
Abstract
We provide generalizable results on the price and promotion tactics employed in the U.S. retail grocery industry. First, we document a large degree of price dispersion for UPCs and brands across stores, both nationally and at the local market level. Base price differences across stores and price promotions contribute to the overall price variance, and we show how to decompose the price variance into base price and promotion components. Second, we document that a large percentage of the variation in prices and promotion tactics across stores can be explained by retail chain and especially market/chain factors, whereas market factors explain only smaller percentage of the variation. Third, we show that the chain-level price and promotions similarity can be explained by similarity in demand. In particular, a large percentage of the variance in price elasticities and promotion effects can be explained by retail chain and especially market/retail chain factors. Further, price elasticities and promotion effects across stores of the same chain are hard to distinguish from the chain-market-level mean, and cross-price elasticities are typically imprecisely estimated. These findings suggest that retail managers may plausibly consider price discrimination across stores to be infeasible.














Similar content being viewed by others

Notes
UPC is the acronym for “universal product code”.
As explained in Section 3.1), we impute prices in weeks when a product did not sell using the most recent base (non-promoted) price.
In work that has a different focus than our study, Kaplan et al. (2019) analyze the extent to which product-level price dispersion is due to persistent price-level differences across stores, based on a sample of 1,000 UPCs from the Nielsen RMS data.
See the Retail Scanner Dataset Manual provided by the Kilts Center for Marketing for the Scantrack market-level data indicating the coverage of spending for the three main retail channels.
See Appendix A.2 for details on the product size (revenue) distribution in our data.
Table 8 also provides chain-level summary statistics on the geographic coverage and the total number of stores of different retail chains.
Njt is the number of stores in \(\mathcal {S}_{jt}\).
The median product is the median of the revenue-weighted distribution of σj.
\(\mathcal {S}_{jmt}\) is the set of all stores that sell product j in market m in week t.
A small number of markets (2 DMAs and 45 3-digit ZIP codes) contain only one store. We exclude these markets from the analysis, and we also exclude markets where only one store carries product j.
This is equivalent to calculating πj based on all Djst observations, pooled across stores and weeks.
The weights are given by total product revenue.
All results are derived in detail in Appendix D.
var(pm) and \(\text {var}(\bar {p}_{s}|m)\) are calculated as weighted averages using the number of observations in each market and the number of observations for each store as weights (see Appendix D).
The total contribution is the sum of the last two components in Eq. 2.
The R2 values from the market indicator regressions are comparable to the across-market price variance component in the variance decomposition (1). The values are not identical, because the variance decomposition in Section 6 is performed using all weeks in 2010, whereas the product-level R2 values in this section are obtained by averaging over the R2 values from separate regressions for each week.
The first two principal components explain 33% of the price variance for the median product. See Appendix E for detailed explanations and more empirical examples.
The color labels are not mutually exclusive across the panels. For example, red dots in two different panels represent the projected prices for stores that belong to two different retail chains.
We use DMAs instead of 3-digit ZIP codes as markets because the large number of 3-digit ZIP codes is hard to visualize.
Table 5 shows analogous patterns based on the ratio of the 95th to 5th percentile of prices and base prices.
\(|\mathcal {S}_{sm}|\) is the number of stores in \(\mathcal {S}_{sm}\).
The distributions are weighted using total product revenue weights.
All but four retail chains have stores that are in this sub-sample. Among the covered retailers, feature ads are recorded for about 20% of stores, and in these stores feature advertising is measured consistently for most products and weeks. Among the covered stores, feature advertising is measured for 99% of all non-imputed product/week observations and for almost 90% of all products.
In particular, the entry of a Walmart Supercenter leads to a 16% drop in the revenue of the nearby retailers, but to no corresponding change in the prices offered by the incumbents.
If s and \(s^{\prime }\) are two stores in the same 3-digit ZIP code, and if t and \(t^{\prime }\) are two weeks in the same year and month, then \(\tau _{j}(s,t)=\tau _{j}(s^{\prime },t^{\prime }).\)
The distribution is weighted using total brand revenue. The weights are brand, not brand/store-specific.
βjs is a vector that includes the own and cross-price elasticities, βjks, and the promotion parameters, γjks.
The own-price elasticity and promotion effect estimates are from the main model specification that includes 3-digit ZIP code/month fixed effects.
For example, DemandTec, which was founded in 1999 and later acquired by IBM, offered analytic services to its retail clients using such demand models.
Brand size is measured by total brand revenue.
We could potentially have obtained more precise demand estimates using data that covered a larger number of years than the three years used in our analysis. In practice, however, demand analyses performed for manufacturers and retailers have typically been based on at most two years of data. Hence, the demand estimates that we analyze are likely to overstate, not understate the precision of the estimates available in the industry practice.
