
Abstract
Information held in working memory (WM) can guide attention during visual search. The authors of recent studies have interpreted the effect of holding verbal labels in WM as guidance of visual attention by semantic information. In a series of experiments, we tested how attention is influenced by visual features versus category-level information about complex objects held in WM. Participants either memorized an object’s image or its category. While holding this information in memory, they searched for a target in a four-object search display. On exact-match trials, the memorized item reappeared as a distractor in the search display. On category-match trials, another exemplar of the memorized item appeared as a distractor. On neutral trials, none of the distractors were related to the memorized object. We found attentional guidance in visual search on both exact-match and category-match trials in Experiment 1, in which the exemplars were visually similar. When we controlled for visual similarity among the exemplars by using four possible exemplars (Exp. 2) or by using two exemplars rated as being visually dissimilar (Exp. 3), we found attentional guidance only on exact-match trials when participants memorized the object’s image. The same pattern of results held when the target was invariant (Exps. 2–3) and when the target was defined semantically and varied in visual features (Exp. 4). The findings of these experiments suggest that attentional guidance by WM requires active visual information.
Similar content being viewed by others

Visual attention allows us to select relevant information and ignore distractions. The ease with which we can do this is influenced by both bottom-up (e.g., stimulus salience) and top-down (e.g., observer’s goal) factors. Working memory (WM), or the ability to maintain and mentally manipulate information, is one top-down process that is important in guiding visual attention (de Fockert, Rees, Frith, & Lavie, 2001; Downing, 2000). Many models of WM conceptualize it as being composed of domain-specific subsystems that are responsible for keeping information active so that it is available for future use (Baddeley, 2001; Courtney, 2004). Two such subsystems are verbal WM—which maintains linguistic information based on either sound or speech—and visual WM—which maintains visual properties of stimuli (e.g., their color, shape, or spatial location; Baddeley, 2001).
WM and visual attention are interactive processes (see Awh, Vogel, & Oh, 2006, for a review), and the information in WM can guide the deployment of visual attention. This interaction can be beneficial or detrimental to task performance. During visual search, for example, WM is presumed to hold information about the target. According to the biased-competition model of visual attention (Desimone & Duncan, 1995), WM maintains an active template of the target and guides visual attention to any matching stimulus once search has commenced. Information held in WM can also influence attention, even when this information is unrelated to the task, as was shown in a study by Downing (2000). In that study, participants had to remember a photograph of a face while they performed a discrimination task on a probe that appeared on either the left or the right side of the screen. The face to be remembered was shown first, followed by an irrelevant display of two faces, one new and the other the same as the memory item. A probe display followed, with the probe at the location of one of the faces. Participants were faster at responding to probes that appeared at the same location as the memory item rather than that of the new face, suggesting that information held in WM guided the deployment of visual attention.
A downside to this relationship between WM and visual attention is that active WM information that is unrelated to an ongoing task (e.g., searching for a target unrelated to the memorized information) can also guide attention, but with a detrimental effect: Attention is guided away from the target by the distractor matching the information currently maintained in WM (Olivers, Meijer, & Theeuwes, 2006; Soto, Heinke, Humphreys, & Blanco, 2005). Such effects have been termed WM-driven attentional guidance (see Soto, Hodsoll, Rotshtein, & Humphreys, 2008, for a review).
We can study this WM-driven attentional guidance using a dual task in which a participant retains one stimulus in memory while searching for an unrelated target in a search display. The distractors in the search display include either an item that matches the memorized item (match trials) or no matching items (neutral trials). The typical finding with simple objects (e.g., with instructions to memorize a red square or search for an angled line) is that the matching distractor slows search times on match relative to neutral trials (Soto et al., 2005).
On the basis of studies using this paradigm, Soto and Humphreys (2007) suggested that semantic information held in WM can guide attention. They had participants memorize either a colored shape or the names of a color and shape (e.g., “red diamond”), then search for an angled line. Search times increased when a distractor that matched the memorized information was present in the display, even in the verbal (names) condition. In fact, the memorized verbal information was almost as effective as visual information in guiding attention. This led the researchers to suggest that attentional guidance is driven not only by visual but also by verbal and semantic information.
Other studies have shown mixed evidence for the proposed interaction between semantic information and attention. Huang and Pashler (2007) had participants first memorize a word and then view an array of three words, each with a unique digit superimposed on it, prior to the memory probe display. Participants had to choose and remember any of the superimposed digits in the array, and in some trials, one of the words in the array was semantically related to the memorized word. Participants were more likely to report the digit superimposed on the word that was related to the memorized word than the other digits. The authors suggested that selective attention during the three-word display was captured by the word that was semantically related to that held in memory. These data suggest that when verbal information is held in memory, its definition and the other information associated with it are all activated, and this can influence the deployment of visual attention. In another study, Grecucci, Soto, Rumiati, Humphreys, and Rotshtein (2010) tested whether the time to localize a face was influenced by a memorized emotional word. They manipulated the match between the memorized emotional word and the emotional expressions of the faces on a two-object display: On some trials, the memorized word matched the target face (valid trials), whereas on other trials, it matched the distractor (invalid trials). Grecucci et al. failed to find any effect of the memorized emotional word on the time that it took to localize the target face.
