
Abstract
Automated driving, in general, and platooning, in particular, represent a highly active field of research. The idea to automate traffic is closely related to high expectations in both individual and public transport. However, the complexity of automated driving requires methods beyond the traditional development approaches. This chapter describes a state-of-the-art methodology to organise and systematically address a comprehensive set of research questions in the context of truck platooning. Following best practices, an evaluation design is presented, which ensures the alignment of research efforts with the actual research agenda, that is, to answer the right questions. Specifically, the benefits of automated driving and their conflicting relationships are explored and the entities that affect automated driving performance and their interactions are presented. Finally, a solution concept that adequately addresses the complexity and the stochastic nature of the problem is presented. The solution concept consists of several key methods such as scenario-based design and stochastic simulation, data mining and complexity and robustness management.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


1 Benefits of Automated Driving
The expected benefits of automated driving, and of platooning in particular, can be grouped into the following five categories:
-
Comfort.
-
Safety.
-
Traffic efficiency.
-
Traffic effectiveness.
-
Vehicle efficiency.
Comfort benefits often translate directly to time that the driver of a vehicle can spend on tasks other than driving. Instead, travelling time can be used for tasks with significantly more added value or even be spent resting, similar to longer train rides.
Safety benefits aim at elimination or at least mitigation of collisions. Currently, up to \(90\%\) of all collisions are caused by human error, which may be eliminated by automation and automated driving functions.
Traffic efficiency benefits fall into two subgroups. First, it is expected that traffic volume across an intersection or through a section of highway can be increased while keeping travel time low and avoiding congestion. Second, it is expected that automated vehicles can be operated at superior efficiency compared to human-driven vehicles, due to predictive driving strategies and cooperative behaviour.
Vehicle efficiency considers energy consumption and energy efficiency. For example, predictive driving strategies may improve vehicle efficiency by saving fuel.
Traffic effectiveness benefits can be achieved by selecting the best mode of traffic in any given situation. In case the road network of the city centre is already congested, the capacity of the system is better utilised if additional journeys are undertaken by metro instead of individual cars. Shared mobility is also a means of utilising this benefit.
These groups are connected, and many benefits are conflicting; see Fig. 4.1.

Conflicting benefits of automated driving
Each benefit category can be investigated individually; however, due to their conflicting nature, the performance in every other category will be poor. The only intrinsic benefit of automated driving is comfort. Therefore, the benefits of all categories must be managed well in order to achieve some sort of satisfactory overall performance. Mathematically speaking, the Pareto front of the benefit criteria (also known as key performance indicators—KPIs) has to be evaluated and properly weighted solutions at the edge of the Pareto front have to be found. In the subsequent sections, different requirement conflicts of the above-mentioned benefits of automated driving are discussed.
1.1 Requirements Conflict Efficiency Versus Safety
Looking at the defining equation for traffic volume \(Q = D\cdot V\) and recalling the fundamental diagram, traffic density D and/or traffic velocity V have to be increased in order to increase the flow rate Q per lane. Higher velocities and higher traffic density correlate positively with larger traffic volume. However, increasing safety in traffic usually translates to reduced velocity and/or lower traffic density. Reducing the velocity reduces collision severity, and reducing traffic density reduces the risk of collision.
1.2 Requirements Conflict Safety Versus Comfort
Most current advanced driver assistance systems (ADAS) are comfort systems by design. They are designed to operate under regular conditions. As soon as a critical traffic situation is reached, these systems delegate responsibility back to the human driver. In contrast, safety systems are designed to operate in critical situations, where these systems assume control. The human driver does not recognise that a safety system is operating under regular driving conditions. Hence, safety systems and common comfort enhancing assistant functions operate reciprocally. The importance of handover scenarios in automation systems, in particular at SAE level 3, must be discussed and addressed by the scientific community .
1.3 Requirements Conflict Comfort Versus Effectiveness
Significantly increasing driving comfort and allowing productive tasks being performed while travelling by car may cause even more individual vehicle traffic on road networks. This will influence the choice of traffic mode, in addition to many other aspects that a person considers while making this choice.
