
Abstract
Blepharospasm is a focal dystonia in which the extraocular muscles contract repetitively, leading to excessive blinking and forced eyelid closure. Botulinum toxin type A (BoNTA) is the primary symptomatic treatment for blepharospasm and its effects have been evaluated using numerous rating scales. The main scales in use today were initially used to determine whether BoNTA treatment was superior to placebo, and most controlled trials have confirmed this. More recently, these scales have been used to determine whether there are efficacy differences between different BoNTs in blepharospasm. However, although the scales used in these trials are able to differentiate the effects of BoNT from placebo, they may not be sensitive enough to differentiate between BoNTs. Most of the scales include only four possible points for each item, which would necessitate a 25% greater improvement in one group than the other to detect any differences. Current scales are also relatively insensitive to patients with mild disability who may experience mainly psychosocial problems related to their blepharospasm. Clinical trials comparing BoNTs that include substantial numbers of mildly affected patients may be unlikely to find differences because the scales do not adequately measure mild symptoms. Additional challenges with evaluating blepharospasm include the lack of precision and objectivity of current measures, symptom variability, the need to evaluate aspects of the disorder that are most important to patients, and the different types of blepharospasm. Although no single scale may be able to capture all relevant aspects of blepharospasm, more sensitive and patient-centered scales are needed.
Similar content being viewed by others


Introduction
Blepharospasm, literally “spasm of the eyelid”, is a focal dystonia characterized by involuntary eyelid closure (Hallett 2002). Although blepharospasm like symptoms can occur secondarily to certain neurologic or ophthalmic disorders or lesions, the etiology is often unknown; in that case it is referred to as idiopathic, essential, or primary blepharospasm (Hallett 2002). Blepharospasm can range in severity from mild cases that do not appreciably interfere with daily activities to severe cases that render individuals functionally blind, preventing them from driving, working, reading, and walking.
Botulinum neurotoxin (BoNT) injections are a primary symptomatic treatment for blepharospasm. BoNTs act by inhibiting the release of acetylcholine at the neuromuscular junction, which reduces excessive muscular contractions and helps normalize muscle activity. The effects of BoNTs are reversible and temporary, lasting approximately 3 months in the treatment of blepharospasm (Jankovic and Orman 1987; Nussgens and Roggenkamper 1995).
A number of different measurement tools and scales have been used to evaluate the effects of BoNT on various aspects of blepharospasm, including force of eyelid closure, severity of muscle spasms, and patient functional status (Cohen et al. 1986; Elston and Russell 1985; Scott et al. 1985). Today, the rating instruments have coalesced into several main clinical scales, including the Jankovic Rating Scale (JRS) and Blepharospasm Disability Index (BSDI). Historically, duration of the beneficial effect has been used as a stand-alone measure of BoNT efficacy (Nussgens and Roggenkämper 1997), but today is typically considered complementary to existing efficacy scales.
In any disorder, precise and meaningful measures of improvement or deterioration in signs and/or symptoms are important in order to evaluate the patient’s disease state and the effects of the therapy. This review examines the different methods of blepharospasm assessment, beginning with a historical overview of early measures and proceeding to a discussion of current scales and their use in BoNT clinical studies. The paper concludes with a discussion and suggestions of how best to assess the efficacy of blepharospasm therapy.
Historical overview of blepharospasm measurement
Force of eyelid closure
Early studies of BoNT injections examined force of eyelid closure in grams using an external device that prevents downward movement of the upper eyelid [e.g., (Scott et al. 1985)]. However, force of eyelid closure is not widely used as an outcome measure today, as treatments for blepharospasm would ideally resolve muscle spasms while leaving eyelid force normal. With the use of BoNT, paralysis of the orbicularis muscle is not necessary for optimal benefit. In this sense, we do not agree with the scale developed by Rahman et al. (2003) in which orbicularis function is assessed as the ability of observers to manually open the eyelids of patients who are attempting to close their eyelids forcefully.
Muscle spasm
Several different muscle spasm scales were reported in the 1980s. Tsoy et al. (1985) used a scale that ranged from 0 = absent to 4 = extreme to rate the intensity of orbicularis oculi muscle spasm, as well as brow spasm. A scale used by Cohen et al. (1986) combined spasm intensity and functional ratings that ranged from 0 = none, 1 = increased blinking caused by external stimuli, 2 = mild fluttering of the lids, not incapacitating, 3 = moderate spasm with mild incapacitation, and 4 = severe spasm resulting in incapacitation (unable to drive, read, etc.).
Fahn scale
The Fahn rating scale for blepharospasm, developed in the 1980s, consists of a movement subscale and a disability scale (Fahn 1985). The movement subscale incorporates the location of involuntary movements (one point for each muscle area), as well as one point for each external factor that influences the dystonia (sunlight, television, etc.) (Fahn 1985). The frequency of involuntary movements is rated according to the percentage of waking time that movements are present (five different frequency categories), and severity of eyelid closure is rated from 0 = absent to 4 = severe, forceful eyelid contractions. The disability subscale consists of seven everyday activities (driving, reading, television, movies, shopping, walking, housework/job) for which the degree of impairment is rated according to descriptors that increase in severity from 1 to 3 or 1 to 5 (Fahn 1985). An eighth item documents the need to wear sunglasses outdoors (1 point) and indoors (1 point).
Elston functional status scales
In the 1980s and early 1990s, Elston and Russell (1985) developed a series of scales that focused on the functional status of blepharospasm patients following BoNT injections. The first of these scales ranged from 1 = functionally blind (eyes shut for >80% of day) to 3 = inconvenienced (eyes shut for 10–30% of day). In a subsequent study, Elston and colleagues asked patients to evaluate the percentage of the day spent functionally blind before and after BoNT injections (Grandas et al. 1988). A third scale by this group ranged from 1 = blind, 2 = dependent outside home, 3 = independent, poor function, 4 = independent, moderate function, 5 = inconvenienced, 6 = normal (Elston 1992).
Current blepharospasm scales and their use in BoNT trials
Current blepharospasm rating scales are largely modified versions of previous scales that have been altered for ease of use or to remedy one or more inadequacies of previous scales. Current scales fall into three general categories: (i) clinical scales, (ii) activities of daily living/functional ability status scales, and (iii) global rating scales. Each of these scale types has been used in recent studies comparing the effects of different BoNTs in blepharospasm. In this section, we briefly review the three general types of scales and, for each type, consider the benefits and drawbacks based on its use in recent BoNT trials.
Overview of clinical scales
Clinical scales focus on clinical signs and/or symptoms and are rated by observers as opposed to patients. These scales often take the form of ordinal, numeric ratings anchored by descriptors. Blepharospasm clinical rating scales in use today are modifications of the frequency and/or severity scales developed by Fahn (1985).
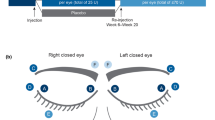
The Jankovic Rating Scale (JRS) is probably the most widely used current clinical scale (Fig. 1) (Jankovic and Orman 1987). The two subscales that make up the JRS—severity and frequency—are 5-point scales ranging from 0 to 4, where 0 indicates no symptoms and 4 indicates the most severe or frequent symptoms. As can be seen from the descriptions in Fig. 1, the JRS primarily focuses on the objective signs of blepharospasm but does incorporate some subjective symptoms such as whether the increased blinking and spasms are incapacitating, as judged by the observer.

Jankovic Rating Scale (Jankovic and Orman 1987)
Advantages of the JRS include its relative simplicity and broad applicability for both patients and physicians. The evaluations required for the scale are readily performed in an office setting without the need for complex equipment or scoring procedures. Disadvantages of the JRS may include a lack of sensitivity to small changes in blepharospasm severity or frequency, particularly at the mild end of the spectrum where patients must change from increased blinking in response to external stimuli (a score of “1”) to “none” in order for an improvement in their condition to be documented on the severity scale. Additionally, the scale does not take into account how the patient’s blepharospasm affects his or her daily activities. It may be noted that a JRS sum score of 1 is not possible, as even mild symptoms (severity score = 1) occurring at the lowest frequency (frequency = 1) give a sum score of 2.
Table 1 lists published clinical studies that were randomized or enrolled at least 50 patients and were designed to evaluate the effects of BoNTs for blepharospasm; as can be seen in this table, a number of these studies used the JRS. It should be noted that various studies have used different versions of the same scale. For example, (Mezaki et al. 1999) used a scale modified from the JRS blepharospasm frequency scale.
Jankovic Rating Scale in 2006 BoNTA non-inferiority trial (Roggenkämper et al. 2006)
The JRS was used as the primary outcome measure in a randomized, controlled, non-inferiority trial comparing Xeomin® (Merz) to BOTOX® (Allergan) published in 2006 (Roggenkämper et al. 2006). This 16-week study included 300 subjects with blepharospasm (n = 148/152 per group) who had achieved a stable response to two previous injections of BOTOX®. Subjects received a single treatment with one or the other medication based on the doses and injection sites of their previous BoNTA treatments (mean doses per eye: 19.8 units Xeomin®; 20.4 units BOTOX®).
In this study, both BoNTA products significantly reduced total JRS scores versus baseline at 3 weeks and ~3.6 months. Mean baseline scores in the two groups were comparable (5.3 Xeomin®, 5.4 BOTOX®), as were adjusted mean improvements at 3 weeks (−2.83 Xeomin®, −2.65 BOTOX®) and ~3.6 months (−0.84 Xeomin®, −0.66 BOTOX®). In this study, the JRS was sensitive enough to detect post-baseline improvements with both BoNT products; this fits with the initial use of the scale, which was to evaluate the effects of BoNTA versus placebo (Jankovic and Orman 1987).
However, the JRS may not be sensitive enough to detect differences between two BoNT products—both of which appear to be effective for the treatment of blepharospasm—and indeed, it was not designed to do so. In the non-inferiority study, a clinically irrelevant difference in the JRS sum score was defined as 0.8 points (Roggenkämper et al. 2006). Because the JRS is rated in whole numbers, a substantial portion of subjects would have needed to rate one or the other BoNTA as approximately 25% lower on either the severity or frequency subscale to achieve a mean difference of at least 0.8 (e.g., a 1-point change on a 5-point subscale scale is approximately a 25% improvement, recognizing that the psychological distance may not be equivalent between ordinal numbers on the scale). This may be somewhat unlikely with two products that are both effective for the treatment of blepharospasm.
Given these considerations with the use of the JRS (and, as discussed later, other current scales) in studies that compare different BoNTs, there is likely a bias toward finding no meaningful differences between groups. Additionally, as previously noted, it may also be more difficult to detect improvements on the JRS in mild cases of blepharospasm for which increased blinking would need to be completely absent to change a rating from 1 to 0. Finally, as a clinical scale evaluating two dimensions of blepharospasm (severity and frequency), nuances in the effects of two different BoNTAs, for instance, in quality of life measures or other more subjective criteria would not be detected.
