
Abstract
Numerous medical studies have shown that Alzheimer’s disease (AD) was present decades before the clinical diagnosis of dementia. As a result of the development of these studies with the discovery of many ideal biomarkers of symptoms of Alzheimer’s disease, it became clear that early diagnosis requires a high-performance computational tool to handle such large amounts of data, as early diagnosis of Alzheimer’s disease provides us with a healthy opportunity to benefit from treatment. The main objective of this paper is to establish a complete framework that is based on deep learning approaches and convolutional neural networks (CNN). Four stages of AD, such as (I) preprocessing and data preparation, (II) data augmentation, (III) cross-validation, and (IV) classification and feature extraction based on deep learning for medical image classification, are implemented. In these stages, two methods are implemented. The first method uses a simple CNN architecture. In the second method, the VGG16 model is the pre-trained model that is trained on the ImageNet dataset but applies the same model to the different datasets. We apply transfer learning, meaning, and fine-tuning to take advantage of the pre-trained models. Seven performance metrics are used to evaluate and compare the two methods. Compared to the most recent effort, the proposed method is proficient of analyzing AD, moreover, entails less labeled training samples and minimal domain prior knowledge. A significant performance gain on classification of all diagnosis groups was achieved in our experiments. The experimental findings demonstrate that the suggested designs are appropriate for basic structures with minimal computational complexity, overfitting, memory consumption, and temporal regulation. Besides, they achieve a promising accuracy, 99.95% and 99.99% for the proposed CNN model in the classification of the AD stage. The VGG16 pre-trained model is fine-tuned and achieved an accuracy of 97.44% for AD stage classifications.
Similar content being viewed by others


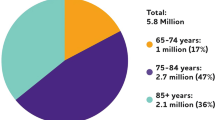
Avoid common mistakes on your manuscript.
1 Introduction
Alzheimer’s disease (AD) is the result of the degeneration of healthy brain cells and results in a continuous decline in memory, mental, and intellectual abilities. It is the most common cause of dementia, which affects mental and social skills. This impairs daily functioning in normal life and deteriorates further over time [22]. This phenomenon appears because of the death of nerve cells, the formation of amyloid plaques and neurofibrillary tangles, and the atrophy of the tissue throughout the brain, which becomes worse progressively [22, 35]. According to statistics from the World Health Organization, in 2021, around 55 million people worldwide will suffer from dementia, with the number expected to climb to 78 million in 2030 and 139 million in 2050, more than two times the number of dementia patients in 2021 [12].
Most people over 65 years of age have a high risk of getting dementia, whereas only 3% of young people have young-onset dementia that may be caused by different diseases [39]. Late treatment leads to damage to brain cells that are connected with the ability to think and memorize, which causes loss of brain function, a decrease in mental skills, language problems, and a decrease in the ability to construct logical thoughts. Starting with the gradual deterioration of nerve cells, the condition advances to an acute stage of dementia that leaves patients unable to carry out fundamental daily activities [36]. So, diagnosing AD in its early stages is very important because it progresses over time. AD is diagnosed through two methods: (1) when the patient has symptoms, and (2) by using neuroimaging techniques. AD shows up before any symptoms appear. This stage is referred to as “preclinical AD,” during which no symptoms are noticeable by either the affected individual or those in their vicinity [13]. This stage of Alzheimer’s disease can last for years, if not decades. Modern imaging technologies are capable of identifying amyloid beta deposits, a protein that is a hallmark of AD, regardless of whether any symptoms are perceptible [5]. The capacity to detect these early deposits could be particularly useful in clinical trials and in the future if novel AD treatments are developed.
Imaging techniques are the most prevalent approach for detecting AD because they allow for a non-invasive internal examination of the body. The history of AD treatment formerly faced a difficult period when the disease could only be discovered after death. But these days, medical imaging tools now play a significant role in the diagnosis and treatment of AD [33]. There are multiple neuroimaging techniques that have an essential role in the diagnosis of brain abnormalities, such as magnetic resonance imaging (MRI), positron emission tomography (PET), functional magnetic resonance imaging (fMRI), and computed tomography (CT). Although the most useful dataset for diagnosing AD is images, there are also handwritten and drawing task data sets that can be used in the diagnosis of patients with AD [11]. In our previous work [7], we showed the difference between them in detail. MRI and PET scanning are the most common imaging modalities that researchers use to diagnose AD. In this study, we combined MRI modalities that show brain structure and functionality with non-invasive techniques that help physicians and researchers detect Alzheimer’s disease [7].
Nowadays, researchers are interested in machine learning in different fields, which has the ability to learn and improve algorithms and predict the solution to any problem. Where [11], proposed diagnosis AD based on machine learning techniques. They apply multi classifier architecture on handwritten and drawing task data like random forest, logistic regression, K-Nearest Neighbor, support vector machine, Gaussian Naive Bayes and Linear Discriminant Analysis. Deep learning (DL) is a subset of machine learning that has to support the best classification in many fields with the best performance, such as computer vision, diagnosis, and natural language processing [28].
Deep neural networks can identify small and complicated changes in brain structure using data, analyze the progression of AD, and provide reliable outcomes for the diagnosis of the disease [41]. DL has more than a few different types, such as convolutional neural networks (CNN), autoencoders, recurrent neural networks, and deep belief networks. CNN is the most well-known of the numerous deep learning models that are specifically built to deal with two-dimensional image data, although they can also be utilised with one-dimensional and three-dimensional data. The deep neural network needs a large dataset to train the model with the best performance [17]. In this paper, a methodology for diagnosing AD is proposed to achieve an accurate diagnosis and save the lives of many people. The proposed model works on the diagnosis of the MRI image to classify AD. This methodology aims to achieve high performance. Based on the issues raised above, we proposed a deep learning (DL) model to diagnose AD.
