
Abstract
This paper considers the iterative solution of linear systems arising from discretization of the anisotropic radiative transfer equation with discontinuous elements on the sphere. In order to achieve robust convergence behavior in the discretization parameters and the physical parameters we develop preconditioned Richardson iterations in Hilbert spaces. We prove convergence of the resulting scheme. The preconditioner is constructed in two steps. The first step borrows ideas from matrix splittings and ensures mesh independence. The second step uses a subspace correction technique to reduce the influence of the optical parameters. The correction spaces are build from low-order spherical harmonics approximations generalizing well-known diffusion approximations. We discuss in detail the efficient implementation and application of the discrete operators. In particular, for the considered discontinuous spherical elements, the scattering operator becomes dense and we show that \(\mathcal {H}\)- or \(\mathcal {H}^2\)-matrix compression can be applied in a black-box fashion to obtain almost linear or linear complexity when applying the corresponding approximations. The effectiveness of the proposed method is shown in numerical examples.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Radiative transfer models describe the streaming, absorption, and scattering of radiation waves propagating through a turbid medium occupying a bounded convex domain \(R\subset \mathbb {R}^d\), and they arise in a variety of applications, e.g., neutron transport [11, 35], heat transfer [39], climate sciences [20], geosciences [38] or medical imaging and treatment [2, 4, 45]. The underlying physical model can be described by the anisotropic radiative transfer equation,
The specific intensity \(u=u(s,r)\) depends on the position \(r\in R\) and the direction of propagation described by a unit vector \(s\in S\), i.e., we assume a constant speed of propagation. The medium is characterized by the total attenuation coefficient \(\sigma _t=\sigma _a+\sigma _s\), where \(\sigma _a\) and \(\sigma _s\) denote the absorption and scattering rates, respectively. The scattering phase function k relates pre- and post-collisional directions, and we consider exemplary the Henyey-Greenstein phase function
with anisotropy factor g. For \(g=0\), we speak about isotropic scattering, and for g close to one, we say that the scattering is (highly) forward peaked. For simplicity, we assume \(0\le g<1\) in the following. The case \(-1<g\le 0\) is similar. Internal sources of radiation are modeled by the function \(q\). Introducing the outer unit normal vector field \(n(r)\) on \(\partial R\), the boundary condition is modeled by
In this paper we consider the iterative solution of the linear systems arising from the discretization of the anisotropic radiative transfer equations (1)–(3) by preconditioned Richardson iterations. We are particularly interested in robustly convergent methods for multiple physical regimes that, at the same time, can embody ballistic regimes \(\sigma _s\ll 1\) and diffusive regimes, i.e., \(\sigma _s\gg 1\) and \(\sigma _a>0\), and highly forward peaked scattering, as it occurs for example in medical imaging applications [22]. Due to the size of the arising systems of linear equations, their numerical solution is challenging, and a variety of methods were developed as briefly summarized next.
1.1 Related Work
Since for realistic problems analytical solutions are not available, numerical approximations are required. Common discretization methods can be classified into two main approaches based on their semidiscretization in \(s\). The spherical harmonics method [5, 19, 35] approximates the solution \(u\) by a truncated series of spherical harmonics, which allows for spectral convergence for smooth solutions. For non-smooth solutions, which is the generic situation, local approximations in \(s\) can be advantageous, which is achieved, e.g., by discrete ordinates methods [26, 35, 43, 44, 46], continuous Galerkin methods [7], the discontinuous Galerkin (DG) method [24, 32, 40], iteratively refined piecewise polynomial approximations [13], or hybrid methods [12, 30].
A common step in the solution of the linear systems resulting from local approximations in \(s\) is to split the discrete system into a transport part and a scattering part. While the inversion of transport is usually straight-forward, scattering introduces a dense coupling in \(s\). The corresponding Richardson iteration resulting from this splitting is called the source iteration [1, 37], and it converges linearly with a rate \(c=\Vert \sigma _s/\sigma _t\Vert _\infty \). For scattering dominated problems, such as the biomedical applications mentioned above, we have \(c\approx 1\) and the convergence of the source iteration becomes too slow for such applications. Acceleration of the source iteration can be achieved by preconditioning, which usually employs the diffusion approximation to (1)–(3) [1], and the resulting scheme is then called diffusion synthetic accelerated (DSA) source iteration [1]. Although this approach is well motivated by asymptotic analysis, it faces several issues, such as a proper generalization to multi-dimensional problems with anisotropy, strong variations in the optical parameters, or the use of unstructured and curved meshes, see [1].
Effective DSA schemes rely on consistent discretization of the corresponding diffusion approximation, see [40, 48] for isotropic scattering, and [41] for two-dimensional problems with anisotropic scattering. The latter employs a modified interior penalty DG discretization for the corresponding diffusion approximation, which has also been used in [47] where it is, however, found that their DSA scheme becomes less effective for highly heterogeneous optical parameters. A discrete analysis of DSA schemes for high-order DG discretizations on possibly curved meshes, which may complicate the inversion of the transport part, can be found in [28]. In the variational framework of [40] consistency is automatically achieved by subspace correction instead of finding a consistent discretization of the diffusion approximation. This variational treatment allowed to prove convergence of the corresponding iteration and numerical results showed robust contraction rates, even in multi-dimensional calculations with heterogeneous optical parameters.
It is the purpose of this paper to generalize the approach of [40] to the anisotropic scattering case, which requires non-trivial extensions as outlined in the next section.
1.2 Approach and Contribution
In this paper we focus on the construction of robustly and provably convergent efficient iterative schemes for the radiative transfer equation with anisotropic scattering. To describe our approach, let us introduce the linear system that we need to solve, which stems from a mixed finite element discretization of (1)–(3) using discontinuous polynomials on the sphere [17, 40], i.e.,
Here, the superscripts in the equation refer to even (‘\(+\)’) and odd (‘−’) parts from the underlying discretization. The matrices \(\mathbf {K}^{\!+}\) and \(\mathbf {K}^{\!-}\) discretize scattering, while \(\mathbf {R}\) incorporates boundary conditions, \(\mathbf {M}^{\!+}\) and \(\mathbf {M}^{\!-}\) are mass matrices related to \(\sigma _t\), and \(\mathbf {A}\) discretizes \(s\cdot \nabla _r\), and their assembly can be done with standard FEM codes. The even part solves the even-parity equations
i.e., the Schur complement of (4), with symmetric positive definite matrix \(\mathbf {E}=\mathbf {A}\!^{\intercal } (\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\mathbf {A}+\mathbf {M}^{\!+}+\mathbf {R}\) and source term \(\mathbf {q}=\mathbf {q}^{\!+}+\mathbf {A}\!^{\intercal } (\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\mathbf {q}^{\!-}\). Once the even part \(\mathbf {u}^{\!+}\) is known, the odd part \(\mathbf {u}^{\!-}\) can be obtained from (4). The preconditioned Richardson iteration considered in this article then reads
with preconditioners \(\mathbf {P}_1\) and \(\mathbf {P}_2\). Comparing to standard DSA source iterations, \(\mathbf {P}_1\) corresponds to a transport sweep, and a typical choice that renders the convergence behavior of (6) independent of the discretization parameters is \(\mathbf {P}_1=\mathbf {E}^{-1}\). More precisely, we show that this choice of \(\mathbf {P}_1\) yields a contraction rate of \(c=\Vert \sigma _s/\sigma _t\Vert _\infty \). The second preconditioner \(\mathbf {P}_2\) aims to improve the convergence behavior in diffusive regimes, \(c\approx 1\). In the spirit of [40], we construct \(\mathbf {P}_2\) via Galerkin projection onto suitable subspaces, which guarantees monotone convergence of (6). The construction of suitable subspaces that give good error reduction is motivated by the observation that error modes that are hardly damped by \(\mathbf {I}-\mathbf {P}_1(\mathbf {E}-\mathbf {K}^{\!+})\) can be approximated well by spherical harmonics of low degree, cf. Sect. 3.4. While for the isotropic case \(g=0\), spherical harmonics of degree zero, i.e., constants in angle, are sufficient for obtaining good convergence rates, we show that higher order spherical harmonics should be used for anisotropic scattering. To preserve consistency, we replace higher order spherical harmonics, which are the eigenfunctions of the integral operator in (1), by discrete eigenfunctions of \(\mathbf {K}^{\!+}\).
The efficiency of the proposed iterative scheme hinges on the ability to efficiently implement and apply the arising operators. While for \(g=0\) it holds \(K^{-} = 0, K^{+}\) can be realized via fast Fourier transformation, and \(\mathbf {E}\) is block-diagonal with sparse blocks allowing for an efficient application of \(\mathbf {E}\), the situation is more involved for \(g>0\). We show that \(\mathbf {K}^{\!+}\) and \(\mathbf {K}^{\!-}\) can be applied efficiently by exploiting their Kronecker structure between a sparse matrix and a dense matrix, which turns out to be efficiently applicable by using \(\mathcal {H}\)- or \(\mathcal {H}^2\)-matrix approximations independently of g. As we show, the practical implementation of \(\mathcal {H}\)- or \(\mathcal {H}^2\)-matrices can be done by standard libraries, such as H2LIB [9] or BEMBEL [15]. This in combination with standard FEM assembly routines for the other matrices ensures robustness and maintainability of the code.
Since \(\mathbf {A}\), \(\mathbf {M}^{\!+}\), and \(\mathbf {R}\) are sparse and block diagonal, the main bottleneck in the application of \(\mathbf {E}\) is the application of \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\). Based on the tensor structure of \(\mathbf {K}^{\!-}\) and its spectral properties, we derive a preconditioner such that \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\) can be applied robustly in g in only a few iterations. Thus, we can apply \(\mathbf {E}\) in almost linear complexity. Efficiency of (6) is further increased by realizing \(\mathbf {P}_1=\mathbf {E}^{-1}\approx \mathbf {P}_1^l\) inexactly by employing a small, fixed number of l steps of an inner iterative scheme. We show that the condition number of \(\mathbf {P}_1^l\mathbf {E}\) is \(O((1-(cg)^{l})^{-1})\), which is robust in the limit \(c\rightarrow 1\). In contrast, we note that the condition number of \(\mathbf {P}_1^l(\mathbf {E}-\mathbf {K}^{\!+})\) is \(O((1-c)^{-1})\), i.e., a straight-forward iterative solution of the even-parity equations using a black-box solver, such as preconditioned conjugate gradients, is in general not robust for \(c\rightarrow 1\).
