
Abstract
Purpose
This study is a comparative analysis of three Large Language Models (LLMs) evaluating their rate of correct answers (RoCA) and the reliability of generated answers on a set of urological knowledge-based questions spanning different levels of complexity.
Methods
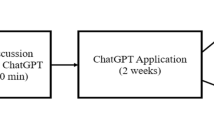
ChatGPT-3.5, ChatGPT-4, and Bing AI underwent two testing rounds, with a 48-h gap in between, using the 100 multiple-choice questions from the 2022 European Board of Urology (EBU) In-Service Assessment (ISA). For conflicting responses, an additional consensus round was conducted to establish conclusive answers. RoCA was compared across various question complexities. Ten weeks after the consensus round, a subsequent testing round was conducted to assess potential knowledge gain and improvement in RoCA, respectively.
Results
Over three testing rounds, ChatGPT-3.5 achieved RoCa scores of 58%, 62%, and 59%. In contrast, ChatGPT-4 achieved RoCA scores of 63%, 77%, and 77%, while Bing AI yielded scores of 81%, 73%, and 77%, respectively. Agreement rates between rounds 1 and 2 were 84% (κ = 0.67, p < 0.001) for ChatGPT-3.5, 74% (κ = 0.40, p < 0.001) for ChatGPT-4, and 76% (κ = 0.33, p < 0.001) for BING AI. In the consensus round, ChatGPT-4 and Bing AI significantly outperformed ChatGPT-3.5 (77% and 77% vs. 59%, both p = 0.010). All LLMs demonstrated decreasing RoCA scores with increasing question complexity (p < 0.001). In the fourth round, no significant improvement in RoCA was observed across all three LLMs.
Conclusions
The performance of the tested LLMs in addressing urological specialist inquiries warrants further refinement. Moreover, the deficiency in response reliability contributes to existing challenges related to their current utility for educational purposes.
Similar content being viewed by others


Data availability
The data sets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Ray PP (2023) ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys Syst. https://doi.org/10.1016/j.iotcps.2023.04.003
Eysenbach G (2023) The role of ChatGPT, generative language models, and artificial intelligence in medical education: a conversation with ChatGPT and a call for papers. JMIR Med Educ. https://doi.org/10.2196/46885
Alfertshofer M, Hoch CC, Funk PF et al (2023) Sailing the seven seas: A multinational comparison of ChatGPT’s performance on medical licensing examinations. Ann Biomed Eng. https://doi.org/10.1007/s10439-023-03338-3
Ali R, Tang OY, Connolly ID et al (2023) Performance of ChatGPT and GPT-4 on neurosurgery written board examinations. Neurosurgery. https://doi.org/10.1227/neu.0000000000002632
Antaki F, Touma S, Milad D et al (2023) Evaluating the performance of ChatGPT in ophthalmology: an analysis of its successes and shortcomings. Ophthalmology Sci. https://doi.org/10.1016/j.xops.2023.100324
Azizoğlu M, Okur MH (2023) How does ChatGPT perform on the European Board of Pediatric Surgery examination? A randomized comparative study. Res Square. https://doi.org/10.21203/rs.3.rs-3018641/v1
Beaulieu-Jones BR, Shah S, Berrigan MT et al (2023) Evaluating capabilities of large language models: performance of GPT4 on surgical knowledge Assessments. medRxiv. https://doi.org/10.1101/2023.07.16.23292743
Caglar U, Yildiz O, Meric A et al (2023) Evaluating the performance of ChatGPT in answering questions related to pediatric urology. J Pediatr Urol. https://doi.org/10.1016/j.jpurol.2023.08.003
Deebel NA, Terlecki R (2023) ChatGPT performance on the American urological association self-assessment study program and the potential influence of artificial intelligence in urologic training. Urology. https://doi.org/10.1016/j.urology.2023.05.010
Friederichs H, Friederichs WJ, März M (2023) ChatGPT in medical school: how successful is AI in progress testing? Med Educ Online. https://doi.org/10.1080/10872981.2023.2220920
Gencer A, Aydin S (2023) Can ChatGPT pass the thoracic surgery exam? A J Med Sci. https://doi.org/10.1016/j.amjms.2023.08.001
Gilson A, Safranek CW, Huang T, et al (2023) How does ChatGPT perform on the United States Medical licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Med Educ. https://doi.org/10.2196/45312
Guerra GA, Hofmann H, Sobhani S et al (2023) GPT-4 artificial intelligence model outperforms ChatGPT, medical students, and neurosurgery residents on neurosurgery written board-like questions. World Neurosurg. https://doi.org/10.1016/j.wneu.2023.08.042
Hoch CC, Wollenberg B, Lüers J-C et al (2023) ChatGPT’s quiz skills in different otolaryngology subspecialties: an analysis of 2576 single-choice and multiple-choice board certification preparation questions. Eur Arch Otorhinolaryngolog. https://doi.org/10.1007/s00405-023-08051-4
Huynh LM, Bonebrake BT, Schultis K et al (2023) New Artificial Intelligence ChatGPT Performs Poorly on the 2022 Self-assessment Study Program for Urology. Urol Pract. https://doi.org/10.1097/UPJ.0000000000000406
Jung LB, Gudera JA, Wiegand TLT et al (2023) ChatGPT passes German state examination in medicine with picture questions omitted. Dtsch Arztebl Int. https://doi.org/10.3238/arztebl.m2023.0113
Kung TH, Cheatham M, Medenilla A et al (2023) Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit Health. https://doi.org/10.1371/journal.pdig.0000198
