
Abstract
The COVID-19 pandemic has profoundly impacted healthcare systems and economies worldwide, leading to the implementation of travel restrictions and social measures. Efforts such as vaccination campaigns, testing, and surveillance have played a crucial role in containing the spread of the virus and safeguarding public health. There needs to be more research exploring the transmission dynamics of COVID-19, particularly within European nations. Therefore, the primary objective of this research was to examine the spread patterns of COVID-19 across various European countries. Doing so makes it possible to implement preventive measures, allocate resources, and optimize treatment strategies based on projected case and mortality rates. For this purpose, a hybrid prediction model combining CNN and LSTM models was developed. The performance of this hybrid model was compared against several other models, including CNN, k-NN, LR, LSTM, MLP, RF, SVM, and XGBoost. The empirical findings revealed that the CNN-LSTM hybrid model exhibited superior performance compared to alternative models in effectively predicting the transmission of COVID-19 within European nations. Furthermore, examining the peak of case and death dates provided insights into the dynamics of COVID-19 transmission among European countries. Chord diagrams were drawn to analyze the inter-country transmission patterns of COVID-19 over 5-day and 14-day intervals.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The COVID-19 pandemic affects almost every field, including healthcare, the economy, management, supply chain, manufacturing, and education [1, 2]. Immediately many restrictions were introduced worldwide, such as a curfew, mask requirement, and suspension of international and domestic flights [3]. The COVID-19 virus is spread by droplet contact with a contaminated surface or infected individual [4]. The biggest challenge in controlling the spread of the virus is that infected people with no symptoms can be contagious, and the virus can spread from them to other people [5]. Some studies have been conducted to obtain the virus’s genetic structure [6]. However, the rapid and unpredictable spread of the virus has placed a heavy burden on healthcare systems [7]. As of December 15, 2021, there were about 500 million confirmed cases and approximately 6 million deaths [7, 8]. Capacity planning should be performed for hospital demand changes, such as bed availability and the number of personal protective equipment [9, 10]. Predicting the spread of the pandemic is vital in the fight against COVID-19.
Pinter et al. [11] proposed a hybrid machine learning model for COVID-19 case prediction in Hungary. This hybrid model includes the combination of Support Vector Machine (SVM), ARIMA, and Long-Short Term Memory (LSTM). The experimental results demonstrated that the proposed hybrid machine learning model effectively predicts COVID-19 cases.
Babukarthik et al. [12] presented a genetic CNN model for predicting COVID-19. The developed model includes a learning process using genetic algorithm. In this process, the model weights are optimized by the genetic algorithm, and the structural features of the model are determined to provide the best performance. The study evaluates the accuracy and performance of the COVID-19 predictions using the GDCNN model. The model makes predictions using data features such as the number of COVID-19 cases, death rates, and test results. Predictions obtained are evaluated by comparing them with actual data. Experimental results demonstrated that the GDCNN model effectively predicts COVID-19 and provides higher accuracy than traditional methods.
Zoabi et al. [13] introduced a model utilizing machine learning techniques to diagnose COVID-19 through symptom analysis. Algorithms predict the likelihood of a patient having COVID-19 by analyzing symptoms. These predictions are validated on the samples in the training dataset, and performance evaluation is made. Algorithms estimate the probability of patients having COVID-19 using the combination of symptoms.
Zhao et al. [14] aimed to diagnose COVID-19 by developing a deep learning model based on computed tomography (CT) images and focused on the knowledge that certain features in the lungs of COVID-19 patients differ from normal lung images. The deep learning model detects these differences and differentiates COVID-19 from other respiratory diseases. Experimental results show that the developed model recognizes COVID-19 with high accuracy.
Ismael and Şengür [15] proposed a deep learning-based approach for detecting COVID-19 using chest X-ray images. The study used a dataset containing both positive and negative cases. Deep learning models have been used to diagnose COVID-19 by identifying and analyzing patterns in these images. Experimental results showed that deep learning models recognize COVID-19 with high accuracy.
Alassafi et al. [16] conducted a comparative analysis of deep learning methods to perform time series prediction of the COVID-19 outbreak. The study used a dataset containing various indicators such as infection numbers, number of hospital admissions, and death rates. Prediction models were created using LSTM and Recurrent Neural Network (RNN) models. Experimental results demonstrated that LSTM has 98.58% accuracy.
