
Abstract
A growing body of evidence indicates that the perception of visual stimuli is altered when they occur near the observer’s hands, relative to other locations in space (see Brockmole, Davoli, Abrams, & Witt, 2013, for a review). Several accounts have been offered to explain the pattern of performance across different tasks. These have typically focused on attentional explanations (attentional prioritization and detailed attentional evaluation of stimuli in near-hand space), but more recently, it has been suggested that near-hand space enjoys enhanced magnocellular (M) input. Here we differentiate between the attentional and M-cell accounts, via a task that probes the roles of position consistency and color consistency in determining dynamic object correspondence through occlusion. We found that placing the hands near the visual display made observers use only position consistency, and not color, in determining object correspondence through occlusion, which is consistent with the fact that M cells are relatively insensitive to color. In contrast, placing observers’ hands far from the stimuli allowed both color and position contribute. This provides evidence in favor of the M-cell enhancement account of altered vision near the hands.
Similar content being viewed by others

Our conscious percept of the world around us appears stable and continuous. Yet this representation is constructed on the basis of dynamic and disrupted visual input. For example, objects can be temporarily invisible due to their movement and occlusion behind other objects (Burke, 1952). In addition, visual input is suppressed during observers’ saccadic eye movements (Matin, 1974). However, in both of these instances, the brain continues to represent such objects (Assad & Maunsell, 1995), and we are able to explicitly recognize objects that continue despite such interruptions. This is called establishing “object correspondence” across temporary invisibility.
Whether object correspondence is determined across such interruptions depends on the consistency of two key properties of objects in their pre- and postinvisibility appearances: spatiotemporal trajectory and surface features (e.g., Hein & Moore, 2012; Hollingworth & Franconeri, 2009; Hollingworth, Richard, & Luck, 2008; Richard, Luck, & Hollingworth, 2008). Spatiotemporal trajectory refers to the path and speed that the object travels. Consistent spatiotemporal trajectory, therefore, reflects the situation in which, after an object has disappeared from view, subsequent stimulus information occurs at the point in space and time that would be expected, had the object continued along the same path at a constant speed. Surface features refer to physical properties of the object, such as color or texture. Surface feature continuity, therefore, reflects the situation in which a reappearing object maintains the same properties as the disappearing object. In this study, we set out to investigate how the contributions of these two properties to object correspondence are affected by the proximity of observers’ hands to the visual display.
Recent findings have indicated that visual perception is influenced by the proximity of visual stimuli to the observer’s hands (“near-hand space”). The typical way that near-hand space is manipulated is to have observers either place both their hands next to the computer screen on which visual stimuli appear (vs. away from the screen, such as on their lap) or place one hand aligned with a particular location on the screen (for a review, see Brockmole, Davoli, Abrams, & Witt, 2013). Importantly, performance differences on perceptual tasks as a function of hand proximity depend neither on the hand(s) near the stimuli being used to respond (Abrams, Davoli, Du, Knapp, & Paull, 2008; Reed, Grubb, & Steele, 2006; Weidler & Abrams, 2013) nor on the observer’s hands being visible to him or her (Abrams et al., 2008). For example, target detection responses are faster for stimuli that appear on the same side as the observer’s hand (Reed et al., 2006). This has led to the proposal that hand position affects the attentional prioritization of space (Reed, Betz, Garza, & Roberts, 2010; Reed et al., 2006).
Not all perceptual tasks, however, are facilitated in near-hand space. Abrams et al. (2008) studied several perceptual tasks in near-hand space and found that visual search times were slowed for letter targets amongst distractor letters, and that inhibition of return (IOR), which reflects attentional disengagement from and subsequent inhibition of a location (Posner & Cohen, 1984), is reduced. Furthermore, the attentional blink (AB)—the deficit in identifying a second target in a rapid serial visual presentation stream for 200 to 500 ms after identification of a first target (see Dux & Marois, 2009, for a review)—is deepened. This led Abrams et al. to suggest that the mechanism of altered perceptual performance is prolonged attentional engagement for detailed evaluation of visual stimuli near the hands. However, the extraction of semantics (i.e., reading) is impaired for stimuli in near-hand space (Davoli, Du, Montana, Gaverick, & Abrams, 2010), which suggests a possible trade-off, whereby basic processing (e.g., detection) is enhanced at the expense of semantic processing.