Recently, Bahrami Balani, Soto, and Humphreys (2010) looked at the effect of semantic information on attention more directly. They asked participants to look for a target in a two-object display while remembering another object and manipulated the semantic relationship between the memorized object and the distractor in the two-object display. In some of their experiments, the distractor was either the memorized object (e.g., picture of a cat) or another exemplar of the memorized object (e.g., picture of another cat). Bahrami Balani et al. analyzed the reaction times (RT) on both target-present and target-absent trials. They found that when the target was absent, distractors that were semantically related to the memorized information led to longer RTs, relative to neutral trials in which no distractors were related.
In summary, evidence for the influence of task-irrelevant memorized semantic or conceptual information on visual attention is mixed, and most of the positive findings are on target-absent trials. In this article, we draw a distinction between attentional guidance that occurs in a target-present condition, which could be considered attentional “capture,” and guidance that occurs in a target-absent condition, which seems to be a different type of guidance, in that it only occurs in the absence of a strong target competitor. We report a series of experiments investigating the role of WM-held information in the guidance of attention during search for an everyday object. Participants either memorized an object (Exps. 1A, 2A, 3A, and 4A) or its category (Exps. 1B, 2B, 3B, and 4B). While holding this information in WM, they searched for a target in a four-object search display. The target was the same object on every trial in Experiments 1–3. In Experiment 4, the target was defined semantically and could vary in its visual features from one trial to the next. After participants responded to the search task, they were shown a memory probe and determined whether the probe was identical to the memorized object (Exps. 1A, 2A, 3A, and 4A) or was from the same category as the object that had been memorized (Exps. 1B, 2B, 3B, and 4B). We manipulated the match between the information in WM and one of the distractors in the search display. On exact-match trials, the memory stimulus reappeared as a distractor in the search display. On category-match trials, another exemplar from the category of the memory stimulus appeared as a distractor in the search display. Neutral trials contained search items that were unrelated to the memory stimulus.
In the experiments here, we used the semantic relationship between a basic-level object category and its exemplars to study WM-driven attentional guidance. Although semantic links can be defined in other ways (e.g., superordinate categories and their members), the use of exemplars is advantageous for the study of semantic effects, because exemplars share lexical representations (names), functional properties, and features. Basic-level categories are also learned earlier than superordinate categories (Rosch, Mervis, Gray, Johnson, & Boyes-Braem, 1976). In contrast, semantic links between superordinate categories and members may have differing associative strengths (Rosch & Mervis, 1975). In essence, then, defining semantic information through typical exemplars offers the best chance to detect an effect on attentional deployment and allows us to compare such an effect with guidance by visual features.
Experiment 1
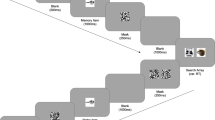
The aims of Experiment 1 were to test whether attention is guided to an object identical to the information in WM, and whether attention is guided to an object that is semantically related to the WM information. Participants viewed an object on the screen and were asked to hold either its image (Exp. 1A) or its category (Exp. 1B) in memory while looking for a target (a cup) in a search display (Fig. 1). In the exact-match search displays, the memory item appeared as a distractor. In the category-match search displays, a second exemplar of the object was a distractor. On neutral trials, the search items were unrelated to the memory item. After responding to the search, participants were asked whether a memory probe was identical to (Exp. 1A) or in the same category (Exp. 1B) as the object that they had memorized. We used two exemplars for each category of objects.

Examples of target-present trials with a a neutral trial, b an exact-match trial, and c a category-match trial search display
Method
Participants
A total of 28 participants (Exp. 1A, 14 participants; Exp. 1B, 14 participants; age range 19–27 years, mean [M] = 21.37, standard deviation [SD] = 2.13) volunteered for these experiments. All of them reported normal or corrected-to-normal vision and normal color vision, and all received course credit for their participation.
Materials
The two exemplars for each of 16 object categories, and the target image, were taken from the picture database of Konkle and colleagues (Konkle, Brady, Alvarez, & Oliva, 2010; available at http://cvcl.mit.edu/MM/index.html; see Supplementary Fig. 1). Each of the 33 grayscale images was scaled to 102 × 102 pixels, and the objects subtended 3.4°–4.0° of visual angle at a viewing distance of ~50 cm.
Design and stimuli
The same design and stimuli were used for Experiments 1A and 1B. We used a 3 (trial type) × 2 (target status) within-subjects design. Three types of trials were based on the match between the memory item and one of the distractors in the search array (see Fig. 1): On exact-match trials, one of the distractors in the search array was the memory item, and the other distractors were randomly drawn from categories other than that to which the memory item belonged. On category-match trials, one of the distractors in the search array belonged to the same category as the memory item, and again, the other distractors were randomly drawn from the other categories. On neutral trials, none of the distractors matched the memory item. On every trial, either exemplar of each category had an equal chance of being drawn as the memory item, with the constraint that the memory item could not be repeated on consecutive trials. The target in the visual search task was always the same cup. Fifty percent of the neutral, exact-match, and category-match trials were target-present trials, with the other 50 % being target-absent trials.
Apparatus
Stimulus presentation and measurement of the behavioral responses for Experiments 1A and 1B were controlled using computers with 1.8-GHz Intel Core 2 Duo processors and ATI Radeon X1300 with 256-MB VRAM video cards. The stimuli were displayed on a 19-in. CRT monitor. We used the Presentation software (Neurobehavioral Systems, San Francisco, CA) to run the experiment and collect data.