Al-Waisy et al. [17] presented a hybrid model for detecting COVID-19 in chest X-ray images. The study aims to develop a model that will help diagnose COVID-19 by using imaging methods such as chest radiography. The dataset used includes images from positive, negative, and normal breasts. Then, a hybrid model, COVID-CheXNet, a combination of deep learning algorithms, was created. CNN is used to extract features from images, while LVQ is used to identify the COVID-19 virus using these features. Experimental results show that COVID-CheXNet effectively detects COVID-19 in chest X-ray images. Experimental results showed that the developed model has high accuracy and sensitivity. In addition, the model minimizes false positive results with its ability to distinguish between normal and COVID-19 negative images.
Aslam and Biswas [18] discuss using machine learning methods to study COVID-19 death cases. Researchers try to identify factors that affect deaths by analyzing a large data set. Using machine learning algorithms, it evaluates data such as patients' demographics, medical history, and symptoms and builds a model to predict the risk of death. The results show that machine learning methods are effective in analyzing COVID-19 death cases and can be used to develop health policies and natural resources.
The motivation of this study is to predict future spread patterns of epidemics such as COVID-19, which have profoundly affected the health systems and economies of countries around the world. Taking preventive measures and planning health services throughout epidemics is possible. By determining the spread patterns of epidemics such as COVID-19, resource allocations can be optimized, measures can be taken to protect public health, and economic strategies can be determined.
This study aims to predict the number of cases and deaths in the top 20 European countries with the greatest caseload. A hybrid prediction model combining CNN and LSTM models was developed and compared extensively with CNN, eXtreme Gradient Boosting (XGBoost), Multilayer Perceptron (MLP), Linear Regression (LR), k-Nearest Neighbors (k-NN), SVM, Random Forest (RF), LSTM. The performance of the models was assessed using R-Squared (R2), Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Mean Squared Error (MSE) metrics. In addition, the dates of the highest cases and deaths were used to assess the transmission dynamics of COVID-19 among European countries.
This paper offers the following significant contributions:
-
A prediction model based on the combination of CNN and LSTM was developed to predict the spread of COVID-19 in Europe.
-
The developed CNN-LSTM model was compared with CNN, k-NN, LR, LSTM, MLP, RF, SVM, and XGBoost.
-
Chord diagrams were drawn to analyze the inter-country transmission patterns of COVID-19 over 5-day and 14-day intervals.
2 Material and method
Time series analysis is a statistical method in which data is organized and analyzed as a time-varying series [19]. This analysis is used to understand data patterns, trends, and regularities measured or recorded over time. Time series analysis is widely used in many fields, such as medicine, economics, finance, meteorology, and marketing. Deep learning methods in time series analysis have become very popular recently. Deep learning is a powerful artificial intelligence approach that can perform automatic feature extraction in complex and large data sets and capture relationships over time [18]. Deep learning methods provide automatic extraction of features, the capture of non-linear relationships, scalability, and long-term forecasting capability in time series analysis.
2.1 Prediction models
k-NN makes predictions for a sample based on the distance between the sample and its Neighbors [20]. The Euclidean distance can be used to calculate the distance between any two points in multi-dimensional space [21]. k-NN requires large memory for storing the entire dataset for prediction.
LR is the most popular multivariable method used in many different application areas. LR analyzes the relationships between variables in the data set and makes predictions. LR predicts the value of dependent variables using a linear equation [22]. RF creates an ensemble model by combining multiple decision trees. Different sub-datasets are created from the dataset by random sampling method. A decision tree is created and trained on each sub-dataset. When constructing decision trees, a random subset of features is chosen at each node, which is used to determine the best split point [23, 24]. SVM creates a decision class to classify data points and aims to best distinguish this class with maximum marginal decomposition [25]. The basic idea of SVM is to find a hyperplane that best separates the classes while representing the data points in a feature space. This hyperplane determines a decision class that provides the best possible classification of data points [26].
XGBoost is a tree-based learning algorithm that makes predictions using decision trees [27]. Combining multiple weak tree models reduces errors and creates a more robust prediction model. This algorithm can be used in various tasks, such as classification and regression [28]. MLP is one of the most basic and widely used types of artificial neural networks [29]. MLP is a feedforward neural network model with at least one hidden layer. Neurons in each layer receive weighted inputs from nodes in the previous layer, apply an activation function, and produce outputs [30].