Summarizing, each step of our iteration (6) can be performed very efficiently. The iteration is provably convergent and numerical results show that the contraction rates are robust for \(c\rightarrow 1\). The result is a highly efficient numerical scheme for the solution of the even parity equations (5) and, thus, also for the overall system (4).
1.3 Outline
The structure of the paper is as follows: In Sect. 2 we recall the variational formulation that builds the basis of our numerical scheme and establish some spectral equivalences for the scattering operator, which are key to the construction of our preconditioners. In Sect. 3 we present iterative schemes for the even-parity equations of radiative transfer in Hilbert spaces, which, after discretization in Sect. 4, result in the schemes described in Sect. 1.2. Details of the implementation and its complexity are described in Sect. 5. Numerical studies of the performance of the proposed methods are presented in Sect. 7. The paper closes with a discussion in Sect. 8.
2 Preliminaries
In the following we recall the relevant functional analytic framework, state the corresponding variational formulation of the radiative transfer problem (1)–(3) and provide some analytical results about the spectrum of the scattering operator, which we will later use for the construction of our preconditioners.
2.1 Function Spaces
By \(L^2(M)\) we denote the usual Hilbert space of square integrable functions on a manifold M, and denote \((u,w)_M=\int _{M} uw\, dM\) the corresponding inner product and \(\Vert u\Vert _{L^2(M)}\) the induced norm. For \(M=D=S\times R\), we write \(\mathbb {V}=L^2(D)\) and \((u,w)=(u,w)_D\). Functions \(w\in \mathbb {V}\) with weak derivative \(s \cdot \nabla _rw\in \mathbb {V}\) have a well-defined trace [36]. We restrict the natural trace space [36], and consider the weighted Hilbert space \(L^2(\partial D_\pm ;|s \cdot n|)\) of measurable functions w on
with \(|s \cdot n|^{1/2} w\in L^2(\partial D_\pm )\). For the weak formulation of (1)–(3) we use the Hilbert space
with corresponding norm \(\Vert w\Vert _\mathbb {W}^2=\Vert s \cdot \nabla _rw\Vert _{L^2(D)}^2+\Vert w\Vert _{L^2(D)}^2+\Vert w\Vert _{L^2(\partial D_-;|s \cdot n|)}^2\).
2.2 Assumptions on the Optical Parameters and Data
The data terms are assumed to satisfy \(q \in L^2(D)\) and \(f\in L^2(\partial D_-;|s \cdot n|)\). Absorption and scattering rates are non-negative and essentially bounded functions \(\sigma _a,\sigma _s\in L^\infty (R)\). We assume that the medium occupied by R is absorbing, i.e., that there exists a constant \(\gamma >0\) such that \(\sigma _a(r)\ge \gamma \) for a.e. \(r\in R\). Thus, the ratio between the scattering rate and the total attenuation rate \(\sigma _t=\sigma _a+\sigma _s\) is strictly less than one, \(c=\Vert \sigma _s/\sigma _t\Vert _\infty <1\).
2.3 Even–Odd Splitting
The space \(\mathbb {V}=\mathbb {V}^+\oplus \mathbb {V}^-\) allows for an orthogonal decomposition into even and odd functions of the variable \(s\in S\). The even part \(u^{\!+}\) and odd part \(u^{\!-}\) of a function \(u\in \mathbb {V}\) is defined a.e. by
Similarly, we denote by \(\mathbb {W}^{\pm }\) the corresponding subspaces of functions \(u\in \mathbb {W}\) with \(u\in \mathbb {V}^\pm \).
2.4 Operator Formulation of the Radiative Transfer Equation
The weak formulation of (1)–(3) presented in [17] can be stated concisely using suitable operators and we refer to [17] for proofs of the corresponding mapping properties. Let \(u^{\!+},w^+\in \mathbb {W}^+\) and \(u^{\!-}\in \mathbb {V}^-\). The transport operator \(\mathcal {A}:\mathbb {W}^+\rightarrow \mathbb {V}^-\) is defined by
Identifying the dual \(\mathbb {V}'\) of \(\mathbb {V}\) with \(\mathbb {V}\), the dual transport operator \(\mathcal {A}':\mathbb {V}^-\rightarrow (\mathbb {W}^+)'\) is defined by
Boundary terms are handled by the operator \(\mathcal {R}:\mathbb {W}^+\rightarrow (\mathbb {W}^+)'\) defined by
Scattering is described by the operator \(\mathcal {S}:L^2(S)\rightarrow L^2(S)\) defined by
where k is the phase function defined in (2). In slight abuse of notation, we also denote the trivial extension of \(\mathcal {S}\) to an operator \(L^2(D)\rightarrow L^2(D)\) by \(\mathcal {S}\). We recall that \(\mathcal {S}\) maps even to even and odd to odd functions [17, Lemma 2.6], and so does \(\mathcal {K}:\mathbb {V}\rightarrow \mathbb {V}\) defined by
We denote by \(\mathcal {K}\) also its restrictions to \(\mathbb {V}^\pm \) and \(\mathbb {W}^+\), respectively. The spherical harmonics \(\{H^l_m: l\in \mathbb {N}_0, -l\le m\le l\}\) form a complete orthogonal system for \(L^2(S)\), and we assume the normalization \(\Vert H^l_m\Vert _{L^2(S)}=1\). Furthermore, \(H^{l}_m\) is an eigenfunction of \(\mathcal {S}\) with eigenvalue \(g^l\), i.e.,
and \(H^l_m\in \mathbb {V}^+\) if l is an even number and \(H^l_m\in \mathbb {V}^-\) if l is an odd number. Attenuation is described by the multiplication operator \(\mathcal {M}:\mathbb {V}\rightarrow \mathbb {V}\) defined by
Introducing the functionals \(\ell ^+ \in (\mathbb {W}^+)'\) and \(\ell ^-\in (\mathbb {V}^-)'\) given by
the operator formulation of the radiative transfer equation (1)–(3) is [17]: Find \((u^{\!+},u^{\!-})\in \mathbb {W}^+\times \mathbb {V}^-\) such that
2.5 Well-Posedness
In the situation of Sect. 2.2, there exists a unique solution \((u^{\!+},u^{\!-})\in \mathbb {W}^+\times \mathbb {V}^-\) of (8) and (9) satisfying
with a constant C depending only on \(\gamma \) and \(\Vert \sigma _t\Vert _\infty \) [17]. Notice that this well-posedness result remains true even if \(\sigma _a\) and \(\sigma _s\) are allowed to vanish [18]. As shown in [17, Theorem 4.1] it holds that \(u^{\!-}\in \mathbb {W}^-\) and \(u^{\!+}+u^{\!-}\in \mathbb {W}\) satisfies (1) a.e. in D and (3) holds in \(L^2(\partial D_-;|s \cdot n|)\).
2.6 Even-Parity Formulation
As in [17], it follows from (7) that
where we write \(\Vert w\Vert _{\mathcal {Q}}^2=(\mathcal {Q}w,w)\) for any positive operator \(\mathcal {Q}\). Thus, \(\mathcal {M}-\mathcal {K}:\mathbb {V}^-\rightarrow \mathbb {V}^-\) is boundedly invertible, and, by (9),
Using (11) in (8) and introducing
and
the even-parity formulation of the radiative transfer equation is: Find \(u^{\!+}\in \mathbb {W}^+\) such that
As shown in [17], the even-parity formulation is a coercive, symmetric problem, which is well-posed by the Lax-Milgram lemma. Solving (12) for \(u^{\!+}\in \mathbb {W}^+\), we can retrieve \(u^{\!-}\in \mathbb {V}^-\) by (11). In turn, \((u^{\!+},u^{\!-})\in \mathbb {W}^+\times \mathbb {V}^-\) solves (8)–(9).
2.7 Preconditioning of \(\mathcal {M}-\mathcal {K}\)
We generalize the inequalities (10) to obtain spectrally equivalent approximations to \(\mathcal {M}-\mathcal {K}\). Since \(\mathcal {K}=\sigma _s\mathcal {S}\), we can construct approximations to \(\mathcal {K}\) by approximating \(\mathcal {S}\). To do so let us define for \(N\in \mathbb {N}\) and \(v\in \mathbb {V}\)
Notice that the summation is only over even integers \(0\le l\le N\) if \(v\in \mathbb {V}^+\) and only over odd ones if \(v\in \mathbb {V}^-\). The approximation of \(\mathcal {K}\) is then defined by \(\mathcal {K}_N=\sigma _s\mathcal {S}_N\).
Lemma 1
The operator \(\mathcal {M}-\mathcal {K}_N\) is spectrally equivalent to \(\mathcal {M}-\mathcal {K}\), that is
for all \(v\in \mathbb {V}\), with \(c=\Vert \sigma _s/\sigma _t\Vert _\infty \). In particular, \(\mathcal {M}-\mathcal {K}_N\) is invertible.
Proof
We use that \(\{H^m_l\}\) is a complete orthonormal system of \(L^2(S)\). Hence, any \(v\in \mathbb {V}=L^2(S)\otimes L^2(R)\) has the expansion
with \(v^l_m\in L^2(R)\) and \(\Vert v\Vert _{\mathbb {V}}^2=\sum _{l=0}^\infty \sum _{m=-l}^l \Vert v^l_m\Vert ^2_{L^2(R)}<\infty \), and
Using \(c=\Vert \sigma _s/\sigma _t\Vert _\infty \) it follows that
The inequalities in the statement then follow from
while invertibility follows from [17, Lemma 2.14].
3 Iteration for the Even-Parity Formulation
We generalize the Richardson iteration of [40] for the radiative transfer equation with isotropic scattering to the anisotropic case and equip the iteration process with a suitable preconditioner, which we will investigate later. We restrict ourselves to a presentation suitable for the error analysis and postpone the linear algebra setting and the discussion of its efficient realization to Sect. 5.
