
Abstract
A significant number of life insurance contracts are based on deterministic investment strategies—this justifies to restrict the set of admissible controls to deterministic controls. Optimal deterministic controls can be identified by Hamilton-Jacobi-Bellman techniques, but for the corresponding partial differential equations only numerical solutions are available and so the general existence of optimal controls is unclear. We present a non-constructive existence result and derive necessary characterizations for optimal controls by using a Pontryagin maximum principle. Furthermore, based on the variational idea of the Pontryagin maximum principle, we derive a numerical optimization algorithm for the calculation of optimal controls.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
- Deterministic Consumption
- Pontryagin Maximum Principle
- Deterministic Investment
- Deterministic Control
- Numerical Optimization Algorithm
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Among many other applications, individual investment strategies arise in pension saving contracts, see for example Cairns [6]. While in dynamic optimal consumption-investment problems one typically aims to find an optimal control from the set of adapted processes, in insurance practice quite a number of contracts rely on deterministic investment strategies. Deterministic investment and consumption strategies have the advantage that they are easier to organize in asset management, that they make future consumption predictable, and that they are easier to communicate. From a mathematical point of view, deterministic control avoids unwanted features of stochastic control such as diffusive consumption, satisfaction points and consistency problems. For further arguments and a detailed comparison of stochastic versus deterministic control see also Menkens [17].
The present paper is motivated by Christiansen and Steffensen [9], where mean-variance-optimal deterministic consumption and investment is discussed in a Black-Scholes market. Sufficient conditions for optimal strategies are derived from a Hamilton-Jacobi-Bellman approach, but only numerical solutions and no analytical solutions are given. That means that the general existence of solutions remains unclear. We fill that gap, allowing for a slightly more general model with non-constant Black-Scholes market parameters. By applying a Pontryagin maximum principle, we additionally verify that the sufficient conditions of Christiansen and Steffensen [9] for optimal controls are actually necessary. Furthermore, we present an alternative numerical algorithm for the calculation of optimal controls. Therefore, we make use of the variational idea behind the Pontryagin maximum principle. In a first step, we define generalized gradients for our objective function, which, in a second step, allows us to construct a gradient ascent method.
Mean-variance investment is a true classic since the seminal work by Markowitz [16]. Since then various authors have improved and extended the results, see for example Korn and Trautmann [12], Korn [13], Zhou and Li [18], Basak and Chabakauri [3], Kryger and Steffensen [15], Kronborg and Steffensen [14], Alp and Korn [1], Björk, Murgoci and Zhou [5] and others.
Deterministic optimal control is fundamental in Herzog et al. [11] and Geering et al. [10]. But apart from other differences, they disregard income and consumption and focus on the pure portfolio problem without cash flows. Bäuerle and Rieder [2] study optimal investment for both, adapted stochastic strategies and deterministic strategies. They discuss various objectives including mean-variance objectives under constraints. In the present paper, we discuss an unconstrained mean-variance-objective and we also control for consumption.
The paper is structured as follows. In Sect. 2, we set up a basic model framework and specify the optimal consumption and investment problem that we discuss here. In Sect. 3, we present an existence result for the optimal control. Section 4 derives necessary conditions for optimal controls by applying a Pontryagin maximum principle. Section 5 defines and calculates generalized gradients for the objective, which helps to set up a numerical optimization algorithm in Sect. 6. In Sect. 7 we illustrate the numerical algorithm.
2 The Mean-Variance-Optimal Deterministic Consumption and Investment Problem
Let \(B([0,T])\) denote the space of bounded Borel-measurable functions, equipped with the uniform norm \(\Vert \cdot \Vert _{\infty }\). On some finite time interval \([0,T]\), we assume that we have a continuous income with nonnegative rate \(a \in B([0,T])\) and a continuous consumption with nonnegative rate \(c \in B([0,T])\). Let \(C([0,T])\) bet the set of continuous functions on \([0,T]\). The positive initial wealth \(x_{0}\) and the stochastic wealth \(X(t)\) at \(t>0\) is distributed between a bank account with risk-free interest rate \(r\in C([0,T]) \) and a stock or stock fund with price process
where \(\alpha (t) >r(t)\ge 0\), \(\sigma (t) >0\) and \(\alpha , \sigma \in C([0,T])\). We write \(\pi (t)\) for the proportion of the total value invested in stocks and call it the investment strategy. The wealth process \(X(t)\) is assumed to be self-financing. Thus, it satisfies
with initial value \( X(0)=x_{0}\) and has the explicit representation
where
It is important to note that the process \((X(t))_{t\ge 0}\) depends on the choice of the investment strategy \((\pi (t))_{t \ge 0}\) and the consumption rate \((c(t))_{t \ge 0}\). In order to make that dependence more visible, we will also write \(X=X^{(\pi ,c)}\). For some arbitrary but fixed risk aversion parameter \(\gamma >0\) of the investor, we define the risk measure
We aim to maximize the functional
with respect to the investment strategy \(\pi \) and the consumption rate \(c\). The parameter \(\rho \ge 0\) describes the preference for consuming today instead of tomorrow.