CNN is a deep learning model that is especially effective in the image and visual data processing problems [31]. CNNs have a particular architecture that can better capture the structure and properties of the data. The convolution layer takes an image or a feature map as input and extracts the feature maps using the convolution process [32]. The activation layer provides non-linearity learning of the model by using activation functions such as Sigmoid, ReLU, and tanh. The pooling layer is used to summarize the outputs of the convolution layer and reduce its size. The fully connected layer provides a unified rendering of features from previous layers [33, 34].
LSTM is mainly used in processing data with sequential structure, such as time series data or language [35]. LSTM can learn longer-term dependencies than RNNs because it can store information from previous timesteps [36]. This is achieved by the cell state and gate mechanisms in the LSTM’s buffer. Cell state is the component that represents the memory of LSTM and is used to store information. The cell state is updated at each time step and can preserve information from previous steps [37]. Forget gate controls what information from the cell state needs to be remembered. The input gate controls how new incoming information is added to the cell state. The output gate determines the output from the cell state [38, 39].
2.2 The developed CNN-LSTM-based prediction model
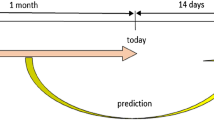
The sliding window method, which is used to transform time series problems into supervised learning problems, divides the time series into small time steps and predicts the target value for each time step. The sliding window method transforms the time series into data points containing an output value and one or more input properties, as shown in Fig. 1. This transformation can predict future values using historical data from the time series [40].

The sliding window method
Data pre-processing has been performed for missing and erroneous data. The size of the sliding window was selected as 3. In this manner, the input to the sliding window consists of observational data from 3 consecutive time steps, while the output comprises the data from the 4th time step. Min–Max normalization was used to scale the dataset. Min–Max normalization is a scaling method used to transform the values of the data set into a particular range. This method converts the values of the dataset from the original range to the range [0, 1]. Min–Max normalization converts each value in the data set into a proportional value between the minimum and maximum values of the original value. This preserves the distribution of each value in the data set, making the values comparable [41].
The dataset was split, allocating 70% for the train set and 30% for the test set. 10% of the train set was split for validation. The validation data played a crucial role in optimizing the model parameters. Grid search was used for hyperparameter tuning.
Walk-forward validation is used to evaluate time series prediction models, as seen in Fig. 2. In this method, time series data is used sequentially from a specific starting point, and training and testing of the model are performed at each time step. Beginning from the starting point, the data set is progressively divided into training and test sets. A data window size is taken from the starting point determined in the first step and is used as a training set. Then, the new data point from the next time step is added to the test set, and the model’s performance is evaluated on this data [42]. Walk-forward validation is shown in Fig. 2.

Walk forward validation
The CNN-LSTM model was developed to capture time and spatial characteristics of time series data. CNN was used to detect local structures of data over time. The LSTM was used to model the long-term dependencies of the time series. The CNN-LSTM model consists of interconnected CNN layers and successive LSTM layers, as seen in Fig. 3. CNN layers perform convolution operations to capture local features in the time series. LSTM layers are used to model long-term dependencies. The model has an output layer.

The developed CNN-LSTM model
The dataset is trained on the generated CNN-LSTM model. In this step, the model’s hyperparameters are determined, and the loss function and the optimizer are selected. The model learns to predict target outputs based on input data in the training process. The number of convolution layers, kernel size, activation function, number of filters of convolution layers, and pooling size parameters were optimized for CNN. Hidden unit number, cell number, epoch number, dropout rate, and activation function parameters were optimized for LSTM.
2.3 Dataset
In this study, official COVID-19 statistics from the World Health Organization (WHO) panel were used as a dataset. The dataset consists of eight columns:
-
Date The date or date range in which the data was recorded.
-
Country The name of the country to which the data relates.
-
Country Code A standard code for the country.
-
Region The country’s regional location or continent name.
-
New Cases Reported new cases to date.
-
Total Cases Reported total cases to date.
-
New Deaths Reported new deaths to date.
-
Total Deaths Reported total deaths to date.
