
Abstract
Early intervention programs are generally considered the most efficient and beneficial approach to providing support to struggling beginning readers. This paper discusses the theoretical background, development, and design of, as well as the first results obtained with, GraphoGame for Standard Indonesian, a technology-enhanced learning environment that trains the basic skills of reading by high but playful exposure to grapheme-phoneme coupling. The results of the pilot study assessing the usability of the program in 69 first-graders show that the more the students with low pre-test phonological skills were exposed to the game, the better their post-test performance on reading and decoding fluency became. Although large-scale, randomized controlled studies are needed to confirm the effectiveness of GraphoGame SI, these promising first results may offer a stepping stone for the development of additional language versions and future systematic comparisons of the method’s results in different languages and populations.
Similar content being viewed by others


Introduction
Most children become proficient readers if they are provided with adequate learning opportunities, have no significant sensory deficit, and if their cognitive capacity is not severely compromised (Richardson and Lyytinen 2014). Still, despite fulfilling the aforementioned prerequisites, it is estimated that in the USA, one in three of all children is a struggling reader by the fourth grade (Aud et al. 2013; U.S. Department of Education 2011). A small proportion will develop dyslexia and face persisting problems with reading and spelling, with possible negative effects on their cognitive development, school motivation, well-being, and self-esteem (Lovio et al. 2012). In transparent orthographies in which the orthography reflects the surface phonology with a high level of consistency, dyslexia is usually characterized by extremely slow and effortful phonological recoding combined with very poor spelling. In languages with an opaque, inconsistent orthography at the grapheme-phoneme correspondence level, dyslexia typically becomes apparent on the basis of inaccurate reading alone although reading speed and spelling skills may also be affected (Ziegler and Goswami 2005).
Among various approaches, early intervention programs aimed at alleviating or even preventing dyslexia in struggling readers are generally regarded as the most efficient and beneficial (Richardson and Lyytinen 2014). In this paper, we present GraphoGame for Standard Indonesian (SI). Originally designed, implemented, and researched at the Finnish University of Jyväskylä and the Niilo Mäki Institute, GraphoGame is a technology-enhanced learning environment that trains basic reading skills by high but playful exposure to grapheme-phoneme coupling. Since its conception, multiple language versions have been developed, each following the same key principles that are adjusted to the specific language characteristics and teaching situations. The first effectiveness studies evaluating various GraphoGame editions have shown promising results (e.g., Brem et al. 2010; Kyle et al. 2013; Saine et al. 2010, 2011).
We discuss the theoretical background, the development, and the design of our edition of GraphoGame aimed at the advancement of early reading acquisition in Standard Indonesian, a highly transparent orthography. Furthermore, to evaluate the program’s usability and collect evidence on the relationship between exposure to the intervention and changes in early reading and reading-related skills, we conducted a pilot study in typical and struggling beginning readers, the results of which are also presented.
SI orthography
Standard Indonesian (SI) is part of the Western Malayo-Polynesian subgroup of the Austronesian languages and a standardized dialect of Malay (Sneddon 2003). For about 23 million Indonesians, SI is their primary language while over 140 million others speak SI as a second language (Lewis et al. 2013). SI features a highly transparent orthography with all but one grapheme having a one-to-one grapheme-to-phoneme correspondence in both the reading and spelling direction, including a close correspondence between letter names and letter sounds (Winskel and Widjaja 2007). The alphabet consists of the 26 letters that correspond to the English alphabet, with the letter <x> only being used in loan words. SI has five vowels: <a, i, u, o>, and <e>. There are six vowel phonemes (/a, i, u, o, ə, e/) as the letter <e> has two phonemic forms, representing either the schwa /ə/ or the /e/. The vowels /i, u, o, e/ generally lower to /ɪ, ʊ, ɔ, ɛ/ in a final closed syllable (Soderberg and Olson 2008). There are three diphthongs (<au> /au/; <oi> /oi/; <ai> /ai/), five digraphs (<gh> /ɣ/; <kh> /x/; <ng> /ŋ/; <ny> /ɲ/; <sy> /ʃ/), and only few consonant clusters (e.g., <gr> /gr/ in anggrek “orchid”; <skr> /skr/ in manuskrip “manuscript”) (Chaer 2009). The syllable is a salient unit in the SI orthography as multisyllabic forms make up the majority of words, rendering monosyllabic words uncommon (Winskel and Widjaja 2007). Syllable structures are simple and have clear boundaries (Prentice 1987; Winskel and Lee 2013) and most frequently appear as V, VC, CV, CVC, and CVV (C = consonant; V = vowel; Prentice 1987). More complex syllable structures and consonant clusters do exist but are introduced mainly through loanwords. SI possesses a rich transparent system of morphemes and affixations, with about 25 derivational affixes (Prentice 1987). However, nonaffixed forms are common in colloquial (spoken) Indonesian. The affixes have at least one semantic function and differ depending on the word class of the stem. The stem word makan (“to eat”), for example, becomes makanan (“food”) or termakan (“to be eaten”) (Winskel and Widjaja 2007). As many instructions in primary-school books already contain words with derivational affixes, Indonesian children need to be able to cope with long words from an early age.
GraphoGame SI
As alluded to above, GraphoGame is a digital educational game that trains children in the basic skills of reading. In general, the program’s goal is to strengthen a child’s phonological awareness and grapheme-phoneme coupling skills while using a more motivating play-like format compared to traditional reading practice (Lyytinen et al. 2009).
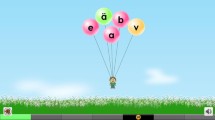
Two important questions guided us in the development of the SI edition of GraphoGame: What does a child need to learn during the first stages of reading acquisition in SI? And how can GraphoGame support children in learning these specific skills? In our SI game presented here, the “player,” or rather his/her game character, moves around on a randomly generated map where (s)he has to reach a door that leads to the next game level. On the way, the player will encounter fields that may contain exercises or items (e.g., a funny helmet for the game character to wear). As we primarily designed GraphoGame SI for use in primary-schoolchildren who are overchallenged when first starting to read, the game’s rules and graphics were kept simple: the speech segments presented are short and the accompanying visuals simple and limited (see Fig. 1). Its main tasks comprise paced and unpaced multiple-choice trials in which the child needs to match an acoustic stimulus (a phoneme, syllable, or word) to a visual item on the screen (a letter or a larger unit). Besides these reactive type trials, in more active tasks children need to construct written words from smaller components to match the spoken target words. For example, the child hears the word buku /buku/ “book” and needs to compose the written word using the two syllable blocks bu. (/bu./) and ku (/ku/).

