
Abstract
Multiple and usually conflicting objectives subject to data uncertainty are main features in many real-world problems. Consequently, in practice, decision-makers need to understand the trade-off between the objectives, considering different levels of uncertainty in order to choose a suitable solution. In this paper, we consider a two-stage bi-objective single source capacitated model as a base formulation for designing a last-mile network in disaster relief where one of the objectives is subject to demand uncertainty. We analyze scenario-based two-stage risk-neutral stochastic programming, adaptive (two-stage) robust optimization, and a two-stage risk-averse stochastic approach using conditional value-at-risk (CVaR). To cope with the bi-objective nature of the problem, we embed these concepts into two criterion space search frameworks, the \(\epsilon \)-constraint method and the balanced box method, to determine the Pareto frontier. Additionally, a matheuristic technique is developed to obtain high-quality approximations of the Pareto frontier for large-size instances. In an extensive computational experiment, we evaluate and compare the performance of the applied approaches based on real-world data from a Thies drought case, Senegal.
Similar content being viewed by others
1 Introduction
Decision-makers (DMs) often face multiple goals, which are in conflict with each other (Ehrgott 2005), e.g., minimization of cost versus maximization of service level, and finding a feasible solution that simultaneously optimizes all criteria is usually impossible. Consequently, it is important for DMs to understand the trade-off between the considered objectives. To cope with this issue, many real-world problems have been modeled as multi-objective optimization (MOO) problems, and a variety of algorithms have been developed to produce the set of trade-off solutions.
Moreover, usually, DMs do not make their decisions in a completely certain environment. Depending on the problem, different levels of uncertainty should be taken into account to make reliable decisions. To deal with this issue in optimization problems, different approaches have been proposed in the literature. The most widely used ones are stochastic programming (Birge and Louveaux 2011) and robust optimization (Ben-Tal et al. 2009). Stochastic optimization assumes that the underlying probability distributions of the uncertain parameters are known or can be estimated, e.g., based on historical data. It allows to model different risk attitudes, e.g., risk-neutral decision making or risk-averse decision making. Unlike stochastic optimization, robust optimization does not assume any probabilistic data but only uncertain parameters stemming from an uncertainty set (e.g., scenarios). Well-known robust concepts are minmax/static robustness and adaptive robust optimization (Bertsimas et al. 2011).
Although many different approaches have been developed to cope with multiple objectives and uncertainty separately in optimization problems, the intersection of these two main domains, i.e., the analysis of decision problems involving multiple objectives and parameter uncertainty simultaneously, only received comparably little attention. Combinations of MOO with stochastic programming concepts (Abdelaziz 2012; Gutjahr and Pichler 2016; Charkhgard et al. 2020) and robustness concepts (Ehrgott et al. 2014; Ide and Schöbel 2016) give a flavor of the diverse possible ways to cope with real-life decision making problems.
Optimization problems arising along the humanitarian relief chain (HRC) are real-world applications that motivated us in combining bi-objective optimization and optimization under uncertainty, as multiple objectives and inherent risk are distinguishing features of humanitarian logistics. HRC problems concern multi-stakeholder decision making in which a population of stakeholders seeks to balance their conflicting objectives and priorities. The objectives can be categorized into three main groups of criteria, efficiency criteria, effectiveness criteria, and equity criteria (Gralla et al. 2014). Besides, in a disaster situation, most of the information received at the disaster management center, such as the number of injured people, the amount of demand of the affected people, traveling times according to the network conditions and available commodities, etc., are inherently imprecise and uncertain. To avoid any inefficiency in the final selected solutions, such inherent uncertainty in input data should be taken into account. Thus, it is desirable to have optimization models and solution techniques to deal with the multi-objective nature and the uncertainty features of HRC simultaneously.
Disaster management operations are usually classified into four phases: mitigation and preparedness (pre-disaster), response, and recovery (post-disaster). These four phases together are known as the disaster management cycle (Altay and Green III 2006). The preparedness and response are relief phases, whereas the mitigation and recovery are development phases. When a disaster strikes (either a sudden-onset disaster that occurs as a single, distinct event, such as an earthquake, or a slow-onset disaster that emerges gradually over time, such as a drought), relief goods are transported to the points of distributions (PODs) by relief organizations. Then, affected people walk or drive to these centers to collect their relief aid. Since the numbers and the locations of the PODs and their capacity directly affect the performance of the relief chain in terms of response time and costs (Balcik and Beamon 2008), facility location decisions in disaster management are of vital importance. This paper deals with a two-stage bi-objective single source capacitated facility location (Bi-SSCFL) problem where one objective is affected by data uncertainty.
We analyze traditional two-stage risk-neutral stochastic and adaptive (two-stage) robust optimization as well as a two-stage risk-averse stochastic framework which can be seen as a method between the other two approaches using a widely applied risk measure, namely the conditional value-at-risk (CVaR(\(\alpha \))). With the help of uncertainty level \(\alpha \) (\(\alpha \in [0,1)\)), it can be adapted to the DM’s risk preference. Two-stage stochastic and adaptive robust optimization are two special cases of the CVaR with \(\alpha =0\) and \(\alpha \approx 1\), respectively. Towards that end, we use the classical linear representation of CVaR. Embedded into the \(\epsilon \)-constraint framework and the balanced box method, we solve small and medium sized instances to optimality, and to solve larger instances, we develop a matheuristic method which finds high-quality approximations of the set of trade-off solutions.
As mentioned earlier, multiple objectives and uncertainty are two major characteristics of humanitarian decision support systems in practice. Uncertainty, as well as multi-objective optimization, have been considered abundantly in the literature on humanitarian relief (see Hoyos et al. 2015; Grass and Fischer 2016; Gutjahr and Nolz 2016). However, let us mention that also in other application areas of Logistics and Supply Chain Management, the issues of uncertainty and multiple objectives play an important role. According to Gutjahr and Nolz (2016), capturing uncertainty in multi-criteria optimization is critical in practice and still a comparably young field.
