
Abstract
The self-potential method (SP) has been used extensively to reveal some model parameters of various ore deposits. However, estimating these parameters can be challenging due to the mathematical nature of the inversion process. To address this issue, we propose here a novel global optimizer called the Modified Barnacles Mating Optimizer (MBMO). We improved upon the original approach by incorporating a variable genital length strategy, a novel barnacle offspring evolving method, and an out-of-bounds correction approach. The MBMO has not been previously applied to geophysical anomalies. Prior to inversion of real data sets, modal and sensitivity Analyzes were conducted using a theoretical model with multiple sources. The Analyzes revealed that the problem is modal in nature, model parameters have varying levels of sensitivity, and an algorithm that can well balance global exploration with local exploitation is required to solve this problem. The MBMO was tested on theoretical SP anomalies and four real datasets from Türkiye, Canada, India, and Germany. Its performance was compared to the original version under equal conditions. Uncertainty determination studies were carried out to comprehend the reliability of the solutions obtained via both algorithms. The findings indicated clearly that the MBMO outperformed its original version in estimating the model parameters from SP anomalies. The modifications presented here improved its ability to search for the global minimum effectively. In addition to geophysical datasets, experiments with 11 challenging benchmark functions demonstrated the advantages of MBMO in optimization problems. Theoretical and field data applications showed that the proposed algorithm can be used effectively in model parameter estimations from SP anomalies of ore deposits with the help of total gradient anomalies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The self-potential (SP) method is one of the well-established geophysical methods that measures naturally-occurring potential differences originating from subsurface electrochemical, electrokinetic, and thermoelectric fields (Santos, 2010). This method requires only a voltage-sensitive device and two non-polarizable electrodes placed on the ground surface. The measured potentials are reported in millivolts (mV), which can be inverted qualitatively and quantitatively using various methods to characterize some parameters of the causative SP sources. Due to the convenient, non-invasive, and cost-effective nature of the SP method, it has been commonly performed for many problems, such as in spring flow studies (Schiavone & Quarto, 1984), earthquake predictions (Laurence et al., 1995), landslide investigations (Lapenna et al., 2003), Archeological investigations (Drahor, 2004), groundwater explorations (Rizzo et al., 2004), buried paleochannel explorations (Revil et al., 2005), landfill leachate detections (Arora et al., 2007), geothermal explorations (Jardani et al., 2008), brine contamination studies (Titov et al., 2010), cavity detections (Eppelbaum, 2021), and for applications related to mineral explorations (Biswas and Sharma, 2014a; Essa, 2020).
When interpreting SP data, subsurface structures are often idealized using some simple geometric shapes (El-Araby, 2004; Biswas & Sharma, 2014b; Essa, 2019; Elhussein, 2021; Abdelrahman et al., 2021). This method can provide information about the causative ore masses’ location, depth, and shape. Like other geophysical methods, the SP method’s ability to reveal ore deposit properties is significantly impacted by the inversion process, which is known to have mathematical difficulties (Sharma & Biswas, 2013). Various techniques have been introduced to predict the model parameters of causative sources from SP anomalies, such as tomographic imaging (Patella 1997), derivative analysis (Abdelrahman et al., 2003), least-squares inversion (EI-Araby, 2004), Euler's deconvolution (Agarwal & Srivastava, 2009), modular neural network (El-Kaliouby & Al-Garni, 2009), regularized inversion based on conjugate gradient (Mehanee, 2014), and spectral analysis (Di Maio et al., 2017).
Nature-inspired and gradient-free global optimization algorithms have recently gained popularity for solving geophysical inversion problems. These algorithms can converge to the global optimum while avoiding local minima. Unlike local optimization algorithms, they do not require a well-defined initial model to estimate a reasonable solution. However, global optimizers generally require more computational resources than local optimizers. Several studies have reported on the inversion of SP anomalies using global optimizers (Gobashy & Abdelazeem, 2021), including genetic algorithm (GA) (Abdelazeem & Gobashy, 2006; Göktürkler & Balkaya, 2012), particle swarm optimization (PSO) (Sweilam et al., 2007; Santos, 2010; Göktürkler & Balkaya, 2012; Essa, 2019; Ekinci et al., 2020), differential evolution (DE) (Li & Yin, 2012; Balkaya, 2013), micro-differential evolution (MDE) (Sungkono, 2020), simulated annealing (SA) (Göktürkler & Balkaya, 2012), very fast simulated annealing (VFSA) (Biswas, 2017; Biswas et al., 2022), genetic price algorithm (GP) (Di Maio et al., 2016), crow search algorithm (CSA) (Haryono et al., 2020), whale optimization algorithm (WOA) (Abdelazeem et al., 2019; Gobashy et al., 2020), black hole algorithm (BHA) (Sungkono, 2018), cuckoo search algorithm (CSA) (Turan-Karaoğlan & Göktürkler, 2021), bat optimizing algorithm (BOA) (Essa et al., 2023), and self-adaptive bare-bones teaching-learning-based optimization (SABBTLBO) (Sungkono, 2023). However, according to the No Free Lunch Theorem of optimization (Wolpert & Macready, 1997), there is no definite algorithm that can handle all types of inverse problems. Thus, researchers continue to develop new mathematical approaches and efficient algorithms to obtain better model solutions.
Most of the SP studies do not focus on determining the number of causative sources before performing inversion procedures. Neglecting a source causes a slight change in the anomaly amplitude but significantly impacts the inversion results, leading to misinterpretation. Here, we present the Modified Barnacles Mating Optimizer (MBMO) for the inversion of SP anomalies. Additionally, for better model parameter estimations from SP anomalies of ore deposits, we propose a simple strategy that can be used to determine the number of causative sources. We integrate three modifications, including a variable genital length plvar strategy, a novel barnacle offspring evolving method, and an out-of-bounds correction approach to make the MBMO more efficient. Before performing inversion studies, we utilized a theoretically-produced SP anomaly of multiple sources to perform modal Analyzes. These processes included producing cost function topography maps and performing sensitivity Analyzes by perturbing model parameters. The Analyzes allowed us to reveal the resolvability characteristics of the inverse problem and the sensitivity levels of the model parameters. The performance of the MBMO was evaluated using theoretical SP responses and four real SP anomalies from Türkiye, Canada, India, and Germany. Additionally, 11 well-known benchmark functions were used to demonstrate the performance of MBMO in solving optimization problems. Post-inversion uncertainty Analyzes were performed to validate the model parameter solutions. We also present an approach that uses the total gradient (TG) anomaly to determine the number of sources causing an anomaly.
Methodology
Anomaly equations
The SP anomaly caused by spherical and cylindrical sources at a point xi can be expressed as (Bhattacharya & Roy, 1981):
where θ represents the polarization angle (°), z0 denotes the depth (m) of the source, q is the shape factor, x0 is the location (m) of source over a profile, xi represents the observation location, and K is the electrical dipole moment (mV × m2q−1) that varies with the shape of the source. The q values for a sphere, a horizontal cylinder, and a semi-infinite vertical cylinder are 1.5, 1.0, and 0.5, respectively. In particular, q is 0 as the source approximates a 2D inclined horizontal thin sheet-like source (Sungkono & Warnana, 2018).
The SP response of a sheet at a point xi is defined as (Murty & Haricharan, 1985):
where K is Iρ/2π (mV), I denotes the medium's current density, ρ represents resistivity, and θ and a are the inclination angle and half-width of the sheet, respectively.
Barnacles Mating Optimizer and Its Modified Version
Sulaiman et al. (2020) developed the Barnacles Mating Optimizer (BMO) by studying the specific mating behaviors of barnacles. The algorithm has been proven effective in solving engineering optimization problems. However, the optimization process of this novel nature-inspired global optimization algorithm, namely global exploration and local exploitation stages, are severely limited by the selection of its control parameter (genital length), the multiple barnacle population evolution approach, and how it handles when a barnacle exceeds the bounds of the model space. In this study, we modified the BMO algorithm by introducing a variable genital length (plvar), a novel method for barnacle offspring evolution, and a boundary-crossing correction approach. We tested the effectiveness of MBMO using the SP anomalies caused by ore masses. The details of BMO and MBMO are described below.
BMO Algorithm
The initial step involves initializing the barnacle population X. This can be done based on a priori information (Sulaiman et al., 2020) or through random generation in the model space, as described by Parsopoulos & Vrahatis (2002). Thus,
where N is the population size of the barnacle, dim is the dimensionality of the optimization problem or the number of solution variables (in this paper, the solution variables are (K, θ, x0, z0, q) or (K, θ, x0, z0, α)), and lbi and ubi are the lower and upper bounds for each variable, respectively.
The selection process of BMO is implemented based on the mating behaviors of barnacles, which is based on the following assumptions (Sulaiman et al., 2020):
-
(i)
Mates are randomly selected within the range of genital length pl.
-
(ii)
All barnacle individuals can contribute or receive sperm but can only be fertilized once.
-
(iii)
Barnacle self-fertilization is not considered.
-
(iv)
Because barnacle sperm migrate with the water, a barnacle's potential mating partner may exceed the range limit of pl, but this phenomenon occurs randomly.
Among the above assumptions, the BMO’s exploitation process is guaranteed by assumptions (i) and (ii), while its exploration process is provided by assumption (iv). If a barnacle selects a mating object beyond its own pl, a reasonable explanation can be provided by assumption (iv), and the selection process is then described as:
where \({\text{randperm}}\left( {\tilde{n}} \right)\) is the function of generating a random sequence of 1 to \(\tilde{n}\), including the barnacle individuals within the pl coverage. The barnacled and barnaclem are the random sequences of male and female barnacles for mating, respectively. Following the Hardy–Weinberg principle (Guo & Thompson, 1992), the reproduction process of the BMO algorithm is implemented as:
where both p and q (q = 1−p) are random numbers between 0 and 1 following uniform distributions, and \(X_{{{\text{barnacle}}_{{\text{d}}} }}\) and \(X_{{{\text{barnacle}}_{{\text{m}}} }}\) are the sires and dams involved in the mating process, respectively. It can be seen from Eq. 5 that p and q represent the percentage of characteristics that the barnacle sires and dams, respectively, embed in their offspring. Thus, the offspring inherits the behavior and characteristics of the ancestor with a random probability between 0 and 1. It is worth repeating that the importance of pl lies in its ability to influence the exploration and exploitation phases of the BMO optimizer. If the barnacle selected for mating is within the coverage of pl, the exploitation process occurs, using Eq. 5 to generate the next generation of offspring. If the chosen barnacle for mating is outside the range of pl, the exploration process occurs instead, using Eq. 6 to update the position of the barnacle's offspring, thus:
where rand is a random number obeying uniform distribution between [0, 1].
MBMO Algorithm
-
i.
plvar strategy
As mentioned before, the pl plays a crucial role in regulating the optimization process of BMO. However, the standard BMO method uses a fixed pl for optimization. A smaller pl significantly improves the BMO algorithm's ability to exploit the model space, but it tends to make the algorithm fall into local minima. In contrast, a large value of pl improves the BMO algorithm's ability to explore the model space but prevents it from approximating the global optimum well. Therefore, we propose plvar strategy to deal with this problem better. The pl varies with the number of iterations, thus:
where iter is the current iteration number, Iter_max is the total number of iterations, plub (plub = 1 × N) and pllb (pllb = 0 × N) are the maximum and minimum genital lengths, respectively. Then, by linearly reducing the initial broad genital coverage (plub reduced to pllb), the algorithm can explore the model space more extensively in the initial stage and exploit the model space more intensively in the later stage, while avoiding the operation of manually tuning the pl.
-
ii.
Novel Barnacle offspring renewal method
Here, the characteristic percentages of the selected barnacle sires and dams embedded in the offspring, i.e., setting p (p = 0.6) and q (q = 0.4), were used for the mating objects falling in the coverage plvar. A new generation of barnacles is produced according to the probabilities explained in the following cases.
-
a.
If rand < p2, the barnacle with the best fitness (minimum cost function value) is used to update the generation.
-
b.
if p2 \(\le\) rand < (p2 + q2), \(X_{{{\text{barnacle}}_{m} }}^{i}\) are utilized for the updating process.
-
c.
if (p2 + q2)\(\le\) rand, Eq. 5 is used to generate the barnacle's offspring.
This modification increases the versatility of the offspring update algorithm to simulate the Hardy–Weinberg principle better, constrained by the premise of solving optimization problems.
-
iii.
Out-of-bounds correction approach
Finally, for barnacle individuals that are excluded from the model space, MBMO corrects their locations using Eq. 8 instead of fixing them at the boundary of the parameter search space, thus:
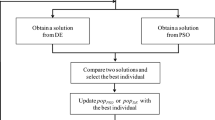
where C is the boundary oscillation factor (a dimensionless number between 0 and 1), which is 0.5 in this study. Equation 8 allows the MBMO to comprehensively explore and utilize the model space to search for the optimal solution within iterations. This improves the algorithm’s ability to capture the global solution, which is impossible with the basic BMO method. Figure 1 demonstrates the flowchart of the MBMO.

