
Abstract
Cognitive ontology has become a popular topic in philosophy, cognitive psychology, and cognitive neuroscience. At its center is the question of which cognitive capacities should be included in the ontology of cognitive psychology and cognitive neuroscience. One common strategy for answering this question is to look at brain structures and determine the cognitive capacities for which they are responsible. Some authors interpret this strategy as a search for neural mechanisms, as understood by the so-called new mechanistic approach. In this article, I will show that this new mechanistic answer is confronted with what I call the triviality problem. A discussion of this problem will show that one cannot derive a meaningful cognitive ontology from neural mechanisms alone. Nonetheless, neural mechanisms play a crucial role in the discovery of a cognitive ontology because they are epistemic proxies for best systematizations.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Talk of cognitive ontology (CO) has become popular in philosophy, cognitive psychology, and cognitive neuroscience in recent years. Various questions and problems are discussed under this label. Here, I will focus on a question and a related problem that together play a central role in discussions about cognitive ontologyFootnote 1 (see Anderson, 2015; Janssen et al., 2017; Viola, 2017, 2021):
As an ontological question, the CO-Question asks what cognitive kinds make up the cognitive domain. Cognitive kinds, in this context, are often taken to be cognitive capacities: candidates include episodic memory, spatial problem-solving, object recognition, language production, and so on. The CO-Question concerns how the cognitive domain should be carved up into different cognitive capacities. There are multiple motivations for asking the CO-Question and multiple ways of motivating the CO-Problem.
Price and Friston (2005) ask the CO-Question because empirical research shows that certain brain regions, such as the left posterior lateral fusiform, are involved in the execution of many different cognitive capacities, such as processing of color information, face and body recognition, word recognition, and within-category identification. However, they argue that a good cognitive ontology should enable one to infer from the activation of brain regions which cognitive capacity is being executed, and vice versa (Price & Friston, 2005, p. 272). Yet if a single brain region, such as the posterior lateral fusiform, is associated with many different cognitive functions, inferring any one of these functions from brain activation alone is not possible. Thus, the CO-Problem arises. Price and Friston’s solution is to come up with a description of cognitive capacities that is sufficiently general that such inferences become possible. In the case of the posterior lateral fusiform, Price and Friston argue, the cognitive capacity it is responsible for is sensory–motor integration (2005, p. 268). In other words: Price and Friston argue that we need to revise our cognitive ontology to solve the CO-Problem, and that by solving it, we will find out which cognitive capacities our cognitive ontology includes and will thereby answer the CO-Question.
A further motivation for asking the CO-Question is the philosopher’s interest in natural kinds. Philosophers who study the mind and cognition want to know how to carve both up “at their joints.” According to the most popular view, the homeostatic property cluster view, natural kinds are property clusters that are held together by underlying mechanisms (Boyd, 1989). This implies that a cognitive capacity is a cluster of cognitive properties that is held together by a mechanism. If this view is empirically adequate, one would expect to find one mechanism for each property cluster. The CO-Problem therefore arises from asking the CO-Question.
In this paper, I focus on a possible way of answering the CO-Question that I will call the new mechanistic answer. It has been formulated in a recent paper by Jolien Francken, Marc Slors, and Carl Craver (2022) (“FSC” in what follows)Footnote 2:
The legitimate ontology of cognitive capacities is (…) thought to correspond to the correct catalogue of identifiable neural mechanisms. Facts about neural mechanisms are (…) supposed to anchor facts about cognitive ontology. (Francken et al., 2022, pp. 377–8)
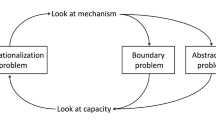
FSC highlight several problems that arise for the new mechanistic answer—the Operationalization Problem, the Abstraction Problem, and the Boundary Problem. According to FSC, these problems give rise to a “cycle of kinds” because solving the Operationalization Problem presupposes solutions to the Abstraction Problem and the Boundary Problem—however, solving the Abstraction Problem and the Boundary Problem presupposes a solution to the Operationalization Problem. FSC close by showing how we can escape the cycle of kinds, and thus how the new mechanistic answer can be used to answer the CO-Question.
This paper has four goals. In Sect. 2, I show that the new mechanistic answer, contrary to what FSC argue, has not been proposed before in the literature on cognitive ontology, but is a novel and prima facie promising approach to answering the CO-Question. In Sect. 3, I show that the new mechanistic answer is problematic—but not for the reason FSC think. The new mechanistic answer does not run into a cycle of kinds. It trivializes the search for a cognitive ontology—this is the triviality problem. In Sect. 4, I show that FSC’s solution to the “cycle of kinds” problem can be used to solve the triviality problem. However, I also show that this comes with a cost for defenders of the new mechanistic answer to the CO-Question: mechanisms are rendered obsolete as the grounds for cognitive kinds. Finally, in Sect. 5, I show that mechanisms still play an important role in the discovery of cognitive capacities. Mechanisms are what I will call “epistemic proxies” for the best systematization of cognitive psychology.
2 A Novel Perspective on Cognitive Ontology: The New Mechanistic Answer
The goal of this section is to show that the new mechanistic answer to the CO-Question is a novel and promising approach to cognitive ontology. Here is a formulation of it:
New mechanistic answer: The cognitive domain should be carved up into cognitive capacities that correspond to neural mechanisms. (Francken et al., 2022, p. 378)Footnote 3
FSC simply assume that the new mechanistic answer is a formulation of a standard approach to the CO-Question. However, it is not clear whether this is indeed the case.Footnote 4 Price and Friston (2005), for example, talk about “brain regions” and “brain areas” (262, 265), “mapping function to anatomy” (264), a “structure–function relationship” (265), “neural correlates” (265), and “brain coordinates” (265). Klein (2012) uses the same notions, only that he argues that attributing functions to brain regions, structures, or areas is context-relative, and that we need to consider sets of brain regions and their functional connectivity (what he calls “networks”) (Klein, 2012, 957). Still others talk about “brain activation patterns” or “brain systems” (Poldrack & Yarkoni, 2016).
