
Abstract
A new class of explicit Milstein schemes, which approximate stochastic differential equations (SDEs) with superlinearly growing drift and diffusion coefficients, is proposed in this article. It is shown, under very mild conditions, that these explicit schemes converge in \(\mathscr {L}^p\) to the solution of the corresponding SDEs with optimal rate.
Similar content being viewed by others

1 Introduction
Following the approach of Kumar and Sabanis [7], Sabanis [10], we extend the techniques of constructing explicit approximations to the solutions of SDEs with super-linear coefficients in order to develop Milstein-type schemes with optimal rate of (strong) convergence.
Recent advances in the area of numerical approximations of such non-linear SDEs have produced new Euler-type schemes, e.g. see [3, 5, 6, 9,10,11], which are explicit in nature and hence achieve reduced computational time when compared with the corresponding implicit schemes. Note that we do not claim that the superiority of the newly developed explicit schemes over the implicit schemes is absolute. For example, implicit schemes may exhibit better stability properties under different scenarios, typically when large step sizes are used or initial conditions are introduced with large numerical values. Nevertheless, we primarily focus on strong convergence of explicit schemes mainly due to their importance in Multi-level (and/or Markov chain) Monte Carlo, see for example Giles [4] and Brosse et al. [2]. High-order schemes have also been developed in this direction. In particular, Milstein-type (order 1.0) schemes for SDEs with super-linear drift coefficients have been studied in Wang and Gan [12] and in Kumar and Sabanis [7] with the latter article extending the result to include Lévy noise, i.e. discontinuous paths. Furthermore, both drift and diffusion coefficients are allowed to grow super-linearly in Zhang [13] and in Beyn et al. [1]. The latter reference has significantly relaxed the assumptions on the regularity of SDE coefficients by using the notions of C-stability and B-consistency. More precisely, the authors in Beyn et al. [1] produced optimal rate of convergence results in the case where the drift and diffusion coefficients are only (once) continuously differentiable functions (see the assumptions A-1 and A-5 precisely stated below). Our results, which were developed at around the same time as the latter reference by using different methodologies, are obtained under the same relaxed assumptions with regards to the regularity that is required of the SDE coefficients. Crucially, we relax further the moments bound requirement which is essential for practical applications.
We illustrate the above statement by considering an example which appears in Beyn et al. [1], namely the one-dimensional SDE given by
with initial value \(x_0\) and a positive constant \(\sigma \). Theorem 2.1 below yields that for \(p_0=14\) (note that \(\rho =2\)) one obtains optimal rate of convergence in \(\mathscr {L}^2\) (when \(\sigma ^2 \le \frac{2}{13}\) and \(p_1>2\) such that \(\sigma ^2(p_1-1)\le 1\)) whereas the corresponding result in Beyn et al. [1], Table 1 in Section 8, requires \(p_0=18\) for their explicit (projective) scheme. The same requirement, i.e. \(p_0=14\), as in this article is only achieved by the implicit schemes considered in Beyn et al. [1].
Finally, we note that Theorem 2.1 establishes optimal rate of convergence results in \(\mathscr {L}^p\) for \(p>2\) under the relaxed assumption of once continuously differentiable coefficients, which is, to the best of the authors’ knowledge, the first such results in the case of SDEs with super-linear coefficients. As an immediate consequence of this, and for high values of p, one can prove an almost sure convergence result of the proposed approximation scheme (2.6) to the solution of SDE (2.1). The interested reader may consult Corollary 1 from Sabanis [10].
We conclude this section by introducing some notations which are used in this article. The Euclidean norm of a d-dimensional vector b and the Hilbert-Schmidt norm of a \(d\times m\) matrix \(\sigma \) are denoted by |b| and \(|\sigma |\) respectively. The transpose of a matrix \(\sigma \) is denoted by \(\sigma ^*\). The ith element of b is denoted by \(b^i\), whereas \(\sigma ^{(i,j)}\) and \(\sigma ^{(j)}\) stand for (i, j)-th element and j-th column of \(\sigma \) respectively for every \(i=1,\ldots ,d\) and \(j=1,\ldots ,m\). Further, xy denotes the inner product of two d-dimensional vectors x and y. The notation \(\lfloor a \rfloor \) stands for the integer part of a positive real number a. Let D denote an operator such that for a function \(f: \mathbb {R}^d \rightarrow \mathbb {R}^d\), Df(.) gives a \(d \times d\) matrix whose (i, j)-th entry is \(\frac{\partial f^i(.)}{\partial x^j}\) for every \(i,j=1,\ldots ,d\). For every \(j=1,\ldots ,m\), let \(\varLambda ^j\) be an operator such that for a function \(g: \mathbb {R}^d \rightarrow \mathbb {R}^{d \times m}\), \(\varLambda ^j g(.)\) gives a matrix of order \(d \times m\) whose (i, k)-th entry is given by
for every \(i=1,\ldots , d\), \(k=1,\ldots ,m\).
