
Abstract
This article derives an accurate, explicit, and numerically stable approximation to the kernel quadrature weights in one dimension and on tensor product grids when the kernel and integration measure are Gaussian. The approximation is based on use of scaled Gauss–Hermite nodes and truncation of the Mercer eigendecomposition of the Gaussian kernel. Numerical evidence indicates that both the kernel quadrature and the approximate weights at these nodes are positive. An exponential rate of convergence for functions in the reproducing kernel Hilbert space induced by the Gaussian kernel is proved under an assumption on growth of the sum of absolute values of the approximate weights.
Similar content being viewed by others
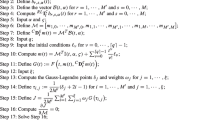

Avoid common mistakes on your manuscript.
1 Introduction
Let \(\mu \) be the standard Gaussian measure on \(\mathbb {R}\) and \(f :\mathbb {R}\rightarrow \mathbb {R}\) a measurable function. We consider the problem of numerical computation of the integral with respect to \(\mu \) of f using a kernel quadrature rule (we reserve the term cubature for rules on higher dimensions) based on the Gaussian kernel
with the length-scale \(\ell > 0\). Given any distinct nodes\(x_1,\ldots ,x_N\), the kernel quadrature rule is an approximation of the form
with its weights\(w_k = (w_{k,1},\ldots ,w_{k,N}) {\in } \mathbb {R}^N\) solved from the linear system of equations
where \([K]_{ij} \,{{:}{=}}\, k(x_i,x_j)\) and \([k_\mu ]_i \,{{:}{=}}\, \int _\mathbb {R}k(x_i,x) \hbox {d}\mu (x)\). This is equivalent to uniquely selecting the weights such that the N kernel translates \(k(x_1,\cdot ),\ldots ,k(x_N,\cdot )\) are integrated exactly by the quadrature rule. Kernel quadrature rules can be interpreted as best quadrature rules in the reproducing kernel Hilbert space (RKHS) induced by a positive-definite kernel [20], integrated kernel (radial basis function) interpolants [5, 35], and posteriors to \(\mu (f)\) under a Gaussian process prior on the integrand [7, 21, 29].
Recently, Fasshauer and McCourt [12] have developed a method to circumvent the well-known problem that interpolation with the Gaussian kernel becomes often numerically unstable—in particular when \(\ell \) is large—because the condition number of K tends to grow with an exponential rate [33]. They do this by truncating the Mercer eigendecomposition of the Gaussian kernel after M terms and replacing the interpolation basis \(\{k(x_n,\cdot )\}_{n=1}^N\) with the first M eigenfunctions. In this article we show that application of this method with \(M=N\) to kernel quadrature yields, when the nodes are selected by a suitable and fairly natural scaling of the nodes of the classical Gauss–Hermite quadrature rule, an accurate, explicit, and numerically stable approximation to the Gaussian kernel quadrature weights. Moreover, the proposed nodes appear to be a good and natural choice for the Gaussian kernel quadrature.
To be precise, Theorem 2.2 states that the quadrature rule \({\widetilde{Q}}_k\) that exactly integrates the first N Mercer eigenfunctions of the Gaussian kernel and uses the nodes
has the weights
\({\widetilde{w}}_k = ({\widetilde{w}}_{k,1}, \ldots , {\widetilde{w}}_{k,N}) \,{\in }\, \mathbb {R}^N\), where \(\alpha \) (for which the value \(1/\sqrt{2}\) seems the most natural), \(\beta \), and \(\delta \) are constants defined in Eq. (2.3), \(\mathrm {H}_n\) are the probabilists’ Hermite polynomials (2.2), and \(x_n^{\mathrm{GH}}\) and \(w_n^{\mathrm{GH}}\) are the nodes and weights of the N-point Gauss–Hermite quadrature rule. We argue that these weights are a good approximation to \(w_{k}\) and accordingly call them approximate Gaussian kernel quadrature weights. Although we derive no bounds for the error of this weight approximation, numerical experiments in Sect. 5 indicate that the approximation is accurate and that it appears that \({\widetilde{w}}_{k} \rightarrow w_{k}\) as \(N \rightarrow \infty \). In Sect. 4 we extend the weight approximation for d-dimensional Gaussian tensor product kernel cubature rules of the form
where \(Q_{k,i}\) are one-dimensional Gaussian kernel quadrature rules. Since each weight of \(Q_k^d\) is a product of weights of the univariate rules, an approximation for the tensor product weights is readily available.
It turns out that the approximate weight and the associated nodes \(\tilde{x}_n\) have a number of desirable properties:
We are not aware of any work on efficient selection of “good” nodes in the setting of this article. The Gauss–Hermite nodes [29, Section 3] and random points [31] are often used, but one should clearly be able to do better, while computation of the optimal nodes [28, Section 5.2] is computationally demanding. As such, given the desirable properties, listed below, of the resulting kernel quadrature rules, the nodes \(\tilde{x}_n\) appear to be an excellent heuristic choice. These nodes also behave naturally when \(\ell \rightarrow \infty \); see Sect. 2.5.
Numerical experiments in Sect. 5.3 suggest that both \(w_{k,n}\) (for the nodes \(\tilde{x}_n\)) and \({\widetilde{w}}_{k,n}\) are positive for any \(N \in \mathbb {N}\) and every \(n = 1,\ldots , N\). Besides the optimal nodes, the weights for which are guaranteed to be positive when the Gaussian kernel is used [28, 32], there are no node configurations that give rise to positive weights as far as we are aware of.
Numerical experiments in Sects. 5.1 and 5.3 demonstrate that computation of the approximate weights is numerically stable. Furthermore, construction of these weights only incurs a quadratic computational cost in the number of points, as opposed to the cubic cost of solving \(w_k\) from Eq. (1.2). See Sect. 2.6 for more details. Note that to obtain a numerically stable method it is not necessary to use the nodes \(\tilde{x}_n\) as the method in [12] can be applied in a straightforward manner for any nodes. However, doing so one forgoes a closed form expression and has to use the QR decomposition.
In Sects. 3 and 4 we show that slow enough growth with N of \(\sum _{n=1}^N \left|\widetilde{w}_{k,n}\right|\) (numerical evidence indicates this sum converges to one) guarantees that the approximate Gaussian kernel quadrature rule—as well as the corresponding tensor product version—converges with an exponential rate for functions in the RKHS of the Gaussian kernel. Convergence analysis is based on analysis of magnitude of the remainder of the Mercer expansion and rather explicit bounds on Hermite polynomials and their roots. Magnitude of the nodes \(\tilde{x}_n\) is crucial for the analysis; if they were further spread out the proofs would not work as such.
We find the connection to the Gauss–Hermite weights and nodes that the closed form expression for \({\widetilde{w}}_k\) provides intriguing and hope that it can be at some point used to furnish, for example, a rigorous proof of positivity of the approximate weights.
2 Approximate weights
This section contains the main results of this article. The main contribution is derivation, in Theorem 2.2, of the weights \({\widetilde{w}}_k\), that can be used to approximate the kernel quadrature weights. We also discuss positivity of these weights, the effect the kernel length-scale \(\ell \) is expected to have on quality of the approximation, and computational complexity.