The applied models were tested using data from 20 countries, with the highest cases among European countries. Figures 4 and 5 show the total number of cases and deaths of the 20 countries with the highest number of cases in Europe until April 2, 2022. Figures 4 and 5 present the countries' total number of cases and deaths comparatively. As seen in Fig. 4, the experimental studies were carried out for the top 20 countries.

Top 20 countries with the highest number of cases in Europe

Total number of deaths for the top 20 countries
As shown in Fig. 4, France stands out with the highest number of cases, reaching 25,068,545. After France, Poland has a higher death toll than any other European country. Finland, Belarus, and Slovenia are countries with less than one million deaths.
Figure 5 shows the cumulative number of deaths in the top 20 countries.
Figure 5 shows France has the highest death toll, with 139,272 deaths. Poland and Romania have a higher death toll than any other European country. Belarus, Ireland, and Slovenia reported the lowest number of deaths.
2.4 The evaluation metrics
MSE, RMSE, MAE, and R2 metrics are commonly used to evaluate the regression models. MSE measures how far the predicted values are from the actual values. It is frequently used, especially in regression analysis and evaluating the performance of machine learning models. As seen in Eq. 1, MSE squares the difference between the estimated and actual values, sums these differences, and divides them by the number of observations to obtain the mean value.
here n denotes the total sample size. \(\hat{y}\) represents the predicted values. y represents the true values. The RMSE measures the difference between the true and the predicted values, making the magnitude of errors more visually understandable. Like the MSE, the RMSE is employed to assess the proximity of the predicted values to the actual values. The value of the RMSE indicates the average amount of error to the true values, as seen in Eq. 2, and a lower RMSE value indicates better forecasting performance.
MAE is used to measure how far the predicted values are, on average, from the true values, as seen in Eq. 3.
R2 as seen in Eq. 4, expresses how much of the independent variables explain the variance of the dependent variable.
here \(\hat{y}\) represents the predicted value and \(\overline{y}\) represents the mean of y.
3 The experimental results
To comprehensively evaluate the developed model, a comparative analysis is conducted against CNN, k-NN, LR, LSTM, MLP, RF, XGBoost, and SVM models.
3.1 The prediction of COVID-19 spread
This section provides the findings of experimental investigations to predict the incidence of cases and fatalities in European nations. Experimental studies were carried out according to each model’s MSE, RMSE, R2, and MAE.
The experimental results for predicting the case count, assessed through the MSE metric, are presented in Table 1.
Table 1 demonstrates that the CNN-LSTM-based model outperforms other models regarding MSE values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
The experimental results for predicting the case count, assessed through the RMSE metric, are presented in Table 2.
Table 2 demonstrates that the CNN-LSTM-based model outperforms other models regarding RMSE values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
The experimental results for predicting the case count, assessed through the MAE metric, are presented in Table 3.
Table 3 demonstrates that the CNN-LSTM-based model outperforms other models regarding MAE values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
The experimental results for predicting the case count, assessed through the R2 metric, are presented in Table 4 and Fig. 6.

The experimental results for R2 values
Table 4 demonstrates that the CNN-LSTM-based model outperforms other models regarding R2 values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
Figure 6 displays the experimental results for R2 values.
The experimental results for predicting the death count, assessed through the MSE metric, are presented in Table 5.
Table 5 demonstrates that the CNN-LSTM-based model outperforms other models regarding MSE values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
The experimental outcomes for predicting the death count, assessed through the RMSE metric, are presented in Table 6.
Table 6 demonstrates that the CNN-LSTM-based model outperforms other models regarding RMSE values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
The experimental outcomes for predicting the death count, assessed through the MAE metric, are presented in Table 7.
Table 7 demonstrates that the CNN-LSTM-based model outperforms other models regarding MAE values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.
The experimental results for predicting the death count, assessed through the R2 metric, are presented in Table 8.
Table 8 and Fig. 7 demonstrate that the CNN-LSTM-based model outperforms other models regarding R2 values. Following the developed model, LSTM, MLP, and CNN exhibit more favorable outcomes than the other models.

The experimental results for R2 values
Figure 8 illustrates the prediction charts of the proposed model for the top 20 European countries with the highest incidence of cases. The developed model has demonstrated superior performance compared to the other models, effectively capturing the variations in the number of cases across different countries.

