
Abstract
We propose an automatically and accurately facial landmark localization algorithm based on Active Shape Model (ASM) and Gabor Wavelets Transformation (GWT), which can be applied to both 2D and 3D facial data. First, ASM is implemented to acquire landmarks’ coarse areas. Then similarity maps are obtained by calculating the similarity between sets of Gabor jets at initial coarse positions and sets of Gabor bunches modeled by its corresponding manually marked landmarks in the training set. The point with the maximum value in each similarity map is extracted as its final facial landmark location. It is showed in our laboratory databases and FRGC v2.0 that the algorithm could achieve accurate localization of facial landmarks with state-of-the-art accuracy and robustness.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Exploring a method of automatic landmark detection with robustness and high accuracy is a challenging task, which plays an important role in applications such as face registration, face recognition, face segmentation, face synthesis, and facial region retrieval. Motivated by such practical applications, extensive work focusing on thinking of methods for automatic landmark localization both on 2D and 3D faces has been done. The active shape model (ASM) and active appearance model (AAM) which proposed by T.F. Cootes et al. [1, 2] can generate good performance on 2D faces. They are both based on point distribution model (PDM) [3], and principal component analysis (PCA) is applied to establish a motion model. An iterative search algorithm is implemented to seek the best location for each landmark. Compared with ASM’s faster searching rate, AAM performs better on texture matching. However, both of the two algorithms suffer from illumination variation and facial expression changes.
Compared to landmark detection on 2D facial images, automatic landmark detection on 3D facial is a newer research topic. Zhao et al. [6] proposed a statistic-based algorithm, which detects landmarks by combining a global training deformation model, a local texture model of landmark, and local shape descriptor. Experiments on FRGC v1.0 achieve a high successful rate of 99.09 %. In [7], Stefano et al. first detects nose tip based on gray value and curvature on range images, then Laplacian of Gaussian (LoG) operator and Derivative of Gaussian (DoG) operator are applied near the nose tip to locate nose ends, and Scale-Invariant Feature Transform (SIFT) descriptor is implemented to detect eye corners and mouth corners at last. However, the algorithm suffer from facial expression as well. Clement Creusot et al. [18] detected keypoints on 3D meshs which was based on a machine-learning approach. With many local features such as Local Volume (VOL), Principal Curvatures, Normals et al. combined together, Linear Discriminant Analysis (LDA) and AdaBoost algorithms are applied separately for machine-learning. The algorithm achieves state-of-the-art performance. However, the algorithm relies heavily on local descriptors. Jahanbin et al. [9] proposed a 2D and 3D multimodal algorithm based on Gabor features, which achieves high accuracy.
Inspired by Jahanbin et al., we propose a novel landmark detecting algorithm based on ASM and GWT in the rest of the paper, which can be applied to 2D and 3D facial images. The rest of this paper is organized as follows. Section 2 is the main body of our proposed algorithm. Firstly, we extend ASM to range image for landmarking; secondly, the notion of “Gabor jet” set and “Gabor bunch” set and their similarity definition are introduced in detail which are the main contributions of our work. Experimental results and evaluation are provided in Sect. 3. Several conclusions and future work are drawn in Sect. 4.
2 Accurate Facial Landmarks Localization Based on ASM and GWT
2.1 Abbreviations
Before we introduce our algorithm, several abbreviations of fiducials are listed here for convenience.
NT: nose tip; LMC: left mouth corner; RMC: right mouth corner; LEIC: left eye inner corner; LEOC: left eye outer corner; REIC: right eye inner corner; REOC: right eye outer corner.
2.2 Landmark Method
Once these definitions are given, the processing pipeline of this section is outlined as follows:
-
1.
A set of 50 range or portrait facial images with different races, ages and genders is selected as the training set, and preprocessing steps are applied to all these images;
-
2.
The “Gabor bunch” set features of 7 manually marked landmarks of each image in the training set are extracted;
-
3.
A \( 25 \times 25 \) pixel search area for each landmark is obtained based on the results of ASM;
-
4.
Take LEIC searching for example, search counterclockwise and start from the center of the search area, and jump to step 6 if the similarity between the “Gabor jet” set at the search point and the “Gabor bunch” set of LEIC in the training set is larger than 0.98 (experienced data), else repeat step 4 until all search points are visited and get a similarity map, as shown in Fig. 4.;
-
5.
The point with the maximum value in each similarity map is extracted as its final facial feature location;
-
6.
The algorithm is done.