Overview of activities of daily living/functional ability status scales
In contrast to clinical scales, instruments that assess activities of daily living or patient functional status are rated by the patients themselves. These scales recognize the importance of improvement in everyday activities as an outcome of therapy (Lindeboom et al. 1995). Here we consider functional ability scales specific to blepharospasm as opposed to general scales such the Medical Outcomes Study 36-item Short Form (SF-36), which assesses multiple health-related domains (physical, social, role limitations, bodily pain, mental health, vitality, general health) that are not specific to blepharospasm and may or may not be expected to improve with blepharospasm treatment.
In the 1980s and 1990s, the Blepharospasm Disability Scale (BDS) emerged as a useful functional ability rating scale. The BDS is an eight-item subsection of the Blepharospasm Rating Scale developed by Fahn (1985). Despite the documented reliability and validity of this scale (Lindeboom et al. 1995), it has certain drawbacks, including the lack of a “non-applicable” option for any of the individual items.
This led to the development of the Blepharospasm Disability Index (BSDI), which has been used in several recent BoNT studies (Table 1). The BSDI consists of six daily activities, each rated on a scale from 0 = no impairment to 4 = not possible due to disease, and also includes a “not applicable” option (Fig. 2) (Goertelmeyer et al. 2002). Advantages of the BSDI include its focus on daily activities and ease of use. The scoring system is also relatively simple: mean item scores on the BSDI are calculated by dividing the sum score by the number of applicable items.

The Craniocervical Dystonia Questionnaire (CDQ) is a dystonia-specific quality of life instrument consisting of 24 questions that make up six subscales: stigma, emotional wellbeing, pain, activities of daily living, and social/family life (Müller et al. 2004). Each question is answered as “never, occasionally, sometimes, often, or always.” An advantage of this scale is that it includes questions on social and emotional aspects of dystonia as opposed to focusing solely on limitations to activities. However, the sensitivity of this scale in comparing treatments may be limited by the five-choice options.
BDS in 2008 Dysport® (Ipsen) trial
A modified version of the BDS was used as the primary outcome measure in a randomized, controlled study of Dysport® versus placebo for the treatment of blepharospasm (Truong et al. 2008). This 16-week study included 120 subjects with blepharospasm who had a minimum score of 8 out of 26 possible points on the BDS. Subjects were assigned to receive a single treatment with placebo or one of three Dysport® doses: 40, 80, or 120 units/eye.
In this study, the BDS was modified to exclude questions that were not relevant for individual patients and include an additional rating of 0 (zero) if an item was not affected by blepharospasm. BDS scores were calculated as the percentage of normal activity, defined as “total points scored divided by the maximum possible individual score, multiplied by 90 and subtracted from 90% (i.e., final score = 90% − 90 [score/maximum possible])” (Truong et al. 2008) based on the scoring system specified by Fahn (1985). BDS outcomes were presented as differences in median percentage of normal activity between the BoNTA and placebo-treated groups.
Neither mean nor median baseline BDS scores were presented in the article, but all subjects must have had a minimum score of 8 to be included in the study. All of the BoNTA doses tested significantly increased the percentage of normal activity on the BDS over placebo at weeks 4, 8, and 12, with the two highest doses also showing significant improvements over placebo at week 16. Thus, as modified in this study, the BDS was able to detect differences between BoNTA versus placebo.
BSDI in 2006 BoNTA non-inferiority comparison trial
Although the JRS was the primary outcome measure in the randomized, non-inferiority trial described in a previous section, this study also included the BSDI as a secondary outcome measure (Roggenkämper et al. 2006). Mean item scores on the BSDI were calculated at 21 and 109–112 days post-treatment. As mentioned above, mean item scores on the BSDI are calculated by dividing the sum score by the number of applicable items.
In this study, both BoNTA products significantly reduced mean item scores on the BSDI versus baseline at the two follow-up time points. Mean item scores on the BSDI at baseline were compared in the two groups (1.67 BOTOX®, 1.60 Xeomin®), and mean improvements at 21 days (−0.83 BOTOX®, −0.82 Xeomin®) and 109–112 days (−0.22 BOTOX®, −0.36 Xeomin®) were not significantly different at the P < 0.05 level.
BSDI in 2010 BoNTA preliminary comparison trial
Total BSDI scores were used as the primary outcome measure in a randomized, controlled trial comparing Xeomin® to BOTOX® (Wabbels et al. 2010). Total BSDI scores are calculated as the sum of scores on all of the BSDI items. This 14-week study included 65 subjects with blepharospasm (n = 32/33 per group) who had received at least one treatment with BOTOX® ≥20 units/eye and required another treatment with the same dose. Subjects were randomized to receive a single treatment with one or the other medication based on the doses and injection sites of their previous BoNTA treatment (mean doses 29 units BOTOX®, 27 units Xeomin®).
In this study, both BoNTA products significantly reduced total BSDI scores versus baseline at 4 and 8 weeks. Mean total baseline scores in the two groups were compared (7.9 BOTOX®, 8.3 Xeomin®), and mean improvements in total BSDI scores at 4 weeks (−2.8 BOTOX®, −1.3 Xeomin®) and 8 weeks (−1.3 BOTOX®, −0.8 Xeomin®) were not significantly different at the P < 0.05 level. Mean item scores on the BSDI were also compared at baseline (1.39 BOTOX®, 1.44 Xeomin®), and improvements in mean item scores on the BSDI at 4 weeks (−0.42 BOTOX®, −0.21 Xeomin®) were not significantly different at the P < 0.05 level.
Again, it seems possible that this scale may not be sensitive enough to detect differences between two BoNT products. The BSDI shares the same sensitivity issues as the JRS in that the ratings for each category range from 0 = no impairment to 4 = not possible due to disease. As with the JRS, the BSDI ratings consist of whole numbers, and subjects would need to rate one or the other BoNTA as approximately 25% lower on one of the items in order to detect any difference between them. Again, this assumes that a 1-point improvement on a 5-point scale constitutes an approximately 25% improvement, recognizing that the psychological distance may not be equivalent between ordinal numbers on the scale. Like the JRS, the BSDI is a modified version of a scale that was originally developed to determine whether BoNT was more effective than placebo in the treatment of focal dystonia (Lindeboom et al. 1995).
Application of the “clinically meaningful” improvement criteria
Jankovic et al. (2009) recently analyzed the metric properties of the JRS and BSDI in blepharospasm patients by evaluating the relationship between various clinical outcome measures. These authors concluded that a 0.7-point improvement in BSDI mean item score and a 2-point improvement in the JRS sum score constituted clinically relevant improvements (Jankovic et al. 2009).
It is important to point out that these criteria are only relevant for patients whose baseline scores are >2 on the JRS and >0.7 on the BSDI (calculated as the mean of all BSDI item scores that are relevant for a given patient). A case in point is the BoNTA comparison study described in the preceding section (Wabbels et al. 2010). In this study, only 19 of the 31 subjects (61%) in the BOTOX® group and 24 of 33 subjects (73%) in the Xeomin® group had high enough baseline BSDI scores to be included in a responder analysis based on the Jankovic criterion (Wabbels et al. 2010).
Caution must therefore be used when applying the Jankovic criteria to overall study population means; only those whose baseline scores exceed the improvement criteria can legitimately be subject to them.
Global rating scales
Global rating scales are usually general rather than disease specific, designed to capture the overall subjective effects of treatment. These scales can be physician or patient rated, and are usually used as secondary instead of primary outcome measures.
One global rating scale that has often been used in BoNT trials is a modification of the one developed by Brin et al. (1995). On this scale, improvement or worsening from baseline is rated from −4 (marked worsening in symptoms and function) to 0 (no effect) to +4 (marked improvement in symptoms and function). This scale has been used in a number of BoNTA trials in several different medical conditions (Naumann and Lowe 2001; Roggenkämper et al. 2006; Simpson et al. 1996).
A percentage of normal function scale developed by Brin et al. (1994; 1995) has been used in other BoNT studies (Wissel et al. 2000). On this scale, patients are asked to rate the function of the body part treated from 0% (fully disabled with no functional activity) to 100% (normal function).
An advantage of patient-rated global scales is that they permit assessment and quantification of improvements in symptoms or functions that are important to patients. Because these scales are non-specific, they may consider more than one aspect of a treatment’s effects and theoretically represent a global judgment of how well the treatment works. Additionally, global assessment scales that are anchored by only a few rating descriptions such as mild, moderate, and marked essentially have built-in clinical relevance in that improvement from marked to moderate or moderate to mild appears to be clinically meaningful. However, the inclusion of such few ratings renders the scale less sensitive than larger scales. Another drawback to global scales is their subjectivity, with ratings possibly influenced by psychological variables such as mental state/mood and expectations. Patients are also typically asked to compare their condition to baseline, which may be difficult to remember.
Global assessments in BoNT comparison trials
A 9-point global assessment scale (−4 to 0 to +4) described in the preceding section was used in both the non-inferiority (Roggenkämper et al. 2006) and preliminary comparison (Wabbels et al. 2010) trials evaluating the effects of BOTOX® versus those of Xeomin®. In both studies, mean improvements with the BoNTA products were generally between +2 and +3, supporting a global effect on blepharospasm. However, statistically significant differences between BoNTA on this measure were not detected in either trial. As with the previously described JRS and BSDI measures, it may not be possible to detect subtle differences between two BoNTAs due to the insensitivity of the scales (only four possible ratings for improvement).
Considerations/conclusions
There are several important considerations with blepharospasm scales beyond the need for reliable and valid measurement of the condition. First, it must be recognized that blepharospasm can be challenging to assess because symptoms may vary depending on time of day, patient stress level, lack of sleep, situation (e.g., home vs. examiner’s office), and environmental stimuli. Thus, blepharospasm measurement is hindered by the variable nature of the complaints. To address this, patients should be evaluated in the same location and the same time of day, recognizing that it will not be possible to control all of the non-medication related factors that may influence blepharospasm severity during rating.
A second consideration is the lack of precision and objectivity of current measures. For conditions such as high blood pressure and diabetes, precise and sensitive measurements can be performed using manual or electronic devices. Historically, blepharospasm has been evaluated using an instrument to measure eyelid force; however, as noted previously, this is not an optimal measure for the effects of BoNTs because the therapeutic goal is elimination of spasms while maintaining normal force of eyelid closure. The development of alternate devices for the measurement of blepharospasm could alleviate the subjectivity issue. Of note, several studies have evaluated the use of video nystagmography as a measurement tool for blinking in blepharospasm before and after botulinum toxin treatment (Casse et al. 2008, 2009). The objectivity of this method is advantageous, although further studies are needed to assess its validity.
A third consideration is the lack of sensitivity of current rating scales. Clearly, more sensitive scales are needed if we are to accurately compare the effects of different BoNTs in the treatment of blepharospasm. Current scales, which were initially used to determine whether BoNTs were superior to placebo, are probably biased against finding differences due to their lack of sensitivity. To address this, scales should incorporate a broader range of ratings. One global assessment scale that does include a broad range is the percentage of normal function (Brin et al. 1995). Perhaps the utility of this scale could be improved by including descriptive anchors such as 50% = half of normal function, 90% = almost normal function, etc. In this vein, it is interesting to note that some of our patients have developed similar scales for themselves (e.g., diaries listing percentage of relief). The sensitivity limitations with existing scales may be in part overcome by the use of visual analogue scales or percentage function scales in which the patient may be asked, for example, to rate the extent to which their disease limits specific activities (e.g., reading, watching television, working, participating in social activities). However, diaries would be particularly important in these analyses because it may be hard for patients to accurately remember the extent of their limitations prior to treatment.
