
Abstract
Assessment of the thermal bioclimatic environmental changes is important to understand ongoing climate change implications on agriculture, ecology, and human health. This is particularly important for the climatologically diverse transboundary Amy Darya River basin, a major source of water and livelihood for millions in Central Asia. However, the absence of longer period observed temperature data is a major obstacle for such analysis. This study employed a novel approach by integrating compromise programming and multicriteria group decision–making methods to evaluate the efficiency of four global gridded temperature datasets based on observation data at 44 stations. The performance of the proposed method was evaluated by comparing the results obtained using symmetrical uncertainty, a machine learning similarity assessment method. The most reliable gridded data was used to assess the spatial distribution of global warming-induced unidirectional trends in thermal bioclimatic indicators (TBI) using a modified Mann–Kendall test. Ranking of the products revealed Climate Prediction Center (CPC) temperature as most efficient in reconstruction observed temperature, followed by TerraClimate and Climate Research Unit. The ranking of the product was consistent with that obtained using SU. Assessment of TBI trends using CPC data revealed an increase in the Tmin in the coldest month over the whole basin at a rate of 0.03–0.08 °C per decade, except in the east. Besides, an increase in diurnal temperature range and isothermally increased in the east up to 0.2 °C and 0.6% per decade, respectively. The results revealed negative implications of thermal bioclimatic change on water, ecology, and public health in the eastern mountainous region and positive impacts on vegetation in the west and northwest.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Climatic variables, especially temperature and precipitation, control the phenology, productivity, abundance, interaction and geographical distribution of biodiversity and biotic ecosystems' overall function. Organisms physiologically react differently to different thermal environments, which prefer homeothermy for adaptation (Błażejczyk 2011; Pour et al. 2020c). Environmental gradient and climate differences affect the germination and seedling process and plant populations' genetic structure (Hamasha et al. 2013). Therefore, the spatial distribution of species and biotic ecosystems depended on the different climatic characteristics. The bioclimate indicators are generally used to represent the climatic characteristics that affect the biotic system (Attorre et al. 2007; Miguet and Groleau 2007; Noce et al. 2020; Schröder et al. 2014; Muhammad et al. 2019; Pour et al. 2020b). Therefore, changes in bioclimatic indicators can indicate the impacts of global warming-induced climate change on living things (Hadi Pour et al. 2019). Climate change impacts on thermal bioclimatic are most certain and visible across the globe. Therefore, changes in thermal bioclimatic indicators (TBIs) and their implications have attracted more attention in recent years (Pour et al. 2020a).
Many studies have been conducted to find how thermal bioclimate conditions affect the ecology (Hadi Pour et al. 2019). However, most of the recent studies were focused on the relations of bioclimatic condition in terms of temperature with human thermal comfort in urban areas where the effect of the urban island are dominant (Daemei et al. 2019; Gaitani et al. 2007; Kim et al. 2019; Ma et al. 2016; Sajani et al. 2008; Salat 2007). Besides, few studies evaluated the implications of thermal bioclimate on crop growth and public health. For example, Moriondo et al. (2013) reported the possible consequence of future climate variability on the olive plants in the Mediterranean Basin. Fraga et al. (2019) showed climate change effect on rice bioclimatic growth conditions in Portugal. Recently, Bashir et al. (2020) showed an association of thermal climate with the spread of disease in New York. They found that temperature, among several other climatic variables, significantly correlate with the COVID-19 epidemic.
The Amu Darya is the most crucial transboundary river basin of Central Asia. Millions of people from five countries living in the basin depend on agriculture for their livelihood (Jalilov et al. 2016). The Amu Darya River basin (ADRB) hydrology has undergone a tremendous change in recent years due to human intervention in river flow. Climate change, particularly the rise in temperature, has worsened the situation. These caused severe damage to the ecology of the basin. The evaporation in the basin is high due to aridic climate conditions. The temperature rises caused an increase in evapotranspiration and water demand in the basin. The changes in the thermal bioclimatic environment also influenced crop growth and yield. The changes in inter-annual and inter-seasonal temperature variability affected soil moisture and land suitability for cultivation. These changes severely affect agricultural productions, ecological services and livelihoods of agricultural dependent people (Sidike et al. 2016). Besides, public health is a growing concern due to changes in different TBIs related to human health. Evaluation of trends in TBIs of the ADRB basin is important for climate-resilient development planning of Central Asia's most important river basin.
High spatial resolution and sufficient reliable temperature dataset are the major obstacles in assessing thermal bioclimate and its trends in the ADRB. Numbers of high-resolution gridded temperature data are available from different research organizations to substitute for observed data to assess climate (Bai et al. 2018; Guo et al. 2020; Yasutomi et al. 2011; Yin et al. 2015). These datasets are generated from in-situ measurement, satellite retrieval, reanalysis, and satellite-observed data integration (Mahmood et al. 2019). These datasets can be used to assess thermal bioclimatic trends in the basin as an alternative to in-situ data. However, gridded datasets are usually associated with large uncertainties (Nijssen and Lettenmaier 2004), originating from numerous factors, including interpolation from heterogeneous distributed gauge networks, measurement representativeness, and records errors (Newman et al. 2015). Therefore, it is required to evaluate their performance and reliability before using them for any purpose (Gampe and Ludwig 2017; Musie et al. 2019).
Several studies evaluated gridded climate data's ability to reconstruct local and global climate. General statistical metrics like correlation coefficient, mean bias and mean error are mostly used for this purpose (Ahmed et al. 2019; Colston et al. 2018). The major limitation of using the conventional metrics is the contradictory results of different metrics (Muhammad et al. 2019; Salman et al. 2018). Artificial intelligence algorithms have recently been proposed to overcome the drawbacks of conventional statistics (Nashwan and Shahid 2019). However, different machine learning algorithms also give different ranking outcomes for gridded climate products. In recent years, the multicriteria group decision-making method (MCGDM) has been used to solve the problem mentioned above. The inconsistent results of various indices can be combined in MCGDM to identify the best product (Salman et al. 2019).
Compromise programming (CP) is a class of multiple criteria decision-making methods known as the "distance-based" method. It is used to analyze multi-objective problems based on the concept of choosing a solution from a set of solutions considering the nearest to the optimum points (Zeleny 1973). Its strength over the conventional weighting approach is that it measures the minimum distance Pareto optimal point, especially when the distribution of the points is nonlinear (Zhang 2003). CP was originally introduced by Zeleny (1973) and later used by many researchers related to their fields of studies, including analyzing hydrological and environmental issues (Brahim and Duckstein 2011).
The selection of gridded temperature products is not straightforward like rainfall products. The gridded temperature data should be selected based on their ability to replicate both maximum and minimum temperatures, as both are equally required for temperature-related studies. MCDA or machine learning algorithms can select different products in estimating maximum and minimum temperature. However, using two different products, one for maximum and the other for minimum temperature, is not practical as it may incur high error in providing inter-dependent indices like diurnal temperature range or maximum temperature in cold months. The present study proposed an innovative method of selecting the best-gridded temperature product by integrating CP indices using MCGDM.
This study aims to (1) rank the best gridded maximum and minimum temperature (Tmax and Tmin) datasets in the ADRB through employing CP and MCGDM; (2) use the best gridded temperature dataset to assess the spatial distribution and trends in thermal bioclimatic indicators in ADRB to understand the possible consequences of global warming on agriculture and ecology in the basin. The performance of the gridded data selection method proposed in this study was evaluated by comparing the results with that obtained using a machine learning algorithm known as symmetrical uncertainty (SU). The SU has been proven effective in feature selection and assessing similarity in time series data (Ahmed et al. 2019; Homsi et al. 2020; Nashwan and Shahid 2019; Sa’adi et al. 2020; Shiru et al. 2020). Four gridded temperature datasets were evaluated, namely the Climate Prediction Centre (CPC) global dataset, University of East Anglia Climatic Research Unit CRU TS V4.03 (CRU), Princeton University Global Meteorological Forcing dataset for land surface modelling (PGF) V3 and TerraClimate dataset. Trends in seven bioclimatic indicators related to the ecological environment of the basin are evaluated. The results presented in this study can be used for policy formulation to achieve sustainable development goals for the Central Asian nations. The identified best gridded temperature dataset can be used for climate change studies in the basin to overcome data scarcity challenges.