2.3 Coarse Area Localization
Though general ASM algorithm which is usually applied in portrait images suffers from illumination variation and facial expression changes, it is a good choice for fast landmarking the coarse area of each landmark. However, few literatures about detecting these coarse areas on 3D face are presented. In our paper, we extend ASM to range image in order to solve this problem.
Prior to landmarks detecting, proper preprocessing steps on 2D and 3D data are appreciated. White balancing is implemented to all portrait images so as to aim a natural rendition of images [8] (see Fig. 1). 3D point clouds are converted to range images by interpolating at the integer x and y coordinates used as the horizontal and vertical indices, respectively. These indices are used to determine the corresponding z coordinate which corresponds to the pixel value on range image [17].

White balancing algorithm: original and processed are in left and right respectively
2.3.1 ASM on Portrait and Range Image
As PDM [3] pointed out, an object can be described by n landmarks that are stacked in shape vectors. The shape vector of portrait and range image is constructed as:
\( (p_{x,i} ,p_{y,i} ) \) refers to the coordinate in portrait and range image. In another way, a shape can be approximated by a shape model:
Where \( \bar{x} \) means the mean shape of all objects in the training set; the eigenvectors corresponding to the s largest eigenvalues \( (\lambda_{1} \ge \lambda_{2} \ge \cdots \ge \lambda_{s} ) \) \( \lambda_{i} ,i = 1,2, \ldots ,s \) are retained in a matrix \( \Phi = \{\Phi _{1} ,\Phi _{2} , \ldots ,\Phi _{s} \} \); \( b \) is the model parameter to be solved.
In order to get the parameter \( b \), local texture models of each sample in the training set are constructed respectively as profile \( g_{i} \), \( i = 1,2, \ldots ,t \), then the mean profile \( \bar{g} \) and the covariance matrix \( C_{\text{g}} \) are computed for each landmark. Given \( g_{i} \) obeys a multidimensional Gaussian distribution, the computation of the Mahalanobis distance between a new profile and the profile model can be defined as follows:
Both shape model and profile model are combined to search each landmark, and points with the minimum values of \( f(g_{i} ) \) are the landmark to find.
2.4 Fine Landmark Detection
Since ASM performs poor in situations such as illumination variation,eye-closing and facial expression changes, we extract a \( 25 \times 25 \) pixel area for each landmark centered at its coarse location as the fine search area. Then Gabor Wavelet Transformation (GWT) is applied to these search area to get the final location of each landmark.
2.4.1 Gabor Jets
Gabor filters which are composed by Gabor kernels with different frequencies and orientations can be formulated as:
In our implementation, \( \sigma = 2\pi \), \( \vec{x} \) is the coordinate of a point, \( u \in \{ 0,1,2, \ldots ,7\} \) and \( v \in \{ 0,1,2, \ldots 4\} \) determine the orientation and scale of the Gabor filters.
The GWT is the response of an image \( I(\vec{x}) \) to Gabor filters, which is obtained by the convolution:
Where \( J_{j} (\vec{x}) \) can be expressed as \( J_{j} = a_{j} \exp (i\phi_{j} ) \), \( a_{j} (\vec{x}) \) and \( \phi_{j} (\vec{x}) \) denote the magnitude and phase respectively. The common method for reducing the computational cost for the above operation is to perform the convolution in Fourierspace [11]:
Where \( F \) denotes the fast Fourier transform, and \( F^{ - 1} \) its inverse. The magnitude of GWT on range image is shown in Fig. 2.

GWT on range image: range image is in left, magnitude of GWT is in right
As proposed in [4], “Gabor jet” is a set \( \vec{J} = \{ J_{j} ,j = u + 8v\} \) of 40 complex Gabor coefficients obtained from a single image point. And the similarity between two jets is defined by the phase sensitive similarity measure as follows:
Here, \( S(J_{j} ,J^{\prime}_{j} ) \in [ - 1,1] \) and a value which is closer to 1 means a higher similarity.
2.4.2 “Gabor Jet” Set and “Gabor Bunch” Set
For any given landmark \( j \) in the image, its Gabor bunch is defined as \( \vec{B}_{j} = \{ J_{x,j} \} \) [12], where \( x = 1,2, \cdots ,n \) denotes different images in the training set. In [13], a set of 50 facial images with different races, ages and genders was selected as the training and Gabor bunch extraction to detect landmarks. This algorithm achieves a good result on portrait image, but performs relatively poor on range image.
