
Abstract
Social media platforms have emerged as primary information sources, offering easy access to a wide audience. Consequently, a significant portion of the global population relies on these platforms for updates on current events. However, fraudulent actors exploit social networks to disseminate false information, either for financial gain or to manipulate public opinion. Recognizing the detrimental impact of fake news, researchers have turned their attention to automating its detection. In this paper, we provide a thorough review of fake news detection in Arabic, a low-resource language, to contextualize the current state of research in this domain. In our research methodology, we recall fake news terminology, provide examples for clarity, particularly in Arabic contexts, and explore its impact on public opinion. We discuss the challenges in fake news detection, outline the used datasets, and provide Arabic annotation samples for label assignment. Likewise, preprocessing steps for Arabic language nuances are highlighted. We also explore features from shared tasks and their implications. Lastly, we address open issues, proposing some future research directions like dataset improvement, feature refinement, and increased awareness to combat fake news proliferation. We contend that incorporating our perspective into the examination of fake news aspects, along with suggesting enhancements, sets this survey apart from others currently available.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The advent of Web 2.0 has facilitated real-time human interaction and the rapid dissemination of news. Alongside traditional news outlets, individuals increasingly rely on online platforms to express themselves and gather information. Social networks serve as hubs for a plethora of data, including opinions, news, rumors, and fake news generated by internet users. While these platforms offer instant access to information, they also facilitate the dissemination of unchecked data, which can inadvertently mislead users. The proliferation of fake news on social media, fueled by sensational and inflammatory language that aims at maximizing engagement, is a growing concern. Additionally, social media platforms often employ fear-based and persuasive language in their content, further amplifying the impact of misinformation. Satirical content, in particular, poses a unique challenge as it can skew public perception and be exploited for political and commercial gain.
The dissemination of misleading or fake statements, often appealing to emotions, can significantly influence public opinion and lead individuals to disregard factual information. The 2016 US presidential campaign, widely reported to have been influenced by fake news, brought heightened awareness to the detrimental impact of misinformation (Bovet and Makse 2019). Furthermore, during the coronavirus pandemic, claims regarding COVID-19 often circulated without credible references (Shahi et al. 2021). Indeed, many studies have reported that on social networks, the pandemic was accompanied by a large amount of fake and misleading news about the virus that has spread faster than the facts (Yafooz et al. 2022) (Alhindi et al. 2021). For example, fake news had claimed that COVID-19 is caused by 5G technology, which led to a misunderstanding of the pandemic among the public (Touahri and Mazroui 2020). Hence, fake news has attracted attention in all countries and cultures, from the US elections to the Arab Spring (Rampersad and Althiyabi 2020). Extensive research related to these claims for the English language has been conducted (Zhou et al. 2020), but few researches have focused on the Arabic language which has specific characteristics (Shahi et al. 2021; Saeed et al. 2018, 2021).
The study of fake news is a multidisciplinary endeavor, bringing together experts from computer and information sciences, as well as political, economic, journalistic, and psychological fields. This collaborative approach is essential for comprehensive understanding and effective solutions.
Online Fake news encompasses various aspects, including the individuals or entities creating the news, the content itself, those disseminating it, the intended targets, and the broader social context in which it circulates (Zhou and Zafarani 2020; Wang et al. 2023). The primary sources of information vary in terms of trustworthiness, with government communication platforms generally being the most trusted, followed by local news channels, while social media platforms are typically viewed with lower levels of trust (Lim and Perrault 2020). People's political orientations can influence their perception of the accuracy of both genuine and fake political information, potentially leading to an overestimation of accuracy based on their ideological beliefs (Haouari et al. 2019). News can be classified as genuine or fake. Moreover, we can find the multi-label datasets and the multi-class level of classification (Shahi et al. 2021). Fake news differs from the truth in content quality, style, and sentiment, while containing similar levels of cognitive and perceptual information (Ali et al. 2022; Al-Ghadir et al. 2021; Ayyub et al. 2021). Moreover, they are often matched with shorter words and longer sentences (Zhou et al. 2020).
Detecting fake news in Arabic presents several unique challenges compared to English. Here are some ways in which Arabic fake news detection differs:
-
Language structure: Arabic morphology is complex since an inflected word in the Arabic language can form a complete syntactic structure. For example, the word “فأعطيناكموه” /f > ETynAkmwh/Footnote 1 (and we gave it to you) contains a proclitic, a verb, a subject and two objects. The linguistic complexity of the Arabic language, complex morphology and a rich vocabulary, may pose challenges for natural language processing (NLP) tasks, including fake news detection.
-
Dialectal variations: Even though Modern Standard Arabic (MSA) is the official language in Arab countries, many social media users use dialects to express themselves. Arabic encompasses numerous dialects across different regions, each with its vocabulary, grammar, and expressions. This diversity makes it challenging to develop models that can effectively identify fake news across various Arabic dialects. Moreover, besides the varieties of languages spoken according to the countries, the written one is also affected by code-switching which is frequent on the Web, as Internet users switch between many languages and dialects using the Web Arabic, namely Arabizi, Franco-Arabic and MSA, which makes their expressions composed of various languages. Some Arabic studies on fake news detection are aware of the presence of dialect in the tweets analyzed. By considering the dialects of North Africa and the Middle East (Ameur and Aliane 2021) (Yafooz et al. 2022), it has been proved that fake news detection systems can perform less well when dialect data is not processed (Alhindi et al. 2021).
-
Cultural nuances: Arabic-speaking communities have distinct cultural norms, beliefs, and sensitivities that influence how information is perceived and shared. Understanding these cultural nuances is essential for accurately detecting fake news in Arabic.
-
Data availability: English fake news detection is characterized by performing systems built on large resources and advanced approaches. The Arabic language in turn can borrow these methodologies to build systems or custom approaches for fake news detection. However, this is faced with the scarcity of its resources and its complex morphology and varieties (Nassif et al. 2022; Himdi et al. 2022; Awajan 2023). Compared to English, there is relatively less labeled data available for training fake news detection models in Arabic. This scarcity of data makes it challenging to develop robust and accurate detection algorithms.
-
Socio-political context: The socio-political landscape in Arabic-speaking regions differs from that of English-speaking countries. Fake news may serve different purposes and target different socio-political issues, requiring tailored approaches for detection.
In summary, Arabic fake news detection requires specialized techniques that account for the language's unique characteristics, dialectal variations, cultural nuances, data availability, and socio-political context. Building effective detection systems in Arabic necessitates interdisciplinary collaboration and a deep understanding of the language and its socio-cultural context. This raises the need for thorough studies to address Arabic fake news detection.
In the following, we define our research methodology. We then delineate the terminologies pertinent to fake news and its processes, providing illustrative examples to aid comprehension, particularly within the context of the Arabic language. We explore the interplay between fake news and public opinion orientation, highlighting overlapping domains and key challenges in detection. Representative datasets and their applications in various studies are outlined, with Arabic annotation samples to illustrate label assignment considerations based on language, context, topic, and information dissemination. We delve into the preprocessing steps, emphasizing the unique characteristics of the Arabic language. Additionally, we discuss the potential features extractable from shared tasks, presenting their implications and main findings. Finally, we address open issues in fake news detection, proposing avenues for future research, including dataset enhancement, feature extraction refinement, and increased awareness to mitigate fake news proliferation.
2 Research methodology
In this section, we define the main research questions based on which our study is performed. Then, we describe the whole research process and we discuss the scope of our research.
2.1 Research questions
We established a set of questions to address the purpose of our research. They range from broad to more specific questions that help in describing, defining and explaining the main aspects of a fake news detection system.
-
RQ1: What is fake news and how it does affect people and society?
-
RQ2: What are the criteria for a fake news detection process?
-
RQ3: What are the main sources from which data are extracted?
-
RQ4: What are the main annotations for the retrieved claims?
-
RQ5: How to create a pertinent model for detecting fake news?
-
RQ6: Are automatic or manual detection of fake news sufficient regarding the large spread of information?
-
RQ7: How to prevent the spread of fake news?
We base the research process on the established questions. During this process, we aim to select papers that discuss Arabic fake news detection.
2.2 Search process
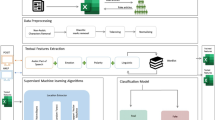
Since we are looking for relevant papers in the domain of Arabic fake news detection, we started by querying Google Scholar using ("Fake" OR "misinformation" OR "disinformation" OR "deception" OR "satirical hoaxes" OR "serious fabrication" OR "clickbait" OR "information pollution" OR "deceptive content" OR "rumors" OR "propaganda") AND ("Arabic" OR "Language"). Applying these search terms resulted in a large number of articles from which we selected those that contained relevant information. Indeed, we have used exclusion criteria to keep only those that align with the scope of our research. We thus collected 75 articles. The search process and the covered aspects are depicted in Fig. 1.

