
Abstract
This chapter describes an actual smart city use-case application for advanced mobility and intelligent traffic management, implemented in the city of Modena, Italy. This use case is developed in the context of the European Union’s Horizon 2020 project CLASS [4]—Edge and Cloud Computation: A highly Distributed Software for Big Data Analytics. This use-case requires both real-time data processing (data in motion) for driving assistance and online city-wide monitoring, as well as large-scale offline processing of big data sets collected from sensors (data at rest). As such, it demonstrates the advanced capabilities of the CLASS software architecture to coordinate edge and cloud for big data analytics. Concretely, the CLASS smart city use case includes a range of mobility-related applications, including extended car awareness for collision avoidance, air pollution monitoring, and digital traffic sign management. These applications serve to improve the quality of road traffic in terms of safety, sustainability, and efficiency. This chapter shows the big data analytics methods and algorithms for implementing these applications efficiently.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others



Keywords
1 Introduction
Current data analytics systems are usually designed following two conflicting priorities to provide (1) a quick and reactive response (referred to as data-in-motion analysis), possibly in real-time based on continuous data flows; or (2) a thorough and more computationally intensive feedback (referred to as data-at-rest analysis), which typically implies aggregating more information into larger models [17].
These approaches have been tackled separately although they provide complementary capabilities. This is especially relevant in the context of smart cities traffic management for example, where both approaches play a fundamental role. On the one hand, delivering timely driving assistance and/or city traffic control requires real-time processing of data provided by city and smart car sensors. On the other hand, city-wide traffic data needs to be collected and processed at bigger time granularity (e.g., hourly, daily, weekly, etc.) to identify traffic issues, monitor air pollution, plan further deployment and maintenance of traffic routes, etc.
This CLASS use-case presented in this chapter demonstrates these mixed requirements. It takes place in the city of Modena (Italy), where different actors are involved. It includes a significant sensor infrastructure to collect and process real-time data across a wide urban area, supported by a private cloud and edge infrastructure, prototype cars equipped with heterogeneous sensors/actuators, and V2I connectivity. Representative applications for traffic management and advanced driving assistance domains are employed to efficiently process very large heterogeneous data streams in real-time, providing innovative services for the public sector, private companies, and citizens. The chapter relates to the technical priorities “Data Processing Architectures” and “Data Analytics” of the European Big Data Value Strategic Research & Innovation Agenda [17]. Moreover, the chapter relates to the “Sensing and Perception” and “Knowledge and Learning” cross-sectorial technology enablers of the AI, Data and Robotics Strategic Research, Innovation & Deployment Agenda [16].
1.1 Processing Distributed Data Sources
The use of combined data-in-motion and data-at-rest analysis provides cities efficient methods to exploit the massive amount of data generated from heterogeneous and geographically distributed sources including pedestrians, traffic, (autonomous) connected vehicles, city infrastructures, buildings, IoT devices, etc. Certainly, exposing city information to a dynamic, distributed, powerful, scalable, and user-friendly big data system is expected to enable the implementation of a wide range of new services and opportunities provided by analytics tools. However, big data challenges stem not only from size and heterogeneity of data but also from its geographical dispersion, making it difficult to be properly and efficiently combined, analyzed, and consumed by a single system.
The CLASS project [4], funded by the European Union’s Horizon 2020 Programme, faces these challenges and proposes a novel software platform that aims to facilitate the design of advanced big data analytics workflows, incorporating data-in-motion and data-at-rest analytics methods, and efficiently collect, store, and process vast amounts of geographically distributed data sources. The software platform is meeting these needs by integrating technologies from different computing domains into a single development ecosystem, and by adopting innovative distributed architectures from the high-performance computing (HPC) domain, as well as highly parallel and energy-efficient hardware platforms from the embedded domain.
Although this chapter aims to describe the big data analytics algorithms involved in the implementation of a real smart city use-case, the next subsection briefly describes the software framework proposed in the CLASS project that supports the execution of such smart city use case and tackles the aforementioned challenges.
1.1.1 The CLASS Software Architecture
The conceptual layout of a typical big-data subsystem setup manifests the so-called compute continuum [3], in which the data is processed, transformed, and analyzed through a range of IT hardware stages, from the field devices close to the source of data (commonly referred to as edge computing) to the heavy-duty analytics in the data centers (commonly referred to as cloud computing).
Figure 1 shows the CLASS software architecture, where different components interact to distribute resources and services in a smart way, so that decision-making occurs as close as possible to where the data is originated (either at edge or cloud side), enabling faster processing time and lowering network costs. The CLASS software components include:
-
Data Analytics Platform: This layer exposes interfaces and tools for the development and deployment of big data analytics applications for the CLASS use-cases. The analytics methods currently available include map/reduce, distributed workflow, and Deep Neural Networks (DNN). The core of the analytics platform is a serverless/FaaS (Function-as-a-Service) layer, which allows analytics to be invoked in response to invocations, or to events such as message arrival or timer. It further allows polyglot programming [6], where different application components using different analytics methods and programming languages to cooperate in computation. In CLASS, the serverless layer is further augmented for low-latency real-time computation.
Fig. 1 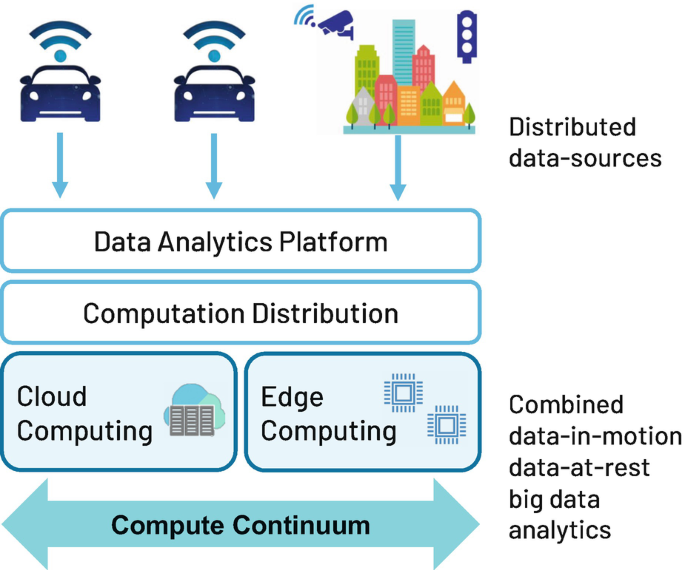
Overview of the CLASS software platform to process distributed data sources
-
Computation Coordination and Distribution Framework: This layer manages the workload distribution across the continuum, with the objective of minimizing the response time of big data analytics workflows and providing real-time guarantees. This layer also provides a shared data storage backbone among the different components of the platform.
-
Cloud Layer: This layer provides a Container-as-a-Service (CaaS) service that abstracts the cloud infrastructure details away from the data analytics service developers. It provides not only service life cycle management but also guaranteed performance of workloads.
-
Edge Layer: This layer provides support for the most advanced highly parallel heterogeneous embedded platforms, e.g., Nvidia GPUs, many-core fabrics, or SoC-FPGAs. On top of this hardware, the software component that supports the development of big data analytics is based on state-of-the-art Deep Neural Networks (DNN). An analytics agent deployed at this layer allows deploying various computations as part of the overall analytics layer discussed above.

