
Abstract
Background
While observational studies show an association between serum lipid levels and cardiovascular disease (CVD), intervention studies that examine the preventive effects of serum lipid levels on the development of CKD are lacking.
Methods
To estimate the role of serum lipid levels in the etiology of CKD, we conducted a two-sample mendelian randomization (MR) study on serum lipid levels. Single nucleotide polymorphisms (SNPs), which were significantly associated genome-wide with serum lipid levels from the GLGC and CKDGen consortium genome-wide association study (GWAS), including total cholesterol (TC, n = 187,365), triglyceride (TG, n = 177,861), HDL cholesterol (HDL-C, n = 187,167), LDL cholesterol (LDL-C, n = 173,082), apolipoprotein A1 (ApoA1, n = 20,687), apolipoprotein B (ApoB, n = 20,690) and CKD (n = 117,165), were used as instrumental variables. None of the lipid-related SNPs was associated with CKD (all P > 0.05).
Results
MR analysis genetically predicted the causal effect between TC/HDL-C and CKD. The odds ratio (OR) and 95% confidence interval (CI) of TC within CKD was 0.756 (0.579 to 0.933) (P = 0.002), and HDL-C was 0.85 (0.687 to 1.012) (P = 0.049). No causal effects between TG, LDL-C- ApoA1, ApoB and CKD were observed. Sensitivity analyses confirmed that TC and HDL-C were significantly associated with CKD.
Conclusions
The findings from this MR study indicate causal effects between TC, HDL-C and CKD. Decreased TC and elevated HDL-C may reduce the incidence of CKD but need to be further confirmed by using a genetic and environmental approach.
Similar content being viewed by others
Background
Chronic kidney disease (CKD) can be defined as a decreased glomerular filtration rate (GFR) (< 60 mL/min*1.73 m2) and affects up to 15% of the population around the world, and the number of cases is increasing [1]. With the continuous deterioration of renal function, most patients have to accept dialysis treatment. There are many reasons for the deterioration of renal function, including dyslipidemia [2]. Recently, many studies have found that most patients with CKD have cardiovascular diseases (CVD) before they develop end-stage renal disease (ESRD), which is related to abnormal lipid metabolism [3]. Although there is a strong association between CKD and serum lipids, this mechanism has not been fully elucidated.
In epidemiological studies, randomized controlled trials (RCTs) are the most powerful way to demonstrate the etiology hypothesis. However, RCTs are more demanding on research design, and the cost of RCTs is higher; therefore, it is difficult to implement RCTs. The application of the Mendelian randomization (MR) method in epidemiological research provides an economical and effective way to solve this problem [4]. The main principle of this method is that different genotypes determine different intermediate phenotypes, and Mendel’s law of independent distribution states that the intermediate genes are randomly assigned to the gametes of the offspring in the process of gamete formation. Therefore, when using the model of “genotype-disease (outcome)” to simulate the model of “intermediate phenotype (exposure)-disease” to conduct causal correlation research, this approach will not be affected by the impact of environmental factors, and the causal sequence is clear [5]. With these situations, MR research is regarded as the best alternative to RCTs by most researchers.
There are several analyses of MR methods, including two-sample Mendelian randomization (TSMR) [6]. Compared with other methods, TSMR has some advantages. First, with the advent of the post-GWASs era, a large number of GWAS data have been published, and the data that we selected are easier to obtain. Second, if we use the association established by observational research to carry out the research phase of two queues, when the sample size of the study is expanded, the efficiency of the test can be improved. In addition, the published GWAS sample size is usually large, and the number of instrument variables (IVs) that can be selected is high, which increases the genetic interpretation of IVs on exposure, can better replace exposure, and is more conducive to the accuracy and reliability of analysis results [7]. In our current study, we assumed that serum lipid levels were associated with the onset of CKD. Next, we used TSMR to estimate the causal effect of serum lipid levels on CKD.
