
Abstract
Neural networks have demonstrated great success; however, large amounts of labeled data are usually required for training the networks. In this work, a framework for analyzing the road and traffic situations for cyclists and pedestrians is presented, which only requires very few labeled examples. We address this problem by combining convolutional neural networks and random forests, transforming the random forest into a neural network, and generating a fully convolutional network for detecting objects. Because existing methods for transforming random forests into neural networks propose a direct mapping and produce inefficient architectures, we present neural random forest imitation—an imitation learning approach by generating training data from a random forest and learning a neural network that imitates its behavior. This implicit transformation creates very efficient neural networks that learn the decision boundaries of a random forest. The generated model is differentiable, can be used as a warm start for fine-tuning, and enables end-to-end optimization. Experiments on several real-world benchmark datasets demonstrate superior performance, especially when training with very few training examples. Compared to state-of-the-art methods, we significantly reduce the number of network parameters while achieving the same or even improved accuracy due to better generalization.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
During the last few years, the availability of spatial data has rapidly developed. An essential aspect of this development is the involvement of a large number of users, who often use smartphones and mobile devices, to generate and make freely available volunteered geographic information (VGI). For example, apps like Waze combine the local velocities of smartphones (in cars) to predict the flow velocities (and time delay) of traffic jams. Users can recommend and comment on specific traffic situations. Although GPS and gyroscope data (e.g., in fitness straps) are common, images allow a comprehensive scene understanding. The collection of large amounts of unlabeled images is easy; however, the development of machine learning methods for scene analysis with limited amounts of labeled data is challenging.
Neural networks have become very popular in many areas, such as computer vision (Krizhevsky et al. 2012; Reinders et al. 2022; Ren et al. 2015; Simonyan and Zisserman 2015; Zhao et al. 2017; Qiao et al. 2021; Rudolph et al. 2022; Sun et al. 2021a), speech recognition (Graves et al. 2013; Park et al. 2019; Sun et al. 2021a), automated game-playing (Mnih et al. 2015; Dockhorn et al. 2017), or natural language processing (Collobert et al. 2011; Sutskever et al. 2014; Otter et al. 2021). Researchers have published many datasets for training neural networks and put enormous effort into providing labels for each data sample. For real-world applications, the dependency on large amounts of labeled data represents a significant limitation (Breiman et al. 1984; Hekler et al. 2019; Barz and Denzler 2020; Qi and Luo 2020; Phoo and Hariharan 2021; Wang et al. 2021). Frequently, there is little or even no labeled data for a particular task, and hundreds or thousands of examples have to be collected and annotated. This particularly affects new applications and rare labels (e.g., detecting rare diseases or defects in manufacturing). Transfer learning and regularization methods are usually applied to reduce overfitting. However, for training with little data, the networks still have a considerable number of parameters that have to be fine-tuned—even if just the last layers are trained.
In contrast to neural networks, random forests are very robust to overfitting due to their ensemble of multiple decision trees. Each decision tree is trained on randomly selected features and samples. Random forests have demonstrated remarkable performance in many domains (Fernández-Delgado et al. 2014). While the generated decision rules are simple and interpretable, the orthogonal separation of the feature space can also be disadvantageous on other datasets, especially with correlated features (Menze et al. 2011). Additionally, random forests are not differentiable and cannot be fine-tuned with gradient-based optimization.
In this research project Comprehensive Conjoint GPS and Video Data Analysis for Smart Maps (COVMAP), we are interested in combining GPS, gyroscope, and image data to analyze road and traffic situations for cyclists and pedestrians. Our standard setting is a smartphone attached to a bicycle, which records the GPS coordinates, images, motion information, local weather information, and time. We present a framework for detecting traffic signs that are of interest for cyclists and pedestrians. Related to this work, Chap. 3 introduces methods for anonymizing and map-matching trajectories, and Chap. 1 presents a geographic knowledge graph for a semantic representation of geographic entities in OSM. The goal of this work is to minimize the costs of annotating a dataset and enable the detection of objects with only a handful of examples per class. For that, we combine neural networks and random forests and bring both worlds together. After generating a classifier for image patches, the random forest is mapped to a neural network to combine all modules in a single pipeline, and a fully convolutional network is created for object detection.
Mapping random forests into neural networks is already used in many applications such as network initialization (Humbird et al. 2019), camera localization (Massiceti et al. 2017), object detection (Reinders et al. 2018), or semantic segmentation (Richmond et al. 2016). State-of-the-art methods (Massiceti et al. 2017; Sethi 1990; Welbl 2014) create a two-hidden-layer neural network by adding a neuron for each split node and each leaf node of the decision trees. The number of parameters of the networks becomes enormous as the number of nodes grows exponentially with the increasing depth of the decision trees. Additionally, many weights are set to zero so that an inefficient representation is created. Due to both reasons, the mappings do not scale and are only applicable to simple random forests.
In this work, we present an imitation learning approach to generate neural networks from random forests, which results in very efficient models. We introduce a method for generating training data from a random forest that creates any amount of input-target pairs. With this data, a neural network is trained to imitate the random forest. Experiments demonstrate that the accuracy of the imitating neural network is equal to the original accuracy or even slightly better than the random forest due to better generalization while being significantly smaller. To summarize, our contributions are:
-
We present a pipeline for detecting and localizing traffic signs for cyclists and pedestrians with very few labeled training examples by combining convolutional neural networks and random forests.
-
We propose a novel method for implicitly transforming random forests into neural networks by generating data from a random forest and training an random forest-imitating neural network. Labeled data samples are created by evaluating the decision boundaries and guided routing to selected leaf nodes.
-
In contrast to direct mappings, our imitation learning approach is scalable to complex classifiers and deep random forests.
-
We enable learning and initialization of neural networks with very little data.
-
Neural networks and random forests can be combined in a fully differentiable, end-to-end pipeline for acceleration and further fine-tuning.
2 Related Work
Many deep learning-based methods have been presented for object detection in recent years. Two-stage methods like R-CNN (Girshick et al. 2014), Fast R-CNN (Girshick 2015), and Faster R-CNN (Ren et al. 2015) include a region proposal mechanism and predict the object scores and boundaries based on the pooled features. Cascade R-CNN (Cai and Vasconcelos 2018) consists of multiple R-CNN stages that progressively refine the predicted bounding boxes. Sparse R-CNN (Sun et al. 2021b) learns a fixed set of bounding box candidates. One-stage methods achieve great performance by regressing and classifying candidate bounding boxes of a predefined set of anchor boxes. Well-known methods are SSD (Liu et al. 2016), YOLO (Redmon and Farhadi 2016), and RetinaNet (Lin et al. 2017). CenterNet (Duan et al. 2019) introduces a triplet representation, including one center keypoint and two corners. FCOS (Tian et al. 2019) presents a center-ness branch for anchor-free detection. YOLOF (Chen et al. 2021) uses a single-scale feature map without feature pyramid network. DETR (Carion et al. 2020) models object detection as a set prediction problem and introduces a vision transformer architecture. R(Det)\({ }^2\) (Li and Wang 2022) presents a combination of soft decision trees and neural networks for randomized decision routing. All the presented methods have a huge number of trainable parameters and require large amounts of labeled data for training.