Flowchart of the proposed MBMO algorithm
Cost Function and Stopping Criterion
We used the root-mean-square-error (RMSE) given below as the cost function to be minimized in the inversion process.
where Vobs and Vcal denote the observed and calculated SP data, respectively, and M represents the number of data points. In this study, we used the maximum iteration number given in Eq. 7 for stopping criterion. In addition, the relative error (Re) defined below was used for the post-inversion studies.
where abs() is the absolute function, Strue and Scal are the true and calculated parameters, respectively.
Pre-inversion Analyzes
Modal Analysis
Pre-inversion studies are carried out to understand the solvability properties of the inversion problem at hand (Ai et al., 2023a). Due to the ill-posed and ambiguous mathematical nature of geophysical inversion problems, numerous models in the search space may produce a desirable low misfit value. This situation increases the complexity of the inversion and decreases the reliability of the inversion outputs. Among the pre-inversion methods, modal analysis, namely mapping and categorizing the cost function topographies between the model parameter pairs (Ekinci et al., 2021; Ai et al., 2022; Ekinci et al., 2023), is the most commonly used strategy. This analysis allows for investigating the dimensionality and shape (symmetric or asymmetric) of the 2D cost function topography maps. Thus, possible correlations and dependencies among the model parameters, and the difficulty of the inversion problem can be analyzed easily. To perform this task, the SP anomaly of a theoretical multiple-source model was used to simulate practical inversion studies for ore masses. The lower panel of Figure 2 shows the spatial distribution of the four sources and their model parameters. Table 1 also gives these parameter values. The theoretical SP anomalies shown in the upper panel of Figure 2 were produced using a 10-m sampling interval and a 400-m long profile. The deep source (vertical cylinder) caused a broad anomaly response, and other shallow sources produced narrow and sharp anomaly amplitudes. It is clear that the polarization angle controls the symmetry of the anomaly curve. For the calculations, 50% perturbations of the true parameter values were considered. The cost function topography maps (Fig. 3) of parameter pairs were generated using log10(RMSE) and a normalizing procedure for better visualization. The black points in the center of each map and black dashed ellipses represent the global minima and the massive local minima zones, respectively.

Theoretical multi-source model and corresponding SP anomalies

Modal analysis showing the cost function topography maps for every parameter pairs
In the literature, three modal types are defined as unimodal (Deb & Gupta, 2006), multimodal (Ray, 2002) and composite modal (Mirjalili & Lewis, 2016). The unimodal type refers to a cost function with only one global minimum. Such inverse problems are relatively easier to solve. The second type, however, represents a case with multiple deceptive minima and a global minimum. In this case, it is extremely difficult for optimization algorithms with insufficient capabilities to escape from many deceptive minima. Therefore, multimodal functions are often used to test the effectiveness of global optimization algorithms (Mirjalili, 2015). In the composite modality, many local minima and complex forms of unimodality and multimodality exist. These functions reveal whether a global optimizer provides an appropriate trade-off between the exploratory and exploitatory procedures.
As seen in Figure 3, the 2D cost function maps of the pairs θ−K, z0−K, K−q or a, x0−θ, z0−x0, x0−q or a, θ−q or a, and z0−q or a have elongated valleys representing the lowest misfit region. These topographies display clearly the multimodal nature, i.e., the parameters in each pair are interdependent. The global minima encircled by almost circular contours in the x0−K and z0−θ maps show the unimodal property. Therefore, these parameters can be solved independently. Considering the modal analysis, the multi-source SP inverse problem has a composite modality character with a high degree of complexity and a high probability of finding model parameters with significant uncertainties. It is clear that the optimization algorithm used to solve this inverse problem should be exploratory enough in the initial inversion stage to escape from massively located local minima and exploitative enough as the optimizer converges to the global minimum effectively.
Sensitivity Analysis
A sensitivity study of the model parameters, another type of pre-inversion evaluation, was also performed to understand the nature of SP inversion problem further. Instead of the exhaustive Jacobian matrix calculation (Pan et al., 2019), a gradient-free sensitivity analysis (Mianshui et al. 2022) was used here. The theoretical multi-source model (Table 1) was used again; 50% perturbations of the model parameter values were considered. The results are demonstrated in Figure 4. The color bar was calibrated to the parameter variability. The combination of shape factor q and sheet half-width a yielded the highest sensitivity. K and x0 were more sensitive than θ and z0. These observations indicated that the data can satisfactorily resolve q or a. However, it should be mentioned that some post-inversion uncertainty Analyzes must be performed to investigate possible errors and ambiguities within the model parameter values obtained.