2 Main results
Suppose \((\varOmega , \{\mathscr {F}_t\}_{t \ge 0}, \mathscr {F}, P)\) is a complete filtered probability space satisfying the usual conditions, i.e. the filtration is right continuous and \(\mathscr {F}_0\) contains all P-null sets. Let \(T>0\) be a fixed constant and \((w_t)_{t \in [0, T]}\) denotes an \({\mathbb {R}}^m\)-valued standard Wiener process. Further, suppose that \(b(\cdot )\) and \(\sigma (\cdot )\) are \(\mathscr {B}(\mathbb R^d)\)-measurable functions with values in \({\mathbb {R}}^d\) and \({\mathbb {R}}^{d\times m}\) respectively. Moreover, \(b(\cdot )\) and \(\sigma (\cdot )\) are continuously differentiable in \(x\in \mathbb {R}^d\). For the purpose of this article, the following d-dimensional SDE is considered,
almost surely for any \(t \in [0,T] \), where \(\xi \) is an \(\mathscr {F}_{0}\)-measurable random variable in \(\mathbb {R}^d\).
Let \(p_0, p_1 \ge 2\) and \(\rho \ge 1\) (or \(\rho =0\)) are fixed constants. The following assumptions are made.
A- 1
\(E|\xi |^{p_0} < \infty \).
A- 2
There exists a constant \(L>0\) such that
for any \(x\in \mathbb {R}^d\).
A- 3
There exists a constant \(L>0\) such that
for any \(x, \bar{x} \in \mathbb {R}^d\).
A- 4
There exists a constant \(L>0\) such that
for any \(x, \bar{x} \in \mathbb {R}^d\).
A- 5
There exists a constant \(L>0\) such that, for every \(j=1,\ldots , m\),
for any \(x,\bar{x} \in \mathbb {R}^d\).
Remark 2.1
Assumption A-4 means that there is a constant \(L>0\) such that
for any \(x \in \mathbb {R}^d\) and for every \(i,j=1,\ldots ,d\). As a consequence, one also obtains that there exists a constant \(L>0\) such that
for any \(x , \bar{x} \in \mathbb {R}^d\). Moreover, this implies that b(x) satisfies,
for any \(x \in \mathbb {R}^d\). Furthermore, due to Assumption A-5, there exists a constant \(L>0\) such that
for any \(x \in \mathbb {R}^d\) and for every \(i,k=1,\ldots ,d\), \(j=1,\ldots ,m\). Also, Assumption A-3 along with the estimate \(|b(x)-b(\bar{x})| \le L (1+|x|+|\bar{x}|)^{\rho }|x-\bar{x}| \) obtained above, implies
for any \(x, \bar{x} \in \mathbb {R}^d\). Moreover, this means \(\sigma (x)\) satisfies,
for any \(x \in \mathbb {R}^d\). In addition, one notices that
for any \(x \in \mathbb {R}^d\) and for every \(j=1,\ldots ,m\).
For every \(n \in \mathbb {N}\) and \(x \in \mathbb {R}^d\), we define the following functions,
where \(\theta \ge \frac{1}{2}\) and, similarly, for the purposes of establishing a new, explicit Milstein-type scheme, for every \(j=1,\ldots ,m\), we define
Throughout this article, \(\theta \) is taken to be 1, which corresponds to an order 1.0 Milstein scheme.
Remark 2.2
The case \(\theta =1/2\) is studied in Sabanis [10], without the use of \(\varLambda ^{n,j}\sigma (x)\), as the aim is the formulation of a new explicit Euler-type scheme. By taking different values of \(\theta =1.5,2,2.5, \ldots \) and by appropriately controlling higher order terms, one can obtain analogous (to the value of \(\theta \)) rate of convergence results for higher order schemes by adopting the approach developed in Sabanis [10], Kumar and Sabanis [7] and in this article. One notes, of course, that further smoothness assumptions are also required in such cases.
