
Abstract
Interval-censored failure time data arise in a number of fields and many authors have recently paid more attention to their analysis. However, regression analysis of interval-censored data under the additive risk model can be challenging in maximizing the complex likelihood, especially when there exists a non-ignorable cure fraction in the population. For the problem, we develop a sieve maximum likelihood estimation approach based on Bernstein polynomials. To relieve the computational burden, an expectation–maximization algorithm by exploiting a Poisson data augmentation is proposed. Under some mild conditions, the asymptotic properties of the proposed estimator are established. The finite sample performance of the proposed method is evaluated by extensive simulations, and is further illustrated through a real data set from the smoking cessation study.



Similar content being viewed by others

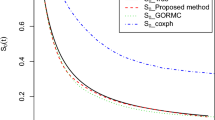
References
Aalen O (1980) A model for nonparametric regression analysis of counting processes. Mathematical statistics and probability theory. Springer, New York, pp 1–25
Banerjee S, Carlin BP (2004) Parametric spatial cure rate models for interval-censored time-to-relapse data. Biometrics 60(1):268–275
Berkson J, Gage RP (1952) Survival curve for cancer patients following treatment. J Am Stat Assoc 47(259):501–515
Betensky RA, Rabinowitz D, Tsiatis AA (2001) Computationally simple accelerated failure time regression for interval censored data. Biometrika 88(3):703–711
Bickel PJ, Kwon J (2001) Inference for semiparametric models: some questions and an answer. Stat Sin 11(4):863–886
Boag JW (1949) Maximum likelihood estimates of the proportion of patients cured by cancer therapy. J R Stat Soc B 11(1):15–53
Cox D (1972) Regression models and life-tables. J R Stat Soc B 34(2):187–220
Farewell VT (1982) The use of mixture models for the analysis of survival data with long-term survivors. Biometrics 38(4):1041–1046
Finkelstein DM (1986) A proportional hazards model for interval-censored failure time data. Biometrics 42(4):845–854
Ghosh D (2001) Efficiency considerations in the additive hazards model with current status data. Stat Neerl 55(3):367–376
Györfi L, Kohler M, Krzyzak A, Walk H (2002) A distribution-free theory of nonparametric regression. Springer-Verlag, Berlin
Hanin L, Huang L (2014) Identifiability of cure models revisited. J Multivar Anal 130:261–274
Hu T, Xiang L (2013) Efficient estimation for semiparametric cure models with interval-censored data. J Multivar Anal 121:139–151
Hu T, Xiang L (2016) Partially linear transformation cure models for interval-censored data. Comput Stat Data Anal 93:257–269
Huang J (1996) Efficient estimation for the proportional hazards model with interval censoring. Ann Stat 24(2):540–568
Huang J, Rossini AJ (1997) Sieve estimation for the proportional-odds failure-time regression model with interval censoring. J Am Stat Assoc 92(439):960–967
Jewell NP, Laan MV (1995) Generalizations of current status data with applications. Lifetime Data Anal 1(1):101–109
Kim YJ, Jhun M (2008) Cure rate model with interval censored data. Stat Med 27(1):3–14
Li C, Taylor JMG, Sy JP (2001) Identifiability of cure models. Stat Prob Lett 54(4):389–395
Lin DY, Ying Z (1994) Semiparametric analysis of the additive risk model. Biometrika 81(1):61–71
Lin DY, Oakes D, Ying Z (1998) Additive hazards regression with current status data. Biometrika 85(2):289–298
Liu H, Shen Y (2009) A semiparametric regression cure model for interval-censored data. Publ Am Stat Assoc 104(487):1168–1178
Liu Y, Hu T, Sun J (2017) Regression analysis of current status data in the presence of a cured subgroup and dependent censoring. Lifetime Data Anal 23(4):626–650
Lorentz GG (1986) Bernstein polynomials. Chelsea Publishing Company, New York
Louis T (1982) Finding the observed information matrix when using the EM algorithm. J R Stat Soc B 44(2):226–233
Lu W (2010) Efficient estimation for an accelerated failure time model with a cure fraction. Stat Sin 20:661–674
Ma S (2010) Mixed case interval censored data with a cured subgroup. Stat Sin 20:1165–1181
Ma S (2011) Additive risk model for current status data with a cured subgroup. Ann Inst Stat Math 63(1):117–134