3.1 Derivation of the Scheme
We consider the solution of (12) along the following two steps:
Step (i) Given \(u^{\!+}_n\in \mathbb {W}^+\) and a symmetric and positive definite operator \(\mathcal {P}_1:(\mathbb {W}^+)'\rightarrow \mathbb {W}^+\), we compute
Step (ii) Compute a subspace correction to \(u^{\!+}_{n+1/2}\) based on the observation that the error \(e^+_{n+1/2}=u^{\!+}-u^{\!+}_{n+1/2}\) satisfies
Solving (16) is as difficult as solving the original problem. Let \(\mathbb {W}_N^+\subset \mathbb {W}^+\) be closed, and consider the Galerkin projection \(\mathcal {P}_G:\mathbb {W}^+\rightarrow \mathbb {W}_N^+\) onto \(\mathbb {W}_N^+\) defined by
Using (16), the correction \(u^{\!+}_{c,n}=\mathcal {P}_G e^+_{n+1/2}\), is then characterized as the solution to
where the right-hand side involves available data only. The update is performed via
3.2 Error Analysis
Since \(\mathcal {P}_G\) is non-expansive in the norm induced by \(\mathcal {E}-\mathcal {K}\), the error analysis for the overall iteration (15) and (19) relies on the spectral properties of \(\mathcal {P}_1\). Therefore, the following theoretical investigations consider the generalized eigenvalue problem
The following well-known lemma asserts that the half-step (15) yields a contraction if an appropriate preconditioner \(\mathcal {P}_1\) is chosen. We provide a proof for later reference.
Lemma 2
Let \(0<\beta \le 1\) and assume that the eigenvalues \(\lambda \) of (20) satisfy \(\beta \le \lambda \le 1\). Then, for any \(u^{\!+}_n\in \mathbb {W}^+\), \(u^{\!+}_{n+1/2}\) defined via (15) satisfies
Proof
Assume that \(\{(w_k,\lambda _k)\}_{k\ge 0}\) is the eigensystem of the generalized eigenvalue problem (20). For any \(u^{\!+}_n\), the error \(e^+_n=u^{\!+}-u^{\!+}_n\) satisfies
Using the expansion \(e^+_n=\sum _{k=0}^\infty a_k w_k\), we compute \(\Vert e^+_n\Vert ^2_{\mathcal {E}-\mathcal {K}} = \sum _{k=0}^\infty a_k^2 \lambda _k\). Using (21), we thus obtain \(e^+_{n+1/2} = \sum _{k=0}^\infty (1-\lambda _k) a_k w_k\), and hence
Since \(0<\beta \le \lambda _k\le 1\) by assumption, the assertion follows.
The next statement asserts that the iterative scheme defined by (19) converges linearly to the even part of the solution of the radiative transfer equation. It is a direct consequence of Lemma 2 and the observation that \(e_{n+1}^+=(\mathcal {I}-\mathcal {P}_G)e_{n+1/2}^+\) satisfies
Lemma 3
Let \(\mathbb {W}_N^+\subset \mathbb {W}^+\) be closed, and assume that the eigenvalues \(\lambda \) of (20) satisfy \(\beta \le \lambda \le 1\) for some \(0<\beta \le 1\). Then, for any \(u^{\!+}_0\in \mathbb {W}^+\), the sequence \(\{u^{\!+}_n\}\) defined in (15) and (19) converges linearly to the solution \(u^{\!+}\) of (12), i.e.,
In view of the previous lemma fast convergence \(u^{\!+}_n\rightarrow u^{\!+}\) can be obtained by ensuring that \(\beta \) is close to one or by making the best-approximation error in (22) small. These two possibilities are discussed in the remainder of this section in more detail.
3.3 Generic Preconditioners
The next result builds the basis for the preconditioner we will use later.
Lemma 4
Let \(\mathcal {P}_1\) be defined either by
-
(i)
\(\mathcal {P}_1^{-1}=\mathcal {E}\) or
-
(ii)
\(\mathcal {P}_1^{-1}=\mathcal {E}_0=(1-cg)^{-1} \mathcal {A}'\mathcal {M}^{-1}\mathcal {A}+ \mathcal {M}+ \mathcal {R}.\)
Then \(\mathcal {P}_1\) is spectrally equivalent to \(\mathcal {E}-\mathcal {K}\), i.e.,
for all \(w^+\in \mathbb {W}^+\). It holds \(1-\beta =c\) in Lemma 3 in both cases.
Proof
Since \(\mathcal {A}w^+\in \mathbb {V}^-\), the result is a direct consequence of Lemma 1.
Remark 1
We can further generalize the choices for \(\mathcal {P}_1^{-1}\) by choosing \(N^+\ge -1\), \(N^-\ge 0\), and \(\gamma _{N^-}=1/(1-cg^{N^-+1})\). Then
and \(\mathcal {E}-\mathcal {K}\) are spectrally equivalent, i.e.,
for all \(w^+\in \mathbb {W}^+\). In particular, \(1-\beta =cg^{\min (N^-,N^+)+1}\) in Lemma 3.
Remark 2
For isotropic scattering \(g=0\), we have that \(\mathcal {E}=\mathcal {E}_0\). Thus, both choices in Lemma 4 can be understood as generalizations of the iteration considered in [40].
The preconditioners in Remark 1 yield arbitrarily small contraction rates for sufficiently large \(N^+\) and \(N^-\). However, the efficient implementation of such a preconditioner seems to be rather challenging. Therefore, we focus on the preconditioners defined in Lemma 4 in the following. Since these choices for \(\mathcal {P}_1\) yield slow convergence for \(c\approx 1\), we need to construct \(\mathbb {W}_N^+\) properly. This construction is motivated next, see Sect. 5.4 for a precise definition.
3.4 A Motivation for Constructing Effective Subspaces
From the proof of Lemma 2, one sees that error modes associated to small eigenvalues \(\lambda \) of (20) converge slowly. Hence, in order to regain fast convergence, such modes should be approximated well by functions in \(\mathbb {W}_N^+\), see (22). Next, we give a heuristic motivation that such slowly convergent modes might be approximated well by low-order spherical harmonics.
Since we use \(\mathcal {P}_1^{-1}\approx \mathcal {E}\) below, let us fix \(\mathcal {P}_1^{-1}=\mathcal {E}\) in this subsection. Furthermore, let w be a slowly damped mode, i.e., w satisfies (20) with \(\lambda \) such that \(\lambda \approx 1-c \approx 0\). Observe that w also satisfies \(\mathcal {K}w = \delta \mathcal {E}w\) with \(\delta =1-\lambda \approx c \approx 1\), and \(\delta \le c\) by Lemma 4(i). Let us expand the angular part of w into spherical harmonics, cf. Sect. 2.4,
where \(w^l_m=0\) if l is odd. As in the proof of Lemma 1, we obtain
Since \(\sigma _s\le \sigma _t\), orthogonality of the spherical harmonics implies
Neglecting the contributions from \(\mathcal {R}\) and \(s \cdot \nabla _r\), we see that
Since \(\delta \approx c\approx 1\) by assumption and \(g<1\), (24) can hold true only if w can be approximated well by spherical harmonics of degree less than or equal to N for some moderate integer N.
To convince the reader that this is likely to be true, we consider in the following the case \(g=0\) and remark that the overall behaviour does not change too much when varying g. If \(c=\delta \), then (24) implies that \(w_m^l=0\) for all \(l>0\). If \(\delta <c\), then (24) is equivalent to
Therefore, using orthogonality of the spherical harmonics once more, we obtain
Rearranging terms yields the estimate
Since, by assumption, \(\delta \approx c\), we conclude that w can be approximated well by \(w_0^0 H_0^0\). Note that this statement quantifies approximation in terms of the \(L^2\)-norm. However, using recurrence relations of spherical harmonics to incorporate the terms \(\langle \mathcal {R}w,w\rangle +\Vert s \cdot \nabla _rw\Vert ^2_{(\mathcal {M}-\mathcal {K})^{-1}}\) into (24), suggests that a similar statement also holds for the \(\mathcal {E}-\mathcal {K}\)-norm. A full analysis of this statement seems out of the scope of this paper, and we postpone it to future research. We conclude that effective subspaces \(\mathbb {W}_N^+\) consist of linear combinations of low-order spherical harmonics, and we employ this observation in our numerical realization.