Prediction charts of the developed model
3.2 Analysis of transmission dynamics of COVID-19 among European countries
The dates of the peak numbers of confirmed cases and deaths were employed to analyze the transmission dynamics of COVID-19 among European nations. The incubation period of COVID-19 is thought to extend to 14 days by WHO. Because the early onset of symptoms has been reported in 5 days, analysis has been performed for 5 days and 14 days. Also, the chord diagrams were drawn to analyze the inter-country transmission patterns of COVID-19 over 5-day and 14-day intervals. Table 9 presents the dates with the maximum case count in each country and the dates that are 5 and 14 days before and after these peak dates.
Figure 9 illustrates the dispersion of COVID-19 cases across European countries considering a 5-day incubation period.

The dispersion of COVID-19 cases across European countries considering a 5-day incubation period
Based on Fig. 9 and Table 9, it is apparent that Bulgaria and France, Croatia and Poland, Czechia and Romania, Hungary and Ireland, Switzerland and Serbia, Bulgaria, and Switzerland, Bulgaria and Poland, Bulgaria and Serbia, Croatia and France, Denmark and Slovakia, France and Switzerland, France and Poland, France and Serbia, Bulgaria and Poland, Poland and Portugal, Romania and Slovenia exhibit a similar spread pattern of COVID-19 cases when considering 5-day incubation period.
Figure 10 illustrates the dispersion of COVID-19 cases across European countries considering a 14-day incubation period.

The dispersion of COVID-19 cases across European countries considering a 14-day incubation period
Based on Fig. 10 and Table 9, it is apparent that Belarus and Denmark, Belarus and Slovakia, Bulgaria and Croatia, Bulgaria and Czechia, Bulgaria and France, Bulgaria and Hungary, Bulgaria and Ireland, Bulgaria and Switzerland, Bulgaria and Poland, Bulgaria and Portugal, Bulgaria and Serbia, Croatia and France, Croatia and Hungary, Croatia and Ireland, Croatia and Switzerland, Croatia and Poland, Croatia and Portugal, Croatia and Serbia, Czechia and Hungary, Czechia and Ireland, Czechia and Romania, Czechia and Slovenia, Czechia and Denmark, France and Switzerland, France and Poland, France and Portugal, France and Serbia, Greece and Romania, Hungary and Ireland, Hungary and Poland, Hungary and Portugal, Hungary and Romania, Hungary and Slovenia exhibit a similar spread pattern of COVID-19 cases when considering 14-day incubation period.
Table 10 shows the dates when the countries experienced the highest number of deaths, as well as the dates that are 5 and 14 days prior to and following these peak dates.
Figure 11 illustrates the dispersion of COVID-19 deaths across European countries considering a 5-day incubation period.

The dispersion of COVID-19 deaths across European countries considering a 5-day incubation period
Based on Fig. 11 and Table 10, it is apparent that Austria and Serbia, Austria and Slovenia, Serbia and Slovenia, Portugal and Ireland, Belarus and France, Bulgaria and Switzerland, Denmark and Finland exhibit a similar spread pattern of COVID-19 cases when considering 14-day incubation period.
Figure 12 illustrates the dispersion of COVID-19 deaths across European countries considering a 14-day incubation period.

The dispersion of COVID-19 deaths across European countries considering a 14-day incubation period
Based on Fig. 12 and Table 10, it is apparent that Austria and Croatia, Austria and Serbia, Austria and Slovenia, Bulgaria and Romania, Denmark and Finland, Ireland and Portugal, Serbia and Slovenia, Lithuania and Croatia, Switzerland and Czechia exhibit a similar spread pattern of COVID-19 cases when considering 14-day incubation period.
4 Conclusions and discussions
This study presents the development of a hybrid prediction model that integrates CNN and LSTM models, enabling the prediction of case and death numbers while facilitating analysis of the inter-country transmission patterns in European nations. Extensive comparisons were conducted between the developed model and CNN, k-NN, LR, LSTM, MLP, RF, SVM, and XGBoost models. The dataset consisted of WHO-confirmed cases and deaths up to April 2, 2022. The experimental studies focused on the top 20 countries in Europe with the highest case count. The models were evaluated using metrics such as MSE, RMSE, R2, and MAE. Experimental findings revealed that the CNN-LSTM model showed superior prediction performance compared to alternative models.