Mao M, Wang JL (2010) Semiparametric efficient estimation for a class of generalized proportional odds cure models. J Am Stat Assoc 105(489):302–311
Martinussen T, Scheike TH (2002) Efficient estimation in additive hazards regression with current status data. Biometrika 89(3):649–658
McMahan CS, Wang L, Tebbs JM (2013) Regression analysis for current status data using the EM algorithm. Stat Med 32(25):4452–4466
Murray RP, Anthonisen NR, Connett JE, Wise RA, Lindgren PG, Greene PG, Nides MA (1998) Effects of multiple attempts to quit smoking and relapses to smoking on pulmonary function. J Clin Epidemiol 51(12):1317–1326
Nelder JA, Mead R (1965) A simplex method for function minimization. Comput J 7(4):308–313
Osman M, Ghosh SK (2012) Nonparametric regression models for right-censored data using Bernstein polynomials. Comput Stat Data Anal 56(3):559–573
Peng Y, Dear KB (2000) A nonparametric mixture model for cure rate estimation. Biometrics 56(1):237–243
Pollard D (1984) Convergence of stochastic processes. Springer, New York
Pollard D (1990) Empirical processes: theory and applications. In: NSF-CBMS regional conference series in probability and statistics, pp 1–86. Institute of Mathematical Statistics and the American Statistical Association
Rossini AJ, Tsiatis AA (1996) A semiparametric proportional odds regression model for the analysis of current status data. J Am Stat Assoc 91(434):713–721
Shen X (1997) On methods of sieves and penalization. Ann Stat 25(6):2555–2591
Shen X, Wong WH (1994) Convergence rate of sieve estimates. Ann Stat 22(2):580–615
Shen Y, Cheng SC (1999) Confidence bands for cumulative incidence curves under the additive risk model. Biometrics 55(4):1093
Sun J (2006) The statistical analysis of interval-censored failure time data. Springer, New York
Sy JP, Taylor JM (2000) Estimation in a Cox proportional hazards cure model. Biometrics 56(1):227–236
Van der Vaart AW, Wellner JA (1996) Weak convergence and empirical processes. Springer, New York
Wang L, Sun J, Tong X (2010) Regression analysis of case II interval-censored failure time data with the additive hazards model. Stat Sin 20:1709–1723
Wang L, McMahan CS, Hudgens MG, Qureshi ZP (2016) A flexible, computationally efficient method for fitting the proportional hazards model to interval-censored data. Biometrics 71(1):222–231
Wu Y, Chambers CD, Xu R (2019) Semiparametric sieve maximum likelihood estimation under cure model with partly interval censored and left truncated data for application to spontaneous abortion. Lifetime Data Anal 25:507–528
Xue H, Lam KF, Li G (2004) Sieve maximum likelihood estimator for semiparametric regression models with current status data. J Am Stat Assoc 99(466):346–356
Yu B, Peng Y (2008) Mixture cure models for multivariate survival data. Comput Stat Data Anal 52(3):1524–1532
Zeng D, Cai J, Shen Y (2006a) Semiparametric additive risks model for interval-censored data. Stat Sin 16:287–302
Zeng D, Yin G, Ibrahim JG (2006b) Semiparametric transformation models for survival data with a cure fraction. J Am Stat Assoc 101(474):670–684
Zhang J, Peng Y (2009) Accelerated hazards mixture cure model. Lifetime Data Anal 15(4):455–467
Zhang Y, Hua L, Huang J (2010) A spline-based semiparametric maximum likelihood estimation method for the Cox model with interval-censored data. Scand J Stat 37(2):338–354
Zhou J, Zhang J, Lu W (2017) An expectation maximization algorithm for fitting the generalized odds-rate model to interval censored data. Stat Med 36(7):1157–1171
Acknowledgements
The authors would like to thank the Editor-in-Chief, the Associate Editor and two reviewers for their constructive comments and helpful suggestions that greatly improved the paper. Funding was provided by National Natural Science Foundation of China (Grant No. 11471065).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
In this appendix, we present the detailed proofs for Theorems 1–3, and the calculation of \(I(\widehat{\pmb {\theta }})\). Our proof relies heavily on some results in empirical processes. To facilitate our proof for the consistency of our estimators, we need the following lemma, which play an important roles in the proof of our Theorem 1. Lemma 1 establishes the covering number of size \(\epsilon \) needed to cover \(\mathcal {L}_1=\{ l(\pmb {\theta };\text{ O}):\pmb {\theta }\in \varvec{\Theta }_n\}\).
