
Abstract
Principal component analysis (PCA) is known to be sensitive to outliers, so that various robust PCA variants were proposed in the literature. A recent model, called reaper, aims to find the principal components by solving a convex optimization problem. Usually the number of principal components must be determined in advance and the minimization is performed over symmetric positive semi-definite matrices having the size of the data, although the number of principal components is substantially smaller. This prohibits its use if the dimension of the data is large which is often the case in image processing. In this paper, we propose a regularized version of reaper which enforces the sparsity of the number of principal components by penalizing the nuclear norm of the corresponding orthogonal projector. If only an upper bound on the number of principal components is available, our approach can be combined with the L-curve method to reconstruct the appropriate subspace. Our second contribution is a matrix-free algorithm to find a minimizer of the regularized reaper which is also suited for high-dimensional data. The algorithm couples a primal-dual minimization approach with a thick-restarted Lanczos process. This appears to be the first efficient convex variational method for robust PCA that can handle high-dimensional data. As a side result, we discuss the topic of the bias in robust PCA. Numerical examples demonstrate the performance of our algorithm.
Similar content being viewed by others


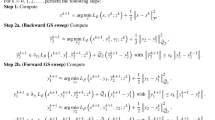
1 Introduction
Principal component analysis (PCA) [37] realizes the dimensionality reduction in data by projecting them onto those affine subspace which minimizes the sum of the squared Euclidean distances between the data points and their projections. Unfortunately, PCA is very sensitive to outliers, so that various robust approaches were developed in robust statistics [17, 28, 46] and nonlinear optimization. In this paper, we focus on the second one.
One possibility to make PCA robust consists in removing outliers before computing the principal components which has the serious drawback that outliers are difficult to identify and other data points are often falsely labeled as outliers. Another approach assigns different weights to data points based on their estimated relevance, to get a weighted PCA [20] or repeatedly estimate the model parameters from a random subset of data points until a satisfactory result indicated by the number of data points within a certain error threshold is obtained [11]. In a similar vein, least trimmed squares PCA models [38, 41] aim to exclude outliers from the squared error function, but in a deterministic way. In [44], a dual principal component pursuit is used for this purpose. The variational model in [4] decomposes the data matrix into a low rank and a sparse part. Related approaches such as [7, 32, 51] separate the low-rank component from the column sparse one using different norms in the variational model. Another group of robust PCA replaces the squared \(L_2\) norm in the PCA model by the \(L_1\) norm [18]. Unfortunately, this norm is not rotationally invariant, i.e., when rotating the centered data points, the minimizing subspace is not rotated in the same way. Replacing the squared Euclidean norm in the PCA model by just the Euclidean one leads to a non-convex robust PCA model with minimization over the Stiefel or Grassmannian manifold, see, e.g., [9, 26, 31, 34]. Instead of the previous model which minimizes over the sparse number of directions spanning the low-dimensional subspace, it is also possible to minimize over the orthogonal projectors onto the desired subspace. This has the advantage that the minimization can be performed over symmetric positive semi-definite matrices, e.g., using methods from semi-definite programming, and the disadvantage that the dimension of the projectors is as large as the data now. This prohibits this approach for many applications in particular in image processing. The projector PCA model is still non-convex, and a convex relaxation, called reaper, was recently proposed by Lerman et el. [27]. An extensive comparison of the benefits and drawbacks of the different approaches in the rich literature of robust PCA as well as of the related numerical algorithms can, for instance, be found in [26].
In this paper, we build up on the advantages of the convex reaper model, but modify it in two important directions: (i) by penalizing the nuclear norm of the approximated projectors, our model does only require an upper bound on the dimension of the desired subspace. Having the same effect as the sparsity promotion of the 1-norm, the nuclear norm—the 1-norm of the eigenvalues—promotes low-rank matrices or, equivalently, sparse eigenvalue decompositions; (ii) by combining primal-dual minimization techniques with a thick-restarted Lanczos process, we are able to handle high-dimensional data. We call our new convex model rreaper. We provide all computation steps leading to an efficient and a provable convergent algorithm to the minimum of the objective function. A performance analysis following the lines of [27] is given. The choice of the offset in robust PCA is an interesting problem which is not fully discussed in the literature so far. Usually, the geometric median is used. We do not provide a full solution of this issue, but show that under some assumptions the affine hyperplane in \(\mathbb {R}^d\) having the smallest Euclidean distance to \(n > d\) given data points goes through \(d+1\) of these points. We underline our theoretical findings by numerical examples.
The outline of this paper is as follows: preliminaries from linear algebra and convex analysis are given in Sect. 2. In Sect. 3, we introduce our regularized reaper model. The basic primal-dual algorithm for its minimization is discussed in Sect. 4. The algorithm is formulated with respect to the full projection matrix. The matrix-free version of the algorithm is given in Sect. 5. It is based on the thick-restarted Lanczos algorithm and is suited for high-dimensional data. In Sect. 6, we examine the performance analysis of rreaper along the lines of [27]. Some results on the offset in robust PCA are proved in Sect. 7. The very good performance of rreaper in particular for high-dimensional data is demonstrated in Sect. 8. Further, the relation between the dimension of the wanted subspace and the regularization parameter is addressed via the L-curve method. Section 9 finishes the paper with conclusions and directions of future research.
2 Notation and Preliminaries
Throughout this paper, we will use the following notation and basic facts from linear algebra and convex analysis which can be found in detail in various monographs and overview papers as [1, 3, 6, 13, 40].
Linear algebra By \(\Vert \cdot \Vert _2\) we denote the Euclidean vector norm and by \(\Vert \cdot \Vert _1\) the norm which sums up the absolute vector components. Recall that for any \(\varvec{x} \in \mathbb {R}^n\),
Let \(\mathbf {1}_n\) resp. \(\mathbf {0}_n\) be the vectors having n entries 1, resp., 0. Analogously, we write \(\varvec{1}_{n,d}\) and \(\varvec{0}_{n,d}\) for the all-one and all-zero matrix in \(\mathbb {R}^{n,d}\). Further, \(\varvec{I}_n\) is the \(n \times n\) identity matrix. Let \({\text {tr}}\varvec{A}\) denote the trace of the quadratic matrix \(\varvec{A} \in \mathbb {R}^{n,n}\), i.e., the sum of its eigenvalues. On \(\mathbb {R}^{n,d}\) the Hilbert–Schmidt inner product is defined by
and the corresponding so-called Frobenius norm by
Let \(\mathscr {S}(n) \subset \mathbb {R}^{n,n}\) denote the linear subspace of symmetric matrices. For two symmetric matrices \(\varvec{A},\varvec{B} \in \mathscr {S}(n)\), we write \(\varvec{A} \preceq \varvec{B}\) if \(\varvec{B} - \varvec{A}\) is positive semi-definite. Every \(\varvec{A} \in \mathscr {S}(n)\) has a spectral decomposition
where \(\varvec{\lambda }_{\varvec{A}} \in \mathbb {R}^n\) denotes the vector containing the eigenvalues of \(\varvec{A}\) in descending order \(\lambda _1 \ge \cdots \ge \lambda _n\) and \(\varvec{U}\) is the orthogonal matrix having the corresponding orthogonal eigenvectors as columns. The nuclear norm (trace norm) of \(\varvec{A} \in \mathscr {S}(n)\) is given by
The trace and Frobenius norm correspond to the Schatten 1-norm and 2-norm, respectively, where the Schatten p-norm with \(1 \le p \le \infty \) of a symmetric matrix \(\varvec{A}\) is defined by \(||\varvec{A}||_{S_p} :=||\varvec{\lambda }_{\varvec{A}}||_p\). Recall that \(\varvec{\varPi } \in \mathbb {R}^{n,n}\) is an orthogonal projector if \(\varvec{\varPi } \in \mathscr {S}(n)\) and \(\varvec{\varPi }^2 = \varvec{\varPi }\). This is equivalent to the statement that \(\varvec{\varPi } \in \mathscr {S}(n)\) and has only eigenvalues in \(\{0,1\}\). The nuclear norm is the unique norm such that
for every orthogonal projector \(\varvec{\varPi }\).
For a given norm \(\Vert \cdot \Vert \) on \(\mathbb {R}^n\), the dual norm is defined by
In particular, for a matrix \(\varvec{X} = (\varvec{x}_1|\ldots |\varvec{x}_N) \in \mathbb {R}^{n,N}\) we will be interested in the norm
which can be considered as norm on \(\mathbb {R}^{nN}\) by arranging the columns of the matrix into a vector. Its dual norm is given by
Convex analysis Let \(\varGamma _0(\mathbb {R}^n)\) denote the space of proper, lower semi-continuous, convex functions mapping from \(\mathbb {R}^n\) into the extended real numbers \((-\infty ,\infty ]\). The indicator function \(\iota _{\mathscr {C}}\) of \(\mathscr {C} \subseteq \mathbb {R}^n\) is defined by
We have \(\iota _{\mathscr {C}} \in \varGamma _0(\mathbb {R}^n)\) if and only if \(\mathscr {C}\) is non-empty, convex and closed.
For \(f \in \varGamma _0(\mathbb {R}^n)\), the proximal mapping is defined by
Indeed, the minimizer exists and is unique [40, Thm. 31.5]. If \(\mathscr {C} \subset \mathbb {R}^n\) is a non-empty, closed, convex set, then the proximal mapping of a multiple of \(\iota _{\mathscr {C}}\) is just the orthogonal projection onto \(\mathscr {C}\), i.e.,
In particular, the orthogonal projection onto the halfspace \(\mathscr {H}(\varvec{a},\beta ) :=\{\varvec{x} \in \mathbb {R}^n: \langle \varvec{a} , \varvec{x} \rangle \le \beta \}\) with \(\varvec{a} \in \mathbb {R}^{n}\) and \(\beta \in \mathbb {R}\) can be computed by
where \((y )_+ :=\max \{0,y\}\). Further, the orthogonal projection onto the hypercube \(\mathscr {Q} := [0,1]^n\) is given by
The Fenchel dual of \(f \in \varGamma _0(\mathbb {R}^n)\) is the function \(f^* \in \varGamma _0(\mathbb {R}^n)\) defined by
The dual function of a norm is just the indicator function of the unit ball with respect to its dual norm. In particular, we have for \(\Vert \cdot \Vert _{2,1}: \mathbb {R}^{n,N} \rightarrow \mathbb {R}\) that
where \( \mathscr {B}_{2,\infty } :=\{\varvec{X} \in \mathbb {R}^{n,N}: \Vert \varvec{x}_k \Vert _2 \le 1 \; \mathrm {for \; all} k=1,\ldots ,N\} \).
3 Regularized reaper
Given N data points \(\varvec{x}_1,\ldots ,\varvec{x}_N \in \mathbb {R}^n\), the classical PCA finds a d-dimensional affine subspace \(\{\varvec{A} \, \varvec{t} + \varvec{b}: \varvec{t} \in \mathbb {R}^d\}\), \(1 \le d \ll n\), by minimizing
over \(\varvec{b} \in \mathbb {R}^n\) and \(\varvec{A} \in \mathbb {R}^{n,d}\). It is not hard to check that the affine subspace goes through the offset (bias)
Therefore, we can reduce our attention to data points \(\varvec{x}_k - \bar{\varvec{b}}\), \(k=1,\ldots ,N\), which we denote by \(\varvec{x}_k\) again, and minimize over the linear d-dimensional subspaces through the origin, i.e.,
where \(\varvec{X} :=(\varvec{x}_1| \ldots |\varvec{x}_N) \in \mathbb {R}^{n,N}\).
Unfortunately, the solution of this minimization problem is sensitive to outliers. Therefore, several robust PCA variants were proposed in the literature. A straightforward approach consists in just skipping the square in the Euclidean norm leading to
This is a non-convex model which requires the minimization over matrices \(\varvec{A}\) in the so-called Stiefel manifold,
Another approach is based on the observation that \(\varvec{\varPi } :=\varvec{A} \varvec{A}^\mathrm {T}\) is the orthogonal projector onto the linear subspace spanned by the columns of \(\varvec{A}\). Since the linear subspace is d-dimensional, exactly d eigenvalues of \(\varvec{\varPi }\) have to be one. Thus, problem (6) can be reformulated as
Having computed \(\varvec{\varPi }\), we can determine \(\varvec{A}\) by spectral decomposition. Unfortunately, (7) is still a non-convex model which is moreover NP hard to solve. Therefore, Lerman et al. [27] suggested to replace it by a convex relaxation, called reaper,
In order to deal with the non-differentiability of the objective function, Lerman et al. [27] iteratively solve a series of positive semi-definite programs. In contrast to models minimizing directly over \(\varvec{A} \in \mathbb {R}^{n,d}\), algorithms for minimizing reaper or rreaper seem to require the handling of a large matrix \(\varvec{P} \in \mathscr {S}(n)\) or, more precisely, the handling of its spectral decomposition which makes the method not practicable for high-dimensional data.