The majority of the studies in the literature that addresses MOO under uncertainty in different phases of disaster relief (e.g., Tzeng et al. 2007; Zhan and Liu 2011; Tricoire et al. 2012; Najafi et al. 2013; Rezaei-Malek and Tavakkoli-Moghaddam 2014; Rath et al. 2016; Haghi et al. 2017; Liu et al. 2017; Kınay et al. 2019; Parragh et al. 2021) use either scenario-based traditional two-stage stochastic programming (e.g., Zhan and Liu 2011; Tricoire et al. 2012; Rath et al. 2016; Parragh et al. 2021) or scenario-based worst-case robust optimization (e.g., Najafi et al. 2013; Rezaei-Malek and Tavakkoli-Moghaddam 2014; Haghi et al. 2017; Liu et al. 2017; Kınay et al. 2019) to cope with uncertainty. Noyan (2012) propose risk averse stochastic programming for single-objective problems in disaster management. This work was extended in Noyan et al. (2019) to a multi-criteria optimization approach with a two-stage stochastic programming model. As in our present work, Noyan et al. (2019) use the CVaR to represent risk averseness. However, the multi-criteria decision approach is different from ours, insofar as Noyan et al. (2019) apply the CVaR in the context of multivariate stochastic dominance constraints, whereas we use the concept of Pareto efficiency (the most prominent concept in multi-objective optimization) to determine the trade-off between our considered objective functions.
From a methodological point of view, some of these studies use the \(\epsilon \)-constraint method (Laumanns et al. 2006) to find the optimal Pareto frontier (e.g., Tricoire et al. 2012; Rath et al. 2016), while others develop metaheuristic algorithms to approximate the Pareto frontier for large-size instances (e.g., Haghi et al. 2017). Let us give details of the mentioned works in the HRC literature, which tackle uncertain multi-objective facility location problems using the concept of Pareto efficiency. Tricoire et al. (2012) develop a bi-objective two-stage stochastic model to deal with distribution center selection for relief commodities and delivery planning. The authors consider the demand as a random parameter and approximate it by a sample of randomly generated scenarios. A new solution approach is proposed based on the \(\epsilon \)-constraint method for the computation of the Pareto frontier of the bi-objective problem using a branch-and-cut algorithm. Finally, they test the proposed algorithm using data of a real-world application in Senegal. In this paper, we address the case of Sengeal using a different model. Rath et al. (2016) formulate several variants of a two-stage bi-objective stochastic programming model in the response phase of disasters. They apply the \(\epsilon \)-constraint method to compute the Pareto frontier. They evaluate the benefit of the stochastic bi-objective model in comparison to the deterministic bi-objective model using the value of stochastic solution (VSS) measure. Haghi et al. (2017) develop a metaheuristic algorithm for a multi-objective location and distribution model with pre/post-disaster budget constraints for goods and casualties logistics. In order to handle the uncertainties, a robust optimization approach is embedded into the \(\epsilon \)-constraint method. To solve large-size instances, they propose a metaheuristic algorithm that is a combination of a genetic algorithm and simulated annealing (Kirkpatrick et al. 1983). Hinojosa et al. (2014) investigate a two-stage stochastic transportation problem with uncertain demands, considering an overall objective function that is composed of total cost associated with the selected links in the first decision stage, and expected distribution cost in the second decision stage.
Fernández et al. (2019) deal with a two-stage stochastic mixed-integer model for a fixed-charge transportation problem with uncertain demand on the assumption that the decision maker is risk-averse. Risk aversion is represented by using the CVaR in the objective function. Filippi et al. (2019) present a bi-objective facility location problem where the first objective is the minimization of cost. The second objective aims at maximizing fairness by considering a conditional \(\beta \)-mean measure. The conditional \(\beta \)-mean is a concept related to the CVaR, but note that in Filippi et al. (2019), it is applied to fairness quantification rather than to the measurement of risk. The authors develop a weighted-sum method to generate the Pareto-frontier for small/medium-size instances. Besides, a Benders decomposition method is employed to deal with the large-size instances. Comparison of the solution shows the efficiency of their proposed methods. Parragh et al. (2021) propose an uncertain bi-objective facility location problem considering stochastic demand in a disaster relief context. They formulate the uncertainty using a scenario-based two-stage risk-neutral stochastic approach. The authors integrate the L-shaped method into a bi-objective branch-and-bound framework to deal with the problem. They test and compare different cutting-plane schemes on instances with varying numbers of samples.
Contributions of the paper The focus of our paper is on the evaluation of different combinations of two criterion space search methods, the well-known \(\epsilon \)-constraint (Laumanns et al. 2006) and the recently proposed balanced box (Boland et al. 2015) methods and three different uncertainty approaches, the widely used risk-neutral two-stage stochastic programming approach, adaptive (two-stage) robust optimization and two-stage risk-averse stochastic programming using CVaR. It aims at finding an efficient method to generate the entire Pareto frontier by considering last-mile setting assumptions. It is assumed that the demand of affected people is uncertain.
In addition, as it is not possible to solve large-size instances to optimality within a reasonable time limit, we propose an iterative mixed integer programming (MIP)-based matheuristic.
The remainder of this paper is organized as follows. In Sect. 2, we define the uncertain bi-objective facility location problem addressed in this paper and its mathematical formulation. After that, in Sect. 3, we summarize the developed solution approaches to solve the problem. Section 4 presents and discusses the computational results. Finally, in Sect. 5 we present conclusion and address potential future work.
2 Problem description
Due to scarcity of resources, in many disaster relief situations, including slow-onset disasters or sudden-onset disasters, humanitarian organizations encounter challenging logistical last-mile operations (Rancourt et al. 2015; Balcik and Beamon 2008). On one hand, the humanitarian organizations’ goal in such a context is to reduce beneficiaries’ vulnerability by maximizing coverage. On the other hand, they face limited monetary resources and want to reduce their costs. Therefore DMs face two conflicting objectives, and a trade-off solution needs to be identified.
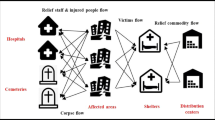
We consider a Bi-SSCFL with simplified assumptions of a last-mile network, motivated by the drought case studies presented by Tricoire et al. (2012) and Rancourt et al. (2015), as well as the earthquake case presented by Noyan et al. (2016) in which the authors design a last-mile aid distribution network. Unlike Tricoire et al. (2012), the two latter studies rely on a single objective approach, albeit the authors acknowledge and analyze different objectives. The main framework for the cases is the same (Fig. 1). Our model is an uncertain bi-objective extension of an uncapacitated deterministic facility location problem proposed by Rancourt et al. (2015) to design a real food aid network in Kenya, Sub-Saharan Africa, in which the objective is to minimize the welfare cost of all the involved stakeholders. The aim is to find the best locations to position PODs in the relief phase of a disaster where beneficiaries walk to these PODs to pick up the aid packages. Two objective functions are considered: the first objective is the minimization of location costs, and the second objective is to minimize the number of uncovered demand of beneficiaries (effectiveness-related criterion).

Last mile relief network. Source Modified from Noyan et al. (2016)
In this paper, we consider the amount of demand as an uncertain parameter, as the demand of the affected people depends on the crisis’s intensity which is uncertain (single source of uncertainty). Without loss of generality, multiple sources of uncertainty (e.g., the demand of the affected people, the capacity of PODs, the availability of transportation links, etc.) can also be considered in the model.