Whether a given class \(\mathcal {L}\) is a Glivenko–Cantelli (GC) or Donsker class depends on the size of the class. A relatively simple way to measure the size of a class \(\mathcal {L}\) is to use entropy numbers. The existing results of the known GC or Donsker class are mostly in the parameter or non-parametric framework, while in the semiparametric framework, the size of the class \(\mathcal {L}\) can be more clearly reflected by the entropy number. Therefore, the technical analysis on the entropy numbers is necessary.
Lemma 1
The covering number of the function class \(\mathcal {L}_1=\{ l(\pmb {\theta };\text{ O}):\pmb {\theta }\in \varvec{\Theta }_n\}\) satisfies
where the degree N of Bernstein polynomials satisfies \(N=o(n^\nu )\) with \(0<\nu <1\) and the size of the sieve space \(\varvec{\Theta }_n\) is controlled by \(M_n=O(n^a)\) with a constant \(a>0\).
Proof of Lemma 1By the Taylor series expansion, for any \(\pmb {\theta }_1=\big (\pmb {\alpha }_{1},\pmb {\beta }_{1},\Lambda _{1}(\cdot )\big ),\pmb {\theta }_2=\big (\pmb {\alpha }_{2},\pmb {\beta }_{2},\Lambda _{2}(\cdot )\big )\in \varvec{\Theta }_n\), there exists a large enough constant C such that
For any \(\Lambda _1(\cdot ),\Lambda _2(\cdot )\in \mathcal {M}_n,\) let \(\pmb {\gamma }_1=(\gamma _{0,1},\ldots ,\gamma _{N,1})^{\intercal }, \pmb {\gamma }_2=(\gamma _{0,2},\ldots ,\gamma _{N,2})^{\intercal }\) be their Bernstein polynomials coefficient vectors, respectively. Then, we have
Therefore one can write that
Let \(\mathcal {B}=\{(\pmb {\alpha }^{\intercal },\pmb {\beta }^{\intercal })^{\intercal } \in \mathbb {R}^{p+q}:\Vert \pmb {\alpha }\Vert +\Vert \pmb {\beta }\Vert \le M \}\) and \(\mathcal {C}=\{\pmb {\gamma }\in \mathbb {R}^{N+1}:\sum _{l=0}^N\mid \gamma _l\mid \le M_n \}.\) Combining Problem 18 in Pollard (1984),(p. 40), that is, tensor product of two \(\epsilon /2C\) balls in \(\mathcal {B}\) and \(\mathcal {C}\), respectively, is contained in a \(\epsilon \)-ball in \(\mathcal {L}_1\); tensor products of balls covering \(\mathcal {B}\) and balls covering \(\mathcal {C}\) produce sets covering the tensor of \(\mathcal {B}\) and \(\mathcal {C}\) of which \(\mathcal {L}_1\) is a subset; Hence the covering number of \(\mathcal {L}_1\) is controlled by the covering numbers of \(\mathcal {B}\) and \(\mathcal {C}\), we obtain that
Using Lemma 4.1 of Pollard (1990) that presents a method for finding the bounds for the packing numbers of a set and the bounds on the packing numbers grow geometrically, thus the packing numbers of \(\mathcal {B}\) and \(\mathcal {C}\) that defined in Pollard (1990),(p.10) satisfy
Next, by Lemma 9.2 in Györfi et al. (2002) shows that the \(L_{(p)}\) covering numbers of the size \(\epsilon \) are controlled by the \(L_{(p)}\) packing numbers of the size \(\epsilon \) where \(p\ge 1\), one can obtain that
Combining the above results, we have the conclusion that
\(\square \)
Proof of Theorem 1 By adopting the notations of Pollard (1984), we write
where \(E_0\) denotes the expectation with respect to \(\text{ O }\) under true values of parameters.
Proving for the consistency of our estimators requires the following steps.
-
(a)
: Calculate the covering number of the function class \(\mathcal {L}_1=\{ l(\pmb {\theta };\text{ O}):\pmb {\theta }\in \varvec{\Theta }_n\}\) by lemma 1.
-
(b)
: Prove uniform convergence, i.e. \(\sup _{\mathcal {L}_1}\big |P_nl-Pl\big | \rightarrow 0\) a.s.
