
Abstract
In this paper, we examine the results of GDP trend–cycle decompositions from the estimation of bivariate unobserved components models that allow for correlated trend and cycle innovations. Three competing variables are considered in the bivariate setup along with GDP: the unemployment rate, the inflation rate, and gross domestic income. We find that the unemployment rate is the preferred variable to accompany GDP in the bivariate setup to obtain accurate estimates of its trend–cycle correlation coefficient and the cycle. We show that the key feature of the unemployment rate that allows for reliable estimates of the cycle of GDP is that its nonstationary component is small relative to its cyclical component. Using quarterly GDP and unemployment rate data from 1948:Q1 to 2019:Q1, we obtain a trend–cycle decomposition of GDP that resembles the conventional CBO estimates; we find positively correlated trend and cycle components.







Similar content being viewed by others


Notes
Here, \(\tilde{\phi } =\frac{1-\phi _2}{(1+\phi _2)(1-\phi _1-\phi _2)(1+\phi _1-\phi _2)}>0\).
In that case, \(\tilde{\phi }>1\).
When testing for statistical significance of the trend–cycle correlation coefficient of GDP, \(\rho _{\eta ^y\varepsilon }\), Clark (1989) assumed that the other two correlation coefficients were zero, implying a less general framework than the one presented here.
In fact, the model Stella and Stock (2016) propose has the unemployment and the inflation rates as observables, as opposed to GDP and the inflation rate. The aim, however, is the same as in the models with GDP as observable: to disentangle the cyclical and trend movements in key macroeconomic variables.
Lee et al. (1968), Wang and Zivot (2000), and Jacquier et al. (2002) conduct Monte Carlo studies similar to ours to explore the properties of the Bayesian estimator proposed in their papers. Usually, the approach investigates the bias of the posterior mean estimators of the parameters of interest and their root mean-squared error.
We compute the properties of the cycle conditional on the posterior mean estimates of the parameters because most papers in the literature focus on the models’ estimated coefficients.
\(\psi _0=1, \psi _1 = \phi _1, \psi _2 = \phi _1\psi _1 + \phi _2, \psi _j = \phi _1\psi _{j-1} +\phi _2\psi _{j-2}\) for \(j\ge 3.\)
The number of draws is 15,000 before burning in and thinning.
In fact, by using the method in Grant and Chan (2017) to compute the marginal data density of an estimated univariate model that allows for correlated trend–cycle disturbances and compare it with that of a model that does not allow it, one would conclude that the model has correlated disturbances 91% of the times for a sample size of 200 observations and 26% of the times for a sample size of 1000 observations, when there is none.
Morley and Wong (2020) find that the unemployment rate provides key information to estimate the Beveridge–Nelson cycle of GDP when using a large set of variables in a Bayesian VAR.
As noted in Fleischman and Roberts (2011), there are prior theoretical reasons to expect the unemployment and output trends to be negatively correlated. When we allow for a negative correlation consistent with the theoretical considerations and our benchmark parameterization (\(\rho _{\eta ^y\eta ^x}=-0.14\)), we find in our Monte Carlo simulations that the trend–cycle correlation of output has an almost negligible negative bias for a sample size equal to 200. The bias increases with the correlation between trends but even at large values in absolute terms, the bias in the trend–cycle correlation is small (around − 0.05). The bias declines with the sample size; it practically disappears for a sample size equal to 1000, regardless of the (negative) value of the trends’ correlation.
Basistha’s estimation also finds a statistically significant MA(1) term, which, along with the other estimated parameters, implies a lower contribution of the variance of the cycle to the variance of inflation compared with the case in which there is not such a term.
The variance decomposition of the auxiliary variable under the benchmark parameterization in Basistha’s Monte Carlo exercise is 5.8%.
We assume the intercept innovation is orthogonal to the other innovations, as is standard in the literature.