Random forests and neural networks share some similar characteristics, such as the ability to learn arbitrary decision boundaries; however, both methods have different advantages. Random forests are based on decision trees. Various tree models have been presented—the most well known are C4.5 (Quinlan 1993) and CART (Breiman et al. 1984). Decision trees learn rules by splitting the data. The rules are easy to interpret and additionally provide an importance score of the features. Random forests (Breiman 2001) are an ensemble method consisting of multiple decision trees, with each decision tree being trained using a random subset of samples and features. Fernández-Delgado et al. (2014) conduct extensive experiments comparing 179 classifiers on 121 UCI datasets (Dua and Graff 2017). The authors show that random forests perform best, followed by support vector machines with a radial basis function kernel. Therefore, random forests are often considered as a reference for new classifiers.
Neural networks are universal function approximators. The generalization performance has been widely studied. Zhang et al. (2017) demonstrate that deep neural networks are capable of fitting random labels and memorizing the training data. Bornschein et al. (2020) analyze the performance across different dataset sizes. Olson et al. (2018) evaluate the performance of modern neural networks using the same test strategy as Fernández-Delgado et al. (2014) and find that neural networks achieve good results but are not as strong as random forests.
Sethi (1990) presents a mapping of decision trees to two-hidden-layer neural networks. In the first hidden layer, the number of neurons equals the number of split nodes in the decision tree. Each of these neurons implements the decision function of the split nodes and determines the routing to the left or right child node. The second hidden layer has a neuron per leaf node in the decision tree. Each of the neurons is connected to all split nodes on the path from the root node to the leaf node to evaluate if the data is routed to the respective leaf node. Finally, the output layer is connected to all leaf neurons and aggregates the results by implementing the leaf votes. By using hyperbolic tangent and sigmoid functions, respectively, as activation functions between the layers, the generated network is differentiable and, thus, trainable with gradient-based optimization algorithms. The method can be easily extended to random forests by mapping all trees.
Welbl (2014) and Biau et al. (2019) follow a similar strategy. The authors propose a method that maps random forests into neural networks as a smart initialization and then fine-tunes the networks by backpropagation. Two training modes are introduced: independent and joint. Independent training fits all networks one after the other and creates an ensemble of networks as a final classifier. Joint training concatenates all tree networks into one single network so that the output layer is connected to all leaf neurons in the second hidden layer from all decision trees and all parameters are optimized together. Additionally, the authors evaluate sparse and full connectivity. Sparse connectivity maintains the tree structures and has fewer weights to train. In practice, sparse weights require a special differentiable implementation, which can drastically decrease performance, especially when training on a GPU. Full connectivity optimizes all parameters of the fully connected network. Massiceti et al. (2017) extend this approach and introduce a network splitting strategy by dividing each decision tree into multiple subtrees. The subtrees are mapped individually and share common neurons for evaluating the split decision.
These techniques, however, are only applicable to trees of limited depth. As the number of nodes grows exponentially with the increasing depth of the trees, inefficient representations are created, causing extremely high memory consumption. In this work, we address this issue by proposing an imitation learning-based method that results in much more efficient models.
3 Traffic Sign Recognition
In the first part of this chapter, we present a framework for object detection and localization that is able to recognize traffic signs for cyclists and pedestrians with very few labeled examples. While there are a lot of datasets for cars, the amount of labeled data for cyclists and pedestrians is very limited. Therefore, the advantages of convolutional neural networks and random forests are combined to build a robust object detector. After the detection of the objects, the image, GPS, and motion data are fused to localize the traffic signs on the map. We introduce an app for collecting and synchronizing data with a customary smartphone and present the captured dataset. Finally, experiments are performed to analyze the recognition performance. All details and further evaluations can be found in Reinders et al. (2018) and Reinders et al. (2019).
3.1 Framework
The framework consists of three modules. First, a system for object detection based on convolutional neural networks and random forests is presented. Afterward, the detected traffic signs are localized on the map by integrating GPS and motion information. Lastly, multiple observations are clustered to improve the precision.
3.1.1 Object Detection
In the first step, we train a convolutional neural network for representation learning on a related task where large amounts of data are available. In this application, the GTSRB (Stallkamp et al. 2012) dataset is selected, which consists of images of traffic signs for cars. The architecture of the network is a standard backbone (Springenberg et al. 2015) with multiple convolutional layers and a global average pooling. For generating the feature representations, the output of the last layer before the final classification layer is calculated.
On the downstream task, we start with a classifier for image patches. The feature representations of all patches and a fixed number of background patches are extracted. Because only a few number of labeled examples are available, we train a random forest to classify the image features and predict one of the C classes or background. The ensemble of multiple decision trees trained on different subsets of features and samples is very robust to overfitting (Breiman 2001).
Afterward, the convolutional neural network for feature generation and random forest for classification are combined in one pipeline. For that, we transform the random forest into a neural network using a method presented by Sethi (1990) and Welbl (2014). The method creates a two-hidden-layer neural network by mapping each decision tree of the random forest. An example of mapping a decision tree into a neural network is visualized in Fig. 5.1. For each split node in the decision tree, a neuron is created in the first hidden layer. The neurons are connected to the respective split features (all other weights are set to zero if no sparse architecture is used) and evaluate the split decisions, i.e., the routing to the left or right child node. In the second hidden layer, a neuron is created for each leaf node in the decision tree. The neurons combine the split decisions from the previous layer and determine whether the sample is routed to the respective leaf. In the output layer, the number of neurons corresponds to the number of classes. Each neuron stores the class votes from the leafs. Mapping a random forest, i.e., multiple decision trees, is done by mapping each decision tree and combining the neural networks. Now, we are able to create a fully convolutional network (Shelhamer et al. 2017) by replacing the fully connected layers with convolutional layers that perform the identical operation. Due to the shared features, the processing of the images is significantly accelerated. The images are analyzed by the fully convolutional network at multiple scales, and the output predicts the probability of each traffic sign class at each spatial position. In a post-processing, all detections with a probability larger than a defined threshold are extracted, and a non-maximum suppression is performed.