The objective of this paper is to present an end-to-end framework based on convolutional neural networks (CNN) that encompasses detailed steps, beginning with image acquisition and culminating in AD classification. The proposed machine learning application, supported by digital image processing, classifies scanned MRI images and predicts the presence and degree of Alzheimer’s disease. The proposed framework achieves the following:
The following is a summary of the current paper’s contributions:
-
To balance our data collection, methods for data expansion have been implemented.
-
To guarantee the unity of the given image, an image processing technique involving the transformation of images to a specific size is introduced.
-
To Equilibrium the used dataset, data augmentation techniques have been implemented.
-
During the categorization step, two models of the diagnosis are presented using the first method offered. The first proposed method used CNN architectures built from scratch. While the second method, the VGG16 model, is a pre-trained model that was trained on the ImageNet dataset but is applied to different datasets using transfer learning, meaning, and fine-tuning.
-
To validate the proposed two approaches, a comparison and evaluation have been discussed and introduced based on the seven important performance metrics.
The rest of this paper is organized as follows: Section 2 presents different related works in this field. Section 3 shows the proposed algorithm and methodology. Experiments and results are shown in Section 4. Section 5 shows a discussion. Finally, this paper is concluded in Section 6.
2 Related work
Many studies in the realm of Alzheimer’s disease diagnosis have recently been published. Several studies based on various datasets used various tools and approaches to aid in the categorization of AD. Table 1 shows the most recent methodologies in the classification of AD, datasets that are used, image types, number of images, and the performance of the techniques. According to recent research on the diagnosis of AD, there are two approaches used in training and classifying the model: traditional techniques and deep neural networks. [15, 21, 25] used traditional techniques to classify Alzheimer’s disease, whereas [1-3, 22, 41] used deep neural networks techniques.
AbdulAzeem et al. [1] proposed a CNN model that consists of three convolution layers and applies a max-pooling layer after every convolution layer for binary classification of AD. The Adam optimizer is used in the optimization process and uses the SoftMax activation function at the classify layer. They apply three experiments to show the effectiveness of the augmentation techniques on training datasets with different image sizes. Images are resized into two-scales (128, 128) and (64, 64). With both sizes, the model is trained with and without dropout to see how the dropout affects accuracy. The result shows the best accuracy when the image size is (128, 128) and without applying dropout. Cross-validation is done by splitting data into this range from 0.1 to 0.5. As the batch size increases, the training accuracy increases, but if the batch size increases to more than 64, the accuracy decreases. The accuracy of their proposed model achieves 95.6% accuracy for binary classification.
Al-Khuzaie et al. [3] proposed a CNN model named “Alzheimer Network” (AlzNet) for the binary classification of AD and CN. The AlzNet model is made up of five convolution layers, each with a ReLU activation function, and a max-pooling layer with a kernel size of 2 * 2. Their model was trained and tested on OASIS datasets that contained 15,200 images with a size of 200 × 200. The Adadelta optimizer was used to optimize the model with a ratio of 0.2 dropouts to overcome the overfitting problem. The model was trained with different numbers of dense units in the hidden layer to achieve the best performance, which was achieved at 121 units. The model achieves 97.99% training accuracy and 99.53% testing accuracy.
Al-Adhaileh et al. [2] suggested two pre-trained CNN models (AlexNet and Resnet50) to determine the best model for the diagnosis of AD. Their model was trained and tested on the Kaggle Alzheimer’s dataset that was divided into 4 classes: MildDemented, ModerateDemented, NonDemented, and VeryMildDemented. The size of the input image is 224 × 224. The first proposed model is AlexNet, which has 34 layers and 5 max-pooling with size 4 × 4. They split the data into a 20% testing set and an 80% training set. The second model is ResNet50, which consists of 177 layers, 5 max-pooling with a size of 5 × 3, and an RMSprop optimizer. In both models, they used the ReLU activation function and the SoftMax function in the last layer to classify four classes. With 94.53% and 58.07% accuracy, respectively, the AlexNet model outperforms the ResNet50 model.
Antony et al. [6] suggested two models, VGG16 and VGG19, for the diagnosis of AD. Their model was trained on the 780-image ADNI dataset. The skull was stripped and augmented at the preprocessing stage before training the model. The input image size is 224 × 224. In VGG16 models, they used the sigmoid activation function in the last layer to classify two classes. In VGG19 models, they used the SoftMax activation function in the last layer to classify two classes. Where VGG16 has 64 and 128 kernel sizes, and VGG19 has 64, 128, and 256 kernel sizes. The accuracy in both models was insufficient; VGG-16 achieved 81% and VGG-19 achieved 84%.
Liu et al. [23] proposed a novel model for the classification of AD. Initially, a CNN model was developed from scratch, consisting of three convolutional layers, three pooling layers, and two fully connected layers, with SoftMax as the activation function in the last layer. Additionally, AlexNet and GoogLeNet models were also utilized, but with transfer learning applied to overcome overfitting issues and improve classification accuracy. However, the models did not yield significantly high classification accuracy. It should be noted that during transfer learning, both the AlexNet and GoogleNet models utilize 5-fold cross-validation and 500 training iterations. The classification accuracy rates achieved by the CNN model, AlexNet model, and GoogleNet model are 78.02%, 91.4%, and 93.02%, respectively. Since GoogleNet has more convolutions and deeper layers than AlexNet, it achieves a higher classification accuracy rate.
Savaş et al. [32] used different CNN models to classify the 2182 image objects that were taken from the ADNI database. The study gave a detailed framework for comparing the performance of 29 models that had already been trained on the images. Preprocessing was applied to images by first converting the image format, cleaning the data, and splitting the images. After applying preprocessing techniques, image input is given to the models. During the test stage, the EfficientNetB0 model achieved the highest accuracy rate of 92.98%. In the comparative evaluation stage, the confusion matrix indicated that the EfficientNetB2 and EfficientNetB3 models achieved the highest precision, sensitivity, and specificity values for the Alzheimer’s disease class, respectively, with rates of 94.42% and 97.28%. The study’s results demonstrated that EfficientNet models performed remarkably well among the pre-trained models and achieved the highest classification performance.
