
Abstract
Landslide susceptibility modelling—a crucial step towards the assessment of landslide hazard and risk—has hitherto not included the local, transient effects of previous landslides on susceptibility. In this contribution, we implement such transient effects, which we term “landslide path dependency”, for the first time. Two landslide path dependency variables are used to characterise transient effects: a variable reflecting how likely it is that an earlier landslide will have a follow-up landslide and a variable reflecting the decay of transient effects over time. These two landslide path dependency variables are considered in addition to a large set of conditioning attributes conventionally used in landslide susceptibility. Three logistic regression models were trained and tested fitted to landslide occurrence data from a multi-temporal landslide inventory: (1) a model with only conventional variables, (2) a model with conventional plus landslide path dependency variables, and (3) a model with only landslide path dependency variables. We compare the model performances, differences in the number, coefficient and significance of the selected variables, and the differences in the resulting susceptibility maps. Although the landslide path dependency variables are highly significant and have impacts on the importance of other variables, the performance of the models and the susceptibility maps do not substantially differ between conventional and conventional plus path dependent models. The path dependent landslide susceptibility model, with only two explanatory variables, has lower model performance, and differently patterned susceptibility map than the two other models. A simple landslide susceptibility model using only DEM-derived variables and landslide path dependency variables performs better than the path dependent landslide susceptibility model, and almost as well as the model with conventional plus landslide path dependency variables—while avoiding the need for hard-to-measure variables such as land use or lithology. Although the predictive power of landslide path dependency variables is lower than those of the most important conventional variables, our findings provide a clear incentive to further explore landslide path dependency effects and their potential role in landslide susceptibility modelling.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Landslide susceptibility modelling is a key component in landslide hazard and risk assessment, crisis management and land use planning. Landslide susceptibility is the probability of landslide occurrence in an area based on a set of conditioning attributes (e.g. morphology, geology, soil) (Brabb 1984). In this context, landslide susceptibility is a time-invariant concept that purely provides an assessment of where a landslide is likely to occur (Guzzetti et al. 1999, 2005). Hence, landslide susceptibility differs from landslide hazard which does consider the temporal probability of landslide occurrence (Varnes and Commission on Landslides and Other Mass-Movements-IAEG 1984; Guzzetti et al. 2005, 2006a) and its magnitude (Guzzetti et al. 2005).
The availability of commercial and open source GIS and of statistical software (Rossi et al. 2010; Rossi and Reichenbach 2016) has allowed many researchers to construct different empirical models for landslide susceptibility modelling. Direct geomorphological mapping, heuristic approaches and quantitative statistical models have all been used to model susceptibility to landslides. Within the category of quantitative statistical models, the last two decades landslide susceptibility modelling has been the playground for new data integration techniques including fuzzy logic (Saboya et al. 2006), artificial neural networks (Kawabata and Bandibas 2009), support vector machines (Kavzoglu et al. 2014), and random forests (Trigila et al. 2015). The various approaches applied in these models always involve estimating the relation between the presence or absence of landslides on the one hand, and a generally large set of conditioning attributes on the other hand. Performance of such models is usually assessed with a strong emphasis on Receiver Operating Characteristic (ROC) curves, and area under curve (AUC) values (Mason and Graham 2002).
The temporal validity of predicted susceptibility levels in landslide susceptibility models have been considered indefinitely in all those approaches. However, there are indications from empirical studies that susceptibility levels are instead dynamic, such as the existence of a “relaxation time” of the landscape, following a major event triggering landslides. In the “relaxation time”, the effects of external triggers (e.g. earthquake, rainfall) and also the strengths of ground change over time. These changes were demonstrated with the impacts of four earthquakes (MW 6.6–7.6) on the rate of landsliding. Marc et al. (2015) showed that the regional susceptibility of landsliding increases immediately after an earthquake, remains high for several months to years, and then returns to the background susceptibility level. This shows that landslide susceptibility levels are dynamic and suggests that these changes need to be reflected in landslide susceptibility modelling.
We recently quantified the duration and strength of path dependency among landslides for the Collazzone study area in central Italy (Samia et al. 2017a, b). Path dependency is a concept from complex system theory stating that the history of a system partly determines the future state of the system (Phillips 2006). In landsliding, path dependency means that the history of landslides at a certain location affects the susceptibility of future landslides at or near that location (Samia et al. 2017b). We found that in our study area earlier landslides locally, temporarily, and positively affect the susceptibility to future landslides. Susceptibility rises immediately after a first landslide and then decays to the original susceptibility values over a period of about two decades in the vicinity of existing landslides (Samia et al. 2017a, b). These results led us to propose the concept of time-variant landslide susceptibility modelling in which a space-time dynamic component reflecting landslide history is added to the purely spatial conditioning attributes that have conventionally been used in landslide susceptibility modelling (Samia et al. 2017a, b).
Our current work presented in this paper includes—for the first time—landslide path dependency in landslide susceptibility modelling, and compares results with conventional landslide susceptibility modelling. To do this, we use a detailed multi-temporal landslide inventory containing 16 time slices of mapped landslides from the Collazzone study area in central Umbria, Italy (Guzzetti et al. 2006a; Ardizzone et al. 2013).
