
Abstract
Fixed-effects modeling has become the method of choice in several panel data settings, including models for stochastic frontier analysis. A notable instance of stochastic frontier panel data models is the true fixed-effects model, which allows disentangling unit heterogeneity from efficiency evaluations. While such a model is theoretically appealing, its estimation is hampered by incidental parameters. This note proposes a simple and rather general estimation approach where the unit-specific intercepts are integrated out of the likelihood function. We apply the theory of composite group families to the model of interest and demonstrate that the resulting integrated likelihood is a marginal likelihood with desirable inferential properties. The derivation of the result is provided in full, along with some connections with the existing literature and computational details. The method is illustrated for three notable models, given by the normal-half normal model, the heteroscedastic exponential model, and the normal-gamma model. The results of simulation experiments highlight the properties of the methodology.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Fixed-effects models are prominent in modern panel data econometrics since they adjust for unit heterogeneity, potentially correlated with the covariates. The robustness of fixed-effects models is rather important in stochastic frontier analysis, which explains the popularity of the true fixed-effects stochastic frontier model (Greene 2005a, b). For a production frontier model, the specification of the true fixed-effects model is given by
where i is the index for the unit of the panel (i = 1, …, n) and t is the index for time (t = 1, …, T), with T assumed to be the same across units without loss of generality. Here yit is the output and xit is a vector of exogenous inputs, both possibly in log form, β is a vector of coefficients and αi the unit fixed effect. In the following, we will also employ yi and Xi to denote the vector of outputs and the matrix of inputs for the i-th panel member, respectively. Furthermore, uit is the one-sided inefficiency term, and vit is the symmetric idiosyncratic error, independent of uit. A simple change in the sign of uit is required for a cost frontier model specification. We assume conditional independence (given αi and xi1, …, xiT) of observations within the same panel member and independence across units. Finally, we denote by θ the set of structural model parameters, given by β plus all the parameters entering the distribution of the error term εit = vit − uit.
The introduction of the unit-specific intercepts αi is the key to disentangle heterogeneity from efficiency, but at the same time, when the intercepts are estimated jointly with the other model parameters, the incidental parameters issue arises; see, for example, Bartolucci et al. (2016). In short, αi is consistently estimated only for T → ∞. For finite T, the resulting bias accumulates across panel members, and it propagates to θ, thus affecting the efficiency evaluation for settings with short panels. Therefore, some caution is required when estimating the structural parameters.
There are some proposals in the econometric literature that overcome the incidental parameters problem for some notable true fixed-effects model specifications, but they all rely on specific distributional properties. This note aims to present a simple and \(\sqrt{n}\)-consistent estimation method that could be effectively applied to a broad array of distributions for εit. Moreover, it provides an efficient estimator which is at least as efficient as existing consistent estimators.
The outline of this note is as follows. Section 2 reviews the econometric literature on consistent estimation of true fixed-effects models. The proposal is presented in Section 3, where mathematical support is provided. Some numerical studies are reported in Section 4, including an application to the challenging normal-gamma model. Section 5 provides a brief discussion.
2 Background
A marginal maximum likelihood estimation for model (1) is developed in Chen et al. (2014) paralleling the usual derivation of the within estimator for linear models. In particular, the authors consider the deviation of each term of the model from the unit mean and then maximize the within likelihood defined on the (T − 1) deviations of the error term for the i-th unit. The method is specific to the normal-half normal model where the components of εit are half normally distributed \({u}_{it} \sim {N}^{+}(0,{\sigma }_{u}^{2})\), and normally distributed \({v}_{it} \sim N(0,{\sigma }_{v}^{2})\), respectively. Using the results from the multivariate closed skew normal distribution (see González-Farías et al. 2004, and the references therein), they show that neglecting a constant additive term, the within log-likelihood function is
where ϕm(⋅) and Φm(⋅) denote the density function and the CDF of the m-dimensional normal distribution, \({\sigma }^{2}={\sigma }_{u}^{2}+{\sigma }_{v}^{2}\), and λ = σu/σv. Further, the notation \(\tilde{{{{\boldsymbol{X}}}}}\) denotes the within transformation of the m-dimensional vector x, namely the deviation of the m values of x from its the sample mean, whereas the notation \({\tilde{{{{\boldsymbol{X}}}}}}^{* }\) denotes that only the first m − 1 such values are retained. Finally, 0m is a vector of m zeros, Im is the identity matrix of size m, and Em is a m × m matrix of ones. The expression (2) is free of αi, and its maximizer defines the maximum marginal likelihood estimator (MMLE), which is consistent for increasing n regardless of the value of the panel length T. Wang and Ho (2010) define a similar estimator, but for a different model where uit = ui hit, with hit being a non-random function of some covariates, and assuming ui half normally distributed. See also Kutlu et al. (2020).