Overall, a smart distribution of computing services, combined with the usage of highly parallel hardware architectures across the compute continuum, is used to significantly increase the capabilities of the data analytics solutions needed to fuel future smart systems based on big data. Multiple domains can leverage the benefits of the CLASS framework since the objective is also to provide sound real-time guarantees on end-to-end analytics responses. This ability opens the door to the use of big data into critical real-time systems, providing to them superior data analytics capabilities to implement more intelligent and autonomous control applications.
The next subsection describes the particular smart city use-case applications implemented on top of the CLASS software framework. More details of the technologies used in this framework can be found in the CLASS project website [4].
1.2 Big Data Analytics on Smart Cities: Applications
The CLASS software framework supports the development and execution of a set of advanced data analytics algorithms. Interestingly, all these data analytics engines can be optimized to execute at both, the edge and the cloud side, providing the required flexibility needed to distribute the computation of complex data analytics workflows composed of different analytics frameworks across the compute continuum.
Upon the described software computing infrastructure, there is a considerable number of city-awareness services that can be implemented. In this chapter, we describe the combined big data analytics that provide meaningful information for three use-case applications:
-
Digital Traffic Sign Application. It offers the opportunity to dynamically change traffic conditions based on real-time traffic information collected by means of the distributed sensor infrastructure. In case of accidents, the traffic signals can advise the “best path to follow,” reducing the induced traffic impact and improving the driver experience. For emergency vehicles (e.g., ambulances, firefighters, and police vehicles), it can dynamically create “green routes” by adjusting the frequency of the traffic lights to reduce the time of intervention.
-
Air Pollution Estimation Application. It offers the possibility of estimating the pollutant emissions of vehicles in real time and segregated by areas. In particular, the proposed technique considers the real-time traffic conditions, e.g., as detected by street cameras, to model and estimate such emissions without the need of dedicated pollution sensors.
-
Obstacle Detection Application. It offers the required real-time services for warning a driver about critical situations that may endanger the safety of the driver and the vulnerable road users (VRUs). The identification of potentially hazardous situations can be enforced at the different levels of the compute continuum, with different precision and latency, and considering the city cameras and vehicles sensors information. The implementation of this application is supported by the V2I communication, improving driving safety, especially in case of blind spots such as in intersections.
The implementation of these three applications is supported by the big data analytics presented in the next section. The rest of the chapter is organized as follows: Sect. 2 describes the concrete big data analytics algorithms and their integration to implement the desired applications; Sect. 3 describes the smart city infrastructure to execute and distribute the proposed algorithms; finally, Sect. 4 concludes the chapter.
2 Big Data Analytics Algorithms
This section describes the big-data analytics algorithms implementing the proposed smart city use-case. All the algorithms contribute to the generating of a Data Knowledge Base (DKB) from which valuable knowledge is extracted from the city and the connected cars. The final goal is to implement the three smart city applications: digital traffic sign, air pollution estimation, and obstacle detection.
Section 2.1 describes the considered big data analytics algorithms, each processing part of the available data. Section 2.2 presents the combined big data analytics workflow that shows the interaction and relationship between the different algorithms to cooperate toward a common objective: the generation of the DKB and the implementation of the proposed applications.
2.1 Description of Data Processing Algorithms
2.1.1 In-Vehicle Sensor Fusion
Autonomous vehicles or ADAS need to have a robust and precise perception of the surrounding environment. A precise categorization and localization of road objects, such as cars, pedestrians, cyclists, and other obstacles, is needed. In order to obtain accurate results, fusing and combining the output of several different devices has become a trend, being a good compromise to obtain good classification and 3D detection. Concretely, the solution explained in this section uses a Light Detection And Ranging (LiDAR) sensor, and multiple camera disposed to cover 360∘ surround the vehicle.
In the context of 2D camera object detection, Convolutional Neural Networks (CNN) are often adopted. YOLO [2] is a good example of real-time object detection and classification, based on a fully CNN. The performance in terms of precision is comparable to other methods, but the performance in terms of inference time is better because it is optimized to be used in NVIDIA Jetson products. LiDARs, instead, produce a 3D point cloud, which is then processed to place 3D bounding boxes (BBs) around the objects via clustering methods [5].
Camera detection and LiDAR clustering are merged by developing a modified parallel algorithm [13] that exploits the features of LiDAR point cloud and optimizes a YOLO CNN, to deploy an open-source real-time framework that combines camera 2D BBs with LiDAR clustering. Figure 2 shows an example of this algorithm: video frame processing and 2D BBs from four cameras installed in the vehicle (each with 120∘ field of view), and LiDAR 3D detections for a 360∘ field of view.