A decision tree (left) can be mapped to a two-hidden-layer neural network (right). For each split node (green circle) in the decision tree, a neuron in the first hidden layer is created which evaluates the split rule. For each leaf node (blue rectangle), a neuron in the second hidden layer is created which determines the leaf membership. A routing to leaf node 11, for example, involves the split nodes 0, 8, and 9. The relevant connections for the corresponding calculation in the neural network are highlighted
3.1.2 Localization
The detected 2D bounding boxes are localized on the map by integrating GPS and heading information. Each image is associated with a GPS position and a heading. The heading points in the direction in which the device is oriented. For each bounding box, the depth is estimated by assuming a simple pinhole camera model, and the relative heading is determined based on the horizontal position in the image. Afterward, the information can be combined with the GPS position and heading of the image to generate the latitude, longitude, and heading of the traffic sign.
3.1.3 Clustering
After localizing the traffic signs, we merge multiple observations of the same traffic sign. Clustering algorithms (MacQueen et al. 1967; Fukunaga and Hostetler 1975; Dockhorn et al. 2015, 2016; Schier et al. 2022) automatically discover natural groupings in the data. If multiple detections exist in an image, we can generate additional constraints because we know that multiple traffic signs exist and the respective traffic signs should not be grouped. The additional information is represented as cannot-link constraints. For weakly supervised clustering with an unknown number of clusters, constrained mean shift (CMS) (Schier et al. 2022) clustering is performed to merge the detections. CMS is a density-based clustering algorithm that extends mean shift clustering (Fukunaga and Hostetler 1975) by enabling sparse supervision using cannot-link constraints. The clustering of the detections improves the localization accuracy and makes the position estimation more robust.
3.2 Dataset
To analyze the road and traffic situations for cyclists and pedestrians, we collected a real-world dataset. For that, we developed an app for capturing and synchronizing images and data from other sensors, like GPS and motion information. The smartphone is attached to the handlebar of the bicycle so that the camera is pointed in the direction of travel. Because monotonous routes, e.g., in rural areas, produce many similar images, we therefore introduce an adaptive filtering of the images to automatically detect points of interest. For that, we integrate motion information and apply a twofold filtering strategy based on decreases in speed and acceleration: (i) Decreases in speed indicate situations where the cyclist has to slow down because of potential traffic obstructions such as traffic jams, construction works, or other road users. (ii) Acceleration is used to analyze the road conditions and to detect, for example, potholes.
The collected dataset consists of 500 tours with a total riding time of 6 days in different cities. A visualization of the collected tours in Hanover is shown in Fig. 5.2. After filtering, the dataset has 56000 images with a size of \(1080 \times 1920\) pixels. For the detection of traffic signs, we selected ten traffic signs that are of interest for cyclists and pedestrians and manually annotated the ground truth for a set of images to have data for training and testing. Overall, 524 bounding boxes are annotated in the images and split 50/50 in training and testing. The splitting is repeated multiple times with different seeds.

Example tracks collected around Hanover. In total, we collected in Hanover, 450 tours, \({>}47\)K images, 5.4 days of riding; Enschede, 40 tours, \({>}8\)K images, 18 hours of riding; and Heidelberg, 11 tours, 1000 images, several hours of riding
3.3 Experiments
The framework is evaluated on the presented dataset to analyze the recognition performance. For that, all bounding boxes are predicted at multiple scales and assigned to the ground truth bounding box with the highest overlap if the IoU is greater or equal than \(0.5\). The resulting precision-recall curve for each class is presented in Fig. 5.3. While the performance of the standard traffic signs is good, the more inconspicuous traffic signs are detected worse. The recognition performance of the latter correlates with the number of examples that are available for training. Qualitative examples are shown in Fig. 5.4. For more details and further analyses, please see Reinders et al. (2018) and Reinders et al. (2019).

Precision-recall curve for each class to analyze the recognition performance on the test set. (a) Standard traffic signs. (b) Info signs

Qualitative results of randomly selected examples on the test set. True positives, false positives, and false negatives are shown for each class. Some classes have less than two false positives or false negatives, respectively
4 Neural Random Forest Imitation
We propose a novel method, called neural random forest imitation (NRFI), for implicitly transforming random forests into neural networks that learns the decision boundaries and generates efficient representations. The advantages of our approach for mapping random forests into neural networks are threefold: (1) We enable the generation of neural networks with very few training examples. (2) The resulting network can be used as a warm start, is fully differentiable, and allows further end-to-end fine-tuning. (3) The generated network can be easily integrated into any trainable pipeline (e.g., jointly with feature extraction), and existing high-performance deep learning frameworks can be used directly. This accelerates the process and enables parallelization via GPUs. In the following, we evaluate on standard benchmark datasets to present a general approach for various domains. While we focus on classification tasks in this work, NRFI can be simply adapted for regression tasks.
4.1 Background and Notation
In this section, we briefly describe decision trees (Breiman et al. 1984), random forests (Breiman 2001), and the notation used throughout this work. Decision trees consist of split nodes\(N^{\text{split}}\) and leaf nodes\(N^{\text{leaf}}\). Each split node \(s \in N^{\text{split}}\) performs a split decision and routes a data sample x to the left or right child node, denoted as \(\operatorname {c}_{\text{left}}(s)\) and \(\operatorname {c}_{\text{right}}(s)\), respectively. When using binary, axis-aligned split decisions, a single feature \(f(s) \in \{1, \dots , N\}\) and a threshold \(\theta (s) \in \mathbb {R}\) are the basis for the split, where N is the number of features. If the value of feature \(f(s)\) is smaller than \(\theta (s)\), the data sample is routed to the left child node and otherwise to the right child node, denoted as
Data samples are routed through a decision tree until a leaf node \(l \in N^{\text{leaf}}\) is reached which stores the target value. For the classification task, these are the estimated class probabilities \(P_{\text{leaf}}(l) = (p^{l}_1, \dots , p^{l}_C)\), where C is the number of classes. Decision trees are trained by creating a root node and consecutively finding the best split of the data based on a criterion. The resulting subsets are assigned to the left and right child node, and the subtrees are processed further. Commonly used criteria are the Gini impurity or entropy.
A single decision tree is very fast and operates on high-dimensional data. However, it tends to overfit the training data by constructing a deep tree that separates perfectly all training examples. While having a very small training error, this easily results in a large test error. Random forests address this problem by learning an ensemble of \(n_T\) decision trees. Each tree is trained with a random subset of training examples and features. The prediction \( \operatorname {RF}(x)\) of a random forest is calculated by averaging the predictions of all decision trees.