4 Galerkin Approximation
The iterative scheme of the previous section has been formulated for infinite-dimensional function spaces \(\mathbb {W}^+\) and \(\mathbb {W}_N^+\subset \mathbb {W}^+\). For the practical implementation we recall the approximation spaces described in [17] and [40, Section 6.3]. Let \(\mathcal {T}_h^R\) and \(\mathcal {T}_h^S\) denote shape regular triangulations of R and S, respectively. For simplicity we assume the triangulations to be quasi-uniform. To properly define even and odd functions associated with the triangulations, we further require that \(-K_S\in \mathcal {T}_h^S\) for each spherical element \(K_S\in \mathcal {T}_h^S\). The latter requirement can be ensured by starting with a triangulation of a half-sphere and reflection. Let \(\mathbb {X}_h^+=\mathbb {P}_1^c(\mathcal {T}_h^R)\) denote the vector space of continuous, piecewise linear functions subordinate to the triangulation \(\mathcal {T}_h^R\) with basis \(\{\varphi _i\}\) and dimension \(n_R^+\), and let \(\mathbb {X}_h^-=\mathbb {P}_0(\mathcal {T}_h^R)\) denote the vector space of piecewise constant functions subordinate to \(\mathcal {T}_h^R\) with basis \(\{\chi _j\}\) and dimension \(n_R^-\). Similarly, we denote by \(\mathbb {S}_h^+=\mathbb {P}_0(\mathcal {T}_h^S)\cap L^2(S)^+\) and \(\mathbb {S}_h^-=\mathbb {P}_1(\mathcal {T}_h^S)\cap L^2(S)^-\) the vector spaces of even, piecewise constant and odd, piecewise linear functions subordinate to the triangulation \(\mathcal {T}_h^S\), respectively. We can construct a basis \(\{\mu _k^+\}\) for \(\mathbb {S}_h^+\) by choosing \(n_S^+\) many triangles with midpoints in a given half-sphere, and define the functions \(\mu _k^+\) to be the indicator functions of these triangles. For any other point \(s\in S\), we find \(K_S\in \mathcal {T}_h^S\) with midpoint in the given half-sphere such that \(-s\in K_S\) and we define \(\mu _k^+(s)=\mu _k^+(-s)\). A similar construction leads to a basis \(\{\psi _l^-\}\) of \(\mathbb {S}_h^-\). The conforming approximation spaces are then defined through tensor product constructions, \(\mathbb {W}_h^+=\mathbb {S}_h^+\otimes \mathbb {X}_h^+\), \(\mathbb {V}_h^-=\mathbb {S}_h^-\otimes \mathbb {X}_h^-\). Thus, for some coefficient matrices \(\big [\mathbf {U}^{\!+}_{i,k}\big ]\in \mathbb {R}^{n_R^+\times n_S^+}\) and \(\big [\mathbf {U}^{\!-}_{j,l}\big ]\in \mathbb {R}^{n_R^-\times n_S^-}\), any \(u^{\!+}_h\in \mathbb {W}_h^+\) and \(u^{\!-}_h\in \mathbb {V}_h^-\) can be expanded as
The Galerkin approximation of (8)–(9) computes \((u^{\!+}_h,u^{\!-}_h)\in \mathbb {W}_h^+\times \mathbb {V}_h^-\) such that
The discrete mixed system (26)–(27) can be solved uniquely [17]. Denoting \(\mathbf {u}^\pm ={\text {vec}}(\mathbf {U}^\pm )\) the concatenation of the columns of the matrices \(\mathbf {U}^\pm \) into a vector, the mixed system (26)–(27) can be written as the following linear system
The matrices in the system are given by
where we denote by Gothic letters the matrices arising from the discretization on R and by Sans Serif letters matrices arising from the discretization on S, i.e.,
The matrices \(\varvec{\mathfrak {M}}\!^{-}_s\) and \(\varvec{\mathfrak {M}}\!^{+}_s\) are defined accordingly. By \(\varvec{\mathsf {M}}\!^{+}\) and \(\varvec{\mathsf {M}}\!^{-}\) we denote the Gramian matrices in \(L^2(S)\). We readily remark that all of these matrices are sparse, except for \(\varvec{\mathsf {S}}\!^{+}\) and \(\varvec{\mathsf {S}}\!^{-}\), which are dense. \(\varvec{\mathsf {M}}\!^{+}\) and \(\varvec{\mathsf {M}}\!^{-}\) are diagonal and \(3\times 3\) block diagonal, respectively. Moreover, we note that \(\varvec{\mathfrak {M}}\!^{-}_t\) is a diagonal matrix.
To conclude this section let us remark that taking the Schur complement of (28) finally yields the matrix counterpart of the even-parity system (12), i.e.,
with \(\mathbf {E}=\mathbf {A}\!^{\intercal }(\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\mathbf {A}+\mathbf {M}^{\!+}+\mathbf {R}\) and \(\mathbf {q}=\mathbf {q}^{\!+}+\mathbf {A}\!^{\intercal } (\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\mathbf {q}^{\!-}\).
5 Discrete Preconditioned Richardson Iteration
After discretization, the iteration presented in Sect. 3 becomes
The preconditioner \(\mathbf {P}_1\) is directly related to \(\mathcal {P}_1\) in (15). By denoting the coordinate vectors of the basis functions of the subspace \(\mathbb {W}^+_{h,N}\subset \mathbb {W}^+_h\) by \(\mathbf {W}\), the matrix representation of the overall preconditioner is
Denoting \(\mathbf {P}_G=\mathbf {W}\big (\mathbf {W}\!^{\intercal }(\mathbf {E}-\mathbf {K}^{\!+})\mathbf {W}\big )^{-1}\mathbf {W}\!^{\intercal }(\mathbf {E}-\mathbf {K}^{\!+})\) the matrix representation of the Galerkin projection \(\mathcal {P}_G\) defined in (17), the iteration matrix admits the factorization
The discrete analog of Lemma 3 implies that the sequence \(\{\mathbf {u}^{\!+}_n\}\) generated by (33) converges for any initial choice \(\mathbf {u}^{\!+}_0\) to the solution \(\mathbf {u}^{\!+}\) of (32). More precisely, by choosing \(\mathbf {P}_1\) according to Lemma 4, there holds
where \(0\le \eta \le c<1\) is defined as
with supremum taken over all \(\mathbf {v}^+\in \mathbb {R}^{n_S^+ n_R^+}\) satisfying \(\Vert \mathbf {v}^+\Vert _{\mathbf {E}-\mathbf {K}^{\!+}}=1\). The realization of (33) relies on the efficient application of \(\mathbf {E}\), \(\mathbf {K}^{\!+}\), \(\mathbf {P}_1\) and \(\mathbf {P}_2\) discussed next.
5.1 Application of \(\mathbf {E}\)
In view of (30) and (31) it is clear that \(\mathbf {A}\), \(\mathbf {M}^{\!+}\), and \(\mathbf {M}^{\!-}\) can be stored and applied efficiently by using their tensor product structure, sparsity, and the characterization
where \(\mathbf {C}\in \mathbb {R}^{m\times n}\), \(\mathbf {X}\in \mathbb {R}^{n\times p}\), \(\mathbf {B}\in \mathbb {R}^{q\times p}\), \(\mathbf {D}\in \mathbb {R}^{m\times q}\). The boundary matrix \(\mathbf {R}\) consists of sparse diagonal blocks, and can thus also be applied efficiently, see Sect. 6 for details. The remaining operation required for the application of \(\mathbf {E}\) as given in (32) is the application of \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\), which deserves some discussion. Since \(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}\) has a condition number of \((1-cg)^{-1}\) due to Lemma 1, a straightforward implementation with the conjugate gradient method may be inefficient for \(cg\approx 1\). To mitigate the influence of cg, we can use Lemma 1 once more and obtain preconditioners derived from \(\mathcal {M}-\mathcal {K}_N\), which lead to bounds on the condition number by \((1-(cg)^{N+2})^{-1}\) for odd N. In what follows, we comment on the practical realization of such preconditioners and their numerical construction. As we will verify in the numerical examples, these preconditioners allow the application of \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\) in only a few iterations even for g close to 1.
After discretization, the continuous eigenvalue problem (7) for the scattering operator becomes the generalized eigenvalue problem
Since \(\varvec{\mathsf {S}}\!^{-}\) and \(\varvec{\mathsf {M}}\!^{-}\) are symmetric and positive, the eigenvalues satisfy \(0\le \lambda _l\le g\), and we assume that they are ordered non-increasingly. The eigenvectors \(\varvec{\mathsf {W}}\!^{-}\) form an orthonormal basis \((\varvec{\mathsf {W}}\!^{-})\!^{\intercal }\varvec{\mathsf {M}}\!^{-}\varvec{\mathsf {W}}\!^{-}=\varvec{\mathsf {I}}\!^{-}\). Truncation of the eigen decomposition at index \(d_N=(N+1)(N+2)/2\), N odd, which is the number of odd spherical harmonics of order less than or equal to N, yields the approximation
The discrete version of \(\mathcal {M}-\mathcal {K}_N\) then reads \(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N\), with \(\mathbf {K}^{\!-}_N=\varvec{\mathsf {S}}\!^{-}_N\otimes \varvec{\mathfrak {M}}\!^{-}_s\). An explicit representation of its inverse is given by the following lemma. Its essential idea is to use an orthogonal decomposition of \(\mathbb {V}_h^-\) induced by the eigendecomposition of \(\varvec{\mathsf {S}}\!^{-}\), and to employ the diagonal representation of \(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N\) in the angular eigenbasis.
Lemma 5
Let \(\mathbf {b}\in \mathbb {R}^{n_S^-n_R^-}\). Then \(\mathbf {x}=(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N)^{-1}\mathbf {b}\) is given by
where \(\varvec{\mathfrak {I}}\!^{-}\) and \(\varvec{\mathsf {I}}\!^{-}\) denote the identity matrices of dimension \(n_R^-\) and \(d_N\), respectively.
Proof
We first decompose \(\mathbf {x}\) as follows
Applying \((\varvec{\mathsf {W}}\!^{-}_N)^\intercal \otimes \varvec{\mathfrak {I}}\!^{-}\) to \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N)\mathbf {x}=\mathbf {b}\), (38), and \(\varvec{\mathsf {M}}\!^{-}\)-orthogonality of \(\varvec{\mathsf {W}}\!^{-}_N\) yield
Inverting \(\varvec{\mathsf {I}}\!^{-}\otimes \varvec{\mathfrak {M}}\!^{-}_t-\varvec{{\Lambda }}\!^-_N\otimes \varvec{\mathfrak {M}}\!^{-}_s\) and applying \(\varvec{\mathsf {W}}\!^{-}_N\otimes \varvec{\mathfrak {I}}\!^{-}\) further yields
For the other part in (40), apply \(\big ((\varvec{\mathsf {M}}\!^{-})^{-1}-\varvec{\mathsf {W}}\!^{-}_N(\varvec{\mathsf {W}}\!^{-}_N)^\intercal \big )\otimes (\varvec{\mathfrak {M}}\!^{-}_t)^{-1}\) to \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N)\mathbf {x}=\mathbf {b}\) and obtain
Substituting both expressions into (40) yields the assertion.
Remark 3
If \(\sigma _s\) has huge variations, a more effective approximation to \(\mathbf {K}^{\!-}\) can be obtained from the eigendecomposition
with diagonal matrix \(\Delta \) with entries \(\Delta _{j}=\int _R \sigma _s\chi _jdr/\int _R\sigma _t\chi _j dr\). The modified approximation \({\widetilde{\mathbf {K}^{\!-}}}\) is then computed by considering only those combinations of spatial and angular eigenfunctions for which \(\lambda _l\Delta _j\) is above a certain tolerance.