Methods
GWAS data
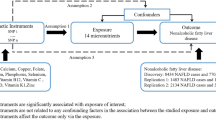
We selected genetic variants associated with serum total cholesterol (TC, n = 187,365), triglyceride (TG, n = 177,861), HDL cholesterol (HDL-C, n = 187,167), LDL cholesterol (LDL-C, n = 173,082), apolipoprotein A1 (ApoA1, n = 20,687) and apolipoprotein B (ApoB, n = 20,690) levels and then extracted the corresponding effect sizes for CKD using the largest GWAS summary-level dataset [8, 9]. The data source of this study is based on re-analyzing previously published GWAS; therefore, there is no ethical approval. CKD data (n = 117,165) were acquired from the CKDGen consortium (n = 117,165) [10]. CKD was defined as an eGFR based on serum creatinine (eGFRcrea) lower than 60 mL/min/1.73 m2. All datasets were obtained from large-scale randomized double-blind trials and population cohort studies based on European descent. Gender, age and body mass index (BMI) should be corrected in regression models of serum lipid GWAS [8, 9], and age and gender were also adjusted in CKDGen. Because of the potential population stratification in our selected datasets, the genome control of each sample is applied to correct for inconsistent test statistics.
TSMR design
In our current analysis, the IVs provided by genetic variants should contain three assumptions as in our previous research [1, 11] IVs must be strongly associated with exposure [2]; IVs should be without any association with known confounders; and [3] the IVs we selected must be conditionally independent of exposure (serum lipid levels), outcomes (CKD) and confounders. If the IVs contained the second and third assumptions, it may be regarded as independent from pleiotropy.
Instrument variables
Initially, IVs should be strongly correlated with exposure (serum lipid level). Then, the P-value that we selected should be < 5 × 10− 8 in the relevant GWAS dataset to ensure the close association between IVs and exposures. After that step, to ensure independence among selected IVs, PLINK 1.90 [12] was performed to calculate the pairwise linkage disequilibrium (LD). If the r2 was greater than 0.001, these SNPs were excluded from our research.
We selected these IVs must be conditionally independent of outcome (CKD), considering the correlated traits of exposures (serum lipid level), and independent of any known confounders. For selected IVs, only exposure factors (serum lipid level) and no other pathways or confounding factors can affect the outcome (CKD). This finding is consistent with the previous two assumptions [13]. First, we made the corresponding effect estimates of these variables on CKD. We should choose the proxy SNPs that are highly correlated (r2 was greater than 0.8) based on the SNP Annotation and Proxy (SNAP) search system for substitution when the selected SNPs cannot be used in CKD [14]. Next, MR-Egger regression was performed to calculate the horizontal pleiotropic [15]. Afterwards, we removed any palindromic SNPs for which the minor allele frequency (MAF) was greater than 0.3 to ensure that the influence of the SNPs on the exposures (serum lipid level) corresponded to the same allele as their influence on CKD [16]. Subsequently, we employed the GWAS Catalog to check for the associations between selected IVs and to adjust for potential confounding. In addition, we calculated the F statistic with a web application (https://sb452.shinyapps.io/overlap/) to examine the association of selected IVs with the exposures [17].
Pleiotropy assessment
MR-Egger regression was employed to calculate the horizontal pleiotropic pathway between IVs and CKD, independent of serum lipid level [15]. As an effective method to detect bias in publication meta-analysis, MR-Egger regression was derived from Egger regression. The method can be expressed through the equation αi = βγi + β0. In this equation, different letters indicate different meanings. αi represented the effect between IVs and CKD; γi was employed to estimate the effect between serum lipid level and IVs; slope β denoted the estimated causal effect of exposure (serum lipid level) on outcome (CKD); and intercept β0 represented the estimated average value of horizontal pleiotropic. When the P-value of the intercept was greater than 0.05, no horizontal pleiotropy could be found. In addition, the slope can also be defined as the estimated pleiotropy-corrected causal effect. However, if the SNPs we selected in this analysis do not account for most of the differences in exposure, then there is a lack of evaluation of this estimate [15].