Sensor fusion algorithm (vehicle’s detections): output from four cameras (120∘ field of view each) and a LiDAR (360∘ field of view)
Moreover, GPS positions of all the detected objects are necessary to create a comprehensive picture of the area. The connected vehicle GPS sensor, if not precise enough, could be enhanced by a previous mapping of the area, or a high-precision map externally provided, using the surrounding features detected by the LiDAR and cameras for matching. After determining a reliable position of the vehicle, the relative position of the surrounding detected objects is added using a vector sum.
As a result, the ouput of the sensor fusion method provides detected and classified objects in real time, their GPS position, and timestamp, as seen from a vehicle point of view. Also, the position of the connected vehicle itself is provided.

2.1.2 Street Camera Object Detection
From cameras located on the streets, objects can also be detected and classified. This is also done with the optimized version of YOLO used in the in-vehicle sensor fusion method, described in the previous section. After detection and classification, the global position of the road user is also computed. To do so, each camera is manually calibrated to match known points in the image with their GPS position on a georeferenced map. As a result, this method provides detected and classified objects in real time, as seen from a street camera point of view. Figure 3 shows a video frame example with the bounding boxes of the objects detected, and an example of the row data generated is shown below:

Object detection output from street camera

2.1.3 Object Tracking
The purpose of this method is to track the road users, i.e., cars, as well as pedestrians, bikes, and motorcycles, detected by both the in-vehicle sensor fusion and the street cameras object detection methods. If only detection is performed, then only different and uncorrelated detections for each video frame occur. Instead, if tracking is also performed there are two main advantages: (1) to make the detection more robust (since detection algorithms are not perfect and detection errors may occur); and (2) to perform path prediction and guess where the objects will go which in turn allows to predict possible collisions. Considering performance on edge devices, this method is based on a Kalman filter on the position points [14] (contrary to visual tracking algorithms that are computationally intensive, and not suitable for a real-time scenario).
After the object detection methods detect the bounding boxes of objects, a point of the bounding box is taken as a reference, and it is used to track each object with an aging mechanism. It means that this algorithm is able to not only correlate objects in different frames but also to compute the speed of the objects. Figure 4 shows two video frames with the bounding boxes of the objects detected, and the lines representing the tracked trajectory. As an example, the car entering into the camera field of view (at the bottom of the image) in the left frame is located at the entrance of the roundabout in the right frame; the yellow line represents the tracking for this vehicle. An example of the row data generated is shown below:

Object tracking output from street camera detections

In this example, the data from the Street camera object detection is considered, after processing multiple video frames. The car with ID 1 has been detected in four different frames; therefore, there are four entries for the same object, each with a different GPS position and timestamp, and with the computed speed.
2.1.4 Data Deduplication
When multiple objects are detected in the same area by street cameras that share part of their field of view, or by a smart connected car moving in the same area, there are duplicated road users detected by those different actors. This method manages these duplicated objects so that they appear only once in the system. A simple method deduplicates objects by searching for all nearest objects with the same category, comparing their position, and discarding the duplicated ones considering a certain threshold value. A different threshold is used depending on the category (and hence size) of the road user.
As an example, the output after the Data deduplication is shown below:

In this example, the data from the Street camera object detection (source cam_1) and the In-vehicle sensor fusion (source veh_1) is considered. After also processing this data by the Object tracking algorithm, the Data deduplication is invoked. As a result, one of the cars, detected by the vehicle, is discarded since it has the same GPS position as Car with ID 1, detected by a street camera.
2.1.5 Trajectory Prediction
In order to foresee possible collisions between vehicles and other road users in the streets, it is necessary to predict the trajectory of all those road users. Based on the detected positions of an object and their associated timestamps, the prediction algorithm computes multiple future positions (predictions) per object, at future time points so that a complete trajectory is obtained. The trajectory prediction is calculated for multiple objects simultaneously, where input samples are not equally apart in time. This method is based on quadratic regression [12] that finds the equation of the parabola that best fits a set of data (using the detected positions). Then, the equation is used to predict the future positions.
Other known works, such as [7], employ Recurrent Neural Networks (RNNs) to compute a trajectory prediction of street objects based on their previous steps and with the environment context. This approach uses Long Short-Term Memory (LSTM) neural networks, a type of RNNs that can extract patterns from a sequence. In this case, the sequence is also a series of GPS positions along the time.
An example of the output after the Trajectory prediction for the Car with ID 1 is shown below:

The trajectory prediction function takes an object id and computes its trajectory based on its updated location history. In this example, given the four detected positions for this car (see the previous section), the algorithm is used to predict three future positions. The core trajectory prediction needs to be applied to each object covered by the cameras, only when new location data is available for the object.
2.1.6 Warning Area Filtering
According to the CLASS use-case design, connected vehicles may receive alert notifications for possible collisions with objects within each vehicle’s respective warning area, which is defined geometrically around the vehicle’s current location. This is achieved by first filtering out all objects outside a given car’s warning area and then detecting a possible collision (see Sect. 2.1.7) between the car and each of the objects found to be within the warning area.
In CLASS, we employ a simple and highly efficient method of approximating a rectangular warning area around a given location, using geohashes. A geohash [15] is a unique string label assigned to each square in a map grid with a specific area granularity. Each GPS position can be efficiently converted to the matching geohash of the grid location containing the GPS coordinates. This is done once for each object’s detected location and persisted in the shared data during the tracking phase.
The length of the geohash string matches a specific area granularity. For example, a 7-character string identifies a square shape of 153 × 153 m. Thus, in CLASS, once the rectangular dimensions of the warning area are determined at design time, the geohash string length is selected to be the longest string (i.e., smallest squares) such that the 3 × 3 grid of squares is guaranteed to cover the warning area of a car located anywhere in the central square. When coverage is guaranteed, determining if an object X is in the warning area of car C is approximated to X and C being in neighbor geohashes—that is, if the geohash of X is in one of the 3 × 3 squares surrounding the geohash of C, including that of C itself:
The neighbor function is highly efficient and common in most geohash libraries.
2.1.7 Collision Detection
For each given pair of objects with established trajectory predictions, it is possible to evaluate potential collisions between the objects. Collision Detection refers to detecting a possible collision between two objects, yielding a warning notification in case of detection. The collision detection algorithm computes predicted path intersections between a car and objects in its warning area as follows:
-
1.
Quadratic regression is again used to compute the equation of the parabola for the two street objects.
-
2.
Parabola equations are used to detect intersection points among them. An intersection indicates a potential collision between both objects, at a given GPS position.
-
3.
If a potential collision is detected, the potential timestamps at which the intersection point occurs for both objects are computed. A threshold variable is used to determine if the intersection point is reached at the same time (within the threshold) for both objects. If this is the case, a potential collision has been detected.
The output of the Collision detection is very simple, as an example:

Both the Trajectory prediction and the Collision detection algorithms work in parallel, since they can be independently computed for each road user (or pairs of them). Both algorithms are suitable for map/reduce operations.
2.1.8 Vehicles Emissions Model
Based on the traffic conditions, and the information of the vehicle fleet composition in the area of study, it is possible to estimate the contamination level of such area. In this context, the interest is on the estimation of the pollution emissions of current traffic conditions in real time.
More specifically, the detected vehicles (category, timestamp, and speed) are a representation of the current traffic conditions, while the vehicle class fleet composition in the area of study is used to estimate the vehicle’s engine power, based on the class of vehicle. The vehicle class compromises information on the shape, weight, and default loading of a vehicle (passenger car, heavy-duty vehicle, …), as well as engine-related properties, for example rated power, fuel type, and most important, the actual emission class (Euro 1, Euro 2, and so on). The emissions can be then interpolated from emission curvescontaining the normalized engine’s power output and vehicle data [8]. The output obtained estimates emissions of NOx, PM, CO, HC, and NO, at a configured time resolution and for road segment.
As an example, the output of the Vehicles emissions model, at a given time instant and for three different streets, is shown below:

2.1.9 Data Aggregation: Data Knowledge Base
This Data aggregation big data analytics method is fundamental given the dispersion nature of data collected in a smart city use-case. Concretely, this method creates and maintains a Data Knowledge Base (DKB), aggregating data into a single system, collected and processed by multiple IoT sensors and devices (located in vehicles or at city streets).
The challenging task of the DKB is to maintain (in real-time) the information anonymized, updated, and consistent across the multiple actors, i.e., the city and the vehicles, to ensure that decisions are taken based on the same updated information at all levels. A key feature of the DKB is to allow taking decisions considering information beyond the field of view of a single actor. As an example, a vehicle can receive relevant information from the city, improving the vehicle’s safety. More information is provided in Sect. 3.
2.1.10 Visualization
An important feature of big data analytics is how to visualize the meaningful information. In this case, it is interesting to visualize the real-time processed information of the DKB, i.e., the traffic conditions, the emissions level, and possible alerts. There are two different final users that need to receive this information, at different levels:
-
At a vehicle level, real-time traffic conditions is available for connected vehicle’s. More specifically, a lightweight 3D user interface shows a map to the driver with its position in the city area, the position of the road users detected, and, more importantly, warnings signals about potential collisions.
-
At a city level, a dashboard visualizes the aggregated data of the DKB, i.e., an interactive map shows the traffic conditions, based on the detected road users, and the emission levels.
2.1.11 Predictive Models
The interest of this method is to understand the potential to improve routing and travel times while responding to traffic accidents. In case of accidents, the digital traffic signals can advise the “best path to follow,” reducing the induced traffic impact and improving the driver experience. For emergency vehicles (e.g., ambulances, firefighters, and police vehicles), this method can dynamically create “green routes” by adjusting the frequency of the traffic lights to reduce the time of intervention.
Trivially, the viability of modifications on a real-world urban area must be carefully planned and tested before the actual deployment. Therefore, this method is based on a well-known MATSim simulator [1] for urban transportation. The baseline version of MATSim is only capable of simulating road users that cannot communicate to nearby cars or the surrounding infrastructure. In contrast, this extended method is able to simulate the interactions among sets of connected vehicles within a smart city. It is composed of multiple modules to simulate cameras, sensors, servers, and communication systems so that connected vehicles are able to react to unexpected events such as traffic accidents.
2.2 Integration Toward a Relevant Smart City Use-Case
The big data analytics methods presented in the previous section are combined into a unique big-data analytics workflow representing the generation of the Data Knowledge Base (DKB) from which valuable knowledge is extracted from the city and the connected cars (see Sect. 2.1.9). Then, the three use-cases applications (digital traffic sign, obstacle detection, and air pollution estimation) are built upon the information included in the DKB.
Figure 5 shows the combined big data analytics workflow representation, including (1) the big data analytics methods presented in previous Sect. 2 (represented as labelled nodes), (3) the interaction between them (represented as arrows), and (3) the actors involved in the smart city system (sensors and use-cases applications).