Sensitivity analysis of the model parameters. The color bar is calibrated in terms of the variability of the parameter values
Parameter Tuning Analysis
The success of global optimization depends largely on the selection of control parameter values of the optimizer, which are problem-dependent and therefore tuning studies should be carried out (Ekinci et al., 2017). As mentioned previously, the genital length pl controls the exploration and exploitation phases of BMO, which must be finely-tuned. However, MBMO uses a variable genital length plvar strategy, eliminating the need for a detailed parameter tuning. To perform a fair comparison between BMO and MBMO, we performed tuning study for pl. The noise-free SP anomaly of multi-source model (Table 1) was inverted to analyze the effect of the control parameter pl of BMO. The search spaces for model parameters were designed using 100% perturbations of the true parameter values. The N and Iter_max values were set to 100 and 200, respectively. We implemented BMO independently 30 times to suppress its stochastic nature and to observe statistical results. Figure 5 shows the mean and standard deviation (STD) of the calculated RMSEs as a function of pl. Here, meanRMSE and STDRMSE represent the accuracy and uncertainty, respectively, of the BMO process. For better visualization, we used a normalization procedure (Fig. 5). As pl increased gradually, the accuracy and stability of BMO improved significantly. This finding showed that pl can significantly affect the success of BMO. As a result, we determined that pl = 1 × N is the best choice for the SP inversion problem presented here.

Tuning results for parameter pl of BMO
Theoretical Anomaly Cases
Inversion with Noisy Data
We present here some comparative studies of the efficiency of BMO and MBMO. The same theoretical SP anomaly was used. All inversion experiments presented here were carried out on a Windows 11 operating system with a 12th Gen Intel (R) CoreTM i9-12900H CPU (2.50 GHz) and 16 GB of RAM. Additionally, BMO (pl = 1 × N) and MBMO (pllb = 0 × N, plub = 1 × N) were run independently 30 times with N = 100 and Iter_max = 200 for all theoretical and real data cases. To complicate the problem for the optimizers, different amounts of pseudo-random noise following a uniform distribution were added to the anomaly using the definition given below (Ai et al., 2023a):
where mean() is the mean of the input, rand1() and rand2() produce values in the range of [0, 1] with a specified size (M). The variable NR is a predefined factor determining the amount of random noise added. Initially, it was set to 5% for case 1. This definition produced about 3% noise content having pseudo-random values with zero-mean and a STD of 0.5. Figure 6 shows the SP responses with and without noise. It was observed that the noise content produced only slight variations in the anomaly curve. The optimization process used a wide-ranging model search space (Table 2). Figure 6 also shows the best SP anomaly obtained from each iteration of the final implementation of the 30 independent runs. The solutions derived from the initial start were represented by a deep green color, which changes to dark purple as the iteration progresses. The best fitting responses calculated via two optimizers are also represented with error bars in Figure 6. To enhance the performance of both optimizers, we followed the approach of averaging solutions within a specific range of the minimum, as suggested by Amato et al. (2021). We sorted the solutions of 30 independent runs in ascending order of RMSEs and used the first two solution sets to compute the mean output as the final output. By this way we compared the performance of two optimizers under their optimal conditions to obtain more objective results. The convergence curves of the two algorithms are shown statistically in Figure 7. The blue solid lines in the panels are the fitting errors between the noisy and the calculated anomalies. In the left panels of each case, black curves illustrate the calculated meanRMSEs between noise-free and calculated SP anomalies while these curves show the changing behavior of the STDRMSEs in the right panels.

Performances of the optimizers on noisy anomaly cases

Convergence curves with inversion uncertainties and stabilities. The blue solid lines in the panels are the fitting errors between noisy and calculated SP responses. In the left panels of each case, black curves represent the calculated meanRMSEs of noise-free and calculated SP responses while they represent the changing behavior of the STDRMSEs, namely the inversion stabilities in the right panels. The gray rectangles represent the iteration process before reaching the convergence plateau according to the changing behavior of the blue curves. The RMSEs at the final iterations are also illustrated
The widths of the rectangles represent the iteration process before BMO and MBMO reach the convergence plateau, which follows the changing behavior of the blue curve. Accordingly, the obtained results, including the derived model parameters with uncertainties and the further calculated data misfits with STDs, are also listed in Table 2. The RMSEs in Table 2 are incompatible with the values shown in Figure 7 because the latter are the mean values of the sorted and thresholded 30 convergence curves, while the former are the mean data misfits calculated based on the sorted and thresholded model parameter set. The findings showed that the improved strategies in the MBMO algorithm approximated the global minimum intensively without compromising the effectiveness of avoiding massive local minima as discussed in the modal analysis section.
To further evaluate the performance of the BMO and MBMO algorithms, a higher noise rate (NR = 30%) was added to the SP anomaly. The definition of NR = 30% resulted in a noise level of approximately 15% (about zero-mean and STD = 3.3). Figure 6 shows that the noisy SP anomaly produced relatively large differences compared to the noise-free one. Following the same inversion procedure as in the first case, uncertainties (pick curves with error bars) and dynamic search process are illustrated in Figure 6. The convergence curves and inversion uncertainties varying with the iteration numbers of the two algorithms are shown in Figure 7. The calculated model parameters with the uncertainties are listed in Table 2. Although both algorithms produced more erroneous results the MBMO algorithm yielded a more coherent SP anomaly, a smoother and more stable optimization process with a faster convergence rate, lower data misfit, and lower inversion uncertainty. These results confirmed that the three strategies we incorporated into the BMO structure, namely the variable genital length, the novel barnacle offspring renewal, and the out-of-bounds correction, improved the effectiveness of optimizer in terms of avoiding massive local minima and effectively converging to the true model parameter values, even when the observed anomaly is noisy and a wide model space is designed. It should be noted that these modifications increased the computational cost negligibly (Table 2). Therefore, the computational cost of two optimizers was not reported in the following experiments. Finally, we experienced the optimizing performances on 11 commonly used challenging composite benchmark functions. The mathematical expressions, search spaces, and global minima of these benchmark functions can be found in the Appendix, along with the results of the experiments. The MBMO algorithm performed better on most of the benchmark functions. This result showed that the three novel strategies are effective enough in solving complex optimization problems.
Uncertainty Analyzes for Theoretical Data Cases
The modal analysis showed that the presented inverse problem has a composite modality, which makes the inversion process error-prone. Additionally, the sensitivity study revealed that the model parameters can affect the SP anomaly with different amplitudes and shapes, leading to varying uncertainties in obtained model solutions. Therefore, uncertainty studies should be performed with the solutions obtained from inversion procedures to validate their reliability (Ai et al., 2022; Ekinci et al., 2023). We used the solutions obtained from 30 independent runs for two theoretical noisy data cases to perform this task. We sorted them according to their misfits, from the smallest to the largest RMSEs. The term An was defined as a variable that determines the number of sorted solutions used to calculate the final results by averaging. Figure 8 shows the results of BMO and MBMO outputs with different An values (An = 2, 7, 12, 17, 22, 27). There are only slight changes regardless of the noise level in BMO curves. However, it is clear that BMO outputs are more sensitive to increases in An. BMO produced solutions with higher error rates. Therefore, Figure 8 confirmed the superior performance of MBMO in anomaly fitting regardless of An and the amount of noise added.

Mean SP responses with respect to different An values. Pointed parts show that BMO is highly sensitive to the increment of An
The Re values between the mean model parameters estimated with two global optimization algorithms for two noisy anomaly (Table 2) and the true model parameter sets (Table 1) were calculated. These Re values associated with the uncertainties are shown in a checkerboard style in Figure 9. According to the results, most of the Re values of the MBMO were smaller than those of the BMO concerning the two different noisy cases. Therefore, considering the reported meanRe values, the MBMO outperformed the BMO in two cases. Similar conclusions can be drawn by looking at the STDRe values and their mean values. The checkerboard patterns in Figure 9 indicated that the MBMO can generally obtain the model parameters with maximum accuracy and minimum uncertainty. This finding agrees with the results of the Analyzes performed in the theoretical experiments.

Re values with uncertainties
Lastly, principal components analysis (PCA), which can be used in geophysical inverse problems (Pallero et al., 2015; Roy et al., 2021; Ekinci et al., 2023), was performed to reduce the high dimensionality of the model parameters to only two components and to produce cost function topography maps. To perform this important analysis, we calculated relative cost function (rCf) values using the following definition:
Figure 10 shows the equivalence rCf landscapes in 2D principal components space. The triangles in the maps indicate the respective global optimum and the error of the best-estimated model, respectively. The locations of the triangles in each topographic map showed the superiority of MBMO. Similar to the previous Analyzes results, PCA application showed that the novel improvements including a variable genital length strategy, a novel barnacle offspring evolving method, and an out-of-bounds correction strategy increased the effectiveness of the BMO algorithm in solving optimization problems.