Gozli, West, and Pratt (2012) hypothesized that the pattern of performances across the various tasks with the hands near the stimuli could be accounted for by differential activation of the two major classes of cells that selectively process different aspects of visual stimuli: magnocellular (M) neurons and parvocellular (P) neurons. In comparison to P cells, M cells have faster conduction speeds, greater temporal sensitivity—that is, greater sensitivity to rapid changes in luminance over time (onsets, offsets, motion)—and greater sensitivity to luminance contrast; they process lower spatial frequencies (the “gist” of a stimulus); and they are insensitive to color (Derrington & Lennie, 1984; Legge, 1978). Although there is cross-talk between streams, M cells provide most of the input to the dorsal cortical stream—which is implicated in visually guided action (e.g., reaching, grasping)—and P cells to the ventral cortical stream—which is implicated in conscious object perception (Goodale & Westwood, 2004).
Gozli et al. (2012) argued that near-hand space receives enhanced M-cell input, resulting in an impairment in tasks requiring fine spatial resolution (such as reading), as well as improved performance for tasks that require temporal precision and rapid processing of luminance, such as target detection. In support on this idea, Gozli et al. showed that a temporal gap detection task was improved in near-hand space, but that spatial gap detection was impaired. However, in both of Gozli et al.’s tasks, the stimuli were presented briefly (<110 ms) with no ramping of luminance onset or offset; this is not an ideal task to differentially tap M and P cells, since these stimulus properties preferentially drive M cells. Following on from this, Goodhew, Gozli, Ferber, and Pratt (2013) found that object substitution masking (OSM) is reduced in near-hand space. Given that OSM reflects a failure to segment the target and mask as separate objects across time (see Goodhew, Pratt, Dux, & Ferber, 2013, for a review), and that OSM is increased when the contribution of M cells is selectively saturated (Goodhew, Boal, & Edwards, 2014), this result is consistent with the notion of enhanced M-cell activation in near-hand space, which would enhance temporal segmentation, and thus reduce masking. However, OSM is also modulated by attention (Dux, Visser, Goodhew, & Lipp, 2010), meaning that this finding cannot unambiguously differentiate between the attentional-based accounts.
Here, therefore, we used a task that could distinguish between the attentional and M-cell accounts. That is, we tested how dynamic object correspondence was affected by hand proximity, because the accounts make differing predictions about the properties that should contribute to object correspondence. According to the attention-based accounts, object correspondence should be enhanced near the hands, but this change in attention should equally affect both the spatiotemporal-trajectory and surface-feature contributions to object correspondence. According to the M-cell account, color should play a reduced role in contributing to object correspondence, because M cells are less sensitive to color.
To test these predictions, we used a paradigm, adapted from Hollingworth and Franconeri (2009), that allowed the independent contributions of color (surface feature) and position (spatiotemporal trajectory) in object correspondence to be quantified. This paradigm involves an object change detection task (see the Method section), and the logic of the paradigm is that the greater the tendency to see the objects as continuing identities across time, the more efficient participants should be in making this change detection judgment, and thus reaction times (RT) would serve as a gauge of object correspondence. Hollingworth and Franconeri found that both color and position consistency made independent contributions to change detection efficiency. Here, we tested whether both color and position would both contribute to object correspondence when hand proximity was manipulated, and whether object correspondence would be improved in near-hand space, as predicted by the attentional accounts.
Method
Participants
The participants were 52 (35 female, 17 male; mean age = 24.3 years, SD = 6.6) students and people (including author S.C.G) from the Australian National University community, who participated in exchange for either course credit or money. All reported normal color vision and provided written informed consent prior to participation.
Stimuli and apparatus
The stimuli were created in Adobe Illustrator. Five unique abstract white shapes (lacking an obvious verbal label) were coupled with square backgrounds that were blue, green, red, purple, and brown (each white shape was coupled with each color, rendering a stimulus set of 100). The squares were 32 × 32 pixels (viewing distance was not fixed). A black rectangular occluder appeared in the center of the screen (90 × 150 pixels). The screen background was gray.
