
Abstract
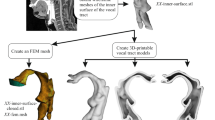
We present a complete system for image-based 3D vocal tract analysis ranging from MR image acquisition during phonation, semi-automatic image processing, quantitative modeling including model-based speech synthesis, to quantitative model evaluation by comparison between recorded and synthesized phoneme sounds. For this purpose, six professionally trained speakers, age 22-34y, were examined using a standardized MRI protocol (1.5 T, T1w FLASH, ST 4mm, 23 slices, acq. time 21s). The volunteers performed a prolonged (≥21s) emission of sounds of the German phonemic inventory. Simultaneous audio tape recording was obtained to control correct utterance. Scans were made in axial, coronal, and sagittal planes each. Computer-aided quantitative 3D evaluation included (i) automated registration of the phoneme-specific data acquired in different slice orientations, (ii) semi-automated segmentation of oropharyngeal structures, (iii) computation of a curvilinear vocal tract midline in 3D by nonlinear PCA, (iv) computation of cross-sectional areas of the vocal tract perpendicular to this midline. For the vowels /a/,/e/,/i/,/o/,/ø/,/u/,/y/, the extracted area functions were used to synthesize phoneme sounds based on an articulatory-acoustic model. For quantitative analysis, recorded and synthesized phonemes were compared, where area functions extracted from 2D midsagittal slices were used as a reference. All vowels could be identified correctly based on the synthesized phoneme sounds. The comparison between synthesized and recorded vowel phonemes revealed that the quality of phoneme sound synthesis was improved for phonemes /a/, /o/, and /y/, if 3D instead of 2D data were used, as measured by the average relative frequency shift between recorded and synthesized vowel formants (p<0.05, one-sided Wilcoxon rank sum test). In summary, the combination of fast MRI followed by subsequent 3D segmentation and analysis is a novel approach to examine human phonation in vivo. It unveils functional anatomical findings that may be essential for realistic modelling of the human vocal tract during speech production.
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Fant, G.: Acoustic Theory of Speech Production. Mouton, den Haag (1960)
Mermelstein, P.: Articulatory Model for the Study of Speech Production. Journal of the Acoustical Society of America 53(4), 1070–1082 (1973)
Baer, T., Gore, J.C., Gracco, R.C.: Analysis of Vocal Tract Shape and Dimension using Magnetic Resonance Imaging: Vowels. JASA 90(2), 799–828 (1991)
Narayanan, S.S., Alwan, A.A., Haker, K.: Towards Articulatory-Acoustic Models for Liquid Approximants based on MRI and EPG Data. JASA 101(2), 1064–1089 (1995)
Titze, I., Story, B.: Vocal Tract Area Functions from Magnetic Resonance Imaging. Journal of the Acoustical Society of America 100(1), 537–554 (1996)
Soquet, A., Lecuit, V.: Segmentation of the Airway from the Surrounding Tissues on Magnetic Resonance Images: A Comparative Study. In: ICSLP (1998)
Woods, R.P., Cherry, S.R., Mazziotta, J.C.: Rapid automated algorithm for aligning and reslicing PET images. JCAT 16, 620–633 (1992)
Der, R., Herrmann, M.: Second-Order Learning in Self-Organizing Maps. In: Oja, E. (ed.) Kohonen Maps (1999)
Kohonen, T.: Self-Organizing Maps. Springer, Heidelberg (2001)
Sondhi, M.M., Schroeder, J.: A Hybrid Time-Frequency Domain Articulatory Speech Synthesizer. IEEE Transactions on Acoustics, Speech, and Signal Processing 50, 1070–1082 (1987)
Author information
Authors and Affiliations
Editor information
Electronic Supplementary Material
Rights and permissions
Copyright information
© 2008 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Wismueller, A., Behrends, J., Hoole, P., Leinsinger, G.L., Reiser, M.F., Westesson, PL. (2008). Human Vocal Tract Analysis by in Vivo 3D MRI during Phonation: A Complete System for Imaging, Quantitative Modeling, and Speech Synthesis. In: Metaxas, D., Axel, L., Fichtinger, G., Székely, G. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2008. MICCAI 2008. Lecture Notes in Computer Science, vol 5242. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-85990-1_37
Download citation
DOI: https://doi.org/10.1007/978-3-540-85990-1_37
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-85989-5
Online ISBN: 978-3-540-85990-1
eBook Packages: Computer ScienceComputer Science (R0)