TSMR analysis
In our current study, inverse variance weighted (IVW) was used as the key method to calculate the causal effect between serum lipid level and CKD for TSMR analysis [18]. The causal effect β was estimated and shown as wi (αi /γi). In this equation, i refers to the IVs, αi represents the association effect of IVs on CKD, γi defines the association effect of IVs on serum lipid level, and wi represents the weights of the causal effect of serum lipid level on CKD.
Sensitivity analysis
We employed various methods to calculate follow-up sensitivity, including maximum likelihood, MR Egg, weight median, penalized weight median, simple mode, weight mode and robust adjusted profile score (RAPS) [19]. Compared with IVW, these methods have greater robustness to individual genetics with strongly outlying causal estimates and would generate a consistent estimate of the causal effect when valid IVs exceed 50% [20]. Then, leave-one-out sensitivity analysis was performed to screen out whether the correlation was out of relationship to be affected by a single SNP. Subsequently, we employed TSMR analysis again, leaving out each SNP, in turn, and the overall analysis including all SNPs was shown for comparison [21]. All of the analysis was implemented by the “TwoSampleMR” package in the R software environment.
Results
IV selection and validation
Seven independent SNPs (P < 5 × 10 − 8, r 2 < 0.001) were associated with TC, thirteen independent SNPs were associated with TG, four SNPs were associated with HDL-C, four SNPs were associated with LDL-C, seven SNPs were associated with ApoA1 and nine SNPs were associated with ApoB by independent and LD analyses (Supplementary Table 1).
Then, we employed the intercept term to calculate the exposures from MR-Egger regression. Table 1 shows the MR-Egger regression intercepts and indicates that no horizontal pleiotropy exists in the current TSMR analysis. Table 2 identified the heterogeneity tests and found that all the P-values were greater than 0.05.
Subsequently, we performed F statistics to identify the strength of the relationship between IVs and exposures. If F > 10, it should be considered to be strong enough to mitigate against any bias of the causal IV estimate. The F statistics for our selected IVs were 107,061.14 for TC, 54722.15 for TG, 173077 for HDL-C, 187162 for LDL-C, 11816.57 for ApoA1 and 9191.11 for ApoB. All the F statistics values were greater than 10, which indicated high strength to mitigate against any bias of the causal IV estimate.
TSMR and sensitivity analysis
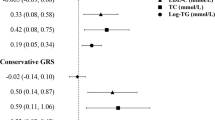
The TSMR analysis results are shown in Fig. 1. The odds ratio (OR) and 95% confidence interval (CI) of TC within CKD was 0.756 (0.579 to 0.933) (P = 0.002), TG was 1.021 (0.898 to 1.144) (P = 0.739), HDL-C was 0.85 (0.687 to 1.012) (P = 0.049), LDL-C was 1 (0.747 to 1.253) (P = 0.998), ApoA1 was 0.999 (0.888 to 1.11) (P = 0.98) and ApoB was 0.909 (0.757 to 1.061) (P = 0.217). These results suggested that this method genetically predicted the causal effect between TC/HDL-C and CKD.

Two-sample mendelian randomization of serum lipid level and the risk of CKD. a TC; b TG; c HDL-C; d LDL-C e ApoA1; f ApoB. Expo., exposure; Outc., outcome. CKD: Chronic kidney disease; TC, Total cholesterol; TG, Triglyceride; HDL-C, High-density lipoprotein cholesterol; LDL-C, Low-density lipoprotein cholesterol; Apo, Apolipoprotein; CI: Confidence interval; MR: Mendelian randomization
Figure 2 indicates the association between serum lipid levels and CKD and shows that there is a positive correlation between a decrease in TC and an increase in HDL-C and the incidence of CKD. The overall estimates, as calculated by IVW or MR-Egg, also reveal causal effects between serum lipid levels and CKD. (Figs. 3 and 4). Sensitivity analyses using the leave-one-out approach confirmed the causal effect (Figs. 5 and 6).

