
Abstract
Multirelational classification aims to discover patterns across multiple interlinked tables (relations) in a relational database. In many large organizations, such a database often spans numerous departments and/or subdivisions, which are involved in different aspects of the enterprise such as customer profiling, fraud detection, inventory management, financial management, and so on. When considering classification, different phases of the knowledge discovery process are affected by economic utility. For instance, in the data preprocessing process, one must consider the cost associated with acquiring, cleaning, and transforming large volumes of data. When training and testing the data mining models, one has to consider the impact of the data size on the running time of the learning algorithm. In order to address these utility-based issues, the paper presents an approach to create a pruned database for multirelational classification, while minimizing predictive performance loss on the final model. Our method identifies a set of strongly uncorrelated subgraphs from the original database schema, to use for training, and discards all others. The experiments performed show that our strategy is able to, without sacrificing predictive accuracy, significantly reduce the size of the databases, in terms of the number of relations, tuples, and attributes.The approach prunes the sizes of databases by as much as 94 %. Such reduction also results in decreasing computational cost of the learning process. The method improves the multirelational learning algorithms’ execution time by as much as 80 %. In particular, our results demonstrate that one may build an accurate model with only a small subset of the provided database.













Similar content being viewed by others
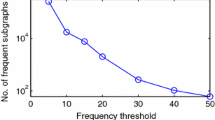
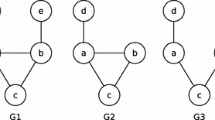

Notes
Further discussions regarding all the resulted join paths for this database will be presented in Example 1 in this section
References
Almuallim, H., & Dietterich, T.G. (1991). Learning with many irrelevant features. In AAAI ’91 (Vol. 2, pp. 547–552). Anaheim, California: AAAI Press.
Almuallim, H., & Dietterich, T.G. (1992). Efficient algorithms for identifying relevant features. Tech. Rep., Corvallis, OR, USA.
Alphonse, E., & Matwin. S. (2004.) Filtering multi-instance problems to reduce dimensionality in relational learning. Journal of Intelligent Information Systems, 22(1), 23–40.
Berka, P. (2000). Guide to the financial data set. In A. Siebes & P. Berka (Eds.), PKDD2000 discovery challenge.
Bhattacharya, I., & Getoor, L. (2007). Collective entity resolution in relational data. ACM Transaction on Knowledge and Discovery Data, 1(1), 5.
Blockeel, H., & Raedt, L.D. (1998). Top-down induction of first-order logical decision trees. Artificial Intelligence 101(1–2), 285–297.
Bringmann, B., & Zimmermann, A. (2009). One in a million: picking the right patterns. Knowledge and Information Systems, 18, 61–81.
Burges, C.J.C. (1998). A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery 2(2), 121–167.
Burnside, J.D.E., Ramakrishnan, R., Costa, V.S., Shavlik, J. (2005). View learning for statistical relational learning: With an application to mammography. In Proceeding of the 19th IJCAI (pp. 677–683).
Ceci, M., & Appice, A. (2006). Spatial associative classification: propositional vs structural approach. Journal of Intelligent Information Systems, 27, 191–213.
Chan, P.K., & Stolfo, S.J. (1993). Experiments on multistrategy learning by meta-learning. In CIKM ’93 (pp. 314–323). New York: ACM Press.
Chen, B.C., Ramakrishnan, R., Shavlik, J.W., Tamma, P. (2009). Bellwether analysis: searching for cost-effective query-defined predictors in large databases. ACM Transaction on Knowledge and Discovery Data, 3(1), 1–49.
Cohen, W. (1995). Learning to classify English text with ILP methods. In L. De Raedt (Ed.), ILP ’95 (pp. 3–24). DEPTCW.
De Marchi, F., & Petit, J.M. (2007). Semantic sampling of existing databases through informative armstrong databases. Information Systems, 32(3), 446–457.
De Raedt, L. (2008). Logical and relational learning. Cognitive Technologies. New York: Springer.