Inspired by “Gabor jet” and “Gabor bunch”, we propose the notion of “Gabor jet” set and “Gabor bunch” set in this work. For any given landmark \( j \), a “Gabor bunch” set is defined as a set constructed by the “Gabor jet” of \( j \) and its eight neighborhood; “Gabor bunch” set is a set constructed by all different images’ “Gabor bunch” set of \( j \) in the training set. Take LEIC for example, its “Gabor jet” set is \( \overrightarrow {J}_{s} = \{ \overrightarrow {J}_{0} ;\overrightarrow {J}_{i} ,i = 1,2, \ldots 8\} \), where \( \vec{J}_{0} \) is the “Gabor jet” of LEIC, \( \vec{J}_{i} \) is the “Gabor jet” of its 8 neighborhoods (see Fig. 3). \( \vec{\vec{B}}^{\prime} = \{ \vec{J}_{s,i} ,i = 1,2, \ldots ,n\} \) is the “Gabor bunch” set of LEIC, where \( \vec{J}_{s,i} \) means different images’ “Gabor jet” set of LEIC in the training set.

“Gabor jet” set of LEIC

Searching path
The similarity between any two “Gabor jet” sets is defined as:
Considering that probes are often not contained in the training set, we define the similarity between a “Gabor jet” set and a “Gabor bunch” set as:
Where \( \mathop {SORT}\nolimits_{n}^{\alpha } \{ f_{i} ,i = 1,2, \ldots ,n\} \) denotes the sum of \( \alpha \) largest values of \( f_{i} \).
3 Experimental Results and Evaluation
In this section, we present the performance of our proposed approach when tested both on the FRGC v2.0 and our laboratory database (OLD).
FRGC v2.0 [14] is one of the largest available public human face datasets, which consists of about 5,000 recordings covering a variety of facial appearances from surprise, happy, puffy cheeks, and to anger divided into training and validation partitions. The training partition which is acquired in Spring 2003 includes 273 individuals with 943 scans. The validation partition for assessing performance of an approach includes 4007 scans belonging to 466 individuals (Fall 2003 and Spring 2004). Since there was a significant time-lapse between the optical camera and the operation of the laser range finder in the data acquisition, 2D and 3D images are usually out of correspondence [9].
OLD consists of 247 scans from 83 individuals with expression, eye-closing, and pose variation. All data are acquired by our laboratory self-developed 3D shape measurement system based on grating projection, where a certain map exists between 2D and 3D data.
3.1 Experiment on Portraits
Two training sets are needed in our work. The ASM training set for finding search areas which consist of 1040 portraits with different expressions, pose, and illumination is selected from FRGC v2.0 and OLD at the rate of 25:1; the Gabor training set for fine landmark detection includes 50 portraits covering facial appearance from subjects with different gender, age, expression, and illumination, which is selected in the same ratio as the ASM training set. The probe set consists of 895 portraits selected at random from the FRGC v2.0 and the remaining portraits in the OLD. All portraits are normalised to \( 320 \times 240 \) pixel.
The Euclidean distance between the manually marked and the automatically detected landmarks is measured as \( d_{e} \) so as to evaluate the accuracy of the algorithm. \( mean \) and \( {\text{std}} \) are the mean and standard deviation of \( d_{e} \) respectively. The positional error of each detected fiducial is normalized by dividing the error by the interocular distance of that face. The normalized positional errors averaged over a group of fiducials is denoted \( m_{e} \), adopting the same notation as in [5].
Compared with general ASM algorithm which suffers from eye-closing, illumination and expression, the algorithm we proposed performs well in such situations as shown in Fig. 5. It is evident from the statistic in Table 1 that LEIC, LEOC, and LMC which have significant texture features perform best in sharply contrast with NT that performs worst. Moreover, the algorithm we proposed achieves a high successful ratio of 96.4 % with just 1.41 mm of \( mean \) and 1.78 mm of \( {\text{std}} \) in FRGC v2.0. By contrast, it performs even better in OLD that the successful ratio is 97.7 %, that \( mean \) and \( {\text{std}} \) are 1.31 mm and 1.49 mm respectively. The reason why the results in OLD outperform FRGC v2.0 may be that there are less probes and facial variation in OLD.

Landmark detection on portraits: the first row is FRGC v2.0, the second row is OLD
3.2 3D Landmark Localization Experiment
Due to the definitely corresponding relationship between 2D and 3D facial datum in OLD, accurate landmark localization can be realized by mapping the 2D localization results to 3D point cloud according to the corresponding relation-ship. However, the corresponding relationship between 2D and 3D faces does not exist in FRGC v2.0. Therefore, to achieve a precise 3D landmark localization, the 3D point cloud is converted into a range image at first, and then ASM is used to locate landmarks coarsely in the range image. Finally, the best landmarks can be found by extracting Gabor wavelet feature in the coarse location area. Both the training set and test set are range images and the selection rules are as described in Sect. 3.1. The results of 3D landmark localization in FRGC v2.0 are as shown in Fig. 6 and Table 2. In OLD, we just need to map the 2D localization results to 3D point cloud according to the corresponding relation-ship, so the localization results are as shown in Table 1.