A child playing GraphoGame SI
To compile the GraphoGame SI content, a database including 27 (one- and two-letter) graphemes, 296 different syllables, and 472 words was created based on widely used first-grade elementary school reading textbooks. Using International Phonetic Alphabet (IPA) transcriptions of every word included in the database, we determined the (relative) frequencies of the grapheme-phoneme correspondences and syllables within the words. This information was used to determine the order in which the items were introduced in the game. All auditory stimuli and instructions were recorded from one male and one female native speaker of Standard Indonesian. All items were subsequently evaluated by other native speakers with respect to their prototypicality, and only the most prototypical items were used in the game. This resulted in one to three different spoken realizations per target.
However simple the game itself, the principles and algorithmic systems operating it are rather complex (also see Richardson and Lyytinen 2014), which is why we will next discuss the game’s design and general GraphoGame principles in more detail, and elucidate some of the specific choices we made for our SI version of the digital learning environment.
The main game is divided into 21 “streams” that are subdivided into 333 “levels” each consisting of several “trials.” The playing frequency aimed at is 10–15 min five times a week. To anticipate school settings in which this is not feasible due to practical reasons, a compressed version was created in which the same 21 streams comprise 177 levels. Each stream focuses on a selection of grapheme-phoneme correspondences or a specific syllable structure, while each level within the stream provides a different exercise with these specific components in different contexts. A key aspect of the method is that per stream, only a small set of grapheme-phoneme correspondences is introduced, with the initial levels focusing on the individual grapheme-phoneme correspondences, after which these same correspondences are used to form syllables and these, in turn, to form words. It is only in the next stream that a new set is introduced and applied following the same principle.
Regardless of the alphabetic orthography to be acquired, a beginner-reader essentially needs to learn to associate letters with sounds in order to access whole-word phonological representations of known words. At first, this phonological recoding will involve a serial letter-by-letter reading strategy. The different letters of the word will be identified one at a time while the beginner-reader learns what sounds they correspond to. This mechanism hinges on two important sources of information available to the beginner-reader at this point: spoken vocabulary and knowledge of the alphabet (Grainger and Ziegler 2011). To effectively support children during these early stages of reading acquisition, the GraphoGame method makes use of the most functional sublexical units of the particular orthography: in order to help the young reader match the mappings of the orthography to the spoken language form, the training focuses on the most frequently and (in less transparent orthographies) most consistently used correspondences between the smallest distinguishable parts specific to the language being learned (Richardson and Lyytinen 2014). Research has shown that when teaching reading in transparent orthographies with consistent grapheme-phoneme correspondences, it makes sense to focus on exactly these connections (Holopainen et al. 2002; Landerl 2000). To typically developing readers, this approach is the quickest and simplest way to learn to decode.
Winskel and Widjaja (2007) studied the acquisition process of first- and second-graders learning to read and spell SI. Overall, and in line with other studies on transparent orthographies (e.g., Holopainen et al. 2002; Ŏney and Durgunoğlu 1997; Wimmer and Hummer 1990), their findings indicated the phoneme to be the prominent phonological unit in these early acquisition stages. The syllable also played a significant role, particularly when long multisyllabic affixed words needed to be mastered. The authors argue that the transparency of the language and the close correspondence between letter names and sounds facilitates access to the smallest grain size, the phoneme, in beginner-readers of SI.
Accordingly, the first stream of the GraphoGame SI training starts with the introduction of a small set of grapheme-phoneme correspondences: a selection of four phonetically and visually distinct consonant grapheme-phoneme combinations. This highly frequent set is initially trained using <a> (/a/), the most frequent vowel in SI. The child is asked to pair the presented audio segment with its correct visual representation and, based on the child’s performance in each particular trial, mastery level, and hence, the game content of the following trials and levels is aimed at achieving about 80% correct responses, which is a prerequisite to move on to the next level. By thus offering both sufficient challenges and opportunities for success, engagement in the game is promoted (Richardson and Lyytinen 2014), while motivation is further boosted by providing the child with immediate and positive feedback only to not discourage it unnecessarily. Following an incorrect response, the child will simply hear the same sound again while all visual distractors (i.e., alternatives) will disappear. It then needs to actively select the correct written response before moving on to the next trial, in order to strengthen the learning of the correct correspondences of spoken and written form. Examples of stream content are presented in Table 1.
The first stream continues with new levels in which psycholinguistically relevant larger sublexical units (i.e., frequently used CV and VC syllables) are introduced, all consisting of the same set of graphemes. Next, this first set of consonants is trained with a different vowel and in subsequent levels combined to form CV and VC syllables and so on until the vowels <a>, <i>, <u>, and <o> have been trained. The vowel <e> is not introduced until later in the game since this grapheme can be pronounced both as the prototypical /ə/ and as the non-prototypical /e/. Once the child has shown to master reading all previously trained graphemes and CV and VC syllables, the game moves on to levels containing CV-CV words composed of these syllables, wherein the initial levels words are built by combining two syllable blocks that are followed by trials in which the child is expected to pair the whole spoken word with its correctly written counterpart. In transparent orthographies such as SI, the expectation is that word decoding is basically attained by learning which sound the individual letters stand for and that by simply combining the sounds the written words will be arrived at (Richardson and Lyytinen 2014). The game provides the child with the opportunity to use sublexical units, both graphemes and syllables, as building blocks to learn to read and spell whole words.