4.2 Methodology
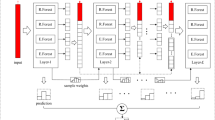
Our proposed neural random forest imitation approach implicitly transforms random forests into neural networks. The main concept includes (1) generating training data from decision trees and random forests, (2) adding strategies for reducing conflicts and increasing the variety of the generated examples, and (3) training a neural network that imitates the random forest by learning the decision boundaries. As a result, NRFI enables the transformation of random forests into efficient neural networks. An overview of the proposed method is shown in Fig. 5.5.

Neural random forest imitation enables an implicit transformation of random forests into neural networks. Usually, data samples are propagated through the individual decision trees, and the split decisions are evaluated during inference. We propose a method for generating input-target pairs by reversing this process and training a neural network that imitates the random forest. The resulting network is much smaller compared to current state-of-the-art methods, which directly map the random forest
4.2.1 Data Generation
First, we propose a method for generating data from a given random forest. A data sample \(x \in \mathbb {R}^N\) is an N-dimensional vector, where N is the number of features. We select a target class \(t \in [1, \dots , C]\) from C classes and generate a data sample for the selected class.
4.2.1.1 Data Initialization
A data sample x is initialized randomly. In the following, the feature-wise minimum and maximum of the training samples will be denoted as \(f_{\text{min}}, f_{\text{max}} \in \mathbb {R}^N\). To initialize x, we sample \(x \sim {U}(f_{\text{min}}, f_{\text{max}})\). In the next step, we will present a method for adapting the data sample to obtain characteristics of the target class.
4.2.1.2 Data Generation from Decision Trees
A decision tree processes an input vector x by routing the data through the tree until a leaf is reached. At each node, a split decision is evaluated, and the input is passed to the left child node or the right child node. Finally, a leaf l is reached which stores the estimated probabilities \(P_{\text{leaf}}(l) = (p^{l}_1, \dots , p^{l}_C)\) for each class.
We reverse this process and present a method for generating training data from a decision tree. An overview of the proposed data generation process is shown in Fig. 5.6. First, the class distribution information is propagated bottom-up from the leaf nodes to the split nodes (see Fig. 5.6a), and we define the class weights \(W(n) = (w^n_1, \dots , w^n_C)\) for every node n as follows:

Overview of the data generation process from a decision tree. First, the class distribution information is propagated from the leaf nodes to the split nodes (a). Afterward, data samples are generated by guided routing (Sect. 5.4.2.1) and modifying the data based on the split decisions (b). The weights for sampling the left or right child node are highlighted in orange
For every leaf node, the class weights are equal to the stored probabilities in the leaf. For every split node, the class weights in the child nodes are summed up.
After preparation, data samples for a target class t are generated (see Fig. 5.6b). For that, characteristics of the target class are successively added to the data sample. Starting at the root node, we modify the input data so that it is routed through selected split nodes until a leaf node is reached. The pseudocode is presented in Algorithm 1.
The routing is guided based on the weights for the target class in the left child node \(w_{\text{left}} = w^{\operatorname {c}_{\text{left}}(n)}_t\) and right child node \(w_{\text{right}} = w^{\operatorname {c}_{\text{right}}(n)}_t\). The weights are normalized by their L2-norm, denoted as \(\hat {w}_{\text{left}}\) and \(\hat {w}_{\text{right}}\). Afterward, the left or right child node is randomly selected as next child node \(n_{\text{next}}\) depending on \(\hat {w}_{\text{left}}\) and \(\hat {w}_{\text{right}}\).
In the next step, the data sample is updated. We verify that the data sample is routed to the selected child node by evaluating the split decision. A split node s routes the data to the left or right child node based on a split feature \(\operatorname {f}(s)\) and a threshold \(\theta (s)\). If the value of the split feature \(x_{\operatorname {f}(s)}\) is smaller than \(\theta (s)\), the data sample is routed to the left child node and otherwise to the right child node. The data sample is modified if it is not already routed to the selected child node by assigning a new value. If the selected child node is the left child node, the value has to be smaller than the threshold \(\theta (s)\), and a new value within the minimum feature value \(f_{\text{min}, \operatorname {f}(s)}\) and \(\theta (s)\) is randomly sampled:
If the data sample is supposed to be routed to the right child node, the new value is randomly sampled between \(\theta (s)\) and the maximum feature value \(f_{\text{max}, \operatorname {f}(s)}\):
This process is repeated until a leaf node is reached. In each node, characteristics are added that classify the data sample as the target class.
During this process, modifications can conflict with previous decisions because features are used multiple times within a decision tree or across multiple decision trees. Therefore, the current routing is weighted with a factor \(w_{\text{path}} \geq 1\) to prioritize the path and not change the data sample if possible. Overall, the presented method enables the generation of data samples and corresponding labels from a decision tree without adding any further data.
Algorithm 1 DataGenerationFromTree Generate data samples from a decision tree

4.2.1.3 Data Generation from Random Forests
In the next step, we extend the method to generate data from random forests. Random forests consist of \(n_T\) decision trees \(RF = \{T_1, \dots , T_{n_T}\}\). For generating a data sample x, the presented method for a single decision tree is applied to multiple decision trees consecutively. The initialization is performed only once, and the visited features are shared. In each decision tree, the data sample is modified and routed to selected nodes based on the target class t. When using all decision trees, data samples are created where all trees agree with a high probability. For generating examples with varying confidence, i.e., the predictions of the individual decision trees diverge, we select a subset of \(n_{\text{sub}}\) decision trees \(RF_{\text{sub}}\subseteq RF \).
All decision trees in \(RF_{\text{sub}}\) are processed in random order to generate a data sample. For each decision tree, the presented method modifies the data sample based on the target class. Finally, the output of the random forest \(y = \operatorname {RF}(x)\) is predicted. In most cases, the prediction matches the target class. Due to factors such as the stochastic process, a small subset size, or varying predictions of the decision trees, it can be different occasionally. Thus, an input-target pair \((x, y)\) has been created, showing similar characteristics as the target class and any amount of data can be generated by repeating this process.
4.2.1.4 Automatic Confidence Distribution
The number of decision trees \(n_{\text{sub}}\) can be set to a fixed value or sampled uniformly. Alternatively, we will present an automatic process for determining an optimal distribution of the confidences for generating a wide variety of different examples. The strategy is motivated by importance weighting (Fang et al. 2020). We generate n data samples (n is empirically set to 1000) for each number of decision trees \(j \in [1, n_T]\). The respective generated datasets will be denoted as \(D_{j}\).
