
Abstract
This chapter aims to explore the differences in EQ-5D-5L value sets between countries/areas, and to investigate whether common patterns can be identified between them. EQ-5D-5L value sets for 25 countries/areas were extracted from published literature. These national value sets were compared on key characteristics, such as: the relative importance of the EQ-5D-5L dimensions; the value scale length and the distribution of values over the value scale. Using these characteristics, distinct preference patterns were identified for Asian, Eastern European and Western countries/areas. The Asian countries/areas were split into East Asian and Southeast Asian countries/areas, as these subgroups shared similar characteristics. Using mean values for countries/areas with similar preference patterns, several aggregate value sets were generated. These aggregate value sets describe mean values for all 3125 health states described by the EQ-5D-5L for countries/areas with similar preference patterns. Applying these values to EQ-5D-5L profile data for 7933 respondents in an international survey showed that these aggregate value sets represent the individual national value sets relatively well. This chapter identified large differences between value sets, yet was able to identify common preference patterns between selected countries/areas.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

6.1 Introduction
Since 2012, 25 EQ-5D-5L value sets have been published using the EuroQol Valuation Technology (EQ-VT), a standardised valuation protocol, as described in Chap. 4 of this book (Oppe et al. 2014; Stolk et al. 2019). These value sets have been developed across the world, concentrated initially in Western Europe and Canada, subsequently including more North American and Asian/Pacific countries/areas and (more recently) including countries/areas from Latin America, the Middle East, Africa and Eastern Europe.
Value sets have been shown to differ between countries/areas in a number of aspects such as: the relative importance of the five dimensions and their associated levels; the length of the value scale; how many health states are given values worse than dead (WTD); the location of the descriptive midpoint (33333) on the scale and the shape of the distribution of the values for all 3125 health states. In principle, there are two reasons why we observe such cross-country/area differences in values: (1) methodological differences and (2) genuine differences in populations’ health state preferences.
In contrast to valuations elicited for the EQ-5D-3L instrument, the EQ-VT protocol used for the EQ-5D-5L instrument provides a standardised method to collect valuation data using a combination of composite Time Trade-Off (cTTO) and Discrete Choice Experiment (DCE). Although the use of EQ-VT standardises a large part of the valuation methodology, some methodological differences may persist between countries/areas. These include the choice of valuation method used for the final dataset (Norman et al. 2009), modelling strategy, translation of the EQ-5D-5L (which may lead to different interpretations of health problems as described by the instrument) and any imbalance in the socio-demographic composition of the sample that might undermine the sample’s representativeness. The EQ-VT protocol allows local research teams to choose a sampling strategy that is acceptable to the HTA bodies of their respective countries/areas (Stolk et al. 2019). It also allows local research teams to decide on the modelling strategy e.g., whether to use both the cTTO and DCE data or cTTO only (see Chap. 2 for more details). All of these aspects introduce heterogeneity due to methodological differences, which may be reflected in the value sets.
The differences in populations’ health state preferences are assumed to be affected by a wide range of institutional and other country/area-specific circumstances that impact individuals’ health opportunities and challenges and may shape health expectations and norms. Countries/areas differ along highly relevant factors such as: their healthcare system (e.g., whether universal coverage is in place or not), social insurance (including sickness benefit schemes), wealth measures such as Gross Domestic Product (GDP), governance, culture (norms and beliefs) and even climate and geography (e.g., the importance of mobility, which may be related to the infrastructure of a country/area).
The aim of this chapter is to identify in which ways currently published EQ-5D-5L value sets differ and whether we can establish distinctive preference patterns which are common across groups of countries/areas. Previous work (Olsen et al. 2018) analysed seven EQ-5D-5L value sets and identified a ‘Western preference pattern’ (WePP). This chapter extends the work of Olsen et al. (2018), using the value sets reported from all 25 countries/areas reported in Chap. 4. We hypothesise that countries/areas that are similar in terms of institutional settings and other country/area-specific circumstances will have similar value sets. As 21 additional value sets have been published since the four Western countries/areas included in the Olsen et al. (2018) study (Canada, England, Netherlands, Spain) (Xie et al. 2016; Devlin et al. 2018; Versteegh et al. 2016; Ramos-Goñi et al. 2017b, 2018), it may be possible to further validate and refine the suggested Western preference pattern identified by Olsen et al. (2018). We also investigate whether other preference patterns emerge for other groups of countries/areas, i.e., whether there are any similarities in the value sets for countries/areas in other regions of the world, that may share similar characteristics.