The second stream introduces a new selection of consonants that are again trained with the various vowels, until CV, VC syllables, and CV-CV words have been mastered. In the third stream, training continues with the introduction of V-CV structures, combining graphemes and syllables trained in the previous two streams. Subsequently, new streams with new sets of graphemes and frequently used word structures (CVC, V-CVC, CV-CVC, CVC-CV, CVC-CVC) are introduced in a similar way and alternated with repetition blocks that repeat and combine the training material so far. Syllables with more than one pronunciation or a non-prototypical pronunciation (e.g., men, either pronounced as the prototypical /mən/ or non-prototypical /meɲ/, depending on the type of consonant following the final letter <n>) are not trained as syllables but only presented in word context later on in the game.
Once the 80% accuracy level has been attained for 1- and 2-syllabic words with highly predictable grapheme-phoneme correspondences, the game moves on to streams introducing digraphs (e.g., ng in stream 12, see Table 1), diphthongs (e.g., ai in stream 16) and vowel clusters, initially in monosyllabic words but followed by levels containing 2-syllabic words. The final streams focus on prefixes (e.g., ter, di), affixes (e.g., nya, ku, mu in stream 19), and 3-syllable words. To guide the beginner-learners in their reading of longer multisyllabic words, every syllable has already been individually trained before the 2- and 3-syllable words containing these syllables are introduced.
To test whether the design and choice of material met the aims set, we had a sample of elementary schoolchildren first learning to read play GraphoGame SI. In the next section, we will present the data of this pilot study, comparing the outcomes of proficient and less proficient readers.
Pilot study
Sample
The 69 first-graders participating in this study were recruited from an Indonesian private primary school in Medan (Sumatra). Education was provided in Standard Indonesian (SI). The students all had a middle socioeconomic background and were fluent in SI, including four bilingual students who spoke regional languages at home (e.g., Batak, Javanese, and Sundanese). Table 2 describes the pre-test demographics of our sample.
Measures and procedures
All students played GraphoGame SI during various prescheduled supervised group sessions at school in the period between October and March, with the player data being recorded on a server for offline analysis. To avoid the complexity of the game content from increasing too slowly compared to the level of the students’ regular classroom reading instruction, they completed the compressed version of the game during this pilot trial.
The students’ reading (and reading-related) skills were assessed during individual test sessions, prior to the GraphoGame SI training in September, in the middle of the training period in January, and at the end of the training in April. The tests were administered at school by the third author, with the assistance of psychologists. A number of the tests used were taken from a recently developed reading assessment battery for beginner-readers of SI (Jap et al. 2017). We additionally administered a newly created auditory synthesis task that we modeled after the Dutch version originally developed by Verhoeven (1993), with its content being drawn from commonly used Indonesian first-grade textbooks. We also used two subtasks of the Snijders-Oomen nonverbal intelligence test (SON-R 6-40, Tellegen and Laros 2011) of which the instructions were translated into SI while maintaining the original task content. The SON-R scores were used to identify students whose intellectual ability could potentially have negatively affected their reading and spelling skills.
The students completed the following pre-test assessments: SON-R analogies and categories (nonverbal intelligence test), digit span forward and backward, phoneme deletion, auditory synthesis, RAN objects, colors, and, if possible, digits and letters. At midpoint, they were assessed for word reading and pseudoword reading skills only, while at post-test they took all previously mentioned tests again except for the SON-R subtasks.
Word reading
The student was shown 100 lowercase bi- and multisyllabic words (with a maximum of four syllables) printed on an A4-size laminated sheet of paper and asked to read these words from top to bottom as fast and as accurately as possible. Reading fluency was defined as the number of words read correctly within one minute.
Pseudoword reading
The student was shown 100 lowercase bi- and multisyllabic pseudowords printed on an A4-size laminated sheet of paper and asked to read these pseudowords from top to bottom as fast and as accurately as possible. The pseudowords were created by changing one or more letters of the words used in the word reading task while keeping the number of letters and syllables constant. Decoding fluency was defined as the number of pseudowords read correctly within two minutes.
Phoneme deletion
The student was asked to repeat a pseudoword articulated by the researcher, after which (s)he was instructed to leave out a particular phoneme from the repeated pseudoword. The location of the phoneme deletion varied between word-initial, word-final, and middle position. The task consisted of 20 words and three practice trials, with a cut-off rule of five consecutive incorrect answers. The phoneme deletion score was calculated as the number of correct answers.
Auditory synthesis
The researcher read out 20 words divided into four clusters of increasing word length (two to five phonemes per word) articulating the individual phonemes one by one. The student was asked to blend these sounds into a single spoken word. The task was preceded by three example trials. After only incorrect answers within a single cluster, the task was discontinued. The auditory synthesis score was calculated as the number of correct answers.
Rapid automatized naming (RAN, Van den Bos 2003)
The student was shown five columns of ten objects, colors, digits, or letters printed on an A4-size laminated sheet of paper and asked to name these from top to bottom as fast and as accurately as possible. Prior to the test, the student practiced using the last column while the rest of the items were covered with a white sheet of paper. The RAN scores were calculated as the number of items named per second.
Digit span forward and backward
The student needed to repeat spans of digits of increasing lengths, in forward fashion during the first and in backward fashion during the second task. Per trial, two sequences with the same number of digits were presented. Both tasks were preceded by two example trials. The cut-off rule was an incorrect answer in two trials with the same span length. Both digit-span scores were based on the number of correctly reproduced trials.
Analogies and categories (SON-R 6-40, Tellegen and Laros 2011)
Both SON-R subtasks gauge abstract reasoning and each consists of three groups of 12 items. In the analogies test, the student had to deduce the principle of change of an example analogy where one geometrical figure changed into another geometrical figure and apply this principle to another comparable figure. With the categories test, the student had to find the common characteristic of three pictures and subsequently point the feature out in two other pictures (out of five new pictures) that also possessed this feature. Both SON-R scores were based on the total number of correct answers.