The above model requires the exact knowledge of the dimension d of the linear subspace the data will be reduced to. In this paper, we suggest to replace the strict trace constraint by a relaxed variant \({\text {tr}}(\varvec{\varPi }) \le d\) and to add the nuclear norm of \(\varvec{\varPi }\) as a regularizer which enforces the sparsity of the rank of \(\varvec{\varPi }\):
Here \(\alpha >0\) is an appropriately fixed regularization parameter.
Since (8) is again hard so solve, we use a relaxation for the eigenvalues and call the new model regularized reaper (rreaper):
Finally, we project the solution of rreaper to the set of orthoprojectors with rank not larger than d:
where
In the following, we will present a primal-dual approach to solve (9) which uses only the sparse spectral decomposition of \(\varvec{P}\), but not the matrix itself within the computation steps.
4 Primal-Dual Algorithm
Rreaper is a convex optimization problem; so we may choose from various convex solvers. Before choosing a specific method, we study the structure of rreaper in more details. For this purpose, we define the forward operator
and rearrange (9) as
where the regularizer \(\mathscr {R} :\mathscr {S}(n) \rightarrow [0,+\infty ]\) is defined by
Since \(\mathscr {C}\) is compact and convex, and since the norms \(||\cdot ||_{2,1}\) and \(||\cdot ||_{{\text {tr}}}\) are continuous, rreaper has a global minimizer. This minimizer is in general not unique. Concerning the adjoint operator \(\mathscr {X}^*: \mathbb {R}^{n, N} \rightarrow \mathscr {S}(n)\), we observe
for all \(\varvec{P} \in \mathscr {S}(n)\) and \(\varvec{Y} \in \mathbb {R}^{n,N}\), where we exploit the symmetry of \(\varvec{P}\) by \(\varvec{P} = \nicefrac {1}{2}(\varvec{P} + \varvec{P}^\mathrm {T})\). Thus, the adjoint is just
The operator norm of \(\mathscr {X}\) is given by the spectral norm of \(\varvec{X} \in \mathbb {R}^{n,N}\), i.e.,
In more detail, for \(\varvec{P} = (\varvec{p}_1|\ldots |\varvec{p}_n) \in \mathscr {S}(n)\), we obtain
Here the inequality becomes sharp for
where \(\varvec{U}\) arises from the singular value decomposition \(\varvec{X} = \varvec{U} {\text {diag}}( \varvec{\sigma }_{\varvec{X}}) \, \varvec{V}^\mathrm {T}\) with descending ordered singular values \(\sigma _1 \ge \cdots \ge \sigma _{\min \{n,N\}}\).
More generally, rreaper is an optimization problem of the form
whose objective consists of two convex, lower semi-continuous functions \(F = ||\cdot - \varvec{X}||_{2,1}\) and \(G = \alpha \mathscr {R}\) and a linear mapping \(\mathscr {A} = \mathscr {X}\). Since both—data fidelity and regularizer of rreaper—are non-differentiable, gradient decent methods as well as the forward-backward splitting or the fast iterative shrinkage-thresholding algorithm (FISTA) cannot be applied. In order to exploit the structure, various saddle-point methods that do not require differentiability can be used. Examples are the alternating directions method of multipliers (ADMM) which is related to the Douglas–Rachford splitting or primal-dual algorithms, see for instance [6] and references therein. Since the iteration variables with respect to \(\varvec{P}\) in rreaper computed via ADMM usually have no sparse spectral decomposition and cannot be handled for high-dimensional instances, we prefer to choose the primal-dual method of Chambolle and Pock [6] with extrapolation of the primal variable to compute the minimizer of rreaper (10).
For the general minimization problem (12), the primal-dual method consists in the iteration
with fixed parameters \(\tau , \sigma >0\) and \(\theta \in [0,1]\). The extrapolation step consisting in the calculation of \(\bar{\varvec{P}}^{(r+1)}\) is here required to ensure the convergence whenever \(\tau \sigma < 1 / ||\mathscr {A}||^2\) and \(\theta = 1\), where \(||\mathscr {A}||\) denotes the operator norm of \(\mathscr {A}\). If the functions F and G possesses more regularity like strong convexity, the parameter \(\theta \) may be varied to prove an acceleration of the convergence and to guarantee certain convergence rates [5, 6]. For rreaper, the above iteration leads us to the following numerical method.
Algorithm 1
(Primal-Dual Algorithm) Input: \(\varvec{X} \in \mathbb {R}^{n,N}\) \(d \in \mathbb {N}\), and \(\sigma ,\tau > 0\) with \(\sigma \tau < 1/\Vert \varvec{X}\Vert _2^2\), and \(\theta \in (0,1]\).
Intialization: \({\varvec{P}}^{(0)} = \bar{\varvec{P}}^{(0)} = \varvec{0}_{n,n}\) , \(\varvec{Y}^{(0)} :=\varvec{0}_{n, N}\).
Iteration:
More generally, Chambolle and Pock [6] have proven that the sequence \(\{\varvec{P}^{(r)} \}_{r\in \mathbb {N}}\) converges to a minimizer \(\hat{\varvec{P}}\) of (10) and the sequence \(\{\varvec{Y}^{(r)} \}_{r\in \mathbb {N}}\) to a minimizer of the dual problem
if the Lagrangian
has a saddle-point which is, however, clear for rreaper.
The algorithm requires the computation of the proximal mapping of the dual data fidelity and of the regularizer which we consider next.
Proposition 1
(Proximal mapping of the dual data fidelity) For \(\varvec{x} \in \mathbb {R}^{n,N}\) and \(\sigma > 0\), we have
Proof
Using (3) and, since \((f(\cdot - x_0))^* = f^* + \langle \cdot , x_0 \rangle \), we obtain
For the maximal dimension d of the target subspace, we henceforth use the half-space
in order to bound the trace of the primal iteration variable \(\varvec{P}^{(r)}\). Then the proximal mapping of the regularizer is given in the following proposition.
Proposition 2
(Proximal mapping of the regularizer) For \(\varvec{P} \in \mathscr {S}(n)\) with spectral decomposition \(\varvec{P} = \varvec{U} {\text {diag}}(\varvec{\lambda }_{\varvec{P}}) \, \varvec{U}^\mathrm {T}\) and \(\mathscr {R}\) in (11) it holds
Proof
A symmetric matrix \(\varvec{P}\) is in \(\mathscr {C}\) if and only if \(\varvec{\lambda }_{\varvec{P}}\) \(\in \) \(\mathscr {Q} \cap \mathscr {H}\). Hence, the regularizer can be written as
and
By the theorem of Hoffmann and Wielandt [16, Thm. 6.3.5], we know that
with equality if and only if \(\varvec{S}\) possesses the same eigenspaces as \(\varvec{P}\). Therefore, the minimizer in (14) has to be of the form \(\varvec{S} = \varvec{U} {\text {diag}}(\varvec{\lambda }_{\varvec{S}}) \, \varvec{U}^\mathrm {T}\), where the columns of \(\varvec{U}\) are the eigenvectors of \(\varvec{P}\). Incorporating this observation in (14), we determine the eigenvalues \(\varvec{\lambda }_{\varvec{S}}\) by solving the minimization problem
\(\square \)
Alternatively to the proof, we could argue with the so-called spectral function related to \(\mathscr {R}\) which is invariant under permutations, see, e.g., [1].
By Proposition 2, the proximal mapping of the regularizer requires the projection onto the truncated hypercube. The following proposition can be found in [1, Ex. 6.32].
Proposition 3
(Projection onto the truncated hypercube) For any \(\varvec{\lambda } \in \mathbb {R}^n\) and any \(d \in (0,n]\), the projection to the truncated hypercube is given by
where \(\hat{t}\) is the smallest root of the function
Due to the projection to the hypercube, see (2), only the positive components of \(\varvec{\lambda }\) influence its projection onto \(\mathscr {Q}\cap {\mathscr {H}}\). More precisely, we have
where the function \((\cdot )_+\) is employed componentwise.
To formulate a projection algorithm, in particular, to compute the zero of \(\varphi \), we study the properties of \(\varphi \) and derive an explicit representation. Within a different setting, the reader may also have a look at [30].
Lemma 1
(Properties of \(\varvec{\varphi }\)) For fixed \(\varvec{\lambda } \in \mathbb {R}^n\) with \(\langle {\text {proj}}_{\mathscr {Q}}(\varvec{\lambda }),\varvec{1}_n\rangle > d\), the function \(\varphi :[0,\infty ) \rightarrow \mathbb {R}\) defined in (15) has the following properties:
-
(i)
\(\varphi \) is Lipschitz continuous.
-
(ii)
\(\varphi \) is monotone decreasing and piecewise linear. More precisely, we can construct a sequence \(0 = s_0< s_1< s_2< \ldots < s_M\) with \(M \le 2n\) such that
$$\begin{aligned} \varphi (t) = \varphi (s_l) - k_l (t-s_l), \end{aligned}$$for \(t \in [s_l,s_{l+1})\), \(l = 0,\ldots , M-1\), where
$$\begin{aligned} k_l :=|\{j \in \{1,\ldots ,n\}: (\varvec{\lambda } - s_l \varvec{1}_n)_j \in (0,1] \}|. \end{aligned}$$Moreover, \(\varphi (t) = -d\) for \(t \ge s_M\).
-
(iii)
The smallest root \(\hat{t}\) of \(\varphi \) is given by
$$\begin{aligned} \hat{t} = s_m + \tfrac{1}{k_m} \varphi (s_m) , \end{aligned}$$where m is the unique index such that \(\varphi (s_m) > 0\) and \(\varphi (s_{m+1}) \le 0\).
Proof
-
(i)
Using the definition of \(\varphi \), the Cauchy–Schwarz inequality, and the non-expansiveness of the projection, we get
$$\begin{aligned}&|\varphi (t) - \varphi (s)|\\&\quad = |\langle {\text {proj}}_{\mathscr {Q} }(\varvec{\lambda } - t \varvec{1}_n ), \varvec{1}_n \rangle - \langle {\text {proj}}_{\mathscr {Q} }(\varvec{\lambda } - s\varvec{1}_n ), \varvec{1}_n \rangle |\\&\quad \le \sqrt{n} \, \Vert {\text {proj}}_{\mathscr {Q} }(\varvec{\lambda } - t \varvec{1}_n ) -{\text {proj}}_{\mathscr {Q} }(\varvec{\lambda } - s\varvec{1}_n )\Vert _2\\&\quad \le \sqrt{n} \, \Vert (s-t) \varvec{1}_n\Vert _2 = n \, |s-t|. \end{aligned}$$ -
(ii)
Starting with \(s_0 = 0\), we construct \(s_l\) with \(l=1,\ldots ,M\) iteratively as follows: given \(s_l\) , we set \(\varvec{\mu } :=\varvec{\lambda } - s_l \varvec{1}_n\) and choose
$$\begin{aligned} s_{l+1} :=s_{l} + h_l, \quad h_l := \min \{s_{\mathrm {leave}},s_{\mathrm {enter}} \}, \end{aligned}$$where
$$\begin{aligned} s_{\mathrm {leave}}&:=\min _j \{\mu _j: \mu _j \in (0,1]\},\\ s_{\mathrm {enter}}&:=\min _j \{\mu _j-1: \mu _j >1\}. \end{aligned}$$Here we use the convention \(\min \emptyset = \infty \). If both sets in the definition of \(s_{\mathrm {leave}}\) and \(s_{\mathrm {enter}}\) are empty, we stop the construction since all components of \(\varvec{\mu }\) are non-positive implying \({\text {proj}}_{\mathscr {Q} }(\varvec{\mu }) = \varvec{0}_n\) and thus \(\varphi (s_M) = -d\) as well as \(\varphi (t) = -d\) for \(t \ge s_M\), where M is the index of the last computed point \(s_l\). Considering the projection to the hypercube \(\mathscr {Q}\) in (2), we see that the index set \(\{j \in \{1,\ldots ,n\}: (\varvec{\lambda } - t \varvec{1}_n)_j \in (0,1] \}\) does not change for \(t \in [s_l, s_{l+1})\) and that a change appears exactly in \(s_{l+1}\), where at least one component enters or leaves the interval (0, 1]. Hence, we have
$$\begin{aligned} \varphi (t) = \varphi (s_l) - k_l (t-s_l), \quad t \in [s_l,s_{l+1}). \end{aligned}$$Let \(s_{M}\) be the first value in this procedure, where all components of \(\varvec{\mu }\) become non-positive. Since each component in \(\varvec{\lambda } - t \varvec{1}_n\) can at most one times enter or leave the interval (0, 1], we know that \(M < 2n\). Further, \(k_l \ge 0\) shows that \(\varphi \) is monotone decreasing.