Integration of the big data analytics
3 Distribution of Big Data Analytics Across the City Infrastructure
This section presents the actual implementation of the proposed big data analytics on a real smart city infrastructure. Section 3.1 describes the smart city infrastructure, in terms of connectivity, sensors, and computing capabilities, to support the use-cases demonstration. Concretely, the proposed big data analytics are being implemented and tested in the Modena Automotive Smart Area (MASA) [9] (see Sect. 3.1.1), using smart cars (Maserati vehicles) and connected cars (see Sect. 3.1.2). Section 3.2 describes the distribution of the big data analytics on the available city and vehicles infrastructure, and presents an example of use-case scenarios. Finally, Sect. 3.3 makes emphasis on one of the key aspects for the successful development of the considered use-cases: the real-time requirements.
3.1 Smart City Infrastructure
3.1.1 City Infrastructure: MASA
The Modena Automotive Smart Area (MASA) is a 1 km2 area in the city of Modena (Italy), equipped with a sensing, communication, and computation infrastructure. MASA is an urban laboratory for the experimentation and certification of new technologies including autonomous driving and connecting driving technologies, and V2X technologies, in general. Figure 6 shows the map of the equipped streets in Modena. The tested technologies to be found in the area include interconnected traffic lights, digital signposting, cameras, and sensors, among others.

Modena Automotive Smart Area (MASA)
Figure 7 provides a detailed description of the sensing, communication, and computation infrastructure of MASA:
-
Bullet cameras, optimized for detection or forensic purposes regardless of light conditions, connected to the fog nodes through optical fiber.
Fig. 7 
Modena Automotive Smart Area (MASA) sensing, communication, and computation infrastructure
-
Four-optics camera (360∘ overview), that provides a full detection and control of the roundabout.
-
Pollution sensors, connected to the LoRa network, for the detection of air quality parameters: carbon monoxide (CO), carbon dioxide (CO2), nitrogen dioxide (NO2), and particulate matter (PM).
-
Wireless communication, a 4G dedicated antenna for private local area network, 5G prototypes, and a Low-Range(LoRa) network to interconnect sensors and devices with low bandwidth needs (e.g., parking and pollution sensors).
-
Optical Fiber network, connects the cameras to the available fog nodes.
-
Fog Nodes, with the following computing features: an Intel®Xeon E3-1245 v.5, 32 GB of RAM, 256 GB of hard disk, and an NVIDIA Volta GPU (TitanV).

Moreover, the city of Modena provides a private cloud infrastructure in a data center, also connected to the fog nodes through optical fiber.
3.1.2 Vehicle Infrastructure
Maserati provides two prototype vehicles that incorporate all the sensing, communication, and computation infrastructure needed to test the use-cases described in this chapter. The vehicles are two Maserati Quattroporte (Model Year ’18 and Model Year ’19, respectively), a four-door full-sized luxury sports sedan vehicle (F segment). For simplicity, these are known as smart cars.
Each vehicle includes a set of sensor devices to obtain information about the position, speed, and typology of the objects that surround the vehicle. In addition to this data, the vehicle also provides information from the vehicle CAN network, including speed, acceleration, and collision and emergency break information. Concretely, the extra sensors installed on each vehicle are:
-
Surrounding high-definition cameras, including four cameras with 120∘ of Field Of View (FOV), and two cameras with 60∘ of FOV.
-
A 3D Light Detection and Ranging (LiDAR) with 360∘ of FOV.
-
A Global Navigation Satellite System (GNSS) to increase the accuracy, redundancy, and availability of the vehicle position, compared to the positioning system already provided in the commercial vehicle.
Moreover, each vehicle is equipped with a 4G-LTE antenna receiver and a powerful embedded high-performance computing platform capable of implementing real-time bigdata analytics. Those platforms are designed to process data from camera, radar, and LiDAR sensors to perceive the surrounding environment. The first vehicle is equipped with an NVIDIA DRIVE PX2 Autochauffeur (dual TX2 SOC plus 2 discrete Pascal GPUs), and the second vehicle is equipped with the NVIDIA DRIVE AGX Pegasus [10].
For testing purposes, and to enlarge the fleet of vehicles involved in the system, without the need for a large budget, connected cars are also considered. A connected car is simply equipped with a regular laptop or an embedded device with LTE connectivity and GPS support, so that it can send its position to the system and receive alerts.
3.2 Big Data Analytics Distribution
The big data analytics methods described in Sect. 2 are executed and distributed in the available city and vehicles infrastructure, to provide the required functionality for the three use-cases: Digital Traffic Sign, Obstacle Detection, and Air Pollution Estimation. Concretely, the actual distribution depends on different factors: the underlying infrastructure, the source of data, and the software architecture that processes it. Moreover, the big data analytics distribution does not need to follow a static approach, but instead it can be based on the current status of the infrastructure (e.g., load or availability of computing nodes). This is one of the main challenges of the CLASS project [4].
Figure 8 shows an example of distribution of the big data analytics on the MASA and vehicles infrastructure, described in Sects. 3.1.1 and 3.1.2, respectively. This example considers three fog nodes, four street cameras, the Modena data center (private cloud), a smart car (acting as an active road user), and two pedestrian (passive vulnerable road users -VRUs-). Cameras 1 and 2 are connected to fog node 1, while cameras 3 and 4 are connected to fog node 2. Therefore, object detection and tracking are executed (independently) for each camera video feed in the corresponding fog node. Also, data deduplication is performed at fog nodes 1 and 2 with the purpose of identifying duplicated objects detected by more than one camera. This happens if two cameras (or more) have an overlapping field of view of a city area. From the smart car, the information from the sensor fusion algorithm, i.e., objects detected and the position of the car itself, is sent to fog node 3, where the tracking of these objects is performed. Then, deduplication is also executed at fog node 3, in case overlapping areas (thus, possible duplicated objects) are being recorded from cameras 1 or 2, cameras 3 or 4, and smart car. Once this data is collected and deduplicated at fog node 3, it can be aggregated into the DKB and make it also available at cloud side. In this example, the rest of big data analytics, i.e., from trajectory prediction and vehicles emission model, to the dashboard visualization and predictive models, are executed in the cloud. The visualization of the real-time traffic conditions and alerts is executed at the smart car.