Equivalence rCf topographies obtained via the solutions of two optimizers
Real Anomaly Cases
After obtaining satisfactory results on theoretical anomalies, the performance of the integrated strategies on real anomalies was investigated on four datasets from Türkiye, Canada, India, and Germany. Both BMO (pl = 1 × N) and MBMO (pllb = 0 × N, plub = 1 × N) were run independently 30 times with Iter_max = 400 and N = 200. Model solutions obtained from both optimizers were interpreted with those of previous geophysical studies and available geological data.
Süleymanköy Anomaly, Türkiye
The SP data set, acquired along a 262-m long profile over a polarized copper ore deposit in eastern Türkiye, was used as the first real data example. We digitized the anomaly presented in Yüngül (1950) with 4-m data spacing. The resampled data vary from 8 to 188 m and contained a positive peak amplitude and a negative valley counterpart within the survey line. This anomaly was inverted by some researchers using different optimization strategies (Tlas & Asfahani, 2007; Göktürkler & Balkaya, 2012; Biswas, 2017; Biswas, 2019; Turan-Karaoğlan & Göktürkler, 2021; Hosseinzadeh et al., 2023). In some previous studies, it was assumed that a single source caused the anomaly while other researchers focused on multiple sources. The reported model parameter values based on the single source assumption are given in Table 3. Table 4 lists the solution of VFSA algorithm under the constraint of three causative sources (Biswas, 2019). We first determined the model parameters by considering a single source to provide a clear overview of the differences that arise from these two assumptions. Then, the inversion process was repeated using multiple causative sources (three or two sources).
The wide parameter search space used for the single source case is given in Table 5, along with the solutions of BMO and MBMO algorithms. The model parameters obtained with these optimizers showed good agreement with the results of recent studies (Göktürkler & Balkaya, 2012; Turan-Karaoğlan & Göktürkler, 2021; Hosseinzadeh et al., 2023). It must be noted that we used a wider search space than the work of Hosseinzadeh et al. (2023). Moreover, the RMSE of ~ 11.6 mV obtained by the MBMO was lower than that of the BMO method (~12.6 mV) and lower than the best data misfit reported in the literature (~12.2 mV). Thus, it can be mentioned that MBMO showed a better inversion performance for the single source case. It is clear that the source resembles a horizontal cylinder (q = 1.17 ± 0.01). Following the suggestion of Biswas (2019), BMO and MBMO were applied to this anomaly again by assuming three causative sources. The wide search spaces used and the inversion solutions obtained with the BMO and MBMO algorithms are given in Table 6. Surprisingly, the RMSE of the BMO increased to 25.5 ± 1.02 mV in this example. However, this value decreased to ~ 2.6 ± 0.47 mV when we used the MBMO algorithm. Thus, the MBMO outperformed the BMO in the multi-source case. The modified version yielded compatible solutions with the parameter estimates performed by Biswas (2019) by fixing the shape factor q of the three models (q = 1) and masking the effect of polarization angle via fitting the TG anomaly. The main difference lies in the parameter set of the third source. The q = 1.35 ± 0.19 obtained with the MBMO can be interpreted as a spherical body rather than a horizontal long cylinder.
Another scenario, including two causative sources, was also used to invert the Süleymanköy anomaly. The search space ranges used and the inversion solutions obtained with the BMO and MBMO are listed in Table 7. The colored curves in Figure 11 show the dynamic search process of the BMO and MBMO algorithms with comparisons of the observed anomaly and the mean output of the two algorithms. The deep green curve represents the initial best output within the population, with the color changing to dark purple, representing the best responses at later iterations. Figure 12 illustrates the convergence rates of the two algorithms concerning the two-source situation. The blue curves are the meanRMSEs between the digitized and calculated anomaly. The black curves are the corresponding inversion uncertainties (STD) obtained from the 30 independent runs. The width of the covered rectangles represents the iteration process before reaching the convergence phase of the algorithms, which follows the variational behavior of the blue curve. The meanRMSE and STDRMSE derived from the sorted and thresholded 30 convergence curves at the last iteration of BMO and MBMO are also shown. The MBMO yielded higher accuracy and lower uncertainty than the BMO. A similar conclusion can be drawn from the calculated RMSEs with uncertainties given in Table 7. Moreover, the MBMO provided a faster convergence rate (less than 200 iterations) than the BMO (more than 300 iterations). These results showed that our new strategies were quite suitable with the algorithm and increased its effectiveness.

Outputs of BMO (upper row) and MBMO (lower row). Triangles represent observed SP data. The best SP anomaly obtained from each iteration of the final round of the 30 independent runs is plotted according to the color scale. The calculated SP responses are shown with error bars

Convergence processes of the BMO and MBMO. Blue curves (left axes) and black curves (right axes) represent the obtained meanRMSEs and inversion uncertainties changing within 400 iterations. The widths of the gray boxes mark the convergence phase of two algorithms, according to the variational behavior of blue curve
Figure 13 shows the source bodies determined with the MBMO with model parameters using different assumptions. The solutions of single-, two- and three-source scenarios are shown with red, blue and gray, respectively, in Figure 13. The calculated SP anomalies from the literature were compared with the SP anomalies estimated by the BMO and MBMO optimizers under the two-source assumption. Comparatively, the MBMO yielded the best performance in terms of data-fitting. A good coherence was apparent when considering the delineated model on the left side of the profile. However, there were significant differences in the other sources. Thus, it is essential to determine the number of anomaly sources before the inversion process. Because there are only few works on setting up a basic rule for addressing this issue (Srivastava and Agarwal 2010; Ekinci et al. 2017), we provide below a in section “Discussion on Qualitatively Determining the Quantity of Causative Sources Contained” in the TG response derived from the observed SP anomaly.