An optimal sampling process generates highly diverse data samples with different confidences. To achieve that, an automated balancing of the distributions is determined. A histogram with H bins is calculated for each \(D_{j}\), where \(h^{j}_{i}\) denotes the number of generated examples in the ith interval (equally distributed) from the distribution with j decision trees. In the next step, a weight \(w^{D}_j\) is defined for each distribution, and we optimize \(w^{D}\) as follows:
where \(w^{D} \in \mathbb {R}^{n_T}\). This optimization finds a weighting of the number of decision trees so that the generated confidences cover the full range equally. For that, the number of samples per bin \(h^{j}_{i}\) is summed up, weighted over all numbers of decision trees. After determining \(w^{D}\), the number of decision trees can be sampled depending on \(w^{D}_j\). An analysis of different sampling methods will be presented in Sect. 5.4.3.4. Automatically balancing the number of decision trees generates data samples with low and high confidence very equally distributed. The process does not require training data and provides a universal solution.
4.2.2 Imitation Learning
Finally, a neural network that imitates the random forest is trained. The network learns the decision boundaries from the generated data and approximates the same function as the random forest. The network architecture is based on a fully connected network with one or multiple hidden layers. The data dimensions are the same as those of the random forest, i.e., an N-dimensional input and C-dimensional output. Each hidden layer is followed by a ReLU activation (Nair and Hinton 2010). The last fully connected layer is using a softmax activation.
For training, we generate input-target pairs \((x, y)\) as described in the last section. These training examples are fed into the training process to teach the network to predict the same results as the random forest. To avoid overfitting, the data is generated on-the-fly so that each training example is unique. In this way, we learn an efficient representation of the decision boundaries and are able to transform random forests into neural networks implicitly. In addition to that, the training is performed end to end on the generated data, and we can easily integrate the original training data.
4.3 Experiments
In this section, we perform several experiments to analyze the performance of neural random forest imitation and compare our method to state-of-the-art methods.
4.3.1 Datasets
The experiments are evaluated on nine classification datasets from the UCI Machine Learning Repository (Dua and Graff 2017) (Car, Connect-4, Covertype, German Credit, Haberman, Image Segmentation, Iris, Soybean, and Wisconsin Breast Cancer (Original)). The datasets cover many real-world problems in different areas, such as finance, computer vision, games, or medicine.
Following Fernández-Delgado et al. (2014), each dataset is split into a training and a test set using a 50/50 split while maintaining the label distribution. Afterward, the number of training examples is limited to \(n_{\text{limit}}\) examples per class. We evaluate the training with 5, 10, 20, and 50 examples per class. In contrast to Fernández-Delgado et al. (2014), we extract validation sets from the training set (e.g., for hyperparameter tuning). This ensures that the training and validation data are not mixed with the test data. For some datasets which provide a separate test set, the test accuracy is evaluated on the respective set. Missing values are set to the mean value of the feature. All experiments are repeated ten times with randomly sampled splits. The methods are repeated additionally four times with different seeds on each split.
4.3.2 Implementation Details
In all our experiments, stochastic gradient descent with Nesterov momentum as optimizer and cross-entropy loss are used. The initial learning rate is set to \(0.1\), momentum to \(0.9\), and weight decay to \(0.0005\). The batch size is set to 128 and 512, respectively, for generated data. The input data is normalized to \([-1, 1]\). For generating a wide variety of data, the prioritization of the current path \(w_{\text{path}} \sim 1 + \lvert \mathcal {N}(0, 5)\rvert \) is sampled for each data sample individually. A new random forest is trained every 100 epochs to average the influence of the stochastic process, and the generated data samples are mixed. In the following, training on generated data will be denoted as NRFI (gen) and training on generated and original data as NRFI (gen+ori). The fraction of NRFI data is set to \(0.9\). Random forests are trained with 500 decision trees, which are commonly used in practice (Fernández-Delgado et al. 2014; Olson et al. 2018). The decision trees are constructed up to a maximum depth of 10. For splitting, the Gini impurity is used, and \(\sqrt {N}\) features are randomly selected, where N is the number of features.
4.3.3 Results
The proposed method generates data from a random forest and trains a neural network that imitates the random forest. The goal is that the neural network approximates the same function as the random forest. This also implies that the network reaches the same accuracy if successful.
We analyze the performance by training random forests for each dataset and evaluating neural random forest imitation with different network architectures. A variety of network architectures with different depths, widths, and additional layers such as dropout have been studied. In this work, we focus on two-hidden-layer networks with an equal number of neurons in both layers for clarity. The results are shown in Fig. 5.7 exemplarily for the Car, Covertype, and Wisconsin Breast Cancer (Original) dataset. The other datasets show similar characteristics. The overall evaluation on all datasets is presented in the next section. The number of training examples per class is shown in parentheses and increases in each row from left to right. For each setting, the test accuracy of the random forest is indicated by a red dashed line. The average test accuracy and standard deviation depending on the network architecture, i.e., the number of neurons in the first and second hidden layer, are plotted for different architectures. NRFI (gen), which is trained with generated data only, is shown in orange, and NRFI (gen+ori), which is trained with generated and original data, is shown in blue.

Test accuracy depending on the network architecture (i.e., number of neurons in both hidden layers). Different datasets are shown per row, with an increasing number of training examples per class from left to right (indicated in parentheses). The red dashed line shows the accuracy of the random forest. NRFI with generated data is shown in orange and NRFI with generated and original data in blue. With increasing network capacity, NRFI is capable of imitating and even outperforming the random forest
The analysis shows that the accuracy of the neural networks trained by NRFI reaches the accuracy of the random forest for all datasets. Only very small networks do not have the required capacity. The proposed method for generating labeled data from random forests by analyzing the decision boundaries enables training neural networks that imitate the random forests. For instance, in the case of 5 training examples per class, a two-hidden-layer network with 16 neurons in both layers already achieves the same accuracy as the random forest across all 3 datasets in Fig. 5.7. Additionally, the experiment shows that the training is very robust to overfitting even when the number of parameters in the network increases. When combining the generated data and original data, the accuracy on Car and Covertype improves with an increasing number of training examples.
Overall, the experiment shows that the accuracy increases with an increasing number of neurons in both layers and NRFI is robust to different network architectures. NRFI is capable of generating a large variety of unique examples from random forests which have been initially trained on a limited amount of data.
4.3.3.1 Comparison to State of the Art
We now compare the proposed method to state-of-the-art methods for mapping random forests into neural networks and classical machine learning classifiers such as random forests and support vector machines with a radial basis function kernel that have shown to be the best two classifiers across all UCI datasets (Fernández-Delgado et al. 2014). In detail, we will evaluate the following methods:
-
DT: A decision tree (Breiman et al. 1984) learns simple and interpretable split decisions to classify data. The Gini impurity is used for splitting.