See, for example, the discussion of pricing and promotion tactics in Consumer-Centric Category Management by ACNielsen (2005).
A new UPC version is created when one or more of the “core” UPC attributes change. The core attributes include the product module (category) code, brand code, pack size (volume), and a multi-pack variable indicating the number of product units bundled together.
If we define a product as a combination of UPC and UPC version (the variable upc_ver_uc) the number is 967,863.
In Kaplan and Menzio (2015) a brand aggregate is obtained using a “set of products that share the same features and the same size, but may have different brands and different UPCs.”
See, for example, Hastie et al. (2009) for a thorough introduction to principal components analysis.
See Table 8 for summary statistics on the number of stores per retail chain at the DMA and ZIP+ 3 level.
References
ACNielsen. (2005). Consumer-Centric Category management: How to Increase Profits by Managing Categories Based on Consumer Needs. Wiley.
Adams, B., & Williams, K. R. (2019). Zone pricing in retail oligopoly. American Economic Journal: Microeconomics, 11, 124–156.
Arcidiacono, P., Ellickson, P. B., Mela, C. F., & Singleton, J. D. (2020). The competitive effects of entry: Evidence from supercenter expansion. American Economic Journal: Applied Economics, 12, 175–206.
Ater, I., & Rigbi, O. (2020). Price Transparency, Media and Informative Advertising. manuscript.
Berry, S., Levinsohn, J., & Pakes, A. (1995). Automobile prices in market equilibrium. Econometrica, 63, 841–890.
Berry, S. T. (1994). Estimating Discrete-Choice models of product differentiation. Rand Journal of Economics, 25, 242–262.
Bijmolt, T. H. A., van Heerde, H. J., & Pieters, R. G. M. (2005). New empirical generalizations on the determinants of price elasticity. Journal of Marketing Research, 42, 141–156.
Boatwright, P., Dhar, S., & Rossi, P. E. (2004). The role of retail competition, demographics and account retail strategy as drivers of promotional sensitivity. Quantitative Marketing and Economics, 2, 169–190.
Bolton, R. N. (1989). The relationship between market characteristics and promotional price elasticities. Marketing Science, 8, 153–169.
Bronnenberg, B. J., Mela, C. F., & Boulding, W. (2006). The periodicity of pricing. Journal of Marketing Research, 43, 477–493.
DellaVigna, S., & Gentzkow, M. (2019). Uniform pricing in US retail chains. Quarterly Journal of Economics, 134, 2011–2084.
Dobson, P. W., & Waterson, M. (2005). Chain-Store Pricing across local markets. Journal of Economics and Management Strategy, 14, 93–119.
Dubois, P., & Perrone, H. (2015). Price Dispersion and Informational Frictions: Evidence from Supermarket Purchases. manuscript.
Eden, B. (2014). Price Dispersion and Demand Uncertainty: Evidence from US Scanner Data. manuscript.
Eizenberg, A., Lach, S., & Oren-Yiftach, M. (2021). Retail prices in a city. American Economic Journal: Economic Policy, 13, 175–206.
Ellickson, P. B., & Misra, S. (2008). Supermarket pricing strategies. Marketing Science, 27, 811–828.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning, second ed. Berlin: Springer.
Hoch, S. J., Kim, B. -D., Montgomery, A. L., & Rossi, P. E. (1995). Determinants of Store-Level price elasticity. Journal of Marketing Research, 32, 17–29.
Honka, E., Hortaçsu, A., & Wildenbeest, M. (2019). Empirical search and consideration sets. In J.-P. Dubé P. E. Rossi (Eds.) Handbook of the Economics of Marketing, chap. 4, (Vol. 1 pp. 193–257). B.V.: Elsevier.
Hwang, M., Bronnenberg, B. J., & Thomadsen, R. (2010). An empirical analysis of assortment similarities across U.S. Supermarkets. Marketing Science, 29, 858–879.
Joo, J. (2020). Rational Inattention as an Empirical Framework: Application to the Welfare Effects of New Product Introduction. manuscript.
Kahneman, D., Knetsch, J. L., & Thaler, R. (1986). Fairness as a constraint on profit seeking: Entitlements in the market. American Economic Review, 76, 728–741.
Kaplan, G., & Menzio, G. (2015). The morphology of price dispersion. International Economic Review, 56, 1165–1205.
Kaplan, G., Menzio, G., Rudanko, L., & Trachter, N. (2019). Relative price dispersion: Theory and evidence. American Economic Journal: Microeconomics, 11, 68–124.
Lach, S. (2002). Existence and persistence of price dispersion: an empirical analysis. The Review of Economics and Statistics, 84, 433–444.
Nakamura, E. (2008). Pass-Through in Retail and Wholesale. NBER Working Paper 13965.