5.2 Application of \(\mathbf {K}^{\!+}\) and \(\mathbf {K}^{\!-}\)
Although \(\mathbf {K}^{\!+}\) and \(\mathbf {K}^{\!-}\) provide a tensor product structure (29) involving the sparse matrices \(\varvec{\mathfrak {M}}\!^{+}_s\) and \(\varvec{\mathfrak {M}}\!^{-}_s\), the density of the scattering operators \(\varvec{\mathsf {S}}\!^{+}\) and \(\varvec{\mathsf {S}}\!^{-}\) becomes a bottleneck for iterative methods due to quadratic complexity in storage consumption and computational cost for assembly and matrix–vector products. \(\mathcal {H}\)- and \(\mathcal {H}^2\)-matrices, which can be considered as abstract variants of the fast multipole method [21, 23], where developed in the context of the boundary element method and can realize the storage, assembly and matrix–vector multiplication in linear or almost linear complexity, see [8, 25] and the references therein. A sufficient condition for compressibility in these formats is the following.
Definition 1
Let \(\tilde{S}\subset \mathbb {R}^d\) such that \(k:\tilde{S}\times \tilde{S}\rightarrow \mathbb {R}\) is defined and arbitrarily often differentiable for all \(\tilde{\mathbf {x}}\ne \tilde{\mathbf {y}}\) with \(\tilde{\mathbf {x}},\tilde{\mathbf {y}}\in \tilde{S}\). Then \(k\) is called asymptotically smooth if
independently of \(\varvec{\alpha }\) and \(\varvec{\beta }\) for some constants \(C,r>0\).
While several methods [14, 16] can operate on the Henyey-Greenstein kernel on the sphere, most classical methods require an extension into space which we define as
The following result allows to use this extension in most \(\mathcal {H}\)- and \(\mathcal {H}^2\)-matrix libraries such as [9, 15, 33] in a black-box fashion.
Lemma 6
Let \(g\ge 0\). Then \(K(\tilde{\mathbf {x}},\tilde{\mathbf {y}})\) is asymptotically smooth for \(\tilde{\mathbf {x}},\tilde{\mathbf {y}}\in \mathbb {R}^d\setminus \{0\}\).
Proof
We first remark that the cosinus theorem implies for \(\mathbf {x},\mathbf {y}\in S\) with angle \(\varphi \) that \(\mathbf {x}\cdot \mathbf {y}= \cos (\varphi ) = 1-\Vert \mathbf {x}-\mathbf {y}\Vert ^2/2\). Moreover, \(\tilde{k}(\xi ) = k(1-\xi ^2/2)\) is holomorphic for \(\Re (\xi )>0\) such that its Taylor series around \(\xi >0\) has convergence radius \(\xi \) and the derivatives of \(\tilde{k}\) satisfy \(\big |\partial _\xi ^\alpha \tilde{k}(\xi )\big |\le cr^\alpha \alpha !|\xi |^{-\alpha }\), \(\alpha \in \mathbb {N}_0\), for all \(\xi >0\). Since \(\tilde{\mathbf {x}}\mapsto \mathbf {x}=\tilde{\mathbf {x}}/\Vert \tilde{\mathbf {x}}\Vert \) is analytic for \(\tilde{\mathbf {x}}\ne 0\) and since \(K(\tilde{\mathbf {x}},\tilde{\mathbf {y}})=\tilde{k}(\Vert \mathbf {x}-\mathbf {y}\Vert )\), the assertion follows in complete analogy to the appendix of [27].
The \(\mathcal {H}\)- or \(\mathcal {H}^2\)-approximation of \(\varvec{\mathsf {S}}\!^{+}\) and \(\varvec{\mathsf {S}}\!^{-}\) and the sparsity of \(\varvec{\mathfrak {M}}\!^{+}_s\) and \(\varvec{\mathfrak {M}}\!^{-}_s\) combined with the tensor product identity (37) then allow for an application of \(\mathbf {K}^{\!+}\) and \(\mathbf {K}^{\!-}\) in almost linear or even linear complexity.
5.3 Choice and Implementation of \(\mathbf {P}_1\)
As shown in Sect. 3, choosing \(\mathbf {P}_1\) as in Lemma 4 leads to contraction rates \(\eta \le c\) in (35), i.e., independent of the mesh-parameters. The choice \(\mathbf {P}_1=\mathbf {E}^{-1}\) can be realized through an inner iterative methods, such as a preconditioned Richardson iteration resulting in an inner-outer iteration scheme when employed in (33). An effective preconditioner for \(\mathbf {E}\) is given by the block-diagonal, symmetric positive definite matrix
which provides the spectral estimates
for all \(\mathbf {x}\in \mathbb {R}^{n_S^+n_R^+}\), cf. Lemma 1. Thus, the condition number of \(\mathbf {E}_0^{-1}\mathbf {E}\) is bounded by \((1-cg)^{-1}\), which is uniformly bounded for \(c\in [0,1]\) for fixed \(g<1\). For clarity of presentation, we will use a preconditioned Richardson iteration for the inner iteration to implement \(\mathbf {P}_1\) in the rest of the paper, but remark that a non-stationary preconditioned conjugate gradient method will lead to even better performance. Applying \(\mathbf {P}_1\) with high accuracy may still involve many iterations. Instead, we use a preconditioner \(\mathbf {P}_1^l\) which performs l steps of an inner iteration, i.e., we set \(\mathbf {P}_1^l \mathbf {b}=\mathbf {z}_l\), where
Notice that, \(\mathbf {P}_1^1=\mathbf {E}_0^{-1}\) while \(\mathbf {P}_1^lb \rightarrow \mathbf {E}^{-1}\mathbf {b}\) as \(l\rightarrow \infty \). In fact, with similar arguments as in Lemma 2, it follows from (43) that
where \(\Vert \mathbf {x}\Vert _\mathbf {E}^2=\mathbf {x}^{\!\intercal }\mathbf {E}\mathbf {x}\). The next result asserts that this inexact realization of the preconditioner leads to a convergent scheme.
Lemma 7
Let \(l\ge 1\) be fixed. The iteration (32) with preconditioner \(\mathbf {P}_1=\mathbf {P}_1^l\) defines a convergent sequence, i.e., (35) holds with \(\eta \le c\) and \(\eta \) as in (36).
Proof
Observing that \(\mathbf {P}_1^l = \sum _{k=0}^{l-1} (\mathbf {E}_0^{-1}(\mathbf {E}_0-\mathbf {E}))^k\mathbf {E}_0^{-1}\) and that each term in the sum is symmetric and positive semi-definite for \(k>0\) and positive definite for \(k=0\), it follows that \(\mathbf {P}_1^l\) is symmetric positive definite. Using (43), we deduce that the sum converges as a Neumann series to \(\mathbf {E}^{-1}\). Hence, it follows that
for all \(\mathbf {x}\in \mathbb {R}^{n_S^+n_R^+}\), which implies that \(\mathbf {x}^{\!\intercal } \mathbf {E}\mathbf {x}\le \mathbf {x}^{\!\intercal } (\mathbf {P}_1^{l})^{-1}\mathbf {x}\le \mathbf {x}^{\!\intercal } \mathbf {E}_0\mathbf {x}\) and, in turn,
where we used Lemma 4. The assertion follows then as in Sect. 3.
Remark 4
On the one hand, inspecting (47) we observe that the condition number of \(\mathbf {P}_1^l(\mathbf {E}-\mathbf {K})\), and, similarly, of \(\mathbf {E}^{-1}(\mathbf {E}-\mathbf {K})\) is \((1-c)^{-1}\), which is not robust for scattering dominated regimes \(c\rightarrow 1\); cf. also Lemma 4. On the other hand, combining the second inequality in (46) with (45), we obtain as in Lemma 1, that
which shows that the condition number of \(\mathbf {P}_1^l\mathbf {E}\) is bounded by \((1-(cg)^l)^{-1}\), which, for fixed \(g<1\), is robust for \(c\rightarrow 1\).
5.4 Implementation of the Subspace Correction
The optimal subspaces for the correction (18) are constructed from the eigenfunctions associated with the largest eigenvalues of the generalized eigenproblem (20) as can be seen from the proof of Lemma 3. The iterative computation of these eigenfunctions is, however, computationally expensive. Instead, we employ a different, computationally efficient tensor product construction that employs discrete counterparts of low-order spherical harmonics expansions motivated in (Sect. 3.4). More precisely, the subspace for the correction is defined as \(\mathbb {W}_{h,N}^+=\mathbb {P}_{0,N}(\mathcal {T}_h^S)\otimes \mathbb {P}_1^c(\mathcal {T}_h^R)\), where \(\mathbb {P}_{0,N}(\mathcal {T}_h^S)\subset \mathbb {P}_{0}(\mathcal {T}_h^S)\) is the space spanned by the eigenfunctions associated to the \(d_N=(N+1)(N+2)/2\) largest eigenvalues of the generalized eigenvalue problem
for the scattering operator, mimicking (7) after discretization. Note that \(d_N\) with N even is the number of even spherical harmonics of order less than or equal to N, and \(\mathbb {P}_{0,N}(\mathcal {T}_h^S)\) approximates their span. Denote \(\varvec{\mathsf {W}}\!^{+}_N\) the corresponding matrix of coefficient vectors. The subspace \(\mathbb {W}^+_{h,N}\) is spanned by the columns of the matrix \(\mathbf {W}^{\!+}=\varvec{\mathsf {W}}\!^{+}_N\otimes \varvec{\mathfrak {I}}\!^{+}\). At the discrete level, the correction equation (18), thus, reads as
The efficient assembly of the matrix on the left-hand side relies on the tensor product structure of \(\mathbf {K}^{\!+}\) and the choice of \(\varvec{\mathsf {W}}\!^{+}_N\) as outlined in the following. A simple and direct representation of the scattering operator on \(\mathbb {W}^+_{h,N}\) is obtained by
Similarly, we have that \({\mathbf {W}^{\!+}}\!^{\intercal }\mathbf {M}^{\!+}\mathbf {W}^{\!+}=\varvec{\mathsf {I}}\!^{+}\otimes \varvec{\mathfrak {M}}\!^{+}_t\), and the block-diagonal structure of \(\mathbf {R}\) allows to compute \({\mathbf {W}^{\!+}}\!^{\intercal }\mathbf {R}\mathbf {W}^{\!+}\), i.e. the (i, j)th block-entry is given by
which requires \(O(n_S^+(n_R^+)^{(d-1)/d}d_N)\) many multiplications. The efficient assembly of the remaining term \({\mathbf {W}^{\!+}}\!^{\intercal }\mathbf {A}\!^{\intercal }(\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\mathbf {A}\mathbf {W}^{\!+}\) relies on another eigenvalue decomposition, which diagonalizes \(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}\) on the column range of \(\mathbf {A}\mathbf {W}^{\!+}\). The arguments are similar to those in Sect. 5.1 and we leave the details to the reader.