Scatter plots of the estimated SNP effects on serum lipid level (x-axis) plotted against the estimated SNPs effects on the CKD (y-axis). a TC; b TG; c HDL-C; d LDL-C (e) ApoA1; f ApoB. The slope of the line corresponds to a causal estimate using a different method

Results of the single and multi SNP analyses for the SNP effect of serum lipid level on CKD. a TC; b TG; c HDL-C; d LDL-C (e) ApoA1; f ApoB. The forest map, where each black dot represented a single SNP as IV, showed the logarithm of the odds the ratio 95% (OR) confidence per standard deviation under the influence of serum lipid level; the red dot showed the use of IVW results for all SNPs; the horizontal line indicated the 95% confidence interval

The details of SNP analyses for the SNP effect of serum lipid level on CKD. a TC; b TG; c HDL-C; d LDL-C (e) ApoA1; f ApoB. Expo., exposure; Outc., outcome. CKD: Chronic kidney disease; TC, Total cholesterol; TG, Triglyceride; HDL-C, High-density lipoprotein cholesterol; LDL-C, Low-density lipoprotein cholesterol; Apo, Apolipoprotein; CI: Confidence interval; MR: Mendelian randomization

Sensitivity analyses using the leave-one-out approach on the association of serum lipid level on CKD. a TC; b TG; c HDL-C; d LDL-C (e) ApoA1; f ApoB. Each black dot represents an IVW method for estimating causal the effect of the line serum lipid level on the CKD does not exclude a case where a particular SNP caused a significant change in the overall results

The details of Sensitivity analyses for the leave-one-out approach on the association of serum lipid level on CKD (a) TC; b TG; c HDL-C; d LDL-C (e) ApoA1; f ApoB. Expo., exposure; Outc., outcome. CKD: Chronic kidney disease; TC, Total cholesterol; TG, Triglyceride; HDL-C, High-density lipoprotein cholesterol; LDL-C, Low-density lipoprotein cholesterol; Apo, Apolipoprotein; CI: Confidence interval; MR: Mendelian randomization
Discussion
There is a consensus in previous studies that dyslipidemia is an independent risk factor for CVD. With further research, the contribution of decreased HDL, increased LDL and cholesterol to CVD is more obvious [22]. At present, studies have only found that dyslipidemia is closely related to CKD, but whether serum lipids can directly lead to CKD has not been determined.
Patients with CKD have dyslipidemia even at early stages of renal disease and dyslipidemia tends to progress with deterioration of kidney function. The dyslipidemia in CKD is largely due to increased triglyceride levels, decreased HDL-C and varying levels of LDL-C. There are many national guidelines for treatment of dyslipidemia in the general population as well as those with CKD and collectively the guidelines advocate for the use of statins as first line therapy in patients with ASCVD or at high risk for ASCVD. The guidelines that included CKD as a specific at-risk population support the use of statins to reduce ASCVD risk in those with pre-end stage CKD and in those post renal transplant [23]. As early as the early 1990s, there was a case report that there was a relationship between hyperlipidemia and CKD. After ten years of follow-up, it was found that the incidence of albuminuria in hypercholesterolemia, hypertriglyceridemia and low-HDL-C was higher than that in the normal group, regardless of gender [24]. Another large, community-based cross-sectional study in Japan also found that hyperlipoproteinemia is closely related to the decline of eGFR [25]. Mendy et al. also found that the correlation between hypercholesterolemia and CKD was not related to race or skin color [26]. With further research, evidence obtained in mouse models has emerged suggesting that renal damage is caused by serum lipids. The proximal renal tubules are the most easily damaged sites of dyslipidemia. Serum lipid accumulation will lead to damage to renal tubules and aggravation of interstitial fibrosis, which will contribute to a decrease in eGFR [27, 28].