6.2 Methods
6.2.1 Analysing Differences Between Value Sets
To determine how the value sets may differ from each other, several important characteristics of the value sets are used. Olsen et al. (2018) previously identified: (1) the relative importance of the different EQ-5D-5L dimensions; (2) differences in scale length between countries/areas, which gives an indication of the willingness to trade-off quality for quantity of life; (3) the marginal effect of moving from one severity level to another severity level; and finally, (4) the location on the value scale of the descriptive midpoint in the EQ-5D-5L, state “33333”. To compare the relative importance of the EQ-5D-5L dimensions, we compare (1) the relative importance of the functional dimensions (mobility (MO), self-care (SC) and usual activities (UA)) versus the symptom dimensions (pain/discomfort (PD), anxiety/depression (AD)); (2) the relative importance of pain; (3) the relative importance of anxiety/depression.
For the current chapter, all 25 value sets published at the time of writing were used. A database was created in which utilities of each value set were assigned to all possible 3125 EQ-5D-5L health states. These value sets include: ten from Europe (Ramos-Goñi et al. 2017b, 2018; Versteegh et al. 2016; Devlin et al. 2018; Andrade et al. 2020; Ludwig et al. 2018; Ferreira et al. 2019; Hobbins et al. 2018; Golicki et al. 2019; Rencz et al. 2020; Jensen et al. 2021); two from North America (Xie et al. 2016; Pickard et al. 2019); three from Latin America (Augustovski et al. 2016; Augustovski et al. 2020; Gutierrez-Delgado et al. 2021); one from Africa (Welie et al. 2020) and nine from Asia (Luo et al. 2017; Shiroiwa et al. 2016; Kim et al. 2016; Mai et al. 2020; Pattanaphesaj et al. 2018; Lin et al. 2018; Purba et al. 2017; Wong et al. 2018; Shafie et al. 2019). As a preliminary exploration of the value sets, the kernel density distributions of each value set were plotted and compared graphically.
The relative importance of the EQ-5D-5L dimensions was assessed by comparing the values for single dimension level 5 problems health states (51111, 15111, 11511, 11151, 11115) between countries/areas, encompassing the maximum value decrement for each dimension.Footnote 1 A further sub-analysis was carried out to determine the relative importance of PD and the relative importance of mental health (i.e., AD), and their ranking compared to the other dimensions.
Differences in scale length between countries/areas are inspected by subtracting the value for state “55555” (extreme problems/unable to on all dimensions) from the value for state “11111” (no problems on any of the dimensions) for each country/area. The location of descriptive midpoint in the value distribution is assessed by taking the difference between the value for state “11111” and state “33333” and dividing this value by the scale length.
Analysing the marginal effect of moving from one severity level to another on a dimension is trivial in cases where a 20-parameter main effects model is used as the preferred model for a value set, as the coefficients of the 20-parameter model can be used for this analysis (see Chap. 4 for a description of the modelling of valuation data). However, this is not the case for at least some of the value sets included in this analysis, such as value sets that included an intercept, or that were defined according to a constrained 8- or 9-parameter model, where the distance between the levels of the EQ-5D-5L is kept constant over the dimensions.Footnote 2 Therefore, we calculated the values for each health state with problems on a single dimension only (e.g. for AD 11111, 11112, 11113, 11114, 11115) and plotted these in a line plot for each dimension for each country/area separately. This allows for a comparison of the 20-parameter model value sets with all other value sets.
6.2.2 Defining Preference Patterns and the Performance of These Patterns
To test the performance of the identified preference patterns, data from the Multi Instrument Comparison (MIC) study (Richardson et al. 2012) were used, as in the Olsen et al. study (Olsen et al. 2018). In the MIC study, patients from seven disease areas (arthritis, asthma, cancer, depression, diabetes, hearing loss and heart disease) as well as a healthy respondent group, completed the EQ-5D-5L, as part of a larger international survey. In total, 7933 respondents from six Western countries/areas (Australia, Canada, Germany, Norway, United Kingdom, United States) completed the EQ-5D-5L. The values for the 25 different value sets used in the current chapter were assigned to the health profiles of the respondents, as were the values generated by the identified preference patterns. Using line plots, we compared the distributions of the values between the countries/areas and identified preference patterns. The preference patterns, or aggregate value sets, will be defined based on the mean of the coefficients of sets of value sets that share common properties. The properties used for this purpose are: (1) the relative importance of the EQ-5D-5L dimensions (calculated as described above, four different sub-characteristics are compared); (2) the distribution over values over the scale (six different sub-characteristics are compared); and (3) geographic proximity and cultural similarity.