3 The proposed methodology
As shown in Section 2, different studies have come up with different ways to diagnose AD. However, some studies didn’t get the best results, while others got good results but had to use a more complicated and time-consuming model. So, in this paper, we try to improve the model and performance of the process of making a diagnosis while using as little computing power and memory as possible. The objectives of this article are to: (1) diagnose AD with the best performance possible; (2) enhance the accuracy of our proposed previous model in [14] by updating the model; (3) build a new CNN model; (4) compare two proposed models in training and testing with different performance metrics; and (5) discuss the effectiveness of the different optimizers on the same model and compare them according to diagnosis performance. In this study, the proposed schema of AD classification, as shown in Fig. 1, consists of four stages: the first stage is data preparation (data acquisition and preprocessing images), the second stage is data augmentation, the third stage is cross-validation, and the fourth stage is classification and feature extraction.

Proposed Framework
3.1 Dataset for the study
The dataset evaluated in this research is from the Kaggle Alzheimer’s classification dataset [4]. The dataset has scans for testing and training, which consist of 1279 and 5121 scans, respectively. This data is divided into 717 MildDemented, 2560 NonDemented, 52 ModerateDemented, and 1792 VeryMildDemented. The dimension of the image is 176 × 208 and the format is jpg. In this study, we distinguish between two classes: mild-demented and non-demented. Dataset available on: https://www.kaggle.com/datasets/tourist55/alzheimers-dataset-4-class-of-images.
3.2 Data preparation
3.2.1 Data acquisition
The acquisition of input images is the initial step required for any medical image processing system. Images characterize the inner parts of the human body that can be captured using various imaging modalities with different procedures, as shown in Fig. 2. Neuroimaging techniques include (1) MRI, (2) PET, (3) fMRI, and (4) CT [34]. The choice of these modalities is based on the researcher’s decision and the target task Datasets can be obtained from a variety of sources, including hospitals, clinics, radiology facilities, and online platforms [40].

Different Imaging Techniques for AD Diagnosis [7]
3.2.2 Image preprocessing
Images are preprocessed in two steps: first, the image is transformed, and then it is normalized. The transformation process involves resizing the input image from 176 × 208 to 64 × 64. Resizing the image is a critical process in model training, as the model trains faster when the image size is smaller. After resizing the image, normalization is applied to each of them. We normalize the image. Normalization is the process of scaling each pixel in the image from a specific range (0 to 255) to a value between 0 and 1 [18]. After doing both the transformation and normalization, the new images are stored in a pickle file.
3.2.3 Image augmentation
The data augmentation process improves the imbalance problem. In the proposed model, to overcome the possible over-fitting problem in the training CNN models and to combine possible image discrepancies, augmented images were generated from the original slices by six operations: rotation, translation, gamma correction, random noise addition, scaling, and random affine transformation. At this stage, the dataset size is increased by using the augmentation technique. By sufficiently shifting the brain’s position, it is possible to achieve this goal and stop a model from memorizing the brain’s location. The classic MRI protocol includes the following operations:
-
Rotation: rotation of an image without cropping because the cropped image may not contain the whole tumor; images have been rotated at 15 angles.
-
Mirroring: are right- or left-mirrored.
-
Flipping: Images are up-down flipped.
We apply augmentation techniques with the following settings: rotation at 15 degrees, width shift with a range of 0.1, height shift with a range of 0.1, shearing with a range of 0.2, zooming with a range of 0.2, and applying horizontal flip. We balanced the dataset to increase the accuracy of classification by augmenting images and copying some of the images randomly to balance classes. After augmenting the dataset, MildDemented has 2519 images, and NonDemented has 2561 images. The augmented data were added to enhance the original training dataset to allow for a sufficiently large sample size. As shown in Fig. 3, this method increases the training and validation groups of MR images for axial.

Samples for applying augmentation techniques. Where (a) is original image that has disease, (b) after applying augmentation techniques
3.3 Cross-Validation
Cross-validation is a common technique used to evaluate the performance of deep learning models. It involves dividing the available dataset into two or more subsets: one for training the model and the other(s) for evaluating its performance. The most common type of cross-validation used in deep learning is k-fold cross-validation [29]. In k-fold cross-validation, the dataset is divided into k subsets, or “folds” of approximately equal size. The model is then trained k times, each time using a different fold as the validation set and the remaining folds as the training set [8]. The results from each of the K-fold models are then averaged to obtain a final estimate of the model’s performance. Cross-validation is necessary in deep learning for several reasons [37]:
-
Performance evaluation: Cross-validation provides a more accurate estimate of the model’s performance on unseen data than simply evaluating the model on a single holdout validation set. By averaging the performance across multiple validation sets, cross-validation reduces the variance of the performance metric and provides a more representative estimate of the model’s performance.
-
Hyperparameter tuning: Deep learning models have many hyperparameters that need to be tuned to achieve optimal performance. Cross-validation allows us to systematically test different hyperparameter configurations and select the one that produces the best performance on unseen data.
-
Overfitting prevention: Deep learning models are prone to overfitting, which occurs when the model performs well on the training data but poorly on the validation or test data. Cross-validation can help detect overfitting by evaluating the model’s performance on multiple validation sets and averaging the results.
-
Data efficiency: In some cases, the dataset may be limited in size. Cross-validation allows us to maximize the use of the available data by using all the available data for training and validation instead of reserving a large portion for testing.
Our dataset is composed of two main parts: the first folder contains training data, and the second contains testing data. We perform cross-validation in many forms to detect the best performance and classification. First, we split the training dataset into 80% training and 20% validation sets. Second, we split the training dataset into 70% training and 30% validation sets. The main objective of this process is to train the model with a different ratio of the training and testing sets and achieve the best performance for the diagnosis of AD.