-
(iii)
By definition of \(\varphi \) and by the assumption \(\langle {\text {proj}}_{\mathscr {Q}}(\varvec{\lambda }),\varvec{1}_n\rangle > d\), we have \(\varphi (0) > 0\). On the other side, \(\varphi (s_m) = -d\) was shown above. Consequently, the smallest zero \(\hat{t}\) of \(\varphi \) has to lie in the interval \([s_{m},s_{m+1}]\) with \(\varphi (s_m) > 0\) and \(\varphi (s_{m+1}) \le 0\) and can be computed by solving
$$\begin{aligned} \varphi (\hat{t}) = \varphi ( s_m) - k_m (\hat{t}-s_m) = 0. \end{aligned}$$This results in \(\hat{t} = s_m + \tfrac{1}{k_m} \varphi (s_m)\) and finishes the proof. \(\square \)
Following Proposition 3 and the previous proof, we obtain the following algorithm for the projection onto \(\mathscr {Q} \cap \mathscr {H}\).
Algorithm 2
(Projection onto truncated hypercube)Input: \(\varvec{\lambda } \in \mathbb {R}^n\), \(d \in \mathbb {N}\).
-
(i)
Compute \(\varvec{\mu } :={\text {proj}}_{\mathscr {Q}} (\varvec{\lambda })\) by (2).
If \(\langle \varvec{\mu }, \varvec{1}_n \rangle \le d\), then return \(\hat{\varvec{\lambda }} = \varvec{\mu }\);
otherwise set \(s :=0\), \(\varphi :=+ \infty \) and \(\varvec{\mu } = \varvec{\lambda }\).
-
(ii)
Repeat until \(\varphi \le 0\):
-
(a)
\(s_{\mathrm {old}} :=s\),
-
(b)
\(s_{\mathrm {leave}} :=\min _j \{\mu _j: \mu _j \in (0,1]\}\),
-
(c)
\(s_{\mathrm {enter}} :=\min _j \{\mu _j-1: \mu _j >1\}\),
-
(d)
\(s :=s + \min \{s_{\mathrm {leave}},s_{\mathrm {enter}}\}\),
-
(e)
\(\varvec{\mu } = \varvec{\lambda } - s \varvec{1}_n\),
-
(f)
\(\varphi = \langle {\text {proj}}_{\mathscr {Q}} (\varvec{\mu }), \varvec{1}_n \rangle - d\),
-
(a)
-
(iii)
Compute
-
(a)
\(k :=|\{j \in \{1,\ldots ,n\}: (\varvec{\lambda } - s_{\mathrm {old}} \varvec{1}_n)_j \in (0,1] \}|\),
-
(b)
\( \hat{t} = s_{\mathrm {old}} + \tfrac{1}{k} \varphi (s_{\mathrm {old}}). \)
-
(a)
Output: \(\hat{\varvec{\lambda }} :={\text {proj}}_{\mathscr {Q}\cap {\mathscr {H}}}(\varvec{\lambda })\).
Based on the derived proximal mappings, the primal-dual Algorithm 2 to solve rreaper (10) can be specified in matrix form as follows.
Algorithm 3
(Primal-dual r reaper) Input: \(\varvec{X} \in \mathbb {R}^{n, N}\), \(d \in \mathbb {N}\), \(\alpha > 0\), and \(\sigma ,\tau > 0\) with \(\sigma \tau < 1/\Vert \varvec{X}\Vert _2^2\), and \(\theta \in [0,1)\).
Initiation: \(\varvec{P}^{(0)} = \bar{\varvec{P}}^{(0)}:=\varvec{0}_{n, n}\), \(\varvec{Y}^{(0)} :=\varvec{0}_{n, N}\).
Iteration:
-
(i)
Dual update:
$$\begin{aligned} \varvec{Y}^{(r+1)} :={\text {proj}}_{\mathfrak {B}_{2, \infty }} \bigl ( \varvec{Y}^{(r)} + \sigma \bigl (\mathscr {X} \bigl (\bar{\varvec{P}}^{(r)} \bigr ) - \varvec{X} \bigr ) \bigr ). \end{aligned}$$ -
(ii)
Primal update:
-
(a)
\(\varvec{U} {\text {diag}}(\varvec{\lambda }) \, \varvec{U}^\mathrm {T}:=\varvec{P}^{(r)} - \tau \mathscr {X}^* \bigl (\varvec{Y}^{(r+1)} \bigr )\),
-
(b)
\(\hat{\varvec{\lambda }} :={\text {proj}}_{_{\mathscr {Q}\cap {\mathscr {H}}}}(\varvec{\lambda } - \tau \alpha \varvec{1}_n)\) (Algorithm 2),
-
(c)
\(\varvec{P}^{(r+1)} :=\varvec{U} {\text {diag}}(\hat{\varvec{\lambda }}) \, \varvec{U}^*\).
-
(a)
-
(iii)
Extrapolation: \( \bar{\varvec{P}}^{(r+1)} :=(1 + \theta ) \, \varvec{P}^{(r+1)} - \theta \, \varvec{P}^{(r)}\).
Output: \(\hat{\varvec{P}}\) (Solution of rreaper (10)).
5 Matrix-Free Realization
Solving rreaper with the primal-dual Algorithm 3 is possible if the dimension of the surrounding space \(\mathbb {R}^n\) is moderate which is often not the case in image processing tasks. While the dual variable \(\varvec{Y} \in \mathbb {R}^{n,N}\) matches the dimension of the data, the primal variable \(\varvec{P}\) is in S(n) instead of \(\mathbb {R}^{n,d}\), \(d \ll n\). How can the primal-dual iteration be realized in the case \(n \gg d\) though the primal variable cannot be hold in memory and the required eigenvalue decomposition cannot be computed in a reasonable amount of time?
Here the nuclear norm in rreaper that promotes low-rank matrices comes to our aid. Our main idea to derive a practical implementation of the primal-dual iteration is thus based on the assumption that the iterates of the primal variable \(\varvec{P}^{(r)}\) possess the form
with small rank \(d_r\). In our simulations, we observed that the rank is usually around the dimension d of the wanted low-dimensional subspace.
In order to integrate the matrix-free representation (16) into the primal-dual iteration efficiently, we further require a fast method to compute the eigenvalue thresholding. For this, we compute a partial eigenvalue decomposition using the well-known Lanczos process [22]. Deriving matrix-free versions of the forward operator \(\mathscr {X}\) and its adjoint \(\mathscr {X}^*\), we finally introduce a complete matrix-free primal-dual implementation with respect to \(\varvec{P}^{(r)}\).
5.1 The Thick-Restarted Lanczos Process
One of the most commonly used methods to extract a small set of eigenvalues and their corresponding eigenvectors of a large symmetric matrix is the Lanczos method [22], which is based on theory of Krylov subspaces. The method builds a partial orthogonal basis first and then uses a Rayleigh–Ritz projection to extract the wanted eigenpairs approximately. If the set of employed basis vectors is increased, the extracted eigenpairs converge to the eigenpairs of the given matrix [13]. Since the symmetric matrix whose partial eigenvalue decomposition is required in the primal-dual method usually is high-dimensional, we would like to chose the number \(k_{\mathrm {max}}\) of basis vectors within the Lanczos method as small as possible such that the convergence of the Krylov method does not emerge. To calculate the dominant \(\ell _{\mathrm {fix}}\) eigenpairs with high-accuracy nevertheless, the Lanczos method can be restarted with the dominant \(\ell _{\mathrm {fix}}\) Ritz pairs. For our purpose, we use the thick-restart scheme of Wu and Simon [50] in Algorithm 4, whose details are discussed below.
Algorithm 4
(Thick-restarted Lanczos process [50, Alg. 3])Input: \(\varvec{P} \in S(n)\), \(k_{\mathrm {max}}> \ell _{\mathrm {fix}} > 0\), \(\delta > 0\).
-
(i)
Choose a unit vector \(\varvec{r}_0 \in \mathbb {R}^n\). Set \(\ell :=0\).
-
(ii)
Lanczos process:
-
1. Initiation:
-
(a)
\(\varvec{e}_{\ell + 1} :=\varvec{r}_\ell / ||\varvec{r}_\ell ||_2\),
-
(b)
\(\varvec{q} :=\varvec{P} \varvec{e}_{\ell + 1}\),
-
(c)
\(\beta _{\ell + 1} :=\langle \varvec{q},\varvec{e}_{\ell + 1}\rangle \),
-
(d)
\(\varvec{r}_{\ell + 1} :=\varvec{q} - \beta _{\ell + 1} \varvec{e}_{\ell + 1} - \sum _{k=1}^\ell \rho _k \varvec{e}_k\),
-
(e)
\(\gamma _{\ell + 1} :=||\varvec{r}_{\ell + 1}||\).
-
(a)
-
2. Iteration (\(k = \ell + 2, \dots , k_{\mathrm {max}}\)):
-
(a)
\(\varvec{e}_k :=\varvec{r}_{k-1} / \gamma _{k-1}\),
-
(b)
\(\varvec{q} :=\varvec{P} \varvec{e}_k\),
-
(c)
\(\beta _k :=\langle \varvec{q},\varvec{e}_k\rangle \),
-
(d)
\(\varvec{r}_k :=\varvec{q} - \beta _k \varvec{e}_k - \gamma _{k-1} \varvec{e}_{k-1}\),
-
(e)
\(\gamma _k :=||\varvec{r}_k||\).
-
(a)
-
-
(iii)
Compute the eigenvalue decomposition \(\varvec{T} = \varvec{Y} \varvec{\varLambda }\varvec{Y}^\mathrm {T}\) of \(\varvec{T}\) in (17). Set \(\varvec{U} :=\varvec{E} \varvec{Y}\).
-
(iv)
If \(\gamma _{k_{\mathrm {max}}} |y_{k_{\mathrm {max}},k}| \le \delta ||\varvec{P}||\) for \(k = 1, \dots , \ell _{\mathrm {fix}}\), then return \(\varvec{U} :=[\varvec{u}_1 | \dots | \varvec{u}_{\ell _{\mathrm {fix}}}]\) and \(\varvec{\varLambda }:={\text {diag}}(\lambda _1, \dots , \lambda _{\ell _{\mathrm {fix}}})\). Otherwise, set \(\ell :=\ell _{\mathrm {fix}}\), \(\varvec{r}_\ell :=\varvec{r}_{k_{\mathrm {max}}}\), and continue with (ii).
Output: \(\varvec{U} \in \mathbb {R}^{n \times \ell _{\mathrm {fix}}}\), \(\varvec{\varLambda }\in \mathbb {R}^{\ell _{\mathrm {fix}} \times \ell _{\mathrm {fix}}}\) with \(\varvec{U}^\mathrm {T}\varvec{P} \varvec{U} = \varvec{\varLambda }\).
Remark 1
Although the Lanczos process computes an orthogonal basis \(\varvec{e}_1, \dots , \varvec{e}_{k_{\mathrm {max}}}\), the orthogonality is usually lost because of the floating-point arithmetic. In order to re-establish the orthogonality, we therefore have to orthogonalize the newly computed \(\varvec{e}_k\) with the previous basis vectors, which can be achieved by the Gram–Schmidt procedure. More sophisticated re-orthogonalization strategies are discussed in [50].