Nakamura, E., & Steinsson, J. (2008). Five facts about prices: a reevaluation of menu cost models. Quarterly Journal of Economics, 123, 1415–1464.
Nakamura, E. (2013). Price rigidity: Microeconomic evidence and macroeconomic implications. Annual Review of Economics, 5, 133–163.
Narasimhan, C., Neslin, S. A., & Sen, S. K. (1996). Promotional elasticities and category characteristics. Journal of Marketing, 60, 17–30.
Nevo, A. (2001). Measuring Market Power in the Ready-to-Eat Cereal Industry. Econometrica, 69, 307–342.
Rossi, P., Allenby, G., & McCulloch, R. (2005). Bayesian Statistics and Marketing. Wiley.
Rossi, P. E. (2014). Even the rich can make themselves poor: The dangers of IV and related methods in marketing applications. Marketing Science, 33, 655–672.
Sorensen, A. T. (2000). Equilibrium price dispersion in retail markets for prescription drugs. Journal of Political Economy, 108, 833–850.
Tellis, G. J. (1988). The price elasticity of selective demand: a Meta-Analysis of econometric models of sales. Journal of Marketing Research, 25, 331–341.
Acknowledgements
We thank Itai Ater, Susan Athey, Pierre Dubois, Wes Hartmann, Kirthi Kalyanam, Carl Mela, Helena Perrone, Stephan Seiler, Steve Tadelis, Raphael Thomadsen, and especially Paul Ellickson for their helpful comments and suggestions. We also benefitted from the comments of seminar participants at the 2017 QME Conference at Goethe University Frankfurt and the 2017 Columbia Business School Marketing Analytics and Big Data Conference. Jacob Dorn, George Gui, Jihong Song, and Ningyin Xu provided outstanding research assistance. Part of this research was funded by the Initiative on Global Markets (IGM) at the University of Chicago Booth School of Business and the Becker Friedman Institute at the University of Chicago. Xiliang Lin worked on the paper and had access to the data when he was a Ph.D. student at the University of Chicago.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Researchers’ own analyses calculated (or derived) based in part on data from Nielsen Consumer LLC and marketing databases provided through the NielsenIQ Datasets at the Kilts Center for Marketing Data Center at The University of Chicago Booth School of Business. The conclusions drawn from the NielsenIQ data are those of the researchers and do not reflect the views of NielsenIQ. NielsenIQ is not responsible for, had no role in, and was not involved in analyzing and preparing the results reported herein.
Appendices
Appendix
A Data description: Details
2.1 A.1 UPCs and UPC versions
The RMS scanner data record sales units and prices at the week-level, separately for all stores and UPCs. Over time, a UPC can be reassigned to a different product. Therefore, the Kilts Center for Marketing also provides a version code (upc_ver_uc) such that the combination of the UPC and UPC version code uniquely identifies a product.Footnote 34 A change of the brand name (description) is one of the reasons why a new UPC version is created. Sometimes, a new UPC version reflects a different spelling or abbreviation of the brand name, for example “MOUNTAIN DEW R” versus “MTN DEW R.” We attempt to identify and correct all such instances.
In the paper we only refer to UPCs, with the understanding that at the most disaggregated level a product is characterized by a unique combination of a UPC and UPC version code.
2.2 A.2 Product size (revenue) distribution
Between 2008 and 2010 the RMS data include information on 967,832 products (UPCs).Footnote 35 A large percentage of the total sales revenue is concentrated among a relatively small number of products. To illustrate, in Fig. 17 we rank all products based on total revenue between 2008 and 2010 and plot the cumulative revenue of the top N products on the y-axis. For example, the top 1,000 products account for 20.7 percent, the top 10,000 products account for 56.5, and the top 50,000 products account for 89.3 percent of the total revenue in the 2008-2010 data, respectively.
2.3 A.3 Product assortments
We document the distribution of product and brand availability across stores and retail chains in our sample. We classify a product (brand) as available in a specific store or retail chain if it was sold in the store or chain at least once during 2010.
Figure 18 displays the distribution of store availability for brands (column one) and products (column two). The histograms are shown separately for the top 100 (based on total revenue), top 1,000, top 10,000, and—at the bottom of the figure— for all brands and products included in the analysis. The median product in the top 100 group is sold in 12,771 stores, whereas the corresponding median brand is sold in 15,985 stores, representing 93% of all 17,184 stores. Hence, the top products and in particular the top brands are widely available. However, even the top 100 products and brands are not consistently available across all stores, indicating differences in store-level assortment choices. Also, the top brands are more consistently available across stores than products, implying assortment differences whereby stores that carry the same brand offer the brand in different pack sizes or forms (e.g. cans versus bottles). Whereas the top 100 and also top 1,000 products and brands are widely available, the corresponding distributions for the top 10,000 and all products and brands indicate a smaller degree of availability across stores. For example, the median product among all products in the sample is available at 3,854 stores, and the median brand is available at 5,281 stores, i.e. 31% of all stores. Overall, we find that assortments across stores tend to be somewhat specialized, with the exception of top-selling products and brands that are typically available at a vast majority of all stores and chains.