Procedure
A trial began with the presentation of a fixation point for 500 ms, followed by the memory item displayed in the center of the screen for 1,600 ms. After a 190-ms interstimulus interval (ISI), the search array was displayed until response. This array contained four objects surrounding a fixation point. Each object was centered on a corner of an imaginary square, and the entire search array subtended 11.86° × 11.86°. All four search items were equidistant from fixation. The target and distractors could appear at any of the four locations. On 50 % of the trials, the target cup was present as one of the four objects. Participants pressed one key if the target was present and another key if it was absent. After a 500-ms ISI, a single object (the memory probe) was centrally presented. On 25 % of the trials, the memory item appeared as the memory probe; on another 25 % of the trials, the other exemplar (of the memory item’s category) appeared; and on 50 % of the trials, a completely different object appeared. For Experiment 1A, participants pressed one key if the probe was identical to the memory item and another key if the probe was not. For Experiment 1B, participants pressed one key if the memory probe belonged to the same object category as the memory item and another key if the probe belonged to a different object category.
Participants performed 20 practice trials. Afterward, they performed 120 neutral, 120 exact-match, and 120 category-match trials, randomly intermingled. There was a rest period every 20 trials. Participants were instructed to respond as quickly and accurately as they could in the search task and were told that only accuracy was important in the memory task. They were not given feedback during the task.
Results
Outliers were defined as reaction times (RTs) faster than 200 ms, longer than 4,000 ms, or greater than three standard deviations (SD) from the condition means (1.61 % of the total trials for Exp. 1A, and 1.67 % of the total trials for Exp. 1B). These data were removed prior to analysis. Search errors and memory errors were low (Exp. 1A, 1.25 % and 4.86 %, respectively; Exp. 1B, 1.43 % and 3.99 %, respectively) and were removed from the main analyses. Thus, all RTs analyzed below were from trials on which both the search and memory responses were correct.
Figure 2 shows the mean correct RTs. Figure 2a shows that on the target-present trials of Experiment 1A (“remember the image”), search times were longer in the exact-match and category-match conditions than in the neutral condition. This was confirmed by a repeated measures analysis of variance (ANOVA) with the within-subjects factor Trial Type (exact-match, category-match, or neutral), which revealed a significant effect of trial type on RTs, F(2, 14) = 4.3, p < .05, η p 2 = .248. Pairwise comparisons confirmed that exact-match and category-match RTs were reliably longer than neutral RTs (ps = .02 and .04, respectively). However, we found no reliable difference between exact-match and category-match RTs (p > .05).

Mean correct reaction times in a Experiment 1A (“remember the image”) target-present trials, b Experiment 1B (“remember the category”) target-present trials, c Experiment 1A target-absent trials, and d Experiment 1B target-absent trials. Note that the scales differ between the top and bottom panels. Error bars show repeated measures standard errors of the means
Figure 2b shows the results from the Experiment 1B (“remember the category”) target-present trials. RTs in the search task were longest in the exact-match condition, followed by the category-match condition and then the neutral condition. A repeated measures ANOVA confirmed a significant effect of trial type on RTs, F(2, 14) = 6.67, p < .05, η p 2 = .339. Pairwise comparisons confirmed that the exact-match RTs were longer than both category-match and neutral RTs (ps = .05 and .01, respectively). Category-match RTs were also reliably longer than neutral RTs (p = .04).
Figure 2c shows the target-absent RTs for Experiment 1A. No significant differences in RTs emerged in the neutral, exact-match, and category-match trials, F(2, 14) = 0.65, p > .05, η p 2 = .048. Figure 2d shows the mean correct RTs in the target-absent conditions of Experiment 1B, in which the RTs of neutral, exact-match, and category-match trials again did not differ significantly, F(2, 14) = 0.63, p > .05, η p 2 = .046.
Discussion
The results of this first experiment show that holding the image of a complex object in WM (Exp. 1A) can interfere with search for another object, which is analogous to previous findings using simple colored shapes (Soto et al., 2005). Search times were longer when the memory item reappeared in the search array as a distractor, as well as when one of the distractors was another exemplar of the memorized object’s category, relative to when the distractors were unrelated to the memory item. Although this second exemplar was not identical to the memory item, it nonetheless influenced the allocation of attention during the search task. When participants were encouraged to encode the object category (Exp. 1B), search times were again longer on trials when either of the two exemplars were present as distractors, although the exact image had a greater effect than the category match exemplar.
The findings of Experiment 1 could be interpreted as evidence that both visual and verbal/semantic WM information involuntarily guide attention. They fit with the results of previous experiments that have shown that names of colors and shapes guided attention to corresponding distractors (Soto & Humphreys, 2007). They also agree with findings from visual search studies showing that a semantic link between target-related information in WM and a distractor interfered with search (Belke, Humphreys, Watson, Meyer, & Telling, 2008; Moores, Laiti, & Chelazzi, 2003). In those experiments, however, the semantic link was between the search target and the distractor. Furthermore, the effect of the semantic link between the memory-held target and the distractor that has emerged has been in target-absent trials (Belke et al., 2008; Moores et al., 2003).
