
Abstract
A simple yet effective architectural design of radial basis function neural networks (RBFNN) makes them amongst the most popular conventional neural networks. The current generation of radial basis function neural network is equipped with multiple kernels which provide significant performance benefits compared to the previous generation using only a single kernel. In existing multi-kernel RBF algorithms, multi-kernel is formed by the convex combination of the base/primary kernels. In this paper, we propose a novel multi-kernel RBFNN in which every base kernel has its own (local) weight. This novel flexibility in the network provides better performance such as faster convergence rate, better local minima and resilience against stucking in poor local minima. These performance gains are achieved at a competitive computational complexity compared to the contemporary multi-kernel RBF algorithms. The proposed algorithm is thoroughly analysed for performance gain using mathematical and graphical illustrations and also evaluated on three different types of problems namely: (i) pattern classification, (ii) system identification and (iii) function approximation. Empirical results clearly show the superiority of the proposed algorithm compared to the existing state-of-the-art multi-kernel approaches.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Machine learning (ML) is an established field with a wide range of applications including control engineering [5, 18, 24, 29], medical imaging [23, 35, 47], bioinformatics [26, 31, 41], and design of forecasting systems [11, 19, 36, 48], etc. It has been successfully used for other innovative applications as well such as in the design of cognitive communication systems [6, 34] and powerful generative models for number of multimedia application [13, 27] . In ML, neural networks are considered to be an important category of tools being frequently used. Therefore number of neural network architectures for example spiking neural neural network (SPNN), multiple layer perceptron (MLP), convolutional neural networks (CNN) and radial basis function neural network (RBFNN) has been proposed.
Due to its compact design and good noise tolerance RBFNN is extensively used in various applications where computational complexity, and data availability is a constrain [4]. Several advances have been proposed to improve its performance. For instance, to improve the parameter learning a variant of gradient decent has been proposed [24], instead of gradient descent algorithms some researchers have used meta-heuristic algorithms to update kernel weights and other network parameters [3, 4, 39, 46]. Aljarah et al. in [4], used bio-geography-based optimization algorithm (BBO) [39]. Alexandridis et al. studied the effectiveness of particle swarm algorithm (PSO) for updating weights of the RBFNN [3].
Recently researchers have successfully blended RBFNN with other established techniques as well. For example [28, 44, 45], Yang et al. in [45] proposed an efficient method for the selection of the centers using the conventional K-means clustering. However, unnecessary points around cluster centers were removed during global K-means clustering using population density method. This slight tweak in the selection procedure of the center, resulted in faster convergence and more robustness. In [44], Wena et al. used Takagi-Sugeno (TS) fuzzy model with the RBF neural network. The proposed designed is particularly useful in environments with data loss, data distortion or signal saturation. It uses K-means clustering for both selecting fuzzy rules and the centers of the RBFNN. Moreover, weighted activation degree (WAD) is used to determine the firing strength of fuzzy node. Liu et al. [28] proposed C-RBFNN (Cloud RBFNN) which uses the cloud theory in fuzzy mathematics to optimize the activation functions. This modification allows RBFNN to effectively express the fuzziness and randomness of the user data such as social media data.
Some hybrid training options have also been recently explored. For instance in [8], Yao and Kuo proposed to combine self-organizing map (SOM) based RBF with evolutionary algorithms such as partical swarm optimization (PSO) and genetic algorithm (GA). This hybrid approach for RBF outperformed conventional non-hybrid approaches. Another emerging variant of RBFNN called spatio-temporal RBFNN, uses the concept of time-space orthogonality to separately model the dynamics and nonlinear complexities [20, 36]. Additionally, an adaptive Nelder Mead Simplex [12], based training method that simultaneously updates weights and kernel width is proposed in [15].
1.1 Motivation and Contribution of this Research
RBFNN typically uses a single type of kernel lacking better generalization. This is because practical learning problems often involve multiple, heterogeneous data sources. Hence, the choice of kernel is heavily dependent on the problem at hand [1, 10]. For example, wavelet kernel, due to its excellent local properties both in time and frequency domains, performs better for some signal approximation and pattern classification problems, however due to lack of prior knowledge choosing the best kernel for the given learning problem is a challenging task. An alternative approach is to use multiple kernels to incorporate design flexibility and generalization [7, 10, 42]. This approach has been successfully employed with other kernel-based methods for instance in support vector machine (SVM) [40, 43]. The most widely used approach to combine multiple kernels of different characteristics is convex combination i.e. all participating kernels are combine linearly such that their coefficients are non-negative and sum to unity [30, 40, 43]. Recently, some researchers have made successful attempts to combine multiple kernels in a nonlinear fashion e.g. Gu, Yanfeng, et al. in [14] showed the effectiveness of combining multiple kernels using Hadamard product.
In the context of RBFNN, multi kernel approach is still an under-explored research area. Fu et al. [10] were the first to introduce the multi kernel RBF-NN. They combined the Gaussian kernel and the wavelet kernel using convex combination and adaptively tuned the kernel coefficients using orthogonal least squares (OLS) algorithm. Later, Aftab et al. in [1] and Khan et al. in [25] explored the area of multi-kernel RBFNN and designed an adaptive multi-kernel RBFNN. Motivated from these works, we propose a novel muti-kernel RBFNN architecture as a Coordinating RBF Neural Network (Co-RBFNN).
Conventional multi-kernel RBF architectures, use the concept of linear combination of various primary kernels (Gaussian, cosine, wavelet etc) with either fixed or adaptive weights, incorporating single degree of freedom [1, 10, 25]. In particular, the conservative choice of the mixing parameters turns out to be the limitation of these conventional approaches. In contrast, the proposed kernel fusion method uses matrix-based mixing weights allowing each participating kernel to learn independently, thereby yielding better performance in most cases. This learning approach of independent mixing weights, make our method novel and unique compared to other contemporary approaches. The main contributions of our research are as follows:
-
1.
A multi-kernel RBFNN architecture is proposed that combines each multi-kernel in the network with its own set of kernel parameters (local weights).
-
2.
Graphical explanation of the algorithm is given to conceptually justify the origin of improved performance.
-
3.
A comprehensive mathematical analysis is performed to identify the convergence bound.
-
4.
The proposed architecture is evaluated for three problems of estimation namely non-linear system identification, pattern classification, and function approximation and extensive comparative analysis is performed with the contemporary approaches.
