
Abstract
The term “artificial intelligence”, which in the past received very different interpretations, is nowadays being identified with deep learning. Deep neural networks bring the promise that, instead of hand-crafting data processing algorithms by mathematical reasoning based on formalized principles, we can simply feed enough data to a neural network, which will learn the right operator from it. In supervised learning, the data are either annotated by humans or obtained from a large set of observed pairs (xn, f(xn)). It is this association of an output f(xn) to an input xn in a learning dataset which is called a “ground truth”. The use of a “ground truth” annotated by humans raises a serious methodological problem, as humans are fallible. Worse even, the performance of these methods is evaluated and compared on subsets of the same annotations. Objective natural ground truths raise similar issues: raw data can be ambiguous or contradictory. In this paper, we shall examine two examples where machine learning methods were used to replicate aspects of human perception and logic: depth perception and the detection of straight lines or segments. We show that a strict control of the geometry in the learning data set, or a rigorous mathematical definition of the geometric task, lead to results widely different from those learned blindly from annotated datasets or from ground truths acquired in the wild. We conclude that a mathematical and principled analysis of learning datasets should precede their use.
En gratitude à Catriona Byrne, mémorable, unique, et irremplaçable chef d’orchestre de l’édition mathématique.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others
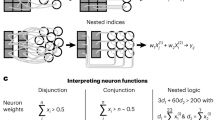


References
M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khosravi,U. Rajendra Acharya, et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information Fusion76, 243–297 (2021).
C. Akinlar and C. Topal. Edlines: Real-time line segment detection by edge drawing (ed). In: 2011 18th IEEE International Conference on Image Processing, pp. 2837–2840, IEEE (2011).
C. Akinlar and C. Topal. EDLines: A real-time line segment detector with a false detection control. Pattern Recognition Letters32(13), 1633–1642 (2011).
I. Alhashim and P. Wonka. High quality monocular depth estimation via transfer learning. arXiv preprint arXiv:1812.11941 (2018).
M. Caron, P. Bojanowski, A. Joulin and M. Douze. Deep clustering for unsupervised learning of visual features. In: Proceedings of the European conference on computer vision (ECCV), pp. 132–149, Springer (2018).
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski and A. Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems33, 9912–9924 (2020).
W. Chen, Z. Fu, D. Yang and J. Deng. Single-image depth perception in the wild. Advances in neural information processing systems29, 730–738 (2016).
W. Chen, S. Qian, D. Fan, N. Kojima, M. Hamilton and J. Deng. Oasis: A large-scale dataset for single image 3d in the wild, In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 679–688, Springer (2020).
A. Courtois, J.-M. Morel and P. Arias. Investigating Neural Architectures by Synthetic Dataset Design. arXiv preprint arXiv:2204.11045 (2022).
P. Denis, J.H. Elder and F.J. Estrada. Efficient edge-based methods for estimating Manhattan frames in urban imagery. In: Proceedings of the European conference on computer vision (ECCV), pp. 197–210, Springer (2008).
A. Desolneux, L. Moisan and J.-M. Morel. From Gestalt Theory to Image Analysis: A Probabilistic Approach. Interdisciplinary Applied Mathematics 34, Springer Science & Business Media (2007).
T. DeVries and G.W. Taylor. Learning confidence for out-of-distribution detection in neural networks. arXiv preprint arXiv:1802.04865 (208).
H. Feng, M. Chen, J. Hu, D. Shen, H. Liu and D. Cai. Complementary pseudo labels for unsupervised domain adaptation on person re-identification. IEEE Transactions on Image Processing30, 2898–2907 (2021).
Y. Gousseau and F. Roueff. The dead leaves model: general results and limits at small scales. arXiv preprint arXiv:math/0312035 (2003).
J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al. Bootstrap your own latent: A new approach to self-supervised learning. Advances in Neural Information Processing Systems33, 21271–21284 (2020).
R. Grompone von Gioi, J. Jakubowicz, J.-M. Morel and G. Randall. LSD: A fast line segment detector with a false detection control. IEEE transactions on pattern analysis and machine intelligence32(4), 722–732 (2008).
G. Gu, B. Ko, SH. Go, S.-H. Lee, J. Lee, M. Shin. Towards light-weight and real-time line segment detection. arXiv preprint arXiv:2106.00186 (2022).