However, there are other potential explanations for attentional guidance in the match conditions of both tasks. For one, attention may have been guided to the second exemplar in the category-match trials because it was visually similar (although not identical) to the memory item. Thus, the visual features of the memory item, and not the semantic association between the memory item and the second exemplar, may have been what biased attention. Another alternative is that participants memorized the images of both exemplars in order to respond more efficiently to the memory task. In Experiment 2, we tested these alternative explanations by increasing the number of exemplars in each category.
Experiment 2
In Experiment 2, we increased the number of exemplars for each object category to four and ensured that the exemplars varied in visual features, thereby reducing their visual similarity. Having four exemplars for each category also reduced the likelihood that participants would encode all of these options when doing the memory task. Consequently, participants in Experiment 2A, who had to remember the exact object image, would be encouraged to encode the visual features of the memory item. Conversely, participants in Experiment 2B, who had to remember the object category, should find it strategic to encode the category (thus prioritizing semantic information in WM) rather than trying to remember the images of four exemplars.
Method
Participants
A total of 31 participants (Exp. 2A, 15 participants; Exp. 2B, 16 participants; age range 19–43 years, M = 25.9, SD = 6.89) volunteered for these experiments. All of them reported normal or corrected-to-normal vision and normal color vision. They received course credit for their participation.
Materials and stimuli
Forty new exemplars (four exemplars for each of ten categories) were selected from the picture database of Konkle et al. (2010).
Design, stimuli, and apparatus
The design and apparatus of Experiment 2 were identical to those of Experiment 1, with the exception that we took four exemplars from each of the ten object categories. On exact-match trials, one of the distractors in the search array was identical to the memory item. On category-match trials, the matching distractor could be one of the three remaining exemplars. Each of the three exemplars had an equal probability of being the key distractor in a category-match trial. The target in the visual search task was always the same cup and was present on 50 % of all trials. Trial type and target status were fully crossed.
Procedure
The procedure for Experiment 2 was identical to that of Experiment 1. As in Experiment 1, the participants of Experiment 2A were asked to remember the memory item’s image, and the participants of Experiment 2B were asked to remember the memory item’s category. When the memory probe was of the same category as the memory item, each of the four exemplars had an equal probability of being the probe.
Results
Outliers were defined as in Experiment 1 (1.49 % of the total trials in Exp. 2A, and 1.83 % of total trials in Exp. 2B) and removed prior to analysis. Search errors and memory errors (Exp. 1A, 1.35 % and 3.93 %, respectively; Exp. 2B, 1.60 % and 3.56 %, respectively) were low and were removed from further analyses.
Figure 3a shows the mean correct RTs for the target-present condition of Experiment 2A (“remember the image”). RTs in the exact-match trials were longer than both the neutral and category-match RTs, partially replicating our finding from Experiment 1A. A repeated measures ANOVA confirmed an effect of trial type (exact-match, category-match, or neutral) on RTs, F(2, 15) = 3.67, p < .05, η p 2 = .208. Pairwise comparisons showed that exact-match RTs were reliably longer than both neutral and category-match RTs (ps = .036 and .017, respectively). We found no reliable difference between neutral and category-match RTs (p = .69).

Mean correct reaction times in a Experiment 2A (“remember the image”) target-present trials, b Experiment 2B (“remember the category”) target-present trials, c Experiment 2A target-absent trials, and d Experiment 2B target-absent trials. Note that the scales differ between the top and bottom panels. Error bars show repeated measures standard errors of the means
Mean correct RTs for the target-absent condition of Experiment 2A are shown on Fig. 3c, where RTs on exact-match trials are again longer than RTs on neutral and category-match trials. A repeated measures ANOVA on target-absent RTs confirmed an effect of trial type F(2, 15) = 3.47, p < .05, η p 2 = .199. Pairwise comparisons showed a reliable difference (p = .038) between exact-match and neutral RTs. The other comparisons showed no reliable differences (p > .1). Thus, only an exact feature match guided attention when participants were asked to remember the image, and this affected both target-present and target-absent trials.
The mean correct RTs of the target-present and target-absent conditions of Experiment 2B (“remember the category”) are shown in Figs. 3b and d, respectively. In neither the target-present nor the target-absent condition did evidence emerge that search was affected by a distractor that belonged to the memorized category. A repeated measures ANOVA failed to show any significant effects of trial type (exact-match, category-match, and neutral) on search times in either target-present or target-absent conditions (F < 1, n.s., and F = 1.7, p = .20, η p 2 = .101, respectively). Thus, when participants were encoding the category rather than the exact image, we did not see any guidance of attention in the visual search task.
One of the explanations for the guidance in the category-match conditions of Experiment 1 is that it was due to the visual similarity between the second exemplar (which appeared on category-match trials) and the memory item. Overall, when we reduced visual similarity by having four more varied exemplars in Experiment 2, we found no evidence that the key distractor on category-match trials affected attention, regardless of the task. This supports the visual similarity argument for the first experimental results. As some exemplars in Experiment 2 were more visually similar than others (although these were in the minority), we could look at the target-present category-match RTs of Experiments 2A and 2B to see whether we would find any support for an exemplar that was visually similar to the memory item affecting attention. We therefore divided the category-match trials into visually similar and visually dissimilar trials and examined their mean RTs. Although there were too few trials in the visually similar category for much statistical power, the means hint that this might have been the case. For Experiment 2A (“remember the image”), the mean RT of visually similar category-match trials was 768 ms, whereas the visually dissimilar mean RT was 726 ms. For Experiment 2B (“remember the category”), the mean RT of visually similar trials was 688 ms, while the mean RT of visually dissimilar trials was 708 ms.
