheme.
From (50) and (119), we deduce that R-VGA is equivalent to the extended Kalman filter using the same formula (110) and (111) as in the linear case. The equivalence between the extended Kalman filter and the natural gradient is already known (Ollivier 2018), we recall the main argument. In the update Eq. (50), the information matrix \(P_t^{-1}\) is of growing size as long as we observe new data. If we pose \(J_t=\frac{1}{t+1}P_t^{-1}\), we can reformulate the update (50) as a moving average:
which is the Fisher matrix update. The derivation from (120) to (121) is not obvious. Martens (2020) introduces it in the context of the generalized Gauss–Newton. To better understand where it comes from, we rather use the proof proposed in Ollivier (2018). Using the relation \(\frac{\partial \log p(y|\theta )}{\partial \eta }=y-{\bar{y}}\) which holds for exponential families, we can write:
\(\square \)
1.4 Output uncertainty assessment

Iso-probabilities of the outputs in function of the inputs for the R-VGA implicit and explicit schemes (left), the EKF, QKF (middle), and the Laplace (right). We have considered \(\sigma _0=10\) and \(\mu _0=0\) with \(N=300\) and \(s=5\)

Values of the function \(F_{\alpha _0,\nu _0,y}\) for \(\alpha _0=100\), \(\nu _0=300\) and \(y=0\). In the upper row, we show the initial value \((\alpha _0, \nu _0)\) which is located on the bound of the domain (blue dot) and the optimal value (red dot)

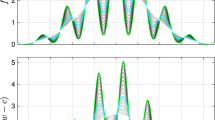
Bounds for the roots \(\alpha \), \(\nu \) of F through the proposed iterative scheme (in green) for \(\nu _0=1, 5\), and 10. Iteration on F for different initial conditions is shown in red and blue

\(s=2\). Upper row: 2D synthetic dataset (left) and KL divergence. Lower row: confidence ellipsoids for the R-VGA implicit and explicit versions (left) and the EKF and QKF (right) at different times (final \(t=N\) in black). The batch Laplace covariance is shown in red and is considered accurate

Same as Fig. 14 in the case where \(s=5\)

Same as Fig. 14 in the case where \(s=10\)
Given an unseen input, a prediction based on the estimated distribution \(q_t\) may either be obtained through the maximum a posteriori (MAP) estimate of the parameter, that is, \(P[y|x]=\sigma (x^T\theta ^*)\), or it may be obtained using the entire (Bayesian) distribution, that is, \(P[y|x]={\mathbf {E}}[y|x]={\mathbf {E}}_{q \sim {{\mathcal {N}}}(\mu ^*,P^*)}[\sigma (x^T\theta )] \approx \sigma (k x^T\mu ^*)\) with \(k=\frac{\beta }{\sqrt{ x^TP^*x +\beta ^2}}\). Because of this, the latter is less confident than the former MAP based-approach. Indeed, we have the following relation for the sigmoid:
This relation comes from the fact the sigmoid is convex for \(x<0\) and concave for \(x>0\). The prediction based on the Bayesian approach is shown in Fig. 11 where we have drawn the iso-probabilities of the outputs in function of the inputs. On this separable dataset, the Laplace gives low probabilities prediction for the unseen inputs, whereas the QKF tends to predict with high probabilities. The R-VGA gives prediction probabilities between both of them.
1.5 Details on the fixed point method
The roots of F are the fixed point of the function \({\tilde{F}}\) defined by:
where:
Function F is displayed in Fig. 12.
We found that \({\tilde{F}}\) is not contractive, so that fixed point iterations shall oscillate and do not converge, as shown in Fig. 13. However, we can further restrict the admissible domain \([\alpha _\mathrm{min}, \alpha _\mathrm{max}] \times [\nu _\mathrm{min}, \nu _\mathrm{max}]\) in which the searched point lies as follows.
Coarse bounds are given by:
Using the fact that \(0 \le k(\nu _\mathrm{max}) \le k(\nu ) \le k(\nu _\mathrm{min})\), the first inequality (127) gives:
And we find the following new bound for \(\alpha \):
For the second inequality (128), we use (129) to bound:
where \(b_1\) and \(b_2\) depend on the sign of \(a_1a_2\):
And we find the following new bound for \(\nu \):
This scheme can be iterated to restrict the search domain.
For moderate values of \(\nu _0\), that is, moderately uncertain prior, the domain shrinks fast. But for highly uncertain priors it does not, as shown in Fig. 13, hence the need to resort to a 2D optimization algorithm.
1.6 Influence of separability of the dataset
We plot here results that reflect the sensitivity to the separability factor s with \(s=2\) (Fig. 14), \(s=5\) (Fig. 15), and \(s=10\) (Fig. 16). The evolution of the ellipsoids over the iterations is also displayed. We see RVG-A consistently yields good performance.
Rights and permissions
About this article

Cite this article
Lambert, M., Bonnabel, S. & Bach, F. The recursive variational Gaussian approximation (R-VGA). Stat Comput 32, 10 (2022). https://doi.org/10.1007/s11222-021-10068-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-021-10068-w