1.4 Requirements Conflict Comfort Versus Efficiency
Public transport is undoubtedly more efficient in terms of passenger per section and time. However, comfort levels of public transport vary with mode type, time of day (crowdedness and cleanliness), particular route requirements, etc., and are generally lower than when travelling in one’s own car.
1.5 Requirements Conflict Traffic Versus Vehicle Efficiency
Traffic and vehicle efficiency are in conflict too. While traffic efficiency sometimes requires high responsiveness and higher accelerations to close distance gaps and still reaches remaining slots of green times, vehicle efficiency normally needs smooth changes in velocities and slow, energy preserving motion patterns for certain street sections and traffic events, like red lights and accelerations after changes to green light.
Summing up, the mentioned main categories of benefits from automated driving are conflicting and oppositional. Comfort is the only intrinsic feature, which comes along on its own purely by the introduction of vehicle automation. A sole automation of vehicles only will not automatically make traffic safer, more efficient and more effective. These properties must be worked out cumbersomely if all the expected benefits of automated driving should be leveraged and be put into real effect. Hence, it is not a matter of optimisation, potential benefits have to be balanced and proper trade-offs have to be found between the counteracting effects. This can only be done by gathering knowledge about the quantitative relations of the described effects. Mathematically speaking, the Pareto front of the benefit criteria (i.e. the KPIs) must be evaluated and properly weighted solutions at the edge of the Pareto front have to be found.
2 Entities with Effects on Automated Driving Performance
When searching a quantitative description of the various performance parameters and dependencies of automated driving effects, the relevant parameters and entities have to be identified first. Figure 4.2 shows the main entities which have influence on the performance of automated driving functions and have to be considered, in case the potential benefits of automated driving should be put into effect. These entities must be described and elaborated numerically. Unfortunately, all these entities have an effect on all the others and, therefore, must be considered simultaneously.

Main entities with influence on the performance and benefits of automated driving
-
ADAS and Automated Driving Functions: Of course, the realisation and certain characteristics of the advanced driver assistance systems and automated driving functions themselves have the primary influence on the benefits of automated driving. The way they brake, steer, manoeuvre and execute their missions has fundamental influence on the re/action of other traffic participants and the traffic situation. The more precise the control algorithms estimate, predict and consider the behaviours of other traffic participants, the better their control performs. Telling other traffic participants and traffic control systems about the own intention respectively being deterministic allows others to better cooperate for optimal overall control.
-
Traffic Control and Management Systems: When optimising traffic is really a goal for automated driving, not only single vehicles but also traffic control and management should be automated to take the new functional possibilities and their potential into account. Traffic control can be improved by vehicle automation because the behaviours of the automated cars become more deterministic and predictable. Communication of the vehicles and traffic participants’ intentions also helps intensively for the interpretation of the traffic situation to adapt optimal control strategies. On the other side, automated vehicles are expected to fulfil advices from traffic control more disciplined and more precisely than humans would do. Of course, such “advices” have to be described properly by laws, regulations and common standards. Being clever in defining such a specification can help improving the overall system performances dramatically.
-
Behaviour of Drivers and Traffic Participants: Traffic participants’ behaviour determines heavily the resulting traffic situation. The more predictable and cooperative the traffic participants behave, the more precise and better vehicle and traffic control systems can become. Automation also allows prescribing beneficial behaviours more strictly, which normally will also be followed then. Automated vehicles also need to be predictable in their behaviour for non-automated traffic participants. Anyhow, this issue deals with all the effects of mixed traffic of automated and non-automated traffic participants and their (hopefully) cooperative interactive behavioural patterns. Due to the fact that there will always be mixed, individual traffic, the interactive behaviour of automated and non-automated traffic participants has to be considered anyway, as long as they are not strictly separated (what will be very difficult, especially in urban environments).
-
Traffic Situation: The traffic situation is mainly influenced by the behaviour of the traffic participants and the traffic and vehicle control strategies. The identification of the traffic situation is also the main control parameter for optimal, adaptive traffic control.
