
Abstract
The study complements the existing literature on the role of credit constraints in the interplay between income inequality and economic growth. The question “what type of financial development matters for inequality-growth relationship” is answered empirically by adopting a multi-dimensional index of financial development. The analysis covers 35 OECD member countries and 34 non-OECD economies starting from the year 1980 with varying coverage across countries. The results of the panel estimation techniques suggest that in the non-OECD countries, income inequality is positively associated with subsequent growth of per capita GDP under sufficiently developed financial markets. If the markets are poorly developed, the partial correlation between inequality and growth is statistically insignificant. For OECD countries, the association seems to be non-existent although weak evidence for growth-dampening inequality is found if both the level of inequality is high and the financial markets are highly developed. The results imply that promoting the development of financial markets – rather than institutions – may alleviate the adverse effects of income inequality on economic growth in under-developed countries.





Similar content being viewed by others


Notes
For a comprehensive review, see Neves et al. (2016), whose meta-analysis suggests that the literature suffers from publication bias: statistically significant results are more willingly reported and published following a predictable time pattern with cyclically alternating positive and negative reduced-form estimates. Their results also suggest that the estimation technique, data quality and the specification choice for the growth regression are not significant drivers of the varying estimates. Rather, cross-sectional analyses tend to find a stronger negative association than panel studies, the negative association is stronger in less developed countries, the inclusion of regional dummies soak up much of the previous finding and the concept of inequality significantly affects the results.
See Fig. 1 in Svirydzenka (2016) for the original artwork.
The Organisation for Economic Co-operation and Development (OECD), The EU-Statistics on Income and Living Conditions (EU-SILC), The Luxembourg Income Study (LIS), The World Bank, The Socio-Economic Database for Latin America and the Caribbean (SEDLAC), national statistical offices and independent research papers.
As a robustness check, a widely-used system GMM estimator is also used. The properties of this panel estimation technique are briefly discussed in the next section when the results of the empirical analysis are presented.
Six of the 34 countries are always above the cut-off, 13 are both over and under during the observation period while 15 are always under.
In the set of countries of this study, the country-specific correlations between the Gini coefficient and the top income shares are on average above 0.97 when the five-year non-overlapping windows are considered. Although the correlations show cross-country variation, the OECD and non-OECD sub-samples share similar characteristics. Similarly to the Gini coefficient, the WIID serves as the source of data for the top income shares. Previously, Leigh (2007) studied the top incomes and broader measures of income inequality, such as the Gini, and found that the former track the latter closely.
For simpler estimators, the \(nR^2\) test developed by White (1980) together with the approach introduced by Breusch and Pagan (1979) is informative, whereas for GMM, the \(nR^2\) statistic does not have the desired statistical properties (Hayashi 2000, p. 234). However, White (1982) notes that when the errors are symmetric, \(nR^2\) is biased towards the rejection of the null hypothesis of conditional homoskedasticity. Hence, under symmetricity, the failure to reject the null is useful evidence in favor of the correctness of the specification. In practice, the test is constructed by regressing the squared residuals on a constant and second-order cross products of the instrumental variables.
The SWIID is based on the WIID, supplemented by other sources and all observations come from its imputation model. See Section 2 for further discussion.
References
Aghion, P., Caroli, E., Garcia-Penalosa, C.: Inequality and economic growth: the perspective of the new growth theories. J Econ. literat. 37(4), 1615–1660 (1999)
Arellano, M., Bond, S.: Some tests of specification for panel data: Monte carlo evidence and an application to employment equations. Rev. Econ. Stud. 58(2), 277–297 (1991)
