
Abstract
A well-known and successful algorithm to compute the singular value decomposition (SVD) of a matrix was published by Golub and Reinsch (Numer. Math. 14:403–420, 1970), together with an implementation in Algol. We give an updated implementation in extended double precision arithmetic in the C programming language. Extended double precision is native for Intel x86 processors and provides improved accuracy at full hardware speed. The complete program for computing the SVD is listed. Additionally, a comprehensive explanation of the original algorithm of Golub and Reinsch (Numer. Math. 14:403–420, 1970) is given at an elementary level without referring to the more general results of Francis (Comput. J. 4:265–271, 1961, 1962).
Similar content being viewed by others


1 Introduction
The IEEE floating point standard, chiefly designed by William Kahan, recommends that hardware implementations should provide an extended precision data format. This is put into effect for x86-64 processors, which provide a native 80-bit extended double precision data format. Higher precisions will be provided in the future [4, p. 43]. In 80-bit extended double precision data format, the significand comprises 64 bits and thus 11 bits more than does the standard IEEE double precision format. In the C programming language, the type specifier long double is reserved for declaration of extended double precision variables. Some compilers, like the GNU compiler, Clang, and Intel’s C/C++ compiler, implement long double using 80-bit extendend double precision numbers on x86-architectures. Extended double precision thus becomes easily available for computations and should be used, as it offers improved accuracy at full computational speed. We give a C implementation of the singular value decomposition (SVD) in extended double precision arithmetic. The program ist based on the algorithm published by Golub and Reinsch in [3].
Let \(A\in \mathbb {R}^{m,n}\) a real m × n matrix, let \(\ell :=\min \limits \{m,n\}\). It is well known that
where \(U\in \mathbb {R}^{m,m}\), \({\Sigma }\in \mathbb {R}^{m,n}\), and \(V\in \mathbb {R}^{n,n}\) such that
all other elements of Σ being zero. The numbers σ1,…, σℓ are the non-negative square roots of the ℓ largest eigenvalues of ATA. We shall assume that
The computation of U, V, and Σ splits into two parts. The first part is a reduction of A to a bidiagonal matrix. The second part is an implicit application of the QR algorithm (with shifts) to this bidiagonal matrix. We describe bidiagonalization in Section 2. Section 3 is a reminder about the QR algorithm for tridiagonal symmetric matrices and gives an elementary explanation of Francis’ method to use implicit shifts. Section 4 explains how QR steps can implicitly be performed on a bidiagonal matrix. Section 5 gives details on how to compute the shift parameter reliably and Section 6 gives a stopping criterion for the QR iteration. Section 7 outlines how to arrange for computations in extended precision and in Section 8, a complete C function for computing the SVD is given. Test cases are investigated in Section 9 and we conclude in Section 10.
2 Bidiagonalization
A = (ai, j) is a real matrix with m rows i = 0,…, m − 1, counting down from top to bottom, and with n columns j = 0,…, n − 1, counting across from left to right.
With the pair of rows 0 and i = 1,…, m − 1 we do the plane rotations from left
overwriting the old with the new values.Footnote 1 We choose \(\cos \limits \) and \(\sin \limits \) as follows: let \(p:=a_{0,0},\ q:=a_{i,0},\ r:=\pm \sqrt {p^{2}+q^{2}}\) with same sign as p, \(\cos \limits =p/r\) and \(\sin \limits =q/r\). (\(\cos \limits =1, \sin \limits =0\) if q = 0). Then ai,0 gets eliminated, i.e., its new value is 0. Note that plane rotations from left leave the sum of squares in a column invariant. Thus while ai,0 gets annihilated, \(a_{0,0}^{2}\) gets bigger. Indeed, the erasing is more some sort of collecting. After i = m − 1, \(a_{0,0}^{2}\) is positive unless A has a zero column. In the same way we do with the pair of columns 1 and j = 2,…, n − 1 plane rotations from right
again overwriting the old with the new values.Footnote 2 Thus we do not only generate zeros in the leftmost column but also zeros in the top row after the first two entries, which here are called d0 and e1. Plane rotations from right leave the sum of squares in a row invariant, thus \({d_{0}^{2}}+{e_{1}^{2}}>0\) unless there is a zero row.