A related consideration is whether the scales are sensitive enough for patients with mild disability or whether the scales need to be adapted for this population, who mainly have discomfort or psychosocial problems due to the visibility of the blepharospasm but are not functionally restricted. For example, in the study that used the BSDI as the primary outcome measure, the mean scores on individual BSDI items before injection were only 1.39 and 1.44 for the two groups, indicating only mild impairment (Wabbels et al. 2010). In such cases, the BSDI would not detect improvement unless subjects obtained a rating of 0, indicating no impairment. It may be possible to address this issue by integrating several items that pertain to the psychosocial or aesthetic aspects of blepharospasm into existing scales.
Another related consideration is whether current scales measure what is important to patients. The BSDI attempts to do this by including activities of daily living; however, it is unclear whether these represent the aspects of blepharospasm that are most important to patients. We have observed that some patients return for their next BoNTA injection when their scores on existing scales are “0” (zero). Although this could be a function of patients seeking re-treatment before the effects of BoNT wear off, it may represent the inadequacy of current scales in measuring what is important to these patients. For instance, more mildly affected patients often note that it is the reaction of others to their eye spasms that is the most bothersome aspect of their condition. This is not captured on current scales, with the exception of the dystonia-specific quality of life scale, CDQ-24, which includes a stigma subscale (Müller et al. 2004). Of course, no scale can capture every aspect of the condition that is important to all patients. However, it may be possible to develop a scale that permits patients to select the top 2 or 3 most bothersome aspects of their condition and rate “percentage of normal” on that variable following treatment. This would represent an adaptation of the Disability Assessment Scale that has been used to evaluate the effects of BoNTs in focal spasticity (Brashear et al. 2002).
It may also be noted that there is more than one type of blepharospasm. There is a “typical” blepharospasm, which may be orbital, palpebral or mixed and may present as either tonic or phasic. There is also a levator inhibition subtype in which the major problem is opening the lid. There may also be patients who present with a hybrid type of blepharospsam that includes components of typical blepharospasm and levator inhibition (Aramideh et al. 1994). True apraxia of the eyelid (not to be confused with levator inhibition) is probably rare; by definition this is not a dystonia and therefore it is not treated with BoNTA. Existing scales do not address differences between subtypes of blepharospasm.
Another consideration in the measurement of BoNT effects is duration. Although duration has frequently been used as a measure of BoNT efficacy, it is imprecise and definitions have varied or, in some cases, have not been specified. For instance, total amelioration of symptoms for 4 weeks is not the same as a reduction in symptoms for 4 weeks (Nussgens and Roggenkämper 1997). Another challenge with measuring duration is that patients often return for re-injection of BoNTA before the effects of their previous treatment have completely worn off. For instance, patients may know that symptoms recur after 13 weeks, so they get injections every 12 weeks. Nevertheless, information about BoNT action over time is important in assessing the real effect of the medication over time and is important to include in clinical studies.
Also critical in comparing different therapies for blepharospasm, or any condition, is the clinical trial design. The study must be adequately powered and the variability controlled to permit detection of expected differences (i.e., avoidance of a type II or beta error). This may involve ensuring that enough subjects are enrolled in the study and designing the inclusion/exclusion criteria to reduce heterogeneity in the study population. Crossover designs may be useful, provided that adequate washout periods are allowed between injections to preclude carryover effects. Administration of questionnaires prior to and following each treatment may also be useful for minimizing differences among subjects.
A final important point has less to do with the assessment scales than the doses of BoNTs. In studies that compare different BoNTs, the products are typically compared at set doses—usually corresponding to each patient’s maintenance dose. Although physicians vary in the doses administered, it is likely that these tend to be at or near the top of the dose–response curve for each patient. Thus, the products are compared at what may be the asymptotic portions of the dose–response curves. If no differences are found, some may interpret this as indicating that the different BoNT products produce the same effects at the same doses. However, this is not necessarily the correct interpretation. A hypothetical example may be one BoNT that produces a maximal effect at 1.25 U/site and another that produces a maximal effect at 2.0 U/site. If the products are compared at 2.5 U/site, the study may find no difference. However, if the BoNTs are compared across a range of doses, differences may become evident and such differences may be particularly evident at the lowest effective doses.
Based on the aforementioned considerations, it seems unlikely that any single measure is adequate to evaluate the effects of treatment on blepharospasm. Objective measures may not be sensitive to features of the condition that are most important to patients, and subjective, patient-rated scales may depend too much on the patient’s memory, expectations, and psychological state at the time of rating. In the absence of a mechanical or electronic device that provides a valid measure of response to treatment, it seems logical to rely on a combination of objective and subjective rating scales. However, as described previously, current measures lack sensitivity and thus we should seek to amend these scales or develop new ones. In this pursuit, it will be important to distinguish clinically meaningful differences in improvement on the various measures, as (Jankovic et al. 2009) have attempted to do for the JRS and BSDI. However, smaller differences on more objective or sensitive measures may also be important in the study of BoNTs, as these could indicate pharmacological or potency differences.
Our overall conclusion is that no single scale is broad enough to capture the entire essential blepharospasm experience; multiple scales are likely necessary to get a full picture of this disorder. Additionally, existing scales are not sensitive enough to differentiate the effects of different BoNTs in clinical trials and may not be sensitive enough for patients with mild blepharospasm. We recommend (i) development of more sensitive scales, including the pursuit of a valid biomechanical or electronic measurement device and (ii) development of a scale that incorporates symptoms that are known to be relevant to patients (e.g., selection of several symptoms for ratings).
References
Aramideh M, Ongerboer de Visser BW, Devriese PP, Bour LJ, Speelman JD (1994) Electromyographic features of levator palpebrae superioris and orbicularis oculi muscles in blepharospasm. Brain 117(Pt 1):27–38
Boyle MH, McGwin G Jr, Flanagan CE, Vicinanzo MG, Long JA (2009) High versus low concentration botulinum toxin A for benign essential blepharospasm: does dilution make a difference? Ophthal Plast Reconstr Surg 25:81–84
Brashear A, Gordon MF, Elovic E, Kassicieh VD, Marciniak C, Do M, Lee CH, Jenkins S, Turkel C (2002) Intramuscular injection of botulinum toxin for the treatment of wrist and finger spasticity after a stroke. N Engl J Med 347:395–400
Brin M, Blitzer A, Herman S, Steward C (1994) Oromandibular dystonia: treatment of 96 cases with botulinum A. In: Jankovic J, Hallett M (eds) Therapy with botulinum toxin. Marcel Dekker, New York, pp 429–435
Brin MF, Jankovic J, Comella C, Blitzer A, Tsui JKC, Pullman SL (1995) Treatment of dystonia using botulinum toxin. In: Kurlan R (ed) Treatment of movement disorders. Lippincott Company, New York, pp 183–246
Casse G, Adenis JP, Sauvage JP, Robert PY (2008) Videonystagmography as a tool to assess blepharospasm before and after botulinum toxin injection. Graefes Arch Clin Exp Ophthalmol 246:1307–1314
Casse G, Adenis JP, Sauvage JP, Robert PY (2009) Videonystagmography to assess eyelid dynamic disorders. Orbit 28:20–24
Cohen DA, Savino PJ, Stern MB, Hurtig HI (1986) Botulinum injection therapy for blepharospasm: a review and report of 75 patients. Clin Neuropharmacol 9:415–429
Elston JS (1992) The management of blepharospasm and hemifacial spasm. J Neurol 239:5–8
Elston JS, Russell RW (1985) Effect of treatment with botulinum toxin on neurogenic blepharospasm. Br Med J (Clin Res Ed) 290:1857–1859
Fahn S (1985) Rating scales for blepharopsasm. In: Bosniak SL (ed) Blepharopsasm, advanced ophthalmology plastic reconstructive surgery. Pergamom Press, New York, pp 97–101
Fahn S, List T, Moskowitz C, Brin M, Bressman S, Burke RE, Scott A (1985) Double-blind controlled study of botulinum toxin for blepharospasm. Neurology 35(Suppl 1):271–272
Frueh BR, Nelson CC, Kapustiak JF, Musch DC (1988) The effect of omitting botulinum toxin from the lower eyelid in blepharospasm treatment. Am J Ophthalmol 106:45–47
Girlanda P, Quartarone A, Sinicropi S, Nicolosi C, Messina C (1996) Unilateral injection of botulinum toxin in blepharospasm: single fiber electromyography and blink reflex study. Mov Disord 11:27–31
Goertelmeyer S, Brinkmann G, Comes A, Delcker A (2002) The Blepharospasm Disability Index (BSDI) for the assessment of functional health in focal dystonia. Clin Neurophysiol 113:S77–S78
Grandas F, Elston J, Quinn N, Marsden CD (1988) Blepharospasm: a review of 264 patients. J Neurol Neurosurg Psychiatry 51:767–772
Hallett M (2002) Blepharospasm: recent advances. Neurology 59:1306–1312
Jankovic J, Orman J (1987) Botulinum A toxin for cranial-cervical dystonia: a double-blind, placebo-controlled study. Neurology 37:616–623
Jankovic J, Kenney C, Grafe S, Goertelmeyer R, Comes G (2009) Relationship between various clinical outcome assessments in patients with blepharospasm. Mov Disord 24:407–413
Lindeboom R, De Haan R, Aramideh M, Speelman JD (1995) The blepharospasm disability scale: an instrument for the assessment of functional health in blepharospasm. Mov Disord 10:444–449
