
Abstract
Given a compact metric space X and a strictly positive Borel measure ν on X, Mercer’s classical theorem states that the spectral decomposition of a positive self-adjoint integral operator T k :L 2(ν)→L 2(ν) of a continuous k yields a series representation of k in terms of the eigenvalues and -functions of T k . An immediate consequence of this representation is that k is a (reproducing) kernel and that its reproducing kernel Hilbert space can also be described by these eigenvalues and -functions. It is well known that Mercer’s theorem has found important applications in various branches of mathematics, including probability theory and statistics. In particular, for some applications in the latter areas, however, it would be highly convenient to have a form of Mercer’s theorem for more general spaces X and kernels k. Unfortunately, all extensions of Mercer’s theorem in this direction either stick too closely to the original topological structure of X and k, or replace the absolute and uniform convergence by weaker notions of convergence that are not strong enough for many statistical applications. In this work, we fill this gap by establishing several Mercer type series representations for k that, on the one hand, make only very mild assumptions on X and k, and, on the other hand, provide convergence results that are strong enough for interesting applications in, e.g., statistical learning theory. To illustrate the latter, we first use these series representations to describe ranges of fractional powers of T k in terms of interpolation spaces and investigate under which conditions these interpolation spaces are contained in L ∞(ν). For these two results, we then discuss applications related to the analysis of so-called least squares support vector machines, which are a state-of-the-art learning algorithm. Besides these results, we further use the obtained Mercer representations to show that every self-adjoint nuclear operator L 2(ν)→L 2(ν) is an integral operator whose representing function k is the difference of two (reproducing) kernels.
Similar content being viewed by others


Notes
We usually omit a symbol for the corresponding σ-algebra, since, in general, we do not use it.
For the sake of simplicity, we restrict our considerations to σ-finite measures, since otherwise we would have to deal with local ν-zero sets and, later, when dealing with liftings, with technically involved assumptions on ν. Since for the applications we are most interested in we typically have a probability measure, the σ-finiteness is no restriction.
References
Agler, J., McCarthy, J.E.: Pick Interpolation and Hilbert Function Spaces. Am. Math. Soc., Providence (2002)
Ali, S.T., Antoine, J.-P., Gazeau, J.-P.: Coherent States, Wavelets and Their Generalizations. Springer, New York (2000)
Alpay, D. (ed.): Reproducing Kernel Spaces and Applications. Birkhäuser Verlag, Basel (2003)
Aronszajn, N.: Theory of reproducing kernels. Trans. Am. Math. Soc. 68, 337–404 (1950)
Bauer, H.: Measure and Integration Theory. De Gruyter, Berlin (2001)
Bennett, C., Sharpley, R.: Interpolation of Operators. Academic Press, Boston (1988)
Berlinet, A., Thomas-Agnan, C.: Reproducing Kernel Hilbert Spaces in Probability and Statistics. Kluwer, Boston (2004)
Caponnetto, A., De Vito, E.: Fast rates for regularized least-squares algorithm. Technical Report CBCL Paper #248, AI Memo #2005-013, MIT, Cambridge, MA (2005)
Caponnetto, A., De Vito, E.: Optimal rates for regularized least squares algorithm. Found. Comput. Math. 7, 331–368 (2007)
Cesa-Bianchi, N., Lugosi, G.: Prediction, Learning, and Games. Cambridge University Press, Cambridge (2006)
Conway, J.B.: A Course in Functional Analysis, 2nd edn. Springer, New York (1990)
Cristianini, N., Shawe-Taylor, J.: An Introduction to Support Vector Machines. Cambridge University Press, Cambridge (2000)
Cucker, F., Smale, S.: On the mathematical foundations of learning. Bull. Am. Math. Soc. 39, 1–49 (2002)