-
Streets and Infrastructure: Infrastructure—when properly maintained—can simplify the control task dramatically (e.g. by clear and consistent markings). On the other hand, vehicle control must also be able to coup with imperfect and disturbed environments.
-
Laws, Regulations and Guidelines: The main role of regulations and laws are defined by the “specification” of the necessary behavioural patterns and technical standards, especially with a priority on safety issues and cooperative control policies.
The mentioned relations between the main entities are not complete. Even more have been identified within the project WienZWA [3]. Due to the complexity and the interdisciplinary aspects of automated driving, the whole issue of vehicle automation cannot be resolved by single parties (e.g. a vehicle manufacturer). Costs and expenses would be much higher compared to collaborative approaches. Each of the described entities also corresponds to different stakeholders and scientific communities with different backgrounds. Bringing them together is not only a technical but also an organisational challenge. Technically, such a collaboration is required. Vehicle and traffic automation means that driving and traffic control is mainly substituted by algorithms. Therefore, if these algorithms should work optimally, they require precise quantitative information about the other entities. Furthermore, other parties need to get a feeling how their contribution influences the others. In the opinion of the authors, the best organisational approach for such a common playground would be an open test field, where all the described entities could be tested in common and brought into the overall context.
3 Additional Sources of Complexity
In the previous section, it has been illustrated that automated vehicles are part of an overall, much more complex (control) system-of-systems, when looking at the aspects of traffic and cooperative driving instead of only looking at single vehicles. This system-of-systems and all its relevant effects on the automated cars have to be taken into account, when validating automated vehicles and proofing their positive effects for improved traffic. Practically, such validation can only be done under real conditions in an open test field with realistic interactions with other traffic participants. But according to [7], there are more reasons, which motivate test fields and accompanying advanced validation methods, even when purely looking at the problem from the single vehicle system point of view.
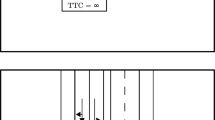
First of all, humans are part of the control loop now, not only externally by interacting with other traffic participants but also internally. Hence, control actions are not only rational and deterministic than anymore. Many decisions in traffic are based on the subjective judgement from traffic participants with very different experiences, backgrounds and skills. For the overlaying control, it is not a matter of objective system identification, but rather about estimating and anticipating the difference between objective and subjective estimations of risks and consequences. But not only humans and their partly irrational re/actions in certain situations are a source of stochastic variability. In addition, also sensors and actors are still far away from being perfect and precise. Besides the uncertainty of the sensor signals, also the classification performance of the algorithms may lack performance. The problem is stochastic; therefore, a probabilistic point of view with according methods is an absolute must. Furthermore, many decisions for the choice of driving strategies are context sensitive. They rely of information, which cannot be sensed directly. And last but not least, the problem is unstable. Even very small changes may lead to completely different results. For example, when looking at Fig. 4.3, dependent on very small differences in the initial velocity of the displayed configuration, the results for one of the cars may be a front crash or a side crash in the other case. From the perspective of automotive safety, these are completely different incidents with very different consequences and necessary countermeasures. On the other side, also very small measures at the right time may help to avoid such critical situations at all. Unfortunately, also the opposite is true. Very small errors or fail behaviours may result in severe crashes or heavy congestions.

Instability due to initial conditions for collisions
4 Development Procedures
In Sects. 4.2 and 4.3, it has been shown that the validation and rating of automated driving is a very complex task with a lot of interfering disciplines and stakeholders. Therefore, traditional knowledge-driven development methods and procedures are not sufficient anymore and have to be extended by modern approaches, which leverage the possibilities of new technologies from connectivity, big data analytics, artificial intelligence, etc., as fundamental part of the development and validation procedure.