The organization of the paper is as follows. In Sect. 2, a brief overview of existing multi-kernel RBFNNs is proposed followed by the proposed Co-RBFNN in Sect. 3. Experimental evaluation and comparative results are discussed in Sect. 4. Finally, the paper is concluded in Sect. 5.
2 Multi-Kernel Radial Basis Function Neural Networks
2.1 Overview of the Architecture of the RBF Neural Network
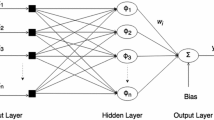
RBFNN is a simple feed forward neural network that consists of only three layers i.e., an input layer, a nonlinear hidden layer and a linear output layer. Fig. 1 depicts the architecture of an RBFNN. Let \({\mathbf {X}} \in {\mathbb {R}}^{a\times S}\) representing an input dataset consist of S samples, and \({\mathbf {x}}_s \in {\mathbb {R}}^{a\times 1}\) be the input vector representing a sample by a number of attributes, then the overall mapping of the RBF network, \(f:{\mathbb {R}}^{a\times 1}\rightarrow {\mathbb {R}}^{1\times 1}\), is given as:
where for all k, \({\mathbf {m}}_k \subset {\mathbf {M}} \in {\mathbb {R}}^{a\times K}\), K is the number of neurons in the hidden layer of the network, \({\mathbf {M}} \in {\mathbb {R}}^{a\times K}\) comprises of K number of \({\mathbf {m}}_k \in {\mathbb {R}}^{a\times 1}\) vectors, each representing a center point of the kernel of k th hidden neuron, \({\mathbf {w}}_k\) is the synaptic weight connecting the k th hidden neuron to the output neuron, b is the bias term of the output neuron and \(\phi _k\) is the radial basis function of the k th hidden neuron. Without the loss of generality and for the sake of simplicity a single output neuron is considered. Conventional RBF networks employ a number of kernels such as multiquadrics, inverse multiquadrics and Gaussian [16].

Architecture of the RBF neural network
2.2 Overview of the Contemporary Multi-Kernel Approaches
Gaussian kernel is considered to be the most commonly used kernel:
where \(\sigma \) is the kernel-width of the Gaussian kernel.
Recently, it has been argued that the cosine kernel offers complimentary information compared to the Gaussian kernel [1]. It is defined as:
where, \(\Vert | \cdot \Vert |\) is the L2 norm or Euclidean distance and \(\epsilon > 0\) is a small constant added to avoid the indeterminant form of Eq (3).
In recent studies [7, 14, 40, 42], it is suggested that combining multiple kernels is more efficient than using the kernels individually. Accordingly, a novel multi-kernel has been proposed combining cosine and Gaussian kernels [1]:
where \(\phi _{g}({\mathbf {x}},{\mathbf {m}}_k)\) and \(\phi _{c}({\mathbf {x}},{\mathbf {m}}_k)\) are output of Gaussian and cosine kernels for k th hidden neuron respectively and, \(\alpha _{g}\) and \(\alpha _{c}\) are their corresponding kernel weights. Further, there are two constraints on \(\alpha _{g}\) and \(\alpha _{c}\), i.e., \(0 \le \alpha _{g},\alpha _{c} \le 1\) and \(\alpha _{g}+\alpha _{c}=1\). The common set of kernel weights i.e., \(\{\alpha _{g}, \alpha _{c}\}\) for all multi-kernels and the above two constraints ensures that the participating kernels will form a convex combination.
The new multi-kernel in (4) has shown some good results compared to the conventional Gaussian kernel [1]. In this method, the fusion of the two kernels is manual and the their weights \(\alpha _{g}\) and \(\alpha _{c}\) are adjusted in a hit-and-trial manner. Without any prior information, a common practice is to assign equal weights to the two kernels i.e. \(\alpha _{g}=\alpha _{c}=0.5\). To resolve this issue, in [25], an adaptive framework is proposed for automatic fusion of kernels. This approach tunes the kernel weights at every iteration n to minimize error [25]:
In [25], both the synaptic weights of hidden neuron and kernel weights are updated using the conventional gradient descent algorithm. This method has shown improvement over the fixed multi-kernel methods [1].
3 The Proposed Coordinating RBFNN (Co-RBFNN)
Motivated by [25], we argue that this adaptive scheme can be further improved by introducing a separate set of kernel weights for each participating kernel. Therefore, the k th kernel of the given RBFNN that consists of two participating kernels will take the form:
where \(\phi _{g_k}({\mathbf {x}},{\mathbf {m}}_k)\) and \(\phi _{c}({\mathbf {x}},{\mathbf {m}}_k)\) are the Gaussian and cosine contributors of the k th multi-kernel with the corresponding weights \(\alpha _{g_k}(n)\) and \(\alpha _{c_k}(n)\) respectively. Eq (6) can be rewritten as:
where, \(l \in L\) and \(L= \{g,c\}\) is the set of participating primary kernels in the k th multi-kernel. So, \(\phi _{l_k}\) is the l th participating primary kernel of the k th kernel and \(\alpha _{l_k}\) is its mixing weight.
Eq (7) can be easily extended for more than two kernels. However, we restrict ourselves to only two kernels for the sake of simplicity. The overall mapping at the n th iteration can be written as:
where K is the number of centers (multi-kernel) of the network, \({\mathbf {m}}_k \in {\mathbb {R}}^{a\times 1}\) is the center of the k th multi-kernel, \({\mathbf {w}}_k\) is the synaptic weight connecting the k th hidden neuron to the output neuron, b is the bias term of the output neuron, \(\phi _{l_k}\) is the l th participating kernel of k th multi-kernel and \(\alpha _{l_k}\) is the corresponding kernel weight.
Eq. (8) can be written as:
where, \(k=1,2,\ldots , K\), \(l \in \{g,c\}\) and \(w_{k,l}(n) = w_{k}(n)\alpha _{l_k}(n)\) is the substitute form of the weight of l th participating kernel in the k th multi-kernel. \({\mathbf {x}}(n)\) is a sample obtained from \({\mathbf {X}}\) at n th iteration.
