
Abstract
Many previous literatures use landmarks to guide the correspondence of 3D faces. However, these landmarks, either manually or automatically annotated, are hard to define consistently across different faces in many circumstances. We propose a general framework for dense correspondence of 3D faces without landmarks in this paper. The dense correspondence goal is revisited in two perspectives: semantic and topological correspondence. Starting from a template facial mesh, we sequentially perform global alignment, primary correspondence by template warping, and contextual mesh refinement, to reach the final correspondence result. The semantic correspondence is achieved by a local iterative closest point (ICP) algorithm of kernelized version, allowing accurate matching of local features. Then, robust deformation from the template to the target face is formulated as a minimization problem. Furthermore, this problem leads to a well-posed sparse linear system such that the solution is unique and efficient. Finally, a contextual mesh refining algorithm is applied to ensure topological correspondence. In the experiment, the proposed method is evaluated both qualitatively and quantitatively on two datasets including a publicly available FRGC v2.0 dataset, demonstrating reasonable and reliable correspondence results.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Current progresses in economical sensors and advanced algorithms have pushed many 3D facial analysis technologies into real-life applications [1, 2]. Compared to its 2D counterpart, 3D face contains extra geometric information that can be utilized to resolve problems caused by illumination, pose, and expression variations. One of the most fundamental and challenging problems in the 3D facial analysis context is dense correspondence, which can contribute to many applications of 3D faces [3,4,5]. The benefit of dense correspondence is generally two-fold: (1) the one-to-one correspondence of points among different faces allows them to be organized in the same vector space, enabling further data analysis as a whole; (2) compared to sparse representations such as landmarks only, dense representations can capture subtle structures of faces, providing more discriminative information.
Inherited from the 2D literature, the methods using landmarks [6,7,8,9,10] have also been very popular for 3D face correspondence. Landmarks are some fiducial points on a face, such as the nose tip and the eye corner, which are very distinctive around their local contexts and can be detected either manually or automatically. The number of landmarks varies from a few tens to a hundred in different applications. It is generally considered that landmarks should dominate over all other points and be used as a guidance to establish full dense point-to-point correspondence. To date, many techniques have been proposed for accurate and robust detection of landmarks in 2D situations as well as in 3D [11,12,13].
Unfortunately, there are some major bottlenecks in using landmarks for 3D face correspondence. Firstly, manual annotation of landmarks is a laborious task, which is impractical for large database. Secondly, automatic landmark labeling is challenging especially for data with non-neutral expressions and variations in age and ethnicity. While it is easy to locate a landmark on one subject, it may be difficult to locate it on another subject with significant difference to ensure the same semantic meaning. Finally, it is even unable to define consistent number of landmarks across all subjects with data defects and noises, let alone the precision of these landmarks. All these considerations are demanding for practical applications.
This work aims at establishing dense point-to-point correspondence of 3D facial shapes without landmarks. We do not use texture here because texture is not always consistent with the underlying shape morphology, e.g. for the eyebrows, although the texture may provide with useful information for detection of some landmarks. Furthermore, shape is generally more reliable and stable feature under pose and illumination variations. Our goal is to seek for reasonable and reliable shape correspondence rather than strict and standard result. Strict correspondence may intuitively and physically exist between different data of the same subject, however, this problem hardly leads to a standard answer across different subjects. We restrict the correspondence problem to facial shapes and clarify the problem in two perspectives. One is semantic correspondence which guarantees that the corresponded points share the same semantic meaning. The other is topological correspondence which guarantees that the corresponded points lie in the same local context. An example for two corresponded faces A and \(A'\) is illustrated in Fig. 1. It shows the corresponded points p and \(p'\) both denote the nose tip, and are both located at the center of their corresponded vicinity points.

Example of two corresponded faces in which points with the same color are in correspondences.
We propose a fully automatic framework to achieve the semantic and topological correspondence goals for 3D faces. A template warping strategy is adopted here. First a face is chosen as a template and used to initially register the target faces, which is referred to as global alignment (Sect. 3.1). Then preliminary correspondence (Sect. 3.2) and robust deformation (Sect. 3.3) from the template to the target are alternated and iterated for a few times to obtain a primary correspondence result. At this stage, semantic correspondence is guaranteed. Finally, a contextual mesh refining algorithm is applied to ensure topological correspondence (Sect. 3.4).