2.1 Eigendecomposition of the Gaussian kernel
Let \(\nu \) be a probability measure on the real line. If the support of \(\nu \) is compact, Mercer’s theorem guarantees that any positive-definite kernel k admits an absolutely and uniformly convergent eigendecomposition
for positive and non-increasing eigenvalues \(\lambda _n\) and eigenfunctions \(\varphi _n\) that are included in the RKHS \(\mathscr {H}\) induced by k and orthonormal in \(L^2(\nu )\). Moreover, \(\sqrt{\lambda _n} \varphi _n\) are \(\mathscr {H}\)-orthonormal. If the support of \(\nu \) is not compact, the expansion (2.1) converges absolutely and uniformly on all compact subsets of \(\mathbb {R}\times \mathbb {R}\) under some mild assumptions [37, 38]. For the Gaussian kernel (1.1) and measure the eigenvalues and eigenfunctions are available analytically. For a collection of explicit eigendecompositions of some other kernels, see for instance [11, Appendix A]
Let \(\mu _\alpha \) stand for the Gaussian probability measure,
with variance \(1/(2\alpha ^2)\) (i.e., \(\mu = \mu _{1/\sqrt{2}}\,\)) and

for the (unnormalised) probabilists’ Hermite polynomial satisfying the orthogonality property \(\left\langle \mathrm {H}_n , \mathrm {H}_m \right\rangle _{L^2(\mu )} = n! \, \delta _{nm}\). Denote
and note that \(\beta > 1\) and \(\delta ^2 > 0\). Then the eigenvalues and \(L^2(\mu _\alpha )\)-orthonormal eigenfunctions of the Gaussian kernel are [12]
and
See [11, Section 12.2.1] for verification that these indeed are Mercer eigenfunctions and eigenvalues for the Gaussian kernel. The role of the parameter \(\alpha \) is discussed in Sect. 2.4. The following result, also derivable from Equation 22.13.17 in [1], will be useful.
Lemma 2.1
The eigenfunctions (2.5) of the Gaussian kernel (1.1) satisfy
for \(m \ge 0\).
Proof
Since an Hermite polynomial of odd order is an odd function, \(\mu (\varphi _{2m+1}^\alpha ) = 0\). For even indices, use the explicit expression
the Gaussian moment formula
and the binomial theorem to conclude that
\(\square \)
2.2 Approximation via QR decomposition
We begin by outlining a straightforward extension to kernel quadrature of the work of Fasshauer and McCourt in [12] and [11, Chapter 13] on numerically stable kernel interpolation. Recall that the kernel quadrature weights \(w_k \in \mathbb {R}^N\) at distinct nodes \(x_1,\ldots ,x_N\) are solved from the linear system \(K w_k = k_\mu \) with \({[K]_{ij} = k(x_i,x_j)}\) and \({[k_{\mu }]_i = \int _\mathbb {R}k(x_i,x) \hbox {d}\mu (x)}\). Truncation of the eigendecomposition (2.1) after \(M \ge N\) termsFootnote 1 yields the approximations \(K \approx \varPhi \varLambda \varPhi ^\mathsf {T}\) and \(k_\mu \approx \varPhi \varLambda \varphi _\mu \), where \({[\varPhi ]_{ij} \,{{:}{=}}\, \varphi _{j-1}^\alpha (x_i)}\) is an \(N \times M\) matrix, the diagonal \(M \times M\) matrix \([\varLambda ]_{ii} \,{{:}{=}}\, \lambda _{i-1}\) contains the eigenvalues in appropriate order, and \({[\varphi _\mu ]_i \,{{:}{=}}\, \mu (\varphi _{i-1})}\) is an M-vector. The kernel quadrature weights \(w_k\) can be therefore approximated by
Equation (2.6) can be written in a more convenient form by exploiting the QR decomposition. The QR decomposition of \(\varPhi \) is
for a unitary \(Q \in \mathbb {R}^{N \times N}\), an upper triangular \(R_1 \in \mathbb {R}^{N \times N}\), and \(R_2 \in \mathbb {R}^{N \times (M-N)}\). Consequently,
The decomposition
of \(\varLambda \in \mathbb {R}^{M \times M}\) into diagonal \(\varLambda _1 \in \mathbb {R}^{N \times N}\) and \(\varLambda _2 \in \mathbb {R}^{(M-N) \times (M-N)}\) allows for writing
Therefore,
where \(I_N\) is the \(N \times N\) identity matrix. If \(\varepsilon ^2/(\alpha ^2+\delta ^2+\varepsilon ^2)\) is small (i.e., \(\ell \) is large), numerical ill-conditioning in Eq. (2.7) for the Gaussian kernel is associated with the diagonal matrices \(\varLambda _1^{-1}\) and \(\varLambda _2\). Consequently, numerical stability can be significantly improved by performing the multiplications by these matrices in the terms \(\varLambda _1^{-1} R_1^{-1} R_2 \varLambda _2 R_2^\mathsf {T}\) and \(\varLambda _1^{-1} R_1^{-1} R_2 \varLambda _2\) analytically; see [12, Sections 4.1 and 4.2] for more details.
Unfortunately, using the QR decomposition does not provide an attractive closed form solution for the approximate weights \({\widetilde{w}}_k^M\) for general M. Setting \(M = N\) turns \(\varPhi \) into a square matrix, enabling its direct inversion and formation of an explicit connection to the classical Gauss–Hermite quadrature. The rest of the article is concerned with this special case.
2.3 Gauss–Hermite quadrature
Given a measure \(\nu \) on \(\mathbb {R}\), the N-point Gaussian quadrature rule is the unique N-point quadrature rule that is exact for all polynomials of degree at most \(2N-1\). We are interested in Gauss–Hermite quadrature rules that are Gaussian rules for the Gaussian measure \(\mu \):
for every polynomial \(p :\mathbb {R}\rightarrow \mathbb {R}\) with \(\deg p \le 2N-1\). The nodes \(x_1^{\mathrm{GH}}, \ldots x_N^{\mathrm{GH}}\) are the roots of the Nth Hermite polynomial \(\mathrm {H}_N\) and the weights \(w_1^{\mathrm{GH}}, \ldots , w_N^{\mathrm{GH}}\) are positive and sum to one. The nodes and the weights are related to the eigenvalues and eigenvectors of the tridiagonal Jacobi matrix formed out of three-term recurrence relation coefficients of normalised Hermite polynomials [13, Theorem 3.1].
We make use of the following theorem, a one-dimensional special case of a more general result due to Mysovskikh [27]. See also [8, Section 7]. This result also follows from the Christoffel–Darboux formula (2.12).
Theorem 2.1
Let \(\nu \) be a measure on \(\mathbb {R}\). Suppose that \(x_1,\ldots ,x_N\) and \(w_1,\ldots ,w_N\) are the nodes and weights of the unique Gaussian quadrature rule. Let \(p_0,\ldots ,p_{N-1}\) be the \(L^2(\nu )\)-orthonormal polynomials. Then the matrix \([P]_{ij} \,{{:}{=}}\, \sum _{n=0}^{N-1} p_n(x_i) p_n(x_j)\) is diagonal and has the diagonal elements \([P]_{ii} = 1/w_i\).