Study area and data
Study area
The hilly Collazzone study area, in central Umbria, Italy, covers an area of 78.9 km2 (Fig. 1). The elevation in the area ranges from 145 to 634 m above sea level, and slope varies between 0 and 64° derived from a Digital Terrain Model. Climate is Mediterranean with annual average precipitation of 885 mm, and snow falls every 2 to 3 years (Rossi et al. 2010). Both forms of precipitation trigger landslides in the area (Guzzetti et al. 2006a). The majority (57%) of the area is used as arable land. Forests, urban areas, pastures, and vineyards are other substantial land uses. Soils have fine to medium textures and their thicknesses vary from a few centimetres to more than 1 m (Rossi et al. 2010). A full description of study area can be found in (Guzzetti et al. 2006b; Galli et al. 2008; Samia et al. 2017b).

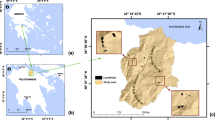
Multi-temporal landslide inventory including 16 time slices of landslide distribution overlaying a shaded relief image (left map) (adapted from (Samia et al. 2017b)). Location of Umbria region and of the Collazzone study area (right map). The coordinate system of both maps is EPSG:32633 (www.spatialreference.org). Note that the time slice from 1939 was only used to compute landslide path dependency variables, and not in landslide susceptibility modelling
Multi-temporal landslide inventory
The Collazzone study area is active in terms of landslide occurrence. Landslides are regularly mapped and monitored using interpretation of aerial photographs, direct field mapping after major external triggers (e.g. intense rainfall and snowmelt), and also remote sensing with stereo couples of GEOEYE and Worldview images (Ardizzone et al. 2013). A multi-temporal landslide inventory based on these sources is available for the study area, containing 3391 landslides mapped in 19 different time slices. All landslides in the multi-temporal landslide inventory are shallow and deep-seated landslides (Guzzetti et al. 2006b). The first three time slices where the dates of previous landslides are not well-constrained were not used in this study. Therefore, the multi-temporal landslide inventory that is used in this work contains 16 time slices with a total of 2383 landslides (Fig. 1). The time slices range from landslides in 1947 to landslides in April 2014. A detailed description of the multi-temporal landslide inventory, with information about the preparation and mapping of time slices of landslides inventories, age of landslides, spatial and temporal uncertainty of mapped landslides and frequency area relation of the multi-temporal landslide inventory is given in (Guzzetti et al. 2006b; Samia et al. 2017b).
Mapping unit for landslide susceptibility modelling
A subdivision of the study area into mapping units (Fig. 2), i.e. morpho-hydrological subdivisions of terrain containing a set of conditions different from neighbouring units, is common for the preparation of landslide susceptibility maps (Carrara et al. 1995; Guzzetti et al. 1999, 2006b; Alvioli et al. 2016). We used a set of previously defined “slope units” that divide the study area into hydrological regions bounded by drainage and divide lines (Carrara et al. 1991; Alvioli et al. 2016). These slope units have proven to be a reliable unit to map susceptibility to landslides in our study area (Guzzetti et al. 2006a, b) and more generally in the Umbria region in Italy (Carrara et al. 1991; Guzzetti et al. 1999; Cardinali et al. 2002). In total, 894 slope units were identified for our study area. Along with the preparation of slope units, 30 morphological and hydrological parameters (Table 1) were created that are part of the set of conditioning attributes used in this work. A detailed description regarding the preparation of slope units and their use for susceptibility modelling can be found in (Carrara et al. 1991; Rossi et al. 2010).

Slope units and slope (a), geology (b), land use (c), and bedding attitude with respect to slope (d) in the Collazzone study area
Conditioning attributes
To classify the slope units according to their susceptibility to landslide, we used the same set of 51 conditioning attributes as previous work (Rossi et al. 2010). This set (Table 1) includes 24 morphological, six hydrological, nine lithological (Fig. 2), three structural, and eight land use classes (Fig. 2), and one attribute showing the presence of ancient deep-seated landslides. A detailed description of the preparation of these attributes and their importance in landslide susceptibility mapping can be found in (Guzzetti et al. 2006a, b; Rossi et al. 2010). For this study, additional variables reflecting landslide path dependency were calculated. These variables describe the spatial probability of earlier landslide causing follow-up landslides and landslide susceptibility temporal decay (Table 1 and see “Landslide path dependency variables”).
Methods
We compared (i) conventional landslide susceptibility modelling, (ii) conventional plus path dependent landslide susceptibility modelling, and (iii) path dependent landslide susceptibility modelling using a forward conditional Multiple Logistic Regression (MLR) (Fig. 3). We assessed the performance of all three models with area under curve (AUC) values of the receiver operating characteristics (ROC) curve. Then, we compared the coefficients estimated in landslide susceptibility models. Finally, we compared the predicted susceptibility maps.