Results
Descriptives
The performance scores on the pre-, mid-, and post-tests are presented in Table 3, listing the mean values and standard deviations of the scores on the 12 tests, in addition to the results from the paired differences t tests between the pre-to-post and mid-to-post-test mean scores. Outliers are restricted to a maximum difference of two standard deviations from the task mean. Due to absence during one of the three assessments or the inability to assess RAN letters at pre-test (in case the letters presented were still unknown), some measures were missing for a number of other students as shown by the sample sizes in the table below. Two students were excluded from further analysis; the first student had been absent during the pre- and post-assessments and had only completed one GraphoGame session. The second student had been absent during the pre-test assessment, had great difficulty understanding the task instructions during mid- and post-test assessment sessions, and was described by the teacher as having severe learning, concentration, and behavioral problems.
As shown, all post-test mean scores were higher than the mid- and pre-test means. Moreover, all paired differences were significant, with the exception of digit span forward.
Descriptive statistics of the GraphoGame SI player data are presented in Table 4. Between October and March, the students attended on average nine (range 5–12) GraphoGame sessions each offering about 15–20 minutes of “computer” time. This is more than the “playing” times listed in Table 4, which represent the true intervals during which the child was actually exposed to the educational content and spent playing the game levels, excluding the time the child navigated the maps in-between levels.
Correlations
Interrelationships among ten tests (excluding SON-R analogies and categories) and the GraphoGame SI variables mentioned in Tables 3 and 4, respectively, were examined using a correlation matrix, listed in Table 5, being taken to be significant when p < .05. Both mid- and post-test reading and decoding fluency scores correlate significantly with the highest GraphoGame level reached, the total number of levels played, the number of levels played per minute, the number of GraphoGame items seen, and the total number of responses given. The data clearly shows that exposure to GraphoGame is related to reading and decoding skills. No significant correlations were found between reading and decoding fluency and total playing time or sessions played.
Other interesting results are the higher correlations at post-test compared to pre-test between phoneme deletion and those for auditory synthesis and the GraphoGame variables. Pre- and post-test differences are smaller for digit span (verbal short-term memory) and the GraphoGame variables, with some correlations being slightly higher at pre-test and others at post-test. While at pre-test digit span forward correlates significantly with the highest GraphoGame level reached, the total number of levels played, the number of levels played per minute, and the number of GraphoGame items seen, at post-test it correlates significantly with the aforementioned variables with the exception of the number of levels played per minute. Both at pre- and post-test, digit span backward correlates significantly with the highest GraphoGame level reached only.
As for the RAN subtasks, RAN objects does not correlate significantly with any of the GraphoGame variables at pre-test. The only significant correlation is between the pre-test scores for RAN colors and the highest GraphoGame level reached, while at post-test both RAN objects and colors correlate significantly with the highest level reached and the number of levels played per minute. Stronger relationships are found for RAN digits and letters and several GraphoGame variables, with correlations being higher at pre-test than at post-test. At pre-test, significant correlations can be observed for both RAN digits and letters and the highest GraphoGame level reached, the total number of levels played, the number of levels played per minute, the number of GraphoGame items seen, and the total number of responses given, whereas at post-test these RAN tasks correlate significantly with the highest level reached and the number of levels played per minute only.
Regression
A linear regression analysis was conducted to determine whether the relationship between pre-test phonological skills and post-test reading and decoding fluency was modulated by the student’s exposure to the game. Prior to these analyses, we created the following factor scores by running a Principal Component Analysis: (1) “pre-phonological skills” created based on pre-test phoneme deletion and auditory synthesis scores, (2) “post-reading and decoding fluency,” created based on post-test reading fluency and decoding fluency scores, (3) “pre-RAN,” created based on pre-test RAN digits and letters scores, and (4) “GG exposure,” including five GraphoGame variables (i.e., the highest level reached, the total number of levels played, the number of levels per minute, the total number of items seen, and the total number of responses given) that formed the first component in a factor analysis including all GraphoGame variables. Intercorrelations between these five GraphoGame variables ranged between .55 (total number of responses and number of levels per minute) and .98 (total number of responses and total number of levels played). We also evaluated mixed effects regression by including a factor for classroom as a random intercept, which did not improve the model fit sufficiently to warrant its inclusion. Based on the initial model fit we excluded observations that caused residuals beyond ± 2 standard deviations, which led to the exclusion of one participant. The final model fit as indicated by R 2 was 0.53 (F(4,49) = 15.8, p < .001), based on 54 participants. We found significant main effects for pre-phonological skills (ß = 0.48, t = 4.48, p < .001) and pre-RAN (ß = 0.26, t = 2.31, p = .025) on post-reading and decoding fluency, as well as a close to significant pre-phonological skills × GG exposure interaction effect (ß = − 0.19, t = − 1.71, p = .094).
To further investigate the possible interaction of GG exposure and pre-test phonological skills we plotted the model predictions in Fig. 2 for low (z score = − 1) and high (z score = 1) scores on GG exposure, and for continuous standardized data on pre-phonological skills while controlling for pre-RAN. Mean post-reading and decoding fluency scores of students with low pre-phonological skills (z scores − 1 and − 2) differed significantly between the two GG exposure levels. The figure shows that while the post-reading and decoding performance of students with average and above-average pre-phonological skills was not moderated by exposure, for below-average pre-phonological skills the model described a significant difference in post-reading and decoding fluency scores between low and high GG exposure.

Plot of the pre-phonological skills × GG exposure interaction effect, controlling for pre-RAN, with post-reading and decoding fluency as the dependent variable
Discussion
Reading is an essential skill in today’s society and early intervention programs have been found most helpful for struggling and dyslexic readers. With the newly developed GraphoGame SI presented here, we have tried to create an efficient and appealing digital learning environment that trains the basic steps of reading in Standard Indonesian (SI). We applied several established key principles and made adjustments to accommodate for the specific characteristics of this highly transparent orthography, focusing on the most frequently used correspondences between the smallest distinguishable parts specific to SI, i.e., the grapheme-phoneme connections. Having tested the game in first-grade students, we noted an effect of game exposure on the reading and decoding abilities of students with below-average pre-phonological skills; the more the first-graders with below-average baseline phonological skills had been exposed to GraphoGame SI, the better they performed on the tasks assessing post-test reading and decoding fluency.