-
(c)
: Prove \(d(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)\rightarrow 0\) a.s.
The function class \(\mathcal {L}_1=\{ l(\pmb {\theta };\text{ O}):\pmb {\theta }\in \varvec{\Theta }_n\}\) has an envelope G with \(Pl^2\le PG^2\le \delta ^2 \). Let \(\alpha _n=n^{-1/2+\phi _1}(\log n)^{1/2}\) with \(\frac{\nu }{2}<\phi _1<\frac{1}{2}\) such that \(\alpha _n\) is a non-increasing sequence of positive numbers. For any given \(\epsilon >0\), we choose \(\epsilon _n=\epsilon \delta ^2\alpha _n\). Then for any \(\pmb {\theta }\in \Theta _n\) and a sufficiently large n, we have
Let \(P_n^{o}\) denote the signed measure that places mass \(\pm n^{-1}\) at each of the observations \(\{O_1,\ldots ,O_n\}\), with the random ± signs being decided independently of the \(O_i\)’s. Applying the symmetrization inequality (Pollard (1984), II (30)) and Hoeffding’s inequality (Pollard (1984), II (31)), it follows that
where the maximum runs over all functions \(\{l_j\} \text { in } \mathcal {L}_1\). Using the law of total probability, we have
Note that \(N=o(n^\nu )\), and \(\nu /2<\phi _1\), which indicate \(N=o(n^{2\phi _1})\). Now we study the first term of the inequality (12),
where \(\tilde{C}\) is a constant. For the second term of the inequality (12), by Lemma 33 of Pollard (1984) it follows that
This result indicates that the second term converges to zero even faster than the first term. Therefore one can obtain that \(\sum _{n=1}^{\infty } P\big (\sup _{\mathcal {L}_1} |P_nl-Pl| > 8\epsilon _n\big ) < \infty \). By adopting the Borel–Contelli lemma, it is easy to obtain that
Note that \(P_nl(\pmb {\theta }_0;\text{ O}) \le P_nl(\widehat{\pmb {\theta }}_n;\text{ O})\), then we have
Therefore, we have the conclusion that
Considering the fact that the Kullback–Leibler information is greater than or equal to the square of the Hellinger metric (Xue et al. 2004), one can obtain that
where \(\check{\pmb {\theta }}\) is between \(\pmb {\theta }_0\) and \(\widehat{\pmb {\theta }}_n\), and the derivative of \(L(\pmb {\theta };\text{ O})\) with respect to \(\pmb {\theta }\) is \(\nabla _{\pmb {\theta }}L(\pmb {\theta };\text{ O})\). Note that \(\frac{\nabla _{\pmb {\theta }}L(\check{\pmb {\theta }};\text{ O})}{2\sqrt{L(\check{\pmb {\theta }};\text{ O})}}\) is not equal to zero and bounded. Therefore, \(d(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)\rightarrow 0\) almost surely. Note that, \(\parallel \widehat{\pmb {\alpha }}_n-\pmb {\alpha }_0\parallel \le d(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)\), \(\parallel \widehat{\pmb {\beta }}_n-\pmb {\beta }_0\parallel \le d(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)\) and \(\parallel \Lambda _{n}-\widehat{\Lambda }_{0}\parallel _2\le d(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)\). Then we have
\(\square \)
Proof of Theorem 2 ne can derive the convergence rate of \(\widehat{\pmb {\theta }}_n\) by verifying the conditions of Theorem 3.2.5 in Van der Vaart and Wellner (1996). First, by the relationship between the Hellinger distance and the Kullback–Leibler information in the proof of theorem 1, we obtain
Second, note from Theorem 1.6.2 of Lorentz (1986) and the conclusions of Osman and Ghosh (2012), there exists the Bernstein polynomials \(\Lambda _{0,n}(\cdot )\) such that \(\parallel \Lambda _0(\cdot ) - \Lambda _{0,n}(\cdot ) \parallel _{\infty } = O(N^{-r/2})\) with \(r\ge 1\). Thus we obtain \(d(\pmb {\theta }_0,\pmb {\theta }_{0,n}) = O(n^{-{r\nu }/2})\), where \(\pmb {\theta }_{0,n}=(\pmb {\alpha }_{0},\pmb {\beta }_{0},\Lambda _{0,n}(\cdot ))\).