This difference in terminology is important, as regions, areas, anatomical structures, and neural correlates are not mechanisms in the new mechanistic sense. Brain activation patterns are not mechanisms either—though they may provide evidence of mechanistic components. The term “brain system” is ambiguous; it is unclear whether it refers to something that would be called a “mechanism” in the new mechanistic sense. Poldrack and Yarkoni seem to use “brain system” synonymously with “neural structure” (Poldrack & Yarkoni, 2016, p. 608). Again, neural structures are not mechanisms in the new mechanistic sense; at least, there is no textual evidence of any resemblance between what Poldrack and Yarkoni take neural structures to be and how the new mechanists characterize mechanisms (see below).
There are at least two crucial differences between mechanisms, as the new mechanists understand them, and brain regions, neural structures, and the like. First, according to the new mechanistic account, mechanisms are entities and activities organized such that they cause or constitute a phenomenon (Craver, 2007; Glennan, 2017; Illari & Williamson, 2012). In that sense, mechanisms are already combinations of functions and structure or anatomy (Boone & Piccinini, 2016); the functions need not yet be cognitive functions but more basic biological ones, such as the firings of neurons.
Second, in the mechanistic view, phenomena are closely linked to their underlying mechanisms: the boundaries of mechanisms depend on the individuation of the phenomena they are supposed to underlie. This co-dependence is captured by Carl Craver’s mutual manipulability account. Take the example of the locomotion of the roundworm: this phenomenon can be characterized by the input “touch on the worm’s head” and the output “the worm turns” (Craver et al., 2021). The way to determine which entities and activities (and which organizational features, according to Zednik, 2019) are parts of the mechanism for the roundworm’s locomotion is mutual manipulability: there is a way to change the entity or activity, and thereby to change the output that characterizes the phenomenon; and there is a way to change the input that characterizes the phenomenon, and thereby to change the entity or activity (Craver et al., 2021). For example, there is a way of changing the activity of the “AVLM neurons” (Craver et al., 2021, p. 8811) that will change how the worm turns, and there is a way of touching its head that will change the activity of the AVLM neurons. Hence, the AVLM neurons are components of the mechanism for the roundworm’s locomotion. The complete mechanism for roundworm locomotion consists of all and only those entities and activities that causally connect the input (a touch on the worm’s head) with the output (the worm turns).
In contrast, Price and Friston, and other authors of the cognitive ontology literature, are interested in anatomical divisions or structures of the brain that are individuated independently of the cognitive capacities in which they are involved. For example, Price and Friston present the different functions that are ascribed to the “left posterior lateral fusiform” (Price & Friston, 2005, 265); Klein’s examples are the “precuneus and posterior cingulate cortex, the temporoparietal junction, and the ventromedial prefrontal cortex” (Klein, 2012, 958). Neural mechanisms are not brain regions but neural entities and their activities or functions, in a certain organization, picked out relative to a phenomenon of interest. There is no prima facie reason to suppose that a mechanism’s boundaries map onto those of a brain region. Rather, it is likely that mechanisms cross-cut predefined brain regions, areas, or structures.
Thus, the new mechanistic answer provides a novel perspective on the CO-Question which is very promising for several reasons. First, it comes with a direct solution to the CO-Problem. Necessarily, each mechanism is responsible for only one phenomenon, and each phenomenon will be brought about by one mechanism only, since a mechanism is made up of those and only those entities, activities, and organizational features that are relevant to the corresponding phenomenon. Thus, each difference between two phenomena will necessarily imply a difference between the underlying mechanisms; and each difference between mechanisms will result in different phenomena. (If it did not, the factor that differs would not be relevant to the phenomenon, and so it would not be part of the mechanism.) Thus, the new mechanistic perspective on cognitive ontology is rather promising as, if successful, it will necessarily give us one-to-one mappings.
Another advantage is that the mechanisms underlying cognitive capacities need not be purely brain-bound (Abramova & Slors, 2019; Kaplan, 2012; Krickel, 2020). If there is an extra-cranial element that is relevant to a cognitive capacity in the mechanistic sense, then this extra-cranial element is part of the mechanism for that cognitive capacity. Therefore, the new mechanistic answer is, in principle, compatible with situated, embodied, and enacted accounts of cognition. As it avoids begging the question against defenders of these accounts, the new mechanistic answer is preferrable to accounts that base their attempts to answer the CO-Question purely on the brain’s neural structure.
A further advantage is that the new mechanistic answer gets rid of the idea that we can carve the brain, more or less contingently, into brain regions, structures, or the like, and map cognitive capacities onto them. While the new mechanistic answer is compatible with the existence of some overlap between anatomical brain structures and mechanistic components, it is not committed to the view that this is generally the case. This is good: Why should it be the case that independently identified brain structures map onto mechanistic components? Or, as Poldrack and Yarkoni put it:
limitations (…) are inherent to any effort to approach mind-brain mapping from a purely neurobiological perspective—that is, by seeking first to identify the “right” functional units at the level of the brain and then to map the revealed structures onto psychological processes. (Poldrack & Yarkoni, 2016, p. 598)
In a nutshell: the new mechanistic answer, according to which our cognitive ontology corresponds to neural mechanisms (as the new mechanists understand them), indeed constitutes a novel and promising proposal for answering the CO-Question and, if successful, it directly gives us a solution to the CO-Problem.
3 Problems for the New Mechanistic Answer
While the new mechanistic answer seems promising, there is a crucial problem: it might not even get off the ground. FSC discuss three problems for the new mechanistic answer that together give rise to what they call the “cycle of kinds”: the Operationalization Problem, the Abstraction Problem, and the Boundary Problem. The Operationalization Problem, according to FSC, concerns the following question:
Operationalization Problem: How are we to establish whether a certain task indeed measures a given cognitive capacity?