Discussion
Two results from Experiment 2 help explain the category-match attentional guidance that we found in Experiment 1. First, when participants were forced to encode the visual features of one exemplar so that they could answer the memory task correctly (Exp. 2A), their search was only influenced by the reappearance of that object (on exact-match trials), but not by other exemplars that were semantically related to that object (on category-match trials), consistent with our findings from Experiment 1A. In addition, we now see guidance on target-absent trials. This may reflect a stronger representation of the image in WM, due to the requirement for greater detail due to the four possible exemplars for each object. Second, by having four exemplars for each category, we increased the probability that participants would encode semantic information in Experiment 2B, rather than perhaps just holding both exemplars in mind. We did not find any guidance in Experiment 2B—even when the exact match distractor was present—consistent with the notion that the participants were encoding or prioritizing different information from that encoded in Experiment 2A. This also rules out a priming-based explanation for our “exact-match” findings in Experiment 2A—simply presenting the same stimulus again in the search array had no effect unless participants were encoding the details of the image into WM. Thus, the results of Experiment 2 do not support the idea that the attentional guidance that we found in Experiment 1 was due to the semantic relationship between the information in WM and the exemplar in the category-match trials. Rather, it seems likely that visual similarity was responsible for this attentional guidance.
Experiment 3
In Experiment 2, increasing the number of exemplars and reducing visual similarity had resulted in attentional guidance only in the exact-match trials when participants were actively encoding the visual image (Exp. 2A). These results suggest that the attentional guidance on category-match trials of Experiment 1 was due to the visual similarity of the two exemplars. It is also possible, however, that semantic guidance does occur with visually dissimilar exemplars, but only when the load is very low; perhaps having four exemplars increased the load of the task (despite participants only having to memorize one category). In our third experiment, we directly tested this possibility by using only two exemplars but ensuring that they were visually dissimilar. We used the same paradigm as in the first two experiments: In Experiment 3A, participants memorized an object’s image, and in Experiment 3B, they memorized an object’s category. If the attentional guidance in Experiment 1 were due to semantic information from WM (which could perhaps only be accessed with two exemplars rather than four), we should see attentional guidance when participants are encouraged to encode the object’s category.
Method
Participants
A total of 41 participants (Exp. 3A, 20 participants; Exp. 3B, 21 participants; age range 19–47 years, M = 24.02, SD = 7.17) volunteered for these experiments. All reported normal or corrected-to-normal vision and normal color vision and received course credit for their participation.
Materials
We asked five independent raters to judge the visual similarity of the different pairs of exemplars that had been used in Experiments 2A and 2B along with exemplars for six new object categories, using a scale from 1 (visually very dissimilar) to 5 (visually very similar). The exemplar pairs with the lowest ratings for visual similarity were used as the stimuli for Experiments 3A and 3B (see Supplementary Fig. 2). The mean rating for all the 16 pairs of exemplars was 2.25, SD = 0.38. All of the images used in Experiments 3A and 3B were taken from the picture database of Konkle et al. (2010).
Design, stimuli, and apparatus
The design and apparatus of Experiment 3 are identical to those of Experiment 1. The same stimuli were used in Experiments 3A and 3B.
Procedure
The procedures for Experiments 3A and 3B were identical to those of Experiments 1A and 1B, respectively.
Results
Outliers were defined as in Experiment 1 (1.85 % of total trials in Exp. 3A, and 1.9 % of total trials in Exp. 3B) and removed prior to analysis. Search and memory errors (Exp. 3A, 2.11 % and 4.72 %, respectively; Exp. 3B, 1.69 % and 2.84 %, respectively) were low and were removed from further analyses.
Figure 4a shows the mean correct RTs for the target-present condition of Experiment 3A (“remember the image”). Search times were longer in exact-match than in neutral trials. This was confirmed by a repeated measures ANOVA with the within-subjects factor Trial Type (exact-match, category-match, and neutral), which revealed a significant effect of trial type on RTs, F(2, 20) = 3.36, p < .05. Pairwise comparisons showed that exact-match RTs were reliably longer than neutral RTs (p = .042). The other comparisons showed no reliable differences (p > .1). Thus, in this experiment we again replicated guidance by the object match seen in the first two experiments.

Mean correct reaction times in a Experiment 3A (“remember the image”) target-present trials, b Experiment 3B (“remember the category”) target-present trials, c Experiment 3A target-absent trials, and d Experiment 3B target-absent trials. Note that the scales differ between the top and bottom panels. Error bars show repeated measures standard errors of the means
Correct RTs for the target-absent conditions of Experiment 3A are shown in Fig. 4c. The RTs of neutral, exact-match, and category-match trials did not differ significantly, F(2, 20) = 1.57, p > .1.
The mean correct RTs of the target-present and target-absent conditions of Experiment 3B (“remember the category”) are shown in Figs. 4b and d, respectively. Again, as in Experiment 2B, we did not find any evidence for attentional guidance by an exemplar related to the memorized semantic information on either target-present or target-absent trials. A repeated measures ANOVA revealed that in both the target-present and target-absent conditions, no effect of trial type (exact-match, category-match, and neutral) was apparent on search times (F = 1.08, p = .35, and F = 1.58, p = .22, respectively). As in Experiment 2B, the lack of guidance by the exact object appearing is consistent with participants encoding category-level information rather than object features, a strategy that is in line with the instructions and the most efficient approach. However, we saw no effect on attention of holding this category-level information in WM.