Knowledge-driven development versus data-driven development procedures
Under knowledge-driven development, the linear, sequential development procedure is meant, which is roughly shown at the top of Fig. 4.4. Based on the knowledge and experience of certain domain experts, a solution concept is drawn and implemented. After that, the implementation is assessed in tests and under real conditions. Dependent on the time duration of that procedure and the complexity of the problem, the assessment often results in the finding that the assumptions of the experts and requirements from the beginning of the development are not valid anymore. The development has to be repeated or heavily adapted. In the case of automated driving, this issue is even intensified. According the different entities from Sect. 4.3, several very different disciplines and fields of expertise are contributing to the topic. There will not be any experts with sufficient knowledge in all of the necessary disciplines and subtopics. Therefore, lots of experts from different domains and organisations have to be coordinated and brought together. Also, each of the topics is running in completely different timescales. While mobile development (which is used, e.g., for traffic information systems) is running in innovation cycles of months, automotive development is running in cycles of years, and infrastructure issues are a matter of decades. Therefore, the synchronisation of the contributing different branches for automated driving will be quite challenging.
A major consequence would be the implementation of a common playground in the form of open test fields, which cover all the described entities. The technical coordination and integration will be done in the form of a data-driven development approach. The principle schema is shown in Fig. 4.4. Basic element is a data pool, where all acquired data from the test field, from naturalistic driving, from dedicated tests and from various simulations is collected and composed. Steadily acquired new data is used to update all the mathematical models and algorithms, which are part of the control application. Data mining and Machine Learning methods are used for continuous adaptation of the models. The results of the updated control applications are again acquired and fed back to the basic data set. In that way, an environment is defined, which allows steady iterations and continuous updates from instantaneously learned results. Such a procedure can also be seen as an agile system and functional development procedure, which is inspired by agile software processes. These allow extremely quick development cycles especially in case of complex systems, where precise requirements and specifications are not available from the beginning. The technological basis is the described solution components from the next chapter as well as connected technologies and Internet of Things solutions, which allow a dramatic acceleration of such learning cycles. Hereby, all the systems change because behavioural changes are captured immediately after application of the new solutions, allowing a quick adaption in case of unexpected effects and changes. In [1, 2, 6], it has been shown that such data-driven product development approaches are much quicker and much more effective and efficient in the case of complex systems than traditional purely knowledge-based approaches.
5 Solution Concept
When validating the effects and benefits of automated driving, first of all each of the described entities from Sect. 4.2 and the corresponding parameters and measurement should be available in a test field for automated driving. Laws and regulations are assumed to be quasi-static and available anyhow. Of course, these also need to be available explicitly, when testing policies and regulations.
But there are some reasons why the sole observation, tracking and logging of automated cars are not sufficient to validate and rate the effects of automated driving efficiently. Due to
-
1.
the stochastic nature and
-
2.
the complexity
of the problem, it would take a lot of test cycles and time to find out and proof the real reasons for the various effects. Therefore, the combination of traffic observation in the test field with some accompanying advanced methods is recommended to increase learning rates dramatically.
Following the data-driven approach from Sect. 4.4, a comprehensive scenario catalogue with numerical simulations is built up, maintained and steadily extended in parallel to the test field. The resulting scenario database covers all relevant cases from the test field and even goes far beyond. The scenario database contains simulation data from all relevant street sections of the test field in detail. In addition, numerous other cases from outside the test field are part of that scenario database. Results from the test field are immediately projected to the scenario database. Accordingly, applied methods to the scenario database then help in the interpretation and generalisation of the test results. The scenario database also includes the evaluation of criteria, which cannot be measured directly, like collision and/or congestion risks. An excerpt of these methods is described in the following. For all the mentioned methods at least, a proof of feasibility is available from the authors. For most of the methods already mature solutions are available. They just have to be combined accordingly and put together for a given test field.
5.1 Scenario-Based Approach and Stochastic Simulation
The basic method accompanying the test field runs is a scenario-based approach for the representation of all possible variations due to traffic and vehicle automation, like it is illustrated in Fig. 4.5. Hereby, a comprehensive collection of simulation scenarios is built up including variations of
-
The infrastructure (e.g. geometry and topology of streets and intersections, road conditions, lane configurations, ...).
-
Traffic situations.
-
Traffic participants and their behaviours.
-
Traffic control strategies.
-
Vehicle control strategies and control actions.