2 Study area and data
2.1 Amu Darya River basin
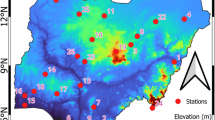
The Amu Darya river is the lengthiest transboundary river shared by five counties of Central Asia, including Afghanistan, Tajikistan, Kyrgyzstan, Turkmenistan and Uzbekistan (Jalilov et al. 2016; Schlüter et al. 2005), as shown in Fig. 1. Rising from headwaters in the glacier and ice-packs in the mountains of Tajikistan, Kyrgyzstan and the north of Hindu Kush, it passes through Karakum and Kyzylkum deserts and drains into the Aral Sea (Kumar et al. 2019; Nezlin et al. 2004; Sun et al. 2019). The basin has a typical continental climate characterized by cold winter, hot summer, low precipitation, and relative humidity (Jalilov et al. 2013). The topography of ADRB ranges from 7500 m in the upstream mountains to around 200 m in the downstream northwest plains with a delta and feeding the Aral Sea. The annual mean precipitation in ADRB is 464 mm. The maximum precipitation occurs upstream (Eastern Pamir) of the ADRB, nearly 2000 mm, while downstream receive a minimum, less than 100 mm/year. Precipitation mostly occurs in the form of snow in winter (Nov-May). The summer (Jun-Sept) is dry and hot with an average temperature of 35 °C which gradually decrease to 18 °C in the autumn and reaches to − 8 to − 20 °C in the winter (Gaybullaev and Chen 2013; Wang et al. 2016).

The geographical position of the Amu Darya River basin in Central Asia and the meteorological stations in the basin; the colour of the circles represents the data sources
Few attempts have been made earlier to estimate historical changes and future temperature projections in the basin using gridded temperature data, considering the scarcity of observed temperature data. Table 1 summarizes the major conclusions of those studies.
2.2 Observed temperature data
The observed monthly Tmax and Tmin data were collected from the Ministry of Energy and Water of Afghanistan (MEW–AFG) and the website of Global Summary of the Day (GSOD): https://www7.ncdc.noaa.gov/CDO/cdoselect.cmd?datasetabbv=GSOD&countryabbv=&georegionabbv = . Data from the above-mentioned sources were collected for different stations, as shown in Fig. 1. The data sources are represented using different colors. After screening the data, 44 stations with a longer period of data coverage were selected. The data were available for the period 1979 –2019. Also, few stations adjacent to the basin's boundary having a longer data availability period were considered. Stations having large missing data were not used in the current study. Most observations were located in the southeast, while relatively less in the west and southwest. Also, observation data were less in the northwest part of the basin. Overall, the station's distributions were more or less homogeneous over the basin.
2.3 Gridded temperature data
Four gridded temperature data that include National Oceanic and Atmospheric Administration (NOAA) Climate Prediction Center (CPC) global dataset, University of East Anglia Climatic Research Unit TS V4.03 (CRU), Princeton University Global meteorological Forcing dataset for land surface modelling V3 (PGF) and TerraClimate were evaluated as shown in Table 2. These data were obtained from the public domain in NetCDF format, which was subsequently extracted and analyzed using statistical software R. The gridded temperature products were evaluated according to their capability to reconstruct observed data for their common period 1979−2016.
TerraClimate is a global gridded monthly climate dataset with 0.04° spatial resolution, available from 1958 to the present. TerraClimate, climatically interpolation for gridding the monthly station data obtained from the WorldClim dataset, coarse-resolution other monthly data productions of various climate variables (Abatzoglou et al. 2018). The TerraClimate data was downloaded from the site https://climatedataguide.ucar.edu/climate–data/terraclimate–global–high–resolution–gridded–temperature–precipitation–and–other–water. The CPC is a station observation‐based product, generated at the Climate Prediction Center, National Centers for Environmental Prediction (Tanarhte et al. 2012; Xie et al. 2010). The data are available at ftp://ftp.cdc.noaa.gov/Datasets/cpc_global_precip/. The CRU used angular distance weighting interpolation for gridding the monthly station data obtained from different international and national organizations covering the global land except for Antarctica (New et al. 2000). The data was downloaded from https://crudata.uea.ac.uk/cru/data/hrg/cru_ts_4.03/. Princeton University has developed the PGF datasets by combining several global observation-based datasets with the National Centers for Environmental Prediction − National Center for Atmospheric Research (NCEP–NCAR) reanalysis (Sheffield et al. 2006). It was downloaded from http://hydrology.princeton.edu/data/pgf/v3/0.25deg/daily/.
3 Research method
3.1 Procedure
The procedure used to rank gridded temperature datasets and analyze TBI trends is shown using a flowchart in Fig. 2. Homogeneity of station data was first evaluated and then compared with the gridded data. The assessment of gridded data is generally done either by interpolation gridded data at observed locations or correlation with nearby stations (Caesar et al. 2006). In the present study, gridded temperature data were interpolated at the observation location using the inverse distance weighting (IDW) method for comparison. The results obtained using different statistical metrics were summarized using CP for the ranking of the products.

The general methodology of the current study
Tmax and Tmin temperature data of the best gridded product were used to estimate the annual time series of the TBIs at each grid location. The Sen's slope was employed to calculate the change in TBIs, and the modified Mann–Kendall (MMK) test was used to assess the statistical significance in change. The methods employed in this study are explained below.
3.2 Performance evaluation
Six statistical indices including the coefficient of determination (R2), normalized root mean square error (NRMSE), percentage of bias (PBIAS), Kling–Gupta Efficiency (KGE), modified index of agreement (MD), and the ratio of standard deviation (rSD) were employed to assess the accuracy of temperature products. These statistics can evaluate the performance of different properties of in-situ temperature like the average, variability and pattern. Table 3 shows the expression, possible range and ideal values of the metrics.
3.3 Compromise program
3.3.1 g (CP)
The present study used CP to merge the outcomes obtained using different statistical indices to derive a single metric. The CP identifies the best product by estimating its lowest distance from the ideal point (Raju et al. 2017; Zeleny 1973). The compromise programming index (CPI) is presented as,
where i is the statistical index; \(x_{i}^{1}\) is the normalized value of index i for gridded dataset 1; \(x_{i}^{*}\) is the normalized ideal value of index i; and p is the parameter (p-value 1 is for linear and 2 for measuring squared Euclidean distance). In the current research, the p-value is considered 1 for the linear measure. CPI can be any positive value, but the smaller CPI of a gridded temperature indicates its closeness to observed temperature data.
CP can rank different data products at a station location. But the challenge remains in deciding about the best product for the whole basin, based on ranking at different stations. A multicriteria group decision–making method (MCGDM) method was used to order the data products based on their performance. In the proposed method, each gridded product was weighted according to the rank obtained by the product at different observation points. The weight to a product is provided as the reverse of the rank, which means if a product obtained 1st, 2nd and 3rd rank at \(r_{1}\), \(r_{2}\) and \(r_{3}\) stations, its integrated index, \(I_{x}\) is calculated as
3.4 Symmetrical uncertainty
SU uses mutual information (MI) to measure similarity between two series, x and y, as below:
where \(H\) represents the entropies of a series. SU values near 1 indicate better similarity. FSelector package of R was employed to implement SU.