It is evident from Eq (9) that there is no explicit need to maintain kernel weight of each participating kernel of a given multi-kernel. Instead, each participating kernel \(\phi _{l_k}\) has its own corresponding weight \(w_{k,l}(n)\). In other words, our proposed multi-kernel RBFNN architecture, consisting of K hidden neurons and L participating kernels (in our case \(L=2\)), may be unfolded into a simple RBFNN architecture consisting of \(K \times L\) centers (hidden neurons), such that there are L sets of K hidden neurons and each of that set employs one of the L different kernels.
In matrix form, Eq (9) can be written as:
where, \(\varvec{w}(n) = [b, w_{g_1}(n), w_{g_2}(n), \cdots , w_{g_K}(n), w_{c_1}(n), w_{c_2}(n), \cdots , w_{c_K}(n)]^{\intercal }\) and \(\varvec{\phi }(n) = [1, \phi _{g_1}({\mathbf {x}}(n),{\mathbf {m}}_k), \cdots , \phi _{g_K}({\mathbf {x}}(n),{\mathbf {m}}_k), \phi _{c_1}({\mathbf {x}}(n),{\mathbf {m}}_k), \cdots , \phi _{c_K}({\mathbf {x}}(n),{\mathbf {m}}_k)]^{\intercal }\) are weights and kernel vectors respectively and \([\cdot ]^{\intercal }\) is the vector transpose operation.
3.1 Weight and Bias Update Rules
The update rule of the synaptic weight \(w_{k,l}(n)\) at \((n+1){th}\) iteration can be given as:
where, \(\eta \) is the learning rate, and \(\ell \) is the mean-square-error (L2) loss function defined as:
The above loss function can be minimized by solving for the instantaneous error, considering instantaneous error function \({\mathcal {E}}(n)\) i.e.,:
where d(n) is the desired output, y(n) is the actual output at the n th iteration and e(n) the instantaneous error.
Using the chain rule of differentiation for the cost function in Eq (14) yields:
which upon simplification of the partial derivatives in Eq (15) results in:
Using Eq (12) and Eq (16), the update rule in Eq (11) will becomes:
similarly, the update rule for bias b(n) can be shown to have the form:
3.2 Training Algorithm
For the training of the proposed network, the steps of the algorithm outlined in Table 1 are followed. Define the inputs, \(X \in {\mathbb {R}}^{a \times S}\), \(M \in {\mathbb {R}}^{a \times K}\) (where the columns are the centers of the K multi-kernels) the initial weight matrix \(W_{init} \in {\mathbb {R}}^{K\times L}\), initial value of bias b, the learning rate \(\eta > 0\) and T number of epochs for training. The algorithm yields a weight matrix \(W \in {\mathbb {R}}^{K \times L}\) as output. Conventional stochastic gradient descent is used to update the weight matrix \(W \in {\mathbb {R}}^{K \times L}\) independently using each of the S training samples in each of the T epochs.

3.3 Illustrative Explanation of the Proposed Method
In this subsection, we consider an illustrative example depicted in Fig. 2. The task is to classify a test point. It is illustratively proved that a primary kernel (which is a Gaussian or a cosine kernel in this example) fails to effectively discriminate the given test point. In contrast, our proposed solution effectively maps the given test point to its true class. This illustration therefore serve to demonstrate the superiority of the proposed method. For the purpose of this illustrative case-study, no assumptions were made except the choice of a highly challenging test point to prove the efficacy of the proposed algorithm for difficult cases.

Illustrative explanation of the proposed RBF algorithm
As depicted in Fig. 2, we consider a challenging binary classification problem, in which the only tunable parameters are the kernel mixing weights. We have four center points obtained using a clustering method such as K-mean clustering (or any other method) representing two classes namely ClassA and ClassB. As shown in Fig. 2, \(Center1_{A}\) and \(Center2_{A}\) are the representative points of ClassA and \(Center1_{B}\) and \(Center2_{B}\) are the representative points of ClassB respectively. Let’s consider a test sample \(TestPoint_{A}\) such that \(dc1_{A}\), \(dc2_{A}\) are Euclidean distances from \(TestPoint_{A}\) to centers \(Center1_{A}\) and \(Center2_{A}\) respectively whereas \(dc1_{B}\), \(dc2_{B}\) are Euclidean distances of test sample \(TestPoint_{A}\) from centers \(Center1_{A}\) and \(Center2_{A}\) respectively. Similarly, \(ac1_{A}\), \(ac2_{A}\) are angles of test sample \(TestPoint_{A}\) with centers \(Center1_{A}\) and \(Center2_{A}\) respectively whereas \(ac1_{B}\), \(ac2_{B}\) are angles of test sample \(TestPoint_{A}\) with centers \(Center1_{B}\) and \(Center2_{B}\) respectively.
Without loss of generality, weights of the model are set to unity. Now, the following relationships hold on model at the time of presentation of test sample \(TestPoint_{A}\).
Let \(\varPsi \) is the discriminative power of a classifier. For Gaussian and cosine kernel classifer, their discriminative powers are respectively equivalent to:
and
similarly, using (21) and (22), we get:
Since, both \(\varPsi _{g}\) and \(\varPsi _{c}\) are zero the probability that \(TestPoint_{A}\) belong to ClassA is equal to that of ClassB i.e. equiprobable using either Gaussian or cosine classifier. The classification of \(TestPoint_{A}\) is therefore solely dependent on the value of the bias.
This lacking of correctly classifying a challenging cases such as \(TestPoint_{A}\) persists even in RBF networks equipped with adaptive kernel fusion (Khan et al.) having global kernel weights as its discriminating power \(\varPsi _{a}\) for (Khan et al.) is defined as:
where \(\alpha _{g} \in {\mathbb {R}}\) and \(\alpha _{c} \in {\mathbb {R}}\) are (global) kernel coefficients of Gaussian and cosine kernels respectively.
Again for difficult cases such as \(TestPoint_{A}\), it is verifiable that \(\varPsi _{a}=0\)
In contrast, the proposed method is not susceptible to such problems due to the novel concept of local weights (kernel coefficient) of each kernel. The discriminative power \(\varPsi _{r}\) of Co-RBFNN can be written as:
where \(\alpha _{c,x} \in {\mathbb {R}}\) is the kernel coefficient for kernel of type x and center c such that \(x \in {g,c}\) and \(c \in {Center1_{A}, Center2_{A}, Center1_{B}, Center2_{B}}\)
It is evident that \(\varPsi _{r}\ne 0\) as \(\alpha _{Center1_{A},g}\ne \alpha _{Center2_{A},g}\), \(\alpha _{Center1_{A},c}\ne \alpha _{Center2_{A},c}\), \(\alpha _{Center1_{B},g}\ne \alpha _{Center2_{B},g}\) and \(\alpha _{Center1_{B},c}\ne \alpha _{Center2_{B},c}\) in general.