3.4 Feature extraction and classification by deep learning
Neural network techniques have recently been popular in medical image classification, computer vision, healthcare, and speech recognition, with the best performance. It is a form of artificial neural network that has neurons that transmit the signal to another neuron, whose output is determined by a non-linear function of the sum of its inputs [24]. Neural network techniques are based on certain complex algorithms that can extract high-level characteristics from data and use those features to classify and solve problems. DL has various algorithms such as CNN, Autoencoder (AE), Deep Belief Network (DBN), Restricted Boltzmann Network (RBN), Deep Neural Network (DNN), Recurrent Neural Network (RNN), etc. [7, 9].
CNN considers this the most popular deep neural network architecture. One of the most essential features of CNN is its ability to handle enormous datasets and achieve good classification performance. CNN has several pre-trained models that are trained on the ImageNet dataset [19], such as VGG16, LeNet, GoogLeNet, ResNet, and AlexNet [31]. In this paper, we used the CNN technique, which is used mainly in object detection and image processing. CNN consists of several layers; each layer has a specific task to help the model extract the feature, such as the convolution layer, max-pooling layer, and fully connected layer. We will discuss it in detail in the next section.
3.4.1 Feature extraction
Feature extraction is one of the most important concepts in deep learning, especially for computer vision. In deep learning, a neural network learns to extract relevant features or patterns from raw input data, such as images, audio, or text, in order to perform a specific task, such as classification, regression, or generation [38]. The purpose of feature extraction is to transform the raw data into a set of features that can be used as inputs to a machine learning model, which then learns to classify or predict new data based on these features [16]. Feature extraction is typically performed using pre-trained deep neural networks, such as convolutional neural networks (CNNs) for images. These networks are trained on large datasets to learn high-level representations of the raw data, which can then be used to extract features from new data.
Deep learning models can learn to automatically extract relevant features from raw data, but feature extraction can still be useful in some cases, particularly when the dataset is small, or the features are known to be important [20]. Feature extraction: Feature extraction involves transforming the input data into a set of features. This can be done using techniques such as principal component analysis (PCA), wavelet analysis, or convolutional neural networks (CNNs), depending on the nature of the data.
3.4.2 Convolution layer
The main part of CNN is the convolution layer, which extracts feature maps by bypassing the kernel at a specific size. This kernel is applied to the input image by sliding the filter across the image and multiplying element by element, to produce a different feature and passing it to the next layer. In the neural network, there are several hidden layers, each of which extracts a specific feature. The first layer usually extracts the basic features, like the edges of the images. Then, the output feature is input for the next layer, which extracts more complex features such as corners. By going to deep layers, it extracts the more complex features, such as objects and faces.
The activation function is used to help the neural network learn complex problems and determine which neuron should be activated or not. The main purpose of the activation function is to transform the input into a non-linear output node to allow it to learn complex tasks. This activation function is added to all hidden layers, and they all have the same activation function. However, the output layer uses a different activation function depending on the classification type. We have used several types of activation functions, which we summarize in Table 2.
3.4.3 Pooling layer
After extracting features with the convolution layer, we have a large number of parameters that require more computation power. To reduce the computational power required to process the data, pooling layers are used to reduce the dimensions of feature maps. As a result, the number of parameters to learn and the amount of processing in the network are both reduced. Pooling layers have two types: max pooling and average pooling. Max pooling is done by sliding a filter over each feature map that is extracted by the convolution layer and selecting the maximum value above this filter. Average pooling is the same concept as max pooling, but it calculates the average of the values above the filter. Thus, the output is a feature map calculated as in Eq. (1) and Eq. (2).
Where W is the width of the feature map, H is the height of the feature map, F is the size of the filter, P is the value of padding if not equal to zero, and S is the stride value.
3.4.4 Fully connected layer
Every neuron in the fully connected layer is linked to every neuron in the next layer. It converts a multi-dimensional feature map to a vector with one dimension. The final few layers in most typical DL models are fully connected layers that compile the data retrieved by the preceding layers to generate the final output. In the last layer, the number of neurons depends on the type of classification, which is either binary or multi-classification. For binary classification, the neuron in the last layer has two neurons, but for multiclassification, the number of neurons equals the number of classes.
3.5 The proposed architecture
We have proposed two architectures to compare them and choose the one that achieves the best performance. Each model has the same input images with the same size of (64 × 64). The first model is trained from scratch, whereas the second is a pre-trained VGG16 model. These models extract features and classify them automatically, not manually, as is done in machine learning. In the next subsection, a detailed description of each of them is provided.
3.5.1 The First Proposed CNN architecture
Figure 4 and Table 3 show the summary of the first proposed CNN model. Our model was trained on the preprocessed images with a size of 64 × 64. We are splitting our trained data into two cross-validations: (1) 20% testing and 80% training; and (2) 30% testing and 70% training. It consists of three convolution layers with a (3,3) kernel size, a ReLU activation function, and padding of type “same.” After each convolution layer, we add a 2D max-pooling layer of different sizes (3,3) and (2,2) as shown in Table 3. Flatten is used to convert all of the feature map’s 2D dimension arrays to a single vector. We used different dropout ratios of 0.2 and 0.5 to show the effectiveness of the dropout in the proposed model. The last layer is the fully connected layer with a sigmoid activation function to classify the data into two classes. We used different training parameters. The number of epochs was used as 10, 15, and 20, where the batch size was 16, 32, 64, and 128.

First Proposed CNN model
Algorithm 1 depicts the steps of our proposed CNN model so that you can understand how it works. The inputs to the model are datasets. Before training the proposed model, the input image must be preprocessed; the first process is the transformation, and the second resizes the image to a suitable size. The dataset is split into training and testing sets. We train our model at different values of epochs and batch sizes. Then we used Adam’s optimizer to compile the model. The output of the proposed model is the performance metrics (loss, accuracy, precision, recall, specificity, and f-score) and graphs. Then we apply the same steps for the second experiment but split the data into different ratios for the training and testing sets.