2.4 Approximate weights at scaled Gauss–Hermite nodes
Let us now consider the approximate weights (2.6) with \(M = N\). Assuming that \(\varPhi \) is invertible, we then have
Note that the exponentially decaying Mercer eigenvalues, a major source of numerical instability, do not appear in the equation for \({\widetilde{w}}_k\). The weights \({\widetilde{w}}_k\) are those of the unique quadrature rule that is exact for the N first eigenfunctions \(\varphi _0^\alpha ,\ldots ,\varphi _{N-1}^\alpha \). For the Gaussian kernel, we are in a position to do much more. Recalling the form of the eigenfunctions in Eq. (2.5), we can write \(\varPhi = \sqrt{\beta } E^{-1} V\) for the diagonal matrix \([E]_{ii} \,{{:}{=}}\, {{\,\mathrm{e}\,}}^{\delta ^2 x_i^2}\) and the Vandermonde matrix
of scaled and normalised Hermite polynomials. From this it is evident that \(\varPhi \) is invertible—which is just a manifestation of the fact that the eigenfunctions of a totally positive kernel constitute a Chebyshev system [17, 30]. Consequently,
Select the nodes
Then the matrix V defined in Eq. (2.8) is precisely the Vandermonde matrix of the normalised Hermite polynomials and \(V V^\mathsf {T}\) is the matrix P of Theorem 2.1. Let \(W_{\mathrm{GH}}\) be the diagonal matrix containing the Gauss–Hermite weights. It follows that \(V^{-\mathsf {T}} = W_{\mathrm{GH}} V\) and
Combining this equation with Lemma 2.1, we obtain the main result of this article.
Theorem 2.2
Let \(x_1^{\mathrm{GH}}, \ldots , x_N^{\mathrm{GH}}\) and \(w_1^{\mathrm{GH}}, \ldots , w_N^{\mathrm{GH}}\) stand for the nodes and weights of the N-point Gauss–Hermite quadrature rule. Define the nodes
Then the weights \( \widetilde{w}_{k} \in \mathbb {R}^N\) of the N-point quadrature rule
defined by the exactness conditions \({\widetilde{Q}}_k(\varphi _n^\alpha ) = \mu _\alpha (\varphi _n^\alpha )\) for \(n = 0,\ldots ,N-1\), are
where \(\alpha \), \(\beta \), and \(\delta \) are defined in Eq. (2.3) and \(\mathrm {H}_{2m}\) are the probabilists’ Hermite polynomials (2.2).
Since the weights \(\widetilde{w}_{k}\) are obtained by truncating of the Mercer expansion of k, it is to be expected that \(\widetilde{w}_k \approx w_k\). This motivates our calling of these weights the approximate Gaussian kernel quadrature weights. We do not provide theoretical results on quality of this approximation, but the numerical experiments in Sect. 5.2 indicate that the approximation is accurate and that its accuracy increases with N. See [12] for related experiments.
An alternative non-analytical formula for the approximate weights can be derived using the Christoffel–Darboux formula [13, Section 1.3.3]
From Eq. (2.9) we then obtain (keep in mind that \(x_1^{\mathrm{GH}},\ldots ,x_N^{\mathrm{GH}}\) are the roots of \(\mathrm {H}_N\))
This formula is analogous to the formula
for the Gauss–Hermite weights. Plugging this in, we get
It appears that both \(w_{k,n}\) and \({\widetilde{w}}_{k,n}\) of Theorem 2.2 are positive for many choices of \(\alpha \); see Sect. 5.3 for experiments involving \(\alpha = 1/\sqrt{2}\). Unfortunately, we have not been able to prove this. In fact, numerical evidence indicates something slightly stronger. Namely that the even polynomial
of degree \(2\lfloor (N-1)/2\rfloor \) is positive for every \(N \ge 1\) and (at least) every \(0 < \gamma \le 1\). This would imply positivity of \({\widetilde{w}}_{k,n}\) since the Gauss–Hermite weights \(w_n^{\mathrm{GH}}\) are positive. For example, with \(\alpha = 1/\sqrt{2}\),
As discussed in [12] in the context of kernel interpolation, the parameter \(\alpha \) acts as a global scale parameter. While in interpolation it is not entirely clear how this parameter should be selected, in quadrature it seems natural to set \(\alpha = 1/\sqrt{2}\) so that the eigenfunctions are orthonormal in \(L^2(\mu )\). This is the value that we use, though also other values are potentially of interest since \(\alpha \) can be used to control the spread of the nodes independently of the length-scale \(\ell \). In Sect. 3, we also see that this value leads to more natural convergence analysis.
2.5 Effect of the length-scale
Roughly speaking, magnitude of the eigenvalues
determines how many eigenfunctions are necessary for an accurate weight approximation. We therefore expect that the approximation (2.11) is less accurate when the length-scale \(\ell \) is small (i.e., \(\varepsilon = 1/(\sqrt{2}\ell )\) is large). This is confirmed by the numerical experiments in Sect. 5.
Consider then the case \(\ell \rightarrow \infty \). This scenario is called the flat limit in scattered data approximation literature where it has been provedFootnote 2 that the kernel interpolant associated to an isotropic kernel with increasing length-scale converges to (i) the unique polynomial interpolant of degree \(N-1\) to the data if the kernel is infinitely smooth [22, 24, 34] or (ii) to a polyharmonic spline interpolant if the kernel is of finite smoothness [23]. In our case, \(\ell \rightarrow \infty \) results in
If the nodes are selected as in Eq. (2.10), \(\tilde{x}_n \rightarrow x_n^{\mathrm{GH}}/(\sqrt{2}\alpha )\). That is, if \(\alpha = 1/\sqrt{2}\)
That the approximate weights convergence to the Gauss–Hermite ones can be seen, for example, from Eq. (2.11) by noting that only the first term in the sum is retained at the limit. Based on the aforementioned results regarding convergence of kernel interpolants to polynomial ones at the flat limit, it is to be expected that also \(w_{k,n} \rightarrow w_n^{\mathrm{GH}}\) as \(\ell \rightarrow \infty \) (we do not attempt to prove this). Because the Gauss–Hermite quadrature rule is the “best” for polynomials and kernel interpolants convergence to polynomials at the flat limit, the above observation provides another justification for the choice \(\alpha = 1{/}\sqrt{2}\) that we proposed the preceding section.
When it comes to node placement, the length-scale is having an intuitive effect if the nodes are selected according to Eq. (2.10). For small \(\ell \), the nodes are placed closer to the origin where most of the measure is concentrated as integrands are expected to converge quickly to zero as \(\left|x\right| \rightarrow \infty \), whereas for larger \(\ell \) the nodes are more—but not unlimitedly—spread out in order to capture behaviour of functions that potentially contribute to the integral also further away from the origin.