Such plane rotations either from left or from right in order to erase a selected matrix entry are called Givens rotations. Together, we have the main step number one. More such main steps follow, all a repetition of the first one, but each time with another column and another row less.
Let us assume for the moment that m ≥ n. Then, with n − 1 such main steps we can reduce the matrix A to bidiagonal form B. Ignoring the trivial (zero) rows i = n,…, m − 1, one has
With e0 := 0 each column of B has the same form. The remaining B is quadratic with \(\det (B)=d_{0}{\cdots } d_{n-1}\) and \(\det (B^{T}\!B)={d_{0}^{2}}{\cdots } d_{n-1}^{2}\).
If required, we accumulate all plane rotations from left in UT and all plane rotations from right in V. These are orthogonal matrices of order m and n. It is helpful for understanding the coming steps to extend the m × n matrix A to the right by the m × m unit matrix Im and down by the n × n unit matrix In. With these two extensions we have a working area with m + n rows/columns of length m + n. At the beginning it is
where A = UBVT. After the plane rotations from left and right it is
All steps of the second part of the algorithm (to be described below) follow this scheme of applying plane rotations from left and right to further reduce B to diagonal form Σ while updating UT and V.
The case m < n had been omitted in the Algol program published in [3], but is included now. It is best to consider AT and to apply the algorithm to the n × m matrix AT. Anyway, as described in Section 7, a copy of A in extended precision format is needed. At the moment this copy is created, one may as well copy AT. The C function given in Section 8 does so and then computes VT instead of UT and U instead of V. It is easy to take this swap into account when returning the matrices U and V. Therefore, we may continue to assume m ≥ n in the following.
The present version of the SVD uses exclusively plane rotations. All Householder reflections from the version of 1967 [3] have been replaced, although they need only half the number of multiplications. But plane rotations will be needed in the second part of the algorithm and can all be done by calling two functions, viz.
- PREPARE() :
-
to compute the desired values \(\cos \limits \) and \(\sin \limits \) for the next plane rotation,
- ROTATE() :
-
to apply this plane rotation to a pair of BLA-vectors x[ ], y[ ] (defined by equidistant storage in memory, for example matrix rows, columns, diagonals, or single elements).
As said above, the second part of the algorithm will consist in applying further plane rotations from left and right to B with the goal to reduce B to a diagonal matrix. When ej = 0 occurs for some index j > 0 (iteration indices are dropped), then the matrix B can be split into two bidiagonal submatrices of order j (rows 0,…, j − 1 of B) and n − j (rows j,…, n − 1 of B), which may be diagonalized independently of each other. At any time, the second part of the algorithm will iteratively diagonalize the southernmost remaining bidiagonal submatrix of B with non vanishing off-diagonal elements. The position of this submatrix is described by two indices ℓ and k, both in the range 0,…, n − 1, defining three diagonal blocks of B, as illustrated in (3):

Here, ℓ = 0 means an empty first block, and k = n − 1 means an empty third block. The third ”bidiagonal” block in fact already is a diagonal matrix and can be ignored for all further computations, \(\lvert d_{k+1}\rvert ,\ldots ,\lvert d_{n-1}\rvert \) are singular values. The middle block with lower row index ℓ and upper row index k is characterized by non vanishing off-diagonal elements eℓ+ 1,…, ek and can be diagonalized independently of the upper bidiagonal block (rows 0,…, ℓ − 1 of B).Footnote 3 The elements e1,…, eℓ− 1 may be zero or not. After each iteration step taken in the second part, k and ℓ are updated by scanning for zero elements ej. When k = ℓ = 0, then B is completely diagonalized. When ℓ = k > 0, then ek = 0, \(\lvert d_{k}\rvert \) is a singular value and the trivial 1 × 1 matrix (ek) may be split off the middle block in (3), thus k will be decremented by 1. When ℓ < k, then one continues to operate on the bidiagonal submatrix of B in rows ℓ,…, k, which will be denoted by
In practice, zero tests must be replaced by tests \(\lvert e_{j}\rvert \leq tol\). A proper choice of tol will be discussed in Section 6.