-
SVM: Support vector machine (Chang and Lin 2011) is a popular classifier that tries to find the best hyperplane that maximizes the margin between the classes. As evaluated by Fernández-Delgado et al. (2014), the best performance is achieved with a radial basis function kernel.
-
RF: Random forest (Breiman 2001) is an ensemble-based method consisting of multiple decision trees. Each decision tree is trained on a different randomly selected subset of features and samples. The classifier follows the same overall setup, i.e., 500 decision trees and a maximum depth of 10.
-
NN: A neural network (Rumelhart et al. 1988) with two hidden layers is trained using ReLU activation and cross-entropy loss. Possible values for the initial learning rate are \(\{0.1, 0.01, 0.001, 0.0001, 0.00001\}\) and \(\{2, 4, 8, 16, 32, 64, 128\}\) for the number of neurons in both hidden layers. The best hyperparameters are selected by performing a fourfold cross-validation.
-
Sethi: The method proposed by Sethi (1990) maps a random forest into a two-hidden-layer neural network by adding a neuron for each split node and each leaf node. The weights are set corresponding to the split decisions.
-
Welbl: Welbl (2014) and Biau et al. (2019) present a similar mapping with subsequent fine-tuning. The authors introduce two training modes: independent and joint. The first optimizes each small network individually, while the latter joins all mapped decision trees into one network. Additionally, the authors evaluate a network with sparse connections and regular fully connected networks (denoted as sparse and full).
-
Massiceti: Massiceti et al. (2017) present a network splitting strategy to reduce the number of network parameters. The decision trees are divided into subtrees and mapped individually while sharing common split nodes. The optimal depth of the subtrees is determined by evaluating all possible values.
First, we analyze the performance of state-of-the-art methods for mapping random forests into neural networks and neural random forest imitation. The results are shown in Fig. 5.8 for different numbers of training examples per class. For each method, the average number of parameters of the generated networks across all datasets is plotted depending on the test error. That means that the methods aim for the lower-left corner (smaller number of network parameters and higher accuracy). Please note that the y-axis is shown on a logarithmic scale. The average performance of the random forests is indicated by a red dashed line.

Comparison of the state-of-the-art and our proposed method for transforming random forests into neural networks. The closer a method is to the lower-left corner, the better it is (fewer number of network parameters and lower test error). For neural random forest imitation, different network architectures are shown. Note that the number of network parameters is shown on a logarithmic scale
The analysis shows that Sethi, Welbl (ind-full), and Welbl (joint-full) generate the largest networks. Network splitting (Massiceti et al. 2017) slightly improves the number of parameters of the networks. Using a sparse network architecture reduces the number of parameters. However, it should be noted that this requires special operations. NRFI with and without the original data is shown for different network architectures. The smallest architecture has 2 neurons in both hidden layers and the largest 128. For NRFI (gen-ori), we can see that a network with 16 neurons in both hidden layers (NN-16-16) is already sufficient to learn the decision boundaries of the random forest and achieve the same accuracy. When fewer training samples are available, NN-8-8 already has the required capacity. In the following, we will further analyze the accuracy and number of network parameters.
4.3.3.2 Accuracy
The average test accuracy and standard deviation for all methods are shown in Table 5.1. Here, we additionally include decision trees, support vector machines, random forests, and neural networks in the comparison. The evaluation is performed on all nine datasets, and results for different numbers of training examples are shown (increasing from left to right). The overall performance of each method is summarized in the last column. For neural random forest imitation, a network architecture with 128 neurons in both hidden layers is used. From the analysis, we can make the following observations: (1) When training neural random forest imitation with generated data only, the method achieves \(99.18\%\) of the random forest accuracy (\(71.44\%\) compared to \(72.03\%\)). This shows that NRFI is capable of learning the decision boundaries. (2) Overall, NRFI trained with generated and original data reaches state-of-the-art performance (50 samples per class) or outperforms the other methods (5, 10, and 20 samples per class).
4.3.3.3 Network Parameters
Finally, we will analyze the number of parameters of the generated networks in detail. The results are shown in Table 5.2. Current state-of-the-art methods directly map random forests into neural networks. The number of parameters of the resulting network is evaluated on all datasets with different numbers of training examples. The overall performance is shown in the last column. Due to the stochastic process when training the random forests, the results can vary marginally.
Sethi, Welbl (ind-full), and Welbl (joint-full) generate networks with around 980 000 parameters on average. Of the four variants proposed by Welbl, joint training has a slightly smaller number of parameters compared to independent training because of shared neurons in the output layer. Network splitting proposed by Massiceti et al. (2017) maps multiple subtrees while sharing common split nodes and reduces the average number of network parameters to 748 000. Using sparse network architectures additionally reduces the number of network parameters to about 142 000; however, this requires a special implementation for sparse matrix multiplication. All of the methods show a drastic increase with the growing complexity of the classifiers. Sethi, for example, generates networks with 374 000 parameters when training with 5 examples per class. The average number of network parameters increases to \(1.9\) million when training with 50 examples per class.
NRFI introduces imitation instead of direct mapping. In the following, a network architecture with 32 neurons in both hidden layers is selected. The previous analysis has shown that this architecture is capable of imitating the random forests (see Fig. 5.8 for details) across all datasets and different numbers of training examples. Our method significantly reduces the number of parameters of the generated networks while reaching the same or even slightly better accuracy. The current best-performing methods generate networks with an average number of parameters of either 142 000, if sparse processing is available, or 748 000 when using usual fully connected neural networks. In comparison, neural random forest imitation requires only 2676 parameters. Another advantage is that the proposed method does not create a predefined architecture but enables arbitrary network architectures. As a result, NRFI enables the transformation of very complex classifiers into neural networks.
4.3.4 Analysis of the Generated Data
To study the sampling process, we analyze the variability of the generated data as well as different sampling modes in the next experiment. Subsequently, we investigate the impact of combining original and generated data.
4.3.4.1 Confidence Distribution
The data generation process aims to produce a wide variety of data samples. This includes data samples that are classified with a high confidence and data samples that are classified with a low confidence to cover the full range of prediction uncertainties. The following analyses are shown exemplarily on the Soybean dataset. This dataset has 35 features and 19 classes. First, we analyze the generated data with a fixed number of decision trees, i.e., the number of sampled decision trees in \(RF_{\text{sub}}\). The resulting confidence distributions for different numbers of decision trees are shown in the first column of Fig. 5.9. When adopting the data sample to only a few decision trees, the confidence of the generated samples is lower (around \(0.2\) for 5 samples per class). Using more decision trees for generating data samples increases the confidence on average.