Mauriello JA Jr, Dhillon S, Leone T, Pakeman B, Mostafavi R, Yepez MC (1996) Treatment selections of 239 patients with blepharospasm and Meige syndrome over 11 years. Br J Ophthalmol 80:1073–1076
Mezaki T, Kaji R, Brin MF, Hirota-Katayama M, Kubori T, Shimizu T, Kimura J (1999) Combined use of type A and F botulinum toxins for blepharospasm: a double-blind controlled trial. Mov Disord 14:1017–1020
Müller J, Wissel J, Kemmler G, Voller B, Bodner T, Schneider A, Wenning GK, Poewe W (2004) Craniocervical dystonia questionnaire (CDQ-24): development and validation of a disease-specific quality of life instrument. J Neurol Neurosurg Psychiatry 75:749–753
Naumann M, Lowe NJ (2001) Botulinum toxin type A in treatment of bilateral primary axillary hyperhidrosis: randomised, parallel group, double blind, placebo controlled trial. BMJ 323:596–599
Nussgens Z, Roggenkamper P (1995) Long-term treatment of blepharospasm with botulinum toxin type A. Ger J Ophthalmol 4:363–367
Nussgens Z, Roggenkämper P (1997) Comparison of two botulinum toxin preparations in the treatment of essential blepharospasm. Graefes Arch Clin Exp Ophthalmol 235:197–199
Price J, Farish S, Taylor H, O’Day J (1997) Blepharospasm and hemifacial spasm. Randomized trial to determine the most appropriate location for botulinum toxin injections. Ophthalmology 104:865–868
Quagliato EM, Carelli EF, Viana MA (2010) Prospective, randomized, double-blind study, comparing botulinum toxins type A Botox and Prosigne for blepharospasm and hemifacial spasm treatment. Clin Neuropharmacol 33:27–31
Rahman R, Berry-Brincat A, Thaller VT (2003) A new grading system for assessing orbicularis muscle function. Eye 17:610–612
Rieder CR, Schestatsky P, Socal MP, Monte TL, Fricke D, Costa J, Picon PD (2007) A double-blind, randomized, crossover study of Prosigne versus Botox in patients with blepharospasm and hemifacial spasm. Clin Neuropharmacol 30:39–42
Roggenkämper P, Jost WH, Bihari K, Comes G, Grafe S (2006) Efficacy and safety of a new botulinum toxin type A free of complexing proteins in the treatment of blepharospasm. J Neural Transm 113:303–312
Sampaio C, Ferreira JJ, Simoes F, Rosas MJ, Magalhaes M, Correia AP, Bastos-Lima A, Martins R, Castro-Caldas A (1997) DYSBOT: a single-blind, randomized parallel study to determine whether any differences can be detected in the efficacy and tolerability of two formulations of botulinum toxin type A—Dysport and Botox—assuming a ratio of 4:1. Mov Disord 12:1013–1018
Scott AB, Kennedy RA, Stubbs HA (1985) Botulinum A toxin injection as a treatment for blepharospasm. Arch Ophthalmol 103:347–350
Simpson DM, Alexander DN, O’Brien CF, Tagliati M, Aswad AS, Leon JM, Gibson J, Mordaunt JM, Monaghan EP (1996) Botulinum toxin type A in the treatment of upper extremity spasticity: a randomized, double-blind, placebo-controlled trial. Neurology 46:1306–1310
Truong D, Comella C, Fernandez HH, Ondo WG (2008) Efficacy and safety of purified botulinum toxin type A (Dysport) for the treatment of benign essential blepharospasm: a randomized, placebo-controlled, phase II trial. Parkinsonism Relat Disord 14:407–414
Tsoy EA, Buckley EG, Dutton JJ (1985) Treatment of blepharospasm with botulinum toxin. Am J Ophthalmol 99:176–179
Wabbels B, Reichel G, Fulford-Smith A, Wright N, Roggenkämper P (2010) Double-blind, randomised, parallel group pilot study comparing two botulinum toxin type A products for the treatment of blepharospasm. J Neural Transm. [Epub ahead of print] PMID:21161715
Wissel J, Muller J, Dressnandt J, Heinen F, Naumann M, Topka H, Poewe W (2000) Management of spasticity associated pain with botulinum toxin A. J Pain Symptom Manag 20:44–49
Yoon JS, Kim JC, Lee SY (2009) Double-blind, randomized, comparative study of Meditoxin versus Botox in the treatment of essential blepharospasm. Korean J Ophthalmol 23:137–141
Acknowledgments
Professional writing assistance in the preparation of this manuscript was provided by Mary Ann Chapman, PhD, and was funded by Allergan, Inc. PD Dr. Wabbels, Prof. Dr. Jost and Prof. Dr. Roggenkämper received research grants and honoraria from Merz and Allergan.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Appendix: Studies or case reports evaluating BoNT for the treatment of blepharospasm
Based on a search of PubMed. Key words: botulinum and blepharospasm; limited to English or German language, clinical studies, case reports, adverse event reports, and meta-analyses.
Appendix: Studies or case reports evaluating BoNT for the treatment of blepharospasm
-
1.
Ainsworth JR, Kraft SP (1995) Long-term changes in duration of relief with botulinum toxin treatment of essential blepharospasm and hemifacial spasm. Ophthalmology 102:2036–2040
-
2.
Albanese A, Colosimo C, Carretta D, Dickmann A, Bentivoglio AR, Tonali P (1992) Botulinum toxin as a treatment for blepharospasm, spasmodic torticollis and hemifacial spasm. Eur Neurol 32:112–117
-
3.
Albanese A, Bentivoglio AR, Colosimo C, Galardi G, Maderna L, Tonali P (1996) Pretarsal injections of botulinum toxin improve blepharospasm in previously unresponsive patients. J Neurol Neurosurg Psychiatry 60:693–694
-
4.
Alderson K, Holds JB, Anderson RL (1991) Botulinum-induced alteration of nerve-muscle interactions in the human orbicularis oculi following treatment for blepharospasm. Neurology 41:1800–1805
-
5.
Allam N, Fonte-Boa PM, Tomaz CA, Brasil-Neto JP (2005) Lack of effect of botulinum toxin on cortical excitability in patients with cranial dystonia. Clin Neuropharmacol 28:1–5
-
6.
Aramideh M, Bour LJ, Koelman JH, Speelman JD, Ongerboer de Visser BW (1994) Abnormal eye movements in blepharospasm and involuntary levator palpebrae inhibition. Clinical and pathophysiological considerations. Brain 117(Pt 6):1457–1474
-
7.
Aramideh M, Ongerboer de Visser BW, Devriese PP, Bour LJ, Speelman JD (1994) Electromyographic features of levator palpebrae superioris and orbicularis oculi muscles in blepharospasm. Brain 117 (Pt 1):27–38
-
8.
Aramideh M, Ongerboer de Visser BW, Koelman JH, Bour LJ, Devriese PP, Speelman JD (1994) Clinical and electromyographic features of levator palpebrae superioris muscle dysfunction in involuntary eyelid closure. Mov Disord 9:395–402
-
9.
Aramideh M, Ongerboer de Visser BW, Brans JW, Koelman JH, Speelman JD (1995) Pretarsal application of botulinum toxin for treatment of blepharospasm. J Neurol Neurosurg Psychiatry 59:309–311
-
10.
Aramideh M, Ongerboer de Visser BW, Koelman JH, Speelman JD (1995) Motor persistence of orbicularis oculi muscle in eyelid-opening disorders. Neurology 45:897–902
-
11.
Arthurs B, Flanders M, Codere F, Gauthier S, Dresner S, Stone L (1987) Treatment of blepharospasm with medication, surgery and type A botulinum toxin. Can J Ophthalmol 22:24–28
-
12.
Ascher B, Klap P, Marion MH, Chanteloub F (1995) Botulinum toxin in the treatment of frontoglabellar and periorbital wrinkles. An initial study. Ann Chir Plast Esthet 40:67–76
-
13.
Badarny S, Susel Z, Honigman S (2008) Effectivity of Dysport in patients with blepharospasm and hemifacial spasm who experienced failure with Botox. Isr Med Assoc J 10:520–522
-
14.
Balash Y, Giladi N (2004) Efficacy of pharmacological treatment of dystonia: evidence-based review including meta-analysis of the effect of botulinum toxin and other cure options. Eur J Neurol 11:361–370
-
15.
Balkan RJ, Poole T (1991) A 5-year analysis of botulinum toxin type A injections: some unusual features. Ann Ophthalmol 23:326–333
-
16.
Barnes MP, Best D, Kidd L, Roberts B, Stark S, Weeks P, Whitaker J (2005) The use of botulinum toxin type-B in the treatment of patients who have become unresponsive to botulinum toxin type-A—initial experiences. Eur J Neurol 12:947–955
-
17.
Behari M, Singh KK, Seshadri S, Prasad K, Ahuja GK (1994) Botulinum toxin A in blepharospasm and hemifacial spasm. J Assoc Physicians India 42:205–208
-
18.
Behari M, Raju GB (1996) Electrophysiological studies in patients with blepharospasm before and after botulinum toxin A therapy. J Neurol Sci 135:74–77
-
19.
Ben Simon GJ, McCann JD (2005) Benign essential blepharospasm. Int Ophthalmol Clin 45:49–75
-
20.
Bentivoglio AR, Fasano A, Ialongo T, Soleti F, Lo Fermo S, Albanese A (2009) Fifteen-year experience in treating blepharospasm with Botox or Dysport: same toxin, two drugs. Neurotox Res 15:224–231
-
21.
Bentley C (1996) Botulinum neurotoxin A in ophthalmology. Ophthalmic Physiol Opt 16(Suppl 1):S9–14
-
22.
Berardelli A, Carta A, Stocchi F, Formica A, Agnoli A, Manfredi M (1990) Botulinum A toxin injection in patients with blepharospasm, torticollis and hemifacial spasm. Ital J Neurol Sci 11:589–593
-
23.
Berardelli A, Formica A, Mercuri B, Abbruzzese G, Agnoli A, Agostino R, Caraceni T, Carella F, De Fazio G, De Grandis D et al (1993) Botulinum toxin treatment in patients with focal dystonia and hemifacial spasm. A multicenter study of the Italian Movement Disorder Group. Ital J Neurol Sci 14:361–367
-
24.
Berlin AJ, Cassen JH, DeNelsky G, Hanson MR, Sweeney PJ (1987) Benign essential blepharospasm treated with botulinum toxin. Cleve Clin J Med 54:421–426
-
25.
Bhidayasiri R, Cardoso F, Truong DD (2006) Botulinum toxin in blepharospasm and oromandibular dystonia: comparing different botulinum toxin preparations. Eur J Neurol 13(Suppl 1):21–29
-
26.
Bigalke H, Wohlfarth K, Irmer A, Dengler R (2001) Botulinum A toxin: Dysport improvement of biological availability. Exp Neurol 168:162–170
-
27.
Bigalke H (2002) The pharmacology of botulinum toxin. Med Monatsschr Pharm 25:305–308
-
28.
Biglan AW, Gonnering R, Lockhart LB, Rabin B, Fuerste FH (1986) Absence of antibody production in patients treated with botulinum A toxin. Am J Ophthalmol 101:232–235
-
29.
Biglan AW, May M, Walden PG (1986) Treatment of facial spasm with oculinum (Clostridium botulinum toxin): a preliminary report. Am J Otol 7:65–70
-
30.
Biglan AW, May M, Bowers RA (1988) Management of facial spasm with Clostridium botulinum toxin, type A (Oculinum). Arch Otolaryngol Head Neck Surg 114:1407–1412
-
31.
Bihari K (2005) Safety, effectiveness, and duration of effect of BOTOX after switching from Dysport for blepharospasm, cervical dystonia, and hemifacial spasm dystonia, and hemifacial spasm. Curr Med Res Opin 21:433–438
-
32.
Birner P, Schnider P, Muller J, Wissel J, Fuchs I, Auff E (1999) Torticollis spasmodicus, blepharospasm and hemifacial spasm. Subjective evaluation of therapy by patients. Nervenarzt 70:903–908
-
33.
Blitzer A, Brin MF, Greene PE, Fahn S (1989) Botulinum toxin injection for the treatment of oromandibular dystonia. Ann Otol Rhinol Laryngol 98:93–97
-
34.
Bodker FS, Olson JJ, Putterman AM (1993) Acquired blepharoptosis secondary to essential blepharospasm. Ophthalmic Surg 24:546–550
-
35.
Boghen D, Tozlovanu V, Iancu A, Forget R (2002) Botulinum toxin therapy for apraxia of lid opening. Ann N Y Acad Sci 956:482–483
-
36.