We evaluate the proposed method both qualitatively and quantitatively on two databases including a publicly available FRGC v2.0 [14] database and our newly collected HQ3DP database in the experiment. It shows that our method can achieve reasonable and reliable correspondence results. Except for a fully automatic algorithm for 3D face dense correspondence, the main contribution of this work is two-fold: (1) we construct a template warping strategy that takes both global and local features into consideration for accurate semantic correspondence, where the meaning of “semantic” we designated here is more than just landmark correspondence; (2) we consider topological correspondence and propose a mesh refining algorithm to achieve it, and this notion may give new insights towards the final solid definition for dense correspondence of 3D faces.
2 Related Work
For a comprehensive overview of 3D shape correspondence methods which are not limited to faces one can refer to [5, 15]. Here we only review and summarize some state-of-the-art representative algorithms for dense point correspondence of 3D faces.
In the seminal work of 3D Morphable Model (3DMM) [3, 16], Blanz and Vetter propose a novel regularized optic flow based algorithm for dense point correspondence. The 3D coordinates of the facial surface are projected to a cylindrical “UV” map, with both the third dimension “radius” (i.e. distance to the cylindrical axis) and the texture encoded as “pixel intensities” with proper weights. Coarse-to-fine and local smoothing strategies are applied in the computational process. Despite its efficiency by reducing the dimensionality of this problem from 3D to 2D, the potential pitfalls are (1) the mapping from 3D coordinates to 2D “UV” space may not be one-to-one, (2) mapping from 3D to 2D and then back to 3D requires resampling and may lose precision of original data.
As an alternative, a thin plate splines (TPS) [17] warp is employed by Patel and Smith for the correspondence task with some manually labeled annotations. Gilani et al.[13] also use the TPS for estimating and minimizing the local bending energy for registering of some seed points which can be much more than landmarks, and further incorporating them into the full shape correspondence. These approaches are considered more robust to handle large variations in facial identity.
Amberg et al.[18] propose an optimal step nonrigid iterative closest point (NICP) algorithm for the registration of 3D shapes. It is used as a benchmark algorithm for face correspondence in some prior arts [19,20,21,22]. More recently in the work of Booth et al.[23, 24], landmark detections are automated using the 3D textures in different viewing directions. And then, these landmarks are used to guide the local affine deformations of NICP with a proper parameter setting. They also compare the performance of several methods for 3D face correspondence and reach a conclusion that NICP is superior to the TPS and optic flow based algorithms.
In the rich literature of 3D face correspondence, many algorithms [6, 25,26,27] give impressive results by their capability to model identity and expression variations or both. For example, Bolkart and Wuhrer [27] propose a multilinear groupwise model for 3D face correspondence to decouple both identity and expression variations. However, a well-established correspondence model is a prerequisite in these methods and the correspondence problem is considered in the restrictive space expressed by the model. Although insightful and practically useful, a chicken-and-egg problem still remains to be solved. A vital question is, if the corresponded model has some errors, they may accumulate and propagate in their subsequent usages.
Existing methods are mostly focusing on semantic correspondence. For example, there is functional face proposed by Zhang et al. [28] who incorporate multiple features into the correspondence strategy by Laplace-Beltrami operators. Some geodesic preserving methods [29, 30] have also shown merits over Euclidean distance based ones on modeling expression variations. We are not going to categorize them by the algorithm details, for example, by whether they employ one-to-one or one-to-many strategies, or they use textures or not. Semantic correspondence may be notably defined in some regions of the face such as the eyes corners. However in other regions such as the cheek and forehead, it is even not uniquely identifiable by a human. In this work, we are seeking for a more definite solution for this problem. The similarity of local data structure, referred as topological correspondence in this work, is an extra constraint we take into consideration.
3 Method
3.1 Global Alignment
An arbitrary but well enough (noiseless) face is chosen as the template and used to initially register the target faces on the first stage, referred as global alignment here. Global alignment aims at aligning two facial shapes such that the true point-to-point correspondence is close to the nearest one. We use a modified iterative closest point (ICP) method to achieve global alignment. ICP [31] is a simple yet efficient point set registration algorithm that iterates between closest-point correspondence and rigid-motion estimation until convergence. Given two sets of corresponded points \(P = \{ {p_1},{p_2},...,{p_n}\}\) and \(Q = \{ {q_1},{q_2},...,{q_n}\}\) in \(\mathbb {R}^{3}\), the rigid-motion estimation is a constraint minimization problem with respect to the optimal rotation \(\mathbf {R}\) and translation \(\mathbf {t}\),
And this problem can be solved efficiently by singular value decomposition.