Remark 2
During the Lanczos process, the norm of the residual \(\gamma _k\) could become zero. In this case, we can stop the process, reduce \(k_{\mathrm {max}}\) to the current k, and proceed with step (iii) and (iv). Then the computed basis \(\varvec{e}_1, \dots , \varvec{e}_k\) spans an invariant subspace of \(\varvec{P}\) such that the eigenpairs in \(\varvec{U}\) and \(\varvec{\varLambda }\) become exact, see [13].
The heart of the Lanczos method in Algorithm 4 is the construction of an orthogonal matrix \(\varvec{E} :=[\varvec{e}_1 | \dots | \varvec{e}_{k_{\mathrm {max}}}] \in \mathbb {R}^{n \times k_{\mathrm {max}}}\) such that \(\varvec{T} :=\varvec{E}^\mathrm {T}\varvec{P} \varvec{E}\) becomes tridiagonal, see (17) with \(\ell = 0\) below. Using the eigenvalue decomposition \(\varvec{T} = \varvec{Y} \varvec{\varLambda }\varvec{Y}^\mathrm {T}\), we then compute the Ritz pairs \((\lambda _k, \varvec{u}_k)\), where \(\varvec{u}_k\) are the columns of \(\varvec{U} :=[\varvec{u}_1 | \dots | \varvec{u}_{k_{\mathrm {max}}}]\) and \(\lambda _k\) the eigenvalues in \(\varvec{\varLambda }\). In the next iteration, we chose \(\ell _{\mathrm {fix}}\) Ritz pairs corresponding to the absolute leading Ritz values denoted by \((\breve{\lambda }_1, \breve{\varvec{u}}_1), \dots , (\breve{\lambda }_{\ell _{\mathrm {fix}}}, \breve{\varvec{u}}_{\ell _{\mathrm {fix}}})\) and restart the Lanczos process. Thereby, the chosen Ritz vectors are extended to an orthogonal basis \(\varvec{E} :=[\breve{\varvec{u}}_1 | \dots | \breve{\varvec{u}}_{\ell _{\mathrm {fix}}} | \varvec{e}_{\ell _{\mathrm {fix}}+1} | \dots | \varvec{e}_{k_{\mathrm {max}}}]\) fulfilling
where \(\rho _k :=\breve{\gamma }_{k_{\mathrm {max}}} \breve{y}_{k_{\mathrm {max}}, k}\) with \(\breve{\gamma }_{k_{\mathrm {max}}}\) and \(\breve{y}_{k_{\mathrm {max}}, k}\) originating from the last iteration, see [50].
The stopping criteria of the thick-restarted Lanczos process is here deduced from the fact that the chosen Ritz pairs fulfill the equation
where \(\breve{\varvec{r}}_{k_{\mathrm {max}}}\) is the last residuum vector of the previous iteration [50]. Consequently, the absolute error of the chosen Ritz pairs is given by
Usually, the absolute value of the leading Ritz value is a good approximation of the required spectral norm \(||\varvec{P}||\) to estimate the current relative error.
Remark 3
(Power method) Besides the Krylov subspace methods like the discussed Lanczos process with thick-restarting, the required eigenpairs may be calculated using the power method. Here the main idea is to start with an orthogonal matrix \(\varvec{U}^{(0)} :=[\varvec{u}_1^{(0)} | \dots | \varvec{u}_{\ell _\mathrm {fix}}^{(0)}] \in \mathbb {R}^{n \times \ell _{\mathrm {fix}}}\) representing an \(\ell _{\mathrm {fix}}\)-dimensional subspace \(\mathscr {U}^{(0)}\) and to successively compute \(\mathscr {U}^{(r)} :=\varvec{P} ( \mathscr {U}^{(r-1)})\) again represented by an orthogonal matrix \(\varvec{U}^{(r)}\). The convergence of the so-called orthogonal iteration may be improved by constructing \(\varvec{U}^{(r)}\) using the eigenvalue decomposition of \(\varvec{P}\) restricted to \(\mathscr {U}^{(r)}\). This approach goes back to [43] and consists in the iteration
where the first step consists in the QR decomposition of \(\varvec{P} \varvec{U}^{(r-1)}\) into an orthogonal matrix \(\varvec{E}^{(r)}\) and an upper triangular matrix \(\varvec{R}^{(r)}\) and the second in the eigenvalue decomposition of \(\varvec{E}^{(r) \mathrm {T}} \varvec{P} \varvec{E}^{(r)}\).
If none of the columns of \(\varvec{U}^{(0)}\) is orthogonal to the \(\ell _{\mathrm {fix}}\) leading eigenvectors of \(\varvec{P}\), and if the \(\ell _{\mathrm {fix}}\)leading eigenvalues are well-defined—both in absolute value, then the columns of \(\varvec{U}^{(r)}\) and the eigenvalues in \(\varvec{\varLambda }^{(r)}\) converge to the leading eigenpairs of \(\varvec{P}\), see [13, 43].
Although there is no convergence guarantee for the restarted Lanczos process, it usually enjoys much faster convergence than the orthogonal iteration (18)–(20) for high-dimensional problems. Moreover, the chosen restarting technique can be easily adapted to compute the proximal mapping of the regularizer as discussed in the next section.
5.2 Matrix-Free Primal Update
The thick-restarted Lanczos method allows us to compute the leading absolute eigenvalues and their corresponding eigenvectors in a matrix-free manner using only the action of the considered matrix. In our primal-dual method for rreaper, we need the action of \(\varvec{P}^{(r)} - \tau \mathscr {X}^*(\varvec{Y}^{(r+1)})\). Incorporating the low-rank representation (16), we see that this can be rewritten as
For the evaluation of the primal proximal mapping, we first compute the eigenvalue decomposition of \(\varvec{P}^{(r)} - \tau \mathscr {X}^*(\varvec{Y}^{(r+1)})\), next shift the eigenvalues, and finally project them to the truncated hypercube \(\mathscr {Q} \cap \mathscr {H}\), see Algorithm 3. Since the projection onto \(\mathscr {Q} \cap \mathscr {H}\) is independent of negative eigenvalues, see note after Proposition 3, it is thus sufficient to compute only the eigenpairs with eigenvalue larger than \(\alpha \tau \).
For the numerical implementation, we compute the relevant eigenpairs with the thick-restarted Lanczos method. In the course of this, we are confronted with the issue that we actually do not know how many eigenpairs has to be computed. To reduce the overhead of Algorithm 4 as much as possible, the parameters \(\ell _{\mathrm {fix}}\) and \(k_{\mathrm {max}}\) can be easily adapted between the restarts. Further, the computation of strongly negative eigenvalues can be avoided by an eigenvalue shift, i.e., actually compute the eigenpairs of \(\varvec{P}^{(r)} - \tau \mathscr {X}^*(\varvec{Y}^{(r+1)}) + \nu \varvec{I}\) with \(\mu \ge 0\), where the required action has the form
Essentially, we may thus implement the primal proximation in the following manner.
Algorithm 5
(Matrix-free primal proximation)Input: \(\varvec{P}^{(r)} \in \mathscr {S}(n)\), \(\varvec{Y}^{(r+1)} \in \mathbb {R}^{n, N}\), \(d > 0\), \(\tau > 0\), \(\alpha > 0\).
-
(i)
Thick-restarted Lanczos method:
Setting \(\nu :=0\), \(\ell _{\mathrm {fix}} :={\text {rank}}(\varvec{P}^{(r)})\), \(k_{\mathrm {max}} :=\min \{2 \ell _{\mathrm {fix}}, n\}\), run Algorithm 4 with action (21). Between restarts, check convergence and update parameters:
-
(a)
If \(\gamma _{k_{\mathrm {max}}} |y_{k_{\mathrm {max}},k}| \le \delta \, ||\varvec{P}^{(r)} - \tau \mathscr {X}^*(\varvec{Y}^{(r+1)}) + \nu \varvec{I}||\) for \(k = 1, \dots , m+1\), and if \(\lambda _1 \ge \dots \ge \lambda _m \ge \alpha \tau + \nu > \lambda _{m+1}\), then return \(\varvec{U} :=[\varvec{u}_1 | \dots | \varvec{u}_m]\) and \(\varvec{\varLambda }:={\text {diag}}(\lambda _1 - \nu , \dots , \lambda _m - \nu )\).
-
(b)
If \(\lambda _{\ell _{\mathrm {fix}}} > \alpha \tau + \nu \), then increase \(\ell _{\mathrm {fix}}\), \(k_{\mathrm {max}}\) so that \(\ell _{\mathrm {fix}} < k_{\mathrm {max}} \le n\).
-
(c)
Set \(\xi :=\max \{[\lambda _1]_-, \dots , [\lambda _{k_{\mathrm {max}}}]_-\}\) and \(\nu :=\nu + \xi \).
Restart with \((\lambda _k + \xi , \varvec{u}_k)\), \(k=1, \dots , \ell _{\mathrm {fix}}\).
-
(a)
-
(ii)
Projection onto \(\mathscr {Q} \cap \mathscr {H}\): Run Algorithm 2 on
$$\begin{aligned} \varvec{\lambda } :=(\lambda _1 - \alpha \tau , \dots , \lambda _m - \alpha \tau , 0, \dots , 0)^\mathrm {T}\in \mathbb {R}^n \end{aligned}$$to get \(\hat{\varvec{\lambda }} :={\text {proj}}_{\mathscr {Q} \cap \mathscr {H}}(\varvec{\lambda })\).
-
(iii)
New low-rank representation:
Determine \(d_{r+1} :=\max \{k : \hat{\lambda }_k > 0\}\) and return
$$\begin{aligned} \varvec{P}^{(r+1)} :=\sum _{k=1}^{d_{r+1}} \hat{\lambda }_k \, \varvec{u}_k \varvec{u}_k^\mathrm {T}. \end{aligned}$$
Output: \(\varvec{P}^{(r+1)} :=\sum _{k=1}^{d_{r+1}} \lambda ^{(r+1)}_k \, \varvec{u}_k^{(r+1)} \bigl ( \varvec{u}_k^{(r+1)} \bigr )^\mathrm {T}\).
Remark 4
If the matrix \(\varvec{P}^{(r)} - \tau \mathscr {X}^*(\varvec{Y}^{(r+1)})\) does not possess any eigenvalues greater than \(\alpha \tau \), then the Lanczos process stops in step (i.a) with \(m=0\). Since the projection to the truncated hypercube is then the zero vector again, the new iteration \(\varvec{P}^{(r+1)}\) can be represented by an empty low-rank representation, i.e., \(d_{r+1}=0\).
5.3 Matrix-Free Dual Update
Compared with the primal update, the derivation of the matrix-free dual update is more straightforward. First, the matrix
is computed, where the over-relaxation \(\bar{\varvec{P}}^{(r)} :=(1+\theta ) \, \varvec{P}^{(r)} - \theta \, \varvec{P}^{(r-1)}\) is already plugged in. The low-rank representations of \(\varvec{P}^{(r)}\) and \(\varvec{P}^{(r-1)}\) similar to (16) can efficiently incorporated by calculating the matrix \(\varvec{Z} :=[\varvec{z}_1 | \dots | \varvec{z}_N]\) column by column. This way of handling the forward operator \(\mathscr {X}\) nicely matches with the projection of the columns \(\varvec{z}_k\) to the Euclidean unit ball in the second step. Writing the matrix \(\varvec{Y}^{(r)} :=[\varvec{y}_1^{(r)}| \dots | \varvec{y}_N^{(r)}]\) column by column too, we obtain the following numerical method.
Algorithm 6
(Matrix-free dual proximation)Input: \(\varvec{Y}^{(r)} \in \mathbb {R}^{n,N}\), \(\varvec{P}^{(r)} \in S(n)\), \(\varvec{P}^{(r-1)} \in S(n)\), \(\sigma > 0\),\(\theta \in (0,1]\).
-
(i)
For \(k = 1, \dots , N\), compute
$$\begin{aligned} \varvec{z}_k&:=\varvec{y}_k^{(r)} + \sigma \, (1 + \theta ) \, \biggl \{ \sum _{\ell =1}^{d_{r}} \lambda _\ell ^{(r)} \bigl \langle \varvec{x}_k,\varvec{u}_\ell ^{(r)}\bigr \rangle \varvec{u}_\ell ^{(r)} \biggr \} \\&\qquad - \sigma \theta \, \biggl \{ \sum _{\ell =1}^{d_{r-1}} \lambda _\ell ^{(r-1)} \bigl \langle \varvec{x}_k,\varvec{u}_\ell ^{(r-1)}\bigr \rangle \varvec{u}_\ell ^{(r-1)} \biggr \} - \sigma \varvec{x}_k. \end{aligned}$$ -
(ii)
For \(k = 1, \dots , N\), compute \(\varvec{z}_k :=\varvec{z}_k / (1 + [||\varvec{z}_k||_2 - 1]_+)\).
