
Abstract
Ensemble pruning can effectively overcome several shortcomings of the classical ensemble learning paradigm, such as the relatively high time and space complexity. However, each predictor has its own unique ability. One predictor may not perform well on some samples, but it will perform very well on other samples. Blindly underestimating the power of specific predictors is unreasonable. Choosing the best predictor set for each query sample is exactly what dynamic ensemble pruning techniques address. This paper proposes a hybrid Time Series Prediction (TSP) algorithm to implement one-step-ahead prediction task, integrating Dynamic Ensemble Pruning (DEP), Incremental Learning (IL), and Kernel Density Estimation (KDE), abbreviated as the EnsPKDE&IncLKDE algorithm. It dynamically selects proper predictor sets based on the kernel density distribution of all base learners’ prediction values. Due to the characteristic of TSP problems that samples arrive in chronological order, the idea of IL is naturally introduced into EnsPKDE&IncLKDE, while DEP is a common technology to address the concept drift issue inherent in IL. The algorithm is divided into three subprocesses: 1) Overproduction, which generates the original ensemble learning system; 2) Dynamic Ensemble Pruning (DEP), achieved by one subalgorithm called EnsPKDE; 3) Incremental Learning (IL), realized by one subalgorithm termed IncLKDE. Benefited from the advantages of integrating Dynamic Ensemble Pruning scheme, Incremental Learning paradigm and Kernel Density Estimation, in the experimental results, EnsPKDE&IncLKDE demonstrates superior prediction performance to several other state-of-the-art algorithms in fulfilling time series forecasting tasks.










Similar content being viewed by others

References
M. C. A. Neto, G. D. C. Cavalcanti, and I. R. Tsang, "Financial time series prediction using exogenous series and combined neural networks," in International Joint Conference on Neural Networks, pp. 2578–2585, 2009
Bodyanskiy YV, Tyshchenko OK (2020) A hybrid Cascade neural network with ensembles of extended neo-fuzzy neurons and its deep learning. Inf Technol Syst Res Comput Phys 945:164–174
Lim JS, Lee S, Pang HS (2013) Low complexity adaptive forgetting factor for online sequential extreme learning machine (OS-ELM) for application to nonstationary system estimations. Neural Comput Applic 22:569–576
Ye Y, Squartini S, Piazza F (2013) Online sequential extreme learning machine in nonstationary environments. Neurocomputing 116:94–101
Yee P, Haykin S (1999) A dynamic regularized radial basis function network for nonlinear, nonstationary time series prediction. IEEE Trans Signal Process 47:2503–2521
Crone SF, Hibon M, Nikolopoulos K (2011) Advances in forecasting with neural networks? Empirical evidence from the NN3 competition on time series prediction. Int J Forecast 27:635–660
J. Villarreal and P. Baffes, "Time series prediction using neural networks," 1993
Castillo O, Melin P (2001) Simulation and forecasting complex economic time series using neural networks and fuzzy logic. IEEE Int Conf Syst 3:1805–1810
Chandra R (2015) Competition and collaboration in cooperative coevolution of Elman recurrent neural networks for time-series prediction. IEEE Trans Neural N Learning Syst 26:3123–3136
Dieleman S, Willett KW, Dambre J (2015) Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon Not R Astron Soc 450:1441–1459
Gaxiola F, Melin P, Valdez F, Castillo O (2015) Generalized type-2 fuzzy weight adjustment for backpropagation neural networks in time series prediction. Inf Sci 325:159–174
Wang L, Zeng Y, Chen T (2015) Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Syst Appl 42:855–863
D. Sotiropoulos, A. Kostopoulos, and T. Grapsa (2002) A spectral version of Perry’s conjugate gradient method for neural network training, in Proceedings of 4th GRACM Congress on Computational Mechanics, pp. 291–298