A novel Go-ICP [32, 33] algorithm, which is an improved version of ICP for 3D shape registration, guarantees an optimum solution even without a good initialization by a branch and bound searching strategy in the parameter space. By virtue of it, detection of some fiducial points (e.g. the nose tip and some other sparse landmarks) for pose estimation of 3D face which is done in many existing works is circumvented here, making the proposed method one step further to be automatic.
3.2 Dichotomic Preliminary Correspondence
To achieve semantic correspondence, we treat the points on a face differently. The points on a face are heuristically categorized into two groups. Points that belongs to the complex regions where the semantic meaning is clear form one group, and the rests that belongs to smooth regions where the semantic meaning is not clearly distinctive form the other. Since the face is an ellipsoid-like surface, the smooth regions can be modeled to be planar or circular. Let \({p}_{j}={p}+{d}_j\,(j=1,...,k)\) be the neighbors of point p and let \(n_j\,(j=1,...,k)\) and n be the corresponding normals. Inspired by the work of [34, 35], we define entropy of a point p on a facial surface as
which is the sum of three terms (also illustrated in Fig. 2).

Meanings of co-planarity, co-circularity, and co-normality. The three sub-figures lead to zero values for each of the three terms, respectively.
1. Co-planarity measures the extent that neighboring vertices lie in each other’s tangent planes.
2. Co-circularity measures the extent that neighboring vertices share similar curvatures.
3. Co-normality measures the extent that neighboring vertices hold the same normal.
The neighbors of p can be defined as points within a local patch around it. Note that all the vectors are normalized to unit length in the computation process. We then classify the points on the template face into two groups by sorting their entropies. Entropy gives a measure to the local distinctiveness for semantic meaning. In this paper we define the top 10% of all points as high-entropy points and they are a well cover for the eyes, nose, and mouth regions. Figure 3 shows an entropy-intensity map for all points and a binary map for the two groups of points on a 3D face.

Mapping of entropy on a 3D face. The left and right sub-figures are an entropy-intensity map with colorbar and a binary map for two classes of points, respectively.
We simply apply the closest-point rule to the low-entropy points for preliminary correspondence for computational efficiency. However as to the high-entropy points, we apply a different local ICP of kernelized version for semantic correspondence. A Gaussian kernel is adopted here to emphasis local features. The optimal rotation \(\mathbf {R}\) and translation \(\mathbf {t}\) are estimated by
Compared to Eq. 1, the objective function is reweighted by a kernel function \(K(p_i)\). The effect of Gaussian kernel is illustrated in Fig. 4. The local shape differences between the template and the target face are commonly manifested as stretching or shrinking of curves to accompany with expression and identity variations. It shows that compared to uniform weighting, Gaussian weighting as a function of distance to the corresponding point, is capable of matching finer local details.

Effect of Gaussian weighting compared to standard ICP (referred as uniform weighting). The point p is corresponded to \(p_{1}\) and \(p_{2}\) by the two different ICP weighting strategies, respectively.
3.3 Nonrigid Robust Deformation
The template face is deformed into the target face to obtain the correspondence result after preliminary correspondence is established. Before formulation of the deformation model, we first give the meaning of some symbols.
-
V and P denotes the point sets of the template face and the target face, respectively.
-
\({v}_{i}\) is a point on V and its preliminary correspondence on P is \({p}_{{v}_i}\).
-
\({o}_i\) denotes the deformation offset to be solved.
-
\(w_i\) denotes the weight assigned to each corresponded point pair.