The problem is formulated on a graph \(G= \left( V_0, A\right) \), where \(V_0\) is the set of nodes, and A is the set of arcs. \(V_0\) can be partitioned into \(\{\{0\}, I\}\), where \(\{0\}\) is the main warehouse (MW), supplying the selected PODs, and I is the set of affected nodes and a superset of the set of potential PODs, J (without loss of generality we assume the set of potential PODs is a subset of the set of affected nodes \(J\subseteq I\): If a potential POD is not affected, it can be represented as a virtual affected node with zero beneficiaries). We assume that the location of the MW is determined before the optimization.
Another assumption is that beneficiaries in each affected location (\(i\in I\)) will walk only to the one opened POD (\(j\in J\)), which they are assigned to, in order to fulfill their demand (\(q_i^{(s)}\)) (single-source assumption). Moreover, beneficiaries will not walk to any PODs, if their distance (\(d_{ij}\)) from an opened POD is more than a certain distance threshold (\(d_{max}\)).
The first stage decision (represented by decision variables \(y_j\)) is the location of PODs with limited capacity (\(c_j\)) and given fixed cost (\(\gamma _j\)). This decision has to be made before the realization of the uncertain parameters. The second stage decisions determine the assignments of demand nodes to the opened PODs (decision variables \(x_{ij}^{(s)}\)) and the amount of relief items delivered to each POD (decision variables \(u_j^{(s)}\)), which are determined based on first stage decisions and realized uncertain information. Table 1, summarizes the employed notation.
2.1 Base formulation
In mathematical terms, a nominal formulation of the first stage is the following. Note that the precise meaning of minimizing \(f_2\) is not yet specified, we shall return to this issue in Sect. 2.2.
The first objective (1) minimizes opening costs, and the second one (2) minimizes the uncovered demand of the affected people. Here \(\xi \) denotes the random data and \(Q(y,\xi )\) is the second objective function associated with the second stage of the problem for a given decision resulting from the first stage. It represents the uncovered demand resulting from decision y, if the uncertain data realize as \(\xi \). The second stage is formulated as follows for the realization of the random data under scenario \(s\in S\) (\(\xi ^s=(q^s)\)):
Constraint (5) indicates coverage constraints. It makes sure that any part of the demand at i is only covered at most once. Constraints (6) ensure that the capacity of POD j is not exceeded. Constraints (7) link the coverage variables with the assignment variables: the covered demand with POD j cannot be higher than the actual demand assigned to this node. Constraints (8) guarantee that a demand node can only be assigned to an opened POD, and finally, constraints (3), (9) and (10) give the domains of the variables.
2.2 Uncertainty treatment
To deal with parameter uncertainty, as mentioned in the introduction, we use three different approaches, two-stage risk-neutral stochastic programming (expected value), two-stage (adaptive) robust optimization, and two-stage risk-averse stochastic programming (CVaR). We consider a scenario-based framework to make a fair comparison among all the above-mentioned approaches. We characterize the uncertainty in parameters via a finite discrete set of random scenarios (\(s\in S\), \(S=\{1,\ldots ,N\}\)) where each scenario has the same probability \(\frac{1}{N}\). In the following, we provide the corresponding models.
2.2.1 Two-stage risk-neutral stochastic optimization
As mentioned before, the nature of the decision-making process in our problem is sequential: the decision on the location of the POD has to be taken before the realization of uncertain data. The assignment of demand points to an opened POD is done afterwards. We capture this setting through a two-stage stochastic programming model and in a risk-neutral context by taking the expected value of the random variable \(f_2\) as the evaluation of second-stage costs. Representing the probability distribution by N equiprobable scenarios as described above, the second-stage objective function (\(f_2\)) will be replaced by the expected value of the uncovered demand in the stochastic model. So, the obtained deterministic counterpart of the bi-objective model (1) to (10) is as follows (M1):
2.2.2 Adaptive robust optimization
The above two-stage stochastic approach is based on the expected value, whereas minmax robustness is based on the worst-case scenario (pessimistic view). Adaptive robust optimization, in which the recourse function is a worst-case value over a set of scenarios (also called “minimax two-stage stochastic programming”), might give less conservative solutions according to Bertsimas et al. (2010), who compared it to static (minmax) robustness. By replacing \(f_2\) with its worst value in (1)-(10), the deterministic counterpart of the bi-objective model is as follow (M2):
2.2.3 Two-stage risk-averse stochastic optimization
So far, to cope with randomness in our problem, we have employed the expected value of coverage, which corresponds to a risk-neutral approach, and the worst-case value of the coverage, which is the adaptive robustness approach. These two approaches are at the two ends of the risk averseness spectrum, in which the risk-neutral approach gives a comparably optimistic view, whereas the adaptive robust approach represents a pessimistic view of the random outcome. Sometimes, DMs are not risk-neutral but less risk-averse than assumed by the adaptive robust approach. For these cases, we consider a two-stage risk-averse stochastic optimization model where the degree of risk-aversion can be specified. We use the widely applied conditional value-at-risk (CVaR) as the risk measure in our study which leads to a computationally tractable model.
In this paper we employ the classical linear representation of CVaR that is valid on the assumption of an underlying finite discrete probability space. The general concept of CVaR and its classical representation is briefly discussed in Appendix A.
In our problem, we calculate the CVaR value for the second-stage objective \(Q(y,\xi ^s)\) with \(s=1,\ldots ,N\). The deterministic equivalent formulation of our model is as follows (M3):
This formulation is equivalent to the two-stage stochastic (expected value) approach in the special case \(\alpha = 0\), and it is equivalent to the adaptive (two-stage) robust approach for sufficiently large values of \(\alpha ,\) \(\alpha \rightarrow 1\).
3 Solution approach
In this section, we first describe two exact bi-objective frameworks that are used to solve small instances. Thereafter, we propose a matheuristic method to deal with large-size instances. It uses the MIP as a backbone and a local search algorithm to heuristically generate better solutions. For the definition of solution concepts in a multi-objective setting, we refer to Appendix B.
3.1 Multi-objective exact solution techniques
Most of the papers in the literature of HRC have deployed metaheuristic techniques to solve large-size (i.e., real-world) instances of mathematical models. Metaheuristic techniques cannot provide performance guarantees, whereas exact methods can. Among exact methods, criterion space search methods (i.e., methods that search in the space of objective function values) are often computationally more efficient than decision space search methods (i.e., methods that search in the space of feasible solutions) (Boland et al. 2015). To find a good approximation of the entire Pareto frontier, we employ two criterion space search frameworks, the well-known \(\epsilon \)-constraint method due to its simplicity (Laumanns et al. 2006) and the recently developed balanced box method (Boland et al. 2015) since it has been shown that it performed well for large-size problems. It is worth noting that these frameworks are exact algorithms that give an approximation of the Pareto frontier if they are terminated before completion, e.g. if a tight time limit is employed.