C. Guo, G. Pleiss, Y. Sun and K.Q. Weinberger. On calibration of modern neural networks. In: International Conference on Machine Learning, pp. 1321–1330, PRML (2017).
M. Hein, M. Andriushchenko and J. Bitterwolf. Why ReLU networks yield high-confidence predictions far away from the training data and how to mitigate the problem. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 41–50, IEEE (2019).
K. Huang, Y, Wang, Z. Zhou, T. Ding, S. Gao and Y. Ma. Learning to parse wireframes in images of man-made environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 626–635, IEEE (2018).
S. Huang, F. Qin, P. Xiong, N. Ding, Y. He and X. Liu. Tp-lsd: Tri-points based line segment detector. In: European Conference on Computer Vision, pp. 770–785, Springer (2020).
P. Isola, J.-Y. Zhu, T. Zhou and A.A. Efros. Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1125–1134, IEEE (2017).
A. Jaiswal, A.R. Babu, M.Z. Zadeh, D. Banerjee and F. Makedon. A survey on contrastive self-supervised learning. Technologies9(1), 2 (2020).
G. Kanizsa. Organization in vision: Essays on Gestalt perception. Praeger Publishers (1979).
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu and D. Krishnan. Supervised contrastive learning. Advances in Neural Information Processing Systems33, 18661–18673 (2020).
Y. Kim and C. Kim. Semi-Supervised Domain Adaptation via Selective Pseudo Labeling and Progressive Self-Training. In: 2020 25th International Conference on Pattern Recognition (ICPR), pp. 1059–1066, IEEE (2021).
D.P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Z. Kou, Z. Shi and L. Liu. Airport detection based on line segment detector. In: 2012 International Conference on Computer Vision in Remote Sensing, pp. 72–77, IEEE (2012).
D. Kundu, L.K. Choi, A.C. Bovik and B.L. Evans. Perceptual quality evaluation of synthetic pictures distorted by compression and transmission. Signal Processing: Image Communication61, 54–72 (2018).
J.H. Lee, M.-K. Han, D.W. Ko and I.H. Suh. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv preprint arXiv:1907.10326 (2019).
J.-H. Lee and C.-S. Kim. Multi-loss rebalancing algorithm for monocular depth estimation. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVII 16, pp. 785–801, Springer (2020).
H. Li, H. Yu, J. Wang, W. Yang, L. Yu and S. Scherer. ULSD: Unified line segment detection across pinhole, fisheye, and spherical cameras. ISPRS Journal of Photogrammetry and Remote Sensing178, 187–202 (2021).
Z. Li and N. Snavely. Megadepth: Learning single-view depth prediction from internet photos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2041–2050, IEEE (2018).
M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In: Advances in neural information processing systems29, Curran Associates, Inc. (2016).
X. Lu, J. Yao, K. Li and L. Li. Cannylines: A parameter-free line segment detector. In: 2015 IEEE International Conference on Image Processing (ICIP), pp. 507–511, IEEE (2015).
W. Metzger. Gesetze des Sehens [1975]. Verlag Waldemar Kramer (2008).
W. Metzger. Laws of Seeing. English translation of “Gesetze des Sehens” (1936, first German edition), by Lothar Spillmann, Steven Lehar, Mimsey Stromeyer and Michael Wertheimer. Cambridge: MIT Press (2006).
S.M. Miangoleh, S. Dille, L. Mai, S. Paris and Y. Aksoy. Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9685–9694, IEEE (2021).
M. Minderer, J. Djolonga, R. Romijnders, F. Hubis, X. Zhai, N. Houlsby, D. Tran and M. Lucic. Revisiting the calibration of modern neural networks. Advances in Neural Information Processing Systems34, pp. 15682–15694, Curran Associates, Inc. (2021).
J. Mukhoti, J. van Amersfoort, P.H.S. Torr and Y. Gal. Deep Deterministic Uncertainty for Semantic Segmentation. arXiv preprint arXiv:2111.00079 (2021).
Y.E. Nesterov. A method for solving the convex programming problem with convergence rate O(1∕k2). Dokl. akad. nauk SSSR269, 543–547 (1983).
R. Pautrat, J.-T. Lin, V. Larsson, M.R. Oswald and M. Pollefeys. SOLD2: Self-supervised occlusion-aware line description and detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11368–11378, IEEE (2021).
A. Power, Y. Burda, H. Edwards, I. Babuschkin and V. Misra. Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. ICLR MATH-AI Workshop (2021).