2.6 On computational complexity
Because the Gauss–Hermite nodes and weights are related to the eigenvalues and eigenvectors of the tridiagonal Jacobi matrix [13, Theorem 3.1] they—and the points \({\tilde{x}}_n\)—can be solved in quadratic time (in practice, these nodes and weights can be often tabulated beforehand). From Eq. (2.11) it is seen that computation of each approximate weight is linear in N: there are approximately \((N-1)/2\) terms in the sum and the Hermite polynomials can be evaluated on the fly using the three-term recurrence formula \(\mathrm {H}_{n+1}(x) = x \mathrm {H}_n(x) - n \mathrm {H}_{n-1}(x)\). That is, computational cost of obtaining \({\tilde{x}}_n\) and \({\widetilde{w}}_{k,n}\) for \(n=1,\ldots ,N\) is quadratic in N. Since the kernel matrix K of the Gaussian kernel is dense, solving the exact kernel quadrature weights from the linear system (1.2) for the points \({\tilde{x}}_n\) incurs a more demanding cubic computational cost. Because computational cost of a tensor product rule does not depend on the nodes and weights after these have been computed, the above discussion also applies to the rules presented in Sect. 4.
3 Convergence analysis
In this section we analyse convergence in the reproducing kernel Hilbert space \(\mathscr {H}\subset C^\infty (\mathbb {R})\) induced by the Gaussian kernel of quadrature rules that are exact for the Mercer eigenfunctions. First, we prove a generic result (Theorem 3.1) to this effect and then apply this to the quadrature rule with the nodes \(\tilde{x}_n\) and weights \({\widetilde{w}}_{k,n}\). If \(\sum _{n=1}^N \left|{\widetilde{w}}_{k,n}\right|\) does not grow too fast with N, we obtain exponential convergence rates.
Recall some basic facts about reproducing kernel Hilbert spaces spaces [4]: (i) \(\left\langle f , k(x,\cdot ) \right\rangle _\mathscr {H}= f(x)\) for any \(f \in \mathscr {H}\) and \(x \in \mathbb {R}\) and (ii) \(f = \sum _{n=0}^\infty \lambda _n^\alpha \left\langle f , \varphi _n^\alpha \right\rangle \varphi _n^\alpha \) for any \(f \in \mathscr {H}\). The worst-case errore(Q) of a quadrature rule \(Q(f) = \sum _{n=1}^N w_n f(x_n)\) is
Crucially, the worst-case error satisfies
for any \(f \in \mathscr {H}\). This justifies calling a sequence \(\{Q_N\}_{N=1}^\infty \) of N-point quadrature rules convergent if \(e(Q_N) \rightarrow 0\) as \(N \rightarrow \infty \). For given nodes \(x_1,\ldots ,x_N\), the weights \(w_k = (w_{k,1},\ldots ,w_{k,N})\) of the kernel quadrature rule \(Q_k\) are unique minimisers of the worst-case error:
It follows that a rate of convergence to zero for e(Q) also applies to \(e(Q_k)\).
A number of convergence results for kernel quadrature rules on compact spaces appear in [5, 7, 14]. When it comes to the RKHS of the Gaussian kernel, characterised in [25, 36], Kuo and Woźniakowski [19] have analysed convergence of the Gauss–Hermite quadrature rule. Unfortunately, it turns out that the Gauss–Hermite rule converges in this space if and only if \(\varepsilon ^2 < 1/2\). Consequently, we believe that the analysis below is the first to establish convergence, under the assumption (supported by our numerical experiments) that the sum of \(\left|{\widetilde{w}}_{k,n}\right|\) does not grow too fast, of an explicitly constructed sequence of quadrature rules in the RKHS of the Gaussian kernel with any value of the length-scale parameter. We begin with two simple lemmas.
Lemma 3.1
The eigenfunctions \(\varphi _n^\alpha \) admit the bound
for a constant \(K \le 1.087\) and every \(x \in \mathbb {R}\).
Proof
For each \(n \ge 0\), the Hermite polynomials obey the bound
for a constant \(K \le 1.087\) [10, p. 208]. See [6] for other such bounds.Footnote 3 Thus
\(\square \)
Lemma 3.2
Let \(\alpha = 1/\sqrt{2}\). Then
for every \(\ell > 0\) if and only if \(\rho \le 2\).
Proof
The function
satisfies \(\gamma (0) = 0\) and \(\gamma (\varepsilon ^2) \rightarrow 1\) as \(\varepsilon ^2 \rightarrow \infty \). The derivative
is positive when \(\rho \le 2\). For \(\rho > 2\), the derivative has a single root at \(\varepsilon _0^2 = 1/(4(\rho -2))\) so that \(\gamma (\varepsilon _0^2) > 1\). That is, \(\gamma (\varepsilon ^2) \in (0,1)\), and consequently \(\gamma (\varepsilon ^2)^{1/2} \in (0,1)\), if and only if \(\rho \le 2\). \(\square \)
Theorem 3.1
Let \(\alpha = 1{/}\sqrt{2}\). Suppose that the nodes \(x_1,\ldots ,x_N\) and weights \(w_1,\ldots ,w_N\) of an N-point quadrature rule \(Q_N\) satisfy
- 1.
\(\sum _{n=1}^N \left|w_{n}\right| \le W_N\) for some \(W_N \ge 0\);
- 2.
\(Q_N(\varphi _n^\alpha ) = \mu (\varphi _n^\alpha )\) for each \(n = 0,\ldots ,M_N-1\) for some \(M_N \ge 1\);
- 3.
\(\sup _{1\le n \le N}\left|x_{n}\right| \le 2 \sqrt{M_N} / \beta \).
Then there exist constants \(C_1,C_2 > 0\), independent of N and \(Q_N\), and \(0< \eta < 1\) such that
Explicit forms of these constants appear in Eq. (3.4).
Proof
For notational convenience, denote
and \(\varphi _n = \varphi _n^\alpha \). Because every \(f \in \mathscr {H}\) admits the expansion \(f = \sum _{n=0}^\infty \lambda _n \left\langle f , \varphi _n \right\rangle _\mathscr {H}\varphi _n\) and \(Q_N(\varphi _n) = \mu (\varphi _n)\) for \(n < M_N\), it follows from the Cauchy–Schwarz inequality and \(\Vert \varphi _n\Vert _\mathscr {H}= 1/\sqrt{\lambda _n}\) that
From Lemma 3.1 we have \(\left|\varphi _n(x)\right| \le K \sqrt{\beta } {{\,\mathrm{e}\,}}^{x^2/4}\) for a constant \(K \le 1.087\). Consequently, the assumption \(\sup _{1\le m \le N} \left|x_m\right| \le 2 \sqrt{M_N}/\beta \) yields
Combining this with Hölder’s inequality and \(L^2(\mu )\)-orthonormality of \(\varphi _n\), that imply \(\mu (\varphi _n) \le \mu (\varphi _n^2)^{1/2} = 1\), we obtain the bound
Inserting this into Eq. (3.2) produces
Noticing that \(\sqrt{\lambda } {{\,\mathrm{e}\,}}^{1/\beta ^2} < 1\) by Lemma 3.2 concludes the proof. \(\square \)
Remark 3.1
From Lemma 3.2 we observe that the proof does not yield \(\eta < 1\) (for every \(\ell \)) if the assumption \(\sup _{1\le n \le N}\left|x_{n}\right| \le 2 \sqrt{M_N} / \beta \) on placement of the nodes is relaxed by replacing the constant 2 on the right-hand side with \(C > 2\).