3 Existence of Optimal Deterministic Control Functions
In Christiansen and Steffensen [9], where a Hamilton-Jacobi-Bellman approach is used, the existence of optimal control functions is related to the existence of solutions for the Hamilton-Jacobi-Bellman partial differential equation. However, only numerical solutions are available, so the general existence of solutions is unclear. Here, we fill that gap by giving an existence result for optimal deterministic control functions. The proof needs rather weak assumptions, but it is not constructive.
Theorem 1
Let \(G:D \rightarrow (-\infty ,\infty )\) be defined by (4) for
with lower and upper consumption bounds \(\underline{c},\overline{c} \in B([0,T])\). Then, the functional \(G\) is continuous and has a finite upper bound.
Proof
We first show that \(MV_{\gamma }[X(T)] = MV_{\gamma }[X^{(\pi ,c)}(T)] \) has a finite upper bound that does not depend on \((\pi ,c)\). Defining the stochastic process
we have \(MV_{\gamma }[X(T)] = E\left[ Y(T) \right] \). So it suffices to show that \(E\left[ Y(T) \right] \) has a finite upper bound that does not depend on \((\pi ,c)\). Since the quadratic variation process of \(X\) satisfies \(\mathrm{d}[X](t)= X(t)^2 \sigma (t)^2 \pi (t) ^2 \mathrm{d}t\), from Ito’s Lemma we get that
Hence, the expectation function of \(Y\) solves the differential equation
The right hand side of (8) is maximal with respect to \(\pi (t)\) for
Plugging (9) into (8) and rearranging terms yields
Recall that we assumed \(\gamma >0\) and \(\sigma (t) >0\), so the first and second denominator are never zero. If the third denominator \(E[X(t)^2]\) is zero, we implicitly get \(E[X(t)]=0\), and (10) is still true by defining \(0/0:=0\). The first line on the right hand side of (10) has an upper bound of
With the help of the equality
and the inequalities \( (E[X(t)])^2 \le E[X(t)^2]\) and \(\mathrm{Var}[X(t)]\le E[X(t)^2]\), we can show that the second line on the right hand side of (10) has an upper bound of
All in all, we obtain
for some finite positive constants \(C_1\) and \(C_2\), since the functions \(r(t), a(t), \alpha (t)\) are uniformly bounded on \([0,T]\), since \(- c(t) \le - \underline{c}(t)\) for a uniformly bounded function \(\underline{c}\), and since the positive and continuous function \(\sigma (t)\) has a uniform lower bound greater than zero. Thus, we have \(E[Y(t)] \le g(t)\) for \(g(t)\) defined by the differential equation
This differential equation for \(g(t)\) has a unique solution, which is bounded on \([0,T]\) and does not depend on the choice of \((\pi ,c)\). Hence, also \(MV_{\gamma }[X(T)] =E[Y(T)]\) has a finite upper bound that does not depend on the choice of \((\pi ,c)\). The same is true for the functional (4), since
Now we show the continuity of the functional \(G\). Suppose that \((\pi _n,c_n)_{n\ge 1} \) is an arbitrary but fixed sequence in \(D\) that converges to \((\pi _0,c_0)\) with respect to the supremum norm. Since \(D\) is a Banach space, the limit \((\pi _0,c_0)\) is also an element of \(D\). Let \(X_n(t) := X^{(\pi _n,c_n)}(t)\) for all \(t\). As the sequence \((\pi _n,c_n)_{n\ge 1} \) is convergent and within \(D\), the absolutes \(|\pi _n(t)|\) and \(|c_n(t)|\) have finite upper bounds, uniformly in \(n\) and uniformly in \(t\). Therefore, analogously to inequality (11), from Eq. (6) we get that