6.3 Differences Between Value Sets
6.3.1 Relative Importance of the Dimensions
Table 6.1 provides information on the geographical region and subregion of the countries/areas in which value set studies were conducted. Furthermore, it shows which protocol version was used for the data collection, which reflects some of the methodological choices made in each study, such as the use of the quality control (QC) procedure, practice health states, a feedback module and dynamic practice examples. More can be read about this elsewhere (Stolk et al. 2019) and in Chap. 2. Furthermore, Table 6.1 shows the order of importance of the dimensions, which differs between countries/areas. In each country/area either MO, PD or AD is identified as the most important dimension. The least important dimension is either SC, UA, AD in Uruguay, and PD in the Indonesian value set. MO is ranked as the most important dimension eleven times (including all of the nine Asian countries/areas), PD is ranked as the most important dimension ten times (including seven Western countries/areas) and AD is ranked as most important four times (including the remaining three Western countries/areas). In 16 value sets, UA is ranked as the least important or is tied as the least important dimension. SC is ranked seven times as the least important dimension, while AD is ranked least important once and PD once.
Table 6.2 reports the individual weights, or partial value decrement, for having a certain level of problems on a certain health dimension compared to not having any problems on that dimension. The table restricts itself to the maximum level, so only the weights for level 5 problems are reported. The smallest value decrement assigned to any dimension with level 5 problems is UA, in Spain, with a value of 0.153. In contrast, the largest value decrement in Spain is for PD, with a value of 0.381. The largest value decrement assigned to any dimension with level 5 problems is AD in Ireland, with a value of 0.646. In contrast, the smallest value decrement assigned to any dimension with level 5 problems in Ireland is 0.187, for UA. The size of the range of value decrements assigned to the dimensions differs substantially between countries/areas. The smallest difference is reported in Japan, where the largest weight (MO) is only 0.079 larger than the smallest weight (SC). The largest differences are reported in Ireland, where the largest weight (AD) is 0.459 larger than the smallest weight (UA). These results show that countries/areas can differ considerably in terms of which dimension is considered most important and the absolute difference in weight assigned to the different dimensions.
6.3.2 Marginal Value Decrements of Moving from One Level to Another
Figures 6.1a and 6.1b report the marginal effect of moving from one level to another, by dimension. For some countries/areas, such as Canada and Japan, the marginal value decrement of moving to another level of problems is relatively similar between the dimensions. However, in countries/areas such as Indonesia, Ireland, Germany, the Netherlands and Poland, the marginal effects for one or two dimensions are significantly more negative. Furthermore, the slopes of the graphs in Figs. 6.1a and 6.1b differ between countries/areas, indicating different marginal value decrements. For example, in Japan the decrements in value by level seem to be relatively linear, while in several Western countries/areas (including Canada, England, Netherlands), there seems to be a “kink” when moving from level 3 to 4 on any dimension, and a “reverse kink” when moving from level 4 to 5.

Value decrements by level and dimension, by country/area for Eastern European and Western countries/areas

Value decrements by level and dimension, by country/area for Asian, African and Latin American countries/areas
These findings are supported by Table 6.3, which reports values for specific health states, representing the same level of problems on all dimensions; 11111, 22222, 33333, 44444, 55555. Table 6.3 shows how these important health states in the descriptive system are spread over the value scale. For example, in China the values assigned to these states correspond well with their location in the descriptive system, with state 33333 being roughly halfway on the value scale between state 11111 and 55555. For other countries/areas, such as France, this is not so: the difference between 11111 and 33333 represents only 15% of the scale, with the remaining 85% representing the difference between 33333 and 55555.
6.3.3 Scale Length and Location of the Descriptive Midpoint on the Health Utility Scale
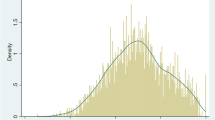
Figure 6.2 reports the kernel density distributions of each value set. The differences in scale length between countries/areas are reflected in these distributions. The scale length for a country/area can be thought of as an indicator of their willingness to give up life years to improve quality of life. The shape of the distributions also differs, although in addition to the scale length, this is also related to the relative importance of the domains and modelling decisions, which may lead to normally or non-normally distributed value sets.

Kernel density distribution plots by country/area
Table 6.3 includes the location of the descriptive midpoint (33333) of the EQ-5D-5L on the value distribution, expressed as a percentage of the total scale length. For the Western European countries/areas, the descriptive midpoints are in most cases assigned a higher value than the mathematical midpoint of the health value scale, indicating a relatively larger weights for severe and extreme health problems, compared to slight and moderate problems. For Asian countries/areas, this is the case as well, with the exception of Korea, where state 33333 is assigned a relatively low value compared to the scale range. Furthermore, Table 6.3 also reports the scale length for each value set. For Western countries/areas, these are relatively similar and are between 1.096 and 1.757. Ireland is an exception with a scale length of 1.974. For the Asian countries/areas, there is a clear distinction between East Asian and Southeast Asian countries/areas in terms of scale length; for East Asian countries/areas such as China, Japan and Korea, these are relatively small (between 1.026 and 1.391). For Southeast Asian countries/areas the scale lengths are much larger, with the lowest being reported in Thailand at 1.420 and the highest in Taiwan at 2.025.