In their lexical quality hypothesis, Perfetti and Hart (2001) postulate that reading skills are influenced by the quality of word representations. High lexical quality entails well-specified and partly redundant representations of both orthographic and phonological forms and representations of meaning and grammatical function, allowing for rapid and reliable meaning retrieval. Low-quality representations lead to specific word-related problems in comprehension (Perfetti 2007). Other researchers have suggested that apart from the quality of mental representations themselves, also the quality of access to these representations might explain the relationship between phonological awareness and reading abilities (e.g., Elbro and Jensen 2005). From early on, GraphoGame SI aims to create high-quality mental representations of both lexical and sublexical units to strengthen the reader’s network of related phonological, orthographic, and semantic representations of words. By offering a multitude of repetitions of exactly the same stimuli in both visual and auditory contexts, the game provides the beginning reader ample opportunities to build these mental representations and to learn the connections needed at these elementary stages of reading acquisition. Conventional learning environments could never offer such a high number of and frequency in stimuli, nor such stability in their quality (Richardson and Lyytinen 2014). Other than for the highly transparent SI orthography, the most effective training method for less transparent orthographies would depend on the kind of connections existing between written and spoken language units (Richardson and Lyytinen 2014). In English, for example, smaller grain sizes (graphemes, phonemes) tend to be less consistent than larger grain sizes (e.g., rimes) (Treiman et al. 1995; Ziegler and Goswami 2005). Indeed, children learning to read in English have been shown to benefit from a focus on larger units such as rimes as part of the reading curriculum (see Kyle et al. 2013 for GraphoGame Phoneme and GraphoGame Rime games for English).
Although large-scale randomized controlled studies are needed to confirm the effectiveness of the SI reading game, our preliminary GraphoGame player data showed that most of its variables were significantly related to mid- and post-test reading and decoding skills. Interestingly, whereas post-test correlations between the GraphoGame variables and phonological awareness (phoneme deletion, auditory synthesis) were larger than the pre-test associations, the post-test correlations with the alphanumeric RAN tasks were smaller than those recorded at baseline. It is possible that, early in the reading acquisition process, the students’ level of phonological awareness as measured with the tests we administered, does not tell us as much about their future reading ability as does their capacity to actually acquire this basic prerequisite after appropriate reading instruction. Students with below-average phonological skills at the start of reading acquisition will not all turn out to be poor readers after exposure to print and extensive reading practice. Factors such as environment or other interests may have kept them from developing phonological skills. Hence, reading and phonological awareness may be mainly reciprocally rather than causally related, as was also suggested by Blomert and Willems (2010). The observed lower post-test correlations between GraphoGame variables and the alphanumeric RAN tasks could possibly be explained by RAN not only measuring the ease with which phonological codes can be retrieved from long-term memory but also the speed of visual perception of stimuli and the required motor response—two skills that are extremely important in the game. Students who are good at RAN are most likely also good at responding rapidly to the game’s educational tasks, are exposed to more items during a GraphoGame session, and thus get more training. The impact of this proficiency may be greater at the start of the game, when reading skills are low and fast responders have an advantage over their less-quick peers. Moreover, at this stage, the game content is still relatively easy and many students will know the correct answers. Once levels are reached where more time and attention are required to be able to select the correct item, the impact of RAN may diminish.
In line with other GraphoGame effectiveness studies (e.g., Kyle et al. 2013; Saine et al. 2010; also see Richardson and Lyytinen 2014), our main game design aimed at five playing sessions of 10–15 minutes a week, for optimal concentration and automatization of reading-related skills. In the current pilot study, the compressed game design was used to avoid the complexity of the game content from increasing too slowly compared to the level of regular classroom reading instruction, and playing sessions were longer (15–20 minutes) but less frequent. With this compressed version, best results of game exposure on post-test reading and decoding fluency were reached for students with below-average pre-phonological skills. It is worth noting, however, that 26 students (37.7%) completed all 177 levels prior to the end of the last (i.e., 12th) GraphoGame session, after on average 8.7 sessions (range 6–12) and 1.85 hours (SD 0.25) of gameplay. By contrast, 10 students (14.5%) had not even finished 50% of the levels by the end of the last session, after on average 8.0 sessions (range 5–11) and 1.45 hours (SD 0.32) of playing. When analyzing the data of both groups further, results show that among the students who had finished all game levels, scores varied on the factor pre-phonological skills (below average: N = 3; average: N = 19; above average: N = 4)Footnote 1 but less on pre-RAN (average: N = 21; above average: N = 4). In contrast, the 10 struggling players had below average (N = 4) to average (N = 4) scores on pre-phonological skills (two scores were missing due to absence during the pre-test assessment). On pre-RAN, scores varied between below average (N = 4), average (N = 1), and above average (N = 2) (one additional student was not able to take the RAN letters task). Although numbers are small, the generally higher pre-RAN scores among those students who finished all game levels compared to those who finished less than 50%, and the varying pre-phonological skills in both groups, are in line with our observations as presented above regarding the correlations between pre-phonological skills and pre-RAN tasks with the GraphoGame variables, including the highest level reached.
Considering the fact that the extensive main game design would not offer exposure to more challenging items, but only more repetition of the same game content, we question the added value of a more extensive training of the same grapheme-phoneme correspondences, syllables and words in future research, for those who are able to attain fluent decoding skills with regular classroom instruction and 1–2 hours of playing the compressed version of the game. Once the grapheme-phoneme correspondences have been learned, word decoding in transparent orthographies such as SI is expected to be attained by basically putting together the different sounds of written words (Richardson and Lyytinen 2014). Decoding skills are then automatized after extensive reading exposure and repetition, and for those good players, the compressed game design may already provide sufficient practice. For the more struggling players, the extended main game design could be beneficial to determine whether even more practice and game exposure could lead to further improved reading and decoding skills.