The Operationalization Problem thus concerns the connection between tasks and cognitive capacities. Tasks are used in controlled experiments to measure cognitive capacities. The crucial challenge is to establish that a given task indeed measures a given cognitive capacity. According to FSC, the standard response to the Operationalization Problem is to look at the underlying mechanism: a task measures a certain cognitive capacity if and only if the task triggers the mechanism that is supposed to underlie that cognitive capacity.
This reliance on mechanisms, then, leads to the Abstraction Problem and the Boundary Problem. Both problems concern the individuation of mechanisms: what should be considered a part of a given mechanism, and what should not. To verify whether the mechanism that is triggered is the same in each case, we need to be able to tell which entities and activities are components of the mechanism and which are not. The new mechanistic approach provides the resources to solve both the Abstraction Problem and the Boundary Problem—as explained in Sect. 2, the identification of mechanistic components is relative to the phenomenon: some acting entity or organizational feature O is a component in the mechanism for phenomenon P if changing O changes P and changing P changes O. Consequently, any solutions to the Abstraction Problem and the Boundary Problem rest on knowing what cognitive capacity a given mechanism is supposed to be responsible for in each case. This, according to FSC, brings us back to the Operationalization Problem, and we have closed the cycle of kinds.
Is this cycle of kinds really a problem for defenders of the new mechanistic answer to the CO-Question? I do not think so. First, let us recall what the issue is here: finding an answer to the CO-Question, that of how to carve up the cognitive domain into cognitive capacities that constitute cognitive kinds. The CO-Question is not the Operationalization Problem that starts the cycle of kinds. The Operationalization Problem concerns the relationship between cognitive capacities and tasks. It concerns the problem of how to measure a cognitive capacity—not the more general issue of which cognitive capacities exist in the first place.Footnote 5 Still, the cycle of kinds might arise for the CO-Question, much as it arises for the Operationalization Problem. This can be shown as follows.
Those defending the new mechanistic answer to the CO-Question are committed to the following two statements:
-
1.
The cognitive domain should be carved up into cognitive capacities that correspond to neural mechanisms. [New mechanistic answer].
-
2.
The individuation of a mechanism (at least partly) depends on the phenomenon that it brings about. [Mechanistic notion of relevance].
The first statement is the new mechanistic answer to the CO-Question, as introduced in Sect. 2. The second statement is a formulation of the new mechanistic answer to the Abstraction Problem and the Boundary Problem, which concern how to individuate mechanisms and identify their parts. What is part of a given mechanism and what is not depends on what the mechanism is for. Only entities and activities that are relevant to the phenomenon will be components of the mechanism. From statement 2, we can derive statement 3:
-
3.
A collection of entities and activities is a mechanism if and only if the entities and activities together bring about a phenomenon. [from 2].
This statement follows from 2 because mechanisms consist of several entities and activities (in a certain organization). The reality of each entity and each activity is presupposed (Illari & Williamson, 2011), but is not sufficient for them to form a mechanism. The entities and activities form a mechanism only if each of them, given the others, is relevant to the same phenomenon. A phenomenon is a cognitive capacity in the present context. Thus, whether certain entities and activities together form a mechanism depends on whether they together bring about such a capacity. Now, there are two interpretations of what that could mean. The strong interpretation is:
-
3′
A collection of entities and activities is a mechanism if and only if the entities and activities together bring about a phenomenon that is part of our ontology.
With 3′ we obviously run into a cycle, which arises from the combination of 1 and 3′: statement 1 tells us that those phenomena are parts of our ontology that correspond to neural mechanisms, while statement 3′ tells us that neural mechanisms can only be identified relative to phenomena that are part of our ontology. This is an epistemic cycle: to know the one, we need to know the other; but to know the other, we need to know the one.
However, there is a weak interpretation of 3 that is more in line with the new mechanistic approach:
-
3″
A collection of entities and activities is a mechanism if and only if the entities and activities together bring about a phenomenon that is realized by the type of system in question.
The core difference between the strong interpretation (3′) and the weak interpretation (3″) is that the former is more restrictive about what counts as a mechanism. According to the strong interpretation, a collection of entities and activities counts as a mechanism only if they together bring about a cognitive phenomenon that corresponds to a cognitive kind, i.e., a cognitive capacity that is part of our cognitive ontology. In contrast, the weak interpretation does not care about cognitive ontology: any collection of entities and activities counts as a mechanism that brings about a phenomenon of interest. All that the weak interpretation requires is a capacity (perhaps arbitrarily characterized) that a system can execute.
Phenomena as 3″ deals with them would be sufficient to determine which entities and activities are part of a mechanism. Accounts of constitutive relevance do not require the phenomenon with respect to which a mechanism is individuated to be part of our ontology, as 3′ does. However, a combination of statements 1 and 3″ is not circular in the way a combination of 1 and 3′ is. Thus, FSC’s diagnosis is wrong: the cycle of kinds does not arise for the new mechanistic answer to the CO-Question.
Does that mean that the new mechanistic answer successfully answers the CO-Question, and can be used to derive a cognitive ontology for cognitive neuroscience and cognitive psychology? Unfortunately, it does not. Rather, defenders of the new mechanistic answer to the CO-Question are confronted with what I call the triviality problem.
- Triviality problem::
-
Trivially, every phenomenon (here: every capacity characterized by an input–output relation) that is realized by a system (e.g., a human brain) will correspond to a (neural) mechanism.