Flowchart of methods used. For difference between sequential split and non-sequential split see section “Sequential and non-sequential splitting of multi-temporal landslide inventory for training and testing”
Landslide path dependency variables
We computed four landslide path dependency variables in an attempt to reflect the history of landslides from the multi-temporal landslide inventory (Fig. 1). The first path dependency variable called susceptibility temporal decay (Table 1) reflects that the additional local susceptibility due to an earlier landslide decays exponentially, following:
For every slope unit in each time slice, we calculated the susceptibility temporal decay depending on when a landslide last time happened in the slope unit, regardless of where in the slope unit the landslide happened. The susceptibility temporal decay values range from 0 to 1. Values close to 1 indicate that landslides happened recently in the slope unit and values close to 0 indicate that the most recent landslide happened a long time ago. This was based on our earlier finding of exponential decay in the number of landslides geographically overlapping with earlier landslides (Samia et al. 2017a). We found that for the Collazzone study area the susceptibility is raised immediately after an earlier landslide by a factor of 15, and then it decreases over time with an exponential coefficient value of b = − 0.12 ± 0.01 y−1 (Fig. 4). The second variable (Table 1) is the spatial probability of earlier landslides causing follow-up landslides, which was quantified according to geometric and topographic attributes of earlier landslides (Samia et al. 2017a). The third variable is the sum of spatial probability of all landslides that may have happened in the most recent time slice experiencing follow-up landslides. The fourth variable is an aggregated number combining the probability of follow-up landslides of all known earlier landslides under the assumption that susceptibility decays exponentially (b = − 0.12) as the following:

Temporal response of landslide path dependency with an exponential decay (Samia et al. 2017a)
Time differences, spatial association among landslides, and geometric and topographic attributes of landslides were the key elements to calculate all these four variables.
Only the first two of these landslide path dependency variables were used in landslide susceptibility modelling because the third and fourth variables were very strongly correlated with the second variable (r > 0.6) for our dataset. However, they may be less correlated and hence useful in other settings with multi-temporal landslide inventory.
Sequential and non-sequential splitting of multi-temporal landslide inventory for training and testing
Usually, in landslide susceptibility modelling, a mono-temporal landslide inventory (i.e. a geomorphological) (Guzzetti et al. 2012) is divided randomly into a training and a testing dataset, with a ratio of 70% of the data for training and 30% of the data for validation (Tien Bui et al. 2016). In previous studies that used almost the same multi-temporal landslide inventory as we do in this work, older time slices have been used for training and younger time slices for testing (Rossi et al. 2010). We named this approach “sequential splitting” (Fig. 3, Table 2) and we used it as a first splitting approach in this work, with the 7 oldest time slices from 1947 to 1991 (covering a period of 44 years) used for training, and the 9 most recent time slices from 1997 to 2014 (covering a period of 17 years) used for testing.
However, this method of splitting is not well-suited where an estimation of the effects of landslide path dependency is required. Note that the landsliding history of the area is not known before the earliest time slice in 1939. That means that for this time slice, the value of the temporal decay susceptibility (Table 1) is unknown, and that also subsequent old time slices may miss an important part of the landslide history of the area. Thus, sequential splitting leads to a narrower distribution of times since previous landslides in the training dataset than in the testing dataset. A model based on the training dataset may hence be uncertain about the role of the time passed since a previous landslide, especially for longer times passed. Additionally, in recent times, time slices are closer together in time due to more frequent availability of high quality remote sensing imagery. The corresponding lack of very short temporal separations in the training dataset will hamper accurate estimation of the role of time as well. More generally, the path dependency paradigm creates room for thought that the conventional space-focussed susceptibility rules change over time. If so, a model trained on an old dataset may not be accurate for a recent dataset.
For these reasons, we also employed a “non-sequential splitting” approach, which to our knowledge is novel in the realm of landslide susceptibility modelling. The non-sequential selection of time slices from the multi-temporal landslide inventory (Fig. 1, Table 2) prioritises an equal range of temporal separations between time slices in the training and the testing datasets, to avoid the disadvantages mentioned above. On the downside, this approach makes it more difficult to have approximately equal numbers of slope units with and without landslides in both datasets. For the training dataset, the 1st, 2nd, 5th, 6th, 9th, 10th, 13th, and 14th time slices were used (covering a period of 63 years). Note that the first time slice here refers to 1947—the first time slice for which a partial history of landsliding is known. For the testing dataset, the 3rd, 4th, 7th, 8th, 11th, 12th, 15th, and 16th time slices were used (covering a period of 49 years) (Table 2).
Multiple logistic regression model
Logistic regression is the most widely used statistical model in landslide susceptibility modelling (Mancini et al. 2010; Martinović et al. 2016). In logistic regression, a set of explanatory (independent) variables explains variation in the binary dependent variable (Menard 2000). In landslide susceptibility modelling, explanatory variables are, e.g. slope and geology, and the dependent variable is the presence or absence of landslides in the mapping unit of choice. The relation between independent variables and dependent variable is used to classify the mapping units (slope unit or pixel) of an area to different levels of susceptibility to landslides. In this context, each mapping unit has a probability of landslide occurrence (ρ) in the range from 0 to 1 (Martinović et al. 2016):
where z is a linear combination of coefficients related to independent variables selected by logistic regression according to their importance and significance reflected as:
where β0 is the intercept of the model, β1, β2, and βn are the coefficients of independent variables, and X1, X2, Xn are independent variables selected by the model.
