
Abstract
We consider computing eigenspaces of an elliptic self-adjoint operator depending on a countable number of parameters in an affine fashion. The eigenspaces of interest are assumed to be isolated in the sense that the corresponding eigenvalues are separated from the rest of the spectrum for all values of the parameters. We show that such eigenspaces can in fact be extended to complex-analytic functions of the parameters and quantify this analytic dependence in a way that leads to convergence of sparse polynomial approximations. A stochastic collocation method on an anisoptropic sparse grid in the parameter domain is proposed for computing a basis for the eigenspace of interest. The convergence of this method is verified in a series of numerical examples based on the eigenvalue problem of a stochastic diffusion operator.
Similar content being viewed by others

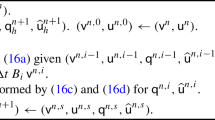

1 Introduction
Multiparametric eigenvalue problems, i.e., eigenvalue problems of operators that depend on a large number of input parameters, arise in a variety of contexts. One may think of optimization of the spectrum of structures which depend on a number of design parameters, but also uncertainty quantification of engineering systems with data uncertainty. Recent literature has considered examples of mechanical vibration problems, where a parametrization of the uncertainties in either the physical coefficients or the geometry of the system results in a multiparametric eigenvalue problem, see e.g. [12, 13, 15, 19, 25, 26].
It is to be noted that multiparametric eigenvalue problems present some additional difficulties when compared to corresponding source problems. First of all, the eigenvalue problem introduces a product of unknowns and hence non-linearities arise. Second of all, one needs to pay special attention to the selection of the right eigenmodes for different parameter values. For these reasons, techniques developed for the analysis and the numerical solution of the source problems are, in general, not directly applicable in the context of the eigenvalue problems. Moreover, some properties of classical solution methods for deterministic eigenvalue problems are lost when the problems are cast into the multiparametric setting. For instance, while a deterministic conforming Galerkin approximation leads to monotonic convergence of the approximate eigenvalues from above, in the multiparametric setting the eigenvalue is in fact a function over the parameter space and such monotonic convergence need not hold except at the chosen sampling points.
Despite the aforementioned difficulties, in recent years several numerical methods have been suggested for solving multiparametric eigenvalue problems. The focus has been on spectral methods, which are based on polynomial approximations of the solution in the parameter domain and which have been shown to exhibit superior convergence rates compared to traditional Monte Carlo methods [3, 5, 23, 27]. These typically rely on either stochastic collocation or stochastic Galerkin approximation of the solution. From an implementational point of view stochastic collocation methods can be viewed as a form of statistical sampling, where a polynomial approximation of the solution is formed based on its values at specific points in the parameter space. The obvious advantage of such strategies is that they are non-intrusive by nature, hence, any existing deterministic solver can be used directly to solve for the individual samples and parallelization is also trivial. On the other hand, stochastic Galerkin methods are intrusive and in the context of eigenvalue problems they lead to a decoupled system of nonlinear equations that is usually solved by an iterative algorithm. A benefit of the stochastic Galerkin methods is that a-posteriori analysis is more natural and can be used to define adaptive strategies for building the respective approximation space, see e.g. [9]. A benchmark for stochastic collocation methods for multiparametric eigenvalue problems is the sparse anisotropic collocation algorithm analyzed by Andreev and Schwab in [1]. In the class of stochastic Galerkin methods, on the other hand, many different variants of the have been proposed over the years [11, 14, 19, 26]. Quite recently, low-rank methods have also been introduced [2, 7, 24].
By their very nature, the spectral methods considered above rely on the assumption that the solution is smooth with respect to the input parameters. More precisely, these methods exhibit optimal rates of convergence only if the eigenpair of interest depends complex-analytically on the vector of parameters. This analytic dependence has been established for nondegenerate eigenvalues and associated eigenvectors in [1]. For such eigenpairs we therefore have optimal rates of convergence for stochastic collocation algorithms, see [1] for details, and optimal asymptotic rates of convergence for the iterative Galerkin based algorithms considered in [14]. However, these results do not apply to cases where the eigenvalues are of higher multiplicity or where they are allowed to cross within the parameter space. As noted in e.g. [15], many interesting engineering applications admit eigenvalues that are clustered close together and therefore the aforementioned eigenvalue crossings may not be avoided when these problems are cast into the parameter-dependent setting.
In some special cases it is possible to identify the eigenmodes by some characteristic features such as Fourier indices. Then it may be possible to track eigenpairs through the parameter space by searching for the modes with the given indices even though the ordering of such modes becomes mixed over the parameter space. In other words, one well-defined basis for a given subspace is readily available. An example of such a problem can be constructed by extending the Dirichlet Laplacian on the unit square (Example 1).
Example 1
(Model problem) Let us consider the Dirichlet Laplacian eigenproblem on the unit square. Note that this can also be seen as an example of the diffusion eigenproblem with a constant diffusion coefficient. It is well-known that the first four eigenpairs are
where the eigenpairs are indexed also by the Fourier indices. The double eigenvalue is due to symmetry as shown in Fig. . Here we are interested in the case where the diffusion coefficient is no longer constant but depends on a countable number of parameters. For example, we could think of a stochastic coefficient given in the form of a Karhunen-Loève expansion. If the variation in the diffusion is restricted to \(x_1\)-direction, say, it is intuitively clear that it follows within the cluster \((u_{(2,1)},u_{(1,2)})\) that \(\lambda _{(2,1)} \ne \lambda _{(1,2)}\). Indeed, the relative order of the eigenvalues \(\lambda _{(2,1)}\) and \(\lambda _{(1,2)}\) ultimately depends on the realisations of the diffusion parameters. This is the mechanism that induces the crossing of eigenvalues in this context. Moreover, in the general setting it has to be established under what assumptions the cluster itself, i.e., the eigenspace associated to \(\lambda _{(2,1)}\) and \(\lambda _{(1,2)}\) remains isolated.
In this paper we consider eigenspaces of an elliptic self-adjoint operator that depends affinely on a countable number of parameters. Our main theoretical contribution is that we extend the results in [1] on analyticity to cover eigenspaces associated to possibly clustered eigenvalues. The underlying assumption is that the eigenspace of interest is isolated in the sense that the corresponding eigenvalues are separated from the rest of the spectrum for all values of the input parameters. We show that the spectral projection operator associated to such an isolated eigenspace can in fact be extended to a complex-analytic function of the input parameters. This allows us to construct a well-defined and smooth basis for the eigenspace of interest and show that optimal convergence rates hold when the basis vectors are approximated using a conveniently chosen set of orthogonal polynomials. We consider the stochastic collocation method defined on an anisotropic sparse grid in the parameter domain, earlier introduced in [1], for computing a basis for the eigenspace of interest. Our numerical experiments show that, even in the presence of eigenvalue crossings, optimal rates of convergence can be achieved for the subspace as a whole, while the convergence order would actually break down if one tried to naively approximate individual eigenpairs. In fact, in our examples we observe fast rates of convergence even if the terms in the Karhunen- Loève series decay too slowly for the current theory to hold.