Then, the deformation problem is formulated as
where \(r_i^{(1)}\) denotes the 1-ring neighbors of the point \({v}_i\) and it contains \(N_{r_i^{(1)}}\) points. The second term in Eq. 7 is a local smoothing constraint, which renders the template face to deform into the target face gradually in each small step. For each step, we set \({v_i} \leftarrow {v_i} + {o_i}\,(i \in V)\) and preliminary correspondence is rebuilt by the method described in Sect. 3.2. The iteration is terminated when the residual error \(\sum \limits _{i \in V} {\left\| {{p_{{v_i}}} - {v_i}} \right\| _2^2}\) is smaller than a predefined threshold \(\varepsilon \).
Solution to the deformation problem. The overall solution to Eq. 7 leads to a linear system:
where

and
N is the total number of points. It is obvious that \(\mathbf {A}\) is a sparse, square, and strict diagonal-dominant matrix such that the system is well-posed, computational efficient, and has a unique solution.
Weighting differently for each point pair. To ensure more reliable preliminary correspondence customized for nonrigid deformation, the weight for each point pair is set by some intuitive rules as follows.
1. Weights for high-entropy points should be larger than some other points such that the semantic correspondence of high-entropy points serves as a guide for the deformation process.
2. If the distance between the corresponded points is larger than a threshold or the inner product between the normal vectors of the corresponded points is smaller than a threshold, we set the weight to be zero to reject unreasonable correspondences.
3. If the corresponded point of the target face lies on the boundary of the mesh, the weight is set to zero.
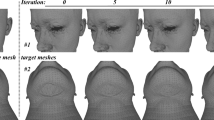
These rules guarantee reasonable deformation to reconstruct the target face. Of course more rules can be devised to meet some specified needs practically. It is different to some landmark guided nonrigid deformation methods [6, 18] in two perspectives. One is that the detection and preliminary correspondence of the high-entropy points are automated by a local ICP of kernelized version. The other is, since high-entropy points are much more than landmarks, the interactions of them with their nearby ones lead to robust solutions which are more tolerant to individual correspondence errors. The preliminary correspondences of high-entropy points also renew themselves for smaller local registration errors (see Fig. 5) as the deformation towards the target proceeds. As shown in Fig. 6, it provides a possible way to model both identity and mild expression variations.

Global reconstruction error of the target face and local registration error of high-entropy points for an example in Fig. 6. The errors are normalized to [0, 1].

The template face deforms into the target face in each small step.
3.4 Contextual Mesh Refinement
We assume two corresponded faces should have similar local mesh structure to ensure topological correspondence. The following steps constitute the algorithm to achieve topological correspondence. It starts from a corresponded mesh by the nonrigid deformation described above.
1. Project the 1-ring neighbors of each point of the template and the target face into their local tangent planes, respectively.
2. For each point \(v_i\) of the template, register its projected 1-ring neighbors to its corresponded projected 1-ring neighbors on the target such that the point of the template is now located at \({p'_{{v_i}}}\).
3. Renew \({p_{{v_i}}}\) to \({p'_{{v_i}}}\) but with a local smoothing strategy determined by
such that \({p_{{v_i}}} \leftarrow {p_{{v_i}}} + {o_i}\,(i \in P)\).
4. Loop from step 1 to step 3 until \(\sum \limits _{i \in P} {\left\| {{{p'}_{{v_i}}} - {p_{{v_i}}}} \right\| _2^2} \) is smaller than a predefined threshold \(\zeta \).
Measuring the mesh structure on the local tangent plane greatly simplifies the problem from 3D to 2D. Furthermore, renewing each point of the target face on its local tangent plane enables the mesh to avoid shrinking. Figure 7(a) depicts the steps visually. Figure 7(b) shows an example of how the local mesh structure is changed after topological correspondence by the proposed algorithm.

(a)The steps for mesh refinement; (b)Effects of topological correspondence for an example. Note that the local structure of the output target mesh by the refining algorithm resembles the template mesh.
4 Experiments
Datasets. We use two datasets for the evaluation of the results. One is our newly collected database (HQ3DP) which includes 330 high-resolution 3D face prototypes by a structured light device. This system merges scans from 4 different directions in a well-controlled environment. The database is originally for building a statistical model and the subjects are mostly in neutral expressions. It is used for some experiments because of the high quality on the mouth, nose, and eyes regions. The other is a benchmark 3D face recognition grand challenge database (FRGC v2.0 [14]) from University of Notre Dame. It is a publicly available database with mild facial expressions used by many existing works, enabling comparison of the correspondence results quantitatively. It is worth mentioning that some famous and publicly available databases (e.g. BU-3DFE [36], Bosphorus [37]) have made a great contribution to the progress for 3D facial analysis. We choose the FRGC v2.0 because its relative high resolution and the subjects are mostly free of occlusions.