Another contribution is Wikström (2015), who defines a method-of-moments estimator and provides a simulation study for the same model considered by Chen et al. (2014). The proposal has some interesting properties, such as its logical simplicity. On the other hand, it is likely to be less efficient than the MMLE since the latter is based on a marginal likelihood (see Pace and Salvan 1997, Chap. 4), and the method of moments is at times prone to numerical instabilities, as testified by the “problematic replications” reported in Wikström (2015).
Belotti and Ilardi (2018) provide some notable estimation strategies. Among other things, they note that the proposal in Chen et al. (2014), exploiting the closure property of the skew normal distribution, could be applied to some extensions of the normal-half normal model, including the truncated normal distribution for the inefficiency term, heteroscedasticity, and autocorrelation between different inefficiencies. They also note that while the T-dimensional normal CDF involved in the log-likelihood (2) can be reduced to a one-dimensional integral, the within log-likelihood for such extensions would involve an irreducible T-dimensional normal CDF, whose computation for large panel lengths may become cumbersome. Hence, they propose another estimator, the pairwise difference estimator (PDE).
The PDE is the maximizer of an objective function involving the distribution of all the differences between pairs of observations belonging to the same panel member, much in the spirit of composite likelihood estimation (Varin et al. 2011). The results reported by Belotti and Ilardi (2018) illustrate the \(\sqrt{n}\)-consistency of the proposal, which is, however, feasible only for truncated normal or exponential inefficiency terms.
Finally, we note that Belotti and Ilardi (2018) propose another estimator, the marginal maximum simulated likelihood estimator (MMSLE), which approximates the MMLE by simulation, also covering some heteroscedastic extensions not considered by Chen et al. (2014). The simulations in Belotti and Ilardi (2018) show that the MMSLE is a good approximation to the MMLE for the normal-half normal model. At any rate, while theoretically interesting, its Monte Carlo nature makes it less appealing than the original MMLE.
3 Estimation via marginal likelihood
A general solution for consistent estimation of the structural parameters θ proceeds by noting that given the sample for the i-th unit, αi acts as a location parameter.
We start by considering the order statistics for the i-th panel member \(({y}_{i(1)},\ldots ,{y}_{i(T)})\), from which we define the following data vector
It is straightforward to verify that the distribution of si is free of the unit-specific intercept αi, which is eliminated by pivoting on the smallest observation. This suggests the following marginal likelihood for θ
where fS(si; θ) is the density of si. The remaining task is to obtain an analytic expression for fS(si; θ). To this end, we rely on the theory of composite group families. In particular, we follow the same steps as Pace and Salvan (1997, Theorem 7.5)Footnote 1 to express the marginal likelihood (aside from a constant factor) as
where fY(yit; αi, θ) is the density function of yit, from which we readily define the marginal log-likelihood \({\ell }_{{{{\rm{M}}}}}({{{\boldsymbol{\theta }}}})=\log {L}_{{{{\rm{M}}}}}({{{\boldsymbol{\theta }}}})\). The expression (4) greatly facilitates the task of obtaining the marginal likelihood based on (3), which would be otherwise rather involved to obtain directly. The only issue is the approximation of the one-dimensional integrals in (4), for which we provide some guidelines in what follows. Moreover, note that the expression (4) requires the density fY(yit; αi, θ) of the response variable yit, that in most cases is not difficult to obtain; at any rate, the example in section 4.3 illustrates how to proceed when this is not the case.