for some positive finite constants \(C_3\) and \(C_4\). Arguing analogously to (12), we obtain that \(E[X_n(t)] \le f(t)\) for some bounded function \(f(t)\). Using similar arguments for \(-E[X_n(t)]\), we get that also the absolute \(|E[X_n(t)]|\) is uniformly bounded in \(n\) and in \(t\). Applying Eq. (7), we obtain
Using the uniform boundedness of \(|E[X_n(t)]|\), \(|\pi _n(t)|\) and \(|c_n(t)|\), we can conclude that
for some positive finite constants \(C_5\) and \(C_6\). Hence, arguing analogously to above, the value \(E[X_n(t)^2]\) is uniformly bounded in \(n\) and in \(t\). Let \(Y_n(t)\) be the process according to definition (5) but with \(X_n\) instead of \(X\). Using (8) and the uniform boundedness of \(|E[X_n(t)]|\), \(E[X_n(t)^2]\), \(|\pi _n(t)|\) and \(|c_n(t)|\), we can show that
for some positive finite constant \(C_7\). Thus, we get
where we used that \(Y_0(0)-Y_n(0)=x_0-x_0=0\). Arguing similarly for \(-E[Y_0(t)-Y_n(t)]\), we can conclude that
for some finite constant \(C_8\), where the processes \(\widetilde{Y}_0(t)\) and \(\widetilde{Y}_n(t)\) are defined as above but with \(\gamma \) replaced by \(\gamma e^{-\rho T}\). Since we assumed that \((\pi _n,c_n)_{n\ge 1} \) converges in supremum norm, we obtain that \(G(\pi _n,c_0)\) converges to \(G(\pi _0,c_0)\), i.e. the functional \(G\) is continuous.
As \(G\) has a finite upper bound on the domain \(D\), the supremum
indeed exists. Since \(G\) is continuous and \(D\) is a Banach space, we can conclude that on each compact subset \(K\) of \(D\) there exists a pair \((\pi ^{*}, c^{*})\) for which
4 A Pontryagin Maximum Principle
Christiansen and Steffensen [9] identify characterizing equations for optimal investment and consumption rate by using a Hamilton-Jacobi-Bellman approach. Here, we show that those characterizing equations are indeed necessary by using a Pontryagin maximum principle (cf. Bertsekas [4]).
Defining the moment functions
as in Christiansen and Steffensen [9], we can represent the objective function \(G(\pi ,c)\) by
for any \(t\) in \([0,T]\). Simple calculations give us that
Similarly to \(m_{1}\) and \(m_{2}\), also \(n_{1}\), \(n_{2}\), \(p_{1}\), \(p_{2}\), and \(k\) solve a system of ordinary differential equations but with terminal instead of initial conditions, see Christiansen and Steffensen [9].
Theorem 2
Let \((\pi ^{*}, c^{*})\) be an optimal control in the sense of (13), and let \(m^{*}_i(t)\), \(p^{*}_i(t)\), \(n^{*}_i(t)\), \(i=1,2\), and \(k^{*}(t)\) be the corresponding moment functions according to (14). Then, we have necessarily
Proof
With \((\pi ^{*},c^{*})\) being an optimal control, we define local alternatives by
for continuous functions \(h\) and \(l\). As \(G(\pi ^{*},c^{*})\) is maximal, by applying (15) for \(t=t_0\) we obtain that
must be nonnegative. Equation (16) implies that
since \(\Vert m^{*}_1- m^{\varepsilon }_1\Vert \rightarrow 0 \) for \(\varepsilon \rightarrow 0\). Moreover, since we have \(m^{*}_1(t) \rightarrow m^{*}_1(t_0)\), \(r(t) \rightarrow r(t_0)\), \(\alpha (t) \rightarrow \alpha (t_0)\), \(\sigma (t) \rightarrow \sigma (t_0)\) for \(t\rightarrow t_0\), we get that
For the squared functions we use
and then apply the asymptotic formula (20), which leads to
Similarly, we can show that
Plugging Eq. (21) into Eq. (19) and rearranging, we get
for all continuous functions \(l\) and \(h\). Note that \( n_1^{*}(t_0) m_1^{*}(t_0)+p_1^{*}(t_0) = m_1^{*}(T)\). Consequently, we must have that the sign of \(l(t_0)\) equals the sign of
which means that (18) holds, and we have necessarily that
which means that (17) is satisfied.
