
Abstract
Multilayer networks proved to be suitable in extracting and providing dependency information of different complex systems. The construction of these networks is difficult and is mostly done with a static approach, neglecting time delayed interdependences. Tensors are objects that naturally represent multilayer networks and in this paper, we propose a new methodology based on Tucker tensor autoregression in order to build a multilayer network directly from data. This methodology captures within and between connections across layers and makes use of a filtering procedure to extract relevant information and improve visualization. We show the application of this methodology to different stationary fractionally differenced financial data. We argue that our result is useful to understand the dependencies across three different aspects of financial risk, namely market risk, liquidity risk, and volatility risk. Indeed, we show how the resulting visualization is a useful tool for risk managers depicting dependency asymmetries between different risk factors and accounting for delayed cross dependencies. The constructed multilayer network shows a strong interconnection between the volumes and prices layers across all the stocks considered while a lower number of interconnections between the uncertainty measures is identified.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Network structures are present in different fields of research. Multilayer networks represent a widely used tool for representing financial interconnections, both in industry and academia [1] and has been shown that the complex structure of the financial system plays a crucial role in the risk assessment [2, 3]. A complex network is a collection of connected objects. These objects, such as stocks, banks or institutions, are called nodes and the connections between the nodes are called edges, which represent their dependency structure. Multilayer networks extend the standard networks by assembling multiple networks ‘layers’ that are connected to each other via interlayer edges [4] and can be naturally represented by tensors [5]. The interlayer edges form the dependency structure between different layers and in the context of this paper, across different risk factors. However, two issues arise:
-
1
The construction of such networks is usually based on correlation matrices (or other symmetric dependence measures) calculated on financial asset returns. Unfortunately, such matrices being symmetric, hide possible asymmetries between stocks.
-
2
Multilayer networks are usually constructed via contemporaneous interconnections, neglecting the possible delayed cause-effect relationship between and within layers.
In this paper, we propose a method that relies on tensor autoregression which avoids these two issues. In particular, we use the tensor learning approach establish in [6] to estimate the tensor coefficients, which are the building blocks of the multilayer network of the intra and inter dependencies in the analyzed financial data. In particular, we tackle three different aspects of financial risk, i.e. market risk, liquidity risk, and future volatility risk. These three risk factors are represented by prices, volumes and two measures of expected future uncertainty, i.e. implied volatility at 10 days (IV10) and implied volatility at 30 days (IV30) of each stock. In order to have stationary data but retain the maximum amount of memory, we computed the fractional difference for each time series [7]. To improve visualization and to extract relevant information, the resulting multilayer is then filtered independently in each dimension with the recently proposed Polya filter [8]. The analysis shows a strong interconnection between the volumes and prices layers across all the stocks considered while a lower number of interconnection between the volatility at different maturity is identified. Furthermore, a clear financial connection between risk factors can be recognized from the multilayer visualization and can be a useful tool for risk assessment. The paper is structured as follows. Section 2 is devoted to the tensor autoregression. Section 3 shows the empirical application while Sect. 4 concludes.