Example of big data analytics distribution on the MASA and vehicles infrastructure
The big-data distribution shown in Fig. 8 is only an example; there are many other possibilities depending on the aforementioned factors. For instance, the data deduplication can be performed only at one level, at fog node 3, but the example shows data deduplication execution at two levels (at nodes 1 and 2, and then at fog node 3) for a twofold reason: (1) to split and distribute the computation of this functionality, and (2) more importantly, to be able to obtain results (e.g., predict possible collisions) at this level, in the fog nodes 1 and 2, without the need of obtaining them in the cloud, contrary to what it is shown in this example. Another possibility is to receive the data from the smart car, directly at fog nodes 1 or 2, again with the purpose of boosting local computation at fog level. There are plenty of distribution options that rapidly increase as the number of actors involved in the use-case (e.g., smart cars, connected cars, fog nodes, etc.) increases as well. If the software framework supports a dynamic balancing of the workload, according to the different scenarios, it will promote the accomplishment of the envisioned use-case results.
3.2.1 Real Scenarios for Collision Avoidance
This section describes two possible scenarios that exploit the capabilities of the distributed big data analytics. Figure 9 shows two different scenarios to be recreated in the city of Modena. There are different actors involved: street cameras (a video frame shows its FOV), smart cars (or connected cars), a passive car and truck, and pedestrians. Arrows show the predicted trajectory of each actor.
-
Scenario 1, Fig. 9a (Attiraglio Street in MASA): It evaluates the “virtual mirror” functionality that increases the field of view of a vehicle beyond its actual vision (or the driver’s vision). In this example, there is a stationary truck that hides the view of both the smart car driver and the pedestrian who is crossing the street. This hazard situation is detected by the two cameras located at the street and processed by the combined big data analytics. As a result, an alert is sent to the smart car.
Fig. 9 
Real collision avoidance demonstration scenarios
-
Scenario 2, Fig. 9b (Roundabout at Via Pico della Mirandola—Parking exit of the Modena train station): It evaluates the “two sources of attention” functionality that aims to alert drivers when attention must be paid to two different events in opposite directions. In this example, there is a smart car exiting the parking, a regular car reaching the roundabout, and a pedestrian crossing the road. This hazard situation is detected by the camera located at the street and processed by the combined big data analytics. As a result, an alert is sent to the smart car.