Discussion
The results of Experiments 3A and 3B suggest that the category-match attentional guidance that we found in Experiment 1 was driven by visual similarity. We did not find any guidance effects in the category-match conditions of Experiment 3 when the distractor was visually dissimilar to the memory item, even when participants were encouraged to encode the category-level (semantic) information about the object. Instead, we only found attentional guidance on exact-match trials, when participants were asked to remember the exact image of the memory item.
Together in Experiments 2 and 3, in which visual similarity among exemplars was controlled, we could find no evidence that an exemplar of a memorized category could guide attention. Although based on a null effect, this pattern could suggest that semantic information such as object categories is not effective in biasing attention, in contrast to the robust guidance from visual features. An alternative explanation for the lack of semantic effects, however, could be that participants were biased toward visual features rather than semantic information during the search task because of the way in which the target for the search was defined: It was the same throughout the whole experiment for each of these tasks (a cup). Participants could therefore have configured their search strategy to use visual features rather than semantic information to guide their search for the target cup. In this case, the semantic content of the critical distractors could not effectively influence attention, because it was not processed. This alternative was tested in Experiment 4, in which the target was defined by a category of items rather than as a featurally invariant object.
Experiment 4
In Experiment 4, we tested whether a task-related bias toward the visual features of the search items had prevented guidance by the category-level information in the previous experiments. In Experiments 4A and 4B, the target was defined semantically (“something you can drink from”) and varied in visual features from trial to trial. Thus, in order to identify a target, participants had to process semantic information from the search items (see also Wolfe, 2012, regarding search for multiple targets). Again, we instructed participants to either encode the exact image of the memory item (Exp. 4A) or the category-level information (Exp. 4B) and looked for the effect of distractors in the visual search task that either exactly matched the memory item or were exemplars of its type.
Method
Participants
A total of 33 participants (Exp. 4A, 17 participants; Exp. 4B, 16 participants; age range 18–48 years, M = 22.42, SD = 7.05) volunteered for these experiments. All reported normal or corrected-to-normal vision and normal color vision and were paid for their participation.
Materials
The materials used in Experiment 4 were identical to those used in Experiment 3, with two visually dissimilar exemplars for each category. In addition, 20 images of possible targets, which consisted of cups, glasses, bottles, wine glasses, and tumblers, were used.
Design, stimuli, and apparatus
The design and apparatus of Experiment 4 were identical to those of Experiments 1–3, and the stimuli of Experiment 4 were identical to those of Experiment 3. We added 20 images to be used as possible targets: four cups, four glasses, four bottles, four wine glasses, and four tumblers. The same stimuli were used in Experiments 4A and 4B.
Procedure
The procedures for Experiments 4A and 4B were nearly identical to those of Experiments 1A and 1B, respectively, except that participants were told to search for an object from which one could drink. They received visual feedback (500 ms) for incorrect search and memory responses.
Results
Outliers were defined as in Experiment 1 (1.47 % of the total trials in Exp. 4A, and 1.56 % of total trials in Exp. 4B) and removed prior to analysis. Search and memory errors (Exp. 4A, 3.12 % and 4.48 %, respectively; Exp. 4B, 1.94 % and 3.18 %, respectively) were low and were removed from further analyses.
Mean correct RTs for the target-present condition of Experiment 4A (“remember the image”) are shown in Fig. 5a. Search times were slower on exact-match than on neutral trials, replicating our previous effect. This result was confirmed by a one-way repeated measures ANOVA: We found a main effect of trial type (exact-match, category-match, and neutral) on RTs, F(2, 32) = 5.02, p < .05. Pairwise comparisons revealed that the exact-match trial RTs were reliably longer than neutral trial RTs (p = .02). The other comparisons did not show any reliable differences (p > .05).

Mean correct reaction times in a Experiment 4A (“remember the image”) target-present trials, b Experiment 4B (“remember the category”) target-present trials, c Experiment 4A target-absent trials, and d Experiment 4B target-absent trials. Note that the scales differ between the top and bottom panels. Error bars show repeated measures standard errors of the means
The mean correct RTs for the target-absent condition of Experiment 4A are shown in Fig. 5c. The search times in the neutral, exact-match, and category-match conditions look similar, and this was confirmed by a repeated measures ANOVA, F(2, 32) = 0.85, p > .44.
The mean correct RTs in the target-present and target-absent conditions of Experiment 4B (“remember the category”) are shown in Figs. 5b and d, respectively. Neither exemplar of the memorized object category slowed search times. This was true for both target-present and target-absent conditions. These results were confirmed by a repeated measures ANOVA showing no effect of trial type (exact-match, category-match, and neutral) on search times in either target-present (F = 0.38, p = .68) or target-absent (F = 0.84, p = .44) conditions. Again, this replicated our findings from the previous experiments, with no effect of category-level information appearing once visual similarity was controlled.