Observed and calculated anomalies. The calculated responses in previous studies are also illustrated. Due to previous efforts focused the TG of Senneterre anomaly, we show the inversion results in Table 8. SP sources reconstructed are shown in the lower row
Senneterre Anomaly, Canada
The Senneterre SP anomaly, which is due to sulfide ore deposits, was used as the second real data case. The data set was digitized with a sampling interval of 2 m. The host rocks in the area consist of meta-sedimentary breccias and tuffs with interbedded lava flows. Pyrite and pyrrhotite are the primary minerals that cover most of the entire zone. These data were previously studied by some researchers using different strategies such as enhanced local wavenumber technique (Srivastava and Agarwal, 2009), a regularized inversion approach (Mehanee, 2014), a nature-inspired ant colony optimization algorithm (ACO) (Srivastava et al., 2014), and a VFSA algorithm (Biswas, 2019). The model parameters reported in the previous studies are listed in Table 8. These previous studies considered four distinct causative sources. Therefore, we followed their way and applied BMO and MBMO algorithms to the Senneterre SP response. Table 9 shows the large model space selected for the parameter set concerning the four-source model. In addition, the model parameters obtained by the two optimizers and the uncertainties in the inversion results are given in Table 9. Figure 11 illustrates the dynamic optimization process of the BMO and MBMO algorithms, where the anomalies obtained are colored from deep green to dark purple as the iteration number increases. The curves with error bars represent the mean outputs of the two approaches, and the triangles represent the observed anomaly. Corresponding convergence curves (blue curves) and STD variations (black curves) are also shown in Figure 12 (right axis). Both the blue curves (meanRMSEs) and the black curves were derived from the sorted and thresholded 30 convergence curves. The convergence phase associated with the changing behavior of the blue curve of the two algorithms was indicated by the width of the covered rectangles. Both methods required more than 250 iterations to reach the convergence phase. The meanRMSE and STDs at the last iteration are further marked in Figure 12. The results showed that the MBMO algorithm provided more satisfactory inversion results. The calculated RMSEs with uncertainties in Table 9 also show a similar property.
The four sources determined by the MBMO are shown in Figure 13, and the solutions were in good agreement with those of previous studies by Srivastava et al. (2014) and Biswas (2019). It should be noted that the obtained fourth body at the right end of the profile showed a significant difference from previous works (the third and fourth sources are close to each other), and its horizontal position exceeds the profile length. The sensitivity test performed by forward modeling using the three left sources confirmed that the Senneterre anomaly is affected by the fourth source without changing the general shape of the anomaly. This finding indicated that the fourth source plays a relatively minor role within the Senneterre anomaly. We, therefore, mention that the three sources on the left are more likely to represent the sulfide ore deposits.
Neem-ka-Thana Anomaly, India
In this real data case, we used the observed SP data of the Neem-Ka-Thana copper belt, India (Reddi et al., 1982). The anomaly between 53 and 299 m were digitized with a sampling interval of 3 m. This anomaly has a very similar character to the Senneterre anomaly; that is, the Neem-Ka-Thana anomaly is also characterized by negative SP responses (Fig. 11). Some researchers used this data set assuming a three-source model (two vertical cylinders and one horizontal cylinder). The previous estimations reported are listed in Table 10. Following the interpretation procedure described in the first real data case, we assumed that the Neem-Ka-Thana anomaly is caused by three causative sources. Two optimizers were run to invert this anomaly. Then, a comparative study was conducted to understand whether a four-source model is the causation of this SP response.
The calculated mean model parameter values of the three-source scenario from the sorted and thresholded 30 results, in conjunction with the uncertainties of the inversion and the selected model search spaces, are given in Table 11. A comparison between the results listed in Table 11 and the previous studies in Table 10 showed that both algorithms yielded similar solutions as predicted by various approaches, including MVDE (Sungkono, 2020), μJADE (Sungkono, 2020), EKI (Sungkono et al., 2021), and SABBTLBO (Sungkono et al., 2023). As mentioned, the estimated model parameters resemble two vertical cylinders and one horizontal cylinder. In addition, the MBMO finalized the inversion process with a smaller RMSE and inversion uncertainty. The three sources determined through the MBMO optimizer are colored gray in Figure 13 and agree well with the three left negative peaks of the Neem-Ka-Thana anomaly. However, the three-source model did not fit the relatively large negative response in the right corner (see Fig. 15 in Sungkono et al., 2023). Therefore, an attempt was made using a four-source model to approximate the actual situation of the subsurface. Table 12 lists the model parameter search spaces and the obtained mean outputs with errors using two optimizers. Accordingly, Figure 11 shows their mean anomalies with error bars compared to the observed Neem-Ka-Thana anomaly. A better agreement was observed between the response calculated via the MBMO and the Neem-Ka-Thana anomaly, especially in the right corner. The left axes in Figure 12 show the convergence curves together with the inversion uncertainties. The right axes exhibit the inversion uncertainties (black curves) obtained by two algorithms throughout the iteration process. The curves were also derived from the sorted and thresholded convergence curves. The widths of the covered gray rectangles in Figure 12 indicates the iteration times of the two optimizers reaching their convergence plateau. They converged at almost the same rate (300 iteration times). The finally obtained meanRMSEs and uncertainties of the two algorithms are also demonstrated in Figure 12. It is clear that the MBMO performed better than the original BMO algorithm. The calculated RMSEs with uncertainties in Table 12 indicated similar results. Both approaches produced better results in the four-source case than in the three-source one. As mentioned above, below is a section on “Discussion on Qualitatively Determining the Quantity of Causative Sources Contained” in the TG response derived from the observed SP anomaly. The SP anomalies digitized from the literature with compared to the SP anomalies obtained by the BMO and MBMO optimizers under the four-source assumption are shown in Figure 13. It is clear that the MBMO outperformed the BMO again regarding data-fitting performance. In Figure 13, the four structures estimated with MBMO are shown in blue. The four-source model agrees well with the three-source model concerning all characteristic parameters except for the inclined sheet at the right end of the profile. This study indicated that drilling works can be performed first over the three sources located on the left.
KTB Anomaly, Germany
The KTB SP anomaly digitized with an interval of 20 m is shown in Figure 11. We used the anomaly between 20 and 1740 m of the profile, observed near two KTB boreholes (Stoll et al., 1995). According to the drilling results, the occurrence is closely related to buried and steeply inclined sheet-like graphitic masses (Bigalke & Grabner, 1997). The anomaly contains two sharp and negative peaks with different amplitudes, indicating the possible location of the sources. Using a simple polarized two-sheet model, the KTB anomaly was analyzed previously with various global optimization methods, including VFSA (Biswas, 2017), WOA (Gobashy et al., 2020), MVDE (Sungkono, 2020), µJADE (Sungkono, 2020), BOA (Essa et al., 2023), and hybrid DE/PSO (Hosseinzadeh et al., 2023). The model parameters obtained from these previous studies are listed in Table 13. Following their works, we applied the BMO and MBMO procedures to the KTB anomaly, with the search space ranges given in Table 14. The parameters for the inversion remained unchanged compared to the three field experiments above. Figure 11 illustrate the dynamic optimization processes. Both optimizers identified coherent SP anomalies concerning the visual assessment. The convergence behaviors of two algorithms are shown in Figure 12. The blue (left axes) and black curves (right axes) represent the obtained meanRMSEs and the inversion uncertainties that change against the 400 iterations. The widths of the gray boxes in Figure 12 mark the convergence phase of two algorithms. The BMO and MBMO required more than 250 iterations to reach the convergence state. When considering the calculated data misfits with the STDs marked, it is clear that the MBMO algorithm showed better performance. This result can also be observed in the calculated RMSEs with uncertainties listed in Table 14.
Estimated mean model parameters with perturbations of the BMO and MBMO derived from the sorted and thresholded results are given in Table 14, which agree with the drilling results and were highly consistent with the study of Hosseinzadeh et al. (2023). Figure 13 further validates data-fitting performance of the MBMO algorithm by comparing the calculated SP responses reported in the literature. The estimated two anomalous sheets with different amplitude factors and geometries utilizing the MBMO optimizer can be also seen in Figure 13. This real data case confirmed that the BMO algorithm modified with novel strategies copes better with the SP inversion problem.
Uncertainty Analyzes for Real Data Cases
Post-inversion uncertainty Analyzes were carried out to understand the validity of the inversion results of the field data cases and to investigate the robustness of two optimizers. As the Analyzes in theoretical cases, the model parameter sets obtained from the 30 independent runs were sorted from best to worst RMSEs. Due to the different model assumptions used in some field applications, the model parameter set related to the two-source model for the Süleymanköy anomaly and the four-source model for the Neem-ka-Thana anomaly were used for these Analyzes. The parameter An was used again to control the number of sorted model parameter sets to be averaged. Figure 14 displays the mean responses calculated with different An values. Only minor differences can be seen in the outputs of the MBMO optimizer, i.e., the MBMO is not sensitive to the increment of An. However, the performance of the BMO weakened significantly when using larger An values regarding the four real anomaly applications. This finding coincided well with the relatively high inversion uncertainties for the four field anomalies. This indicated that the BMO has a higher probability of obtaining inaccurate solutions, which makes it less robust than the MBMO. In addition, Figure 14 demonstrates the superiority of the MBMO in the anomaly fitting process, regardless of the An value. This situation clearly highlighted the need to sort the model parameters obtained by multiple runs according to their misfits and generate the final mean solution within a small misfit range (e.g.,, An = 2). The model parameter solutions obtained with the BMO for the real data experiments would be worse if we averaged the model parameter sets obtained from all independent runs. Based on the real data inversion results and uncertainty appraisal analysis, it is clear that the MBMO algorithm performed better by using the three proposed strategies in the global exploration and local exploitation steps.

Post-inversion uncertainty appraisal Analyzes of the real data cases
Discussion on Qualitatively Determining the Quantity of Causative Sources Contained
Prior information about the number of anomaly sources before the inversion process may constrain the solutions and lead to more accurate model estimations. Findings from previous geological and/or geophysical surveys can be used for this purpose. However, this information may not be available or sufficient in some cases. Remarkable amplitude peaks in the observed SP data can be counted to estimate the number of sources causing the anomaly. However, this approximation may suffer from low resolution; some peak signals may be unclear and unnoticeable, and if the noise ratio is high these signals may be masked. In addition, the polarization angle affects the shape of the SP response significantly, making the peak detection process complex and challenging to implement. Therefore, we used the TG technique to address this issue better. TG anomaly calculated from the horizontal and vertical derivatives can reduce the polarization angle effect and sharpen the peaks caused by ore masses with limited horizontal extension. Some previous studies incorporated the TG technique into the SP data inversion problem and obtained promising results (Biswas, 2019; Srivastava and Agarwal, 2010). However, this neglects the polarization angle, leading to an incomplete interpretation instead of directly inverting the observed SP anomalies. Therefore, we used the TG technique as a qualitative indicator instead of a quantitative metric. Before the real data Analyzes, we produced the TG anomaly of the previously used theoretical noise-free SP anomaly caused by a four-source model with the comparison of the TG of the anomaly calculated by the MBMO. The right axis in Figure 15 shows the TG amplitudes. The two responses from TG correlated satisfactorily with each other regarding the general shape and horizontal locations of the four apparent peaks. There are only minor differences across the spherical body. Notably, the four peaks agreed well with the horizontal locations of the four causative sources. This finding confirmed the feasibility of detecting the peaks of the TG anomaly to determine the number of source bodies. In addition, the TG response calculated from the inverted SP data, which approximates the TG signal derived from the observed data, also reflected the reliability of the obtained model parameters.

TG of the theoretical noise-free SP anomaly due to four causative sources (covered gray area) with the comparison of the TG of the anomaly calculated using MBMO (covered dark orange area; NR = 5%)
Figure 16 shows the TG Analyzes for the four field cases with different properties. All blue solid lines illustrate the variation in the observed anomalies (left axis). The calculated TG responses of the four real anomalies are shown as gray areas in Figure 16 (right axis). Due to the computational process of the derivatives, enhanced short-wavelength components related to noise content can be easily seen in these TG responses. The blue area in Figure 16 shows the computed TG response based on the single source model concerning the Süleymanköy anomaly. The light pink area shows the TG anomaly derived from the three-source model. The dark orange area shows the calculated TG anomaly concerning the two-source model. All information from TG with different model assumptions yielded only a single peak located over the leftmost source within Figure 13. This feature confirmed the existence of the leftmost causative source. The three- and two-source models produced similar TG responses compared to the calculated ones. However, the three-source model should be neglected due to the lack of obvious peak information to prove the existence of the second source of the three-source model. The reason for not discarding the two-source model is that the right source's horizontal location exceeds the measurement line's range. In addition, the dark orange region better fits the gray region than the blue region. Therefore, the two-source model was the best choice concerning the Süleymanköy anomaly. As in the case of the Senneterre anomaly, the two anomalies of TG showed good coherence. This property confirmed the suitability of the four-source model used. Nevertheless, only three peaks were demonstrated within the measurement line. This situation is the same as for the Süleymanköy anomaly because the rightmost source estimated from the fit of the Senneterre anomaly was also outside the profile. Therefore, combining the peak information and fitting the two TG responses guarantees the best inversion performance.