3.4 Mean Convergence Analysis of Our Proposed Model
In this subsection, we mathematically prove that our proposed algorithm will effectively converge provided that we strategically set the learning rate \(\eta \) less than \(\lambda _{max}\), the maximum eigenvalue of the auto-correlation matrix R. We assume that, for the Wiener filter, the signal and (additive) noise are stationary linear stochastic processes with known spectral characteristics or known auto-correlation and cross-correlation [17].
The weight update rules of our proposed model i.e. (17) and (18) in the matrix form can be collectively rewritten as:
where \(\eta \) is the learning rate, \(\varvec{w}(n)\) is the weight vector of n th iteration and e is the error between the desired and actual output signals i.e.
Let’s define the vector \(\varvec{\varDelta }_{opt}\) as the difference of our proposed model estimated weight vector \(\varvec{w}(n)\) with the optimal weight vector \(\varvec{w}_{opt}\):
where optimal weight vector \(\varvec{w}_{opt}\) is that of Wiener filter obtained by solving the standard equation of Wiener filter i.e.
where \(\varvec{P}\) is the cross-correlation matrix between input signal to m hidden neurons (i.e. \(\varvec{\phi }\)) and desired output \(\varvec{d}\), and \(\varvec{R}\) is the auto-correlation matrix of input signal to m hidden neurons i.e. \(\varvec{\phi }\). Mathematically,
Substituting the value of \(\varvec{e}\) from (30) and subtracting \(\varvec{w}_{opt}\) from both sides of (29), we get:
Substituting the value of y and \(\varvec{w}(n)\) from (10) and (31) respectively into (29), we get:
Taking expectation on both sides of (36) and rearranging few term, we obtain:
Further simplifying the above equation using (32), (33) and (34), we get:
After applying usual assumptions of Wiener filter [17], we obtain:
Decomposing R using singular value decomposition (SVD) and further simplification leads us to:
where, \(\lambda _{max}\) is the maximum eigenvalue of the autocorrelation matrix R.
3.5 Mathematical Analysis of the Proposed Model Co-RBFNN
In this subsection, we mathematically prove that our proposed solution is superior to the adaptive kernel fusion [25]. We prove that the mean square error of our proposed solution is always less than that of the adaptive kernel fusion [25]. During this mathematical analysis, we made a usual assumption that the errors induced by the two models (i.e. our proposed solution and adaptive kernel fusion [25]) are zero mean Gaussian noise.Footnote 1
Lemma 1
Our proposed model has following relationship with adaptive kernel fusion (Khan et al.) model [25]
where, \(y_{d}\) and \(y_{a}\) are the estimated responses of our proposed model and adaptive kernel fusion [25] respectively and \(e_{x}\) is the noise. Mathematically, the estimated responses of the two models \(y_{a}\) and \(y_{d}\) respectively are defined as:
and,
where \(\varvec{w}_{g}\) and \(\varvec{w}_{c}\) are Gaussian and cosine weight vectors of our proposed model respectively and, \(\varvec{w}\) and \(\alpha \) are the weight vector and multi-kernel coefficient of adaptive kernel fusion [25] respectively.
Prove: Consider our proposed model that estimates the desired response by minimizing the least square error i.e.
where, d is the desired response vector, \(y_{d}\) is the estimated response of our proposed model and \(e \in {\mathcal {N}}(0,\sigma )\) is the Gaussian noise of the proposed model.
Further, the following relationships hold among weight vectors \(\varvec{w}\), \(\varvec{w}_{g}\) and \(\varvec{w}_{c}\):
where \(\varvec{e}_{g} \in {\mathcal {N}}(0,\sigma _{g})\) and \(\varvec{e}_{c} \in {\mathcal {N}}(0,\sigma _{c})\) are Gaussian noises and \(\alpha \) is the kernel coefficient of multi-kernel as defined in adaptive kernel fusion [25].
By adding (45) and (46), we get another relation i.e.
Adding and subtracting the term \(\varvec{w_{g}}^{T}\varvec{\phi _{c}}(\varvec{x})\) on R.H.S of (41), substituting the value of \(y_{d}\) from (43) and simplifying, we get:
After substituting the value of \(\varvec{w_{g}}\) from (45) and that of \((\varvec{w_{g}} + \varvec{w_{c}})\) from (47) into (48) and simplifying, we obtain:
After substituting the value of \(\alpha \varvec{w}^{T} \varvec{\phi _{g}} + (1 - \alpha ) \varvec{w}^{T} \varvec{\phi _{c}}\) from (42), we obtain:
Let the error term \(\varvec{e}_{g}^{T}\varvec{\phi _{g}}(\varvec{x}) + \varvec{e}_{c}^{T}\varvec{\phi _{c}}(\varvec{x})\) be represented as \(\varvec{e}_{x}\), (50) becomes:
substituting the value of d from (44) into (51) and simplifying, we get:
Corollary 1
The error term \(e_{x}\) is mean zero Gaussian noise i.e. \(e_{x} \in {\mathcal {N}}(0,\sigma _{x})\).
Prove: Since adaptive kernel fusion [25] estimates the desired response d by minimizing the least square error. Therefore, it is mathematically definable as:
where, \(y_{a}\) is the estimated response and \(e_{a} \in {\mathcal {N}}(0,\sigma _{a})\) is the Gaussian noise of the model respectively and d is the desired response vector.
Substituting the value of d from (51) into (53) and simplifying, we get:
Since, \(e_{x}\) is the difference of two zero mean Gaussian noises i.e. e and \(e_{a}\), \(e_{x}\) is also a zero mean Gaussian noise i.e. \(e_{x} \in {\mathcal {N}}(0,\sigma _{x})\), hence proved.
Corollary 2
Mean squared error of adaptive kernel fusion (Khan et al.) model [25] \(\Vert e_{a}\Vert _{2}^{2}\) is always greater than or equal to that of our proposed model \(\Vert e_{a}\Vert _{2}^{2}\) i.e.