Landslide susceptibility modelling
Conventional landslide susceptibility modelling was performed using a set of 51 previously used conditioning attributes (Rossi et al. 2010) (Table 1). The conventional plus path dependent landslide susceptibility modelling was performed using the same 51 conditioning attributes, plus spatial probability of earlier landslides causing follow-up landslides and susceptibility temporal decay variables describing landslide path dependency (Table 1). Path dependent landslide susceptibility modelling was performed using only the two new landslide path dependency variables (Table 1). The number of slope units without landslides is more than the number of slope units with landslides (Fig. 3). To make a dataset with equal numbers of slope units with and without landslides, all slope units with landslides and a random but equal number of slope units without landslides were selected. To explore the effect of this random selection, it was repeated 10 times. After preparation of the 10 training datasets with sequential splitting, and 10 training datasets with non-sequential splitting, we applied logistic regression to all 20. We imposed an entry probability of 0.05 and a removal probability of 0.06 to reduce the risk of overfitting in the model. To avoid multicollinearity, we allowed only inter-variable correlations less than 0.6. Then, the contingency tables were computed to show the True positive (slope units with landslide and predicted with landslide), true negative (slope units without landslide and predicted without landslide), false positive (slope units without landslide but predicted with landslide), and false negative (slope unites with landslide and predicted without landslide) (Jolliffe and Stephenson 2003). Finally, the area under curve values (AUC), quantifying the accuracy of performance of predicted models (Mason and Graham 2002; Fawcett 2006), and the Akaike Information Criterion (AIC) which quantifies the goodness of fit while penalising for the complexity of the model (Akaike 1974; Petschko et al. 2012) were computed for the training datasets. To test the models, the models were applied to the 20 testing datasets, and again contingency tables and the AUC values for these testing datasets were calculated. The coefficients of variables selected by logistic regression in conventional landslide susceptibility were compared with the coefficients of variables selected by logistic regression in conventional plus path dependent landslide susceptibility. Finally, we averaged the probability of landslide occurrence in the 10 training and 10 testing datasets and used this to map susceptibility to landslides.
Results
Model performance
In our test case, conventional plus path dependent landslide susceptibility modelling resulted in similar model performance to conventional landslide susceptibility modelling. This was true for both sequential and non-sequential splitting of the multi-temporal landslide inventory (Table 3). In sequential splitting, the best training result was obtained with conventional plus path dependent landslide susceptibility modelling with highest AUC = 0.775 ± 0.006 (Table 3, Fig. 5) and lowest Akaike information criterion (AIC) = 2281 ± 23. In non-sequential splitting, the best training result was obtained again with conventional plus path dependent landslide susceptibility modelling with highest AUC = 0.767 ± 0.007 and lowest AIC = 1515 ± 15.

Examples of receiver operating characteristic (ROC) curves with highest AUC values for training in conventional plus path dependent landslide susceptibility modelling for the sequential splitting (right) and for testing in conventional plus path dependent landslide susceptibility modelling for the non-sequential splitting (left)
The best testing result was obtained with conventional plus path dependent landslide susceptibility for the non-sequential splitting, with AUC = 0.754 ± 0.012 (Table 3 and Fig. 5). The landslide susceptibility model using only landslide path dependency variables performed acceptably as well, with best AUC = 0.688 ± 0.009 for training in non-sequential splitting, and AUC = 0.682 ± 0.022 for testing in the sequential splitting (Table 3).
The clearest difference between these three landslide susceptibility models is that the testing results are higher or closer to the training results when only using landslide path dependency variables. In general, non-sequential splitting has larger differences between model performance and testing (Table 3).
The contingency tables values (from these two models Table 4) calculated with a probabilistic cut off value of 0.5 showed slight differences between conventional and conventional plus path dependent susceptibility, in sequential and non-sequential splitting. The path dependent susceptibility model differs substantially from these two models.
Effect of landslide path dependency variables on variable selection
The spatial probability that an earlier landslide will cause a follow-up landslide was selected as an explanatory variable (independent variable) in all 10 repetitions of conventional plus path dependent susceptibility modelling using sequential splitting, and in 8 out of 10 repetitions using non-sequential splitting (Table 5). In these 18 cases, the significance of this variable was always better than 0.0001. The susceptibility temporal decay variable was selected 6 times, both in sequential and non-sequential splitting of conventional plus path dependent susceptibility (Table 5). In these 12 cases, susceptibility temporal decay variable was always significant as imposed during the training of the model (p < 0.05). When using only the two path dependency variables, the spatial probability of earlier landslide causing follow-up landslide variable was always selected (i.e. 20 times), whereas susceptibility decay variable was selected 6 times in sequential and 10 times in non-sequential splitting. These variables were significant (p < 0.05) in all 36 cases as well. The importance of the landslide path dependency variables is also shown by their effects on the number and coefficients of variables selected by the model (Table 5, Figs. 6 and 7).

Percentage change in the coefficients with adding two landslide path dependency variables in sequential splitting. The changes of coefficients in variables that were 6 times or more common between two models were reported. Error bars represent standard error

Percentage change in the coefficients with adding two landslide path dependency variables in non-sequential splitting. The changes of coefficients in variables that were 6 times or more common between two models were reported. Error bars represent standard error
In sequential splitting, for conventional susceptibility, on average 13.7 variables and for conventional plus path dependent susceptibility 14 variables were selected (Table 5). Also, in non-sequential splitting the conventional landslide susceptibility selected on average 10.7 variables and the conventional plus path dependent susceptibility selected 11 variables on average. With adding the two landslide path dependency variables into the conventional landslide susceptibility, the inclusion and exclusion of other variables also changed. These were seen both in sequential and non-sequential splitting. In conventional plus path dependent susceptibility in sequential splitting, on average 3.25 variables were removed and 2.7 variables were added. In conventional plus path dependent susceptibility in non-sequential splitting, on average 3.5 variables were removed and 3.1 variables were added. In path dependent susceptibility, for the sequential splitting on average 1.6 variables (out of two landslide path dependency in 10 times repetition) were selected, and for non-sequential splitting both landslide path dependency variables were selected in all of the10 times repetition (Table 5).