Physicalism and the absence of magic are (implicit) assumptions in the cognitive ontology literature, which is why there must be a mechanistic explanation, and thus a mechanism, for every phenomenon we observe (if we have made no mistakes in our observations).Footnote 6 The Triviality Problem points to a feature of the new mechanistic approach, not to a bug. The mechanistic approach is first and foremost an account of scientific explanation, and our explanatory interests may be independent of our cognitive ontology. For example, we may be interested in how a cognitive system recognizes the main character from the eponymous Japanese manga series Sailor Moon.Footnote 7 If the cognitive system is able to do this, then there is a mechanism that enables the recognition of Sailor Moon. For the mechanistic explanation of how a cognitive system recognizes Sailor Moon, it does not matter whether “recognizing Sailor Moon” is a cognitive kind, i.e., a cognitive capacity in our cognitive ontology. Thus, the triviality problem is not a problem for the new mechanistic approach in general. It is only a problem for those who want to use the resources of the new mechanistic approach to answer the CO-Question by adopting the new mechanistic answer.
In a nutshell: the problem for the new mechanistic answer to the CO-Question is that it gives us a cognitive ontology that will include absolutely any capacity that is characterized by an input–output relation which is realized by humans. While the new mechanistic answer solves the CO-Problem—we will get one-to-one mappings only—such an overpopulated cognitive ontology is not what we aimed for, so the new mechanistic answer seems to be useless for answering the CO-Question. However, FSC do not think so. As I will show in the next Section, their proposal, intended to address the apparent cycle created by the Operationalization Problem, can also be applied to the triviality problem.
4 How (not) to Save the New Mechanistic Answer
While Craver (2009) used to be rather pessimistic, FSC are more optimistic about the usefulness of the new mechanistic answer:
Progress in this iterative practice involves reducing the incongruities among tasks, cognitive ontologies, and our understanding of mechanisms. We cycle from a functional description of capacities, to the neural implementation, to the task choice and task model, and back again. Repetition of this circular process need not involve stagnation but may yield increasingly more refined functional concepts and informed decisions about what to count as and in a mechanism. It would, after all, be a tremendous achievement to bring our solutions to these three component problems in the cycle of kinds (tasks, capacities/functional roles, and mechanisms) into unforced alignment for any given practical project. Such alignment is the stop signal in the search for cognitive kinds, halting the cycle of accommodation among the solutions to its constituent problems. (Francken et al., 2022, p. 378)
In other words: FSC argue that the cycle of kinds can be stretched so that it turns into a wavy line rather than a loop—let us call this the wavy line strategy (see Fig. 1). Scientists start with any characterization of the cognitive capacity they are interested in, then identify the mechanism that is responsible for the capacity; based on this, they revise the characterization of the cognitive capacity; they then identify the mechanism underlying the phenomenon under this characterization, and so on.

The wavy line strategy for solving the “cycle of kinds” problem, as suggested by FSC. The empirical task that follows this line, which involves both finding the mechanism and characterizing the phenomenon, will also involve re-characterizing the operationalizations and task models that are used to investigate the phenomenon and the mechanism
The wavy line strategy might indeed help us to solve the triviality problem. This strategy accepts that one starts with a potentially arbitrary characterization of a cognitive capacity, for which one will find a mechanism. The key idea is that instead of stopping there one should revise the characterization of the capacity in light of what one has learned about the mechanism. (For a discussion of how this revision proceeds see, for example, Chang, 2004; Feest, 2010; Dubova & Goldstone, 2023). Hence, this strategy might avoid leading us into a trivial, infinitely large, and useless cognitive ontology.
However, the wavy line strategy is problematic—and the problem it faces directly follows from the triviality problem. The triviality problem arises because we find mechanisms for any cognitive capacity characterized by an input–output relation which is realizable by humans. For example, if a cognitive system is able to recognize Sailor Moon, there will be a mechanistic explanation of how it does so. If we take the new mechanistic answer seriously, it implies that we are to stop following the wavy line as soon as we have found a mechanism (i.e., already at tn-5 in Fig. 1). Since we have now found a mechanism that enables a cognitive system to recognize Sailor Moon, if we follow this strategy we need to stop there and accept “recognizing Sailor Moon” in our cognitive ontology. This is the triviality problem. To avoid it, we need a further criterion for deciding when to remain on the wavy line and when to stop. Such an additional criterion would have to provide restrictions on the mechanistically explainable cognitive capacities that are to be allowed in our cognitive ontology.
FSC provide a hint as to what such an additional criterion might look like:
Our proposal aligns well with key features of Boyd’s “homeostatic property cluster” theory of natural kinds (Boyd, 1989). (…) Boyd’s historic view expresses concisely the idea that scientists should populate their models and theories with kinds that best systematize our knowledge of the world’s causal structure (Salmon, 1984) and that therefore offer the most “bang for the buck,” maximizing predictive leverage and instrumental control in the most economical way (Strevens, 2008). (Francken et al., 2022, p. 378)
In other words, whether we keep moving along the wavy line or not depends on whether the cognitive capacity (under a certain characterization) and the mechanism that we have found belong to kinds that “best systematize our knowledge of the world’s causal structure.” In the present context we may not need to aim at optimal systematizations of causal knowledge about the whole world. Since we are interested in carving up the cognitive domain, a focus on the causal structure of that domain is all we need. What could be meant by “best systematization”? While FSC do not elaborate, the general idea seems to be that an ontology of the cognitive domain should be such that it maximizes the predictive and explanatory strength of our theories and models of cognition while remaining parsimonious.
FSC’s attempt to rescue the new mechanistic answer thus amounts to a modification of it. The modification is added in italics:
New mechanistic answer*: The cognitive domain should be carved up into cognitive capacities that correspond to neural mechanisms and that best systematize our knowledge of the causal structure of the cognitive domain.