3 Symmetric QR steps with shifts
This section is a reminder about one of the most successful algorithms of Linear Algebra, the QR iteration for the diagonalization of matrices. Heinz Rutishauser invented it in 1961 (then in the form of an equivalent LR iteration). The name comes from the basic iteration step for the matrix to be diagonalized, which is here X =: X(0):
The step from X(i) to X(i+ 1) is a similarity transformation: X(i+ 1) = Q(i)TX(i)Q(i). All X(i) have the same eigenvalues. The absolute values of these invariant eigenvalues, arranged in decreasing order, play a decisive role in analyzing the asympotic behavior of the sequence X(i). The QR iteration will be applied to the symmetric tridiagonal matrix
where B is initially given by (2) and more generally by (4), but in this section it is considered in its own right. To describe a single QR step applied to a tridiagonal symmetric matrix, the iteration index (i) is dropped. Let
As a consequence of the tridiagonal form, each QR step is rather special:
-
(1)
Q is a product of n − 1 rotations Qj in plane (j − 1, j), j = 1,…, n − 1, to eliminate εj,
-
(2)
X stays symmetric and tridiagonal (the minor steps are \(\ X \rightarrow {Q_{j}^{T}}XQ_{j}\)).
-
(3)
The number of operations per step is only O(n) rather than O(n3).
-
(4)
The eigenvalues of X are real and non-negative.
-
(5)
Also the upper triangular matrix R has only three non-trivial diagonals, see Fig. 1.
Fig. 1 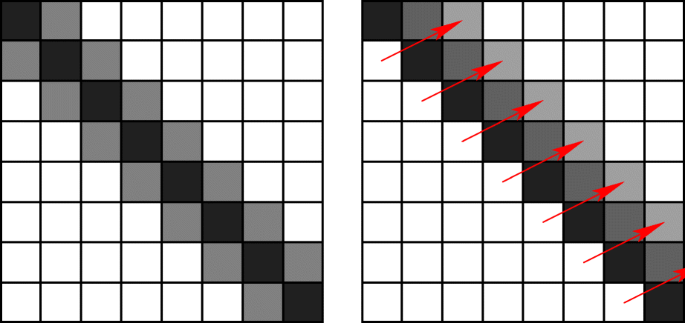
X = BT B before elimination and R after elimination

The basic iteration step for the QR algorithm with shifts is described as
where Q and R are orthogonal and upper triangular, respectively, but not the same as above, depending on the value of s. As before, one has \(\overline {X}=Q^{T}XQ\). The value s is called the shift. It should be chosen close to one of the eigenvalues of X. The closer the shift is to such an eigenvalue, the smaller is some diagonal element of R (in most cases the last one) and the smaller is the (last) row and column of \(\overline {X}\). Good shifts make Rutishauser’s LR or QR iteration so successful. In [5] Wilkinson proved global convergence of the sequence X(i) to a diagonal matrix for two different strategies to choose a shift. The convergence rate usually is cubic, i.e., for sufficiently small η follows from \(\lvert \varepsilon _{n-1}\rvert \leq \eta \) that the next iteration will reduce \(\lvert \varepsilon _{n-1}\rvert \) to \(O(\lvert \varepsilon _{n-1}\rvert ^{3})\). We devote Section 5 to Wilkinson’s idea and proposals for the shift.