3.5.2 The Second Pretrained VGG16 architecture
The VGG16 model is a pre-trained model that was trained on the ImageNet dataset but can be applied to other datasets as well. We use transfer learning and fine-tuning. In transfer learning, the model is trained on different small datasets, and the layer is frozen to avoid destroying the information. In this model, we are freezing 16 layers of convolution and pooling to keep the feature extraction the same and adding a new classifier layer to be compatible with our dataset. Due to the first layer’s ability to extract simpler and more general features, we freeze the layer that extracts general features and train the layer that extracts complicated patterns depending on the dataset. So, we used fine-tuning, which is the approach of transfer learning. In fine-tuning, we do not freeze all convolution and pooling layers. The final convolution and pooling layer have been unfrozen. We retrained only the last layer of convolution and pooling and added three fully connected layers as shown in Table 4.
Figure 5 and Table 4 show the summary of the second proposed VGG16 model. Our model was trained on the preprocessed image with a size of 64 × 64. We are splitting our trained data into 40% testing and 60% training. We apply the augmentation process to images with a 15° rotation range, a 0.1 width and height shift, a 0.2 shear, and a 0.2 zoom factor. The first 16 layers are frozen and retrained at the last convolution and pooling layer. We are adding dropout with a ratio of 0.2 to avoid the overfitting problem. The number of epochs and batch size were used (50, 250, and 512) and (32, and 64), respectively. Different optimizers (Adam, SGD, Adadelta, RMSprop, and Adagrad) are applied to our model to show the effectiveness of each of them on the data.

Second VGG16 model
Algorithm 2 demonstrates the steps of the pre-trained VGG16 model with fine tuning and transfer learning. The inputs to the model are MR images. Before training the proposed model, the input images must be preprocessed, which consists of two operations; the first is the transformation operation, and the second is resizing the image to a suitable size. The dataset is split into training and testing sets. We train our model at different values of epochs and batch sizes. To get the best performance, we need to increase the datasets by using data augmentation techniques. The model compiles with different optimizers (Adam, Adagrad, Adadelta, SGD, and RMSprop). The output of the proposed model is the performance metrics (loss, accuracy, precision, recall, specificity, and f-score) and graphs. Then we tested the proposed model to evaluate the training model.

Algorithm 1: Proposed CNN Model

Algorithm 2: Proposed VGG16 Model
3.6 Performance evaluation parameters
Recent studies have used the confusion matrix to analyze a model and provide information about the classification performance since it is robust to categorize data relationships and any distribution. The confusion matrix gives valuable information for classification models based on different metrics [30]. First, four primary keys are used to test the classifier: true positive (Tp), true negative (Tn), false positive (Fp), and false negative (Fn) values. Then, based on the four outcome values, the performance of the model will be calculated: accuracy (ACC), sensitivity (Recall), specificity (SPC), precision (PPV), F1-score.
Accuracy, as given in eq. (3), is the number of correctly predicted to the total predicted number.
Sensitivity (Recall), as given in eq. (4), is the number of samples predicted to be positive from the total number of samples that are positive, also known as the true positive rate.
Specificity (SPC, TNR) for the true negative rate, as given in eq. (5) is the number of samples predicted as negative from the total number of samples negative.
Precision, as in Eq. (6), also called positive predictive value, represents the number of samples actually and predicted as positive from the total number of samples predicted as positive.
The harmonic means of precision and recall, known as the F1-score, is shown in eq. (7).
4 Experiments and results
In our study, the developed system’s processing and classification used the Python programming language, and the models were trained using Google Colab and a graphical processing unit. For the purpose of formally determining whether the first or the second model has a significant improvement, we conducted three experiments with three configurations. The first and second are for figuring out how to classify AD when splitting data with different ratios. In experiment 1, we split the data into 20% testing and 80% training, whereas in experiment 2, we split the data into 30% testing and 70% training. And both of these experiments used different ratios of dropout (0.2 and 0.5) to demonstrate the efficacy of the dropout in the proposed model. The final layer is a fully connected layer that utilizes a sigmoid activation function to classify the data into two classes. We utilized various training parameters. The number of epochs was 10, 15, and 20, and the batch sizes were 16, 32, 64, and 128.
The third looked at how well the VGG16 model worked with different optimizers and transfer learning. The initial sixteen layers are preserved, while the final convolution and pooling layers are retrained. To avoid the overfitting issue, we are implementing a dropout ratio of 0.2. There were 50, 250, and 512 epochs, and the batch sizes were 32 and 64, respectively. Several optimizers (Adam, SGD, Adadelta, RMSprop, and Adagrad) are applied to our model in order to demonstrate the efficacy of each on the data.
4.1 Experiment 1
Table 5 shows the diagnostic performance metrics of experiment 1 on the training dataset (on the first proposed model) and the effect of the model with different batch sizes, number of epochs, and with or without dropout ratio. Batch size values are 16, 32, 64, and 128. The number of epoch values is 10, 15, and 20 with or without dropout. The best training accuracy (100%) is achieved without dropout and with an increasing number of epochs and decreasing batch size. The best average accuracy of training results, 99.95%, is achieved at 32 batch sizes and without applying dropout. To further demonstrate the effectiveness of the proposed framework, the training performance of the model is evaluated with different batch sizes and dropout ratios as shown in Fig. 6, each for the first and the second experiment. Based on the results presented in this figure, we can observe that the best accuracy achieved at first experiment with 32-batch size and without using dropout.