Reading acquisition and dyslexia have as yet not been extensively studied in Indonesia and some of the tests we used are part of a recently developed literacy assessment battery that still requires optimization and validation (see Jap et al. 2017). It is therefore possible that these test results may have a higher “noise” level than results obtained with more widely applied and validated tests. Moreover, there may have been other factors that we did not monitor, such as motivation or other (reading related) classroom activities, that could (partly) explain the improvements we recorded. Another limitation of our study worth noting is that the students we tested all stemmed from mid-SES families, spoke SI as their first language, and attended the same private school in one of Indonesia’s largest cities. Our results can hence not be generalized to the wider Indonesian primary-school population. Future studies should examine a more diverse sample including students from different parts of the country and various ethnic and socioeconomic backgrounds.
To conclude, based on our preliminary but promising results, the next step will be to implement GraphoGame SI in a larger, more diverse sample of beginning readers and include active and passive control groups to further investigate and improve its effectiveness in promoting basic reading and reading-related skills. Future improvement of the stimulus selection algorithm will hopefully at some point make different versions of this game redundant and will enable the game to truly adapt to the student’s capabilities. Pending our results, we hope that our study will be a stepping stone for the development of additional language versions of this or similar digital-based learning environments. Effective language-specific reading interventions such as GraphoGame not only support less proficient and struggling readers but can potentially also play a role in secondary prevention. By identifying those readers that are at risk of developing serious reading deficits or dyslexia at an early stage while simultaneously offering additional learning opportunities like GraphoGame, we can break the vicious cycle of negative learning experiences and minimize the sequelae of transient or ongoing reading disabilities.
Notes
Below average: z scores ≤ − 1; average: − 1 < z scores < 1; above average: z scores ≥ 1.
References
Aud, S., Wilkinson-Flicker, S., Kristapovich, P., Rathbun, A., Wang, X., & Zhang, J. (2013). The Condition of Education 2013 (NCES 2013–037). U.S. Department of Education, National Center for Education Statistics, Washington, DC. Retrieved 03.11.2016 from https://nces.ed.gov/pubs2013/2013037.pdf.
Brem, S., Bach, S., Kucian, K., Kujala, J. V., Guttorm, T. K., Martin, E., Lyytinen, H., Brandeis, D., & Richardson, U. (2010). Brain sensitivity to print emerges when children learn letter–speech sound correspondences. Proceedings of the National Academy of Sciences, 107, 7939–7944.
Blomert, L., & Willems, G. (2010). Is there a causal link from a phonological awareness deficit to reading failure in children with familiar risk for dyslexia? Dyslexia, 16, 300–317. https://doi.org/10.1002/dys.405.
Chaer, A. (2009). Fonologi Bahasa Indonesia. Jakarta: Rineka Cipta.
Elbro, C., & Jensen, M. N. (2005). Quality of phonological representations, verbal learning, and phoneme awareness in dyslexic and normal readers. Scandinavian Journal of Psychology, 46, 375–384. https://doi.org/10.1111/j.1467-9450.2005.00468.x.
Grainger, J., & Ziegler, J. C. (2011). A dual-route approach to orthographic processing. Frontiers in Psychology, 2, 1–13. https://doi.org/10.3398/fpsyg.2011.00054.
Holopainen, L., Ahonen, T., & Lyytinen, H. (2002). The role of reading by analogy in first grade Finnish readers. Scandinavian Journal of Educational Research, 46, 83–98. https://doi.org/10.1080/00313830120115624.
Jap, B. A. J., Borleffs, E., & Maassen, B. A. M. (2017). Towards identifying dyslexia in Standard Indonesian: the development of a reading assessment battery. Reading and Writing: An interdisciplinary Journal, 30, 1729–1751.
Kyle, F., Kujala, J., Richardson, U., Lyytinen, H., & Goswami, U. (2013). Assessing the effectiveness of two theoretical motivated computer-assisted reading interventions in the United Kingdom: GG Rime and GG Phoneme. Reading Research Quarterly, 48, 61–76.
Landerl, K. (2000). Influences of orthographic consistency and reading instruction on the development of nonword reading skills. European Journal of Psychology of Education, 15, 239–257.
Lewis, M. P., Simons, G. F., & Fennig, C. D. (Eds.). (2013). Ethnologue: Languages of the world (Seventeenth ed.). Dallas: SIL International Online version: http://www.ethnologue.com.
Lovio, R., Halttunen, A., Lyytinen, H., Näätänen, R., & Kujala, T. (2012). Reading skill and neural processing accuracy improvement after a 3-hour intervention in preschoolers with difficulties in reading-related skills. Brain Research, 1448, 42–55. https://doi.org/10.1016/j.brainres.2012.01.071.
Lyytinen, H., Erskine, J., Kujala, J., Ojanen, E., & Richardson, U. (2009). In search of a science-based application: a learning tool for reading acquisition. Scandinavian Journal of Psychology, 50, 668-675.
Ŏney, B., & Durgunoğlu, A. Y. (1997). Beginning to read in Turkish: A phonologically transparent orthography. Applied PsychoLinguistics, 18, 1–15. https://doi.org/10.1017/S014271640000984X.
Perfetti, C. (2007). Reading ability: lexical quality to comprehension. Scientific Studies of Reading, 11, 357–383. https://doi.org/10.1080/10888430701530730.
Perfetti, C. A., & Hart, L. (2001). The lexical quality hypothesis. In L. Verhoeven, C. Elbro, & P. Reitsma (Eds.), Precursors of functional literacy (pp. 189–214). Amsterdam: John Benjamins.
Prentice, D. J. (1987). Malay (Indonesian and Malaysian). In B. Comrie (Ed.), The world’s major languages. London: Croom Helm.
Richardson, U., & Lyytinen, H. (2014). The GraphoGame method: the theoretical and methodological background of the technology-enhanced environment for learning to read. Human Technology, 10, 39–60.
Saine, N. L., Lerkkanen, M.-K., Ahonen, T., Tolvanen, A., & Lyytinen, H. (2010). Predicting word-level reading fluency outcomes in three contrastive groups: remedial and computer-assisted remedial reading intervention, and mainstream instruction. Learning and Individual Differences, 20, 402–414. https://doi.org/10.1016/j.lindif.2010.06.004.