6 Full Algorithm and Complexity
For the convenience of the reader we provide here the full algorithm of our numerical scheme. To simplify presentation we start with the application of \(\mathbf {E}\) as given in Algorithm 1 and the application of \(\mathbf {P}_1\) as given in Algorithm 2. The full preconditioned Richardson iteration (33) is outlined in Algorithm 3.



For the efficient implementation of these algorithms one may exploit that, except for \(\mathbf {R}\), all matrices provide a tensor product structure, see (29)–(31), allowing for efficient storage in \({\mathcal {O}}(n_S^{\pm }+n_R^{\pm })\) or \({\mathcal {O}}(c_{H}n_S^{\pm }+n_R^{\pm })\) complexity by using their sparsity or their \(\mathcal {H}^2\)-matrix representation.Footnote 1 Here, \(c_{H}\) is a constant related to the compression pattern of the \(H^2\)-matrix. The storage requirements and application of \(\mathbf {R}\) have complexity \({\mathcal {O}}(n_S^+(n_R^+)^{(d-1)/d})\). The relation (37) then allows for an efficient application of all matrices occurring in (28) in \({\mathcal {O}}(n_S^{\pm }n_R^{\pm })\) or \({\mathcal {O}}(c_{H}n_S^{\pm }n_R^{\pm })\) operations. Since the solution vector itself has size \(n_S^+n_R^+\), see also (25), and since \(3n_S^+=n_S^-\) and \(n_R^+\sim n_R^-\), all matrices appearing in (28) can be stored and applied with linear complexity.
In the following we elaborate the algorithmic complexities of Algorithm 1–Algorithm 3 in more detail.
6.1 Complexity of Applying \(\mathbf {E}\)
The listing of Algorithm 1 directly indicates that the main effort of applying \(\mathbf {E}\) lies in the preconditioned conjugate gradient method for applying \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\). From Lemma 5, we obtain that \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N)^{-1}(\mathbf {M}^{\!-}-\mathbf {K}^{\!-})\) is applicable in \({\mathcal {O}}((d_N+c_{H}) n_S^- n_R^-)\) operations, while its condition number is \((1-(cg)^{N+2})^{-1}\). This implies an iteration count for the application of \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\) proportional to \((1-(cg)^{N+2})^{-1/2}\) for \(cg\approx 1\) when using the preconditioned conjugate gradient method with a fixed tolerance. The overall complexity for applying \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\) and, thus, also \(\mathbf {E}\) is then \({\mathcal {O}}((d_N+c_{H}) n_S^- n_R^-/(1-(cg)^{N+2})^{1/2})\). We note that typically \(d_N\ll c_{H}\) for moderate N.
6.2 Complexity of Applying the Preconditioner \(\mathbf {P}_1^l\)
\(\mathbf {P}_1^l\) consists of \(l-1\) applications of \(\mathbf {E}\) and l applications of \(\mathbf {E}_0^{-1}\). Since \(\mathbf {E}_0\) is block-diagonal with \(n_S^+\) sparse blocks of size \(n_R^+\times n_R^+\), the application of \(\mathbf {E}_0^{-1}\) can be performed in \({\mathcal {O}}(n_S^+ (n_R^+)^\gamma )\) if the inversion of each block has \({\mathcal {O}}((n_R^+)^\gamma )\) complexity. This amounts to \({\mathcal {O}}(l (d_N+c_{H}) n_S^+ n_R^+/(1-(cg)^{N+2})^{1/2}+ l n_S^+ (n_R^+)^\gamma )\) complexity for the application of \(\mathbf {P}_1^l\). For moderate N, the subspace correction amounts to solving an elliptic system that is reminiscent of an order N spherical harmonics approximation, which can be solved efficiently with a conjugate gradient method preconditioned by a V-cycle geometric multigrid with Gauss-Seidel smoother, cf. [3].
Let us also remark that each diagonal block of \(\mathbf {E}_0\) discretizes an anisotropic diffusion problem with a diffusion tensor \(\sigma _t^{-1}\int _{K_S} s\cdot s^\intercal ds\) for \(K_S\in \mathcal {T}_h^S\). The results reported in [29] indicate that such problems can be treated efficiently by multigrid methods with line smoothing allowing for \(\gamma =1\). A full analysis in the present context is out of the scope of this paper, but any method that gives \(\gamma =1\) allows to perform one step in the Richardson iteration (33) in linear complexity in the dimension of the solution vector. Although \(\gamma >1\), sparse direct solvers may work well, too, cf. Table 9.
6.3 Complexity of the Overall Iteration
We start our considerations by remarking that the truncated eigendecompositions of the smaller matrices \(\varvec{\mathsf {S}}\!^{+}\) and \(\varvec{\mathsf {S}}\!^{-}\) can be obtained by a few iterations of an iterative eigensolver. Once this is achieved, the computation of the reduced matrix \(\mathbf {E}_c\) can be achieved in \(O(n_S^+n_R^+d_N)\) operations, see Sect. 5.4. Thus, the offline cost for the construction of the preconditioners are \(O(n_S^+n_R^+d_N)\). The discussion on the application of \(\mathbf {E}\) and \(\mathbf {P}_1\) shows that a single iteration of Algorithm 3 can be accomplished in \({\mathcal {O}}(l (d_N+c_{H}) n_S^+ n_R^+/(1-(cg)^{N+2})^{1/2}+ l n_S^+ (n_R^+)^\gamma )\) operations.
Let us remark that in the case \(\gamma =1\) each iteration has linear complexity and it can be implemented such that it offers a perfect parallel weak scaling in \(n_S^+n_R^+\) as long as the number of processors is bounded by \(n_S^+\) and \(n_R^+\). To see this, we note that, with \(\mathbf {R}\) being the only exception, we are only relying on matrix–vector products of matrices having tensor-product structure (or sums thereof). Using the identity (37), it is clear that these operations offer the promised weak scaling when these matrix–matrix products are accelerated by a parallelization over the rows and columns of the middle matrix. The matrix \(\mathbf {R}\) does not directly provide such a structure, but its block diagonal structure, cf. (31), provides possibilities for a perfectly weakly scaling implementation as well.
In summary, each step in (33) can be executed very efficiently with straight-forward parallelization. In the next section we show numerically that the number of iterations required to decrease the error below a given threshold is small already for small values of l and N.
7 Numerical Realization and Examples
We present the performance of the proposed iterative schemes using a lattice type problem [10], see Fig. 1. Here, \(R=(0,7)\times (0,7)\), the inflow boundary source \(f=0\), and \(c= \Vert \sigma _s/\sigma _t\Vert _\infty \approx 0.999\). The coarsest triangulation of the sphere consists of 128 element, i.e., \(n_S^+=64\), and \(n_R^+=3249\) vertices to discretize the spatial domain. Finer meshes are obtained by uniform refinement; the new grid points for \(\mathcal {T}_h^S\) are projected to the sphere. To minimize consistency errors, we use higher-order integration rules for the spherical integrals.

Left: geometry of the lattice problem. The optical parameters are \(\sigma _s=10\) and \(\sigma _a=0.01\) in the white and grey regions, \(\sigma _s=0\) and \(\sigma _a=1\) in the black regions and \(q=1\) in the grey region and \(q=0\) outside the grey region. Right: Sketch of the spherical grid
The timings are performed using an AMD dual EPYC 7742 with 128 cores and with 1024GB memory.
7.1 Application of \((\mathcal {M}-\mathcal {K})^{-1}\)
We show that \((\mathbf {M}^{\!-}-\mathbf {K}^{\!-})^{-1}\) can be applied efficiently and robustly in g. To that end, we implemented a preconditioned conjugate gradient method with preconditioner \(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}_N\), see Sect. 5.1. Table 1 shows the required iteration counts to achieve a relative error below \(10^{-13}\). For all g, the iteration counts decrease with N as predicted by the considerations in Sect. 6. In particular, since \(\mathbf {K}^{\!-}=\mathbf {K}^{\!-}_N=0\), only one iteration is needed for convergence for \(g=0\). Moreover, we see that, although increasing the value of N increases the workload per iteration, the overall solution time can decrease, which is due to the fact that the scattering operator dominates the computational cost for moderate \(d_N\), see Sect. 6. In the remainder of the paper, we employ \(N=5\), which yields fast convergence for the considered values of g.
7.2 Convergence Rates
We study the norm \(\eta \) of the iteration matrix \((\mathbf {I}^{\!+}-\mathbf {P}_G)(\mathbf {I}^{\!+}-\mathbf {P}_1^l(\mathbf {E}-\mathbf {K}^{\!+}))\) defined in (36) and its spectral radius
for different choices of preconditioners \(\mathbf {P}_1=\mathbf {P}_1^l\), anisotropy factors g and dimensions \(d_N\) chosen for the subspace correction. Since \(\mathbf {P}_G\) is a projection, we have that
Therefore, \(\eta ^2\) is the largest eigenvalue of the eigenvalue problem
We use Matlab’s eigs function to compute \(\rho \) and \(\eta \) with tolerance \(10^{-7}\) and maximum iterations set to 300.