In epidemiology, RCT is the most authoritative method to prove the etiology hypothesis. However, RCTs often require a large sample size, a more rigorous experimental design procedure, a longer follow-up time and a higher cost, which inhibits researchers from conducting RCTs, thereby limiting the verification of many hypotheses. In recent years, with the continuous updating of research methods, MR has been recognized as the best alternative to RCT [29]. One of the important processes of MR is to select IVs, and single nucleotide polymorphism is one of the most commonly used IVs. In addition, there is abundant GWAS research related to serum lipids, and as the sample size is large enough, it has considerable credibility for the inference of MR.
In fact, some risk factors related to CKD have been found by using MR. Jordan et al. found that using genetics does not support a causal effect of serum urate level on eGFR level or CKD risk, and reducing SU levels is unlikely to reduce the risk of CKD development [30]. This finding is not in keeping with our traditional understanding. Del Greco et al. showed a 1.3% increase in eGFR per standard deviation increase in iron (95% confidence interval 0.4–2.1%, P = 0.004), which suggests a protective effect of iron on kidney function in the general population [31]. There are also some studies on the relationship between serum lipids and CKD, but there are some differences with our research focus. Lanktree et al. found that higher HDL cholesterol concentration was causally associated with better kidney function, and there was no association between genetically altered LDL cholesterol or triglyceride concentration and kidney function [32]. But serum HDL and CKD mortality show a U-shaped curve, with elevated HDL reducing the mortality rate of CKD within a certain range, while persistently elevated HDL significantly increases the risk of death from CKD [33]. In the conclusion of HDL-C, it is the same as our current research. Compared with the studies by this researcher, we used IVW to make a direct inference and used a variety of methods to verify this conclusion. At the same time, we made a judgment on the level of the horizontal pleiotropic pathway and sensitivity, avoiding the interference of false negatives with the conclusion. Liu et al. [34] also found that HDL-C is related to the pathogenesis of CKD, while TC, TG and LDL-C are not. Compared with the studies conducted by these researchers, there are some differences in the selected GWAS results in our current study, and we paid more attention to the correlation between the change range and trend of serum lipids and the incidence of CKD to guide the clinical diagnosis and treatment.
There were several limitations in our studies. First, as we can only download the data collected from the website for analysis, in this case, we cannot obtain the clinical result value of each individual in the original data; therefore, we cannot perform further analysis according to the subtype of CKD. Second, different standards of quality control in individual-level GWAS may affect our results. Third, these results only consider the causal relationship between serum lipid levels and CKD. In fact, the pathogenesis of CKD is a highly complex process, and other pathogenic factors need to be evaluated. The results of this study provide a new vision for the clinical understanding of the relationship between serum lipid levels and CKD and provide a theoretical basis for clinical decision-making.
Conclusion
By performing TSMR analysis, we identified that serum TC and HDL-C are causally associated with CKD risk. Decreased TC and elevated HDL-C may reduce the incidence of CKD. However, additional human and animal studies are still needed to further confirm these results by using a genetic and environmental approach.
Availability of data and materials
The datasets generated and/or analysed during the current study are publicly available.
References
Hill NR, Fatoba ST, Oke JL, Hirst JA, O'Callaghan CA, Lasserson DS, et al. Global Prevalence of Chronic Kidney Disease - A Systematic Review and Meta-Analysis. PLoS One. 2016;11(7):e0158765.
Tonelli M, Muntner P, Lloyd A, Manns B, Klarenbach S, Pannu N, et al. Association between LDL-C and risk of myocardial infarction in CKD. J Am Soc Nephrol. 2013;24(6):979–86.
Gai Z, Wang T, Visentin M, Kullak-Ublick GA, Fu X, Wang Z. Lipid Accumulation and Chronic Kidney Disease. Nutrients. 2019;11(4):722. https://doi.org/10.3390/nu11040722.
Emdin CA, Khera AV, Kathiresan S. Mendelian Randomization. JAMA. 2017;318(19):1925–6.
Sekula P, Del Greco MF, Pattaro C, Kottgen A. Mendelian Randomization as an Approach to Assess Causality Using Observational Data. J Am Soc Nephrol. 2016;27(11):3253–65.
Lawlor DA. Commentary: Two-sample Mendelian randomization: opportunities and challenges. Int J Epidemiol. 2016;45(3):908–15.