Consider now the N-point approximate Gaussian kernel quadrature rule \({{\widetilde{Q}}_{k,N} = \sum _{n=1}^N {\widetilde{w}}_{k,n} f(\tilde{x}_n)}\) whose nodes and weights are defined in Theorem 2.2 and set \(\alpha = 1/\sqrt{2}\). The nodes \(x_n^{\mathrm{GH}}\) of the N-point Gauss–Hermite rule admit the bound [2]
for every \(N \ge 1\). That is,
Since the rule \({\widetilde{Q}}_{k,N}\) is exact for the first N eigenfunctions, \(M_N = N\). Hence the assumption on placement of the nodes in Theorem 3.1 holds. As our numerical experiments indicate that the weights \({\widetilde{w}}_{k,n}\) are positive and \(\sum _{n=1}^N \left|{\widetilde{w}}_{k,n}\right| \rightarrow 1\) as \(N \rightarrow \infty \), it seems that the exponential convergence rate of Theorem 3.1 is valid for \({\widetilde{Q}}_{k,N}\) (as well as for the corresponding kernel quadrature rule \(Q_{k,N}\)) with \(M_N = N\). Naturally, this result is valid whenever the growth of the absolute weight sum is, for example, polynomial in N.
Theorem 3.2
Let \(\alpha = 1/\sqrt{2}\) and suppose that \(\sup _{N \ge 1} \sum _{n=1}^N \left|{\widetilde{w}}_{k,n}\right| < \infty \). Then the quadrature rules \({\widetilde{Q}}_{k,N}(f) = \sum _{n=1}^N {\widetilde{w}}_{k,n} f(\tilde{x}_n)\) and \(Q_{k,N}(f) = \sum _{n=1}^N w_{k,n} f(\tilde{x}_n)\) satisfy
for \(0< \eta < 1\).
Another interesting case are the generalised Gaussian quadrature rulesFootnote 4 for the eigenfunctions. As the eigenfunctions constitute a complete Chebyshev system [17, 30], there exists a quadrature rule \(Q^*_N\) with positive weights \(w_1^*,\ldots ,w_N^*\) such that \(Q_N^*(\varphi _n) = \mu (\varphi _n)\) for every \(n=0,\ldots ,2N-1\) [3]. Appropriate control of the nodes of these quadrature rules would establish an exponential convergence result with the “double rate” \(M_N = 2N\).
4 Tensor product rules
Let \(Q_1,\ldots ,Q_d\) be quadrature rules on \(\mathbb {R}\) with nodes \(X_i = \{ x_{i,1},\ldots ,x_{i,N_i} \}\) and weights \(w_{1}^i,\ldots ,w_{N_i}^i\) for each \(i=1,\ldots ,d\). The tensor product rule on the Cartesian grid \({X \,{{:}{=}}\, X_1 \times \cdots \times X_d \subset \mathbb {R}^d}\) is the cubature rule
where \({\mathscr {I}} \in \mathbb {N}^d\) is a multi-index, \({\mathscr {N}} \,{{:}{=}}\, (N_1,\ldots ,N_d) \in \mathbb {N}^d\), and the nodes and weights are
We equip \(\mathbb {R}^d\) with the d-variate standard Gaussian measure
The following proposition is a special case of a standard result on exactness of tensor product rules [28, Section 2.4].
Proposition 4.1
Consider the tensor product rule (4.1) and suppose that, for each \(i=1,\ldots ,d\), \(Q_i(\varphi ^i_n) = \mu (\varphi ^i_n)\) for some functions \(\varphi ^i_1,\ldots ,\varphi _{N_i}^i :\mathbb {R}\rightarrow \mathbb {R}\). Then
When a multivariate kernel is separable, this result can be used in constructing kernel cubature rules out of kernel quadrature rules. We consider d-dimensional separable Gaussian kernels
where \(\ell _i\) are dimension-wise length-scales. For each \(i=1,\ldots ,d\), the kernel quadrature rule \(Q_{k,i}\) with nodes \(X_i = \{ x_{i,1},\ldots ,x_{i,N_i} \} \) and weights \(w_{k,1}^i,\ldots ,w_{k,N_i}^i\) is, by definition, exact for the \(N_i\) kernel translates at the nodes:
for each \(n=1,\ldots ,N_i\). Proposition 4.1 implies that the d-dimensional kernel cubature rule \(Q_k^d\) at the nodes \(X = X_1 \times \cdots \times X_d\) is a tensor product of the univariate rules:
with the weights being products of univariate Gaussian kernel quadrature weights, \({w_{k,{\mathscr {I}}} = \prod _{i=1}^d w_{k,{\mathscr {I}}(i)}}\). This is the case because each kernel translate \(k^d(x,\cdot )\), \(x \in X\), can be written as
by separability of \(k^d\).
We can extend Theorem 2.2 to higher dimensions if the node set is a Cartesian product of a number of scaled Gauss–Hermite node sets. For this purpose, for each \(i=1,\ldots ,d\) we use the \(L(\mu _{\alpha _i})^2\)-orthonormal eigendecomposition of the Gaussian kernel \(k_i\). The eigenfunctions, eigenvalues, and other related constants from Sect. 2.1 for the eigendecomposition of the ith kernel are assigned an analogous subscript. Furthermore, use the notation
Theorem 4.1
For \(i=1,\ldots ,d\), let \(x_{i,1}^{\mathrm{GH}},\ldots ,x_{i,N_i}^{\mathrm{GH}}\) and \(w_{i,1}^{\mathrm{GH}}, \ldots w_{i,N_i}^{\mathrm{GH}}\) stand for the nodes and weights of the \(N_i\)-point Gauss–Hermite quadrature rule and define the nodes
Then the weights of the tensor product quadrature rule
that is defined by the exactness conditions \({\widetilde{Q}}_k^d(\varphi _{\mathscr {I}}) = \mu ^d(\varphi _{\mathscr {I}})\) for every \({\mathscr {I}} \le {\mathscr {N}}\), are \({{\widetilde{w}}_{k,{\mathscr {I}}} = \prod _{i=1}^d {\widetilde{w}}_{k,{\mathscr {I}}(i)}^i}\) for
where \(\alpha \), \(\beta \), and \(\delta \) are defined in Eq. (2.3) and \(\mathrm {H}_{2m}\) are the probabilists’ Hermite polynomials (2.2).
As in one dimension, the weights \(\widetilde{w}_{k,{\mathscr {I}}}\) are supposed to approximate \(w_{k,{\mathscr {I}}}\). Moreover, convergence rates can be obtained: tensor product analogues of Theorems 3.1 and 3.2 follow from noting that every function \(f :\mathbb {R}^d \rightarrow \mathbb {R}\) in the RKHS \(\mathscr {H}^d\) of \(k^d\) admits the multivariate Mercer expansion
See [18] for similar convergence analysis of tensor product Gauss–Hermite rules in \(\mathscr {H}^d\).