Prove: Substituting the value of d from (51) into (53) and simplifying, we get:
Since, \(e_{a} \in {\mathcal {N}}(0,\sigma _{a})\) is the sum of two mean zero Gaussian noises i.e. \(e \in {\mathcal {N}}(0,\sigma )\) and \(e_{x} \in {\mathcal {N}}(0,\sigma _{x})\). Hence,
This lead us to:
so,
hence, proved.
4 Experimental Results
In this section, we compare the performance of our proposed solution against two state-of-the-art multi-kernel radial basis function neural network algorithms namely manually fused multi-kernel proposed by Aftab et al. [1] and adaptively fused multi-kernel proposed by Khan et al. in [25]. All three algorithms are tested on pattern classification, system identification and function approximation problems for standard performance measures. All tests are preformed using Matlab R2017b on Intel CORE i5-2540M CPU @2.60GHz 4GB RAM. Results are averaged over 100 independent random runs.
4.1 Pattern Classification
Pattern classification has several applications in security, industry, medicine and defense. Examples include iris identification, speaker identification, fingerprint identification, statistical pattern recognition of seismic data, and automatic medical diagnosis.
A well known Iris flower dataset [9] is selected for pattern classification problem. The dataset consist of three classes (flower species). Each class has 50 samples and four attributes i.e. sepal length, sepal width, petal length, and petal width. Forty samples of each class are randomly selected for training where as remaining ten samples of each class are used for testing.
The three RBF networks are trained with the following specifications. 16 neurons are used with kernel centers selected using subtractive clustering [33] with influence factor 0.2. Gaussian kernel width is set to unity. Learning rate is \(5\times 10^{-3}\). The weights as well as bias are initialized randomly.
Fig. 3 shows MSE curves obtained during training. It is evident that our proposed architecture requires only 160 epochs to achieve mean squared error of \(-30.17\) dB whereas the other two algorithms require at least 240 epochs to reach the same MSE. Moreover, the proposed architecture settles on an MSE of \(-35.39\) dB after 2000 epoch whereas the other two algorithms achieve a worse error of \(-33.33\) dB after same number of epochs. Hence, our proposed architecture outperforms other two state-of-the-art techniques both in term of rate of convergence and steady-state error.

MSE curves of different RBF algorithms on Iris Flowers dataset
Classification accuracy achieved by different RBF algorithms on the given dataset is shown in Table 1. During the training phase, the proposed architecture showed accuracy of \(98.35\%\) that is \(0.64\%\) higher than that manual kernel fusion [1] but \(0.24\%\) less compared to the adaptive kernel fusion [25] that attain the accuracy of \(98.59\%\). However, our proposed approach attained the best testing accuracy of \(99.13\%\) comparing to \(97.00\%\) that of manual kernel fusion [1] and \(98.50\%\) that of adaptive kernel fusion [25]. It established that the proposed architecture is significantly tolerable to over-fitting. Moreover, our architecture is even not susceptible to the initial weights (and the bias) as it exhibited the lowest standard deviation of \(0.12\%\) (on the training data) and the second lowest standard deviation of \(1.47\%\) (on the test data). Fig. 4 and Fig. 5 show the training and testing accuracy curves of the three approaches respectively. Our proposed architecture exhibited better training accuracy from the start thus achieved the training accuracy of \(95.67\%\) at 100 epoch whereas the other two algorithm achieved \(92.84\%\) only at 100 epoch. On testing data, the manual kernel fusion [1] initially exhibited the best accuracy precisely \(96.5\%\) at 100. But, our proposed approach became the best at 600 epoch and marked the best steady-state accuracy of \(99.27\%\) at 2000 epoch comparing to that \(98.27\%\) by adaptive kernel fusion [25] and \(97.23\%\) by manual kernel fusion [1].
Sensitivity and specificity are also two important performance metric to analyze a classifier for its biasedness of a classifier. Sensitivity and specificity of different algorithms are tabulated in Table 2 and Table 3 respectively. Our proposed algorithm exhibits the best sensitivity of \(97.50\%\) and \(100\%\) on Versicolor and Setosa classes respectively during training and that of \(100\%\) and \(100\%\) on Virginica and Versicolor classes respectively in testing phases. Moreover, the sensitivity obtained by the proposed algorithm for all three classes are very close to each other in the range of \(0\%\) to \(0.35\%\) in testing phase showing unbiasedness of the proposed method.

Training accuracy curves of different RBF algorithms on Iris Flowers Dataset

Testing accuracy curves of different RBF algorithms on Iris Flowers dataset
During the training phase, our proposed algorithm shows the best specificity of \(98.75\%\) and \(100\%\) on Versicolor and Setosa classes respectively. Whereas, it achieved the average specificity of 98.75 on Versicolor class which is the second best specificity (i.e. \(0.55\%\) less than that of the best specificity of \(99.33\%\) reached by adaptive kernel fusion [25]) on that class. Specificity results of testing phase are also very similar. Our algorithm attained the specificity of \(100\%\) on both Versicolor and Setosa classes. However, it achieved the specificity of \(98.70\%\) on Versicolor class which is the second best specificity on that class, \(0.35\%\) less than the best (\(99.05\%\)) attained by adaptive kernel fusion [25].
Table 4 is showing Youden index of different algorithms on Iris Flowers dataset. It is a popular index used to quantified the overall capacity of the model for pattern classification. During the training phase, adaptive kernel fusion [25] attained the best indices of 0.9721, 0.9646 and 1.0000 for Virginica, Versicolor and Setosa classes respectively. Followed by our algorithm with indices of 0.9630 (0.0091 less than the best), 0.9628 (0.0018 less than the best) and 1.0000 for Virginica, Versicolor and Setosa classes respectively. Manual kernel fusion [1] is in the last with indices of 0.9511, 0.9458 and 1.0000 for Virginica, Versicolor and Setosa classes respectively.
During testing phase, our algorithm achieved the best Youden indices of 1.0000 and 0.9870 for classes Virginica and Versicolor respectively. However, it attained the second best Youden index of 0.9740 on Setosa class (i.e. 0.0070 less than 0.9810 the best Youden index reached by adaptive kernel fusion [25]). In the light of our simulation results of Virginica and Versicolor classes, adaptive kernel fusion [25] is the second best (with Youden indices of 0.9870 and 0.9745 for Virginica and Versicolor classes respectively) and manual kernel fusion [1] is the worst (with Youden indices of 1.0000 and 0.9550 for Virginica and Versicolor classes respectively) in term of Youden index during testing phase.