Then, we further explore \(P_nl(\widehat{\pmb {\theta }}_n;\text{ O}) - P_nl(\pmb {\theta }_0;\text{ O})\). In the proof of consistency, we know that
We can construct a set of brackets for the class \(\mathcal {L}_2=\{l(\vartheta _{0},\Lambda (\cdot ))-l(\vartheta _{0},\Lambda _{0}(\cdot )): \Lambda (\cdot )\in M_{n}\ \text {and} \parallel \Lambda _0(\cdot ) - \Lambda _{0,n}(\cdot ) \parallel _{\infty } \le Cn^{-r\nu /2}\}\) with the \(\epsilon \)-bracketing number bounded by \((1/\epsilon )^{C(N+1)}\). This yields a finite value bracketing integral. Hence the class \(\mathcal {L}_2\) is P-Donsker. Using similar arguments as those in Zhang et al. (2010), we can obtain \(I_{1n}=o_p(n^{-r\nu })\) and \(I_{2n}\ge -O(n^{-r\nu })\). Thus, we have \(P_nl(\widehat{\pmb {\theta }}_n;\text{ O}) - P_nl(\pmb {\theta }_0;\text{ O})\ge -O_p(n^{-r\nu })=O_{p}(n^{-2\min (r\nu /2),(1-\nu )/2})\).
Let \(\mathcal {L}_2(\varsigma )=\big \{l(\pmb {\theta };\text{ O})-l(\pmb {\theta }_0;\text{ O}): \pmb {\theta }\in \varvec{\Theta }_n \text { and } d(\pmb {\theta },\pmb {\theta }_0)\le \varsigma \big \}\). Moreover, one can obtain \(P\big \{l(\pmb {\theta };\text{ O})-l(\pmb {\theta }_0;\text{ O})\big \}^2 \le Cd^2(\pmb {\theta },\pmb {\theta }_0)\le C\varsigma ^2\) for any \(l(\pmb {\theta };\text{ O})-l(\pmb {\theta }_0;\text{ O})\in \mathcal {L}_2(\varsigma )\). Note that \(\mathcal {L}_2(\varsigma )\) is uniformly bounded with conditions (C1)–(C3). Obeying the calculating results in Shen and Wong (1994),(p.597), we can establish that for \(0<\epsilon <\varsigma \), the bracketing entropy \(\log N_{[\,]}(\epsilon ,\mathcal {L}_2(\varsigma ),L_2(P))\) is bounded by \(C\tilde{N}\log {(\varsigma /\epsilon })\) with \(\tilde{N}=N+1\), where \(N_{[\,]}(\epsilon ,\mathcal {L}_2(\varsigma ),L_2(P))\) is the \(\epsilon \)-bracketing number of \(\mathcal {L}_2(\varsigma )\) presented in Definition 2.1.6 of Van der Vaart and Wellner (1996).
Therefore, according to Lemma 3.4.2 in Van der Vaart and Wellner (1996) that the continuity modulus of the empirical process \(\sqrt{n}(P_{n}-P)\) gives an upper bounded on the rate, we obtain that
where \(J_{[\,]}\{\varsigma ,\mathcal {L}_2(\varsigma ),L_2(P) \} = \int _0^{\varsigma }\bigl [ 1 +\log N_{[\,]}\{\epsilon ,\mathcal {L}_2(\varsigma ),L_2(P)\} \bigr ]^{1/2}d\epsilon \le C\tilde{N}^{1/2}\varsigma \). This result implies that the function \(\phi _n(\varsigma )\) of Theorem 3.2.5 in Van der Vaart and Wellner (1996) can be given by \(\phi _n(\varsigma )=\tilde{N}^{1/2}\varsigma +\tilde{N}/n^{1/2}\) and we know that \(\phi _{n}(\varsigma )/\varsigma \) is decreasing in \(\varsigma \). Note that
If \(r\nu /2 \le (1-\nu )/2\), then \(n^{r\nu }\phi _n(1/n^{{r\nu }/2})\le n^{1/2}\). Thus \(r_n\) is given by \(r_n=n^{\min \{r\nu /2,(1-\nu )/2\}}\), which leads to \(r_n^2\phi _n(1/r_n)\le n^{1/2}\).