TG (gray areas; the right axis) of the four real anomalies (blue solid lines; the left axis) with the comparison of the TG of the anomalies calculated using MBMO with different model assumptions (areas colored in blue, light pink, and dark orange)
The peaks identified from the calculated TG anomaly indicated only the number of causative sources below the survey line. The agreement between the TG anomalies obtained from the observed and calculated data sets allowed us to adjust the selected subsurface model. The result of TG derived from the four-source model showed better performance than the three-source model in terms of the number of peaks and fitness level in the Neem-ka-Thana anomaly case. In addition, the TG anomaly calculated from the observed Neem-ka-Thana anomaly contains many small peaks, possibly due to the noise content. Therefore, these relatively small peaks should be paid attention, as they may lead to misinterpretations. Ai et al. (2023b) recently proposed a modified non-local means (MNLM) filter that can be implemented flexibly to suppress the noise effect by tuning two control parameters if the observed responses are highly noise-contaminated. The findings obtained in the KTB case indicated that the SP anomaly was due mainly to the inclined two-sheet model. Therefore, when deciding the number of sources to be used in the inversion, it is helpful to consider the number of peaks in the TG of the observed anomaly. Additionally, the number of causative sources can be adjusted by controlling the fit between the TG amplitudes calculated from the observed data and model response.
Conclusions
The SP method, one of the oldest passive geophysical methods, measures naturally-occurring potential differences produced by the electrochemical, electrokinetic, and thermoelectric fields of the subsurface. This method has proved to be useful for exploring various ore deposits, and inversion of SP anomalies can be used to determine some model parameters. From a mining point of view, knowing these important model parameter values in advance can be used effectively in reducing some geological complexities, and can also provide suitable information for decision-making in the early understanding of ore bodies or deposits. However, most of the geophysical inverse problems are complicated due to their complex mathematical nature caused by the non-uniqueness and ill-posedness. Thus the inversion technique to be used for this type of problems should be effective in the trade-off between global exploratory and local exploitatory processes. Before implementation of the inversion procedures, some modal Analyzes were performed using a theoretical SP model with multiple sources. Cost function topography maps of model parameter pairs showed that the inverse problem presented here has high complexity, composite modality and probability of obtaining model parameters with significant uncertainties, as expected. Perturbation-based model parameter sensitivity studies performed here also confirmed the findings obtained from modal Analyzes. Thus, we determined that the reliability of the model solutions obtained through the inversion procedures should also be tested by performing some post-inversion studies.
Considering the mathematically complex nature of the SP anomaly inversion problem, we developed some novel strategies and incorporated them into the recently proposed BMO algorithm, an efficient nature-inspired and gradient-free global optimizer. To increase its performance in terms of accuracy and robustness, we integrated a variable genital length strategy, a novel barnacle offspring evolving method, and an out-of-bounds correction approach. The effectiveness of the MBMO was then tested on theoretically produced different SP anomaly scenarios and on four available field anomalies from Türkiye, Canada, India, and Germany. Additionally, some unbiased and fair comparisons with the BMO algorithm were carried out. The model solutions of the real data cases obtained by the two optimizers were interpreted with the findings from previous geophysical and geological studies. Post-inversion uncertainty appraisal Analyzes were performed accordingly to understand the reliability of the solutions obtained. Considering the inversion performances and uncertainty Analyzes, the MBMO algorithm performed better than the original version. The modifications increased the computational cost negligibly. Thus, the three novel strategies we developed for BMO proved useful in the inversion of SP anomalies caused by ore masses. Moreover, TG calculation, which enables to mask the effect of polarization angle on the SP anomalies, provided beneficial information in determining the number of causative sources. Apart from the geophysical problems, experiments on commonly used 11 challenging benchmark functions confirmed the outstanding performance of the MBMO in solving optimization problems with different modalities. Therefore, it is clear that this modified algorithm is a promising global optimization tool for solving low-dimensional geophysical inverse problems, such as estimating some model parameters of ore masses or deposits. Additionally, these scheme can be adapted easily to invert other potential fields such as gravity and magnetic anomalies.
Data Availability
The data are available upon request (E-mail: hanbingai@foxmail.com).
REFERENCES
Abdelazeem, M., & Gobashy, M. (2006). Self potential inversion using genetic algorithm. Journal of King Abdulaziz University, Earth Sciences, 17, 83–101.
Abdelazeem, M., Gobashy, M., Khalil, M. H., & Abdrabou, M. (2019). A complete model parameter optimization from self-potential data using Whale algorithm. Journal of Applied Geophysics, 170, 103825.
Abdelrahman, E., El-Araby, H. M., Hassaneen, A., & Hafez, M. A. (2003). New methods for shape and depth determinations from SP data. Geophysics, 68(4), 1202–1210.
Abdelrahman, E. M., & Gobashy, M. M. (2021). A fast method for interpretation of self-potential anomalies due to buried bodies of simple geometry. Pure and Applied Geophysics, 178, 3027–3038.
Agarwal, B., & Srivastava, S. (2009). Analyzes of self-potential anomalies by conventional and extended Euler deconvolution techniques. Computers & Geosciences, 35(11), 2231–2238.
Ai, H., Alvandi, A., Ghanati, R., Pham, L. T., Alarifi, S. S., Nasui, D., & Eldosouky, A. M. (2023b). Modified non-local means: A novel denoising approach to process gravity field data. Open Geosciences, 15(1), 20220551.
Ai, H., Ekinci, Y. L., Balkaya, Ç., & Essa, K. S. (2023a). Inversion of geomagnetic anomalies caused by ore masses using hunger games search algorithm. Earth and Space Sciences, 10(11), e2023EA003002.
Ai, H., Essa, K. S., Ekinci, Y. L., Balkaya, Ç., Li, H., & Géraud, Y. (2022). Magnetic anomaly inversion through the novel barnacles mating optimization algorithm. Scientific Reports, 12, 22578.
Amato, F., Pace, F., Comina, C., & Vergnano, A. (2021). TDEM prospections for inland groundwater exploration in semiarid climate, Island of Fogo, Cape Verde. Journal of Applied Geophysics, 184, 104242.
Arora, T., Linde, N., Revil, A., & Castermant, J. (2007). Nonintrusive characterization of the redox potential of landfill leachate plumes from self-potential data. Journal of Contaminant Hydrology, 92(3–4), 274–292.
Balkaya, Ç. (2013). An implementation of differential evolution algorithm for inversion of geoelectrical data. Journal of Applied Geophysics, 98, 160–175.
Bhattacharya, B. B., & Roy, N. (1981). A note on the use of nomograms for self-potential anomalies. Geophysical Prospecting, 29(1), 102–107.
Bigalke, J., & Grabner, E. W. (1997). The geobattery model: A contribution to large scale electrochemistry. Electrochimica Acta, 42(23–24), 3443–3452.
Biswas, A. (2017). A review on modeling, inversion and interpretation of self-potential in mineral exploration and tracing paleo-shear zones. Ore Geology Reviews, 91, 21–56.
Biswas, A. (2019). Inversion of amplitude from the 2-D analytic signal of self-potential anomalies. In K. S. Essa (Ed.), Minerals (pp. 13–45). IntechOpen. https://doi.org/10.5772/intechopen.79111
Biswas, A., Rao, K., & Biswas, A. (2022). Inversion and uncertainty estimation of self-potential anomalies over a two-dimensional dipping layer/Bed: Application to mineral exploration, and Archeological targets. Minerals, 12, 1484.
