
Abstract
We consider entropy conservative and dissipative discretizations of nonlinear conservation laws with implicit time discretizations and investigate the influence of iterative methods used to solve the arising nonlinear equations. We show that Newton’s method can turn an entropy dissipative scheme into an anti-dissipative one, even when the iteration error is smaller than the time integration error. We explore several remedies, of which the most performant is a relaxation technique, originally designed to fix entropy errors in time integration methods. Thus, relaxation works well in consort with iterative solvers, provided that the iteration errors are on the order of the time integration method. To corroborate our findings, we consider Burgers’ equation and nonlinear dispersive wave equations. We find that entropy conservation results in more accurate numerical solutions than non-conservative schemes, even when the tolerance is an order of magnitude larger.
Similar content being viewed by others

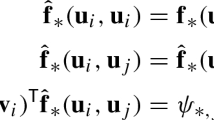
Avoid common mistakes on your manuscript.
1 Introduction
For many partial differential equations (PDEs) in computational fluid dynamics (CFD), the notion of mathematical entropy plays an important role. It can be that entropy is preserved or that the solution satisfies an entropy inequality. Alternatively, for nonlinear systems such as the Euler equations, an entropy inequality can be used to select a unique weak solution, at least in 1D. Enforcing such an entropy inequality on the discrete level has, for certain equations, led to schemes that are provably convergent to weak entropy solutions [1].
In recent years it has been observed that the robustness of high-order discontinuous Galerkin (DG) discretizations for compressible turbulent flows, greatly benefits from discrete entropy stability; see [2] and the references therein for an overview. Following the groundbreaking paper [3], a space-time version of the DG spectral element method (DG-SEM) with a specific choice of fluxes, was proven to be entropy-stable for systems of hyperbolic conservation laws [4], giving the first fully discrete high order scheme with this property. This method is inherently implicit.
Proofs of entropy stability for schemes involving implicit time integration assume that the arising systems of nonlinear equations are solved exactly. In practice, iterative solvers are used, which are terminated when a tolerance is reached. These in turn, have rarely been constructed with the intention of preserving physical invariants. Indeed, the impact of iterative solvers on the conservation of linear invariants was analyzed in [5,6,7], and it was found that many iterative methods violate global or local conservation. A recent study of Jackaman and MacLachlan [8] focuses on Krylov subspace methods for linear problems with quadratic invariants, and is related in spirit to this paper. Given the importance of entropy estimates in discrete schemes, there is a need to analyze the role played by iterative solvers in this context.
We consider PDEs posed in a single spatial dimension with periodic boundary conditions:
Here, \(\mathcal{L}\) is a nonlinear differential operator. The cases considered are such that there is a convex nonlinear functional \(\eta (u)\), here called the entropy, which is conserved. By splitting the spatial terms in certain ways, entropy conservative semi-discretizations are obtained with the aid of skew-symmetric difference operators. Next, we apply well-known implicit time integration methods that are able to either conserve or dissipate entropy, resulting in nonlinear algebraic systems with entropy bounded solutions.
Using convergent iterative solvers within implicit time integration, the iteration error (and thus the entropy error) can be made arbitrarily small by iterating long enough. However, such an approach is ill-advised since the number of iterations dictates the efficiency of the scheme. On the other hand, it is desirable to iterate long enough to prevent the iteration error from affecting the time integration error. The iteration error should thus be kept on the order of the local time integration error, but smaller in magnitude. The interested reader will find an overview of the use of iterative solvers in computational fluid dynamics in [9].
In this setting, we analyze the entropy behavior of Newton’s method, which forms the basis of many iterative solvers. As it turns out, Newton’s method can generate undesired growth (or decay) of the entropy. We consider Burgers’ equation in Sect. 2 and demonstrate that Newton’s method can turn an entropy dissipative scheme into an anti-dissipative method when the tolerance is comparable to the error in the time step. A detailed analysis reveals that the source of the entropy error is the Jacobian of the spatial discretization. In Sect. 3, strategies are evaluated that recover the entropy conservation after each Newton iteration. It is seen that these strategies come with a large cost to the efficiency of the solver, since they significantly reduce the convergence rate.
To get the best of both worlds—entropy conservation and fast convergence—we introduce relaxation methods in Sect. 4. Under mild assumptions, relaxation can be used to recover any convex entropy. We apply relaxation to nonlinear dispersive wave equations in Sects. 5 and 6. Experiments reveal that entropy conservation leads to numerical solutions of considerably higher quality than non-conservative schemes, even when larger tolerances on the iterations are used. We thus conclude that relaxation works well in combination with iterative methods. Finally, we summarize the developments and discuss our conclusions in Sect. 7.
1.1 Software
The numerical experiments discussed in this article are implemented in Julia [10]. We use the Julia packages SummationByPartsOperators.jl [11], ForwardDiff.jl [12], and Krylov.jl [13]. All source code required to reproduce the numerical experiments is available in our repository [14].
2 Burgers’ equation
As a starting point, we consider Burgers’ equation as a classical model for nonlinear conservation laws. It is well known how to design both entropy conservative and entropy dissipative discretizations for this problem. The purpose of this section is to demonstrate that Newton’s method can destroy the entropic behavior of the discretization and cause undesired entropy growth (or decay). This example serves as an illustration of a general truth: Iterative methods may destroy the design principles upon which a discretization has been built.
2.1 The continuous case
Consider the inviscid Burgers’ equation defined on a 1D periodic domain,
The factor 6 has been added for consistency with the Korteweg-de Vries equation discussed in Sect. 5. Multiplying (2) by the solution u and integrating in space results in the identity
where periodicity has been used to eliminate the boundary terms. Here, \(\Vert \cdot \Vert \) denotes the \(L^2\) norm. Evidently, the quantity \(\eta (u) = \frac{1}{2} \Vert u \Vert ^2\) is conserved. Throughout, we refer to \(\eta \) as an entropy for Burgers’ equation (2).
2.2 The semi-discrete case
It is well known how to design discretizations of (2) that mimic the entropy conservation of the continuous problem. Let \(\mathbf {\varvec{\textsf{D}}}\) be a skew-symmetric matrix that approximates the spatial derivative operator. In this section, we use classical fourth-order accurate central finite differences with periodic boundaries. Consider the semi-discretization
Here and elsewhere a sans serif font is used to denote quantities evaluated on a discrete, uniform computational grid with grid spacing \(\Delta x\). The formulation (3) constitutes a so-called skew-symmetric split form [15, eq. (6.40)]. It arises from the identity \(6 u u_x = 2 \bigl ((u^2)_x + u u_x\bigr )\).
Multiplying (3) by \(\Delta x\mathbf {\varvec{\textsf{u}}}^\top \) and using the skew-symmetry of \(\mathbf {\varvec{\textsf{D}}}\) yields
The final equality follows from the skew-symmetry of \(\mathbf {\varvec{\textsf{D}}}\). Here we have defined the discrete norm \(\Vert \mathbf {\varvec{\textsf{u}}} \Vert ^2 \equiv \Delta x\mathbf {\varvec{\textsf{u}}}^\top \mathbf {\varvec{\textsf{u}}}\) with a slight notational abuse. Evidently the semi-discrete entropy \(\eta (\mathbf {\varvec{\textsf{u}}}) = \frac{1}{2} \Vert \mathbf {\varvec{\textsf{u}}} \Vert ^2\) is conserved.