Parameter setting. The template face is resampled to include 20, 969 points in the experiments. The parameter \(\lambda \) controls the influence of the template shape and should be decreasing. We set \(\lambda \) to decrease from 1 to 0.1 by a step size 0.1. Note that it should also be affected by the resolution of the template face. When the resolution becomes higher, \(\lambda \) should also be larger to maintain the same effective range. The setting of parameter \(\eta \) is trivial because it shows little influence to the final results. We set \(\eta \) to be a constant 0.5.
Computational time. The computational time increases linearly with the number of points for the representation of a face. Table 1 summarize the runtime (VC++ implementation, Core i7-6700k single thread) for the reconstruction of a target face from a template face with 20, 969 points. Since there are many per-vertex operations that are independent to each other, parallel implementation can be developed to accelerate the process.
4.1 Visualizing the Correspondence Result
The correspondence result is evaluated qualitatively first. We adopted three intuitive criteria for it.
Criterion 1: Sharpness of the average face. It can be argued that if the correspondence results for all the faces are semantically accurate, the average face should be clear on the edges (e.g. edges for the eyes, nose, and mouth region). The average face can be further used as the template face. It shows in Fig. 8 that the average face of 330 faces in HQ3DP maintains the key structure of human face, which indicates good correspondence.
Criterion 2: Texture-to-shape mapping. Some existing works [4, 28] transfer the texture of one face to the shape of another face to assess the correspondence result qualitatively. Following it we extract several corresponded face prototypes in HQ3DP, and paste their textures to the average shape, respectively. Figure 8 shows a well match of semantic meaning between shape and textures.

Average face and texture-to-shape mappings.
Criterion 3: Expression transfer. A robust correspondence method should also be able to deal with mild facial expressions. We calculate the error between a corresponded neutral face and face with expression of the same identity, and then add it to another neutral face of different identity. It shows a realistic synthetic result in Fig. 9 for expression transfer.

An example of expression transfer result.
4.2 Compactness of Bases Derived by PCA
Figure 7(b) has already shown more reasonable local mesh structure for the representation of a corresponded face visually. To demonstrate the effectiveness of this mesh refining algorithm quantitatively, we apply PCA to 330 corresponded faces in HQ3DP database after Procrustes alignment. Figure 10 shows the percentage of energy preserved by varying the number of principal components before and after the mesh refining algorithm in Sect. 3.4. We also implement the NICP algorithm [18] for comparison. It shows that there is no significant differences between sparse landmark guided correspondence (NICP) and denser high-entropy guided one. However, the proposed mesh refining algorithm has made the bases more compact to a considerable extent. It is worth mentioning that this algorithm can start from the correspondence results by any of the existing algorithms.

Compactness of the fitted model.
Compactness of PCA components implies less variability of the local mesh structure for all the corresponded faces. The proposed algorithm, derived from the assumption of similar local mesh structure for topological correspondence, inherently meet this goal. One practical significance is for the 3DMM fitting process, more compact bases may indicate less chance to be trapped in local minima, enabling better 3D reconstructed results.
4.3 Landmark Correspondence
The proposed algorithm is different from some existing landmark guided ones. Nevertheless, it can also be used for 3D face landmark detection. A merit of the proposed algorithm is that it can detect any number of user defined landmarks. The method is simple: manually label some landmarks on the template face and then find the points with the same indexes on other target faces as their respective landmarks. Figure 11 shows some landmark detection results qualitatively on HQ3DP database, which are accurate and competitive with manual annotation. Note that we do not give specific anthropometric meaning to these landmarks here.

Landmark correspondences. The left sub-figure is the manually annotated template and the rests are the landmark detection results.
To quantitatively assess the proposed method, we also compare the landmark detection results with some previous literatures on the FRGC v2.0 database. The manual annotations from [11, 38] are used as the ground truth for comparison. Figure 12(a) shows the template we used and the anthropometric meanings of the annotations. Table 2 shows the comparison for the correspondence results. It demonstrates that our method achieves state-of-the-art performance and fulfills the requirement for semantic correspondence. A little degradation for the lower lip midpoint (li) may result from large noises in the mouth region for this database. Note that we do not use textures for locating it, although textures should be helpful and are used for accurate manual annotations.