3.5 Thermal bioclimatic indicators
The spatiotemporal changes in 7 TBIs were evaluated in this study. The details of the TBIs are summarised in Table 4.
3.6 Trend analysis
Sen's slope is a nonparametric method that estimates the change over time from time series data (Sen 1968). It estimates the change as the median of all slopes calculated for two successive data points.
Man-Kendall (MK) is a nonparametric test used for non-normally distributed data (Kendall 1975; Mann 1945). It provides two measures, significant level and sign; the farmer shows the strength while the latter indicates the direction of change. Hamed (2008) improved the MK test to remove the impacts of long-term persistence in data series on-trend significance. This allows unidirectional trend evaluation due to global warming. The modified MK (MMK) test procedure begins with assessing the trend using the MK test. If there is a significant trend in the time series, the MMK test de-trends the series and estimates the Hurst coefficient. This estimate of the secular trend due to global warming by omitting the trends that arise from natural climate fluctuation. Different recently published articles provide details of the MMK test (Nashwan et al. 2019a).
4 Results
4.1 Performance assessment of gridded Tmax
4.1.1 Mean daily Tmax
Figure 3 shows the geographical distributions of observed and estimated Tmax over ADRB. For a fair comparison, the spatiotemporal resolution of all datasets was made homogenous. Datasets (Observed, PGF and TerraClimate), which were not available at 0.5° resolution, were interpolated to 0.5° resolution using the IDW method. Figure 3 shows that the spatial distribution of Tmax of all gridded datasets was almost similar to the observed one. Overall, a higher temperature (~ 33 °C) was noticed in the center and western part of the basin and lower in the basin's east (nearly − 10 °C). The spatial distribution of CPC Tmax was most similar to observation. However, CPC estimated relatively lower temperatures (5 to 10 °C) in the south and east of the basin. The underestimation was highest for Terra (nearly − 10 °C) in the east. The spatial pattern of observed and estimated Tmin by different products were more or less similar to Tmax, as provided in the supplementary.

Annual average of daily Tmax estimated by different gridded datasets over the basin for the available periods
4.1.2 Statistical evaluation of Tmax
The metrics, R2, KGE, MD, rSD, PBIAS and NRMSE, were computed at all the station locations for all the gridded data to assess their capability in reconstructing observed Tmax. Figure 4 presents the results obtained for different data products at all locations using box plots. The highest median of R2 was observed for CRU followed by CPC, PGF and TerraClimate. The KGE for all the products at all the locations was negatively skewed. The TerraClimate received the highest value of KGE. The median of MD was higher for CPC while more or less the same for the other products. The median of rSD was nearest to its ideal value was for CPC, followed by TerraClimate, CRU and PGF. The CPC showed the lowest bias (PBIAS) and NRMSE.

Boxplot shows different gridded dataset's performances in replicating Tmax at different locations based on the statistical metrics
Table 5 shows the ranking of the products in replicating Tmax in terms of six statistical metrics. The values in the table indicate the number of stations at which a product ranked first in terms of a particular metric. The results showed the best performance of CRU in R2 at most of the locations (28), followed by CPC (25) and PGF (12). More than one product received the same R2 at some stations and thus, obtained the same rank. For example, CRU and CPC obtained the highest R2 value (1) at locations (lat, long), (39.083, 63.6), (40.467, 62.283), (41.75, 59.817) and (37.833, 65.2). Therefore, both were ranked 1st at those locations. It made the total number of stations where different products received the highest rank more than the total station number (44).
In terms of KGE, TerraClimate was the best at 18 stations, followed by CPC. The TerraClimate achieved the best rank at most stations in rSD (23) and NRMSE (23). The CPC was best in MD at most stations (30) and CRU for PBAS (15). The results indicate contradictory outcomes based on different metrics. Therefore, CP was employed to merge the outcomes of all metrics to have a common index (CPI) for ranking.
4.1.3 Ranking of gridded Tmax datasets
Figure 5 shows the CPI estimated for different gridded Tmax datasets at 44 stations using a heatmap. A lower value of CPI represents good performance, and therefore, the red color in the heatmap indicates higher capability. Similarly, the green color represents less capability. Figure 5 reflects many cells with colors ranging from deep red to yellow for CPC, followed by TerraClimate, PGF and CRU.

Heatmap of CPI for all gridded Tmax datasets used in this study
4.2 Performance assessment of gridded Tmin
A similar analysis was conducted for Tmin. The spatial distribution of Tmin over the basin for 1979−2016, estimated using the station and gridded data, is given in Figure S-1. Like Tmax, the higher value of Tmin was in the center and west part, and the lowest temperature was in the east part of the basin. TerraClimate showed the lowest estimation of Tmin (− 24.48 °C) followed by PGF (− 14.78 °C), CRU (− 12.84 °C) and CPC (− 7.73 °C). Figures S-2 presents the performance of the gridded data in replicating observed Tmin at different stations based on CPI (heatmaps). The figure indicates the better performance of CPC in most of the stations.
4.3 Group decision-making process of Tmax and Tmin
The MCGDM was used to merge the ranks of the gridded data products at different stations to select the best product for the entire basin rationally. Table 6 presents the ranks for Tmax and Tmin datasets obtained using CPI and the ranks obtained by merging them using MCGDM. The data products were assigned a weight based on the number of stations they were ranked 1st, 2nd and 3rd. Finally, an integrated MCGDM index was estimated using Eq. (2). The higher value of the index indicates a better performance of a product. The overall ranking using MCGDM revealed CPC as the best temperature product in the basin, followed by TerraClimate and PGF.
4.4 Performmance evaluation using symmetrical uncertainty
The results obtained for Tmax using SU are provided in Fig. 6 as a heatmap. CPC obtained higher SU values at more stations (indicated by red cells) than other products. The result was also very consistent with that obtained using CPI in Fig. 5. Table 7 shows the overall ranking of the gridded Tmax and Tmin datasets in the Amu Darya River basin obtained using SU. The results showed the best performance of CPC Tmax and Tmin at most of the stations. The results approve the findings obtained using CPI.

Heatmap showed the performance of gridded Tmax datasets at different stations using symmetrical uncertainty
4.5 Spatial analysis of the trends in thermal bioclimate indicators
The estimated trends in the TBIs at 241 CPC grids locations were used to generate maps and assess the geographical distribution of their trends over the ADRB. A similar legend was applied to present the value of change in all bioclimate indicators except TBI3 (different unit) to easily compare the changes among different indicators. The color ramp of the maps indicates the changes estimated by Sen's slope. The red indicates a positive, while the green indicates a negative change. The black dot placed in the center of each box specifies the trend significance obtained using MMK test at a 95% confidence interval.
4.5.1 Annual average temperature (TBI1)
The TBI1 indicates the average thermal condition in the basin. It gives information about approximate total energy inputs received in the basin for an ecosystem. Figure 7a, represents the geographical variability of TBI1, and Fig. 6b shows the trends in TBI1 in the ADRB. The TBI1 over the basin ranges from − 2 to 18.8 °C. The maximum TBI1 is in the center and the minimum in the east of the basin. Figure 7b reveals a significant reduction in TBI1 in the north-western and central parts of the basin. Despite a rising tendency in the TBI1 in the eastern part of the basin, the increases are still not significant. In general, a reduction in average temperature in the high-temperature zone and increasing tendency in the cold region indicates a more homogeneous temperature distribution in the basin in recent years.