Discussion
One possible explanation for the lack of semantic effects in Experiments 2 and 3 was that the invariant target for the visual search caused participants to prioritize visual features in their search. In Experiment 4, the visual features of the target could change from one trial to another, and in order to identify it, participants had to process the semantic features of the search items (in this case, whether an object was typically something one could drink from). Thus, we should have been maximizing the possibility of semantic influences emerging in this experiment. The results of Experiment 4 again replicated the robust effect of holding an exact image in WM, even when search was guided by semantic information instead of visual features (Exp. 4A). In contrast, holding category-level information in WM again had no effect on visual search (Exp. 4B). This final experiment therefore replicated the pattern seen in the previous experiments with a search task that actively required semantic processing of the distractors.
General discussion
Here, we report four experiments testing the influence of information held in WM on attention during a search task. Although we showed clear evidence of guidance using these complex object stimuli, the important factor for attentional guidance appears to be the visual similarity of other exemplars rather than their semantic-level information. Importantly, although the lack of category-level guidance is a null effect, it was replicated across three separate experiments (noting that the positive finding in Experiment 1 could be explained by visual similarity) with separate groups of participants, and was in contrast to the consistent and robust guidance that we found when asking participants to encode the visual image. We found the same pattern of results when we defined a search target semantically (Exp. 4) as we had found with an invariant target (Exps. 1–3).
Almost all of our effects were seen in target-present trials, showing strong competition of a matching distractor with the target. Only in Experiment 2A did we see effects on target-absent trials. This might have been due to the relatively low loads of the WM task in the other experiments (only two possible exemplars for Exps. 3A and 4A) and the higher load (four possible exemplars) of Experiment 2A. It seems likely that in the presence of four potentially confusable memory items, the representation of the exact image may need to be more detailed or stronger to successfully do the memory task, and this seems to carry forward so as to affect both target-present and target-absent trials in the search task.
Previous studies have demonstrated that verbal forms of simple features can guide attention (e.g., memorizing the words “red diamond” leads to attentional guidance by a red diamond in a search display), which has been interpreted as irrelevant conceptual information guiding attention (Soto & Humphreys, 2007). However, little direct evidence has shown that this type of attentional guidance is driven by the semantic relationships between an external stimulus and the contents of WM rather than, for example, the use of imagery.
Bahrami Balani et al. (2010) tested for semantic guidance using a two-item search display and found effects primarily on target-absent trials. They did not find consistent effects of semantic information held in WM on target-present trials, which is congruous with our present results and our interpretation that semantic information does not compete effectively with a target template to guide or capture attention. The difference in the target-absent patterns, however, is less easy to explain, and may come down to differences in methodology. RTs on target-absent trials reflect the decision about when to quit the search task (Chun & Wolfe, 1996), and therefore provide different information than do target-present trials. It is possible that due to Bahrami Balani et al. only having two items in the search display, this quitting decision was more affected by the semantic link between the memory item and the distractor than was seen in our experiments.
Our present results suggest that guidance of attention by the contents of WM depends strongly on the visual features of the memorized information, answering a question posed by Soto et al. (2008) about the reliance of such guidance on an active visual representation. The data also concur with previous findings showing that visual WM has a stronger influence on attention than does verbal WM (Dombrowe, Olivers, & Donk, 2010). The findings of the experiments reported here therefore support the notion that visual, but not category-type, information biases attention, as was suggested by Olivers et al. (2006).
Alternative explanations for our pattern of results do not seem consistent with the overall set of experimental findings. First, it could be argued that perhaps memorizing a category uses up more WM resources than does simply memorizing a specific image. Previous studies have suggested that WM-driven attentional guidance depends on having enough spare resources: Loading up WM reduces or abolishes guidance effects (Houtkamp & Roelfsema, 2006; Soto & Humphreys, 2008, Exp. 4). However, the load of memorizing the category should have been the same in both Experiments 1B and 3B, and yet we only saw evidence of guidance in the former experiment, with visually similar exemplars. A second alternative explanation would be that instead of memorizing the category as instructed, participants over the course of the experiment were instead trying to hold all exemplars in WM. Although such a strategy would work for Experiments 1 and 3, Experiment 2B would have then had a much greater load. Again, however, this strategy should have resulted in guidance in Experiment 3 as well as Experiment 1. Finally, we can ask whether participants in the “remember the category” experiments may have memorized the exemplar and then only made their category judgment at the end of each trial. If this was the case, however, we should have seen guidance in the exact-match conditions of these experiments (Exps. 2B, 3B, and 4B), which was not the case. The most parsimonious explanation of the results from our experiments is therefore that attentional guidance by WM depends on an active visual WM representation.
Our results provide further evidence that WM-driven attentional guidance can occur with complex stimuli such as everyday objects, and not just with simple features that are easily visualized if presented in verbal form. The results also highlight that attentional biases depend critically on the type of information being encoded in WM. Despite seeing robust guidance effects in conditions in which participants were asked to encode the details of an image, and visually similar (or identical) items were present as distractors in the search display, we found no evidence of guidance by category-level semantic information. Our results cannot be explained by simple priming. We therefore conclude that attentional deployment is primarily influenced by the visual, rather than the semantic, contents of working memory.