Since ℓM(θ) is a marginal log-likelihood based on n independent data vectors, it can be treated as a bona fide log-likelihood function for θ. Hence its maximizer is \(\sqrt{n}\)-consistent and the inverse of its negative Hessian evaluated at the maximizer is a valid estimate of the sampling variance. Note that for an incidental parameter of a different nature than a location parameter, the elimination through integration as in (4) may not provide any improvement on the incidental parameter bias; see Schumann et al. (2021) and the references therein. We note in passing that the marginal likelihood (4) is an instance of a class of integrated likelihood functions studied in Arellano and Bonhomme (2009). A connection between the results presented here and the theory of the latter paper is illustrated in Appendix B.
The marginal likelihood in (4) provides a rather general and relatively simple estimation approach without needing specific distributional properties. As a general fact in the frontier specification, the integrals in (4) do not have a closed-form solution, and they must be approximated by numerical methods. For panel data settings, however, the n integrals must be approximated with high accuracy; otherwise, the error in the approximation accumulates across panel groups. For this reason, we endorse the use of adaptive Gaussian quadrature (Liu and Pierce 1994) with Q quadrature points, which gives the following approximation to ℓM(θ) (neglecting a constant additive term)
where zq and wq are the Gauss-Hermite quadrature nodes and weights. Furthermore, \({z}_{q}^{* }\) are the adjusted nodes \({z}_{q}^{* }=\sqrt{2}\,{{{{\rm{se}}}}}_{i}({{{\boldsymbol{\theta }}}})\,{z}_{q}+{\widehat{\alpha }}_{i}({{{\boldsymbol{\theta }}}})\), where \({\widehat{\alpha }}_{i}({{{\boldsymbol{\theta }}}})\) is the mode of \(\sum_{t = 1}^{T}\log {f}_{Y}({y}_{it};{\alpha }_{i},{{{\boldsymbol{\theta }}}})\) in αi, and sei(θ) is the reciprocal of the squared root of the second derivative of \(-\sum_{t = 1}^{T}\log {f}_{Y}({y}_{it};{\alpha }_{i},{{{\boldsymbol{\theta }}}})\) with respect to αi, evaluated at \({\widehat{\alpha }}_{i}({{{\boldsymbol{\theta }}}})\).
The important advantage of the approximation (5) is that, by tuning Q, we can keep the approximation error under strict control. Indeed, having a \(\sqrt{n}\)-consistent estimator as a target, it seems reasonable to aim for an approximation error smaller than the inferential error n−1/2. Following Stringer and Bilodeau (2022), we should choose Q at least equal to \(\lceil (3/2){\log }_{T}(n)-2\rceil\), where ⌈⋅⌉ is the ceiling function. For instance, for T = 5, which is the smallest panel length considered in the aforementioned stochastic frontier literature, the latter formula implies that around 10 quadrature points are sufficient for n as large as 100,000. All the results of the next section were obtained with Q = 25, well above the required number, and indeed, we cross-checked the high accuracy of the approximation by comparison with the more computationally expensive Gauss-Kronrod quadrature.
4 Some notable models
In this section, we apply the Integrated Likelihood Estimator (ILE) defined by the maximizer of (4) to some models of interest.
4.1 The normal-half normal model
A fundamental model is the normal-half normal model, studied by both Chen et al. (2014) and Belotti and Ilardi (2018). For the case where \({u}_{it} \sim {{{{{N}}}}}^{+}(0,{\sigma }_{u}^{2})\) and \({v}_{it} \sim N(0,{\sigma }_{v}^{2})\), we followed these authors and considered the same single-input simulation scenario. Since we found that the ILE matches the MMLE for all the model parameters with high numerical accuracy, we do not report any results here. The equivalence between ILE and MMLE is encouraging since the latter is a benchmark estimator for the normal-half normal TFE model. Notice that the same equivalence occurs in the case of panel data models with fixed effects and normal errors (Schumann et al. 2021).