Search process
2.3 Scope of the study
After selecting the articles that align with the scope of our research, we attempted to answer the previous research questions (RQs). Among these articles, some authors constructed the datasets and corpora used in their research, detailing the various stages of data construction. Others utilized existing datasets and applied diverse machine learning techniques, including classical methods, deep neural networks, and transformers. Additionally, certain articles focused on strategies to curb the dissemination of fake news.
The general framework of fake news detection and related components are depicted in Fig. 2. The construction of basic knowledge represents the main step in the development of a fake news detection system. It requires careful source selection and definition of annotation levels. The multiple annotation levels are helpful to deal with variations in the style of claims. Moreover, the detection model addressed the main corpus characteristics and studied its usefulness when generalizing its application. Awareness techniques, in turn, have been described to make people aware of fake news.

General framework of our study
In the following, we define the fake news terminology, and we present the fake news detection processes by describing their approaches and illustrating them with examples.
3 Fake news terminology
Fake news is a common term employed to describe the fake content spread on the Web (Saadany et al. 2020). Digital communication has generated a set of concepts related to fake news that can be used interchangeably, namely misinformation, disinformation, deception, satirical hoaxes, serious fabrication, clickbait, information pollution, and deceptive content (Elsayed et al. 2019; Touahri and Mazroui 2018). They can mislead users' opinions since they include misleading information, rumors, propaganda, and techniques that influence people's mindsets (Touahri and Mazroui 2020; Shahi et al. 2021; Barron-Cedeno et al. 2020; Baly et al. 2018). The aforementioned categories differ in dependence on many factors such as targeted audience, genre, domain, and deceptive intent (Da San Martino et al. 2019).
The emergence of fake news on the Web has motivated domain interested researchers to perform various tasks and develop automated systems that support multiple languages (Alhindi et al. 2021) in order to detect fake news and prevent its disastrous effects from occurring. Among these tasks, we have:
-
Check-worthiness that determines whether a claim is check-worthy (Haouari et al. 2019). It is a ranking task where the systems are asked to produce sentence scores according to check-worthiness. Checkworthiness is the first step in determining the relevance of a claim to be checked.
-
Stance detection is a fake news detection subtask that searches documents for evidence and defines the documents that support the claim and those that contradict it (Touahri and Mazroui 2019; Ayyub et al. 2021). Stance detection aims to judge a claim's factuality according to the supporting information. Related information can be annotated as discuss, agree or disagree with a specific claim. Stance detection differs from fake news detection in that it is not for veracity but consistency. Thus, stance detection is insufficient to predict claim veracity since a major part of documents may support false claims (Touahri and Mazroui 2019; Elsayed et al. 2019; Alhindi et al. 2021; Hardalov et al. 2021).
-
Fact-checking is a task that assesses the public figures and the truthfulness of claims Khouja (2020). A claim is judged trustful or not based on its source, content and spreader credibility. Factuality detection identifies whether a claim is fake or true. The terms genuine, true, real and not fake can be used interchangeably.
-
Sentiment analysis is the emotion extraction task, such as customer reviews of products. The task is not to do a claim objective verification but it aims to detect opinions to not be considered facts and hence prevent their misleading effects (Touahri and Mazroui 2018, 2020; Saeed et al. 2020, 2021; Ayyub et al. 2021).
We exemplify the concepts using the statement "حماية أجهزة أبل قوية بحيث لا تتعرض للفيروسات" (Protection for Apple devices is strong so that they are not exposed to viruses). In Table 1, the first sentence aligns with the claim, while the second contradicts it. Specifically, "قوية" contradicts "ليست قوية" and " لا تتعرض " contrasts with " تتعرض ". Consequently, when the FactChecking system encounters conflicting sentences, it labels the claim as false; otherwise, it deems it as true.
There are several steps to detect fake news that were covered by Barrón-Cedeno et al. (Barrón-Cedeño et al. 2020) discussed various tasks such as determining the check-worthiness of claims as well as their veracity. Stance detection between a claim-document pair (supported, refuted, not-enough-information); (agree, disagree, discuss, unrelated) has been studied (Baly et al. 2018) as well as defining claim factuality as fake or real (Ameur and Aliane 2021).
4 Challenges
The old-fashioned manual rhythm to detect fake news cannot be kept by fact-checkers regarding the need for momentary detection of claims veracity (Touahri and Mazroui 2019). Truth often cannot be assessed by computers alone, hence the need for collaboration between human experts and technology to detect it. Automatic fake news detection is technically challenging for several reasons:
-
Data diversity: Online information is diverse since it covers various subjects, which complicates the fake news detection task (Khalil et al. 2022; Najadat et al. 2022). The data may come from different sources and domains, which may complicate their processing (Zhang and Ghorbani 2020). The Arabic language can also be considered a criterion when dealing with its complex morphology.
-
Momentary detection: Fake news is written to deceive readers. It spreads rapidly and its generation mode varies momentarily, making existing detection algorithms ineffective or inapplicable. To improve information reliability, systems to detect fake news in real time should be built (Brashier et al. 2021). Momentary detection of fake news on social media seeks to identify them on newly emerged events. Hence, one cannot rely on news propagation information to detect fake news momentarily as it may not exist. Most of the existing approaches that learn claim-specific features can hardly handle the challenge of detecting newly emerged factuality since the features cannot be transferred to unseen events (Haouari et al. 2021).
-
Lack of information context: The information context is important to detect fake news (Himdi et al. 2022). In some cases, retrieving information context is not evident since it requires a hard research process to find the context and real spreader. Moreover, data extraction ethics may differ from one social media to another, which may affect the data sufficiency to detect fake news.
-
Misinformation: Sometimes fake information is spread by web users unintentionally, and based on their credibility fake news may be considered true (Hardalov et al. 2021; Sabbeh and Baatwah 2018).
An example of fake news is depicted in Fig. 3. An account owner denies the claim spread by The Atlas Times page on Twitter. The post has many likes and retweets besides some comments that support it by ironing the predicate. The predicate can therefore be considered false.

Example of the spread of Arabic fake news
5 Datasets
In this section, we delve into the datasets curated for Arabic fake news detection. We provide illustrative examples of annotated tweets from prior investigations alongside the methods used for their annotation. Subsequently, we outline their sources, domains, and sizes. Additionally, we explore the research endeavors that have utilized these datasets (Table 2).
Given the limited availability of resources for Arabic fake news detection, numerous studies have focused on developing linguistic assets and annotating them using diverse methodologies, including manual, semi-supervised, or automatic annotation techniques.
5.1 Manual annotation
The study (Alhindi et al. 2021) presented AraStance, an Arabic Stance Detection dataset of 4,063 news articles that contains true and false claims from politics, sports, and health domains, among which 1642 are true. Each claim–article pair has a manual stance label either agree, disagree, discuss, or unrelated. Khouja (Khouja 2020) constructed an Arabic News Stance (ANS) corpus related to international news, culture, Middle East, economy, technology, and sports; and was collected from BBC, Al Arabiya, CNN, Sky News, and France24. The corpus is labeled by 3 to 5 annotators who selected true news titles and generated fake/true claims from them through crowdsourcing. The corpus contains 4,547 Arabic News annotated as true or false, among which 1475 are fake. The annotators have used the labels paraphrase, contradiction, and other/not enough information to associate 3,786 pairs with their evidence. (Himdi et al. 2022) have introduced an Arabic fake news articles dataset for different genres composed through crowdsourcing. An Arabic dataset related to COVID-19 was constructed (Alqurashi et al. 2021). The tweets are labeled manually as containing misinformation or not. The dataset contains 1311 misinformation tweets out of 7,475. The study (Ameur and Aliane 2021) presented the manually annotated multi-label dataset “AraCOVID19-MFH” for fake news and hate speech detection. The dataset contains 10,828 Arabic tweets annotated with 10 different labels which are hate, Talk about a cure, Give advice, Rise moral, News or opinion, Dialect, Blame and negative speech, Factual, Worth Fact-Checking and contains fake information. The corpus contains 459 tweets labeled as fake news; whereas, for 1,839 tweets the annotators were unable to decide which tag to affect. Ali et al. (Ali et al. 2021) introduced AraFacts, a publicly available Arabic dataset for fake news detection. The dataset collected from 5 Arabic fact-checking websites consists of 6,222 claims along with their manual factual labels as true or false.