2 Tensor Regression
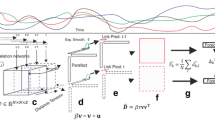
Tensor regression can be formulated in different ways: the tensor structure is only in the response or the regression variable or it can be on both. The literature related to the first specification is ample [9, 10] whilst the fully tensor variate regression received attention only recently from the statistics and machine learning communities employing different approaches [6, 11]. The tensor regression we are going to use is the Tucker tensor regression proposed in [6]. The model is formulated making use of the contracted product, the higher order counterpart of matrix product [6] and can be expressed as:
where \(\varvec{\mathcal {\MakeUppercase {X}}}\in \mathbb {R}^{N \times I_1 \times \cdots \times I_N}\) is the regressor tensor, \(\varvec{\mathcal {\MakeUppercase {Y}}} \in \mathbb {R}^{N \times J_1\times \cdots \times J_M} \) is the response tensor, \(\varvec{\mathcal {\MakeUppercase {E}}}\in \mathbb {R}^{N \times J_1\times \cdots \times J_M}\) is the error tensor, \(\varvec{\mathcal {\MakeUppercase {A}}}\in \mathbb {R}^{1 \times J_1\times \cdots \times J_M}\) is the intercept tensor while the slope coefficient tensor, which represents the multilayer network we are interested to learn, is \(\varvec{\mathcal {\MakeUppercase {B}}}\in \mathbb {R}^{I_1 \times \cdots \times I_N \times J_1 \times \cdots \times J_M}\). Subscripts \(\varvec{\mathcal {\MakeUppercase {I_x}}}\) and \(\varvec{\mathcal {\MakeUppercase {J_B}}}\) are the modes over winch the product is carried out. In the context of this paper, \(\varvec{\mathcal {\MakeUppercase {X}}}\) is a lagged version of \(\varvec{\mathcal {\MakeUppercase {Y}}}\), hence \(\varvec{\mathcal {\MakeUppercase {B}}}\) represents the multilinear interactions that the variables in \(\varvec{\mathcal {\MakeUppercase {X}}}\) generate in \(\varvec{\mathcal {\MakeUppercase {Y}}}\). These interactions are generally asymmetric and take into account lagged dependencies being \(\varvec{\mathcal {\MakeUppercase {B}}}\) the mediator between two separate in time tensor datasets. Therefore, \(\varvec{\mathcal {\MakeUppercase {B}}}\) represents a perfect candidate to use for building a multilayer network. However, the \(\varvec{\mathcal {\MakeUppercase {B}}}\) coefficient is high dimensional. In order to resolve the issue, a Tucker structure is imposed on \(\varvec{\mathcal {\MakeUppercase {B}}}\) such that it is possible to recover the original \(\varvec{\mathcal {\MakeUppercase {B}}}\) with smaller objects.Footnote 1 One of the advantages of the Tucker structure is, contrarily to other tensor decompositions such as the PARAFAC, that it can handle dimension asymmetric tensors since each factor matrix does not need to have the same number of components.
2.1 Penalized Tensor Regression
Tensor regression is prone to over-fitting when intra-mode collinearity is present. In this case, a shrinkage estimator is necessary for a stable solution. In fact, the presence of collinearity between the variables of the dataset degrades the forecasting capabilities of the regression model. In this work, we use the Tikhonov regularization [12]. Known also as Ridge regularization, it rewrites the standard Least Squares problem as
where \(\lambda >0\) is the regularization parameter and \(\Vert \Vert ^2_F\) is the squared Frobenius norm. The greater the \(\lambda \) the stronger is the shrinkage effect on the parameters. However, high values of \(\lambda \) increase the bias of the tensor coefficient \(\varvec{\mathcal {\MakeUppercase {B}}}\). Indeed, the shrinkage parameter is usually set via data driven procedures rather than input by the user. The Tikhonov regularization can be computationally very expensive for big data problem. To solve this issue, [13] proposed a decomposition of the Tikhonov regularization. The learning of the model parameters is a nonlinear optimization problem that can be solved by iterative algorithms such as the Alternating Least Squares (ALS) introduced by [14] for the Tucker decomposition. This methodology solves the optimization problem by dividing it into small least squares problems. Recently, [6] developed an ALS algorithm for the estimation of the tensor regression parameters with Tucker structure in both the penalized and unpenalized settings. For the technical derivation refer to [6].
3 Empirical Application: Multilayer Network Estimation
In this section, we show the results of the construction of the multilayer network via the tensor regression proposed in Eq. 1.
3.1 Data and Fractional Differentiation
The dataset used in this paper is composed of stocks listed in the Dow Jones (DJ). These stocks time series are recorded on a daily basis from 01/03/1994 up to 20/11/2019, i.e. 6712 trading days. We use 26 over the 30 listed stocks as they are the ones for which the entire time series is available. For the purpose of our analysis, we use log-differenciated prices, volumes, implied volatility at 10 days (IV10) and implied volatility at 30 days (IV30). In particular, we use the fractional difference algorithm of [7] to balance stationarity and residual memory in the data. In fact, the original time series have the full amount of memory but they are non-stationary while integer log-differentiated data are stationary but have small residual memory due to the process of differentiation. In order to preserve the maximum amount of memory in the data, we use the fractional differentiation algorithm with different levels of fractional differentiation and then test for stationarity using the Augmented Dickey-Fuller test [15]. We find that all the data are stationary when the order of differentiation is \(\alpha =0.2\). This means that only a small amount of memory is lost in the process of differentiation.