The factorization X − sI = QR and the recombination \(QR+sI=\overline {X}\) may be combined to what is known as a QR step with implicit shift. This was found by Francis [1] in a much more general setting, but shall be explained here on an elementary level. Assume that no off-diagonal element of X vanishes, i.e., εj≠ 0 for j = 1,…, n − 1. In this case, the orthogonal matrix Q is unique up to a scaling of its columns by ± 1. The matrix Q can always be written as a product of n − 1 rotations Qj in plane (j − 1, j), j = 1,…, n − 1. The first rotation \({Q_{1}^{T}}\) is to be chosen such that (schematically, just noting the upper 2 × 2-minors)
which is achieved by
(or the negatives of these values). Since ε1≠ 0, there cannot be a zero division in (5) and moreover \(\sin \limits \neq 0\). It is known that
is tridiagonal, but the matrices Xi, i = 1,…, n − 2, deviate from the tridiagonal form. Schematically, one has
The extra element β2 is called bulge element. It is defined by \(\beta _{2}=\sin \limits \!\cdot \varepsilon _{2}\) with \(\sin \limits \) from (5), so that β2≠ 0. Now choose a rotation \(\tilde {Q}_{2}^{T}\) in plane (1,2), such that multiplication of X1 from the left with \(\tilde {Q}_{2}^{T}\) eliminates β2 in position (2,0). This is achieved by the choice
Schematically, one gets
The bulge β2 moved down one position along the diagonal to become \(\beta _{3}=\sin \limits \!\cdot \varepsilon _{3}\) with the value \(\sin \limits \) defined in (7). Since β2≠ 0, one has \(\sin \limits \neq 0\) again and therefore β3≠ 0. Continuing this way chasing down the bulge along the diagonal, one arrives at
again with βn− 1≠ 0. A last rotation \(\tilde {Q}_{n-1}^{T}\) in plane (n − 2, n − 1) is chosen such that multiplication of \(\tilde {X}_{n-2}\) from the left with \(\tilde {Q}_{n-1}^{T}\) eliminates βn− 1 in position (n − 1, n − 3). Then \(\tilde {X}_{n-1}=\tilde {Q}_{n-1}^{T}\tilde {X}_{n-2}\tilde {Q}_{n-1}\) is tridiagonal again. Because all bulges are non-zero, all rotations \(\tilde {Q}_{i}\), i = 2,…, n − 1, are uniquely determined (up to phase factors, i.e., up to multiplications by ± 1). This means that once Q1 is set, the need to chase down the bulge until it disappears and to re-establish the tridiagonal form of
uniquely determines \(\tilde {Q}_{2},\ldots ,\tilde {Q}_{n-1}\) (up to phase factors). But tridiagonal form will also be established by using the rotations Q2,…, Qn− 1 as in (6). The conclusion is that \(\tilde {Q}_{i}=Q_{i}\), i = 2,…, n − 1 (up to phase factors). The choice of Q1 according to (5) — which is the only place where the shift explicitly enters the computation — and the choice of \(\tilde {Q}_{2},\ldots ,\tilde {Q}_{n-1}\) such as to chase down the bulge, will make (8) an implementation of the QR step.
Thus, the symmetric QR step with shift for the matrix X = BT B can be done as follows:
-
(1)
Choose a good shift s.
-
(2)
Choose \({Q_{1}^{T}}\) according to (5) and compute \(X_{1}={Q_{1}^{T}}XQ_{1}\).
-
(3)
Choose rotations \(\tilde {Q}_{j}\) in plane (j − 1, j) in order to chase down the bulge and successively build \(X_{j}:=\tilde {Q}_{j}^{T}X_{j-1}\tilde {Q}_{j}\), j = 2,…, n − 1. \(\overline {X}:=X_{n-1}\) is the next matrix X.
4 Implicit QR steps on bidiagonal matrix
The QR iteration could explicitly be applied to the matrix X = BT B with B = Bℓ, k from (4) — the double index of Bℓ, k will be dropped now. The non-trivial diagonal and off-diagonal entries of X then are
However, for reasons of economy and accuracy, one should avoid dealing with BT B. Rather, it is preferable to work with B alone. In fact it is possible to do the similarity transformations on X with two-sided plane rotations, viz. HCode \(B \rightarrow {P_{j}^{T}}B Q_{j}\), j = ℓ,…, k − 1, where all matrices Qj and \({P_{j}^{T}}\) are Givens rotations. To be precise, assume that
— according to (9) this means that X has no vanishing off-diagonal elements — and choose Qℓ as if performing the first minor step of one QR iteration step (with shift) for X. From (5) and (9) it can be seen that this means to choose Qℓ as a rotation in the plane (ℓ, ℓ + 1) with
(or the negatives of these values), depending on the shift parameter s. Multiplying B with Qℓ from the right gives (schematically)