6.4 Identifying Preference Patterns
Based on these findings, it appears that we can now differentiate between four regions: Asian, Western, Eastern European, Latin-American and African. Tables 6.4a and 6.4b provide more details on certain properties that are shared between the value sets for different countries/areas and by contrast also identifies differences. The Asian countries/areas can further be divided into the East Asian (Japan, Korea and China) and Southeast Asian (Vietnam, Thailand, Taiwan, Hong Kong, Indonesia and Malaysia) subgroups. The Latin-American (Mexico, Peru and Uruguay) and African (Ethiopia) regions are pooled due to the fact that there are few value sets available for that region and they do not fit into the other categories.
What can be seen from Tables 6.1, 6.2, 6.3, 6.4a and 6.4b, is that the relative importance of the dimensions differs fundamentally between Western countries/areas and Asian, Latin-American, African and Eastern European countries/areas. For the Asian value sets, MO is always the most important dimension, mostly followed by PD, with UA and SC being of least concern. In contrast, PD or AD is usually the most important dimension in Western countries/areas, followed by MO, SC and UA. Eastern European countries/areas show a high importance for PD and MO, followed by SC, AD and UA. For the Latin-American and African value sets, the orders of relative importance are more mixed. Other characteristics, such as a drop at the top of the scale, i.e., the drop in value associated to not being in state 11111 regardless of the health problems experienced and relative drops in value over the levels, seem mixed. Although Olsen et al. (2018) found substantial differences in the value sets from the first wave of valuation studies for the EQ-5D-5L, these differences are less apparent in the newer studies.
The scale length also differs substantially between countries/areas, as can be seen from Tables 6.4a and 6.4b. Western countries/areas seem more similar regarding how the values for some key points on the scale (states 22222, 33333, 44444 and 55555) are distributed over the value scale, as compared to other countries/areas. Between the Asian countries/areas, there seems to be a distinction in scale length between Southeast Asian countries/areas and East Asian countries/areas, with East Asian countries/areas reporting shorter scale length than Southeast Asian countries/areas, indicating less willingness to trade life years for quality of life in East Asian countries/areas, compared to Southeast Asian countries/areas.
Olsen et al. (2018) found a Western preference pattern (WePP) in their previous study, which represented a hybrid of the value sets for England, Canada, Spain and the Netherlands. Of the ten key characteristics in their WePP-model (the characteristics in Tables 6.4a and 6.4b, except for the drop at the top/N1 term), Canada and England fulfilled all 10 characteristics, while the Netherlands and Spain met 9. The new value sets from other Western countries/areas appear to confirm the existence of this WePP, with Portugal and Ireland fulfilling 8 of the criteria, Denmark fulfilling 7, while France and Germany fulfilled 6 of the criteria. The US and the two Eastern European countries/areas are somewhat different from the Western preference patterns, as they only adhere to 4 or 5 of the criteria. Interestingly, the relative importance of AD is much lower in the Eastern European countries/areas, while MO and SC are more important, although this also applies to a lesser extent to France and Portugal.
Table 6.4b reveals more heterogeneous preferences behind the value sets. It seems that Asian countries/areas share similar characteristics, but can be sub-grouped into East Asian and Southeast Asian preference patterns. The remaining countries/areas (Mexico, Peru, Uruguay and Ethiopia) are different in their characteristics from the (Southeast and East) Asian, Eastern European and Western value sets. As they also differ between each other, these are not grouped as another preference pattern. However, one common aspect of the value sets from Mexico, Peru, Uruguay and Ethiopia that can be clearly identified is that the value for state 55555 is lower than −0.2 in all these countries/areas.
Preference patterns and the aggregate value sets associated with them, are generated and defined as the means of the groups of value sets they represent. Taking the means of the values from several value sets that share similar characteristics ensures that the aggregate value sets broadly represent the value sets they should represent, without large variation. These aggregate value sets are reported in Table 6.5 and are presented as weights for the level dimension combinations (e.g., UA3 represents the weight for having moderate problems on UA).