The \(\epsilon \)-constraint method generates all NDPs step by step iteratively. Let us describe the method for the special case of two objectives. It starts by finding the endpoints of the Pareto frontier using lexicographic optimization. Lexicographic optimization is performed as follows: we optimize the first objective function (\(f_1\)) and gain the optimal minimum value \(f_1=f^{min}_1\). Then, we optimize the second objective function (\(f_2\)) by adding constraint \(f_1=f^{min}_1\) to the model in order to keep the optimal solution value of the first optimization and \(f^{max}_2\) is obtained. The solution to this procedure gives the first extreme point (\(Z^T\)). This procedure can be represented in the following notation (note that \(R(z^1,z^2)\) is the box in the criterion space defined by the points \(z^1=(f_{1}^1,f_{2}^1)\) and \(z^2=(f_{1}^2,f_{2}^2)\) where \(f_{1}^1 \le f_{1}^2\) and \(f_{2}^2 \le f_{2}^1\)):
The second extreme point (\(Z^B\)) is found by optimizing the second objective function (\(f_2\)) and obtaining the optimal minimum value \(f_2=f^{min}_2\). Then, the first objective function (\(f_1\)) is optimized by adding constraint \(f_2=f^{min}_2\) to the model and \(f^{max}_1\) is gained:
The \(\epsilon \)-constraint algorithm enumerates each NDP one by one from the direction of one endpoint to the other. In all iterations, one and the same of the objective functions is considered as the main objective and the other in terms of an \(\epsilon \)-constraint. The parameter \(\epsilon \) is set as given in lines 5 and 7 in Algorithm 1.
We note that the choice of direction in the \(\epsilon \)-constraint method can play an essential role in the performance of the algorithm. In our case, we optimize \(f_2\) as the main objective and handle \(f_1\) in the \(\epsilon \)-constraint based on preliminary results. That is, the Pareto solutions are enumerated from \(Z^B\) to \(Z^T\). Since the first objective takes integer values in our problem, the smallest difference value (d) is 1. Algorithm 1 shows the procedure of the \(\epsilon \)-constraint framework.

On the other hand, the balanced box method keeps a priority queue of boxes in criterion space in non-decreasing order of their areas. In the beginning, the priority queue is empty. So, similar to the \(\epsilon \)-constraint method, the algorithm first finds the endpoints of the Pareto frontier (\(Z^T, Z^B\)). These two points define the initial box \(R(Z^T, Z^B)\). It contains all not yet found NDPs. Subsequently, all the other boxes are generated and explored iteratively.
In each iteration, the largest box in the priority queue pops out, and the algorithm then splits the box horizontally into two equal parts \(R^T\) and \(R^B\). It first explores the bottom box for a NDP by optimizing the first objective function. It then explores the top box for a NDP with minimization of the second objective function. The procedure can be repeated until no more boxes are left unexplored in the priority queue. The pseudocode of this framework is presented in Algorithm 2.

3.2 A matheuristic solution algorithm
Although small instances can be solved to optimality by the exact solution techniques, we develop a matheuristic method to compute high-quality approximated Pareto frontiers for the large-size instances. It combines the feature of the \(\epsilon \)-constraint method and bi-objective generalizations of two single-objective variable fixing heuristic algorithms, namely local branching (Fischetti and Lodi 2003) and relaxation induced neighborhood search (RINS) (Danna et al. 2005)
Local branching (Fischetti and Lodi 2003) is a general MIP-based framework which explores a neighborhood of a feasible reference solution \(\bar{y}\) to identify a better solution. Assume \(\bar{A}=\{j \in J: \bar{y}_j=1\}\) is the set of indices of potential POD variables where their value is equal to one. To construct an l-OPT neighborhood \(N(\bar{y},l)\) of the reference solution, the following local branching constraint is added to the model:
Constraint (22) states that at most l variables of the reference solution \(\bar{y}\) switch their values either from 1 to 0 or from 0 to 1.
Note that the cardinality of the binary support of any feasible solution is a constant in our model. Therefore, constraint (22) can equivalently be written in its asymmetric form:
Moreover, RINS (Danna et al. 2005) is another general MIP-based mechanism to search a neighborhood of a feasible solution. It uses the information retrieved within the branch-and-bound tree comparing the incumbent solution and the continuous relaxation solution concerning variables which take the same values in both solutions. By fixing the variables with identical values, its focus is on the variables with different values. Similarly, comparing the Pareto solutions corresponding to NDPs along the Pareto frontier in the Bi-SSCFL problem, with identical opening costs, show that they have many variables with the same values. We observed that when moving along the frontier solution by solution from one end-point (\(Z^B\)) to the other one (\(Z^T\)), very often one of the opened facilities (i.e., \(y_j=1\)) is closed, and the set of closed facilities is kept unchanged (i.e., \(y_j=0\)). Therefore the variables with value 0 could be fixed.
Assume \(A=\{j \in J: y_{j}^b=0\}\) is the set of indices of potential POD variables related to a solutions, where its POD variable values \(y^b\) are equal to zero. We developed the following procedure in order to find a high-quality approximation of the Pareto frontier (cf. Algorithm 3):
(i) we find the optimal Pareto efficient endpoints (\(Z^T\) and \(Z^B\)) and create the initial box \(R(Z^T,Z^B)\) and \(y^b\) is the vector of POD variable values corresponding to \(Z^B\); (ii) noting that we move along the frontier in the direction from \(Z^B\) to \(Z^T\) in our \(\epsilon \)-constraint method, we add the linear constraint of \(y_{j}=0\quad \forall j\in A\), and we approximate the next efficient solution, namely x, if the MIP problem is solved in a certain time limit (TiLim). Otherwise, we approximate the efficient solution x by solving the linear relaxation (LR) of the model, rounding the fractional values in order to obtain an integer solution, and we deploy local branching to approximate a better solution. We denote the POD decision variable values of x by \(y^a\); (iii) we generate the entire Pareto frontier iteratively updating the set A with \(y^a\).
Leitner et al. (2016) propose a two-phase heuristic approach that uses a generalization of RINS called BINS and local branching to solve bi-objective binary integer linear programs. Our method differs from theirs in two ways. First, we combine an adaptation of RINS with the \(\epsilon \)-constraint framework to explore the criterion space, whereas Leitner et al. (2016) apply BINS in the first phase of their method, to explore each box found in a weighted-sum framework. Secondly, our method employs the local branching scheme where the problem cannot be solved to optimality fast enough by only fixing the variables, they applied local branching to refine the NDPs found in the first phase.