Information such as fact-checking article content, topics, and links to web pages or posts spreading the claim are also available. In order to target the topics most concerned by rumors, Alkhair et al. (Alkhair et al. 2019) constructed a fake news corpus that contains 4,079 YouTube information related to personalities deaths which gave 3435 fake news after their annotation based on keywords and pretreatment, among which 793 are rumor. Al Zaatari et al. (Al Zaatari et al. 2016) constructed a dataset that contains a total of 175 blog posts with 100 posts annotated as credible, 57 as fairly credible, and 18 as non-credible. There are 1570 tweets related to these posts manually annotated as credible out of 2708. Haouari et al. (Haouari et al. 2021) introduced ArCOV19-Rumors an Arabic Twitter dataset for misinformation detection composed of 138 verified claims related to COVID-19. The 9,414 relevant tweets to those claims identified by the authors were manually annotated by veracity to support research on misinformation detection, which is one of the major problems faced during a pandemic. Among the annotated tweets 1,753 are fake, 1,831 true and 5,830 others. ArCOV19-Rumors covers many domains politics, social, entertainment, sports, and religious. Besides the aforementioned annotation approaches, data true content can be manually altered to generate fake claims about the same topic Khouja (2020).
5.2 Semi-supervised and automatic annotation
Statistical approaches face limitations due to the absence of labeled benchmark datasets for fake news detection. Deep learning methods have shown superior performance but demand large volumes of annotated data for model training. However, online news dynamics render annotated samples quickly outdated. Manual annotation is costly and time-intensive, prompting a shift towards automatic and semi-supervised methods for dataset generation. To bolster fact-checking systems, fake news datasets are automatically generated or extended using diverse approaches, including automatic annotation. In this respect, various papers presented their approaches. In (Mahlous and Al-Laith 2021), there was a reliance on the France-Press Agency and the Saudi Anti-Rumors Authority fact-checkers to extract a corpus that was manually annotated into 835 fake and 702 genuine tweets. Then an automatic annotation was performed based on the best performing classifier. Elhadad et al. (Elhadad et al. 2021) automatically annotated the bilingual (Arabic/English) COVID-19-FAKES Twitter dataset using 13 different machine learning algorithms and employing 7 various feature extraction techniques based on reliable information from different official Twitter accounts. The authors (Nakov et al. 2021) have collected 606 Arabic and 2,589 English Qatar fake tweets about COVID-19 vaccines. They have analyzed the tweets according to factuality, propaganda, harmfulness, and framing. The automatic annotation of the Arabic tweets gave 462 factual and 144 not. The study (Saadany et al. 2020) introduced datasets concerned with political issues related to the Middle East. A dataset that consists of fake news contains 3,185 articles scraped from ‘Al-Hudood’ and ‘Al-Ahram Al-Mexici’ Arabic satirical news websites. They also collected a dataset from ‘BBC-Arabic’, ‘CNN-Arabic’ and ‘Al-Jazeera news’ official news sites. The dataset consists of 3,710 real news articles. The websites from which data has been scraped are specialized in publishing true and fake news. Nagoudi et al. (Nagoudi et al. 2020) have presented AraNews, a POStagged news dataset. The corpus was constructed based on a novel method for the automatic generation of Arabic manipulated news based on online news data as seeds for the generation model. The dataset contains 10,000 articles annotated using true and false tags. Moreover, Arabic fake news can be generated by translating fake news from English into Arabic (Nakov et al. 2018).
We summarize in Table 3 the main datasets by specifying their sources, their sizes, the domains concerned, the tags adopted, and the labeling way.
6 Fake news detection
6.1 Preprocessing
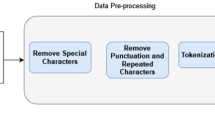
The content posted online is often chaotic and marked by considerable ambiguity. Therefore, before proceeding to feature extraction, it is imperative to conduct a preprocessing phase. Below, we outline the general procedures along with those tailored specifically for the Arabic language:
-
1)
General steps
-
2)
Special characters removal: special characters such as {∗ ,@,%,&…} are not criteria to detect fake news and are not specific to a language, their removal helps to clean the text (Alkhair et al. 2019).
-
3)
Punctuation removal: they are considered non significant to detect fake news (Al-Yahya et al. 2021).
-
4)
URL links removal: their presence in the raw text may be considered noise. However, they may represent a page with important content (Alkhair et al. 2019).
-
5)
Duplicated comments removal: the retweet or duplicate comments have to be deleted since it is sufficient to process a piece of text just once (Alkhair et al. 2019).
-
6)
Balancing data: data imbalance can mislead the classification process. Therefore, it is essential to balance the data to represent each factual or false class equally (Jardaneh et al. 2019).
-
7)
Reducing repeated letters, characters and multiple spaces (Al-Yahya et al. 2021): since letters are not repeated more than twice in a word, nor are spaces that are unique between words in a sentence, it is essential to eliminate these repetitions to achieve the correct form of a word or a sentence.
-
8)
Tokenization helps in splitting sentences into word sequences using delimiters such as space or punctuation marks. This step precedes converting texts into features (Oshikawa et al. 2018) .
-
9)
Stemming, lemmatization, and rooting are language related steps that help to cover a large set of words by representing them with their common stems, lemmas and roots (Oshikawa et al. 2018).
-
10)
Normalization and standardization: Normalizing data giving them the same representation. In the Arabic language, some letters may be replaced with others (Jardaneh et al. 2019).
-
11)
Arabic specific steps
-
12)
Foreign language words removal: they don’t belong to the processed language (Alkhair et al. 2019).
-
13)
Non-Arabic letter removal: the transliterated text can be removed since it is lowly represented within the studied corpora (Alkhair et al. 2019).
-
14)
Replacing hashtags and emojis with relevant signification (Al-Yahya et al. 2021): for example ☺ may be replaced with سعيد.
-
15)
Removing stop words: stop words such as أنت لكن ما are considered non significant in detecting fake news (Al-Yahya et al. 2021). The stop words are specific to each language.
-
16)
Diacritization removal: since diacritic marks don’t cover all the terms, their suppression helps to normalize the terms representation (Al-Yahya et al. 2021).
6.2 Feature extraction
Previous studies on fake news detection have relied on various features extracted from labeled datasets to represent information. In this section, we detail the most commonly utilized features in fake news detection:
-
Source features: These check whether a specific user account is verified, determine its location, creation date, activity, user details and metadata including, the job, affiliation and political party of the user and whether the account is with a real name (Jardaneh et al. 2019; Sabbeh and Baatwah 2018). The account real name and details are important to assess the news creator credibility. Moreover, it is important to know whether the news spreader belongs to opposite parties which tend to be fake. Also, the creation date is important since an account nearly created during a specific event can be considered fake in comparison to an early created one. Source features are very helpful in determining the credibility of a news creator; However, Fake information may be spread unintentionally on account of high credibility.
-
Temporal features: These capture the temporal spread of information and the overlap between the posting time of user comments. Fake news may be retweeted rapidly, so it is important to capture the comment temporal information and whether it overlaps with a specific event that pushes the spreader to publish fake information. The temporal features are among the most important ones to detect fake news; however, they are still not sufficient to deal with the strength of such a phenomenon.
-
Content features: Content can be true if it contains pictures, hashtags or URLs since they may lead to a trustful source of information to prove the factuality of a claim. Also, if the content is retweeted by trustful accounts or has positive comments from users, it can be considered true (Sabbeh and Baatwah 2018). Content features cover information and their references; However, there is a need to check the references credibility.
-
Lexical features: These include character and word level features extracted from text (Sabbeh and Baatwah 2018). Analyzing claims at the term level is crucial for determining their sentiment (positive or negative) and verifying their factual accuracy. Identifying common lexical features among claims is also valuable. However, while lexical features are significant, they should be complemented with additional features to effectively identify fake claims.
-
Linguistic features: Analyzing the linguistic features of a claim can help determine its veracity without considering external factual information. Term frequency, bag-of-words, n-grams, POS tagging, and sentiment score are some of the main features used for fake news detection Khouja (2020). Linguistic features categorize data based on language and highlight its defining elements, relying on lexical, semantic, and structural characteristics. While linguistic features aid in content analysis and representation, the absence of contextual information can potentially lead to misidentification during fake news detection.
-
Semantic features: These are features that capture the semantic aspects of a text that are useful to extract data meaning (Sabbeh and Baatwah 2018) and their variations according to the context. Semantic features identify the meaning of a claim but not its veracity.
-
Sentiment features: Sentiment analysis may improve the fake news prediction accuracy (Jardaneh et al. 2019) since a sentimental comment may be fake as it doesn’t depend on facts. As opinions influence people’s behaviors, it has numerous applications in real life such as in politics, marketing, and social media (Ayyub et al. 2021). Sentiment features are important to distinguish between opinions and facts; However, we may express a fact using an opinion such as I like the high quality of Apple smartphones.
The mentioned features are complimentary, so we can’t rely on one feature without the other. Each feature has its main characteristics that make it indispensable for fake news detection.