6.5 How Do These Preference Patterns Perform?
Figure 6.3a-e show how these aggregate value sets perform compared to the national value sets they represent. These figures represent values assigned to the EQ-5D-5L health profiles of the respondents of the MIC study, based on the value sets for each country/area in the geographic region, and the aggregate value sets developed here, referred to with the prefix MN to each region. These values are plotted against the relative severity of the health profiles of those respondents, as defined by the level sum score, calculated by taking the sum of the levels of problems for all dimensions of the EQ-5D-5L (e.g., for state 12315 this is 1 + 2 + 3 + 1 + 5 = 12) and rescaled to a scale in which 0 is the worst health state and 1 is the best health state. This allows us to see whether the aggregate value sets could represent single country/area value sets well, when used in patient populations. If they perform well, these aggregate value sets may be useful to assess the quality of life in multi-country/area studies. What these figures show is that the Western aggregate value set based on means (MN-WEPP) performs relatively well and can be seen as an extension of the Western preference pattern (‘WePP’) model suggested by Olsen et al. (2018). However, this preference pattern may misrepresent the value sets of some countries/areas to some degree, such as Ireland and France. The values for Ireland are consistently lower than the MN-WEPP. The value set for France generates values that are frequently substantially higher than the other value sets for the mild and moderate states, yet the values for France become more comparable to the other European value sets and the aggregate value set for more severe states. Eastern European values (MN-EUR-E, Fig. 6.3c) are quite similar for the mild and moderate states, yet seem to diverge for the more severe states.

Performance of the preference patterns: MN-WEPP
The results for the Asian aggregate value set (MN-ASIA, Fig. 6.3b) are mixed. The Southeast Asian aggregate value set (MN-SEA, Fig. 6.3e) performs relatively well for mild and moderate states, yet for severe states, there seems to be a split between two sets of 3 countries/areas. Taiwan, Hong Kong and Indonesia show substantially lower values than Thailand, Malaysia and Vietnam. For East Asia, Korea and Japan appear to have very similar preference patterns, yet China performs quite differently from those, leading to a misrepresentation of the East Asian aggregate value set (MN-EASIA, Fig. 6.3d). For the whole of Asia, there seems to be a lot of heterogeneity, with smaller groups of countries/areas being more alike, but no real pattern in values that is shared among all countries/areas.

Performance of the preference patterns: MN-ASIA

Performance of the preference patterns: MN-EUR-E

Performance of the preference patterns: MN-EASIA

Performance of the preference patterns: MN-SEA
6.6 Discussion
6.6.1 Main Findings
In this chapter we have identified several key differences between currently published value sets, by examining the distributions, scale lengths, relative importance of the dimensions, marginal differences in values between levels, and a focus on symptoms versus the functional dimensions. Furthermore, we were able to identify several preference patterns for countries/areas that share common characteristics in terms of geography and/or institutional settings.
6.6.2 Preference Patterns
We have identified five preference patterns; for Western countries/areas, Asian countries/areas, further subdivided into an East-Asian preference pattern and a Southeast Asian preference pattern and Eastern-European countries/areas. Our findings show that the countries/areas identified by Olsen et al. (2018) as having a similar pattern can be supplemented with other Western countries/areas as well, as they are also similar in value set characteristics.
Eastern European countries/areas differ substantially from the Western preference pattern, as MO is considered more important than in Western countries/areas, compared to PD or AD. Furthermore, AD is given low priority in general, compared to the Western preference pattern.
The Asian preference patterns are distinct from the Western preference pattern as MO is considered the most important dimension in all Asian value sets. Furthermore, a clear distinction between the Eastern European and Asian preference patterns is that on average, there is a higher importance for AD in the Asian value sets, compared to the Eastern European preference pattern. The scale lengths do not differ substantially from the Western and Eastern European preference patterns, yet differ substantially within the Asian preference pattern. Figures 6.3b, 6.3d and 6.3e illustrate this. The difference in scale length and divergence between the Eastern Asian and Southeast Asian countries/areas for the severe health states is the main difference between the two and leads us to distinguish two separate Asian preference patterns. This confirms findings by Xie et al. who concluded that there is less variation within Western value sets compared to Asian value sets (Xie et al. 2017).
6.6.3 Data Quality and Modelling Strategies
In addition to the factors discussed in the methods and results sections, there are two other key elements that may cause differences between value sets: (1) data quality and (2) modelling strategies. Especially in the first wave of valuation studies, some studies reported issues with data quality. Two key data issues identified were a lack of worse than dead (WTD) responses due to the fact that the WTD task of the cTTO was not explained to the respondents and satisficing by the respondents, leading to low values for very mild health states (Stolk et al. 2019; Ramos-Goñi et al. 2017a, b). Both of these are undesirable and may affect value sets, resulting in poor face validity. The lack of negative values may lead to a narrower value range than could have been found when genuine preferences had been captured, while low values for mild health states may lead to imprecision and underestimation at the top of the scale, resulting in low values for mild states in the value sets.