-
(iii)
Return \(\varvec{Y}^{(r+1)} :=[\varvec{z}_1 | \dots | \varvec{z}_N]\).
Output: \(\varvec{Y}^{(r+1)}\)
5.4 Matrix-Free Projection onto the Orthoprojectors
With the matrix-free implementations of the primal and dual proximal mappings, we are already able to solve rreaper (9) numerically. Before summarizing the compound algorithm, we briefly discuss the last needed component to tackle the robust PCA problem (8). The final step is to project the solution \(\hat{\varvec{P}}\) of rreaper onto the set of orthoprojectors with rank not larger than d:
where
We may calculate the projection explicitly in the following manner.
Proposition 4
(Projection onto the orthoprojectors) For \(\varvec{P} \in S(n)\) with eigenvalue decomposition \(\varvec{P} = \varvec{U} {\text {diag}}(\varvec{\lambda }_{\varvec{P}}) \varvec{U}^\mathrm {T}\), and for every \(1 \le p \le \infty \), the projection onto \(\mathscr {O}_d\) with respect to the Schatten p-norm is given by
Proof
The key ingredient to prove this statement is the theorem of Lidskii–Mirsky–Wielandt, see for instance [29]. Using this theorem to estimate the Schatten p-Norm, we obtain
where we have equality if \(\varvec{\varPi }\) has the same eigenvectors as \(\varvec{P}\). Recall that the eigenvalues in \(\varvec{\lambda }_{\varvec{P} }\) appear in descending order. The right-hand side of (22) thus becomes minimal if we choose the eigenvalues of \(\varvec{\varPi }\) for \(k=1,\dots , d\) as
and set \( \hat{\lambda }_{\varvec{\varPi },k} :=0 \) for \(k=d+1,\ldots ,n\). This is exactly the projection onto \(\mathscr {E}_d\). \(\square \)
Because of the low-rank representation
of the primal variable, the construction of the orthoprojector \(\hat{\varvec{\varPi }} \in \mathscr {O}_d\) is here especially simple.
Algorithm 7
(Matrix-free projection onto orthoprojectors)Input: \(\varvec{P} = \sum _{k=1}^\kappa \lambda _k \, \varvec{u}_k \varvec{u}_k^\mathrm {T}\in \mathscr {S}(n)\), \(d \in \mathbb {N}\).
-
(i)
Projection onto \(\mathscr {O}_d\):
Determine \(s :=\max \{ k : \lambda _k \ge \nicefrac 12, k \le \min \{d, \kappa \}\}\).
-
(ii)
Matrix-free presentation:
Return \(\varvec{\varPi } = \sum _{k=1}^s \varvec{u}_k \varvec{u}_k^\mathrm {T}\).
Output: \(\varvec{\varPi } = {\text {proj}}_{\mathscr {O}_d}(\varvec{P})\).
5.5 Matrix-Free Robust PCA by Rreaper
Combining the matrix-free implementations of the primal and dual proximal mappings, we finally obtain a primal-dual method to solve rreaper (9) without evaluating the primal variable \(\varvec{P}^{(r)}\) representing the relaxed orthoprojector explicitly.
Algorithm 8
(Matrix-free robust PCA)Input: \(\varvec{X} \in \mathbb {R}^{n, N}\), \(d \in \mathbb {N}\), \(\alpha > 0\), and \(\sigma ,\tau > 0\) with \(\sigma \tau < 1/\Vert \varvec{X}\Vert _2^2\), and \(\theta \in (0,1]\).
Initiation: \(\varvec{P}^{(0)} = \bar{\varvec{P}}^{(0)}:=\varvec{0} \in \mathbb {R}^{n, n}\), \(\varvec{Y}^{(0)} :=\varvec{0} \in \mathbb {R}^{n, N}\).
Iteration:
-
(i)
Dual update: Compute \(\varvec{Y}^{(r+1)}\) with Algorithm 6.
-
(ii)
Primal update: Compute \(\varvec{P}^{(r+1)}\) with Algorithm 5.
Projection: Compute \(\hat{\varvec{\varPi }}\) with Algorithm 7.
Output: \(\hat{\varvec{\varPi }}\) (Orthoprojector onto recovered subspace).
Due to the convexity of rreaper, every minimizer of (9) is global. Thus, our proposed algorithm cannot get stuck in local minima. Since the Lagrangian (13) has a saddle-point by [40, Cor. 28.2.2], the convergence of the underlying primal-dual method to a saddle-point \((\hat{\varvec{P}}, \hat{\varvec{Y}})\) is guaranteed for parameter choices \(\sigma \tau < 1/\left| \left| \varvec{X}\right| \right| _2^2\) and \(\theta = 1\) as proven in [5, Thm. 1]. Finally, the primal variable \(\hat{\varvec{P}}\) minimizes rreaper by [40, Thm. 28.3].
However, using the thick-restarted Lanczos process to evaluate the proximal mapping of the regularizer in Proposition 2, we introduce a systematic error since the required eigenvalue decompositions are only computed approximately. Fortunately, we may control this error by choosing the accuracy \(\delta \) in Algorithm 4 appropriately small. If the accuracies becomes higher during the primal-dual iteration, we will see that the underlying primal-dual iteration converges nevertheless.
Theorem 1
(Convergence of Algorithm 8) Let
be the argument in the rth primal-dual iteration of Algorithm 8, and \(\tilde{\varvec{Q}}^{(r)}\) the computed low-rank approximation of the leading positive eigenvalues greater than \(\tau \alpha \) by the thick-restarted Lanczos process. Define the approximation error by
where \(( \cdot )_{\succeq \varvec{0}}\) denotes the projection to the positive-definite cone. Then, for \(\sigma \tau < 1 / ||\varvec{X}||_2^2\) and \(\theta = 1\), the primal-dual iteration in Algorithm 8 converges to a global minimizer of rreaper whenever \(\sum _{r=0}^\infty E_r^{\nicefrac 12} (||\varvec{Q}^{(r)}||_F + \sqrt{d})^{\nicefrac 12} < \infty \).
Proof
The key idea of the proof is to show that the approximations \(\tilde{\varvec{P}}^{(r)} = {\text {prox}}_{\tau \alpha \mathscr {R}} (\tilde{\varvec{Q}}^{(r)})\) are so-called type-one approximations of the proximal points \(\varvec{P}^{(r)}\) in the second step of Algorithm 1. For this, we have to compare the objective
of \({\text {prox}}_{\tau \alpha \mathscr {R}}\) at the points \(\tilde{\varvec{P}}^{(r)}\) and \(\varvec{P}^{(r)}\). By the triangle inequality, we obtain
Using
the non-expansiveness of the projection and assuming without loss of generality that \(E_r \le 1\), we conclude
Thus, \(\tilde{\varvec{P}}^{(r)}\) fulfills the definition of the type-one approximation with precision \(C E_r (||\varvec{Q}^{(r)}||_F + \sqrt{d})\), see [39, p. 385]. Since the square roots of the precisions are summable, [39, Thm. 2] ensures the convergence of the inexactly performed primal-dual iteration to a saddle-point of the Lagrangian in (13) and thus to a solution \(\hat{\varvec{P}}\) of rreaper. \(\square \)
6 Performance Analysis
Inspired by ideas of Lerman et al. [27], we examine the performance analysis of rreaper. To this end, we assume that the ‘ideal’ subspace L of the given data \(\varvec{x}_k \in \mathbb {R}^n\), \(k=1,\ldots ,N\) has dimension \(d_L \le d\). As in [27], we determine the best fit of the data by two measures: the first one is the distance of the data from the subspace
where \(\varPi _L\) denotes the orthogonal projector onto L. For the second measure, we assume that the projected data \(\{\varvec{\varPi } \varvec{x}_k: k=1,\ldots ,N \}\), \(N \ge d_L\), form a frame in L meaning that there exist constants \(0< c_L \le C_L < \infty \) such that
for all \(\varvec{u} \in L\) with \(\Vert u\Vert _2 = 1\). In order to recover the entire subspace L, the data have obviously to cover each direction in L with sufficiently many data points. This well-localization of the data is measured by the permeance statistic
which can be seen as \(\ell _1\) counterpart of the lower frame bound. Clearly, \(\mathscr {P}_L\) becomes large if all direction in L are uniformly covered by the data. The lower frame bound and the permeance statistic come into the play in the following lemma, compared with [27, Sect. A2.3].
Lemma 2
Let \(\varvec{\varPi }_L\) be the orthogonal projector onto a subspace L of \(\mathbb {R}^n\) of dimension \(d_L\) and \(\varvec{x}_k \in \mathbb {R}^n\), \(k=1,\ldots ,N\), \(N \ge d_L\) which form the columns of the matrix \(\varvec{X}\). Then, for any \(\varvec{A} \in \mathbb {R}^{n,n}\), the following relations hold true:
and
Proof
We restrict our attention to (25). The relation (24) follows similar lines. Let \(\varvec{A} \, \varvec{\varPi }_L\) have the singular value decomposition \(\varvec{A} \, \varvec{\varPi }_L = \varvec{U} \varvec{\varSigma }\varvec{V}^\mathrm {T}\), where the singular values \(\sigma _k\), \(k=1,\ldots ,n\) are in descending order and \(\sigma _{d_L+1}= \ldots = \sigma _n = 0\) and we can arrange \(\varvec{V}\) such that the transpose of the first \(d_L\) rows of \(\varvec{V}\) belong to L. Then it holds
Using orthogonality of \(\varvec{U}\) and concavity of the square root function, we obtain
The second estimate in (25) follows by (1). \(\square \)
Now we can estimate the reconstruction error of rreaper.
Theorem 2
Let \(\varvec{\varPi }_L\) be the orthogonal projector onto a subspace L of \(\mathbb {R}^n\) of dimension \(d_L\) and \(\varvec{x}_k \in \mathbb {R}^n\), \(k=1,\ldots ,N\), \(N \ge d_L\) such that their projections onto L form a frame of L. Define \(\mathscr {P}_L\) by (23) and set \(\gamma _L :=\frac{1}{2\sqrt{2 d_L}} \mathscr {P}_L\). Let \(\hat{\varvec{P}}\) be the solution of (9) and \(\hat{\varvec{\varPi }}\) the projection of \(\hat{\varvec{P}}\) onto \(\mathscr {O}_d\). Then, for \(\alpha \le 2\gamma _L\) and \(d \ge d_L\), the reconstruction error is bounded by
Proof
Since \(\hat{\varvec{P}}\) is a minimizer of (9), we obtain
It remains to estimate
from below. To this end, we decompose \(\varvec{\varDelta }:= \hat{\varvec{P}} - \varvec{\varPi }_L\) as
Since \(\varvec{0}_{n,n} \preceq \hat{ \varvec{P}} \preceq \varvec{I}_n\), we obtain be conjugation with \(\varvec{\varPi }_L\), resp. \(I_n - \varvec{\varPi }_L\) that \(\varvec{\varDelta }_1 \preceq \varvec{0}_{n,n}\) and \(\varvec{0}_{n,n} \preceq \varvec{\varDelta }_3\), so that \(\Vert \varvec{\varDelta }_1 \Vert _{{\text {tr}}} = -{\text {tr}}{\varvec{\varDelta }_1}\) and \(\Vert \varvec{\varDelta }_3 \Vert _{{\text {tr}}} = {\text {tr}}{\varvec{\varDelta }_3}\). Then we conclude
which implies
Now we can estimate the last summand by (1) and Lemma 2 as
Using the triangular inequality \(\Vert \hat{\varvec{P}} - \varvec{\varPi }_L\Vert _{{\text {tr}}} \ge | d_L - \Vert \hat{\varvec{P}}\Vert _{{\text {tr}}}|\), we get
We next employ the estimate
which results in
if \(\alpha < 2 \gamma _L\). Alternatively, we apply (32) in (30) together with \(|d_L - \Vert \hat{\varvec{P}}\Vert _{{\text {tr}}}| \le d\), since \(d_L \le d\), and obtain
The final assertion follows by
\(\square \)
The error depends basically on the quotient of the distance of the normalized data from the subspace and the permeance statistics, where the normalization is indirectly contained in the quotient. For \(\alpha = \gamma _L\), the terms of the minimum in (26) are the same and both terms become small; the second term is preferred for \(\alpha \) near zero or \(2 \gamma _L\). Compared to our experimental results, the estimate is in general too pessimistic.