Dehaspe, L., Toivonen, H., King, R.D. (1998). Finding frequent substructures in chemical compounds. In AAAI Press (pp. 30–36).
Dzeroski, S., & Lavrac, N. (2001). Relational data mining. In S. Dzeroski & N. Lavrac (Eds.). Berlin: Springer.
Frank, R., Moser, F., Ester, M. (2007). A method for multi-relational classification using single and multi-feature aggregation functions. In PKDD 2007 (pp. 430–437).
Getoor, L., & Taskar, B. (2007). Statistical relational learning. MIT Press: Cambridge.
Ghiselli, E.E. (1964). Theory of psychological measurement. New York: McGrawHill Book Company.
Giraud-Carrier, C.G., Vilalta, R., Brazdil, P. (2004). Introduction to the special issue on meta-learning. Machine Learning, 54(3), 187–193.
Guo, H., & Viktor, H.L. (2006). Mining relational data through correlation-based multiple view validation. In KDD ’06 (pp. 567–573). New York, NY, USA.
Guo, H., & Viktor, H.L. (2008). Multirelational classification: a multiple view approach. Knowledge and Information Systems, 17(3), 287–312.
Guo, H., Viktor, H.L., Paquet, E. (2007). Pruning relations for substructure discovery of multi-relational databases. In PKDD (pp. 462–470).
Guo, H., Viktor, H.L., Paquet, E. (2011). Privacy disclosure and preservation in learning with multi-relational databases. JCSE, 5(3), 183–196.
Habrard, A., Bernard, M., Sebban, M. (2005). Detecting irrelevant subtrees to improve probabilistic learning from tree-structured data. Fundamenta Informaticae, 66(1–2), 103–130.
Hall, M. (1998). Correlation-based feature selection for machine learning. Ph.D thesis, Department of Computer Science, University of Waikato, New Zealand.
Hamill, R., & Martin, N. (2004). Database support for path query functions. In Proc. of 21st British national conference on databases (BNCOD 21) (pp. 84–99).
Han, J., & Kamber, M. (2005). Data mining: Concepts and techniques (2nd Edition). San Francisco, CA, USA: Morgan Kaufmann Publishers Inc..
Heckerman, D. (1998). A tutorial on learning with bayesian networks. In Proceedings of the NATO advanced study institute on learning in graphical models (pp. 301–354). Norwell, MA, USA: Kluwer Academic Publishers.
Heckerman, D., Geiger, D., Chickering, D.M. (1995). Learning bayesian networks: the combination of knowledge and statistical data. Machine Learning, 20(3), 197–243.
Hogarth, R. (1977). Methods for aggregating opinions. In H. Jungermann & G. de Zeeuw (Eds.), Decision making and change in human affairs. Dordrecht-Holland.
Jamil, H.M. (2002). Bottom-up association rule mining in relational databases. Journal of Intelligent Information Systems, 19(2), 191–206.
Jensen, D., Jensen, D., Neville, J. (2002). Schemas and models. In Proceedings of the SIGKDD-2002 workshop on multi-relational learning (pp. 56–70).
Kietz, J.U., Zücker, R., Vaduva, A. (2000). Mining mart: Combining case-based-reasoning and multistrategy learning into a framework for reusing kdd-applications. In 5th international workshop on multistrategy learning (MSL 2000). Guimaraes, Portugal.
Kira, K., & Rendell, L.A. (1992). A practical approach to feature selection. In ML92 proceedings of the 9th international workshop on machine learning (pp. 249–256). San Francisco, CA, USA: Morgan Kaufmann Publishers Inc..
Knobbe, A.J. (2004). Multi-relational data mining. PhD thesis, University Utrecht.
Kohavi, R., & John, G.H. (1997). Wrappers for feature subset selection. Artificial Intelligence, 97(1–2), 273–324.
Kohavi, R., Langley, P., Yun, Y. (1997). The utility of feature weighting in nearest-neighbor algorithms. In ECML ’97. Prague, Czech Republic: Springer.
Koller, D., & Sahami, M. (1996). Toward optimal feature selection. In ICML ’96 (pp. 284–292).