3D landmark localization in FRGC v2.0 (first row) and OLD (second row)
The first row is in FRGC v2.0, the second row is that in OLD. Tables 1 and 2 show that the algorithm in this paper can also achieve better results in 3D landmark localization: in the case of a small error \( {\text{m}}_{\text{e}} \le 0.06 \), the accuracy can be 94.2 % in FRGC v2.0. Meanwhile, in OLD, because of the corresponding relationship, we can directly locate landmarks on portrait images which have richer texture information, then we can map the localization results to the 3D point cloud. Finally, the accuracy we achieve is 97.7 %.
3.3 Landmark Localization Results Comparing
The landmark detection algorithm proposed in this paper first locates the landmarks coarsely basing on ASM, then the accurate localization is accomplished by the use of Gabor features. The algorithm can overcome the shortage of the ASM that the reduced accuracy is caused by eyes slightly open, eyes closed, large expressions and obvious illumination changes and so on. Furthermore, the landmark localization performance is greatly improved compared with ASM. AAM is also a sophisticated 2D facial landmark localization algorithm. As is pointed out in literature [15], the accuracy of AAM algorithm to locate the landmarks is only 70 % under the circumstance that error satisfies \( m_{e} \le 0.1 \). However, the accuracy of the algorithm locating landmarks in 2D faces in both literature [13] and this paper is over 99 % under the same circumstance. But compared with the automatic landmark localization algorithm pro-posed in this paper, the algorithm in literature [13] is only semi-automatic because its coarse landmark localization area cannot be completely determined automatically. Figure 7 describes the relationship between permissible error \( m_{e} \le 0.1 \) and the accuracy of 2D landmark localization resulting from the algorithm in literature [13] and this paper. We can also conclude that the algorithm in this paper has a better performance than that of the algorithm in literature [13] from it.

The relationship between permissible
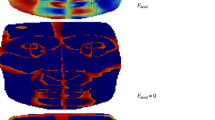
Table 3 displays the results of the comparison among three 3D landmark detection algorithms. The literature [16] used the Shape Index and Spin Image as local descriptors to locate landmarks coarsely, and FLM is used as topological constraint among landmarks, then the group of landmarks which meets FLM model in the coarse location area is chosen as the best landmarks. This method can also locate each landmark well in the case of large deflection in faces, but its average error is larger than that of the method in this paper from Table 3. The 3D landmark-locating algorithm in literature [13] also shows a good performance, and has a higher locating accuracy than that in literature [16]. However, compared with the automatic landmark localization algorithm pro-posed in this paper, the 3D landmark detection algorithm in literature [16] is only semi-automatic. What’s more, Fig. 8 shows that the algorithm in this paper has a higher locating accuracy than that in literature [13]. Figure 9 also shows 3D landmark localization can be realized by transforming it into corresponding 2D landmark localization to improve locating accuracy due to the mapping relationship between 2D and 3D images.

The relationship between permissible error and in accuracy error and accuracy in 3D
4 Conclusion
This paper proposes an automatic facial landmark localization algorithm on the basis of ASM and GWT. The method is based on the coarse localization using ASM, then the concepts of “Gabor jet” set and “Gabor bunch” set are introduced. Hence, the precise localization of the facial landmarks can be realized. The experimental results show that the landmark localization algorithm proposed in this paper has a higher accuracy and is robust to facial expressions and illumination changes. The algorithm has the following characteristics: (1) it is suitable for both 2D and 3D facial data; (2) it is based on ASM coarse localization, then the accurate localization is realized because of the use of “Gabor jet” set and “Gabor bunch” set. The localization accuracy is significantly increased compared with ASM.
GWT algorithm which has been used to locate landmarks accurately in this paper is rotation invariant. If ASM algorithm can be improved to realize coarse localization, the accurate landmark localization in faces having arbitrary pose can be achieved. This paper uses 5 directions, 8 scales and 40 Gabor filters to make up a filter group. If coupling filters in it can be reduced, the instantaneity of the algorithm in this paper will be better.