Arellano, M., Bover, O.: Another look at the instrumental variable estimation of error-components models. J. Econ. 68(1), 29–51 (1995)
Atkinson, A.B., Brandolini, A.: Promise and pitfalls in the use of secondary data-sets: Income inequality in oecd countries as a case study. J. Econ. Literat. 39(3), 771–799 (2001)
Barro, R.J., Lee, J.W.: A new data set of educational attainment in the world, 1950–2010. J. Develop. Econ. 104, 184–198 (2013)
Bazzi, S., Clemens, M.A.: Blunt instruments: Avoiding common pitfalls in identifying the causes of economic growth. Am. Econ. J. Macroecon. 5(2), 152–86 (2013)
Berg, A., Ostry, J.D., Tsangarides, C.G., Yakhshilikov, Y.: Redistribution, inequality, and growth: new evidence. J. Econ. Growth 23(3), 259–305 (2018)
Blau, B.M.: Income inequality, poverty, and the liquidity of stock markets. J. Develop. Econ. 130, 113–126 (2018)
Blundell, R., Bond, S.: Initial conditions and moment restrictions in dynamic panel data models. J. Econ. 87(1), 115–143 (1998)
Breusch, T.S., Pagan, A.R (1979). A simple test for heteroscedasticity and random coefficient variation. Econometrica: Journal of the Econometric Society, 1287–1294
Cihak, M., Demirgüç-Kunt, A., Feyen, E., Levine, R. (2012). Benchmarking financial systems around the world
Deininger, K., Squire, L.: A new data set measuring income inequality. World Bank Econ. Rev. 10(3), 565–591 (1996)
Feenstra, R.C., Inklaar, R., Timmer, M.P.: The next generation of the penn world table. Am. Econ. Rev. 105(10), 3150–82 (2015)
Furceri, D., Loungani, P.: The distributional effects of capital account liberalization. J. Develop. Econ. 130, 127–144 (2018)
Galor, O., Moav, O.: From physical to human capital accumulation: Inequality and the process of development. Rev. Econ. Stud. 71(4), 1001–1026 (2004)
Galor, O., Zeira, J.: Income distribution and macroeconomics. Rev. Econ. Stud. 60(1), 35–52 (1993)
Hansen, L.P. (1982). Large sample properties of generalized method of moments estimators. Econometrica: Journal of the Econometric Society, 1029–1054
Hayashi, F.: Econometrics. Princeton University Press, Princeton (2000)
Holtz-Eakin, D., Newey, W., Rosen, H.S.: Estimating vector autoregressions with panel data. Econometrica: J. Econ. Soc. 1, 1371–1395 (1988)
Jäntti, M., Pirttilä, J., Rönkkö, R. (2018). The determinants of redistribution around the world. Review of Income and Wealth
Jenkins, S.P.: World income inequality databases: an assessment of wiid and swiid. J. Econ. Inequal. 13(4), 629–671 (2015)
Kraay, A.: Weak instruments in growth regressions: implications for recent cross-country evidence on inequality and growth. The World Bank (2015)
Lane, P.R., Milesi-Ferretti, G.M.: The external wealth of nations mark ii: Revised and extended estimates of foreign assets and liabilities, 1970–2004. J. Int. Econ. 73(2), 223–250 (2007)
Leigh, A.: How closely do top income shares track other measures of inequality? Econ. J. 117(524), F619–F633 (2007)
Marshall, M.G., Jaggers, K., Gurr, T.R.: Polity iv project: Dataset users’ manual. University of Maryland, College Park (2002)
Neves, P.C., Afonso, Ó., Silva, S.T.: A meta-analytic reassessment of the effects of inequality on growth. World Develop. 78, 386–400 (2016)
Nickell, S.: Biases in dynamic models with fixed effects. Econometrica: Journal of the econometric society, pages 1417–1426 (1981)
OECD: Income distribution database. Accessed: 2019-7-31 (2019)
Ostry, M.J.D., Berg, M.A., Tsangarides, M.C.G.: Redistribution, inequality, and growth. International Monetary Fund (2014)
Rajan, R., Zingales, L.: Financial development and growth. Am. Econ. Rev. 88(3), 559–586 (1998)
Roodman, D.: How to do xtabond2: An introduction to difference and system gmm in stata. Stata J. 9(1), 86–136 (2009)
Solt, F.: The standardized world income inequality database. Soc. Sci. Quart. 97(5), 1267–1281 (2016)
Svirydzenka, K.: Introducing a new broad-based index of financial development. International Monetary Fund (2016)
UNU-WIDER: World income inequality database (wiid4). Accessed: 2018-12-21 (2018)
White, H.: A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica 48(4), 817–838 (1980)
White, H.: Instrumental variables regression with independent observations. Econometrica: Journal of the Econometric Society, pages 483–499 (1982)
Windmeijer, F.: A finite sample correction for the variance of linear efficient two-step gmm estimators. J. Econ. 126(1), 25–51 (2005)
Acknowledgements