The regression coefficients of variables that were present in both the conventional and the conventional plus path dependent models changed slightly (less than 10%) with sequential splitting (Fig. 6). The largest change is for recent alluvial deposit, around 11%. With non-sequential splitting, limestone and cultivated area changed, about 12 and 14% respectively (Fig. 7).
Landslide susceptibility maps
The landslide susceptibility maps for conventional and conventional plus path dependent in sequential and non-sequential splitting are presented in Fig. 8. Note that in all cases, the landslide susceptibility maps were made by averaging the probability of landslide occurrence in the slope units of all training and testing datasets. In both splitting approaches, there were no substantial differences between the histograms of probability of landslide occurrence between conventional and conventional plus path dependent landslide susceptibility (Fig. 8a–d). These slight differences between conventional and conventional plus path dependence susceptibility maps both in sequential and non-sequential splitting are in accordance with the slight differences in AUC values of their susceptibility models (Table 3). However, somewhat more slope units were predicted with probability of landslide occurrence lower than 0.2, and less slope units with probability larger than 0.8 using conventional plus path dependent susceptibility than using conventional landslide susceptibility.

Conventional landslide susceptibility maps in sequential and non-sequential splitting (a, c) and conventional plus path dependent landslide susceptibility maps in sequential and non-sequential splitting (b, d). Highlighted slope units in black indicate substantial differences in susceptibility between conventional and conventional plus path dependent landslide susceptibility maps
The difference map for the sequential splitting, made by subtracting conventional susceptibility map from the conventional plus path dependent susceptibility map, shows that the susceptibility of slope units did not change substantially in about 46% of our study area (409 slope units) (Fig. 9a). In about 21% of the slope units, the probability of susceptibility slightly increased (192 slope units) and in 33% of the slope units (293 slope units) the probability of susceptibility slightly decreased. The difference map for non-sequential splitting showed similar results as well.

Difference between conventional landslide susceptibility map with conventional plus path dependent landslide susceptibility map in sequential (a) and non-sequential (b) splitting
Path dependent landslide susceptibility maps in sequential and non-sequential splitting had substantial different geographical patterns in comparison to conventional and conventional plus path dependent landslide susceptibility maps (Fig. 10a, b). The clear differences were in the slope units that did not have susceptibility smaller than 0.2 (Fig. 10a) and larger than 0.8 (Fig. 10a, b). This is due to the fact that susceptibility of the slope units to landslides decreases over time, which has been implemented into this model.

Path dependent landslide susceptibility maps predicted with only landslide path dependency variables in sequential splitting (a) and non-sequential splitting. The highlighted slope unit was selected as an example to show the change in susceptibility over time in Fig. 12
In sequential splitting, the difference map between conventional and path dependent landslide susceptibility maps showed that in 23% of the slope units, the susceptibility did not change, in about 23% of the slope units, the susceptibility increased, and in about 54% of the slope units, the susceptibility decreased (Fig. 11a). In non-sequential splitting, in 21% of the slope units, the susceptibility did not change, in 11% of the slope units, the susceptibility increased, and in 68% of the slope units, the susceptibility decreased (Fig. 12b).

Difference between conventional landslide susceptibility map with path dependent landslide susceptibility in sequential (a) and non-sequential splitting (b)

Modelled landslide susceptibility in the highlighted slope unit in Fig. 10 using conventional, conventional plus path dependent and path dependent landslide susceptibility models and sequential splitting
Discussion
We will first discuss the concept of time-variant landslide susceptibility and then focus on the performance of the three landslide susceptibility models and then discuss the importance of landslide path dependency variables in landslide susceptibility mapping. We will also discuss the possibility to create a simpler and easier to calculate landslide susceptibility model using DEM-derivative variables and landslide path dependency variables.
Time-variant landslide susceptibility modelling
By definition, conventional landslide susceptibility is considered to be constant over decadal timescales (Guzzetti et al. 1999, 2005) (Fig. 12). In conventional plus path dependent susceptibility, due to the effect of landslide path dependency, landslide susceptibility is dynamic and changes over the timescale of analysis. The fact that the change in the intensity of susceptibility is only slight, is due the fact that the set of 51 conditioning attributes already captures most of the spatio-temporal variation in landslide occurrence. This of course no longer the case in susceptibility maps prepared using the model with only the two landslide path dependency variables. Here, there is a quite intensive and dynamic change in the level of susceptibility, reflecting the imposed exponential decay of landslide path dependency (Samia et al. 2017a) (Fig. 12).
Performance of landslide susceptibility models
We found that adding landslide path dependency variables to the conditioning attributes variables used in conventional landslide susceptibility model slightly improved the performance of the susceptibility model (Table 1). These slight improvements in model performance are reflected in the high significance of landslide path dependency variables, affected the coefficients and significances of other variables (Figs. 6 and 7, and inclusion and exclusion of other variables. The fact that the model improvement due to path dependent variables is nonetheless only slight, can be explained by (a) the 51 conventional variables (conditioning attributes) already capture almost all systematic variation; (b) area under curve (AUC) considers the overall performance of the model without any spatial consideration while landslide path dependency attempts to describe the “local” effect on susceptibility and (c) simply limited performance and relevance of landslide path dependency variables.