6.3 Classification approaches
In this section, we outline various studies conducted in Arabic fake news detection, detailing the features employed, the models developed, and the achieved performances. We categorize these studies into three main approaches: those based on classical machine learning, deep learning or transformers.
6.3.1 Classical machine learning
Classical machine learning for fake news detection involves the application of traditional algorithms and techniques to analyze and classify textual data to discern between authentic and fabricated news articles. These methods typically rely on feature engineering, where relevant characteristics of the text are extracted and used to train models such as support vector machines (SVM), logistic regression (LR), decision trees (DT), and random forests (RF). Features can include linguistic patterns, sentiment analysis, lexical and syntactic features, and metadata associated with the news articles. The trained models are then employed to classify new articles as either genuine or fake based on the learned patterns and characteristics present in the data. Researchers may collect a dataset of Arabic news articles labeled as fake or genuine. They then preprocess the text, extract relevant features, and train a machine learning classifier on the labeled dataset. The classifier can then be used to predict the authenticity of new Arabic news articles. Arabic satirical news have lexico-grammatical features that distinguish them (Saadany et al. 2020). Based on this claim, a set of machine learning models for identifying satirical fake news has been tested. The model achieved an accuracy of up to 98.6% based on a dataset containing 3,185 fake and 3,710 real articles. (Alkhair et al. 2019) have used a dataset of 4,079 news, where 793 are rumors, based on which they have trained a model on 70% of the data and tested it on the remainder. They have classified comments as rumor and no rumor using the most frequent words as features and three machine learning classifiers namely, Support Vector Machine (SVM), Decision Tree (DT) and Multinomial Naïve Bayes (MNB). They attained a 95.35% accuracy rate with SVM. The researchers (Sabbeh and Baatwah 2018) utilized a dataset comprising 800 news items sourced from Twitter and devised a machine learning model for assessing the credibility of Arabic news. They incorporated topic and user-related features in their model to evaluate news credibility, ensuring a more precise assessment. By verifying content and analyzing user comments' polarity, they classified credibility using various classifiers, including Decision Trees. Consequently, they achieved an accuracy of 89.9%. The authors (Mahlous and Al-Laith 2021) extracted n-gram TF-IDF features from a dataset containing 835 fake and 702 genuine tweets, achieving an F1-score of 87.8% using Logistic Regression (LR). The authors (Thaher et al. 2021) have extracted a Bag of Words and features including content, user profiles, and word-based features from a Twitter dataset comprising 1,862 tweets (Al Zaatari et al. 2016). Their results showed that the Logistic Regression classifier with TF-IDF model achieved the highest scores compared to other models. They reduced dimensionality using the binary Harris Hawks Optimizer (HHO) algorithm as a wrapper-based feature selection approach. Their proposed model attained an F1-score of 0.83, marking a 5% improvement over previous work on the same dataset. (Al-Ghadir et al. 2021) evaluated the stance detection model based on the TF-IDF feature and varieties of K-nearest Neighbors (KNN) and SVM on the SemEval-2016 task 6 benchmark dataset. They reached a macro F-score of 76.45%. The authors (Gumaei et al. 2022) conducted experiments on a public dataset containing rumor and non-rumor tweets. They have built a model using a set of features, including topic-based, content-based, and user-based features; besides XGBoost-based approach that has achieved an accuracy of 97.18%. Jardaneh et al. (Jardaneh et al. 2019) have extracted 46 content and user related features from 1,862 tweets published on topics covering the Syrian crisis and employed sentiment analysis to generate new features. They have based the identification of fake news on a supervised classification model constructed based on Random Forest (RF), Decision Tree, AdaBoost, and Logistic Regression classifiers. The results revealed that sentiment analysis led to improving the prediction accuracy of their system that filters out fake news with an accuracy of 76%.
6.3.2 Deep learning
Deep neural approaches for fake news detection involve the use of deep learning models based on neural network architectures, to automatically learn and extract relevant features from textual data to distinguish genuine news articles from fabricated news articles. These approaches typically utilize neural network architectures such as Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and more recently, Transformer-based models like BERT and GPT. In deep neural approaches, the models are trained on large volumes of labeled data, where the neural networks learn to represent the underlying patterns and relationships within the text. These models can be used for Arabic fake news detection since they automatically learn representations of the text and capture complex patterns and relationships. Researchers may build a deep neural network architecture tailored to Arabic text data. For example, they can use a CNN for text classification, where the network learns to identify important features in the text through convolutional layers. By training the model on a large dataset of labeled Arabic news articles, it can learn to distinguish between fake and genuine news. (Yafooz et al. 2022) proposed a model to detect fake news about the Middle-east COVID-19 vaccine on YouTube videos. The model is based on sentiment analysis features and a deep learning approach which helped to reach an accuracy of 99%. The authors (Harrag and Djahli 2022) have used an Arabic balanced corpus to build their model that unifies stance detection, relevant document retrieval and fact-checking. They proposed a deep neural network approach to classify fake and real news by exploiting CNNs. The model trained on selected attributes reached an accuracy of 91%. (Alqurashi et al. 2021) have exploited FastText and word2vec word embedding models for more than two million Arabic tweets related to COVID-19. (Helwe et al. 2019) extracted various features from a dataset containing 12.8 K annotated political news statements along with their metadata. These features included content and user-related attributes. Their initial model, based on TF-IDF and SVM classifier, achieved an F1-score of 0.57. They also explored word-level, character-level, and ensemble-based CNN models, yielding F1-scores of 0.52, 0.54, and 0.50 respectively. To address the limited training data, they introduced a deep co-learning approach, a semi-supervised method utilizing both labeled and unlabeled data. By training multiple weak deep neural network classifiers in a semi-supervised manner, they achieved significant performance improvement, reaching an F1-score of 0.63.
6.3.3 Transformer-based approaches
Transformer approaches for fake news detection involve the use of transformer-based models, which are a type of deep learning architecture that has gained prominence in NLP tasks. The transformer model has become the foundation for many state-of-the-art NLP models. In the context of fake news detection, transformer-based models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) are used to analyze and classify textual data. These models can process and understand large amounts of text data by leveraging self-attention mechanisms, which allow them to capture contextual relationships between words and phrases in a given text. Transformer-based models are pre-trained on massive unlabeled corpora of text data and then fine-tuned on specific tasks such as fake news detection. During fine-tuning, the model learns to classify news articles as either genuine or fake based on the patterns and relationships it has learned from the pre-training phase. Transformer-based approaches have shown promising results in fake news detection tasks due to their ability to capture semantic meaning, context, and long-range dependencies within textual data. These models have shown remarkable performance in understanding context and semantics in text. Researchers may fine-tune pre-trained transformer models on Arabic fake news detection datasets. For instance, they can use AraBERT as a base model and fine-tune it on a dataset of labeled Arabic news articles. During fine-tuning, the model learns to effectively capture linguistic nuances and identify linguistic patterns indicative of fake news in Arabic text. The study (Nagoudi et al. 2020) aimed to measure the human ability to detect machine manipulated Arabic text based on a corpus that contains 10,000 articles. They reported that changing a certain POS does not automatically flip the sentence veracity. Their system for Arabic fake news detection reached an F1-score of 70.06. They have made their data and models publicly available. Khouja (Khouja 2020) explored textual entailment and stance prediction to detect fake news from a dataset that contains 4,547 Arabic news where 1475 are fake. They have constructed models based on pretraining BERT. Their system predicts stance by an F1-score of 76.7 and verifies claims by an F1-score of 64.3. (Al-Yahya et al. 2021) have compared language models based on neural networks and transformers for Arabic fake news detection from ArCOV19-Rumors (Haouari et al. 2021) and Covid-19-Fakes (Elhadad et al. 2021) datasets. They then reported that models based on transformers perform the best, achieving an F1-score of 0.95.
6.3.4 Approach distinction for Arabic fake news
We may differentiate between machine learning (ML), deep learning (DL), and transformer-based approaches in terms of their approach, capabilities, and suitability for Arabic fake news detection based on the following criteria:
-
Classical machine learning: ML models are effective when the features are well-defined and the dataset is not too large. They can handle relatively small datasets and are interpretable, making it easier to understand why a particular prediction was made. ML approaches are suitable for Arabic fake news detection when the features can effectively capture linguistic patterns indicative of fake news in Arabic text. They may be less effective in capturing complex semantic relationships and context compared to DL and transformer-based models.
-
Deep learning: DL models excel at learning hierarchical representations of data and can handle large volumes of text data. They can automatically learn features from raw text, making them suitable for tasks where feature engineering may be challenging. DL approaches are suitable for Arabic fake news detection when the dataset is large and diverse, and the linguistic patterns indicative of fake news are complex. They may outperform ML approaches in capturing subtle linguistic cues and context.