The distributions of brand and product availability across retail chains, shown in columns three and four of Fig. 18, are similar to the corresponding distributions across stores. In particular, whereas the top-selling brand and products are widely available (for example, the median brand among the top 100 is sold in 76 out of 81 retail chains), availability is much more limited among the top 10,000 and among all brands and products in the sample. Compared to the store availability distributions, however, the differences across the top and bottom groups are less pronounced. For example, the median brand among all brands in the sample is still available in the majority of retail chains (45 out of 81). In particular, the brand availability distribution for all brands exhibits a pronounced bi-modal shape, indicating a mass of brands available at most retailers and a mass of brands available at a very limited number of retail chains.
2.4 A.4 Private label products
The Nielsen data contain both national brand and private label products. However, the brand description of private label products is always “CTL BR” (control brand), and hence we do not know the brand name under which the product is sold. Also, we cannot infer the brand name based on the store where the product was sold because the name of the retail chain that the store belongs to is not revealed. However, we know the product (UPC) description of a product, such as “CTL BR RS BRAN RTE” for a private label Raisin Bran product in the ready-to-eat breakfast cereal category.
In our analysis we treat all private label UPCs as the same product if they share the same product description and contain the same volume. In particular, we treat such UPCs as the same product even if the UPCs are different. The UPCs are typically different because the product is sold by different retail chains, whereas the product itself of often physically identical because it is produced by the same manufacturer that supplies multiple retailers. Even if the product is identical the packaging and specific brand name (e.g. “Kroger Raisin Bran”) will differ across retailers. Hence, treating different private label UPCs as the same product is not entirely innocuous, but it is the best we can do to compare the price dispersion of national brands to the price dispersion of private label products across retail chains.
Table 1 shows the percentage of observations accounted for by private label products. Private label products account for 10.8 percent of all price observations and 15.4 percent of total revenue.
B Additional price dispersion results
3.1 B.1 Price dispersion: Sensitivity analysis
We calculate two alternative dispersion statistics that are related to the standard deviation of log-prices. First, the distribution of percentage price differences can be measured using the standard deviation of prices normalized relative to the mean price (nationally or at the market level), \(p_{jst}/\bar {p}_{jmt}\), which is the approach used in Kaplan and Menzio (2015). Second, we can report the square root of the variance of log-prices calculated using the following approach:
Note that we do not use Bessel’s correction in these two variance formulas. This approach is equivalent to demeaning each \(\log (p_{jst})\) observation with respect to the average log price in market m, and then calculating the variance over all observations. We include this approach because it is more closely related to the variance decomposition in Section 6.
Summary statistics for these two alternative approach are shown in Table 7, separately for products defined as UPCs and brands. As expected the difference between the dispersion statistics based on the standard deviation of log prices and the standard deviation of normalized prices is negligible. On the other hand, the standard deviation calculated as the square root of Eq. 5 is slightly larger at the DMA and 3-digit ZIP code level compared to the standard deviation of the log of prices. Overall, our main conclusions are unchanged using these two alternative dispersion statistics.
3.2 B.2 Comparison to Kaplan and Menzio 2015
Our results are not directly comparable to Kaplan and Menzio (2015) because their work is based on different data and a substantially smaller number of products, as we already discussed in Section 2. Also, they measure price dispersion using the standard deviation of prices normalized relative to the market-average price level, \(p_{jst}/\bar {p}_{jmt}\), whereas our main price dispersion measure is the standard deviation of log prices. However, as expected, the different dispersion statistics yield almost identical dispersion measures (see the sensitivity analysis in Appendix A) and hence they are not a source of differences in the results.