Cucker, F., Zhou, D.X.: Learning Theory: An Approximation Theory Viewpoint. Cambridge University Press, Cambridge (2007)
De Vito, E., Caponnetto, A., Rosasco, L.: Model selection for regularized least-squares algorithm in learning theory. Found. Comput. Math. 5, 59–85 (2005)
Hein, M., Bousquet, O.: Kernels, associated structures and generalizations. Technical Report 127, Max-Planck-Institute for Biological Cybernetics (2004)
Hille, E.: Introduction to general theory of reproducing kernels. Rocky Mt. J. Math. 2, 321–368 (1972)
Kato, T.: Perturbation Theory for Linear Operators, 2nd edn. Springer, Berlin–New York (1976)
König, H.: Eigenvalue Distribution of Compact Operators. Birkhäuser, Basel (1986)
Mendelson, S., Neeman, J.: Regularization in kernel learning. Ann. Stat. 38, 526–565 (2010)
Meschkowski, H.: Hilbertsche Räume mit Kernfunktion. Springer, Berlin (1962)
Novak, E., Woźniakowski, H.: Tractability of Multivariate Problems. Linear Information, vol. 1. European Mathematical Society (EMS), Zürich (2008)
Pietsch, A.: Eigenvalues and s-Numbers. Geest & Portig K.-G., Leipzig (1987)
Rao, M.M.: Measure Theory and Integration, 2nd edn. Dekker, New York (2004)
Riesz, F., Nagy, B.Sz.: Functional Analysis, 2nd edn. Dover, New York (1990)
Ritter, K.: Average-Case Analysis of Numerical Problems. Lecture Notes in Math., vol. 1733. Springer, Berlin (2000)
Rudin, W.: Functional Analysis, 2nd edn. McGraw-Hill, New York (1991)
Saitoh, S.: Theory of Reproducing Kernels and Applications. Longman Scientific & Technical, Harlow (1988)
Saitoh, S.: Integral Transforms, Reproducing Kernels and Their Applications. Longman Scientific & Technical, Harlow (1997)
Saitoh, S., Alpay, D., Ball, J.A., Ohsawa, T. (eds.): Reproducing Kernels and Their Applications, Kluwer Academic, Dordrecht (1999)
Schölkopf, B., Smola, A.J.: Learning with Kernels. MIT Press, Cambridge (2002)
Schölkopf, B., Smola, A.J., Müller, K.-R.: Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. 10, 1299–1319 (1998)
Shawe-Taylor, J., Williams, C.K.I., Cristianini, N., Kandola, J.: On the eigenspectrum of the Gram matrix and the generalization error of kernel-PCA. IEEE Trans. Inf. Theory 51, 2510–2522 (2005)
Smale, S., Zhou, D.-X.: Estimating the approximation error in learning theory. Anal. Appl. 1, 17–41 (2003)
Smale, S., Zhou, D.-X.: Learning theory estimates via integral operators and their approximations. Constr. Approx. 26, 153–172 (2007)
Steinwart, I., Christmann, A.: Support Vector Machines. Springer, New York (2008)
Steinwart, I., Hush, D., Scovel, C.: Optimal rates for regularized least squares regression. In: Dasgupta, S., Klivans, A. (eds.) Proceedings of the 22nd Annual Conference on Learning Theory, pp. 79–93 (2009)
Steinwart, I., Hush, D., Scovel, C.: Training SVMs without offset. J. Mach. Learn. Res. 12, 141–202 (2011)
Strauss, W., Macheras, N.D., Musiał, K.: Liftings. In: Pap, E. (ed.) Handbook of Measure Theory, vol. II, pp. 1131–1184. Elsevier, Amsterdam (2002)
Sun, H.: Mercer theorem for RKHS on noncompact sets. J. Complex. 21, 337–349 (2005)
Tartar, L.: An Introduction to Sobolev Spaces and Interpolation Spaces. Springer, Berlin (2007)
Ionescu Tulcea, A., Ionescu Tulcea, C.: Topics in the Theory of Lifting. Springer, New York (1969)
Wahba, G.: Spline Models for Observational Data. Series in Applied Mathematics, vol. 59. SIAM, Philadelphia (1990)
Wendland, H.: Scattered Data Approximation. Cambridge University Press, Cambridge (2005)
Werner, D.: Funktionalanalysis. Springer, Berlin (1995)
Yao, Y., Rosasco, L., Caponnetto, A.: On early stopping in gradient descent learning. Constr. Approx. 26, 289–315 (2007)
Zhou, D.-X.: The covering number in learning theory. J. Complex. 18, 739–767 (2002)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by G. Kerkyacharian.
Appendices
Appendix A: Related Operators and the Spectral Theorem
This appendix recalls some facts from the spectral theory of compact, self-adjoint operators acting between Hilbert spaces. We begin with the classical spectral theorem, see, e.g., [18, Theorem V.2.10 on p. 260] or [45, Theorem VI.3.2].