Our method constructs a basis for the eigenspace. This can be useful for at least two reasons. First of all, once the basis has been computed, we may project our original eigenproblem on this basis. It then becomes easier to track the individual eigenpairs as we no longer need to deal with the original full eigenvalue problem. Instead, the actual eigeninformation, values and modes, could be recovered, for instance, by sampling realisations of the eigenmodes of the projected problem. Second of all, in important applications such as frequency response analysis, finding a representation for the eigenspace may be of independent interest, and here it is obtained directly.

Dirichlet Laplacian in the unit square: First four eigenfunctions
The rest of this paper is structured as follows: In Sect. 2 the model problem is defined in its multiparametric form, the main result, analyticity of isolated eigenspaces is established in Sect. 3, the collocation scheme is defined in Sect. 4, and the numerical experiments in Sect. 5, before concluding remarks in Sect. 6.
2 Problem formulation
We consider a class of self-adjoint operators that depend affinely on a countable number of real parameters. This affine dependence is often of independent interest but may also result from first order approximation of more general smooth dependence. In particular, the commonly used model problem for a stochastic diffusion operator falls within our framework.
2.1 Multiparametric variational eigenvalue problems
Let V and H be separable Hilbert spaces over \({\mathbb {R}}\) and denote the associated inner products by \((\cdot , \cdot )_V\) and \((\cdot , \cdot )_H\) and norms by \(\left\Vert \ \cdot \ \right\Vert _{V}\) and \(\left\Vert \ \cdot \ \right\Vert _{H}\). Assume that V and H form the so-called Gel’fand triple \(V \subset H \subset V^*\) with dense and compact embeddings. We denote by \(\mathcal {L}(V,V^*)\) the space of bounded linear operators from V to its dual \(V^*\). Furthermore, we denote by \(\langle \cdot , \cdot \rangle _{V \times V^*}\) the duality pairing on V and \(V^*\), which may be interpreted as an extension of the inner product \((\cdot , \cdot )_H\).
For each \(m \in {\mathbb {N}}_0\) let \(b_m \! : V \times V \rightarrow {\mathbb {R}}\) be a symmetric and continuous bilinear form, which we can associate with an operator \(B_m \in \mathcal {L}(V,V^*)\) using
Suppose that there exists \(\alpha _0 > 0\) such that
and a sequence \(\varvec{\kappa } = (\kappa _1, \kappa _2, \ldots )\) of positive real numbers such that \(\left\Vert \varvec{\kappa }\right\Vert _{\ell ^1({\mathbb {N}})} < 1\) and
We define a multiparametric bilinear form
where \({\textbf{y}}= (y_1, y_2, \ldots )\) is a vector of parameters, each of which takes values in a closed interval of \({\mathbb {R}}\). Equivalently, we can call (3) a multiparametric family of bilinear forms. Without loss of generality we may assume a scaling such that \({\textbf{y}}\in \varGamma := [-1,1]^{\infty }\). We associate the form (3) with a multiparametric family of operators \(B \! : \varGamma \rightarrow \mathcal {L}(V,V^*)\) given by
Remark 1
The ellipticity condition (1) could be weakened by assuming G\({ \mathring{a} }\)rding’s inequality
for some \(w > 0\) and \(\alpha _0 > 0\). This can be reduced to the elliptic case using a standard shift procedure.
The assumptions above imply that \(b({\textbf{y}};\cdot ,\cdot )\) is uniformly bounded and uniformly elliptic, i.e.,
and
for some \(C > 0\) and \(\alpha > 0\). Consider the following multiparametric eigenvalue problem: find \(\mu \! : \varGamma \rightarrow {\mathbb {R}}\) and \(u \! : \varGamma \rightarrow V \backslash \{ 0 \}\) such that
or in variational form
The Lax-Milgram lemma guarantees that for any \({\textbf{y}}\in \varGamma \) the operator \(B({\textbf{y}})\) is boundedly invertible and its inverse \(B^{-1}({\textbf{y}}) \! : H \rightarrow V\) is compact due to the compact embedding \(V \subset H\). Therefore, the problem admits a countable number of real eigenvalues of finite multiplicity and associated eigenfunctions that form an orthogonal basis of H.
Remark 2
A commonly used model problem is the stochastic diffusion eigenvalue problem on \(D \subset {\mathbb {R}}^n\)
where the diffusion coefficient is a random field expressed in its Karhunen-Loève expansion
Indeed, if D is a bounded domain with a Lipschitz-smooth boundary, the variational formulation of (7) is given by (6) with the choice \(V = H^1_0(D)\), \(H = L^2(D)\) and
Assume that
where \(C_D\) denotes the Poincaré constant for D. Then it is easy to see that the assumptions (1) and (2) are satisfied with the choice \(\alpha _0 := (1 + C_D)^{-1} {{\,\mathrm{ess\,inf}\,}}_{{\textbf{x}}\in D} a_0({\textbf{x}})\) and \(\kappa _m := \alpha _0^{-1}\left\Vert a_m\right\Vert _{L^{\infty }(D)}\).
We will assume an increasing enumeration of the eigenvalues so that
where each eigenvalue may be listed several times according to its multiplicity. We denote by \(\{ u_i({\textbf{y}}) \}_{i=1}^{\infty }\) a set of associated eigenfunctions which are orthonormal in H for every \({\textbf{y}}\in \varGamma \). Ultimately we would like to compute any given subset of the eigenpairs \(\{ (\mu _i, u_i) \}_{i=1}^{\infty }\) of problem (5). However, due to possible eigenvalue crossings, this may sometimes be an extremely difficult task to perform computationally, see e.g. [15, 14]. Therefore, we will work under the assumption that the eigenspace of interest is isolated, i.e., the associated eigenvalues are strictly separated from the rest of the spectrum.
2.2 Isolated eigenspaces
Let \(J \subset {\mathbb {N}}\) and \(S = \#J\) denote its cardinality. For \({\textbf{y}}\in \varGamma \) let \(\sigma _J({\textbf{y}}) := \{ \mu _i({\textbf{y}}) \}_{i \in J}\) denote a set of eigenvalues of the problem (5) and \(U_J({\textbf{y}}) := {{\,\textrm{span}\,}}\{u_i({\textbf{y}})\}_{i \in J}\) denote the associated eigenspace. We use a shorthand notation \(U_S\) for the eigenspace \(U_J\) with \(J = \{1,2, \ldots , S\}\). We call an eigenspace \(U_J\) isolated with parameter \(\delta > 0\) (or simply just isolated) if
A set of functions \(\{g_i\}_{i=1}^S \subset V^{\varGamma }\) is called a basis of \(U_J\) if
Moreover, this basis is called orthonormal if \(\{g_i({\textbf{y}})\}_{i=1}^S\) is orthonormal in H for every \({\textbf{y}}\in \varGamma \). In the context of this paper we are interested in computing a basis for a given isolated eigenspace \(U_J\). We aim to demonstrate that, though the set of eigenvectors \(\{u_i\}_{j \in J}\) clearly is an orthonormal basis of \(U_J\), it may not always be computationally the most accessible one.