To explore the first of these three possibilities, we compared a landslide susceptibility model with only the two most significant conditioning attributes variables with path dependent landslide susceptibility model (with the two landslide path dependency variables). The performance of the conventional model was much closer to the performance of the path dependency model (Tables 6 and 3), indicating a relatively similar importance of landslide path dependency variables as the importance of conditioning attributes conventionally being used in landslide susceptibility modelling.
In an additional exploration, we found that a very simple landslide susceptibility model using only DEM-derived variables and landslide path dependency variables can lead to acceptable results (Table 6). This is potentially interesting since such landslide susceptibility models can be prepared easily, globally and within a short period of time. DEM-derived variables could easily be calculated for global extent with GIS related software, and high-resolution, accurate multi-temporal landslide inventories may be expected in the near future due to the recent widespread availability of high resolution remote sensing images. Therefore, landslide susceptibility model potentially could be prepared with a combination of DEM-derived variables and landslide path dependency variables derived from multi-temporal landslide inventory maps.
Regarding the second point, performance of path dependence variables may have been limited by using the slope unit as mapping unit in the landslide susceptibility models. The values of landslide path dependency variables themselves were calculated based on geographical overlap with earlier landslides (Samia et al. 2017a). Since landslides are generally much smaller than the slope units, the landslide path dependency variables reflect a process that affects landsliding at smaller spatial scale than the scale at which they have now been used (slope units). The value of exponential decay (b = − 0.12) (Samia et al. 2017a) that was used was derived at the landslide scale, and may have needed to be re-estimated at the slope unit scale. This reasoning leaves open the possibility that for pixel-based susceptibility modelling the effect of landslide path dependency variables can be higher.
Regarding the two sampling strategies used in this work, the non-sequential splitting of the multi-temporal landslide inventory has the best performing in testing, and has also the smallest difference in the performance of the model between training and testing (Tables 3 and 6). We maintain that this is important, as it indicates we are less overfitting our susceptibility models.
Landslide path dependency as conditioning attributes in landslide susceptibility modelling
We implemented our previously quantified landslide path dependency (Samia et al. 2017a) in landslide susceptibility modelling using only two landslide path dependency variables (Table 1). The landslide susceptibility predictions from these models (Fig. 10a, b) performed acceptably with AUC > 0.660 (Table 3) both for training and testing. This suggests that it is possible to use only landslide inventory itself to predict landslide susceptibility in areas where conditioning attributes are not available, or difficult to obtain. This could be potentially interesting since it has been always said that to do landslide susceptibility modelling, many conditioning attributes variables are needed (van Westen et al. 2003; Guzzetti et al. 2006a; Ghosh et al. 2011). We showed that this is not necessarily the case (Table 3, Fig. 10a, b). For the calculation of landslide path dependency variables, time of landslide occurrence or mapping time of landslide, spatial association among landslides, geometric and topographic attributes of landslides were needed. Clearly, none of the landslide path dependency variables can be extracted from mono-temporal landslide inventory or from landslide inventories where landslides are mapped as points. This stresses the importance of monitoring of earlier landslides where multi-temporal landslides inventory can be provided and landslides are mapped with polygon (Samia et al. 2017b). Providing multi-temporal landslide inventory could be facilitated by remote sensing images and techniques. However, if there is no spatial association among landslides then the effect of landslide path dependency might be difficult to extract as we have only one test study site with multi-temporal landslide inventory. Besides that, if a landslide goes down slope and it is no longer present in the slope, then the effect of path dependency could be limited or even absent. For deep-seated landslides and earthflows, it has been speculated that reactivation is caused by a thin layer of smeared clays under the landslide body—the so-called bathtub effect (Baum and Reid 2000; Van Den Eeckhaut et al. 2007). If this effect is also behind some of the shallow landslides that we studied, then explanatory variables reflecting clay content and mineralogy may be useful to identify regions and hillslopes that are particularly susceptible to path dependency in landsliding.
Data and method differences with previous landslide susceptibility modelling in the study area
The previous landslide susceptibility modelling in our study area (Rossi et al. 2010) differs from ours in terms of data and the way of calculating the dependent variable. First, the multi-temporal landslide inventory has increased by four time slices (March and May 2010, April 2013 and April 2014) (Fig. 1) using high-resolution remote sensing images which have been used in this study, but were not available to Rossi et al. (2010). Besides, in our study, landslides in the first available time slice (1939) were only used for computation of landslide path dependency variables, but were used as targets in landslide susceptibility modelling in Rossi et al. (2010). We calculated the dependent variable in slope units according to the presence or absence of each individual landslide. This allowed us to use the effect of each individual landslide purely in landslide susceptibility modelling while Rossi et al. (2010), combined all the landslides first, and then calculated the dependent variable with the presence or absence of all the combined landslides in slope units. These differences led to clear differences in the number of slope units located in different classes of probability to landslide occurrence. In Rossi et al. (2010), more slope units (502 slope units) were predicted in the higher probability classes (0.6–0.8 and 0.8–1), whereas we predicted less slope units (235 slope units in sequential splitting, and 197 slope units in non-sequential splitting) in the same high classes of probability (Fig. 8a, c). Also, the number of slope units in the probability class of 0.4–0.6 in our conventional landslide susceptibility maps is higher (264 slope units in sequential splitting, 309 slope units in non-sequential splitting) in comparison with 68 slope units predicted in this probability class by Rossi et al. (2010).