Kaplan and Menzio (2015) report that the standard deviation of normalized prices for the mean UPC at the Scantrack/quarter level is 0.19. In our data, the corresponding standard deviation is 0.10 for the median UPC at the 3-digit ZIP code/week level and 0.12 at the the Scantrack/week level. Hence, the price dispersion of identical products at a given moment in time is substantially smaller than the dispersion level that Kaplan and Menzio report at the quarter level for a small product sample. Comparable brand-level results are not reported in Kaplan and Menzio (2015).Footnote 36
C Base prices and promotions: Details
4.1 C.1 Choice of promotion threshold \(\bar {\delta }\)
Assuming that every event when the price of a product is strictly less than the base price is a price promotion, we could define the promotion indicator as \(D_{jst}=\mathbb {I}\{\delta _{jst}>0\}\). However, it is unlikely that any brand or category manager designs a price promotion that offers only a negligible price discount. Hence, to find a suitable threshold value \(\bar {\delta }\) to use in our analysis we examine the distribution of the percentage price discounts, δjst, pooled across all products, stores, and weeks when pjst < bjst ⇔ δjst > 0. This distribution is shown in the top right panel of Fig. 4 and summarized in Table 3. The median percentage price discount across all events is 17.7%. There are instances of small percentage price discounts, but the overall incidence of such events is small. For example, in only slightly less than 10% of all events the price discount is less than 5%, 0 < δjst < 0.05. It is implausible that these observations represent a planned price promotion. Rather, such observations are likely due to measurement error in either the price or base price. Such measurement error can arise due to differences between the promotional calendar in a store and the Nielsen RMS definition of a week. For example, suppose a product was offered at a 20 percent price discount during a two week period starting on a Monday and ending on Sunday, May 30. Because a week in the RMS data ends on a Saturday, the RMS week that begins on May 30 and ends on Saturday, June 4 will include one day when the product was offered at the 20 percent price discount and six days when the product was sold at the regular (base) price. The data report the average price over these seven days, which is an average over the promoted and non-promoted prices. The inferred percentage price discount, δjst, is likely to be small in this example, and it will not accurately represent the promotional price discount. In order to ameliorate measurement error we use the threshold of \(\bar {\delta }=0.05\), as discussed in Section 5.2.
4.2 C.2 Calculation of percent volume sold on promotion and lift factors
The percentage of product volume that is sold during a promotional period is given by
Here, qjst is the number of product j units sold in store s in week t. To calculate a corresponding product-level statistic, νj, we take a weighted average of νjs over all stores s, with weights Njs, the number of observations for store s.
The lift factor (promotion multiplier) is given by
Alternatively, we could calculate Ljs using the predicted volume in the absence of a promotion in the denominator, based on a demand model or a weighted average of the observed non-promoted volume. To obtain a product-level lift factor Lj we aggregate over Ljs using the same approach that we use to aggregate the volume percentages.
D Derivation of price variance decompositions
All decompositions are performed at the product level, hence we drop the subscript j. \({\mathscr{M}}\) is the set of all markets, \(\mathcal {S}_{m}\) is the set of all stores in market \(m\in {\mathscr{M}},\) and \(\mathcal {S}=\cup _{m\in {\mathscr{M}}}\mathcal {S}_{m}\) is the set of all stores. For each store s we observe prices in periods \(t\in \mathcal {T}_{s}.\) Correspondingly, Sm is the number of stores in market m, \(S={\sum }_{m\in {\mathscr{M}}}S_{m}\) is the number of all stores, and Ns is the number of observations for stores s. Then the total number of observations is \(N={\sum }_{s\in \mathcal {S}}N_{s}\), and the number of observations in market m is \(N_{m}={\sum }_{s\in \mathcal {S}_{m}}N_{s}\).
Define the overall (national) average price, the average price in market m, and the average price in stores s:
Similarly, define the average base price in market m and the average base price in store s :
Our goal is to provide a decomposition for the overall variance of prices,
5.1 D.1 Basic decomposition
Define
var(pm) is the variance of average market-level prices across markets, \(\text {var}(\bar {p}_{s}|m)\) is the within-market variance of average store-level prices, and var(pst|s) is the within-store variance of prices over time. Note that var(pm) and \(\text {var}(\bar {p}_{s}|m)\) are calculated as weighted averages, using the number of observations in each market and the number of observations for each store as weights.
We first decompose the overall variance of prices, var(pst), into an across-market and a within-market term:
Note that the third line in this formula follows because
To further decompose the within-market term, note that
Here, to derive the second line we used
Substituting (7) in Eq. 6, we obtain the desired decomposition of the overall price variance into the variance of average market-level prices, the weighted average of the within-market variances of average store-level prices, and the weighted average of the within-store variances of prices:
5.2 D.2 Decomposition into base price and promotion components
We start with an alternative decomposition of the within-market term (7):
Note that
Substituting (10) in (9) and rearranging terms, we obtain
Define
Rearranging (12) and substituting in Eq. 11, we obtain
Define the within-market covariance between the promotional price discounts, bst − pst, and the difference between the store-level base price and the average market price, \(b_{st}-\bar {p}\):
Rearranging and substituting (14) in Eq. 13, we then obtain
Finally, we substitute (15) in Eq. 6 and note that \(\text {cov}(b_{st}-p_{st},b_{st}-\bar {p}_{m}|m)=\text {cov}(b_{st}-p_{st},b_{st}|m)\) to obtain the variance decomposition:
5.3 D.3 Example: Price promotions may decrease the overall price variance
We focus only on price variation within one market. Assume that base prices in each store s are constant over time, \(b_{st}\equiv \bar {b}_{s},\) and uniformly distributed around the mean base price \(\bar {b}\) on the interval \([\bar {b}-\nu ,\bar {b}+\nu ].\) Suppose that only stores with above average base prices, \(b_{st}=\bar {b}_{s}>\bar {b}\), promote the product, and that the promoted price is always \(p_{st}=\bar {b}.\) All stores with base prices \(b_{st}=\bar {b}_{s}\leq \bar {b}\) always sell the product at the base price, pst = bst. Define the promotion indicator \(D_{st}=\mathbb {I}\{p_{st}<b_{st}\}\) (this corresponds to the promotion definition in Section 5.2 with a threshold \(\bar {\delta }=0\)). The incidence of promotions is constant, \(\pi \equiv \Pr \{D_{st}=1|b_{st}>\bar {b}\}\). There is a continuum of stores with mass 1, and promotions are independent across stores and across time periods.