Remark 5
In [27], the following estimate was given for the original reaper
where the data points \(\varvec{X} = [\varvec{X}_{\mathrm {in}} | \varvec{X}_{\mathrm {out}}]\) were divided into inliers \(\varvec{X}_{\mathrm {in}} \in \mathbb {R}^{n,N_{\mathrm {in}}}\) and outliers \(\varvec{X}_{\mathrm {out}} \in \mathbb {R}^{n,N_{\mathrm {out}}}\) and \((\cdot )^\sim \) normalizes the columns of a matrix one. Following the lines of the proof in those paper, we would obtain the estimate
for rreaper. Therefore, rreaper inherits the robustness from reaper as well as the theoretical guarantees for certain data models. However, in our numerical examples, we realized that the above estimate is often not defined due to division by zero, especially in the presents of already small inlier noise, i.e., if the columns of \(\varvec{X}_{\mathrm {in}}\) are only near the subspace L. Moreover, it is not clear how the division into in- and outliers can be achieved for real data sets. In our estimate (26), we do not distinguish between in- and outliers. Using alternatively \(\Vert \varvec{I}_n - (\hat{\varvec{P}} - \varvec{\varPi }_L)\Vert _2 \le 1 + \Vert \hat{\varvec{P}} - \varvec{\varPi }_L\Vert _{{\text {tr}}}\) in (31), we would obtain the estimate
7 Incorporating the Offset
So far, we have assumed that the offset \(\varvec{b}\) in the robust PCA problem is given, so that we can just search for a low-dimensional linear subspace which represents the data well. While in the classical PCA (4), the affine subspace always passes through the mean value (5) of the data, it is not clear which value \(\varvec{b}\) must be chosen in order to minimize
Clearly, if \((\hat{\varvec{A}}, \hat{\varvec{b}})\) is a minimizer of E, then, for every \(\varvec{b} \in {\text {ran}}(\hat{\varvec{A}})\), also \((\hat{\varvec{A}}, \hat{\varvec{b}} + \varvec{b})\) is a minimizer.
A common choice for the offset is the geometric median of the data points defined by
which can be computed, e.g., by the Weiszfeld algorithm and its generalizations, see, e.g., [2, 36, 42, 49]. Other choices arising, e.g., from Tyler’s M-estimator or other robust statistical approaches [19, 24, 26, 33, 47], were proposed in the literature. However, they do in general not minimize (35) as the following example from [35] shows: given three points in \(\mathbb {R}^n\) which form a triangle with angles smaller than 120\(^\circ \), the geometric median is the point in the inner of the triangle from which the points can be seen under an angle of 120\(^\circ \). In contrast, the line (\(d=1\)) having smallest distance from the three points is the one which passes through those two points with the largest distance from each other.
In the following, we show that there always exists an optimal hyperplane of dimension \(d=n-1\) in \(\mathbb {R}^n\) determined by a minimizer of E in (35) that contains at least n data points. Further, if the number N of data points is odd, then every optimal hyperplane contains at least n data points. Recall that the hyperplane spanned by the columns of \(\varvec{A} = (\varvec{a}_1|\ldots |\varvec{a}_{n-1}) \in \mathrm {St}(n,n-1)\) with offset \(\varvec{b}\) is given by
where \(\varvec{a}^\perp \perp \varvec{a}_i\), \(i=1,\ldots ,n-1\) is a unit normal vector of the hyperplane, which is uniquely determined up to its sign and \(\langle \varvec{a}^\perp ,\varvec{b} \rangle = - \beta \).
The following lemma describe the placement of the data points with respect to the halfspaces determined by a minimizing hyperplane.
Lemma 3
Let \(\varvec{x}_k \in \mathbb {R}^n\), \(k=1,\ldots ,N\). Let \((\hat{\varvec{A}},\hat{\varvec{b}})\) be a minimizer of E and \(N=M + M_+ + M_-\) with
Then it holds \(|M_+ - M_-| \le M\). In particular, it holds \(M \ge 1\) if N is odd. Also for even N there exists a minimizing hyperplane with \(\hat{\varvec{b}} = \varvec{x}_k\) for some \(k \in \{1,\ldots ,N\}\).
Proof
W.l.o.g. assume that \(M_+ \ge M_-\). If \(M_+ = 0\), then all data points are in the minimizing hyperplane and we are done. Otherwise, the value
is positive, and we consider the shifted hyperplane \(\{\varvec{x} \in \mathbb {R}^n: \langle \varvec{a}^\perp , \varvec{x} \rangle = \beta + \varepsilon \}\), which contains at least one data point. The sum of the distances of the data points from this hyperplane is
Since \((\hat{\varvec{A}},\hat{\varvec{b}})\) is a minimizer of E, this implies that \(M_+ \le M + M_-\). If \(M = 0\), then \(M_- = M_+\) and the shifted hyperplane is also minimizing. However, this case cannot appear for odd N so that \(M \ge 1\) for odd N. This finishes the proof. \(\square \)
Theorem 3
Let \(\varvec{x}_\ell \in \mathbb {R}^n\), \(\ell =1,\ldots ,N\). Then there exists a minimizer \((\hat{\varvec{A}},\hat{\varvec{b}})\) of E such that the corresponding minimizing hyperplane contains at least n data points. If N is odd, every minimizing hyperplane contains at least n data points.
Proof
By Lemma 3, there exists a data point \(\varvec{x}_\ell \) such that \((\hat{\varvec{A}}, \hat{\varvec{b}})\) with \(\hat{\varvec{b}} = \varvec{x}_\ell \) is a minimizer of E and for odd N every minimizing hyperplane passes through a data point. Let \(\hat{\varvec{a}}^\perp \) be a unit vector orthogonal to the columns of \(\hat{\varvec{A}}\). Set \(\varvec{y}_k :=\varvec{x}_k - \varvec{x}_\ell \), \(k=1,\ldots ,N\). Next, we show: if the subspace normal to \(\hat{\varvec{a}}^\perp \) contains M linearly independent vectors \(\varvec{y}_1, \dots , \varvec{y}_M\) with \(0 \le M \le n-2\), then exactly one of the following situations apply. (i) The remaining vectors \(\varvec{y}_k\) with \(k=M+1, \dots , N\) are linearly dependent from the first M vectors and thus in the same linear subspace \(\mathrm {span} \{\varvec{y}_k: k=1,\ldots ,M\}\). (ii) We find a further independent vector, say \(\varvec{y}_{M+1}\), contained in the subspace normal to \(\hat{\varvec{a}}^\perp \) such that we can increase M to \(M+1\). Repeating this argumentation until \(M = n-2\), we are done since \(\varvec{y}_k + \varvec{x}_\ell \), \(k=1,\ldots ,n-1\) and \(\varvec{x}_\ell \) itself are in the subspace corresponding to \((\hat{\varvec{A}}, \hat{\varvec{b}})\).
Because the vectors \(\varvec{y}_k\) with \(k=1,\ldots ,M\) are independent and are contained in the subspace normal to \(\hat{\varvec{a}}^\perp \) by assumption, there exists a matrix
with \({\text {ran}}(\varvec{A}) = {\text {ran}}(\varvec{B})\), whose first columns have the same span as \(\varvec{y}_1, \dots , \varvec{y}_M\), i.e.,
This especially implies \(\varvec{y}_k \perp \varvec{u}_\ell \) for \(k = 1, \dots , M\) and \(\ell = M+1, \dots , n-1\). Note that the normal unit vector of \({\text {ran}}(\varvec{B})\) is also \(\hat{\varvec{a}}^\perp \), and that the objectives coincides, i.e.,
Now, let the matrix-valued function
be defined by
where the three building factors are given by
Figuratively, the function \(\phi _{\varvec{B}}\) takes the orthonormal columns of \(\varvec{B}\) and rotates the last vector \(\varvec{u}_{n-1}\) by the angle \(\alpha \) in the plane spanned by \(\varvec{u}_{n-1}\) and \(\hat{\varvec{a}}^\perp \). Clearly, we have \(\phi _{\varvec{B}}(0) = \varvec{B}\). Due to (36), the function
has moreover a minimum in \(\alpha = 0\). For the summands of F, we obtain
since \(\varvec{Q}_{\varvec{B}}\) and \(\varvec{R}(\alpha )\) are orthogonal by construction. Hence, we get
Here the first M summands vanish because of the mentioned orthogonality \(\varvec{y}_k \perp \varvec{u}_{n-1}\) and \(\varvec{y}_k \perp \hat{\varvec{a}}^\perp \) for \(k=1, \dots , M\).
If all remaining given points \(\varvec{y}_k\) with \(k=M+1,\ldots ,N\) are in \(\mathrm {span}\{\varvec{y}_1, \ldots , \varvec{y}_M\}\), then the corresponding remaining summands of \(F(\alpha )\) become zero too, and the first situation (i) applies; so we are done.
If this is not the case, consider only those \(\varvec{y}_k\) with \(k=M+1,\ldots ,N\) that are linearly independent of the \(\varvec{y}_k\), \(k=1,\ldots ,M\). Let us denote the corresponding non-empty index set by \(\mathscr {I}\). Assume that there exists a \(k \in \mathscr {I}\) such that \(f_k\) is not differentiable in \(\alpha = 0\). This is only possible if the argument of the absolute value vanishes implying
Thus, the vector \(\varvec{y}_k\) is in the subspace spanned by the columns of \(\hat{\varvec{A}}\), and we are done. Otherwise, if \(f_k(0) \not = 0\) for all \(k\in \mathscr {I}\), then it is differentiable in \(\alpha = 0\) and, by straightforward differentiation, we obtain
But then \(\alpha = 0\) cannot be a minimizer of F which is a contradiction. Hence, this case cannot occur and the proof is complete. \(\square \)
If the target dimension d of the minimizing subspace is strictly less than \(n-1\), then it does not have to contain any data point as the following example shows.
Counterexample 1
(Lower-dimensional subspace approximation) Initially, we consider the approximation of some given points in \(\mathbb {R}^3\) by an one-dimensional subspace—a line. More precisely, for a fixed \(T \gg 1\), we consider the six given points
We thus have two well-separated clusters around \((0,0, T)^\mathrm {T}\) and \((0,0,-T)^\mathrm {T}\).
Obviously, the optimal line has somehow to go through each cluster. One possible candidate for the approximation line is simply the axis \(\{(0,0,t) : t \in \mathbb {R}\}\), whose distance to the given points is by construction 6—for each cluster 3. Now, assume that the line goes through one given point, say \((1,0,T)^\mathrm {T}\). If T is very large, then we can neglect the slope of the line. Only considering the distances within the cluster around \((0,0,T)^\mathrm {T}\), we notice that the distance increases from 3 to approximately \(2 \sqrt{3}\). Although the axis is maybe not the optimal line, the distance to the given points is smaller than for a line going through a data point. Therefore, we can conclude that the optimal line has not to contain any given point.
The same construction can be done for arbitrary subspaces of dimension \(d < n-1\). For example, consider just the points
with
where \(\varvec{e}_k\) is the kth unit vector. Using the same argumentation as above, the distance to the subspace \(\mathrm {span} \{ \pm \varvec{e}_k : k=1,\dots , d\}\) is smaller than to any d-dimensional subspace containing at least one data point.