Let us define \(\kappa (n,t):=\lfloor nt \rfloor / n\) for any \(t \in [0,T]\). Moreover, let us also define
and hence set
almost surely for any \(x \in \mathbb {R}^d\), \(n \in \mathbb {N}\) and \(t \in [0,T] \). The above equality holds true when x is replaced by an \(\mathscr {F}_{\kappa (n,t)}\)-measurable random variables, which is the case always throughout this article.
Remark 2.3
In the following, \(K>0\) denotes a generic constant that varies from place to place, but is always independent of \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\).
Lemma 2.1
Let Assumptions A-3 to A-5 hold, then
for every \(n \in \mathbb {N}, x \in \mathbb {R}^d\) and \(j=1,\ldots ,m\) where the positive constant K does not depend on n.
Proof
Clearly, Assumptions A-3 to A-5 give Remark 2.1 which are used throughout the proof of this lemma. Recall the definition of \(b^n(x)\),
for every \(n\in \mathbb {N}\), \(x\in \mathbb {R}^d\) and \(\theta \ge 1/2\). For any \(\theta \ge 1/2\), by noticing that the denominator of \(b^n(x)\) is greater than 1, one can write
for any \(n\in \mathbb {N}\) and \(x\in \mathbb {R}^d\). Also, notice from Remark 2.1 that \(|b(x)| \le L(1+|x|)^{\rho +1}\) for any \(x\in \mathbb {R}^d\) which further gives,
for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). By raising the power \(1/(2\theta )\) on both the sides, one obtains
where \(K:=(L2^{2\theta \rho -1})^{1/(2\theta )}\), for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). Also, since in the definition of \(b^n(x)\) above, the denominator is always greater than one, hence,
for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). On combining the estimates in (2.2) and (2.3), one obtains,
for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\).
The same proof will work for \(\varLambda ^{n,j}\sigma (x)\) because \(\varLambda ^{j}\sigma (x)\) has same polynomial growth as b(x) (see Remark 2.1). Also, similar proofs can be constructed for \(\sigma ^n(x)\) by raising the power to \(4\theta \) instead of \(2\theta \). Again, recall definition of \(\sigma ^n(x)\),
for every \(n\in \mathbb {N}\), \(x\in \mathbb {R}^d\) and \(\theta \ge 1/2\). For any \(\theta \ge 1/2\), by noticing that the denominator of \(\sigma ^n(x)\) is greater than 1, one can write
for any \(n\in \mathbb {N}\) and \(x\in \mathbb {R}^d\). Also, notice that due to Remark 2.1, \(|\sigma ^n(x)| \le L(1+|x|)^{\frac{\rho }{2}+1}\) which gives
for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). By raising the power \(1/(4\theta )\) on both the sides, one obtains
where \(K:=(L2^{2\theta \rho -1})^{1/(4\theta )}\), for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). Also, since in the definition of \(\sigma ^n(x)\) above, the denominator is always greater than one, hence,
for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). On combining the estimates in (2.4) and (2.5), one obtains,
for every \(n \in \mathbb {N}\) and \(x\in \mathbb {R}^d\). This completes the proof.
We propose below a new variant of the Milstein scheme with coefficients which vary according to the choice of the time step. The aim is to approximate solutions of non-linear SDEs such as Eq. (2.1). The new explicit scheme is given below
almost surely for any \(t \in [0,T]\).
The main result of this article is stated in the following theorem.
Theorem 2.1
Let Assumptions A-1 to A-5 be satisfied with \(p_0\ge 2(3\rho +1)\) and \(p_1>2\). Then, the explicit Milstein-type scheme (2.6) converges in \(\mathscr {L}^p\) to the true solution of SDE (2.1) with a rate of convergence equal to 1.0, i.e. for every \(n \in \mathbb {N}\)
when \(p=2\). Moreover, if \(p_0\ge 4(3\rho +1)\), then (2.7) is true for any \(p \le \frac{p_0}{3\rho +1}\) provided that \(p<p_1\).
Remark 2.4
One observes immediately that for the case \(\rho =0\), one recovers, due to Assumptions A-1 to A-5 and Theorem 2.1, the classical Milstein framework and results (with some improvement perhaps as the coefficients of (2.1) are required only to be once continuously differentiable in this article).