The mean price is given by:
The across-store variance of base prices is given by the variance of a uniform distribution,
To derive the variance of the promotional price discounts we first calculate
Similarly, to derive the covariance between the promotional price discounts and the base prices we use the expression for \(\mathbb {E}\left [(b_{st}-p_{st})^{2}\right ]\) above to obtain
Also, the squared difference between the mean base price and shelf price is:
Hence,
Also,
Combining the three components we obtain the variance of prices,
The EDLP vs. Hi-Lo adjustment factor is positive if π > 0 and strictly increasing in π, and the variance of prices is strictly decreasing in the frequency of promotions, π:
E Visualization of price similarity using principal component analysis
We examine the similarity of pricing patterns across stores based on the whole time series of store-level prices. For product j, we observe the vector of prices \(\boldsymbol {p}_{s}=(p_{s1},\dots ,p_{sT})\) for each store \(s\in \mathcal {S}\) and over the prior 2008-2010 (we suppress the index j for notational simplicity). The sample of prices for product j then consists of \(\boldsymbol {p}_{1},\dots ,\boldsymbol {p}_{S}.\) Our goal is to visualize the price vectors ps, which is not directly feasible given the dimensionality of ps. Instead, we conduct a principal components analysis (PCA) of the store-level price vectors. PCA is an unsupervised dimensionality reduction technique that allows us to represent each ps in a low-dimensional space while maintaining as much of the original information (variance) contained in ps as possible.Footnote 37
We perform a PCA for the top 1,000 products (UPCs) in our sample, based on total revenue rank. We only choose these top products because we need to be able to consistently observe the weekly prices, pst, across stores for the analysis to be feasible. For smaller products there is a larger incidence of missing values.
The top panel in Fig. 20 displays box plots of the percentage of the price variance that is explained by the first twenty principal components. Each box plot shows the distribution (weighted by total product revenue) of these percentages across the products in our sample. The first principal component explains 20% of the price variance for the median product, and all the first five principal components explain at least 5% of the price variance. In the bottom panel of Fig. 20 we display box plots of the cumulative percentage of the price variance explained by the top principal components. The top five principal components explain 53% and the top ten principal components explain 68% of the price variance for the median product. Hence, a large percentage of the information in the original store-level price vectors over the 2008-2010 period can be explained by a small number of principal components. A representation of the original, high-dimensional price data in a low-dimensional space is therefore meaningful.
Following the case of Tide HE Liquid Laundry Detergent (100 oz) in Figs. 7 and 8, we present additional examples in Fig. 21, including Prilosec (42 count), Pepsi (12 oz cans 12 pack), and private-label milk (2 percent, 1 gallon). In this graph we only include the store-level price vectors for a subset of all retail chains. For Prilosec and Pepsi we find a pattern that is similar to the case of Tide laundry detergent—a large degree of price similarity within retail chains and a significantly smaller degree of price similarity at the market level. The case of private-label milk is quite different, however, as there is much heterogeneity in prices both at the chain and the market level.
F Overview of promotion coordination
To provide an overview of promotion coordination we summarize the percentage of all stores in a retail chain that promote a specific product during week t.
Promotions are captured using the indicator Djst ∈{0, 1}, such that Djst = 1 if product j is promoted in store s in week t. We calculate the chain/market level promotion percentage for product j:
\(\mathcal {S}_{jcmt}\) includes the stores that belong to retail chain c in market m and carry product j in week t, and \(|\mathcal {S}_{jcmt}|\) is the corresponding number of stores.