Remark 3
Note that even if the eigenspace \(U_J\) is isolated, double eigenvalues or eigenvalue crossings may still exist within the set \(\{\mu _i\}_{i \in J}\). In other words, we might have \(\mu _i({\textbf{y}}) = \mu _j({\textbf{y}})\) and \(i \not = j\) for some \(i, j \in J\) and \({\textbf{y}}\in \varGamma \).
The following is an adaptation of the classical theorem by Weyl.
Proposition 1
Under assumptions (1) and (2) the eigenvalues of the problem (5) satisfy
Proof
Recall the min-max characterization of eigenvalues. For \(i \in {\mathbb {N}}\) let \(V^{(i)}\) denote the set of all subspaces of V with dimension equal to i. Given a subspace \(U \subset V\) we set \({\widehat{U}} = \{ v \in U \ | \ \left\Vert v\right\Vert _{H} = 1 \}\). For some \(u \in {\widehat{U}}_i({\textbf{y}})\) we now have
and
It follows that
Similarly for some \(u \in U_i(\textbf{0})\) we have
and
so that
\(\square \)
As a corollary we obtain sufficient criteria for an eigenspace to be isolated. For simplicity we state these only in the case of an eigenspace \(U_S\) with \(S \in {\mathbb {N}}\).
Corollary 1
Assume (1) and (2). Given \(S \in {\mathbb {N}}\) let
Then the eigenspace \(U_S\) of the problem (5) is isolated with parameter
Proof
Clearly \(\delta > 0\). By Proposition 1 we have
for all \({\textbf{y}}\in \varGamma \). \(\square \)
2.3 Canonical bases
Given a set \(J \subset {\mathbb {N}}\) with cardinality S, we define a canonical basis \(\{ {\hat{u}}_i \}_{i=1}^S\) for the eigenspace \(U_J\) by setting
Here J(i) denotes the ith element in any fixed permutation of J. Observe that the canonical basis vectors \(\{ {\hat{u}}_i \}_{i=1}^S\) now only depend on the eigenspace \(U_J\) and not on the choice of the individual eigenvectors \(\{ u_i \}_{i \in J}\). Moreover, if the matrix \(\{ (u_{J(i)}(\textbf{0}),u_{J(j)}({\textbf{y}}))_H \}_{i,j=1}^S\) is nonsingular, then \(\{ {\hat{u}}_i \}_{i=1}^S\) is in fact a basis for \(U_J\). Note that \({\hat{u}}_i({\textbf{y}})\) need not be orthonormal for \({\textbf{y}}\ne \textbf{0}\) and that the inverse of the lowermost singular value of the Gram matrix \(\{ (u_{J(i)}(\textbf{0}),u_{J(j)}({\textbf{y}}))_H \}_{i,j=1}^S\) denotes the condition number of the basis and is uniformly bounded away from infinity due to the spectral separation assumption as given by the standard results for the convergence radii for the perturbation expansions of spectral projections from [18].
3 Analyticity of isolated eigenspaces
Next we will prove that any isolated eigenspace is in fact analytic with respect to the parameter vector \({\textbf{y}}\in \varGamma \) in a suitable sense. To this end we extend our analysis for complex valued arguments: In this section we assume that V and H are separable Hilbert spaces over \({\mathbb {C}}\) and extend the inner products \((\cdot , \cdot )_V\) and \((\cdot , \cdot )_H\) as well as the duality pairing \(\langle \cdot , \cdot \rangle _{V \times V^*}\) for complex-valued arguments sesquilinearly. Now (4) can be treated as the restriction to \(\varGamma \) of the operator-valued function
We equip \(\varGamma \subset {\mathbb {C}}^{\infty }\) with the Hausdorff topology so that this fits the framework of [16].
3.1 Riesz spectral projection
For \({\textbf{z}}\in {\mathbb {C}}^{\infty }\) let \(\varOmega ({\textbf{z}})\) be a closed curve in the complex plane, which encloses a set of eigenvalues of \(B({\textbf{z}})\), denoted by \(\sigma _J({\textbf{z}})\), but no other elements in the spectrum of \(B({\textbf{z}})\). We define the spectral projection
We call the mapping \({\textbf{z}}\mapsto U_J({\textbf{z}})\) analytic if \({\textbf{z}}\mapsto P_J({\textbf{z}})\) is analytic, i.e., the mapping \({\textbf{z}}\mapsto (P_J({\textbf{z}})v,u)_H\) is analytic for all \(v,u \in V\). Note that \({\textbf{z}}\mapsto (P_J({\textbf{z}})v,u)_H\) is a standard complex function of a complex variable.
The canonical basis from Sect. 2.3 can now be expressed as
3.2 Analyticity in one parameter
We first restrict our analysis to operators depending on a single parameter. In other words we consider the eigenvalues of (5) when \({\textbf{y}}\in \varGamma \) is replaced by \(t \in [-1,1]\) and our operator thus takes the form
Here (10) will be understood as the restriction to \([-1,1]\) of the operator-valued function
The assumptions (1) and (2) now imply
and
for some \(\alpha _0 > 0\) and \(0< \kappa _1 < 1\). We obtain the following result.
Proposition 2
Consider the problem (5) with \(B_m = 0\) for \(m \ge 2\), i.e., \(B \! : [-1,1] \rightarrow \mathcal {L}(V,V^*)\) is of the form (10) and satisifies (11) and (12). Given a finite \(J \subset {\mathbb {N}}\) assume that the eigenspace \(t \rightarrow U_J(t)\) is isolated with parameter \(\delta > 0\) for \(t \in [-1,1]\). Then it admits a complex-analytic extension \(z \rightarrow U_J(z)\) to the region
where
Moreover, for every \(z \in E(r)\) the spectrum of B(z) is separated into two parts \(\sigma _J(z)\) and \(\sigma _{{\mathbb {N}}\backslash J}(z)\) such that \({{\,\textrm{dist}\,}}(\sigma _J(z), \sigma _{{\mathbb {N}}\backslash J}(z)) > 0\).
Proof
Assume first that J is a set of consecutive natural numbers. Let \(t \in [-\,1,1]\) and denote \(\gamma (t) := {{\,\textrm{dist}\,}}(\sigma _J(t),\sigma _{{\mathbb {N}}\backslash J}(t)) > 0\). Let \(\varOmega (t)\) be the positively oriented circle of radius
centered at
Then \(\varOmega (t)\) encloses \(\sigma _J(t)\) but no elements of \(\sigma _{{\mathbb {N}}\backslash J}(t)\). Moreover, for every \(\omega \in \varOmega (t)\) we have
so that
for all \(v \in V\). By Remark VII.2.9 in [18] there exists \(r_0(t) > 0\) such that whenever \(|z - t| < r_0(t)\) the spectrum of B(z) is separated into two parts \(\sigma _J(z)\) and \(\sigma _{{\mathbb {N}}\backslash J}(z)\) by the curve \(\varOmega (t)\). Moreover, for such values of z the spectral projection valued function \(z \mapsto P_J(z)\) is complex-analytic. In fact we may set \(a = c = 0\) and \(b = \kappa _1(1 - \kappa _1 |t|)^{-1}\) in the definition of \(r_0(t)\) and obtain
Since \(t \in [-1,1]\) was arbitrary we conclude that \(z \rightarrow P_J(z)\) is complex-analytic in E(r).