Theorem 4.2
Let \(\alpha _1 = \cdots = \alpha _d = 1/\sqrt{2}\). Suppose that the nodes \(x_{i,1},\ldots ,x_{i,N_i}\) and weights \(w_{1}^i,\ldots ,w_{N_i}^i\) of the \(N_i\)-point quadrature rules \(Q_{1,N_1},\ldots ,Q_{d,N_d}\) satisfy
- 1.
\(\sup _{1\le i \le d} \sum _{n=1}^{N_i} \left|w_{n}^i\right| \le W_{\mathscr {N}}\) for some \(W_{\mathscr {N}} \ge 1\);
- 2.
\(Q_{i,N_i}(\varphi _n^\alpha ) = \mu (\varphi _n^\alpha )\) for each \(n = 0,\ldots ,M_{N_i}-1\) and \(i=1,\ldots ,d\) for some \(M_{N_i} \ge 1\);
- 3.
\(\sup _{1\le n \le {N_i}}\left|x_{i,n}\right| \le 2 \sqrt{M_{N_i}} / \beta \) for each \(i=1,\ldots ,d\).
Define the tensor product rule
Then there exist constants \(C > 0\), independent of \({\mathscr {N}}\) and \(Q_{\mathscr {N}}^d\), and \(0< \eta < 1\) such that
where \(M = \min (M_{N_1},\ldots ,M_{N_d})\). Explicit forms of C and \(\eta \) appear in Eq. (4.10).
Proof
The proof is largely analogous to that of Theorem 3.1. Since \(f \in \mathscr {H}^d\) can be written as
by defining the index set
we obtain
Consequently, the Cauchy–Schwarz inequality yields
where we again use the notation
Since \(\mu (\varphi _n) \le 1\) for any \(n \ge 0\), integration error for the eigenfunction \(\varphi _{\mathscr {I}}\) satisfies
Define the index sets \({\mathscr {B}}_{\mathscr {M}}^j({\mathscr {I}}) = \left\{ j \le i \le d \,:\, {\mathscr {I}}(i) \ge M_{N_i} \right\} \) and their cardinalities \(b_{\mathscr {M}}^j({\mathscr {I}}) = \#{\mathscr {B}}_{\mathscr {M}}^j({\mathscr {I}}) \le d-j+1\) for \(j \ge 1\). Because \(\left|\mu (\varphi _{{\mathscr {I}}(i)}) - Q_{i,N_i}(\varphi _{{\mathscr {I}}(i)})\right| = 0\) and \(\left|Q_{i,N_{i}}(\varphi _{{\mathscr {I}}(i)})\right| = \left|\mu (\varphi _{{\mathscr {I}}(i)})\right| \le 1\) if \({\mathscr {I}}(i) < M_{N_i}\), expansion of the recursive inequality (4.7) gives
Equation (3.3) provides the bounds \({\left|\mu (\varphi _{{\mathscr {I}}(i)}) {-} Q_{i,N_i}(\varphi _{{\mathscr {I}}(i)})\right| {\le } 1 {+} K \sqrt{\beta } W_{{\mathscr {N}}}{{\,\mathrm{e}\,}}^{M_{N_i}/\beta ^2}}\) and \(\left|Q_{i,N_i}(\varphi _{{\mathscr {I}}(i)})\right| \le K \sqrt{\beta } W_{\mathscr {N}} {{\,\mathrm{e}\,}}^{M_{N_i}/\beta ^2}\) for the constant \(K = 1.087\) that, when plugged in Eq. (4.8), yield
where the last inequality is based on the facts that \(i \in {\mathscr {B}}_{\mathscr {M}}^i({\mathscr {I}})\) if \({i \in {\mathscr {B}}_{\mathscr {M}}^1({\mathscr {I}})}\) and \({1 + K \sqrt{\beta } W_{{\mathscr {N}}} {{\,\mathrm{e}\,}}^{M_{N_i}/\beta ^2} \le 2 K \sqrt{\beta } W_{{\mathscr {N}}} {{\,\mathrm{e}\,}}^{M_{N_i}/\beta ^2}}\), a consequence of \({K, \beta , W_{\mathscr {N}} \ge 1}\). Equations (4.6) and (4.9), together with Lemma 3.2, now yield
The claim therefore holds with
\(\square \)
A multivariate version of Theorem 3.2 is obvious.
5 Numerical experiments
This section contains numerical experiments on properties and accuracy of the approximate Gaussian kernel quadrature weights defined in Theorems 2.2 and 4.1. The experiments have been implemented in MATLAB, and they are available at https://github.com/tskarvone/gauss-mercer. The value \(\alpha = 1/\sqrt{2}\) is used in all experiments. The experiments indicate that
- 1.
Computation of the approximate weights in Eq. (2.11) is numerically stable.
- 2.
The weight approximation is quite accurate, its accuracy increasing with the number of nodes and the length-scale, as predicted in Sect. 2.5.
- 3.
The weights \(w_{k,n}\) and \({\widetilde{w}}_{k,n}\) are positive for every N and \(n=1,\ldots ,N\) and their sums converge to one exponentially in N.
- 4.
The quadrature rule \({\widetilde{Q}}_{k}\) converges exponentially, as implied by Theorem 3.2 and empirical observations on the behaviour of its weights.
- 5.
In numerical integration of specific functions, the approximate kernel quadrature rule \({\widetilde{Q}}_{k}\) can achieve integration accuracy almost indistinguishable from that of the corresponding Gaussian kernel quadrature rule \(Q_{k}\) and superior to some more traditional alternatives.
This suggest Eq. (2.11) can be used as an accurate and numerically stable surrogate for computing the Gaussian kernel quadrature weights when the naive approach based on solving the linear system (1.2) is precluded by ill-conditioning of the kernel matrix. Furthermore, the choice (2.10) of the nodes by scaling the Gauss–Hermite nodes appears to yield an exponentially convergent kernel quadrature rule that has positive weights.
5.1 Numerical stability and distribution of weights
We have not encountered any numerical issues when computing the approximate weights (2.11). In this example we set \(N=99\) and examine the distribution of approximate weights \({\widetilde{w}}_{k,n}\) for \(\ell = 0.05\), \(\ell = 0.4\) and \(\ell = 4\). Figure 1 depicts (i) approximate weights \({\widetilde{w}}_{k,n}\), (ii) absolute kernel quadrature weights \(\left|w_{k,n}\right|\) obtained by solving the linear system (1.2) for the points \({\tilde{x}}_{n}\) and, for \(\ell = 4\), (iii) Gauss–Hermite weights \(w_n^{\mathrm{GH}}\). The approximate weights \({\widetilde{w}}_{k,n}\) display no signs of numerical instabilities; their magnitudes vary smoothly and all of them are positive. That \({\widetilde{w}}_{k,1} > {\widetilde{w}}_{k,2}\) for \(\ell = 0.05\) appears to be caused by the sum in Eq. (2.11) having not converged yet: the constant \(2\alpha ^2\beta ^2/(1+2\delta ^2) - 1\), that controls the rate of convergence of this sum, converges to 1 as \(\ell \rightarrow 0\) (in this case its value is 0.9512) and \(H_{2m}(x_1^{\mathrm{GH}}) > 0\) for every \(m = 1,\ldots ,49\) while \(H_{2m}(x_n^{\mathrm{GH}}) < 0\) for \(m = 46,47,48,49\). This and further experiments in Sect. 5.2 merely illustrates that quality of the weight approximation deteriorates when \(\ell \) is small—as predicted in Sect. 2.5. Behaviour of \({\widetilde{w}}_{k,n}\) is in stark contrast to the naively computed weights \(w_{k,n}\) that display clear signs of numerical instabilities for \(\ell = 0.4\) and \(\ell = 4\) (condition numbers of the kernel matrices were roughly \(2.66 \times 10^{16}\) and \(3.59 \times 10^{18}\)). Finally, the case \(\ell = 4\) provides further evidence for numerical stability of Eq. (2.11) since, based on Sect. 2.5, \({\widetilde{w}}_{k,n} \rightarrow w_n^{\mathrm{GH}}\) as \(\ell \rightarrow \infty \) and, furthermore, there is reason to believe that \(w_{k,n}\) would share this property if they were computed in arbitrary-precision arithmetic. Section 5.3 and the experiments reported by Fasshauer and McCourt [12] provide additional evidence for numerical stability of Eq. (2.11).