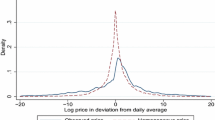
The graphs in the top row of Fig. 22 display histograms of the promotion percentages ϕjcmt, pooled over all products, chains, markets, and time periods between 2008 and 2010 (Table 11 contains detailed summary statistics). The distributions are weighted using total product revenue weights. We display the promotion percentage distributions conditional on ϕjcmt > 0, i.e. weeks when at least one store in chain c and market m promotes the product, to avoid that the histograms are dominated by large mass points at 0. The percentage of observations when none of the stores promoted the product, ϕjcmt = 0, is indicated separately at the bottom of each graph. We define markets as DMAs to ensure that the chains have a sufficiently large number of stores in a local market.Footnote 38 To see why this is important consider the case when a chain has only one local store. Then the promotion percentage is always 0 or 1, indicating perfect promotion coordination. For the same reason, we summarize the promotion percentage distributions only for observations when the retail chain c carries the product in at least five stores in the local market.
The top row in Fig. 22 shows the promotion percentage distributions for all products (left panel) and the top 1,000 products as measured by annual, national product revenue (right panel). Both histograms reveal a large mass point at 1, indicating perfect promotion coordination. The promotion percentages, conditional on ϕjcmt > 0, are overall larger among the top 1,000 products, with a median of 0.548 compared to a median of 0.41 for all products. This indicates a larger degree of promotion coordination among the top-selling products, although the percentage of ϕjcmt = 0 observations is smaller for the top 1,000 products: 55.1% versus 62.2% among all products. However, the latter finding may simply reflect an overall higher promotion frequency among the top 1,000 products, not a smaller degree of coordination on weeks when none of the stores in the chain promote the product.
Although suggestive of promotion coordination, the overall extent of promotion coordination conveyed by Fig. 22 is difficult to assess without a comparison to a baseline where promotions are not coordinated. To provide such a baseline we simulate data assuming that promotions are chosen independently across stores. For each product j and stores s we calculate the promotion frequency πjs using the 2008-2010 data, as in Section 5.2. For each store s and week t we then draw a promotion indicator \(\tilde {D}_{jst}\) from a Bernoulli distribution with success probability πjs. The distributions of promotion percentages for the simulated data are shown in the second row of Fig. 22. The histograms indicate a much smaller degree of promotion coordination compared to the observed promotion percentages. The median promotion percentage among all products in the simulated data is 0.200, compared to 0.41 in the actual data, and the corresponding percentages among the top 1,000 products are 0.279 in the simulated data versus 0.548 in the observed data. Indeed, the displayed distributions understate the difference between the simulated and the original data because they are conditional on ϕjcmt > 0, and hence do not reveal the large difference in observations where none of the stores in a chain promotes a product. In the observed data, ϕjcmt = 0 for 62.2% of all observations, compared to 28.3% of all observations in the simulated data.
The distributions in the top rows of Fig. 22 are based on observations at the chain/market level in a given week, conditional on at least one store in the chain promoting product j. This leads to an asymmetry between observations with highly coordinated promotions and observations with a small number of stores promoting a product. For example, suppose that all promotions were perfectly coordinated within a retail chain, such that ϕjcmt = 1 in the week when the promotion is held. Suppose there were some small differences in the timing of the end date of the promotion across stores in the chain, such that a small number of stores would still offer the promotion for a few days in week t + 1. Then each perfectly coordinated promotion observation, ϕjcmt = 1, would have an associated observation with a small, positive ϕjcm, t+ 1 value, suggesting that perfectly coordinated promotion events were as frequent as almost completely uncoordinated promotion events. Hence, as an alternative summary of promotion coordination we associate each store-level promotion event, Djst = 1, with the corresponding promotion percentage, ϕjcmt, and display the distribution of the promotion percentages based on all store level observations such that Djst = 1. This is equivalent to displaying the distribution of ϕjcmt weighted by the number of stores that promote product j in chain c and market m in week t. The results are shown in the third row of Fig. 22 (Table 11 contains detailed numbers), and strongly indicate that store-level promotions are coordinated at the chain-market level. Furthermore, the differences between the actual and simulated data, shown in the bottom row of Fig. 22, are large.
G Bayesian hierarchical demand model
This section provides an overview of the Bayesian hierarchical linear regression model to estimate the brand/store-level demand parameters. See Rossi et al. (2005), Chapter 3.7, for a detailed exposition of the model and the MCMC sampling approach.
The goal is to obtain the posterior distribution of the demand parameters for brand j and store s in model (4). The store-level parameter vector 𝜃js = (αjs,βjs, γjs) includes the intercept, αjs, the own and cross-price elasticities, βjks, and the promotion parameters, γjks. We do not estimate the large number of 3-digit ZIP code/time fixed effects, τj(s, t), as part of the Bayesian hierarchical model. Instead, we first project all variables in the demand model, \(\log (1+q_{jst})\), \(\log (p_{kst})\), and Dkst, on the fixed effects. We then use the residuals from this projection to estimate the store-level demand parameters in the model:
𝜖jst is i.i.d. across stores and time. From now on we drop the brand index j to simplify the notation.