Hwang LD, Lawlor DA, Freathy RM, Evans DM, Warrington NM. Using a two-sample Mendelian randomization design to investigate a possible causal effect of maternal lipid concentrations on offspring birth weight. Int J Epidemiol. 2019;48(5):1457–67.
Kettunen J, Demirkan A, Wurtz P, Draisma HH, Haller T, Rawal R, et al. Genome-wide study for circulating metabolites identifies 62 loci and reveals novel systemic effects of LPA. Nat Commun. 2016;7:11122.
Willer CJ, Schmidt EM, Sengupta S, Peloso GM, Gustafsson S, Kanoni S, et al. Discovery and refinement of loci associated with lipid levels. Nat Genet. 2013;45(11):1274–83.
Pattaro C, Teumer A, Gorski M, Chu AY, Li M, Mijatovic V, et al. Genetic associations at 53 loci highlight cell types and biological pathways relevant for kidney function. Nat Commun. 2016;7:10023.
Miao L, Deng GX, Yin RX, Nie RJ, Yang S, Wang Y, et al. No causal effects of plasma homocysteine levels on the risk of coronary heart disease or acute myocardial infarction: A Mendelian randomization study. Eur J Prev Cardiol. 2019:2047487319894679.
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007;81(3):559–75.
Geng T, Smith CE, Li C, Huang T, Childhood BMI. Adult Type 2 Diabetes, Coronary Artery Diseases, Chronic Kidney Disease, and Cardiometabolic Traits: A Mendelian Randomization Analysis. Diabetes Care. 2018;41(5):1089–96.
Johnson AD, Handsaker RE, Pulit SL, Nizzari MM, O'Donnell CJ, de Bakker PI. SNAP: a web-based tool for identification and annotation of proxy SNPs using HapMap. Bioinformatics. 2008;24(24):2938–9.
Bowden J, Davey Smith G, Burgess S. Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression. Int J Epidemiol. 2015;44(2):512–25.
Davey Smith G, Hemani G. Mendelian randomization: genetic anchors for causal inference in epidemiological studies. Hum Mol Genet. 2014;23(R1):R89–98.
Palmer TM, Lawlor DA, Harbord RM, Sheehan NA, Tobias JH, Timpson NJ, et al. Using multiple genetic variants as instrumental variables for modifiable risk factors. Stat Methods Med Res. 2012;21(3):223–42.
Burgess S, Butterworth A, Thompson SG. Mendelian randomization analysis with multiple genetic variants using summarized data. Genet Epidemiol. 2013;37(7):658–65.
Benn M, Nordestgaard BG. From genome-wide association studies to Mendelian randomization: novel opportunities for understanding cardiovascular disease causality, pathogenesis, prevention, and treatment. Cardiovasc Res. 2018;114(9):1192–208.
Hemani G, Zheng J, Elsworth B, Wade KH, Haberland V, Baird D, et al. The MR-Base platform supports systematic causal inference across the human phenome. Elife. 2018;7:e34408. https://doi.org/10.7554/eLife.34408.
Mokry LE, Ross S, Timpson NJ, Sawcer S, Davey Smith G, Richards JB. Obesity and Multiple Sclerosis: A Mendelian Randomization Study. PLoS Med. 2016;13(6):e1002053.
Miao L, Yin RX, Pan SL, Yang S, Yang DZ, Lin WX. BCL3-PVRL2-TOMM40 SNPs, gene-gene and gene-environment interactions on dyslipidemia. Sci Rep. 2018;8(1):6189.
Hager MR, Narla AD, Tannock LR. Dyslipidemia in patients with chronic kidney disease. Rev Endocr Metab Disord. 2017;18(1):29–40.
Yamagata K, Ishida K, Sairenchi T, Takahashi H, Ohba S, Shiigai T, et al. Risk factors for chronic kidney disease in a community-based population: a 10-year follow-up study. Kidney Int. 2007;71(2):159–66.