Modelling strategies may also affect some of the key aspects of a value set. These refer to: (1) whether cTTO data are combined with DCE data (hybrid modelling); (2) the assumptions on censoring at −1; (3) the way heteroskedasticity is dealt with; (4) accounting for preference heterogeneity; and (5) allowing for nonlinear terms. Hybrid modelling combines the DCE and cTTO data into a single likelihood function, which allows the researcher to model both sets of data simultaneously (Ramos-Goñi et al. 2018). There is evidence that the scale length is somewhat longer in studies that use hybrid models when compared to cTTO models. For example, in the case of the US valuation study, the scale length differed by 0.126 between the cTTO and hybrid models, and the order of importance of the dimensions also differed (Pickard et al. 2019). Furthermore, there is an ongoing debate on whether hybrid modelling is an appropriate strategy when the DCE and cTTO data are not in agreement.
Taking into account the censored nature of cTTO data is another matter of concern that may affect value sets systematically. In the cTTO task, respondents are constrained by a minimum value of −1 that they can assign to health states. In practice, respondents may be willing to assign an even lower value to a health state. To account for this, assumptions can be made about the distribution of the responses at −1, which may be beyond this value. Tobit models are a way to deal with this and they may substantially lengthen the scale compared to models that make no assumptions about censored data. For example, in the Dutch study, the scale length differed by 0.119 between the Tobit and regular linear models (Versteegh et al. 2016). Furthermore, there may be consequences for the values at the top of the scale as well.
Models accounting for heteroskedasticity may be better at providing more exact estimates for cTTO data, as the standard errors are substantially smaller for the milder health states compared to the more severe states on the scale. Furthermore, accounting for preference heterogeneity by employing random intercept models may also account for differences between value sets. Finally, allowing for non-linear terms such as interactions in the models may cause differences between value sets, producing non-normal distributions.
6.6.4 Differences Between Value Sets Between and Within Preference Patterns
As identified in the introduction, there are many factors that may explain differences and similarities between value sets. Differences in genuine preferences may result from differences in cultural values, wealth, characteristics of health systems, whereas methodological differences can be caused by differences in measurement method, data quality and modelling strategies.
A study by Wang et al. investigated the results of seven Asian cTTO datasets, used for generating EQ-5D-5L value sets (Wang et al. 2019). They found substantial differences between value sets for Asian countries/areas and recommend developing value sets for each country/area independently, on the basis that a value set from one Asian country/area may not adequately represent the values from a neighbouring country/area. We also find some differences between Asian countries/areas, yet also some similarities that allow us to approximately group Asian value sets into two groups. One can speculate what may cause these differences between the two groups. It could be that some countries/areas are more similar in their preferences, as they share similar characteristics in terms of their wealth, healthcare systems, social insurance and culture. However, looking at the effect of culture, mixed results have been found. One study finds a relationship between the relative importance of the different attributes and differences in culture (Bailey and Kind 2010), while another study finds no relationship between scale length and differences in cultural values (Roudijk et al. 2019). Other factors such as study protocol and QC could also be an important factor in explaining differences between value sets. For example, the studies from the earlier waves of EQ-5D-5L valuation studies (Japan, China, Korea) report much smaller scale lengths than most of the other Asian value sets (Shiroiwa et al. 2016; Luo et al. 2017; Kim et al. 2016). This may partially explain differences between Asian countries/areas. A similar observation can be made for Western countries/areas, yet the difference seems to be smaller between Western value sets. More research, possibly in the form of a meta-analysis, is needed to assess key methodological differences between the value sets within geographical regions and to explore whether these methodological differences and macroeconomic determinants such as health systems may explain differences between the value sets.
6.6.5 Limitations
A limitation of this chapter is that the number of countries/areas included in each preference pattern differs substantially. For example, the Western aggregate value set includes value sets from ten countries/areas, while the Eastern European aggregate value set contains only two. Another limitation is that geographical/cultural regions such as Africa, the Middle East and Latin America are underrepresented in the number of available value sets. Once more value sets are available from these regions, it will become more feasible to determine if there are any preference patterns in these regions and compare them with the currently identified preference patterns. Finally, another limitation is that the patient data used to test the preference patterns was collected in Western countries/areas only. Therefore, the value sets from non-Western countries/areas (and subsequent aggregate value sets) may not adequately reflect the values for patients. Future research using patient data from non-Western countries/areas may improve our understanding of how well these aggregate value sets perform in non-Western countries/areas.
6.7 Conclusions
This chapter identified key differences between value sets and attempts to group value sets on similarities according to certain relevant characteristics. Five different preference patterns were identified. As differences between value sets for countries/areas included within a preference pattern can still be substantial, we still recommend the development and use of national value sets rather than using a value set from a different country/area or from a composite of countries/areas. However, these aggregate value sets could be used for sensitivity analyses when applying foreign value sets.