In order to analyze the inter-country, spread of COVID-19 in European countries, the incubation period of COVID-19 was extended to 14 days, according to WHO’s report. Because the early onset of symptoms has been reported in 5 days, analysis has been performed for 5 and 14 days. According to the experimental results, Bulgaria and France, Croatia and Poland, Czechia and Romania, Hungary and Ireland, Switzerland and Serbia, Bulgaria and Switzerland, Bulgaria and Poland, Bulgaria and Serbia, Croatia and France, Denmark and Slovakia, France and Switzerland, France and Poland, France and Serbia, Bulgaria and Poland, Poland and Portugal, Romania and Slovenia exhibit a similar spread pattern of COVID-19 cases when considering a 5-day incubation period.
This study is an essential source of information to guide decision-makers and researchers in areas such as epidemic management, health policy, and resource planning. The research results showed that the developed CNN-LSTM model effectively predicts the spread of COVID-19. The developed model possesses the capability to predict the trajectory of the epidemic by leveraging historical data.
The theoretical innovation of the hybrid model presented in this study is that a model has been developed that determines the spread pattern of COVID-19 more successfully than popular machine learning and deep learning models. By combining CNN and LSTM models, the developed model is capable of better modeling the spread dynamics of COVID-19 in European countries. In the developed hybrid model, CNN is used to extract the features' spatial features, while LSTM enables the extraction of time-dependent relationships. The experimental results showed that the CNN-LSTM model had a better prediction performance than the compared models and was more effective in managing the epidemic. Such theoretical innovations of the developed model enable more successful predictions to overcome future epidemics such as COVID-19.
The CNN-LSTM hybrid model takes advantage of the prominent features of CNN and LSTM models. CNN automatically extracts features in input data, while LSTM effectively captures long-term dependencies between consecutive time series data. In this way, complex patterns in the data are extracted.
The fact that CNN-LSTM is more successful than kNN, LR, RF, SVM, and XGBoost can be explained by the ability of LSTM to model temporal and spatial features. CNN-LSTM has a feature learning ability that can automatically extract complex data patterns. However, traditional machine learning methods require data engineering processes. In addition, with LSTM in the structure of the model, a more effective learning process is achieved by performing operations such as remembering long-term dependencies, updating the model, and remembering and forgetting.
The fact that CNN-LSTM is more successful than MLP can be explained by processing historical data through feature extraction processes. CNN-LSTM reduces feature engineering by automating the feature extraction process by capturing relationships between different features and components in the data. However, in MLP, features must be defined beforehand. Additionally, LSTM can model changes over time, allowing trends in the data to be captured. The fact that CNN-LSTM is more successful than CNN and LSTM can be interpreted as CNN and LSTM alone are effective only at specific points. CNN is particularly effective at feature extraction and dimensionality reduction on image data and 1D time series data. LSTM, on the other hand, is effective in remembering and learning long-term dependencies and identifying trends in data. While CNN alone is not effective in the learning step, LSTM is not effective in the feature extraction stage. Therefore, the CNN-LSTM model, which combines these two models in a hybrid model, was more successful than the compared models.
In the studies examined in the introduction section, it is seen that the studies in the literature are aimed at predicting the number of COVID-19 cases/deaths and detecting COVID-19 from lung X-ray images. There is no study in the literature to analyze the spread of COVID-19 between countries and to predict the number of cases and deaths in European countries. This research provides a valuable tool for controlling the epidemic and tackling future outbreaks. Using deep learning techniques provides a solid basis for monitoring the epidemic’s spread rate, assessing risks, and taking appropriate action. In addition, it is essential not to use estimates alone for outbreak management and policy decisions but to consider other factors and expert opinions.
Data availability
The data that support the finding of this study are available from https://covid19.who.int/WHO-COVID-19-global-data.csv.