Boghen DR, Lesser RL (2000) Blepharospasm and Hemifacial Spasm. Curr Treat Options Neurol 2:393–400
-
37.
Bogucki A (1999) Serial SFEMG studies of orbicularis oculi muscle after the first administration of botulinum toxin. Eur J Neurol 6:461–467
-
38.
Borodic G, Pearce LB, Johnson E (1994) Antibodies to botulinum toxin. Ophthalmology 101: 1158–1159
-
39.
Borodic G (1998) Myasthenic crisis after botulinum toxin. Lancet 352:1832
-
40.
Borodic GE, Cozzolino D (1989) Blepharospasm and its treatment, with emphasis on the use of botulinum toxin. Plast Reconstr Surg 83:546–554
-
41.
Borodic GE, Joseph M, Fay L, Cozzolino D, Ferrante RJ (1990) Botulinum A toxin for the treatment of spasmodic torticollis: dysphagia and regional toxin spread. Head Neck 12:392–399
-
42.
Borodic GE, Cozzolino D, Ferrante R, Wiegner AW, Young RR (1991) Innervation zone of orbicularis oculi muscle and implications for botulinum A toxin therapy. Ophthal Plast Reconstr Surg 7:54–60
-
43.
Borodic GE, Ferrante R (1992) Effects of repeated botulinum toxin injections on orbicularis oculi muscle. J Clin Neuroophthalmol 12:121–127
-
44.
Borodic GE, Pearce LB, Cheney M, Metson R, Brownstone D, Townsend D, McKenna M (1993) Botulinum A toxin for treatment of aberrant facial nerve regeneration. Plast Reconstr Surg 91:1042–1045
-
45.
Boyle MH, McGwin G Jr, Flanagan CE, Vicinanzo MG, Long JA (2009) High versus low concentration botulinum toxin A for benign essential blepharospasm: does dilution make a difference? Ophthal Plast Reconstr Surg 25:81–84
-
46.
Brin MF, Fahn S, Moskowitz C, Friedman A, Shale HM, Greene PE, Blitzer A, List T, Lange D, Lovelace RE, et al (1987) Localized injections of botulinum toxin for the treatment of focal dystonia and hemifacial spasm. Mov Disord 2:237–254
-
47.
Brin MF (1991) Interventional neurology: treatment of neurological conditions with local injection of botulinum toxin. Arch Neurobiol (Madr) 54:173–189
-
48.
Burgunder JM (1992) Treatment of movement disorders using botulinum toxin. Schweiz Med Wochenschr 122:1311–1316
-
49.
Burns CL, Gammon JA, Gemmill MC (1986) Ptosis associated with botulinum toxin treatment of strabismus and blepharospasm. Ophthalmology 93:1621–1627
-
50.
Cakmur R, Ozturk V, Uzunel F, Donmez B, Idiman F (2002) Comparison of preseptal and pretarsal injections of botulinum toxin in the treatment of blepharospasm and hemifacial spasm. J Neurol 249:64–68
-
51.
Calace P, Cortese G, Piscopo R, Della Volpe G, Gagliardi V, Magli A, De Berardinis T (2003) Treatment of blepharospasm with botulinum neurotoxin type A: long-term results. Eur J Ophthalmol 13:331–336
-
52.
Calne S (1993) Local treatment of dystonia and spasticity with injections of botulinum-A toxin. Axone 14:85–88
-
53.
Cardoso F, de Oliveira JT, Puccioni-Sohler M, Fernandes AR, de Mattos JP, Lopes-Cendes I (2000) Eyelid dystonia in Machado-Joseph disease. Mov Disord 15:1028–1030
-
54.
Carruthers J, Stubbs HA (1987) Botulinum toxin for benign essential blepharospasm, hemifacial spasm and age-related lower eyelid entropion. Can J Neurol Sci 14:42–45
-
55.
Carruthers J, Carruthers A, Bagaric D (1995) Can ptosis incidence be reduced after lid injections of botulinum A exotoxin for blepharospasm and hemifacial spasm? Can J Ophthalmol 30:147
-
56.
Carruthers J, Carruthers A (2007) Complications of botulinum toxin type A. Facial Plast Surg Clin North Am 15:51–54
-
57.
Carruthers JD (1985) Ophthalmologic use of botulinum A exotoxin. Can J Ophthalmol 20:135–141
-
58.
Casse G, Adenis JP, Sauvage JP, Robert PY (2008) Videonystagmography as a tool to assess blepharospasm before and after botulinum toxin injection. Graefes Arch Clin Exp Ophthalmol 246:1307–1314
-
59.
Casse G, Adenis JP, Sauvage JP, Robert PY (2009) Videonystagmography to assess eyelid dynamic disorders. Orbit 28:20–24
-
60.
Ceballos-Baumann A (2008) Botulinum toxin. Development for therapeutic purposes. Nervenarzt 79(Suppl 1):3–8
-
61.
Ceballos-Baumann AO, Gasser T, Dengler R, Oertel WH (1990) Local injection treatment with botulinum toxin A in blepharospasm, Meige syndrome and hemifacial spasm. Observations in 106 patients. Nervenarzt 61:604–610
-
62.
Chang LB, Tsai CP, Liao KK, Kao KP, Yuan CL, Yen DJ, Lin KP (1999) Use of botulinum toxin A in the treatment of hemifacial spasm and blepharospasm. Zhonghua Yi Xue Za Zhi (Taipei) 62:1–5
-
63.
Chapman KL, Bartley GB, Waller RR, Hodge DO (1999) Follow-up of patients with essential blepharospasm who underwent eyelid protractor myectomy at the Mayo Clinic from 1980 through 1995. Ophthal Plast Reconstr Surg 15:106–110
-
64.
Chen R, Karp BI, Hallett M (1998) Botulinum toxin type F for treatment of dystonia: long-term experience. Neurology 51:1494–1496
-
65.
Cillino S, Raimondi G, Guepratte N, Damiani S, Cillino M, Di Pace F, Casuccio A (2009) Long-term efficacy of botulinum toxin A for treatment of blepharospasm, hemifacial spasm, and spastic entropion: a multicentre study using two drug-dose escalation indexes. Eye (Lond) 38(4):554–60
-
66.
Coban A, Matur Z, Hanagasi HA, Parman Y (2010) Iatrogenic Botulism After Botulinum Toxin Type A Injections. Clin Neuropharmacol 33(3):158–60
-
67.
Cohen DA, Savino PJ, Stern MB, Hurtig HI (1986) Botulinum injection therapy for blepharospasm:a review and report of 75 patients. Clin Neuropharmacol 9:415–429
-
68.
Cole H (1985) Botulinum toxin may help blepharospasm sufferers. Jama 254:1688–1690
-
69.
Colosimo C, Chianese M, Giovannelli M, Contarino MF, Bentivoglio AR (2003) Botulinum toxin type B in blepharospasm and hemifacial spasm. J Neurol Neurosurg Psychiatry 74:687
-
70.
Conte A, Fabbrini G, Belvisi D, Marsili L, Di Stasio F, Berardelli A (2009) Electrical activation of the orbicularis oculi muscle does not increase the effectiveness of botulinum toxin type A in patients with blepharospasm. Eur J Neurol 17:449–455
-
71.
Corridan P, Nightingale S, Mashoudi N, Williams AC (1990) Acute angle-closure glaucoma following botulinum toxin injection for blepharospasm. Br J Ophthalmol 74:309–310
-
72.
Costa J, Espirito-Santo C, Borges A, Ferreira JJ, Coelho M, Moore P, Sampaio C (2005) Botulinum toxin type A therapy for blepharospasm. Cochrane Database Syst Rev: CD004900
-
73.
Cote TR, Mohan AK, Polder JA, Walton MK, Braun MM (2005) Botulinum toxin type A injections: adverse events reported to the US Food and Drug Administration in therapeutic and cosmetic cases. J Am Acad Dermatol 53:407–415
-
74.
Cox NH, Duffey P, Royle J (1999) Fixed drug eruption caused by lactose in an injected botulinum toxin preparation. J Am Acad Dermatol 40:263–264
-
75.
Dai Z, Wang YC (1992) Treatment of blepharospasm, hemifacial spasm and strabismus with botulinum a toxin. Chin Med J (Engl) 105:476–480
-
76.
Defazio G, Lamberti P, Lepore V, Livrea P, Ferrari E (1989) Facial dystonia: clinical features, prognosis and pharmacology in 31 patients. Ital J Neurol Sci 10:553–560
-
77.
Defazio G, Lepore V, Lamberti P, Livrea P, Ferrari E (1990) Botulinum A toxin treatment for eyelid spasm, spasmodic torticollis and apraxia of eyelid opening. Ital J Neurol Sci 11:275–280
-
78.
Dodel RC, Kirchner A, Koehne-Volland R, Kunig G, Ceballos-Baumann A, Naumann M, Brashear A, Richter HP, Szucs TD, Oertel WH (1997) Costs of treating dystonias and hemifacial spasm with botulinum toxin A. Pharmacoeconomics 12:695–706
-
79.
Dresel C, Haslinger B, Castrop F, Wohlschlaeger AM, Ceballos-Baumann AO (2006) Silent event-related fMRI reveals deficient motor and enhanced somatosensory activation in orofacial dystonia. Brain 129:36–46
-
80.
Dressler D (2000) Complete secondary botulinum toxin therapy failure in blepharospasm. J Neurol 247:809–810
-
81.
Drummond GT, Hinz BJ (2001) Botulinum toxin for blepharospasm and hemifacial spasm: stability of duration of effect and dosage over time. Can J Ophthalmol 36:398–403
-
82.
Dutton JJ, Buckley EG (1986) Botulinum toxin in the management of blepharospasm. Arch Neurol 43:380–382
-
83.
Dutton JJ, Buckley EG (1988) Long-term results and complications of botulinum A toxin in the treatment of blepharospasm. Ophthalmology 95:1529–1534
-
84.
Dutton JJ (1996) Botulinum-A toxin in the treatment of craniocervical muscle spasms: short- and long-term, local and systemic effects. Surv Ophthalmol 41:51–65
-
85.
Dutton JJ, White JJ, Richard MJ (2006) Myobloc for the treatment of benign essential blepharospasm in patients refractory to Botox. Ophthal Plast Reconstr Surg 22:173–177
-
86.
Eleopra R, Tugnoli V, Caniatti L, De Grandis D (1996) Botulinum toxin treatment in the facial muscles of humans: evidence of an action in untreated near muscles by peripheral local diffusion. Neurology 46:1158–1160
-
87.
Eleopra R, Tugnoli V, De Grandis D (1997) The variability in the clinical effect induced by botulinum toxin type A: the role of muscle activity in humans. Mov Disord 12:89–94
-
88.
Elston JS, Russell RW (1985) Effect of treatment with botulinum toxin on neurogenic blepharospasm. Br Med J (Clin Res Ed) 290:1857–1859
-
89.
Elston JS (1987) Long-term results of treatment of idiopathic blepharospasm with botulinum toxin injections. Br J Ophthalmol 71:664–668
-
90.