M. Ramamonjisoa, Y. Du and V. Lepetit. Predicting sharp and accurate occlusion boundaries in monocular depth estimation using displacement fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14648–14657, IEEE (2020).
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler and V. Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020).
A. Rozantsev, M. Salzmann and P. Fua. Beyond sharing weights for deep domain adaptation. IEEE transactions on pattern analysis and machine intelligence41(4), 801–814 (2018).
L. Schmarje, M. Santarossa, S.-M. Schröder and R. Koch. A survey on semi-, self- and unsupervised learning for image classification. IEEE Access9, 82146–82168 (2021).
B. Sun, J. Feng and K. Saenko. Return of frustratingly easy domain adaptation. In: Proceedings of the AAAI Conference on Artificial Intelligence30(1) (2016).
B. Sun and K. Saenko. Deep coral: Correlation alignment for deep domain adaptation. In: European conference on computer vision, pp. 443–450, Springer (2016).
R. Grompone von Gioi, J. Jakubowicz, J.-M. Morel and G. Randall. On straight line segment detection. Journal of Mathematical Imaging and Vision32(3), 313–347 (2008).
Y. Tay, M. Dehghani, S. Abnar, Y. Shen, D. Bahri, P. Pham, J. Rao, L. Yang, S. Ruder and D. Metzler. Long Range Arena: A Benchmark for Efficient Transformers. In: International Conference on Learning Representations (2021). https://openreview.net/forum?id=qVyeW-grC2k
T. Tommasi, N. Patricia, B. Caputo and T. Tuytelaars. A deeper look at dataset bias. In: Domain adaptation in computer vision applications, pp. 37–55, Springer (2017).
A. Torralba and A.A. Efros. Unbiased look at dataset bias. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2011, pp. 1521–1528, IEEE (2011).
D.-B. Wang, L. Feng and M.-L. Zhang. Rethinking Calibration of Deep Neural Networks: Do Not Be Afraid of Overconfidence. In: Advances in Neural Information Processing Systems34, pp. 11809–11820, Curran Associates, Inc. (2011).
L. Wang, J. Zhang, Y. Wang, H. Lu and X. Ruan. Cliffnet for monocular depth estimation with hierarchical embedding loss. In: European Conference on Computer Vision, pp. 316–331, Springer (2020).
M. Wang and W. Deng. Deep visual domain adaptation: A survey. Neurocomputing312, 135–153 (2018).
K. Xian, C. Shen, Z. Cao, H. Lu, Y. Xiao, R. Li and Z. Luo. Monocular relative depth perception with web stereo data supervision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 311–320, IEEE (2018).
K. Xian, J. Zhang, O. Wang, L. Mai, Z. Lin and Z. Cao. Structure-guided ranking loss for single image depth prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 611–620, IEEE (2020).
Z. Xie, Y. Lin, Z. Zhang, Y. Cao, S. Lin and H. Hu. Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16684–16693, IEEE (2021).
Y. Xu, W. Xu, D. Cheung and Z. Tu. Line segment detection using transformers without edges. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4257–4266, IEEE (2021).
H. Yu, N. Xu, Z. Huang, Y. Zhou and H. Shi. High-Resolution Deep Image Matting. Proceedings of the AAAI Conference on Artificial Intelligence35(4), 3217–3224 (2021).
F. Zhang, P. Torr, R. Ranftl and S. Richter. Looking Beyond Single Images for Contrastive Semantic Segmentation Learning. In: Advances in Neural Information Processing Systems34, pp. 3285–3297, Curran Associates, Inc. (2021).
L. Zhang and X. Gao. Transfer adaptation learning: A decade survey. arXiv preprint arXiv:1903.04687 (2019).
J.-Y. Zhu, T. Park, P. Isola and A.A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision, pp. 2223–2232, IEEE (2017).
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Courtois, A., Ehret, T., Arias, P., Morel, JM. (2023). Can We Teach Functions to an Artificial Intelligence by Just Showing It Enough “Ground Truth”?. In: Morel, JM., Teissier, B. (eds) Mathematics Going Forward . Lecture Notes in Mathematics, vol 2313. Springer, Cham. https://doi.org/10.1007/978-3-031-12244-6_31
Download citation
DOI: https://doi.org/10.1007/978-3-031-12244-6_31
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-12243-9
Online ISBN: 978-3-031-12244-6
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)