This modification of the new mechanistic answer solves the triviality problem because not just any capacity that is brought about by a mechanism will do—a cognitive capacity is part of our cognitive ontology only if it is part of the best systematization of our knowledge of the causal structure of the cognitive domain. At this point I will leave open whether something like the best systematization really exists, or whether all one can plausibly get is the best systematization in a given context (in line with, e.g., McCaffrey & Wright, 2022). This issue must be left for future research. What is relevant to my argument here is (a) that the correspondence between cognitive capacities and neural mechanisms is not sufficient for a useful cognitive ontology, as it leads to the triviality problem; but also (b) that the triviality problem can be solved by adding a further criterion that restricts the set of mechanistically explainable cognitive capacities that are allowed in our cognitive ontology. As FSC suggest, one promising candidate for such an additional criterion is that a mechanistically explainable cognitive capacity must also be part of the best systematization of the causal structure of the cognitive domain. There might be other additional criteria that could us help to solve the triviality problem; developing, discussing, and comparing those, however, is beyond the scope of this article. The focus on the “best systematization” criterion is justified because (a) as I have shown, it can be found in the literature on mechanisms and cognitive ontology already; (b) as FSC have stated (see quotation above), the usefulness of the “best systematization” idea is supported by the literature on natural kinds, which is concerned with ontology as well; and (c) focusing on the “best systematization” criterion allows me to develop an alternative account, given below, of mechanisms’ role in cognitive ontology.Footnote 8
Adding the “best systematization” criterion solves the triviality problem and tells us when we must revise a characterization of a phenomenon and when we need not. For example, even if “recognizing Sailor Moon” turns out to be mechanistically explainable, it does not follow that this capacity should be accepted into our cognitive ontology; “recognizing Sailor Moon” is surely not part of the best systematization of the causal structure of the cognitive domain. For example, it may be too specific to allow for any interesting predictions, it yields no interesting generalizations that can be used to explain other phenomena, and so on.
However, there is a problem for defenders of the new mechanistic answer to the CO-Question: mechanisms become obsolete. To find the mechanisms that are relevant for our cognitive ontology—those that bring about capacities that are part of the best systematization—we must already know what the best systematization of the cognitive domain is. But if we know that, adding knowledge about the mechanisms will not add anything relevant—at least, not for building a cognitive ontology. For example, one might think that “recognizing fictional characters” is a better candidate than “recognizing Sailor Moon” for inclusion in our cognitive ontology. Let us assume that we know that the additional criterion is satisfied by this more general capacity, so that adding “recognizing fictional characters” to our cognitive ontology increases the predictive and explanatory strength of our theories and models of cognition while keeping our ontology parsimonious. Knowing this would be reason enough to accept the cognitive capacity “recognizing fictional characters” into our cognitive ontology. Adding mechanistic knowledge would not add anything relevant. As we are interested in finding an ontology of cognitive capacities, we need to find the best systematization of the causal structure of the cognitive domain—and that may not map onto the best systematization of mechanisms. Consequently, it turns out that mechanisms cannot play the role they were supposed to play in cognitive ontology and in finding cognitive kinds.Footnote 9
5 The Epistemic Benefit of Mechanisms: Mechanisms as Epistemic Proxies
So, is there a place left for mechanisms in our search for a cognitive ontology? I think there is. Mechanisms provide an epistemic benefit to the empirical endeavor of cognitive ontology and the investigation of cognitive kinds. Knowing whether the “best systematization” criterion is satisfied—whether a given cognitive capacity is part of the best systematization of our causal knowledge about the cognitive domain—is epistemically rather demanding; it requires the integration of a huge amount of causal knowledge about cognition, and an ability to compare different possible systematizations and identify the best one. It is very unlikely that cognitive neuroscience works like this, or even could work like this. What we need are methods to approximate best systematizations without overburdening us epistemically. Here, mechanisms may at least be part of the story.
The idea that I want to put forward is that mechanisms are epistemic proxies for best systematizations. Certain types of mechanistic knowledge can provide hints as to the best systematization of the causal structure of the cognitive domain. Mechanisms can do this because they realize the causal profiles of our cognitive capacities: every causal property of a cognitive capacity is due to its underlying mechanism.Footnote 10 This implies that certain types of knowledge about the causal properties of mechanisms can justify claims about cognitive ontology. Which types of knowledge, then, and which claims?
Since the causal properties of our cognitive capacities are fully realized by their underlying mechanisms, mechanistic knowledge can help us to identify splitting and lumping errors in our models and theories of cognition. A splitting error is made by mistaking one cognitive capacity for two or more different capacities. Mechanisms can help us identify such an error: if we find a characterization of a capacity that incorporates more specific capacities, and the more general capacity is realized by one and the same mechanism whenever it is executed, we can infer that the more specific capacities that we thought were different are in fact versions of one and the same general capacity. A lumping error occurs if one falsely takes two or more capacities to be the same capacity. If this happens, we will find two or more different mechanisms for what we falsely thought was one and the same capacity.
By helping us to detect splitting and lumping errors in the cognitive domain, mechanisms can function as epistemic proxies for the best systematization: mechanisms tell us that the carving we started with was not the best systematization, as it included splitting or lumping errors. We can infer that the systematization we end up with once such errors have been corrected is better than the one we were using before—but we cannot infer that it is the best systematization. Thus, mechanisms as epistemic proxies for best systematizations have their limits: we cannot infer positive claims about cognitive ontology, only negative ones. Even if, say, working memory turns out to correspond to just one mechanism in all tasks, it may still not be part of the best systematization of our causal knowledge about the cognitive domain. Whether this is the case depends on what else is part of the best systematization. For example, it may turn out that a broader theory of memory will be both simpler and stronger if we delineate memory phenomena in a way that gets rid of working memory. And in an even broader theory of cognition, for example, there might be no place for memory at all (rather unlikely), or it might turn out that a theory of cognition is simplest and strongest when its delineation of some memory phenomena reveals them to be, say, attention phenomena. This shows that, from an empirical perspective, cognitive ontology is a rather complex issue—one that cannot be addressed based on mechanistic knowledge alone. It requires other methods to determine what is (not) part of the best systematization of our causal knowledge of the cognitive domain. Since the goal of this article is to clarify the role of mechanisms in cognitive ontology, I will not discuss here which other, non-mechanistic methods there are.Footnote 11
One might object that my “epistemic proxy” account of mechanisms’ role in cognitive ontology brings us back to where FSC started. Since we need to operationalize cognitive capacities in order to find their underlying mechanisms, do we not run into the “cycle of kinds” problem, as FSC argue? This is not the case; the Operationalization Problem does not lead to a cycle of kinds, since operationalization is just the second step when doing empirical research in cognitive psychology and cognitive neuroscience. The first step is (or should be) to come up with a clear characterization of the phenomenon that one wants to explain. This is the whole idea behind the wavy line strategy: we start with a characterization, possibly arbitrary but clear, of the capacity that we aim to explain. That is, before we start operationalizing a phenomenon—before we identify the experimental tasks that can be used to measure it—we need a description of it. For example, we could decide to operationalize working memory by having subjects perform the n-back task, the dual-task weather prediction task, the change detection task, the WAIS digit span task, or any other task. However, to decide which tasks can be used to measure working memory, one needs a characterization of what working memory is supposed to be. Providing a clear characterization of a cognitive capacity is a major challenge: for any cognitive capacity that contemporary researchers explore, there are several different characterizations in place, so that different researchers, labs, or projects, all researching what is putatively the same cognitive capacity, work with different characterizations of it.