a Spatial pattern of yearly average temperature (TBI1); b trends in TBI1 (°C/decade) in the study area
TBI1 is directly related to vegetation health and the species richness of an area. Islam et al. (2021) showed positive relation of TBI1 with NDVI of Bangladesh. Adhikari et al. (2018) showed that TBI1 determines the species richness in the mountainous region of South Korea. Sosa and Loera (2017) found the highest positive correlation of TBI1 with species richness in Mesoamerica among all other indicators. Käfer et al. (2020) assessed the thermal limits of European Seed Bugs, critical to thermal maxima (mean = 45.3 °C) and showed their high correlation with TBI1 and TBI5. The decrease in TBI1 over a major region of ADRB can have severe negative implications on vegetation and ecology in the basin.
4.5.2 Diurnal temperature range (TBI2)
This TBI2 indicates the daily fluctuation of temperature or the differences in daily Tmax and Tmin. Therefore, TBI2 indicates the relative change in Tmax and Tmin. Figure 8a, b show the spatial distribution of TBI2 and its trend over ADRB. The TBI2 is higher in the high-temperature region in the west and less in the cold region in the east. The TBI2 trends revealed a significant rise in the cold eastern zone. The increases were more than 0.17 °C/decade in some locations. A faster rise in Tmax than Tmin in the cold region caused a sharp increase in TBI2.

a Spatial distribution of diurnal range (TBI2); b trends in TBI2 (°C/decade) in the basin
The TBI2 defines the relative difference in Tmax and Tmin and is often used to show global warming-induced climate change (Noce et al. 2020; Shahid et al. 2012). Increases in TBI2 can significantly affect the vegetation and public health of a region. Evans and Lyons (2013) found an increase in the TBI2 caused forest death in the east of Perth in Western Australia. Yaro et al. (2021) found TBI2 has significant impacts on the geospatial distribution of soil-transmitted helminths (STHs). TBI2 is positively related to mortality, especially from heart and respiratory-related diseases (Cheng et al. 2014). Therefore, increases in TBI2 in the east of the basin can severely affect the region's vegetation, soil, and public health. The TBI2 is generally negatively related to the precipitation of a region (He et al. 2015). The increase in TBI2 can reduce precipitation over the eastern mountainous zone, which is the basin's water supply source. This can severely affect the water availability in the basin.
4.5.3 Isothermality (TBI3)
TBI3 is the ratio of the diurnal temperature range (DTR) or TBI2 to seasonal temperature fluctuation expressed as a percentage. Figure 9a shows that TBI3 in ADRB varies from 31.5 to 54.3%, with higher variability in the center, south and western part of the basin. Results of the trend analysis showed a steady rise in TBI3 in the basin's east (Fig. 9b). A large increase in TBI2 in the east of the basin was the cause of a significant rise in TBI3.

a Geographical distribution of isothermally (TBI3); b trends in TBI3 (%/decade) in the basin
The species distribution of an area depends on the temperature fluctuation of the area within a year (Nix 1986; O'donnell and Ignizio 2012). Therefore, isothermality plays a vital role in the biodiversity and ecology of a region. Rai et al. (2016) reported the most significant effect of TBI3 on the plant composition among all the indicators. Sommer et al. (2010) estimated a reduction of biological diversity with an increase in temperature. Reitalu et al. (2014) also found an inverse relationship of species richness, particularly grasslands with TBI3. Other studies also showed negative consequences of increasing TBI3 on forest and bird species (Distler et al. 2015; Zhang et al. 2013). The TBI3 showed a significant rise in the east and central-north of the basin. Increasing TBI3 would negatively affect mountain forests and mountain ecology in those mountainous regions significantly.
4.5.4 Temperature seasonality (TBI4)
TBI4 estimates the SD of the monthly mean temperature over a year, and thus, temperature variability within a year. The larger SD shows more variability of temperature in a region (Noce et al. 2020). Therefore, higher TBI4 indicates both hot and cold extremes in a region. The TBI4 in the study area (Fig. 10a) ranges from 7.4 to 11.5 °C. It is maximum in the northwest, where the temperature is predominantly high. Besides, it is high in the cold eastern region. The MMK test showed the TBI4 changes in the basin are insignificant (Fig. 10b). However, there was a rising tendency in TBI4 in the east of the basin.

a Geographical variability; and b trends in temperature seasonality (°C/decade) in the basin
Generally, people experience higher thermoregulatory stress in a high TBI4 region (Monterroso et al. 2014). Wang et al. (2017) found that TBI4 and annual rainfall (TBI12) as the major drivers of coniferous forest coverage across China. A small change in TBI4 strongly affects the distribution of many species. Besides, the increase in temperature seasonality may increase temperature-related risks (Hadi Pour et al. 2019). Mancinelli et al. (2019) showed the direct association of thermal seasonality with non-arboreal foliage coverage. The rises in TBI4 can affect public health and vegetation in the southeast of the basin.
4.5.5 Maximum temperature of warmest month (TBI5)
TBI5 provides an understanding of the effect of warm temperature anomalies over the year, which greatly influences species distribution. The TBI5 in the basin ranges from 16.5 to 40.1 °C (Fig. 11a). The higher values of TBI5 were in the center, west and northwest of the basin. It indicates a higher susceptibility to the region of heat extremes. The MMK test revealed an increase in TBI5 in the center part of the basin by up to 0.3 °C/decade (Fig. 11b). It indicates increasing TBI5 in the region where it is already high. The increasing TBI5 in the region with high summer temperatures has increased the vulnerability of hot extremes like heatwaves in the region. This increase in TBI5 would also increase the discomfort to the residents of this aridic region, reduce water availability through the increase of evaporation and decline agricultural productivity.

a Spatial distribution of maximum temperature of the warmest month (TBI5); b trends in TBI5 (°C/decade) in the basin
Reitalu et al. (2014) showed that the TBI5 is negatively associated with phylogenetic diversity within the Baltic Sea region. Therefore, a rise in TBI5 in central ADRB may disturb the thermotolerant level of many species, spread diseases and cause other environmental effects (Hadi Pour et al. 2019).
4.5.6 Minimum temperature of coldest month (TBI6)
TBI6 measures Tmin in the coldest month, and therefore, it provides an understanding of susceptibility to clod extremes. The Tmin in the coldest month is below zero in most of the basin (Fig. 12a). The Tmin is less than − 20 °C in the eastern mountainous region and nearly zero in the central region, where summer maximum temperature goes as high as 40 °C. The MMK test revealed a rise in TBI6 over the whole basin, except in the west (Fig. 12b). Increases in TBI6 is most of the basin indicates a gradual reduction of clod extreme in most region. However, the TBI6 is not changing in the east, where it is lowest. This means cold wave vulnerability remains in the high susceptible region of the basin. Besides, the increase in Tmin in the coldest month over a large region of the basin might affect the population of coniferous plants in the tundra, which prolific more in a frost environment (Li et al. 2016). It can also increase species distribution in the west and northwest of the basin, where TBI6 was increasing fast (Ancillotto et al. 2016; Koo et al. 2015).

a Spatial distribution of minimum temperature of the coldest month (TBI6); b trends in TB6 (°C/decade) in the basin
4.5.7 Temperature annual range (TBI7)
TBI7 is the difference in Tmin of the coolest month and Tmax of the hottest month. Therefore, it provides an understanding of temperature anomalies over a year. This information helps to know the impact of extreme temperature conditions on biodiversity. Figure 13a presents the geographical variability of TBI7 in the basin. The highest TBI7 was in the northwest (> 32 °C) and lowest in the central region (< 25 °C). The large values of TBI7 in the northwest indicate the area's susceptibility to both hot and cold extremes. The MMK test showed an increase in TBI7 only over a small area in the center north at a rate of nearly 0.1 °C/decade (Fig. 13b). The increase in TBI7 was mostly in the region where it is less. This indicates the susceptibility of both hot and cold extremes in the less susceptible region is increasing. The increase in TBI7 in the central-south region of the basin can have some other implications. Dakhil et al. (2019) reported a greater influence of TBI7 on coniferous forests distribution than precipitation in Tibetan Plateau China. Hradilová et al. (2019) showed significant relation of TBI7 to germination responsivity of pea seed. Yaro et al. (2021) significant relationship of TB7 with the geospatial variability of soil helminths (STHs) in Kogi East, North Central Nigeria.