Comparison between first and second experiment, for each experiment we perform training with different batch size and with different dropout ratio
Table 6 shows the performance metric of experiment 1 with the testing dataset (on the first proposed model). By comparing Table 5, the best testing accuracy is achieved at batch sizes of 32 without applying dropout, and the number of epochs is 20. The best average accuracy of the testing result was achieved at 16 batch size and without applying dropout, with 0.2 ratios and 32 batch size, and with 0.5 ratios and 32 batch size, with 99.98, 99.84, and 99.81, respectively.
4.2 Experiment 2
Table 7 shows the performance metric of experiment 2 with the training dataset (on the first proposed model) and the effect of the model with different batch sizes, number of epochs, and with or without dropout ratio. The data was split into a 30% testing set and a 70% training set. Batch size values are 16, 32, 64, and 128. The number of epoch values is 10, 15, and 20 with or without dropout. The best training accuracy (100%) is achieved without dropout and with an increasing number of epochs and decreasing batch size. The best average accuracy of training results, 99.99%, is achieved at a 32-batch size and without applying dropout.
Table 8 shows the performance metric of experiment 2 with the testing dataset (on the first proposed model). By comparing Table 7. The best testing accuracy is achieved at batch size 32, with a 0.2 dropout ratio, and the number of epochs is 20. The best average accuracy of the testing result was achieved at 32 batch size and without applying dropout, with 0.2 ratios and 16 batch size, and with 0.5 ratios and 16 batch size, at 99.79, 99.9, and 99.53, respectively.
4.3 Experiment 3
Table 9 shows the performance metric of experiment 3 with the training dataset (on the second VGG16 proposed model) and the effect of the model with different batch sizes, number of epochs, and different optimizers such as Adam, SGD, Adadelta, RMSprop, and Adagrad. The data was split into a 40% testing set and a 60% training set. Batch size values are 32 and 64. The number of epoch values is 50, 250, and 512. Experiment 3 shows the Adam optimizer achieves the best accuracy of other optimizers by 97.44%. This result was achieved after 512 epochs and with 64 batch sizes. The RMSprop has a higher accuracy of 94.42% than the other. To further demonstrate the effectiveness of the proposed framework, the training performance of the model is evaluated with different batch sizes and different optimizers, as shown in Fig. 7. Based on the results presented in this figure, we can observe that Adam optimizers achieved the best accuracy with a 64-batch size.

Comparison for VGG16 model with different optimizers (Adam, SGD, Adadelta, RMSprop, Adagrad) and at different epochs and batch size
Table 10 shows the performance metric of experiment 3 with the testing dataset (on the first proposed model). By comparing Table 9. The Adam optimizer achieved the best testing accuracy of 93.25% when the batch size was 64 and after 512 epochs. Also, RMSprop has the best value among other optimizers, achieving 92.87%.
Table 11 shows a comparison between the proposed models and the other state-of-the-art techniques. The result showed the proposed model (an experimental one) achieved the best result compared with others. In Experiment 1, training was proposed for CNN from scratch at a 16-batch size without dropout. Moreover, Fig. 8 shows a comparison of our developed models with other previous models. Based on the results presented in this figure, we can observe that our model achieved the best performance.

Comparison between all experiments with the best testing and training accuracy
5 Discussion
With a high death rate, AD is considered one of the most common types of irreversible dementia worldwide, eventually causing death. Early detection of AD at early stages could enhance the survival opportunities of the patients and lead to better drug effects. In this study, we extensively examined the role of applying deep learning models with different architectures in AD diagnosis. The study contributes to a new end-to-end DL-based model for differentiating between AD and NC. Our proposed model has several stages for the diagnosis of AD: the first is for preparing the dataset by processing it to minimize the size of the image to reduce the complexity of the computational process; the second is to apply augmentation techniques to overcome the overfitting problem; the third is to apply cross validation; and finally, we apply our proposed model that will be trained on processed data with different optimizers to optimize the diagnosis of AD.
By comparing other studies with our proposed model. Liu et al. [6], built a CNN model, and the accuracy reached 78.02%. However, they proposed two pretrained models, AlexNet and GoogleNet, that achieved 91.4% and 93.02% respectively. Liu et al. [6] note that the limitation of this study is that it does not achieve high accuracy, and the number of images or cases not mentioned in the article. Al-Khuzaie et al. [1] proposed the CNN model. Although it has more images than other studies, it did not achieve high accuracy compared to our proposed model. Whereas in the proposal by Antony et al. [2], the accuracy reached 81%. Although Murugan et al. [27] and Mggdadi et al. [26] used the same dataset (the Kaggle Alzheimer’s dataset), we used it in our proposed model. They didn’t achieve a proper performance. Mggdadi et al. [26] suggested two models, CNN and VGG16, that attained 67.5% and 70.3% accuracy, respectively. And Murugan et al. [27] they proposed CNN model which achieved 95.23%.
Based on these results, no work achieved high performance on Kaggle Alzheimer’s dataset, we believe that our proposed VGG16 model and CNN model has better performance than other methods, verifying the effectiveness of CNN for AD diagnosis. Whereas our proposed CNN model reaches 99.98% accuracy and the accuracy of our VGG16 model reaches 97.44%. Our proposed architecture provided promising results. However, there are number of limitations that need to be addressed in order to go forward with further clinical trials. Firstly, the number of cases need to be increased. Secondly, the dataset is acquired from one hospital. Thirdly, binary classification where there are multi classes for AD. One of the future works will be to investigate integrating the proposed framework into clinical workflow as a decision support tool and diagnosis multiclass of AD.