3.2 Model Selection
The tensor regression presented in Eq. 1 has some parameters to be set, i.e. the Tucker rank and the shrinkage parameter \(\lambda \) for the penalized estimation of Eq. 2 as discussed in [6]. Regarding the Tucker rank, we used the full rank specification since we do not want to reduce the number of independent links. In fact, using a reduced rank would imply common factors to be mapped together, an undesirable feature for this application. Regarding the shrinkage parameter \(\lambda \), we selected the value as follows. First, we split the data in a training set composed of \(90\%\) of the sample and in a test set with the remaining \(10\%\). We then estimated the regression coefficients for different values of \(\lambda \) on the training set and then we computed the predicted \(R^2\) on the test set. We used a grid of \(\lambda =0,1,5,10,20,50.\) and the predicted \(R^2\) is maximized at \(\lambda =0\) (no shrinkage).
3.3 Results
In this section, we show the results of the analysis carried out with the data presented in Sect. 3.1. The multilayer network built via the estimated tensor autoregression coefficient \(\varvec{\mathcal {\MakeUppercase {B}}}\) represents the interconnections between and within each layer. In particular \(\varvec{\mathcal {\MakeUppercase {B}}}_{i,j,k,l}\) is the connection between stock i in layer j and stock k in layer l. It is important to notice that the estimated dependencies are in general not symmetric, i.e. \(\varvec{\mathcal {\MakeUppercase {B}}}_{i,j,k,l}\ne \varvec{\mathcal {\MakeUppercase {B}}}_{k,j,i,l}\). However, the multilayer network constructed using \(\varvec{\mathcal {\MakeUppercase {B}}}\) is fully connected. For this reason, a method for filtering those networks is necessary. Different methodologies are available for filtering information from complex networks [8, 16]. In this paper, we use the Polya filter of [8] as it can handle directed weighted networks and it is both flexible and statistically driven. In fact, it employs a tuning parameter a that drives the strength of the filter and returns the p-values for the null hypotheses of random interactions. We filter every network independently (both intra and inter connections) using a parametrization such that \(90\%\) of the total links are removed.Footnote 2 In order to asses the dependency across the layers, we analyze two standard multilayer network measures, i.e. inter-layer assortativity and edge overlapping. A standard way to quantify inter-layer assortativity is to calculate Pearson’s correlation coefficient over degree sequences of two layers and it represents a measure of association between layers. High positive (negative) values of such measure mean that the two risk factors act in the same (opposite) direction. Instead, overlapping edges are the links between pair of stocks present contemporaneously in two layers. High values of such measure mean that the stocks have common connections behaviour. As it can be possible to see from Fig. 1, prices and volatility have a huge portion of overlapping edges, still, these layers are disassortative as the correlation between the nodes sequence across the two layer is negative. This was an expected result since the negative relationship between prices and volatility is a stylized fact in finance. Not surprisingly, the two measures of volatility are highly assortative and have a huge fraction of overlapping edges.

Multilayer network assortativity matrix and edge overlapping matrix. Linear scale. Darker colour represents higher values.
Finally, we show in Fig. 2 the filtered multilayer network constructed via the tensor coefficient \(\varvec{\mathcal {\MakeUppercase {B}}}\) estimated via the tensor autoregression of Eq. 1. As it can be possible to notice, the volumes layer has more interlayer connections rather than intralayer connections. Since each link represents the effect that one variable has on itself and other variables in the future, this means that stocks’ liquidity risk mostly influences future prices and expected uncertainty. The two volatility networks have a relatively small number of interlayer connections despite being assortative. This could be due to the fact that volatility risk tends to increase or decrease through a specific maturity rather than across maturities. It is also possible to notice that more central stocks, depicted as bigger nodes in Fig. 2, have more connections but that this feature does not directly translate in a higher strength (depicted as darker colour of the nodes). This is a feature already emphasized in [3] for financial networks.

Estimated multilayer network. Node colours: loglog scale; darker colour is associated to higher strength of the node. Node size: loglog scale; darker colour is associated to higher k-coreness score. Edge colour: uniform.