I wish to thank Mika Nieminen, the participants of the 42nd Annual Meeting of the Finnish Economic Association, and two anonymous referees for valuable comments.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The author declares no conflict of interest. The work was supported by the Finnish Cultural Foundation under Grant 12181963 and the OP Group Research Foundation under Grant 20190078.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
A Data selection for the WIID
As informatively summarized by Jenkins (2015), Atkinson and Brandolini (2001) state that non-comparability in secondary data sets may arise because of differences in the definitions of income, in the data sources or in the processing of the income data in the original source. Differences both within countries in time and across countries may emerge. Many of the differences are associated with predictable patterns on inequality if their nature is not drastically heterogeneous over time and across countries. Unfortunately, the assumption of homogeneity is unlikely to hold for the WIID despite major improvements on the earlier databases and thus the practical implications need to assessed by comparing the WIID series with other sources of at least as good a quality.
In the WIID, each observation is labeled as one of possible income, consumption or expenditure concepts as strongly recommended by the seminal evaluative studies. Following the assertive conclusion of Jenkins (2015), I explicitly report the data selection algorithm inspired by Jäntti et al. (2018) in “Appendix A”. After separating the net income observations from the rest, two issues remain for empirical work: the observations are of varying quality and there are often multiple observations for each country-year pair. Some of the multiple observations are due to multiple surveys but predominantly the measurements come from the same survey and it is just the computation (and the statisticians in charge) that change. Helpfully, the WIID team has introduced a variable called a quality score, which ranks the observations from 3 to 13. By ranking the observations based on this score, presented in “Appendix A”, and picking the highest, I can use the observations of best possible quality to form the final country panel and get rid of many of the duplicate observations. In case of observations tied on the quality score for a given country-year pair, a simple average is taken to obtain unique observations. I believe that this data selection procedure may be helpful for future researchers who need to merge the WIID into some other cross-country panel.
Many recent studies, of which some have received much attention (Ostry et al. 2014), have used the Standardized World Income Inequality Database (Solt 2016, SWIID) as their source for data on the Gini coefficients. The SWIID is based on the WIID, supplemented by other sources and all observations come from its imputation model. In his conclusions, Jenkins (2015) states that costs associated with the use of the WIID are present for the SWIID too. Additionally, he urges to set questions about the imputation model against the benefits of coverage and draws a conclusion that the WIID should be used instead of the SWIID given that the use of the WIID is accompanied by a tractable data selection algorithm.
Data selection in practice. The observation is defined as net income if the WIID4 variable resource_detailed, previously labeled as welfare definition, is one of the following: “Earnings, net”, “Income, net”, “Monetary income, net”, “Monetary income, net (excluding property income)” or “Taxable income, net”; as consumption income if resource_detailed is “Consumption”; and as market income if resource_detailed is one of the following: “Earnings, gross”, “Factor income”, “Income, gross”, “Market income”, “Monetary income, gross”, “Taxable income, gross” or “Taxable income, gross (including deductions)”.
Based on the variable quality_score running from 3 to 13, I rank the observations and pick the highest to use the observations of best possible quality to form the final country panel and get rid of many of the duplicate observations. In case of observations tied on the quality score for a given country-year pair, a simple average is taken to obtain unique observations.