\(B_{\ell +1}^{\prime }\) is no longer an upper bidiagonal matrix because of the bulge element \(b_{\ell +1}^{\prime }=\sin \limits \!\cdot d_{\ell +1}\). The bulge element cannot vanish, since \(\sin \limits \neq 0\) and dℓ+ 1≠ 0, see (10). To eliminate \(b_{\ell +1}^{\prime }\), multiply \(B_{\ell +1}^{\prime }\) from the left by a rotation \(P_{\ell }^{T}\) in the plane (ℓ, ℓ + 1). Up to a phase factor, this rotation must be given by
such that (schematically)
The bulge has moved and becomes \(b_{\ell +1}=\sin \limits \!\cdot e_{\ell +2}\). Since \(b_{\ell +1}^{\prime }\neq 0\), also bℓ+ 1≠ 0. To eliminate bℓ+ 1, multiply from the right with a rotation \(\tilde {Q}_{\ell +1}\) like in (12), but now in the plane (ℓ + 1, ℓ + 2). Because of bℓ+ 1≠ 0, this rotation must have a component \(\sin \limits \neq 0\). The multiplication results in
with \(b_{\ell +2}^{\prime }=\sin \limits \!\cdot d_{\ell +2}\neq 0\). To eliminate the bulge \(b_{\ell +2}^{\prime }\), multiply from the left by a rotation \(P_{\ell +2}^{T}\) in the plane (ℓ + 1, ℓ + 2). Since \(b_{\ell +2}^{\prime }\neq 0\), this rotation once more is uniquely determined (up to a phase factor) with \(\sin \limits \neq 0\). One gets
with \(b_{\ell +2}=\sin \limits \!\cdot e_{\ell +3}\neq 0\). Continuing this way the bulge initially introduced by multiplication with Qℓ is chased down in knight’s moves until it disappears. This is illustrated in Fig. 2, where the bulge at different moments in the computation is notated as x, \(x^{\prime }\), \(x^{\prime \prime }\), and \(x^{\prime \prime \prime }\). All moves in north-eastern direction are effected by plane rotations from left and all moves in south-western direction are effected by plane rotations from right. The rotations \(\tilde {Q}_{\ell +1},\ldots ,\tilde {Q}_{k-1}\) from the right and \(P_{\ell }^{T},\ldots ,P_{k-1}^{T}\) from the left are all uniquely determined (up to phase factors) once Qℓ is chosen. In the end, with
the matrix \(P^{T}B\tilde {Q}=:\overline {B}\) is bidiagonal again. Therefore
is a tridiagonal matrix again. The first rotation Qℓ was explicitly chosen as needed to perform a step of the QR iteration. It was seen in Section 3, that this and the fact that \(\tilde {Q}^{T}X\tilde {Q}\) is tridiagonal are enough to conclude that \(\tilde {Q}^{T}X\tilde {Q}\) is the result of a full QR step performed on X.

Chasing the bulge
The conclusion is that one step of the QR iteration (with shift s) for X = BTB can be done implicitly as follows
-
(1)
Depending on the chosen shift s set Qℓ as in (11), and multiply B from the right with Qℓ.
-
(2)
Multiply with further rotations \(\tilde {Q}_{\ell +1},\ldots ,\tilde {Q}_{k-1}\) and \(P_{\ell }^{T},\ldots ,P_{k-1}^{T}\) to chase down the bulge until it disappears.
The above arguments depend on (10), but a violation of these conditions even is an advantage, since then savings are possible. In case \(\lvert e_{k}\rvert \leq tol\), \(\lvert d_{k}\rvert \) is accepted as a singular value and k is decremented by 1. In case \(\lvert e_{i}\rvert \leq tol\) for some ℓ ≤ i < k, ei is neglected and the matrix B is split in two bidiagonal matrices which are diagonalized separately. The saving on di = 0 is almost as obvious: one can chase this zero to the right with plane rotations \(\hat {P}_{i+1}^{T},\ldots ,\hat {P}_{k}^{T}\) from left in rows i and j = i + 1,…, k, so that the matrix B gets a zero row:
Now B can be split in two bidiagonal matrices to be diagonalized separately. In case \(\lvert d_{i}\rvert \leq tol\), the effect is the following. Multiplication with \(\hat {P}_{i+1}^{T}\) annihilates ei+ 1 and creates new elements xi+ 1 in position (i, i + 2) and ηi+ 1 in position (i + 1, i). Multiplication with \(\hat {P}_{i+2}^{T}\) annihilates xi+ 1 (in row i) and creates new elements xi+ 2 in position (i, i + 3) and ηi+ 2 in position (i + 2, i). Multiplication with \(\hat {P}_{k}^{T}\) annihilates xk− 1 (in row i) and creates ηk in position (k, i). The result is a matrix of the form (all modified elements are overlined)
By the orthogonality of plane rotations
which shows that all elements \(\bar {d}_{i},\eta _{i+1},\ldots ,\eta _{k}\) have a magnitude less than or equal tol and can be neglected. B can again be split in two bidiagonal matrices. The case of a vanishing or negligible diagonal element di is called cancellation.