An arbitrary \(J \subset {\mathbb {N}}\) may always be partitioned in such a way that each partition is a set of consecutive natural numbers. The previous proof applies for all partitions separately and thus the spectrum of B(z) is separated for all \(z \in E(r)\) and the total projection \(z \mapsto P_J(z)\) is complex-analytic in E(r).
3.3 Analyticity in a countable number of parameters
We start with a simple Lemma that can be deduced from standard perturbation theory for analytic operators, see Chapter VII in [18].
Lemma 1
Let \({\textbf{z}}\in {\mathbb {C}}^{\infty }\) and \(J \subset {\mathbb {N}}\) be such that the spectrum of \(B({\textbf{z}})\) can be separated into two parts \(\sigma _J({\textbf{z}})\) and \(\sigma _{J \backslash {\mathbb {N}}}({\textbf{z}})\) with \({{\,\textrm{dist}\,}}(\sigma _J({\textbf{z}}), \sigma _{J \backslash {\mathbb {N}}}({\textbf{z}})) > 0\). Let \(m \in {\mathbb {N}}\) and \(\textbf{e}_m\) denote the m:th unit vector in \({\mathbb {R}}^{\infty }\). Then there exists \(\epsilon ({\textbf{z}}) > 0\) such that the eigenspace \(\zeta \rightarrow U_J({\textbf{z}}+ \textbf{e}_m \zeta )\) is complex-analytic for all \(\zeta \in {\mathbb {C}}\) such that \(|\zeta | < \epsilon ({\textbf{z}})\).
Suppose now that \(\varvec{\kappa } \in \ell ^p({\mathbb {N}})\) for some \(p \in (0,1]\). Then we have the following result.
Theorem 1
Consider the problem (5) with assumptions (1) and (2). Assume that \(\varvec{\kappa } \in \ell ^p({\mathbb {N}})\) for some \(p \in (0,1]\). Given a finite \(J \subset {\mathbb {N}}\) assume that the eigenspace \({\textbf{y}}\rightarrow U_J({\textbf{y}})\) is isolated with parameter \(\delta > 0\) for \({\textbf{y}}\in \varGamma \). Then it admits a complex-analytic extension \({\textbf{z}}\rightarrow U_J({\textbf{z}})\) in the region
where \(\varvec{\tau } = (\tau _1, \tau _2, \ldots )\) is given by
and \(\varepsilon \in (0,1)\) is arbitrary.
Proof
Let \({\textbf{z}}\in E(\varvec{\tau })\) and take \({\textbf{y}}\in \varGamma \) such that \(| z_m - y_m| < \tau _m\) for all \(m \ge 1\). Denote \(\varvec{\zeta } := {\textbf{z}}- {\textbf{y}}\). We now have
and
where
Proposition 2 now applies for the shifted operator
and therefore the associated eigenspace \(t \mapsto U_J({\textbf{y}}+ t\varvec{\zeta })\) can be extended to a function \({\tilde{z}} \mapsto U_J({\textbf{y}}+ {\tilde{z}} \varvec{\zeta })\) which is complex-analytic for all \({\tilde{z}} \in {\mathbb {C}}\) such that
In particular the eigenspace \({\tilde{z}} \mapsto U_J({\textbf{y}}+ {\tilde{z}}\varvec{\zeta })\) is analytic in the vicinity of \({\tilde{z}} = 1\). By Lemma 1 the eigenspace \(U_J\) is now separately complex-analytic in the vicinity of \({\textbf{z}}\). Since \({\textbf{z}}\in E(\varvec{\tau })\) was arbitrary, we see that the eigenspace is separately complex-analytic in \(E(\varvec{\tau })\). Therefore, we may take Hartogs’s theorem (Theorem 2.2.8 in [17]) and extend it to infinite dimensions (Definition 2.3.1, Proposition 3.1.2 and Theorem 3.1.5 in [16]) to see that the eigenspace is jointly complex-analytic in \(E(\varvec{\tau })\).
4 Stochastic collocation on sparse grids
For computing the subspace of interest, we employ the anisotropic sparse grid collocation operator from [1]. There the collocation operator is defined with respect to finite and monotone multi-index sets and it generalizes some collocation methods introduced earlier in e.g. [20] and [21]. In this section we recapitulate the basic formulation of the operator as well as the main results on convergence.
4.1 General multi-index collocation
We start by defining standard one-dimensional Lagrange interpolation operators, and then extend these to multiple dimensions in a sparse fashion. The interpolation points are chosen to be zeros of orthogonal (Legendre) polynomials.
Let \(L_p\) denote the univariate Legendre polynomial of degree \(p \in {\mathbb {N}}_0\), \(\{ \chi _k^{(p)} \}_{k=0}^p\) denote the abscissae of \(L_{p+1}\) and \(\{ w_k^{(p)} \}_{k=0}^p\) denote the associated Gauss-Legendre quadrature weights. We define one-dimensional interpolation operators \(\mathcal {I}^{(m)}_p\) which map a function \(f \in C([-1,1])\) to the unique polynomial of degree p that interpolates f at the points \(\{ \chi _k^{(p)} \}_{k=0}^p\). This may be written in Lagrange form as
where \(\{ \ell _k^{(p)} \}_{k=0}^p\) are the standard Lagrange basis polynomials of degree p. We also have an alternative representation
where the coefficients \(\{d_k\}_{k=0}^p\) are given by
This is due to the fact that Gauss-Legendre quadrature of order p integrates any polynomial of degree \(2p +1\) exactly. For more information we refer to [6].
Now let \((\mathbb {N}_0^{\infty })_c\) denote the set of all multi-indices with finite support, i.e.,
where \(\mathop {\textrm{supp}}(\varvec{\alpha }) = \{ m \in \mathbb {N} \ | \ \alpha _m \not = 0 \}\). Given a finite set \(\mathcal {A} \subset (\mathbb {N}_0^{\infty })_c\) we define the greatest active dimension \(M_{\! \mathcal {A}} := \max \{ m \in {\mathbb {N}}\ | \ \exists \varvec{\alpha } \in \mathcal {A} \text { s.t. } \alpha _m \not = 0 \}\). For \(\varvec{\alpha }, \varvec{\beta } \in \mathcal {A}\) we write \(\varvec{\alpha } \le \varvec{\beta }\) if \(\alpha _m \le \beta _m\) for all \(m \ge 1\). We call the multi-index set \(\mathcal {A}\) monotone if whenever \(\varvec{\beta } \in (\mathbb {N}_0^{\infty })_c\) is such that \(\varvec{\beta } \le \varvec{\alpha }\) for some \(\varvec{\alpha } \in \mathcal {A}\), then \(\varvec{\beta } \in \mathcal {A}\).