a Spatial distribution of the difference in minimum temperature of the coolest month and maximum temperature of the hottest month (TBI7); b trends in TBI7 (°C/decade) in the basin
5 Discussion
Though gridded temperature data are widely used for various climatic studies, uncertainty in results obtained using gridded data is always a major concern (Ahmed et al. 2017; Khan et al. 2018). The uncertainty in gridded temperature data primarily occurs from the interpolation technique, lacks observation, quality of in-situ data, data homogenization method (Nashwan et al. 2019a, b, c; Bador et al. 2020; Alexander et al. 2020). None of the datasets performs well at all locations of the globe. Bador et al. (2020) evaluated 22 gridded rainfall data products and suggested that none of the datasets can be considered the best globally. However, their study showed that a particular dataset could perform better than other data products at the regional or national scale. This is particularly true in the catchment scale like ADRB.
It is also vital to use the most suitable gridded dataset for reliable analysis of the climate of a region. Bador et al. (2020) showed considerable uncertainty in one-day maximum precipitation estimated using different gridded data products. Therefore, estimating future changes in rainfall extremes using different gridded data products as a reference can significantly vary. Nashwan showed different rainfall trend directions using different data products, even over a small region. Therefore, climate change analysis without selecting suitable data product can provide misleading information.
The performance of four widely used gridded temperature datasets was assessed in this study. The objective was to find the most appropriate product for temperature analysis in the ADRB, where scarcity of in-situ data is the major barrier for climatological studies. The CP was employed to evaluate the ability of gridded temperature products. The CP is a multicriteria decision-making method known as the "distance-based" method, which solves multi-objective problems by measuring the distance of a solution closer to the ideal point. It is less computationally intensive and avoids decision makers' choices (Gan et al. 1996). The major strength of CP is to find the real Pareto optimum curve when the optimal points are heterogeneously distributed, a task that the conventional weighting methods are failed to do (Zhang 2003). Statistical measures fail when the gridded data over- and underestimate in-situ data simultaneously. Therefore, GP overcomes these problems by combining the overall performance of a gridded dataset by comparing the statistically obtained outcomes (Behar et al. 2015; Fan et al. 2018; Jamil et al. 2020). Also, the statistical measure cannot rank and compare numerous models in such a way as to select the best. Still, GP does it easily and accurately by using all measures (Despotovic et al. 2015). Therefore, it is expected that the ranking of gridded temperature obtained using CP is robust.
The present study identified CPC as the most suitable product for replicating both Tmax and Tmin. Literature review suggests limited studies in the basin to evaluate the ability of gridded temperature products (Haag et al. 2019; Sidike et al. 2016; White et al. 2014). Therefore, it was not possible to make a critical comparison with previous findings. However, the findings of those few existing studies collaborate with the results presented in this article. White et al. (2014) used CRU for the ADRB and showed that the product is not fair to provide good climatic input for water assessment. The present study also showed relatively poor performance of CRU data. Sidike et al. (2016) used Tmax and Tmin of PGF, WSD and CRUNCEP datasets for hydrological simulations in ADRB. They found that PGF simulated the observed data well, although underestimated high and overestimated low temperature. Haag et al. (2019) used CRU data to assess temperature changes in central Asia. Their results showed a good correlation of CRU data with available observed data. However, Sidike et al. (2016) and Haag et al. (2019) did not evaluate the ability of CRU and PGF with other gridded temperature datasets used in this study. The present study revealed that though CRU and PGF showed good correlations with observed temperature, their performance is poorer than CPC in ADRB.
Several previous studies used different gridded temperature datasets to evaluate temperature changes in the ADRB. Wang et al. (2016) used PGF temperature data to assess temperature trends in ADRB. They showed a rise in average Tmax and Tmin by 0.2 and 0.3 °C/decade at a 99% confidence interval. It indicates a rise in daily mean temperature in ADRB. The present studies also showed a rise in the average temperature over most of the basin. Haag et al. (2019) used CRU data and showed a rise in annual mean temperature by 0.28 °C/decade at a 95% confidence level. They also showed that the plain area has a relatively higher temperature trend compare to mountains areas. It is also consistent with the results presented in this study. The present study showed an increase in average temperature in the central plain land and no significant change in the eastern mountainous region.
The results discussed above indicate similar estimates of spatiotemporal variability of temperature trends in ADRB using CPC, the best product and CRU, the least performing product. However, the spatial coverage of the trends estimated using CPC data was different from the earlier studies. The trend significance was also much less in this study than in the previous studies. This is because of the usage of CPC data and the MMK test. Nashwan et al. (2019b) estimated the relative capability of different gridded rainfall products for trend analysis in Bangladesh. They showed rainfall trends significantly vary for different gridded data products. Therefore, they suggested evaluating the relative performance of different gridded data products to find the best product before their use for trend analysis. Therefore, the difference in spatial coverage of trends between CPC in the present study and CRU in the earlier studies is due to the quality of gridded temperature data. The present study suggests that temperature studies in ADRB should be conducted using CPC data for better reliability.
The MMK test rather than MK test was employed in this study to evaluate change significance. The trends in climate series may occur due to existing multi-year cycles in temperature series. Such cycles arise due to the influence of different atmospheric oscillations like the Mediterranean oscillation. The length of the cycles varies widely, with some being higher than 50 years (Khan et al. 2019). The MK test shows significant trends, often due to variability in data series because of these embedded cycles. The MMK test can avoid this and provides unidirectional trends. Therefore, the trend detected in this study is much less than that detected in previous studies. The trends presented in this study is due to climate variability caused by global warming.
The present study revealed an increasing trend in TBI1 in the deserts arid zone of the basin. It was not changing in the eastern low-temperature region. However, TBI2 revealed a significant rise in the cold eastern region. This indicates an increase in both Tmax and Tmin in arid desert zones in the center and west of ADRB. The increase in Tmin was much higher than the Tmin in the cold eastern region. Therefore, the increase in TBI2 was significant only in the cold eastern region. The results agree with the earlier studies conducted by (You et al. 2011) in China, (Araghi et al. 2016) in Iran and (Khan et al. 2019) in Pakistan. They showed a faster increase in TBI2 in the cold region than in the warm region. The results are also in harmony with the temperature changes in ADRB reported by (Wang et al. 2016). TBI3 showed a higher increase in temperature in cold months than in warmer months, which is significant in the cold region of the basin. This indicates the significant influence of TBI3 on critical thermal tolerance (Käfer et al. 2020). The trends in TBI4 collaborates with the results obtained by (Hadi Pour et al. 2019) in Iran. The TBI6 showed a significant increase over the west and central region of ADRB. An increase in temperature of the coldest month can be favourable for vegetation health and forest growth in the west and central region. The TBI7 showed significant change in a small patch in the south, and therefore, less implication in the basin.
6 Conclusion
The main objective of this study was the suitability assessment of gridded temperature datasets and the use of the best gridded temperature datasets to evaluate the trends in TBIs in ADRB. The CPI was used to rank the contradictory outcomes obtained by six statistical metrics in performance assessment of Tmax and Tmin datasets to find the most suitable dataset among selected products. Furthermore, the MCGDM method was employed to integrate the CPI of all stations to get a homogeneous result. The finding indicates CPC as the most suitable gridded dataset in replicating in-situ temperature over the ADRB. The TBI analysis revealed an increasing trend in temperature in the warmest and coldest month, particularly over the center and south of the basin. The increase in Tmax in the warmest month was more pronounced over the basin than in Tmin. In the future, other reanalysis and remote sensing temperature datasets can be compared to evaluate their performance in the basin. Other recently developed algorithms, particularly machine learning algorithms, can be employed to evaluate the ability of gridded data. The reliability of daily gridded temperature data to replicate the temperature extremes in the basin can also be evaluated in the future.