Absolute kernel quadrature weights, as computed directly from the linear system (1.2), and the approximate weights (2.11) for \(N = 99\), nodes \({\tilde{x}}_{k,n}\), and three different length-scales. Red is used to indicate those of \(w_{k,n}\) that are negative. The nodes are in ascending order, so by symmetry it is sufficient to display weights only for \(n=1,\ldots ,50\) (in fact, \(w_{k,n}\) are not necessarily numerically symmetric; see Sect. 5.2). The Gauss–Hermite nodes and weights were computed using the Golub–Welsch algorithm [13, Section 3.1.1.1] and MATLAB’s variable precision arithmetic. Equation (2.11) did not present any numerical issues as the sum, which can contain both positive and negative terms, was always dominated by the positive terms and all its terms were of reasonable magnitude
5.2 Accuracy of the weight approximation
Next we assess quality of the weight approximation \({\widetilde{w}}_{k} \approx w_{k}\). Figure 2 depicts the results for a number of different length-scales in terms of norm of the relative weight error,
As the kernel matrix quickly becomes ill-conditioned, computation of the kernel quadrature weights \(w_{k}\) is challenging, particularly when the length-scale is large. To partially mitigate the problem we replaced the kernel quadrature weights with their QR decomposition approximations \({\widetilde{w}}_k^M\) derived in Sect. 2.2. The truncation length M was selected based on machine precision; see [12, Section 4.2.2] for details. Yet even this does not work for large enough N. Because kernel quadrature rules on symmetric point sets have symmetric weights [16, 28, Section 5.2.4], breakdown in symmetricity of the computed kernel quadrature weights was used as a heuristic proxy for emergence of numerical instability: for each length-scale, relative errors are presented in Fig. 2 until the first N such that \(\left|1-w_{k,N}/w_{k,1}\right| > 10^{-6}\), ordering of the nodes being from smallest to the largest so that \(w_{k,N} = w_{k,1}\) in absence of numerical errors.

Relative weight approximation error (5.1) for different length-scales
5.3 Properties of the weights
Figure 3 shows the minimal weights \(\min _{n=1,\ldots ,N} {\widetilde{w}}_{k,n}\) and convergence to one of \(\sum _{n=1}^N \left|{\widetilde{w}}_{k,n}\right|\) for a number of different length-scales. These results provide strong numerical evidence for the conjecture that \({\widetilde{w}}_{k,n}\) remain positive and that the assumptions of Theorem 3.2 hold. Exact weights, as long as they can be reliably computed (see Sect. 5.2), exhibit behaviour practically indistinguishable from the approximate ones and are not therefore depicted separately in Fig. 3.

Minimal weights and convergence to one of the the sum of absolute values of the weights for six different length-scales
5.4 Worst-case error
The worst-case error e(Q) of a quadrature rule \(Q(f) = \sum _{n=1}^N w_n f(x_n)\) in a reproducing kernel Hilbert space induced by the kernel k is explicitly computable:
Figure 4 compares the worst-case errors in the RKHS of the Gaussian kernel for six different length-scales of (i) the classical Gauss–Hermite quadrature rule, (ii) the quadrature \({\widetilde{Q}}_{k}(f) = \sum _{n=1}^N {\widetilde{w}}_{k,n} f({\tilde{x}}_n)\) of Theorem 2.2, and (iii) the kernel quadrature rule with its nodes placed uniformly between the largest and smallest of \({\tilde{x}}_n\). We observe that \({\widetilde{Q}}_{k}\) is, for all length-scales, the fastest of these rules to converge (the kernel quadrature rule at \({\tilde{x}}_n\) yields WCEs practically indistinguishable from those of \({\widetilde{Q}}_{k}\) and is therefore not included). It also becomes apparent that the convergence rates derived in Theorems 3.1 and 3.2 for \({\widetilde{Q}}_{k}\) are rather conservative. For example, for \(\ell = 0.2\) and \(\ell = 1\) the empirical rates are \(e({\widetilde{Q}}_{k}) = {\mathscr {O}}({{\,\mathrm{e}\,}}^{-c N})\) with \(c \approx 0.21\) and \(c \approx 0.98\), respectively, whereas Eq. (3.4) yields the theoretical values \(c \approx 0.00033\) and \(c \approx 0.054\), respectively.

Worst-case errors (5.2) in the Gaussian RKHS as functions of the number of nodes of the quadrature rule of Theorem 2.2 (SGHKQ), the kernel quadrature rule with nodes placed uniformly between the largest and smallest of \({\tilde{x}}_n\) (UKQ), and the Gauss–Hermite rule (GH). WCEs are displayed until the square root of floating-point relative accuracy (\(\approx 1.4901 \times 10^{-8}\)) is reached
5.5 Numerical integration
Set \(\ell = 1.2\) and consider the integrand
When \(0< c_i < 4\) and \(m_i \in \mathbb {N}\) for each \(i=1,\ldots ,d\), the function is in \(\mathscr {H}\) [25, Theorems 1 and 3]. Furthermore, the Gaussian integral of this function is available in closed form:
when \(m_i\) are even (when they are not even, the integral is obviously zero). Figure 5 shows integration error of the three methods (or, in higher dimensions, their tensor product versions) used in Sect. 5.4 and the kernel quadrature rule based on the nodes \({\tilde{x}}_n\) for (i) \(d=1\), \(m_1 = 6\), \(c_1 = 3/2\) and (ii) \(d=3\), \(m_1=6\), \(m_2 = 4\), \(m_3 = 2\), \(c_1 = 3/2\), \(c_2 = 3\), \(c_3 = 1/2\). As expected, there is little difference between \({\widetilde{Q}}_{k}\) and \(Q_{k}\).

Error in computing the Gaussian integral of the function (5.3) in dimensions one and three using the quadrature rule of Theorem 2.2 (SGHKQ), the corresponding kernel quadrature rule (KQ), the kernel quadrature rule with nodes placed uniformly between the largest and smallest of \({\tilde{x}}_n\) (UKQ), and the Gauss–Hermite rule (GH). Tensor product versions of these rules are used in dimension three
Notes
Low-rank approximations (i.e., \(M < N\)) are also possible [12, Section 6.1].