Templates used for (a) correspondence, (b) face recognition for the full shape, and (c) face recognition for the nose region.
4.4 3D Face Recognition
Since more accurate correspondence results tend to give better 3D face recognition performances, we extend the proposed method into a challenging face recognition task on the database FRGC v2.0. The ROC III mask defined in [14] is used for the 3D shape based face recognition experiment. Under this mask, the gallery and probe sets include a total number of 4, 007 3D scans of 466 subjects collected during Fall 2003 and Spring 2004, respectively. It is also an extremely challenging experiment conducted by many previous works because of the cross-seasonal variations imposed. We follow a PCA+LDA face recognition pipeline [40] after correspondence of all faces are established. Since the database meets some common problems such as being occluded by hair or hat and masked by tremendous noises especially around the mouth region, the faces are cropped after correspondences are established. Figure 12(b) and Fig. 12(c) shows the shapes of the cropped faces for face recognition based on the full shape and the nose region, respectively. To compare the performance with the previous literatures, both face identification and verification are conducted. Face identification results are obtained by nearest-neighbor search to get Rank-\(\mathbf 1 \) performance. And face verification results are obtained by interpolating the ROC curves, in which verification rates under \(0.1\%\) false alarm rate are shown. The comparative results are included in Table 3. It shows that our method achieves both the best face verification (\(95.8\%\)) and identification (\(98.5\%\)) performances for the nose region and the best average performance (\(98.6\%\)) for the full shape, respectively, which demonstrates reliable correspondences.
5 Discussion and Conclusion
The proposed algorithm for correspondence can handle mild facial expression variations. A transitive strategy instead of the one-template strategy is preferred for faces with large expressions, such as the BU-3DFE [36] database. “Transitive” means correspondences are transferred from low-level to high-level expressions. With the established correspondences of a number of sampling faces, it would be easy to learn a prior model of 3D faces and then generalize to circumstances with occlusions and partial data. Although the inter-individual correspondence problem may not have strict and standard answer, the experiments demonstrate reasonable and reliable results by the proposed method. We hope this work including the notion of semantic and topological correspondence, will be helpful for a final solid definition for dense correspondence of 3D faces.
References
Corneanu, C.A., Simon, M.O., Cohn, J.F., Guerrero, S.E.: Survey on rgb, 3d, thermal, and multimodal approaches for facial expression recognition: History, trends, and affect-related applications. IEEE Trans. Pattern Anal. Mach. Intell. 38(8), 1548–1568 (2016)
Matthews, I., Xiao, J., Baker, S.: 2d vs. 3d deformable face models: representational power, construction, and real-time fitting. Int. J. Comput. Vis. 75(1), 93–113 (2007)
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. In: Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, pp. 187–194. ACM Press/Addison-Wesley Publishing Co. (1999)
Mohammadzade, H., Hatzinakos, D.: Iterative closest normal point for 3d face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35(2), 381–397 (2013)
Tam, G.K., et al.: Registration of 3d point clouds and meshes: a survey from rigid to nonrigid. IEEE Trans. Vis. Comput. Gr. 19(7), 1199–1217 (2013)
Pan, G., Zhang, X., Wang, Y., Hu, Z., Zheng, X., Wu, Z.: Establishing point correspondence of 3d faces via sparse facial deformable model. IEEE Trans. Image Process. 22(11), 4170–4181 (2013)
Gilani, S.Z., Mian, A., Eastwood, P.: Deep, dense and accurate 3d face correspondence for generating population specific deformable models. Pattern Recognit. 69, 238–250 (2017)