Participants always responded via two computer mice, each of which had only one response-active button. In the “hands-up” condition, the mice were attached to either side of the screen via Velcro, and supports were used under the participants’ elbows to maintain their comfort. This setup placed the visual stimuli in near-hand space (with approximately 22 cm between the hands and the center of the screen). In the “hands-down” condition, the mice were detached from the screen and placed on the desk (creating a greater distance between the participant’s hands and the visual stimuli on the screen; i.e., placing the stimuli in far hand space, approximately 55 cm between each hand and the center of the screen). Stimuli were presented using the Psychophysics Toolbox extension in MATLAB on a cathode-ray tube monitor with a refresh rate of 75 Hz.
Procedure
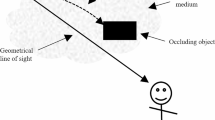
Each trial began with the presentation of two differently colored squares, one on either side of a central rectangular occluder (horizontally separated, vertically aligned; see Fig. 1). Next, white shapes were shown on both of the squares (preview display). The shapes then disappeared from the squares, leaving visible the two squares in their original colors, and then the squares moved: One traveled toward the bottom of the occluder, and the other toward the top (which square traveled which way was randomized). The objects remained occluded briefly, but then the rectangular occluder disappeared, revealing the two colored squares, each containing its white shape again, now vertically separated but horizontally aligned (test display).

Schematic illustration of an objects-same trial (since the same two white shapes are shown in the preview and test displays). This is a position-consistent, color-consistent trial, because the white shapes have the same locations relative to their spatiotemporal history, and the mapping of the white shapes onto the colored squares is preserved between preview and test. Note that the diagram is not to scale (the size of the objects has been increased in order for them to be clearly visible). Also not shown here, but as in Hollingworth and Franconeri (2009), each trial began with the presentation of four digits, which participants were instructed to rehearse throughout the trial to ensure that the task tapped visual rather than verbal memory
On half of the trials, the two shapes displayed on the squares were the same as those on in the preview display, whereas on the other half, one of the shapes was new. The participants’ task was change detection (i.e., a same/different judgment for the shapes in the test display relative to the preview display). On half of the trials, the mapping of the white shapes onto the colored squares would switch. For example, if a given white shape had appeared on the blue square in the preview display, it would now appear on the green square instead (color consistency manipulation). Similarly, on half of the trials, the location of the shapes would switch. For example, if the square on which a given shape had appeared during preview traveled toward the bottom of the occluder, this shape would now appear instead on the other shape in the test display (position consistency manipulation). These featural and position/location switches were fully crossed (see Fig. 2). The intertrial interval (during which the screen was blank) was 1,563 ms. Participants completed the “hands-up” and “hands-down” conditions as separate blocks, the order of which was counterbalanced across participants. Each block consisted of 120 trials.

An illustration of an example trial for each of the four conditions. The upper panel represents the preview display, and the lower panels, the corresponding test displays for each condition. Note that the arrows illustrate the direction of motion for the objects, but were not visible during stimulus presentation
Results
As per Hollingworth and Franconeri (2009), we focused the analysis on those trials in which the objects did not change. The data from 11 participants were excluded due to failure to comply with the task instructions (eight who scored below chance accuracy in one or more blocks [including six who scored 0% in a particular position/color consistency condition], likely due to confusing color or position switches with object changes, and three whose average condition RTs exceeded 2 s), and another one was excluded who did not complete both experimental blocks. The accuracy for the remaining 40 data sets was reasonably high (88% and above in each hand proximity by position/color consistency combination; see Table 1). Trials were excluded from the analysis if the RTs were less than 100 ms or exceeded a participant’s mean RT by 2.5 standard deviations (average 3.0% [hands-down] and 2.7% [hands-up] of trials excluded).
Correct trial RTs were submitted to a 2 (hand proximity) × 2 (position consistency) × 2 (color consistency) repeated measures analysis of variance (ANOVA), for which the order of block completion was included as a between-subjects variable. This revealed that the main effect of hand proximity was not significant (F < 1), but the interaction between hand proximity and order of block completion was significant, F(1, 38) = 19.09, p < .001, η 2p = .334. The main effect of position consistency was significant, F(1, 38) = 22.64, p < .001, η 2p = .373, and did not interact with either block order (F < 1) or hand proximity (F < 1). The main effect of color consistency was also significant, F(1, 38) = 7.10, p = .011, η 2p = .158, but did not interact with block order (F < 1), or hand proximity, F(1, 38) = 1.65, p = .207, η 2p = .042. The interaction between position consistency and color consistency was significant, F(1, 38) = 7.17, p = .011, η 2p = .159, as was the three-way interaction among position consistency, color consistency, and block order, F(1, 38) = 4.50, p = .040, η 2p = .106. None of the other interactions reached significance, ps ≥ .201 and η 2p s ≤ .043.