Given a finite and monotone set \(\mathcal {A} \subset (\mathbb {N}_0^{\infty })_c\) we define the sparse collocation operator
with the convention \(\mathcal {I}_{-1}^{(m)} := 0\). Using the so called sparse grid combination technique originally presented in [10] (see also [4] for generalizations), we can rewrite the operator (15) in a computationally more convenient form
with coefficients
Note that aggregate quantities of our collocated solution may now be computed simply by applying Gauss-Legendre quadrature rules on the components of (16).
By following Lemma 5 in [1] we may express the collocated solution (16) as an expansion of multivariate Legendre polynomials. Given \(\varvec{\beta }, \varvec{\gamma } \in \mathcal {A}\) we define multi-dimensional collocation points
associated multi-dimensional quadrature weights
and tensorized Legendre polynomials
Using the relation (14) we obtain
so that
with expansion coefficients given by
This expression is particularly convenient for evaluating our numerical solution in polynomial form. The number of collocation points required to evaluate the solution from equation (17) is
4.2 Convergence for a class of monotone multi-index sets
The convergence rate of our collocation scheme depends on both the regularity of the solution at hand as well as the selection of the underlying multi-index sets. Here we follow the framework of [3] and [1] and restrict ourselves to a particular choice of monotone multi-index sets. We then recapitulate the main convergence results from [1].
Given a sequence \(\varvec{\eta } = (\eta _1, \eta _2, \ldots )\) such that \(1 > \eta _1 \ge \eta _2 \ge \ldots \ge 0\) and \(\eta _m \rightarrow 0\) we define the multi-index set
where \(\varvec{\eta }^{\varvec{\alpha }} := \prod _{m \in \mathop {\textrm{supp}}{\varvec{\alpha }}} \eta _m^{\alpha _m}\) (with the convention \(0^0 := 1\)). The set \(\mathcal {A}_{\varepsilon }(\varvec{\eta })\) is clearly finite and monotone. In view of Theorem 1 we may set
where
is equal to the sum of the semiaxes of a Bernstein ellipse (see [6] p. 19-20 and 312). We then obtain the following result.
Proposition 3
Let H be a Hilbert space. Assume that \(v \!: \varGamma \rightarrow H\) admits a complex-analytic extension in the region
where \(\varvec{\tau } = (\tau _1, \tau _2, \ldots )\) is a sequence of positive numbers such that \(\tau _m \rightarrow \infty \). Define \(\mathcal {A_{\varepsilon }}(\varvec{\eta }) \subset ({\mathbb {N}}_0^{\infty })_c\) according to (18), (19) and (20). Assume that \(\eta _m m^{\sigma } \rightarrow 0\) for some \(\sigma > 2(1 + \log 4)\). Then for any \(1> \varkappa > 2(1 + \log 4)/ \sigma \) there exists \(C > 0\) such that
for all \(0 < \varepsilon \le \eta _1\). Here \(\nu \) denotes the uniform probability measure on \(\varGamma \).
Proof
Clearly there exists \(M \ge 1\) such that
Lemma 7 and Proposition 3 in [1] now imply that the so-called asymptotic overhead order of \(\varvec{\eta }\) is
Hence, the result follows by taking \(\varkappa > 2(1 + \log 4)/\sigma \ge \varkappa ^*(\varvec{\eta })\) in Theorem 6 (note also Remark 10) of [1].
We may also estimate the convergence rate with respect to the number of collocation points.
Theorem 2
Let the conditions of Proposition 3 hold. Then for any \(s < \sigma - 2(1 + \log 4)\) there exists \(C = C(v) > 0\) such that
as \(\varepsilon \rightarrow 0\).
Proof
By Lemma 6 in [1] the cardinality of the multi-index sets \(\mathcal {A}_{\varepsilon }(\varvec{\eta })\) at the limit \(\varepsilon \rightarrow 0\) is given by
For any \(\omega > 1\) we have the bound
and therefore \(\varepsilon \lesssim (\# \mathcal {A}_{\varepsilon }(\varvec{\eta }))^{-{\tilde{\sigma }}}\) whenever \({\tilde{\sigma }} < \sigma \). Proposition 3 now implies that
for any \(1> \varkappa > 2(1 + \log 4)/\sigma \). Given \(s < \sigma - 2(1 + \log 4)\) we may now choose \(\varkappa > 2(1 + \log 4)/\sigma \) and \({\tilde{\sigma }} < \sigma \) so that
and therefore
Finally, Lemma 4 in [1] implies that \(N_{\! \mathcal {A}_{\varepsilon }(\varvec{\eta })} \le (\# \mathcal {A}_{\varepsilon }(\varvec{\eta }))^2\) and the claim follows. \(\square \)
4.3 Application to eigenspace computation
In the following we briefly illustrate how the previous results can be applied to eigenspace computation in the particularly interesting case that the coefficients \(\varvec{\kappa } = (\kappa _1, \kappa _2, \ldots )\) in (2) decay at an algebraic rate.
Suppose that the eigenspace \({\textbf{y}}\rightarrow U_J({\textbf{y}})\) of the problem (5) is isolated for some finite \(J \subset {\mathbb {N}}\). In addition to (1) and (2) assume that
where \(\varsigma -1> \sigma > 2(1 + \log 4)\). Note that this implies \(\varvec{\kappa } \in \ell ^p({\mathbb {N}})\) for \(p > \varsigma ^{-1}\). By Theorem 1 the eigenspace \({\textbf{y}}\rightarrow U_J({\textbf{y}})\) admits a complex analytic extension in the region
where \(\tau _m \gtrsim (m+1)^{\varsigma (1-p)}\). The sequence \(\varvec{\eta }\) in (19) now converges at the rate
where \(\varsigma (1-p) > \sigma \) for sufficiently large p. Therefore \(\eta _m m^{\sigma } \rightarrow 0\) and the conditions of Proposition 3 and Theorem 2 hold. This means that we should expect the convergence rate
when the sparse stochastic collocation algorithm is used to approximate the canonical basis vectors \(\{ {\hat{u}}_i \}_{i \in J}\) of \(U_J\).
Remark 4
We may apply the Gram-Schmidt process at every collocation point in order to obtain an approximately orthonormal basis for \(U_J\).
5 Numerical examples: stochastic diffusion equation
In this section we present numerical examples to verify the convergence rate (21) of our stochastic collocation algorithm. To this end we consider the model problem from Remark 2, i.e., the eigenvalue problem of a stochastic diffusion operator, and compute a canonical basis for one of its isolated eigenspaces. A standard finite element method is employed to obtain the discretization in physical space: In each of the examples the deterministic mesh is a grid of second order elements of diameter at most h, and the finite element space is then obtained by projecting the variational equation (6) onto the corresponding finite approximation space \(V_h \subset V\). In the context of the current paper, however, we focus on the convergence in the parameter space and disregard the approximation error related to the spatial discretization.