Recalling that \( n_1^{*}(t_0) m_1^{*}(t_0)+p_1^{*}(t_0) = m_1^{*}(T)\), we observe that Eqs. (17) and (18) are equal to Eqs. (19) and (20) in Christiansen and Steffensen [9], which means that the latter equations are not only sufficient but also necessary.
5 Generalized Gradients for the Objective
For differentiable functions on the Euclidean space, a popular method to find maxima is to use the gradient ascent method. We want to follow that variational concept, however our objective is a mapping on a functional space. Therefore, we first need to discuss the definition and calculation of proper gradient functions.
Theorem 3
Let \((\pi ,c) \in D\) for \(D\) as defined in Theorem 1. For each pair of continuous functions \((h,l)\) on \([0,T]\), we have
with
and
The limit
is the so-called Gateaux derivative (or directional derivative) of the functional \(G\) at \((\pi ,c)\) in direction \((h,l)\). Following Christiansen [7], we interpret the two-dimensional function \((\nabla _{\pi } G(\pi ,c), \nabla _{\pi } G(\pi ,c))\) as the gradient of \(G\) at \((\pi ,c)\).
Proof
(Proof of Theorem 3) In the proof of Theorem 2 we already implicitly showed that
for all \(t_0 \in [0,T]\), \((\pi ,c) \in D\), and \(h,l \in C([0,T])\). Defining an equidistant decomposition of the interval \([0,T]\) by
we can rewrite the difference \(G(\pi +\delta h,c+\delta l) - G(\pi , c )\) to
for all \(0 < \delta \le 1\). The moments \(p_1,p_2,n_1,n_2,k\), interpreted as mappings of \((\pi ,c)\) from the domain \(B([0,T])^2\) with \(L_2\)-norm into the codomain \(C([0,T])\) with supremum norm, are continuous. Hence, the gradient functions on the right hand side of the last equation are continuous with respect to the parameters \(\tau _{i-1}\) and \(\tau _{i}\). Thus, for \(n\rightarrow \infty \) we obtain
Since the moment functions \(p_1,p_2,n_1,n_2,k\) (interpreted as mappings of \((\pi ,c)\) from the domain \(B([0,T])^2\) with supremum-norm into the codomain \(C([0,T])\) with supremum norm) are even uniformly continuous, the above gradient functions are uniformly continuous with respect to parameter \(\delta \). Thus, for \(\delta \rightarrow 0\) we end up with the statement of the theorem.
6 Numerical Optimization by a Gradient Ascent Method
With the help of the gradient function \((\nabla _{\pi } G(\pi ,c), \nabla _{\pi } G(\pi ,c))\) of the objective \(G(\pi ,c)\), we can construct a gradient ascent method. A similar approach is also used in Christiansen [8].
Algorithm
-
1.
Choose a starting control \((\pi ^{(0)},c^{(0)})\).
-
2.
Calculate a new scenario by using the iteration
$$\begin{aligned} (\pi ^{(i+1)},c^{(i+1)}) := (\pi ^{(i)},c^{(i)}) + K\, \Big (\nabla _{\pi } G(\pi ^{(i)},c^{(i)}), \nabla _{\pi } G(\pi ^{(i)},c^{(i)})\Big ) \end{aligned}$$where \(K > 0\) is some step size that has to be chosen. If \(c^{(i+1)}\) is above or below the bounds \(\overline{c}\) and \(\underline{c}\), we cut it off at the bounds.
-
3.
Repeat step 2 until \( \big | G(\pi ^{(i+1)},c^{(i+1)}) - G(\pi ^{(i)},c^{(i)})\big | \) is below some error tolerance.
7 Numerical Example
Here, we demonstrate the gradient ascent method of the previous section with a numerical example. For simplicity, we fix the consumption rate \(c\) and only control the investment rate \(\pi \). We take the same parameters as in Christiansen and Steffensen [9] in order to have comparable results: For the Black-Scholes market we assume that \(r=0.04\), \(\alpha =0.06\) and \(\sigma =0.2\). The time horizon is set to \(T=20\), the initial wealth is \(x_{0}=200\), and the savings rate is \(a(t)-c(t)=100-80=20\). The preference parameter of consuming today instead tomorrow is set to \(\rho =0.1\), and the risk aversion parameter is set to \( \gamma =0.003\).