2.3 The fully discrete case
Since the entropy \(\eta \) is a quadratic functional of the solution, a fully discrete scheme that conserves entropy is obtained by discretizing (3) in time using the implicit midpoint rule. Further, any B-stable Runge–Kutta method will be entropy dissipative [16, Sect. 357]. Here, we consider both the (conservative) implicit midpoint rule and the (dissipative) fourth-order, three-stage Lobatto IIIC method. The entropy analyses in this section and the next are for simplicity reserved for the midpoint rule. The analogous results for Lobatto IIIC are found in Appendix A. They heavily utilize the fact that Lobatto IIIC is equivalent to a Summation-By-Parts (SBP) method in time [17]; see [18,19,20,21,22] for further developments of this topic.
For a generic system of ordinary differential equations \(\mathbf {\varvec{\textsf{u}}}_t = \mathbf {\varvec{\textsf{f}}}(\mathbf {\varvec{\textsf{u}}})\), the midpoint rule can be expressed as a Runge–Kutta method as follows:
Here, \(\mathbf {\varvec{\textsf{U}}}\) denotes an intermediate stage used to define the numerical solution \(\mathbf {\varvec{\textsf{u}}}^{n+1} \approx \mathbf {\varvec{\textsf{u}}}(t_{n+1})\) in terms of the solution at the previous time step; \(\mathbf {\varvec{\textsf{u}}}^n \approx \mathbf {\varvec{\textsf{u}}}(t_n)\). It is understood that \(\Delta t_n = t^{n+1} - t^n\).
Applied to the semi-discretization (3), the fully discrete scheme becomes, after slight rearrangement,
From the second line in (4), the entropy \(\eta (\mathbf {\varvec{\textsf{u}}}^{n+1})\) is given by
Left multiplication of the first line in (4) by \(\mathbf {\varvec{\textsf{U}}}^\top \) reveals that
where the skew-symmetry of \(\mathbf {\varvec{\textsf{D}}}\) has been used in the same way as in the semi-discrete analysis. Consequently, \(\eta (\mathbf {\varvec{\textsf{u}}}^{n+1}) = \eta (\mathbf {\varvec{\textsf{u}}}^n)\), hence entropy is conserved.
2.4 Newton’s method
The analysis above assumes that the stage equations in the first line of (4) are solved exactly. In practice this is infeasible. Instead, the stage vector \(\mathbf {\varvec{\textsf{U}}}\) is approximated using iterative methods. Here we consider Newton’s method as an illustrative example. If Newton iterates are computed until the residual is sufficiently small, then entropy conservation is effectively retained. However, for efficiency reason it is desirable to terminate the iterates when the residual is smaller than some tolerance, chosen to reflect the overall expected accuracy of the scheme. We will show that Newton’s method is not entropy conservative from one iteration to the next. Consequently, schemes utilizing Newton’s method (and other iterative methods) tend to lose the design principle upon which the discrete scheme is built, namely entropy conservation.
The iterates produced by Newton’s method applied to the stage equation in (4) are obtained as
Here, \(\mathbf {\varvec{\textsf{F}}}'\) denotes the Jacobian of \(\mathbf {\varvec{\textsf{F}}}\) and can be explicitly evaluated; see [23]:
Here, \(\mathbf {\varvec{\textsf{I}}}\) is the identity matrix. Inserting this expression into (7), explicitly writing out \(\mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k)})\) from (4), and utilizing the fact that \(\Delta \mathbf {\varvec{\textsf{U}}} = \mathbf {\varvec{\textsf{U}}}^{(k+1)} - \mathbf {\varvec{\textsf{U}}}^{(k)}\) leads to the following equation for \(\mathbf {\varvec{\textsf{U}}}^{(k+1)}\):
This equation replaces the stage equations in (4) when \(k+1\) Newton iterations are performed.
Suppose that Newton’s method is terminated after \(k+1\) iterations and that the solution is updated as \(\mathbf {\varvec{\textsf{u}}}^{n+1} = 2 \mathbf {\varvec{\textsf{U}}}^{(k+1)} - \mathbf {\varvec{\textsf{u}}}^n\). As in (5), the entropy is given by
Upon computing the paranthesized term, note from (4) that the first line of (9) is precisely \(\mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k+1)})\) linearized around \(\mathbf {\varvec{\textsf{U}}}^{(k)}\). By the same derivation as in (6), it follows that the contribution to the entropy change of these terms is zero. Consequently,
and hence
A slightly more elegant expression is obtained by replacing \((\mathbf {\varvec{\textsf{U}}}^{(k+1)})^\top \) with \(\Delta \mathbf {\varvec{\textsf{U}}}^\top \). This can be done since the vector \(\mathbf {\varvec{\textsf{U}}}^{(k)}\) lies in the kernel of \(\mathbf {\varvec{\textsf{M}}}^\top \). To see this, note that
Here, the skew-symmetry of \(\mathbf {\varvec{\textsf{D}}}\) has been used together with the fact that any vector \(\mathbf {\varvec{\textsf{v}}}\) satisfies \(\mathbf {\varvec{\textsf{v}}} = \textrm{diag}(\mathbf {\varvec{\textsf{v}}}) \mathbf {\varvec{\textsf{1}}}\), where \(\mathbf {\varvec{\textsf{1}}}\) is the vector of ones. The final equality follows by the commutativity of diagonal matrices.
We summarize these observations in the following:
Proposition 1
Consider the discretization (4) of Burgers’ equation (2) and apply \((k+1)\) iterations with Newton’s method to the stage equations. The entropy of the resulting numerical solution satisfies
Thus, the entropy error \(\eta (\mathbf {\varvec{\textsf{u}}}^{n+1}) - \eta (\mathbf {\varvec{\textsf{u}}}^n)\) depends on the indefinite quadratic form
Consequently, Newton’s method may cause both entropy growth and decay.
With Lobatto IIIC in place of the midpoint rule, the entropy error has an identical form, although \(\Delta \mathbf {\varvec{\textsf{U}}}\) and \(\mathbf {\varvec{\textsf{M}}}\) incorporate all intermediate stages in this case. Assuming that the iterates converge, \(\Delta \mathbf {\varvec{\textsf{U}}}\) will decrease until the entropy error is vanishingly small. However, in practical applications, we terminate the iterations at some tolerance matching the accuracy of the scheme. In such circumstances, the entropy error must be corrected by other means.
As an illustrative example we compute a single time step for Burgers’ equation (2). The spatial domain is set to \((-10,10]\) and the initial condition is given by
where \(c=2\). In the spatial discretization we set \(\Delta x= 0.1\). Both Lobatto IIIC and the midpoint rule are used in time. For Lobatto IIIC we use \(\Delta t= 0.1\) and for the midpoint rule, \(\Delta t= 0.5\) in this experiment. The entropy \(\eta (\mathbf {\varvec{\textsf{u}}}^n)\) (with \(n=1\)) and residual \(\Vert \mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k)}) \Vert \) are shown in Fig. 1 when k Newton iterations have been used to approximate the solution to the stage equation in (4). Throughout, \(\mathbf {\varvec{\textsf{U}}}^{(0)} = \mathbf {\varvec{\textsf{u}}}^n\) is used as initial guess. This choice is known to conserve linear invariants [5, 6].
The entropy visibly grows when too few Newton iterations are used. As expected, it drops back to its correct value with further iterations, testifying to the indefiniteness of the quadratic form in (10). The residual converges quadratically as expected for Newton’s method.
These examples show that if Newton’s method is applied with a tolerance around \(10^{-3}\), then entropy growth is to be expected in these simulations. Note that entropy growth may occur even for the provably entropy dissipative discretization.

Entropy \(\eta (\mathbf {\varvec{\textsf{u}}}^n) = \Vert \mathbf {\varvec{\textsf{u}}}^n\Vert / 2\) and residual \(\Vert \mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k)}) \Vert \) after \(n=1\) time steps with k Newton iterations applied to Burgers’ equation with \(\Delta x= 0.1\)
3 Strategies for recovering entropy conservation
There are several ways in which we can recover entropy conservation within Newton’s method. The most obvious is to simply keep iterating until the entropy error is negligible. However, this process might be costly since we may be forced to iterate to residuals that are smaller than what is motivated by the accuracy of the discretization.