3.3 Real-Time Requirements
One important aspect of the big data system presented in this chapter is the notion of real time: data is constantly being produced and processed, and big data analytics are highly parallelizable, e.g., new objects are detected, while tracking previous objects, or the warning area computation can be simultaneous for multiple objects. Exploiting this parallelism, along with an efficient use of the underlying infrastructure, is extremely important to guarantee that the results are meaningful by the time they are computed. This is especially relevant for the Obstacle Detection use-case, since alerts must raise within a time interval that is useful for the driver to react. A reasonable metric, considered in the scope of the CLASS project, is to get updated results at a rate between 10 and 100 ms. Assuming that the maximum speed of a vehicle within the city is 60 km/h, vehicles will advance between 0.17 and 1.7 m. This level of granularity is enough to implement the proposed use-cases.
4 Conclusions
One of the smart computing domains in which big data can have a larger impact on people’s day-to-day life is the smart city domain. Nowadays, cities consume 70% of the world’s resources, with an estimated population rate growth of 66% by 2050, according to United Nation reports [11]. Smart cities are increasingly seen as an effective technology capable of controlling the available city resources safely, sustainability, and efficiently to improve economical and societal outcomes.
This chapter described the CLASS [4] use-case, a realistic yet visionary use-case from the smart city domain, which includes the real-time elaboration of huge amounts of data coming from a large set of sensors distributed along a wide urban area, supporting intelligent traffic management and advanced driving assistant systems. The CLASS framework and use-case are currently under deployment and evaluation in the city of Modena (Italy). More details and up-to-date information can be found on the CLASS project website: https://class-project.eu/.
For the successful outcome of this research project in particular, and for addressing the big-data challenge of future smart cities in general, it is fundamental to combine multi-dimensional and multidisciplinary contexts and teams, from artificial intelligence and machine learning to data storage and engineering.
References
Axhausen, K. W., Horni, A., & Nagel, K. (2016). The multi-agent transport simulation MATSim. Ubiquity Press.
Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. M. (2020). YOLOv4: Optimal speed and accuracy of object detection. https://arxiv.org/abs/2004.10934. Online. Accessed November 2020.
Buchholz, D., Intel IT Principal Engineer, Dunlop, J., & Intel IT Client Architect. (2011). The future of enterprise computing: Preparing for the compute continuum. IT Intel White Paper, Intel IT.
Edge and Cloud Computation: A Highly Distributed Software for Big Data Analytics (CLASS). (2020). https://class-project.eu/. Online. Accessed October 2020.
Ester, M., Kriegel, H.-P., Sander, J., Xu, X., et al. (1996). Adensity-based algorithm for discovering clusters in large spatial databases with noise. In Kdd (Vol. 96, pp. 226–231).
Hadad, E., & Jbara, S. (2020). Using OpenWhisk as a polyglot real-time event-driven programming model in CLASS. https://class-project.eu/news/using-openwhisk-polyglot-real-time-event-driven-programming-model-class. Online. Accessed November 2020.
Haddad, S., Wu, M., Wei, H., & Lam, S. K. (2019). Situation-aware pedestrian trajectory prediction with spatio-temporal attention model. Preprint. arXiv:1902.05437.
Hausberger, S., Rexeis, M., & Dippold, M. (2017). Passenger car and heavy duty emission model (phem) light. User guide v1.
Modena Automotive Smart Area (MASA). (2020). https://www.automotivesmartarea.it/?lang=en. Online. Accessed October 2020.
NVIDIA Drive: End-to-End Solutions for Software-Defined Autonomous Vehicles. (2020). https://www.nvidia.com/en-sg/self-driving-cars/. Online. Accessed November 2020.
United Nations. World urbanization prospects. ISBN 978-92-1-151517-6, 2014 Revision.
Varsity Tutors. Quadratic Regression. https://www.varsitytutors.com/hotmath/hotmath_help/topics/quadratic-regression. Online. Accessed November 2020.
Verucchi, M., Bartoli, L., Bagni, F., Gatti, F., Burgio, P., & Bertogna, M. (2020). Real-time clustering and lidar-camera fusion on embedded platforms for self-driving cars. In IEEE Robotic Computing proceedings (2020).
Welch, G., Bishop, G., et al. (1995). An introduction to the Kalman filter. Chapel Hill, NC, USA.
Wikipedia Community. (2020). Geohash. https://en.wikipedia.org/wiki/Geohash. Online. Accessed November 2020.
Zillner, S., Bisset, D., Milano, M., Curry, E., Garcia Robles, A., Hahn, T., Irgens, M., Lafrenz, R., Liepert, B., O’Sullivan, B., & Smeulders, A. (Eds.). (2020). Strategic research and innovation agenda - AI, data and robotics partnership. Third Release. https://ai-data-robotics-partnership.eu/wp-content/uploads/2020/09/AI-Data-Robotics-Partnership-SRIDA-V3.0.pdf. Online. Accessed February 2021.
Zillner, S., Curry, E., Metzger, A., & Seidl, R. (Eds.). (2017). European Big Data Value Strategic Research and Innovation Agenda. https://bdva.eu/sites/default/files/BDVA_SRIA_v4_Ed1.1.pdf. Online. Accessed October 2020.
Acknowledgements
The research leading to these results has received funding from the European Union’s Horizon 2020 Programme under the CLASS Project (www.class-project.eu), grant agreement No. 780622.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Serrano, M.A. et al. (2022). Distributed Big Data Analytics in a Smart City. In: Curry, E., Auer, S., Berre, A.J., Metzger, A., Perez, M.S., Zillner, S. (eds) Technologies and Applications for Big Data Value . Springer, Cham. https://doi.org/10.1007/978-3-030-78307-5_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-78307-5_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-78306-8
Online ISBN: 978-3-030-78307-5
eBook Packages: Computer ScienceComputer Science (R0)