Notes
- 1.
Note that this is a different and less sophisticated way of assessing dimension importance compared to that reported in Chap. 4 for each value set.
- 2.
The results of 8- or 9-parameter models can be presented as 20-parameter models, without changing anything of substance relating to the model.
References
Andrade LF, Ludwig K, Ramos-Goni JM, Oppe M, de Pouvourville G (2020) A French value set for the EQ-5D-5L. PharmacoEconomics 38(4):413–425
Augustovski F, Rey-Ares L, Irazola V, Garay OU, Gianneo O, Fernández G, Morales M, Gibbons L, Ramos-Goñi JM (2016) An EQ-5D-5L value set based on Uruguayan population preferences. Qual Life Res 25(2):323–333
Augustovski F, Belizán M, Gibbons L, Reyes N, Stolk E, Craig BM, Tejada RA (2020) Peruvian valuation of the EQ-5D-5L: a direct comparison of time trade-off and discrete choice experiments. Value Health 23(7):880–888
Bailey H, Kind P (2010) Preliminary findings of an investigation into the relationship between national culture and EQ-5D value sets. Qual Life Res 19(8):1145–1154
Devlin NJ, Shah KK, Feng Y, Mulhern B, van Hout B (2018) Valuing health-related quality of life: An EQ-5D-5L value set for England. Health Econ 27(1):7–22
Ferreira PL, Antunes P, Ferreira LN, Pereira LN, Ramos-Goñi JM (2019) A hybrid modelling approach for eliciting health state preferences: the Portuguese EQ-5D-5L value set. Qual Life Res 28(12):3163–3175
Golicki D, Jakubczyk M, Graczyk K, Niewada M (2019) Valuation of EQ-5D-5L health states in Poland: the first EQ-VT-based study in Central and Eastern Europe. PharmacoEconomics 37(9):1165–1176
Gutierrez-Delgado C, Galindo-Suárez RM, Cruz-Santiago C, Shah K, Papadimitropoulos M, Feng Y, Zamora B, Devlin N (2021) EQ-5D-5L health-state values for the Mexican population. Appl Health Econ Health Policy. https://doi.org/10.1007/s40258-021-00658-0
Hobbins A, Barry L, Kelleher D, Shah K, Devlin N, Ramos-Goni JMR, O’Neill C (2018) Utility values for health states in Ireland: a value set for the EQ-5D-5L. PharmacoEconomics 36(11):1345–1353
Jensen CE, Sørensen SS, Gudex C, Jensen MB, Pedersen KM, Ehlers LH (2021) The Danish EQ-5D-5L value set: a hybrid model using cTTO and DCE Data. Appl Health Econ Health Policy 19(4):579–591
Kim SH, Ahn J, Ock M, Shin S, Park J, Luo N, Jo MW (2016) The EQ-5D-5L valuation study in Korea. Qual Life Res 25(7):1845–1852
Lin HW, Li CI, Lin FJ, Chang JY, Gau CS, Luo N, Pickard AS, Ramos Goñi JM, Tang CH, Hsu CN (2018) Valuation of the EQ-5D-5L in Taiwan. PLoS One 13(12). https://doi.org/10.1371/journal.pone.0209344
Ludwig K, von der Schulenburg JMG, Greiner W (2018) German value set for the EQ-5D-5L. PharmacoEconomics 36(6):663–674
Luo N, Liu G, Li M, Guan H, Jin X, Rand-Hendriksen K (2017) Estimating an EQ-5D-5L value set for China. Value Health 20(4):662–669
Mai VQ, Sun S, Van Minh H, Luo N, Giang KB, Lindholm L, Sahlen KG (2020) An EQ-5D-5L value set for Vietnam. Q Life Res 29(7):1923–1933
Norman R, Cronin P, Viney R, King M, Street D, Ratcliffe J (2009) International comparisons in valuing EQ-5D health states: a review and analysis. Value Health 12(8):1194–1200
Olsen JA, Lamu AN, Cairns J (2018) In search of a common currency: a comparison of seven EQ-5D-5L value sets. Health Econ 27(1):39–49
Oppe M, Devlin NJ, van Hout B, Krabbe PF, de Charro F (2014) A program of methodological research to arrive at the new international EQ-5D-5L valuation protocol. Value Health 17(4):445–453
Pattanaphesaj J, Thavorncharoensap M, Ramos-Goñi JM, Tongsiri S, Ingsrisawang L, Teerawattananon Y (2018) The EQ-5D-5L valuation study in Thailand. Expert Rev Pharmacoecon Outcomes Res 18(5):551–558