We end this example by noting that for the extension to truncated normal inefficiency coupled with heteroscedasticity, the computation of MMLE would require the evaluation of the T-dimensional normal CDF, with a computational burden increasing with the group size. On the contrary, the marginal likelihood (4) would retain the same order of complexity.
4.2 The heteroscedastic exponential model
This is another example considered in Belotti and Ilardi (2018), for which the PDE provides good estimation performance. Here we assume \({u}_{it} \sim {{{\mathcal{E}}}}({\sigma }_{iu})\) and \({v}_{it} \sim {{{{N}}}}(0,{\sigma }_{v}^{2})\), where \({\sigma }_{iu}=\exp ({\gamma }_{0}+{z}_{i}\,{\gamma }_{1})\). With such a specification, and after setting \({r}_{it}={y}_{it}-{\alpha }_{i}-{{{{\boldsymbol{x}}}}}_{it}^{\top }{{{\boldsymbol{\beta }}}}\), the density of each observation of the i-th panel member becomes
We focus here on some of the simulation experiments reported in Belotti and Ilardi (2018) and compared our implementation of the ILE with the PDE; the latter was computed using the Stata code made available by Belotti et al. (2013).
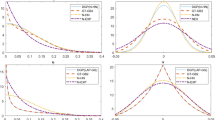
Plots in Fig. 1 display the results based on 1000 simulated datasets for the same simulation scenario of section 6.1 in Belotti and Ilardi (2018), with the setting corresponding to their Table 1, namely n = 100, T = 5, and “signal to noise ratio” set to 1; this setting was chosen since it is the most challenging, but the results for the other settings are rather similar and are reported in the Supplementary Material. The two estimators may differ on a sample-by-sample basis, yet they exhibit very little bias (if any). The ILE slightly outperforms the PDE in terms of MSE since it is based on a marginal likelihood rather than a pairwise likelihood, yet the difference in efficiency is small.

4.3 The normal-gamma model
As mentioned at the outset, the important property of the proposal (4) is its broad generality, and to illustrate this point, we consider here the normal-gamma model. First introduced by Greene (1990), this model has been somewhat underused in applications since it involves computations that are notoriously challenging; see Ritter and Simar (1997), Tsionas (2000), Greene (2003) and the references therein. To the best of our knowledge, the normal-gamma model has never been adopted for the true fixed-effects stochastic frontier model. While the results of Ritter and Simar (1997) illustrate the difficulties that may arise in estimating the efficiency parameters, they also suggest that estimation issues are much less severe with large sample sizes. Since, in the setting of interest, we can glean information about the efficiency parameter from n panel units, the total number of observations may be large enough for meaningful estimation. A similar positive note comes from the Bayesian inferential approach in Tsionas (2000), where it is reported that for a normal-gamma model with a total sample size of 1000, “results are satisfactory”.
The model assumes \({u}_{it} \sim {{{\mathcal{G}}}}(\gamma ,\lambda )\) and \({v}_{it} \sim N(0,{\sigma }_{v}^{2})\). The model density requires the numerical approximation of an integral; letting again \({r}_{it}={y}_{it}-{\alpha }_{i}-{{{{\boldsymbol{x}}}}}_{it}^{\top }{{{\boldsymbol{\beta }}}}\), the density of each observation of the i-th panel member is
For the ILE, this implies that a double integral is required, and a meticulous numerical implementation is called for. Our strategy entails coding the normal-gamma convolution integral (6) in C++ using adaptive Gauss-Kronrod quadrature with a large number of nodes, plus other steps required for successful implementation of the approximation (5); further details are provided in the Supplementary Material. A fact worth mentioning is that the numerical optimization of the log-likelihood (5) is best achieved with the re-parameterization in which γ and σv are replaced by the mean and the standard deviation of the gamma term, namely
The fact that very high accuracy is required for both the inner and outer integrals involved in the log-likelihood function makes its optimization rather expensive; while other models are estimated in a matter of seconds, the estimation of the normal-gamma model may take several minutes.