Theorem A.1
(Spectral Theorem)
Let H be a Hilbert space and A:H→H be a compact, positive, and self-adjoint operator. Then there exist an at most countable ONS (e i ) i∈I of H and a family (μ i ) i∈I converging to 0 such that μ 1≥μ 2≥…>0 and


Moreover, (μ i ) i∈I is the family of nonzero eigenvalues of A (including geometric multiplicities), and, for all i∈I, e i is an eigenvector for μ i . Finally, both (53) and (54) actually hold for all ONSs \((\tilde{e}_{i})_{i\in I}\) of H for which, for all i∈I, the vector \(\tilde{e}_{i}\) is an eigenvector of μ i .
The next well known theorem, see, e.g., [27, Theorem 12.10], relates the image of an operator B to the null-space of its adjoint B ∗.
Theorem A.2
Let H 1 and H 2 be Hilbert spaces and B:H 1→H 2 be a bounded linear operator. Then we have
In particular, B ∗ is injective if and only if B has a dense image.
The following theorem lists other well-known facts about the eigenvalues and the spectral representations of certain operators. These facts are widely known, but since we are unaware of a reference for the particular formulation we need, we decided to include its relatively straightforward proof for the sake of completeness. The name for this theorem was borrowed from [23, Sect. 3.3.4].
Theorem A.3
(Principle of Related Operators)
Let H 1 and H 2 be Hilbert spaces and B:H 1→H 2 be a bounded linear operator. We define the self-adjoint and positive operators A 1:H 1→H 1 and A 2:H 2→H 2 by A 1:=B ∗ B and A 2:=BB ∗, respectively. Then the following statements are true:
-
(i)
Given a μ>0, we denote the eigenspaces of A 1 and A 2 that correspond to μ by
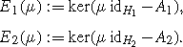
Then the map
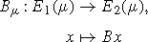
is well defined, bijective, and, in addition, we have \(B^{*}_{\mu}B_{\mu}=\mu \operatorname {id}_{E_{1}(\mu)}\).
-
(ii)
We have kerA 1=kerB and kerA 2=kerB ∗.
-
(iii)
Assume that A 1 is compact, and let (e i ) i∈I be an at most countable ONS of H 1 and (μ i ) i∈I be a family converging to 0 such that μ 1≥μ 2≥…>0 and
$$A_1x = \sum_{i \in I} \mu_i\langle x,e_i\rangle_{H_1} e_i,\quad x\in H_1,$$where we note that there exist such (e i ) i∈I and (μ i ) i∈I by Theorem A.1. For i∈I, we define \(f_{i} := \mu_{i}^{-1/2} B e_{i}\). Then (f i ) i∈I is an ONS of H 2, and A 2 has the spectral representation
$$ A_2 y = \sum_{i \in I}\mu_i \langle y,f_i\rangle_{H_2}f_i, \quad y\in H_2.$$(55)Finally, we have \(e_{i} = \mu_{i}^{-1/2} B^{*} f_{i}\) for all i∈I.
-
(iv)
A 1 is compact if and only if A 2 is compact.
-
(v)
If A 1 is compact, we have \(\overline{\operatorname {ran}B} = \overline {\operatorname {span}\{f_{i}:i\in I \}} = \overline{\operatorname {ran}A_{2}}\) and \(\overline{\operatorname {ran}B^{*}} = \overline{\operatorname {span}\{e_{i}:i\in I \}} =\overline{\operatorname {ran}A_{1}}\).
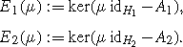
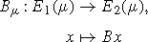
Proof
(i) It is easy to check that A 1 and A 2 are indeed self-adjoint and positive. Let us first show that B μ is well defined, that is, that Bx∈E 2(μ) for all x∈E 1(μ). To this end, we pick an x∈E 1(μ); i.e., we have A 1 x=μx. From this we conclude A 2 Bx=BB ∗ Bx=BA 1 x=μBx, and thus we have Bx∈E 2(μ). Similarly, for x∈E 1(μ) with Bx=0, we obtain μx=Ax=B ∗ Bx=0, and since μ>0, we conclude x=0; i.e., B μ is injective. By interchanging the role of B and B ∗, we analogously see that

is well defined and injective. To show that B μ is surjective, we now pick an y∈E 2(μ) and define x:=μ −1 B ∗ y. Our previous consideration then gives x∈E 1(μ), and since we further have Bx=μ −1 BB ∗ y=μ −1 A 2 y=y, we obtain the surjectivity of B μ . The last assertion is a consequence of B ∗ B=A 1.