Exportability of landslide path dependency variables in other areas for landslide susceptibility modelling
Where multi-temporal landslide inventories are available (to our knowledge the only large multi-temporal landslide inventory available worldwide is the multi-temporal landslide inventory used in this work), and the geological, climate conditions and type of landslides are similar to our study area, our exponential decay coefficient b = − 0.12 from susceptibility temporal decay (Table 1 and Eq. 1), and spatial probability of each landslide causing follow-up landslide could directly be used to model susceptibility to landslide. However, most landslide inventories are mono-temporal usually recorded after extreme external triggers (e.g. rainfall and earthquake). From such landslide inventories, the exponential decay coefficient from susceptibility temporal decay cannot be computed. However, from geometric attributes (e.g. size, shape) and topographic attributes of each landslide in the mono-temporal landslide inventory, the spatial probability of earlier landslides causing follow-up landslides (Table 1) is computable if we assume that the model to predict the occurrence of follow-up landslides by Samia et al. (2017a) is valid. In this context, for every known landslide we would have a probability that shows whether a landslide will have a follow-up landslide, or not. This landslide path dependency variable in our study area was found to be the most significant and selected variable by the logistic regression when using it individually, or combined with conditioning attributes variables in landslide susceptibility modelling (Table 1). Therefore, a combination of path dependent variables with a range of other possibility conditioning attributes or DEM-derived variables could be used to model susceptibility to landslide.
Conclusion
For our study area, where adding landslide path dependency variables to the conditioning attributes conventionally used in landslide susceptibility modelling improves the performance of landslide susceptibility model slightly. However, the resulting landslide susceptibility maps from conventional and conventional plus path dependent landslide susceptibility models are not substantially different. The highest performance for landslide susceptibility model was obtained in conventional plus path dependent landslide susceptibility model with the AUC = 0.775 ± 0.006 in sequential splitting and AUC = 0.754 ± 0.012 in non-sequential splitting. In addition, a landslide susceptibility model purely made by two landslide path dependency variables has decent model performance with the AUC values > 0.660 in sequential and non-sequential splitting. The non-sequential sampling strategy has a better model performance in the testing dataset, and less difference with the performance of the model between training and testing datasets. Moreover, the spatial probability of earlier landslide causing follow-up landslide was selected in 18 out of 20 runs logistic regression for landslide susceptibility modelling. The susceptibility temporal decay was also selected in 60% of the runs (12 out of 20) of logistic regression. These landslide path dependency variables also changed the significance, inclusion and exclusion of other variables selected by logistic regression. A simple, easily computed landslide susceptibility model with reliable model performance can be obtained using combination of DEM-derived variables and landslide path dependency variables. Our landslide path dependency variables can possibly be applied to model susceptibility to landslide in areas similar to our study area where multi-temporal landslide inventory or mono-temporal landslide inventory are available.
References
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19:716–723
Alvioli M, Marchesini I, Reichenbach P, Rossi M, Ardizzone F, Fiorucci F, Guzzetti F (2016) Automatic delineation of geomorphological slope units with r.slopeunits v1.0 and their optimization for landslide susceptibility modeling. Geosci Model Dev 9:3975–3991. https://doi.org/10.5194/gmd-9-3975-2016
Ardizzone F et al. (2013) Very-high resolution stereoscopic satellite images for landslide mapping. In: Landslide science and practice. Springer, pp 95–101
Baum R, Reid M (2000) Ground Water isolation by low-permeability clays in landslide shear zones. In: Landslides in Research, Theory and Practice: Proceedings of the 8th International Symposium on Landslides held in Cardiff on 26–30 June 2000. Thomas Telford Publishing, pp 1: 139–144
Brabb EE (1984) Innovative approaches to landslide hazard mapping, Proceedings 4th International Symposium on Landslides, Toronto, vol 1 (1984), pp. 307–324
Cardinali M, Carrara A, Guzzetti F, Reichenbach P (2002) Landslide hazard map for the upper Tiber River basin. CNR, Gruppo Nazionale per la Difesa dalle Catastrofi Idrogeologiche
Carrara A, Cardinali M, Detti R, Guzzetti F, Pasqui V, Reichenbach P (1991) GIS techniques and statistical models in evaluating landslide hazard. Earth Surf Process Landf 16:427–445
Carrara A, Cardinali M, Guzzetti F, Reichenbach P (1995) GIS technology in mapping landslide hazard. In: Geographical information systems in assessing natural hazards. Kluwer Academic Publisher, Dordrecht, pp 135–175
Fawcett T (2006) An introduction to ROC analysis. Pattern Recogn Lett 27:861–874. https://doi.org/10.1016/j.patrec.2005.10.010
Galli M, Ardizzone F, Cardinali M, Guzzetti F, Reichenbach P (2008) Comparing landslide inventory maps. Geomorphology 94:268–289