6 Conclusion
This study proposed a framework for the diagnosis of AD that focused on deep learning and CNN architecture. Two models are proposed. First, the CNN model was trained from scratch with different ratios of dropout and by splitting the data into different training and testing set ratios. Second, we used a pre-trained VGG16 model, applying transfer learning and fine-tuning and measuring the effectiveness of different optimizers (Adam, Adagrad, Adadelta, SGD, RMSprop) with the model. The evaluation and comparison of the two methods implement seven performance metrics. The experimental results indicate that the proposed architectures are appropriate for simple structures with low computational complexity, memory consumption, overfitting, and controllable time. The proposed models achieved very promising accuracies by comparing with other researchers, as we present in the result section: 99.95% and 99.99% for the proposed CNN model in the classification of the AD stage. The VGG16 pre-trained model is fine-tuned and has achieved an accuracy of 97.44% for AD stage classifications. In the future, we intend to apply hyperparameter optimization techniques to each model and perform multi-classification for AD stages.
Table of Abbreviations
Table 12 presents the used abbreviations in the current survey with the corresponding definitions. They are sorted in alphabetical order.
Data availability
We confirm that no datasets were users, generated, or analyzed during the current study.
References
AbdulAzeem Y, Bahgat WM, Badawy M (2021) A CNN based framework for classification of Alzheimer’s disease. Neural Comput Applic 33(16):10415–10428. https://doi.org/10.1007/s00521-021-05799-w
Al-Adhaileh MH (2022) Diagnosis and classification of Alzheimer’s disease by using a convolution neural network algorithm. Soft Comput 26:7751–7762. https://doi.org/10.1007/s00500-022-06762-0
Al-Khuzaie FEK, Bayat O, Duru AD (2021) Diagnosis of Alzheimer Disease Using 2D MRI Slices by Convolutional Neural Network. Appl Bionics Biomech 2021:1–9. https://doi.org/10.1155/2021/6690539
“Alzheimer’s Dataset (4 class of Images) | Kaggle.” (n.d.) https://www.kaggle.com/datasets/tourist55/alzheimers-dataset-4-class-of-images. Accessed 20 May 2022
“Alzheimer’s stages: How the disease progresses - Mayo Clinic.” (n.d.) https://www.mayoclinic.org/diseases-conditions/alzheimers-disease/in-depth/alzheimers-stages/art-20048448. Accessed 07 Apr 2022
Antony F, Anita HB, George JA (2023) Classification on Alzheimer’s Disease MRI Images with VGG-16 and VGG-19, vol. 312. https://doi.org/10.1007/978-981-19-3575-6_22
Arafa DA, Moustafa HE-D, Ali-Eldin AMT, Ali HA (2022) Early detection of Alzheimer’s disease based on the state-of-the-art deep learning approach: a comprehensive survey. Multimed Tools Appl 81:23735–23776. https://doi.org/10.1007/s11042-022-11925-0
Berrar D (n.d.) Cross-Validation Call for Papers for Machine Learning journal: Machine Learning for Soccer View project Cross-validation. https://doi.org/10.1016/B978-0-12-809633-8.20349-X
Bhangale KB, Kothandaraman M (2022) Survey of Deep Learning Paradigms for Speech Processing. Wirel Pers Commun 125:1913–1949. https://doi.org/10.1007/s11277-022-09640-y
Deepa N, Chokkalingam SP (2022) Optimization of VGG16 utilizing the Arithmetic Optimization Algorithm for early detection of Alzheimer’s disease. Biomed Signal Process Control 74:103455. https://doi.org/10.1016/J.BSPC.2021.103455
De Gregorio G, Desiato D, Marcelli A, Polese G (2021) A Multi Classifier Approach for Supporting Alzheimer’s Diagnosis Based on Handwriting Analysis, vol. 12661 LNCS. https://doi.org/10.1007/978-3-030-68763-2_43
“Dementia.” (n.d.) https://www.who.int/news-room/fact-sheets/detail/dementia. Accessed 07 Apr 2022
Dubois B et al (2016) Preclinical Alzheimer’s disease: Definition, natural history, and diagnostic criteria. Alzheimer’s Demen 12(3):292–323. https://doi.org/10.1016/j.jalz.2016.02.002
Ebrahim D, Ali-Eldin AMT, Moustafa HE, Arafat H (2020) Alzheimer Disease Early Detection Using Convolutional Neural Networks. In: Proceedings of ICCES 2020–2020 15th International Conference on Computer Engineering and Systems. https://doi.org/10.1109/ICCES51560.2020.9334594
El-Sappagh S, Saleh H, Ali F, Amer E, Abuhmed T (2022) Two-stage deep learning model for Alzheimer’s disease detection and prediction of the mild cognitive impairment time. Neural Comput Applic 34:14487–14509. https://doi.org/10.1007/s00521-022-07263-9
“Feature Extraction Definition | DeepAI.” (n.d.) https://deepai.org/machine-learning-glossary-and-terms/feature-extraction. Accessed 27 Feb 2023
“How Do Convolutional Layers Work in Deep Learning Neural Networks?” (n.d.) https://machinelearningmastery.com/convolutional-layers-for-deep-learning-neural-networks/. Accessed 12 May 2022
“How to Manually Scale Image Pixel Data for Deep Learning.” (n.d.) https://machinelearningmastery.com/how-to-manually-scale-image-pixel-data-for-deep-learning/. Accessed 20 May 2022
“ImageNet.” (n.d.) https://www.image-net.org/index.php. Accessed 24 May 2022
Ishaque M, Hudec L (May 2019) Feature extraction using Deep Learning for Intrusion Detection System. 2nd International Conference on Computer Applications and Information Security, ICCAIS 2019. https://doi.org/10.1109/CAIS.2019.8769473
Kamal M et al (2022) Machine Learning and Image Processing Enabled Evolutionary Framework for Brain MRI Analysis for Alzheimer’s Disease Detection. Comput Intell Neurosci 2022:1–8. https://doi.org/10.1155/2022/5261942
Kong Z, Zhang M, Zhu W, Yi Y, Wang T, Zhang B (2022) Multi-modal data Alzheimer’s disease detection based on 3D convolution. Biomed Signal Process Control 75:103565. https://doi.org/10.1016/J.BSPC.2022.103565