Romdhani, S.: Face image analysis using a multiple features fitting strategy. Ph.D. thesis, University\_of\_Basel (2005)
Guo, J., Mei, X., Tang, K.: Automatic landmark annotation and dense correspondence registration for 3d human facial images. BMC Bioinf. 14(1), 232 (2013)
Grewe, Carl Martin, Zachow, Stefan: Fully automated and highly accurate dense correspondence for facial surfaces. In: Hua, Gang, Jégou, Hervé (eds.) ECCV 2016. LNCS, vol. 9914, pp. 552–568. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-48881-3_38
Creusot, C., Pears, N., Austin, J.: A machine-learning approach to keypoint detection and landmarking on 3d meshes. Int. J. Comput. Vis. 102(1–3), 146–179 (2013)
Song, M., Tao, D., Sun, S., Chen, C., Maybank, S.J.: Robust 3d face landmark localization based on local coordinate coding. IEEE Trans. Image Process. 23(12), 5108–5122 (2014)
Zulqarnain Gilani, S., Shafait, F., Mian, A.: Shape-based automatic detection of a large number of 3d facial landmarks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4639–4648 (2015)
Phillips, P.J., et al.: Overview of the face recognition grand challenge. In: . IEEE Computer Society Conference on Computer vision and Pattern Recognition, 2005, CVPR 2005, Vol. 1, pp. 947–954. IEEE (2005)
Castellani, U., Bartoli, A.: 3d shape registration. In: 3D Imaging, Analysis and Applications, pp. 221–264. Springer (2012)
Blanz, V., Vetter, T.: Face recognition based on fitting a 3d morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 25(9), 1063–1074 (2003)
Patel, A., Smith, W.A.: 3d morphable face models revisited. In: IEEE Conference on Computer Vision and Pattern Recognition, 2009, CVPR 2009, pp. 1327–1334. IEEE (2009)
Amberg, B., Romdhani, S., Vetter, T.: Optimal step nonrigid icp algorithms for surface registration. In: IEEE Conference on Computer Vision and Pattern Recognition, 2007, CVPR’07, pp. 1–8. IEEE (2007)
Cheng, S., Marras, I., Zafeiriou, S., Pantic, M.: Statistical non-rigid icp algorithm and its application to 3d face alignment. Image Vis. Comput. 58, 3–12 (2017)
Li, H., Sumner, R.W., Pauly, M.: Global correspondence optimization for non-rigid registration of depth scans. In: Computer graphics forum. Vol. 27, pp. 1421–1430. Wiley Online Library (2008)
Ferrari, C., Lisanti, G., Berretti, S., Del Bimbo, A.: A dictionary learning based 3d morphable shape model. IEEE Trans. Multimed. (2017)
Ferrari, C., Lisanti, G., Berretti, S., Del Bimbo, A.: Dictionary learning based 3d morphable model construction for face recognition with varying expression and pose. In: 2015 International Conference on 3D Vision (3DV), pp. 509–517. IEEE (2015)
Booth, J., Roussos, A., Zafeiriou, S., Ponniah, A., Dunaway, D.: A 3d morphable model learnt from 10,000 faces. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5543–5552 (2016)
Booth, J., Roussos, A., Ponniah, A., Dunaway, D., Zafeiriou, S.: Large scale 3d morphable models. Int. J. Comput. Vis. 1–22 (2017)
Vlasic, D., Brand, M., Pfister, H., Popović, J.: Face transfer with multilinear models. In: ACM Transactions on Gaphics (TOG), vol. 24, pp. 426–433. ACM (2005)
Cheng, S., Marras, I., Zafeiriou, S., Pantic, M.: Active nonrigid icp algorithm. In: 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Vol. 1, pp. 1–8. IEEE (2015)
Bolkart, T., Wuhrer, S.: A groupwise multilinear correspondence optimization for 3d faces. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3604–3612 (2015)
Zhang, C., Smith, W.A., Dessein, A., Pears, N., Dai, H.: Functional faces: Groupwise dense correspondence using functional maps. In: CVPR, pp. 5033–5041 (2016)
Sidorov, K.A., Richmond, S., Marshall, D.: Efficient groupwise non-rigid registration of textured surfaces. In: 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2401–2408. IEEE (2011)