It is worth mentioning that based on our preliminary computational experiments, computing the endpoints \(Z^T\) and \(Z^B\) was not expensive in our problem. However, in cases where the exact computation of the two endpoints is too demanding, we suggest to use the local branching approach to approximate them.
4 Computational study
In the following, we present the computational experiments conducted to evaluate the performance of the proposed methods. We first describe the test instances and then, the quality indicators employed to assess the performance of the methods. This is followed by a recapitulation of the expected value of perfect information (EVPI), and the value of stochastic solution (VSS) used to show the value of incorporating risk measurement. Thereafter, we discuss the computational results.
All experiments have been implemented in C++ using the Concert Technology component library of IBM \(\circledR \)ILOG \(\circledR \)CPLEX \(\circledR \)12.9 as a MIP solver where multi-threading is disabled. The algorithms are run on a cluster where each node consists of two Intel Xeon X5570 CPUs at 2.93 GHz and 8 cores, with 48GB RAM. A time limit (TL) of 7200 s has been applied. In addition, the TiLim parameter for the matheuristic technique is set to 150 s and \(l'=N\).
4.1 Test instances
To test and evaluate the integration of the above-mentioned uncertainty approaches into the stated multi-objective frameworks, a data set inspired by a real-world study for a slow-onset drought case presented in Tricoire et al. (2012) has been utilized. Tricoire et al. (2012) provided us with the data set from the region of Thies in western Senegal. Senegal is a developing country in sub-Saharan Africa where droughts occur frequently. Politically, the region is split into 32 rural areas where each contains between 9 and 31 villages (demand nodes). In total, the region contains 500 nodes. In order to test the performance of the proposed solution approaches, we create new networks and artificially generate larger instances with between 21 and 500 nodes by aggregating the demand nodes in the region. For example, the first instance contains 21 nodes, and the second one has 44 nodes, i.e., an instance with 23 nodes is added to the first 21 nodes, and the second instance of 44 nodes is derived. Our data set contains 23 test instances.
The distance matrix is obtained by road distances between each pair of nodes. Opening costs for PODs are assumed to be identical for all demand locations (5000 cost units). We also assume that the affected people in a demand node will walk to the closest POD if the distance is less than 6km. The capacity of each POD is set equal to the population size of the demand nodes times three. We start by considering 10 sample scenarios (|S|= 10) to cope with demand uncertainty. Thereafter, to assess the algorithms for a larger number of scenarios, samples with 100, 500, and 1000 scenarios are generated. The uncertain demand of each demand node (village) i is considered as \(\xi _iq_i\), where \(\xi _i\) and \(q_i\) are the uncertainty factor and the population size of the node i, respectively. The uncertainty factor is a sum of a random baseline term (\(\xi _{base}\)), which is the same for all nodes, and a correction term, which is unique for each demand point. Correction terms for different demand points are assumed as stochastically independent. In mathematical formulas, \(\xi _i= \xi _{base} - \lambda _2 + 2\lambda _2Z_i\), where \(\xi _{base}={\bar{\xi }}-\lambda _1+2\lambda _1Z\). Therein, \({\bar{\xi }}\) is a constant value set to 1, Z and \(Z_i\) are random numbers uniformly distributed between 0 and 1, and \(\lambda _1=\lambda _2\ge 0\) are constant parameters chosen to be 0.5. We refer to Tricoire et al. (2012) for further details.
4.2 Solution quality indicators
Different quality indicators for multi-objective approximation algorithms have been proposed in the literature. Zitzler et al. (2003) review the existing quality measures. We employ the hypervolume indicator to assess the performance of the proposed methods.
Given a bi-objective framework with minimization objective functions, let X be the set of feasible solutions in decision space and \(Z=f(X)\) be the set of feasible solutions in criterion space. We assume \(A \subseteq Z\) is an approximation set of a Pareto frontier, and \(R \subseteq Z\) is a reference set, e.g., the true Pareto frontier.
The hypervolume indicator (\(I_H\)) (Zitzler and Thiele 1998) computes the area of the portion of the criterion space, which is weakly dominated by approximation set A with respect to a reference point (e.g., the Nadir point). The complete Pareto frontier generally has a maximum value of \(I_H\). The higher the value of \(I_H\), the higher is the quality of the approximated Pareto frontier.
4.3 Value of using a risk measure stochastic model
Due to the computational challenges of decision making under uncertainty, one of the first questions that DMs might come up with is whether it pays off to consider a stochastic instead of a deterministic model. An answer can be given by using two well-known measures: the expected value of perfect information (EVPI) and the value of stochastic solution (VSS). These measures assess the value of using a single objective two-stage risk-neutral programming model (see, Birge and Louveaux 2011).
In this section, we start by recalling these two measures. After that, similarly as in Noyan (2012) where the measures are extended to a single-objective two-stage mean-risk model involving the CVaR, we adapt these concepts to our bi-objective two-stage CVaR model.
The EVPI measures the expected gain of perfect information over the stochastic solution. It is the difference between the wait-and-see solution (WS) and the solution obtained by solving the risk-neutral stochastic model referred to as the recourse problem (RP). WS is obtained by solving the model for each scenario as realized data with a probability of 1, and then taking the expected objective function value:
Therein, \(\bar{y}(\xi ^s)\) denotes the optimal solution of the individual problem for each scenario. Then, by definition: EVPI = RP−WS.
On the other hand, the VSS evaluates the stochastic model in comparison to an expected value solution, where the latter is defined as the solution of the deterministic problem obtained by replacing each random parameter by its expected value. The VSS is calculated as the difference between the RP solution value and the solution value EEV of the expected value problem. EEV is obtained by solving a deterministic expected value scenario problem in the first step. Then, the resulting optimal first-stage variables are saved and fixed in the model, and the second stage is solved:
where \({\bar{\xi }}= E (\xi ^s)\), and \(\bar{y}({\bar{\xi }})\) is the the expected value solution. Then, VSS is calculated as follow: VSS = EEV−RP.