Figure 2 summarizes the estimation results for 1000 data sets at each of four different settings, with the true efficiency parameter values set at γ = 2, λ = 1 and σv = 0.25. This choice of parameters avoids the “relatively difficult” case where γ < 1 (Tsionas 2000), for which, in our settings, the optimization becomes far too slow for a Monte Carlo study. Note that the minimum total sample size considered is 1250: compared to the previous example, the results for the setting n = 100 and T = 5 are not reported, since the estimation turned out to be unreliable.

Normal-gamma model. Boxplots of ILE results in four different settings, with horizontal lines corresponding to the true parameter value
Despite the challenging estimation, the results are reasonably satisfactory since the distribution of each of the estimators has a median matching the true parameter value in all cases, and it becomes more concentrated around it when the total sample size increases. Though the two settings n = 500, T = 5 and n = 250, T = 10 have the same total sample size, the latter shows slightly better results.
Another useful point concerns the possibility of distinguishing the gamma model from simpler ones. A natural competitor is the normal-exponential, which is obtained as a special case of the model of section 4.2. Table 1 reports the estimated power for a fixed level α = 0.05 of the log-likelihood ratio test for the hypothesis γ = 1, i.e., the test of exponentiality
where \(\widehat{{{{\boldsymbol{\theta }}}}}\) is the estimator from the normal-gamma model and \({\widehat{{{{\boldsymbol{\theta }}}}}}_{0}\) the estimator from the normal-exponential model. This is a power computation since the data were generated under the normal-gamma model with γ = 2.
The results suggest that while the setting n = 100 and T = 5 is very far from being suitable to distinguish the gamma model from the exponential one, things get progressively better for the four settings reported in Fig. 2.
5 Discussion
The estimator based on the marginal likelihood obtained by integrating out the panel-specific intercepts in the true fixed-effects stochastic frontier model represents a simple and efficient methodology. The proposal recovers the existing consistent estimators whenever available and can provide a useful solution in other cases. It seems worth noting that the same strategy where group-specific intercepts are integrated out may be relevant to other fixed-effects panel data models with continuous response as an alternative to differencing, providing a \(\sqrt{n}\)-consistent estimator and avoiding any issue related to the size of T.
The ILE may also be useful in connection with four-component panel stochastic frontier models; see Kumbhakar and Lai (2022) for a recent review. Such models include two random group-specific effects in place of αi in (1), namely αi = τi − ηi, where τi is a group effect and ηi is the persistent inefficiency components. Such an approach allows for more informative efficiency evaluations than the true fixed-effects setting, at the expense of stronger distributional specifications. For those researchers willing to adopt the four-component specification, a recommended approach may be to supplement the analysis with the estimates of several alternative models along the lines of what was done by Kumbhakar et al. (2014). We endorse the inclusion of the true fixed-effects model among the array of considered specifications since its robust nature will provide some coverage against input endogeneity issues. A simple comparison of the estimates of structural parameters and estimated inefficiencies across several models could then provide some valuable information. To this end, the availability of resources for true-fixed effects analysis, including software, may represent a useful addition.
In closing, among possible directions for extension of the current paper, we mention the adoption of other distributions for the inefficiency term or the inclusion of semiparametric effects for the production or cost function, along the lines of the proposal in Bellio and Grassetti (2011). The implementation of the latter, however, would require special care.
6 Software
A public repository with R code for fitting the models presented in this note is available at github.com/lucagrassetti/ilsfa.