Finally, Combining above results that satisfy the conditions of Theorem 3.2.5 in Van der Vaart and Wellner (1996). We have \(r_nd(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)=O_p(1)\); that is, \(d(\widehat{\pmb {\theta }}_n,\pmb {\theta }_0)=O_p(n^{-\min \{r\nu /2,(1-\nu )/2\}})\). The proof of Theorem 2 is completed.
Proof of Theorem 3 For any \(v^*\in \varvec{\Theta }_0\), by Theorem 1.6.2 in Lorentz (1986) and the conclusions of Osman and Ghosh (2012), there exists \(\pi _n v^*\in \varvec{\Theta }_n\) such that \(\parallel \pi _n v^*-v^*\parallel =O(n^{-\frac{r\nu }{2}})\). Note that \(\delta _n\parallel \pi _n v^*-v^*\parallel =o(n^{-1/2})\) with \(r>1\) and \(r\nu >1/2\). Let \(\varepsilon _{n}\) be any positive sequence with \(\varepsilon _{n}=o(n^{-1/2})\) and define \(\rho [\pmb {\theta }-\pmb {\theta }_0;\text{ O}]=l(\pmb {\theta };\text{ O})-l(\pmb {\theta }_0;\text{ O})-\dot{l}(\pmb {\theta }_0;\text{ O})[\pmb {\theta }-\pmb {\theta }_0]\). Then by the \(P\{\dot{l}(\widehat{\pmb {\theta }}_{0};\text{ O})[\pi _{n}v^{*}]\}=0\). One can obtain that
Next, we will study the asymptotic properties of \(I_1, I_2\) and \(I_3\).
For \(I_1\), by the Chebyshev’s inequality, \(P\dot{l}(\pmb {\theta }_0;\text{ O})[\pi _nv^*-v^*]=0\) and \(\parallel \pi _nv^*-v^*\parallel =o(1)\), we obtain
which indicates that \(P_n\dot{l}(\pmb {\theta }_0;\text{ O})[\pi _nv^*-v^*]=o_p(n^{-1/2})\). Thus, we have \(I_1=\varepsilon _{n}\times o_p(n^{-1/2})\).
For \(I_2\), by the mean value theorem, we have
where \(\check{\pmb {\theta }}\) is between \(\widehat{\pmb {\theta }}_n\) and \(\widehat{\pmb {\theta }}_n\pm \varepsilon _n\pi _nv^*\). Consider the function class \(\mathcal {L}_3=\{\dot{l}(\pmb {\theta };\text{ O})[\pi _nv^*] :\pmb {\theta }\in \varvec{\Theta }_n \text { and } \parallel \pmb {\theta }-\pmb {\theta }_0\parallel = O(\delta _n)\}\). For any \(\dot{l}(\pmb {\theta }_i;\text{ O})[\pi _nv^*]\in \mathcal {L}_3\ (i=1,2)\), we have \(\bigl |\dot{l}(\pmb {\theta }_1;\text{ O})[\pi _nv^*] - \dot{l}(\pmb {\theta }_2;\text{ O})[\pi _nv^*]\bigr |\le C\parallel \pmb {\theta }_1-\pmb {\theta }_2\parallel \). Thus it yields that
Similar to the proof of Lemma 1, one can obtain that \(N(\epsilon ,\mathcal {L}_3,L_2(Q)) \le (\frac{C\delta _n}{\epsilon })^{N+1}\). Then we have the finiteness of the entropy inequality, i.e. \(\int _0^{\infty }\sup _{Q}\sqrt{N(\epsilon ,\mathcal {L}_3,L_2(Q))}d\epsilon < \infty \) with \(\nu <1/2\) and \(r>1\). Note that \(\dot{l}(\pmb {\theta };\text{ O})[\pi _nv^*]\) is uniformly bounded under conditions (C1)–(C3). Hence \(\mathcal {L}_3\) is a Donsker class by Theorem 2.8.3 of Van der Vaart and Wellner (1996). Applying the relationship between Donsker and asymptotic equicontinuity given by Corollary 2.3.12 of Van der Vaart and Wellner (1996), one can obtain that
Therefore, we have \(I_2=\epsilon _n\times o_p(n^{-1/2})\).