References
Muhammad LJ, Algehyne EA, Usman SS, Mohammed IA, Abdulkadir A, Jibrin MB, Malgwi YM (2022) Deep learning models for predicting COVID-19 using chest X-ray images. In: Trends and advancements of image processing and its applications. Springer, Cham, pp 127–144
Mesgarpour M, Abad JMN, Alizadeh R, Wongwises S, Doranehgard MH, Jowkar S, Karimi N (2022) Predicting the effects of environmental parameters on the spatio-temporal distribution of the droplets carrying coronavirus in public transport—a machine learning approach. Chem Eng J 430:132761
Ghany KKA, Zawbaa HM, Sabri HM (2022) Gulf area COVID-19 cases prediction using deep learning. In: Digital transformation technology. Springer, Singapore, pp 521–530
Bisanzio D, Reithinger R, Alqunaibet A, Almudarra S, Alsukait RF, Dong D, Zhang Y, El-Saharty S, Herbst CH (2022) Estimating the effect of non-pharmaceutical interventions to mitigate COVID-19 spread in Saudi Arabia. BMC Med 20(1):1–14
Xiong Y, Ma Y, Ruan L, Li D, Lu C, Huang L (2022) Comparing different machine learning techniques for predicting COVID-19 severity. Infect Dis Poverty 11(1):1–9
Shorten C, Khoshgoftaar TM, Furht B (2021) Deep learning applications for COVID-19. J Big Data 8(1):1–54
Worldometers (2021) https://www.worldometers.info/coronavirus/. Accessed 15 Dec 2021
Shibuya K (2022) Formalizing models on COVID-19 pandemic. In: The rise of artificial intelligence and big data in pandemic society. Springer, Singapore, pp 95–125
Menezes B, Franzoi R, Yaqot M, Sawaly M, Sanfilippo A (2022) Advanced analytics for medical supply chain resilience in healthcare systems: an infection disease case. In: International conference of reliable information and communication technology. Springer, Cham, pp 759–768
Zeroual A, Harrou F, Dairi A, Sun Y (2020) Deep learning methods for forecasting COVID-19 time-series data: a comparative study. Chaos Solitons Fractals 140:110121
Pinter G, Felde I, Mosavi A, Ghamisi P, Gloaguen R (2020) COVID-19 pandemic prediction for Hungary; a hybrid machine learning approach. Mathematics 8(6):890
Babukarthik RG, Adiga VAK, Sambasivam G, Chandramohan D, Amudhavel JJIA (2020) Prediction of COVID-19 using genetic deep learning convolutional neural network (GDCNN). IEEE Access 8:177647–177666
Zoabi Y, Deri-Rozov S, Shomron N (2021) Machine learning-based prediction of COVID-19 diagnosis based on symptoms. npj Digit Med 4(1):3
Zhao W, Jiang W, Qiu X (2021) Deep learning for COVID-19 detection based on CT images. Sci Rep 11(1):1–12
Ismael AM, Şengür A (2021) Deep learning approaches for COVID-19 detection based on chest X-ray images. Expert Syst Appl 164:114054
Alassafi MO, Jarrah M, Alotaibi R (2022) Time series predicting of COVID-19 based on deep learning. Neurocomputing 468:335–344
Al-Waisy AS, Al-Fahdawi S, Mohammed MA, Abdulkareem KH, Mostafa SA, Maashi MS, Arif M, Garcia-Zapirain B (2023) COVID-CheXNet: hybrid deep learning framework for identifying COVID-19 virus in chest X-rays images. Soft Comput 27(5):2657–2672
Aslam H, Biswas S (2023) Analysis of COVID-19 death cases using machine learning. SN Comput Sci 4(4):403
Tang H (2022) Using machine learning techniques to study economic trends in various US industries in the post-epidemic era. In: International conference on computational modeling, simulation, and data analysis (CMSDA 2021), vol 12160. SPIE, pp 472–479
Prihatmono MW, Arni S, Iin JN, Moeis D (2022) Application of the K-NN algorithm for predicting data card sales at PT. XL Axiata Makassar. In: Conference series, vol 4, pp 59–64
Nayak S, Bhat M, Reddy NS, Rao BA (2022) Study of distance metrics on k-nearest neighbor algorithm for star categorization. J Phys Conf Ser 2161(1):012004
Vaulet T, Al-Memar M, Fourie H, Bobdiwala S, Saso S, Pipi M, Stalder C, Bennett P, Timmerman D, Bourne T, De Moor B (2022) Gradient boosted trees with individual explanations: an alternative to logistic regression for viability prediction in the first trimester of pregnancy. Comput Methods Programs Biomed 213:106520