For the isotropic case \(g=0\), \(\mathbf {P}_1^l=\mathbf {E}_0^{-1}=\mathbf {E}^{-1}\), i.e., \(\rho \) and \(\eta \) do not depend on l. For \(N=0\), Table 2 shows that the values of \(\eta \) and \(\rho \) are essentially independent of the discretization parameters, see also [40]. We observed numerically that choosing \(N\in \{2,4\}\) improves the values of \(\rho \) and \(\eta \) only slightly.
In the next experiments, we vary g from 0.1 to 0.9 in steps of 0.2. Tables 3, 4, 5, 6 and 7 display the corresponding values of \(\rho \) and \(\eta \). For these anisotropic cases, the iteration count l for the preconditioner \(\mathbf {P}_1^l\) as well as the number \(d_N\), defined in Sect. 5.4, play an important role. For all combinations of \(d_N\) and l, we observe a convergent behavior with \(\eta \le c<1\), which is in line with Lemma 7. The values of \(\rho \) and \(\eta \) decrease substantially with increasing \(d_N\) which is inline with the motivation of Sect. 3.4, while, for fixed \(d_N\) a saturation in l can be observed. For \(d_N\) sufficiently large, it seems that \(\rho =\eta =g^{l}\), see, e.g. Table 6 for \(d_4\) and \(1\le l\le 4\). We may conclude that we can achieve very good convergence rates for moderate values of \(d_N\) and l if combined appropriately.
7.3 \(\mathcal {H}^2\)-Matrix Approximation of \(\mathcal {S}\)
We demonstrate the \(\mathcal {H}^2\)-compressibility of the scattering operator \(\mathcal {S}\). Since every \(\mathcal {H}^2\)-matrix can be represented as an \(\mathcal {H}\)-matrix, this also demonstrates the compressibility of \(\mathcal {S}\) by means of \(\mathcal {H}\)-matrices. For the implementation we use a Mex interface to include the library H2Lib [9] into our Matlab-implementation.
For the numerical experiments themselves, we choose \(g=0.5\) and the same quadrature formula in our Matlab implementation and in our implementation within the H2Lib. The compression algorithm of \(\textsc {H2Lib}\) uses multivariate polynomial interpolation, requiring the extension of the Henyey–Greenstein kernel as in (42). The compression parameters are set to an admissibility parameter \(\eta _{H}=1.4\), \(p=4\) interpolation points on a single interval and a minimal block size parameter \(n_{\min }=64\), see [8, 25]. We also tested an implementation without the need for an extension within the Bembel library [15] which yields similar results, but requires a finite element discretization on quadrilaterals, rather than triangles. In both cases, the differences between dense and compressed scattering matrix are below the discretization error.
Table 8 lists the memory requirements, setup time, and time for a single matrix–vector multiplication of \(\varvec{\mathsf {S}}\!^{+}\) in dense and \(\mathcal {H}^2\)-compressed form. We can clearly observe the quadratic complexity for storage and matrix–vector multiplication of the dense matrices and the asymptotically linear complexity of the \(\mathcal {H}^2\)-matrices. The scaling of the assembly times for dense and \(\mathcal {H}^2\)-matrices seems to be worse than predicted by theory, which is possibly caused by memory issues. Nevertheless, the scaling of the \(\mathcal {H}^2\)-matrices for the assembly times is much better than the one for dense matrices.
7.4 Benchmark Example
The viability of the preconditioned Richardson iteration (33) is shown for some larger computations. We fix \(g=0.5\) and solve the even-parity equations (32) for the lattice problem. We fix \(l=4\) steps to realize the preconditioner \(\mathbf {P}_1^l\) and \(N=4\), i.e., we use \(d_4=15\) eigenfunctions of \(\varvec{\mathsf {S}}\!^{+}\) for the subspace correction, cf. (5.4). In view of Table 5, we expect a contraction rate \(\eta \approx 0.16\). Therefore, in order to achieve an error bound \(\Vert \mathbf {u}^{\!+}-\mathbf {u}^{\!+}_{n}\Vert _{\mathbf {E}-\mathbf {K}^{\!+}}<10^{-8}\), we expect to require \(n\approx 10\) iterations. In our implementation, we choose \(\mathbf {u}^{\!+}_0=0\), and we stop the iteration at index n for which
Note that, assuming a contraction rate \(\eta =0.16\), Banach’s fixed point theorem asserts that the error satisfies \(\Vert \mathbf {u}^{\!+}-\mathbf {u}^{\!+}_{n}\Vert _{\mathbf {E}-\mathbf {K}^{\!+}} \le 0.2 \Vert \mathbf {u}^{\!+}_{n} - \mathbf {u}^{\!+}_{n-1}\Vert _{\mathbf {E}-\mathbf {K}^{\!+}}\). The dimension of the problem on the finest grid is \(n_R^+n_S^+=207{,}360{,}000\), i.e., storing the solution vector requires 1.5 GB of memory. Note that the corresponding dimension of the solution vector to the mixed system is about \(1.5\times 10^9\). Motivated by Table 8 we implement the scattering operators \(\varvec{\mathsf {S}}\!^{+}\) and \(\varvec{\mathsf {S}}\!^{-}\) using dense matrices in this example. The application of \(\mathbf {E}_0^{-1}\) is implemented with Matlab’s sparse LU factorization, i.e., here, \(\gamma \le 1.5\) in the complexity estimates of Sect. 6.

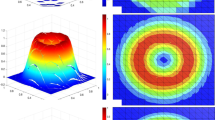
\(\log _{10}\)-plot of the spherical average of the numerical solution \(\mathbf {u}^+\) to the benchmark problem as in Sect. 7.4 for \(n_S^+=1024\) and \(n_R^+=12{,}769\)
Figure 2 shows exemplary the spherical average of the computed solution for \(n_S^+=1024\) and \(n_R^+=12{,}769\). Table 9 displays the iteration counts and timings for different grid refinements. We observe mesh-independent convergence behavior of the iteration, which matches well the theoretical bound \(n\approx 10\). Furthermore, the computation time scales like \((n_R^+)^{1.3}\) for fixed \(n_S^+\). If \(n_S^+\) increases from 1024 to 4096, the superlinear growth in computation time can be explained by using dense matrices for \(\varvec{\mathsf {S}}\!^{+}\) and \(\varvec{\mathsf {S}}\!^{-}\), which, as shown in Table 8, can be remedied by using the compressed scattering operators.
8 Conclusions
We have presented efficient preconditioned Richardson iterations for anisotropic radiative transfer that are provably convergent and show robust convergence in the optical parameters, which comprises forward peaked scattering and heterogeneous absorption and scattering coefficients. This has been achieved by employing black-box matrix compression techniques to handle the scattering operator efficiently, and by construction of appropriate preconditioners. In particular, we have shown that, for anisotropic scattering, subspace corrections constructed from low-order spherical harmonics expansions considerably improve the convergence of our iteration.
On the discrete level, our preconditioners can be obtained algebraically from the matrices of any FEM code providing the matrices from the mixed system (28). We discussed further implementational details and their computational complexity, which, supported by several numerical tests, showed the efficiency of our method. If a solver with linear computational complexity for anisotropic elliptic problems is employed to realize \(\mathbf {E}_0^{-1}\), each single iteration of our scheme has linear computational complexity in the discretization parameters. Our numerical examples employed low-order polynomials for discretization, but the presented methodology directly applies to high-order polynomial approximations as well.
Let us mention that the saddle-point problem (4) may also be solved using the MINRES algorithm after appropriate multiplication of the second equation by \(-1\). In view of the inf-sup theory for (8)–(9) given in [17], block-diagonal preconditioners with blocks \(\mathbf {E}-\mathbf {K}^{\!+}\) and \(\mathbf {M}^{\!-}-\mathbf {K}^{\!-}\) lead to robust convergence behavior [50, Section 5.2], but the efficient inversion of \(\mathbf {E}-\mathbf {K}^{\!+}\) is as difficult as solving the even-parity equations, which has been considered in this paper.
Our subspace correction approach can also be related to multigrid schemes [51], and we refer to [31, 34, 42] and the references there in the context of radiative transfer. Comparing to non-symmetric Krylov space methods, such as GMRES or BiCGStab, see [1, 6, 49] and the references there, our approach is very memory effective and monotone convergence behavior is guaranteed. Moreover, in view of its good convergence rates, the preconditioned Richardson iteration presented here is competitive to these multilevel and Krylov space methods.
Data Availability
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
Code Availability
The code used in this study is available from the authors upon reasonable request.
Notes
The storage requirements of \(\mathbf {K}^{\!+}\) and \(\mathbf {K}^{\!-}\) are \({\mathcal {O}}(c_{H}n_S^{\pm }\log (n_S^{\pm })+n_R^{\pm })\) if \(\mathcal {H}\)-matrices are used instead of \(\mathcal {H}^2\)-matrices. In practice, \(c_{H}\) may depend on additional implementation dependent parameters, see [8, 25], which we neglect here for sake of simplicity.