Elston JS (1988) Botulinum toxin therapy for involuntary facial movement. Eye (Lond) 2(Pt 1):12–15
-
91.
Elston JS (1988) Botulinum toxin treatment of blepharospasm. Adv Neurol 50:579–581
-
92.
Elston JS (1992) A new variant of blepharospasm. J Neurol Neurosurg Psychiatry 55:369–371
-
93.
Engstrom PF, Arnoult JB, Mazow ML, Prager TC, Wilkins RB, Byrd WA, Hofmann RJ (1987) Effectiveness of botulinum toxin therapy for essential blepharospasm. Ophthalmology 94:971–975
-
94.
Erbguth F, Claus D, Neundorfer B (1990) Experience with botulinum toxin treatment of facial-cervical dystonias and hemifacial spasm. Nervenarzt 61:611–614
-
95.
Esmaeli-Gutstein B, Nahmias C, Thompson M, Kazdan M, Harvey J (1999) Positron emission tomography in patients with benign essential blepharospasm. Ophthal Plast Reconstr Surg 15:23–27
-
96.
Etgen T, Muhlau M, Gaser C, Sander D (2006) Bilateral grey-matter increase in the putamen in primary blepharospasm. J Neurol Neurosurg Psychiatry 77:1017–1020
-
97.
Fabbrini G, Berardelli I, Moretti G, Pasquini M, Bloise M, Colosimo C, Biondi M, Berardelli A Psychiatric disorders in adult-onset focal dystonia: a case–control study. Mov Disord 25:459–465
-
98.
Fabbrini G, Pantano P, Totaro P, Calistri V, Colosimo C, Carmellini M, Defazio G, Berardelli A (2008) Diffusion tensor imaging in patients with primary cervical dystonia and in patients with blepharospasm. Eur J Neurol 15:185–189
-
99.
Fiacchino F, Grandi L, Soliveri P, Carella F, Bricchi M (1997) Sensitivity to vecuronium after botulinum toxin administration. J Neurosurg Anesthesiol 9:149–153
-
100.
Flanders M, Chin D, Boghen D (1993) Botulinum toxin: preferred treatment for hemifacial spasm. Eur Neurol 33:316–319
-
101.
Flynn JT, Bachynski B (1986) Botulinum toxin therapy for strabismus and blepharospasm: Bascom Palmer Eye Institute experience. Trans New Orleans Acad Ophthalmol 34:73–88
-
102.
Forget R, Tozlovanu V, Iancu A, Boghen D (2002) Botulinum toxin improves lid opening delays in blepharospasm-associated apraxia of lid opening. Neurology 58:1843–1846
-
103.
Fota-Markowska H, Mitosek-Szewczyk K, Hasiec T (2007) Generalized botulism: diagnostic problems in a patient treated with botulinum toxin type A. Acta Ophthalmol Scand 85:231–232
-
104.
Frueh BR, Felt DP, Wojno TH, Musch DC (1984) Treatment of blepharospasm with botulinum toxin. A preliminary report. Arch Ophthalmol 102:1464–1468
-
105.
Frueh BR, Nelson CC, Kapustiak JF, Musch DC (1988) The effect of omitting botulinum toxin from the lower eyelid in blepharospasm treatment. Am J Ophthalmol 106:45–47
-
106.
Gausas RE, Lemke BN, Sherman DD, Dortzbach RK (1994) Oculinum injection-resistant blepharospasm in young patients. Ophthal Plast Reconstr Surg 10:193–194
-
107.
Girlanda P, Vita G, Nicolosi C, Milone S, Messina C (1992) Botulinum toxin therapy: distant effects on neuromuscular transmission and autonomic nervous system. J Neurol Neurosurg Psychiatry 55:844–845
-
108.
Girlanda P, Quartarone A, Sinicropi S, Nicolosi C, Messina C (1996) Unilateral injection of botulinum toxin in blepharospasm: single fiber electromyography and blink reflex study. Mov Disord 11:27–31
-
109.
Gomez-Wong E, Marti MJ, Tolosa E, Valls-Sole J (1998) Sensory modulation of the blink reflex in patients with blepharospasm. Arch Neurol 55:1233–1237
-
110.
Grandas F, Elston J, Quinn N, Marsden CD (1988) Blepharospasm: a review of 264 patients. J Neurol Neurosurg Psychiatry 51:767–772
-
111.
Grandas F, Traba A, Alonso F, Esteban A (1998) Blink reflex recovery cycle in patients with blepharospasm unilaterally treated with botulinum toxin. Clin Neuropharmacol 21:307–311
-
112.
Grivet D, Robert PY, Thuret G, De Feligonde OP, Gain P, Maugery J, Adenis JP (2005) Assessment of blepharospasm surgery using an improved disability scale: study of 138 patients. Ophthal Plast Reconstr Surg 21:230–234
-
113.
Gusek-Schneider GC, Erbguth F (1998) Protective ptosis by botulinum A toxin injection in corneal affectations. Klin Monbl Augenheilkd 213:15–22
-
114.
Hara K, Matsuda A, Kitsukawa Y, Tanaka K, Nishizawa M, Tagawa A (2007) Botulinum toxin treatment for blepharospasm associated with myasthenia gravis. Mov Disord 22:1363–1364
-
115.
Harris CP, Alderson K, Nebeker J, Holds JB, Anderson RL (1991) Histologic features of human orbicularis oculi treated with botulinum A toxin. Arch Ophthalmol 109:393–395
-
116.
Harrison AR, Erickson JP, Anderson JS, Lee MS (2008) Pain relief in patients receiving periocular botulinum toxin A. Ophthal Plast Reconstr Surg 24:113–116
-
117.
Haug BA, Dressler D, Prange HW (1990) Polyradiculoneuritis following botulinum toxin therapy. J Neurol 237:62–63
-
118.
Helmstaedter V, Wittekindt C, Huttenbrink KB, Guntinas-Lichius O (2008) Safety and efficacy of botulinum toxin therapy in otorhinolaryngology: experience from 1,000 treatments. Laryngoscope 118:790–796
-
119.
Holds JB, Alderson K, Fogg SG, Anderson RL (1990) Motor nerve sprouting in human orbicularis muscle after botulinum A injection. Invest Ophthalmol Vis Sci 31:964–967
-
120.
Holds JB, Fogg SG, Anderson RL (1990) Botulinum A toxin injection. Failures in clinical practice and a biomechanical system for the study of toxin-induced paralysis. Ophthal Plast Reconstr Surg 6:252–259
-
121.
Holds JB, White GL Jr, Thiese SM, Anderson RL (1991) Facial dystonia, essential blepharospasm and hemifacial spasm. Am Fam Physician 43:2113–2120
-
122.
Horn AK, Porter JD, Evinger C (1993) Botulinum toxin paralysis of the orbicularis oculi muscle. Types and time course of alterations in muscle structure, physiology and lid kinematics. Exp Brain Res 96:39–53
-
123.
Horwath-Winter J, Bergloff J, Flogel I, Haller-Schober EM, Mullner K, Schmut O (2002) The effect of botulinum toxin a treatment on tear function parameters and on the ocular surface. Adv Exp Med Biol 506:1241–1246
-
124.
Horwath-Winter J, Bergloeff J, Floegel I, Haller-Schober EM, Schmut O (2003) Botulinum toxin A treatment in patients suffering from blepharospasm and dry eye. Br J Ophthalmol 87:54–56
-
125.
Hsiung GY, Das SK, Ranawaya R, Lafontaine AL, Suchowersky O (2002) Long-term efficacy of botulinum toxin A in treatment of various movement disorders over a 10-year period. Mov Disord 17:1288–1293
-
126.
Iwashige H, Nemeto Y, Takahashi H, Maruo T (1995) Botulinum toxin type A purified neurotoxin complex for the treatment of blepharospasm: a dose–response study measuring eyelid force. Jpn J Ophthalmol 39:424–431
-
127.
Jamora RD, Tan AK, Tan LC (2006) A 9-year review of dystonia from a movement disorders clinic in Singapore. Eur J Neurol 13:77–81
-
128.
Jankovic J, Orman J (1987) Botulinum A toxin for cranial-cervical dystonia: a double-blind, placebo-controlled study. Neurology 37:616–623
-
129.
Jankovic J (1988) Botulinum A toxin in the treatment of blepharospasm. Adv Neurol 49:467–472
-
130.
Jankovic J (1988) Blepharospasm and oromandibular-laryngeal-cervical dystonia: a controlled trial of botulinum A toxin therapy. Adv Neurol 50:583–591
-
131.
Jankovic J, Schwartz K, Donovan DT (1990) Botulinum toxin treatment of cranial–cervical dystonia, spasmodic dysphonia, other focal dystonias and hemifacial spasm. J Neurol Neurosurg Psychiatry 53:633–639
-
132.
Jankovic J, Schwartz KS (1993) Longitudinal experience with botulinum toxin injections for treatment of blepharospasm and cervical dystonia. Neurology 43:834–836
-
133.
Jankovic J (1996) Pretarsal injection of botulinum toxin for blepharospasm and apraxia of eyelid opening. J Neurol Neurosurg Psychiatry 60:704
-
134.
Jankovic J (2009) Clinical efficacy and tolerability of Xeomin in the treatment of blepharospasm. Eur J Neurol 16(Suppl 2):14–18
-
135.
Jankovic J, Kenney C, Grafe S, Goertelmeyer R, Comes G (2009) Relationship between various clinical outcome assessments in patients with blepharospasm. Mov Disord 24:407–413
-
136.
Johnstone SJ, Adler CH (1998) Headache and facial pain responsive to botulinum toxin: an unusual presentation of blepharospasm. Headache 38:366–368
-
137.
Jost WH, Kohl A (2001) Botulinum toxin: evidence–based medicine criteria in blepharospasm and hemifacial spasm. J Neurol 248(Suppl 1):21–24
-
138.
Jost WH, Blumel J, Grafe S (2007) Botulinum neurotoxin type A free of complexing proteins (XEOMIN) in focal dystonia. Drugs 67:669–683
-
139.
Kalra HK, Magoon EH (1990) Side effects of the use of botulinum toxin for treatment of benign essential blepharospasm and hemifacial spasm. Ophthalmic Surg 21:335–338
-
140.
Kanazawa M, Shimohata T, Sato M, Onodera O, Tanaka K, Nishizawa M (2007) Botulinum toxin A injections improve apraxia of eyelid opening without overt blepharospasm associated with neurodegenerative diseases. Mov Disord 22:597–598
-
141.
Karpati S, Desaknai S, Desaknai M, Biro J, Nagy K, Horvath A (2000) Human herpesvirus type 8-positive facial angiosarcoma developing at the site of botulinum toxin injection for blepharospasm. Br J Dermatol 143:660–662
-
142.
Kennedy RH, Bartley GB, Flanagan JC, Waller RR (1989) Treatment of blepharospasm with botulinum toxin. Mayo Clin Proc 64:1085–1090
-
143.
Kenney C, Jankovic J (2008) Botulinum toxin in the treatment of blepharospasm and hemifacial spasm. J Neural Transm 115:585–591
-
144.
Koh S, Hosohata J, Tano Y (2006) Bilateral upper eyelid ectropion associated with blepharospasm. Br J Ophthalmol 90:1437–1438
-
145.