The entropy error in (10) opens up several avenues for modifying Newton’s method to recover entropy conservation in each iteration. In the following subsections we describe two strategies that are independent of the choice of tolerance. However, as we will see, they both converge slower than Newton’s method. The two methods are, respectively
-
Method of Newton-type: By modifying the Jacobian, the entropy error is removed in its entirety.
-
Inexact Newton: Entropy conservation is recovered using a line search.
Throughout this section, we confine our attention to the entropy conservative discretization that utilizes the implicit midpoint rule.
3.1 Method of Newton-type
The entropy error (10) caused by Newton’s method originates from the Jacobian of the spatial discretization. A simple remedy is thus to modify the Jacobian by removing the problematic terms, thereby obtaining a method of Newton-type. In other words, replacing the exact Jacobian \(\mathbf {\varvec{\textsf{F}}}'\) in (8) with the approximation
should result in a vanishing entropy error. However, this will simultaneously reduce the convergence speed from quadratic to linear [24, Chapter 5].
Repeating the experiment in Sect. 2.4 reveals that this is indeed the case. Figure 2 shows the entropy and residual. Clearly the entropy is conserved as desired. However, the convergence is no longer quadratic but linear. After 14 iterations, the residual is comparable to four iterations with Newton’s method. It is thus questionable if anything has been gained.

Entropy \(\eta (\mathbf {\varvec{\textsf{u}}}^n)\) and residual \(\Vert \mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k)}) \Vert \) after \(n=1\) time steps with \(k \in \{ 0,\dots ,14 \}\) iterations of a method of Newton-type for the implicit midpoint rule applied to Burgers’ equation with \(\Delta x= 0.1\) and \(\Delta t= 0.5\). The convergence is linear
3.2 Inexact Newton and line search
As a second alternative, entropy conservation can be recovered through a line search. We replace Newton’s method as stated in (7) by
where \(\alpha _k \in [0,1]\) is a sequence of scalar parameters. This formulation is equivalent to the inexact Newton’s method
If the sequence \(\{ \alpha _k \}\) is such that \((1-\alpha _k) = {\mathcal {O}}(\Vert \mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k)}) \Vert )\), then quadratic convergence is retained under standard assumptions. Under the much less severe condition \(0 \le 1-\alpha _k < 1\), covergence is generally linear [25].
The essential property used in the proof that the fully discrete scheme (4) is entropy conservative is that the stage vector \(\mathbf {\varvec{\textsf{U}}}\) satisfies \(\mathbf {\varvec{\textsf{U}}}^\top \mathbf {\varvec{\textsf{U}}} - \mathbf {\varvec{\textsf{U}}}^\top \mathbf {\varvec{\textsf{u}}}^n = 0\). Proposition 1 shows that the same relation does not hold for the Newton iterations. To ensure entropy conservation for the inexact Newton method, \(\alpha _k\) must therefore be chosen such that
where \(\mathbf {\varvec{\textsf{U}}}^{(k+1)}\) is given as in (12). This is a quadratic equation in \(\alpha _k\). Assuming that \(\mathbf {\varvec{\textsf{U}}}^{(k)}\) has correct entropy, the two roots are \(\alpha _k = 0\) and
Here, \(\langle \cdot , \cdot \rangle \) denotes the Euclidean inner product scaled by \(\Delta x\). The trivial root \(\alpha _k = 0\) results in \(\mathbf {\varvec{\textsf{U}}}^{(k+1)} = \mathbf {\varvec{\textsf{U}}}^{(k)}\) and is of no use, hence only the second root needs to be considered.
Repeating the previous experiment with inexact Newton leads to the results displayed in Fig. 3. Entropy is conserved as expected. The convergence is faster than it was with the method of Newton-type, however it is still linear. This happens since \(\alpha _k \in [0,1]\) for each k but does not approach unity, as is necessary for quadratic convergence. Instead, its value appears to plateau around 0.95 in this particular experiment.

Entropy \(\eta (\mathbf {\varvec{\textsf{u}}}^n)\) and residual \(\Vert \mathbf {\varvec{\textsf{F}}}(\mathbf {\varvec{\textsf{U}}}^{(k)}) \Vert \) after \(n=1\) time steps with \(k \in \{ 0,\dots ,6 \}\) inexact Newton iterations for the implicit midpoint rule applied to Burgers’ equation with \(\Delta x= 0.1\) and \(\Delta t= 0.5\). The convergence is linear
4 Theory of relaxation methods
The idea of a line search discussed in the previous section can be applied, not necessarily after each Newton iteration, but alternatively just once after a full time step computed using multiple Newton iterations. The resulting schemes are known as relaxation methods [26,27,28]. As we will see, relaxation solves the problem with entropy growth without impacting the convergence speed of Newton’s method, or that of any other iterative method.
While a general theory of relaxation methods that includes multistep methods is available [28], we restrict the following discussion to one-step methods for simplicity. Thus, we consider a system of ODEs \(\mathbf {\varvec{\textsf{u}}}'(t) = f\bigl (\mathbf {\varvec{\textsf{u}}}(t)\bigr )\) and a one-step method. We again assume that there is a (nonlinear and sufficiently smooth) functional \(\eta \) of interest, which we call an entropy.
In this setting, the basic idea of relaxation methods is to perform a line search along the secant line connecting the new approxiation \(\mathbf {\varvec{\textsf{u}}}^{n+1}\) produced by a given time integration method, and the previous value \(\mathbf {\varvec{\textsf{u}}}^{n}\). This results in the relaxed value
where \(\gamma \approx 1\) is the relaxation parameter chosen to enforce the desired conservation or dissipation of \(\eta \). This idea goes back to Sanz-Serna [29, 30] and Dekker and Verwer [31, pp. 265–266], who considered entropies \(\eta \) given by inner product norms. However, the first approaches resulted in an order reduction [32], which has been fixed in [26] for inner product norms and extended to general entropies in [27, 28]. Some further developments can be found in [33,34,35,36,37,38].
To motivate the approach, we augment the ODE by the equations \(t' = 1\) and the entropy evolution given by the chain rule, leading to
Given a suitable estimate of the entropy \(\eta ^\textrm{new} = \eta \bigl (\mathbf {\varvec{\textsf{u}}}(t^{n+1})\bigr ) + {\mathcal {O}}(\Delta t^{p+1})\), where p is the order of the time integration method, relaxation methods enforce
by inserting the second equation into the third one, resulting in a scalar equation for the relaxation parameter \(\gamma \). Next, the numerical solution is updated according to the second equation and the current simulation time is set to \(t^{n+1}_\gamma \). The last step is required to avoid order reduction. Finally, the time integration is continued using \((t^{n+1}_\gamma , \mathbf {\varvec{\textsf{u}}}^{n+1}_\gamma )\) instead of \((t^{n+1}, \mathbf {\varvec{\textsf{u}}}^{n+1})\).
If entropy conservation is to be enforced, the canonical choice of the entropy estimate is \(\eta ^\textrm{new} = \eta \bigl (\mathbf {\varvec{\textsf{u}}}^{n}\bigr )\). In case of entropy dissipation, \(\eta ^\textrm{new}\) can be estimated [26,27,28]: For an RK method
with non-negative weights \(b_i \ge 0\), choose
This leads to an entropy dissipative scheme.