Given that order of block completion was interacting with the key variables (along with other two-way interactions), we split the data according to the order of block completion. For the participants who completed the hands-up block first (see Fig. 3), we observed a main effect of hand position, F(1, 20) = 7.02, p = .015, η 2p = .260, such that RTs were faster for the hands-down block (964.5 ms) than for the hands-up block (1,084.8 ms), reflecting a practice effect. A main effect of position consistency also emerged, F(1, 20) = 9.76, p = .005, η 2p = .328, whereby RTs were faster when position was consistent (982.3 ms) than when it was inconsistent (1,067.0 ms), whereas no other main effects or interactions reached significance (ps ≥ .054, η 2p s ≤ .173). This means that position, but not color, contributed to object correspondence through occlusion in both hand proximity conditions for those who completed the hands-up block first.

Reaction times to change detection judgments for those participants who completed the hands-up block first. The shapes on the bars reflect the positions of the objects on the test display, given the example preview display shown at the top of the graph (see Fig. 1 for the trial sequence). Error bars represent within-subjects standard errors (Cousineau, 2005). Position consistency refers to whether the white shape appears in the location consistent with the movement of the square on which it first appeared. As per Hollingworth and Franconeri (2009), color consistency is defined according to the match between a given white shape and the color that it appeared on between the preview and test arrays. Color-position consistency refers to whether the color of the shape that appears in a location matches the color of the shape that disappeared behind that part of the occluder
For those participants who completed the hands-down block first (see Fig. 4), a significant main effect of hand proximity was apparent, F(1, 18) = 15.00, p = .001, η 2p = .454, such that RTs on average were faster in the hands-up block (993.3 ms) than in the hands-down block (1,132.1 ms), reflecting a practice effect. We also found a significant main effect of position consistency, F(1, 18) = 15.99, p = .001, η 2p = .470, whereby RTs were faster when the position of the shapes was consistent between preview and test (1,024.4 ms) than when they were inconsistent (1,101.0 ms). Importantly, the interaction between position consistency and color consistency was significant, F(1, 18) = 11.94, p = .003, η 2p = .399. This means that both position and color contributed to object correspondence through occlusion in both hand proximity conditions for those who completed the hands-down block first. None of the other effects were significant (ps ≥ .088, η 2p s ≤ .153).

Reaction times to change detection judgments for those participants who completed the hands-down block first. The shapes on the bars reflect the positions of the objects on the test display, given the example preview display shown at the top of the graph (see Fig. 1 for the trial sequence). Error bars represent within-subjects standard errors (Cousineau, 2005)
We did not expect the interaction between position and color consistency (this interaction was apparent in both the hands-down-block-first analysis and the overall ANOVA), as Hollingworth and Franconeri (2009) had previously found that these properties contributed independently to object correspondence. However, on closer examination, whereas Hollingworth and Franconeri defined color consistency as the match between the color of the disc on which a given white shape appeared between preview and test, our results suggest that here another form of color consistency contributed to object correspondence: color-position consistency. That is, Hollingworth and Franconeri deemed trials in which Shape A appeared on a blue disc, which then travelled toward the bottom of the occluder, and then Shape B appeared on this blue disc as “color inconsistent.” But here, if the visual system was tracking the blue disc, then in fact a blue disc appearing in this location would be color-position consistent (see Figs. 3 and 4). The interaction between position and color consistency suggests that consistency between the color of the square that disappeared behind the occluder and the color at that location postocclusion is also a determinant of object correspondence.
Discussion
Here we found that for participants who completed the hands-up block first, position exclusively contributed to object correspondence through occlusion for both the hands-up and hands-down conditions. However, for those who completed the hands-down block first, both color and position contributed to object correspondence through occlusion. The fact that color did not contribute after initial completion of the hands-up block is consistent with the M-cell activation account of processing in near-hand space (Gozli et al., 2012; see also Abrams & Weidler, 2013). It also suggests that the pattern of processing induced by the first block that participants completed transferred to their second block. This transfer of the processing style induced by the first block occurred irrespective of which block participants completed first. That is, it was also true that, for those who completed the hands-down block first, the pattern of properties contributing to object correspondence from this block carried over into their performance on the subsequent hands-up block. In contrast, we found no evidence for the attention-based accounts of near-hand space perception, since object correspondence was not facilitated overall in either block; instead, participants merely performed more efficiently in whichever block they performed second. The implications of each of these findings are discussed below.