Our numerical examples cover two different scenarios. First, we consider the model problem on the unit square and assume that the diffusion coefficient is constant in the second coordinate direction (Example 1). By separation of variables we may then either reduce this problem to a one-dimensional problem (in physical space), where each eigenvalue is well separated, or we may solve the full two-dimensional problem, where eigenmodes are tangled together. In particular we show that our subspace algorithm applied to the full two-dimensional problem converges to the same result as when a simple eigenvalue algorithm is employed to the dimensionally reduced problem. Second, we apply our algorithm to the model problem in a dumbbell shaped domain and let the diffusion coefficient depend on both spatial coordinates. In this case the crossing of eigenvalues is intrinsic by nature and the eigenmodes can not be untangled by mere separation of variables. We illustrate that similar convergence rates hold as in the first example.
5.1 Reducible uncertainty model in the unit square
Consider the stochastic diffusion problem from Remark 2 with \(D := (0,1)^2\). We let \(a_0 := 1 + C_D\), where \(C_D\) denotes the Poincaré constant for D, i.e., the inverse of the smallest eigenvalue of the Laplacian with Dirichlet boundary condition. For \(m \in {\mathbb {N}}\) and \(\varsigma > 1\) we set
It is easy to see that the assumptions (1) and (2) hold with \(\alpha _0 = 1\) and \(\kappa _m = (m+1)^{-\varsigma }\). For \(\varsigma \) large enough, in particular for \(\varsigma \ge 2\), we have \(\left\Vert \varvec{\kappa }\right\Vert _{\ell ^1({\mathbb {N}})} < 1\). In the following examples we have used the values \(\varsigma = 3\) and \(\varsigma = 6\). Moreover, we have used multi-index sets \(\mathcal {A}_{\varepsilon }(\varvec{\eta }) \subset ({\mathbb {N}}_0^{\infty })_c\) as defined in the Eqs. (18)–(20). The sequence \(\varvec{\tau } = (\tau _1, \tau _2, \ldots )\) is set as \(\tau _m := (m+1)^{\varsigma -1}\) which is in accordance with e.g. the numerical experiments in [14].
Since the diffusion coefficient \(a({\textbf{x}}) = a(x_1)\) is independent of \(x_2\) we may now reduce the original problem to a one-dimensional problem. By separation of variables we see that functions of the form \(u({\textbf{x}},{\textbf{y}}) = \varphi (x_1, {\textbf{y}})\sin (\pi k x_2)\), where \(k \in {\mathbb {N}}\) and \(\varphi (x_1, {\textbf{y}})\) solves
for all \({\textbf{y}}\in \varGamma \), form a complete set of eigenfunctions for our original problem (7). Classical Sturm-Liouville theory implies that the eigenvalues of (22) are simple and separated for every fixed \({\textbf{y}}\in \varGamma \). This separation of eigenvalues also holds uniformly with respect to \({\textbf{y}}\in U\), see Sect. 2.2 in [8]. Hence, we may solve the eigenpairs of this one-dimensional problem via any simple stochastic eigenvalue algorithm such as the one presented in [1].
Let us now investigate the subspace \(U_S\) of our model problem for \(S = 3\). In Fig. we have illustrated the first three eigenvalues of the problem as a function of the first parameter \(y_1 \in [-1,1]\) when the rest are held constant. We see that there is an eigenvalue crossing at \(y_1 = 0\) as is expected due to symmetry. As a result, there’s multiple ways to choose the eigenfunction at this point. One example of the first three eigenfunctions at \({\textbf{y}}= \textbf{0}\) has been shown in Fig. 1.
At \({\textbf{y}}= \textbf{0}\) the model problem reduces to a standard Laplace eigenvalue problem, the eigenvalues of which are \(2\pi ^2, 5\pi ^2, 5\pi ^2, 8\pi ^2 \ldots \) Hence, for \(S=3\) we have \(\delta _0 = 0.6\) in equation (9). Moreover, from \(\kappa _m = (m+1)^{-\varsigma }\) we compute \(\left\Vert \varvec{\kappa }\right\Vert _{\ell ^1({\mathbb {N}})} \approx 0.20206\) when \(\varsigma = 3\) and \(\left\Vert \varvec{\kappa }\right\Vert _{\ell ^1({\mathbb {N}})} \approx 0.01734\) when \(\varsigma = 6\). With these values the conditions of Corrollary 1 hold and the subspace \(U_3\) is in fact isolated with parameters \(\delta \approx 0.062\) and \(\delta \approx 0.55\) for the cases \(\varsigma = 3\) and \(\varsigma = 6\) respectively.

Model problem in the unit square with \(\varsigma = 3\): First few eigenvalues as a function of \(y_1 \in [-1,1]\) when \(y_2 = y_3 = \cdots = 0\)
Let us first investigate the case \(\varsigma = 6\) and employ our sparse stochastic collocation algorithm to compute a canonical basis for the subspace \(U_3\). We compute a reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\) from the one-dimensional equation (22) using a mesh of 800 second order line elements. When computing this reference solution we set \(\varepsilon > 0\) so that the number of multi-indices is \(\# \mathcal {A}_{\varepsilon }(\varvec{\eta }) = 28\) and the greatest active dimension is \(M_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 16\). This results in \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 77\) collocation points. Next we compute a series of solutions \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) from the two-dimensional equation (7) using different values of \(\varepsilon > 0\) and a mesh of 147456 second order quadrilateral elements. Convergence of the approximate basis \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) towards the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\) with respect to the error measure
has been illustrated in Fig. . The error behaves like \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-3.0}\) with respect to the number of collocation points.

Model problem in the unit square when \(\varsigma = 6\): Convergence of the approximate solution \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) to the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\). The points represent values of the error measure \(\theta _{\epsilon }\) on a log-log scale. Dashed lines represent algebraic rates \(\varepsilon ^{1.0}\) and \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-3.0}\)
We now repeat the previous exercise for \(\varsigma = 3\). Note that Theorem 2 does not in fact hold for this value of \(\varsigma \) but numerically we observe convergence nevertheless. The faster rate of convergence of the terms in the Karhunen-Loève expansion (8) justifies the use of a sparser discretization in physical space. In this case the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\) is obtained from the one-dimensional equation (22) using a mesh of 160 second order line elements. For the reference solution we set \(\varepsilon > 0\) so that the number of multi-indices is \(\# \mathcal {A}_{\varepsilon }(\varvec{\eta }) = 302\) and the greatest active dimension is \(M_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 129\), which gives us \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 1053\) collocation points. Again we compute a series of solutions \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) from the two-dimensional equation (7) using different values of \(\varepsilon > 0\) and a mesh of 6724 second order quadrilateral elements. Convergence of the approximate basis \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) towards the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\) has been illustrated in Fig. . In this case the error behaves like \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-1.5}\) with respect to the number of collocation points.