Saine, N. L., Lerkkanen, M.-K., Ahonen, T., Tolvanen, A., & Lyytinen, H. (2011). Computer-assisted remedial reading intervention for school beginners at risk for reading disability. Child Development, 82, 1013–1028. https://doi.org/10.1111/j.1467-8624.2011.01580.x.
Sneddon, J. (2003). The Indonesian language: its history and role in modern society. Sydney: University of New South Wales.
Soderberg, C. D., & Olson, K. S. (2008). Illustrations of the IPA: Indonesian. Journal of the International Phonetic Association, 38, 209–213. https://doi.org/10.1017/S0025100308003320.
Tellegen, P. J., & Laros, J. A. (2011). SON-R 6-40. Snijders-Oomen niet-verbale intelligentietest. I. Verantwoording. Amsterdam: Hogrefe uitgevers.
Treiman, R., Mullennix, J., Bijeljac-Babic, R., & Richmond-Welty, E. D. (1995). The special role of rimes in the description, use, and acquisition of English orthography. Journal of Experimental Psychology: General, 124, 107–136. https://doi.org/10.1037/0096-3445.124.2.107.
U.S. Department of Education. (2011). National assessment of educational progress (NAEP) reading assessments. Washington, DC: Institute of Education Sciences, National Center for Education Statistics.
Van den Bos, K. P. (2003). Snel Serieel Benoemen; Experimentele versie. Groningen: Rijksuniversiteit Groningen.
Verhoeven, L. (1993). Grafementoets. Toets voor Auditieve Synthese. Handleiding. Arnhem: Cito.
Wimmer, H., & Hummer, P. (1990). How German speaking first graders read and spell: doubts on the importance of the logographic stage. Applied PsychoLinguistics, 11, 349–368. https://doi.org/10.1017/S0142716400009620.
Winskel, H., & Lee, L. W. (2013). Learning to read and write in Malaysian/Indonesian: a transparent alphabetic orthography. In H. Winskel & P. Padakannaya (Eds.), South and southeast Asian Psycholinguistics. Cambridge: Cambridge University Press.
Winskel, H., & Widjaja, V. (2007). Phonological awareness, letter knowledge, and literacy development in Indonesian beginner readers and spellers. Applied PsychoLinguistics, 28, 23–43. https://doi.org/10.1017/S0142716407070026.
Ziegler, J. C., & Goswami, U. (2005). Reading acquisition, developmental dyslexia, and skilled reading across languages: a psycholinguistic grain size theory. Psychological Bulletin, 131, 3–29. https://doi.org/10.1037/0033-2909.131.1.3.
Acknowledgements
The authors thank the students, their parents, and teachers for their cooperation. Moreover, the authors thank Ade R. Siregar and Indri K. Nasution (University of Sumatera Utara, Medan, Indonesia) for their assistance during data collection. We thank the University of Jyväskylä and the Niilo Mäki Institute (Jyväskylä, Finland) for letting us use the GraphoGame concept, and the GraphoGame developers and Bernard A. J. Jap (University of Groningen, The Netherlands) for their support during the creation of GraphoGame SI.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
All authors have read and approved the final manuscript. This manuscript has not been published elsewhere and is not under consideration by another journal. The Research Ethics Committee (CETO) of the Faculty of Arts, University of Groningen, the Netherlands, has reviewed and approved the research proposal.
Permission has been granted for the publication of the photograph used as Fig. 1 in print and/or electronically in scientific papers related to GraphoGame SI.
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Elisabeth Borleffs. Center for Language and Cognition Groningen (CLCG) & School of Behavioral andCognitive Neurosciences (BCN), University of Groningen, The Netherlands, P.O. Box 716, 9700 AS Groningen, The Netherlands. Email: l.e.borleffs@rug.nl; Website: http://www.rug.nl/research/clcg/
Current themes of research:
Dyslexia. Orthographic transparency and reading. Diagnostics and treatment of dyslexia in Standard Indonesian. GraphoGame reading intervention.
Most relevant publication in the field of Psychology of Education:
Jap, B. A. J., Borleffs, E., & Maassen, B. A. M. (2017). Towards identifying dyslexia in Standard Indonesian: the development of a reading assessment battery. Reading and Writing: An interdisciplinary Journal, 30, 1729–1751.
Toivo K. Glatz. Center for Language and Cognition Groningen (CLCG) & School of Behavioral and Cognitive Neurosciences (BCN), University of Groningen, The Netherlands, P.O. Box 716, 9700 AS Groningen, The Netherlands. Email: t.k.glatz@rug.nl; Website: http://www.rug.nl/research/clcg/
Current themes of research:
Dyslexia. EEG. Game-based learning.
Most relevant publication in the field of Psychology of Education:
N/A.
Debby A. Daulay. Department of Developmental Psychology, University of Sumatera Utara, Indonesia, Jalan Dr. T. Mansur No. 7, Kampus Padang Bulan, Medan, 20155, Sumatera Utara, Indonesia. Email: debby_anggraini@usu.ac.id; Website: http://www.usu.ac.id/fakultas-psikologi.html
Current themes of research:
Diagnostics and treatment of dyslexia in Standard Indonesian. GraphoGame reading intervention. Social adjustment and achievement motivation of hearing-impaired adolescents. Self-concept and self-regulated learning of obese adolescents.
Most relevant publication in the field of Psychology of Education:
N/A.
Ulla Richardson. Centre for Applied Language Studies, University of Jyväskylä, Finland, P. O. Box 35, FI-40014 University of Jyväskylä, Jyväskylä. Finland. Email: ulla.a.richardson@jyu.fi; Website: https://www.jyu.fi/hytk/fi/laitokset/solki/en
Current themes of research:
Language education. Psycholinguistics. Phonetics. Neurolinguistics. Speech and language processing. Language acquisition. Language learning. Language development. GraphoGame reading intervention. Technology enhanced language learning.
Most relevant publications in the field of Psychology of Education:
Richardson, U., & Nieminen, L. (2017). The contributions and limits of phonological awareness in learning to read. In N. Kucirkova, C. E. Snow, V. Grøver, & C. McBride (Eds.), The Routledge International Handbook of Early Literacy Education: A Contemporary Guide to Literacy Teaching and Interventions in a Global Context (pp. 21). Routledge.