Remark 2.5
In order to ease notation, it is chosen not to explicitly present the calculations for, and thus it is left as an exercise to the reader, the case where the drift and/or the diffusion coefficients contain parts which are Lipschitz continuous and grow at most linearly (in x). In such a case, the analysis for these parts follows closely the classical approach and the main theorem/results of this article remain true. Furthermore, note that such a statement applies also in the case of non-autonomous coefficients in which typical assumptions for the smoothness of coefficients in t are considered (as, for example, in [1]).
The details of the proof of the main result, i.e. Theorem 2.1, and of the required lemmas are given in the next two sections.
3 Moment bounds
It is a well-known fact that due to Assumptions A-1 to A-3, the \(p_0\)-th moment of the true solution of (2.1) is bounded uniformly in time.
Lemma 3.1
Let Assumptions A-1 to A-3 be satisfied. Then, there exists a unique solution \((x_t)_{t \in [0,T]}\) of SDE (2.1) and the following holds,
The proof of the above lemma can be found in many textbooks, e.g. see Mao [8]. The following lemmas are required in order to allow one to obtain moment bounds for the new explicit scheme (2.6).
Remark 3.1
Another useful observation is that for every fixed \(n \in \mathbb {N}\) and due to Remark 2.1, the \(p_0\)-th moment of the new Milstein-type scheme (2.6) is bounded uniformly in time (as in the case of the classical Milstein scheme/framework with SDE coefficients which grow at most linearly). Clearly, one cannot claim at this point that such a bound is independent of n. However, the use of stopping times in the derivation of moment bounds henceforth can be avoided.
Lemma 3.2
Let Assumption A-5 be satisfied. Then,
for any \(t \in [0,T]\) and \(n \in \mathbb {N}\).
Proof
On using an elementary inequality of stochastic integrals and Hölder’s inequality, one obtains
which due to Remark 2.1 gives
and hence the proof completes.
The following corollary is an immediate consequence of Lemma 3.2 and Remark 2.1.
Corollary 3.1
Let Assumption A-5 be satisfied. Then
for any \(n \in \mathbb {N}\) and \(t \in [0,T]\).
Lemma 3.3
Let Assumptions A-1 to A-5 be satisfied. Then, the explicit Milstein-type scheme (2.6) satisfies the following,
Proof
By Itô’s formula on the functional \((1+|x|^2)^{p/2}\) for \(x\in \mathbb {R}^d\), one obtains
and then on taking expectation along with Schwarz inequality,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Then, one uses \(|z_1+z_2|^2 = |z_1|^2+2\sum _{i=1}^{d}\sum _{j=1}^{m}z_1^{(i,j)}z_2^{(i,j)}+|z_2|^2\) for \(z_1,z_2 \in \mathbb {R}^{d\times m}\) to obtain the following estimates,
Here, \(C_1:=E(1+|\xi |^2)^{p_0/2} \). For \(C_2\), one notices that it can be written as
which on the application of Remark 2.1 and Young’s inequality gives,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Further, one observes that the second term of the above equation is zero and the third term can be estimated by the application of Itô’s formula as below,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Due to Remark 2.1 along with an elementary inequality of stochastic integrals, the following estimates can be obtained,
for any \(t\in [0,T]\) and \(n\in \mathbb {N}\). Noticing that when \(p_0\le 3\), \((1+|x_r^n|^2)^{(p_0-3)/2}\le 1\), one can obtain the following estimate,
and then one uses Young’s inequality to obtain the following estimates,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Further, by the application of Hölder’s inequality and an elementary inequality of stochastic integrals, one obtains the following estimates,
which due to Corollary 3.1 and Young’s inequality yields
for any \(t\in [0,T]\) and \(n\in \mathbb {N}\). Now, one only requires the estimates of the last term of \(C_2\) which can be done as follows. Due to Remark 2.1, one has
and then the application of and an elementary inequality of stochastic integrals,
which again due to Remark 2.1 gives,
for any \(t\in [0,T]\) and \(n\in \mathbb {N}\). By substituting the estimates from (3.2) in \(C_2\) above, one obtains the following,
for any \(t\in [0,T]\) and \(n\in \mathbb {N}\). For \(C_3\), one uses Assumption A-2 to obtain the following,
which due to Young’s inequality gives,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Furthermore, by using Young’s inequality, \(C_4\) in (3.1) is estimated as,
and then on the application of Lemma 3.2, one obtains
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Now, for estimating \(C_5\), one writes
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Clearly, the first term is zero and one uses Itô’s formula for the second term to obtain the following,
which on using Schwarz inequality and Remark 2.1 along with an elementary inequality of stochastic integrals yields,
and this can further be estimated as,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). Further, one uses Young’s inequality to obtain the following estimates,
which on using Hölder’s inequality, Lemma 3.2 and Corollary 3.1 gives,
and then one again uses Young’s inequality to obtain,
for any \(t\in [0,T]\) and \(n\in \mathbb {N}\). Thus by the estimates obtained in (3.2), one has
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). By substituting estimates from (3.3), (3.4), (3.5) and (3.6) in (3.1), the following estimates are obtained,
for any \(t \in [0,T]\) and \(n\in \mathbb {N}\). The proof is completed by the Gronwall’s lemma.