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR (2012) Improving neural networks by preventing co-adaptation of feature detectors. Comput Sci 4:212–223
Huang GB, Zhu QY, Siew CK (2005) Extreme learning machine: a new learning scheme of feedforward neural networks. IEEE Int Joint Confer Neural Networks 2:985–990
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70:489–501
Huang GB, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybernetics Part B 42:513–529
Wang X, Han M (2014) Online sequential extreme learning machine with kernels for nonstationary time series prediction. Neurocomputing 145:90–97
Ye R, Dai Q (2018) A novel transfer learning framework for time series forecasting. Knowl-Based Syst 156:74–99
W. Hong, L. Lei, and F. Wei (2016) Time series prediction based on ensemble fuzzy extreme learning machine, in IEEE International Conference on Information & Automation, pp. 2001–2005
W. Hong, F. Wei, F. Sun, and X. Qian (2015) An adaptive ensemble model of extreme learning machine for time series prediction," in International Computer Conference on Wavelet Active Media Technology & Information Processing, pp. 80–85
Lin L, Fang W, Xie X, Zhong S (2017) Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst Appl 83:164–176
X. Qiu, L. Zhang, Y. Ren, P. N. Suganthan, and G. Amaratunga (2014) Ensemble deep learning for regression and time series forecasting, in Computational Intelligence in Ensemble Learning, pp. 1–6
Li J, Dai Q, Ye R (2019) A novel double incremental learning algorithm for time series prediction. Neural Comput & Applic 31:6055–6077
Parzen E (1962) On estimation of a probability density function and mode. Ann Math Stat 33:1065–1076
E. Ley and M. F. Steel (1993) Bayesian econometrics: Conjugate analysis and rejection sampling, in Economic and Financial Modeling with Mathematica®, ed: Springer, pp. 344–367
Elman JL (1990) Finding structure in time. Cogn Sci 14:179–211
M. I. Jordan, "Serial order: A parallel distributed processing approach," in Advances in Psychology. vol. 121, ed: Elsevier, 1997, pp. 471–495
Schuster M, Paliwal KK (1997) Bidirectional recurrent neural networks. IEEE Trans Signal Process 45:2673–2681
Hochreiter S, Schmidhuber JR (1997) Long short-term memory. Neural Computation 9:1735–1780
Liang N-Y, Huang G-B, Saratchandran P, Sundararajan N (2006) A fast and accurate online sequential learning algorithm for feedforward networks. IEEE Trans Neural Netw 17:1411–1423
Polikar R, Upda L, Upda SS, Honavar V (2001) Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans Syst Man Cybernetics, Part C (Applications Rev) 31:497–508
Muhlbaier MD, Topalis A, Polikar R (2008) Learn++.NC: combining Ensemble of Classifiers with Dynamically Weighted Consult-and-Vote for efficient incremental learning of new classes. IEEE Trans Neural Netw 20:152–168
Zhang W, Xu A, Ping D, Gao M (2019) An improved kernel-based incremental extreme learning machine with fixed budget for nonstationary time series prediction. Neural Comput & Applic 31:637–652
Yang Y, Che J, Li Y, Zhao Y, Zhu S (2016) An incremental electric load forecasting model based on support vector regression. Energy 113:796–808
Woloszynski T, Kurzynski M (2011) A probabilistic model of classifier competence for dynamic ensemble selection. Pattern Recogn 44:2656–2668
Zhai JH, Xu HY, Wang XZ (2012) Dynamic ensemble extreme learning machine based on sample entropy. Soft Comput 16:1493–1502
Cruz RM, Sabourin R, Cavalcanti GD, Ren TI (2015) META-DES: a dynamic ensemble selection framework using META-learning. Pattern Recogn 48:1925–1935
H. Yao, F. Wu, J. Ke, X. Tang, Y. Jia, S. Lu, et al.(2018) Deep multi-view spatial-temporal network for taxi demand prediction," in Thirty-Second AAAI Conference on Artificial Intelligence
R. Senanayake, S. O'Callaghan, and F. Ramos (2016) Predicting spatio-temporal propagation of seasonal influenza using variational Gaussian process regression," in Thirtieth AAAI Conference on Artificial Intelligence, pp. 3901–3907