Lyytinen, H., Shu, H., & Richardson, U. (2015). Predictors of reading skills across languages. In E.L. Balwin, & L.R. Naigles (Eds)., The Cambridge Handbook of Child Language (pp. 703-723). Cambridge University Press.
Ojanen, E., Ronimus, M., Ahonen, T., Chansa-Kabali, T., February, P., Jere-Folotiya, J., Kauppinen, K-P., Ketonen, R., Ngorosho, D., Pitkänen, M., Puhakka, S., Sampa, F., Walubita, G., Yalukanda, C., Pugh, K., Richardson, U., Serpell, R. & Lyytinen, H. (2015). GraphoGame—a catalyst for multi-level promotion of literacy in diverse contexts. Frontiers in Psychology, 6, 1–13.
Richardson, U., & Lyytinen, H. (2014). The GraphoGame method: the theoretical and methodological background of the technology-enhanced environment for learning to read. Human Technology, 10, 39–60.
Kyle, F., Kujala, J.V., Richardson, U., Lyytinen, H. & Goswami, U. (2013). Assessing the effectiveness of two theoretically motivated computer-assisted reading interventions in the United Kingdom: GG Rime and GG Phoneme. Reading Research Quarterly, 48, 61–76.
Richardson, U., Aro, M., & Lyytinen, H. (2011). Prevention of reading difficulties in highly transparent Finnish. In P. McCardle, B. Miller, J. R. Lee & O.J.L. Tzeng (Eds.), Dyslexia Across Languages: Orthography and the Brain-Gene-Behavior Link, Paul H. Brookes Publishing Co., 62-75.
Lyytinen, H., Aro, M., Eklund, K., Erskine, J., Guttorm, T., Laakso, M.-L., Leppänen, P. H. T., Lyytinen, P., Poikkeus, A. M., Richardson, U., Torppa, M. (2004). The development of children at familial risk for dyslexia: birth to early school age. Annals of Dyslexia, 54, 184–220.
Richardson, U., Thomson, J., Scott, S. K., & Goswami, U. (2004). Auditory processing skills and phonological representation in dyslexic children. Dyslexia, 10, 215–233.
Frans Zwarts. Center for Language and Cognition Groningen (CLCG) & School of Behavioral and Cognitive Neurosciences (BCN), University of Groningen, The Netherlands, P.O. Box 716, 9700 AS Groningen, The Netherlands. Email: f.zwarts@rug.nl; Website: http://www.rug.nl/research/clcg/
Current themes of research:
Dyslexia. Orthographic transparency and reading. Diagnostics and treatment of dyslexia in Standard Indonesian. GraphoGame reading intervention.
Most relevant publication in the field of Psychology of Education:
Rispens, J. E., Been, P. H., & Zwarts, F. (2006). Brain responses to subject-verb agreement violations in spoken language in developmental dyslexia: An ERP study. Dyslexia, 12, 134–149.
Stowe, L. A., Haverkort, M., & Zwarts, F. (2005). Rethinking the neurological basis of language. Lingua, 115, 997–1042.
Been, P. H., & Zwarts, F. (2004). Language disorders across modalities: the case of developmental dyslexia. In L. Verhoeven & H. van Balkom (Eds), Classification of developmental language disorders: theoretical issues and clinical implications. (pp. 61–97). Lawrence Erlbaum Associates Publishers.
Stowe, L. A., Broere, C. A. J., Paans, A. M. J., Wijers, A. A., Mulder, G., Vaalburg, W., & Zwarts, F. (1998). Localizing components of a complex task: sentence processing and working memory. Neuroreport: An International Journal for the Rapid Communication of Research in Neuroscience, 9, 2995–2999.
Ben A. M. Maassen. Center for Language and Cognition Groningen (CLCG) & School of Behavioral and Cognitive Neurosciences (BCN), University of Groningen, The Netherlands, P.O. Box 716, 9700 AS Groningen, The Netherlands. Email: b.a.m.maassen@rug.nl; Website: http://www.rug.nl/research/clcg/
Current themes of research:
Dyslexia. Clinical neuropsychology. Speech-language pathology. Phonetics. Serious gaming. Orthographic transparency. GraphoGame reading intervention.
Most relevant publications in the field of Psychology of Education:
Jap, B. A. J., Borleffs, E., & Maassen, B. A. M. (2017). Towards identifying dyslexia in Standard Indonesian: the development of a reading assessment battery. Reading and Writing: An interdisciplinary Journal, 30, 1729–1751.
Van Setten, E. R. H., Martinez-Ferreiro, S., Maurits, N. M., & Maassen, B. A. M. (2016). Print-tuning lateralization and handedness: an event-related potential study in dyslexic higher education students. Dyslexia, 22, 64–82.
Maassen, B. A. M. (2015). Developmental models of childhood apraxia of speech. In R. H. Bahr, & E. R. Silliman (Eds.), Routledge handbook of communication disorders (pp. 124–133) Routledge.
Maassen, B. A. M., & Terband, H. R. (2015). Process-oriented diagnosis of childhood and adult apraxia of speech (CAS and AOS). In M. A. Redford (Ed.), The handbook of speech production (First Edition ed., pp. 331–350) John Wiley & Sons, Inc.
Nijland, L., Terband, H., & Maassen, B. (2015). Cognitive functions in childhood apraxia of speech. Journal of Speech, Language, and Hearing Research, 58, 550–65.
Van der Leij, A., van Bergen, E., van Zuijen, T., Jong, P. D., Maurits, N., & Maassen, B. (2013). Precursors of developmental dyslexia: an overview of the longitudinal Dutch Dyslexia Programme Study. Dyslexia, 19(4), 191–213.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Borleffs, E., Glatz, T.K., Daulay, D.A. et al. GraphoGame SI: the development of a technology-enhanced literacy learning tool for Standard Indonesian. Eur J Psychol Educ 33, 595–613 (2018). https://doi.org/10.1007/s10212-017-0354-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10212-017-0354-9