The general theory of relaxation methods yields the following result [27, 28]:
Theorem 2
Consider the system of ODEs \(\mathbf {\varvec{\textsf{u}}}'(t) = f\bigl (\mathbf {\varvec{\textsf{u}}}(t)\bigr )\). Assume \(\mathbf {\varvec{\textsf{u}}}^{n} = \mathbf {\varvec{\textsf{u}}}(t^{n})\) and \(\mathbf {\varvec{\textsf{u}}}^{n+1} = \mathbf {\varvec{\textsf{u}}}(t^{n+1}) + {\mathcal {O}}(\Delta t^{p+1})\) with \(p \ge 2\) and \(t^{n+1} = t^{n} + \Delta t\). If \(\eta ^\textrm{new} = \eta \bigl (\mathbf {\varvec{\textsf{u}}}(t^{n+1})\bigr ) + {\mathcal {O}}(\Delta t^{p+1})\), \(\Delta t> 0\) is small enough, and the non-degeneracy condition
is satisfied with \(c \ne 0\), then there is a unique \(\gamma = 1 + {\mathcal {O}}( \Delta t^{p-1} )\) that satisfies the relaxation condition (13) and the resulting relaxation method is of order p such that
The crucial observation for our application in this article is that there is no further assumption on the preliminary time step update \(\mathbf {\varvec{\textsf{u}}}^{n+1}\) other than the accuracy constraint \(\mathbf {\varvec{\textsf{u}}}^{n+1} = \mathbf {\varvec{\textsf{u}}}(t^{n+1}) + {\mathcal {O}}(\Delta t^{p+1})\) in Theorem 2. In particular, the results can be applied to implicit Runge–Kutta methods where the stage equations are solved inexactly with Newton’s method (or another iterative method) up to some tolerance as long as the tolerance of the nonlinear solver does not affect the accuracy of the time integration method. A perturbation analysis shows that an approximation \(\mathbf {\varvec{\textsf{u}}}^{n+1} + \mathbf {\varvec{\mathsf {\varepsilon }}}\) results in a perturbed relaxation parameter that can be estimated. In general, we need that the size of the perturbation \(\mathbf {\varvec{\mathsf {\varepsilon }}}\) is at most of the same order as the local error of the baseline time integration method, i.e. \({\mathcal {O}}(\Delta t^{p+1})\). This is precisely the situation desired for iterative methods in practice.
We end this section by revisiting Burgers’ equation (2). As before, a single time step is computed with the midpoint rule and Newton’s method. The Newton residuals are identical to those seen in Fig. 1b. However, since the relaxation alters the length of the time step, it may be argued that the original Newton residual is not the only one of interest: The numerical solution \(\mathbf {\varvec{\textsf{u}}}_\gamma ^{n+1}\) approximates the true solution at the relaxed time \(t_\gamma ^{n+1} = t^n + \gamma \Delta t\), hence a residual \(\Vert \mathbf {\varvec{\textsf{F}}}_\gamma ( \cdot ) \Vert \) evaluated at this time is also appropriate. Such a residual can be obtained by introducing a relaxed stage vector \(\mathbf {\varvec{\textsf{U}}}_\gamma \) defined through the relation \(\mathbf {\varvec{\textsf{u}}}_\gamma ^{n+1} = 2 \mathbf {\varvec{\textsf{U}}}_\gamma - \mathbf {\varvec{\textsf{u}}}^n\) and inserting it into the full discretization (4) evaluated at the relaxed time.
Applying relaxation to preserve a quadratic invariant yields a linear equation for the relaxation parameter that we solve analytically. For the implicit midpoint rule, it is given by
The relaxed residual and entropy are shown in Fig. 4. Although we have not presented a theoretical justification, the residual is seen to converge quadratically with values comparable to those of the usual Newton iterations in Fig. 1b. Additionally, the entropy is conserved as expected.

Entropy \(\eta (\mathbf {\varvec{\textsf{u}}}^n)\) and relaxed residual \(\Vert \mathbf {\varvec{\textsf{F}}}_\gamma (\mathbf {\varvec{\textsf{U}}}^{(k)}_\gamma ) \Vert \) after \(n=1\) time steps with \(k \in \{ 0,\ldots ,5 \}\) Newton iterations for the implicit midpoint rule applied to Burgers’ equation with \(\Delta x= 0.1\) and \(\Delta t= 0.5\). The convergence is quadratic and entropy is conserved
5 Korteweg-de Vries equation
We have motivated our study by looking at the influence of inexact solutions obtained by Newton’s method applied to provably entropy conservative and entropy dissipative time discretization methods for Burgers’ equation. Next, we will look at a more complicated equation where i) implicit methods are required due to stiffness constraints and ii) entropy conservative methods have a significant advantage. Indeed, the classical Korteweg-de Vries (KdV) equation
is stiff due to the linear dispersive term \(u_{xxx}\). We consider solutions of the form
In the context of the KdV equation, (15) describes a soliton propagating with speed c. The behavior of numerical time integration methods applied to soliton solutions has been analyzed in [39]: If the time integration method conserves the linear invariant \(\int u\) and the quadratic invariant \(\int u^2\), the error of the numerical solution has a leading-order term that grows linearly with time. Otherwise, the error grows quadratically in time at leading order.
De Frutos and Sanz-Serna [39] verified this numerically using the implicit midpoint rule and an entropy non-conservative third order SDIRK method. They used essentially exact solutions of the stage equations. Under such conditions, relaxation has been demonstrated to yield the same reduced error growth when applied to the SDIRK method [33].
Here, we extend the investigations and focus on the influence of non-negligible tolerances of the nonlinear solver. In other words, we approximate the stage solutions to the stage equations with a tolerance that matches that of the time discretization.
5.1 Numerical methods
We consider the soliton solution (15) of the KdV equation (14) in the periodic domain \(x \in (-10,10]\). The spatial discretization is the same as for Burgers’ equation, i.e., five-point centered (i.e. skew-symmetric) differences with a spatial increment \(\Delta x= 0.1\). In time, the implicit midpoint rule is used with time step \(\Delta t= 0.05\). The final time is set to \(t=1000\).
The solution to the nonlinear system arising within each time step is approximated with Newton-GMRES. Here and eleswhere, GMRES is used without preconditioning. The absolute tolerance for Newton’s method is set to zero and the relative tolerance is chosen as \(tol \in \{ 10^{-3}, 10^{-4}, 10^{-5} \}\). The tolerances for GMRES are chosen using the procedure suggested by Eisenstat and Walker [25], which is designed to recover quadratic convergence without over-iterating the linear solver in the early Newton iterations. This procedure requires the choice of two scalar parameters, \(\eta _{\textrm{max}}\) and \(\gamma \) (not to be confused with the relaxation parameter). Here, we follow the implementation described in [24, Chapter 6.3] with the parameter choices \((\gamma ,\eta _{\textrm{max}}) = (0.9,0.9)\).
5.2 Numerical results
Figure 5 shows the discrete \(L^2\) error and the error in the quadratic invariant \(\eta (\mathbf {\varvec{\textsf{u}}}) = \frac{1}{2} \Vert \mathbf {\varvec{\textsf{u}}}\Vert ^2\) for four cases: The unrelaxed solver with relative tolerance chosen from the set \(\{ 10^{-3}, 10^{-4}, 10^{-5} \}\) and the relaxed solver with relative tolerance \(10^{-3}\). The relaxation parameter is computed in the same way as for Burger’s equation. The absolute tolerance is set to zero.

Error of numerical solutions and entropy error of the KdV equation (14) with periodic boundary conditions using the implicit midpoint rule with time step size \(\Delta t= 0.05\). The implicit equations are solved with Newton-GMRES and different relative tolerances
The discrete \(L^2\) error after the first time step is roughly \(10^{-3}\). Newton’s method with a relative tolerance of \(10^{-3}\) results in a superlinear error growth in time. The error eventually plateaus due to the fact that the numerical solution drifts completely out of phase with the true solution. It subsequently drifts in and out of phase, which gives rise to the oscillating nature of the error. Subsequent growth is also a consequence of the soliton losing its initial shape.