4.2 Function Approximation Problem
Function approximation is a way to describe the behavior of complicated functions using available observations from the domain through ensembles of simpler functions. It has special importance in several research domains like dynamic system modeling, nonlinear complex-valued signal processing, and biological activity modeling etc [22, 38, 47].
For the function approximation problem, we consider the following non linear function defined as:
For training phase, \(x_{1}\) and \(x_{2}\) were selected over the interval \([-1,1]\) with sampling spacing of 0.2. Whereas for the testing phase, \(x_{1}\) and \(x_{2}\) were selected over the interval \([-0.9,0.9]\) at the same rate. Hence, 121 and 100 samples were used for training and testing respectively.
All the RBF algorithms were initialized with the following specifications. Learning rate was set to \(1\times 10^{-3}\) and the Gaussian kernel spread was taken to be unity. All 121 hidden neurons were configured by selecting training samples as centers for the kernel. Weights and bias were initialized randomly for every run.
MSE curves of different RBF algorithms during training are shown in Fig. 6. Adaptive kernel fusion architecture [25] showed the highest convergence rate for first 50 epochs but then got stuck in a local minima and achieved the higher error of \(-20.5\) db at 2000 epochs. In contrast, our proposed architecture showed moderate but consistent convergence rate thus achieved the minimum error \(-39.83\) dB at 2000 epochs. Moreover, manual kernel fusion architecture [1] exhibited moderate final convergence by attaining the error of \(-36.53\) db at 2000 epochs.
Instantaneous error of our proposed architecture is well bounded between \(-0.1\) and 0.1 whereas that of manual kernel fusion [1] is bounded between \(-0.15\) and 0.15 and that of Adaptive kernel fusion [25] is bounded between 4.5 and \(-3.0\) as depicted in 8. Hence, Adaptive kernel fusion [25] is the worst in term of instantaneous error among all the three algorithms. As the result, the predicted output of our proposed architecture mapped the actual output in the best manner as showed in Fig. 7.

MSE curves of different RBF algorithms on function approximation problem

Predicted output of different RBF algorithms on test data of function approximation problem

Instantaneous error of different RBF algorithms on test Data of function approximation problem

Error surfaces of different RBF algorithms on train data of function approximation Problem

Error surfaces of different RBF algorithms on test data of function approximation problem
Figures 9 and 10 are showing the error surfaces of different RBF algorithms on training and testing data. Error surface of Adaptive kernel fusion [25] is quite spiky for both the training and testing data i.e. bounded between 4.5 and \(-3.0\) (training data) and 8.0 and \(-3.5\) (testing data) respectively. It indicates that the algorithm poorly approximated the given function. In contrast, error surfaces of our proposed architecture are very flat bounded between 1.0 and \(-1.0\) in case training data and that \(-0.12\) and \(-0.14\) in case of testing data. This indicates that given function is well approximated by Co-RBFNN. Manual kernel fusion is moderately spiky with error bound of \((-0.15,0.15)\) for training data and that of \((-0.22,0.13)\) for testing data. Thus, its ability of function approximation of the given function is average.
4.3 Nonlinear System Identification
System identification/nonlinear system identification is a systematic approach to build mathematical models of dynamic systems using measurements of only the system’s input and output signals. It has several applications in diverse fields ranging from wireless communication systems [2, 21, 37] to geo localization of mines [32] etc. It is considered to be a highly challenging research problem in the domain of signal processing and can be effectively addressed using neural networks [19]. Fig. 11 depicts a general systematic approach used by the RBF neural networks for this purpose. For the evaluation of the proposed architecture, we consider a first order non linear system defined by the following equation:
where, \(u_{t}\) and \(y_{t}\) are the system input and output respectively. The input signal is a unit amplitude square wave of length 400 samples and \(50\%\) duty cycle. For model estimation, during training phase a Gaussian noise of zero mean and 0.2 variance was added.

Nonlinear system identification using RBF neural network
The following specifications are used for the RBF algorithms: (1) a learning rate of \(1 \times 10^{-4}\), (2) the Gaussian kernel spread is set to 0.5, and (3) for 5 neurons, the centers are selected as \({{\textbf {m}}} = \{-100, -50, 0, 50, -100 \}\).

MSE curves of different RBF algorithms on system identification problem
MSE curves of different RBF algorithms are depicted in Fig. 12. The proposed architecture yields the highest convergence rate with a minimum error of 3.48 dB which is identical to the manual and adaptive fusion method [1, 25]. Comparison of the actual and estimated test signals for the different RBF algorithms is illustrated in Fig. 13. In an inset plot, it is evident that our proposed algorithm estimates the actual test signal significantly better compared to the other algorithms.

Estimated output of different the RBF algorithms on test data of system identification problem
5 Conclusion
In this paper, we proposed a novel multi-kernel RBF neural network architecture called Co-RBFNN. The proposed kernel fusion method uses matrix-based mixing weights enabling each (primary and sub-primary) kernel to learn independent weights. A graphical explanation highlighting the underlying reasons for the improvement is provided along with a detailed mathematical analysis. We demonstrated the efficacy of the proposed solution on three important problems, namely: (i) Nonlinear system identification, (ii) pattern classification and (iii) function approximation. The proposed algorithm has shown to comprehensively outperform the two state-of-the-art methods i.e. manual and adaptive fusion of kernels. For the problem of pattern classification, the proposed framework achieved the lowest error floor of \(-35.39\) dB after 2000 epochs of training. For the testing phase the proposed Co-RBFNN achieved a high classification accuracy of \(99.13\%\) (approximately) which compares favorably with the contemporary methods. For the function approximation problem, our proposed method converged to the lowest error of \(-39.83\) dB after 2000 epochs. The convergence rate of the proposed algorithm was also found to be better than the competing methods. For the nonlinear system identification problem, the proposed Co-RBFNN algorithm exhibited the fastest convergence rate achieving a minimum error of \(-3.48\) dB. The unseen test signal was more accurately estimated by the proposed approach compared to the contemporary methods. MATLAB code for a sample problem can be downloaded from https://github.com/Shujaat123/Robust_RBF.