See Haltmaier (2012), Ball (2014), and Reifschneider et al. (2015) for discussions of the role of hysteresis. The finding of a positive correlation between trend and cycle appears to be importantly affected by the experience after the Great Recession. If the estimation were to be conducted with data ending in 2017:Q4 (or earlier), the 68% credibility interval would include \(\rho _{\eta ^y\varepsilon } = 0\).
Estimation allowing for a different variance–covariance structure pre- and post-Great Moderation appears in Appendix F. This estimation yields very similar results compared with the homoskedastic case regarding the GDP cycle and trend as well as the correlation coefficients, although it increases the uncertainty around these latter estimates.
We use a training sample that covers 1948:Q1 to 1967:Q4 to condition our Bayes factor. The one-cycle model obtains a log marginal density equal to − 142.48, whereas the two-cycle model, − 430.96.
Grant and Chan (2017) obtain conditional log marginal data densities for GDP for bivariate models that include the unemployment and inflation rates as the accompanying variables and that allow for separate cycles for each variable. They find that the preferred model includes the unemployment rate. However, these authors do not consider bivariate models in which the observable variables share a single cycle as in the present paper.
Strictly speaking, we assume that the scale matrix of the inverse Wishart distribution has degrees of freedom equal to the dimension of the matrix plus two, when we had assumed in our previous simulation exercises that the degrees of freedom were equal to the dimension of the matrix plus one only.
We also used the intrinsic Bayes factor to compare the estimated models, using a training sample equivalent to a third of the whole sample, and the results still indicated, incorrectly, that the data preferred the one-cycle model, although to a lesser extent than when the usual Bayes factor was used.
References
Abel AB, Bernanke B, Croushore D (2013) Macroeconomics, 8th edn. Prentice Hall, Prentice
Ball L (2014) Long-term damage from the Great Recession in OECD countries. Eur J Econ Econ Policies Interv 11:149–160
Basistha A (2007) Trend-cycle correlation, drift break and the estimation of trend and cycle in Canadian GDP (Corrélation tendance-cycle, discontinuité, et estimation de la tendance et du cycle dans le PIB canadien). Can J Econ 40:584–606
Basistha A (2009) Hours per capita and productivity: evidence from correlated unobserved components models. J Appl Econom 24:187–206
Basistha A, Nelson CR (2007) New measures of the output gap based on the forward-looking new Keynesian Phillips curve. J Monet Econ 54:498–511
Basistha A, Startz R (2008) Measuring the NAIRU with reduced uncertainty: a multiple-indicator common-cycle approach. Rev Econ Stat 90:805–811
Berger JO, Pericchi LR (1996) The intrinsic Bayes factor for model selection and prediction. J Am Stat Assoc 91:109–122
Berger T, Everaert G, Vierke H (2016) Testing for time variation in an unobserved components model for the U.S. economy. J Econ Dyn Control 69:179–208
Chan JCC, Grant AL (2017) Measuring the output gap using stochastic model specification search. CAMA Working Paper No. 2/2017
Chib S (1995) Marginal likelihood from the Gibbs output. J Am Stat Assoc 90:1313–1321
Clark PK (1987) The cyclical component of U.S. economic activity. Q J Econ 102:797–814
Clark PK (1989) Trend reversion in real output and unemployment. J Econom 40:15–32
Fixler DJ, Nalewaik JJ (2007) News, noise, and estimates of the “true” unobserved state of the economy. Finance and Economics Discussion Series 2007–34, Board of Governors of the Federal Reserve System (U.S.)
Fleischman C, Roberts JM (2011) From many series, one cycle: improved estimates of the business cycle from a multivariate unobserved components model. Finance and Economics Discussion Series 2011-46, Board of Governors of the Federal Reserve System (U.S.)
Grant AL, Chan JCC (2017) A Bayesian model comparison for trend-cycle decompositions of output. J Money Credit Bank 49:525–552
Haltmaier J (2012) Do recessions affect potential output? International Finance Discussion Papers 1066, Board of Governors of the Federal Reserve System (U.S.)