Shrinking the tolerance to \(10^{-4}\) reduces the error growth rate significantly. However, the growth is still superlinear and reaches the same plateau seen with the larger tolerance. Yet another tolerance reduction to \(10^{-5}\) leads to considerably improved results. The error grows linearly throughout the simulation time. However, the quadratic invariant is still not conserved.
By instead applying relaxation after every time step and using the original tolerance \(10^{-3}\), the error growth rate is reduced even further. Additionally, the entropy is conserved up to machine precision. Thus, entropy conservation yields a better numerical solution even with a two orders of magnitude larger tolerance compared to the non-conservative scheme.
Table 1 displays statistics on the number of Newton iterations and function evaluations used by the different solvers. Note that this experiment has been set up so that the relaxed solver takes the same number of time steps as the other ones. Since relaxation alters the length of each time step, the end time of the relaxed run is slightly different from the others at \(t_{final} = 997.9\). The data for the relaxed solver, marked (r) in Table 1, suggests that it requires less effort than the unrelaxed versions.

Error of numerical solutions and entropy error of the KdV equation (14) with periodic boundary conditions using the fourth-order, three-stage Lobatto IIIC method with time step size \(\Delta t= 0.1\). The implicit equations are solved with Newton-GMRES and different absolute and relative tolerances
Figure 6 shows the results using the same space discretization but the fourth-order, three-stage Lobatto IIIC method in time with \(\Delta t= 0.1\). Since this method is B-stable, it dissipates the quadratic entropy when the stage equations are solved exactly. Here, we again apply Newton-GMRES with different tolerances. In this case, we set the absolute and relative tolerances to the same value, again chosen from the set \(\{ 10^{-3}, 10^{-4}, 10^{-5} \}\). The \(L^2\) error after one time step is approximately \(10^{-3}\).
The resulting scheme is anti-dissipative with tolerances \(10^{-3}\) and \(10^{-4}\). The error displays similar characteristics to that of the midpoint rule with an initially superlinear growth.
With the tolerance \(10^{-5}\) the entropy error is negative. The \(L^2\) error shows a hump, suggesting that the numerical solution first drifts out of phase in one direction, then turns around and drifts the other way. Eventually the error starts to grow superlinearly as seen for the other tolerances.
As for the midpoint rule, relaxation leads to entropy conservation, a slower error growth and an overall better numerical solution. Again, this holds even when the tolerance is two orders of magnitude larger than the non-conservative scheme.
Table 2 shows statistics for the four solvers. As before, the number of time steps is kept fixed, resulting in a final time \(t_{final} = 295.3\) for the relaxed solver. Again, the resources required to obtain the results with relaxation are noticeably smaller than without relaxation.
6 Benjamin–Bona–Mahony equation
An alternative to the stiff dispersive term of the KdV equation has been proposed by Benjamin, Bona, and Mahony (BBM) in [40], leading to the BBM equation
Due to the mixed-derivative term \(-u_{txx}\), the system is not stiff, but a linear elliptic equation must be solved to evaluate the time derivative \(u_t\). Assuming periodic boundary conditions, the functionals
are invariants of solutions to the BBM equation [41]. The error growth under time discretization has been analyzed in [42]: For methods conserving the linear invariant and one of the nonlinear invariants, the error of solitary waves grows linearly in time while general methods have a quadratically growing error (both at leading order). We use this example to investigate the behavior of the methods also for non-quadratic entropies.
6.1 Numerical methods
We introduce numerical methods conserving important invariants of the BBM equation (16) with periodic boundary conditions. To broaden the scope of the following derivations, we assume that a discrete inner product is given by a diagonal, symmetric, and positive-definite matrix \(\mathbf {\varvec{\textsf{M}}}\). For the classical finite-difference methods described above, \(\mathbf {\varvec{\textsf{M}}} = \Delta x\mathbf {\varvec{\textsf{I}}}\). Next, we need derivative operators \(\mathbf {\varvec{\textsf{D}}}_{1,2}\) approximating the first and second derivative operators. We require compatibility with integration by parts, i.e., we need that \(\mathbf {\varvec{\textsf{D}}}_1\) is skew-symmetric with respect to \(\mathbf {\varvec{\textsf{M}}}\) and that \(\mathbf {\varvec{\textsf{D}}}_2\) is symmetric and negative semidefinite with respect to \(\mathbf {\varvec{\textsf{M}}}\). This is satisfied by classical central finite differences and Fourier collocation methods but also by appropriate continuous and discontinuous Galerkin methods; see e.g. [43].
For brevity, let \(\mathbf {\varvec{\textsf{u}}}^2 = \textrm{diag}(\mathbf {\varvec{\textsf{u}}}) \mathbf {\varvec{\textsf{u}}}\) denote the elementwise square of \(\mathbf {\varvec{\textsf{u}}}\). The convention can similarly be extended to other elementwise powers as necessary.
Using such periodic derivative operators, the semidiscretization
conserves both the linear and the quadratic invariant [43], which are discretely represented as
All symplectic Runge–Kutta methods, such as the implicit midpoint rule, conserve these linear and quadratic invariants [44].
Next, we construct a method conserving the cubic invariant.
Theorem 3
The semidiscretization
conserves the linear invariant \(J^{\text {BBM}}_1(\mathbf {\varvec{\textsf{u}}})\) and the cubic invariant
for commuting periodic derivative operators \(\mathbf {\varvec{\textsf{D}}}_1\), \(\mathbf {\varvec{\textsf{D}}}_2\).
Proof
Conservation of the linear invariant follows from Lemma 2.1 and Lemma 2.2 of [43] since
Given conservation of the linear invariant, conservation of the cubic invariant is equivalent to conservation of the Hamiltonian
This Hamiltonian is conserved, since \(\mathbf {\varvec{\textsf{M}}} (\mathbf {\varvec{\textsf{I}}} - \mathbf {\varvec{\textsf{D}}}_2)^{-1} \mathbf {\varvec{\textsf{D}}}_1\) is skew-symmetric [43, Lemma 2.3] and
\(\square \)
The average vector field (AVF) method [45] for an ODE \(\mathbf {\varvec{\textsf{u}}}'(t) = f\bigl ( \mathbf {\varvec{\textsf{u}}}(t) \bigr )\) is given by
It conserves the Hamiltonian \({\mathcal {H}}\) of Hamiltonian systems \(\mathbf {\varvec{\textsf{u}}}'(t) = S \, {\mathcal {H}}'\bigl ( \mathbf {\varvec{\textsf{u}}}(t) \bigr )\) with a constant (in time) skew-symmetric operator S [46]. For quadratic Hamiltonians, it is equivalent to the implicit midpoint rule; for (up to) quartic Hamiltonians, it is equivalent to
see [47]. Thus, we obtain
Proposition 4
The time integration method (20) applied to the semidiscretization (19) of the BBM equation with periodic boundary conditions conserves the linear and cubic invariants under the conditions given in Theorem 3.
6.2 Numerical results
We consider the traveling wave solution
with speed \(c = 1.2\) in the periodic domain \((-90, 90]\). We apply the semidiscretizations described above with Fourier collocation methods [48, Chapter 4] using \(2^6\) nodes. The time integration methods use fixed time steps \(\Delta t= 0.25\). The nonlinear systems are solved with the same Newton-GMRES method as for the KdV equation. The relative tolerances are chosen as \(tol \in \{ 10^{-3}, 10^{-4} \}\).