The proposed novel approach enables independent learning of the mixing weights making it superior compared to the contemporary approaches. However, one sophistication of the current method is that it requires fine-tuning and pre-processing of data, which requires some experience on behalf of inexperienced users. For such users, in future, we are interested in designing a toolbox version that can facilitate the adaptation of the proposed method. Additionally, it would be interesting to incorporate more sophisticated learning strategies such as evolutionary methods and expanding the domain of our experiments to other more practical problems.
Notes
Without loss of generality, the bias of the considered RBF models are assumed to be zero during the proofs of the following lemma and its two corollaries.
References
Aftab W, Moinuddin M, Shaikh MS (2014) A Novel Kernel for RBF Based Neural Networks. Abstract and Applied Analysis 2014:1–10. https://doi.org/10.1155/2014/176253
Ahmad J, Khan S, Usman M, Naseem I, Moinuddin M, Syed HJ (2017) Fclms: Fractional complex lms algorithm for complex system identification. In: 2017 IEEE 13th International Colloquium on Signal Processing & its Applications (CSPA), 39–43. IEEE
Alexandridis A, Chondrodima E, Sarimveis H (2016) Cooperative learning for radial basis function networks using particle swarm optimization. Applied Soft Computing 49:485–497. https://doi.org/10.1016/j.asoc.2016.08.032
Aljarah I, Faris H, Mirjalili S, Al-Madi N (2018) Training radial basis function networks using biogeography-based optimizer. Neural Computing and Applications 29(7):529–553. https://doi.org/10.1007/s00521-016-2559-2
de Almeida Rego JB, de Medeiros Martins A, Costa EdB (2014) Deterministic System Identification Using RBF Networks. Mathematical Problems in Engineering 2014:1–10. https://doi.org/10.1155/2014/432593
Bu K, He Y, Jing X, Han J (2020) Adversarial transfer learning for deep learning based automatic modulation classification. IEEE Signal Processing Letters
Bucak SS, Jin R, Jain AK (2014) Multiple Kernel Learning for Visual Object Recognition: A Review. IEEE Transactions on Pattern Analysis and Machine Intelligence 36(7):1354–1369. https://doi.org/10.1109/TPAMI.2013.212
Chen ZY, Kuo RJ (2019) Combining SOM and evolutionary computation algorithms for RBF neural network training. Journal of Intelligent Manufacturing 30(3):1137–1154. https://doi.org/10.1007/s10845-017-1313-7
Fisher RA (1936) THE USE OF MULTIPLE MEASUREMENTS IN TAXONOMIC PROBLEMS. Annals of Eugenics 7(2):179–188. https://doi.org/10.1111/j.1469-1809.1936.tb02137.x
Fu L, Zhang M, Li H (2010) Sparse RBF Networks with Multi-kernels. Neural Processing Letters 32(3):235–247. https://doi.org/10.1007/s11063-010-9153-x
Gan M, Peng H, Dong Xp (2012) A hybrid algorithm to optimize RBF network architecture and parameters for nonlinear time series prediction. Applied Mathematical Modelling 36(7):2911–2919. https://doi.org/10.1016/j.apm.2011.09.066
Gao F, Han L (2012) Implementing the Nelder-Mead simplex algorithm with adaptive parameters. Computational Optimization and Applications 51(1):259–277. https://doi.org/10.1007/s10589-010-9329-3
Goodfellow I (2016) Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160
Gu Y, Liu T, Jia X, Benediktsson JA, Chanussot J (2016) Nonlinear Multiple Kernel Learning With Multiple-Structure-Element Extended Morphological Profiles for Hyperspectral Image Classification. IEEE Transactions on Geoscience and Remote Sensing 54(6):3235–3247. https://doi.org/10.1109/TGRS.2015.2514161
Hassan AK, Moinuddin M, Al-Saggaf UM, Shaikh MS (2018) On the Kernel Optimization of Radial Basis Function Using Nelder Mead Simplex. Arabian Journal for Science and Engineering 43(6):2805–2816. https://doi.org/10.1007/s13369-017-2888-1
Haykin SS (1999) Neural networks: a comprehensive foundation, 2nd edn. Prentice Hall, Upper Saddle River, N.J
Haykin SS (2014) Adaptive filter theory, 5th edn. Pearson, Upper Saddle River, New Jersey
Ibrahim MS, Dong W, Yang Q (2020) Machine learning driven smart electric power systems: Current trends and new perspectives. Applied Energy 272:115,237
Khan S, Ahmad J, Naseem I, Moinuddin M (2018) A novel fractional gradient-based learning algorithm for recurrent neural networks. Circuits, Systems, and Signal Processing 37(2):593–612
Khan S, Ahmad J, Sadiq A, Naseem I, Moinuddin M (2018) Spatio-Temporal RBF Neural Networks. In: 2018 3rd International Conference on Emerging Trends in Engineering, Sciences and Technology (ICEEST), pp. 1–5. IEEE, Karachi, Pakistan. https://doi.org/10.1109/ICEEST.2018.8643322
Khan S, Ahmed N, Malik MA, Naseem I, Togneri R, Bennamoun M (2017) Flmf: Fractional least mean fourth algorithm for channel estimation in non-gaussian environment. In: 2017 International Conference on Information and Communication Technology Convergence (ICTC), 466–470. IEEE
Khan S, Huh J, Ye JC (2019) Universal plane-wave compounding for high quality us imaging using deep learning. In: 2019 IEEE International Ultrasonics Symposium (IUS), 2345–2347. IEEE
Khan S, Huh J, Ye JC (2020) Adaptive and compressive beamforming using deep learning for medical ultrasound. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control 1–1
Khan S, Naseem I, Malik MA, Togneri R, Bennamoun M (2018) A fractional gradient descent-based rbf neural network. Circuits, Systems, and Signal Processing 37(12):5311–5332
Khan S, Naseem I, Togneri R, Bennamoun M (2017) A novel adaptive kernel for the rbf neural networks. Circuits, Systems, and Signal Processing 36(4):1639–1653
Khan S, Naseem I, Togneri R, Bennamoun M (2018) Rafp-pred: Robust prediction of antifreeze proteins using localized analysis of n-peptide compositions. IEEE/ACM Transactions on Computational Biology and Bioinformatics 15(1):244–250