As it is mentioned, these two measures are based on expected values which are used to assess a risk-neutral stochastic model. However, they cannot be used directly to evaluate a two-stage risk-averse stochastic model. Therefore, we adapt these measures and apply the risk function (CVaR) instead of the expected value in computing the WS and EEV approach. More precisely, we use the following measures for the two-stage CVaR model at the risk level of \(\alpha \) (see, Noyan 2012):
Therein, RRP\((\alpha )\) is the solution obtained by solving the risk-averse CVaR model at the risk level of \(\alpha \), RWS\((\alpha )= \text {CVaR}_\alpha (Q(\bar{y}(\xi ^s),\xi ^s))\) is obtained by solving the model for each scenario as realized data with a probability of 1 and then taking the CVaR objective function value at the risk level of \(\alpha \), and REV\((\alpha )= \text {CVaR}_\alpha (Q(\bar{y}({\bar{\xi }}),\xi ^s))\) is obtained by solving a deterministic expected value scenario problem in the first step. Then, the resulting optimal first-stage variables are saved and fixed in the model, and the second stage of the risk-averse model is solved at the risk level of \(\alpha \).
RVPI measures the gain of perfect information based on the CVaR value of the objective values obtained from WS solutions. The RVSS measures the gain from solving the risk-averse model with a specific risk preference. The higher the values of RVSS, the more is the value-added of considering a risk-averse model instead of a risk-neutral problem.
In order to employ these measures to our bi-objective model, we apply them to each non-dominated solution where \(f_1\) is bounded as \(\epsilon \)-constraint, and \(f_2\) is the main objective.
4.4 Results
In this section, we conduct numerical experiments to assess the proposed approaches. We compare all combinations; \(\epsilon \)-constraint (e), balanced box (BB) frameworks, and proposed matheuristic (Mat) integrated into deterministic counterparts of the M1, M2, and M3 models. Additionally, we consider the generic feasibility pump based heuristic (FPBH) method recently proposed by Pal and Charkhgard (2019). To implement it, we employed the Julia package, namely “FPBHCPLEX.jl”, which uses CPLEX 12.7 as a MIP solver. It is available as an open-source package on GitHub. Since it was difficult to set up this package on the cluster, FPBH is run on a local computer with Intel\(\circledR \) Core\(^{\mathrm{TM}}\) i5-7200U CPU at 2.50 GHz with 16GB RAM. For the sake of a fair comparison, our proposed matheuristic is also run on the same system using CPLEX 12.7 as the solver. Let {e-M1, BB-M1, e-M2, BB-M2, e-M3, BB-M3, Mat-M3, FPBH-M3} denote the set of all methods considered in this study. Since special cases of M3 model are identical with M1 and M2 models, we just address the performance of Mat method integrated with the M3 model.
We first study the combinations of exact multi-objective methods with two widely used uncertainty approaches, two-stage stochastic, and two-stage robust approach (e-M1, BB-M1, e-M2, BB-M2). Then, we compare the performance of their deterministic counterpart with two-stage CVaR deterministic counterpart in its two special cases where \(\alpha = 0\) (risk-neutral) and \(\alpha \)= 0.9 (where |S|=10 \(\rightarrow \) the worst value of \(\alpha =1-\frac{1}{10}\) = 0.9). Later, we address the combination of exact and matheuristic multi-objective methods to two-stage CVaR for different levels of risk (e-M3, BB-M3, Mat-M3).
Table 2 indicates the run time of e-M1, BB-M1, e-M2, BB-M2, e-M3, BB-M3 in seconds for different instances. “TL” indicates that the run-time limit, which we fixed at 7200 s, is reached.
As can be seen from Table 2, the combination of the \(\epsilon \)-constraint framework with M1 model (e-M1) finds the complete Pareto frontier even for rather large instances. Furthermore, the deterministic counterpart of two-stage risk-neutral stochastic (M1) and adaptive robust (M2) models outperform the deterministic counterpart of the CVaR model in its special cases (\(\alpha =0\) and \(\alpha =0.9\)).
Next, we show the computational results for the M3 model on the instances solved in Table 2, obtained on different levels of \(\alpha \) integrated into two exact multi-objective frameworks (Table 3). These results also indicate that a combination of different \(\alpha \) levels with the \(\epsilon \)-constraint method performs better than their combination with the BB technique.
After analyzing the two exact multi-objective techniques, we apply the proposed matheuristic method to the M3 model in order to solve the test instances. As indicated in Table 4, contrary to the exact methods, the Mat method successfully solves all the instances within the given time-limit and finds an approximation of the entire Pareto frontier. Additionally, we solve a few instances with a larger number of scenarios. The results show that the Mat method also works when the number of scenarios increases (see Appendix C).
Computational results of the performance measurements are summarized in Table 5. Table 5 details the performance of the \(\epsilon \)-constraint method, the BB method, and the Mat method on all of the instances. We report the number of found NDPs and the \(I_H\) values. For this purpose, we compute the nadir point as a reference point by calculating the worst objective values over the found optimal efficient set in the \(\epsilon \)-constraint method. As can be seen from Table 5, the \(\epsilon \)-constraint and the BB method do not perform well on larger instances within the time limit. However, the BB method, which bidirectionally explores the criterion space, finds more NDPs. Furthermore, the number of found NDPs and \(I_H\) values associated with the Mat method shows that it outperforms the two exact methods on the large-size instances.
The performance of the generic FPBH method is reported in Table 6. The results show that the proposed Mat method strongly outperforms the FPBH on our MIP model. The FPBH approach usually reaches the time-limit.
As an example, the Logarithmic plot of the Pareto frontier resulting from different approaches, for the instance size of 90 nodes is shown in Fig. 2. It shows that the Mat method generates almost the same Pareto frontier as the reference set. The main differences are at the right-end of the Pareto frontier, where the location cost is high, and the uncovered demand is at the lower values.

Logarithmic plot of Pareto frontier for the instance size 90
As mentioned before, we compute the stochastic measures in order to demonstrate the effectiveness of incorporating the risk measure of CVaR into the model. We compute the RVPI and RVSS for different levels of \(\alpha \). In Table 7, we report the relative values of RVPI and RVSS, which are the absolute values divided by the optimal objective value of the RRP (i.e., RVPI/RRP and RVPI/RRP). The results are the average and maximum of the computed values over all non-dominated solutions for the instance size of 21 and 44 nodes with a scenario sample size of 10. According to the results, the value of RVSS is significantly large relative to the RRP value, which indicates that it is worth solving the risk-averse model with respect to different risk preferences. Moreover, RVPI values are also high, but they get smaller with increasing levels of \(\alpha \).
Furthermore, we compute the RVSS values at first by fixing the value of the first-stage decisions (\(y_j\)) based on the solutions of the deterministic average model (EA) and then, based on the risk-neutral solutions (SP). Table 8 shows the results for the instance size 21 and 44 with a scenario sample size of 10. Comparing the RVSS values indicates that once the randomness has been taken into consideration, the solutions are more robust than the deterministic average model.