8 Numerical Examples
In this section, we demonstrate the performance of rreaper by numerical examples implemented in MATLAB\(^{\textregistered }\) (R2019b, 64-bit) and calculated using an Intel\(^{\copyright }\) Core\(^{\mathrm{TM}}\) i7-8700 CPU (6 \(\times \) 3.20 GHz) and 32 GiB main memory. For synthetic data, we employ the so-called haystack model introduced by Lerman et al. in [27]. The idea is to generate a set of inliers \(\varvec{X}_{\mathrm {in}} \in \mathbb {R}^{n,N_{\mathrm {in}}}\) lying near an \(d_L\)-dimensional subspace—here the subspace spanned by the first \(d_L\) unit vectors—and a set of outliers \(\varvec{X}_{\mathrm {out}} \in \mathbb {R}^{n,N_{\mathrm {out}}}\) located somewhere in the surrounding space. More precisely, the elements of the in- and outliers are drawn form the Gaussians
and
The complete data set then consists of the matrix
Further, we compare the results of the matrix-free rreaper with several other robust PCA methods which can be applied to high-dimensional images. More precisely, we consider the following methods:
-
PCA-L1 method [21] maximizes the L1 dispersion \(||\varvec{P} \varvec{X}||_{1,1}\). The method is based on a greedy search algorithm that determines the maximum \(\hat{\varvec{P}}\) by finding the rank-one projections to the principal components. The method finds a local maximum, but there is no guarantee to compute the global one. Indeed, the results heavily depends on the start value, which is the reason why we restart the algorithm several times (actually 10 times). Further, in contrast to the other three methods, this one is not rotationally invariant due to the objective function which often results in lower quality.
-
Nested Weiszfeld algorithm [35] aims to approximate the minimizer of \(||(\varvec{I}_n - \varvec{P}) \varvec{X}||_{2,1}\). The projection is determined by a greedy-like method by computing the principle components sequentially. In general, this does not yield a (local) minimizer of \(||(\varvec{I}_n - \varvec{P}) \varvec{X}||_{2,1}\).
-
R1-PCA [9, 34], which minimizes again the data fidelity \(||(\varvec{I}_n - \varvec{P}) \varvec{X}||_{2,1}\). The minimization is performed by a gradient descent method on the Grassmannian manifold which is equivalent to a conditional gradient algorithm—also known as Frank–Wolfe algorithm. Convergence to a (local) minimizer is only guaranteed under certain assumptions on the anchor set.
-
Fast Median Subspace method (FMS) [25] is a heuristic method to minimize the energy \(||(\varvec{I}_n - \varvec{P}) \varvec{X}||_{2,p} := \sum _{k=1}^N ||(\varvec{I}_n - \varvec{P}) \varvec{x}_k||_2^p\) with \(0< p < 2\) iteratively. For this, a sequence of subspaces is constructed on the basis of weighted PCAs. FMS always converge to a stationary point (or to a continuum of stationary points), which are usually (local) minimizers of the energy functional.
-
Geodesic Gradient Descent (GGD) [31] intends to minimizes \(||(\varvec{I}_n - \varvec{P}) \varvec{X}||_{2,1}\) by a geodesic descent performed on the Grassmannian. Under certain conditions on the problem and starting value, this method linear converges to the underlying unknown subspace.
8.1 (2,1)-Norm versus Frobenius Norm
This example with simple synthetic data will show that the (2,1)-norm in the data term is more robust against outliers than the Frobenius norm
For the Frobenius norm here abbreviated as F-norm, we have only to replace the projection onto \(\mathfrak B_{2, \infty }\) with the projection to the Frobenius norm ball
We want to recover a line in the plane. Since this recovery problem is invariant under rotations, we restrict ourselves to \(\mathrm {span} \{ (1,0)^\mathrm {T}\}\). The data are generated randomly using the haystack model and consist of 50 points near the considered axis—we added a small amount of noise in the second coordinate—and of 10 outliers located somewhere in the plane, see Fig. 1. Besides the data points, the recovered lines using rreaper with the (2,1)-norm (solid line) as data fidelity and the Frobenius norm (dashed line) with parameters \(d=1\) and \(\alpha = 5\) are presented. In this toy example, rreaper yields nearly a perfect result regardless of the outliers and is in particular more robust than the same model with the Frobenius norm.

Performance of rreaper with (2,1)-norm and Frobenius norm in the data fidelity term, respectively. The first one appears to be more robust against outliers
8.2 Nuclear Norm and Truncated Hypercube Constraints
In this example, we are interested how the rank reduction is influenced by the nuclear norm and the projection to the truncated hypercube. In this synthetic experiment, we approximate the given data \(\varvec{x}_k \in \mathbb {R}^{100}\) by a 10-dimensional subspace. The data are again generated randomly with respect to the haystack model with \(\sigma _{\mathrm {in}} = \sigma _{\mathrm {out}} = 1\) and \(\sigma _{\mathrm {noise}} = 0.1\), where 100 points lie near the subspace L spanned by the first ten unit vectors and additional 25 outliers. In Fig. 2a, the data set is represented by the distance to the subspace L and to the orthogonal complement \(L^\perp \).

Performance of rreaper for different upper dimension estimators \(d=10,100\) and regularization parameters \(\alpha = \nicefrac 14, \nicefrac 12, \nicefrac 34 , 1, 2\) (top down for each d)
We apply rreaper in Algorithm 8 with different parameter combination. For the target dimension, we choose in our first experiment \(d=10\), which is the wanted dimension, and second one \(d=100\), which does not truncate the unit hypercube at all. The influence of the regularization parameter \(\alpha \) on the rank of \(\varvec{P}^{(r)}\) is shown in Fig. 2b, where the lines from top to down correspond to the regularization parameters \(\alpha = \nicefrac 14, \nicefrac 12, \nicefrac 34 , 1, 2\). Since we start the iteration with the zero-rank matrix \(\varvec{P}^{(0)} :=\varvec{0}\), the first iterations for \(d=10\) and \(d=100\) coincides up to the point, where the trace of \(\varvec{P}^{(r)}\) exceeds the value 10. The reconstruction errors are recorded in Table 1.
Considering only the results for \(d=100\) (dashed lines), we see that the nuclear norm reduces the rank of the iteration variable \(\varvec{P}^{(r)}\) with an increasing regularization parameter. Further, the rank during the primal-dual algorithm is very sensitive to the regularization parameter. For \(d=10\) (solid lines), the situation changes dramatically. After the initial stages, the rank of \(\varvec{P}^{(r)}\) decreases nearly to the target dimension. Since the matrices \(\varvec{P}^{(r)}\) are no orthogonal projections, rank and trace do not coincide. Due to this fact, the rank is not strictly bounded by the maximal trace of the truncated hypercube. Nevertheless, the projection to the truncated hypercube significantly reduces the rank.
For an optimal rank evolution during the matrix-free primal-dual method, the projection to the truncated hypercube by Algorithm 2 appears to be important. Moreover, the projection makes the rank evolution less sensitive to the regularization parameter \(\alpha \) so that a wider range of regularization parameters can be applied without losing the computational benefits of the low rank. Thus, the truncated hypercube projection is an elementary key component of the algorithm.
Finally, we compare the performance of rreaper in this experiment with the other robust PCA methods mentioned above. For this, we repeat the experiment 100 times with random data. For rreaper, we choose the parameters \(d=10\) and \(\alpha =0.75\). The mean reconstruction errors and the mean run times have been recorded in Table 2. In this experiment, the PCA-L1 fail to approximate the true underlying subspace. Interestingly, rreaper here always yields a slightly better approximation than R1-PCA, FMS, and GGD. The reason for this behavior is that the nuclear norm regularization suppress the Gaussian noise within the computed principle components.
8.3 Choosing the Parameters
In the last example, we have seen that the target dimension is achieved by choosing either d or \(\alpha \) appropriately. To understand the relation between the parameters in more detail and finally to get a clue how to choose \(\alpha \) if d is just taken large enough, we provide some additional experiments.
First, we repeat the experiment in Sect. 8.2 sequentially 25 times and consider the mean of the reconstruction error \(||\hat{\varvec{\varPi }} - \varvec{\varPi }_L||\) of all 25 experiments, see Fig. 3. For each choice of \(\alpha \) and d, the experiment has been repeated with the same sets of data. For this specific haystack model, the unknown subspace is recovered by choosing either \(d=10\) or \(\alpha \in [2.25, 6.75]\). Hence, the first conclusion is that the reconstruction error is much less sensitive to choice of \(\alpha \) than to those of d.

Mean reconstruction error \(||\hat{\varvec{\varPi }} - \varvec{\varPi }_L||_{{\text {tr}}}\) for varying \(\alpha \) and d. For every parameter choice, the experiment has been repeated 25 times
Next, considering again the variational nature of rreaper in (9), we recall that \(||\varvec{P} \varvec{X} - \varvec{X}||_{2,1}\) describes the error between the ‘projected data’ \(\varvec{P} \varvec{X}\) and the given data \(\varvec{X}\), and that the \(||\varvec{P}||_{{\text {tr}}}\) controls the rank of \(\varvec{P}\). In order to find a good subspace, both terms have to be small. Notice that the data fidelity becomes small if the rank/trace becomes large and vice versa. Consequently, \(\alpha \) has to be chosen such that both complementary aspects are balanced. One approach coming from inverse problems is the so-called L-curve, see for instance [14, 15]. The L-curve is a usual or a log-log plot of the data fidelity and the regularizer. For the haystack data set, the corresponding L-curve—once computed for the outcome \(\hat{\varvec{P}}\) of rreaper, and once for its projection \(\hat{\varvec{\varPi }} = {\text {proj}}_{\mathscr {O}_{25}}(\hat{\varvec{P}})\)—is shown in Fig. 4, where \(d = 25\). Notice that both L-curves have a singularity, especially in the log-log plot. For the sake of clarity, we also plotted the data fidelity and the trace norm over \(\alpha \), see Fig. 5. The corner of the L-curve for \(\hat{\varvec{\varPi }}\) corresponds to \( \alpha = 9.2\). Further, the L-curve slows down at the singularity and is nearly constant for \(\alpha \in [2.1,9.2]\). The interval corresponds to the plateaus of the data fidelity and the trace norm in dependence of the regularization parameter \(\alpha \), see Fig. 5. At the interval, data fidelity and regularizer are balanced. More importantly, for every \(\alpha \in [2.1,9.2]\), the determined subspace has dimension 10 and thus coincides with the true dimension.

The L-curve for \(d=25\) of the data set in Sect. 8.2 consisting of 100 inliers (\(\sigma _{\mathrm {in}} = 1\)) and 25 outliers (\(\sigma _{\mathrm {out}} = 1\)) with noise \(\sigma _{\mathrm {noise}} = 0.1\)

The two components of the L-curves in Fig. 4 in dependence of the regularization parameter \(\alpha \)
We repeated this experiment around 500 times for random chosen d, \(d_L\), \(N_{\mathrm {in}}\), \(N_{\mathrm {out}}\), and \(\sigma _{\mathrm {noise}}\) and observe the same behavior of the L-curve meaning that the edge of the curve has been clearly visible and corresponds to the true subspace dimension. Therefore, it seems that the unknown subspace dimension can be detected and that an appropriate regularization parameter \(\alpha \) may be chosen by studying the L-curve of the given data set. Notice that the L-curve, also well studied in the literature, is a heuristic parameter choice rule. Finally let us mention that if the inlier noise is too large or if the outliers hide the linear structure of the inliers, then the L-curve loses its singularity.
8.4 Face Approximation
The idea to use the principle components of face images—the so-called eigenfaces—for recognition, classification and reconstruction was considered in various paper and goes probably back to [45]. In this experiment, we adopt this idea to show that our matrix-free reaper can handle high-dimensional data. Since the computation of an optimal offset is non-trivial as discussed in Sect. 7, we choose just the geometric median. For the experiment, we use the ‘Extended Yale Face Data Set B’ [12, 23] consisting of several series of faces images under different lighting conditions but with the same facial expression. The basis of our noisy data set are 64 images of size \(640\times 480\) pixels with integer values between 0 and 255. We place some artifacts in the first four images covering the right eye, the nose, the right ear and the mouth, respectively, and serving as outliers. The complete employed data set is shown in Fig. 6a.

The used data set based on the Extended Yale Face Data Set B and its projections onto the determined subspace using matrix-free rreaper

Restoration of the first sample by projecting to the principle components determined by several robust PCA’s

Restoration of the artifact in the first sample by projecting to the principle components determined by several robust PCA’s
It is well-known that such images can be well approximated by a subspace covering around five directions [10]. To remove the artifacts by unsupervised learning, we therefore approximate the full data set including the artificial face images by a five-dimensional subspace (\(d=5\)) using rreaper and project the corrupted images to the computed subspace. An typical effect of this procedure is that dark regions are lightened, shadows are removed, and reflections at skin and eyes are cleared away. Besides this effects, the major part of the unwanted artefacts is removed, see Fig. 6b. Note that in this example the projection \(\hat{\varvec{\varPi }}\) corresponds to a 307,200 \(\times \) 307,200 matrix, which would require 703.125 GiB for double precision whereas the matrix-free representation only requires around 14.063 MiB since the rank of the primal variable has been bounded by six due to the choice of \(\alpha :=4.2 \cdot 10^4\). The primal-dual algorithm for rreaper has converged after 30 iterations.