-
Transformer-based approaches: Transformer-based models are state-of-the-art in natural language understanding tasks and excel at capturing context and semantics in text. They can capture bidirectional relationships between words and are highly effective in capturing nuanced linguistic features. Transformer-based approaches are highly suitable for Arabic fake news detection, especially when the dataset is large and diverse. They can effectively capture complex semantic relationships and context in Arabic text, making them well-suited for tasks where understanding linguistic nuances is crucial.
In summary, classical ML approaches are suitable for Arabic fake news detection when the features can effectively capture linguistic patterns, while DL and transformer-based approaches excel at capturing complex semantic relationships and context in Arabic text, making them highly effective for detecting nuanced linguistic cues indicative of fake news. These three families of approaches can interact and complement each other in various ways:
-
Feature engineering and representation: ML methods often require handcrafted features extracted from the text, such as word frequencies, n-grams, and syntactic features. DL methods can automatically learn features from raw text data, making them suitable for tasks where feature engineering may be challenging. Transformer-based models, such as BERT, leverage pre-trained representations of text that capture rich semantic information. These representations can be fine-tuned for specific tasks, including fake news detection.
-
Model complexity and performance: ML methods are generally simpler and more interpretable compared to DL and transformer-based models. They may be suitable for tasks where transparency and interpretability are important. DL methods, with their ability to learn hierarchical representations of data, can capture complex patterns and relationships in the text. They may outperform ML methods on tasks that require understanding subtle linguistic cues and context. Transformer-based models, with their attention mechanisms and contextual embeddings, have achieved state-of-the-art performance on various NLP tasks, including fake news detection. They excel at capturing fine-grained semantic information and context.
-
Ensemble learning: ML, DL, and transformer-based models can be combined in ensemble learning approaches to leverage the strengths of each method. Ensemble methods combine predictions from multiple models to make a final prediction. This can lead to improved performance and robustness, especially when individual models have complementary strengths and weaknesses. In (Noman Qasem et al. 2022), several standalone and ensemble machine learning methods were applied to the ArCOV-19 dataset that contains 1480 Rumors and 1677 non-Rumors tweets based on which they have extracted user and tweet features. The experiments showed an interesting accuracy of 92.63%.
-
Progression and evolution: There is a progression from traditional ML methods to more advanced DL and transformer-based approaches in NLP tasks, including fake news detection. As the field of NLP continues to evolve, researchers are exploring novel architectures, pre-training techniques, and fine-tuning strategies to improve the performance of models on specific tasks, such as fake news detection.
In practice, these approaches are often used in parallel, with researchers and practitioners selecting the method or combination of methods that best suit the task requirements, data characteristics, and computational resources available. The choice of approach may depend on factors such as dataset size, complexity of linguistic patterns, interpretability requirements, and performance goals.
We recall in Table 4 the various studies carried out on the detection of Arab fake news. The conducted studies employed various datasets, features, models, and evaluation metrics. The primary metrics used include Accuracy, Precision, Recall, F1-score, and AUC score. These studies aimed to identify fake news by utilizing diverse approaches, ranging from classical machine learning algorithms to deep learning models.
From Table 4, a wide range of accuracies achieved by the system, spanning from 76% to over 99%, attributable to differences in datasets and underlying knowledge bases. However, a pertinent question arises when applying the best-performing models to other datasets, often resulting in reduced accuracy. To address this issue and facilitate a fair comparison of proposed approaches, some shared task organizers have made publicly available datasets and proposed tasks. These initiatives aim to mitigate model sensitivity to training data and enhance overall system efficiency.
7 Fake news shared tasks
The organizers of the competition CLEF–2019 CheckThat! Lab (Elsayed et al. 2019) proposed task revolves around the Automatic Verification of Claims, as presented by CheckThat! that outlines two primary tasks. The first task focuses on identifying claim fact-check worthiness within political debates. Meanwhile, the second task follows a three-step process. The initial step involves ranking web pages according to their utility for fact-checking a claim. The systems achieved an nDCG@10 lower than 0.55 which is the original ranking in the search result list considered as baseline. The second step classifies the web pages according to their degree of usefulness, the best performing system reached an F1 of 0.31, and the third task extracts useful passages from the useful pages, in which the most occurring model reached an F1 of 0.56. The second step is designed to help automatic fact-checking represented in the fourth task that uses the useful pages to predict a claim factuality in the system that used textual entailment with embedding-based representations for classification has reached the best F1 performance measured by 0.62. The task organizers have released datasets in English and Arabic in order to enable the research community in checkworthiness estimation and automatic claim verification. CheckThat! Lab 2021 task (Shahi et al. 2021) focuses on multi-class fake news detection. The lab covers Arabic, English, Spanish, Turkish, and Bulgarian. The best performing systems achieved a macro F1-score between 0.84 and 0.88 in the English language. The paper (Al-Qarqaz et al. 2021) describes NLP4IF, the Arabic shared task to check COVID-19 disinformation. The best ranked model for Arabic is based on transformer-based pre-trained language, an ensemble of AraBERT-Base, Asafya-BERT, and ARBERT models and achieved an F1-Score of 0.78. The authors (Rangel et al. 2020) have presented an overview of Author Profiling shared task at PAN 2020. The best results have been obtained in Spanish with an accuracy of 82% using combinations of character and word n-grams; and SVM. The task has focused on identifying potential spreaders of fake news based on the authors of Twitter comments, highlighting challenges related to the lack of domain specificity in news. It attracted 66 participants, whose systems were evaluated by the organizers of the task.
8 Discussion
The Arabic fake news detection systems have achieved satisfactory results. However, given the ongoing generation of content, dataset quality struggles to encompass the diversity of generated content. Datasets vary in size, sources, and the hierarchical annotation steps used to detect fake news. Human annotation remains challenging, as multiple aspects must be considered before labeling a claim based on its content. Therefore, semi-supervised and automatic annotation methods have been explored to alleviate the burden of manual annotation.
Detecting fake news requires further effort to be successful, especially in terms of real-time detection, which remains challenging due to the absence of comprehensive detection aspects such as information spread. For instance, information shared by a reputable individual may be perceived as true. Improving public literacy is crucial since individuals need to be educated to discern factual content from misinformation.
The spread of fake news may have disastrous effects on people and society, hence, the detection step must be taken before allowing the spread of data especially on social media which is characterized by wide sets of data. Moreover, social media users have to agree to ethical aspects, and punishments have to be applied to those who spread fake data. Trustful sources must be explored when seeking factual information. The exploration of new models may be useful also. It can be an approach that relies on scoring social media users based on their trustworthiness that pops up every time a new post is created. The score is decreased each time until a specific account is marked as untrustworthy, which can either help prevent the spread of fake information or destroy its base account. Special information may be requested when creating an account in order to not allow a specific person to create more than one account.
In the following, we describe some future directions that may be helpful in detecting fake news and preventing the spread of its negative effects.
9 Future directions for Arabic fake news detection
Researchers have employed a variety of features, including source, context, and content, to enhance fake news detection. Source features aid in targeting analysis, often complemented by content features for improved accuracy. Linguistic analysis has played a role in identifying content characteristics, with lexical and semantic features helping to identify relevant terms such as sentiment. Temporal features capture data spread and event relationships, though content features may lose effectiveness across different contexts. Sentiments alone may not reliably indicate fake news, as they can accompany both genuine and fake information. Additionally, the absence of typos may signal attackers' efforts to enhance content credibility. Profile and graph-based features, used to assess source credibility based on network connections, can provide valuable information for attackers to strategize long-term attacks.
The presented data and results inspire motivation to detail open issues of fake news detection. Consequently, there is a need for potential research tasks that:
-
Differentiate fake news from other related concepts based on content, intention and authenticity;
-
Enhance content features by non-textual data;
-
Investigate the importance of the automatically annotated corpora, lexical features, hand-crafted rules and pretrained models with the aim to facilitate fake news detection and improve its accuracy;
-
Analyze in depth the performance of current fake news detection models, and at what level their accuracy remains by varying the fields of application or the attack manners,
-
Improve the detection by adding pertinent features since old ones can be exploited by attackers to make users believe that fake news is true,
-
Propose new techniques to raise Internet users' awareness of fake news and the devastating effect of this phenomenon.
The aforementioned points highlight some directions and open issues for fake news detection. Besides these common points with other languages, the Arabic language is faced with its dialectal varieties and its complex morphology, which reflect its challenging nature. It is therefore important to explore in future research on Arab fake news these points from different angles to improve existing detection approaches and results.
Arabic can also benefit from studies on other languages to create and expand datasets, improve annotation and classification models in addition to improving customized fake news awareness techniques.
