
Abstract
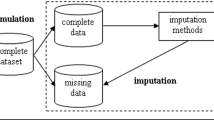
Imputation procedures such as fully efficient fractional imputation (FEFI) or multiple imputation (MI) create multiple versions of the missing observations, thereby reflecting uncertainty about their true values. Multiple imputation generates a finite set of imputations through a posterior predictive distribution. Fractional imputation assigns weights to the observed data. The focus of this article is the development of FEFI for partially classified two-way contingency tables. Point estimators and variances of FEFI estimators of population proportions are derived. Simulation results, when data are missing completely at random or missing at random, show that FEFI is comparable in performance to maximum likelihood estimation and multiple imputation and superior to simple stochastic imputation and complete case anlaysis. Methods are illustrated with four data sets.
Similar content being viewed by others


References
Blumenthal S (1968) Multinomial sampling with partially categorized data. J Am Stat Assoc 63: 542–551
Box GEP, Tiao GC (1992) Bayesian inference in statistical analysis. Wiley Classics Library Edition. Wiley, New York
Chen TT, Fienberg SE (1974) Two-dimensional contingency tables with both completely and partially cross-classified data. Biometrics 30: 629–642
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm (with discussion). J Royal Stat Soc Ser B 39: 1–38
Fay RE (1996) Alternative paradigms for the analysis of imputed survey data. J Am Stat Assoc 91: 490–498
Kalton G, Kish L (1981) Two efficient random imputation procedures. In: Proceedings of the survey research methods section. American Statistical Association, pp 146–151
Kim JK, Fuller W (2004) Fractional Hot deck imputation. Biometrika 91: 559–578
Little RJA (1982) Models for nonresponse in sample surveys. J Am Stat Assoc 77: 237–250
Little RJA, Rubin DB (2002) Statistical analysis with missing data. Wiley, New York
Magder LS (2003) Simple approaches to assess the possible impact of missing outcome information on estimates of risk ratios, odds ratios, and risk differences. Controlled Clin Trials 24: 411–421
Meng XL, Rubin DB (1991) Using EM to obtain asymptotic variance-covariance matrices: the SEM algorithm. J Am Stat Assoc 86: 899–909
Meng XL, Rubin DB (1993) Maximum likelihood estimation via the ECM algorithm: a general framework. Biometrika 80: 267–278
Molenberghs G, Kenward MG, Goetghebeur E (2001) Sensitivity analysis for incomplete contingency tables: the Slovenian plebiscite case. Appl Stat 50: 15–29
Rubin DB (1976) Infernece and missing data (with discussion). Biometrika 63: 581–592
Rubin DB (1978) Multiple imputation in sample surveys—a phenomenological bayesian approach to nonresponse. In: Proceedings of the survey research methods section. American Statistical Association, pp 20–34
Rubin DB (1987) Multiple imputation for nonresponse in surveys. Wiley, New York
Rubin DB (1996) Multiple imputation after 18+ years. J Am Stat Assoc 91: 473–489
Rubin DB, Stern HS, Vehovar V (1995) Handling don’t know survey responses: the case of the Slovenian plebiscite. J Am Stat Assoc 90: 822–828
Schafer JL (1997) Analysis of incomplete multivariate data. Chapman & Hall, London
van Dyk DA, Meng XL, Rubin DB (1995) Maximum likelihood estimation via the ECM algorithm: computing the asymptotic variance. Stat Sinica 5: 55–75
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kang, SS., Koehler, K.J. & Larsen, M.D. Fractional imputation for incomplete two-way contingency tables. Metrika 75, 581–599 (2012). https://doi.org/10.1007/s00184-011-0343-y
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00184-011-0343-y