Figure 3 compares the Pareto frontiers obtained by solving the RRP, the RRP with fixed first-stage solutions from the average model (REA), and the RRP with fixed first-stage solutions from the risk-neutral model (RSP) at \(\alpha =0.7\). It shows that incorporating randomness in the model gives a more robust solution. Note that the REA model obtains solutions at the left-end of the Pareto frontier that are almost as good as RRP and RSP.

Pareto frontiers for instance size 21
We also compare the efficient solutions in the solution space for the average deterministic model and the CVaR model with different levels of \(\alpha \) for the instance size 21 (Fig. 4). The reported solutions are associated with one point (solution 6 out of 12 Pareto solutions) along the Pareto frontier. A comparison of efficient solutions also highlights the previous finding. It shows that once the randomness in different levels of \(\alpha \) is considered, the decisions of the opened PODs (\(y_j\)) and the allocation of demand points (\(x_{ij}\)) are more or less similar, whereas, these decisions in the average deterministic case are entirely different.

Comparison of the value of the decision variables for one of the solutions of the efficient set for size 21: a \(\alpha =0\), b \(\alpha =0.7\), c \(\alpha =0.9\) and d average deterministic case
5 Conclusions
In this paper, we investigate a two-stage Bi-SSCFL model extendable to design a last-mile relief network problem. It incorporates the trade-off between a deterministic objective (minimization of location cost) and an uncertain one (minimization of uncovered demand) where demand values are uncertain.
To find an efficient and reliable methodology to address the problem, we evaluate different methods. We combined two criterion space search frameworks, the \(\epsilon \)-constraint and the balanced box methods, and three different uncertainty approaches, the widely used two-stage risk-neutral stochastic programming, two-stage adaptive robust optimization, and two-stage risk-averse stochastic programming using CVaR. Two variants of linear reformulations of CVaR are taken into consideration.
Moreover, we introduce a matheuristic method in order to find high-quality approximations of the Pareto frontier for large-size instances. It is a combination of an adaptive RINS approach, a local branching framework, and the \(\epsilon \)-constraint method.
We perform an in-depth computational study and compare the results. The experiment illustrates how the proposed matheuristic method not only outperforms the exact frameworks for large-size instances, but also outperforms the FPBH method (Pal and Charkhgard 2019). Additionally, quantifying the VSS measure also shows that incorporating uncertainty into the model gives more robust results in comparison with the deterministic model. In our future research, we would like to extend the model by considering routing constraints where there are multiple sources of uncertainty. There are also potentials for improvement of solution methods by further research on the combination of MIP and metaheuristics for bi-objective optimization. For example, a decomposition-based approach to deal with the polyhedral subset-based representation of the CVaR might be explored.
References
Abdelaziz, F. B. (2012). Solution approaches for the multiobjective stochastic programming. European Journal of Operational Research, 216(1), 1–16.
Altay, N., & Green, W. G., III. (2006). OR/MS research in disaster operations management. European Journal of Operational Research, 175(1), 475–493.
Balcik, B., & Beamon, B. M. (2008). Facility location in humanitarian relief. International Journal of Logistics, 11(2), 101–121.
Ben-Tal, A., El Ghaoui, L., & Nemirovski, A. (2009). Robust optimization (Vol. 28). Princeton: Princeton University Press.
Bertsimas, D., Brown, D. B., & Caramanis, C. (2011). Theory and applications of robust optimization. SIAM Review, 53(3), 464–501.
Bertsimas, D., Doan, X. V., Natarajan, K., & Teo, C.-P. (2010). Models for minimax stochastic linear optimization problems with risk aversion. Mathematics of Operations Research, 35(3), 580–602.
Birge, J. R., & Louveaux, F. (2011). Introduction to stochastic programming. Berlin: Springer Science & Business Media.
Boland, N., Charkhgard, H., & Savelsbergh, M. (2015). A criterion space search algorithm for biobjective integer programming: The balanced box method. INFORMS Journal on Computing, 27(4), 735–754.
Charkhgard, H., Takalloo, M., & Haider, Z. (2020). Bi-objective autonomous vehicle repositioning problem with travel time uncertainty. 4OR, pp. 1–29.
Danna, E., Rothberg, E., & Le Pape, C. (2005). Exploring relaxation induced neighborhoods to improve MIP solutions. Mathematical Programming, 102(1), 71–90.
Ehrgott, M. (2005). Multicriteria optimization (Vol. 491). Berlin: Springer Science & Business Media.
Ehrgott, M., Ide, J., & Schöbel, A. (2014). Minmax robustness for multi-objective optimization problems. European Journal of Operational Research, 239(1), 17–31.
Fernández, E., Hinojosa, Y., Puerto, J., & Saldanha-da Gama, F. (2019). New algorithmic framework for conditional value at risk: Application to stochastic fixed-charge transportation. European Journal of Operational Research, 277(1), 215–226.
Filippi, C., Guastaroba, G., & Speranza, M. (2019). On single-source capacitated facility location with cost and fairness objectives. European Journal of Operational Research, 289(3), 959–974.
Fischetti, M., & Lodi, A. (2003). Local branching. Mathematical programming, 98(1–3), 23–47.
Gralla, E., Goentzel, J., & Fine, C. (2014). Assessing trade-offs among multiple objectives for humanitarian aid delivery using expert preferences. Production and Operations Management, 23(6), 978–989.
Grass, E., & Fischer, K. (2016). Two-stage stochastic programming in disaster management: A literature survey. Surveys in Operations Research and Management Science, 21(2), 85–100.
Gutjahr, W. J., & Nolz, P. C. (2016). Multicriteria optimization in humanitarian aid. European Journal of Operational Research, 252(2), 351–366.
Gutjahr, W. J., & Pichler, A. (2016). Stochastic multi-objective optimization: a survey on non-scalarizing methods. Annals of Operations Research, 236(2), 475–499.
Haghi, M., Ghomi, S. M. T. F., & Jolai, F. (2017). Developing a robust multi-objective model for pre/post disaster times under uncertainty in demand and resource. Journal of Cleaner Production, 154, 188–202.
Hinojosa, Y., Puerto, J., & Saldanha-da Gama, F. (2014). A two-stage stochastic transportation problem with fixed handling costs and a priori selection of the distribution channels. Top, 22(3), 1123–1147.
Hoyos, M. C., Morales, R. S., & Akhavan-Tabatabaei, R. (2015). Or models with stochastic components in disaster operations management: A literature survey. Computers and Industrial Engineering, 82, 183–197.
Ide, J., & Schöbel, A. (2016). Robustness for uncertain multi-objective optimization: a survey and analysis of different concepts. OR Spectrum, 38(1), 235–271.