5 Choosing a shift
The way shifts are chosen is an essential and characteristic part of the SVD. The shift has only one purpose: to decrease \(\lvert e_{k}\rvert \), the last off-diagonal entry in the current iteration matrix B = Bℓ, k (again, the double index (ℓ, k) will be dropped). Remember, that a good shift is close to one of the eigenvalues of the matrix BT B, which are the squares of the singular values. The non-trivial elements in the last two columns of B are
One may assume that g, y, h and z are all non-zero, otherwise B would have been split. One of the simplest and most effective choices for the shift is the last diagonal element of BT B, which is h2 + z2, one of the Wilkinson shifts, also known as Rayleigh shift. An alternative, used in the original SVD of 1967, is to choose one eigenvalue of the last 2 × 2 diagonal block of BT B. This choice was originally designed for the cases where one needs a pair of conjugate complex shifts. However, if one needs just one shift, it is mandatory to select the eigenvalue which is closer to h2 + z2 because the other one could be far away. (Indeed this had been done in [3], but not been pointed out sufficiently.) Then the shift s comes from the quadratic
We want the root s which is closer to h2 + z2, i.e., the root t := h2 + z2 − s closest to zero of the quadratic
It is good numerical practice to first compute the larger root t1 and then the smaller one t2 from t1t2 = −h2y2. As h and y are non-zero one can form
Let \(w=\sqrt {f^{2}+1}\), then t has the roots hy(−f ± w). If f > 0, then yh(−f − w) is the one with bigger modulus and t = yh/(f + w) is the one with smaller modulus. If f < 0, then yh(−f + w) is the one with bigger modulus and yh/(f − w) is the one with smaller modulus. The shift to be chosen thus is
for f > 0 or f < 0, respectively. The only place where the shift enters into the computation of the implicit QR step is (11). Evidently the values for \(\cos \limits \) and \(\sin \limits \) in (11) do not change if \(d_{\ell }^{2}-s\) is replaced by dℓ − s/dℓ and if dℓeℓ+ 1 is replaced by eℓ+ 1. This fact will be used in the program of Section 8.
For this second choice of shift (called shift strategy (b) in [5]), Wilkinson proved global convergence with a guaranteed quadratic convergence rate. Almost always convergence is cubic, as confirmed by the test cases examined in Section 9. One therefore expects \(s \rightarrow z^{2}\) from \(h \rightarrow 0\) and y bounded. After convergence, k is decremented until with enough QR steps k = 0 is reached.
6 Test for convergence
When \(\lvert e_{k}\rvert \leq tol\), then \(\lvert d_{k}\rvert \) is accepted as new singular value and k is decremented by 1. When \(\lvert e_{i}\rvert \leq tol\) for some i < k, then the matrix B is split in two parts and the singular values of both parts are computed separately, as said above. The cancellation case \(\lvert d_{i}\rvert \leq tol\) was considered in Section 4. It remains to choose the tolerance tol. Here, we repeat the proposal from [3] to choose
with 𝜖mach the machine precision and B the initial bidiagonal matrix from (2).
7 Extended precision arithmetic
On the preceding pages all algorithmical aspects of computing the real matrices A, U, V, Σ and B have been described without mentioning their common data type. Now we are specific. We assume that a user keeps A stored as a variable in standard IEEE double floating point format and wants to get U, V, and Σ also as variables in double format. We call the corresponding variables external and use lower case letters to notate them. We perform the SVD computation inside a C function SVD in long double extended precision format. This function needs internal copies of data type long double of the external variables. The internal variables shall be denoted by upper case letters. We thus have
matrix | external variable | internal variable |
|---|---|---|
A | a | A |
U | u | P or Q |
V | v | Q or P |
Σ | d | D |
B | – | D, E |
where the dash in the last line means that B is only computed internally. Its diagonal is stored in D(which will be overwritten by the singular values on the diagonal of Σ) and its superdiagonal is stored in E. Explanations for the internal variables P and Q will be given in a moment.