4 Proof of main result
A simple application of the mean value theorem, which appears in the Lemma below, allows us to simplify substantially the proof of Theorem 2.1. Furthermore, throughout this section, it is assumed that \(p_0\ge 2(3\rho +1)\) and \(p_1>2\).
Lemma 4.1
Let \(f:\mathbb {R}^d \rightarrow \mathbb {R}\) be a continuously differentiable function which satisfies the following,
for all \(x ,\bar{x}\in \mathbb {R}^d\) and for a fixed \(\gamma \in \mathbb {R} \). Then, there exists a constant L such that
for any \(x,\bar{x} \in \mathbb {R}^d\).
Proof
By mean value theorem,
for some \(q\in (0,1)\). Hence, for a fixed \(q \in (0,1)\),
which on using equation (4.1) completes the proof.
Lemma 4.2
Let Assumptions A-1 to A-5 be satisfied. Then, for every \(n\in \mathbb {N} \)
for any \(p \le \frac{p_0}{\rho +1}\).
Proof
By the application of an elementary inequality of stochastic integrals, Hölder’s inequality, Lemma 2.1 and Remark 2.1, one obtains
which due to Lemma 3.3 completes the proof.
As a consequence of the above lemma, one obtains the following corollary.
Corollary 4.1
Let Assumptions A-1 to A-5 be satisfied. Then, for every \(n \in \mathbb {N}\),
for any \(p \le \frac{p_0}{\rho +1}\).
Lemma 4.3
Let Assumptions A-1 to A-5 be satisfied. Then, for every \(n \in \mathbb {N}\),
for any \(p \le \frac{p_0}{\rho +1}\).
Proof
Due to the scheme (2.6),
and then the application of Hölder’s inequality along with an elementary inequality of stochastic integrals gives
which on using Lemma 2.1 and Remark 2.1 yields the following estimates,
for any \(t \in [0,T]\). Thus, one uses Lemma 3.3 and Corollary 4.1 to complete the proof.
Lemma 4.4
Let Assumptions A-1 to A-5 be satisfied. Then, for every \(n \in \mathbb {N}\),
for any \(p \le \frac{p_0}{3 \rho +1}\).
Proof
One observes that
and hence Lemma 3.3 completes the proof.
Lemma 4.5
Let Assumptions A-1 to A-5 be satisfied. Then, for for every \(n \in \mathbb {N}\),
for any \(p \le \frac{p_0}{2.5 \rho +1}\).
Proof
The proof follows using same arguments as used in Lemma 4.4.
Lemma 4.6
Let Assumptions A-1 to A-5 be satisfied. Then, for every \(n \in \mathbb {N}\),
for any \(p \le \frac{p_0}{3\rho +1}\).
Proof
First, one observes that
for any \(t \in [0,T]\). Also, one can write the following,
and hence due to equation (4.2), Remark 2.1 and Lemma 4.1 (with \(\gamma =(\rho -2)/2\)), one obtains
for any \(t \in [0,T]\). Thus, on the application of Hölder’s inequality and an elementary inequality of stochastic integrals along with Lemma 2.1 and Remarks 2.1, the following estimates are obtained,
for any \(t\in [0,T]\). One again uses Hölder’s inequality and obtains,
for any \(t \in [0,T]\). The proof is completed by Lemmas [3.3, 4.3, 4.2].