Pickard AS, Law EH, Jiang R, Pullenayegum E, Shaw JW, Xie F, Oppe M, Boye KS, Chapman RH, Gong CL, Balch A, Busschbach JJV (2019) United States valuation of EQ-5D-5L health states using an international protocol. Value Health 2(8):931–941
Purba FD, Hunfeld JAM, Iskandarsyah A, Fitriana TS, Sadarjoen SS, Ramos-Goñi JM, Passchier J, Busschbach JJV (2017) The Indonesian EQ-5D-5L value set. PharmacoEconomics 35(11):1153–1165
Ramos-Goñi JM, Oppe M, Slaap B, Busschbach JJ, Stolk E (2017a) Quality control process for EQ-5D-5L valuation studies. Value Health 20(3):466–473
Ramos-Goñi JM, Pinto-Prades JL, Oppe M, Cabasés JM, Serrano-Aguilar P, Rivero-Arias O (2017b) Valuation and modeling of EQ-5D-5L health states using a hybrid approach. Med Care 55(7):51–58
Ramos-Goñi JM, Craig BM, Oppe M, Ramallo-Fariña Y, Pinto-Prades JL, Luo N, Rivero-Arias O (2018) Handling data quality issues to estimate the Spanish EQ-5D-5L value set using a hybrid interval regression approach. Value Health 21(5):596–604
Rencz F, Brodszky V, Gulácsi L, Golicki D, Ruzsa G, Pickard AS, Law EH, Péntek M (2020) Parallel valuation of the EQ-5D-3L and EQ-5D-5L by time trade-off in Hungary. Value Health 23(9):1235–1245
Richardson J, Khan MA, Iezzi A, Maxwell A (2012) Cross-national comparison of twelve quality of life instruments. MIC paper, 2. Monash University, Australia
Roudijk B, Donders ART, Stalmeier PF (2019) Cultural values: can they explain differences in health utilities between countries? Med Decis Mak 39(5):605–616
Shafie AA, Vasan Thakumar A, Lim CJ, Luo N, Rand-Hendriksen K, Yusof FAM (2019) EQ-5D-5L valuation for the Malaysian population. PharmacoEconomics 37(5):715–725
Shiroiwa T, Ikeda S, Noto S, Igarashi A, Fukuda T, Saito S, Shimozuma K (2016) Comparison of value set based on DCE and/or TTO data: scoring for EQ-5D-5L health states in Japan. Value Health 19(5):648–655
Stolk E, Ludwig K, Rand K, van Hout B, Ramos-Goñi JM (2019) Overview, update, and lessons learned from the International EQ-5D-5L valuation work: version 2 of the EQ-5D-5L valuation protocol. Value Health 22(1):23–30
Versteegh MM, Vermeulen KM, Evers SMAA, De Wit GA, Prenger R, Stolk EA (2016) Dutch tariff for the five-level version of EQ-5D. Value Health 19(4):343–352
Wang P, Liu GG, Jo MW, Purba FD, Yang Z, Gandhi M, Pattanaphesaj J, Ahn J, Wong ELY, Shafie AA, Busschbach JJV, Luo N (2019) Valuation of EQ-5D-5L health states: a comparison of seven Asian populations. Expert Rev Pharmacoecon Outcomes Res 19(4):445–451
Welie AG, Gebretekle GB, Stolk E, Mukuria C, Krahn MD, Enquoselassie F, Fenta TG (2020) Valuing health state: an EQ-5D-5L value set for Ethiopians. Value Health Reg Issues 22:7–14
Wong EL, Ramos-Goni JM, Cheung AW, Wong AY, Rivero-Arias O (2018) Assessing the use of a feedback module to model EQ-5D-5L health states values in Hong Kong. Patient 11(2):235–247
Xie F, Pullenayegum E, Gaebel K, Bansback N, Bryan S, Ohinmaa A, Poissant L, Johnson JA (2016) A time trade-off-derived value set of the EQ-5D-5L for Canada. Med Care 54(1):98–105
Xie F, Pullenayegum E, Pickard AS, Ramos Goñi JM, Jo MW, Igarashi A (2017) Transforming latent utilities to health utilities: East does not meet west. Health Econ 26(12):1524–1533
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Roudijk, B., Janssen, B., Olsen, J.A. (2022). How Do EQ-5D-5L Value Sets Differ?. In: Devlin, N., Roudijk, B., Ludwig, K. (eds) Value Sets for EQ-5D-5L. Springer, Cham. https://doi.org/10.1007/978-3-030-89289-0_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-89289-0_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-89288-3
Online ISBN: 978-3-030-89289-0
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)