Model problem in the unit square when \(\varsigma = 3\): Convergence of the approximate solution \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) to the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\). The points represent values of the error measure \(\theta _{\epsilon }\) on a log-log scale. Dashed lines represent algebraic rates \(\varepsilon ^{1.0}\) and \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-1.5}\)
For comparison, let us naively try to solve the second eigenvector \(u_2\) using our stochastic collocation algorithm. From Fig. 2 it is obvious that \(\mu _2({\textbf{y}})\) is not separated from the rest of the spectrum for all \({\textbf{y}}\in \varGamma \) and the subspace \(U_{\{2\}}\) is thus not isolated. We compute the reference solution \(\{ {\hat{u}}^*_2 \}\) using the two-dimensional equation (7) and a mesh of 6724 quadrilateral elements. Again we set \(\varepsilon > 0\) so that the number of multi-indices is \(\# \mathcal {A}_{\varepsilon }(\varvec{\eta }) = 302\) and the greatest active dimension is \(M_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 129\), which gives us \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 1053\) collocation points for the reference solution. Figure illustrates the convergence of the approximate eigenvalue \(\{ {\hat{u}}^{\varepsilon }_2 \}\) computed on the same deterministic mesh for different values of \(\varepsilon > 0\) towards the reference solution \(\{ {\hat{u}}^*_2 \}\) when \(\varsigma = 3\). In this case convergence is virtually nonexistent compared to the one observed in Fig. 4. Hence, we conclude that the convergence order predicted by Proposition 3 may indeed break down for eigenvalues that are not separated from the rest of the spectrum or for subspaces that are not isolated. Moreover, using the canonical basis vectors from Sect. 2.3 is essential to the algorithm as the subspace cannot necessarily be constructed by naively computing the respective individual eigenvectors.

Model problem in the unit square when \(\varsigma = 3\): Convergence of the approximate solution \(\{ {\hat{u}}^{\varepsilon }_2 \}\) to the reference solution \(\{ {\hat{u}}^*_2 \}\). The points represent values of the \(L^2_{\nu }(\varGamma ) \otimes H^1(D)\) error on a log-log scale. Dashed lines represent algebraic rates \(\varepsilon ^{1.0}\) and \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-1.5}\) that were observed in the previous example of Fig. 4
5.2 General uncertainty model in a dumbbell shaped domain
In this section we consider the stochastic diffusion problem (7) in a dumbbell shaped domain. The geometry of the domain D is illustrated in Fig. . Again we let \(a_0 := 1 + C_D\), where \(C_D\) is the Poincaré constant for D. For \(m \in {\mathbb {N}}\) and \(\varsigma > 1\) we set
where \((k_m, l_m)\) denotes the m:th element of \({\mathbb {N}}^2\) with respect to increasing graded lexicographic order. As previously, the assumptions (1) and (2) hold with \(\alpha _0 = 1\) and \(\kappa _m = (m+1)^{-\varsigma }\), whereas for \(\varsigma \ge 2\) we have \(\left\Vert \varvec{\kappa }\right\Vert _{\ell ^1({\mathbb {N}})} < 1\). In the following examples we again use the values \(\varsigma = 3\) and \(\varsigma = 6\) and define the multi-index sets \(\mathcal {A}_{\varepsilon }(\varvec{\eta }) \subset ({\mathbb {N}}_0^{\infty })_c\) according to the Eqs. (18)–(20).

The dumbbell domain: Two unit squares connected by a small middle part of size \(h_D = w_D = 3/10\) (height and width)
In this example we focus on the subspace \(U_J\) for \(J = \{ 3,4,5,6 \}\). Figure illustrates the corresponding eigenvalues as a function of the first parameter \(y_1 \in [-\,1,1]\) when the rest are held constant. Now it seems that all four eigenvalues are tightly clustered and we observe multiple crossing points for the eigenvalues. An example of the associated eigenfunctions at \({\textbf{y}}= \textbf{0}\) has been shown in Fig. .

Model problem in the dumbbell domain with \(\varsigma = 3\): First few eigenvalues as a function of \(y_1 \in [-1,1]\) when \(y_2 = y_3 = \ldots = 0\)
The approximate eigenvalues of the model problem at \({\textbf{y}}= \textbf{0}\) obtained using a standard deterministic solver are
Hence, for \(S=3\) we have \(\delta _0 \approx 1.4205\) and for \(S=6\) we have \(\delta _0 \approx 0.59766\) in Eq. (9). Moreover, \(\varvec{\kappa }\) is as in the previous example. Again with these values the conditions of Corrollary 1 hold for both \(S = 2\) and for \(S = 6\) and the subspace \(U_{\{ 3,4,5,6 \}}\) is isolated with parameter \(\delta \approx 0.061\) and \(\delta \approx 0.54\) for the cases \(\varsigma = 3\) and \(\varsigma = 6\) respectively.

Model problem in the dumbbell domain: Eigenfunctions 3 to 6 at \({\textbf{y}}= \textbf{0}\)
We start our convergence analysis from the case \(\varsigma = 6\). We compute a reference solution \(\{ {\hat{u}}^*_i \}_{i=3}^6\) using a mesh of 220,756 second order triangular elements. In computing this reference solution we set \(\varepsilon > 0\) so that the number of multi-indices is \(\# \mathcal {A}_{\varepsilon }(\varvec{\eta }) = 28\) and the greatest active dimension is \(M_{\mathcal {A}} = 16\). This results in \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 77\) collocation points. We then compute a series of solutions \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=3}^6\) using the same deterministic mesh. Convergence of these approximate basis vectors \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=3}^6\) towards the reference solution \(\{ {\hat{u}}^*_i \}_{i=3}^6\) with respect to the error measure
has been illustrated in Fig. . The error behaves like \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-3.0}\) with respect to the number of collocation points.

Model problem in the dumbbell domain when \(\varsigma = 6\): Convergence of the approximate solution \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) to the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\). The points represent values of the error measure \(\theta _{\epsilon }\) on a log-log scale. Dashed lines represent algebraic rates \(\varepsilon ^{1.0}\) and \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-3.0}\)
Finally we repeat the previous exercise for \(\varsigma = 3\). Again, Theorem 2 does not hold for this value of \(\varsigma \) but we still observe convergence numerically. In this case we use a mesh of 10,074 second order triangular elements. We compute a reference solution \(\{ {\hat{u}}^*_i \}_{i=3}^6\) with \(\varepsilon > 0\) such that the number of multi-indices is \(\# \mathcal {A}_{\varepsilon }(\varvec{\eta }) = 302\) and the greatest active dimension is \(M_{\mathcal {A}} = 129\), which gives us \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })} = 1053\) collocation points. We then compute a series of solutions \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=3}^6\) using different values of \(\varepsilon > 0\) and the same deterministic mesh. Convergence of the approximate basis \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=3}^6\) towards the reference solution \(\{ {\hat{u}}^*_i \}_{i=3}^6\) has been illustrated in Fig. . Again the error behaves like \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-1.5}\) with respect to the number of collocation points.

Model problem in the dumbbell domain when \(\varsigma = 3\): Convergence of the approximate solution \(\{ {\hat{u}}^{\varepsilon }_i \}_{i=1}^3\) to the reference solution \(\{ {\hat{u}}^*_i \}_{i=1}^3\). The points represent values of the error measure \(\theta _{\epsilon }\) on a log-log scale. Dashed lines represent algebraic rates \(\varepsilon ^{1.0}\) and \(N_{\mathcal {A}_{\varepsilon }(\varvec{\eta })}^{-1.5}\)
6 Conclusions and future prospects
We have studied the eigenvalue problem of an operator that depends affinely on a countable number of input parameters. We have shown that if a set of eigenvalues is strictly separated from the rest of the spectrum, then the subspace spanned by the corresponding eigenvectors exhibits analytic dependence on the input parameters. We have then defined a set of canonical basis vectors that span this subspace and are smooth also in the vicinity of eigenvalue crossings. Hence, stochastic collocation methods, with known rates of convergence, may be applied to compute these canonical basis vectors.