Jacquier E, Polson NG, Rossi P (2002) Bayesian analysis of stochastic volatility models. J Bus Econ Stat 20:69–87
Kim C-J, Kim J (2018) Trend-cycle decompositions of real GDP revisited: classical and Bayesian perspectives on an unsolved puzzle. Technical report, Available at SSRN 2883438
Kim J, Chon S (2020) Why are Bayesian trend-cycle decompositions of US real GDP so different? Empir Econ 58:1339–1354
Kuttner KN (1994) Estimating potential output as a latent variable. J Bus Econ Stat 12:361–368
Lee TC, Judge GG, Zellner A (1968) Maximum likelihood and Bayesian estimation of transition probabilities. J Am Stat Assoc 63:1162–1179
Luo S, Startz R (2014) Is it one break or ongoing permanent shocks that explains U.S. real GDP? J Monet Econ 66:155–163
Morley JC, Nelson CR, Zivot E (2003) Why are the Beveridge-Nelson and unobserved-components decompositions of GDP so different? Rev Econ Stat 85:235–243
Morley J, Wong B (2020) Estimating and accounting for the output gap with large Bayesian vector autoregressions. J Appl Econom 35:1–18
Nalewaik JJ (2010) The income- and expenditure-side estimates of U.S. output growth. Brook Pap Econ Act 41:71–127
Nelson CR, Plosser CR (1982) Trends and random walks in macroeconmic time series: some evidence and implications. J Monet Econ 10:139–162
Perron P, Wada T (2009) Let’s take a break: trends and cycles in US real GDP. J Monet Econ 56:749–765
Reifschneider D, Wascher W, Wilcox D (2015) Aggregate supply in the United States: recent developments and implications for the conduct of monetary policy. IMF Econ Rev 63:71–109
Roberts JM (2001) Estimates of the productivity trend using time-varying parameter techniques. B.E. J Macroecon 1:1–32
Sinclair TM (2009) The relationships between permanent and transitory movements in U.S. output and the unemployment rate. J Money Credit Bank 41:529–542
Stella A, Stock JH (2016) A state-dependent model for inflation forecasting. In: Koopman SJ, Shephard N (eds) Unobserved components and time series econometrics. Oxford University Press, Oxford, pp 14–29 Chap. 3
Stock JH, Watson M (2007) Why Has U.S. inflation become harder to forecast? J Money Credit Bank 39:3–33
Stock J, Watson M (1999) Business cycle fluctuations in U.S. macroeconomic Time Series. In: Taylor J, Woodford M Handbook of Macroeconomics. Amsterdam: Elsevier, pp. 3–64
Wada T (2012) On the correlations of trend-cycle errors. Econ Lett 116:396–400
Wang J, Zivot E (2000) A Bayesian time series model of multiple structural changes in level, trend, and variance. J Bus Econ Stat 18:374–386
Watson MW (1986) Univariate detrending methods with stochastic trends. J Monet Econ 18:49–75
Zellner A, Ando T (2010) A direct Monte Carlo approach for Bayesian analysis of the seemingly unrelated regression model. J Econom 159:33–45
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank Timothy Hills, Philip Coyle, and Mark Wilkinson for speedy and accurate research assistance. An anonymous referee provided insightful comments that helped us improve an earlier version of this paper. The views expressed in this paper are solely the responsibility of the authors and should not be interpreted as reflecting the views of the Board of Governors of the Federal Reserve System.
Appendices
Appendix A: Effect of the trend–cycle correlation on the contribution of the cycle to the variance of output growth
With the variance decomposition of the change in output growth given by
one can obtain the partial derivative with respect to \(\rho _{\eta ^y \varepsilon }\), yielding the following expression:
where
We note that \(\tilde{\phi }>1\) for \(\phi _2\in (-1,0)\) and \(\phi _1 \in (0,1-\phi _2)\). Therefore, a sufficient condition for the derivative (A.1) to be positive, i.e., that the contribution of the cycle to the variance decomposition of output is increasing with the value of the trend–cycle correlation, is
Appendix B: Monte Carlo results from the bivariate model for the other correlation coefficients
In this section, we assume the benchmark parameterization in Table 1 and vary the sample size (Fig. 8) and the variance of the trend of the accompanying variable (Fig. 9), as we did in Sect. 4.1.1. We report the distributions of the posterior mean estimates of the different correlation coefficients of the bivariate model.