Takamatsu N, Abe H, Tominaga T, Nakahara K, Ito Y, Okumoto Y, et al. Risk factors for chronic kidney disease in Japan: a community-based study. BMC Nephrol. 2009;10:34.
Mendy VL, Azevedo MJ, Sarpong DF, Rosas SE, Ekundayo OT, Sung JH, et al. The association between individual and combined components of metabolic syndrome and chronic kidney disease among African Americans: the Jackson Heart Study. PLoS One. 2014;9(7):e101610.
Kang HM, Ahn SH, Choi P, Ko YA, Han SH, Chinga F, et al. Defective fatty acid oxidation in renal tubular epithelial cells has a key role in kidney fibrosis development. Nat Med. 2015;21(1):37–46.
Gibbs PE, Lerner-Marmarosh N, Poulin A, Farah E, Maines MD. Human biliverdin reductase-based peptides activate and inhibit glucose uptake through direct interaction with the kinase domain of insulin receptor. FASEB J. 2014;28(6):2478–91.
Nitsch D, Molokhia M, Smeeth L, DeStavola BL, Whittaker JC, Leon DA. Limits to causal inference based on Mendelian randomization: a comparison with randomized controlled trials. Am J Epidemiol. 2006;163(5):397–403.
Jordan DM, Choi HK, Verbanck M, Topless R, Won HH, Nadkarni G, et al. No causal effects of serum urate levels on the risk of chronic kidney disease: A Mendelian randomization study. PLoS Med. 2019;16(1):e1002725.
Del Greco MF, Foco L, Pichler I, Eller P, Eller K, Benyamin B, et al. Serum iron level and kidney function: a Mendelian randomization study. Nephrol Dial Transplant. 2017;32(2):273–8.
Lanktree MB, Theriault S, Walsh M, Pare G. HDL Cholesterol, LDL Cholesterol, and Triglycerides as Risk Factors for CKD: A Mendelian Randomization Study. Am J Kidney Dis. 2018;71(2):166–72.
Vaziri ND. HDL abnormalities in nephrotic syndrome and chronic kidney disease. Nat Rev Nephrol. 2016;12(1):37–47.
Liu HM, Hu Q, Zhang Q, Su GY, Xiao HM, Li BY, et al. Causal Effects of Genetically Predicted Cardiovascular Risk Factors on Chronic Kidney Disease: A Two-Sample Mendelian Randomization Study. Front Genet. 2019;10:415.
Acknowledgments
Data on coronary artery disease have been contributed by the CKDGen and GLGC Consortium working group who used the resource. The authors thank all investigators for sharing these data. The submission of the manuscript has been in Research Square (https://www.researchsquare.com/article/rs-52857/v1).
Funding
The authors acknowledge the essential role of the funding of National Natural Science Foundation of China (NSFC: 82060072), National Natural Science Foundation of Guangxi (2020JJA140129), Project of Liuzhou Science and Technology (2020NBAB0818), Guangxi self-financing research projects(Z20190025, Z20201226 and Z20200165), the project of Liuzhou people’s Hospital (LRY202007 and LRY2020026) and Guangxi Medical and health key discipline construction project.
Author information
Authors and Affiliations
Contributions
L.M. and Y.M. conceived the study, participated in the design, performed the statistical analyses, and drafted the manuscript. R.-S.L. conceived the study, participated in the design and helped to draft the manuscript. C.-M.Z., G.-X.D., J.-H.C. and B.Q. drafted the paper. Y.W. and J.-F.L. revised the paper. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This analysis of publicly available data does not require ethical approval.
Consent for publication
Not applicable.
Competing interests
The authors have no potential conflicts of interest to report.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Supplemetary Table 1.
The details of SNP IVs.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Miao, L., Min, Y., Qi, B. et al. Causal effect between total cholesterol and HDL cholesterol as risk factors for chronic kidney disease: a mendelian randomization study. BMC Nephrol 22, 35 (2021). https://doi.org/10.1186/s12882-020-02228-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12882-020-02228-3