Next, we compare rreaper with the robust PCA methods mentioned above. Figure 7 shows examples of the projection of the first corrupted image to the computed subspace of the four considered methods. The restoration of the artifact covering the right eye is shown in Fig. 8 in more details. Taking a closer look in Fig. 8, we notice that PCA-L1, although very fast, yields the worst result, which has also been reported in [35]. The nested Weiszfeld algorithm and R1-PCA nearly remove the artifact. The result of rreaper is comparable but appears to be slightly smoother, which is an effect of the additional regularization.
Comparing the required run times, we notice that PCA-L1 with 10 restarts is the fastest method with 10.189 (in seconds) due to its linear structure, followed by FMS with 12.313, and the nested Weiszfeld algorithm with 18.875. R1-PCA, rreaper and GGD behave similarly with 43.441, 43.439 and 55.968, respectively. Note that the run times are only comparable to a limited extent due to the different nature of the algorithms and hence different stopping criteria. For instance, GGD here requires a very small step size to stay numerically at the Grassmannian. We can clearly see that rreaper is slower than the sequential or heuristic approaches. It seems that the numerical effort of rreaper is however comparable with the non-convex methods like R1-PCA. Rreaper converges however to a global minimizer, where the non-convex methods may be stuck in local minima, which here happens for GGD.
9 Conclusion
Convex models are usually preferable over non-convex ones due to their unique local minimum. While robust PCA models that can handle high-dimensional data are usually non-convex, a convex relaxation was proposed by the reaper model. Relying on the projector approach, it is however not applicable for high-dimensional data in its original form. To manage such data, we have combined primal-dual optimization techniques from convex analysis with sparse factorization techniques from the Lanczos algorithm. Moreover, we extended the model by penalizing the nuclear norm of the operator and called it rreaper. This results in the first convex variational method for robust PCA that can handle high-dimensional data since the required memory is reduced from \(O(nN + n^2)\) to \(O(nN + nr)\), where r is the maximal rank during the primal-dual iteration and has usually the same magnitude as d. The rreaper minimization algorithm always converges to a global minimizer of the regularized objective. Moreover, using the L-curve method an advantage of the new method seems to be that the dimension of the low-dimensional subspace must not be known in advance, but may be overestimated. We intend to further investigate this direction from the point of view of multi-objective optimization [8, 48]. We addressed the problem of the bias in robust PCA, but more research in this directions appears to be necessary. Further other sparsity promoting norms then the nuclear norm could be involved. Our method can be enlarged to 3D images as videos, 3D stacks of medical or material images, where tensor-free methods will come into the play. Finally, it may be interesting to couple PCA ideas with approaches from deep learning to better understand the structure of both.
References
Beck, A.: First-Order Methods in Optimization. Society for Industrial and Applied Mathematics (SIAM), Mathematical Optimization Society, Philadelphia (2017)
Beck, A., Sabach, S.: Weiszfeld’s method: old and new results. J. Optim. Theory Appl. 164(1), 1–40 (2015)
Burger, M., Sawatzky, A., Steidl, G.: First order algorithms in variational image processing. In: Glowinski, R., Osher, S.J., Yin, W. (eds.) Splitting Methods in Communication, Imaging, Science, and Engineering, pp. 345–407. Springer, Cham (2016)
Candes, E.J., Li, X., Ma, Y., Wright, J.: Robust principal component analysis? J. ACM 58(3), 11 (2011)
Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40(1), 120–145 (2011)
Chambolle, A., Pock, T.: An introduction to continuous optimization for imaging. Acta Numerica 25, 161–319 (2016)
Cherapanamjeri, Y., Jain, P., Netrapalli, P.: Thresholding based efficient outlier robust PCA. Proc. Mach. Learn. Res. 65, 1–36 (2017)
Ciak, R., Shafei, B., Steidl, G.: Homogeneous penalizers and constraints in convex image restoration. J. Math. Imaging Vis. 47(3), 210–230 (2013)
Ding, C., Zhou, D., He, X., Zha, H.: \({R}_1\)-PCA: rotational invariant \({L}_1\)-norm principal component analysis for robust subspace factorization. In: Proceedings of the 23rd International Conference on Machine Learning, pp. 281–288. ACM, New York (2006)
Epstein, R., Hallinan, P.W., Yuille, A.L.: \(5\pm 2\) eigenimages suffice: an empirical investigation of low-dimensional lighting models. In: Proceedings of the Workshop on Physics-Based Modeling in Computer Vision, 18–19 June 1995, Cambridge, USA, pp. 108–116 (1995)
Fischler, M.A., Bolles, R.C.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. In: Readings in Computer Vision, pp. 726–740. Elsevier, Amsterdam (1987)
Georghiades, A., Belhumeur, P., Kriegman, D.: From few to many: illumination cone models for face recognition under variable lighting and pose. IEEE Trans. Pattern Anal. Mach. Intell. 23(6), 643–660 (2001)
Golub, G.H., Van Loan, C.F.: Matrix Computations, 4th edn. The John Hopkins University Press, Baltimore (2013)
Hanke, M., Hansen, P.C.: Regularization methods for large scale problems. Surv. Ind. Math. 3, 253–264 (1993)
Hansen, P.C.: The \(L\)-curve and its use in the numerical treatment of inverse problems. In: Johnston, P. (ed.) Computational Inverse Problems in Electrocardiology, Advances in Computational Bioengineering, pp. 119–142. WIT Press, Southampton (2000)
Horn, R.A., Johnson, C.R.: Matrix Analysis. Cambridge University Press, Cambridge (1991)
Huber, P.J., Ronchetti, E.M.: Robust Statistics, 2nd edn. Wiley, New York (2009)
Ke, Q., Kanade, T.: Robust \(\ell _1\) norm factorization in the presence of outliers and missing data by alternative convex programming. In: Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, vol. 1, pp. 739–746. IEEE (2005)
Kent, J.T., Tyler, D.E., Vard, Y.: A curious likelihood identity for the multivariate \(t\)-distribution. Commun. Stat. Simul. Comput. 23(2), 441–453 (1994)
Kriegel, H.P., Kröger, P., Schubert, E., Zimek, A.: A general framework for increasing the robustness of PCA-based correlation clustering algorithms. In: Scientific and Statistical Database Management. Lecture Notes in Computer Science, vol. 5069, pp. 418–435 (2008)
Kwak, N.: Principal component analysis based on L1-norm maximation. IEEE Trans. Pattern Anal. Mach. Intell. 30(9), 1672–1680 (2008)
Lanczos, C.: An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. J. Res. Natl. Bur. Stand. 45(4), 255–282 (1950)
Lee, K., Ho, J., Kriegman, D.: Acquiring linear subspaces for face recognition under variable lighting. IEEE Trans. Pattern Anal. Mach. Intell. 27(5), 684–698 (2005)
Lellmann, J., Neumayer, S., Nimmer, M., Steidl, G.: Methods for finding the offset in robust subspace fitting. PAMM 19(1) (2019)
Lerman, G., Maunu, T.: Fast, robust and non-convex subspace recovery. Inf. Inference J. IMA 7(2), 277–336 (2018). https://doi.org/10.1093/imaiai/iax012
Lerman, G., Maunu, T.: An overview of robust subspace recovery. Proc. IEEE 106(8), 1380–1410 (2018)
Lerman, G., McCoy, M., Tropp, J.A., Zhang, T.: Robust computation of linear models by convex relaxation. Found. Comput. Math. 15(1), 363–410 (2015)
Leroy, A.M., Rousseeuw, P.J.: Robust regression and outlier detection. Wiley Series in Probability and Mathematical Statistics (1987)
Li, C.K., Mathias, R.: The Lidskii–Mirsky–Wielandt theorem—additive and multiplicative versions. Numer. Math. 81, 377–413 (1999)
Liu, Y., Wang, S., Juhe, S.: Finding the projection onto the intersection of a closed half-space and a variable box. Oper Res Lett 41, 259–315 (1993). https://doi.org/10.1016/j.orl.2013.01.014
Maunu, T., Zhang, T., Lerman, G.: A well-tempered landscape for non-convex robust subspace recovery. J. Mach. Learn. Res. 20(37), 1–59 (2019)
McCoy, M., Tropp, J.A.: Two proposals for robust PCA using semidefinite programming. Electron. J. Stat. 5, 1123–1160 (2011)
Meng, X.L., Van Dyk, D.: The EM algorithm—an old folk-song sung to a fast new tune. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 59(3), 511–567 (1997)
Neumayer, S., Nimmer, M., Setzer, S., Steidl, G.: On the rotational invariant \(l_1\)-norm PCA. Linear Algebra Appl. 587, 243–270 (2020)
Neumayer, S., Nimmer, M., Setzer, S., Steidl, G.: On the robust PCA and Weiszfeld’s algorithm. Appl. Math. Optim. (To appear)
Ostresh Jr., L.M.: On the convergence of a class of iterative methods for solving the Weber location problem. Oper. Res. 26(4), 597–609 (1978)
Pearson, K.: On lines and planes of closest fit to systems of points in space. Phil. Mag. 2(11), 559–572 (1901)
Podosinnikova, A., Setzer, S., Hein, M.: Robust PCA: optimization of the robust reconstruction error over the Stiefel manifold. In: German Conference on Pattern Recognition, pp. 121–131. Springer, Berlin (2014)
Rasch, J., Chambolle, A.: Inexact first-order primal-dual algorithms. Comput. Optim. Appl. 76(2), 381–430 (2020)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (1970)
Rousseeuw, P.J., Leroy, A.M.: Robust regression and outlier detection, vol. 589. John Wiley & Sons, New York (2005)
Setzer, S., Steidl, G., Teuber, T.: On vector and matrix median computation. J. Comput. Appl. Math. 236(8), 2200–2222 (2012)
Stewart, G.W.: Accelerating the orthogonal iteration for the eigenvectors of a Hermitian matrix. Numer. Math. 13(4), 362–376 (1969)
Tsakiris, M.C., Vidal, R.: Dual principal component pursuit. J. Mach. Learn. Res. (JMLR) 19, 684–732 (2018)
Turk, M., Pentland, A.: Eigenfaces for recognition. J. Cogn. Neurosci. 3(1), 71–86 (1991)
Tyler, D.E.: A distribution-free \({M}\)-estimator of multivariate scatter. Ann. Stat. 15(1), 234–251 (1987)
Tyler, D.E.: A distribution-free \(M\)-estimator of multivariate scatter. Ann. Stat. 15(1), 234–251 (1987)
van den Berg, E., Friedlander, M.P.: Probing the pareto frontier for basis pursuit solutions. SIAM J. Sci. Comput. 31(2), 890–912 (2008)
Weiszfeld, E.: Sur le point pour lequel les sommes des distances de \(n\) points donnés et minimum. Tôhoku Math. J. 43, 355–386 (1937)
Wu, K., Simon, H.: Thick-restart Lanczos method for large symmetric eigenvalue problems. SIAM J. Matrix Anal. Appl. 22(2), 602–616 (2000)
Xu, H., Caramanis, C., Sanghavi, S.: Robust PCA via outlier pursuit. IEEE Trans. Inf. Theory 58(3), 3047–3064 (2012)
Acknowledgements
The authors want to thank G. Schneck for providing the idea of the proof for Theorem 3 and the unknown reviewers for there valuable comments and suggestions to improve this manuscript. Funding by the German Research Foundation (DFG) within the project STE 571/16-1 and by the Austrian Science Fund (FWF) within the project P28858 is gratefully acknowledged.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
R. Beinert was supported by the Austrian Science Fund (FWF) Grant P28858, and G. Steidl by German Research Foundation (DFG) Grant STE 571/16-1.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Beinert, R., Steidl, G. Robust PCA via Regularized Reaper with a Matrix-Free Proximal Algorithm. J Math Imaging Vis 63, 626–649 (2021). https://doi.org/10.1007/s10851-021-01019-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10851-021-01019-1