References
Adams, M.L., Larsen, E.W.: Fast iterative methods for discrete-ordinates particle transport calculations. Prog. Nucl. Energy 40(1), 3–159 (2002)
Ahmedov, B., Grepl, M., Herty, M.: Certified reduced-order methods for optimal treatment planning. Math. Models Methods Appl. Sci. 26(04), 699–727 (2016). https://doi.org/10.1142/S0218202516500159
Arridge, S., Egger, H., Schlottbom, M.: Preconditioning of complex symmetric linear systems with applications in optical tomography. Appl. Numer. Math. 74, 35–48 (2013)
Arridge, S.R., Schotland, J.C.: Optical tomography: forward and inverse problems. Inverse Probl. 25(12), 123010 (2009). https://doi.org/10.1088/0266-5611/25/12/123010
Aydin, E.D., de Oliveira, C.R.R., Goddard, A.J.H.: A finite element-spherical harmonics radiation transport model for photon migration in turbid media. J. Quant. Spectrosc. Radiat. Transf. 84, 247–260 (2004)
Badri, M., Jolivet, P., Rousseau, B., Favennec, Y.: Preconditioned Krylov subspace methods for solving radiative transfer problems with scattering and reflection. Comput. Math. Appl. 77(6), 1453–1465 (2019)
Becker, R., Koch, R., Bauer, H.J., Modest, M.: A finite element treatment of the angular dependency of the even-parity equation of radiative transfer. J. Heat Transf. 132(2), 023404 (2010)
Börm, S.: Efficient Numerical Methods for Non-Local Operators, EMS Tracts in Mathematics, vol. 14. European Mathematical Society (EMS), Zürich (2010)
Börm, S.: Scientific Computing Group of Kiel University: H2Lib. https://www.h2lib.org
Brunner, T.A.: Forms of approximate radiation transport. In: Nuclear Mathematical and Computational Sciences: A Century in Review, A Century Anew Gatlinburg. American Nuclear Society, LaGrange Park, IL (2003). Tennessee, April 6–11 (2003)
Case, K.M., Zweifel, P.F.: Linear Transport Theory. Addison-Wesley, Reading (1967)
Crockatt, M.M., Christlieb, A.J., Hauck, C.D.: Improvements to a class of hybrid methods for radiation transport: Nyström reconstruction and defect correction methods. J. Comput. Phys. 422, 109765 (2020). https://doi.org/10.1016/j.jcp.2020.109765
Dahmen, W., Gruber, F., Mula, O.: An adaptive nested source term iteration for radiative transfer equations. Math. Comput. 89(324), 1605–1646 (2020). https://doi.org/10.1090/mcom/3505
Dahmen, W., Harbrecht, H., Schneider, R.: Compression techniques for boundary integral equations. Asymptotically optimal complexity estimates. SIAM J. Numer. Anal. 43(6), 2251–2271 (2006)
Dölz, J., Harbrecht, H., Kurz, S., Multerer, M., Schöps, S., Wolf, F.: Bembel: the fast isogeometric boundary element C++ library for Laplace, Helmholtz, and electric wave equation. SoftwareX 11, 100476 (2020). https://doi.org/10.1016/j.softx.2020.100476
Dölz, J., Harbrecht, H., Peters, M.: An interpolation-based fast multipole method for higher-order boundary elements on parametric surfaces. Int. J. Numer. Methods Eng. 108(13), 1705–1728 (2016). https://doi.org/10.1002/nme.5274
Egger, H., Schlottbom, M.: A mixed variational framework for the radiative transfer equation. Math. Models Methods Appl. Sci. 22(03), 1150014 (2012)
Egger, H., Schlottbom, M.: Stationary radiative transfer with vanishing absorption. Math. Mod. Methods Appl. Sci. 24, 973–990 (2014)
Egger, H., Schlottbom, M.: A perfectly matched layer approach for \({P}_{{N}}\)-approximations in radiative transfer. SIAM J. Numer. Anal. 57(5), 2166–2188 (2019). https://doi.org/10.1137/18M1172521
Evans, K.F.: The spherical harmonics discrete ordinate method for three-dimensional atmospheric radiative transfer. J. Atmos. Sci. 55(3), 429–446 (1998)
Fong, W., Darve, E.: The black-box fast multipole method. J. Comput. Phys. 228(23), 8712–8725 (2009). https://doi.org/10.1016/j.jcp.2009.08.031
González-Rodríguez, P., Kim, A.D.: Light propagation in tissues with forward-peaked and large-angle scattering. Appl. Opt. 47(14), 2599 (2008). https://doi.org/10.1364/ao.47.002599
Greengard, L., Rokhlin, V.: A fast algorithm for particle simulations. J. Comput. Phys. 73(2), 325–348 (1987)
Guermond, J.L., Kanschat, G., Ragusa, J.C.: Discontinuous Galerkin for the radiative transport equation. In: Recent Developments in Discontinuous Galerkin Finite Element Methods for Partial Differential Equations, IMA Volumes in Mathematics and its Applications, vol. 157, pp. 181–193. Springer, Cham (2014)
Hackbusch, W.: Hierarchical Matrices: Algorithms and Analysis. Springer, Heidelberg (2015)
Han, W., Huang, J., Eichholz, J.A.: Discrete-ordinate discontinuous Galerkin methods for solving the radiative transfer equation. SIAM J. Sci. Comput. 32(2), 477–497 (2010). https://doi.org/10.1137/090767340
Harbrecht, H., Peters, M.: Comparison of fast boundary element methods on parametric surfaces. Comput. Methods Appl. Mech. Eng. 261–262, 39–55 (2013)
Haut, T.S., Southworth, B.S., Maginot, P.G., Tomov, V.Z.: Diffusion synthetic acceleration preconditioning for discontinuous Galerkin discretizations of \({S}_{N}\) transport on high-order curved meshes. SIAM J. Sci. Comput. 42(5), B1271–B1301 (2020). https://doi.org/10.1137/19M124993X
Hemker, P.: Multigrid methods for problems with a small parameter in the highest derivative. In: Griffiths, D. (ed.) Numerical Analysis. Lecture Notes in Mathematics, vol. 1066, pp. 106–121. Springer, Berlin (1984)
Heningburg, V., Hauck, C.D.: A hybrid finite-volume, discontinuous Galerkin discretization for the radiative transport equation. Multiscale Model. Simul. 19(1), 1–24 (2021). https://doi.org/10.1137/19M1304520
Kanschat, G., Ragusa, J.C.: A robust multigrid preconditioner for \(S_N{\rm DG}\) approximation of monochromatic, isotropic radiation transport problems. SIAM J. Sci. Comput. 36(5), A2326–A2345 (2014). https://doi.org/10.1137/13091600X
Kópházi, J., Lathouwers, D.: A space-angle DGFEM approach for the Boltzmann radiation transport equation with local angular refinement. J. Comput. Phys. 297, 637–668 (2015)
Kriemann, R.: HLib Pro. https://www.hlibpro.com
Lee, B.: A multigrid framework for \(S_N\) discretizations of the Boltzmann transport equation. SIAM J. Sci. Comput. 34(4), A2018–A2047 (2012)
Lewis, E.E., Miller, W.F., Jr.: Computational Methods of Neutron Transport. Wiley, New York (1984)
Manteuffel, T.A., Ressel, K.J., Starke, G.: A boundary functional for the least-squares finite-element solution for neutron transport problems. SIAM J. Numer. Anal. 2, 556–586 (2000)
Marchuk, G.I., Lebedev, V.I.: Numerical Methods in the Theory of Neutron Transport. Harwood Academic Publishers, London (1986)
Meng, X., Wang, S., Tang, G., Li, J., Sun, C.: Stochastic parameter estimation of heterogeneity from crosswell seismic data based on the Monte Carlo radiative transfer theory. J. Geophys. Eng. 14, 621–632 (2017)
Modest, M.F.: Radiative Heat Transfer, 2nd edn. Academic Press, Amsterdam (2003)
Palii, O., Schlottbom, M.: On a convergent DSA preconditioned source iteration for a DGFEM method for radiative transfer. Comput. Math. Appl. 79(12), 3366–3377 (2020). https://doi.org/10.1016/j.camwa.2020.02.002
Ragusa, J.C., Wang, Y.: A two-mesh adaptive mesh refinement technique for SN neutral-particle transport using a higher-order DGFEM. J. Comput. Appl. Math. 233(12), 3178–3188 (2010). https://doi.org/10.1016/j.cam.2009.12.020
Shao, W., Sheng, Q., Wang, C.: A cascadic multigrid asymptotic-preserving discrete ordinate discontinuous streamline diffusion method for radiative transfer equations with diffusive scalings. Comput. Math. Appl. 80(6), 1650–1667 (2020). https://doi.org/10.1016/j.camwa.2020.08.002
Sun, Z., Hauck, C.D.: Low-memory, discrete ordinates, discontinuous Galerkin methods for radiative transport. SIAM J. Sci. Comput. 42(4), B869–B893 (2020). https://doi.org/10.1137/19M1271956
Tano, M.E., Ragusa, J.C.: Sweep-net: an artificial neural network for radiation transport solves. J. Comput. Phys. (2021). https://doi.org/10.1016/j.jcp.2020.109757
Tarvainen, T., Pulkkinen, A., Cox, B.T., Arridge, S.R.: Utilising the radiative transfer equation in quantitative photoacoustic tomography. In: Oraevsky, A.A., Wang, L.V. (eds.) Photons Plus Ultrasound: Imaging and Sensing. International Society for Optics and Photonics (2017). https://doi.org/10.1117/12.2249310
Wang, C., Sheng, Q., Han, W.: A discrete-ordinate discontinuous-streamline diffusion method for the radiative transfer equation. Commun. Comput. Phys. 20(5), 1443–1465 (2018). https://doi.org/10.4208/cicp.310715.290316a
Wang, Y., Ragusa, J.C.: Diffusion synthetic acceleration for high-order discontinuous finite element SN transport schemes and application to locally refined unstructured meshes. Nucl. Sci. Eng. 166(2), 145–166 (2010). https://doi.org/10.13182/nse09-46
Warsa, J.S., Wareing, T.A., Morel, J.E.: Fully consistent diffusion synthetic acceleration of linear Discontinuous SN Transport discretizations on unstructured tetrahedral meshes. Nucl. Sci. Eng. 141(3), 236–251 (2002). https://doi.org/10.13182/nse141-236
Warsa, J.S., Wareing, T.A., Morel, J.E.: Krylov iterative methods applied to multidimensional \(s_n\) calculations in the presence of material discontinuities. Tech. rep., Los Alamos National Laboratory (2002)
Wathen, A.J.: Preconditioning. Acta Numer. 24, 329–376 (2015). https://doi.org/10.1017/s0962492915000021
Xu, J., Zikatanov, L.: The method of alternating projections and the method of subspace corrections in Hilbert space. J. Am. Math. Soc. 15(3), 573–597 (2002). https://doi.org/10.1090/s0894-0347-02-00398-3
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funding
The authors did not receive support from any organization for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dölz, J., Palii, O. & Schlottbom, M. On Robustly Convergent and Efficient Iterative Methods for Anisotropic Radiative Transfer. J Sci Comput 90, 94 (2022). https://doi.org/10.1007/s10915-021-01757-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-021-01757-9