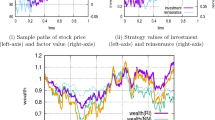
Starting from \(\pi ^{(0)}=0.5\), Fig. 1 shows the converging series of investment rates \(\pi ^{(i)}\), \(i=0,\ldots ,40\) for \(K=0.2\). The last iteration step \(\pi ^{(40)}\) perfectly fits the corresponding numerical result in Christiansen and Steffensen [9].

Sequence of investment rates \(\pi ^{(i)}\), \(i=0,\ldots ,40\) calculated by the gradient ascent method. The higher the number \(i\) the darker the color of the corresponding graph
References
Alp, Ö.S., Korn, R.: Continuous-time mean-variance portfolios: a comparison. Optimization 62, 961–973 (2013)
Bäuerle, N., Rieder, U.: Optimal deterministic investment strategies for insurers. Risks 1, 101–118 (2013)
Basak, S., Chabakauri, G.: Dynamic mean-variance asset allocation. Rev. Financ. Stud. 23, 2970–3016 (2010)
Bertsekas, D.P.: Dynamic Programming and Optimal Control. Athena Scientific, Belmont (1995)
Björk, T., Murgoci, A., Zhou, X.: Mean-variance portfolio optimization with state dependent risk aversion. Math. Financ. 24, 1–24 (2014)
Cairns, A.J.G.: Some notes on the dynamics and optimal control of stochastic pension fund models in continuous time. ASTIN Bull. 20, 19–55 (2000)
Christiansen, M.C.: A sensitivity analysis concept for life insurance with respect to a valuation basis of infinite dimension. Insur.: Math. Econ. 42, 680–690 (2008)
Christiansen, M.C.: Making use of netting effects when composing life insurance contracts. Eur. Actuar. J. 1(Suppl 1), 47–60 (2011)
Christiansen, M.C., Steffensen, M.: Deterministic mean-variance-optimal consumption and investment. Stochastics 85, 620–636 (2013)
Geering, H.P., Herzog, F., Dondi, G.: Stochastic optimal control with applications in financial engineering. In: Chinchuluun, A., Pardalos, P.M., Enkhbat, R., Tseveendorj, I. (eds.) Optimization and Optimal Control: Theory and Applications, pp. 375–408. Springer, Berlin (2010)
Herzog, F., Dondi, G., Geering, H.P.: Stochastic model predictive control and portfolio optimization. Int. J. Theor. Appl. Financ. 10, 231–244 (2007)
Korn, R., Trautmann, S.: Continuous-time portfolio optimization under terminal wealth constraints. Z. für Op. Res. 42, 69–92 (1995)
Korn, R.: Some applications of \(L^2\)-hedging with a non-negative wealth process. Appl. Math. Financ. 4, 64–79 (1997)
Kronborg, M.T., Steffensen, M.: Inconsistent investment and consumption problems. Available at SSRN: http://ssrn.com/abstract=1794174 (2011)
Kryger, E.M., Steffensen, M.: Some solvable portfolio problems with quadratic and collective objectives. Available at SSRN: http://ssrn.com/abstract=1577265 (2010)
Markowitz, H.M.: Portfolio selection. J. Financ. 7, 77–91 (1952)
Menkens, O.: Worst-case scenario portfolio optimization given the probability of a crash. In: Glau, K. et al. (eds.) Innovations in Quantitative Risk Management, Springer Proceedings in Mathematics & Statistics, vol. 99 (2015)
Zhou, X., Li, D.: Continuous-time mean-variance portfolio selection: a stochastic LQ framework. Appl. Math. Optim. 42, 19–33 (2000)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is distributed under the terms of the Creative Commons Attribution Noncommercial License, which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Copyright information
© 2015 The Author(s)
About this paper
Cite this paper
Christiansen, M.C. (2015). A Variational Approach for Mean-Variance-Optimal Deterministic Consumption and Investment. In: Glau, K., Scherer, M., Zagst, R. (eds) Innovations in Quantitative Risk Management. Springer Proceedings in Mathematics & Statistics, vol 99. Springer, Cham. https://doi.org/10.1007/978-3-319-09114-3_13
Download citation
DOI: https://doi.org/10.1007/978-3-319-09114-3_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-09113-6
Online ISBN: 978-3-319-09114-3
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)