When SVD is called, at first the C library function malloc is invoked to dynamically allocate memory for the internal variables. Then matrix A is copied from a to A, if m ≥ n. If, however, m < n, then AT is copied to A, as announced in Section 2. With
A can always be considered a ma × mi matrix. All rotations from left will be accumulated in P (of dimension ma × ma) and all rotations from right will be accumulated in Q (of dimension mi × mi). As seen in Section 2, at the end of the computation, P holds UT and Q holds V, if m ≥ n. If, however, m < n, then Q holds U and P holds VT. Of course, P and Q must be initialized as identity matrices before the accumulations can start.
As already said in the introduction, on the Intel x86 architecture all arithmetic operations are done in 64 bit precision with full hardware speed. Also, the exponent of long double has 15 bits and thus four more bits than are provided for double. Therefore, there will be no problems with exponent overflow or underflow when squaring elements ai, j of A.
At the end of the computation in function SVD, the internal variables are rounded to double format and copied to the external variables a, u, v, and d. This is the moment to copy singular values in descending order from D to d. Columns / rows of P and Q must be copied in corresponding order. Finally the allocated memory for the internal variables must be freed (the 64 bit precision results get lost).
8 C program
An implementation of the SVD in the C programming language is available from the web page https://www.unibw.de/eit_mathematik/forschung/eprecsvd as the na59 package.
In the header file SVD.h one may switch on or off computations in extended double precision and choose between Rayleigh shifts (corresponding to shift strategy (a) in [5]) and Wilkinson shifts (shift strategy (b) in [5]).
The file SVD.c contains an implementation of the SVD algorithm. All constants of data type long double are marked by a suffix W. The printf statements are included for testing only and can be omitted. At the end of SVD a function testSVD is called, which is implemented in SVDtestFunc.c. Its purpose is to test whether the fundamental identities UTU = Im, VTV = In and AV = UΣ (nearly) hold. The calling of this function can also be omitted, of course.
The file SVDtest2.c contains an implementation of all the test cases discussed in the following section.
9 Test results
Computations were carried out on an Intel processor i7-9850H, programs were compiled with the GNU compiler, version 10.2.0. The results obtained by computations in extended double precision arithmetic are noted as \(\tilde {U}\), \(\tilde {V}\) and \(\tilde {\Sigma }\). These results were rounded to standard double precision format to give \(\hat {U}\), \(\hat {V}\) and \(\hat {\Sigma }\). The singular values on the diagonal of \(\hat {\Sigma }\) are noted as \(\hat \sigma _{k}\).
When exact singular values are known, they are rounded to standard double precision format and noted as σk. In the cases where exact singular values are not known, numerical approximations were computed via an implementation of the SVD in 256-bit arithmetic, based on the GNU MPFR multiple precision library. The singular values obtained from a multiple precision computation were then rounded to standard double precision format and taken as substitutes for the unknown exact singular values. The abbreviation \(\mu (A)=\max \limits \lvert a_{i,j}\rvert \) for a matrix A = (ai, j) is used below.
A first example is taken from [3]. It is the matrix
with exactly known singular values
After a total of 6 QR iteration steps, the singular values \(\hat \sigma _{k}\) from Table 1 were found.
A value of 0 in the second column of Table 1 means that both, exact and computed singular values, are identical after rounding to standard double precision format. The accuracy of the achieved decomposition is characterized by
and
These fundamental identities were checked before the results were rounded to standard double precision by calling the function testSVD from within function SVD.
A second example is the 10 × 7 Hilbert matrix A defined by
In this case, exact singular values are not known and substitutes for them were obtained from a computation in 256-bit arithmetic, as described above. After a total of 8 QR iteration steps, the results given in Table 2 were found.
Concerning the fundamental identities, the results
and
were obtained.
A third example is taken from [2]. Setting
an 18 × 12 matrix is defined by
Since this matrix has rank 6, σ7 = … = σ12 = 0. Substitutes for the exact singular values σ1,…, σ6 of A were obtained from a computation in 256-bit arithmetic, as described above. After a total of 12 QR iteration steps, the results shown in Table 3 were found.