9.1 Datasets
The Arabic datasets are mainly related to politics and the COVID-19 pandemic that has emerged recently. Hence, as further studies, the Arabic language can benefit from foreign language datasets either by translation or collection manner. In this context, many datasets can be explored since they are characterized by a considerable size and variety of domains. Wang (2017) manually labeled LIAR that contains 12,800 English short statements about political statements in the U.S related to various domains among which elections, economy, healthcare, and education. (Sahoo and Gupta 2021; Zhang et al. 2020; Shu et al. 2017; Kaur et al. 2020; Wang et al. 2020) datasets are related to English politics and their size varies between 4,048 and 37 000 tweets. The datasets of tweets presented in (Shu et al. 2017; Karimi et al. 2018) have a considerable size that exceeds 22,140 news articles related to politics, celebrity reports, and entertainment stories. Moreover, Arabic studies need to explore the balance of datasets to reduce the error of differentiating between fake and genuine news (Jones-Jang et al. 2021). They should also explore multimodal fake news detection (Haouari et al. 2021).
The training of deep learning models requires a large amount of annotated data. Moreover, due to the dynamic nature of online news, annotated samples may become outdated quickly which makes them non-representative of newly emerged events. Manual annotation can’t be the ultimate annotation manner since it is expensive and time-consuming. Hence, automatic and semi-supervised approaches have to be used to generate labeled datasets. To increase the robustness of fact-checking systems, the available fake news datasets can be generated or extended automatically based on various approaches. Among these the ones based on Generative Enhanced Model (Niewinski et al. 2019) or reinforced weakly supervised fake news detection approaches (Wang et al. 2020) and the alteration of genuine content to generate fake claims about the same topic Khouja (2020).
Improving existing datasets for Arabic fake news detection involves several strategies aimed at enhancing the quality, diversity, and representativeness of the data. Here are some ways to improve existing datasets:
-
Data annotation and labeling: Invest in rigorous and consistent annotation and labeling processes to ensure accurate classification of news articles as fake or genuine. Use multiple annotators to mitigate bias and improve inter-annotator agreement. Include diverse perspectives and expertise in the annotation process to capture nuances in fake news detection.
-
Data augmentation: Augment existing datasets by generating synthetic examples of fake news articles using techniques such as back-translation, paraphrasing, and text summarization. This can help increase the diversity of the dataset and improve model generalization.
-
Balancing class distribution: Ensure that the dataset has a balanced distribution of fake and genuine news articles to prevent classifier bias towards the majority class. Use techniques such as oversampling, undersampling, or synthetic sampling to balance class distribution and improve classifier performance.
-
Multimodal data integration: Integrate additional modalities such as images, videos, and metadata (e.g., timestamps, sources) into the dataset to provide richer contextual information for fake news detection. Multimodal datasets can capture subtle cues and patterns that may not be apparent in text alone.
-
Fine-grained labeling: Consider incorporating fine-grained labels or sub-categories of fake news (e.g., clickbait, propaganda, satire) to provide more detailed insights into the nature and characteristics of fake news articles. Fine-grained labeling can enable more nuanced analysis and model interpretation.
-
Cross-domain and cross-lingual datasets: Collect and incorporate data from diverse domains and languages to improve model robustness and generalization. Cross-domain and cross-lingual datasets expose models to a wider range of linguistic and contextual variations, enhancing their ability to detect fake news across different domains and languages.
-
Continuous updating and evaluation: Regularly update and evaluate existing datasets to reflect evolving trends, emerging fake news techniques, and changes in language use. Incorporate feedback from users and domain experts to iteratively improve dataset quality and relevance.
-
Open access and collaboration: Foster an open-access culture and encourage collaboration within the research community to share datasets, tools, and resources for fake news detection. Open datasets facilitate reproducibility, benchmarking, and model comparison, leading to advancements in the field.
-
Ethical considerations: Adhere to ethical guidelines and data privacy regulations when collecting and using data, ensuring the protection of individuals' privacy and rights.
By implementing these strategies, researchers and practitioners can enhance the quality and effectiveness of existing datasets for Arabic fake news detection, leading to more robust and reliable detection models.
9.2 Feature extraction
Many features should be explored to develop more sophisticated linguistic and semantic features specific to Arabic language characteristics, including morphology, syntax, and semantics. Indeed, the analysis of the source-credibility features, the number of authors, their affiliations, and their history as authors of press articles can play an important role in fake news detection. Additionally, word count, lexical, syntactic and semantic levels, discourse-level news sources (Shu et al. 2020; Elsayed et al. 2019; Sitaula et al. 2020), as well as Publishing Historical Records (Wang et al. 2018) can also contribute to the detection of fake news. The temporal features and hierarchical propagation network on social media must be explored (Shu et al. 2020; Ruchansky et al. 2017). The studies can be enhanced by the extraction of event-invariant features (Wang et al. 2018).
9.3 Classification
Besides the existing classification approaches, the Arabic models have to be domain and content nature aware. Improving existing models for Arabic fake news detection can involve the following approaches:
-
Model architecture enhancement: Explore advanced neural network architectures and techniques tailored to handle Arabic text, by enhancing attention mechanisms, and memory networks, and enlarging the size of the existing pretrained models to increase the fake news detection systems (Khan et al. 2021; Ahmed et al. 2021).
-
Multimodal learning: Incorporate multimodal information, such as images, videos, and metadata, in addition to textual content, to improve the model's understanding and detection of fake news.
-
Semi-supervised learning: Leverage semi-supervised learning techniques to make more efficient use of limited labeled data by combining it with a large amount of unlabeled data, which is often abundant in real-world scenarios.
-
Domain adaptation: Investigate domain adaptation methods to transfer knowledge learned from other languages or domains to improve model performance on Arabic fake news detection tasks. Exploring multi-source, multi-class and multi-lingual Fake news Detection (Karimi et al. 2018; Wang 2017).
-
Ensemble methods: Combine predictions from multiple models or model variants to enhance the robustness and generalization ability of the overall system.
-
Continuous evaluation and updating: Regularly evaluate model performance on new data and fine-tune the model parameters or architecture based on feedback to ensure adaptability to evolving fake news detection challenges.
9.4 Fake news awareness techniques
Researchers have investigated the repercussions of fake news on various fronts, proposing methods to counter its influence without relying solely on identification systems. They advocate for raising awareness among individuals and propose alternative detection strategies. To summarize, the awareness techniques encompass the following points:
-
Investigating the influence of culture and demographics on the fake news spread via social media since culture has the most significant impact on the spread of fake news (Rampersad and Althiyabi 2020).
-
Studying fake news impact on consumer behavior by performing an empirical methodological approach (Visentin et al. 2019) and identifying the key elements of fake news that is misleading content that intends to cause reputation harm (Jahng et al. 2020).
-
Sensitizing adults since they are the most targeted by fake news as they share the most misinformation, and this phenomenon could intensify in years to come (Rampersad and Althiyabi 2020; Brashier and Schacter 2020).
-
Boosting resilience to misinformation, which may make people more immune to misinformation (Lewandowsky and van der Linden 2021).
-
Increasing fake news identification by helping the rise of information literacy (Jones-Jang et al. 2021).
-
Preventing misinformation on the widespread adoption of health protective behaviors in the population (Yafooz et al. 2022), in particular for COVID-19.
-
Improving the ability to spot misinformation by introducing online games to detect fake news (Basol et al. 2020).
10 Conclusion
This survey was structured to help researchers in the field to define their roadmaps based on the proposed and presented information. Indeed, we presented the terminologies related to automatic fake news detection. We highlighted the impact of fake news on the public opinion orientation and the importance of the distinction between facts and opinions. Then, we presented recent Arabic benchmark datasets and addressed the potentially extracted features along with their categories. We described various studies and hence several approaches and experimental results. We have then compared each system results and proposed new recommendations for future approaches. Based on the compiled findings, fake news detection continues to confront numerous challenges, with ample opportunities for enhancement across various facets including feature extraction, model development, and classifier selection. Addressing the open issues and future research directions in fake news detection involves distinguishing between fake news and related concepts like satire, as well as identifying check-worthy content within extensive datasets. The construction of pre-trained models that are invariant to domains, topics, and source or language changes also represents a challenge to be met. Moreover, the construction of models for the detection of newly emergent data to which the system is not accustomed is strongly recommended. Furthermore, the systems must be able to explain what news are fake or true to enhance the existing models. While our survey comprehensively covers contemporary aspects of fake news detection, its scope is constrained by the dynamic nature of fake news research, preventing us from incorporating real-time updates on research advancements.