Lewandowski M, Łukowicz P, Świetlik D, Barańska-Rybak W (2023) An original study of ChatGPT-3.5 and ChatGPT-4 Dermatological Knowledge Level based on the Dermatology Specialty Certificate Examinations. Clin Exp Dermatol. https://doi.org/10.1093/ced/llad255
May M, Körner-Riffard K, Marszalek M, Eredics K (2023) Would the generative artificial intelligence Uro_Chat, a newly developed large language model, have successfully passed the In-Service Assessment questions of the European Board of Urology in the year 2022? Eur Urol Oncol. https://doi.org/10.1016/j.euo.2023.08.013
Moshirfar M, Altaf AW, Stoakes IM, et al (2023) Artificial intelligence in ophthalmology: a comparative analysis of GPT-3.5, GPT-4, and human expertise in answering StatPearls questions. Cureus. https://doi.org/10.7759/cureus.40822
Oh N, Choi G-S, Lee WY (2023) ChatGPT goes to the operating room: evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models. Ann Surg Treat Res. https://doi.org/10.4174/astr.2023.104.5.269
Saad A, Iyengar KP, Kurisunkal V, Botchu R (2023) Assessing ChatGPT’s ability to pass the FRCS orthopaedic part A exam: a critical analysis. Surgeon. https://doi.org/10.1016/j.surge.2023.07.001
Singhal K, Tu T, Gottweis J et al (2023) Towards expert-level medical question answering with large language models. arXiv. https://doi.org/10.48550/arxiv.2305.09617
Skalidis I, Cagnina A, Luangphiphat W et al (2023) ChatGPT takes on the European exam in core cardiology: an artificial intelligence success story? Eur Heart J Digit Health. https://doi.org/10.1093/ehjdh/ztad029
Suchman K, Garg S, Trindade AJ (2023) Chat Generative Pretrained Transformer Fails the Multiple-Choice American College of Gastroenterology Self-Assessment. Am J Gastroenterol. https://doi.org/10.14309/ajg.0000000000002320
Takagi S, Watari T, Erabi A, Sakaguchi K (2023) Performance of GPT-3.5 and GPT-4 on the Japanese medical licensing examination: comparison study. JMIR Med Educ. https://doi.org/10.2196/48002
Thirunavukarasu AJ, Hassan R, Mahmood S et al (2023) Trialling a large language model (ChatGPT) in general practice with the applied knowledge test: observational study demonstrating opportunities and limitations in primary care. JMIR Med Educ. https://doi.org/10.2196/46599
Weng T-L, Wang Y-M, Chang S et al (2023) ChatGPT failed Taiwan’s Family medicine board exam. J Chin Med Assoc. https://doi.org/10.1097/jcma.0000000000000946
Khene Z-E, Bigot P, Mathieu R et al (2023) Development of a personalized chat model based on the european association of urology oncology guidelines: harnessing the power of generative artificial intelligence in clinical practice. Eur Urol Oncol. https://doi.org/10.1016/j.euo.2023.06.009
May M, Körner-Riffard K, Kollitsch L (2024) Can ChatGPT realistically and reproducibly assess the difficulty level of written questions in the In-Service Assessment of the European Board of Urology? Urology 183:302–303. https://doi.org/10.1016/j.urology.2023.09.036
Acknowledgements
We extend our heartfelt gratitude to the Executive Committee of the European Board of Urology (EBU) for their support and for confidentially providing the In-Service Assessment questions from the year 2022.
Funding
None.
Author information
Authors and Affiliations
Contributions
MM had full access to all the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. MM, LK, and KK-R contributed to study concept and design, and analysis and interpretation of data. MM, LK, KE, and KK-R performed acquisition of data. MM, LK, KK-R, KE, and SDB-M performed drafting of the manuscript. All authors performed critical revision of the manuscript for important intellectual content. MM carried out statistical analysis. None obtained funding. MR provided administrative, technical, or material support. MM, MB, SDB-M, and MM performed supervision.
Corresponding author
Ethics declarations
Conflict of interest
Matthias May certifies that all conflicts of interest, including specific financial interests and relationships and affiliations relevant to the subject matter or materials discussed in the manuscript (e.g., employment/affiliation, grants or funding, consultancies, honoraria, stock ownership or options, expert testimony, royalties, or patents filed, received, or pending), are the following: None. The authors declare that they have no conflict of interest.
Human participants
Prior to the commencement of this study, ethical consultation was sought from the Ethics Committee of the University Hospital Regensburg (Germany), which concluded that no additional ethical approval was necessary for this type of study and that there were no ethical concerns regarding the conduct of the study. We certify that the study was performed in accordance with the ethical standards as laid down in the 1964 Declaration of Helsinki.
Informed consent
Not required, as no patients were enrolled in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kollitsch, L., Eredics, K., Marszalek, M. et al. How does artificial intelligence master urological board examinations? A comparative analysis of different Large Language Models’ accuracy and reliability in the 2022 In-Service Assessment of the European Board of Urology. World J Urol 42, 20 (2024). https://doi.org/10.1007/s00345-023-04749-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00345-023-04749-6