Frequency distribution of correlation coefficients varying sample size

Frequency distribution of correlation coefficients varying variance of accompanying variable
Appendix C: Mapping between the coefficients of the two- and one-cycle models when the latter is the true data generating process
Under the DGP, we have that \(c_t^y = c_t\) and \(c_t^x = \theta c_t\), where \(c_t = \phi _1 c_{t-1} + \phi _2 c_{t-2} + \varepsilon _t\), as in Eq. (18). Hence, the autocovariance function of \(c_t^x\) is as follows:
for all j, where \(\gamma _j = {{\,\mathrm{cov}\,}}(c_t,c_{t-j})\), and the autocorrelation function is as shown below:
for all j, where \(r_j = {{\,\mathrm{corr}\,}}(c_t,c_{t-j})\). As a consequence, we have that \(\phi ^x_1 = \phi _1\) and \(\phi _2^x = \phi _2\). Moreover, because \(\gamma _0^x = \theta ^2 \gamma _0\), we obtain that
In addition, we can prove that the correlation coefficient between the cycle innovations in the estimated two-cycle model should be (plus or minus) one if the DGP has only one cycle, as follows. First, because \(c_t^x = \theta c_t = \theta c_t^y\) in the estimated model, we know that
Second, using the Wold decomposition and the fact that \(\phi ^x_1 = \phi _1=\phi ^y_1\) and \(\phi _2^x = \phi _2 = \phi _2^y\), we also know that
where \(\psi _j\), for \(j=0,1,\ldots ,\infty \), are the coefficients of the Wold decomposition of an AR(2) process with coefficients \(\phi _1\) and \(\phi _2\). Combining (C.2) and (C.3), we obtain that
Hence, from (C.1) and (C.4), the correlation between the cycle innovations in the estimated two-cycle model would be given by the following:
Finally, all the other correlation coefficients between innovations in the estimated two-cycle model should be zero if the same holds in the DGP.
Appendix D: Mapping between the coefficients of the one- and two-cycle models when the latter is the true data generating process
Under the one-cycle estimated model, using (16), we have that
and
Under the DGP,
where
with \(\tilde{\phi }_1^j = \phi _1^j-1\) for \(j=x,y\). Hence,
where \(\tilde{\psi }_i^j\) for \(i=0,1,2,\ldots ,\infty \) and \(j=x,y\) are the coefficients of the Wold decomposition of the AR(2) processes (D.1) and (D.2), respectively.
Appendix E: Estimation results from alternative specifications
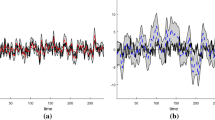
This section presents the results from all the bivariate specifications considered in the paper and adds the specification proposed by Sinclair (2009) in which there are specific trends and cycles in real GDP and the unemployment rate. Figure 10 depicts the estimated GDP cycles and their 68% credibility intervals, Fig. 11 shows the estimated mean trend output growth rate and its 68% credibility interval, and Table 7 contains the posterior mean estimates of the parameters of the different models.

Smoothed GDP cycle

Mean trend output growth rate

Estimation results under heteroskedasticity
Appendix F: GDP–unemployment rate model estimation results under heteroskedasticity
As a sensitivity exercise, we estimate the GDP–unemployment rate model of Sect. 5 allowing for heteroskedasticity. In particular, we assume that the variance–covariance matrix of the innovations of the model suffers a structural break starting in 1986, a period denominated as the Great Moderation. This specification implies that both variances and correlation coefficients are allowed to differ between the two parts of the sample. Results appear in Fig. 12.
As can be seen, the output gap estimate is very similar to that obtained under the homoskedasticity assumption shown in Fig. 7, except perhaps for a reduction in the uncertainty around the estimate starting around the second half of the 1980s, as a consequence of the lower variance estimates whose estimates appear in Table 8. In general, all the innovations of the model experience a reduction in their variance during the Great Moderation compared with the previous period.
Regarding the correlation coefficients, their posterior mean estimates keep their signs compared with the homoskedastic case. However, splitting the sample has consequences on the uncertainty around them. In particular, the trend–cycle correlation coefficient of output has credible sets that now include zero.
Rights and permissions
About this article

Cite this article
González-Astudillo, M., Roberts, J.M. When are trend–cycle decompositions of GDP reliable?. Empir Econ 62, 2417–2460 (2022). https://doi.org/10.1007/s00181-021-02105-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-021-02105-4