How can this evidence for the M-cell account be reconciled with the previous literature? Gozli et al. (2012) described how many of the findings that have appeared to support attentional accounts could actually be explained within the M-cell framework. For example, it is possible that the finding of impaired performance in visual search and the AB in Abrams et al.’s (2008) study resulted from the use of alphanumeric stimuli for the targets and distractors. Although this is the norm for these paradigms, it would be difficult for M cells to process such stimuli, since these cells are most responsive to low spatial frequencies. One such finding that Gozli et al. did not account for but that is relevant here is that change detection for colored squares is improved in near-hand space (Tseng & Bridgeman, 2011). We think that the most plausible reason for why their results diverge from ours is that some of the color changes in their task involved dramatic changes in luminance (e.g., white to black). M cells are relatively insensitive to color, but they have superior luminance sensitivity, and thus this task may have been mediated by improved luminance processing in near-hand space. Altogether, then, it possible that the previous results can actually also be explained by the M-cell account of processing in near-hand space; however, further research will be needed to examine whether the M-cell account does indeed encompass these findings, or whether multiple mechanisms mediate altered vision near the hands.
The strong effect of order of block completion in the present study suggests that the brain’s definition of “near-hand space” can be malleable, in that recent experience can alter whether identical physical proximity is deemed as near- or far-hand space. This is surprising, since no previous studies of processing in near-hand space have reported this effect. In light of this, we reanalyzed the data from a previous study on the effect of hand proximity on perception, in which we had found a hand proximity by mask duration interaction in object substitution masking (Goodhew, Gozli, et al., 2013). This revealed no evidence of a block order effect in either Experiment 1 or 2 of that study; instead the hand proximity by mask duration interaction was robust, irrespective of which block participants completed first. This places limits of the generalizability of our present result: One possible reason for the presence of a transfer effect in the present experiment is that observers were using the same apparatus in both blocks, whereas in the Goodhew, Gozli, et al. study, different response apparatus was used between the blocks (mice for near-hand space and keyboard for far-hand space). Future research should further examine the generalizability of such a transfer effect.
To summarize, the results of the present experiment are consistent with the theory that near-hand space is the purview of increased M-cell activation, and also suggest that hand proximity and the perceptual style that it induces can be affected by recent experience.
References
Abrams, R. A., Davoli, C., Du, F., Knapp, W. H., & Paull, D. (2008). Altered vision near the hands. Cognition, 107, 1035–1047. doi:10.1016/j.cognition.2007.09.006
Abrams, R. A., & Weidler, B. J. (2013). Trade-offs in visual processing for stimuli near the hands. Attention, Perception, & Psychophysics. doi:10.3758/s13414-013-0583-1
Assad, J. A., & Maunsell, J. H. R. (1995). Neuronal correlates of inferred motion in primate posterior parietal cortex. Nature, 373, 518–521. doi:10.1038/373518a0
Brockmole, J. R., Davoli, C., Abrams, R. A., & Witt, J. K. (2013). The world within reach: Effects of hand posture and tool use on visual cognition. Current Directions in Psychological Science, 22, 38–44. doi:10.1177/0963721412465065
Burke, L. (1952). On the tunnel effect. Quarterly Journal of Experimental Psychology, 4, 121–138. doi:10.1080/17470215208416611
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorial in Quantitative Methods for Psychology, 1, 42–45.
Davoli, C. C., Du, F., Montana, J., Gaverick, S., & Abrams, R. A. (2010). When meaning matters, look but don’t touch: The effects of posture on reading. Memory & Cognition, 38, 555–562. doi:10.3758/MC.38.5.555
Derrington, A. M., & Lennie, P. (1984). Spatial and temporal contrast sensitivities of neurones in the lateral geniculate nucleus of the macaque. Journal of Physiology, 357, 219–240.