Ghosh S, Carranza EJM, van Westen CJ, Jetten VG, Bhattacharya DN (2011) Selecting and weighting spatial predictors for empirical modeling of landslide susceptibility in the Darjeeling Himalayas (India). Geomorphology 131:35–56. https://doi.org/10.1016/j.geomorph.2011.04.019
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 31:181–216
Guzzetti F, Reichenbach P, Cardinali M, Galli M, Ardizzone F (2005) Probabilistic landslide hazard assessment at the basin scale. Geomorphology 72:272–299
Guzzetti F, Galli M, Reichenbach P, Ardizzone F, Cardinali M (2006a) Landslide hazard assessment in the Collazzone area, Umbria, Central Italy. Nat Hazards Earth Syst Sci 6:115–131
Guzzetti F, Reichenbach P, Ardizzone F, Cardinali M, Galli M (2006b) Estimating the quality of landslide susceptibility models. Geomorphology 81:166–184
Guzzetti F, Mondini AC, Cardinali M, Fiorucci F, Santangelo M, Chang K-T (2012) Landslide inventory maps: new tools for an old problem. Earth Sci Rev 112:42–66
Jolliffe IT, Stephenson DB (2003) Forecast verification: a practitioner’s guide in atmospheric science. Wiley, Chichester
Kavzoglu T, Sahin EK, Colkesen I (2014) Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 11:425–439. https://doi.org/10.1007/s10346-013-0391-7
Kawabata D, Bandibas J (2009) Landslide susceptibility mapping using geological data, a DEM from ASTER images and an artificial neural network (ANN). Geomorphology 113:97–109. https://doi.org/10.1016/j.geomorph.2009.06.006
Mancini F, Ceppi C, Ritrovato G (2010) GIS and statistical analysis for landslide susceptibility mapping in the Daunia area, Italy. Nat Hazards Earth Syst Sci 10:1851–1864
Marc O, Hovius N, Meunier P, Uchida T, Hayashi S (2015) Transient changes of landslide rates after earthquakes. Geology 43:883–886. https://doi.org/10.1130/G36961.1
Martinović K, Gavin K, Reale C (2016) Development of a landslide susceptibility assessment for a rail network. Eng Geol 215:1–9. https://doi.org/10.1016/j.enggeo.2016.10.011
Mason SJ, Graham NE (2002) Areas beneath the relative operating characteristics (ROC) and relative operating levels (ROL) curves: statistical significance and interpretation. Q J R Meteorol Soc 128:2145–2166. https://doi.org/10.1256/003590002320603584
Menard S (2000) Coefficients of determination for multiple logistic regression analysis. Am Stat 54:17–24
Petschko H, Bell R, Brenning A, Glade T (2012) Landslide susceptibility modeling with generalized additive models—facing the heterogeneity of large regions. In: Eberhardt E, Froese C, Turner AK, Leroueil S (eds) Landslides and engineered slopes, protecting society through improved understanding. Taylor & Francis, Banff, Alberta, pp769–777
Phillips J (2006) Evolutionary geomorphology: thresholds and nonlinearity in landform response to environmental change. Hydrol Earth Syst Sci 10:731–742
Rossi M, Reichenbach P (2016) LAND-SE: a software for statistically based landslide susceptibility zonation, version 1.0. Geosci Model Dev 9:3533–3543
Rossi M, Guzzetti F, Reichenbach P, Mondini AC, Peruccacci S (2010) Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 114:129–142. https://doi.org/10.1016/j.geomorph.2009.06.020
Saboya F, da Glória Alves M, Dias Pinto W (2006) Assessment of failure susceptibility of soil slopes using fuzzy logic. Eng Geol 86:211–224. https://doi.org/10.1016/j.enggeo.2006.05.001
Samia J, Temme A, Bregt A, Wallinga J, Guzzetti F, Ardizzone F, Rossi M (2017a) Characterization and quantification of path dependency in landslide susceptibility. Geomorphology 292:16–24
Samia J, Temme A, Bregt A, Wallinga J, Guzzetti F, Ardizzone F, Rossi M (2017b) Do landslides follow landslides? Insights in path dependency from a multi-temporal landslide inventory. Landslides 14:547–558. https://doi.org/10.1007/s10346-016-0739-x
Tien Bui D, Tuan TA, Klempe H, Pradhan B, Revhaug I (2016) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13:361–378. https://doi.org/10.1007/s10346-015-0557-6
Trigila A, Iadanza C, Esposito C, Scarascia-Mugnozza G (2015) Comparison of logistic regression and random forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 249:119–136. https://doi.org/10.1016/j.geomorph.2015.06.001
Van Den Eeckhaut M, Poesen J, Dewitte O, Demoulin A, De Bo H, Vanmaercke-Gottigny M (2007) Reactivation of old landslides: lessons learned from a case-study in the Flemish Ardennes (Belgium). Soil Use Manag 23:200–211
van Westen CJ, Rengers N, Soeters R (2003) Use of geomorphological information in indirect landslide susceptibility assessment. Nat Hazards 30:399–419. https://doi.org/10.1023/B:NHAZ.0000007097.42735.9e
Varnes DJ, Commission on Landslides and Other Mass-Movements-IAEG (1984) Landslide hazard zonation: a review of principles and practice. The Unesco Press, Paris
Acknowledgements
This work is part of JS PhD project at laboratory of Geo-Information Science and Remote Sensing and Soil Geography and Landscape groups of Wageningen University and Research financed by Ministry of Science, Research and Technology of Iran. We would like to thank the two anonymous reviewers for their constructive comments on the preparation of the final manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Samia, J., Temme, A., Bregt, A.K. et al. Implementing landslide path dependency in landslide susceptibility modelling. Landslides 15, 2129–2144 (2018). https://doi.org/10.1007/s10346-018-1024-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10346-018-1024-y