Data availability
All the data are available in the public domain at the links provided in the texts.
Code availability
The codes used for the processing of data can be provided on request to the corresponding author.
References
Abatzoglou JT, Dobrowski SZ, Parks SA, Hegewisch KC (2018) TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015. Sci Data 5(1):1–12
Adhikari P, Shin M-S, Jeon J-Y, Kim HW, Hong S, Seo C (2018) Potential impact of climate change on the species richness of subalpine plant species in the mountain national parks of South Korea. J Ecol Environ 42(1):1–10
Ahmed K, Shahid S, Ali RO, Bin Harun S, Wang XJ (2017) Evaluation of the performance of gridded precipitation products over Balochistan Province, Pakistan. Desalin Water Treat 79:73–86
Ahmed K, Shahid S, Wang X, Nawaz N, Khan N (2019) Evaluation of gridded precipitation datasets over arid regions of Pakistan. Water 11(2):210
Alexander LV, Bador M, Roca R, Contractor S, Donat MG, Nguyen PL (2020) Intercomparison of annual precipitation indices and extremes over global land areas from in situ, space-based and reanalysis products. Environ Res Lett 15(5):055002
Ancillotto L, Santini L, Ranc N, Maiorano L, Russo D (2016) Extraordinary range expansion in a common bat: the potential roles of climate change and urbanization. Sci Nat 103(3–4):15
Araghi A, Mousavi-Baygi M, Adamowski J (2016) Detection of trends in days with extreme temperatures in Iran from 1961 to 2010. Theoret Appl Climatol 125(1):213–225
Attorre F, Alfo’ M, De Sanctis M, Francesconi F, Bruno F (2007) Comparison of interpolation methods for mapping climatic and bioclimatic variables at regional scale. Int J Climatol J R Meteorol Soc 27(13):1825–1843
Bador M, Alexander LV, Contractor S, Roca R (2020) Diverse estimates of annual maxima daily precipitation in 22 state-of-the-art quasi-global land observation datasets. Environ Res Lett 15(3):035005
Bai L, Shi C, Li L, Yang Y, Wu J (2018) Accuracy of CHIRPS satellite-rainfall products over mainland China. Remote Sens 10(3):362
Bashir MF, Ma B, Komal B, Bashir MA, Tan D, Bashir M (2020) Correlation between climate indicators and COVID-19 pandemic in New York, USA. Sci Total Environ 728:138835
Behar O, Khellaf A, Mohammedi K (2015) Comparison of solar radiation models and their validation under Algerian climate–the case of direct irradiance. Energy Convers Manag 98:236–251
Błażejczyk K (2011) Assessment of regional bioclimatic contrasts in Poland. Misc Geogr 15(1):79–91
Brahim HB, Duckstein L (2011) Descriptive methods and compromise programming for promoting agricultural reuse of treated wastewater. In: Computational Methods for Agricultural Research: Advances and Applications, pp 355–388, IGI Global
Caesar J, Alexander L, Vose R (2006) Large-scale changes in observed daily maximum and minimum temperatures: creation and analysis of a new gridded data set. J Geophys Res Atmos. https://doi.org/10.1029/2005JD006280
Cheng J, Xu Z, Zhu R, Wang X, Jin L, Song J, Su H (2014) Impact of diurnal temperature range on human health: a systematic review. Int J Biometeorol 58(9):2011–2024
Colston JM, Ahmed T, Mahopo C, Kang G, Kosek M, de Sousa Junior F, Shrestha PS, Svensen E, Turab A, Zaitchik B, The ME (2018) Evaluating meteorological data from weather stations, and from satellites and global models for a multi-site epidemiological study. Environ Res 165:91–109
Daemei AB, Eghbali SR, Khotbehsara EM (2019) Bioclimatic design strategies: a guideline to enhance human thermal comfort in Cfa climate zones. J Build Eng 25:100758
Dakhil MA, Xiong Q, Farahat EA, Zhang L, Pan K, Pandey B, Olatunji OA, Tariq A, Wu X, Zhang A, Tan X (2019) Past and future climatic indicators for distribution patterns and conservation planning of temperate coniferous forests in southwestern China. Ecol Indic 107:105559
Despotovic M, Nedic V, Despotovic D, Cvetanovic S (2015) Review and statistical analysis of different global solar radiation sunshine models. Renew Sustain Energy Rev 52:1869–1880
Distler T, Schuetz JG, Velásquez-Tibatá J, Langham GM (2015) Stacked species distribution models and macroecological models provide congruent projections of avian species richness under climate change. J Biogeogr 42(5):976–988
Evans BJ, Lyons T (2013) Bioclimatic extremes drive forest mortality in southwest, Western Australia. Climate 1(2):28–52
Fan J, Wang X, Wu L, Zhang F, Bai H, Lu X, Xiang Y (2018) New combined models for estimating daily global solar radiation based on sunshine duration in humid regions: a case study in South China. Energy Convers Manag 156:618–625
Fraga H, Guimarães N, Santos JA (2019) Future changes in rice bioclimatic growing conditions in Portugal. Agronomy 9(11):674
Gaitani N, Mihalakakou G, Santamouris M (2007) On the use of bioclimatic architecture principles in order to improve thermal comfort conditions in outdoor spaces. Build Environ 42(1):317–324
Gampe D, Ludwig R (2017) Evaluation of gridded precipitation data products for hydrological applications in complex topography. Hydrology 4(4):53
Gan, J., Colletti, J. P., and Kolison Jr, S. H. (1996). A compromise programming approach to integrated natural resource management. In: Paper presented at the Society of American foresters
Gaybullaev B, Chen S-C (2013) Water salinity changes of the gauging stations along the Amu Darya River. J Agric For 62(1):1–14
Guo B, Zhang J, Meng X, Xu T, Song Y (2020) Long-term spatio-temporal precipitation variations in China with precipitation surface interpolated by ANUSPLIN. Sci Rep 10(1):1–17
Haag I, Jones PD, Samimi C (2019) Central Asia’s changing climate: how temperature and precipitation have changed across time, space, and altitude. Climate 7(10):123
Hadi Pour S, Abd Wahab AK, Shahid S, Wang X (2019) Spatial pattern of the unidirectional trends in thermal bioclimatic indicators in Iran. Sustainability 11(8):2287
Hamasha H, Schmidt-Lebuhn A, Durka W, Schleuning M, Hensen I (2013) Bioclimatic regions influence genetic structure of four Jordanian Stipa species. Plant Biol 15(5):882–891
Hamed KH (2008) Trend detection in hydrologic data: the Mann-Kendall trend test under the scaling hypothesis. J Hydrol 349(3–4):350–363
He B, Huang L, Wang Q (2015) Precipitation deficits increase high diurnal temperature range extremes. Sci Rep 5(1):1–7
Homsi R, Shiru MS, Shahid S, Ismail T, Harun SB, Al-Ansari N et al (2020) Precipitationprojection using a CMIP5 GCM ensemble model: a regional investigation of Syria. Eng AppComput Fluid Mech 14(1):90–106
Hradilová I, Duchoslav M, Brus J, Pechanec V, Hýbl M, Kopecký P, Smržová L, Štefelová N, Vaclávek T, Bariotakis M, Machalová J (2019) Variation in wild pea (Pisum sativum subsp. elatius) seed dormancy and its relationship to the environment and seed coat traits. PeerJ 7:e6263
Islam AR, Islam HT, Shahid S, Khatun MK, Ali MM, Rahman MS, Ibrahim SM, Almoajel AM (2021) Spatiotemporal nexus between vegetation change and extreme climatic indices and their possible causes of change. J Environ Manag 289:112505
Jalilov S-M, Amer SA, Ward FA (2013) Reducing conflict in development and allocation of transboundary rivers. Eurasian Geogr Econ 54(1):78–109