Kınay, Ö. B., Saldanha-da Gama, F., & Kara, B. Y. (2019). On multi-criteria chance-constrained capacitated single-source discrete facility location problems. Omega, 83, 107–122.
Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by simulated annealing. Science, 220(4598), 671–680.
Laumanns, M., Thiele, L., & Zitzler, E. (2006). An efficient, adaptive parameter variation scheme for metaheuristics based on the epsilon-constraint method. European Journal of Operational Research, 169(3), 932–942.
Leitner, M., Ljubić, I., Sinnl, M., & Werner, A. (2016). ILP heuristics and a new exact method for bi-objective 0/1 ILPs: Application to FTTX-network design. Computers and Operations Research, 72, 128–146.
Liu, X., Küçükyavuz, S., & Noyan, N. (2017). Robust multicriteria risk-averse stochastic programming models. Annals of Operations Research, 259(1–2), 259–294.
Najafi, M., Eshghi, K., & Dullaert, W. (2013). A multi-objective robust optimization model for logistics planning in the earthquake response phase. Transportation Research Part E: Logistics and Transportation Review, 49(1), 217–249.
Noyan, N. (2012). Risk-averse two-stage stochastic programming with an application to disaster management. Computers and Operations Research, 39(3), 541–559.
Noyan, N., Balcik, B., & Atakan, S. (2016). A stochastic optimization model for designing last mile relief networks. Transportation Science, 50(3), 1092–1113.
Noyan, N., Meraklı, M., & Küçükyavuz, S. (2019). Two-stage stochastic programming under multivariate risk constraints with an application to humanitarian relief network design. Mathematical Programming, pp. 1–39.
Pal, A., & Charkhgard, H. (2019). FPBH: A feasibility pump based heuristic for multi-objective mixed integer linear programming. Computers and Operations Research, 112, 104760.
Parragh, S. N., Tricoire, F., & Gutjahr, W. J. (2021). A branch-and-Benders-cut algorithm for a bi-objective stochastic facility location problem. OR Spectrum, https://doi.org/10.1007/s00291-020-00616-7.
Rancourt, M. -È., Cordeau, J.-F., Laporte, G., & Watkins, B. (2015). Tactical network planning for food aid distribution in Kenya. Computers and Operations Research, 56, 68–83.
Rath, S., Gendreau, M., & Gutjahr, W. J. (2016). Bi-objective stochastic programming models for determining depot locations in disaster relief operations. International Transactions in Operational Research, 23(6), 997–1023.
Rezaei-Malek, M., & Tavakkoli-Moghaddam, R. (2014). Robust humanitarian relief logistics network planning. Uncertain Supply Chain Management, 2(2), 73–96.
Rockafellar, R. T., & Uryasev, S. (2000). Optimization of conditional value-at-risk. Journal of Risk, 2, 21–42.
Tricoire, F., Graf, A., & Gutjahr, W. J. (2012). The bi-objective stochastic covering tour problem. Computers and operations research, 39(7), 1582–1592.
Tzeng, G.-H., Cheng, H.-J., & Huang, T. D. (2007). Multi-objective optimal planning for designing relief delivery systems. Transportation Research Part E: Logistics and Transportation Review, 43(6), 673–686.
Zhan, S.-l., & Liu, N. (2011). A multi-objective stochastic programming model for emergency logistics based on goal programming. In 2011 Fourth international joint conference on computational sciences and optimization (CSO) (pp. 640–644). IEEE.
Zitzler, E., & Thiele, L. (1998). Multiobjective optimization using evolutionary algorithms: A comparative case study. In International conference on parallel problem solving from nature (pp. 292–301). Springer.
Zitzler, E., Thiele, L., Laumanns, M., Fonseca, C. M., & Da Fonseca, V. G. (2003). Performance assessment of multiobjective optimizers: An analysis and review. IEEE Transactions on Evolutionary Computation, 7(2), 117–132.
Acknowledgements
The authors want to thank Tricoire et al. (2012) for providing us with the real-world data set of the drought case study. The valuable comments and suggestions of two anonymous reviewers are also greatly appreciated. This research was funded in part by the Austrian Science Fund (FWF) [P 31366-NBL]. For the purpose of open access, the authors have applied a CC BY public copyright license to any Author Accepted Manuscript version arising from this submission.
Funding
Open access funding provided by Johannes Kepler University Linz.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Conditional value-at-risk (CVaR)
The precise definition of CVaR at confidence level \(\alpha \in [0,1) \) of a random variable X is given by Rockafellar and Uryasev (2000) as follows:
Therein, \([b]_+=\text {max}\{b,0\}, b \in {\mathbb {R}}\) and \(\eta \) is the Value-at-Risk, VaR\(_\alpha (X)\), of variable X at confidence level \(\alpha \). It is defined as follows, where \(F_X(.)\) is the cumulative distribution function of a random variable X.
CVaR\(_\alpha (X)\) can be interpreted as the conditional expected value exceeding the VaR at the confidence level \(\alpha \) (see, Rockafellar and Uryasev 2000).
The auxiliary real variables \(w_s\) for \(s=1,\ldots ,N\) are introduced to reduce (28) to a linear programming problem:
Appendix B: Multi-objective concepts and definitions
Due to the bi-objective nature of our problem, it is not possible to find a unique optimal solution, but rather the so-called set of efficient solutions. A MOO problem is given as follows:
Therein, \(m \ge 2\) is the number of objectives, \(x\in X\), where X is the set of feasible solutions in the decision space and functions \(f_i: X \rightarrow {\mathbb {R}}\) are the objective functions, and \(Z = f(X)\) the image of the set of feasible solutions in the criterion space.
Definition B.1
Pareto dominance
Solution \(x^* \in X\) dominates \(x \in X\) if and only if \(x^*\) is as good as x with respect to all objectives, and better than x with respect to at least one of the objectives, i.e.,
Definition B.2
Pareto frontier
\(x \in X\) is an efficient solution of MOO (34) if there is no \(x^* \in X\) that dominates x. The set of efficient solutions of MOO is denoted by \(X_e\). The objective vector f(x) of an efficient solution \(x \in X_e\) is called non-dominated solution, and \(Z=f(X_e)=\{f(x): x \in X_e\}\) is the set of non-dominated objective points (NDP) or Pareto frontier.
Appendix C: Results for larger number of scenarios
See the Table 9.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nazemi, N., Parragh, S.N. & Gutjahr, W.J. Bi-objective facility location under uncertainty with an application in last-mile disaster relief. Ann Oper Res 319, 1689–1716 (2022). https://doi.org/10.1007/s10479-021-04422-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-021-04422-4