Notes
Reported in Appendix A
References
Arellano M, Bonhomme S (2009) Robust priors in nonlinear panel data models. Econometrica 77:489–536
Bartolucci F, Bellio R, Salvan A, Sartori N (2016) Modified profile likelihood for fixed-effects panel data models. Econ Rev 35:1271–1289
Bellio R, Grassetti L (2011) Semiparametric stochastic frontier models for clustered data. Comput Stat Data Anal 55:71–83
Belotti F, Daidone S, Ilardi G, Atella V (2013) Stochastic frontier analysis using Stata. Stata J 13:719–758
Belotti F, Ilardi G (2018) Consistent inference in fixed-effects stochastic frontier models. J Econ 202:161–177
Chen Y-Y, Schmidt P, Wang H-J (2014) Consistent estimation of the fixed effects stochastic frontier model. J Econ 181:65–76
González-Farías G, Domínguez-Molina A, Gupta AK (2004) Additive properties of skew normal random vectors. J Stat Plan Inference 126:521–534
Greene WH (1990) A gamma-distributed stochastic frontier model. J Econom 46:141–163
Greene WH (2003) Simulated likelihood estimation of the normal-gamma stochastic frontier function. J Prod Anal 19:179–190
Greene WH (2005)a Fixed and random effects in stochastic frontier models. J Prod Anal 23:7–32
Greene WH (2005)b Reconsidering heterogeneity in panel data estimators of the stochastic frontier model. J Econ 126:269–303
Kumbhakar SC, Lai H-P (2022) Recent advances in the panel stochastic frontier models: Heterogeneity, endogeneity and dependence. Int J Empir Econ 01:2250002
Kumbhakar SC, Lien G, Hardaker JB (2014) Technical efficiency in competing panel data models: a study of Norwegian grain farming. J Prod Anal 41:321–337
Kutlu L, Tran KC, Tsionas MG (2020) Unknown latent structure and inefficiency in panel stochastic frontier models. J Prod Anal 54:75–86
Liu Q, Pierce DA (1994) A note on Gauss-Hermite quadrature. Biometrika 81:624–629
Pace L, Salvan A (1997) Principles of statistical inference: from a neo-fisherian perspective (World Scientific, Singapore).
Ritter C, Simar L (1997) Pitfalls of normal-gamma stochastic frontier models. J Prod Anal 8:167–182
Schumann M, Severini TA, Tripathi G (2021) Integrated likelihood based inference for nonlinear panel data models with unobserved effects. J Econ 223:73–95
Stringer A, Bilodeau B (2022) Fitting generalized linear mixed models using adaptive quadrature. arXiv. 2202.07864.
Tsionas EG (2000) Full likelihood inference in normal-gamma stochastic frontier models. J Prod Anal 13:183–205
Varin C, Reid N, Firth D (2011) An overview of composite likelihood methods. Stat Sin 21:5–42
Wang H-J, Ho C-W (2010) Estimating fixed-effect panel stochastic frontier models by model transformation. J Econ 157:286–296
Wikström D (2015) Consistent method of moments estimation of the true fixed effects model. Econ Lett 137:62–69
Acknowledgements
A very preliminary version of this work was presented at the 35th International Workshop on Statistical Modelling (IWSM), held online in July 2020. The authors are very grateful to Luigi Pace for insightful comments. We are also grateful to the Editor, the Associate Editor, and two Reviewers for valuable comments and suggestions. This work was supported by the Departmental Strategic Plan (PSD) of the University of Udine, Department of Economics and Statistics (2022-2025).
Funding
Open access funding provided by Università degli Studi di Udine within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Contributions
Ruggero Bellio mainly contributed to the theoretical investigation and model specification (sections 1, 3, and the appendices) and contributed to the code writing. Literature review, further code writing (software repository), and analysis were performed by Luca Grassetti (sections 2 and 4). Ruggero Bellio wrote the first draft of the manuscript, and Luca Grassetti performed text review and editing. All authors read and approved the final manuscript and contributed to the conclusions.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Appendices
Appendix A: Inference based on the integrated likelihood
We need to show that marginal likelihood based on si in expression (3) of the main paper equals the integrated likelihood
To this end, we follow the same steps of the proof of Theorem 7.5 of Pace and Salvan (1997), which covers an even more complex setting for location and scale transformations.