Lee D, Kim J, Moon WJ, Ye JC (2019) Collagan: Collaborative gan for missing image data imputation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2487–2496
Liu Y, Zhao J, Xiao Y (2018) C-RBFNN: A user retweet behavior prediction method for hotspot topics based on improved RBF neural network. Neurocomputing 275:733–746. https://doi.org/10.1016/j.neucom.2017.09.015
Meng X, Rozycki P, Qiao JF, Wilamowski BM (2018) Nonlinear System Modeling Using RBF Networks for Industrial Application. IEEE Transactions on Industrial Informatics 14(3):931–940. https://doi.org/10.1109/TII.2017.2734686
Muhammad M, Naseem I, Aftab W, A Bencherif S, Memich A (2017) A Weighted Cosine RBF Neural Networks. J Mol Biol Biotech 2(2): 1–8. URL http://www.imedpub.com/articles/a-weighted-cosine-rbf-neural-networks.pdf
Naseem I, Khan S, Togneri R, Bennamoun M (2017) Ecmsrc: A sparse learning approach for the prediction of extracellular matrix proteins. Current Bioinformatics 12(4):361–368
Nerguizian C, Despins C, Affès S (2006) Geolocation in mines with an impulse response fingerprinting technique and neural networks. IEEE transactions on wireless communications 5(3):603–611
Pal NR, Chakraborty D (2000) Mountain and subtractive clustering method: Improvements and generalizations. International Journal of Intelligent Systems 15(4):329–341. 10.1002/(SICI)1098-111X(200004)15:4\(<\)329::AID-INT5\(>\)3.0.CO;2-9. URL http://doi.wiley.com/10.1002/%28SICI%291098-111X%28200004%2915%3A4%3C329%3A%3AAID-INT5%3E3.0.CO%3B2-9
Peng S, Jiang H, Wang H, Alwageed H, Zhou Y, Sebdani MM, Yao YD (2018) Modulation classification based on signal constellation diagrams and deep learning. IEEE transactions on neural networks and learning systems 30(3):718–727
Pratiwi M, Alexander, Harefa J, Nanda S (2015) Mammograms Classification Using Gray-level Co-occurrence Matrix and Radial Basis Function Neural Network. Procedia Computer Science 59: 83–91. https://doi.org/10.1016/j.procs.2015.07.340. URL https://linkinghub.elsevier.com/retrieve/pii/S1877050915018694
Sadiq A, Ibrahim MS, Usman M, Zubair M, Khan S (2018) Chaotic time series prediction using spatio-temporal rbf neural networks. In: 2018 3rd International Conference on Emerging Trends in Engineering, Sciences and Technology (ICEEST), 1–5. IEEE
Sadiq A, Khan S, Naseem I, Togneri R, Bennamoun M (2019) Enhanced q-least mean square. Circuits, Systems, and Signal Processing 38(10):4817–4839
Sikora R, Giza Z, Filipowicz F, Sikora J (2000) The bell function approximation of material coefficients distribution in the electrical impedance tomography. IEEE Transactions on Magnetics 36(4):1023–1026
Simon D (2008) Biogeography-Based Optimization. IEEE Transactions on Evolutionary Computation 12(6):702–713. https://doi.org/10.1109/TEVC.2008.919004
Tuia D, Camps-Valls G, Matasci G, Kanevski M (2010) Learning Relevant Image Features With Multiple-Kernel Classification. IEEE Transactions on Geoscience and Remote Sensing 48(10):3780–3791. https://doi.org/10.1109/TGRS.2010.2049496
Usman M, Khan S, Lee JA (2020) Afp-lse: Antifreeze proteins prediction using latent space encoding of composition of k-spaced amino acid pairs. Scientific Reports 10(1):1–13
Varma M, Babu BR (2009) More generality in efficient multiple kernel learning. In: Proceedings of the 26th Annual International Conference on Machine Learning - ICML ’09, pp. 1–8. ACM Press, Montreal, Quebec, Canada. https://doi.org/10.1145/1553374.1553510. URL http://portal.acm.org/citation.cfm?doid=1553374.1553510
Vetrivel A, Gerke M, Kerle N, Nex F, Vosselman G (2018) Disaster damage detection through synergistic use of deep learning and 3d point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS Journal of Photogrammetry and Remote Sensing 140:45–59. https://doi.org/10.1016/j.isprsjprs.2017.03.001
Wen Z, Xie L, Feng H, Tan Y (2019) Robust fusion algorithm based on RBF neural network with TS fuzzy model and its application to infrared flame detection problem. Applied Soft Computing 76:251–264. https://doi.org/10.1016/j.asoc.2018.12.019
Yang X, Li Y, Sun Y, Long T, Sarkar TK (2018) Fast and Robust RBF Neural Network Based on Global K-means Clustering with Adaptive Selection Radius for Sound Source Angle Estimation. IEEE Transactions on Antennas and Propagation 1–1. https://doi.org/10.1109/TAP.2018.2823713. URL http://ieeexplore.ieee.org/document/8335765/
Yang XS (2010) Nature-inspired metaheuristic algorithms, 2nd edn. Luniver Press, Frome
Yoon YH, Khan S, Huh J, Ye JC (2018) Efficient b-mode ultrasound image reconstruction from sub-sampled rf data using deep learning. IEEE transactions on medical imaging 38(2):325–336
Zhu JZ, Cao JX, Zhu Y (2014) Traffic volume forecasting based on radial basis function neural network with the consideration of traffic flows at the adjacent intersections. Transportation Research Part C: Emerging Technologies 47:139–154. https://doi.org/10.1016/j.trc.2014.06.011
Acknowledgements
Syed Muhammad Atif acknowledges the support of HEC, Pakistan under Indigenous Ph.D. Fellowship Program (PIN 315-13358-2EG3-204).
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Shujaat Khan designed the research, Syed Muhammad Atif and Shujaat Khan conducted and conceived the experiments and performed analysis, The initial draft of the manuscript was written by Syed Muhammad Atif and all authors commented on previous versions of the manuscript. All authors discussed the results and approved the final manuscript.
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Atif, S.M., Khan, S., Naseem, I. et al. Multi-Kernel Fusion for RBF Neural Networks. Neural Process Lett 55, 1045–1069 (2023). https://doi.org/10.1007/s11063-022-10925-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-022-10925-3