References
Awh, E., Vogel, E. K., & Oh, S.-H. (2006). Interactions between attention and working memory. Neuroscience, 139, 201–208. doi:10.1016/j.neuroscience.2005.08.023
Baddeley, A. D. (2001). Is working memory still working? American Psychologist, 56, 851–864. doi:10.1037/0003-066X.56.11.851
Bahrami Balani, A., Soto, D., & Humphreys, G. W. (2010). Working memory and target-related distractor effects on visual search. Memory & Cognition, 38, 1058–1076. doi:10.3758/MC.38.8.1058
Belke, E., Humphreys, G. W., Watson, D. G., Meyer, A. S., & Telling, A. L. (2008). Top-down effects of semantic knowledge in visual search are modulated by cognitive but not perceptual load. Perception & Psychophysics, 70, 1444–1458. doi:10.3758/PP.70.8.1444
Chun, M. M., & Wolfe, J. M. (1996). Just say no: How are visual searches terminated when there is no target present? Cognitive Psychology, 30, 39–78. doi:10.1006/cogp.1996.0002
Courtney, S. M. (2004). Attention and cognitive control as emergent properties of information representation in working memory. Cognitive, Affective, & Behavioral Neuroscience, 4, 501–516. doi:10.3758/CABN.4.4.501
de Fockert, J. W., Rees, G., Frith, C. D., & Lavie, N. (2001). The role of working memory in visual selective attention. Science, 291, 1803–1806. doi:10.1126/science.1056496
Desimone, R., & Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18, 193–222. doi:10.1146/annurev.ne.18.030195.001205
Dombrowe, I., Olivers, C. N. L., & Donk, M. (2010). The time course of working memory effects on visual attention. Visual Cognition, 18, 1089–1112.
Downing, P. E. (2000). Interactions between visual working memory and selective attention. Psychological Science, 11, 467–473. doi:10.1111/1467-9280.00290
Grecucci, A., Soto, D., Rumiati, R. I., Humphreys, G. W., & Rotshtein, P. (2010). The interrelations between verbal working memory and visual selection of emotional faces. Journal of Cognitive Neuroscience, 22, 1189–1200. doi:10.1162/jocn.2009.21276
Houtkamp, R., & Roelfsema, P. R. (2006). The effect of items in working memory on the deployment of attention and the eyes during visual search. Journal of Experimental Psychology: Human Perception and Performance, 32, 423–442. doi:10.1037/0096-1523.32.2.423
Huang, L., & Pashler, H. (2007). Working memory and the guidance of visual attention: Consonance-driven orienting. Psychonomic Bulletin & Review, 14, 148–153. doi:10.3758/BF03194042
Konkle, T., Brady, T. F., Alvarez, G. A., & Oliva, A. (2010). Conceptual distinctiveness supports detailed visual long-term memory for real-world objects. Journal of Experimental Psychology: General, 139, 558–578. doi:10.1037/a0019165
Moores, E., Laiti, L., & Chelazzi, L. (2003). Associative knowledge controls deployment of visual selective attention. Nature Neuroscience, 6, 182–189. doi:10.1038/nn996
Olivers, C. N. L., Meijer, F., & Theeuwes, J. (2006). Feature-based memory-driven attentional capture: Visual working memory content affects visual attention. Journal of Experimental Psychology: Human Perception and Performance, 32, 1243–1265. doi:10.1037/0096-1523.32.5.1243
Rosch, E., & Mervis, C. B. (1975). Family resemblances: Studies in the internal structure of categories. Cognitive Psychology, 7, 573–605. doi:10.1016/0010-0285(75)90024-9
Rosch, E., Mervis, C. B., Gray, W. D., Johnson, D. M., & Boyes-Braem, P. (1976). Basic objects in natural categories. Cognitive Psychology, 8, 382–439. doi:10.1016/0010-0285(76)90013-X
Soto, D., Heinke, D., Humphreys, G. W., & Blanco, M. J. (2005). Early, involuntary top-down guidance of attention from working memory. Journal of Experimental Psychology: Human Perception and Performance, 31, 248–261. doi:10.1037/0096-1523.31.2.248
Soto, D., Hodsoll, J., Rotshtein, P., & Humphreys, G. W. (2008). Automatic guidance of attention from working memory. Trends in Cognitive Sciences, 12, 342–348. doi:10.1016/j.tics.2008.05.007
Soto, D., & Humphreys, G. W. (2007). Automatic guidance of visual attention from verbal working memory. Journal of Experimental Psychology: Human Perception and Performance, 33, 730–737. doi:10.1037/0096-1523.33.3.730
Soto, D., & Humphreys, G. W. (2008). Stressing the mind: The effect of cognitive load and articulatory suppression on attentional guidance from working memory. Perception & Psychophysics, 70, 924–934. doi:10.3758/PP.70.5.924
Wolfe, J. M. (2012). Saved by a log: How do humans perform hybrid visual and memory search? Psychological Science, 23, 698–703. doi:10.1177/0956797612443968
Author note
M.O.C. was supported by a United Board for Christian Higher Education–Macquarie University PhD scholarship and by a Macquarie postgraduate grant. A.N.R. was supported by the Australian Research Council (Grant No. DP0984494) and the Menzies Foundation. The authors thank Max Coltheart and Matthew Finkbeiner for helpful discussions and comments.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOC 513 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Calleja, M.O., Rich, A.N. Guidance of attention by information held in working memory. Atten Percept Psychophys 75, 687–699 (2013). https://doi.org/10.3758/s13414-013-0428-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0428-y