Russell Poldrack’s Cognitive AtlasFootnote 12 is intended to address this conceptual mess by providing characterizations (called “concepts” in the Cognitive Atlas) of cognitive capacities, so that each can function as the common starting ground for all research on that particular cognitive capacity. For example, working memory is characterized by the Cognitive Atlas as “the ability to actively maintain or update goal/task relevant information in a form that resists interference but has limited capacity”. Such common conceptual ground is necessary if mechanisms are to serve as epistemic proxies for best systematizations. If we have such a common ground, the cycle of kinds does not arise. Whether we have such a common ground does not depend on mechanistic knowledge but is a conceptual matter on which researchers must decide. To illustrate this, let us take a closer look at the example of working memory.
According to the Cognitive Atlas’s characterization of it, different tasks measure working memory insofar as they measure “the ability to actively maintain or update goal/task relevant information in a form that resists interference but has limited capacity.” At this point, no commitment has been made as to whether this is the best characterization of working memory, or as to whether our cognitive ontology will ultimately include working memory. All we need here (and all we can plausibly get) is a characterization of working memory that is not completely implausible and that constitutes the common ground for all working memory research (which is not yet the case). On this characterization of working memory, to identify the mechanism for it is to identify all those entities, activities, and their organizational features that are relevant to any of three things: the capacity limits; resistance to interference; and actively maintaining or updating goal- or task-relevant information. This is surely not a trivial empirical task. This search for working memory’s mechanism is independent of which task we use—as long as the task is adequate for measuring the relevant properties that we have attributed to working memory.
According to the new mechanistic account, and as presented in Sect. 2, identifying the mechanism(s) of working memory involves the following procedure. First, one manipulates the phenomenon, here working memory: for example, by changing the amount of information that must be actively maintained, or by changing the number or strength of interfering factors, or by changing the cognitive load. Next, one detects the causal consequences of this change in the brain (or possibly in extra-cranial factors). Finally, one manipulates the putative mechanistic components that were identified in the first step to see whether this causes a change in the phenomenon—whether these manipulations change the capacity limits, the resistance to interference, or the active maintenance or update of goal- or task-relevant information. If so, these manipulations can be regarded as changes to working memory as it is characterized here.
Thus, the cycle of kinds does not arise as long as we start with a clear characterization of the cognitive capacity under investigation. This will tell us which changes in a subject’s behavior while performing a task count as relevant changes—ones that constitute a change in what the characterization of working memory refers to, i.e., changes in the capacity limits, in resistance to interference, and in the active maintenance or updating of goal- or task-relevant information. Relative to this, the mechanisms underlying instances of working memory can be identified. As FSC correctly note when describing the Abstraction Problem, no two mechanisms are exactly the same: “There is inevitable biological variation from one person to the next, and even one instant to the next in the same person” (Francken et al., 2022, p. 377). According to the new mechanistic account, these differences are relevant and tell us that actually there are different mechanisms underlying a phenomenon only if the differences between them make a difference to the phenomenon. In the present context: differences between mechanisms are relevant only insofar as they make a difference to the capacity limits, resistance to interference, or the active maintenance or updating of goal- or task-relevant information.
We might conclude that the characterization of working memory that we used was not good after all. For example, we might observe changes that are not relevant according to our original characterization, but that intuitively should be counted as relevant changes. One might then suggest a revision of our characterization of working memory. Whether such a revision is required will depend on whether it would improve our explanations, predictions, and generalizations—in short, the systematization of our causal knowledge about the cognitive domain. Here the impetus for re-conceptualization is independent of mechanistic knowledge.
These considerations show how conceptual clarity, including clear characterizations of cognitive concepts, is crucial for any empirical search for an ontology of the cognitive domain. If we had started with different characterizations of working memory, it is highly likely that we would have ended up with different mechanisms. Without a clear characterization of working memory that provides the common ground for research into it, inferences that splitting or lumping errors have occurred are not justified.
In a nutshell: for mechanisms to play the role of epistemic proxies for best systematizations, and thereby for cognitive ontology, we need clear characterizations of the relevant cognitive capacities, and we need consistent use of these characterizations by researchers who are investigating the same cognitive capacity. If both conditions are satisfied, knowledge about the mechanism(s) underlying the cognitive capacity under that characterization can help us identify splitting or lumping errors when we individuate that cognitive capacity. Mechanistic knowledge thus helps us to determine which cognitive capacities are not part of the ontology of cognitive psychology and cognitive neuroscience.