Again, the fundamental identities were checked, with the following results:
and
A fourth example is taken from [3]. It is the 20 × 21 matrix defined by
with exact singular values
The method converged after 39 QR iterations with the results shown in Table 4.
In this example, all values \(\lvert \sigma _{k}-\hat {\sigma }_{k}\rvert \) were 0, i.e., computed and exact values were identical, when both rounded to standard double precision. The fundamental identities were checked with the following results:
and
A fifth example is again taken from [3]. It is the 30 × 30 matrix defined by
Substitutes for the exact singular values were computed numerically in multiple precision arithmetic. The method converged after 48 QR iterations. Again, all values \(\lvert \sigma _{k}-\hat {\sigma }_{k}\rvert \) were 0, i.e., computed and exact values were identical, when both rounded to double precision. The fundamental identities were checked with the following results:
and
10 Conclusions
An implementation of the SVD in extended precision arithmetic substantially improves the accuracy of the computed results. This improvement comes at no loss in computational speed, when extended precision arithmetic is native, as for the x86 architecture. Only a minor programming effort is necessary to use the capabilities of extended precision arithmetic and the same program also runs in standard double precision arithmetic. So it is advantageous to use the updated program.
We have also given a full, elementary explanation of the algorithm of Golub and Reinsch. In [3], not all details were fully explained on an elementary level.
Data Availability
No empirical data are used. The test cases discussed in Section 9 can be reproduced by the program which may be downloaded from https://www.unibw.de/eit_mathematik/forschung/eprecsvd.
Notes
\({P_{i}^{T}}\!A\) with the orthogonal m × m matrix \(\ {P_{i}^{T}} = \left (\begin {array}{cc}\ {\cos \limits } & {\sin \limits } \\\!\!\!-\sin \limits &\cos \limits \end {array}\right )\) in rows/columns 0 and i
AQj with the orthogonal n × n matrix \(\ Q_{j} = \left (\begin {array}{cc}{\cos \limits } & -{\sin \limits } \\ \sin \limits &\ \ \cos \limits \end {array}\right )\) in rows/columns 1 and j
Formally, k is defined as the lowest row index such that ek+ 1 = … = en− 1 = 0 (initially k = n − 1) and ℓ is defined as the highest row index with ℓ ≤ k and eℓ = 0. Since e0 = 0, ℓ must exist for any k.
References
Francis, J.: The QR transformation. A unitary analogue to the LR transformation. Comput. J. 4, 265–271 (1961, 1962)
Gander, W.: The first algorithms to compute the SVD, https://people.inf.ethz.ch/gander/talks/Vortrag2022.pdf
Golub, G.H., Reinsch, C.: Singular value decomposition and least squares solutions. Numer. Math. 14, 403–420 (1970)
Higham, N.J.: Acuracy and Stability of Numerical Algorithms, 2nd edn. SIAM (2002)
Wilkinson, J.H.: Global convergence of tridiagonal QR algorithm with origin shifts, Lin. Alg. Appl., 409–420 (1968)
Acknowledgements
Professor Christian Reinsch passed away on October 8, 2022. A year before his death he told me (M.R.) he was working on a revision of the SVD algorithm published in 1970 by Golub and himself. Because of his rapidly worsening eyesight he was no longer able to do the work all on his own. I offered my help and took over the programming, testing, and writing of this article. It was his wish that this work should be published under our joint authorship. I am honored by this proposal. I am very thankful for having met and worked with this outstanding mathematician to whom I owe very much.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
Both authors wrote and reviewed the first versions of the manuscript together. C.R. initiated the work and had the principal idea to use extended precision arithmetic. M.R. wrote the C program (based on the Algol version of C.R.), did the testing and added the explanation of the implicit QR algorithm. M.R. wrote and reviewed the final version of the manuscript and is responsible for all errors.
Corresponding author
Ethics declarations
Ethical approval
Not applicable
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Reinsch, C., Richter, M. Singular value decomposition in extended double precision arithmetic. Numer Algor 93, 1137–1155 (2023). https://doi.org/10.1007/s11075-022-01459-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11075-022-01459-9