Before proceeding, note that since αi is a location parameter and \({{{{\boldsymbol{x}}}}}_{it}^{\top }{{{\boldsymbol{\beta }}}}\) acts on the location as well, we can define f0(⋅) such that
where ψ denotes the set of structural parameters without β, i.e., θ = (β, ψ).
First, we perform a sufficiency reduction to the order statistic for the i-th unit in the panel \(\left({y}_{i(1)},\ldots ,{y}_{i(T)}\right)\), having density
Since the distribution of si does not depend on αi, without losing generality we may assume αi = 0, and the distribution (A.3) becomes
The next step is to consider the one-to-one transformation
having inverse
and unitary Jacobian. It follows that
from which we can integrate out zi to obtain the marginal distribution of si
Furthermore, note that the constant T! can be omitted in the likelihood definition, and then we proceed with another change of variable ui = zi − yi(1), for i = 1, …, n, having again unitary Jacobian. With some simple algebra, we obtain
A further change of variable αi = − ui finally gives the result (A.1), using again the identity (A.2), so that
Appendix B: Relation to the results in Arellano and Bonhomme (2009)
The integrated likelihood (4) corresponds to the choice of the uniform prior according to Arellano and Bonhomme (2009). The fact that it corresponds to the marginal likelihood obtained from the distribution of (3) implies that the uniform prior resolves the incidental parameter issue, and this, in turn, must imply that condition (11) in the cited article holds. In what follows, we illustrate that this is the case.
As reminded by the authors, to prove this fact, it suffices that ρi(θ, αi) does not depend on αi, where ρi(θ, αi) is the following vector
with \({i}_{{{{\boldsymbol{\theta }}}}{\alpha }_{i}}({{{\boldsymbol{\theta }}}},{\alpha }_{i})\) and \({i}_{{\alpha }_{i}{\alpha }_{i}}({{{\boldsymbol{\theta }}}},{\alpha }_{i})\) denoting the θαi-block and the αiαi-block of the expected Fisher information matrix, respectively.
The fact that the expected Fisher information does not depend on αi is straightforward to verify. To this aim, let us consider the log-likelihood function for the i-th unit corresponding to the TFE model (1), using again the identity (A.2)
From this, we obtain the score function for αi
where \({f}_{0}^{{\prime} }(z;{{{\boldsymbol{\psi }}}})=\partial {f}_{0}(z;{{{\boldsymbol{\psi }}}})/\partial z\), and then the αiαi-block of the observed information matrix
where again \({f}_{0}^{{''} }(z;{{{\boldsymbol{\psi }}}})={\partial }^{2}{f}_{0}(z;{{{\boldsymbol{\psi }}}})/\partial {z}^{2}\). Note that we can write
for a suitable q(⋅; ψ) function. Then
from which we make a change of variable \({r}_{it}={y}_{it}-{\alpha }_{i}-{{{{\boldsymbol{x}}}}}_{it}^{\top }{{{\boldsymbol{\beta }}}}\), obtaining
which shows that \({i}_{{\alpha }_{i}{\alpha }_{i}}({{{\boldsymbol{\theta }}}},{\alpha }_{i})\) is a function of ψ only. Similarly, we obtain that the \({i}_{{{{\boldsymbol{\theta }}}}{\alpha }_{i}}({{{\boldsymbol{\theta }}}},{\alpha }_{i})\) depends on ψ only, and so does ρi(θ, αi).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bellio, R., Grassetti, L. Efficient estimation of true fixed-effects stochastic frontier models. J Prod Anal 62, 111–118 (2024). https://doi.org/10.1007/s11123-024-00725-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-024-00725-3