Applying relaxation to preserve a quadratic invariant yields a linear equation for the relaxation parameter that we solve analytically. For a cubic invariant, the relaxation parameter is determined by a quadratic equation that we solve analytically; we always choose the solution closer to unity.

Discrete \(L^2\) error of numerical methods for the BBM equation (16) with periodic boundary conditions. The implicit equations are solved with Newton-GMRES and different relative tolerances
The results of these numerical experiments are shown in Fig. 7. The discrete \(L^2\) error after the first time step is of the order \(10^{-3}\). Using a relative tolerance of \(10^{-3}\) for Newton-GMRES results in a discrete \(L^2\) error that grows superlinearly in time. Reducing the relative tolerance of Newton’s method to \(10^{-4}\) reduces the error growth rate to linear, resulting in significantly better results for long-time simulations. Applying relaxation after each time step with a relative tolerance of \(10^{-3}\) for Newton’s method also yields a linear error growth rate and even slightly smaller discrete \(L^2\) errors for long-time simulations.
Table 3 shows the run statistics for the three solvers. The data is identical for the two spatial discretizations, hence only one data set is shown. In contrast to previous experiments, here the final time is fixed at \(t_{final} = 1,500\) for all solvers. In this case, this leads to fewer time steps required for the relaxed solver. All in all, the resources required to obtain the results are smaller with relaxation enabled, while simultaneously yielding a more accurate solution.
7 Conclusion
We have analyzed entropy properties of iterative solvers in the context of time integration methods for nonlinear conservation laws. Continuing recent work on linear invariants in [5,6,7], we have focused on the conservation of nonlinear functionals. In particular, we have considered combinations of space and implicit time discretization that result in entropy conservative and entropy dissipative schemes when the arising equation systems were solved exactly. In practice, the iterative solver is terminated once a tolerance is reached. This tolerance is chosen such that the iteration error is smaller than the time integration error. We have demonstrated that, in this situation, Newton’s method can result in an entropically incorrect behavior, both for entropy conservative and dissipative schemes.
Based on an analysis for Burgers’ equation, we have explored several possible entropy fixes for Newton’s method. Of these, an idea stemming from the recently developed relaxation methods is most performant. These methods are designed as small modifications of time integrations schemes that are able to preserve the correct evolution of nonlinear functionals. Here we have shown that, as long as the iteration error is small enough in the sense described above, relaxation can also be used within implicit time integrators with inexact solves.
We have demonstrated that Newton’s method with inexact linear solves and reasonable tolerances combines well with the relaxation approach, in particular for nonlinear dispersive wave equations. The numerical results show that, for the problems considered here, entropy conservation leads to smaller errors than non-conservative methods, even when the tolerance of the iterative method is an order of magnitude larger. Additionally, the computational resources required to obtain the results are reduced when relaxation is enabled.
Data availability
Not applicable.
Code Availability
We have set up a reproducibility repository [14] for this article, containing all Julia source code required to fully reproduce the numerical experiments discussed in this article.
References
Kröner, D., Ohlberger, M.: A posteriori error estimates for upwind finite volume schemes for nonlinear conservation laws in multi dimensions. Math. Comput. 69(229), 25–39 (1999). https://doi.org/10.1090/S0025-5718-99-01158-8
Gassner, G.J., Winters, A.R.: A novel robust strategy for discontinuous Galerkin methods in computational fluid mechanics: why? when? what? where? Front. Phys. 8, 500690 (2021). https://doi.org/10.3389/fphy.2020.500690
Fisher, T.C., Carpenter, M.H.: High-order entropy stable finite difference schemes for nonlinear conservation laws: finite domains. J. Comput. Phys. 252, 518–557 (2013). https://doi.org/10.1016/j.jcp.2013.06.014
Friedrich, L., Schnücke, G., Winters, A.R., Del Rey Fernández, D.C., Gassner, G.J., Carpenter, M.H.: Entropy stable space-time discontinuous Galerkin schemes with summation-by-parts property for hyperbolic conservation laws. J. Sci. Comput. 80(1), 175–222 (2019). https://doi.org/10.1007/s10915-019-00933-2
Birken, P., Linders, V.: Conservation properties of iterative methods for implicit discretizations of conservation laws. J. Sci. Comput. 92(2), 1–32 (2022). https://doi.org/10.1007/s10915-022-01923-7
Linders, V., Birken, P.: Locally conservative and flux consistent iterative methods, SIAM J. Sci. Comput. (2023) forthcoming. https://doi.org/10.48550/arXiv.2206.10943
Linders, V., Birken, P.: On the consistency of Arnoldi-based Krylov methods for conservation laws. PAMM 23(1), 202200157 (2023). https://doi.org/10.1002/pamm.202200157
Jackaman, J., MacLachlan, S.: Constraint-satisfying Krylov solvers for structure-preserving discretisations arxiv:2212.05127 (2022)
Birken, P.: Numerical Methods for Unsteady Compressible Flow Problems. Chapman and Hall/CRC, New York (2021). https://doi.org/10.1201/9781003025214
Bezanson, J., Edelman, A., Karpinski, S., Shah, V.B.: Julia: a fresh approach to numerical computing. SIAM Rev. 59(1), 65–98 (2017). https://doi.org/10.1137/141000671
Ranocha, H.: SummationByPartsOperators.jl: a Julia library of provably stable semidiscretization techniques with mimetic properties. J. Open Source Softw. 6(64), 3454 (2021). https://doi.org/10.21105/joss.03454
Revels, J., Lubin, M., Papamarkou, T.: Forward-Mode Automatic Differentiation in Julia arxiv:1607.07892 (2016)
Montoison, A., Orban, D., contributors: Krylov.jl: A Julia Basket of Hand–Picked Krylov Methods (2020). https://doi.org/10.5281/zenodo.822073
Linders, V., Ranocha, H., Birken, P.: Reproducibility repository for “Resolving Entropy Growth from Iterative Methods” (2023). https://doi.org/10.5281/zenodo.7669546
Richtmyer, R.D., Morton, K.W.: Difference Methods for Boundary-Value Problems. Wiley, New York (1967)
Butcher, J.C.: Numerical Methods for Ordinary Differential Equations. Wiley, Chichester (2016). https://doi.org/10.1002/9781119121534
Ranocha, H.: Some notes on summation by parts time integration methods. Results Appl. Math. 1, 100004 (2019). https://doi.org/10.1016/j.rinam.2019.100004
Versbach, L.M., Linders, V., Klöfkorn, R., Birken, P.: Theoretical and practical aspects of space-time DG-SEM implementations. SMAI J. Comput. 9, 61–93 (2023). https://doi.org/10.5802/smai-jcm.95
Nordström, J., Lundquist, T.: Summation-by-parts in time. J. Comput. Phys. 251, 487–499 (2013). https://doi.org/10.1016/j.jcp.2013.05.042