Let us at this point introduce \(e_t^n:=x_t-x_{t}^n\) for any \(t \in [0,T]\).
Lemma 4.7
Let Assumptions A-1 to A-5 be satisfied. Then, for every \(n \in \mathbb {N}\) and \(t \in [0,T]\),
for \(p=2\). Furthermore, if \(p_0 \ge 4(3\rho +1)\), then (4.3) holds for any \(p \le \frac{p_0}{3\rho +1}\).
Proof
First, one writes the following,
for any \(t \in [0,T]\).
Notice that when \(p=2\), \(|e_s^n|^{p-2}\) does not appear in \(T_2\) and \(T_3\) of the above equation. One keeps this in mind in the following calculations because their estimations require less computational efforts as compared to the case of \(p \ge 4\).
Now, \(T_1\) can be estimated by using Lemma 4.1 (with \(\gamma =\rho -1\)) as below,
which on the application of Young’s inequality and Hölder’s inequality gives
and then by using Lemmas [3.3, 4.3], one obtains
for any \(t \in [0,T]\).
For \(T_2\), one uses Schwarz, Young’s and Hölder’s inequalities and obtains the following estimates,
which on the application of Lemma 2.1 and Remark 2.1 yields
for any \(t \in [0,T]\). Furthermore, due to Lemma 3.3, the following estimates are obtained,
for any \(t \in [0,T]\). One can now proceed to the estimation of \(T_3\). For this, one uses Itô’s formula and obtains the following estimates,
for any \(s \in [0,T]\).
In the above equation, notice that when \(p=2\), the last five terms are zero, \(|e_{\kappa (n,s)}^n|^{p-2}\) is absent from the first term and \(|e_r^n|^{p-2}\) does not appear in the second and third terms. Hence, this on substituting in \(T_3\) and then using Schwarz inequality gives the following estimates,
for any \(t \in [0,T]\). In order to estimate \(T_{31}\), one writes,
for any \(t \in [0,T]\). In the above, notice that first term is zero. Then, on using the Young’s inequality, Hölder’s inequality and an elementary inequality of stochastic integrals, one obtains,
and then by using Lemmas [3.3, 4.2], one obtains
for any \(t \in [0,T]\). Moreover, for estimating \(T_{32}\), one uses the following splitting,
and hence \(T_{32}\) can be estimated by
which on the application of Young’s inequality gives
for any \(t \in [0,T]\). Due to Hölder’s inequality and an elementary inequality of stochastic integrals, one obtains
and this further implies due to Hölder’s inequality,
for any \(t \in [0,T]\). Again, by using the Hölder’s inequality along with Lemmas [3.1, 3.3, 4.4], one obtains the following estimates,
for any \(t \in [0,T]\). Hence, on using Lemmas [3.3, 4.3] and Corollary 4.1, one obtains,
for any \(t\in [0,T]\). Further, one observes that the estimation of \(T_{33}\) and \(T_{34}\) can be done together as described below. First, one observes that \(T_{33}\) can be expressed as
which due to Schwartz inequality and Remark 2.1 yields
for any \(t \in [0,T]\). Similarly, \(T_{34}\) can be estimated as
which on using Remark 2.1 gives
for any \(t \in [0,T]\). For estimating \(T_{33}+T_{34}\), one uses the following splitting,
and hence obtains the following estimates,
which also gives the following expressions,
for any \(t \in [0,T]\). Also, on the application of Young’s inequality, one obtains
for any \(t \in [0,T]\). Moreover, one uses Hölder’s inequality to get the following estimates,
and then Lemmas [3.3, 4.5, 4.6] and Corollary 4.1 yield
for any \(t \in [0,T]\). For \(T_{35}\), due to (4.11),
which on using Young’s inequality yields,
and then on applying Hölder’s inequality, one obtains
for any \(t \in [0,T]\). Further, one uses Remark 2.1, an elementary inequality of stochastic integrals and Hölder’s inequality to obtain the following estimates,
which due to further application of Young’s inequality gives,
and finally on the application of Lemmas [3.3, 4.5, 4.6] and Corollary 4.1, one obtains
for any \(t \in [0,T]\). Hence, on substituting estimates from (4.8), (4.10), (4.12) and (4.13) in (4.7), one obtains
for any \(t \in [0,T]\). Thus, the proof is completed by combining estimates from (4.5), (4.6) and (4.14) in (4.4).