Probability distribution of the predicted confidences for different data generation settings on Soybean with 5 (top) and 50 samples per class (bottom). Generating data with different numbers of decision trees is visualized in the left column. Additionally, a comparison between random sampling (red), NRFI uniform (orange), and NRFI dynamic (green) is shown in the right column. By optimizing the decision tree sampling, NRFI dynamic automatically balances the confidences and generates the most diverse and evenly distributed data
NRFI uniform and NRFI dynamic sample the number of decision trees for each data point uniformly, respectively, optimized via automatic confidence distribution (see Sect. 5.4.2.1). The confidence distributions for both sampling modes are visualized in the second column of Fig. 5.9. Additionally, sampling random data points without generating data from the random forest is included as a baseline. The analysis shows that random data samples and uniform sampling have a bias to generate data samples that are classified with high confidence. NRFI dynamic automatically balances the number of decision trees and archives an evenly distributed data distribution, i.e., generates the most diverse data samples.
In the next step, the imitation learning performance of the sampling modes is evaluated. The results are shown in Table 5.3. Random data generation reaches a mean accuracy of \(63.80\%\), while NRFI uniform and NRFI dynamic achieve \(87.46\%\) and \(88.14\%\), respectively. This shows that neural random forest imitation is able to generate significantly better data samples based on the knowledge in the random forest. NRFI dynamic improves the performance by automatically optimizing the decision tree sampling and generating the largest variation in the data.
4.3.4.2 Original and Generated Data
In the next experiment, we study the effects of training with original data, NRFI data, and combinations of both. For that, the fraction of NRFI data \(w_{\text{gen}}\) is varied, which weights the loss of the generated data. Accordingly, the weight for the original data is set to \(w_{\text{ori}} = 1 - w_{\text{gen}}\). The average accuracy over all datasets for different number of samples per class is shown in Fig. 5.10. When the fraction of NRFI data is set to 0%, the network is trained with only the original data. When the fraction is set to 100%, the network is trained completely with the generated data. The study shows that training with NRFI data performs better than training with original data except for 50 samples per class where training with original data is slightly better. Combining original and NRFI data improves the performance. The best result is achieved when using mainly NRFI data with a small fraction of original data.

Analyzing the influence of training with original data, NRFI data, and combinations of both for different number of samples per class. Using only NRFI data (\(w_{\text{gen}} = 100\%\)) achieves better results than using only the original data (\(w_{\text{gen}} = 0\%\)) for less than 50 samples per class. Combining the original data and generated data improves the performance
5 Conclusion
In this work, we brought two worlds together by combining neural networks and random forests. First, we presented an object detection framework for analyzing the road and traffic situations for cyclists and pedestrians. The combination of convolutional neural networks and random forests enables the training with very few labeled examples. Both methods are combined in an end-to-end pipeline by transforming the random forest into a neural network and generating a fully convolutional network.
Because existing approaches for mapping random forests into neural networks generate inefficient networks, we presented a novel method for transforming random forests into neural networks. Instead of a direct mapping, we introduced a process for generating data from random forests by analyzing the decision boundaries and guided routing of data samples to selected leaf nodes. Based on the generated data and corresponding labels, a network is trained that imitates the random forest. Experiments on several real-world benchmark datasets demonstrate that NRFI is capable of learning the decision boundaries very efficiently. Compared to state-of-the-art methods, the presented implicit transformation significantly reduces the number of parameters of the networks while achieving the same or even slightly improved accuracy due to better generalization. Our approach has shown that it scales very well and is able to imitate highly complex classifiers.
References
Barz B, Denzler J (2020) Deep learning on small datasets without pre-training using cosine loss. In: IEEE Winter Conference on Applications of Computer Vision (WACV), pp 1360–1369
Biau G, Scornet E, Welbl J (2019) Neural Random Forests. Sankhya A 81:347–386
Bornschein J, Visin F, Osindero S (2020) Small data, big decisions: Model selection in the small-data regime. In: Proceedings of the 37th International Conference on Machine Learning, PMLR, vol 119, pp 1035–1044
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Breiman L, Friedman JH, Olshen RA, Stone CJ (1984) Classification and Regression Trees. Wadsworth and Brooks, Monterey
Cai Z, Vasconcelos N (2018) Cascade r-cnn: Delving into high quality object detection. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 6154–6162
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: Vedaldi A, Bischof H, Brox T, Frahm JM (eds) Computer Vision—ECCV 2020. Springer, Cham, pp 213–229
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2(3):1–27
Chen Q, Wang Y, Yang T, Zhang X, Cheng J, Sun J (2021) You only look one-level feature. In: IEEE Conference on Computer Vision and Pattern Recognition
Collobert R, Weston J, Bottou L, Karlen M, Kavukcuoglu K, Kuksa P (2011) Natural language processing (almost) from scratch. J Mach Learn Res 12:2493–2537
Dockhorn A, Braune C, Kruse R (2015) An alternating optimization approach based on hierarchical adaptations of dbscan. In: 2015 IEEE Symposium Series on Computational Intelligence (SSCI), 2, pp 749–755
Dockhorn A, Braune C, Kruse R (2016) Variable density based clustering. In: 2016 IEEE Symposium Series on Computational Intelligence (SSCI), pp 1–8
Dockhorn A, Doell C, Hewelt M, Kruse R (2017) A decision heuristic for Monte Carlo tree search doppelkopf agents. In: 2017 IEEE Symposium Series on Computational Intelligence (SSCI), pp 1–8
Dua D, Graff C (2017) UCI machine learning repository. http://archive.ics.uci.edu/ml
Duan K, Bai S, Xie L, Qi H, Huang Q, Tian Q (2019) Centernet: keypoint triplets for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Fang T, Lu N, Niu G, Sugiyama M (2020) Rethinking importance weighting for deep learning under distribution shift. In: Advances in Neural Information Processing Systems (NeurIPS)
Fernández-Delgado M, Cernadas E, Barro S, Amorim D (2014) Do we need hundreds of classifiers to solve real world classification problems? J Mach Learn Res 15(1):3133–3181
Fukunaga K, Hostetler L (1975) The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans Inform Theory 21(1):32–40
Girshick R (2015) Fast R-CNN. In: 2015 IEEE International Conference on Computer Vision (ICCV), pp 1440–1448