We specify a normal first-stage prior or population distribution for the the store-level demand parameters, 𝜃s:
The parameter vectors for different stores are conditionally independent, given μ and V𝜃. More flexible priors are possible, such as a mixture of normal distributions, which has been used in the literature (Rossi et al., 2005).
We further specify the second-stage prior distribution of V𝜃 and μ:
IW denotes an inverse Wishart distribution. The error term variances, \({\sigma _{s}^{2}}\), are independent draws from an inverse chi-squared distribution,
Here, ν𝜖 denotes the degrees of freedom and \({r_{s}^{2}}\) is a scale parameter.
The MCMC algorithm to obtain the posterior distribution of the model parameters is performed using Peter Rossi’s bayesm packageFootnote 39 in R. We run the algorithm using the default settings for the hyper-parameters in the bayesm package. These settings allow for a diffuse prior:
Here, n is the dimension of the parameter vector 𝜃s.
We choose a chain length of 20,000 (after 2,000 initial burn-in draws) and keep every 10th draw to calculate the posterior means and the 95% credible intervals of the parameters. A visual inspection of the trace plots for a large number of randomly selected parameters (across brands and stores) indicates convergence of the chain.
H Causal price and promotion effects: Sensitivity analysis
Price and promotion endogeneity occurs if the retail chains set prices or promotions based on demand shocks that are observed to them but not to us. To avoid endogeneity bias we include time-invariant store fixed effects αjs in the demand model (4). The store fixed effects account for systematic demand differences across stores that are associated with systematic differences in prices and promotions. Further, we include the market/time fixed effects τj(s, t) to account for demand shocks and brand-specific trends in demand at a narrowly defined geographic level.
We can interpret the price and promotion estimates as causal if (i) τj(s, t) captures all time-varying demand components that may be correlated with pkst and Dkst, (ii) there is variation in the price and promotion changes over time across stores, and (iii) the difference in price and promotion changes across stores reflects store or chain-specific changes in costs, wholesale prices, markups, or other factors that affect prices and promotion but not directly demand. These assumptions are not directly testable, but we can perform an analysis to indicate if our estimates are sensitive to the inclusion and exact specification of the fixed effects. Thus, we first estimate demand without fixed effects, and then including τj(s, t) defined at the 3-digit ZIP code/quarter, 3-digit ZIP code/month, and 3-digit ZIP code/week levels.
The estimated distributions of the price effects are shown in Fig. 24 and summarized in Table 12. The median elasticity estimate is -1.767 in the model without fixed effects, -1.924 in the model with 3-digit ZIP code/quarter fixed effects, -1.93 with 3-digit ZIP code/month fixed effects, and -1.859 with 3-digit ZIP code/week fixed effects. Hence, controlling for time fixed effects at the local market level moderately changes the distribution of the estimates, and the direction of this change is consistent with price endogeneity if positive demand shocks are correlated with higher prices. However, the elasticity estimates are not particularly sensitive to the exact choice of fixed effects, and the direction of the change in the estimated elasticities when we use year-month or year-week fixed effects instead of year-quarter fixed effects is not indicative of a price endogeneity problem. For a severe price endogeneity problem to exist it would have to be true that there are high-frequency demand shocks that occur at level that is more local than a 3-digit ZIP code area, and that the store or chain managers are able to predict these shocks and correspondingly change prices. This seems a priori implausible, and in particular such localized price-setting is inconsistent with the strong similarity in price and promotion patterns at the retail chain level that we document.

Predicted base prices, Tide liquid laundry detergent (70 oz)

Predicted base prices, Kellogg’s Raisin Bran (20 oz)

Cumulative revenue for top 100,000 products

Product and brand availability across stores and retail chains. Note: The graph displays the distribution of the number of stores (the two columns to the left) and chains (the two columns to the right) at which a product or brand is available. The median of each distribution is indicated using a vertical line. A product (brand) is classified as available if it was sold at least once in a store or chain in 2010. The sample includes 17,184 stores and 81 retail chains

Base prices dispersion statistics: Brand-level base prices

Percentage and cumulate percentage of price variance explained by principal component

Projected store-level price vectors colored by retail chain and DMA

Distribution of chain/DMA promotion percentages

Promotion coordination regression results: Promotion incidence and inside and outside promotion percentages

Own-price elasticity estimates for different fixed effects definitions
Rights and permissions
About this article

Cite this article
Hitsch, G.J., Hortaçsu, A. & Lin, X. Prices and promotions in U.S. retail markets. Quant Mark Econ 19, 289–368 (2021). https://doi.org/10.1007/s11129-021-09238-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11129-021-09238-x