(ii) By symmetry, it suffices to show kerA 1=kerB. Moreover, the inclusion kerA 1⊃kerB immediately follows from A 1=B ∗ B. To show the converse inclusion, we fix an x∈kerA 1. Then the definition of A 1 yields \(0 = \langle A_{1}x,x\rangle_{H_{1}} =\langle Bx,Bx\rangle_{H_{2}}\), which implies x∈kerB.
(iii) Let us show that (f i ) i∈I is an ONS of H 2. To this end, we fix i,j∈I and find
and since (e i ) i∈I is an ONS, we then conclude that (f i ) i∈I is an ONS. Moreover, by (i) we have
By Theorem A.1 and (ii), the compactness of A 1 further implies

Using Theorem A.2 and (ii), we then find
and combining this with (56), we obtain (55) by Theorem A.1. The last assertion follows from \(\mu_{i}^{-1/2} B^{*} f_{i} = \mu_{i}^{-1} B^{*}B e_{i} = e_{i}\), where in the last step we used (i).
(iv) If A 1 is compact, we obtain the spectral representation (55) for A 2, and hence A 2 is compact. The inverse implication follows by symmetry.
(v) The proof of (iii) has already shown \(\overline {\operatorname {ran}B} = \overline{\operatorname {span}\{f_{i}:i\in I \}}= \overline{\operatorname {ran}A_{2}}\), and the second equality follows by symmetry and (iv). □
Appendix B: Liftings
In this appendix, we briefly recall some results related to liftings on the space of bounded measurable functions. To this end, we assume that \((X,\mathcal {A})\) is a measurable space. We denote by
the space of all bounded measurable functions on X and equip this space with the usual supremum norm ∥⋅∥∞. Furthermore, if ν is a σ-finite measureFootnote 2 on \((X,\mathcal {A})\), we define, for a measurable f:X→ℝ,
This leads to the space
of essentially bounded, measurable functions on X. By considering a sequence \(\alpha_{n}\searrow \Vert f \Vert _{\mathcal {L}_{\infty}(\nu)}\), it is straightforward to show that the infimum in the definition of \(\Vert \cdot \Vert _{\mathcal {L}_{\infty}(\nu)} \) is actually attained; that is,
Furthermore, we write \({L}_{\infty}(\nu):= \mathcal {L}_{\infty}(\nu)_{/\sim}\) for the quotient space with respect to the usual equivalence relation f∼g:⇔ν({f≠g})=0 on \(\mathcal {L}_{\infty}(\nu)\). From (57), we can then conclude that the linear map

is a metric surjection, and hence its quotient map \(\bar{I}_{\nu}:\mathcal {L}_{\infty}(X)_{/\sim} \to {L}_{\infty}(\nu)\), which is given by \(\bar{I}([f]_{\sim}) = [f]_{\sim}\), is an isometric isomorphism. Here we note that, given an \(f\in \mathcal {L}_{\infty}(X)\), the equivalence class [f]∼ in L ∞(ν) consists, in general, of more functions than the corresponding equivalence class [f]∼ in \(\mathcal {L}_{\infty}(X)_{/\sim}\). Nevertheless, \(\bar{I}_{\nu}\) gives us a canonical tool to identify the spaces \(\mathcal {L}_{\infty}(X)_{/\sim}\) and L ∞(ν). Our next goal is to find a continuous and linear right-inverse of I ν . To this end, we recall the definition of a lifting on \(\mathcal {L}_{\infty}(X)\).
Definition B.1
Let \((X,\mathcal {A})\) be a measurable space and ν be a σ-finite measure on \((X,\mathcal {A})\). We say that a map \(\rho:\mathcal {L}_{\infty}(X)\to \mathcal {L}_{\infty}(X)\) is a ν-lifting if the following conditions are satisfied:
-
(i)
ρ is an algebra homeomorphism; that is, ρ is linear and ρ(fg)=ρ(f)ρ(g) for all \(f,g\in \mathcal {L}_{\infty}(X)\).