Krogel, M.A. (2005). On propositionalization for knowledge discovery in relational databases. PhD thesis, Otto-von-Guericke-Universität Magdeburg.
Krogel, M.A., & Wrobel, S. (2003). Facets of aggregation approaches to propositionalization. In ILP’03.
Landwehr, N., Kersting, K., Raedt, L.D. (2007). Integrating naive bayes and foil. Journal of Machine Learning Research, 8, 481–507.
Landwehr, N., Passerini, A., Raedt, L.D., Frasconi, P. (2010). Fast learning of relational kernels. Machine Learning 78(3), 305–342.
Lipton, R.J., Naughton, J.F., Schneider, D.A., Seshadri, S. (1993). Efficient sampling strategies for relational database operations. Theoretical Computer Science, 116(1–2), 195–226.
Liu, H., & Setiono, R. (1996). A probabilistic approach to feature selection - a filter solution. In ICML ’96 (pp. 319–327).
Margaritis, D. (2009). Toward provably correct feature selection in arbitrary domains. In NIPS (pp. 1240–1248).
Merz, C.J. (1999). Using correspondence analysis to combine classifiers. Machine Learning, 36(1–2), 33–58.
Neville, J., Jensen, D., Friedland, L., Hay, M. (2003). Learning relational probability trees. In Proceedings of the ninth ACM SIGKDD (pp 625–630). New York, NY, USA: ACM Press.
Olken, F., & Rotem, D. (1986). Simple random sampling from relational databases. In VLDB (pp. 160–169).
Pearl, J. (1988). Probabilistic reasoning in intelligent systems: Networks of plausible inference. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc..
Perlich, C., & Provost, F. (2006). Distribution-based aggregation for relational learning with identifier attributes. Machine Learning, 62(1–2), 65–105.
Perlich, C., & Provost, F.J. (2003). Aggregation-based feature invention and relational concept classes. In KDD’03 (pp. 167–176).
Press, W.H., Flannery, B.P., Teukolsky, S.A., Vetterling, W.T. (1988). Numerical recipes in C: The art of scientific computing. Cambridge: Cambridge University Press.
Quinlan, J.R. (1993). C4.5: Programs for machine learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc..
Quinlan, J.R., & Cameron-Jones, R.M. (1993). Foil: A midterm report. In ECML ’93 (pp. 3–20).
Reutemann, P., Pfahringer, B., Frank, E. (2004). A toolbox for learning from relational data with propositional and multi-instance learners. In Australian conference on artificial intelligence (pp. 1017–1023).
Rückert, U., & Kramer, S. (2008). Margin-based first-order rule learning. Machine Learning, 70, 189–206.
Singh, L., Getoor, L., Licamele, L. (2005). Pruning social networks using structural properties and descriptive attributes. In ICDM ’05 (pp. 773–776).
Ting, K.M., & Witten, I.H. (1999). Issues in stacked generalization. Journal of Artificial Intelligence Research (JAIR), 10, 271–289.
Witten, I.H., & Frank, E. (2000). Data mining: Practical machine learning tools and techniques with Java implementations. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc..
Wolpert, D.H. (1990). Stacked generalization. Tech. Rep. LA-UR-90-3460, Los Alamos, NM.
Yin, X., Han, J., Yang, J., Yu, P.S. (2006). Efficient classification across multiple database relations: A crossmine approach. IEEE Transactions on Knowledge and Data Engineering, 18(6), 770–783.
Zajonic, R. (1962). A note on group judgements and group size. Human Relations, 15, 177–180.
Zhong, N., & Ohsuga, S. (1995). KOSI - an integrated system for discovering functional relations from databases. Journal of Intelligent Information Systems, 5(1), 25–50.
Zucker, J.D., & Ganascia, J.G. (1996). Representation changes for efficient learning in structural domains. In ICML ’96( pp. 543–551).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Guo, H., Viktor, H.L. & Paquet, E. Reducing the size of databases for multirelational classification: a subgraph-based approach. J Intell Inf Syst 40, 349–374 (2013). https://doi.org/10.1007/s10844-012-0229-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-012-0229-0