Lundquist, T., Nordström, J.: The SBP-SAT technique for initial value problems. J. Comput. Phys. 270, 86–104 (2014). https://doi.org/10.1016/j.jcp.2014.03.048
Boom, P.D., Zingg, D.W.: High-order implicit time-marching methods based on generalized summation-by-parts operators. SIAM J. Sci. Comput. 37(6), 2682–2709 (2015). https://doi.org/10.1137/15M1014917
Linders, V., Nordström, J., Frankel, S.H.: Properties of Runge–Kutta-summation-by-parts methods. J. Comput. Phys. 419, 109684 (2020). https://doi.org/10.1016/j.jcp.2020.109684
Chan, J., Taylor, C.G.: Efficient computation of Jacobian matrices for entropy stable summation-by-parts schemes. J. Comput. Phys. 448, 110701 (2022). https://doi.org/10.1016/j.jcp.2021.110701
Kelley, C.T.: Iterative Methods for Linear and Nonlinear Equations. SIAM, Philadelphia (1995)
Eisenstat, S.C., Walker, H.F.: Choosing the forcing terms in an inexact Newton method. SIAM J. Sci. Comput. 17(1), 16–32 (1996). https://doi.org/10.1137/0917003
Ketcheson, D.I.: Relaxation Runge–Kutta methods: conservation and stability for inner-product norms. SIAM J. Numer. Anal. 57(6), 2850–2870 (2019). https://doi.org/10.1137/19M1263662
Ranocha, H., Sayyari, M., Dalcin, L., Parsani, M., Ketcheson, D.I.: Relaxation Runge–Kutta methods: fully-discrete explicit entropy-stable schemes for the compressible Euler and Navier–Stokes equations. SIAM J. Sci. Comput. 42(2), 612–638 (2020). https://doi.org/10.1137/19M1263480
Ranocha, H., Lóczi, L., Ketcheson, D.I.: General relaxation methods for initial-value problems with application to multistep schemes. Numer. Math. 146, 875–906 (2020). https://doi.org/10.1007/s00211-020-01158-4
Sanz-Serna, J.M.: An explicit finite-difference scheme with exact conservation properties. J. Comput. Phys. 47(2), 199–210 (1982). https://doi.org/10.1016/0021-9991(82)90074-2
Sanz-Serna, J.M., Manoranjan, V.: A method for the integration in time of certain partial differential equations. J. Comput. Phys. 52(2), 273–289 (1983). https://doi.org/10.1016/0021-9991(83)90031-1
Dekker, K., Verwer, J.G.: Stability of Runge–Kutta Methods for Stiff Nonlinear Differential Equations. CWI Monographs, vol. 2. North-Holland, Amsterdam (1984)
Calvo, M., Hernández-Abreu, D., Montijano, J.I., Rández, L.: On the preservation of invariants by explicit Runge–Kutta methods. SIAM J. Sci. Comput. 28(3), 868–885 (2006). https://doi.org/10.1137/04061979X
Ranocha, H., Ketcheson, D.I.: Relaxation Runge–Kutta methods for Hamiltonian problems. J. Sci. Comput. 84(1) (2020). https://doi.org/10.1007/s10915-020-01277-y
Ranocha, H., Dalcin, L., Parsani, M.: Fully-discrete explicit locally entropy-stable schemes for the compressible Euler and Navier–Stokes equations. Comput. Math. Appl. 80(5), 1343–1359 (2020). https://doi.org/10.1016/j.camwa.2020.06.016
Bencomo, M.J., Chan, J.: Discrete adjoint computations for relaxation Runge–Kutta methods. J. Sci. Comput. 94(3), 59 (2023). https://doi.org/10.1007/s10915-023-02102-y
Kang, S., Constantinescu, E.M.: Entropy-preserving and entropy-stable relaxation IMEX and multirate time-stepping methods. J. Sci. Comput. 93, 23 (2022). https://doi.org/10.1007/s10915-022-01982-w
Li, D., Li, X., Zhang, Z.: Implicit-explicit relaxation Runge–Kutta methods: construction, analysis and applications to PDEs. Math. Comput. (2022). https://doi.org/10.1090/mcom/3766
Li, D., Li, X., Zhang, Z.: Linearly implicit and high-order energy-preserving relaxation schemes for highly oscillatory Hamiltonian systems. J. Comput. Phys. 111925 (2023). https://doi.org/10.1016/j.jcp.2023.111925
De Frutos, J., Sanz-Serna, J.M.: Accuracy and conservation properties in numerical integration: the case of the Korteweg–de Vries equation. Numer. Math. 75(4), 421–445 (1997). https://doi.org/10.1007/s002110050247
Benjamin, T.B., Bona, J.L., Mahony, J.J.: Model equations for long waves in nonlinear dispersive systems. Philos. Trans. R. Soc. A 272(1220), 47–78 (1972). https://doi.org/10.1098/rsta.1972.0032
Olver, P.J.: In: Euler operators and conservation laws of the BBM equation. Mathematical Proceedings of the Cambridge Philosophical Society 85, 143–160 (1979). https://doi.org/10.1017/S0305004100055572. Cambridge University Press
Araújo, A., Durán, A.: Error propagation in the numerical integration of solitary waves. The regularized long wave equation. Appl. Numer. Math. 36(2–3), 197–217 (2001). https://doi.org/10.1016/S0168-9274(99)00148-8
Ranocha, H., Mitsotakis, D., Ketcheson, D.I.: A broad class of conservative numerical methods for dispersive wave equations. Commun. Comput. Phys. 29(4), 979–1029 (2021). https://doi.org/10.4208/cicp.OA-2020-0119
Hairer, E., Lubich, C., Wanner, G.: Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations. Springer Series in Computational Mathematics, vol. 31. Springer, Berlin (2006). https://doi.org/10.1007/3-540-30666-8
McLachlan, R.I., Quispel, G., Robidoux, N.: Geometric integration using discrete gradients. Philos. Trans. R. Soc. A 357(1754), 1021–1045 (1999). https://doi.org/10.1098/rsta.1999.0363
Quispel, G., McLaren, D.I.: A new class of energy-preserving numerical integration methods. J. Phys. A Math. Theor. 41(4), 045206 (2008). https://doi.org/10.1088/1751-8113/41/4/045206
Celledoni, E., McLachlan, R.I., McLaren, D.I., Owren, B., Quispel, G.R.W., Wright, W.: Energy-preserving Runge–Kutta methods. ESAIM-Math. Model. Numer. 43, 645–649 (2009). https://doi.org/10.1051/m2an/2009020
Kopriva, D.A.: Implementing Spectral Methods for Partial Differential Equations: Algorithms for Scientists and Engineers. Springer, Dordrecht (2009). https://doi.org/10.1007/978-90-481-2261-5
Linders, V., Lundquist, T., Nordström, J.: On the order of accuracy of finite difference operators on diagonal norm based summation-by-parts form. SIAM J. Numer. Anal. 56(2), 1048–1063 (2018). https://doi.org/10.1137/17M1139333
Linders, V.: On an eigenvalue property of summation-by-parts operators. J. Sci. Comput. 93(3), 82 (2022). https://doi.org/10.1007/s10915-022-02042-z
Fernández, D.C.D.R., Boom, P.D., Zingg, D.W.: A generalized framework for nodal first derivative summation-by-parts operators. J. Comput. Phys. 266, 214–239 (2014). https://doi.org/10.1016/j.jcp.2014.01.038
Acknowledgements
We thank Gregor Gassner for stimulating discussions about this research topic and comments on an early draft of the manuscript. We also thank Wasilij Barsukow for finding a typo in the preprint.
Funding
Open access funding provided by Lund University. Viktor Linders was partially funded by The Royal Physiographic Society in Lund. Hendrik Ranocha was supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation, Project Number 513301895) and the Daimler und Benz Stiftung (Daimler and Benz foundation, project number 32-10/22).
Author information
Authors and Affiliations
Contributions
Conceptualization: Viktor Linders, Hendrik Ranocha, Philipp Birken; Formal analysis and investigation: Viktor Linders, Hendrik Ranocha; Code writing and numerical experiments: Viktor Linders, Hendrik Ranocha; Writing—original draft: Viktor Linders, Hendrik Ranocha, Philipp Birken; Writing—review and editing: Viktor Linders, Hendrik Ranocha, Philipp Birken.