Biswas, A., & Sharma, P. S. (2014a). Optimization of self-potential interpretation of 2-D inclined sheet-type structures based on very fast simulated annealing and analysis of ambiguity. Journal of Applied Geophysics, 105, 235–247.
Biswas, A., & Sharma, S. P. (2014b). Resolution of multiple sheet-type structures in self-potential measurement. Journal of Earth System Science, 123(4), 809–825.
Deb, K., & Gupta, H. (2006). Introducing robustness in multi-objective optimization, evolutionary computation. Evolutionary Computation, 14(4), 463–494.
Di Maio, R., Piegari, E., & Rani, P. (2017). Source depth estimation of self-potential anomalies by spectral methods. Journal of Applied Geophysics, 136, 315–325.
Di Maio, R., Rani, P., Piegari, E., & Milano, M. (2016a). Self-potential data inversion through a genetic-price algorithm. Computers & Geosciences, 94, 86–95.
Drahor, M. G. (2004). Application of the self-potential method to Archeological prospection: Some case histories. Archeological Prospection, 11, 77–105.
Ekinci, Y. L., Balkaya, Ç., & Göktürkler, G. (2020). Global optimization of near-surface potential field anomalies through metaheuristics. Springer GeophysicsIn A. Biswas & S. Sharma (Eds.), Advances in modeling and interpretation in near surface geophysics (pp. 155–188). Springer. https://doi.org/10.1007/978-3-030-28909-6_7
Ekinci, Y. L., Balkaya, Ç., Göktürkler, G., & Ai, H. (2023). 3-D gravity inversion for the basement relief reconstruction through modified success-history-based adaptive differential evolution. Geophysical Journal International, 235(1), 377–400.
Ekinci, Y. L., Balkaya, Ç., Göktürkler, G., & Özyalın, Ş. (2021). Gravity data inversion for the basement relief delineation through global optimization: A case study from the Aegean Graben system, Western Anatolia, Turkey. Geophysical Journal International, 224(2), 923–944.
Ekinci, Y. L., Özyalın, Ş, Sındırgı, P., Balkaya, Ç., & Göktürkler, G. (2017). Amplitude inversion of 2D analytic signal of magnetic anomalies through differential evolution algorithm. Journal of Geophysics and Engineering, 14(6), 1492–1508.
El-Araby, H. M. (2004). A new method for complete quantitative interpretation of self-potential anomalies. Journal of Applied Geophysics, 55(3–4), 211–224.
Elhussein, M. (2021). A novel approach to self-potential data interpretation in support of mineral resource development. Natural Resources Research, 30, 97–127.
El-Kaliouby, H. M., & Al-Garni, M. A. (2009). Inversion of self-potential anomalies caused by 2D inclined sheets using neural networks. Journal of Geophysics and Engineering, 6(1), 29–34.
Eppelbaum, L. V. (2021). Review of processing and interpretation of self-potential anomalies: Transfer of methodologies developed in magnetic prospecting. Geosciences, 11(5), 194.
Essa, K. S. (2019). A particle swarm optimization method for interpreting self-potential anomalies. Journal of Geophysics and Engineering, 16(2), 463–477.
Essa, K. S. (2020). Self potential data interpretation utilizing the particle swarm method for the finite 2D inclined dike: mineralized zones delineation. Acta Geodaetica et Geophysica, 55, 203–221.
Essa, K. S., Diab, Z. E., & Mehanee, S. A. (2023). Self-potential data inversion utilizing the Bat optimizing algorithm (BOA) with various application cases. Acta Geophysica, 71, 567–586.
Gobashy, M., & Abdelazeem, M. (2021). Metaheuristics inversion of self-potential anomalies. Springer GeophysicsIn A. Biswas (Ed.), Self-Potential method: theoretical modeling and applications in geosciences. Springer. https://doi.org/10.1007/978-3-030-79333-3_2
Gobashy, M., Abdelazeem, M., Abdrabou, M., & Khalil, M. H. (2020). Estimating model parameters from self-potential anomaly of 2D inclined sheet using whale optimization algorithm: Applications to mineral exploration and tracing shear zones. Natural Resources Research, 29, 499–519.
Göktürkler, G., & Balkaya, Ç. (2012). Inversion of self-potential anomalies caused by simple geometry bodies using global optimization algorithms. Journal of Geophysics and Engineering, 9(5), 498–507.
Guo, S. W., & Thompson, E. A. (1992). Performing the exact test of Hardy–Weinberg proportion for multiple alleles. Biometrics, 48(2), 361–372.
Haryono, A., Agustin, R., Santosa, B. J., Widodo, A., & Ramadhany, B. (2020). Model parameter estimation and its uncertainty for 2-D inclined sheet structure in self-potential data using crow search algorithm. Acta Geodaetica et Geophysica, 55, 691–715.
Hosseinzadeh, S., Göktürkler, G., & Turan-Karaoğlan, S. (2023). Inversion of self-potential data by a hybrid DE/PSO algorithm. Acta Geodaetica et Geophysica, 58, 241–272.
Jardani, A., Revil, A., Boleve, A., & Dupont, J. P. (2008). Three-dimensional inversion of self-potential data used to constrain the pattern of groundwater flow in geothermal fields. Journal of Geophysical Research-Solid Earth, 113, B9.
Lapenna, V., Lorenzo, P., Perrone, A., Piscitelli, S., Sdao, F., & Rizzo, E. (2003). High-resolution geoelectrical tomographies in the study of Giarrossa landslide (southern Italy). Bulletin of Engineering Geology and the Environment, 62, 259–268.
Laurence, J., & Pozzi, J.-P. (1995). Streaming potential and permeability of saturated sandstones under triaxial stress: Consequences for electrotelluric anomalies prior to earthquakes. Journal of Geophysical Research, 100(B6), 10197–10209.
Li, X., & Yin, M. (2012). Application of differential evolution algorithm on self-potential data. PLoS ONE, 7(12), e51199.
Mehanee, S. A. (2014). An efficient regularized inversion approach for self-potential data interpretation of ore exploration using a mix of logarithmic and non-logarithmic model parameters. Ore Geology Reviews, 57, 87–115.
Mianshui, R., Li-Yun, F., Francisco José, S. S., & Weijia, S. (2022). Joint inversion of earthquake-based horizontal-to-vertical spectral ratio and phase velocity dispersion: applications to Garner Valley. Frontiers in Earth Science, 10, 948697.
Mirjalili, S. (2015). Shifted robust multi-objective test problems. Structural and Multidisciplinary Optimization, 52, 217–226.
Mirjalili, S., & Lewis, A. (2016). Obstacles and difficulties for robust benchmark problems: A novel penalty-based robust optimisation method. Information Sciences, 328, 485–509.
Murty, B. V. S., & Haricharan, P. (1985). Nomogram for the complete interpretation of spontaneous potential profiles over sheet-like and cylindrical two-dimensional sources. Geophysics, 50, 1127–1135.
Pallero, J., Fernández-Martínez, J., Bonvalot, S., & Fudym, O. (2015). Gravity inversion and uncertainty assessment of basement relief via particle swarm optimization. Journal of Applied Geophysics, 116, 180–191.
Pan, L., Chen, X., Wang, J., Yang, Z., & Zhang, D. (2019). Sensitivity analysis of dispersion curves of Rayleigh waves with fundamental and higher modes. Geophysical Journal International, 216, 1276–1303.
Parsopoulos, K. E., & Vrahatis, M. N. (2002). Recent approaches to global optimization problems through particle swarm optimization. Natural Computing, 1, 235–306.
Patella, D. (1997). Introduction to ground self-potential tomography. Geophysical Prospecting, 45, 653–681.
Ray, T. (2002). Constrained robust optimal design using a multiobjective evolutionary algorithm. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC'02, Honolulu, USA, pp. 419–424. https://doi.org/10.1109/CEC.2002.1006271
Reddi, A. G. B., Madhusudan, I. C., Sarkar, B., & Sharma, J. K. (1982). An album of geophysical responses from base metal belts of Rajasthan and Gujarat (Calcutta: Geological Survey of India). Miscellaneous Publication.
Revil, A., Cary, L., Fan, Q., Finizola, A., & Trolard, F. (2005). Self-potential signals associated with preferential ground water flow pathways in a buried paleo-channel. Geophysical Research Letters, 32, L07401.
Rizzo, E., Suski, B., Revil, A., Straface, S., & Troisi, S. (2004). Self-potential signals associated with pumping tests experiments. Journal of Geophysical Research, 109, B10203.
Roy, A., Dubey, C. P., & Prasad, M. (2021). Gravity inversion of basement relief using particle swarm optimization by automated parameter selection of Fourier coefficients. Computers & Geosciences, 156, 104875.
Santos, F. (2010). Inversion of self-potential of idealized bodies’ anomalies using particle swarm optimization. Computers & Geosciences, 36(9), 1185–1190.