Jalilov S-M, Keskinen M, Varis O, Amer S, Ward FA (2016) Managing the water–energy–food nexus: gains and losses from new water development in Amu Darya River basin. J Hydrol 539:648–661
Jamil B, Irshad K, Algahtani A, Islam S, Ali MA, Shahab A (2020) On the calibration and applicability of global solar radiation models based on temperature extremities in India. Environ Prog Sustain Energy 39(1):13236
Käfer H, Kovac H, Simov N, Battisti A, Erregger B, Schmidt AK, Stabentheiner A (2020) Temperature tolerance and thermal environment of European seed bugs. Insects 11(3):197
Kendall M (1975) Rank correlation methods. 2nd impression. Charles Griffin and Company Ltd. London and High Wycombe
Khan N, Shahid S, Ahmed K, Ismail T, Nawaz N, Son M (2018) Performance assessment of general circulation model in simulating daily precipitation and temperature using multiple gridded datasets. Water 10(12):1793
Khan N, Shahid S, bin Ismail T, Wang X-J (2019) Spatial distribution of unidirectional trends in temperature and temperature extremes in Pakistan. Theor Appl Climatol 136(3):899–913
Khaydarov M, Gerlitz L (2019) Climate variability and change over Uzbekistan–an analysis based on high resolution CHELSA data. Central Asian Journal of Water Research (CAJWR) Цeнтpaльнoaзиaтcкий жypнaл иccлeдoвaний вoдныx pecypcoв 5(2):1–19
Kim Y, Park C, Koo KA, Lee MK, Lee DK (2019) Evaluating multiple bioclimatic risks using Bayesian belief network to support urban tree management under climate change. Urban For Urban Green 43:126354
Koo KA, Kong W-S, Nibbelink NP, Hopkinson CS, Lee JH (2015) Potential effects of climate change on the distribution of cold-tolerant evergreen broadleaved woody plants in the Korean Peninsula. PloS One 10(8):e0134043
Kumar N, Khamzina A, Tischbein B, Knöfel P, Conrad C, Lamers JP (2019) Spatio-temporal supply–demand of surface water for agroforestry planning in saline landscape of the lower Amudarya Basin. J Arid Environ 162:53–61
Li WJ, Peng MC, Higa M, Tanaka N, Matsui T, Tang CQ, Ou XK, Zhou RW, Wang CY, Yan HZ (2016) Effects of climate change on potential habitats of the cold temperate coniferous forest in Yunnan province, southwestern China. J Mt Sci 13(8):1411–1422
Lutz AF, Immerzeel WW, Gobiet A, Pellicciotti F, Bierkens MF (2013) Comparison of climate change signals in CMIP3 and CMIP5 multi-model ensembles and implications for Central Asian glaciers. Hydrol Earth Syst Sci 17(9):3661–3677
Ma Q, Wu J, He C (2016) A hierarchical analysis of the relationship between urban impervious surfaces and land surface temperatures: spatial scale dependence, temporal variations, and bioclimatic modulation. Landsc Ecol 31(5):1139–1153
Mahmood R, Jia S, Zhu W (2019) Analysis of climate variability, trends, and prediction in the most active parts of the Lake Chad basin, Africa. Sci Rep 9(1):1–18
Mancinelli G, Mali S, Belmonte G (2019) Species richness and taxonomic distinctness of zooplankton in ponds and small lakes from Albania and North Macedonia: the role of bioclimatic factors. Water 11(11):2384
Mann HB (1945) Nonparametric tests against trend. Econom J Econom Soc 13(3):245–259
Miguet F, Groleau D (2007) Urban bioclimatic indicators for urban planners with the software tool SOLENE. Portugal SB07 Sustainable Construction, materials and practices: challenges of the industry for the new millennium, Lisbon, Portugal, 348–355
Monterroso P, Alves PC, Ferreras P (2014) Plasticity in circadian activity patterns of mesocarnivores in Southwestern Europe: implications for species coexistence. Behav Ecol Sociobiol 68(9):1403–1417
Moriondo M, Trombi G, Ferrise R, Brandani G, Dibari C, Ammann CM, Lippi MM, Bindi M (2013) Olive trees as bio-indicators of climate evolution in the M editerranean B asin. Glob Ecol Biogeogr 22(7):818–833
Muhammad MKI, Nashwan MS, Shahid S, bin Ismail T, Song YH, Chung E-S (2019) Evaluation of empirical reference evapotranspiration models using compromise programming: a case study of Peninsular Malaysia. Sustainability 11(16):4267
Musie M, Sen S, Srivastava P (2019) Comparison and evaluation of gridded precipitation datasets for streamflow simulation in data scarce watersheds of Ethiopia. J Hydrol 579:124168
Nashwan MS, Shahid S (2019) Symmetrical uncertainty and random forest for the evaluation of gridded precipitation and temperature data. Atmos Res 230:104632
Nashwan MS, Shahid S, Chung ES (2019a) Development of high-resolution daily gridded temperature datasets for the central north region of Egypt. Sci Data 6(1):1–13
Nashwan MS, Shahid S, Abd Rahim N (2019b) Unidirectional trends in annual and seasonal climate and extremes in Egypt. Theoret Appl Climatol 136(1):457–473
Nashwan MS, Shahid S, Wang X (2019c) Uncertainty in estimated trends using gridded rainfall data: a case study of Bangladesh. Water 11(2):349
New M, Hulme M, Jones P (2000) Representing twentieth-century space–time climate variability. Part II: development of 1901–96 monthly grids of terrestrial surface climate. J Clim 13(13):2217–2238
Newman AJ, Clark MP, Craig J, Nijssen B, Wood A, Gutmann E, Mizukami N, Brekke L, Arnold JR (2015) Gridded ensemble precipitation and temperature estimates for the contiguous United States. Journal of Hydrometeorology 16(6):2481–2500
Nezlin NP, Kostianoy AG, Lebedev SA (2004) Interannual variations of the discharge of Amu Darya and Syr Darya estimated from global atmospheric precipitation. J Mar Syst 47(1–4):67–75
Nijssen B, Lettenmaier DP (2004) Effect of precipitation sampling error on simulated hydrological fluxes and states: anticipating the Global Precipitation Measurement satellites. J Geophys Res Atmos. https://doi.org/10.1029/2003JD003497
Nix HA (1986) A biogeographic analysis of Australian elapid snakes. Atlas Elapid Snakes Aust 7:4–15
Noce S, Caporaso L, Santini M (2020) A new global dataset of bioclimatic indicators. Sci Data 7(1):1–12
O’Donnell MS, Ignizio DA (2012) Bioclimatic predictors for supporting ecological applications in the conterminous United States. US Geol Surv Data Ser 691(10):4–9
Pour SH, Abd Wahab AK, Shahid S (2020a) Spatiotemporal changes in precipitation indicators related to bioclimate in Iran. Theoret Appl Climatol 141(1):99–115
Pour SH, Abd Wahab AK, Shahid S, Ismail ZB (2020b) Changes in reference evapotranspiration and its driving factors in peninsular Malaysia. Atmos Res 246:105096
Pour SH, Abd Wahab AK, Shahid S, Asaduzzaman M, Dewan A (2020c) Low impact development techniques to mitigate the impacts of climate-change-induced urban floods: current trends, issues and challenges. Sustain Cities Soc 62:102373
Rai S, Sharma S, Shrestha K, Gajurel J, Devkota S, Nobis M, Scheidegger C (2016) Effects of the environment on species richness and composition of vascular plants in Manaslu Conservation Area and Sagarmatha region of Nepalese Himalaya. Banko Janakari 26(1):3–16
Raju KS, Sonali P, Kumar DN (2017) Ranking of CMIP5-based global climate models for India using compromise programming. Theoret Appl Climatol 128(3–4):563–574