References
Ahmed B, Ali G, Hussain A, Baseer A, Ahmed J (2021) Analysis of text feature extractors using deep learning on fake news. Eng Technol Appl Sci Res 11:7001–7005. https://doi.org/10.48084/etasr.4069
Al Zaatari A, El Ballouli R, ELbassouni S, El-Hajj W, Hajj H, Shaban K, Habash N, Yahya E (2016) Arabic corpora for credibility analysis. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16) (pp 4396–4401)
Al-Ghadir AI, Azmi AM, Hussain A (2021) A novel approach to stance detection in social media tweets by fusing ranked lists and sentiments. Inf Fusion 67:29–40. https://doi.org/10.1016/j.inffus.2020.10.003
Alhindi T, Alabdulkarim A, Alshehri A, Abdul-Mageed M, Nakov P (2021) AraStance: a multi-country and multi-domain dataset of arabic stance detection for fact checking. ArXiv210413559 Cs
Ali K, Li C, Muqtadir SA (2022) The effects of emotions, individual attitudes towards vaccination, and social endorsements on perceived fake news credibility and sharing motivations. Comput Hum Behav 134:107307
Ali ZS, Mansour W, Elsayed T, Al‐Ali A (2021) AraFacts: the first large Arabic dataset of naturally occurring claims. In Proceedings of the sixth Arabic natural language processing workshop (pp 231–236)
Alkhair M, Meftouh K, Smaïli K, Othman N (2019) An Arabic corpus of fake news: collection, analysis and classification. In: Smaïli K (ed) Arabic language processing: from theory to practice, communications in computer and information science. Springer International Publishing, Cham, pp 292–302. https://doi.org/10.1007/978-3-030-32959-4_21
Al-Qarqaz A, Abujaber D, Abdullah MA (2021) R00 at NLP4IF-2021 fighting COVID-19 infodemic with transformers and more transformers. In: Proceedings of the fourth workshop on NLP for internet freedom: censorship, disinformation, and propaganda, online. pp 104–109. https://doi.org/10.18653/v1/2021.nlp4if-1.15
Alqurashi S, Hamoui B, Alashaikh A, Alhindi A, Alanazi E (2021) Eating garlic prevents COVID-19 infection: detecting misinformation on the Arabic content of twitter. ArXiv210105626 Cs
Al-Yahya M, Al-Khalifa H, Al-Baity H, AlSaeed D, Essam A (2021) Arabic fake news detection: comparative study of neural networks and transformer-based approaches. Complexity 2021:1–10. https://doi.org/10.1155/2021/5516945
Ameur MSH, Aliane H (2021) AraCOVID19-MFH: Arabic COVID-19 multi-label fake news and hate speech detection dataset. ArXiv210503143 Cs
Awajan ALBARA (2023) Enhancing Arabic fake news detection for Twitters social media platform using shallow learning techniques. J Theor Appl Inf Technol 101(5):1745–1760
Ayyub K, Iqbal S, Nisar MW, Ahmad SG, Munir EU (2021) Stance detection using diverse feature sets based on machine learning techniques. J Intell Fuzzy Syst 40(5):9721–9740
Baly R, Mohtarami M, Glass J, Màrquez L, Moschitti A, Nakov P (2018) Integrating stance detection and fact checking in a unified corpus. arXiv preprint arXiv:1804.08012
Barron-Cedeno A, Elsayed T, Nakov P, Martino GDS, Hasanain M, Suwaileh R, Haouari F, Babulkov N, Hamdan B, Nikolov A, Shaar S, Ali ZS (2020) Overview of CheckThat! 2020: automatic identification and verification of claims in social media. ArXiv200707997 Cs
Barrón-Cedeño A, Elsayed T, Nakov P, Da San Martino G, Hasanain M, Suwaileh R, Haouari F, Babulkov N, Hamdan B, Nikolov A, Shaar S (2020) Overview of CheckThat! 2020: automatic identification and verification of claims in social media. In: International conference of the cross-language evaluation forum for European languages. Springer, Cham, pp 215–236
Basol M, Roozenbeek J, Van der Linden S (2020) Good news about bad news: gamified inoculation boosts confidence and cognitive immunity against fake news. J Cogn 3:2. https://doi.org/10.5334/joc.91
Bovet A, Makse HA (2019) Influence of fake news in Twitter during the 2016 US presidential election. Nat Commun 10:7. https://doi.org/10.1038/s41467-018-07761-2
Brashier NM, Schacter DL (2020) Aging in an era of fake news. Curr Dir Psychol Sci 29:316–323. https://doi.org/10.1177/0963721420915872
Brashier NM, Pennycook G, Berinsky AJ, Rand DG (2021) Timing matters when correcting fake news. Proc Natl Acad Sci 118:e2020043118. https://doi.org/10.1073/pnas.2020043118
Da San Martino G, Seunghak Y, Barrón-Cedeno A, Petrov R, Nakov P (2019) Fine-grained analysis of propaganda in news article. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). Association for Computational Linguistics, pp 5636–5646
Elhadad MK, Li KF, Gebali F (2021) COVID-19-FAKES: a twitter (Arabic/English) dataset for detecting misleading information on COVID-19. In: Barolli L, Li KF, Miwa H (eds) Advances in intelligent networking and collaborative systems, advances in intelligent systems and computing. Springer International Publishing, Cham, pp 256–268. https://doi.org/10.1007/978-3-030-57796-4_25
Elsayed T, Nakov P, Barrón-Cedeno A, Hasanain M, Suwaileh R, Da San Martino G, Atanasova P (2019) Overview of the CLEF-2019 CheckThat! Lab: automatic identification and verification of claims. In Experimental IR Meets Multilinguality, Multimodality, and Interaction: 10th International Conference of the CLEF Association, CLEF 2019, Lugano, Switzerland, September 9–12, 2019, Proceedings 10. Springer International Publishing, pp 301–321
Gumaei A, Al-Rakhami MS, Hassan MM, De Albuquerque VHC, Camacho D (2022) An effective approach for rumor detection of arabic tweets using extreme gradient boosting method. ACM Trans Asian Low-Resour Lang Inf Process 21:1–16. https://doi.org/10.1145/3461697
Haouari F, Ali ZS, Elsayed T (2019) bigIR at CLEF 2019: automatic verification of arabic claims over the Web. In CLEF (working notes)
Haouari F, Hasanain M, Suwaileh R, Elsayed T (2021) ArCOV19-rumors: Arabic COVID-19 twitter dataset for misinformation detection. ArXiv201008768 Cs
Hardalov M, Arora A, Nakov P, Augenstein I (2021) A survey on stance detection for mis- and disinformation identification. ArXiv210300242 Cs
Harrag F, Djahli MK (2022) Arabic fake news detection: a fact checking based deep learning approach. ACM Trans Asian Low-Resour Lang Inf Process 21:1–34. https://doi.org/10.1145/3501401
Helwe C, Elbassuoni S, Al Zaatari A, El-Hajj W (2019) Assessing arabic weblog credibility via deep co-learning. In: Proceedings of the Fourth Arabic natural language processing workshop. Presented at the proceedings of the fourth Arabic natural language processing workshop. Association for Computational Linguistics, Florence. pp 130–136. https://doi.org/10.18653/v1/W19-4614
Himdi H, Weir G, Assiri F, Al-Barhamtoshy H (2022) Arabic fake news detection based on textual analysis. Arab J Sci Eng 47(8):10453–10469
Jahng MR, Lee H, Rochadiat A (2020) Public relations practitioners’ management of fake news: exploring key elements and acts of information authentication. Public Relat Rev 46:101907. https://doi.org/10.1016/j.pubrev.2020.101907
Jardaneh G, Abdelhaq H, Buzz M, Johnson D (2019) Classifying Arabic tweets based on credibility using content and user features. In: 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT). Presented at the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT). IEEE, Amman. pp 596–601. https://doi.org/10.1109/JEEIT.2019.8717386
Jones-Jang SM, Mortensen T, Liu J (2021) Does media literacy help identification of fake news? Information literacy helps, but other literacies don’t. Am Behav Sci 65:371–388. https://doi.org/10.1177/0002764219869406
Karimi H, Roy P, Saba-Sadiya S, Tang J (2018) Multi-source multi-class fake news detection. In Proceedings of the 27th international conference on computational linguistics, pp 1546–1557
Kaur S, Kumar P, Kumaraguru P (2020) Automating fake news detection system using multi-level voting model. Soft Comput 24:9049–9069. https://doi.org/10.1007/s00500-019-04436-y
Khalil A, Jarrah M, Aldwairi M, Jaradat M (2022) AFND: Arabic fake news dataset for the detection and classification of articles credibility. Data Brief 42:108141