In our numerical examples we have applied a sparse multi-index stochastic collocation algorithm to computing subspaces of a stochastic diffusion operator written in its Karhunen-Loève expansion. Our examples show that optimal rates of convergence hold even in the presence of eigenvalue crossings. In fact, in our examples we observe fast rates of convergence even if the terms in the Karhunen-Loève series decay too slowly for the current theory to hold. The validity of our collocated solution has been verified by comparing the results of our subspace algorithm to the results of a simple eigenvalue algorithm applied to the same problem in a dimensionally reduced form. We note, that a computationally more efficient solver for the problem at hand could be obtained by a sparse composition of the stochastic and spatial approximation operators, see e.g. [3] and [1].
In the current paper we have introduced an algorithm for computing a basis for the eigenspace of interest with the drawback that the individual eigenvalues and eigenvectors are lost in this process. In some cases, see for instance [15], we could try to regain the eigenvalues by tracking smooth branches of the eigenmodes within the parameter space. However, in the general case with more than one parameter, smooth branches might not always exist: See the example by Rellich given in [22], page 60. In order to overcome this problem, we would need to consider non-smooth solution methods, i.e., ones that does not rely on the analyticity of the solution. This topic is left for future research.
References
Andreev, R., Schwab, C.: Sparse tensor approximation of parametric eigenvalue problems. In: Lecture Notes in Computational Science and Engineering, vol. 83, pp. 203–241. Springer Berlin Heidelberg (2012)
Benner, P., Onwunta, A., Stoll, M.: A low-rank inexact Newton–Krylov method for stochastic eigenvalue problems. Comput. Methods Appl. Math. 19(1), 5–22 (2018)
Bieri, M., Andreev, R., Schwab, C.: Sparse tensor discretization of elliptic sPDEs. SIAM J. Sci. Comput. 31(6), 4281–4304 (2009)
Bungartz, H., Griebel, M.: Sparse grids. Acta Numer. 13, 147–269 (2004)
Cohen, A., DeVore, R., Schwab, C.: Convergence rates of best N-term Galerkin approximations for a class of elliptic sPDEs. Found. Comput. Math. 10(6), 615–646 (2010)
Davis, P.J.: Interpolation and Approximation. Numerical Mathematics and Scientific Computation. Dover Publications Inc, New York (1975)
Elman, H., Su, T.: Low-rank solution methods for stochastic eigenvalue problems. SIAM J. Sci. Comput. 41(4), A2657–A2680 (2019)
Gilbert, A.D., Graham, I.G., Kuo, F.Y., Scheichl, R., Sloan, I.H.: Analysis of quasi-Monte Carlo methods for elliptic eigenvalue problems with stochastic coefficients. Numer. Math. 142, 863–915 (2019)
Gittelson, C.J.: An adaptive stochastic Galerkin method for random elliptic operators. Math. Comput. 82, 1515–1541 (2013)
Griebel, M., Schneider, M., Zenger, C.: A combination technique for the solution of sparse grid problems. Iterative Methods in Linear Algebra pp. 263–281 (1992)
Hakula, H., Kaarnioja, V., Laaksonen, M.: Approximate methods for stochastic eigenvalue problems. Appl. Math. Comput. 267(C), 664–681 (2015). https://doi.org/10.1016/j.amc.2014.12.112
Hakula, H., Kaarnioja, V., Laaksonen, M.: Cylindrical shell with junctions: uncertainty quantification of free vibration and frequency response analysis. Shock Vib. (2018). https://doi.org/10.1155/2018/5817940
Hakula, H., Laaksonen, M.: Hybrid stochastic finite element method for mechanical vibration problems. Shock Vib. (2015). https://doi.org/10.1155/2015/812069
Hakula, H., Laaksonen, M.: Asymptotic convergence of spectral inverse iterations for stochastic eigenvalue problems. Numer. Math. 142(3), 577–609 (2019)
Hakula, H., Laaksonen, M.: Multiparametric shell eigenvalue problems. Comput. Methods Appl. Mech. Eng. 343, 721–745 (2019)
Hervé, M.: Analyticity in Infinite Dimensional Spaces, De Gruyter Studies in Mathematics, vol. 10. Walter De Gruyter Inc., Berlin (1989)
Hörmander, L.: An introduction to complex analysis in several variables. Amsterdam, New York: North-Holland Pub. Co.; American Elsevier Pub. Co (1973)
Kato, T.: Perturbation Theory for Linear Operators, 2nd edn. Springer-Verlag, Berlin Heidelberg (1995)
Meidani, H., Ghanem, R.: Spectral power iterations for the random eigenvalue problem. AIAA J. 52(5), 912–925 (2014)
Nobile, F., Tempone, R., Webster, C.G.: An anisotropic sparse grid stochastic collocation method for partial differential equations with random input data. SIAM J. Numer. Anal. 46(5), 2411–2442 (2008)
Nobile, F., Tempone, R., Webster, C.G.: A sparse grid stochastic collocation method for elliptic partial differential equations with random input data. SIAM J. Numer. Anal. 46(5), 2309–2345 (2008)
Reed, M., Simon, B.: IV: Analysis of Operators. Methods of Modern Mathematical Physics. Academic Press, Cambridge (1978)
Schwab, C., Todor, R.A.: Convergence rates for sparse chaos approximations of elliptic problems with stochastic coefficients. IMA J. Numer. Anal. 27, 232–261 (2006)
Sirković, P.: Low-rank methods for parameter-dependent eigenvalue problems and matrix equations. Ph.D. thesis, École Polytechnique Fédérale de Lausanne (2016)
Sousedík, B., Elman, H.C.: Inverse subspace iteration for spectral stochastic finite element methods. SIAM/ASA J. Uncertain. Quantif. 4(1), 163–189 (2016)
Verhoosel, C.V., Gutiérrez, M.A., Hulshoff, S.J.: Iterative solution of the random eigenvalue problem with application to spectral stochastic finite element systems. Int. J. Numer. Methods Eng. 68(4), 401–424 (2006)
Xiu, D., Hesthaven, J.S.: High-order collocation methods for differential equations with random inputs. SIAM J. Sci. Comput. 27(3), 1118–1139 (2005)
Funding
Open Access funding provided by Aalto University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The work of L.G. has been supported by the Croatian Science Foundation Grant IP-2019-04-6268. We gratefully acknowledge the support.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Grubišić, L., Saarikangas, M. & Hakula, H. Stochastic collocation method for computing eigenspaces of parameter-dependent operators. Numer. Math. 153, 85–110 (2023). https://doi.org/10.1007/s00211-022-01339-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-022-01339-3