Dux, P. E., & Marois, R. (2009). How humans search for targets through time: A review of data and theory from the attentional blink. Attention, Perception, & Psychophysics, 71, 1683–1700. doi:10.3758/APP.71.8.1683
Dux, P. E., Visser, T. A. W., Goodhew, S. C., & Lipp, O. V. (2010). Delayed re-entrant processing impairs visual awareness: An object substitution masking study. Psychological Science, 21, 1242–1247. doi:10.1177/0956797610379866
Goodale, M. A., & Westwood, D. A. (2004). An evolving view of duplex vision: Separate but interacting cortical pathways for perception and action. Current Opinion in Neurobiology, 14, 203–211. doi:10.1016/j.conb.2004.03.002
Goodhew, S. C., Boal, H. L., & Edwards, M. (2014). A magnocellular contribution to conscious perception via temporal object segmentation. Journal of Experimental Psychology: Human Perception and Performance. doi:10.1037/a0035769
Goodhew, S. C., Gozli, D. G., Ferber, S., & Pratt, J. (2013a). Reduced temporal fusion in near-hand space. Psychological Science, 24, 891–900. doi:10.1177/0956797612463402
Goodhew, S. C., Pratt, J., Dux, P. E., & Ferber, S. (2013b). Substituting objects from consciousness: A review of object substitution masking. Psychonomic Bulletin & Review, 20, 859–877. doi:10.3758/s13423-013-0400-9
Gozli, D. G., West, G. L., & Pratt, J. (2012). Hand position alters vision by biasing processing through different visual pathways. Cognition, 124, 244–250. doi:10.1016/j.cognition.2012.04.008
Hein, E., & Moore, C. M. (2012). Spatio-temporal priority revisited: The role of feature identity and similarity for object correspondence in apparent motion. Journal of Experimental Psychology: Human Perception and Performance, 38, 975–988. doi:10.1037/a0028197
Hollingworth, A., & Franconeri, S. L. (2009). Object correspondence across brief occlusion is established on the basis of both spatiotemporal and surface feature cues. Cognition, 113, 150–166. doi:10.1016/j.cognition.2009.08.004
Hollingworth, A., Richard, A. M., & Luck, S. J. (2008). Understanding the function of visual short-term memory: Transsaccadic memory, object correspondence, and gaze correction. Journal of Experimental Psychology: General, 137, 163–181. doi:10.1037/0096-3445.137.1.163
Legge, G. E. (1978). Sustained and transient mechanisms in human vision: Temporal and spatial properties. Vision Research, 18, 69–81. doi:10.1016/0042-6989%2878%2990079-2
Matin, E. (1974). Saccadic suppression: A review and an analysis. Psychological Bulletin, 81, 899–917. doi:10.1037/h0037368
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance X (pp. 531–556). Hillsdale: Erlbaum.
Reed, C., Betz, R., Garza, J. P., & Roberts, R. J. (2010). Grab it! Biased attention in functional hand and tool space. Attention, Perception, & Psychophysics, 72, 236–245. doi:10.3758/APP.72.1.236
Reed, C., Grubb, J., & Steele, C. (2006). Hands up: Attentional prioritization of space near the hand. Journal of Experimental Psychology: Human Perception and Performance, 32, 166–177. doi:10.1037/0096-1523.32.1.166
Richard, A. M., Luck, S. J., & Hollingworth, A. (2008). Establishing object correspondence across eye movements: Flexible use of spatiotemporal and surface information. Cognition, 109, 66–88. doi:10.1016/j.cognition.2008.07.004
Tseng, P., & Bridgeman, B. (2011). Improved change detection with nearby hands. Experimental Brain Research, 209, 257–269. doi:10.1007/s00221-011-2544-z
Weidler, B. J., & Abrams, R. A. (2013). Hand proximity—not arm posture—alters vision near the hands. Attention, Perception, & Psychophysics, 75, 650–653. doi:10.3758/s13414-013-0456-7
Author note
This research was supported by an Australian Research Council (ARC) Discovery Early Career Research Award (DECRA) awarded to S.C.G. (No. DE140101734), and by an NSERC discovery grant awarded to J.P. The authors thank Peter Zhang and Erin Walsh for assistance with the data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Goodhew, S.C., Fogel, N. & Pratt, J. The nature of altered vision near the hands: Evidence for the magnocellular enhancement account from object correspondence through occlusion. Psychon Bull Rev 21, 1452–1458 (2014). https://doi.org/10.3758/s13423-014-0622-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-014-0622-5