Khan JY, Khondaker MdTI, Afroz S, Uddin G, Iqbal A (2021) A benchmark study of machine learning models for online fake news detection. Mach Learn Appl 4:100032. https://doi.org/10.1016/j.mlwa.2021.100032
Khouja J (2020) Stance prediction and claim verification: an Arabic perspective. ArXiv200510410 Cs
Lewandowsky S, van der Linden S (2021) Countering misinformation and fake news through inoculation and prebunking. Eur Rev Soc Psychol:1–38. https://doi.org/10.1080/10463283.2021.1876983
Lim G, Perrault ST (2020) Perceptions of News sharing and fake news in Singapore. ArXiv201007607 Cs
Mahlous AR, Al-Laith A (2021) Fake news detection in arabic tweets during the COVID-19 pandemic. Int J Adv Comput Sci Appl 12. https://doi.org/10.14569/IJACSA.2021.0120691
Mohammad S, Kiritchenko S, Sobhani P, Zhu X, Cherry C (2016) SemEval-2016 task 6: detecting stance in tweets, proceedings of the 10th international workshop on Semantic Evaluation (SemEval-2016). Association for Computational Linguistics, San Diego, pp 31–41. https://doi.org/10.18653/v1/S16-1003
Nagoudi EMB, Elmadany A, Abdul-Mageed M, Alhindi T, Cavusoglu H (2020) Machine generation and detection of Arabic manipulated and fake news. arXiv preprint arXiv:2011.03092
Najadat H, Tawalbeh M, Awawdeh R (2022) Fake news detection for Arabic headlines-articles news data using deep learning. Int J Elec Comput Eng (2088–8708) 12(4):3951
Nakov P, Barrón-Cedeno A, Elsayed T, Suwaileh R, Màrquez L, Zaghouani W, Atanasova P, Kyuchukov S, Da San Martino G (2018) Overview of the CLEF-2018 CheckThat! Lab on automatic identification and verification of political claims. In Experimental IR meets multilinguality, multimodality, and interaction: 9th International Conference of the CLEF Association, CLEF 2018, Avignon, France, Proceedings 9. Springer International Publishing, pp 372–387
Nakov P, Alam F, Shaar S, Martino GDS, Zhang Y (2021) A second pandemic? Analysis of fake news about COVID-19 vaccines in Qatar. ArXiv210911372 Cs
Nassif AB, Elnagar A, Elgendy O, Afadar Y (2022) Arabic fake news detection based on deep contextualized embedding models. Neural Comput Appl 34(18):16019–16032
Niewinski P, Pszona M, Janicka M (2019) GEM: generative enhanced model for adversarial attacks. Proceedings of the second workshop on Fact Extraction and VERification (FEVER). Association for Computational Linguistics, Hong Kong, pp 20–26. https://doi.org/10.18653/v1/D19-6604
Noman Qasem S, Al-Sarem M, Saeed F (2022) An ensemble learning based approach for detecting and tracking COVID19 rumors. Comput Mater Contin 70:1721–1747. https://doi.org/10.32604/cmc.2022.018972
Oshikawa R, Qian J, Wang WY (2018) A survey on natural language processing for fake news detection. arXiv preprint arXiv:1811.00770
Rampersad G, Althiyabi T (2020) Fake news: acceptance by demographics and culture on social media. J Inf Technol Polit 17:1–11. https://doi.org/10.1080/19331681.2019.1686676
Rangel F, Giachanou A, Ghanem BHH, Rosso P (2020) Overview of the 8th author profiling task at pan 2020: profiling fake news spreaders on twitter. In CEUR workshop proceedings. Sun SITE Central Europe, (vol. 2696, pp 1–18)
Ruchansky N, Seo S, Liu Y (2017) CSI: a hybrid deep model for fake news detection. Proceedings of the 2017 ACM on conference on information and knowledge management. Singapore, pp 797–806. https://doi.org/10.1145/3132847.3132877
Saadany H, Mohamed E, Orasan C (2020) Fake or real? A study of Arabic satirical fake news. ArXiv201100452 Cs
Sabbeh SF, Baatwah SY (2018) Arabic news credibility on twitter: an enhanced model using hybrid featureS. J Theor Appl Inf Technol 96(8)
Saeed NM, Helal NA, Badr NL, Gharib TF (2020) An enhanced feature-based sentiment analysis approach. Wiley Interdiscip Rev: Data Min Knowl Disc 10(2):e1347
Saeed RM, Rady S, Gharib TF (2021) Optimizing sentiment classification for Arabic opinion texts. Cogn Comput 13(1):164–178
Saeed NM, Helal NA, Badr NL, Gharib TF (2018) The impact of spam reviews on feature-based sentiment analysis. In 2018 13th Int Conf Comput Eng Sys (ICCES) IEEE, pp 633–639
Sahoo SR, Gupta BB (2021) Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl Soft Comput 100:106983. https://doi.org/10.1016/j.asoc.2020.106983
Shahi GK, Struß JM, Mandl T (2021) Overview of the CLEF-2021 CheckThat! lab task 3 on fake news detection. Working Notes of CLEF
Shu K, Wang S, Liu H (2017) Exploiting tri-relationship for fake news detection. arXiv preprint arXiv:1712.07709, 8
Shu K, Mahudeswaran D, Wang S, Liu H (2020) Hierarchical propagation networks for fake news detection: Investigation and exploitation. In Proceedings of the international AAAI conference on web and social media (vol. 14, pp 626–637)
Sitaula N, Mohan CK, Grygiel J, Zhou X, Zafarani R (2020) Credibility-based fake news detection. In: Disinformation, Misinformation, and fake news in social media. Springer, Cham, pp 163–182
Thaher T, Saheb M, Turabieh H, Chantar H (2021) Intelligent detection of false information in arabic tweets utilizing hybrid harris hawks based feature selection and machine learning models. Symmetry 13:556. https://doi.org/10.3390/sym13040556
Touahri I, Mazroui A (2018) Opinion and sentiment polarity detection using supervised machine learning. In 2018 IEEE 5th Int Congr Inf Sci Technol (CiSt) IEEE, pp 249–253
Touahri I, Mazroui A (2019) Automatic verification of political claims based on morphological features. In CLEF (working notes)
Touahri I, Mazroui A (2020) Evolution team at CLEF2020-CheckThat! lab: integration of linguistic and sentimental features in a fake news detection approach. In CLEF (working notes)
Visentin M, Pizzi G, Pichierri M (2019) Fake news, real problems for brands: the impact of content truthfulness and source credibility on consumers’ behavioral intentions toward the advertised brands. J Interact Mark 45:99–112. https://doi.org/10.1016/j.intmar.2018.09.001
Wang Y, Yang W, Ma F, Xu J, Zhong B, Deng Q, Gao J (2020) Weak supervision for fake news detection via reinforcement learning. Proc AAAI Conf Artif Intell 34:516–523. https://doi.org/10.1609/aaai.v34i01.5389
Wang Y, Ma F, Jin Z, Yuan Y, Xun G, Jha K, Su L, Gao J (2018) Eann: event adversarial neural networks for multi-modal fake news detection. In Proceedings of the 24th acm sigkdd international conference on knowledge discovery & data mining, pp 849–857
Wang J, Makowski S, Cieślik A, Lv H, Lv Z (2023) Fake news in virtual community, virtual society, and metaverse: a survey. IEEE Trans Comput Soc Sys
Wang WY (2017) "Liar, liar pants on fire": a new benchmark dataset for fake news detection. arXiv preprint arXiv:1705.00648
Yafooz W, Emara AHM, Lahby M (2022) Detecting fake news on COVID-19 vaccine from YouTube videos using advanced machine learning approaches. In: Combating fake news with computational intelligence techniques. Springer, Cham, pp 421–435
Zhang J, Dong B, Yu PS (2020) FakeDetector: effective fake news detection with deep diffusive neural network. In: 2020 IEEE 36th International Conference on Data Engineering (ICDE). Presented at the 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, Dallas, pp 1826–1829. https://doi.org/10.1109/ICDE48307.2020.00180
Zhang X, Ghorbani AA (2020) An overview of online fake news: characterization, detection, and discussion. Inf Process Manage 57(2):102025
Zhou X, Zafarani R (2020) A survey of fake news: fundamental theories, detection methods, and opportunities. ACM Comput Surv (CSUR) 53(5):1–40
Zhou X, Jain A, Phoha VV, Zafarani R (2020) Fake news early detection: a theory-driven model. Digit Threats Res Pract 1:1–25. https://doi.org/10.1145/3377478
Author information
Authors and Affiliations
Contributions
The corresponding authors wrote the manuscript and prepared tables. The second authors reviewed the manuscript. Both authors made corrections.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Touahri, I., Mazroui, A. Survey of machine learning techniques for Arabic fake news detection. Artif Intell Rev 57, 157 (2024). https://doi.org/10.1007/s10462-024-10778-3
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10778-3