Proof of Theorem 2.1
Let \(\bar{b}^n(s):=b(x_s)-b^n(x_{\kappa (n,s)}^n)\) and \(\bar{\sigma }^n(s):=\sigma (x_s)-\tilde{\sigma }^n(x_{\kappa (n,s)}^n)\) and then one writes
for any \(t \in [0,T]\). By the application of Itô’s formula,
for any \(t \in [0,T]\). As before, when \(p=2\) the third term does appear on the right hand side of the above equation and \(|e_s^n|^{p-2}\) is absent from the rest of the terms. Due to Cauchy–Bunyakovsky–Schwartz inequality, one obtains
for any \(t \in [0,T]\). Furthermore, one observes that for \(z_1,z_2 \in \mathbb {R}^{d \times m}\), \(|z_1+z_2|^2 = |z_1|^2+2\sum _{i=1}^{d}\sum _{j=1}^{m} z_1^{(i,j)} z_2^{(i,j)}+|z_2|^2\), which on using Young’s inequality further implies \(|z_1+z_2|^2 \le (1+\epsilon )|z_1|^2+(1+1/\epsilon )|z_2|^2\) for every \(\epsilon >0\). Let us now fix \(\epsilon >0\). Hence, one can use this arguments for estimating \(|\sigma (x_s)-\sigma (x_s^n)|^2\) when using the splitting given in equation (4.11). This along with the splitting of equation (4.9) gives
for any \(t \in [0,T]\). Notice that the constant \(K>0\) (a large constant) in the last two terms of the above inequality depends on \(\epsilon \). Also, one obtains the following estimates,
for any \(t \in [0,T]\). Since \(p < p_1\), thus on using Assumption A-3, Lemmas [4.6, 4.7] and Young’s inequality, one obtains
and hence Lemmas [4.4, 4.5] give
for any \(t \in [0,T]\). Finally, the use of Gronwall’s lemma completes the proof.
5 Numerical example
In this section, numerical experiments are implemented by using the proposed Milstein type scheme and it is demonstrated that their findings support our theoretical results.
5.1 First example
Consider a one-dimensional SDE which is given by
for any \(t \in [0,1],\) with initial value \(x_0=2.0\) and \(\sigma =0.3\). Our Milstein type scheme of SDE (5.1) at the \((l+1)h\)-th gridpoint is given by, for any \(l=0, 1, \ldots , 2^{n}-1\),
with \(h=2^{-n}\) where \(\varDelta w_{lh}:=w_{(l+1)h}-w_{lh}\). Our aim is to calculate
where \(x_1^{\text {exact}}\) is the exact solution of the SDE (5.1) and \(x_1^n\) is the value of the scheme at \((l+1)h=1\) and for step length h. Since the exact solution of the SDE is not known, the scheme (5.2) with \(h^*=2^{-21}\) and \(n^*=21\) is taken to be the true solution of SDE (5.1). Letting
to denote one particular (i.e. the i-th) realization of the driving Wiener process with \(h^*=2^{-21}\), the corresponding sequences of Wiener increments with step size \(h=2^{-n}\) and for the same realisation, where \(n=6,\ldots , 20\), are given according to
where
Hence,
Let \(Y_i:=|x_1^{\text {exact},i}-x_1^{n,i}|^p\) for the i-th path and let \(M_n\) denote the Monte Carlo estimate of \(E(|x_1^{\text {exact}}-x_1^n|^p)\). Then, one defines
to denote the corresponding sample variance. Thus, the \(100\alpha \)% confidence interval is given by
meaning that
Hence, the confidence interval for \((E(|x_1^{\text {exact}}-x_1^n|^p))^{1/p}\) is given by
The numerical values for the MC estimate of \((E(|x_1^{\text {exact}}-x_1^n|^p))^{1/p}\), \(p=2,3\) with 60,000 paths and the corresponding 95% confidence intervals (with \(\alpha =0.95\)) are given in the Tables 1 and 2 below.


Figure 1 indicates that the rate of \(\mathscr {L}^2\)- and \(\mathscr {L}^3\)-convergence of the scheme (5.2) is 1.0.