The quality score is defined in the following way by the WIID team (UNU-WIDER 2018): We award points to the observations based on their attributes in the following way (maximum is 13 points). Gini coefficient is available (1). Resource concept: Consumption, Income (net), Income (gross), Monetary income (gross), Monetary income (net) (5), Income, Monetary income, Market income (3), Factor income, Primary income, Taxable income, Earnings (1). Equivalence scale: Per capita or equivalized (3), No adjustment (2). Area coverage: All, Urban, Rural (1). Population coverage: All (1). Distributional share information: All of d1-q5 are available (2), All of q1-q5 are available (at least one of d1-d10 is missing) (1).
Comparative analysis between different data sources. The OECD Income Distribution Database (OECD 2019)Footnote 10 provides data on the net income Gini coefficients for its member states. All series correspond to same OECD income definitions and thus they should be more comparable across time and across the OECD countries than the WIID ones. Therefore, the OECD database offers a point of reference to evaluate whether the WIID series differ from series of likely higher quality in a subsample of OECD countries. For non-OECD countries, a comparative exercise would be a cumbersome task since the reference series would have to be gathered from various sources listed under footnote\(^{3}\) and improvements on comparability relative to the WIID would be difficult to establish.
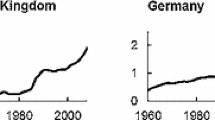
Following Atkinson and Brandolini (2001), the WIID, the OECD data and the Standardized World Income Inequality Database (Solt 2016, SWIID)Footnote 11 are used to form cross-country inequality rankings and to compare within-country inequality trends. The WIID series correspond to the result of the above-described data selection algorithm and thus the observations are averages over the periods 2000–2004 and 2010–2014. Due to gaps in the WIID and OECD data, the comparison is restricted to 14 countries. Other choices of reference years would reduce the ranking sample even further. A single major glitch clearly emerges: the 2010 WIID ranking places Denmark as fifth while all others rank the country in the top two. As can be seen in Fig. 6, the WIID very likely overestimates the level of inequality in Denmark in 1995 and 2000. Otherwise, the rankings are fairly stable although changes occur especially within the Nordic countries who share low levels of income inequality and whose values for the Ginis are close to one another irrespective of the data source. All pairwise correlations between the rankings in a point in time are well above 0.95. (Tables 6 ,7,8,9)
Based on graphical analysis, of which Fig. 6 is an example, the WIID in general matches the data provided by the OECD modestly well although some of the time variation is undoubtedly due to differences between surveys or calculations of the income distributions. Canada is an example of a case where all three alternatives paint a similar picture, the SWIID probably underestimates the extent of inequality in Mexico while the WIID series show lower values than the OECD ones for the US (Figs. 7, 8) (Tables 10,11,12,13)
B Full fixed effects panel regression tables
See Tables 7, 8, 9, 10, 11, 12, 13.
C Association between the top income shares and growth of per capita GDP

The disposable income Gini coefficients in Canada, Denmark, Mexico and the United States

The distributions of top disposable income shares in OECD and non-OECD countries

Estimated association (95 % level confidence interval) between the top 20 % income share and per capita growth conditional on different measures of financial development, non-OECD countries
D Controlling for endogeneity: system GMM

Estimated association (95 % level confidence interval) between the top 10 % income share and per capita growth conditional on different measures of financial development, non-OECD countries
where FM stands for the development of financial markets while otherwise the notation follows equation (1). Since the sGMM estimator is for numerical issues ill-suited for subsample analysis due to the limited data coverage of this study, additional interactions are introduced.

System GMM estimates (95 % level confidence interval) for the Gini coefficient at the top 25 % and at the bottom 75 % percent on per capita growth conditional on development of financial markets (FM)
Rights and permissions
About this article

Cite this article
Juuti, T. The role of financial development in the relationship between income inequality and economic growth: an empirical approach using cross-country panel data. Qual Quant 56, 985–1021 (2022). https://doi.org/10.1007/s11135-021-01163-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11135-021-01163-1