Bronstein, Alexander M., Bronstein, Michael M., Kimmel, Ron: Expression-invariant 3D face recognition. In: Kittler, Josef, Nixon, Mark S. (eds.) AVBPA 2003. LNCS, vol. 2688, pp. 62–70. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-44887-X_8
Besl, P.J., McKay, N.D.: A method for registration of 3-d shapes. IEEE Trans. Pattern Anal. Mach. Intell. 14(2), 239–256 (1992)
Yang, J., Li, H., Jia, Y.: Go-icp: Solving 3d registration efficiently and globally optimally. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1457–1464 (2013)
Yang, J., Li, H., Campbell, D., Jia, Y.: Go-icp: a globally optimal solution to 3d icp point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 38(11), 2241–2254 (2016)
Szeliski, R., Tonnesen, D.: Surface Modeling with Oriented Particle Systems. Vol. 26. ACM (1992)
Linsen, L.: Point cloud representation. Univ., Fak. für Informatik, Bibliothek (2001)
Yin, L., Wei, X., Sun, Y., Wang, J., Rosato, M.J.: A 3d facial expression database for facial behavior research. In: 7th International Conference on Automatic Face and Gesture Recognition, 2006, FGR 2006, pp. 211–216. IEEE (2006)
Savran, Arman, Alyüz, Neşe, Dibeklioğlu, Hamdi, Çeliktutan, Oya, Gökberk, Berk, Sankur, Bülent, Akarun, Lale: Bosphorus database for 3D face analysis. In: Schouten, Ben, Juul, Niels Christian, Drygajlo, Andrzej, Tistarelli, Massimo (eds.) BioID 2008. LNCS, vol. 5372, pp. 47–56. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-89991-4_6
Szeptycki, P., Ardabilian, M., Chen, L.: A coarse-to-fine curvature analysis-based rotation invariant 3d face landmarking. In: IEEE 3rd International Conference on Biometrics: Theory, Applications, and Systems, 2009, BTAS’09, pp. 1–6. IEEE (2009)
Segundo, M.P., Silva, L., Bellon, O.R.P., Queirolo, C.C.: Automatic face segmentation and facial landmark detection in range images. IEEE Trans. Syst. Man, Cybern. Part B (Cybernetics) 40(5), 1319–1330 (2010)
Gupta, S., Markey, M.K., Bovik, A.C.: Anthropometric 3d face recognition. Int. J. Comput. Vis. 90(3), 331–349 (2010)
Al-Osaimi, F., Bennamoun, M., Mian, A.: An expression deformation approach to non-rigid 3d face recognition. Int. J. Comput. Vis. 81(3), 302–316 (2009)
Alyuz, N., Gokberk, B., Akarun, L.: Regional registration for expression resistant 3-d face recognition. IEEE Trans. Inf. Forensics Sec. 5(3), 425–440 (2010)
Wang, Y., Liu, J., Tang, X.: Robust 3d face recognition by local shape difference boosting. IEEE Trans. Pattern Anal. Mach. Intell. 32(10), 1858–1870 (2010)
Berretti, S., Del Bimbo, A., Pala, P.: 3d face recognition using isogeodesic stripes. IEEE Trans. Pattern Anal. Mach. Intell. 32(12), 2162–2177 (2010)
Queirolo, C.C., Silva, L., Bellon, O.R., Segundo, M.P.: 3d face recognition using simulated annealing and the surface interpenetration measure. IEEE Trans. Pattern Anal. Mach. Intell. 32(2), 206–219 (2010)
Spreeuwers, L.: Fast and accurate 3d face recognition. Int. J. Comput. Vis. 93(3), 389–414 (2011)
Drira, H., Amor, B.B., Srivastava, A., Daoudi, M., Slama, R.: 3d face recognition under expressions, occlusions, and pose variations. IEEE Trans. Pattern Anal. Mach. Intell. 35(9), 2270–2283 (2013)
Emambakhsh, M., Evans, A.: Nasal patches and curves for expression-robust 3d face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 39(5), 995–1007 (2017)
Acknowledgement
All correspondences should be forwarded to X. Hu via xiyuan.hu@ia.ac.cn. This work is supported by the National Key R&D Program of China (2017YFC0803505) and the Open Project of National Engineering Laboratory for Forensic Science (2017NELKFKT02).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Fan, Z., Hu, X., Chen, C., Peng, S. (2018). Dense Semantic and Topological Correspondence of 3D Faces without Landmarks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11220. Springer, Cham. https://doi.org/10.1007/978-3-030-01270-0_32
Download citation
DOI: https://doi.org/10.1007/978-3-030-01270-0_32
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01269-4
Online ISBN: 978-3-030-01270-0
eBook Packages: Computer ScienceComputer Science (R0)