Scenario-based approach for the development and validation of vehicle and traffic automation
The variations are done with the help of multi-layered stochastic simulations (also known as Monte Carlo simulations) including the consideration of conditional probabilities (Bayesian approaches). The distributions for the Monte Carlo simulations are taken from the observations in the test field and from naturalistic driving studies, assuring representativeness of the data. The scenario catalogue contains the test field itself in detail. Furthermore, any other kind of street sections and intersection layouts are collected and composed in the scenario catalogue. These are built up automatically with the help of geoinformation systems like the Austrian graph integration platform (GIP), OpenStreetMap or similar other sources. The traffic situations are varied with respect to the real distributions of traffic situations taken from observations. Doing so, not only traffic volumes are varied, but also the distribution of the traffic participants and their behaviour is varied. The distributions are taken from external observations (e.g. by video tracking) or from their internal tracking with naturalistic driving/riding/walking data. Further possible control actions for traffic control as well as for vehicle control are varied. For these, special care has to be taken, according to [7], to assure the validity of the data and its interpretation. Once a test run is done in the real test field, the observations are mapped to the scenario catalogue. Thereby a single observation is put into the context of the occurring stochastic variations and can be classified as either a regular or an abnormal incident. With the help of the variations for the control actions in the scenario catalogue, also the consequences of the application of alternative driving control strategies and traffic control policies can be evaluated immediately. When observing that an event/situation is not yet represented in the scenario catalogue, the catalogue will be extended by that new situation. The scenario catalogue does not only contain driving situations. It contains different levels of details, ranging from vehicle dynamic simulation via traffic micro-simulation to macro-simulation. These different hierarchy levels of control are combined according to [4, 5]. Special multi-layered stochastic simulations and hierarchical approaches (some are betoken in [2, 5, 7]) allow the evaluation of realistic collision probabilities, criticality rates, collision risks, reserves with respect to safety, traffic volumes, etc. Many of such not directly measurable values are calculated in the scenarios catalogue and used later for the effectiveness rating (see Sect. 4.5.5) or the development of virtual sensors (see Sect. 4.5.6).
5.2 Big Data Analytics and Machine Learning
When having real big data in the scenario database and the test runs, it is obvious to approach this data with suitable, modern data mining, respectively, machine learning methods. These methods help to identify dependencies and relations between the relevant entities, parameters and influence factors. It is also the method of choice for the identification and predictions of the traffic situations. Once having captured all the relevant effects in the scenario catalogue, the resulting machine learning models can be used as control models as well, for instance, to estimate/predict the behaviours of the other traffic participants, for traffic control or for the selection of the proper driving and traffic control strategies according to the given traffic situations. Because the machine learning models can be adapted and updated quickly after new findings from the test runs, these are also the appropriate method to incorporate the learning from the test field results.
5.3 Incident and Anomalies Detection
Incident and anomalies detection is a generic method for quality assurance of any kind of data. It can be used for several use cases within the test field:
-
The identification of abnormal situations helps to fill up the scenario catalogue with all kind of relevant traffic situations.
-
New control concepts can be cancelled immediately if they result in surprising or unfavourable effects.
-
The quality of the simulation and test data can be assured, by sorting out false and buggy data.
5.4 Naturalistic Driving and Behavioural Models
Naturalistic Driving is the common keyword for the evaluation of driver behaviour through observation of drivers under naturalistic conditions in real traffic. That way, the behaviour of drivers with respect to the environmental conditions in different traffic situations can be assessed. The resulting models can be used for the automated driving functions to anticipate the behaviour of the other traffic participants. Further on, these models can be used in the scenario database to evaluate the consequences of a different behaviour of the traffic participants. When using naturalistic driving in a test field with the according sensor measurements, the method can also be used as usability test for infrastructure and traffic control systems. In that sense also, the acceptance of control strategies can be evaluated.
5.5 Effectiveness Rating
Automated driving and traffic automation is a new field, where still the best control actions and strategies with respect to the different possible situations have to be found and identified. Therefore, it is rather an issue of identifying the most effective measures and actions first and not of being efficient in the execution of the actions. According to [7], the proof of effectiveness for automated driving functions can be quite tricky. Anyhow, the scenario database in combination with relevance measures from the test field is a very powerful method for the efficient development and validation of automated driving and traffic control functions. In fact, “effectiveness” is a validation criterion by itself.