6 Conclusion
This article had four goals. The first was to show that the new mechanistic answer, contrary to what FSC argue, constitutes a novel, and prima facie promising, approach to the CO-Question and the CO-Problem. The second goal was to clarify why and how the new mechanistic answer still fails as an answer to the CO-Question: it is confronted with the triviality problem. The third goal was to show how, in trying to solve the triviality problem, one renders the mechanistic answer obsolete. The fourth goal was to clarify the role that mechanisms can play for cognitive ontology. The suggestion was to treat mechanisms not as ontic grounds for cognitive kinds but as epistemic proxies for the best systematization of the cognitive domain.
This paper’s main contribution lies in clarifying the role of (neural) mechanisms in cognitive ontology. Neuroscientists and cognitive psychologists should work together to identify the ontology of cognitive capacities. Neuroscientists contribute to this endeavor by detecting differences or similarities between mechanisms; based on these we can infer that a splitting or lumping error has been made, and therefore which cognitive capacities should not be included in our cognitive ontology. Cognitive psychologists contribute analyses of how a given cognitive capacity improves the systematization of causal knowledge of the cognitive domain. This paper, however, is only the starting point for a bigger project. Crucial questions remain: How should we understand the notion of a best systematization in the current context? What exactly is the relevant domain of knowledge? How, in practice, can cognitive psychologists and neuroscientists determine whether a cognitive capacity improves a systematization of the cognitive domain?
Notes
The literature on cognitive ontology mainly focuses on human cognition. Here, I will leave open the topic of whether this focus is justified or not. For the view that it is not see Figdor (2022).
This paper focuses on mechanisms as they are understood within the new mechanistic approach; this is not necessarily what neuroscientists take “mechanism” to mean (Ross and Bassett 2024). Here, the focus will be on mechanisms as understood by the new mechanists. This is justified for two reasons: first, one of the new mechanists’ main goals is to provide a descriptively adequate analysis of how the notion of a mechanism is used in neuroscience and other disciplines—i.e., they aim at clarifying a potentially ambiguous or vague scientific concept. Second, Carl Craver is one of the leading figures in the new mechanistic literature. This and other textual evidence suggests that FSC talk about mechanisms as the new mechanists understand them.
The new mechanistic answer is not identical with the new mechanistic approach. The new mechanistic approach is, first and foremost, an account of scientific explanation; as such, it does not come with any commitments regarding the CO-Question. Thus, a proponent of the new mechanistic approach is not committed to defending the new mechanistic answer to the CO-Question, but could even reject it as a good approach to cognitive ontology.
To my knowledge, only McCaffrey (2015) makes explicit use of new mechanistic ideas to address the CO-Problem. However, he does not adopt the new mechanistic answer, but holds onto the idea that brain regions (or brain parts), not mechanisms, are to be mapped onto capacities. His general insight is that some brain regions (or parts) play different roles in different mechanisms for different capacities; others play the same role in different mechanisms for different capacities. According to McCaffrey, the CO-Problem arises only for regions (or parts) with variable roles, not for those with conserved roles. In her recent dissertation, Annelli Janssen (2019) asks whether the mechanistic approach can be used to address the CO-question. Her critical assessment of this idea motivates further doubt that the new mechanistic answer is indeed the standard approach in cognitive ontology.
This holds at least for the realist position regarding cognitive capacities, or for any position that takes the identity criteria of cognitive capacities to be something more than the criteria for measuring a cognitive capacity (e.g., as operationalists argue). I take FSC to be realists (or at least not operationalists).
This does not amount to a claim about “mechanistic hegemony” (Shapiro 2017). Physicalism implies that there are mechanistic explanations of all (non-fundamental) natural phenomena. It does not commit us to the claim that there are only mechanistic explanations; neither does it commit us to the claim that that all putatively non-mechanistic explanations either are actually mechanistic explanations or are not explanatory at all.
This example was inspired by one used by Marco Viola and Fausto Caruana.
This does not exclude the possibility of an alternative additional criterion that solves the triviality problem while leaving room for a different role for mechanisms. I think that this could be the topic of a new research project on the non-mechanistic constraints on cognitive ontology and their implications for mechanisms’ role within the cognitive ontology project.
In this regard, the situation is like the one that motivates so-called epistemic accounts to natural kinds (Slater 2015). According to defenders of such accounts, mechanisms are irrelevant for a theory of natural kinds; what is relevant is the feature of property clusters that explains which property clusters lead to successful inferential practices. The “best systematization” strategy is similar in that it renders the mechanisms underlying property clusters irrelevant—what is crucial is that a property cluster is part of the best systematization of our causal knowledge.
The mechanism will have many causal properties that do not correspond to causal properties of the capacity—the relation between the causal properties of mechanisms and those of capacities is plausibly one of subset realization (Shoemaker 2007).
One such non-mechanistic method might be that of finding what may be called “local best systematizations.” We do not ask how stipulating a cognitive capacity C increases the predictive and explanatory strength of all of our causal knowledge about the cognitive domain. Instead, we ask how stipulating C changes the predictive and explanatory strength of some particular model or theory, or of a particular set of models or theories.
The Cognitive Atlas is a project, led by Russell Poldrack at Stanford University, that “aims to develop a knowledge base (or ontology) that characterizes the state of current thought in cognitive science” (see: http://www.cognitiveatlas.org/about [05/18/2022; see also Poldrack et al., 2011].
References
Abramova, E., & Slors, M. (2019). Mechanistic explanation for enactive sociality. Phenomenology and the Cognitive Sciences, 18, 401–424.
Anderson, M. L. (2015). Mining the brain for a new taxonomy of the mind. Philosophy Compass, 10, 68–77.
Boone, W., & Piccinini, G. (2016). The cognitive neuroscience revolution. Synthese, 193, 1509–1534.
Boyd, R. (1989). What realism implies and what it does not. Dialectica, 43, 5–29.
Chang, H. (2004). Inventing temperature. Oxford University Press.
Craver, C. F. (2007). Explaining the brain: Mechanisms and the mosaic unity of neuroscience. Oxford University Press.