5.2 Second example
Consider the following one-dimensional SDE,
for any \(t \in [0,1],\) where the initial value \(x_0\) follows a Pareto distribution with density function \(f(x)=(1+\xi x)^{-(1+1/\xi )}\) for \(x >0\) and \(\xi \ge 0\). Notice that \(E|x_0|^p<\infty \) iff \(p<1/\xi \). Take \(\xi =1/18\) so that \(E|x_0|^p<\infty \) for all \(p<18\) which implies that Theorem 2.1 holds for \(p=2\). Our Milstein-type scheme of SDE (5.12) at the \((l+1)h\)-th gridpoint is given by, for any \(l=0, 1, \ldots , 2^{n}-1\),
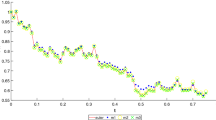
with \(h=2^{-n}\) where \(\varDelta w_{lh}:=w_{(l+1)h}-w_{lh}\). Figure 2a and Table 3a indicate that the rate of \(\mathscr {L}^2\)-convergence of the scheme (5.13) is 1.0. The scheme (5.2) with \(h=2^{-21}\) is taken to be the true solution of SDE (5.12). The number of paths is 60, 000.
Let us now take \(\xi =1/35\) so that \(E|x_0|^{p_0}< \infty \) for all \(p_0<35\) which implies that Theorem 2.1 holds for \(p=2,3,4\). Figure 2b and Table 3b show that the theoretical rate of convergence is realised in these three cases.
Change history
08 October 2019
In the originally published version of this article, the acknowledgement was unfortunately not yet in the final version. It should read as follows:
References
Beyn, W.-J., Isaak, E., Kruse, R.: Stochastic C-stability and B-consistency of explicit and implicit Milstein-type schemes. J. Sci. Comput. 70–3, 1042–1077 (2017)
Brosse, N., Durmus, A., Moulines, E., Sabanis, S.: The tamed unadjusted Langevin algorithm. Stoch. Process. Appl. 1, 2 (2018). https://doi.org/10.1016/j.spa.2018.10.002. (in press)
Dareiotis, K., Kumar, C., Sabanis, S.: On tamed Euler approximations of SDEs driven by Lévy noise with applications to delay equations. SIAM J. Numer. Anal. 54–3, 1840–1872 (2016)
Giles, M.B.: Multilevel Monte Carlo path simulation. Oper. Res. 56–3, 607–617 (2008)
Hutzenthaler, M., Jentzen, A.: Numerical approximations of stochastic differential equations with non-globally Lipschitz continuous coefficients. Mem. Am. Math. Soc. 236, 1112 (2015)
Hutzenthaler, M., Jentzen, A., Kloeden, P.E.: Strong convergence of an explicit numerical method for SDEs with nonglobally Lipschitz continuous coefficients. Ann. Appl. Probab. 22–4, 1611–1641 (2012)
Kumar, C., Sabanis, S.: On tamed Milstein schemes of SDEs driven by Lévy noise. Discrete Contin. Dyn. Syst. Ser. B 22–2, 421–463 (2017)
Mao, X.: Stochastic Differential Equations and Applications. Horwood Publishing, Chichester (1997)
Sabanis, S.: A note on tamed Euler approximations. Electron. Commun. Probab. 18–47, 1–10 (2013)
Sabanis, S.: Euler approximations with varying coefficients: the case of superlinearly growing diffusion coefficients. Ann. Appl. Probab. 26–4, 2083–2105 (2016)
Tretyakov, M.V., Zhang, Z.: A fundamental mean-square convergence theorem for SDEs with locally Lipschitz coefficients and its applications. SIAM J. Numer. Anal. 51–6, 3135–3162 (2013)
Wang, X., Gan, S.: The tamed Milstein method for commutative stochastic differential equations with non-globally Lipschitz continuous coefficients. J. Differ. Equ. Appl. 19–3, 466–490 (2013)
Zhang, Z.: New Explicit Balanced Schemes for SDEs with Locally Lipschitz Coefficients (2014). arXiv:1402.3708v1 [math.NA]
Acknowledgements
This work has made use of the resources provided by the Edinburgh Compute and Data Facility (ECDF) http://www.ecdf.ed.ac.uk/. All simulations included in this article are performed in c programming language using MPI parallel system.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by David Cohen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kumar, C., Sabanis, S. On Milstein approximations with varying coefficients: the case of super-linear diffusion coefficients. Bit Numer Math 59, 929–968 (2019). https://doi.org/10.1007/s10543-019-00756-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-019-00756-5