5.6 Cosimulation and Virtual Sensors
Not all necessary control parameters can be measured directly. For example, danger, collision risk, congestion probability, capacity reserve, etc., are values which cannot be measured or evaluated directly during a test run. Either these are measured with so-called virtual sensors, or cosimulations are executed with the test runs, where the desired values are taken from the simulation results then. The scenario database can also be seen as a form of cosimulation, only that the simulations are executed in advance and special methods help to access the data in time. That way, the scenario database can be a much easier variant of cosimulation. Traditional cosimulation may technically be very tricky, though. Virtual sensors can be implemented easily with the help of machine learning, where said unmeasurable criteria are trained from the simulations in the scenario database. Afterwards, they can be applied on the sensor measurements of the test run, enabling to have the “unmeasurable” values available in real time during the test runs.
5.7 Complexity and Robustness Management
When doing automation and control (traffic as well as vehicle control), this is mainly about optimisation with respect to certain control targets. When optimising, it must be talked about robustness as well in general. Squeezing a system(-of-systems) to be optimal, this normally tends to lack robustness. Therefore, robustness must be assessed compulsory. One way for doing such is the described scenario-based approach. Within the scenario catalogue, not only different alternative control actions are evaluated. In a similar way also, perturbations and disturbances are evaluated to find out if the control solutions tend to become disastrous in case of small errors. Such robustness must be incorporated in any design and therefore must be part of any validation procedure. While robustness normally can only be checked in post-analysis, there is a way to improve robustness from the beginning, by reduction and control of complexity. Measuring complexity of traffic flows, behavioural patterns, data streams, control solutions, infrastructure, etc., can help to reduce complexity by design. Reduced complexity makes life easier and more robust for human traffic as well as for automated traffic.
References
Hons C, Neubohn A, Weiss C, Keck F, Kuhn A (2007) Kiss-weiterentwicklung und umsetzung eines methodischen ansatzes zur systemauslegung in der fahrzeugsicherheit. VDI-Berichte (2012)
Keck F, Kuhn A, Sigl S, Altenbuchner M, Palau T, Roth F, Stoll J, Zobel R, Kohsiek A, Zander A (2010) Pruef-und evaluationsverfahren fuer den vorausschauenden fussgaengerschutz im spannungsfeld zwischen simulation und realer erprobung. VDI-Berichte (2106)
Kuhn A, Carmona J, Novak T, Aigner W, Schildorfer W, Patz D (2018) Test fields and advanced accompanying methods as necessity for the validation of automated driving. In: Proceedings of 7th transport research arena TRA 2018, Vienna, Austria
Kuhn A, Carmona J, Palau T (2015) A hierarchical, subsidiary system architecture for traffic control with connected vehicles. Technical report
Kuhn A, Eibl G, Fasig T (2012) Concept for an “intelligent” traffic control network. In: 19th ITS world congress ERTICO-ITS European Commission ITS America ITS Asia-Pacific
Neubohn A, Weiss C, Keck F, Kuhn A (2005) Kiss—A universal approach to the development and design of occupant restraint systems. In: Proceedings: international technical conference on the enhanced safety of vehicles, vol 2005. National Highway Traffic Safety Administration, pp 13–13
Sigl S, Gollewski T, Miehling T, Kuhn A (2014) About development processes and accompanying performance evaluations of integral automotive safety systems. In: Proceedings of FISITA 2014 world automotive congress, Maastricht
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Kuhn, A., Carmona, J., Thonhofer, E. (2022). Research Design and Evaluation Strategies for Automated Driving. In: Schirrer, A., Gratzer, A.L., Thormann, S., Jakubek, S., Neubauer, M., Schildorfer, W. (eds) Energy-Efficient and Semi-automated Truck Platooning. Lecture Notes in Intelligent Transportation and Infrastructure. Springer, Cham. https://doi.org/10.1007/978-3-030-88682-0_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-88682-0_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-88681-3
Online ISBN: 978-3-030-88682-0
eBook Packages: EngineeringEngineering (R0)