A. Venkatraman, M. Hebert, and J. A. Bagnell (2015) Improving multi-step prediction of learned time series models," in Twenty-Ninth AAAI Conference on Artificial Intelligence, pp. 3024–3030
S. Dasgupta and T. Osogami (2017) Nonlinear dynamic Boltzmann machines for time-series prediction, in Thirty-First AAAI Conference on Artificial Intelligence
Z. Liu and M. Hauskrecht (2016) Learning adaptive forecasting models from irregularly sampled multivariate clinical data, in Thirtieth AAAI Conference on Artificial Intelligence, pp. 1273–1279
Zhou ZH, Wu J, Jiang Y (2001) Genetic algorithm based selective neural network ensemble. Int Joint Conf Artif Intell:797–802
Zhou ZH, Wu J, Tang W (2002) Ensembling neural networks: many could be better than all. Artif Intell 137:239–263
He H, Chen S, Li K, Xu X (2011) Incremental learning from stream data. IEEE Trans Neural Netw 22:1901–1914
J. O. Gama, R. Sebastião, and P. P. Rodrigues (2009) Issues in evaluation of stream learning algorithms, in Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 329–338
Bifet A, Holmes G, Kirkby R, Pfahringer B (2010) Moa: massive online analysis. J Mach Learn Res 11:1601–1604
Carlo E. Bonferroni, "Il calcolo delle assicurazioni su gruppi di teste," In Studi in Onore del Professore Salvatore Ortu Carboni, Rome: Italy, pp. 13–60, 1935
Zhou T, Gao S, Wang J, Chu C, Todo Y, Tang Z (2016) Financial time series prediction using a dendritic neuron model. Knowl-Based Syst 105:214–224
Soares E, Costa P, Costa B, Leite D (2018) Ensemble of evolving data clouds and fuzzy models for weather time series prediction. Appl Soft Comput 64:445–453
Svarer C, Hansen LK, Larsen J (1993) On Design And Evaluation Of Tapped-Delay Neural-Network Architectures. IEEE Int Conf Neural Netw 1–3:46–51
Bezerra CG, Costa BSJ, Guedes LA, Angelov PP (2016) An evolving approach to unsupervised and real-time fault detection in industrial processes. Expert Syst Appl 63:134–144
D. Kangin and P. Angelov (2015) Evolving clustering, classification and regression with TEDA, in 2015 International Joint Conference on Neural Networks (IJCNN), pp. 1–8
Yao C, Dai Q, Song G (2019) Several novel dynamic ensemble selection algorithms for time series prediction. Neural Process Lett 50:1789–1829
Acknowledgements
This work is supported by the National Key R&D Program of China (Grant Nos. 2018YFC2001600, 2018YFC2001602), and the National Natural Science Foundation of China under Grant no. 61473150.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
APPENDIX Online Extreme Learning Machine with Kernels
APPENDIX Online Extreme Learning Machine with Kernels
1.1 Extreme Learning Machine (ELM)
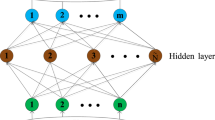
As shown in Fig. 11, the architecture of Extreme Learning Machine (ELM) [15] is the same with a SLFN. The weights between its input and hidden layers are initialized as random values. While its output weight matrix is to be computed. Supposing that there are N arbitrary distinct samples (xi, ti), where xi ∈ Rn, ti ∈ R, ELM could be formulated as:
where θi ∈ Rn represents the weight vector of the connection between the input layer and the i-th hidden neuron, bi ∈ R represents the bias value of the i-th hidden neuron, g(.) is the activation function, wi is the weight vector of the connection between the i-th hidden neuron and the output neurons, L denotes the hidden neurons number, and oj denotes the output of the j-th sample. Eq. (13) can be more concisely formulated as:
where

ELM architecture
o = [o1, o2, …, oN]T represents the output of ELM, and w = [w1, w2, …, wL]T is weight matrix connecting the hidden and the output layers. The value of w can be calculated by:
where t = [t1, t2, …, tN]T denotes the vector of target values, HΨ represents the Moore-Penrose generalized inverse of H.