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Computer Vision and Pattern Recognition
Graves A, Mohamed A, Hinton G (2013) Speech recognition with deep recurrent neural networks. In: IEEE International Conference on Acoustics, Speech and Signal Processing, pp 6645–6649
Hekler EB, Klasnja PV, Chevance G, Golaszewski NM, Lewis DM, Sim I (2019) Why we need a small data paradigm. BMC Medicine 17:133
Humbird KD, Peterson JL, McClarren RG (2019) Deep neural network initialization with decision trees. IEEE Trans Neural Netw Learn Syst 30(5):1286–1295
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems (NeurIPS), vol 25
Li Y, Wang S (2022) R(det)2: Randomized decision routing for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp 4825–4834
Lin TY, Goyal P, Girshick R, He K, Dollár P (2017) Focal loss for dense object detection. In: 2017 IEEE International Conference on Computer Vision (ICCV), pp 2999–3007
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, Berg AC (2016) Ssd: Single shot multibox detector. In: European Conference on Computer Vision. Springer, Berlin, pp 21–37
MacQueen J, et al (1967) Some methods for classification and analysis of multivariate observations. In: Proceedings of the fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, vol 1, pp 281–297
Massiceti D, Krull A, Brachmann E, Rother C, Torr PH (2017) Random forests versus neural networks—what’s best for camera localization? In: IEEE International Conference on Robotics and Automation (ICRA), pp 5118–5125
Menze BH, Kelm BM, Splitthoff DN, Koethe U, Hamprecht FA (2011) On oblique random forests. In: Machine Learning and Knowledge Discovery in Databases, pp 453–469
Mnih V, Kavukcuoglu K, Silver D, a Rusu A, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D (2015) Human-level control through deep reinforcement learning. Nature 518:529–533
Nair V, Hinton GE (2010) Rectified linear units improve restricted boltzmann machines. In: Proceedings of the 27th International Conference on International Conference on Machine Learning, pp 807–814
Olson M, Wyner A, Berk R (2018) Modern neural networks generalize on small data sets. In: Advances in Neural Information Processing Systems (NeurIPS), vol 31
Otter D, Medina JR, Kalita JK (2021) A survey of the usages of deep learning for natural language processing. IEEE Trans Neural Netw Learn Syst 32:604–624
Park DS, Chan W, Zhang Y, Chiu CC, Zoph B, Cubuk ED, Le QV (2019) SpecAugment: a simple data augmentation method for automatic speech recognition. In: Proc. Interspeech 2019, pp 2613–2617
Phoo CP, Hariharan B (2021) Self-training for few-shot transfer across extreme task differences. In: Proceedings of the International Conference on Learning Representations
Qi GJ, Luo J (2020) Small data challenges in big data era: a survey of recent progress on unsupervised and semi-supervised methods. IEEE Trans Pattern Anal Mach Intell 44(4):2168–2187
Qiao S, Chen LC, Yuille AL (2021) Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Quinlan JR (1993) C4.5: programs for machine learning. Morgan Kaufmann Publishers, San Francisco
Redmon J, Farhadi A (2016) Yolo9000: better, faster, stronger. arXiv preprint arXiv:161208242
Reinders C, Ackermann H, Yang MY, Rosenhahn B (2018) Object recognition from very few training examples for enhancing bicycle maps. In: IEEE Intelligent Vehicles Symposium (IV)
Reinders C, Ackermann H, Yang MY, Rosenhahn B (2019) Learning convolutional neural networks for object detection with very little training data. Multimodal Scene Understanding
Reinders C, Schubert F, Rosenhahn B (2022) ChimeraMix: Image classification on small datasets via masked feature mixing. In: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI, pp 1298–1305
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: towards real-time object detection with region proposal networks. In: NIPS
Richmond D, Kainmueller D, Yang M, Myers E, Rother C (2016) Mapping auto-context decision forests to deep convnets for semantic segmentation. In: Proceedings of the British Machine Vision Conference (BMVC)
Rudolph M, Wehrbein T, Rosenhahn B, Wandt B (2022) Fully convolutional cross-scale-flows for image-based defect detection. In: Winter Conference on Applications of Computer Vision (WACV)
Rumelhart DE, Hinton GE, Williams RJ (1988) Learning representations by back-propagating errors. MIT Press, Cambridge, pp 696–699
Schier M, Reinders C, Rosenhahn B (2022) Constrained mean shift clustering. In: Proceedings of the 2022 SIAM International Conference on Data Mining (SDM)
Sethi IK (1990) Entropy nets: from decision trees to neural networks. Proc IEEE 78(10):1605–1613
Shelhamer E, Long J, Darrell T (2017) Fully convolutional networks for semantic segmentation. IEEE Trans Pattern Anal Mach Intell 39(4):640–651
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations
Springenberg JT, Dosovitskiy A, Brox T, Riedmiller M (2015) Striving for simplicity: the all convolutional net. In: ICLR, pp 1–14, 1412.6806
Stallkamp J, Schlipsing M, Salmen J, Igel C (2012) Man vs. computer: benchmarking machine learning algorithms for traffic sign recognition. Neural Netw 32:323–332
Sun B, Li B, Cai S, Yuan Y, Zhang C (2021a) Fsce: Few-shot object detection via contrastive proposal encoding. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Sun P, Zhang R, Jiang Y, Kong T, Xu C, Zhan W, Tomizuka M, Li L, Yuan Z, Wang C, Luo P (2021b) Sparse R-CNN: End-to-end object detection with learnable proposals. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp 14449–14458
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems (NeurIPS), vol 27
Tian Z, Shen C, Chen H, He T (2019) Fcos: Fully convolutional one-stage object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang P, Fan E, Wang P (2021) Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recogn Lett 141:61–67
Welbl J (2014) Casting random forests as artificial neural networks (and profiting from it). In: German Conference on Pattern Recognition
Zhang C, Bengio S, Hardt M, Recht B, Vinyals O (2017) Understanding deep learning requires rethinking generalization. In: 5th International Conference on Learning Representations (ICLR)
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 6230–6239
Acknowledgements
This research was supported by the German Research Foundation DFG (COVMAP—RO 2497/12-2) within Priority Research Program 1894 Volunteered Geographic Information: Interpretation, Visualization, and Social Computing; the Federal Ministry of Education and Research (BMBF), Germany, under the project LeibnizKILabor (grant no. 01DD20003); the Center for Digital Innovation (ZDIN); and the German Research Foundation (DFG) under Germany’s Excellence Strategy within the Cluster of Excellence PhoenixD (EXC 2122).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2024 The Author(s)
About this chapter

Cite this chapter
Reinders, C., Yang, M.Y., Rosenhahn, B. (2024). Two Worlds in One Network: Fusing Deep Learning and Random Forests for Classification and Object Detection. In: Burghardt, D., Demidova, E., Keim, D.A. (eds) Volunteered Geographic Information. Springer, Cham. https://doi.org/10.1007/978-3-031-35374-1_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-35374-1_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-35373-4
Online ISBN: 978-3-031-35374-1
eBook Packages: Computer ScienceComputer Science (R0)