Liu J, Li M, Luo Y, Yang S, Li W, Bi Y (2021) Alzheimer’s disease detection using depthwise separable convolutional neural networks. Comput Methods Prog Biomed 203:106032. https://doi.org/10.1016/J.CMPB.2021.106032
Mehmood A, Abugabah A, AlZubi AA, Sanzogni L (2022) Early Diagnosis of Alzheimer’s Disease Based on Convolutional Neural Networks. Comput Syst Sci Eng 43(1):305–315. https://doi.org/10.32604/csse.2022.018520
Meng X, Wu Y, Liu W, Wang Y, Xu Z, Jiao Z (2022) Research on Voxel-Based Features Detection and Analysis of Alzheimer’s Disease Using Random Survey Support Vector Machine. Front Neuroinform 16:856295. https://doi.org/10.3389/fninf.2022.856295
Mggdadi E, Al-Aiad A, Al-Ayyad MS, Darabseh A (May 2021) Prediction Alzheimer’s disease from MRI images using deep learning. 2021 12th International Conference on Information and Communication Systems, ICICS 2021, pp. 120–125. https://doi.org/10.1109/ICICS52457.2021.9464543
Murugan S et al (2021) DEMNET: A Deep Learning Model for Early Diagnosis of Alzheimer Diseases and Dementia from MR Images. IEEE Access 9:90319–90329. https://doi.org/10.1109/ACCESS.2021.3090474
Poloni KM, Ferrari RJ (2022) A deep ensemble hippocampal CNN model for brain age estimation applied to Alzheimer’s diagnosis. Expert Syst Appl 195:116622. https://doi.org/10.1016/j.eswa.2022.116622
Raschka S (2018) Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning
Ruuska S, Hämäläinen W, Kajava S, Mughal M, Matilainen P, Mononen J (2018) Evaluation of the confusion matrix method in the validation of an automated system for measuring feeding behaviour of cattle. Behav Process 148:56–62
Sarraf S, Tofighi G, Org S (2016) Classification of Alzheimer’s Disease Structural MRI Data by Deep Learning Convolutional Neural Networks. https://doi.org/10.48550/arXiv.1607.06583
Savaş S (2022) Detecting the Stages of Alzheimer’s Disease with Pre-trained Deep Learning Architectures. Arab J Sci Eng 47(2):2201–2218. https://doi.org/10.1007/s13369-021-06131-3
Shanmugam JV, Duraisamy B, Simon C, Bhaskaran P (2022) Alzheimer’s disease classification using pre-trained deep networks. Biomed Signal Process Control 71:103217. https://doi.org/10.1016/j.bspc.2021.103217
Theodore WH, Dorwart R, Holmes M, Porter RJ, DiChiro G (1986) Neuroimaging in refractory partial seizures: Comparison of PET, CT, and MRI. Neurology 36(6):750–759. https://doi.org/10.1212/wnl.36.6.750
Tufail AB, Ma Y-K, Zhang Q-N (2020) Binary Classification of Alzheimer’s Disease Using sMRI Imaging Modality and Deep Learning. J Digit Imaging 33(5):1073–1090. https://doi.org/10.1007/s10278-019-00265-5
Turkson RE, Qu H, Mawuli CB, Eghan MJ (2021) Classification of Alzheimer’s Disease Using Deep Convolutional Spiking Neural Network. Neural Process Lett 53(4):2649–2663. https://doi.org/10.1007/s11063-021-10514-w
“What is Cross-Validation?. Testing your machine learning models… | by Mohammed Alhamid | Towards Data Science.” (n.d.) https://towardsdatascience.com/what-is-cross-validation-60c01f9d9e75. Accessed 24 Feb 2023
“What is Feature Extraction? Feature Extraction in Image Processing | Great Learning.” (n.d.) https://www.mygreatlearning.com/blog/feature-extraction-in-image-processing/. Accessed 27 Feb 2023
“World Alzheimer Report 2021 | Alzheimer’s Disease International (ADI).” (n.d.) https://www.alzint.org/resource/world-alzheimer-report-2021/. Accessed 08 Apr 2022
Wu O et al (2019) Big data approaches to phenotyping acute ischemic stroke using automated lesion segmentation of multi-center magnetic resonance imaging data. Stroke 50(7):1734–1741. https://doi.org/10.1161/STROKEAHA.119.025373
Zeng N, Li H, Peng Y (2021) A new deep belief network-based multi-task learning for diagnosis of Alzheimer’s disease. Neural Comput Applic. https://doi.org/10.1007/s00521-021-06149-6
Acknowledgments
The authors would like to express appreciation to Prof Hesham Arafat, who assisted in the research work, and to Mansoura University for supporting the authors with the dataset collection.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). The authors declare that they did not receive any funding for the current study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Authors agreement
We confirm that the manuscript has been read and approved by all named authors and that there are no other persons who satisfied the criteria for authorship but are not listed. We further confirm that the order of authors listed in the manuscript has been approved by all of us.
Corresponding author
We understand that the declared corresponding author is the sole contact for the editorial process (including Editorial Manager and direct communications with the office). He/she is responsible for communicating with the other authors about progress, submissions of revisions, and final approval of proofs. We confirm that we have provided a current, correct email address that is accessible by the Corresponding Author.
Intellectual property
We confirm that we have given due consideration to the protection of intellectual property associated with this work and that there are no impediments to publication, including the timing of publication, concerning intellectual property. In so doing we confirm that we have followed the regulations of our institutions concerning intellectual property.
Conflict of interest
The authors declare that they have no competing interests nor conflict of interests for the current study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Arafa, D.A., Moustafa, H.ED., Ali, H.A. et al. A deep learning framework for early diagnosis of Alzheimer’s disease on MRI images. Multimed Tools Appl 83, 3767–3799 (2024). https://doi.org/10.1007/s11042-023-15738-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15738-7