In particular, the factor \(n^{-1/6}\) could be added on the right-hand side. This would make little difference in convergence analysis of Theorem 3.1.
Note that the cited results are for kernels and functions on compact intervals. However, generalisations for the whole real line are possible [15, Chapter VI].
References
Abramowitz, M., Stegun, I.A.: Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. United States Department of Commerce, National Bureau of Standards (1964)
Area, I., Dimitrov, D.K., Godoy, E., Ronveaux, A.: Zeros of Gegenbauer and Hermite polynomials and connection coefficients. Math. Comput. 73(248), 1937–1951 (2004)
Barrow, D.L.: On multiple node Gaussian quadrature formulae. Math. Comput. 32(142), 431–439 (1978)
Berlinet, A., Thomas-Agnan, C.: Reproducing Kernel Hilbert Spaces in Probability and Statistics. Springer, Berlin (2004)
Bezhaev, A.Yu.: Cubature formulae on scattered meshes. Russ. J. Numer. Anal. Math. Model. 6(2), 95–106 (1991)
Bonan, S.S., Clark, D.S.: Estimates of the Hermite and the Freud polynomials. J. Approx. Theory 63(2), 210–224 (1990)
Briol, F.-X., Oates, C.J., Girolami, M., Osborne, M.A., Sejdinovic, D.: Probabilistic integration: a role in statistical computation? Stat. Sci. 34(1), 1–22 (2019)
Cools, R.: Constructing cubature formulae: the science behind the art. Acta Numer. 6, 1–54 (1997)
Driscoll, T.A., Fornberg, B.: Interpolation in the limit of increasingly flat radial basis functions. Comput. Math. Appl. 43(3–5), 413–422 (2002)
Erdélyi, A.: Higher Transcendental Functions, vol. 2. McGraw-Hill, New York (1953)
Fasshauer, G., McCourt, M.: Kernel-Based Approximation Methods Using MATLAB. Number 19 in Interdisciplinary Mathematical Sciences. World Scientific Publishing, Singapore (2015)
Fasshauer, G.E., McCourt, M.J.: Stable evaluation of Gaussian radial basis function interpolants. SIAM J. Sci. Comput. 34(2), A737–A762 (2012)
Gautschi, W.: Orthogonal Polynomials: Computation and Approximation. Numerical Mathematics and Scientific Computation. Oxford University Press, Oxford (2004)
Kanagawa, M., Sriperumbudur, B.K., Fukumizu, K.: Convergence analysis of deterministic kernel-based quadrature rules in misspecified settings. Found. Comput. Math. (2019). https://doi.org/10.1007/s10208-018-09407-7
Karlin, S., Studden, W.J.: Tchebycheff Systems: With Applications in Analysis and Statistics. Interscience Publishers, New York (1966)
Karvonen, T., Särkkä, S.: Fully symmetric kernel quadrature. SIAM J. Sci. Comput. 40(2), A697–A720 (2018)
Kellog, O.D.: Orthogonal function sets arising from integral equations. Am. J. Math. 40(2), 145–154 (1918)
Kuo, F.Y., Sloan, I.H., Woźniakowski, H.: Multivariate integration for analytic functions with Gaussian kernels. Math. Comput. 86, 829–853 (2017)
Kuo, F.Y., Woźniakowski, H.: Gauss-Hermite quadratures for functions from Hilbert spaces with Gaussian reproducing kernels. BIT Numer. Math. 52(2), 425–436 (2012)
Larkin, F.M.: Optimal approximation in Hilbert spaces with reproducing kernel functions. Math. Comput. 24(112), 911–921 (1970)
Larkin, F.M.: Gaussian measure in Hilbert space and applications in numerical analysis. Rocky Mt. J. Math. 2(3), 379–422 (1972)
Larsson, E., Fornberg, B.: Theoretical and computational aspects of multivariate interpolation with increasingly flat radial basis functions. Comput. Math. Appl. 49(1), 103–130 (2005)
Lee, Y.J., Micchelli, C.A., Yoon, J.: On convergence of flat multivariate interpolation by translation kernels with finite smoothness. Constr. Approx. 40(1), 37–60 (2014)
Lee, Y.J., Yoon, G.J., Yoon, J.: Convergence of increasingly flat radial basis interpolants to polynomial interpolants. SIAM J. Math. Anal. 39(2), 537–553 (2007)
Minh, H.Q.: Some properties of Gaussian reproducing kernel Hilbert spaces and their implications for function approximation and learning theory. Constr. Approx. 32(2), 307–338 (2010)
Minka, T.: Deriving quadrature rules from Gaussian processes. Technical report, Statistics Department, Carnegie Mellon University (2000)
Mysovskikh, I.P.: On the construction of cubature formulas with fewest nodes. Sov. Math. Dokl. 9, 277–280 (1968)
Oettershagen, J.: Construction of Optimal Cubature Algorithms with Applications to Econometrics and Uncertainty Quantification. PhD thesis, Institut für Numerische Simulation, Universität Bonn (2017)
O’Hagan, A.: Bayes–Hermite quadrature. J. Stat. Plan. Inference 29(3), 245–260 (1991)
Pinkus, A.: Spectral properties of totally positive kernels and matrices. In: Gasca, M., Micchelli, C.A. (eds.) Total Positivity and Its Applications. Springer, pp. 477–511 (1996)
Rasmussen, C.E., Ghahramani, Z.: Bayesian Monte Carlo. In: Becker, S., Thrun, S., Obermayer, K. (eds.) Advances in Neural Information Processing Systems, vol. 15, pp. 505–512 (2002)
Richter-Dyn, N.: Properties of minimal integration rules II. SIAM J. Numer. Anal. 8(3), 497–508 (1971)
Schaback, R.: Error estimates and condition numbers for radial basis function interpolation. Adv. Comput. Math. 3(3), 251–264 (1995)
Schaback, R.: Multivariate interpolation by polynomials and radial basis functions. Constr. Approx. 21(3), 293–317 (2005)
Sommariva, A., Vianello, M.: Numerical cubature on scattered data by radial basis functions. Computing 76(3–4), 295–310 (2006)
Steinwart, I., Hush, D., Scovel, C.: An explicit description of the reproducing kernel Hilbert spaces of Gaussian RBF kernels. IEEE Trans. Inf. Theory 52(10), 4635–4643 (2006)
Steinwart, I., Scovel, C.: Mercer’s theorem on general domains: on the interaction between measures, kernels, and RKHSs. Constr. Approx. 35(3), 363–417 (2012)
Sun, H.: Mercer theorem for RKHS on noncompact sets. J. Complex. 21(3), 337–349 (2005)
Acknowledgements
Open access funding provided by Aalto University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Tom Lyche.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by the Aalto ELEC Doctoral School as well as Academy of Finland projects 266940, 304087, and 313708.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Karvonen, T., Särkkä, S. Gaussian kernel quadrature at scaled Gauss–Hermite nodes. Bit Numer Math 59, 877–902 (2019). https://doi.org/10.1007/s10543-019-00758-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-019-00758-3