From a financial point of view, such graphical representation put together three different aspects of financial risk: market risk, liquidity risk (in terms of volumes exchanged) and forward looking uncertainty measures, which account for expected volatility risk. In fact, the stocks in the volumes layer are not strongly interconnected but produce a huge amount of risk propagation through prices and volatility. Understanding the dynamics of such multilayer network representation would be a useful tool for risk managers in order to understand risk balances and propose risk mitigation techniques.
4 Conclusions
In this paper, we proposed a methodology to build a multilayer network via the estimated coefficient of the Tucker tensor autoregression of [6]. This methodology, in combination with a filtering technique, has proven able to reproduce interconnections between different financial risk factors. These interconnections can be easily mapped to real financial mechanisms and can be a useful tool for monitoring risk as the topology within and between layers can be strongly affected in distressed periods. In order to preserve the maximum memory information in the data but requiring stationarity, we made use of fractional differentiation and found out that the variables analyzed are stationary with differentiation of order \(\alpha =0.2\). The model can be extended to a dynamic framework in order to analyze the dependency structures under different market conditions.
Notes
- 1.
If the imposed Tucker rank is lower than the dimension of the tensor dataset, we have dimensionality reduction.
- 2.
Using hard thresholding the results are qualitatively equivalent.
References
Musmeci, N., Nicosia, V., Aste, T., Di Matteo, T., Latora, V.: The multiplex dependency structure of financial markets. Complexity 2017, 1–13 (2017)
Musmeci, N., Aste, T., Di Matteo, T.: Risk diversification: a study of persistence with a filtered correlation-network approach. J. Netw. Theory Finan. 1(1), 77–98 (2015)
Macchiati, V., Brandi, G., Cimini, G., Caldarelli, G., Paolotti, D., Di Matteo, T.: Systemic liquidity contagion in the European interbank market. J. Econ. Interact. Coord. (2020, Submitted to)
Boccaletti, S., et al.: The structure and dynamics of multilayer networks. Phys. Rep. 544(1), 1–122 (2014)
Brandi, G., Gramatica, R., Di Matteo, T.: Unveil stock correlation via a new tensor-based decomposition method. J. Comput. Sci. (2020, Accepted in)
Brandi, G., Di Matteo., T.: Predicting multidimensional data via tensor learning. J. Comput. Sci. (2020, Submitted to)
Jensen, A.N., Nielsen, M.Ø.: A fast fractional difference algorithm. J. Time Ser. Anal. 35(5), 428–436 (2014)
Marcaccioli, R., Livan, G.: A pólya urn approach to information filtering in complex networks. Nat. Commun. 10(1), 1–10 (2019)
Zhou, H., Li, L., Zhu, H.: Tensor regression with applications in neuroimaging data analysis. J. Am. Stat. Assoc. 108(502), 540–552 (2013)
Li, L., Zhang, X.: Parsimonious tensor response regression. J. Am. Stat. Assoc. 112(519), 1131–1146 (2017)
Lock, E.F.: Tensor-on-tensor regression. J. Comput. Graph. Stat. 27(3), 638–647 (2018)
Tikhonov, A.N.: On the stability of inverse problems. In: Doklady Akademii Nauk SSSR, vol. 39, pp. 195–198 (1943)
Arcucci, R., D’Amore, L., Carracciuolo, L., Scotti, G., Laccetti, G.: A decomposition of the tikhonov regularization functional oriented to exploit hybrid multilevel parallelism. Int. J. Parallel Prog. 45(5), 1214–1235 (2017)
Kroonenberg, P.M., De Leeuw, J.: Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 45(1), 69–97 (1980)
Fuller, W.A.: Introduction to Statistical Time Series, vol. 428. Wiley, Hoboken (2009)
Aste, T., Di Matteo, T., Hyde, S.T.: Complex networks on hyperbolic surfaces. Phys. A: Stat. Mech. Appl. 346(1–2), 20–26 (2005)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Brandi, G., Di Matteo, T. (2020). A New Multilayer Network Construction via Tensor Learning. In: Krzhizhanovskaya, V., et al. Computational Science – ICCS 2020. ICCS 2020. Lecture Notes in Computer Science(), vol 12142. Springer, Cham. https://doi.org/10.1007/978-3-030-50433-5_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-50433-5_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-50432-8
Online ISBN: 978-3-030-50433-5
eBook Packages: Computer ScienceComputer Science (R0)