Jui SJJ, Ahmed AM, Bose A, Raj N, Sharma E, Soar J, Chowdhury MWI (2022) Spatiotemporal hybrid random forest model for tea yield prediction using satellite-derived variables. Remote Sens 14(3):805
Alnahit AO, Mishra AK, Khan AA (2022) Stream water quality prediction using boosted regression tree and random forest models. Stoch Environ Res Risk Assess 36:1–20
Zouhri W, Homri L, Dantan JY (2022) Identification of the key manufacturing parameters impacting the prediction accuracy of support vector machine (SVM) model for quality assessment. Int J Interact Des Manuf 16:1–20
Harimoorthy K, Thangavelu M (2021) Multi-disease prediction model using improved SVM-radial bias technique in healthcare monitoring system. J Ambient Intell Humaniz Comput 12(3):3715–3723
Alim M, Ye GH, Guan P, Huang DS, Zhou BS, Wu W (2020) Comparison of ARIMA model and XGBoost model for prediction of human brucellosis in mainland China: a time-series study. BMJ Open 10(12):e039676
Wang Y, Guo Y (2020) Forecasting method of stock market volatility in time series data based on mixed model of ARIMA and XGBoost. China Commun 17(3):205–221
Li RYM, Tang B, Chau KW (2019) Sustainable construction safety knowledge sharing: a partial least square-structural equation modeling and a feedforward neural network approach. Sustainability 11(20):5831
Demir I, Karaboga HA (2021) Modeling mathematics achievement with deep learning methods. Sigma J Eng Nat Sci 39(5):33–40
Cheon S, Lee H, Kim CO, Lee SH (2019) Convolutional neural network for wafer surface defect classification and the detection of unknown defect class. IEEE Trans Semicond Manuf 32(2):163–170
Rahman T, Chowdhury ME, Khandakar A, Islam KR, Islam KF, Mahbub ZB, Kashem S (2020) Transfer learning with deep convolutional neural network (CNN) for pneumonia detection using chest X-ray. Appl Sci 10(9):3233
Liu T, Bao J, Wang J, Zhang Y (2018) A hybrid CNN–LSTM algorithm for online defect recognition of CO2 welding. Sensors 18(12):4369
Hartawan DR, Purboyo TW, Setianingsih C (2019) Disaster victims detection system using convolutional neural network (CNN) method. In: 2019 IEEE international conference on Industry 4.0, artificial intelligence, and communications technology (IAICT). IEEE, pp 105–111
Shewalkar A (2019) Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J Artif Intell Soft Comput Res 9(4):235–245
Liu Y, Gong C, Yang L, Chen Y (2020) DSTP-RNN: a dual-stage two-phase attention-based recurrent neural network for long-term and multivariate time series prediction. Expert Syst Appl 143:113082
Dalgkitsis A, Louta M, Karetsos GT (2018) Traffic forecasting in cellular networks using the LSTM RNN. In: Proceedings of the 22nd Pan-Hellenic conference on informatics, pp 28–33
Sunny MAI, Maswood MMS, Alharbi AG (2020) Deep learning-based stock price prediction using LSTM and bi-directional LSTM model. In: 2020 2nd novel intelligent and leading emerging sciences conference (NILES). IEEE, pp 87–92
Poornima S, Pushpalatha M (2019) Prediction of rainfall using intensified LSTM based recurrent neural network with weighted linear units. Atmosphere 10(11):668
Brownlee J (2018) Deep learning for time series forecasting: predict the future with MLPs, CNNs and LSTMs in Python. Machine Learning Mastery, Vermont
Brownlee, J. (2022). Data preparation for machine learning.
Wan R, Mei S, Wang J, Liu M, Yang F (2019) Multivariate temporal convolutional network: a deep neural networks approach for multivariate time series forecasting. Electronics 8(8):876
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors of this manuscript declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Utku, A., Akcayol, M.A. Spread patterns of COVID-19 in European countries: hybrid deep learning model for prediction and transmission analysis. Neural Comput & Applic 36, 10201–10217 (2024). https://doi.org/10.1007/s00521-024-09597-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-09597-y