For \(I_{3}\), note that \(P\big \{\ddot{l}(\pmb {\theta }_0;\text{ O})[\widehat{\pmb {\theta }}_n-\pmb {\theta }_0,\widehat{\pmb {\theta }}_n-\pmb {\theta }_0]\big \}=-P\big \{\dot{l}(\pmb {\theta }_0;\text{ O})[\widehat{\pmb {\theta }}_n-\pmb {\theta }_0]\dot{l}(\pmb {\theta }_0;\text{ O})[\widehat{\pmb {\theta }}_n-\pmb {\theta }_0]\big \}.\) For any \(\pmb {\theta }\in \big \{\pmb {\theta }:d(\pmb {\theta },\pmb {\theta }_0)=O(\delta _n)\big \}\), \(P\big \{\ddot{l}({\pmb {\theta }};\text{ O})[\pmb {\theta }-\pmb {\theta }_0,\pmb {\theta }-\pmb {\theta }_0] - \ddot{l}(\pmb {\theta }_0;\text{ O})[\pmb {\theta }-\pmb {\theta }_0,\pmb {\theta }-\pmb {\theta }_0]\big \} = O(\delta _n^3)\), \(\delta _n^3 = o(n^{-1})\) with \(2/3r<\nu <1/3\) and \(r>2\). Then we have
where \(\check{\pmb {\theta }}\) is between \(\widehat{\pmb {\theta }}_n\) and \(\pmb {\theta }_0\). By the facts \(\parallel \pi _nv^*\parallel ^2\rightarrow \parallel v^*\parallel ^2<\infty \), Cauchy-Schwarz inequality, and \(\delta _n\parallel \pi _n v^*-v^*\parallel =o(n^{-1/2})\), we have
Combining the above results, we can obtain
Note that \(P\dot{l}(\pmb {\theta }_0;\text{ O})[v^*]=0\) and \(Var(\dot{l}(\pmb {\theta }_0;\text{ O})[v^*]) = \Vert v^{*}\Vert ^2\). Therefore, by the Central Limits Theorem we obtain
in distribution. Note that \(G(\pmb {\theta })-G(\pmb {\theta }_0)=\dot{G}(\pmb {\theta }_0)[\pmb {\theta }-\pmb {\theta }_0]\). By the Riesz representation theorem, there exists \(v^{*}\in \mathcal {\bar{V}} \text { such that } \dot{G}(\pmb {\theta }_0)[v]=\langle v,v^*\rangle \) for any \(v\in \mathcal {\bar{V}}\) and \(\Vert v^*\Vert = \Vert \dot{G}(\pmb {\theta }_0)\Vert \). Then we have
in distribution, namely, \( \sqrt{n} \Bigl \{\text{ b}_{1}^{\intercal }(\widehat{\pmb {\alpha }}_{n}-\pmb {\alpha }_{0})+\text{ b}_{2}^{\intercal }(\widehat{\pmb {\beta }}_{n}-\pmb {\beta }_{0})+ \int _0^{\tau } b_3(t)\big (\widehat{\Lambda }_n(t)-\Lambda _0(t)\big )dt \Bigr \}\xrightarrow {L} N(0,\Vert \dot{G}(\pmb {\theta }_0)\Vert ^2)\). Adopting Theorem 4 in Shen (1997) or the conclusions of Bickel and Kwon (2001), we can establish the semiparametric efficiency of the estimators. The proof is completed.
The calculation of \(I(\widehat{\pmb {\theta }})\)
One can obtain \(Q(\widetilde{\pmb {\theta }}; \widehat{\pmb {\theta }})\) with respect to \(\widetilde{\pmb {\theta }}\). Then, the quantities of the first part in \(I(\widehat{\pmb {\theta }})\) are given by
The second part of the \(I(\widehat{\pmb {\theta }})\) derived from Eq. (6) is listed as follows
where
Denote \(\widehat{c}_{i}=1-\exp {(-\widehat{\lambda }_{i})}\), \(\widehat{d}_{i}=1-\exp {(-\widehat{\omega }_{i})}\), then we can obtain \(I(\widehat{\pmb {\theta }})\) by Eq. (11) and these closed forms make the estimation of variance-covariance matrix easy to be calculated. \(\square \)
Rights and permissions
About this article

Cite this article
Wang, X., Wang, Z. EM algorithm for the additive risk mixture cure model with interval-censored data. Lifetime Data Anal 27, 91–130 (2021). https://doi.org/10.1007/s10985-020-09507-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10985-020-09507-z
Keywords
- Interval-censored data
- Additive risk model
- Cure fraction
- Sieve maximum likelihood estimation
- EM algorithm