Koltringer P, Haselwander H, Reisecker F (1990) The treatment of blepharospasm with botulinum toxin A. Wien Klin Wochenschr 102:403–407
-
146.
Kowal L (1997) Pretarsal injections of botulinum toxin improve blephospasm in previously unresponsive patients. J Neurol Neurosurg Psychiatry 63:556
-
147.
Kowal L, Davies R, Kiely PM (1998) Facial muscle spasms: an Australian study. Aust N Z J Ophthalmol 26:123–128
-
148.
Krack P, Marion MH (1994) “Apraxia of lid opening,” a focal eyelid dystonia: clinical study of 32 patients. Mov Disord 9:610–615
-
149.
Krack P, Porschke H, de Decker W, Deuschl G (1997) Inability to close eyelids as a feature of palpebral dystonia. Mov Disord 12:251–252
-
150.
Kraft SP, Lang AE (1988) Cranial dystonia, blepharospasm and hemifacial spasm: clinical features and treatment, including the use of botulinum toxin. CMAJ 139:837–844
-
151.
Kraft SP, Lang AE (1988) Botulinum toxin injections in the treatment of blepharospasm, hemifacial spasm, and eyelid fasciculations. Can J Neurol Sci 15:276–280
-
152.
Kristan RW, Stasior OG (1987) Treatment of blepharospasm with high dose brow injection of botulinum toxin. Ophthal Plast Reconstr Surg 3:25–27
-
153.
Kwan MC, Ko KF, Chan TP, Chan YW (1998) Treatment of dystonia with botulinum A toxin: a retrospective study of 170 patients. Hong Kong Med J 4:279–282
-
154.
Kwek AB, Tan EK, Luman W (2004) Dysphagia as a side effect of botulinum toxin injection. Med J Malaysia 59:544–546
-
155.
Kwiat DM, Bersani TA, Bersani A (2004) Increased patient comfort utilizing botulinum toxin type A reconstituted with preserved versus nonpreserved saline. Ophthal Plast Reconstr Surg 20:186–189
-
156.
Lang J (1985) The treatment of eye muscle diseases with botulinum toxin. Klin Monbl Augenheilkd 186:453–454
-
157.
Latimer PR, Hodgkins PR, Vakalis AN, Butler RE, Evans AR, Zaki GA (1998) Necrotising fasciitis as a complication of botulinum toxin injection. Eye (Lond) 12(Pt 1):51–53
-
158.
Lepore V, Defazio G, Acquistapace D, Melpignano C, Pomes L, Lamberti P, Livrea P, Ferrari E (1995) Botulinum A toxin for the so-called apraxia of lid opening. Mov Disord 10:525–526
-
159.
Levy RL, Berman D, Parikh M, Miller NR (2006) Supramaximal doses of botulinum toxin for refractory blepharospasm. Ophthalmology 113:1665–1668
-
160.
Lindeboom R, De Haan R, Aramideh M, Speelman JD (1995) The blepharospasm disability scale: an instrument for the assessment of functional health in blepharospasm. Mov Disord 10:444–449
-
161.
Linder JS, Edmonson BC, Laquis SJ, Drewry RD Jr, Fleming JC (2002) Skin cooling before periocular botulinum toxin A injection. Ophthal Plast Reconstr Surg 18:441–442
-
162.
Lingua RW (1985) Sequelae of botulinum toxin injection. Am J Ophthalmol 100:305–307
-
163.
Lopez Valdes E, Posada Rodriguez IJ, Bilbao-Calabuig R (2008) Botulinum toxin A injections improve apraxia of eyelid opening without overt blepharospasm associated with neurodegenerative diseases. Mov Disord 23:773; author reply 773
-
164.
MacAndie K, Kemp E (2004) Impact on quality of life of botulinum toxin treatments for essential blepharospasm. Orbit 23:207–210
-
165.
Manning KA, Evinger C, Sibony PA (1990) Eyelid movements before and after botulinum therapy in patients with lid spasm. Ann Neurol 28:653–660
-
166.
Marchetti A, Magar R, Findley L, Larsen JP, Pirtosek Z, Ruzicka E, Jech R, Slawek J, Ahmed F (2005) Retrospective evaluation of the dose of Dysport and BOTOX in the management of cervical dystonia and blepharospasm: the REAL DOSE study. Mov Disord 20:937–944
-
167.
Mauriello JA, Aljian J (1991) Natural history of treatment of facial dyskinesias with botulinum toxin: a study of 50 consecutive patients over seven years. Br J Ophthalmol 75:737–739
-
168.
Mauriello JA Jr (1985) Blepharospasm, Meige syndrome, and hemifacial spasm: treatment with botulinum toxin. Neurology 35:1499–1500
-
169.
Mauriello JA Jr, Coniaris H (1987) Use of botulinum in the treatment of 100 patients with blepharospasm. N J Med 84: 43–44
-
170.
Mauriello JA Jr, Coniaris H, Haupt EJ (1987) Use of botulinum toxin in the treatment of one hundred patients with facial dyskinesias. Ophthalmology 94:976–979
-
171.
Mauriello JA Jr, Dhillon S, Leone T, Pakeman B, Mostafavi R, Yepez MC (1996) Treatment selections of 239 patients with blepharospasm and Meige syndrome over 11 years. Br J Ophthalmol 80:1073–1076
-
172.
Maurri S, Brogelli S, Alfieri G, Barontini F (1988) Beneficial effect of botulinum A toxin in blepharospasm: 16 months’ experience with 16 cases. Ital J Neurol Sci 9:337–344
-
173.
Mezaki T, Kaji R, Kohara N, Fujii H, Katayama M, Shimizu T, Kimura J, Brin MF (1995) Comparison of therapeutic efficacies of type A and F botulinum toxins for blepharospasm: a double-blind, controlled study. Neurology 45:506–508
-
174.
Mezaki T, Kaji R, Brin MF, Hirota-Katayama M, Kubori T, Shimizu T, Kimura J (1999) Combined use of type A and F botulinum toxins for blepharospasm: a double-blind controlled trial. Mov Disord 14:1017–1020
-
175.
Mezaki T, Sakai R (2005) Botulinum toxin and skin rash reaction. Mov Disord 20:770
-
176.
Mohammadi B, Kollewe K, Wegener M, Bigalke H, Dengler R (2009) Experience with long-term treatment with albumin-supplemented botulinum toxin type A. J Neural Transm 116:437–441
-
177.
Moon NJ, Lee HI, Kim JC (2006) The changes in corneal astigmatism after botulinum toxin-a injection in patients with blepharospasm. J Korean Med Sci 21:131–135
-
178.
Muller J, Kemmler G, Wissel J, Schneider A, Voller B, Grossmann J, Diez J, Homann N, Wenning GK, Schnider P, Poewe W (2002) The impact of blepharospasm and cervical dystonia on health-related quality of life and depression. J Neurol 249:842–846
-
179.
Muller J, Wissel J, Kemmler G, Voller B, Bodner T, Schneider A, Wenning GK, Poewe W (2004) Craniocervical dystonia questionnaire (CDQ-24): development and validation of a disease-specific quality of life instrument. J Neurol Neurosurg Psychiatry 75:749–753
-
180.
Naumann M, Albanese A, Heinen F, Molenaers G, Relja M (2006) Safety and efficacy of botulinum toxin type A following long-term use. Eur J Neurol 13(Suppl 4):35–40
-
181.
Nepp J, Wenzel T, Kuchar A, Steinkogler FJ (1998) Blepharospasm and acupuncture–initial results of a treatment trial. Wien Med Wochenschr 148:457–458
-
182.
Nussgens Z, Roggenkamper P (1995) Long-term treatment of blepharospasm with botulinum toxin type A. Ger J Ophthalmol 4:363–367
-
183.
Nussgens Z, Roggenkamper P (1997) Comparison of two botulinum-toxin preparations in the treatment of essential blepharospasm. Graefes Arch Clin Exp Ophthalmol 235:197–199
-
184.
Ochudlo S, Bryniarski P, Opala G (2007) Botulinum toxin improves the quality of life and reduces the intensification of depressive symptoms in patients with blepharospasm. Parkinsonism Relat Disord 13:505–508
-
185.
Pang AL, O’Day J (2006) Use of high-dose botulinum A toxin in benign essential blepharospasm: is too high too much? Clin Experiment Ophthalmol 34:441–444
-
186.
Park YC, Lim JK, Lee DK, Yi SD (1993) Botulinum a toxin treatment of hemifacial spasm and blepharospasm. J Korean Med Sci 8:334–340
-
187.
Patrinely JR, Whiting AS, Anderson RL (1988) Local side effects of botulinum toxin injections. Adv Neurol 49:493–500
-
188.
Poonyathalang A, Preechawat P, Jamnansiri U (2005) Low-dose botulinum toxin a for treatment of blepharospasm and hemifacial spasm. Jpn J Ophthalmol 49:327–328
-
189.
Poungvarin N, Devahastin V, Viriyavejakul A (1995) Treatment of various movement disorders with botulinum A toxin injection: an experience of 900 patients. J Med Assoc Thai 78:281–288
-
190.
Poungvarin N, Devahastin V, Chaisevikul R, Prayoonwiwat N, Viriyavejakul A (1997) Botulinum A toxin treatment for blepharospasm and Meige syndrome: report of 100 patients. J Med Assoc Thai 80:1–8
-
191.
Price J, O’Day J (1993) A comparative study of tear secretion in blepharospasm and hemifacial spasm patients treated with botulinum toxin. J Clin Neuroophthalmol 13:67–71
-
192.
Price J, O’Day J (1994) Efficacy and side effects of botulinum toxin treatment for blepharospasm and hemifacial spasm. Aust N Z J Ophthalmol 22:255–260
-
193.
Price J, Farish S, Taylor H, O’Day J (1997) Blepharospasm and hemifacial spasm. Randomized trial to determine the most appropriate location for botulinum toxin injections. Ophthalmology 104:865–868
-
194.
Quagliato EM, Carelli EF, Viana MA Prospective, randomized, double-blind study, comparing botulinum toxins type a botox and prosigne for blepharospasm and hemifacial spasm treatment. Clin Neuropharmacol 33:27–31
-
195.
Quartarone A, Girlanda P, Di Lazzaro V, Majorana G, Battaglia F, Messina C (2000) Short latency trigemino-sternocleidomastoid response in muscles in patients with spasmodic torticollis and blepharospasm. Clin Neurophysiol 111:1672–1677
-
196.
Quartarone A, Sant’Angelo A, Battaglia F, Bagnato S, Rizzo V, Morgante F, Rothwell JC, Siebner HR, Girlanda P (2006) Enhanced long-term potentiation-like plasticity of the trigeminal blink reflex circuit in blepharospasm. J Neurosci 26:716–721
-
197.
Racette BA, Stambuk M, Perlmutter JS (2002) Secondary nonresponsiveness to new bulk botulinum toxin A (BCB2024). Mov Disord 17:1098–1100
-
198.
Rahman R, Berry-Brincat A, Thaller VT (2003) A new grading system for assessing orbicularis muscle function. Eye (Lond) 17:610–612
-
199.