Craver, C. F. (2009). Mechanisms and natural kinds. Philosophical Psychology, 22, 575–594.
Craver, C. F., Glennan, S., & Povich, M. (2021). Constitutive relevance & mutual manipulability revisited. Synthese, 199, 8807–8828.
Dubova, M., & Goldstone, R. L. (2023). Carving joints into nature: Reengineering scientific concepts in light of concept-laden evidence. Trends in Cognitive Sciences, 27, 656–670.
Feest, U. (2010). Concepts as tools in the experimental generation of knowledge in cognitive neuropsychology. Spontaneous Generations: A Journal for the History and Philosophy of Science, 4, 173–190.
Figdor, C. (2022). What could cognition be, if not human cognition? Individuating cognitive abilities in the light of evolution. Biology and Philosophy, 37, 1–21.
Francken, J. C., Slors, M., & Craver, C. F. (2022). Cognitive ontology and the search for neural mechanisms: Three foundational problems. Synthese, 200, 378.
Glennan, S. (2017). The new mechanical philosophy. Oxford University Press.
Illari, P. M., & Williamson, J. (2011). Mechanisms are real and local. In P. M. Illari, F. Russo, & J. Williamson (Eds.), Causality in the sciences (pp. 818–844). Oxford University Press.
Illari, P. M., & Williamson, J. (2012). What is a mechanism? Thinking about mechanisms across the sciences. European Journal for Philosophy of Science, 2, 119–135.
Janssen, A. (2019). Explanations in neuroimaging research. Radboud Repository of the Radboud University Nijmegen.
Janssen, A., Klein, C., & Slors, M. (2017). What is a cognitive ontology, anyway? Philosophical Explorations, 20, 123–128.
Kaplan, D. M. (2012). How to demarcate the boundaries of cognition. Biology and Philosophy, 27, 545–570.
Klein, C. (2012). Cognitive ontology and region- versus network-oriented analyses. Philosophy of Science, 79, 952–960.
Krickel, B. (2020). Extended cognition, the new mechanists’ mutual manipulability criterion, and the challenge of trivial extendedness. Mind & Language, 35, 539–561.
McCaffrey, J., & Wright, J. (2022). Neuroscience and cognitive ontology: A case for pluralism. In F. De Brigard & W. Sinnott-Armstrong (Eds.), Neuroscience and philosophy (pp. 427–466). MIT Press.
McCaffrey, J. B. (2015). The brain’s heterogeneous functional landscape. Philosophy of Science, 82, 1010–1022.
Poldrack, R. A., Kittur, A., Kalar, D., Miller, E., Seppa, C., Gil, Y., Stott Parker, D., Sabb, F. W., & Bilder, R. M. (2011). The cognitive atlas: Toward a knowledge foundation for cognitive neuroscience. Frontiers in Neuroinformatics, 5, 1–11.
Poldrack, R. A., & Yarkoni, T. (2016). From brain maps to cognitive ontologies: Informatics and the search for mental structure. Annual Review of Psychology, 67, 587–612.
Price, C. J., & Friston, K. J. (2005). Functional ontologies for cognition: The systematic definition of structure and function. Cognitive Neuropsychology, 22, 262–275.
Ross, L. N., & Bassett, D. S. (2024). Causation in neuroscience: keeping mechanism meaningful. Nature Reviews Neuroscience, 25, 81–90.
Salmon, W. C. (1984). Scientific explanation and the causal structure of the world. Princeton University Press.
Shapiro, L. A. (2017). Mechanism or bust? Explanation in psychology. The British Journal for the Philosophy of Science, 68, 1037–1059. https://doi.org/10.1093/bjps/axv062
Shoemaker, S. (2007). Physical realization. Oxford University Press.
Slater, M. H. (2015). Natural kindness. British Journal for the Philosophy of Science, 66, 375–411.
Strevens, M. (2008). Depth: An account of scientific explanation. Harvard University Press.
Viola, M. (2017). Carving mind at brain’s joints The debate on cognitive ontology. Phenomenology and Mind, 12, 162–172.
Viola, M. (2021). Beyond the platonic brain: Facing the challenge of individual differences in function-structure mapping. Synthese, 199, 2129–2155.
Zednik, C. (2019). Models and mechanisms in network neuroscience. Philosophical Psychology, 32, 23–51.
Acknowledgements
I have conducted the main work for this article during my research stay at the Philosophy Department at Uppsala in 2022 funded by Riksbankens Jubileumsfond. I want to especially thank Sofia Bokros, Ekrem Çetinkaya, Matti Eklund, Sebastian Lutz, Miguel F. Dos Santos, Jonathan Shaheen, and Nick Wiltsher for their very helpful and motivating philosophical discussions during coffee breaks and meetings (and everyone else at the Uppsala department). Furthermore, I want to thank Carl Craver, Mariel Goddu, Matej Kohár, Dimitri Coelho Mollo, Marc Slors, Marco Viola, Barbara Vetter and the attendees of Barbara’s colloquium at FU Berlin for comments on earlier drafts of this article. Also, I presented the paper at various occasions: I thank the attendees of the colloquia at Uppsala University and Umea University for the great discussions. Also, I thank the attendees of my talk at GWP, MPI Cognition Academy, and the Neurocognitive Foundations of Mind Conference. Finally, I want to thank two anonymous referees for the helpful and charitable comments.
Funding
Open Access funding enabled and organized by Projekt DEAL. The research leading to these results was funded by Riksbankens Jubileumsfond (Humboldt-Fellowship in the context of the 31st Swedish Prize).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No other interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Krickel, B. The New Mechanistic Approach and Cognitive Ontology—Or: What Role do (Neural) Mechanisms Play in Cognitive Ontology?. Minds & Machines 34, 17 (2024). https://doi.org/10.1007/s11023-024-09679-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11023-024-09679-9