References
Cootes, T.F., Taylor, C.J., Hill, A., Halsam, J.: The use of active shape models for locating structures in media images. Image Vis. Comput. 12(6), 355–366 (1994)
Cootes, T.F., Edwards, G., Taylor, C.J.: Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 23(6), 681–685 (2001)
Cootes, T.F., Taylor, C.J.: Active shape models-smartsnakes. In: Proceedings of British Machine Vision Conference, Leeds, pp. 266–275. BMVC, UK (1992)
Clark, M., Bovik, A., Geisler, W.: Texture segmentation using Gabor modulation/demodulation. Pattern Recognit. Lett. 6(4), 261–267 (1987)
Cristinacce, T., Cootes, D.: A comparison of shape constrained facial feature detectors. In: Proceedings of Sixth IEEE International Conference on Automatic Face and Gesture Recognition, 2004, pp. 375–380 May 17–19 (2004)
Zhao, X., Dellandréa, E., Chen, L.: A 3D statistical facial feature model and its application on locating facial landmarks. In: Blanc-Talon, J., Philips, W., Popescu, D., Scheunders, P. (eds.) ACIVS 2009. LNCS, vol. 5807, pp. 686–697. Springer, Heidelberg (2009)
Berretti, S., Amor, B.B., Daoudi, M., et al.: 3D facial expression recognition using SIFT descriptor so automatically detected keypoints. Visual Comput. 27(11), 1021–1036 (2011)
Ancuti, C.O., Ancuti, C.: Single image dehazing by multi-scale fusion. IEEE Trans. Image Process. 22(8), 3271–3282 (2013)
Jahanbin, S., Choi, H., Bovik, A.C.: Passive multimodal 2-D + 3-D face recognition using Gabor features and landmark distances. IEEE Trans. Inf. Forensics Secur. 6(4), 1287–1304 (2011)
Daugman, J.G.: Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. J. Opt. Soc. Am. B 2(7), 1160–1169 (1985)
Hj Wan Yussof, W.N.J., Hitam, M.S.: Invariant gabor-based interest points detector under geometric transformation. Digt. Sig. Proc. 25(10), 190–197 (2014)
Wiskott, L., Fellous, J.M., Kuiger, N., der Malsburg von, C.: Face recognition by elastic bunch graph matching. IEEE Trans. Pattern Anal. Mach. Intell. 19(7), 775–779 (1997)
Jahanbin, S., Jahanbin, R., Bovik, A.C.: Passive three dimensional face recognition using iso-geodesic contours and procrustes analysis. Int. J. Comput. Vis. 105(1), 87–108 (2013)
Phillips, P.J., Flynn, P.J., Scruggs, T. et al.: Overview of the face recognition grand challenge. In: Computer Vision and Pattern Recognition CVPR, 2005, pp. 947–954. San Diego, CA, USA (2005)
Cristinacce. T., Cootes, D.A.: Comparison of shape constrained facial feature detectors. In: Proceedings of Sixth IEEE International Conference on Automatic Face and Gesture Recognition, pp. 375–380. Los Alamitos, CA, USA (2004)
Perakis, P., Passalis, G., Theoharis, T., et al.: 3D facial landmark detection under large yaw and expression variations. IEEE Trans. Pattern Anal. Mach. Intell. 35(7), 1552–1564 (2013)
Lei, Y., Bennamoun, M., Hayat, M., et al.: An efficient 3D face recognition approach using local geometrical signatures. Pattern Recognit. 47(2), 509–524 (2014)
Creusot, C., Pears, N., Austin, J.: A machine-learning approach to keypoint detection and landmarking on 3D meshes. Int. J. Comput. Vis. 102(1–3), 146–179 (2013)
Acknowledgement
The authors gratefully thank the Scientific Research Program Funded by National Natural Science Foundation of China (51175081, 61405034), a Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions and the Doctoral Scientific Fund Project of the Ministry of Education of China (20130092110027). Moreover, heartfelt thanks to Jahanbin S and Bovik A C et al. for guiding and program providing.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Liu, J., Da, F., Deng, X., Yu, Y., Zhang, P. (2015). An Automatic Landmark Localization Method for 2D and 3D Face. In: Zhang, YJ. (eds) Image and Graphics. ICIG 2015. Lecture Notes in Computer Science(), vol 9217. Springer, Cham. https://doi.org/10.1007/978-3-319-21978-3_47
Download citation
DOI: https://doi.org/10.1007/978-3-319-21978-3_47
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-21977-6
Online ISBN: 978-3-319-21978-3
eBook Packages: Computer ScienceComputer Science (R0)