Reifler DM (1988) The effect of omitting botulinum toxin from the lower eyelid in blepharospasm treatment. Am J Ophthalmol 106:637–638
-
200.
Reimer J, Gilg K, Karow A, Esser J, Franke GH (2005) Health-related quality of life in blepharospasm or hemifacial spasm. Acta Neurol Scand 111:64–70
-
201.
Rieder CR, Schestatsky P, Socal MP, Monte TL, Fricke D, Costa J, Picon PD (2007) A double-blind, randomized, crossover study of prosigne versus botox in patients with blepharospasm and hemifacial spasm. Clin Neuropharmacol 30:39–42
-
202.
Roehm PC, Perry JD, Girkin CA, Miller NR (1999) Prevalence of periocular depigmentation after repeated botulinum toxin A injections in African American patients. J Neuroophthalmol 19:7–9
-
203.
Roggenkamper P (1986) Blepharospasm treatment with botulinum toxin (follow-up). Klin Monbl Augenheilkd 189:283–285
-
204.
Roggenkamper P, Laskawi R, Damenz W, Schroder M (1991) Changes in the blink reflex in patients with essential blepharospasm and hemifacial spasm. Fortschr Ophthalmol 88:411–415
-
205.
Roggenkamper P, Nussgens Z (1997) Oculinum injection-resistant blepharospasm in young patients. Ophthal Plast Reconstr Surg 13:73
-
206.
Roggenkamper P, Jost WH, Bihari K, Comes G, Grafe S (2006) Efficacy and safety of a new Botulinum Toxin Type A free of complexing proteins in the treatment of blepharospasm. J Neural Transm 113:303–312
-
207.
Rollnik JD, Matzke M, Wohlfarth K, Dengler R, Bigalke H (2000) Low-dose treatment of cervical dystonia, blepharospasm and facial hemispasm with albumin-diluted botulinum toxin type A under EMG guidance. An open label study. Eur Neurol 43:9–12
-
208.
Roselli F, De Tommaso M, Stella Aniello M, Livrea P, Defazio G (2002) Blepharospasm in bardet-biedl syndrome: a case report. Eur Neurol 48:230–232
-
209.
Ruusuvaara P, Setala K (1990) Long-term treatment of involuntary facial spasms using botulinum toxin. Acta Ophthalmol (Copenh) 68:331–338
-
210.
Sami MS, Soparkar CN, Patrinely JR, Hollier LM, Hollier LH (2006) Efficacy of botulinum toxin type a after topical anesthesia. Ophthal Plast Reconstr Surg 22:448–452
-
211.
Sampaio C, Ferreira JJ, Simoes F, Rosas MJ, Magalhaes M, Correia AP, Bastos-Lima A, Martins R, Castro-Caldas A (1997) DYSBOT: a single-blind, randomized parallel study to determine whether any differences can be detected in the efficacy and tolerability of two formulations of botulinum toxin type A–Dysport and Botox–assuming a ratio of 4:1. Mov Disord 12:1013–1018
-
212.
Sanders DB, Massey EW, Buckley EG (1986) Botulinum toxin for blepharospasm: single-fiber EMG studies. Neurology 36:545–547
-
213.
Schnider P, Birner P, Moraru E, Auff E (1999) Long-term treatment with botulinum toxin: dosage, treatment schedules and costs. Wien Klin Wochenschr 111:59–65
-
214.
Scott AB, Kennedy RA, Stubbs HA (1985) Botulinum A toxin injection as a treatment for blepharospasm. Arch Ophthalmol 103:347–350
-
215.
Scott AB (1988) Antitoxin reduces botulinum side effects. Eye (Lond) 2(Pt 1):29–32
-
216.
Scott AB (1997) Preventing ptosis after botulinum treatment. Ophthal Plast Reconstr Surg 13:81–83
-
217.
Seiff SR, Shorr N (1988) The effect of omitting botulinum toxin from the lower eyelid in blepharospasm treatment. Am J Ophthalmol 106:764–766
-
218.
Seiff SR, Freeman LN, Bluestone DL, Berg BO (1989) Use of botulinum toxin to treat blepharospasm in a 16-year-old with a dystonic syndrome. Pediatr Neurol 5:121–123
-
219.
Seiff SR, Zwick OM (2005) Botulinum toxin management of upper facial rhytidosis and blepharospasm. Otolaryngol Clin North Am 38:887–902
-
220.
Shore JW, Leone CR Jr, O’Connor PS, Neuhaus RW, Arnold AC (1986) Botulinum toxin for the treatment of essential blepharospasm. Ophthalmic Surg 17:747–753
-
221.
Shorr N, Seiff SR, Kopelman J (1985) The use of botulinum toxin in blepharospasm. Am J Ophthalmol 99:542–546
-
222.
Siatkowski RM, Tyutyunikov A, Biglan AW, Scalise D, Genovese C, Raikow RB, Kennerdell JS, Feuer WJ (1993) Serum antibody production to botulinum A toxin. Ophthalmology 100:1861–1866
-
223.
Silveira-Moriyama L, Goncalves LR, Chien HF, Barbosa ER (2005) Botulinum toxin A in the treatment of blepharospasm: a 10-year experience. Arq Neuropsiquiatr 63:221–224
-
224.
Snir M, Weinberger D, Bourla D, Kristal-Shalit O, Dotan G, Axer-Siegel R (2003) Quantitative changes in botulinum toxin a treatment over time in patients with essential blepharospasm and idiopathic hemifacial spasm. Am J Ophthalmol 136:99–105
-
225.
Sojer M, Wissel J, Muller J, Poewe W (2001) Treatment of focal dystonia with botulinum toxin A. Wien Klin Wochenschr 113(Suppl 4):6–10
-
226.
Sommer M, Ferbert A (2001) The stimulus intensity modifies the blink reflex recovery cycle in healthy subjects and in blepharospasm. Clin Neurophysiol 112:2293–2299
-
227.
Soylev MF, Kocak N, Kuvaki B, Ozkan SB, Kir E (2002) Anesthesia with EMLA cream for botulinum A toxin injection into eyelids. Ophthalmologica 216:355–358
-
228.
Tan AK (1998) Botulinum toxin for neurological disorders in a movement disorders clinic in Singapore. Singapore Med J 39:403–405
-
229.
Taylor JD, Kraft SP, Kazdan MS, Flanders M, Cadera W, Orton RB (1991) Treatment of blepharospasm and hemifacial spasm with botulinum A toxin: a Canadian multicentre study. Can J Ophthalmol 26:133–138
-
230.
Thill R, Koltringer P, Reisecker F, Maller J, Leblhuber F (1991) Botulinum toxin A in therapy of craniocervical dystonias and hemifacial spasm. Acta Med Austriaca 18:125–129
-
231.
Thomas R, Mathai A, Rajeev B, Sen S, Jacob P (1993) Botulinum toxin in the treatment of paralytic strabismus and essential blepharospasm. Indian J Ophthalmol 41:121–124
-
232.
Thussu A, Barman CR, Prabhakar S (1999) Botulinum toxin treatment of hemifacial spasm and blepharospasm: objective response evaluation. Neurol India 47:206–209
-
233.
Truong D, Comella C, Fernandez HH, Ondo WG (2008) Efficacy and safety of purified botulinum toxin type A (Dysport) for the treatment of benign essential blepharospasm: a randomized, placebo-controlled, phase II trial. Parkinsonism Relat Disord 14:407–414
-
234.
Tsai CP, Chiu MC, Yen DJ, Guo YC, Yuan CL, Lee TC (2005) Quantitative assessment of efficacy of Dysport (botulinum toxin type A) in the treatment of idiopathic blepharospasm and hemifacial spasm. Acta Neurol Taiwan 14:61–68
-
235.
Tsoy EA, Buckley EG, Dutton JJ (1985) Treatment of blepharospasm with botulinum toxin. Am J Ophthalmol 99:176–179
-
236.
Tucha O, Naumann M, Berg D, Alders GL, Lange KW (2001) Quality of life in patients with blepharospasm. Acta Neurol Scand 103:49–52
-
237.
Valls-Sole J, Tolosa ES, Ribera G (1991) Neurophysiological observations on the effects of botulinum toxin treatment in patients with dystonic blepharospasm. J Neurol Neurosurg Psychiatry 54:310–313
-
238.
Van den Bergh P, Francart J, Mourin S, Kollmann P, Laterre EC (1995) Five-year experience in the treatment of focal movement disorders with low-dose Dysport botulinum toxin. Muscle Nerve 18:720–729
-
239.
Vargel I, Canter HI, Topaloglu H, Erk Y (2006) Results of botulinum toxin: an application to blepharospasm Schwartz-Jampel syndrome. J Craniofac Surg 17:656–660
-
240.
Verhulst S, Smet H, De Wilde F, Tassignon MJ (1994) Levator aponeurosis dehiscence in a patient treated with botulinum toxin for blepharospasms and eyelid apraxia. Bull Soc Belge Ophtalmol 252:51–53
-
241.
Vissenberg I, Dieleman-Smet H, Tassignon MJ (1993) Botulinum A toxin therapy in ophthalmology: a report of patients with facial dystonias. Bull Soc Belge Ophtalmol 248:77–82
-
242.
Vogt T, Lussi F, Paul A, Urban P (2008) Long-term therapy of focal dystonia and facial hemispasm with botulinum toxin A. Nervenarzt 79:912–917
-
243.
Wan XH, Vuong KD, Jankovic J (2005) Clinical application of botulinum toxin type B in movement disorders and autonomic symptoms. Chin Med Sci J 20:44–47
-
244.
Whitaker J, Butler A, Semlyen JK, Barnes MP (2001) Botulinum toxin for people with dystonia treated by an outreach nurse practitioner: a comparative study between a home and a clinic treatment service. Arch Phys Med Rehabil 82:480–484
-
245.
Wirtschafter JD, Rubenfeld M (1991) Botulinum toxin injections for treatment of blepharospasm and hemifacial spasm. Int Ophthalmol Clin 31:117–132
-
246.
Wojno T, Campbell P, Wright J (1986) Orbicularis muscle pathology after botulinum toxin injection. Ophthal Plast Reconstr Surg 2:71–74
-
247.
Wutthiphan S, Kowal L, O’Day J, Jones S, Price J (1997) Diplopia following subcutaneous injections of botulinum A toxin for facial spasms. J Pediatr Ophthalmol Strabismus 34:229–234
-
248.
Yomtoob DE, Dewan MA, Lee MS, Harrison AR (2009) Comparison of pain scores with 30-gauge and 32-gauge needles for periocular botulinum toxin type A injections. Ophthal Plast Reconstr Surg 25:376–377
-
249.
Yoon JS, Kim JC, Lee SY (2009) Double-blind, randomized, comparative study of Meditoxin versus Botox in the treatment of essential blepharospasm. Korean J Ophthalmol 23:137–141
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Wabbels, B., Jost, W.H. & Roggenkämper, P. Difficulties with differentiating botulinum toxin treatment effects in essential blepharospasm. J Neural Transm 118, 925–943 (2011). https://doi.org/10.1007/s00702-010-0546-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00702-010-0546-9