Schiavone, D., & Quarto, R. (1984). Self-potential prospecting in the study of water movements. Geoexploration, 22(1), 47–58.
Sharma, S. P., & Biswas, A. (2013). Interpretation of self-potential anomaly over a 2D inclined structure using very fast simulated-annealing global optimization—An insight about ambiguity. Geophysics, 78(3), WB3–WB15.
Srivastava, S., & Agarwal, B. (2009). Interpretation of self-potential anomalies by enhanced local wave number technique. Journal of Applied Geophysics, 68(2), 259–268.
Srivastava, S., & Agarwal, B. N. P. (2010). Inversion of the amplitude of the two-dimensional analytic signal of the magnetic anomaly by the particle swarm optimization technique. Geophysical Journal International, 182(2), 652–662.
Srivastava, S., Datta, D., Agarwal, B., & Mehta, S. (2014). Applications of ant colony optimization in determination of source parameters from total gradient of potential fields. Near Surface Geophysics, 12(3), 373–389.
Stoll, J., Bigalke, J., & Grabner, E. W. (1995). Electrochemical modeling of self-potential anomalies. Surveys in Geophysics, 16, 107–120.
Sulaiman, M. H., Mustaffa, Z., Saari, M. M., & Daniyal, H. (2020). Barnacles mating optimizer: A new bio-inspired algorithm for solving engineering optimization problems. Engineering Applications of Artificial Intelligence, 87, 103330.
Sungkono. (2020). An efficient global optimization method for self-potential data inversion using micro-differential evolution. Journal of Earth System Science, 129, 178.
Sungkono, Muftihan, R. A., Desa, W. D., Alwi, H., & Hendra, G. (2023). Self-adaptive bare-bones teaching–learning-based optimization for inversion of multiple self-potential anomaly sources. Pure and Applied Geophysics, 180, 2191–2222.
Sungkono, S., Apriliani, E., Saifuddin, N., Fajriani, F., & Srigutomo, W. (2021). Ensemble Kalman inversion for determining model parameter of self-potential data in the mineral exploration. In A. Biswas (Ed.), Self-potential method: Theoretical modeling and applications in geosciences, springer geophysics (pp. 179–202). Springer International Publishing. https://doi.org/10.1007/978-3-030-79333-3_7
Sungkono, & Warnana, D. D. (2018). Black hole algorithm for determining model parameter in self-potential data. Journal of Applied Geophysics, 148, 189–200.
Sweilam, N. H., El-Metwally, K., & Abdelazeem, M. (2007). Self potential signal inversion to simple polarized bodies using the particle swarm optimization method: A visibility study. Journal of Applied Geophysics, 6, 195–208.
Titov, K., Revil, A., Konosavsky, P., Straface, S., & Troisi, S. (2010). Numerical modeling of self-potential signals associated with a pumping test experiment. Geophysical Journal International, 162(2), 641–650.
Tlas, M., & Asfahani, J. (2007). A best-estimate approach for determining self-potential parameters related to simple geometric shaped structures. Pure and Applied Geophysics, 164(11), 2313–2328.
Tlas, M., & Asfahani, J. (2008). Using of the adaptive simulated annealing (ASA) for quantitative interpretation of self potential anomalies due to simple geometrical structures. JKAU Earth Sciences, 19, 99–118.
Tlas, M., & Asfahani, J. (2013). An approach for interpretation of self-potential anomalies due to simple geometrical structures using fair function minimization. Pure and Applied Geophysics, 170(5), 895–905.
Turan-Karaoğlan, S., & Göktürkler, G. (2021). Cuckoo search algorithm for model parameter estimation from self-potential data. Journal of Applied Geophysics, 194, 104461.
Wolpert, D. H., & Macready, W. G. (1997). No free lunch theorems for optimization. IEEE Transactions on Evolutionary Computation, 1, 67–82.
Yüngül, S. (1950). Interpretation of spontaneous polarization anomalies caused by spheroidal orebodies. Scandinavian Journal of Public Health, 15(2), 49–51.
Acknowledgments
We thank the TÜBİTAK ULAKBİM (The Scientific and Technological Research Council of Türkiye, National Academic Network and Information Centre) for funding this work. The authors would like to thank five anonymous reviewers for their comments and suggestions that have improved the paper.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
All authors declare that they have no known Conflict of interest.
APPENDIX
APPENDIX
Mean outputs with errors (STD) obtained from independent runs (N = 100, Iter_max = 500). n in the table represents the dimensionality of the benchmark function, and n = 2 is the default in this study. The bolded parts in the last two columns of the table are the mean results of the MBMO and BMO after 30 independent runs, and the unbolded data are the STDs.
Benchmark function | Mathematical expression | Model space | Global minimum | BMO | MBMO |
|---|---|---|---|---|---|
De Jong No. 5 | \(\begin{aligned} {\text{F}}_{1} = & \left( {0.002 + \sum\limits_{i = 1}^{25} {\frac{1}{{i + (x_{1} - a_{1i} )^{6} + (x_{2} - a_{2i} )^{6} }}} } \right) \\ {\mathbf{a}} = & \left( \begin{gathered} - 32\; - 16\;0\;16\;32\; - 32\;...\;0\;16\;32 \hfill \\ - 32\; - 32\; - 32\; - 32\; - 32\; - 16\;...\;32 \hfill \\ \end{gathered} \right) \\ \end{aligned}\) | [− 65.536, 65.536] | 0.998 | 1.26877627712753 | 0.998011054322419 |
0.374387132452405 | 2.26234349322556e−05 | ||||
Ackley | \(\begin{aligned} F_{2} = & - a\exp \left( { - b\sqrt {\frac{1}{n}\sum\limits_{i = 1}^{n} {x_{i}^{2} } } } \right) - \exp \left[ {\frac{1}{n}\sum\limits_{i = 1}^{n} {\cos \left( {cx_{i} } \right)} } \right] + a + \exp (1) \\ a = & 20,\,b = 0.2,\,c = 2\pi . \\ \end{aligned}\) | [− 5, 5] | 0 | 0.00118267402799782 | 8.88178419700125e−16 |
0.00612790713738788 | 0 | ||||
Bukin No. 6 | \({\text{F}}_{3} = 100\sqrt {\left| {x_{2} - 0.01x_{1}^{2} } \right|} + 0.01\left| {x_{1} + 10} \right|\) | [− 15, 5] | 0 | 0.0581196866431028 | 0.1 |
0.0123479365473518 | 4.23450964056278e−17 | ||||
Cross-in-tray | \({\text{F}}_{4} = - 0.0001\left[ {\left| {\sin (x_{1} )\sin (x_{2} )\exp \left( {\left| {100 - \frac{{\sqrt {x_{1}^{2} + x_{2}^{2} } }}{\pi }} \right|} \right)} \right| + 1} \right]^{0.1}\) | [− 10, 10] | − 2.06261 | − 2.06260011457477 | − 2.06261175344103 |
2.69522461258171e−05 | 2.13833200106557e−07 | ||||
Schaffer No. 4 | \({\text{F}}_{5} = 0.5 + \frac{{\cos^{2} \left[ {\sin \left( {\left| {x_{1}^{2} - x_{2}^{2} } \right|} \right)} \right] - 0.5}}{{\left[ {1 + 0.001\left( {x_{1}^{2} + x_{2}^{2} } \right)} \right]^{2} }}\) | [− 50, 50] | 0.29257 | 0.292836475207794 | 0.292580804297462 |
0.000596043812519029 | 3.98608624808112e−06 | ||||
Schaffer No. 2 | \({\text{F}}_{6} = 0.5 + \frac{{\sin^{2} \left( {x_{1}^{2} - x_{2}^{2} } \right) - 0.5}}{{\left[ {1 + 0.001\left( {x_{1}^{2} + x_{2}^{2} } \right)} \right]^{2} }}\) | [− 50, 50] | 0 | 4.31861914990746e−05 | 0 |
7.66776492893576e−05 | 0 | ||||
Rastrigin | \({\text{F}}_{7} = 10n + \sum\limits_{i = 1}^{n} {\left[ {x_{i}^{2} - 10\cos \left( {2{\uppi }x_{i} } \right)} \right]}\) | [− 5.12, 5.12] | 0 | 0.00852347620924861 | 0 |
0.0137726464594897 | 0 | ||||
Styblinski-Tang | \({\text{F}}_{8} = \frac{1}{2}\sum\limits_{i = 1}^{n} {\left( {x_{i}^{4} - 16x_{i}^{2} + 5x_{i} } \right)}\) | [− 5, 5] | − 39.16599n | − 78.0509970048540 | − 78.3323269656770 |
0.905792239965644 | 5.71557269584507e−06 | ||||
Michalewicz | \({\text{F}}_{9} = - \sum\limits_{i = 1}^{n} {\sin x_{i} \sin^{2m} \left( {\frac{{ix_{i}^{2} }}{{\uppi }}} \right)} ,\;m = 10.\) | [− 0, π] | − 1.8013 | − 1.80128119088065 | − 1.80130299913776 |
6.21315906263708e−05 | 1.19670203192333e−06 | ||||
Eggholder | \({\text{F}}_{10} = - \left( {x_{2} + 47} \right)\sin \sqrt {\left| {x_{2} + \frac{{x_{1} }}{2} + 47} \right|} - x_{1} \sin \sqrt {\left| {x_{1} - (x_{2} + 47)} \right|}\) | [− 512, 512] | − 959.6407 | − 796.657674724017 | − 952.963502261971 |
87.9274201691879 | 6.44248162826183 | ||||
Schwefel | \({\text{F}}_{11} = 418.9829n - \sum\limits_{i = 1}^{n} {x_{i} \sin \sqrt {x_{i} } }\) | [− 500, 500] | 0 | 87.7805630499056 | 0.000701828100693547 |
48.8311918718022 | 0.00106523186628861 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ai, H., Ekinci, Y.L., Balkaya, Ç. et al. Modified Barnacles Mating Optimizing Algorithm for the Inversion of Self-potential Anomalies Due to Ore Deposits. Nat Resour Res (2024). https://doi.org/10.1007/s11053-024-10331-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11053-024-10331-7