-
(ii)
ρ(1 X )=1 X .
-
(iii)
[ρ(f)]∼=[f]∼ for all \(f\in \mathcal {L}_{\infty}(X)\).
-
(iv)
ρ(f)=ρ(g) for all \(f,g\in \mathcal {L}_{\infty}(X)\) with [f]∼=[g]∼.
If \(\rho:\mathcal {L}_{\infty}(X)\to \mathcal {L}_{\infty}(X)\) is a ν-lifting and \(f\in \mathcal {L}_{\infty}(X)\) satisfies f(x)≥0, then \(h:=\sqrt{f} \in \mathcal {L}_{\infty}(X)\), and hence we obtain
Consequently, ρ also respects the ordering on \(\mathcal {L}_{\infty}(X)\). From this we can conclude that ρ is also continuous with respect to ∥⋅∥∞. Indeed, if we have an \(f\in \mathcal {L}_{\infty}(X)\) with ∥f∥∞≤1, we find −1 X ≤f≤1 X , and since ρ is linear and respects the ordering, we obtain
that is, ∥ρ(f)∥∞≤1. In other words, we have shown ∥ρ∥≤1. Moreover, from conditions (iii) and (iv), we can conclude that
where the equivalence class [0]∼ is the one in \(\mathcal {L}_{\infty}(X)\). Consequently, the quotient map \(\bar{\rho}:\mathcal {L}_{\infty}(X)_{/\sim} \to \mathcal {L}_{\infty}(X)\), defined by [f]∼↦f, is a well-defined, bounded, linear, and injective operator with \(\Vert \bar{\rho}\Vert \leq1\). Moreover, from condition (ii), we obtain
that is, \([\,\cdot \,]_{\sim}\circ\bar{\rho}= \operatorname {id}_{\mathcal {L}_{\infty}(X)_{/\sim}}\). Considering the isometric isomorphism \(\bar{I}_{\nu}^{-1}: {L}_{\infty}(\nu)\to \mathcal {L}_{\infty}(X)_{/\sim}\), we can now define the bounded, linear, and injective operator
which, by construction and our previous considerations, satisfies ∥φ∥≤1 and
where the outer [ ⋅ ]∼ on the left-hand side and [ ⋅ ]∼ on the right-hand side both refer to equivalence classes in \(\mathcal {L}_{\infty}(X)_{/\sim}\). Applying \(\bar{I}_{\nu}\) to both sides, we conclude that \(I_{\nu}\circ\varphi= \operatorname {id}_{{L}_{\infty}(\nu)}\); i.e., φ is the desired right-inverse of I ν . In other words, φ picks from each equivalence class of L ∞(ν) a bounded representative in a linear and continuous way. Moreover, it is not hard to check that φ is actually an algebra homeomorphism with φ([1 X ]∼)=1 X , and, in addition, it also respects the ordering of L ∞(ν) and \(\mathcal {L}_{\infty}(X)\). Consequently, the map φ has highly desirable properties. So far, however, we have not shown that there actually exists a ν-lifting, and hence we do not know whether a map φ with the above properties exists. This gap is filled by the following theorem:
Theorem B.2
(Existence of liftings)
Let \((X,\mathcal {A})\) be a measurable space and ν be a σ-finite measure on \((X,\mathcal {A})\) such that \(\mathcal {A}\) is ν-complete. Then there exists a ν-lifting \(\rho:\mathcal {L}_{\infty}(X)\to \mathcal {L}_{\infty}(X)\).
Proof
See [39, Theorem 3.2], where we note that σ-finite measures are strictly localizable and Carathéodory completeness of \(\mathcal {A}\) equals ν-completeness. □
As [39, Theorem 3.2] shows, the σ-finiteness of the measure is not necessary if one assumes, instead, some other, technically more involved conditions on ν. Finally, further information on liftings and their applications can be found in, e.g., [24, 42].
Rights and permissions
About this article
Cite this article
Steinwart, I., Scovel, C. Mercer’s Theorem on General Domains: On the Interaction between Measures, Kernels, and RKHSs. Constr Approx 35, 363–417 (2012). https://doi.org/10.1007/s00365-012-9153-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00365-012-9153-3
Keywords
- Reproducing Kernel Hilbert spaces
- Integral operators
- Interpolation spaces
- Eigenvalues
- Statistical learning theory