Reitalu T, Helm A, Pärtel M, Bengtsson K, Gerhold P, Rosén E, Takkis K, Znamenskiy S, Prentice HC (2014) Determinants of fine-scale plant diversity in dry calcareous grasslands within the Baltic Sea region. Agriculture, ecosystems & environment 182:59–68
Sa’adi Z, Shiru MS, Shahid S, Ismail T (2020) Selection of general circulation models for the projections of spatio-temporal changes in temperature of Borneo Island based on CMIP5. Theor Appl Climatol 139(1):351–371
Sajani SZ, Tibaldi S, Scotto F, Lauriola P (2008) Bioclimatic characterization of an urban area: a case study in Bologna (Italy). Int J Biometeorol 52(8):779–785
Salat S (2007) Energy and bioclimatic efficiency of urban morphologies: towards a comparative analysis of Asian and European cities. In: Paper presented at the proceedings of the international conference on sustainable building Asia
Salman SA, Shahid S, Ismail T, Ahmed K, Wang X-J (2018) Selection of climate models for projection of spatiotemporal changes in temperature of Iraq with uncertainties. Atmos Res 213:509–522
Salman SA, Shahid S, Ismail T, Al-Abadi AM, Wang X-J, Chung E-S (2019) Selection of gridded precipitation data for Iraq using compromise programming. Measurement 132:87–98
Savoskul O, Shevnina E (2015) Irrigated crop production in the Syr Darya basin: climate change rehearsal in the 1990s. Clim Change Agric Water Manag Dev Ctries 8:176
Schlüter M, Savitsky AG, McKinney DC, Lieth H (2005) Optimizing long-term water allocation in the Amudarya River delta: a water management model for ecological impact assessment. Environ Model Softw 20(5):529–545
Schröder W, Schmidt G, Schönrock S (2014) Modelling and mapping of plant phenological stages as bio-meteorological indicators for climate change. Environ Sci Eur 26(1):1–13
Sen PK (1968) Estimates of the regression coefficient based on Kendall’s tau. J Am Stat Assoc 63(324):1379–1389
Shahid S, Harun SB, Katimon A (2012) Changes in diurnal temperature range in Bangladesh during the time period 1961–2008. Atmos Res 118:260–270
Sheffield J, Goteti G, Wood EF (2006) Development of a 50-year high-resolution global dataset of meteorological forcings for land surface modeling. J Clim 19(13):3088–3111
Shibuo Y, Jarsjö J, Destouni G (2007) Hydrological responses to climate change and irrigation in the Aral Sea drainage basin. Geophys Res Lett. https://doi.org/10.1029/2007GL031465
Shiru MS, Chung ES, Shahid S, Alias N (2020) GCM selection and temperature projection of Nigeria under different RCPs of the CMIP5 GCMS. Theor Appl Climatol 141(3):1611–1627
Sidike A, Chen X, Liu T, Durdiev K, Huang Y (2016) Investigating alternative climate data sources for hydrological simulations in the upstream of the Amu Darya River. Water 8(10):441
Sommer JH, Kreft H, Kier G, Jetz W, Mutke J, Barthlott W (2010) Projected impacts of climate change on regional capacities for global plant species richness. Proc R Soc B Biol Sci 277(1692):2271–2280
Sosa V, Loera I (2017) Influence of current climate, historical climate stability and topography on species richness and endemism in Mesoamerican geophyte plants. PeerJ 5:e3932
Sun J, Li Y, Suo C, Liu Y (2019) Impacts of irrigation efficiency on agricultural water-land nexus system management under multiple uncertainties—a case study in Amu Darya River basin, Central Asia. Agric Water Manag 216:76–88
Tanarhte M, Hadjinicolaou P, Lelieveld J (2012) Intercomparison of temperature and precipitation data sets based on observations in the Mediterranean and the Middle East. J Geophys Res Atmos. https://doi.org/10.1029/2011JD017293
Törnqvist R (2013) Basin-scale change in water availability and water quality under intensified irrigated agriculture. Department of Physical Geography and Quaternary Geology, Stockholm University
Wang X, Luo Y, Sun L, He C, Zhang Y, Liu S (2016) Attribution of runoff decline in the Amu Darya River in Central Asia during 1951–2007. J Hydrometeorol 17(5):1543–1560
Wang S, Xu X, Shrestha N, Zimmermann NE, Tang Z, Wang Z (2017) Response of spatial vegetation distribution in China to climate changes since the last glacial maximum (LGM). PloS One 12(4):e0175742
White CJ, Tanton TW, Rycroft DW (2014) The impact of climate change on the water resources of the Amu Darya Basin in Central Asia. Water Resour Manag 28(15):5267–5281
Xie P, Chen M, Shi W (2010) CPC unified gauge-based analysis of global daily precipitation. In: Paper presented at the Preprints, 24th Conference on Hydrology, Atlanta, GA, American Meteorological Society
Yaro CA, Kogi E, Luka SA, Nassan MA, Kabir J, Opara KN, Hetta HF, Batiha GE (2021) Edaphic and climatic factors influence on the distribution of soil transmitted helminths in Kogi East, Nigeria. Sci Rep 11(1):1–12
Yasutomi N, Hamada A, Yatagai A (2011) Development of a long-term daily gridded temperature dataset and its application to rain/snow discrimination of daily precipitation. Glob Environ Res 15(2):165–172
Yin H, Donat MG, Alexander LV, Sun Y (2015) Multi-dataset comparison of gridded observed temperature and precipitation extremes over China. Int J Climatol 35(10):2809–2827
You Q, Kang S, Aguilar E, Pepin N, Flügel WA, Yan Y, Xu Y, Zhang Y, Huang J (2011) Changes in daily climate extremes in China and their connection to the large scale atmospheric circulation during 1961–2003. Climate Dynamics 36(11–12):2399–2417
Zeleny M (1973) Compromise programming, multiple criteria decision-making. Multiple Criteria Decis Making 263-301
Zhang W (2003) A compromise programming method using multibounds formulation and dual approach for multicriteria structural optimization. Int J Numer Meth Eng 58(4):661–678
Zhang J, Zhou Y, Zhou G, Xiao C (2013) Structure and composition of natural Gmelin larch (Larix gmelinii var. gmelinii) forests in response to spatial climatic changes. Plos one 8(6):e66668
Acknowledgements
Author(s) are grateful to Universiti Teknologi Malaysia (UTM) for providing support to this research through grant no. Q.J130000.2451.09G07. The first author is grateful to the Ministry of Education of Afghanistan for providing fund to conduct this study. The authors are also thankful to the Ministry of Energy and Water of Afghanistan (MEW–AFG) and the National Oceanic and Atmospheric Administration (NOAA), the United States, for providing the data through their web portal to conduct this study.
Funding
Author(s) are grateful to Universiti Teknologi Malaysia (UTM) for providing support to this research through Grant No. Q.J130000.2451.09G07.
Author information
Authors and Affiliations
Contributions
All the authors contributed to the conceptualization and design phases of the study. The data were gathered by OS and SSS; the programming code was written by SS and AM; an initial draft of the paper was prepared by OS and SSS; individual revisions and the final version were provided by TbI and XW.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Salehie, O., Ismail, T.b., Shahid, S. et al. Selection of the gridded temperature dataset for assessment of thermal bioclimatic environmental changes in Amu Darya River basin. Stoch Environ Res Risk Assess 36, 2919–2939 (2022). https://doi.org/10.1007/s00477-022-02172-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-022-02172-8