1.2 Extreme Learning Machine with Kernels (ELMK)
ELMK [16] is one promotion of ELM. Define h(x) ∈ Rd(d > > n) as a mapping from low dimensions to high ones. Let H = [h(x1), h(x2), …, h(xN)]T, the loss function of ELMK is:
Using Lagrange multiplier method to solve Eq. (17), then Eq. (18) can be obtained:
where x represents the test instance, and f(x) expresses the predicted value. Let K(xi, xj) = h(xi)T ⋅ h(xj), K is a kernel function. Eq. (18) can be rewritten as:
1.2.1 Online Sequential ELMK (OS-ELMK)
ELM and ELMK are substantially offline learning models. While in TSP problems, samples tend to enter the model one-by-one or batch-by-batch over time, therefore, online learning is especially important for TSP. And thus, online sequential ELMK (OS-ELMK) [17] came into being.
The corresponding Lagrangian dual problem of Eq. (17) could be formulated as:
The KKT optimality conditions of Eq. (20) are listed as below:
If Eqs. (21) and (22) are substituted into Eq. (23), it could be obtained that:
When some new samples \( \left({\mathrm{x}}_k^{new},{t}_k^{new}\right),k=1,\dots, m \) arrive, Eq. (24) can be updated as:
where \( {\theta}_i^{\ast } \) indicates the updated θi, \( {\theta}_k^{new} \) indicates the new k-th θ. It is defined that \( {\uptheta}^{new}={\left[{\theta}_1^{new},\dots, {\theta}_m^{new}\right]}^T \), and Δθ = [Δθ1, Δθ2, …, ΔθN]T, where \( {\theta}_j^{\ast }={\theta}_j+\varDelta {\theta}_j \), j = 1,2,…,N. Combining Eq. (24) with Eq. (25), then it can be obtained that:
where Kj, i = K(xj, xi), \( {K}_{k,i}^{\prime }=K\left({\mathrm{x}}_k^{new},{\mathrm{x}}_i\right) \). Equation (27) can be reformulated as its matrix presentation:
For making the expression more concise, the below definitions are made:
Equation (28) can be rewritten compactly as:
Substituting \( {\theta}_j^{\ast }={\theta}_j+\varDelta {\theta}_j \), j = 1,2,…,N into Eq. (26), we can get:
The matrix form of the above formula is:
where \( {K}_{i,j}^{{\prime\prime} }=K\left({\mathrm{x}}_i^{new},{\mathrm{x}}_j^{new}\right) \). Let:
where f(.) is the regression function without being trained by using the newly added samples.
The compact matrix-vector expression of Eq. (34) is:
We get:
After θnew has been obtained, ∆θ can be computed according to Eq. (32), and finally the updated θupdate = [(θ + Δθ)T, (θnew)T]T can be acquired. When the new samples are added, R in Eq. (29) also needs to be updated. The kernel matrix in the updated R* is:
The updated R* is:
After a series of matrix calculations, can we get the updated R*:
In the end, the online sequential learning algorithm of ELMK (OS-ELMK) is presented, in detail, in Algorithm 4.

Rights and permissions
About this article

Cite this article
Zhu, G., Dai, Q. EnsPKDE&IncLKDE: a hybrid time series prediction algorithm integrating dynamic ensemble pruning, incremental learning, and kernel density estimation. Appl Intell 51, 617–645 (2021). https://doi.org/10.1007/s10489-020-01802-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-020-01802-4