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no financial or proprietary interests in any material discussed in this article.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Communicated by Marko Huhtanen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Entropy analysis for Lobatto IIIC
Appendix A: Entropy analysis for Lobatto IIIC
The purpose of this appendix is to provide details of the entropic behavior of the Lobatto IIIC method used in the numerical experiments in Sect. 2. The analysis will be kept general enough to encompass methods of arbitrary order of accuracy. It utilizes the Summation-By-Parts (SBP) property [19, 21] satisfied by the RK method. The same argument can be made for any RK method associated with the SBP framework such as Radau IA and IIA [17]. See [18, 22] for details about the properties and implementation of such methods.
1.1 A.1 The fully discrete scheme
For a system of ordinary differential equations \(\mathbf {\varvec{\textsf{u}}}_t = \mathbf {\varvec{\textsf{f}}}(\mathbf {\varvec{\textsf{u}}})\), the Runge–Kutta stage equations and update are given by
In the experiment in Sect. 2, the 3-stage Lobatto IIIC method is used, which is associated with the Butcher tableau
It will be convenient for our purposes to express (A1) in a vector format as
Here, \(\mathbf {\varvec{A}} = \{ a_{ij} \}_{i,j=1}^s\) is the Butcher coefficient matrix, \(\mathbf {\varvec{1}}\) is the s-element vector of all ones, \(\mathbf {\varvec{\textsf{U}}}\) is the (column) vector containing the stacked stage vectors \(\mathbf {\varvec{\textsf{y}}}^1, \dots , \mathbf {\varvec{\textsf{y}}}^s\) and \(\otimes \) denotes the Kronecker product.
The update \(\mathbf {\varvec{\textsf{u}}}^{n+1}\) can be computed as in (A2) due to the fact that the final row of \(\mathbf {\varvec{A}}\) is identical to the vector \(\mathbf {\varvec{b}}^\top \). This property can be generalized by considering methods for which there is a vector \(\mathbf {\varvec{\textsf{v}}} \in {\mathbb {R}}^s\) such that \(\mathbf {\varvec{A}}^\top \mathbf {\varvec{v}} = \mathbf {\varvec{b}}\), in which case \(\mathbf {\varvec{\textsf{u}}}^{n+1} = (\mathbf {\varvec{v}}^\top \otimes \mathbf {\varvec{\textsf{I}}}) \mathbf {\varvec{\textsf{U}}}\). For the 3-stage Lobatto IIIC method, we have \(\mathbf {\varvec{v}} = (0,0,1)^\top \).
We now revisit the spatial discretization of Burgers’ equation in (3) by setting \(\mathbf {\varvec{\textsf{f}}}(\mathbf {\varvec{\textsf{u}}}) = -2(\mathbf {\varvec{\textsf{D}}} \textrm{diag}(\mathbf {\varvec{\textsf{u}}}) \mathbf {\varvec{\textsf{u}}} + \textrm{diag}(\mathbf {\varvec{\textsf{u}}}) \mathbf {\varvec{\textsf{D}}} \mathbf {\varvec{\textsf{u}}})\). The entropy behavior of the fully discrete scheme can be analyzed with the aid of the SBP property, which can be expressed as
Here, \(\mathbf {\varvec{B}} = \textrm{diag}(\mathbf {\varvec{b}})\) and \(\mathbf {\varvec{e}}_j\) denotes the jth column of the \(s \times s\) identity matrix. In this context, \(\mathbf {\varvec{A}}^{-1}\) can be viewed as a difference operator adjoined with an initial condition, and \(\mathbf {\varvec{B}}\) as a quadrature rule [49]. The SBP property (A3) is thus a discrete version of integration by parts.
We begin by left-multiplying the stage equations in (A2) by \(\Delta x\mathbf {\varvec{\textsf{U}}}^\top (\mathbf {\varvec{B}} \mathbf {\varvec{A}}^{-1} \otimes \mathbf {\varvec{\textsf{I}}})\). This is a well-defined operation since \(\mathbf {\varvec{A}}\) is invertible for any s [50]. By a derivation identical to (6), it holds that \((\mathbf {\varvec{\textsf{y}}}^i)^\top \mathbf {\varvec{\textsf{f}}}(\mathbf {\varvec{\textsf{y}}}^i) = \mathbf {\varvec{\textsf{0}}}\) for each \(i=1,\dots ,s\). Since \(\mathbf {\varvec{B}}\) is diagonal it follows that \(\Delta x\mathbf {\varvec{\textsf{U}}}^\top (\mathbf {\varvec{B}} \otimes \mathbf {\varvec{\textsf{I}}}) \mathbf {\varvec{\textsf{f}}}(\mathbf {\varvec{\textsf{U}}}) = \mathbf {\varvec{\textsf{0}}}\), and consequently
The left-hand side of (A4) is a quadratic form and is therefore equal to its symmetric part. The right-hand side is simplified by the relation \(\mathbf {\varvec{B}} \mathbf {\varvec{A}}^{-1} \mathbf {\varvec{1}} = \mathbf {\varvec{e}}_1\); see [22, Lemma 3]. The identity (A4) therefore reduces to
Simplification using the SBP property (A3) allows us to express this in terms of the first and last stages as
By adding and subtracting \(\frac{1}{2} \Vert \mathbf {\varvec{\textsf{u}}}^n \Vert ^2\) from the right-hand side, the entropy, given by \(\eta (\mathbf {\varvec{\textsf{u}}}^{n+1}) = \frac{1}{2} \Vert \mathbf {\varvec{\textsf{y}}}^s \Vert ^2\), can be expressed as
Lobatto IIIC therefore dissipates entropy. This result is independent of the number of stages and holds more generally for RK methods with the SBP property. A slight generalization (to the so called gSBP property [51]) is necessary for the analysis to hold for some RK methods such as the Radau family.
1.2 A.2 Newton’s method
The Jacobian \(\mathbf {\varvec{\textsf{F}}}'\) is explicitly given by
where \(\mathbf {\varvec{\textsf{f}}}'\) is the Jacobian of the spatial discretization. The form of \(\mathbf {\varvec{\textsf{f}}}'\) is identical to that seen for the midpoint rule, except that it is now repeated for each stage \(\mathbf {\varvec{\textsf{y}}}^i\) in a block-diagonal fashion. This leads to an equation for \(\mathbf {\varvec{\textsf{U}}}^{(k+1)}\) of the form
Here, \(\mathbf {\varvec{\textsf{f}}}(\mathbf {\varvec{\textsf{U}}}^{(k)}, \mathbf {\varvec{\textsf{U}}}^{(k+1)})\) is short-hand notation for the spatial discretization linearized around \(\mathbf {\varvec{\textsf{U}}}^{(k)}\). The matrix \(\tilde{\mathbf {\varvec{\textsf{M}}}}\) is block-diagonal with each block identical to the case for the midpoint rule, but evaluated at the individual stages. As before, (A6) represents a linearization of the fully discrete scheme around the iterate \(\mathbf {\varvec{\textsf{U}}}^{(k)}\), perturbed by a term arising from the spatial Jacobian.
By an analysis completely analogous to that in the previous subsection, the entropy relation evaluates to
where \(\mathbf {\varvec{\textsf{M}}} = (\mathbf {\varvec{B}} \otimes \mathbf {\varvec{\textsf{D}}}) \textrm{diag}(\mathbf {\varvec{\textsf{U}}}^{(k)}) + \textrm{diag}((\mathbf {\varvec{B}} \otimes \mathbf {\varvec{\textsf{D}}}) \mathbf {\varvec{\textsf{U}}}^{(k)})\). The entropy error induced by Newton’s method is thus of the same form as for the midpoint rule (for which \(\mathbf {\varvec{B}}=1\)), but includes all s stages of the Runge–Kutta scheme.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Linders, V., Ranocha, H. & Birken, P. Resolving entropy growth from iterative methods. Bit Numer Math 63, 45 (2023). https://doi.org/10.1007/s10543-023-00992-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10543-023-00992-w